
Palabras clave:Agente de IA inteligente, Modelo de lenguaje grande, Gemini 2.5 Pro, Supercomputadora de IA de NVIDIA, Conferencia Microsoft Build, Agente de investigación científica, Evaluación de capacidades de razonamiento, Programación con IA, Agente de codificación que repara errores de forma autónoma, Plataforma de investigación Microsoft Discovery, Tecnología NVLink Fusion, Supernodo CloudMatrix 384, Algoritmo EdgeInfinite
🔥 Enfoque
Los AI agents redefinen el paradigma del desarrollo y la investigación científica: Microsoft Build presentó una serie de herramientas de AI agent, incluyendo Coding Agent para la reparación autónoma de bugs y el mantenimiento de código, así como la plataforma de agentes de investigación científica Microsoft Discovery, capaz de generar ideas, simular resultados y aprender de forma autónoma. Paralelamente, Kevin Weil, CPO de OpenAI, y Dario Amodei, CEO de Anthropic, afirmaron que la IA ya posee capacidades avanzadas de programación, lo que augura que los puestos de programador júnior podrían ser reemplazados y que el rol de los desarrolladores evolucionará hacia el de “guías de IA”. Estos avances indican que los AI agents están evolucionando de herramientas auxiliares a fuerzas centrales capaces de operar independientemente en proyectos complejos, lo que transformará profundamente los procesos y la eficiencia del desarrollo de software y la investigación científica (Fuente: GitHub Trending, X)
La capacidad de razonamiento de los Large Language Models enfrenta nuevos desafíos y evaluaciones: Múltiples estudios y debates recientes revelan las limitaciones de los Large Language Models en tareas de razonamiento complejo. Investigaciones de instituciones como la Universidad de Harvard señalan que la Chain-of-Thought (CoT) a veces puede llevar a una disminución en la precisión del modelo al seguir instrucciones, debido a su excesiva concentración en la planificación del contenido en detrimento de restricciones simples. Asimismo, tareas físicas del mundo real (como el mecanizado de piezas) y el razonamiento visoespacial complejo (como problemas de apilamiento de cubos) también exponen las deficiencias de los modelos de IA de primer nivel (incluidos o3, Gemini 2.5 Pro). Para evaluar con mayor precisión las capacidades de los modelos, se han propuesto nuevos benchmarks como EMMA y SPOT, diseñados para detectar el nivel real de la IA en la fusión multimodal, la validación científica, entre otros, impulsando la evolución de los modelos hacia un razonamiento más robusto y fiable (Fuente: HuggingFace Daily Papers, 量子位)
Google AI despliega toda su artillería, Gemini 2.5 Pro muestra un rendimiento robusto: Google demuestra una ofensiva integral en el campo de la IA, con su modelo Gemini 2.5 Pro destacando en múltiples benchmarks (como LMSYS Chatbot Arena), alcanzando un nivel superior especialmente en contexto largo y comprensión de vídeo, y superando a versiones anteriores en WebDev Arena. En la conferencia Google Cloud Next ‘25, Google lanzó más de 200 actualizaciones, incluyendo Gemini 2.5 Flash, Imagen 3, Veo 2, Vertex AI Agent Development Kit (ADK) y el protocolo Agent2Agent (A2A), demostrando su determinación de integrar la IA en todos los niveles de su plataforma en la nube e impulsar la implementación a escala empresarial. Google Labs también continúa incubando productos innovadores nativos de IA, como NotebookLM, mostrando una fuerte capacidad de innovación y iteración de productos (Fuente: Google, GoogleDeepMind)
Nvidia lanza supercomputadora de IA de escritorio y soluciones de AI factory para empresas: En la Computex, Nvidia presentó varios productos de gran impacto, incluyendo la computadora personal de IA DGX Station equipada con el superchip GB300, con hasta 784GB de memoria unificada y capaz de ejecutar modelos grandes de 1T de parámetros; y el RTX PRO Server para empresas, que puede acelerar AI agents, IA física, computación científica y otras aplicaciones. Al mismo tiempo, Nvidia lanzó la tecnología semicustomizada NVLink Fusion y la plataforma de datos NVIDIA AI, y anunció colaboraciones con Disney y otros para desarrollar el motor de IA física Newton. Estas iniciativas indican que Nvidia está transformándose de una empresa de chips a una empresa de infraestructura de IA, con el objetivo de construir un ecosistema de IA completo desde el escritorio hasta el centro de datos (Fuente: nvidia, 量子位)

🎯 Tendencias
Kimi.ai lanza el modelo de pensamiento de texto largo kimi-thinking-preview: Kimi.ai ha lanzado su último modelo de pensamiento de texto largo, kimi-thinking-preview, ya disponible en platform.moonshot.ai. Se dice que este modelo posee excelentes capacidades multimodales y de razonamiento. Los nuevos usuarios registrados pueden obtener un cupón de 5 dólares para probarlo. Los comentarios de la comunidad sugieren que el modelo sea evaluado por terceros y mencionan que Kimi ya había logrado el liderazgo en livecodebench con un modelo de pensamiento dedicado (Fuente: X)
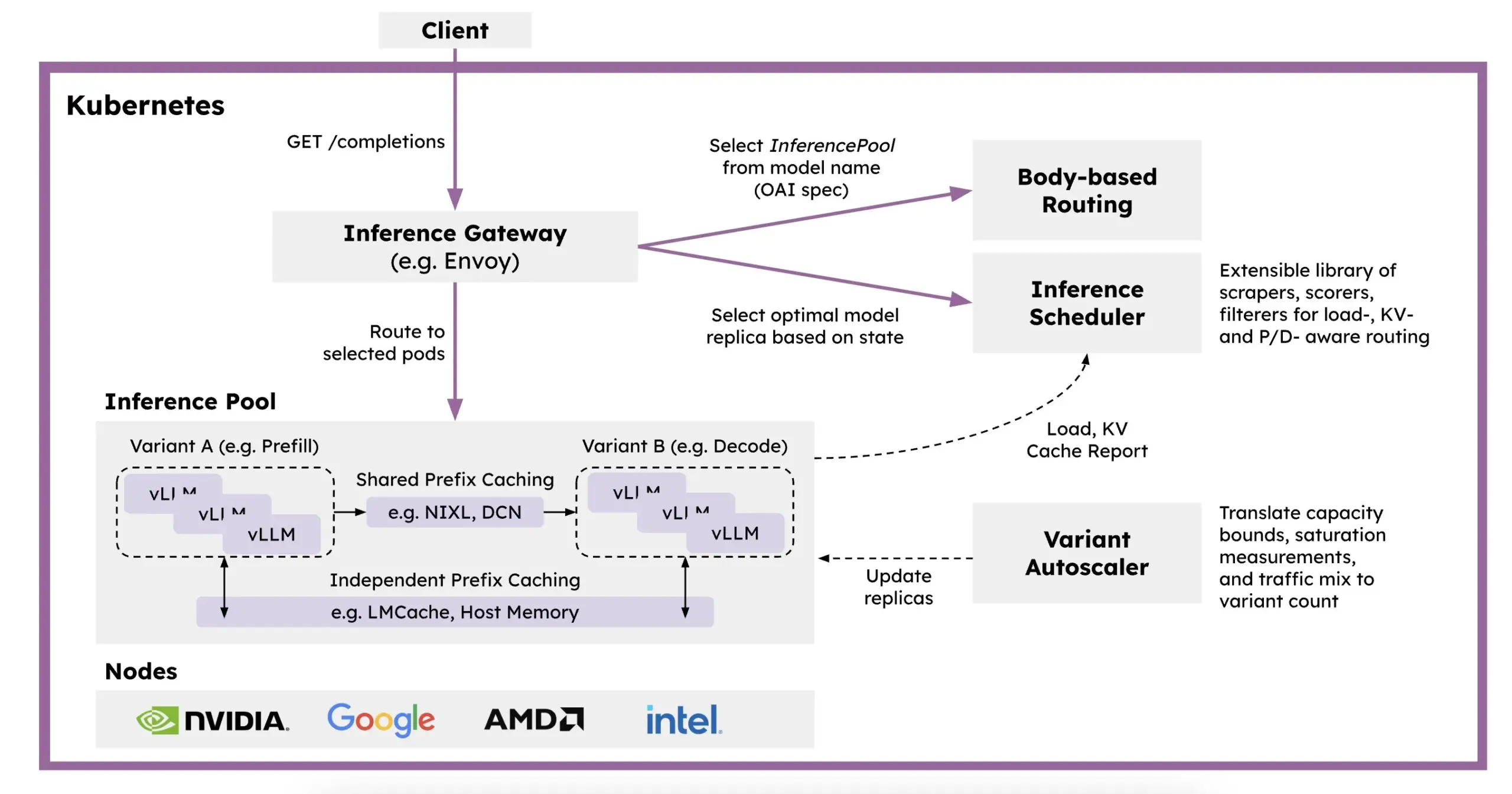
Red Hat presenta llm-d: un framework de inferencia distribuida basado en Kubernetes: Para abordar los problemas de lentitud, alto costo y dificultad de escalado de la inferencia de LLM, Red Hat ha lanzado llm-d, un framework de inferencia distribuida nativo de Kubernetes. Este framework utiliza vLLM, programación inteligente y cómputo desacoplado para optimizar la inferencia de LLM. llm-d se basa en tres pilares de código abierto: vLLM (motor de inferencia de LLM de alto rendimiento), Kubernetes (estándar de orquestación de contenedores) e Inference Gateway (IGW) (que implementa enrutamiento inteligente mediante la extensión Gateway API), con el objetivo de mejorar la eficiencia y escalabilidad de la inferencia de LLM (Fuente: X, X)
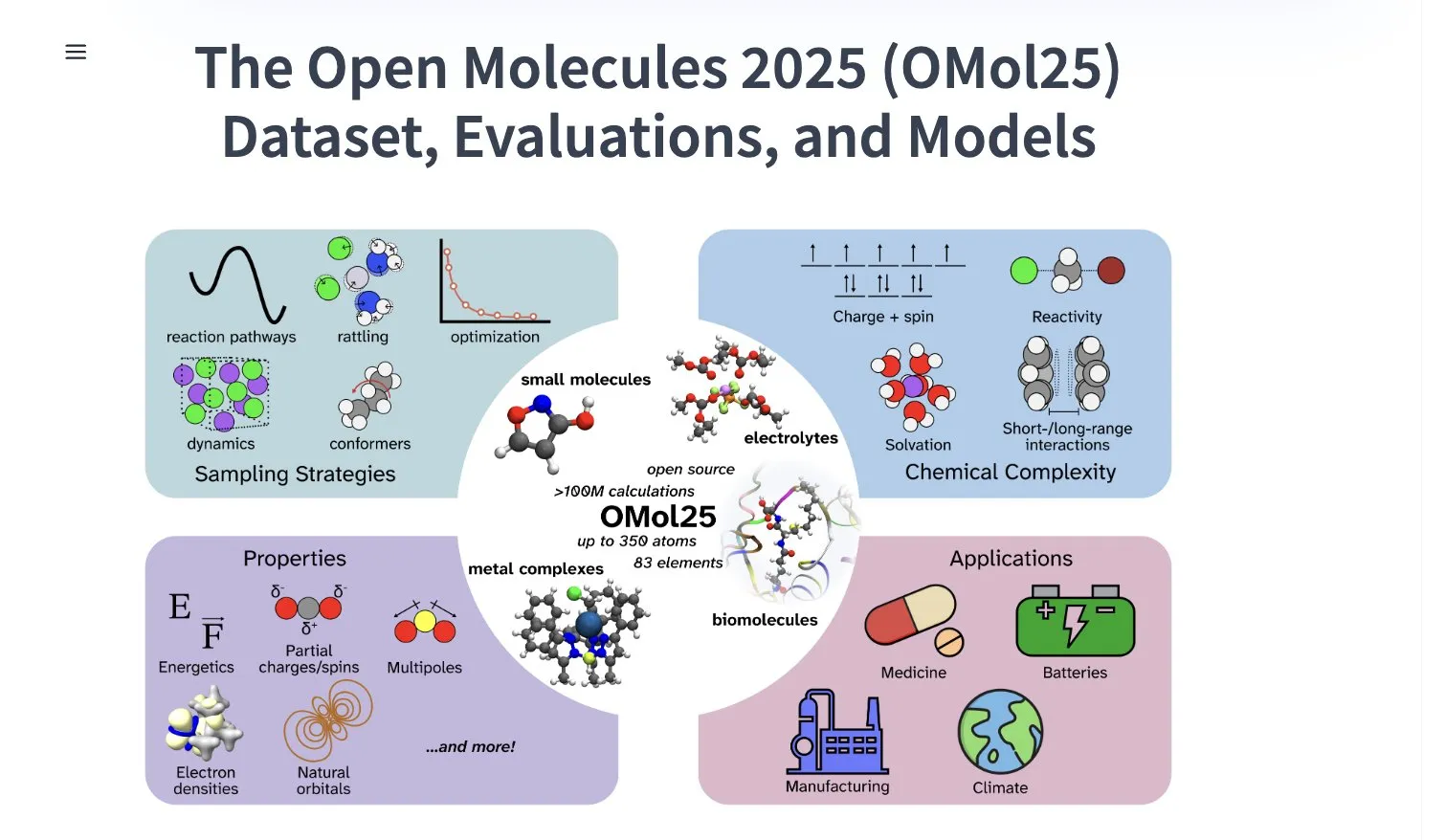
Meta AI publica el conjunto de datos OMol25, que contiene más de 100 millones de confórmeros moleculares: Meta AI ha publicado en HuggingFace el conjunto de datos OMol25, que incluye más de 100 millones de confórmeros moleculares, abarcando 83 elementos y diversos entornos químicos. Este conjunto de datos tiene como objetivo entrenar modelos de machine learning capaces de alcanzar una precisión a nivel de DFT (Teoría del Funcional de la Densidad), reduciendo significativamente los costos computacionales. Esto ayudará a acelerar la investigación y aplicación en áreas como el descubrimiento de fármacos, el diseño de materiales avanzados y las soluciones de energía limpia (Fuente: X)
Gemini 2.5 Pro en NotebookLM se lanza en la App Store de iOS en Alemania: La aplicación NotebookLM de Google (integrada con Gemini 2.5 Pro) ya está disponible en la App Store de iOS en Alemania. Anteriormente, la versión para iOS en la Unión Europea solo se ofrecía a través de TestFlight. Mientras tanto, la versión para Android parece estar disponible de forma más amplia. NotebookLM está diseñado para ayudar a los usuarios a comprender y procesar documentos largos, notas y otros contenidos (Fuente: X)
ByteDance activa en investigación de IA, publica múltiples artículos recientemente: El equipo SEED de ByteDance ha publicado al menos 13 artículos de investigación relacionados con la IA en los últimos dos meses, abarcando áreas como la fusión de modelos, la Chain-of-Thought adaptativa activada por aprendizaje por refuerzo (AdaCoT), la optimización de la inferencia mediante representaciones latentes (LatentSeek), entre otros. Estas investigaciones demuestran la continua inversión y exploración de ByteDance en la mejora de la eficiencia, la capacidad de razonamiento y los métodos de entrenamiento de los Large Language Models (Fuente: X, X)
La IA impulsa una nueva generación de baterías de zinc que alcanzan un 99.8% de eficiencia y 4300 horas de funcionamiento: Mediante la optimización con inteligencia artificial, una nueva generación de baterías de zinc ha logrado una eficiencia coulómbica del 99.8% y un tiempo de funcionamiento de hasta 4300 horas. Este avance tecnológico demuestra el potencial de aplicación de la IA en la ciencia de materiales y el almacenamiento de energía, y se espera que impulse el desarrollo de tecnologías de baterías más eficientes y duraderas, lo cual es de gran importancia para el almacenamiento de energía renovable y los dispositivos electrónicos portátiles (Fuente: X)

