
Palabras clave:Agente de programación de IA, Codex, AlphaEvolve, Paradigma de razonamiento de IA, Modelo MoE, Chip de IA, Educación en IA, Cortometrajes de IA, Modelo OpenAI Codex-1, Google DeepMind AlphaEvolve, ByteDance Seed1.5-VL, Tecnología Qwen ParScale, Sistema GB300 de NVIDIA
🔥 Foco
OpenAI lanza el agente de programación de IA en la nube Codex, impulsado por el nuevo modelo codex-1: OpenAI ha lanzado Codex, un agente de programación de IA en la nube basado en codex-1, una versión de o3 especialmente ajustada y optimizada para la ingeniería de software. Codex puede procesar múltiples tareas en paralelo de forma segura en un sandbox en la nube y, gracias a su integración con GitHub, puede invocar directamente repositorios de código, permitiendo la construcción rápida de módulos, la resolución de problemas en repositorios de código, la corrección de vulnerabilidades, el envío de PRs y la validación automática mediante pruebas. Tareas que antes llevaban días u horas, Codex puede completarlas en 30 minutos. La herramienta ya está disponible para los usuarios de ChatGPT Pro, Enterprise y Team, con el objetivo de convertirse en el “ingeniero 10x” para los desarrolladores y remodelar el proceso de desarrollo de software. (Fuente: 36氪)
Google DeepMind presenta AlphaEvolve, la IA evoluciona autónomamente logrando avances en matemáticas y algoritmos: El sistema de IA AlphaEvolve de Google DeepMind, mediante la autoevolución y el entrenamiento de grandes modelos de lenguaje, ha logrado avances en múltiples campos de las matemáticas y la ciencia. Mejoró el algoritmo de multiplicación de matrices de 4×4 (por primera vez en 56 años), optimizó el problema de empaquetamiento hexagonal (por primera vez en 16 años) y avanzó en el “problema del número de osculación”. AlphaEvolve puede optimizar algoritmos de forma autónoma, e incluso encontró un método para acelerar el entrenamiento del modelo Gemini, y ya se ha aplicado para optimizar la infraestructura de computación interna de Google, ahorrando un 0.7% de los recursos computacionales. Esto marca un hito, ya que la IA no solo resuelve problemas, sino que también descubre nuevo conocimiento, con el potencial de revolucionar el paradigma de la investigación científica y lograr la creación científica por IA. (Fuente: 36氪)
Discurso de Altman en la Cumbre de IA de Sequoia: La IA entrará en el mundo real en tres años, remodelando la vida y el trabajo: El CEO de OpenAI, Sam Altman, predijo en la Cumbre de IA de Sequoia que los agentes de IA se volverán prácticos en 2025 (especialmente en el campo de la codificación), la IA impulsará descubrimientos científicos importantes en 2026, y los robots entrarán en el mundo físico para crear valor en 2027. Repasó la trayectoria de OpenAI desde sus primeras exploraciones hasta el nacimiento de ChatGPT, y propuso que los futuros productos de IA serán servicios de “suscripción central de IA”, capaces de albergar la totalidad de las experiencias vitales de una persona, convirtiéndose en la interfaz inteligente por defecto. OpenAI se centrará en modelos centrales y escenarios de aplicación, y mantendrá la eficiencia organizativa de “equipos pequeños, grandes responsabilidades”. (Fuente: 36氪)
