
Palabras clave:AlphaEvolve, Gemini, Algoritmos evolutivos, Agentes de IA, Optimización de algoritmos, Multiplicación de matrices, Centro de datos Borg, Optimización de multiplicación de matrices complejas 4×4, Descubrimiento de algoritmos de Google DeepMind, Diseño automatizado de algoritmos con IA, Aplicación de Gemini 2.0 Pro, Optimización de asignación de recursos en Borg
🔥 Enfoque
Google DeepMind presenta AlphaEvolve: un agente de codificación de algoritmos evolutivos basado en Gemini que logra avances en matemáticas e informática: Google DeepMind ha lanzado AlphaEvolve, un agente que utiliza el modelo de lenguaje grande Gemini 2.0 Pro para descubrir y optimizar automáticamente código de algoritmos mediante algoritmos evolutivos. AlphaEvolve puede, a partir de código inicial proporcionado por humanos e indicadores de evaluación, generar, evaluar y mejorar de forma autónoma soluciones candidatas. El sistema ha demostrado un rendimiento sobresaliente en más de 50 problemas matemáticos, reproduciendo soluciones conocidas en aproximadamente el 75% de los casos y descubriendo soluciones mejores en el 20% de los casos. Cabe destacar que AlphaEvolve redujo el número de cálculos para la multiplicación de matrices complejas de 4×4 de 49 a 48, batiendo un récord que se mantenía desde hace 56 años. Además, optimizó el algoritmo de programación del centro de datos Borg interno de Google, recuperando el 0.7% de los recursos computacionales globales, y mejoró el diseño de la próxima generación de chips TPU, reduciendo el tiempo de entrenamiento de Gemini en un 1%. Este logro demuestra el enorme potencial de la IA en el descubrimiento automatizado de algoritmos y la innovación científica. Aunque actualmente se enfoca principalmente en problemas que pueden evaluarse automáticamente, sus perspectivas de aplicación en campos de ciencias aplicadas como el descubrimiento de fármacos son amplias. (Fuente: , 量子位, 36氪)
Nvidia anuncia múltiples avances en IA en Computex 2025, Jensen Huang enfatiza la visión de Agentic AI y Physical AI: El CEO de Nvidia, Jensen Huang, pronunció un discurso principal en Computex 2025, enfatizando que la IA está evolucionando de una “respuesta única” a una “Agentic AI” (IA de agentes) de tipo pensante y razonador, y una “Physical AI” (IA física) que comprende el mundo físico. Para respaldar esta tendencia, Nvidia lanzó una versión ampliada de la plataforma Blackwell (Blackwell Ultra AI) y anunció que el sistema Grace Blackwell GB300 ha entrado en producción completa, con un rendimiento de inferencia 1.5 veces superior al de la generación anterior. Huang también ofreció un avance del superchip de IA de próxima generación, Rubin Ultra, con un rendimiento 14 veces superior al del GB300. Para promover la construcción de infraestructura de IA, Nvidia presentó la tecnología NVLink Fusion y se asoció con TSMC, Foxconn y otros para establecer un superordenador de IA en Taiwán, China. Además, Nvidia actualizó su modelo base de robot humanoide Isaac GR00T N1.5, mejorando su adaptabilidad al entorno y sus capacidades de ejecución de tareas, y planea abrir el código del motor de física Newton, desarrollado en colaboración con DeepMind y Disney Research. (Fuente: AI 前线, 量子位, Reddit r/artificial)
El equipo de OpenAI Codex revela en un AMA planes de integración para GPT-5 y productos futuros: El equipo de OpenAI Codex realizó un evento de “Pregúntame cualquier cosa” (AMA) en Reddit, donde el vicepresidente de investigación, Jerry Tworek, reveló que el objetivo del modelo base de próxima generación, GPT-5, es mejorar las capacidades de los modelos existentes y reducir la necesidad de cambiar entre modelos. Se planea integrar herramientas existentes como Codex, Operator (agente de ejecución de tareas), Deep Research (herramienta de investigación profunda) y Memory (función de memoria) para formar una experiencia de asistente de IA unificada. Los miembros del equipo también compartieron la motivación original detrás del desarrollo de Codex (surgida de una reflexión interna sobre la subutilización de los modelos), el aumento de aproximadamente 3 veces en la eficiencia de programación gracias al uso interno de Codex, y su visión para el futuro de la ingeniería de software: transformar requisitos en software ejecutable de manera eficiente y confiable. Actualmente, Codex utiliza principalmente información cargada en el tiempo de ejecución del contenedor, y en el futuro podría combinar la tecnología RAG para adquirir conocimientos actualizados. OpenAI también está explorando esquemas de precios flexibles y planea ofrecer créditos de API gratuitos para que los usuarios de Plus/Pro los utilicen con Codex CLI. (Fuente: 36氪)
VS Code anuncia la apertura del código de la extensión GitHub Copilot Chat, planea construir una plataforma de edición de código AI de código abierto: El equipo de Visual Studio Code anunció planes para convertir VS Code en un editor de IA de código abierto, adhiriéndose a los principios fundamentales de apertura, colaboración e impulso comunitario. Como parte de este plan, la extensión GitHub Copilot Chat ha sido liberada en GitHub bajo la licencia MIT. En el futuro, VS Code planea integrar gradualmente estas funciones de IA en el núcleo del editor, con el objetivo de construir una plataforma de edición de código AI completamente de código abierto e impulsada por la comunidad para mejorar la eficiencia, la transparencia y la seguridad del desarrollo. Esta medida se considera un paso importante de Microsoft en el ámbito del código abierto y podría tener un profundo impacto en el ecosistema de herramientas de programación asistida por IA. (Fuente: dotey, jeremyphoward)
Huawei Ascend colabora con DeepSeek, el rendimiento de inferencia del modelo MoE supera a Nvidia Hopper: Huawei Ascend anunció que su supernodo CloudMatrix 384 y sus servidores de inferencia Atlas 800I A2 han logrado un gran avance en el rendimiento de inferencia al desplegar modelos MoE a gran escala como DeepSeek V3/R1, superando a la arquitectura Nvidia Hopper en condiciones específicas. El supernodo CloudMatrix 384 superó los 1920 Tokens/s de rendimiento de decodificación por tarjeta con una latencia de 50 ms, mientras que el Atlas 800I A2 alcanzó los 808 Tokens/s de rendimiento por tarjeta con una latencia de 100 ms. Huawei atribuye esto a una estrategia de “complementar la física con las matemáticas”, utilizando optimizaciones de algoritmos y sistemas para compensar las limitaciones del proceso de hardware. Ya se ha publicado un informe técnico relacionado y el código principal se abrirá en un mes. Las medidas de optimización incluyen soluciones de paralelismo de expertos para modelos MoE, despliegue separado de PD, adaptación del framework vLLM, estrategia de cuantización A8W8C16, así como el esquema de comunicación FlashComm, conversión de paralelismo dentro de la capa, motor de inferencia especulativa FusionSpec y optimización de afinidad de hardware para operadores MLA/MoE. (Fuente: 量子位, WeChat)
🎯 Tendencias
Apple libera el eficiente modelo de lenguaje visual FastVLM de código abierto, optimizando la experiencia de IA en el dispositivo: Apple ha liberado el código de FastVLM (Fast Vision Language Model), un modelo de lenguaje visual diseñado específicamente para una ejecución eficiente en dispositivos de borde como el iPhone. FastVLM, mediante la introducción de un nuevo codificador visual híbrido FastViTHD que combina capas convolucionales con módulos Transformer y utiliza técnicas de pooling multiescala y submuestreo, reduce significativamente la cantidad de tokens visuales necesarios para el procesamiento de imágenes (16 veces menos que el ViT tradicional). Esto permite que el modelo mantenga una alta precisión mientras que la velocidad de salida del primer token (TTFT) mejora hasta 85 veces en comparación con modelos similares. FastVLM es compatible con los principales LLM y es fácil de adaptar al ecosistema iOS/Mac, ofreciendo versiones de 0.5B, 1.5B y 7B parámetros, adecuadas para diversas tareas de texto e imagen en tiempo real como descripción de imágenes, respuesta a preguntas y análisis. (Fuente: WeChat)
Meta lanza el modelo KernelLLM 8B, superando a GPT-4o en benchmarks específicos: Meta ha lanzado el modelo KernelLLM 8B en Hugging Face. Según se informa, en el benchmark KernelBench-Triton Level 1, este modelo de 8 mil millones de parámetros superó en rendimiento de inferencia única a modelos de mayor escala como GPT-4o y DeepSeek V3. En el caso de inferencias múltiples, el rendimiento de KernelLLM también fue superior al de DeepSeek R1. Este lanzamiento ha llamado la atención de la comunidad de IA y se considera otro ejemplo de cómo los modelos de tamaño mediano y pequeño demuestran una fuerte competitividad en tareas específicas. (Fuente: ClementDelangue, huggingface, mervenoyann, HuggingFace Daily Papers)
El modelo Mistral Medium 3 muestra un fuerte rendimiento en Arena, destacando especialmente en el ámbito técnico: El nuevo modelo Mistral Medium 3 de Mistral AI ha mostrado un rendimiento sobresaliente en la evaluación comunitaria de lmarena.ai, clasificándose en el puesto 11 en capacidad general de chat, una mejora significativa respecto a Mistral Large (aumento de 90 puntos en la puntuación Elo). El modelo destaca especialmente en el ámbito técnico, ocupando el quinto lugar en capacidad matemática, el séptimo en prompts complejos y capacidad de codificación, y el noveno en WebDev Arena. Los comentarios de la comunidad sugieren que su rendimiento en el ámbito técnico se acerca al nivel de GPT-4.1, mientras que su coste podría ser más competitivo, similar al precio de un GPT-4.1 mini. Los usuarios pueden probar el modelo de forma gratuita en la interfaz de chat oficial de Mistral. (Fuente: hkproj, qtnx_, lmarena_ai)
Hugging Face Datasets añade la función de visualización directa de conversaciones de chat: La plataforma Hugging Face Datasets ha recibido una importante actualización que permite a los usuarios leer directamente el contenido de las conversaciones de chat dentro de los conjuntos de datos. Esta función es considerada por miembros de la comunidad (como Caleb, Maxime Labonne) como un gran paso para resolver problemas de calidad de datos, ya que la consulta directa de los datos de conversación originales ayuda a comprender mejor los datos, realizar la limpieza de datos y mejorar los resultados del entrenamiento de modelos. Anteriormente, ver el contenido específico de las conversaciones podía requerir código o herramientas adicionales; la nueva función simplifica este proceso, mejorando la comodidad y la transparencia del trabajo con datos. (Fuente: eliebakouch, _lewtun, _akhaliq, maximelabonne, ClementDelangue, huggingface, code_star)
MLX LM se integra con Hugging Face Hub, simplificando la ejecución local de modelos en Mac: MLX LM ahora está directamente integrado en Hugging Face Hub, lo que permite a los usuarios de Mac ejecutar localmente más de 4400 LLM en dispositivos Apple Silicon de manera más conveniente. Los usuarios solo necesitan hacer clic en “Use this model” en la página de un modelo compatible en Hugging Face Hub para ejecutar rápidamente el modelo en la terminal, sin necesidad de complejas configuraciones en la nube o esperas. Además, también se pueden iniciar servidores compatibles con OpenAI directamente desde la página del modelo. Esta integración tiene como objetivo reducir la barrera de entrada para ejecutar modelos localmente y mejorar la eficiencia del desarrollo y la experimentación. (Fuente: awnihannun, ClementDelangue, huggingface, reach_vb)
Nvidia libera el modelo de inferencia de IA física Cosmos-Reason1-7B de código abierto: Nvidia ha liberado en Hugging Face su modelo Cosmos-Reason1-7B, parte de su serie de modelos de Physical AI. Este modelo está diseñado para comprender el sentido común del mundo físico y generar las correspondientes decisiones incorporadas (embodied decisions). Esto marca un nuevo paso de Nvidia en la promoción de la combinación del mundo físico y la IA, proporcionando nuevas herramientas y bases de investigación para aplicaciones como la robótica y la conducción autónoma, que requieren interacción con el entorno físico. (Fuente: reach_vb)
El modelo de generación de vídeo de Baidu, Steamer-I2V, encabeza la lista de VBench para generación de vídeo a partir de imágenes: El modelo de generación de vídeo de Baidu, Steamer-I2V, se ha clasificado en primer lugar en la categoría de generación de vídeo a partir de imágenes (I2V) de la prestigiosa lista de evaluación de generación de vídeo VBench, con una puntuación total del 89.38%, superando a modelos conocidos como OpenAI Sora y Google Imagen Video. Las ventajas técnicas de Steamer-I2V incluyen un control preciso de la imagen a nivel de píxel, movimientos de cámara de nivel maestro, calidad de imagen cinematográfica de alta definición de hasta 1080P y estética dinámica, así como una comprensión semántica precisa del chino basada en una base de datos multimodal china de cientos de millones de entradas. Este logro demuestra la fortaleza de Baidu en el campo de la generación multimodal y forma parte de su estrategia para construir un ecosistema de contenido de IA. (Fuente: 36氪)