Perplexity lanza el navegador inteligente con IA Comet para pruebas tempranas: Perplexity ha comenzado a distribuir entre los primeros evaluadores su navegador web Comet, dotado de funcionalidades de agente inteligente. Se espera que este navegador ofrezca una nueva experiencia de “vibe browsing”, posiblemente combinando las potentes capacidades de búsqueda e integración de información mediante IA de Perplexity, para brindar a los usuarios una forma de navegación web más inteligente y personalizada (Fuente: X)
Intel lanza tarjetas gráficas Arc Pro Serie B de alta rentabilidad, enfocadas en gran VRAM: Intel ha presentado las tarjetas gráficas Arc Pro B50 (16GB VRAM, 299 dólares) y Arc Pro B60 (24GB VRAM, 500 dólares por tarjeta), diseñada para estaciones de trabajo de IA. La B60 supera a la Nvidia RTX A1000 en pruebas de inferencia de IA, y su mayor VRAM le otorga ventaja al ejecutar modelos grandes. La estación de trabajo Project Battlematrix utiliza procesadores Xeon y puede equipar hasta 8 GPUs B60 (192GB VRAM total), soportando modelos de más de 70 mil millones de parámetros. Esta medida se considera una estrategia de Intel para buscar un avance en rentabilidad en el mercado de hardware de IA (Fuente: 量子位)

Huawei Cloud lanza el supernodo CloudMatrix 384, mejorando la potencia de cómputo de IA: Huawei Cloud ha presentado el supernodo CloudMatrix 384, que utiliza una arquitectura de interconexión totalmente peer-to-peer, capaz de interconectar 384 tarjetas aceleradoras de IA para formar un super servidor en la nube, ofreciendo hasta 300 Petaflops de potencia de cómputo. Su objetivo es resolver los desafíos de eficiencia de comunicación, muro de memoria y fiabilidad en el entrenamiento e inferencia de IA. Esta arquitectura enfatiza especialmente la afinidad con los modelos MoE, el fortalecimiento del cómputo mediante la red y el almacenamiento, y ya se ha aplicado para soportar servicios de inferencia de modelos grandes como DeepSeek-R1 (Fuente: 量子位)