Presentación de Nvidia en Computex: Computadoras personales con IA en producción, lanzamiento del sistema GB300 de próxima generación, planes para construir un superordenador de IA en Taiwán: El CEO de Nvidia, Jensen Huang, anunció en Computex 2025 que la computadora personal con IA DGX Spark ha entrado en producción completa y estará disponible en unas semanas; el sistema de IA de próxima generación GB300 (equipado con 72 GPUs Blackwell Ultra y 36 CPUs Grace) se lanzará en el tercer trimestre. Nvidia colaborará con TSMC y Foxconn para establecer un centro de supercomputación de IA en Taiwán. También se presentó la serie de estaciones de trabajo Blackwell RTX Pro 6000 y el Grace Blackwell Ultra Superchip, y se planea abrir el código del motor de física Newton en julio para el entrenamiento de robots. Huang enfatizó que la IA estará en todas partes, reiterando su impacto revolucionario. (Fuente: 36氪)

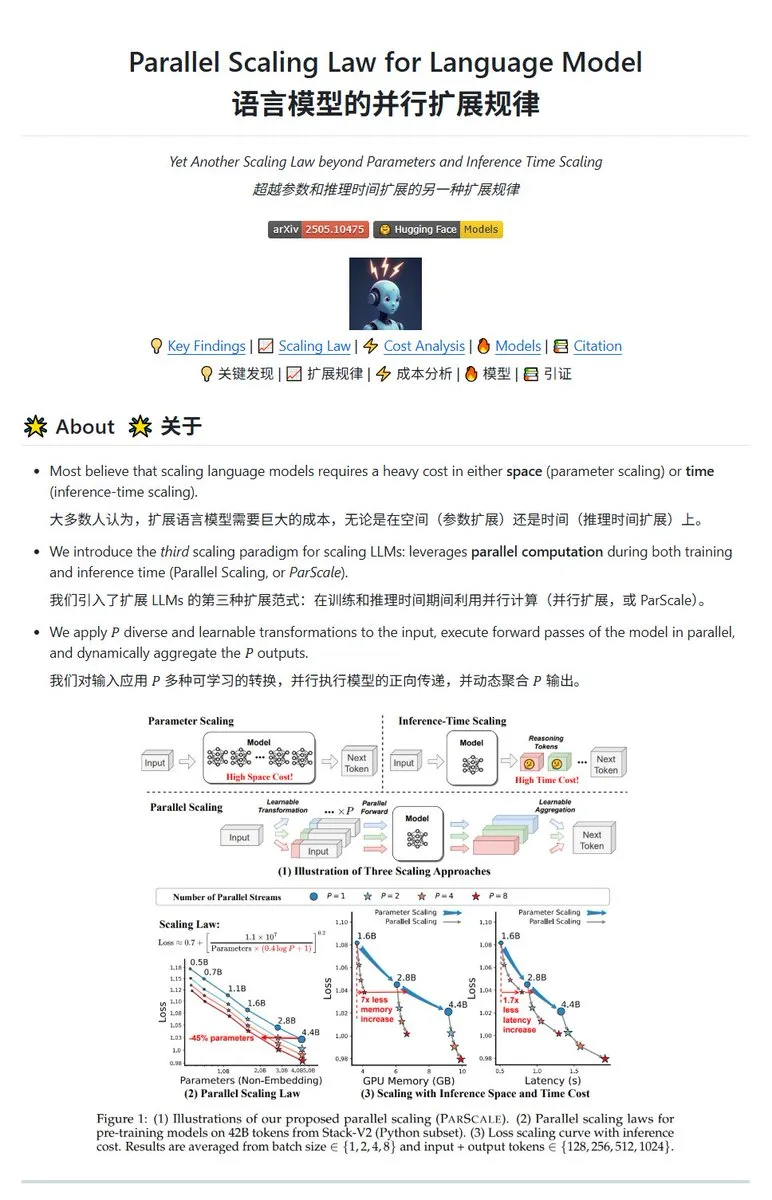
Qwen lanza la tecnología de escalado paralelo ParScale, modelos pequeños pueden alcanzar el efecto de modelos grandes: El equipo de Qwen ha presentado la tecnología ParScale, que mejora la capacidad del modelo mediante la inferencia en paralelo. Este método utiliza n flujos paralelos para la inferencia, cada flujo procesa la entrada mediante una transformación diferenciada aprendible, y finalmente los resultados se combinan mediante un mecanismo de agregación dinámica. La investigación indica que el efecto de P flujos paralelos es aproximadamente equivalente a aumentar la cantidad de parámetros del modelo en O(log P) veces; por ejemplo, un modelo de 30B con 8 flujos paralelos puede alcanzar el efecto de un modelo de 42.5B. Se espera que esta tecnología mejore el rendimiento del modelo sin aumentar significativamente el uso de memoria de vídeo, o reduzca el tamaño de los modelos existentes aumentando el paralelismo, aunque esto podría ser a costa de una mayor demanda computacional y una menor velocidad de inferencia. (Fuente: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
🎯 Tendencias
Informe de Poe: OpenAI y Google lideran la carrera de la IA, Anthropic muestra signos de debilidad: El último informe de uso de Poe (enero-mayo de 2025) muestra un cambio drástico en el panorama del mercado de la IA. En la generación de texto, GPT-4o (35.8%) lidera, mientras que Gemini 2.5 Pro (31.5%) encabeza la capacidad de razonamiento. La generación de imágenes está dominada por Imagen3, GPT-Image-1 y la serie Flux. En el campo de la generación de vídeo, Kling-2.0-Master ha surgido con fuerza, mientras que la cuota de Runway ha disminuido significativamente. En cuanto a los agentes, o3 muestra el mejor rendimiento. El informe señala que la capacidad de razonamiento se ha convertido en un campo de batalla clave, la cuota de mercado de Claude de Anthropic ha disminuido, y la proporción de usuarios de DeepSeek R1 también ha retrocedido desde su pico. Las empresas deben prestar atención a la precisión y fiabilidad de los modelos en tareas complejas y elegir modelos de IA de forma flexible. (Fuente: 36氪)