Los LLM muestran un bajo rendimiento en tareas temporales como leer relojes y calendarios: Investigadores de la Universidad de Edimburgo y otras instituciones han descubierto que, a pesar del excelente rendimiento de los modelos de lenguaje grandes (LLM) y los modelos de lenguaje grandes multimodales (MLLM) en diversas tareas, su precisión en tareas de lectura de tiempo aparentemente simples (como identificar la hora en relojes analógicos y comprender las fechas del calendario) es preocupantemente baja. El estudio construyó dos conjuntos de pruebas personalizados, ClockQA y CalendarQA, y los resultados mostraron que la precisión de los sistemas de IA para leer relojes fue solo del 38.7%, y para determinar las fechas del calendario fue solo del 26.3%. Incluso modelos avanzados como Gemini-2.0 y GPT-o1 tuvieron dificultades evidentes, especialmente al procesar números romanos, manecillas estilizadas o cálculos de fechas complejos (como años bisiestos o determinar el día de la semana para fechas específicas). Los investigadores creen que esto expone las deficiencias de los modelos actuales en el razonamiento espacial, el análisis de diseños estructurados y la capacidad de generalización a patrones poco comunes. (Fuente: 36氪, WeChat)

Microsoft anuncia en la conferencia Build la incorporación del modelo Grok a Azure AI Foundry: En la conferencia de desarrolladores Microsoft Build 2025, Microsoft anunció que el modelo Grok de la empresa xAI se unirá a su serie de modelos Azure AI Foundry. Los usuarios podrán probar Grok-3 y Grok-3-mini de forma gratuita en Azure Foundry y GitHub hasta principios de junio. Esta medida significa que Azure AI Foundry ampliará aún más su gama de modelos de terceros compatibles, y en el futuro los usuarios podrán utilizar modelos de múltiples proveedores como OpenAI, xAI, DeepSeek, Meta, Mistral AI, Black Forest Labs, entre otros, a través de un rendimiento reservado unificado. (Fuente: TheTuringPost, xai)
Según informes, Apple planea permitir a los usuarios de iPhone en la UE reemplazar Siri con asistentes de voz de terceros: Según Mark Gurman, Apple planea permitir por primera vez a los usuarios de iPhone en la Unión Europea reemplazar Siri con asistentes de voz de terceros. Esta medida podría ser una respuesta a los requisitos regulatorios cada vez más estrictos del mercado digital de la UE, con el objetivo de mejorar la apertura de la plataforma y la libertad de elección del usuario. Si este plan se implementa, tendrá un impacto importante en el panorama del mercado de asistentes de voz, ofreciendo a otros asistentes de voz la oportunidad de ingresar al ecosistema de Apple. (Fuente: zacharynado)

Meta lanza el conjunto de datos Open Molecules 2025 y el modelo UMA, acelerando el descubrimiento de moléculas y materiales: Meta AI ha lanzado Open Molecules 2025 (OMol25) y el Meta Universal Atomic model (UMA). OMol25 es actualmente el conjunto de datos de cálculos de química cuántica de alta precisión más grande y diverso, que incluye biomoléculas, complejos metálicos y electrolitos. UMA es un modelo de potencial interatómico de aprendizaje automático entrenado con más de 30 mil millones de átomos, diseñado para proporcionar predicciones más precisas del comportamiento molecular. La apertura de estas herramientas tiene como objetivo acelerar el descubrimiento y la innovación en la ciencia de moléculas y materiales. (Fuente: AIatMeta)
Hugging Face Datasets añade la función de edición incremental de archivos Parquet: Hugging Face Datasets anunció que la versión nocturna de su biblioteca de dependencia subyacente, PyArrow, ahora admite la edición incremental de archivos Parquet sin necesidad de reescribir completamente el archivo. Esta nueva función mejorará enormemente la eficiencia de las operaciones con conjuntos de datos a gran escala, especialmente cuando se necesiten actualizaciones o modificaciones frecuentes de datos parciales, reduciendo significativamente el tiempo y el consumo de recursos computacionales. Se espera que esta medida mejore la experiencia de los desarrolladores en el procesamiento y mantenimiento de grandes conjuntos de datos de entrenamiento de IA. (Fuente: huggingface)
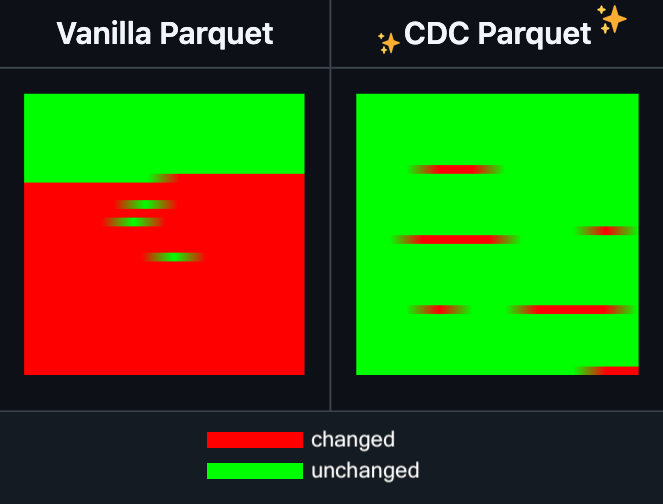
LangGraph añade función de caché a nivel de nodo, mejorando la eficiencia del flujo de trabajo: LangGraph anunció que su versión de código abierto ha añadido una función de caché de nodos/tareas. Esta función tiene como objetivo acelerar los flujos de trabajo evitando cálculos repetidos, especialmente útil para flujos de trabajo de agentes (Agent) que contienen partes comunes o que requieren depuración frecuente. Los usuarios pueden utilizar la caché en la API imperativa o en la API gráfica, lo que permite iterar y optimizar sus aplicaciones de IA más rápidamente. Esta es la primera de una serie de actualizaciones de la versión de código abierto de LangGraph de esta semana. (Fuente: hwchase17)