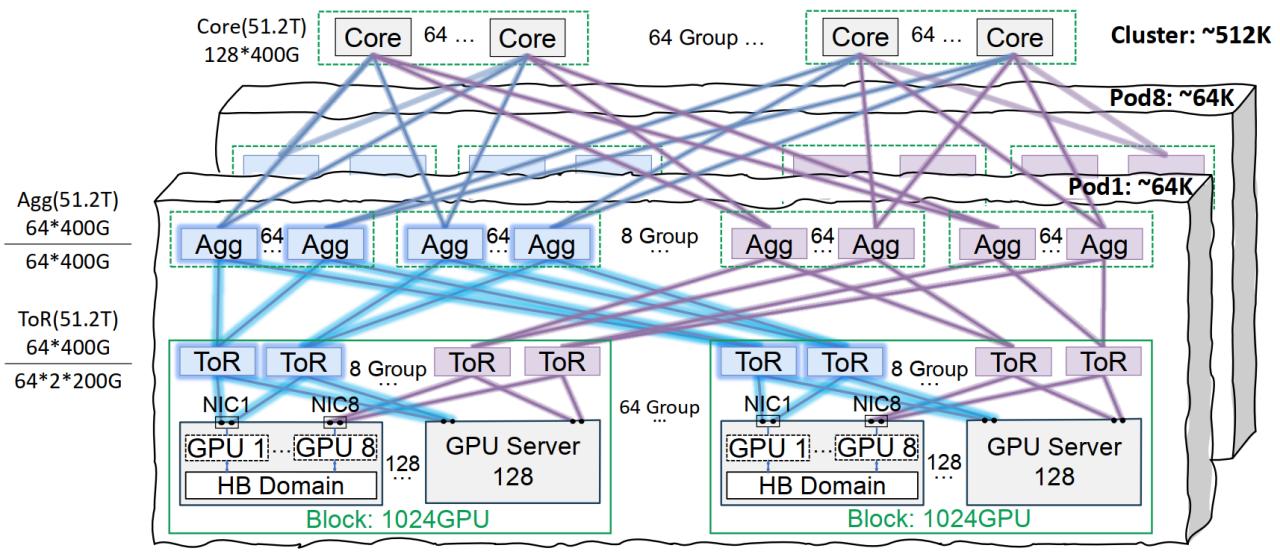
La infraestructura de red Xingmai de Tencent Cloud optimiza el entrenamiento de modelos grandes: Tencent Cloud ha lanzado la solución de infraestructura de red de alto rendimiento Xingmai, diseñada específicamente para el entrenamiento e inferencia de modelos de IA a gran escala. Esta solución, mediante una arquitectura de interconexión en el mismo carril (que soporta redes de 64,000 GPUs por Pod y 512,000 GPUs en todo el clúster), soluciones optimizadas de gestión de energía y refrigeración, y un sistema de monitorización inteligente, aborda los puntos débiles de los centros de datos tradicionales en cuanto a red, densidad de implementación y localización de fallos. Xingmai ya soporta negocios propios de Tencent como Hunyuan, y ha proporcionado optimización de rendimiento para el framework de comunicación DeepEP de DeepSeek (Fuente: 量子位)
Stability AI lanza el modelo SV4D2.0, lo que podría indicar su regreso al campo de la generación de vídeo: Stability AI ha lanzado en Hugging Face un modelo llamado sv4d2.0, generando atención en la comunidad. Aunque los detalles son escasos, esta medida podría significar que Stability AI tiene nuevos avances tecnológicos o iteraciones de productos en la generación de vídeo o campos relacionados 3D/4D, sugiriendo que, tras un período de ajuste, podría regresar a la vanguardia del campo de la IA generativa (Fuente: X)
Meta AI lanza el algoritmo de aprendizaje Adjoint Sampling: Meta AI ha propuesto un nuevo algoritmo de aprendizaje llamado Adjoint Sampling, para entrenar modelos generativos basados en recompensas escalares. Este algoritmo, basado en fundamentos teóricos desarrollados por FAIR, es altamente escalable y se espera que se convierta en la base para futuras investigaciones sobre métodos de muestreo escalables. Se han publicado el artículo de investigación, modelos, código y benchmarks relacionados (Fuente: X)
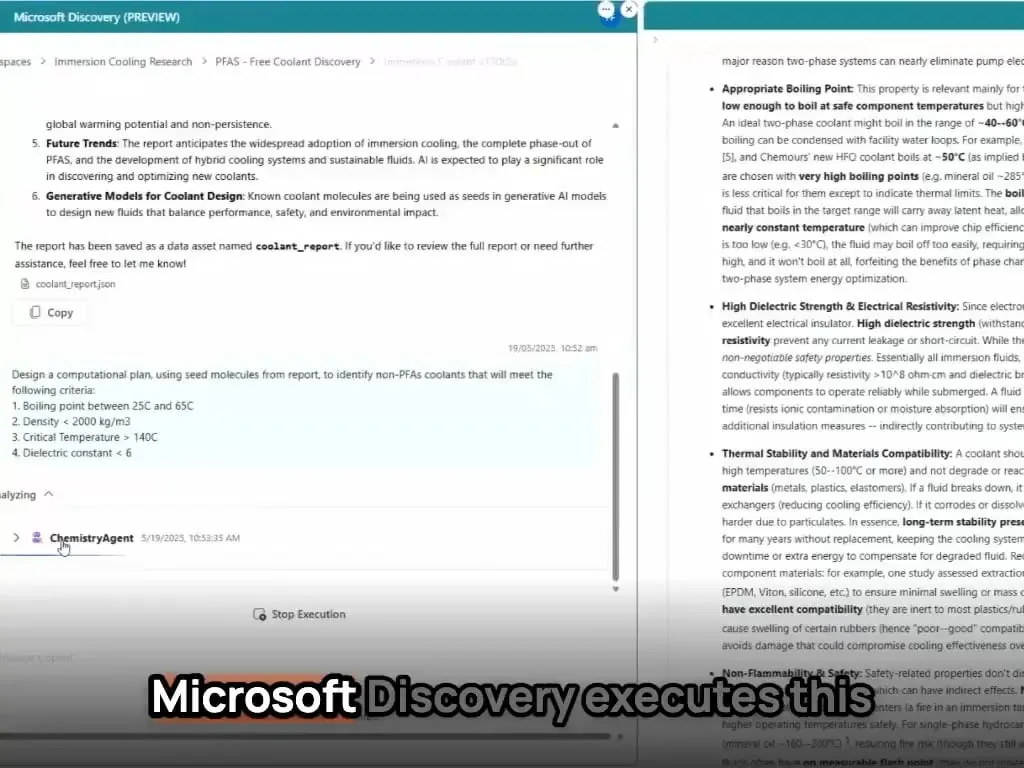
AI agents de Microsoft completan el descubrimiento y síntesis de nuevos materiales en cuestión de horas: Microsoft ha demostrado la potente capacidad de sus AI agents en la investigación y desarrollo científico. Estos agentes son capaces de escanear literatura científica, elaborar planes, escribir código, ejecutar simulaciones y completar en cuestión de horas el descubrimiento de un nuevo refrigerante para centros de datos, un proceso que normalmente requeriría años de investigación. Además, el equipo logró sintetizar con éxito el nuevo refrigerante diseñado por IA y realizó una demostración en una placa base real, mostrando el enorme potencial de la IA para acelerar el descubrimiento y la creación autónoma en campos como la ciencia de materiales (Fuente: Reddit r/artificial)
El Instituto de Investigación de Inteligencia Artificial de Beijing (BAAI) lanza tres modelos vectoriales de la serie BGE, enfocados en la recuperación de código y multimodal: El BAAI, en colaboración con universidades, ha lanzado BGE-Code-v1 (modelo vectorial de código), BGE-VL-v1.5 (modelo vectorial multimodal general) y BGE-VL-Screenshot (modelo vectorial de documentos visuales). Estos modelos han demostrado un rendimiento excelente en benchmarks como CoIR, Code-RAG, MMEB y MVRB. BGE-Code-v1 se basa en Qwen2.5-Coder-1.5B, BGE-VL-v1.5 en LLaVA-1.6, y BGE-VL-Screenshot en Qwen2.5-VL-3B-Instruct. Su objetivo es mejorar el rendimiento en la recuperación de código, la comprensión de imágenes y texto, y la recuperación de documentos visuales complejos, y ya son completamente de código abierto (Fuente: WeChat)
La tecnología OmniPlacement de Huawei optimiza la inferencia de modelos MoE, reduciendo teóricamente la latencia de DeepSeek-V3 en un 10%: Para abordar el problema del desequilibrio de carga en las redes de expertos (expertos “calientes” vs. “fríos”) en los modelos Mixture of Experts (MoE), que limita el rendimiento de la inferencia, el equipo de Huawei ha propuesto la tecnología OmniPlacement. Esta tecnología, mediante la reorganización de expertos, la implementación redundante entre capas y la programación dinámica casi en tiempo real, puede reducir teóricamente la latencia de inferencia en modelos como DeepSeek-V3 en aproximadamente un 10% y aumentar el throughput en aproximadamente un 10%. Esta solución será completamente de código abierto próximamente (Fuente: WeChat)

vivo lanza el algoritmo EdgeInfinite, logrando un procesamiento eficiente de texto largo de 128K en dispositivos móviles: El Instituto de Investigación de IA de vivo ha publicado una investigación en ACL 2025, presentando el algoritmo EdgeInfinite, diseñado específicamente para dispositivos edge. Mediante un módulo de memoria controlada entrenable y tecnologías de compresión/descompresión de memoria, procesa eficientemente texto ultralargo en la arquitectura Transformer. Este algoritmo, probado en el modelo BlueLM-3B, puede procesar 128K tokens en dispositivos con 10GB de memoria GPU y ha demostrado un rendimiento excelente en múltiples tareas de LongBench, reduciendo significativamente el tiempo hasta el primer token y el consumo de memoria (Fuente: WeChat)

🧰 Herramientas
LlamaParse se actualiza, mejorando la capacidad de análisis de documentos: LlamaParse ha lanzado múltiples actualizaciones, mejorando su rendimiento como herramienta de análisis de documentos impulsada por AI agents. Las nuevas funciones incluyen soporte para Gemini 2.5 Pro y GPT-4.1, y la adición de detección de sesgo (skew detection) y puntuaciones de confianza. Además, se ha introducido un botón de fragmentos de código para que los usuarios puedan copiar directamente la configuración de análisis a sus repositorios de código, y se han añadido preajustes de casos de uso y la capacidad de cambiar entre la exportación en Markdown renderizado o sin formato (Fuente: X)
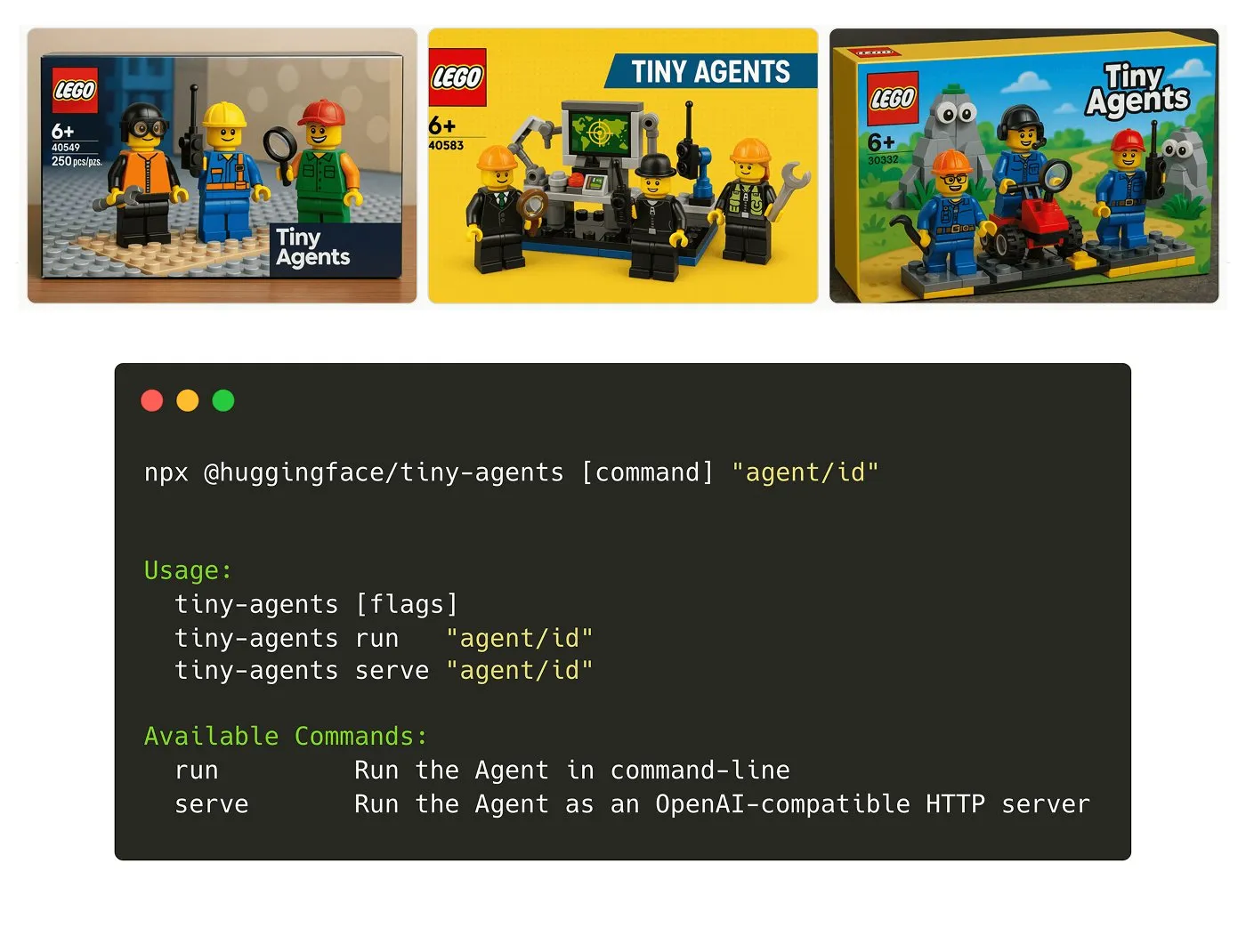
Hugging Face lanza el paquete NPM Tiny Agents: Julien Chaumond ha lanzado Tiny Agents, un paquete NPM de agentes ligero y componible. Está construido sobre el Inference Client de Hugging Face y la pila MCP (Model Component Protocol), con el objetivo de facilitar a los desarrolladores el inicio rápido y la construcción de pequeñas aplicaciones de agentes. Se proporciona un tutorial de inicio oficial (Fuente: X)
La plataforma LangGraph añade soporte para MCP, simplificando la integración de agentes: La plataforma LangGraph ahora soporta MCP (Model Component Protocol). Cada agente desplegado en la plataforma expondrá automáticamente un endpoint MCP. Esto significa que los usuarios pueden utilizar estos agentes como herramientas en cualquier cliente que soporte MCP sobre HTTP con streaming, sin necesidad de escribir código personalizado o configurar infraestructura adicional, simplificando la integración e interoperabilidad entre agentes (Fuente: X)