El lanzamiento del modelo de IA insignia de Meta, Behemoth (Llama 4), se retrasa, lo que podría provocar un ajuste en la estrategia de IA: Según informes, el lanzamiento del modelo grande de 2 billones de parámetros Behemoth (Llama 4) de Meta, originalmente planeado para abril, se ha pospuesto hasta otoño o más tarde debido a que el rendimiento no cumplió con las expectativas. Este modelo, preentrenado con 30T de tokens multimodales en 32K GPUs, tiene como objetivo competir con OpenAI, Google, etc. Las dificultades de desarrollo han generado decepción interna con el rendimiento del equipo de Llama 4 y podrían llevar a ajustes en el equipo de productos de IA. Al mismo tiempo, 11 de los 14 miembros iniciales del equipo de Llama 1 ya han renunciado. Ejecutivos de Meta negaron los rumores de que “el 80% del equipo renunció”, enfatizando que los que se fueron eran principalmente del equipo del paper de Llama 1. Este incidente agrava las preocupaciones externas sobre si Meta está experimentando un cuello de botella en la carrera de la IA. (Fuente: 36氪)

ByteDance y Google DeepMind publican nueva investigación sobre modelos MoE, centrándose en la eficiencia y la aplicación en sistemas de producción: El paper de ByteDance “MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production” presenta un sistema de producción diseñado específicamente para el entrenamiento eficiente de modelos MoE a gran escala. Al superponer la comunicación y la computación a nivel de operador, logra una mejora de eficiencia de 1.88 veces sobre Megatron-LM y ya se ha implementado en sus centros de datos para entrenar modelos de producción (como Internal-352B, 32 expertos, top-3). Google DeepMind ha lanzado AlphaEvolve, que mediante la autoevolución de la IA y el entrenamiento de LLMs, ha logrado avances en matemáticas y algoritmos, como la mejora de la multiplicación de matrices 4×4 y el problema de empaquetamiento hexagonal, demostrando el potencial de la IA en el descubrimiento científico. (Fuente: teortaxesTex, 36氪)

OpenAI discute el paradigma de inferencia de IA, enfatizando su papel crucial en la mejora del rendimiento: El investigador de OpenAI, Noam Brown, señaló que el desarrollo de la IA ha pasado del paradigma de preentrenamiento (predecir la siguiente palabra a través de datos masivos) al paradigma de inferencia. El preentrenamiento es costoso, mientras que el paradigma de inferencia mejora la calidad de la respuesta aumentando el tiempo de “pensamiento” del modelo (cantidad de cómputo de inferencia), incluso si el costo de entrenamiento permanece sin cambios. Por ejemplo, los modelos de la serie o, en competiciones de matemáticas (AIME) y problemas científicos de nivel doctoral (GPQA), lograron una precisión muy superior a GPT-4o mediante un mayor tiempo de inferencia. El economista jefe de OpenAI, Ronnie Chatterji, discutió cómo la IA está remodelando el panorama empresarial, argumentando que la clave radica en cómo las empresas integran la IA para mejorar o reemplazar roles humanos, y cómo la tecnología de IA se integra en la cadena de valor. (Fuente: 36氪)