Sakana AI presenta una nueva arquitectura de IA: “Máquinas de Pensamiento Continuo” (CTM): La startup de IA de Tokio, Sakana AI, ha lanzado una nueva arquitectura de modelos de IA denominada “Máquinas de Pensamiento Continuo” (Continuous Thought Machines, CTM). CTM tiene como objetivo permitir que los modelos razonen de manera similar al cerebro humano, con menos orientación. Esta nueva arquitectura podría ofrecer nuevas ideas para abordar los desafíos actuales que enfrentan los modelos de IA en el razonamiento complejo y el aprendizaje autónomo. (Fuente: dl_weekly)
Microsoft y Nvidia profundizan su colaboración en RTX AI PC, TensorRT llega a Windows ML: Durante Microsoft Build y COMPUTEX Taipei, Nvidia y Microsoft anunciaron una mayor promoción de la cooperación en el desarrollo de RTX AI PC. La biblioteca de optimización de inferencia TensorRT de Nvidia ha sido rediseñada e integrada en la nueva pila de inferencia de Microsoft, Windows ML. Esta medida tiene como objetivo simplificar el proceso de desarrollo de aplicaciones de IA y aprovechar al máximo el rendimiento máximo de las GPU RTX en tareas de IA en PC, impulsando la popularización y aplicación de la IA en dispositivos de computación personal. (Fuente: nvidia)
Bilibili libera el modelo de generación de vídeo de animación Index-AniSora de código abierto, alcanzando SOTA en múltiples métricas: Bilibili anunció la liberación del código de su modelo de generación de vídeo de animación desarrollado internamente, Index-AniSora, que fue presentado en IJCAI 2025. AniSora está diseñado específicamente para la generación de vídeos de estilo anime, soportando diversos estilos como series de anime, producciones chinas y adaptaciones de manga, y permite un control fino como la guía de regiones locales del vídeo y la guía temporal (por ejemplo, guía del primer/último fotograma, interpolación de fotogramas clave). El contenido de código abierto del proyecto incluye el código de entrenamiento e inferencia para AniSoraV1.0 basado en CogVideoX-5B y AniSoraV2.0 basado en Wan2.1-14B, herramientas para la construcción de conjuntos de datos de entrenamiento, un sistema de benchmark específico para animación y el modelo AniSoraV1.0_RL optimizado mediante aprendizaje por refuerzo basado en preferencias humanas. (Fuente: WeChat)

Tencent Hunyuan libera el primer modelo de recompensa CoT multimodal unificado, UnifiedReward-Think, de código abierto: Tencent Hunyuan, en colaboración con Shanghai AI Lab, la Universidad de Fudan y otras instituciones, ha propuesto UnifiedReward-Think, el primer modelo de recompensa multimodal unificado con capacidad de razonamiento en cadena larga (CoT). Este modelo tiene como objetivo permitir que los modelos de recompensa “aprendan a pensar” al evaluar tareas complejas de generación y comprensión visual, mejorando así la precisión de la evaluación, la capacidad de generalización entre tareas y la interpretabilidad del razonamiento. El proyecto se ha abierto completamente, incluyendo el modelo, el conjunto de datos, los scripts de entrenamiento y las herramientas de evaluación. (Fuente: WeChat)
Alibaba libera el modelo de generación y edición de vídeo Tongyi Wanxiang Wan2.1-VACE de código abierto: Alibaba ha liberado oficialmente el código de su modelo de generación y edición de vídeo Tongyi Wanxiang Wan2.1-VACE. Este modelo cuenta con múltiples funciones como generación de vídeo a partir de texto, generación de vídeo con referencia de imagen, redibujado de vídeo, edición local de vídeo, extensión del fondo del vídeo y extensión de la duración del vídeo. Esta vez se han liberado dos versiones, 1.3B y 14B, de las cuales la versión 1.3B puede ejecutarse en tarjetas gráficas de consumo, con el objetivo de reducir la barrera de entrada para la creación de vídeo AIGC. (Fuente: WeChat)
ByteDance lanza el modelo de lenguaje visual Seed1.5-VL, líder en múltiples benchmarks: ByteDance ha construido el modelo de lenguaje visual Seed1.5-VL, compuesto por un codificador visual de 532M de parámetros y un LLM de mezcla de expertos (MoE) con 20B de parámetros activos. A pesar de su arquitectura relativamente compacta, ha alcanzado un rendimiento SOTA en 38 de 60 benchmarks públicos, y ha superado a modelos como OpenAI CUA y Claude 3.7 en tareas centradas en agentes como el control de GUI y el juego, demostrando una potente capacidad de razonamiento multimodal. (Fuente: WeChat)
MiniMax presenta el modelo TTS autorregresivo MiniMax-Speech, compatible con clonación de voz zero-shot en 32 idiomas: MiniMax ha propuesto MiniMax-Speech, un modelo de texto a voz (TTS) autorregresivo basado en Transformer. Este modelo puede extraer características de timbre de un audio de referencia sin necesidad de transcripción, logrando generar voz expresiva y consistente con el timbre de referencia de forma zero-shot, y admite la clonación de voz de una sola muestra. Mediante la tecnología Flow-VAE, se ha mejorado la calidad del audio sintetizado y es compatible con 32 idiomas. Este modelo alcanza un nivel SOTA en métricas objetivas de clonación de voz y ocupa el primer lugar en la clasificación pública de TTS Arena, pudiendo además extenderse a aplicaciones como el control emocional de la voz, la conversión de texto a sonido y la clonación de voz profesional. (Fuente: WeChat)
Lanzamiento de OuteTTS 1.0 (0.6B), modelo TTS de código abierto Apache 2.0 compatible con 14 idiomas: OuteAI ha lanzado OuteTTS-1.0-0.6B, un modelo ligero de texto a voz (TTS) construido sobre Qwen-3 0.6B. Este modelo utiliza la licencia Apache 2.0 y es compatible con 14 idiomas, incluyendo chino, inglés, japonés y coreano. Su biblioteca de inferencia Python OuteTTS v0.4.2 se ha actualizado para admitir la inferencia por lotes asíncrona EXL2, la inferencia por lotes experimental vLLM y el procesamiento por lotes continuo y la inferencia de modelos desde URL externas para el servidor Llama.cpp. Las pruebas de rendimiento en una única GPU NVIDIA L40S muestran que vLLM OuteTTS-1.0-0.6B FP8 puede alcanzar un RTF (factor de tiempo real) de 0.05 con un tamaño de lote de 32. Los pesos del modelo (ST, GGUF, EXL2, FP8) están disponibles en Hugging Face. (Fuente: Reddit r/LocalLLaMA)

Hugging Face y Microsoft Azure profundizan su colaboración, más de 10,000 modelos de código abierto llegan a Azure AI Foundry: En la conferencia Microsoft Build, el CEO Satya Nadella anunció una ampliación de la colaboración con Hugging Face. Actualmente, más de 11,000 de los modelos de código abierto más populares están disponibles a través de Hugging Face en Azure AI Foundry, facilitando su despliegue a los usuarios. Esta medida enriquece aún más el ecosistema de IA de Azure, ofreciendo a los desarrolladores más opciones de modelos y una experiencia de desarrollo más conveniente. (Fuente: ClementDelangue, _akhaliq)

Intel lanza las GPU de la serie Arc Pro B50/B60, enfocadas en el mercado de IA y estaciones de trabajo, la versión de 24GB costará alrededor de 500 dólares: Intel presentó en Computex las nuevas tarjetas gráficas profesionales de la serie Arc Pro B, incluyendo la Arc Pro B50 (16GB de VRAM, aproximadamente 299 dólares) y la Arc Pro B60 (24GB de VRAM, aproximadamente 500 dólares). Entre ellas, también se presentó la solución de estación de trabajo “Project Battlematrix”, compuesta por dos GPU B60 con un total de 48GB de VRAM, con un precio estimado inferior a 1000 dólares. Estos productos tienen como objetivo proporcionar soluciones rentables para la computación de IA y las estaciones de trabajo profesionales, especialmente la configuración de alta VRAM es atractiva para ejecutar grandes modelos de lenguaje localmente. Se espera que los nuevos productos salgan al mercado en el tercer trimestre de este año, inicialmente a través de fabricantes OEM, y en el cuarto trimestre podrían lanzarse versiones para el mercado DIY. (Fuente: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

🧰 Herramientas
Moondream Station lanza versión para Linux, simplificando la ejecución local de Moondream: Moondream Station, una herramienta diseñada para simplificar la ejecución de Moondream (un modelo de lenguaje visual) en dispositivos locales, ha anunciado ahora soporte para el sistema operativo Linux. Esto significa que los usuarios de Linux pueden desplegar y utilizar modelos Moondream de forma más conveniente para experimentos de IA multimodal y desarrollo de aplicaciones. (Fuente: vikhyatk)
Flowith lanza el agente inteligente infinito NEO, compatible con pasos, contexto y llamadas a herramientas ilimitadas: La empresa de aplicaciones de IA Flowith ha lanzado su último producto de agente inteligente, NEO, que se anuncia como el primer agente del mundo compatible con pasos ilimitados, contexto ilimitado y llamadas a herramientas ilimitadas. Este agente está diseñado para funcionar durante largos períodos en la nube, posee un nivel de inteligencia que supera los benchmarks y se promociona como de coste cero y sin restricciones. Este lanzamiento podría representar un nuevo avance en la capacidad de los agentes de IA para manejar tareas complejas a largo plazo e integrar capacidades externas. (Fuente: _akhaliq, op7418)

Kapa AI utiliza Weaviate para construir la herramienta interactiva de preguntas y respuestas sobre documentación técnica “Ask AI”: Kapa AI ha desarrollado un widget inteligente llamado “Ask AI” que permite a los usuarios consultar toda una base de conocimientos técnicos, incluyendo documentación, blogs, tutoriales, issues de GitHub y foros, mediante conversaciones en lenguaje natural. Para lograr una búsqueda semántica y recuperación de conocimiento eficientes, Kapa AI ha adoptado la base de datos vectorial Weaviate, valorando su capacidad de búsqueda híbrida incorporada, compatibilidad con Docker y características multi-inquilino para soportar un rápido crecimiento de usuarios y volumen de datos. (Fuente: bobvanluijt)