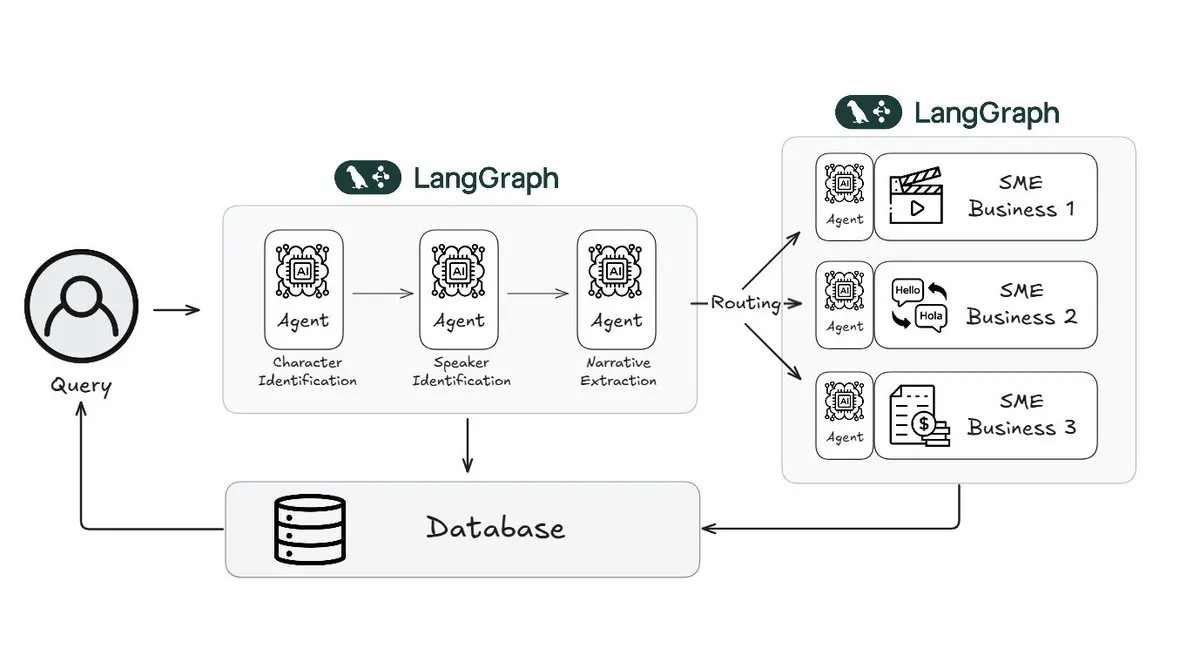
Webtoon utiliza LangGraph para reducir la carga de trabajo de revisión de historias en un 70%: Webtoon, líder en cómics digitales, ha construido Webtoon Comprehension AI (WCAI), utilizando LangGraph para automatizar la comprensión narrativa de su masiva biblioteca de contenido. WCAI reemplaza la revisión manual con agentes multimodales inteligentes capaces de realizar identificación de personajes y hablantes, extracción de tramas y tonos, y consultas de insights en lenguaje natural, reduciendo la carga de trabajo de sus equipos de marketing, traducción y recomendación en un 70% y aumentando la creatividad (Fuente: X)
OpenMemory MCP permite compartir memoria privada persistente entre herramientas de IA: El proyecto Mem0 ha lanzado el servidor OpenMemory MCP, diseñado para proporcionar memoria privada persistente entre plataformas y sesiones para aplicaciones de IA. Los usuarios pueden desplegarlo localmente y conectar OpenMemory a herramientas cliente como Cursor a través del protocolo MCP, permitiendo añadir, buscar, listar y eliminar recuerdos. Esta herramienta ofrece funciones de gestión de memoria a través de un panel de control y se espera que mejore la personalización y la capacidad de comprensión contextual de los AI agents (Fuente: WeChat)

Miaoduo AI 2.0 se lanza, posicionándose como asistente de IA para diseño de interfaces: Miaoduo AI 2.0 se ha lanzado como un asistente de IA en el campo del diseño de interfaces, con el objetivo de colaborar con los usuarios para completar tareas de diseño. La nueva versión mejora la interacción a través de un “cuadro mágico de IA”, soporta la edición conversacional y el diseño iterativo de soluciones, puede generar múltiples versiones de interfaces basadas en estilos preestablecidos o entradas del usuario (texto largo, bocetos, imágenes de referencia), y es compatible con los principales sistemas de diseño. Además, ofrece procesamiento de imágenes y texto, consultoría de diseño y comandos rápidos (lenguaje natural a llamada API). Miaoduo AI es compatible con el protocolo MCP y optimiza los datos de los diseños para que los modelos grandes los lean y generen código frontend de alta fidelidad (Fuente: 量子位)

llmbasedos: Prueba de concepto de sistema operativo de IA de código abierto y arrancable basado en MCP: El desarrollador iluxu, tres días antes de que Microsoft anunciara el concepto “USB-C for AI apps” (basado en MCP), liberó el proyecto de código abierto llmbasedos. Este proyecto es un sistema operativo de IA que se puede arrancar rápidamente desde un USB o una máquina virtual. Se comunica a través de una puerta de enlace FastAPI con pequeños demonios Python mediante JSON-RPC, permitiendo que los scripts de usuario sean invocados por ChatGPT/Claude/VS Code, etc., mediante una simple configuración cap.json. Por defecto, utiliza llama.cpp sin conexión, pero también se puede cambiar a GPT-4o o Claude 3. Su objetivo es promover un estándar abierto de conexión para aplicaciones de IA (Fuente: Reddit r/LocalLLaMA)
📚 Aprendizaje
¿Por qué es eficaz la Knowledge Distillation (KD)? Una nueva investigación ofrece una explicación concisa: Kyunghyun Cho y otros proponen una explicación concisa para la eficacia de la Knowledge Distillation (KD). Suponen que el uso de un muestreo aproximado de baja entropía del modelo profesor conduce a que el modelo estudiante tenga una mayor precisión pero una menor exhaustividad (recall). Dado que los modelos de lenguaje autorregresivos son esencialmente cascadas infinitas de distribuciones mixtas, verificaron esta hipótesis a través de SmolLM. El estudio argumenta que los métodos de evaluación actuales pueden centrarse demasiado en la precisión, ignorando la pérdida de exhaustividad, lo que se relaciona con el contenido y los grupos de usuarios que los modelos generales a gran escala podrían omitir (Fuente: X)

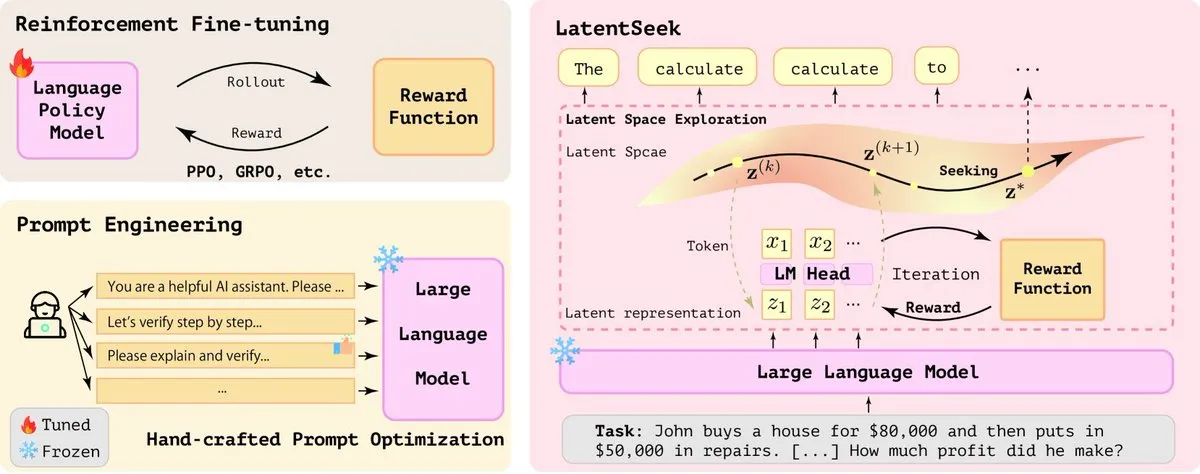
LatentSeek: Mejora de la capacidad de razonamiento de los LLM mediante la optimización con gradiente de política en el espacio latente en tiempo de prueba: Un artículo titulado “Seek in the Dark” propone LatentSeek, un nuevo paradigma para mejorar la capacidad de razonamiento de los Large Language Models (LLM) en tiempo de prueba mediante el gradiente de política a nivel de instancia en el espacio latente. Este método no requiere entrenamiento, datos ni modelos de recompensa, y tiene como objetivo mejorar el proceso de razonamiento del modelo optimizando las representaciones latentes. Este enfoque independiente del entrenamiento muestra potencial para mejorar el rendimiento de los LLM en tareas de razonamiento complejo (Fuente: X)
Microsoft propone CoML: Chain-of-Model Learning para modelos de lenguaje: Microsoft Research ha propuesto un nuevo paradigma de aprendizaje llamado “Chain-of-Model Learning” (CoML). Este método integra las relaciones causales de los estados ocultos en una estructura de cadena en cada capa de la red, con el objetivo de mejorar la eficiencia de escalado del entrenamiento del modelo y la flexibilidad de inferencia en el despliegue. Su concepto central, “Chain-of-Representation” (CoR), descompone el estado oculto de cada capa en múltiples cadenas de sub-representaciones. Las cadenas posteriores pueden acceder a las representaciones de entrada de todas las cadenas anteriores, permitiendo así que el modelo se expanda progresivamente añadiendo cadenas y pueda ofrecer submodelos de diversas escalas para una inferencia elástica seleccionando diferentes cantidades de cadenas. El CoLM (Chain-of-Language-Model) diseñado bajo este principio y su variante CoLM-Air (que introduce un mecanismo de compartición de KV) demuestran un rendimiento comparable al Transformer estándar, aportando las ventajas de la expansión progresiva y la inferencia elástica (Fuente: X, HuggingFace Daily Papers)