El CEO de Google, Pichai, responde a la “teoría de la muerte de Google”, enfatizando la evolución de la búsqueda impulsada por IA y las ventajas de infraestructura: El CEO de Google, Sundar Pichai, en una entrevista exclusiva, respondió a las preocupaciones sobre “la búsqueda de Google siendo reemplazada por IA”, afirmando que Google está transformando la búsqueda de consultas reactivas a un asistente inteligente predictivo y personalizado a través de funciones como “AI Overviews” y “AI Mode”. Enfatizó que la inversión a largo plazo de Google en infraestructura de IA (TPUs de desarrollo propio, centros de datos a gran escala) y la eficiencia del modelo son ventajas centrales, lo que permite ofrecer modelos avanzados a un costo competitivo. Pichai considera que la IA es una “plataforma tecnológica para todos los escenarios” que remodelará negocios centrales como Search, YouTube, Cloud, y dará lugar a nuevas formas. También mencionó que la competitividad de la IA china (como DeepSeek) no debe subestimarse y señaló que la electricidad será un cuello de botella clave para el desarrollo de la IA. (Fuente: 36氪)

Resumen de startups de IA en el sector educativo: El artículo resume 13 startups de IA en educación a las que prestar atención en 2025, que están cambiando la enseñanza a través de rutas de aprendizaje personalizadas, sistemas de tutoría inteligente, calificación automática y creación de contenido inmersivo. Por ejemplo, Merlyn es un asistente de IA controlado por voz que aligera la carga administrativa de los profesores; Brisk Teaching es una extensión de Chrome que simplifica las tareas de enseñanza; Edexia es una plataforma de calificación con IA que aprende el estilo del profesor; Storytailor combina la biblioterapia con la IA para crear historias personalizadas; Brainly ofrece ayuda con las tareas mejorada por IA. Estas empresas demuestran el amplio potencial de aplicación de la IA en la educación, desde mejorar la eficiencia hasta lograr un aprendizaje personalizado y la equidad educativa. (Fuente: 36氪)
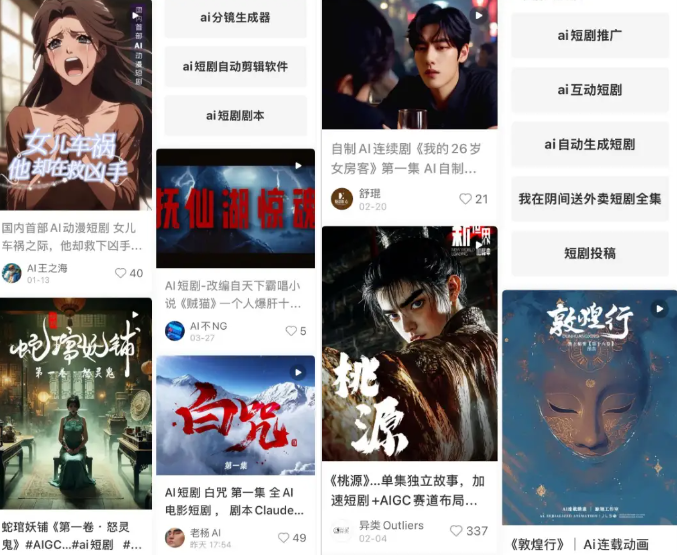
Las miniseries de IA enfrentan desafíos técnicos y de comercialización, con una brecha entre los efectos de producción y las expectativas: Aunque se espera que las herramientas de IA reduzcan los costos de producción de miniseries y acorten los ciclos, los profesionales encuentran importantes dificultades técnicas en aspectos como la consistencia de los personajes, la sincronización labial y la naturalidad del lenguaje cinematográfico, lo que hace que muchas obras parezcan más “miniseries estilo PPT”. La IA tiene dificultades para comprender ideas creativas surrealistas, lo que limita el desarrollo de géneros de fantasía y ciencia ficción. Actualmente, la tecnología de IA es más adecuada para producir cortometrajes que miniseries completas, y las perspectivas de comercialización son inciertas. Grandes productoras cinematográficas como Bona Film Group y Huace Group tienen más probabilidades de abrirse paso gracias a sus ventajas en recursos, mientras que la mayoría de los creadores pequeños enfrentan altos costos de prueba y error y el problema de que sus obras se vuelvan obsoletas rápidamente debido a la rápida iteración tecnológica. (Fuente: 36氪)