Un desarrollador utiliza Gemini Flash para construir rápidamente una herramienta MVP que convierte capturas de pantalla en HTML: El desarrollador Daniel Huynh utilizó el modelo Gemini Flash de Google AI para construir una herramienta MVP (Producto Mínimo Viable) en un fin de semana, capaz de convertir rápidamente diseños, capturas de pantalla de la competencia o inspiración en código HTML. La herramienta ya está disponible para prueba gratuita en Hugging Face Spaces, demostrando el potencial de los modelos multimodales en la asistencia al desarrollo frontend. (Fuente: osanseviero, _akhaliq)
Azure AI Foundry Agent Service ya está disponible de forma general, con integración de LlamaIndex: Microsoft ha anunciado que Azure AI Foundry Agent Service ya está disponible de forma general (GA) y ofrece soporte de primera clase para LlamaIndex. Este servicio está diseñado para ayudar a los clientes empresariales a construir asistentes de soporte al cliente, robots de automatización de procesos, sistemas multiagente y soluciones que se integran de forma segura con los datos y herramientas empresariales, impulsando aún más el desarrollo y la aplicación de agentes de IA a nivel empresarial. (Fuente: jerryjliu0)
tinygrad: un framework de aprendizaje profundo minimalista entre PyTorch y micrograd: tinygrad es un framework de aprendizaje profundo diseñado con la simplicidad como concepto central, con el objetivo de ser el framework más fácil para añadir nuevos aceleradores, soportando inferencia y entrenamiento. Es compatible con modelos como LLaMA y Stable Diffusion, y utiliza evaluación perezosa (lazy evaluation) para fusionar operaciones y optimizar el rendimiento. tinygrad es compatible con múltiples aceleradores como GPU (OpenCL), CPU (código C), LLVM, Metal, CUDA, entre otros. Su código es conciso, con las funciones principales implementadas en una pequeña cantidad de código, lo que facilita su comprensión y extensión por parte de los desarrolladores. (Fuente: GitHub Trending)
La búsqueda Nano AI lanza la función “Súper Búsqueda”, integrando múltiples modelos y la caja de herramientas MCP: La búsqueda Nano AI (bot.n.cn) ha añadido una función de “Súper Búsqueda”, diseñada para proporcionar una capacidad más profunda de adquisición y procesamiento de información. Esta función integra cientos de modelos grandes nacionales e internacionales, y puede cambiar automáticamente según sea necesario; incorpora la caja de herramientas universal MCP, compatible con miles de herramientas de IA, capaz de procesar archivos en diversos formatos como páginas web, imágenes, vídeos, PDF, y realizar generación de código, análisis de datos, etc. Al mismo tiempo, combina la búsqueda en el dominio público con la búsqueda privada en bases de conocimiento locales para proporcionar resultados más completos, e incluye capacidades de generación de imágenes y vídeos a partir de texto. La experiencia del usuario muestra que esta función puede organizar los resultados de la búsqueda en informes detallados con gráficos y páginas web atractivas, adecuada para diversos escenarios como investigación de mercado, comparación de precios de compras, organización de conocimientos, etc. (Fuente: WeChat)
Clara: Espacio de trabajo AI modular y offline, integra LLM, Agentes, automatización y generación de imágenes: Un desarrollador ha lanzado un proyecto de código abierto llamado Clara, con el objetivo de crear un espacio de trabajo AI completamente offline y modular. Los usuarios pueden organizar en un panel de control, en forma de widgets, chats con LLM locales (compatible con RAG, imágenes, documentos, ejecución de código, compatible con Ollama y API tipo OpenAI), crear Agentes con memoria y lógica, ejecutar flujos de automatización mediante la integración nativa de N8N (ofreciendo más de 1000 plantillas gratuitas), y generar imágenes localmente usando Stable Diffusion (ComfyUI). Clara ofrece versiones para Mac, Windows y Linux, con el objetivo de resolver el problema de los usuarios que cambian frecuentemente entre múltiples herramientas de IA, logrando una operación de IA centralizada. (Fuente: Reddit r/LocalLLaMA)
AI Playlist Curator: Herramienta Python que utiliza LLM para organizar listas de reproducción de YouTube personalizadas: Un desarrollador ha creado un proyecto Python llamado AI Playlist Curator, diseñado para ayudar a los usuarios a organizar automáticamente sus extensas y desordenadas listas de reproducción de YouTube. La herramienta utiliza LLM para clasificar canciones según las preferencias del usuario y crear sub-listas de reproducción personalizadas, admitiendo el procesamiento de cualquier lista de reproducción guardada y canciones favoritas. El proyecto está disponible en código abierto en GitHub, y el desarrollador espera recibir comentarios de la comunidad para seguir mejorándolo. (Fuente: Reddit r/MachineLearning)
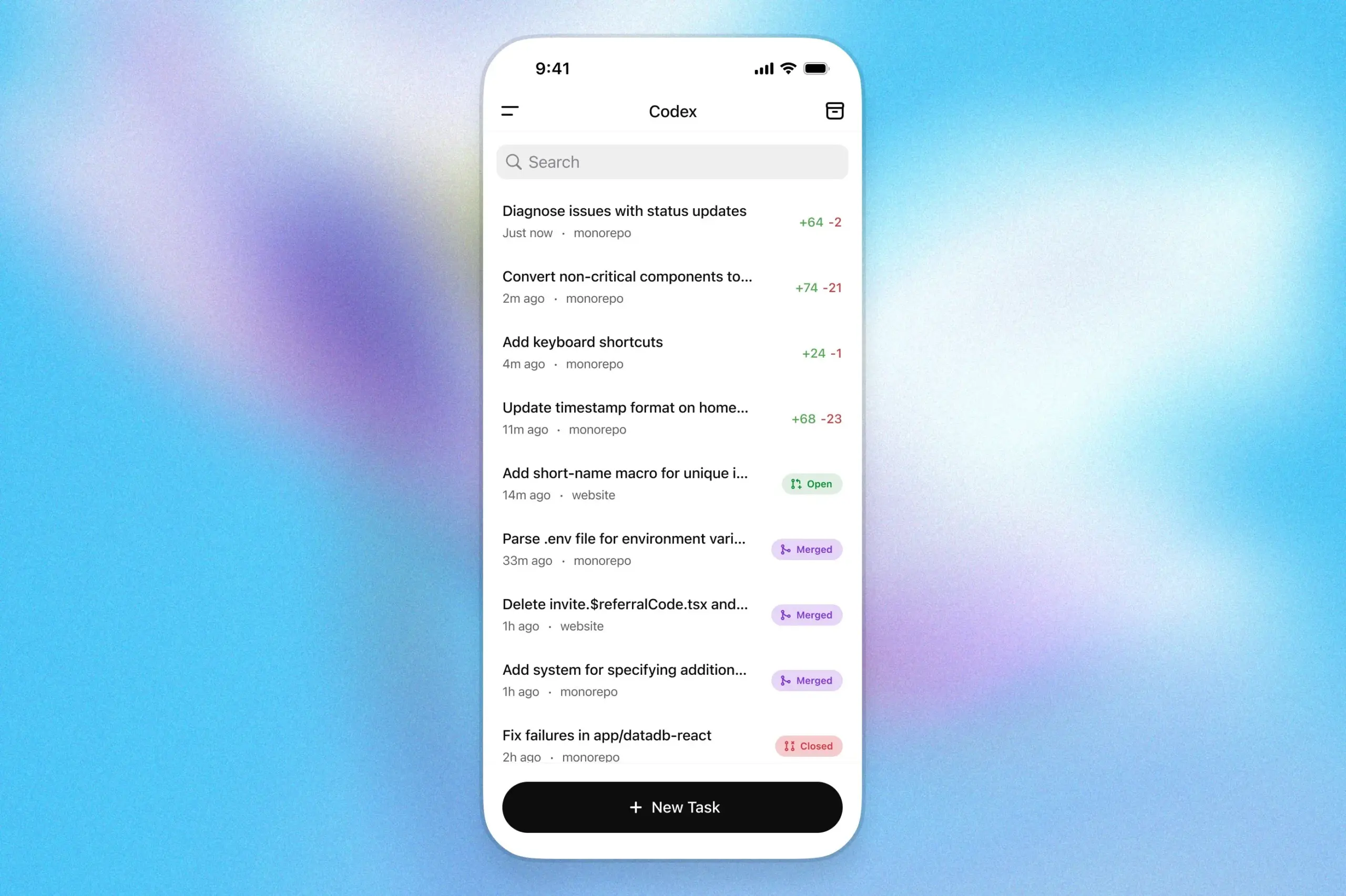
El asistente de programación OpenAI Codex llega a la aplicación ChatGPT para iOS: OpenAI ha anunciado que su asistente de programación Codex ya está integrado en la aplicación ChatGPT para iOS. Los usuarios pueden iniciar nuevas tareas de programación, ver diferencias de código, solicitar modificaciones e incluso enviar pull requests (PR) desde sus dispositivos móviles. La función también permite seguir el progreso de Codex en tiempo real a través de las actividades de la pantalla de bloqueo, facilitando a los usuarios cambiar de trabajo sin problemas entre diferentes dispositivos. (Fuente: openai)
Kollektiv: Herramienta que utiliza el protocolo MCP para resolver el problema de copiar y pegar repetidamente el contexto en chats con LLM: Un desarrollador ha lanzado la herramienta Kollektiv, diseñada para solucionar el problema de los usuarios que necesitan copiar y pegar repetidamente grandes cantidades de contexto (como artículos de investigación, documentación de SDK, notas personales, contenido de libros) al chatear con LLM (como Claude). Kollektiv permite a los usuarios cargar estas fuentes de documentos una sola vez y llamarlas bajo demanda desde cualquier IDE compatible o cliente MCP (como Cursor, Windsurf, PyCharm, etc.) a través de un servidor MCP (Model Control Protocol). El servidor MCP se encarga de la autenticación del usuario, el aislamiento de datos y la transmisión de datos bajo demanda a la interfaz de chat. Actualmente, no se recomienda el uso de esta herramienta para materiales sensibles o confidenciales. (Fuente: Reddit r/ClaudeAI)
📚 Aprendizaje
Google DeepMind publica un informe técnico sobre AlphaEvolve, revelando su capacidad de descubrimiento de algoritmos: Google DeepMind ha publicado un informe técnico sobre su sistema de IA AlphaEvolve. AlphaEvolve es un agente de codificación basado en Gemini capaz de diseñar y optimizar algoritmos mediante algoritmos evolutivos. El informe detalla cómo AlphaEvolve genera, evalúa y mejora de forma autónoma soluciones algorítmicas candidatas a través de un ciclo de retroalimentación estructurado, logrando así avances en múltiples problemas matemáticos y de ciencias de la computación, incluyendo la superación del récord del algoritmo de multiplicación de matrices complejas de 4×4. Este informe proporciona una referencia importante para comprender el potencial de la IA en el descubrimiento científico automatizado y la innovación algorítmica. (Fuente: , HuggingFace Daily Papers)
DeepLearning.AI lanza el curso “Construyendo Agentes de Navegador con IA”: DeepLearning.AI ha lanzado un nuevo curso titulado “Building AI Browser Agents”. El curso es impartido por Div Garg y Naman Agarwal, cofundadores de AGI, y tiene como objetivo ayudar a los estudiantes a dominar las técnicas para construir agentes de IA (Agent) capaces de interactuar con navegadores. El contenido del curso podría cubrir la automatización web, la extracción de información, la interacción con la interfaz de usuario y otras aplicaciones de la IA en el entorno del navegador. (Fuente: DeepLearningAI)
Publicado el informe técnico de Qwen3: Alibaba ha publicado el informe técnico de su última generación de modelos de lenguaje grandes, Qwen3. El informe detalla la arquitectura del modelo Qwen3, los métodos de entrenamiento, la evaluación del rendimiento y su desempeño en diversas pruebas de referencia. La serie de modelos Qwen3 tiene como objetivo proporcionar capacidades más sólidas de comprensión del lenguaje, generación y procesamiento multimodal. La publicación de su informe técnico ofrece a investigadores y desarrolladores la oportunidad de comprender en profundidad los detalles técnicos de este modelo. (Fuente: _akhaliq)