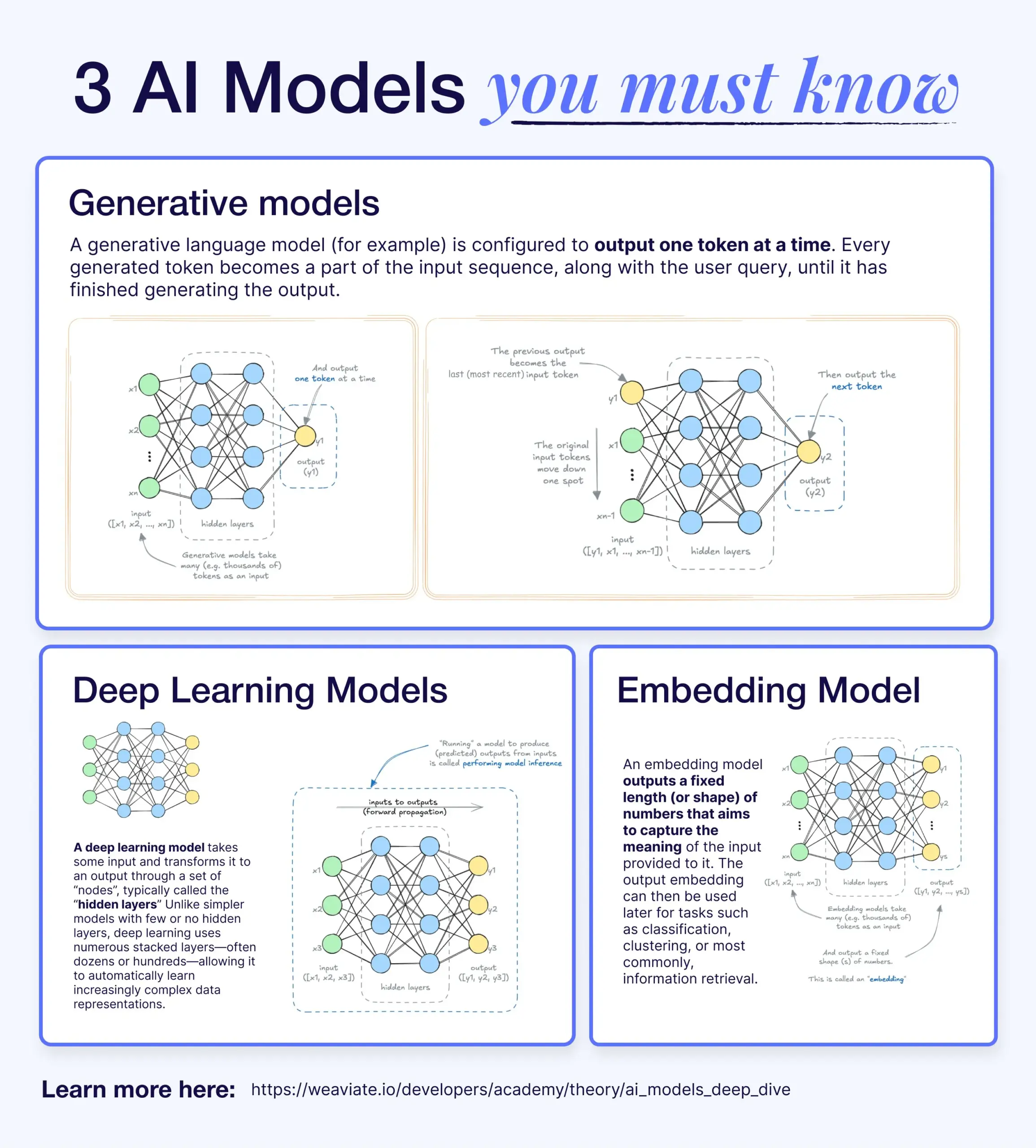
Diferencias y conexiones entre Deep Learning, modelos generativos y modelos de incrustación: Un artículo divulgativo explica la relación entre los modelos de Deep Learning, los modelos generativos y los modelos de incrustación (embedding models). Los modelos de Deep Learning son la infraestructura base, que procesan entradas y salidas numéricas a través de redes neuronales multicapa. Los modelos generativos son un tipo de modelo de Deep Learning, especializados en crear nuevo contenido similar a sus datos de entrenamiento (como GPT, DALL-E). Los modelos de incrustación también son un tipo de modelo de Deep Learning, utilizados para convertir datos (texto, imágenes, etc.) en representaciones vectoriales numéricas que capturan información semántica, comúnmente utilizados en búsqueda de similitud y sistemas RAG. En muchos sistemas de IA, estos modelos trabajan en conjunto; por ejemplo, un sistema RAG utiliza modelos de incrustación para la recuperación y luego un modelo generativo para generar la respuesta (Fuente: X)
DSPy propone una filosofía de inversión en sistemas de IA: DSPy comparte su filosofía sobre la inversión en sistemas de IA, enfatizando que los esfuerzos deben centrarse en las tres capas fundamentales de los sistemas de IA: datos, modelos y algoritmos. Argumentan que, al proporcionar módulos componibles de alto nivel (Prompts, Demonstrations, Optimizers, Metrics, Tools, Agents, Reasoning Modules), los desarrolladores pueden iterar rápidamente sobre estas tres capas fundamentales, construyendo así sistemas de IA más potentes (Fuente: X)
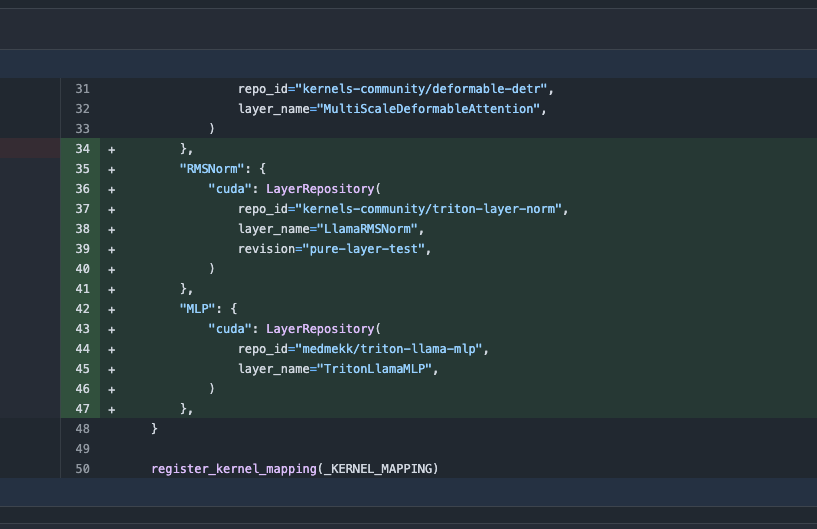
Actualización de la biblioteca Transformers, cambia automáticamente a núcleos optimizados para mejorar el rendimiento: La última versión de la biblioteca Transformers de Hugging Face implementa el cambio automático a núcleos optimizados cuando el hardware lo permite. Esta actualización integra la biblioteca kernels, dirigida a modelos populares como Llama, utilizando los núcleos comunitarios más populares de Hugging Face Hub, con el objetivo de mejorar la eficiencia y el rendimiento de los modelos en hardware compatible (Fuente: X)
Publicado el benchmark ARC-AGI-2, desafiando a los sistemas de IA de vanguardia en razonamiento: François Chollet y otros han publicado un artículo sobre el benchmark ARC-AGI-2, detallando sus principios de diseño, su dificultad, el análisis del rendimiento humano y el rendimiento de los modelos actuales. Este benchmark tiene como objetivo evaluar la capacidad de razonamiento abstracto de la IA. Los humanos pueden resolver el 100% de las tareas, mientras que los modelos de IA de vanguardia actuales obtienen puntuaciones inferiores al 5%, lo que demuestra una enorme brecha entre la IA y los humanos en el razonamiento abstracto avanzado (Fuente: X)

Terence Tao publica un tutorial sobre cómo usar GitHub Copilot para ayudar a demostrar límites de funciones: El matemático Terence Tao ha publicado un video tutorial que demuestra cómo usar GitHub Copilot para ayudar a demostrar problemas de límites de funciones, incluyendo teoremas de suma, resta y producto. Enfatiza que, aunque Copilot puede generar rápidamente el esqueleto del código y sugerir funciones de bibliotecas existentes, todavía se requiere una gran cantidad de intervención y ajuste manual en detalles matemáticos complejos, manejo de casos especiales y soluciones creativas. A veces, combinar la deducción en papel y lápiz antes de la verificación formal puede ser más eficiente (Fuente: 36氪)
El framework PhyT2V utiliza LLM para mejorar la consistencia física en la generación de vídeo a partir de texto: Un equipo de investigación de la Universidad de Pittsburgh ha propuesto el framework PhyT2V, que mediante un razonamiento en cadena (CoT) guiado por Large Language Models y un mecanismo de autocorrección iterativa, optimiza los prompts de texto para mejorar el realismo físico del contenido generado por los modelos existentes de texto a vídeo (T2V). Este método no requiere reentrenamiento del modelo; analiza los desajustes semánticos entre el vídeo ya generado y el prompt, y combina reglas físicas para corregir el prompt, con el objetivo de mejorar la consistencia física de los modelos T2V al procesar escenarios fuera de distribución (OOD). Los experimentos demuestran que PhyT2V puede mejorar significativamente el rendimiento de modelos como CogVideoX y OpenSora en benchmarks como VideoPhy y PhyGenBench (Fuente: WeChat)