MSI presenta una PC con IA integrada con el superchip NVIDIA GB10, con 6144 núcleos CUDA y 128GB de memoria LPDDR5X: MSI ha mostrado su EdgeExpert MS-C931 S, una PC con IA que incorpora el superchip NVIDIA GB10. Se ha confirmado que este chip cuenta con 6144 núcleos CUDA y 128GB de memoria LPDDR5X. Este es otro fabricante, después de ASUS, Dell y Lenovo, en lanzar una computadora personal con IA basada en la arquitectura DGX Spark de NVIDIA. El lanzamiento de este tipo de productos marca la progresiva popularización de la capacidad de cómputo de IA de alto rendimiento hacia dispositivos personales y de borde, aunque algunos comentarios señalan que su precio podría dificultar la competencia con productos como el Mac Mini. (Fuente: Reddit r/LocalLLaMA)
Qwen3-30B logra un alto rendimiento en VLLM, adecuado para la gestión de conjuntos de datos: El modelo Qwen3-30B-A3B ha demostrado una excelente velocidad de inferencia (5K t/s de prellenado, 1K t/s de generación) en el framework VLLM y tarjetas gráficas RTX 3090s, lo que lo hace muy adecuado para tareas como el filtrado y la gestión de conjuntos de datos. Aunque podría haber una ligera regresión en comparación con QwQ, su ventaja en velocidad lo hace más práctico para el procesamiento de datos. El principal problema actual es la velocidad de entrenamiento extremadamente lenta, pero ya existe un PR en la biblioteca Hugging Face Transformers que intenta solucionar este problema, y se espera que en el futuro se puedan lanzar modelos RpR con conjuntos de datos mejorados basados en Qwen3-30B. (Fuente: Reddit r/LocalLLaMA)
Bilibili (B站) lanza el modelo de generación de vídeo de animación de código abierto Index-AniSora, compatible con múltiples estilos de anime: Bilibili ha lanzado Index-AniSora, un modelo de código abierto especializado en la generación de vídeos de estilo anime, basado en su framework tecnológico AniSora (aceptado en IJCAI25). Este modelo puede generar animaciones a partir de cómics con un solo clic y es compatible con diversos estilos como series de anime, producciones nacionales, adaptaciones de manga, VTubers, etc. El sistema AniSora, mediante la construcción de un conjunto de datos de decenas de millones de pares texto-vídeo de alta calidad, el desarrollo de un framework de generación por difusión unificado y la introducción de un mecanismo de enmascaramiento espaciotemporal, logra un control preciso de la sincronización labial y los movimientos de los personajes. Al mismo tiempo, Bilibili ha diseñado un benchmark de evaluación para vídeos de animación y un sistema de evaluación automatizado optimizado basado en VLM. El contenido de código abierto incluirá AniSoraV1.0 (basado en CogVideoX-5B), AniSoraV2.0 (basado en Wan2.1-14B, compatible con el entrenamiento en Huawei 910B) y herramientas relacionadas para la construcción de conjuntos de datos y evaluación. (Fuente: WeChat)

ByteDance lanza el modelo de lenguaje visual Seed1.5-VL, con un rendimiento sobresaliente en tareas multimodales: ByteDance ha presentado Seed1.5-VL, un modelo de lenguaje visual compuesto por un codificador visual de 532M de parámetros y un LLM de Mixture-of-Experts (MoE) con 20B de parámetros activos. Este modelo ha alcanzado un rendimiento SOTA en 38 de 60 benchmarks públicos y ha superado a sistemas líderes como OpenAI CUA y Claude 3.7 en tareas centradas en agentes, como el control de GUI y la jugabilidad en videojuegos, demostrando una potente capacidad de comprensión y razonamiento multimodal. (Fuente: WeChat)