Discusión de artículo: Búsqueda multivista y gestión de datos mejoran la demostración progresiva de teoremas (MPS-Prover): Un nuevo artículo presenta MPS-Prover, un novedoso sistema de demostración automática progresiva de teoremas (ATP). Este sistema supera el problema de la guía de búsqueda sesgada en los demostradores progresivos existentes mediante una estrategia eficiente de gestión de datos post-entrenamiento (podando alrededor del 40% de los datos redundantes sin sacrificar el rendimiento) y un mecanismo de búsqueda en árbol multivista (integrando un modelo crítico aprendido con reglas heurísticas). Los experimentos demuestran que MPS-Prover alcanza un rendimiento SOTA en múltiples benchmarks como miniF2F y ProofNet, generando demostraciones más cortas y diversas. (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Planificación Visual — Pensar solo con imágenes (Visual Planning): Un nuevo artículo propone el paradigma de “planificación visual”, que permite a los modelos planificar completamente a través de representaciones visuales (secuencias de imágenes), en lugar de depender del texto. Los investigadores argumentan que en tareas que involucran información espacial y geométrica, el lenguaje puede no ser el medio de razonamiento más natural. Introdujeron el marco de planificación visual mediante aprendizaje por refuerzo VPRL y utilizaron GRPO para la optimización post-entrenamiento de grandes modelos visuales, logrando mejoras significativas en tareas de navegación visual como FrozenLake, Maze y MiniBehavior, superando a las variantes de planificación basadas puramente en razonamiento textual. (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Escalar el razonamiento puede mejorar la factualidad de los modelos de lenguaje grandes (Scaling Reasoning can Improve Factuality): Un estudio explora si escalar el proceso de razonamiento de los modelos de lenguaje grandes (LLM) puede mejorar su precisión factual en la respuesta a preguntas complejas de dominio abierto (QA). Los investigadores extrajeron trayectorias de razonamiento de modelos como QwQ-32B y DeepSeek-R1-671B, y ajustaron varias series de modelos Qwen2.5, integrando al mismo tiempo rutas de grafos de conocimiento en las trayectorias de razonamiento. Los experimentos demuestran que, en una sola ejecución, los modelos de razonamiento más pequeños muestran una mejora significativa en la precisión factual en comparación con los modelos originales ajustados por instrucciones. Al aumentar el cálculo en tiempo de prueba y el presupuesto de tokens, la precisión factual puede mejorar de forma estable entre un 2% y un 8%. (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Mergenetic — una biblioteca simple para la fusión evolutiva de modelos: Un nuevo artículo presenta Mergenetic, una biblioteca de código abierto para la fusión evolutiva de modelos. La fusión de modelos permite combinar las capacidades de modelos existentes en nuevos modelos sin entrenamiento adicional. Mergenetic facilita la combinación de métodos de fusión y algoritmos evolutivos, e incorpora evaluadores de aptitud ligeros para reducir los costes de evaluación. Los experimentos demuestran que Mergenetic puede producir resultados competitivos en diversas tareas e idiomas utilizando hardware modesto. (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Pensamiento Grupal — Múltiples agentes de razonamiento concurrentes colaboran a nivel de token (Group Think): Un nuevo artículo propone el “Pensamiento Grupal” (Group Think), que permite a un único LLM actuar como múltiples agentes de razonamiento concurrentes (pensadores). Estos agentes comparten la visibilidad del progreso parcial de generación de los demás, adaptándose dinámicamente a las trayectorias de razonamiento de los otros a nivel de token, lo que reduce el razonamiento redundante, mejora la calidad y disminuye la latencia. Este método es adecuado para la inferencia en el borde en GPU locales, y los experimentos demuestran que también puede mejorar la latencia al utilizar LLM de código abierto no entrenados específicamente. (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Los humanos esperan racionalidad y cooperación de los oponentes LLM en juegos de estrategia (Humans expect rationality and cooperation from LLM opponents): Un primer experimento de laboratorio controlado con incentivos monetarios investiga las diferencias de comportamiento humano al enfrentarse a otros humanos frente a LLM en concursos P-beauty multijugador. Los resultados muestran que los humanos eligen números significativamente más bajos cuando se enfrentan a LLM, principalmente debido a un aumento en la prevalencia de la elección del equilibrio de Nash “cero”. Este cambio es impulsado principalmente por sujetos con alta capacidad de razonamiento estratégico, quienes perciben que los LLM poseen una mayor capacidad de razonamiento y una mayor propensión a la cooperación. (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Destilación de conocimiento semisupervisada simple desde modelos de lenguaje visual mediante optimización de doble cabezal (Dual-Head Optimization for KD): Un nuevo artículo propone DHO (Dual-Head Optimization), un marco de destilación de conocimiento (KD) simple y efectivo para transferir conocimiento de modelos de lenguaje visual (VLM) a modelos compactos específicos de tareas en un entorno semisupervisado. DHO introduce cabezales de predicción dobles que aprenden de forma independiente los datos etiquetados y las predicciones del profesor, y combina linealmente sus salidas en tiempo de inferencia, mitigando así el conflicto de gradientes entre la señal de supervisión y la señal de destilación. Los experimentos demuestran que DHO supera a las líneas base de KD de un solo cabezal en múltiples dominios y conjuntos de datos de grano fino, alcanzando SOTA en ImageNet. (Fuente: HuggingFace Daily Papers)
Discusión de artículo: GuardReasoner-VL — Protegiendo VLM mediante razonamiento reforzado: Para mejorar la seguridad de los modelos de lenguaje visual (VLM), un nuevo artículo introduce GuardReasoner-VL, un modelo de protección de VLM basado en el razonamiento. La idea central es incentivar al modelo de protección a realizar un razonamiento prudente antes de tomar decisiones de moderación mediante el aprendizaje por refuerzo en línea (RL). Los investigadores construyeron un corpus de razonamiento, GuardReasoner-VLTrain, que contiene 123K muestras y 631K pasos de razonamiento, e iniciaron en frío la capacidad de razonamiento del modelo mediante ajuste fino supervisado (SFT), para luego mejorarla aún más mediante RL en línea. Los experimentos demuestran que este modelo (las versiones 3B/7B ya son de código abierto) tiene un rendimiento superior, superando al segundo mejor modelo en 19.27% en la puntuación F1 promedio. (Fuente: HuggingFace Daily Papers)
Discusión de artículo: La predicción multi-token necesita registros (Multi-Token Prediction Needs Registers): Un nuevo artículo propone MuToR, un método simple y efectivo para la predicción multi-token que predice objetivos futuros intercalando tokens de registro aprendibles en la secuencia de entrada. En comparación con los métodos existentes, MuToR tiene un aumento de parámetros insignificante, no requiere cambios arquitectónicos, es compatible con modelos preentrenados existentes y se mantiene alineado con el objetivo de preentrenamiento del siguiente token, siendo especialmente adecuado para el ajuste fino supervisado. Este método demuestra efectividad y generalidad en tareas generativas en los dominios del lenguaje y la visión. (Fuente: HuggingFace Daily Papers)
Discusión de artículo: MMLongBench — Benchmark eficaz y exhaustivo para modelos de lenguaje visual de contexto largo: En respuesta a la necesidad de evaluar modelos de lenguaje visual de contexto largo (LCVLM), un nuevo artículo introduce MMLongBench, el primer benchmark que cubre una variedad de tareas de lenguaje visual de contexto largo. MMLongBench contiene 13331 muestras, abarcando cinco categorías de tareas como RAG visual, ICL de múltiples muestras, y proporciona múltiples tipos de imágenes. Todas las muestras se proporcionan en cinco longitudes de entrada estandarizadas de 8K-128K tokens. A través de la evaluación comparativa de 46 LCVLM de código cerrado y abierto, el estudio encontró que el rendimiento en una sola tarea no es representativo de la capacidad general de contexto largo, los modelos actuales todavía tienen un gran margen de mejora, y los modelos con una fuerte capacidad de razonamiento tienden a tener un mejor rendimiento en contextos largos. (Fuente: HuggingFace Daily Papers)
Discusión de artículo: MatTools — Un benchmark de modelos de lenguaje grandes para herramientas de ciencia de materiales: Un nuevo artículo propone el benchmark MatTools para evaluar la capacidad de los modelos de lenguaje grandes (LLM) para responder preguntas de ciencia de materiales generando y ejecutando de forma segura código para paquetes de software de ciencia de materiales computacional basados en la física. MatTools incluye un benchmark de preguntas y respuestas (QA) sobre herramientas de simulación de materiales (basado en pymatgen, con 69225 pares de QA) y un benchmark de uso de herramientas en el mundo real (con 49 tareas y 138 subtareas). La evaluación de varios LLM revela que: los modelos generales superan a los modelos especializados; la IA entiende mejor a la IA; y los métodos simples son más efectivos. (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Un marco universal de marca de agua simbiótica que equilibra la robustez, la calidad del texto y la seguridad en las marcas de agua de LLM: Abordando el compromiso existente entre robustez, calidad del texto y seguridad en los esquemas actuales de marcas de agua para modelos de lenguaje grandes (LLM), un nuevo artículo propone un marco universal de marca de agua simbiótica. Este marco integra métodos basados en logits y en muestreo, y diseña tres estrategias: serial, paralela e híbrida. El marco híbrido utiliza la entropía de tokens y la entropía semántica para incrustar adaptativamente la marca de agua, con el objetivo de optimizar el rendimiento en todos los aspectos. Los experimentos demuestran que este método supera a las líneas base existentes y alcanza un nivel SOTA. (Fuente: HuggingFace Daily Papers)
Discusión de artículo: CheXGenBench — Un benchmark unificado para la fidelidad, privacidad y utilidad de radiografías de tórax sintéticas: Un nuevo artículo presenta CheXGenBench, un marco multifacético para evaluar la generación de radiografías de tórax sintéticas, evaluando simultáneamente la fidelidad, los riesgos de privacidad y la utilidad clínica. El marco incluye particiones de datos estandarizadas y un protocolo de evaluación unificado (más de 20 métricas cuantitativas), analizando la calidad de generación, las posibles vulnerabilidades de privacidad y la aplicabilidad clínica aguas abajo de 11 arquitecturas líderes de texto a imagen. El estudio encontró que los protocolos de evaluación existentes son deficientes para evaluar la fidelidad de la generación. El equipo también lanzó el conjunto de datos sintéticos de alta calidad SynthCheX-75K. (Fuente: HuggingFace Daily Papers)
Fallece Peter Lax, autor del clásico libro de texto “Análisis Funcional”, a los 99 años: El gigante de las matemáticas aplicadas y primer matemático aplicado en recibir el Premio Abel, Peter Lax, ha fallecido a la edad de 99 años. Lax era conocido por su clásico libro de texto “Análisis Funcional” y realizó contribuciones fundamentales en campos como las ecuaciones diferenciales parciales, la mecánica de fluidos y el cálculo numérico, como el teorema de equivalencia de Lax, y los métodos de Lax-Friedrichs y Lax-Wendroff. También fue uno de los pioneros en aplicar la tecnología informática al análisis matemático, y su trabajo influyó profundamente en el desarrollo de las matemáticas en la era de la computación. (Fuente: 量子位)