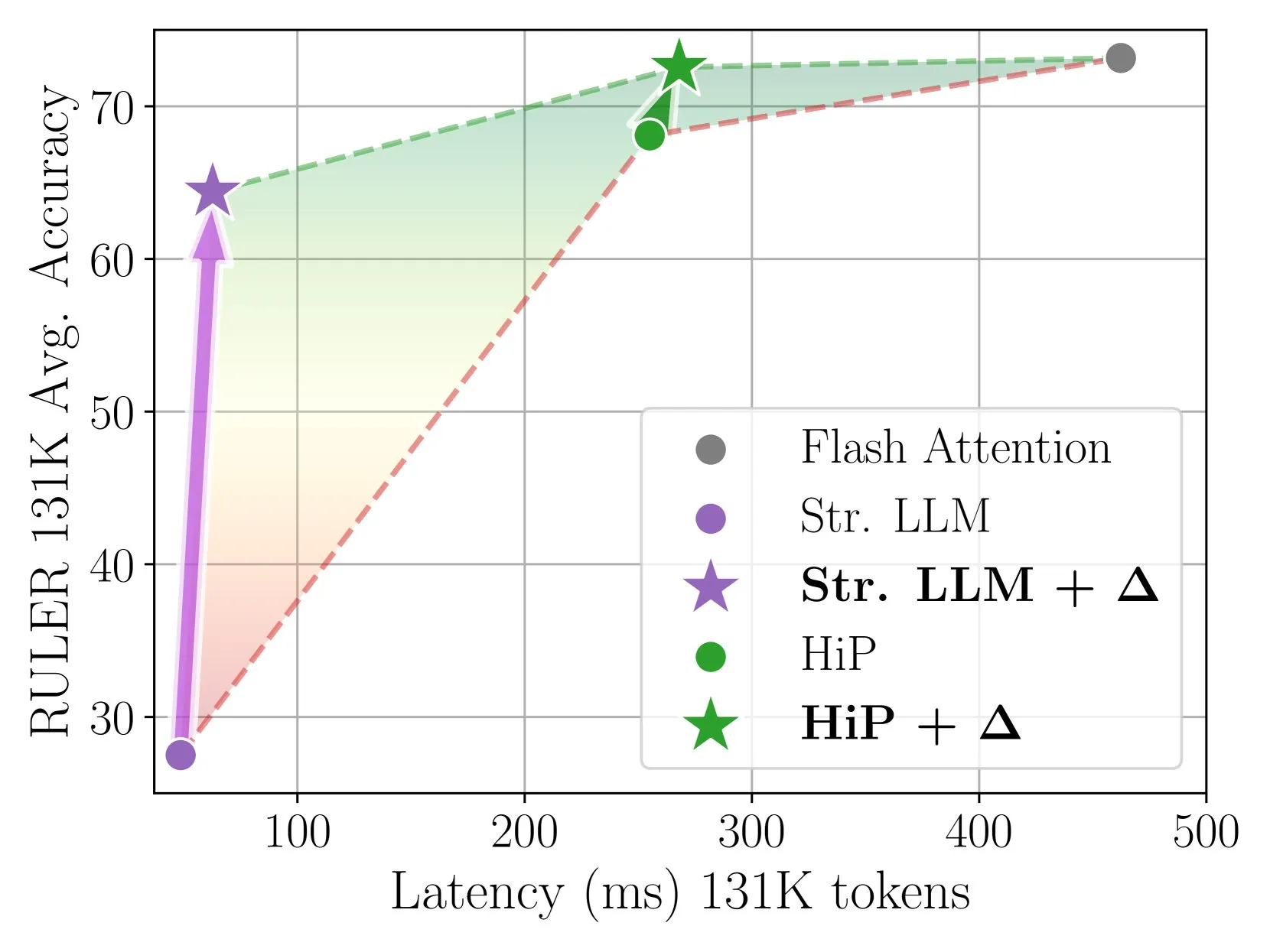
Delta Attention logra una inferencia de atención dispersa rápida y precisa mediante corrección incremental: Esta investigación descubre que el cálculo de atención dispersa (sparse attention) provoca un desplazamiento en la distribución de la salida de la atención, lo que reduce el rendimiento del modelo. Delta Attention, al corregir este desplazamiento de distribución, hace que la distribución de salida de la atención dispersa se asemeje más a la de la atención completa. De este modo, manteniendo una alta dispersión (aproximadamente 98.5%), mejora significativamente el rendimiento, recuperando el 88% de la precisión de la atención completa de la atención de ventana deslizante (con sink tokens) en el benchmark RULER, y con un bajo costo computacional. Al procesar un prellenado de 1M de tokens, es 32 veces más rápido que Flash Attention 2 (Fuente: HuggingFace Daily Papers)
El framework Thinkless permite a los LLM aprender cuándo realizar razonamiento CoT: Para resolver el problema de la ineficiencia computacional causada por el uso de un complejo razonamiento Chain-of-Thought (CoT) por parte de los Large Language Models (LLM) en todas las consultas, los investigadores proponen el framework Thinkless. Este framework entrena a los LLM mediante aprendizaje por refuerzo para que puedan elegir adaptativamente entre un razonamiento corto o largo según la complejidad de la tarea y su propia capacidad. El algoritmo central DeGRPO descompone el objetivo de aprendizaje en una pérdida de token de control (que decide el modo de razonamiento) y una pérdida de respuesta (que mejora la precisión de la respuesta), estabilizando así el proceso de entrenamiento. Los experimentos demuestran que Thinkless puede reducir el uso de cadenas de pensamiento largas en un 50%-90% en benchmarks como Minerva Algebra, mejorando significativamente la eficiencia de la inferencia (Fuente: HuggingFace Daily Papers)
El algoritmo CPGD mejora la estabilidad del aprendizaje por refuerzo de modelos de lenguaje basados en reglas: Para abordar el problema de la posible inestabilidad en el entrenamiento de modelos de lenguaje que pueden presentar los métodos existentes de aprendizaje por refuerzo basados en reglas (como GRPO, REINFORCE++, RLOO), los investigadores proponen el algoritmo CPGD (Optimización de Gradiente de Política Recortado con Deriva de Política). CPGD introduce una restricción de deriva de política basada en la divergencia KL para regularizar dinámicamente la actualización de la política, y utiliza un mecanismo de recorte de la razón logarítmica para evitar actualizaciones excesivas de la política. El análisis teórico y empírico demuestra que CPGD puede mitigar la inestabilidad y mejorar significativamente el rendimiento mientras mantiene la estabilidad del entrenamiento (Fuente: HuggingFace Daily Papers)
El compilador de consultas neurosimbólicas QCompiler mejora la capacidad de los sistemas RAG para procesar consultas complejas: Para resolver el problema de que los sistemas de Retrieval Augmented Generation (RAG), al procesar consultas complejas con estructuras anidadas y dependencias, especialmente en situaciones de recursos limitados, tienen dificultades para identificar con precisión la intención de búsqueda, se ha propuesto el framework QCompiler. Este framework, inspirado en las reglas gramaticales lingüísticas y el diseño de compiladores, primero diseña una gramática BNF mínima y suficiente G[q] para formalizar consultas complejas. Luego, mediante un transformador de expresiones de consulta, un analizador léxico-sintáctico y un procesador de descenso recursivo, compila la consulta en un Árbol de Sintaxis Abstracta (AST) para su ejecución. La atomicidad de las subconsultas en los nodos hoja asegura una recuperación de documentos y generación de respuestas más precisas (Fuente: HuggingFace Daily Papers)
El conjunto de datos Jedi y el benchmark OSWorld-G impulsan la investigación sobre la localización de elementos GUI en escenarios de uso de computadoras: Para abordar el cuello de botella en la localización en Interfaces Gráficas de Usuario (GUI) (mapear instrucciones en lenguaje natural a operaciones GUI), los investigadores han publicado el benchmark OSWorld-G (564 muestras anotadas con granularidad fina, que cubren coincidencia de texto, reconocimiento de elementos, comprensión de diseño y operaciones precisas) y el conjunto de datos sintético a gran escala Jedi (4 millones de muestras). Los modelos multiescala entrenados en Jedi superan a los métodos existentes en ScreenSpot-v2, ScreenSpot-Pro y OSWorld-G, y pueden mejorar la capacidad de los agentes de los modelos fundacionales generales en tareas informáticas complejas (OSWorld), pasando del 5% al 27% (Fuente: HuggingFace Daily Papers)
El razonamiento Chain-of-Thought fragmentado (Fractured CoT) mejora la eficiencia y el rendimiento de la inferencia en LLM: Para abordar el alto costo de tokens asociado con el razonamiento CoT, los investigadores descubrieron que truncar el CoT (detener el razonamiento antes de completarlo y generar directamente la respuesta) generalmente puede alcanzar un rendimiento comparable al CoT completo, pero con un consumo de tokens significativamente menor. Basándose en esto, proponen la estrategia de inferencia unificada Fractured Sampling, que ajustando tres dimensiones (el número de trayectorias de razonamiento, el número de soluciones finales por trayectoria y la profundidad de truncamiento de la traza de razonamiento) logra un mejor equilibrio entre precisión y costo en múltiples benchmarks de razonamiento y escalas de modelos, allanando el camino para una inferencia de LLM más eficiente y escalable (Fuente: HuggingFace Daily Papers)
Validación multimodal de fórmulas químicas mediante condicionamiento contextual de LLM y prompting PWP: Los investigadores exploran el condicionamiento contextual estructurado de LLM, combinado con los principios de Persistent Workflow Prompting (PWP), para ajustar el comportamiento de los LLM durante el razonamiento, con el objetivo de mejorar su fiabilidad en tareas de validación precisa (como fórmulas químicas), especialmente al procesar documentos científicos complejos que contienen imágenes. Este método utiliza únicamente interfaces de chat estándar (Gemini 2.5 Pro, ChatGPT Plus o3), sin necesidad de API o modificaciones del modelo. Los experimentos preliminares demuestran que este método mejora la identificación de errores textuales y ayudó a Gemini 2.5 Pro a identificar errores en fórmulas de imágenes que la revisión manual había pasado por alto (Fuente: HuggingFace Daily Papers)
Uso de PWP, meta-prompting y meta-razonamiento para la revisión por pares académica impulsada por IA: Los investigadores proponen el método de Persistent Workflow Prompting (PWP) para realizar revisiones críticas por pares de manuscritos científicos a través de interfaces de chat LLM estándar. PWP adopta una arquitectura modular jerárquica (estructurada en Markdown) para definir flujos de trabajo de análisis detallados, codificando sistemáticamente los procesos de revisión experta (incluido el conocimiento tácito) mediante meta-prompting y meta-razonamiento. PWP guía al LLM para realizar una evaluación multimodal sistemática, como distinguir afirmaciones de evidencia, integrar análisis de texto/imágenes/gráficos, realizar comprobaciones de viabilidad cuantitativa, etc. En los casos de prueba, identificó con éxito deficiencias metodológicas (Fuente: HuggingFace Daily Papers)
El benchmark SPOT evalúa la capacidad de la IA para validar automáticamente la investigación científica: Para evaluar la capacidad de los Large Language Models (LLM) como “co-científicos de IA” en la validación automatizada de manuscritos académicos, los investigadores han lanzado el benchmark SPOT. Este benchmark incluye 83 artículos publicados y 91 errores lo suficientemente graves como para justificar erratas o retractaciones, validados cruzadamente por los autores originales y anotadores humanos. Los resultados experimentales muestran que incluso los LLM más avanzados (como o3) no superan el 21.1% de exhaustividad (recall) en SPOT, con una precisión inferior al 6.1%. Además, la confianza del modelo es baja y los resultados son inconsistentes entre ejecuciones, lo que indica que los LLM actuales están muy lejos de las necesidades reales para una validación académica fiable (Fuente: HuggingFace Daily Papers)
ExTrans logra traducción con razonamiento profundo multilingüe mediante aprendizaje por refuerzo con aumento de muestras: Para mejorar la capacidad de los modelos de razonamiento grande (LRM) en traducción automática, especialmente en escenarios multilingües, los investigadores proponen ExTrans. Este método diseña un nuevo enfoque de modelado de recompensas, cuantificando la recompensa al comparar las traducciones del modelo de política con las de un LRM fuerte (como DeepSeek-R1-671B). Los experimentos demuestran que un modelo entrenado con Qwen2.5-7B-Instruct como base alcanza el estado del arte en traducción literaria y supera a OpenAI-o1 y DeepSeeK-R1. Mediante un modelado de recompensas ligero, este método puede transferir eficazmente la capacidad de traducción unidireccional a 90 direcciones de traducción en 11 idiomas (Fuente: HuggingFace Daily Papers)
VSA, una atención dispersa entrenable, acelera los modelos de difusión de vídeo: Para abordar el problema de la complejidad cuadrática del mecanismo de atención 3D completa en los Diffusion Transformers de vídeo (DiT), los investigadores proponen VSA (Trainable Sparse Attention). VSA agrupa los tokens en bloques mediante una fase preliminar ligera e identifica los tokens clave, para luego realizar cálculos de atención a nivel de token de grano fino dentro de estos bloques. VSA es un único núcleo diferenciable entrenable de extremo a extremo, que no requiere análisis de postprocesamiento y mantiene el 85% del MFU de FlashAttention3. Los experimentos demuestran que VSA reduce los FLOPS de entrenamiento en 2.53 veces sin disminuir la pérdida de difusión, y acelera el tiempo de atención del modelo de código abierto Wan-2.1 en 6 veces, reduciendo el tiempo de generación de extremo a extremo de 31 a 18 segundos (Fuente: HuggingFace Daily Papers)
SoftCoT++: Expansión en tiempo de prueba mediante razonamiento Chain-of-Thought flexible: Para mejorar la capacidad de exploración del método SoftCoT, que realiza razonamiento en un espacio latente continuo, los investigadores proponen SoftCoT++. Este método perturba las ideas latentes mediante diversas perturbaciones especializadas de tokens iniciales y aplica aprendizaje contrastivo para promover la diversidad de las representaciones de ideas flexibles, extendiendo así SoftCoT al paradigma de expansión en tiempo de prueba (TTS). Los experimentos demuestran que SoftCoT++ mejora significativamente el rendimiento de SoftCoT y supera a SoftCoT con expansión de autoconsistencia, además de ser altamente compatible con técnicas de expansión tradicionales como la autoconsistencia (Fuente: HuggingFace Daily Papers)
MTVCrafter: Tokenización de movimiento 4D para la animación de imágenes humanas en mundos abiertos: Para resolver el problema de que los métodos existentes dependen de imágenes de pose 2D, lo que limita su capacidad de generalización, MTVCrafter propone modelar directamente secuencias de movimiento 3D originales (movimiento 4D). Su núcleo es 4DMoT (4D Motion Tokenizer), que cuantifica secuencias de movimiento 3D en tokens de movimiento 4D, proporcionando pistas espacio-temporales más robustas. Luego, mediante un diseño único de atención al movimiento y codificación de posición 4D, MV-DiT (Motion-aware Video DiT) utiliza eficazmente estos tokens como contexto para lograr la animación de imágenes humanas en mundos 3D complejos. Los experimentos demuestran que MTVCrafter alcanza 6.98 en FID-VID, superando significativamente el estado del arte, y puede generalizar bien a múltiples personajes en diferentes estilos y escenarios (Fuente: HuggingFace Daily Papers)
QVGen: Llevando al límite los modelos de generación de vídeo cuantizados: Para abordar la gran demanda computacional y de memoria de los modelos de difusión de vídeo (DM), QVGen propone un nuevo framework de entrenamiento consciente de la cuantización (QAT) diseñado específicamente para cuantización de bits extremadamente bajos (como 4 bits e inferiores). Mediante análisis teórico, los investigadores descubren que reducir la norma del gradiente es crucial para la convergencia de QAT e introducen un módulo auxiliar (Phi) para mitigar grandes errores de cuantización. Para eliminar el costo de inferencia de Phi, proponen una estrategia de decaimiento de rango, eliminando gradualmente Phi mediante SVD y regularización basada en el rango. Los experimentos demuestran que QVGen, en una configuración de 4 bits, alcanza por primera vez una calidad comparable a la de precisión completa y supera significativamente a los métodos existentes (Fuente: HuggingFace Daily Papers)
ViPlan: Benchmark de predicados simbólicos y modelos de lenguaje visual para la planificación visual: Para cerrar la brecha comparativa entre la planificación simbólica impulsada por VLM y los métodos de planificación directa con VLM, se ha propuesto ViPlan como el primer benchmark de planificación visual de código abierto. ViPlan incluye tareas de dificultad creciente en dos dominios principales: una versión visual de Blocksworld y un entorno simulado de robot doméstico. Las pruebas de benchmark en 9 familias de VLM de código abierto y algunos modelos de código cerrado revelaron que la planificación simbólica funciona mejor en Blocksworld (donde la localización precisa de imágenes es clave), mientras que la planificación directa con VLM es superior en tareas de robot doméstico (donde el conocimiento de sentido común y la capacidad de recuperación de errores son importantes). El estudio también indica que el prompting CoT no ofrece beneficios significativos para la mayoría de los modelos y métodos, lo que sugiere que la capacidad actual de razonamiento visual de los VLM aún es deficiente (Fuente: HuggingFace Daily Papers)
De los gritos primarios a la gramática: un estudio sobre la evolución del lenguaje en entornos cooperativos de búsqueda de alimento: Para investigar el origen y la evolución del lenguaje, los investigadores simularon escenarios cooperativos de los primeros humanos en un juego de búsqueda de alimento multiagente. Mediante aprendizaje por refuerzo profundo de extremo a extremo, los agentes aprendieron desde cero estrategias de acción y comunicación. El estudio descubrió que los protocolos de comunicación desarrollados por los agentes exhibían características distintivas del lenguaje natural: arbitrariedad, intercambiabilidad, desplazamiento, transmisión cultural y composicionalidad. Este marco proporciona una plataforma para estudiar cómo evoluciona el lenguaje en entornos multiagente encarnados, parcialmente observables, que requieren razonamiento temporal e impulsados por objetivos cooperativos (Fuente: HuggingFace Daily Papers)
Tiny QA Benchmark++: Generación de conjuntos de datos sintéticos multilingües ultraligeros y prueba de humo para la evaluación continua de LLM: Tiny QA Benchmark++ (TQB++) es un conjunto de pruebas de humo (smoke test) ultraligero y multilingüe, diseñado para proporcionar una red de seguridad similar a las pruebas unitarias para los pipelines de LLM, que se puede ejecutar en segundos a un costo extremadamente bajo. TQB++ incluye un conjunto de referencia (golden set) en inglés de 52 ítems y proporciona un generador de datos sintéticos en miniatura basado en LiteLLM (paquete pypi), que permite a los usuarios generar pequeños paquetes de prueba personalizados por idioma, dominio o dificultad. El proyecto ya ofrece paquetes prefabricados en 10 idiomas y es compatible con herramientas como OpenAI-Evals y LangChain, facilitando su integración en flujos de CI/CD para la detección rápida de errores en plantillas de prompts, deriva de tokenizadores y efectos secundarios del fine-tuning (Fuente: HuggingFace Daily Papers)
HelpSteer3-Preference: Conjunto de datos abierto de preferencias anotadas por humanos para múltiples tareas e idiomas: Para satisfacer la demanda de datos de preferencias abiertos, diversos y de alta calidad, NVIDIA ha lanzado el conjunto de datos HelpSteer3-Preference. Este conjunto de datos contiene más de 40,000 muestras de preferencias anotadas por humanos, bajo licencia CC-BY-4.0, y cubre aplicaciones reales de LLM como STEM, codificación y escenarios multilingües. Los modelos de recompensa (RM) entrenados con este conjunto de datos alcanzan un rendimiento de vanguardia (SOTA) tanto en RM-Bench (82.4%) como en JudgeBench (73.7%), mejorando los mejores resultados anteriores en aproximadamente un 10%. Este conjunto de datos también se puede utilizar para entrenar RM generativos y alinear modelos de política mediante RLHF (Fuente: HuggingFace Daily Papers)
SEED-GRPO: GRPO mejorado con entropía semántica para la optimización de políticas consciente de la incertidumbre: Para abordar el problema de que GRPO no considera la incertidumbre del LLM ante los prompts de entrada durante la actualización de la política, los investigadores proponen SEED-GRPO. Este método mide explícitamente la incertidumbre del LLM ante los prompts de entrada (es decir, la diversidad semántica de múltiples respuestas generadas) mediante la entropía semántica, y utiliza esta medida para regular la magnitud de la actualización de la política. Este mecanismo de entrenamiento consciente de la incertidumbre permite actualizaciones más conservadoras para problemas de alta incertidumbre, mientras mantiene la señal de aprendizaje original para problemas de alta confianza. Los experimentos demuestran que SEED-GRPO alcanza un rendimiento de vanguardia (SOTA) en cinco benchmarks de razonamiento matemático (Fuente: HuggingFace Daily Papers)
Creación de un Modelo de Usuario General (GUM) a partir del uso de la computadora: Los investigadores proponen una arquitectura de Modelo de Usuario General (GUM) que aprende el conocimiento y las preferencias del usuario observando cualquier interacción del usuario con la computadora (como capturas de pantalla del dispositivo) y construye proposiciones ponderadas por confianza. GUM es capaz de inferir nuevas proposiciones a partir de observaciones multimodales no estructuradas, recuperar proposiciones relevantes como contexto y corregir continuamente las proposiciones existentes. Esta arquitectura tiene como objetivo mejorar los asistentes de chat, gestionar las notificaciones del sistema operativo y permitir que los agentes interactivos se adapten a las preferencias del usuario en todas las aplicaciones. Los experimentos demuestran que GUM puede realizar inferencias de usuario calibradas y precisas, y que los asistentes basados en GUM pueden identificar y ejecutar proactivamente operaciones útiles no solicitadas explícitamente por el usuario (Fuente: HuggingFace Daily Papers)
DataExpert-io/data-engineer-handbook: Un proyecto popular en GitHub que ofrece un repositorio completo de recursos de aprendizaje para ingeniería de datos, incluyendo una hoja de ruta para principiantes en 2024, materiales de un bootcamp gratuito de 6 semanas en YouTube, casos de proyectos, consejos para entrevistas, libros recomendados, y listas de comunidades y boletines informativos. Entre los libros recomendados se encuentran “Fundamentals of Data Engineering”, “Designing Data-Intensive Applications” y “Designing Machine Learning Systems”. El manual también enumera empresas en diversos campos de la ingeniería de datos, como Mage (orquestación), Databricks (data lake), Snowflake (data warehouse), dbt (calidad de datos), LangChain (biblioteca de aplicaciones LLM), etc., y proporciona enlaces a blogs de ingeniería de datos de empresas reconocidas y white papers importantes (Fuente: GitHub Trending)
💼 Negocios
Cohere y SAP colaboran para llevar AI agents de nivel empresarial a negocios globales: Cohere anunció una colaboración con SAP para integrar su tecnología de AI agents de nivel empresarial en SAP Business Suite, proporcionando capacidades de IA seguras y escalables a empresas de todo el mundo. Los modelos de vanguardia de Cohere también llegarán a SAP AI Core, permitiendo a las empresas en sectores como finanzas y salud utilizar sus modelos de IA multilingües y específicos de dominio (Command, Embed, Rerank), con el objetivo de acelerar las aplicaciones de IA empresariales y liberar valor comercial real (Fuente: X, X)
xAI busca utilizar datos gubernamentales para expandir sus negocios empresariales y gubernamentales: Según The Information, la empresa xAI de Elon Musk planea utilizar datos de agencias gubernamentales para desarrollar modelos y aplicaciones, y venderlos a clientes gubernamentales. Esta iniciativa podría convertirse en una parte importante de la estrategia de comercialización de xAI, pero también ha generado discusiones sobre el uso de datos y posibles sesgos (Fuente: X)
Weaviate y AWS profundizan su colaboración global para acelerar las iniciativas de IA generativa: La empresa de bases de datos vectoriales Weaviate anunció el fortalecimiento de su colaboración global con AWS, con el objetivo de acelerar conjuntamente los proyectos de IA generativa. Esta colaboración se centrará en proporcionar a los desarrolladores de todo el mundo mayor velocidad, mayor escala y una mejor experiencia de desarrollo, impulsando la aplicación y el desarrollo de la tecnología de IA generativa (Fuente: X)

🌟 Comunidad
El auge de los AI agents de programación desencadena un debate sobre las perspectivas profesionales de los programadores: Empresas como Microsoft y OpenAI están lanzando o reforzando AI agents de programación (Coding Agents), como GitHub Copilot Coding Agent y OpenAI Codex, capaces de completar de forma autónoma tareas de codificación, reparación de bugs y mantenimiento de código. Dario Amodei, CEO de Anthropic, predice que la IA podría escribir la mayor parte o incluso todo el código a corto plazo, y Kevin Weil, CPO de OpenAI, también cree que la IA evolucionará de ingeniero júnior a arquitecto. Esto ha provocado un amplio debate en la comunidad sobre el futuro profesional de los programadores: algunos temen que los puestos de nivel inicial sean reemplazados y que la IA automatice gran parte del trabajo de programación; otros, en cambio, creen que la IA aumentará la eficiencia de los programadores, permitiéndoles centrarse en el diseño de arquitecturas de más alto nivel y en la innovación, transformando su rol en “guías de IA”. La tendencia general indica que aprender a colaborar eficientemente con la IA se convertirá en una habilidad fundamental para los programadores (Fuente: X, X, 36氪, 36氪)
Intenso debate sobre el concepto y los estándares de los AI Agents, el protocolo MCP recibe atención: Con el auge de las aplicaciones de AI Agents (como Manus, Genspark Super Agent, Fellou.ai), la comunidad debate activamente sobre la definición, los niveles de capacidad y los paradigmas de desarrollo de los Agents. La conocida firma de capital riesgo BVP ha propuesto una clasificación de siete niveles para los Agents, de L0 a L6. Al mismo tiempo, el Model Component Protocol (MCP) ha ganado atención como tecnología clave para lograr la interoperabilidad entre aplicaciones de IA. Grandes empresas internacionales como Anthropic, OpenAI y Google ya soportan o planean soportar MCP, mientras que en China, empresas como Alibaba Cloud y Tencent Cloud también están comenzando a construir plataformas de desarrollo de Agents localizadas en torno a MCP. El desarrollador iluxu incluso liberó el proyecto llmbasedos, similar al concepto “USB-C for AI apps” de Microsoft, antes de su anuncio, con el objetivo de promover estándares abiertos de conexión para Agents (Fuente: X, X, WeChat, Reddit r/LocalLLaMA)
El bajo rendimiento de los LLM en tareas específicas de razonamiento genera debate sobre los límites de su capacidad: La comunidad debate acaloradamente el fenómeno del “fracaso” colectivo de los LLM en ciertas tareas de razonamiento físico o visoespacial aparentemente simples. Por ejemplo, una pregunta sobre apilar cubos para formar un cubo más grande, incluso los modelos de primer nivel como o3 y Gemini 2.5 Pro dieron respuestas incorrectas. Al mismo tiempo, un artículo de evaluación señala que en tareas físicas básicas como la fabricación de piezas, los LLM (incluido o3) rinden peor que los trabajadores experimentados, debido principalmente a una capacidad visual insuficiente, errores de razonamiento físico y la falta de conocimiento tácito del mundo real. Estos casos han suscitado discusiones sobre la verdadera capacidad de comprensión de los LLM, el problema de las alucinaciones (como el aumento de la tasa de alucinaciones de o3 durante el razonamiento) y la validez de los benchmarks actuales, enfatizando que la IA todavía tiene un gran margen de mejora en el conocimiento de dominios específicos y el razonamiento complejo (Fuente: 量子位, 36氪)