La ex vicepresidenta de OpenAI, Lilian Weng, publica un extenso artículo de diez mil palabras, “Why We Think”, que explora la computación en tiempo de prueba y la cadena de pensamiento: La ex vicepresidenta de OpenAI, Lilian Weng, ha publicado un extenso artículo de diez mil palabras titulado “Why We Think”, en el que explora en profundidad cómo tecnologías como la “computación en tiempo de prueba” (Test-time Compute) y la “cadena de pensamiento” (Chain-of-Thought, CoT) mejoran significativamente el rendimiento y el nivel de inteligencia de los modelos de lenguaje grandes. El artículo establece una analogía con la teoría de los dos sistemas de pensamiento humano, “pensar rápido, pensar despacio”, y señala que permitir que los modelos “piensen” más antes de generar una salida (por ejemplo, mediante decodificación inteligente, razonamiento CoT, modelado de variables latentes, etc.) puede superar los cuellos de botella de capacidad actuales. El artículo revisa detalladamente los avances y desafíos en múltiples direcciones de investigación, incluyendo el pensamiento basado en tokens, el muestreo paralelo y la revisión secuencial, el aprendizaje por refuerzo y la integración de herramientas externas, la fidelidad del pensamiento y el pensamiento en espacios continuos. (Fuente: 量子位)

HIT y UPenn presentan conjuntamente PointKAN, un nuevo SOTA para el análisis de nubes de puntos basado en KANs: Equipos de investigación del Instituto de Tecnología de Harbin (Shenzhen) y la Universidad de Pensilvania han presentado PointKAN, una solución para el análisis de nubes de puntos 3D basada en Kolmogorov-Arnold Networks (KANs). Este método, mediante un módulo afín geométrico y un módulo de extracción de características locales en paralelo, y utilizando funciones de activación aprendibles en lugar de las funciones de activación fijas de los MLP tradicionales, captura de manera más efectiva las complejas características geométricas de las nubes de puntos. Al mismo tiempo, el equipo propuso la estructura Efficient-KANs, que reemplaza las funciones B-spline con funciones racionales y comparte parámetros dentro del grupo, reduciendo significativamente la cantidad de parámetros y la sobrecarga computacional. Los experimentos demuestran que PointKAN y su versión ligera PointKAN-elite logran un rendimiento SOTA o competitivo en tareas como clasificación, segmentación parcial y aprendizaje con pocas muestras. (Fuente: WeChat)

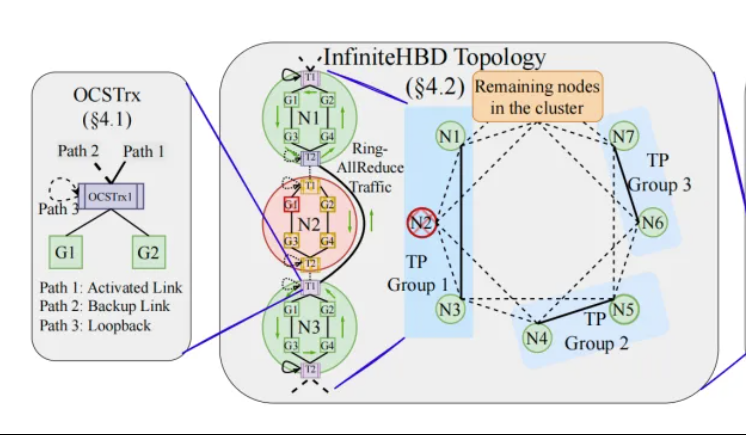
Peking University/StepStar/Enflame Tech proponen InfiniteHBD: una arquitectura de interconexión de GPU de alto ancho de banda de nueva generación para reducir los costos de entrenamiento de modelos grandes: Equipos de investigación de la Universidad de Pekín, StepStar y Enflame Technology, abordando las limitaciones de las arquitecturas actuales de dominio de alto ancho de banda (HBD) en el entrenamiento distribuido de modelos grandes, han propuesto la solución InfiniteHBD. Esta arquitectura, centrada en un módulo de conversión optoelectrónica con capacidad de conmutación de ruta óptica (OCS) integrada, logra una conexión punto a multipunto dinámicamente reconfigurable, con capacidad de aislamiento de fallos a nivel de nodo y baja fragmentación de recursos. La investigación muestra que el costo unitario de InfiniteHBD es solo el 31% del de NVIDIA NVL-72, la tasa de desperdicio de GPU es cercana a cero y la MFU (utilización de FLOPs del modelo) puede aumentar hasta 3.37 veces en comparación con NVIDIA DGX. Esta investigación ha sido aceptada en SIGCOMM 2025. (Fuente: WeChat, 量子位)
Avance de artículo de ICML 2025: OmniAudio genera audio espacial a partir de vídeos de 360°: Una investigación que se presentará en ICML 2025 propone el marco OmniAudio, capaz de generar directamente audio espacial de primer orden ambisónico (FOA) con sensación direccional a partir de vídeos panorámicos de 360°. La investigación primero construyó un conjunto de datos a gran escala de vídeos de 360° emparejados con audio espacial, Sphere360. OmniAudio adopta un entrenamiento en dos etapas: primero, un preentrenamiento autosupervisado de coincidencia de flujo de grueso a fino, utilizando datos de audio no espaciales a gran escala para aprender características de audio generales; luego, un ajuste fino supervisado combinado con un codificador de vídeo de doble rama (que extrae características visuales globales y locales). Los resultados experimentales muestran que OmniAudio supera significativamente a los modelos base existentes tanto en métricas de evaluación objetivas como subjetivas. (Fuente: WeChat)

Huawei Selftok: Tokenizador visual autorregresivo basado en difusión inversa, unificando la generación multimodal: El equipo de generación multimodal Pangu de Huawei ha propuesto la tecnología Selftok, una innovadora solución de tokenización visual que, mediante un proceso de difusión inversa, integra un prior autorregresivo en los tokens visuales, transformando el flujo de píxeles en una secuencia discreta que sigue estrictamente la ley de causalidad. Esto tiene como objetivo resolver el problema del conflicto entre los esquemas de tokenización espacial existentes y el paradigma autorregresivo (AR). El Selftok Tokenizer utiliza un codificador de doble flujo (la rama de imagen hereda el VAE de SD3, la rama de texto es un grupo de vectores continuos aprendibles) y un cuantizador con mecanismo de reactivación. Los experimentos demuestran que Selftok alcanza SOTA en las métricas de reconstrucción de ImageNet, y el Selftok dAR-VLM entrenado con la IA Ascend y el framework MindSpeed supera a GPT-4o en benchmarks de generación de texto a imagen como GenEval. Este trabajo ha sido seleccionado como candidato a mejor artículo en CVPR 2025. (Fuente: WeChat)
El equipo de Yan Shuicheng lidera la publicación del marco de evaluación General-Level y el benchmark General-Bench, clasificando los modelos multimodales generalistas: Liderado por el profesor Yan Shuicheng de la Universidad Nacional de Singapur y el profesor Zhang Hanwang de la Universidad Tecnológica de Nanyang, entre otros, diez universidades de primer nivel han publicado conjuntamente el marco de evaluación General-Level y el conjunto de datos de benchmark a gran escala General-Bench para modelos multimodales generalistas. Este marco, inspirándose en la clasificación de la conducción autónoma, establece cinco niveles (Level 1-5) para evaluar la generalidad y el rendimiento de los modelos de lenguaje grandes multimodales (MLLM). El criterio de evaluación principal es el “efecto de generalización sinérgica” (Synergy), que examina la transferencia y mejora del conocimiento del modelo entre tareas, entre paradigmas de comprensión y generación, y entre modalidades. General-Bench incluye más de 700 tareas y 320,000 muestras. La evaluación de más de 100 MLLM existentes muestra que la mayoría de los modelos se encuentran en el nivel L2-L3, y ningún modelo ha alcanzado el L5. (Fuente: WeChat)

💼 Negocios
Sakana AI y Mitsubishi UFJ Financial Group (MUFG) alcanzan una asociación plurianual: La startup japonesa de IA Sakana AI anunció la firma de un acuerdo de asociación integral plurianual con el banco más grande de Japón, MUFG Bank. Sakana AI proporcionará a MUFG Bank tecnología de IA ágil y potente, con el objetivo de ayudar a este banco centenario a mantenerse competitivo en el campo de la IA en rápida evolución. Se espera que esta colaboración ayude a Sakana AI a alcanzar la rentabilidad en un año. (Fuente: SakanaAILabs, SakanaAILabs)

Cohere se asocia con Dell para llevar su plataforma de agentes inteligentes seguros Cohere North a las soluciones de IA empresarial localizadas de Dell: La empresa de IA Cohere anunció una colaboración con Dell Technologies para acelerar conjuntamente soluciones de IA empresarial seguras y con capacidad de agentes. Dell se convertirá en el primer proveedor en ofrecer a las empresas la implementación localizada (on-premises) de la plataforma de agentes seguros de Cohere, Cohere North. Esta colaboración es especialmente crucial para las industrias que manejan datos sensibles y tienen requisitos de cumplimiento estrictos, permitiendo a las empresas desplegar y ejecutar la avanzada tecnología de agentes de IA de Cohere dentro de sus propios centros de datos. (Fuente: sarahookr)

Mistral AI se asocia con MGX y Bpifrance para construir el mayor parque de IA de Europa en Francia: Mistral AI anunció una asociación con MGX, una empresa de inversión tecnológica respaldada por Abu Dabi, y el banco nacional de inversiones de Francia, Bpifrance, para construir conjuntamente el mayor parque de IA de Europa en la región de París, Francia. El parque integrará centros de datos, recursos de computación de alto rendimiento, e instalaciones educativas y de investigación. Nvidia también participará, proporcionando soporte técnico. Esta iniciativa tiene como objetivo impulsar el desarrollo del ecosistema de IA europeo y mejorar la posición estratégica de Francia en el ámbito global de la IA. (Fuente: arthurmensch, arthurmensch)
🌟 Comunidad
La prevalencia del TDAH entre los profesionales de la IA llama la atención, podría superar el 20-30%: En las redes sociales ha surgido un debate sobre la prevalencia del Trastorno por Déficit de Atención e Hiperactividad (TDAH) entre los profesionales del sector de la IA. Algunos usuarios han observado que este campo parece atraer a muchos talentos con características de neurodiversidad. Minh Nhat Nguyen comentó que podría haber más de un 20-30% de personas con TDAH en la industria de la IA. Este fenómeno podría estar relacionado con las demandas de alta concentración, iteración rápida y pensamiento creativo del trabajo de investigación y desarrollo en IA, rasgos que a veces coinciden con ciertas manifestaciones del TDAH. (Fuente: Dorialexander)
La devaluación de habilidades en la era de la IA invita a la reflexión profunda, la reestructuración del sistema, y no el dominio de herramientas, es la clave: Un artículo de análisis profundo señala que la verdadera crisis de la era de la IA no es “saber o no usar herramientas de IA”, sino la devaluación de las propias habilidades y la reestructuración de todo el sistema de trabajo. El artículo, a través de ejemplos como la Línea Maginot, la contenedorización y la sustitución de mecanógrafos por procesadores de texto, argumenta que simplemente aprender a usar nuevas herramientas no garantiza la vanguardia; la clave está en comprender cómo la IA cambia la estructura, los procesos y la lógica organizativa del trabajo. Cuando el sistema se reescribe, las habilidades que antes eran de alto valor pueden quedar rápidamente marginadas. El aumento de la productividad no necesariamente se traduce en un aumento del valor individual, ya que el valor fluirá hacia quienes controlen la capa de coordinación del nuevo sistema. El artículo refuta ocho falacias populares como “aprender IA te pondrá a la vanguardia”, “la IA me hace trabajar más, por lo tanto, soy más valioso” y “los puestos de trabajo no cambian, solo la forma de trabajar”, enfatizando la necesidad de pensar en la propia posición y valor desde una perspectiva sistémica. (Fuente: 36氪)
Ex CEO de Google, Schmidt: El auge de la inteligencia no humana remodelará el panorama global, es necesario estar alerta a los riesgos y desafíos de la IA: El ex CEO de Google, Eric Schmidt, advirtió en una entrevista exclusiva que la sociedad subestima gravemente el potencial disruptivo de la “inteligencia no humana”. Considera que la IA ha pasado de la generación de lenguaje a la toma de decisiones estratégicas, capaz de completar tareas complejas de forma independiente. Schmidt destacó tres desafíos centrales que plantea la IA: los cuellos de botella de energía y capacidad de cómputo (EE. UU. necesita agregar 90 gigavatios de electricidad), el agotamiento cercano de los datos públicos (la siguiente etapa requerirá datos generados por IA) y cómo hacer que la IA supere el conocimiento humano existente para crear “nuevo conocimiento”. También señaló tres riesgos principales: la automejora recursiva descontrolada de la IA, la obtención del control de armas y la autorreplicación no autorizada. Considera que, en el contexto de la creciente competencia en IA entre China y EE. UU., la rápida difusión de la IA de código abierto podría generar riesgos de seguridad e incluso desencadenar una situación de “ataque preventivo” similar a la “disuasión nuclear”. Schmidt pidió un diálogo global inmediato sobre la gobernanza de la IA y enfatizó que la protección de la libertad humana debe integrarse en el diseño del sistema desde el principio. (Fuente: 36氪)

El CEO de GitHub refuta la “teoría de la inutilidad de la programación”, enfatizando que los programadores humanos siguen siendo importantes en la era de la IA: En respuesta a las opiniones de personas como el CEO de Nvidia, Jensen Huang, de que “en el futuro ya no será necesario aprender a programar”, el CEO de GitHub, Thomas Dohmke, expresó su desacuerdo en una entrevista. Considera que 2025 será el año del agente de programación (SWE Agent), pero el papel de los programadores humanos seguirá siendo crucial. Dohmke enfatizó que la IA debe ser un asistente para mejorar las capacidades de los desarrolladores, no para reemplazarlos por completo. Imagina que el desarrollo de software futuro evolucionará hacia un modelo de colaboración entre humanos e IA, donde los desarrolladores actuarán como “directores de orquesta de agentes inteligentes”, responsables de asignar tareas y revisar resultados. El CPO de GitHub, Mario Rodríguez, también afirmó que la empresa se compromete a mejorar las capacidades individuales con Copilot. Consideran que, con el desarrollo de la IA, comprender cómo programar y reprogramar máquinas que puedan representar el pensamiento y la acción humanos es crucial, y renunciar al aprendizaje del código equivale a renunciar a tener voz en el futuro de los agentes inteligentes. (Fuente: 36氪, 量子位)

Los informes de vulnerabilidades de baja calidad generados por IA proliferan, el fundador de curl introduce un mecanismo de filtrado para resistir la “basura de IA”: Daniel Stenberg, fundador del proyecto curl, ha declarado que, debido a la gran cantidad de informes de vulnerabilidades de baja calidad e inválidos generados por IA que ha recibido, se siente abrumado. Estos informes consumen mucho tiempo de los mantenedores y equivalen a un ataque DDoS. Por ello, al enviar informes de seguridad relacionados con curl en HackerOne, se ha añadido una casilla de verificación para preguntar si se utilizó IA. Si la respuesta es afirmativa, se requiere evidencia adicional para demostrar la autenticidad de la vulnerabilidad; de lo contrario, el informante podría ser bloqueado. Stenberg afirma que el proyecto nunca ha recibido un informe de error válido generado por IA. El desarrollador de Python Seth Larson también expresó preocupaciones similares, considerando que este tipo de informes causa confusión, estrés y frustración a los mantenedores, exacerbando el problema del agotamiento en los proyectos de código abierto. La discusión en la comunidad considera que la proliferación de informes generados por IA refleja la sobrecarga de información y el intento de algunas personas de explotar los mecanismos de recompensa por vulnerabilidades, e incluso algunos directivos de alto nivel han sido inducidos a error al creer que la IA puede reemplazar a programadores experimentados. (Fuente: WeChat)