La competencia tecnológica entre China y EE. UU. y las estrategias de desarrollo de IA generan atención: En una entrevista, Jensen Huang, CEO de Nvidia, habló sobre la regulación de chips, las AI factories y el pragmatismo empresarial. Sus puntos de vista fueron interpretados como una profunda visión del actual panorama de la competencia tecnológica entre China y EE. UU. Algunos comentaristas creen que EE. UU. intenta mantener su liderazgo limitando el acceso de China a recursos de IA de alta gama, pero esto podría llevar a una situación en la que ambas partes pierden, desacelerando el desarrollo global de la IA. Huang, por otro lado, parece creer que la verdadera competencia es a largo plazo, y que EE. UU. debería liderar en todos los frentes (chips, fábricas, infraestructura, modelos, aplicaciones), en lugar de buscar simplemente una ventaja relativa a corto plazo, ya que de lo contrario podría perder la oportunidad de desarrollo en la era de la IA y, finalmente, quedarse atrás en la competencia por el poder nacional integral (Fuente: X)
Aplicación y debate sobre herramientas de IA como ChatGPT en el apoyo a la salud mental: Usuarios de la comunidad de Reddit comparten experiencias utilizando herramientas de IA como ChatGPT para apoyo en salud mental, considerando que pueden ayudar entre sesiones de terapia profesional, especialmente para organizar y expresar emociones complejas. Los usuarios, al hacer preguntas a la IA o permitir que la IA les pregunte sobre sus sentimientos, logran comprender mejor el origen de sus emociones y elaborar planes de mejora. En los comentarios, algunos usuarios (incluidos algunos que se identifican como terapeutas) consideran que la IA, en ciertos casos, puede ser incluso superior a algunos terapeutas humanos, especialmente para individuos que tienen dificultades para acceder a ayuda profesional o que tienen barreras de confianza con terapeutas humanos. Sin embargo, también hay usuarios que recuerdan que la IA no puede reemplazar completamente la terapia profesional y que se debe prestar atención a la privacidad de los datos personales (Fuente: Reddit r/ChatGPT)
💡 Otros
Arranca el concurso de algoritmos “Qizhi Cup”, centrado en tres direcciones de vanguardia de la IA: El Laboratorio Qiyuan ha lanzado el concurso de algoritmos “Qizhi Cup”, con una bolsa total de premios de 750.000 yuanes. El concurso establece tres pistas: “Segmentación robusta de instancias en imágenes de teledetección por satélite”, “Detección de objetivos terrestres desde drones para plataformas embebidas” y “Adversarial attacks on large multimodal models”, con el objetivo de impulsar la innovación y la aplicación práctica de tecnologías centrales de IA como la percepción robusta, la implementación ligera y la defensa adversarial. El evento está abierto a instituciones de investigación, empresas y entidades públicas de China (Fuente: WeChat)

El Chicago Sun-Times publica contenido generado por IA con errores, recomendando libros y expertos inexistentes: En una de sus recomendaciones de actividades de verano, parte del contenido del Chicago Sun-Times parece haber sido generado por IA, incluyendo recomendaciones de libros ficticios atribuidos a autores reales y citas de “expertos” aparentemente inexistentes. Por ejemplo, se listaron “Nightshade Market” de Min Jin Lee y “Boiling Point” de Rebecca Makkai como lecturas recomendadas, pero estos libros no existen. Este incidente ha generado preocupación sobre la precisión y los mecanismos de revisión cuando los medios de comunicación utilizan contenido generado por IA (Fuente: Reddit r/artificial)
Debate sobre si el uso de IA constituye “hacer trampa”: La comunidad discute los límites del uso de herramientas de IA (como ChatGPT, Claude) en el trabajo y el estudio. La opinión generalizada es que, en ausencia de reglas explícitas que lo prohíban (como en tareas universitarias), usar herramientas de IA para mejorar la eficiencia, completar tareas repetitivas o ayudar en la reflexión no es “hacer trampa”, sino similar a usar una calculadora o un motor de búsqueda. La clave radica en si el usuario comprende la salida de la IA, puede ajustarla y validarla eficazmente, y si declara honestamente la ayuda de la IA (especialmente en contextos académicos). Sin embargo, si se depende completamente del contenido generado por IA y se presenta como original sin discernimiento, podría implicar deshonestidad académica o afectar el desarrollo de habilidades personales (Fuente: Reddit r/ArtificialInteligence)