La programación asistida por IA genera un intenso debate: la eficiencia aumenta significativamente, pero el papel del desarrollador humano sigue siendo crucial: Un desarrollador con décadas de experiencia en programación compartió cómo la IA (posiblemente Codex o una herramienta similar) resolvió en minutos un error que lo había atormentado durante horas y optimizó el código, maravillándose de que la IA es como un “compañero de equipo superpoderoso e incansable”. Esta experiencia generó un debate en la comunidad. La mayoría reconoce la poderosa capacidad de la IA para generar código, corregir errores y resumir información, lo que puede aumentar significativamente la eficiencia. Sin embargo, algunos desarrolladores señalan que la IA actualmente todavía comete errores, especialmente en lógica compleja, condiciones de borde y soluciones creativas, donde no iguala a los humanos, y su producción requiere la revisión y evaluación crítica de desarrolladores experimentados. El CEO de Microsoft, Satya Nadella, también enfatizó que la IA es una herramienta de empoderamiento, que el desarrollo de software ya no puede prescindir de la IA, pero la ambición y la agencia humanas siguen siendo importantes. La discusión general considera que la IA cambiará la forma de programar, y los desarrolladores deberán adaptarse a un nuevo paradigma de colaboración con la IA, centrándose en el diseño de arquitecturas de nivel superior y la definición de problemas. (Fuente: Reddit r/ChatGPT, WeChat)
AI Agent Manus abre registros pero con precios elevados, enfrenta competencia de gigantes nacionales e internacionales, y la versión en chino está en duda: La plataforma de AI Agent Manus, después de una oleada de códigos de invitación, ha abierto oficialmente los registros, pero actualmente solo para usuarios extranjeros, sin ofrecer una versión en chino. Los usuarios informan que utiliza un sistema de consumo de puntos; los puntos gratuitos (1000 al registrarse, 300 diarios) solo alcanzan para tareas simples, mientras que tareas complejas (como crear un juego de Sudoku para la web) requieren la compra de puntos, con un promedio de 1 dólar por 100 puntos, lo que resulta caro. Analistas de la industria indican que Manus depende de modelos grandes de terceros (como Claude para la versión internacional), lo que eleva los costos, y la ejecución en sandbox en la nube también aumenta los gastos. La demora en el lanzamiento de la versión en chino podría estar relacionada con la presentación de modelos nacionales, los hábitos de pago de los usuarios y la competencia en el mercado. Productos nacionales e internacionales como Coze de ByteDance y la aplicación “Xin Xiang” de Baidu ya compiten en este espacio. Aunque Manus ha obtenido nueva financiación, la barrera de entrada de su modelo “ligero en modelos, pesado en aplicaciones” se enfrenta a un desafío. (Fuente: 36氪)
Los modelos de IA fracasan colectivamente en un problema de razonamiento visual de “completar el cubo”, lo que suscita un debate sobre su verdadera capacidad de comprensión: Un problema de razonamiento visual que requería calcular el número de pequeños cubos necesarios para completar un cubo incompleto ha desconcertado a múltiples modelos de IA convencionales, incluidos OpenAI o3, Google Gemini 2.5 Pro, DeepSeek y Qwen3. Las respuestas dadas por los distintos modelos fueron variadas, principalmente debido a las diferentes interpretaciones de las especificaciones del cubo grande final (como 3x3x3, 4x4x4, 5x5x5). Incluso con pistas de orientación, a los modelos les resultó difícil responder correctamente de una sola vez. Algunos internautas señalaron que la propia formulación del problema podría ser ambigua y que los humanos también se sentirían confundidos. Este fenómeno ha suscitado un debate sobre si los modelos de IA realmente comprenden los problemas o si simplemente dependen del reconocimiento de patrones, lo que pone de manifiesto las limitaciones actuales de la IA en el razonamiento espacial complejo y la comprensión visual. (Fuente: 36氪)
Usuarios discuten el problema del “pensamiento excesivo” de los LLM al seguir instrucciones y razonar: Discusiones en redes sociales y artículos señalan que los modelos de lenguaje grandes (LLM), al utilizar procesos de razonamiento como la cadena de pensamiento (CoT), a veces “piensan demasiado”, lo que paradójicamente les impide seguir con precisión instrucciones simples. Por ejemplo, cuando se les pide que escriban un número específico de palabras o repitan una frase concreta, el CoT puede hacer que el modelo se centre más en el contenido general de la tarea e ignore estas restricciones básicas, o que introduzca contenido explicativo adicional. Los investigadores han propuesto la métrica de “atención restringida” para cuantificar este fenómeno y han probado estrategias de mitigación como el aprendizaje contextual, la autorreflexión, el razonamiento autoseleccionado y el razonamiento seleccionado por clasificador. Esto sugiere que no todas las tareas son adecuadas para CoT, y que las instrucciones simples pueden requerir un modo de ejecución más directo. (Fuente: menhguin, omarsar0)

Reflexión sobre la economía de la IA: El trabajo cognitivo barato rompe los modelos económicos tradicionales, la distribución del valor se enfrenta a una remodelación: Una opinión que ha generado debate sostiene que el auge de la IA está haciendo que el trabajo cognitivo (como la redacción de informes, el análisis de datos, la escritura de código) sea extremadamente barato, lo que desafía fundamentalmente los modelos económicos clásicos basados en la premisa de que “la inteligencia humana es escasa y costosa”. Cuando la IA puede realizar una gran cantidad de trabajo intelectual con un costo marginal cercano a cero, la productividad puede dispararse, pero el valor de una sola tarea se desplomará y la ventaja de la especialización se erosionará. La distribución del valor ya no se basará simplemente en la eficiencia o la producción, sino que dependerá de quién controle los nuevos recursos escasos (como los datos, las plataformas, los propios modelos de IA). Esto es similar a cómo, en cambios tecnológicos históricos (como la moda rápida para la industria de la confección, el streaming para la industria musical), los beneficios del aumento de la eficiencia no fluyeron completamente hacia los trabajadores, sino que fueron capturados por los coordinadores del sistema. El artículo advierte que la IA no solo automatiza tareas, sino que también mercantiliza el “pensamiento”, lo que podría ser la fuerza más disruptiva en la historia económica moderna. (Fuente: Reddit r/artificial)
Estrategia empresarial en la era de la IA: evitar la trampa de la “empresa inteligente”, se necesita reconstruir en lugar de optimizar los procesos antiguos: Muchas empresas, al adoptar la IA, tienden a utilizarla como una herramienta para optimizar los procesos existentes y reducir costos, cayendo en la trampa de la “empresa inteligente” de “hacer lo mismo de forma más inteligente”. Sin embargo, la verdadera transformación no consiste en hacer más inteligentes los procesos antiguos, sino en reflexionar sobre si esos procesos siguen siendo necesarios y en construir sistemas y modelos de negocio completamente nuevos y nativos de la IA. La tecnología no se adaptará simplemente a los sistemas antiguos, sino que los remodelará. Las empresas deben evitar invertir demasiados recursos en optimizar procesos que pronto serán obsoletos debido a la IA, y en su lugar deben centrarse en definir nuevas reglas, cambiando fundamentalmente la forma de tomar decisiones, los mecanismos de coordinación y la estructura organizativa. (Fuente: 36氪)
💡 Otros
Evento de networking de LangChain en Nueva York: LangChain anunció que el 22 de mayo (jueves) organizará un evento de networking en Nueva York junto con Tabs y TavilyAI. El evento incluirá charlas informales, demostraciones de productos y oportunidades para establecer contactos con otros constructores. (Fuente: hwchase17, LangChainAI)

La Conferencia Global de IA en Tokio se celebrará en junio: Un evento llamado “Conferencia Global de IA · Estación de Tokio” está programado para celebrarse del 7 al 8 de junio en Tokio, Japón. Contará con la participación de numerosos desarrolladores de IA, artistas, inversores y otras personalidades de renombre. Aquellos interesados en el campo de la IA y que planeen viajar a Japón pueden estar atentos a la información de inscripción. (Fuente: op7418)

El paradigma de la arquitectura de servicios de IA está migrando de “Modelo como Servicio” a “Agente como Servicio”: Con el desarrollo de la tecnología de IA, la arquitectura de servicios de IA está experimentando una profunda transición de “Modelo como Servicio” (MaaS) a “Agente como Servicio” (AaaS). Los Agentes de IA, con su capacidad de ser impulsados por objetivos, percibir el entorno, tomar decisiones autónomas y aprender, superan el modelo tradicional de los modelos de IA que ejecutan pasivamente instrucciones. Pueden pensar de forma independiente, desglosar tareas, planificar rutas y recurrir a herramientas externas para completar objetivos complejos. Esta transformación está impulsando un desarrollo integral de la cadena industrial, desde la infraestructura subyacente (capacidad de cómputo, datos), los algoritmos centrales y los grandes modelos, hasta la capa intermedia de componentes y plataformas de Agentes, y finalmente las aplicaciones de productos terminales (Agentes de tipo general, de industria vertical, embebidos). Empresas chinas de Agentes de IA como HeyGen, Laiye Technology, Waveform Intelligence, etc., también están expandiéndose activamente en el extranjero, explorando mercados internacionales. A pesar de enfrentar desafíos como los altos costos de la capacidad de cómputo y la oferta insuficiente, el potencial de los Agentes de IA se está liberando continuamente a través de la optimización de algoritmos, chips especializados, computación en el borde y otras soluciones. (Fuente: 36氪)