Nous Research lanza Psyche Network, logrando el preentrenamiento distribuido de un LLM de 40B de parámetros: Nous Research ha lanzado Psyche Network, una red de entrenamiento descentralizada basada en la arquitectura DeepSeek V3 MLA, que en su primera prueba ha preentrenado un gran modelo de lenguaje de 40 mil millones de parámetros. La red utiliza el optimizador DisTrO y una pila de red peer-to-peer personalizada para integrar la potencia de cálculo de GPU distribuida globalmente, permitiendo a individuos y pequeños grupos entrenar en un solo H/DGX y ejecutar en GPUs 3090. Esta iniciativa tiene como objetivo romper el monopolio de la potencia de cálculo de los gigantes tecnológicos y hacer que el entrenamiento de modelos a gran escala sea más accesible. (Fuente: 量子位)

🧰 Herramientas
Sim Studio: Constructor de flujos de trabajo de agentes de IA de código abierto: Sim Studio es una plataforma de construcción de flujos de trabajo de agentes de IA de código abierto y ligera, que ofrece una interfaz intuitiva para que los usuarios puedan construir e implementar rápidamente aplicaciones LLM conectadas a diversas herramientas. Admite una versión alojada en la nube y autoalojamiento (se recomienda un entorno Docker, compatible con modelos locales como Ollama). Su stack tecnológico incluye Next.js, Bun, PostgreSQL, Drizzle ORM, Better Auth, Shadcn UI, Tailwind CSS, Zustand, ReactFlow y Turborepo. (Fuente: GitHub Trending)

Cherry Studio: Aplicación de escritorio frontend para LLM de código abierto y con todas las funciones recibe atención: Cherry Studio es una aplicación de escritorio frontend para LLM de código abierto que integra RAG, búsqueda web, acceso a modelos locales (a través de Ollama, LM Studio) y modelos en la nube (como Gemini, ChatGPT), entre otras funciones. Los usuarios comentan que su compatibilidad y gestión de MCP (Protocolo de Control Múltiple) son superiores a Open WebUI y LibreChat, y es fácil de instalar y configurar. La aplicación también admite la conexión directa a bases de conocimiento de Obsidian. Aunque algunos usuarios expresan preocupación por su origen, su completo conjunto de funciones la convierte en una opción atractiva. (Fuente: Reddit r/LocalLLaMA)

MLX-LM-LoRA: Añade LoRA a modelos MLX y admite múltiples métodos de entrenamiento: El proyecto de código abierto mlx-lm-lora permite a los usuarios integrar módulos LoRA (Low-Rank Adaptation) en modelos bajo el framework MLX de Apple. Este proyecto no solo admite la adición de LoRA, sino que también incorpora múltiples métodos de entrenamiento de alineación como ORPO, DPO, CPO, GRPO, facilitando a los usuarios el ajuste fino de modelos según sus propias necesidades, la generación de módulos LoRA personalizados y su aplicación en sus modelos MLX preferidos. (Fuente: karminski3)
DeepDrone: Proyecto de dron controlado por IA basado en Qwen de código abierto: Un desarrollador ha creado un proyecto de dron controlado por IA llamado DeepDrone, basado en el gran modelo Qwen, y lo ha hecho de código abierto en HuggingFace y GitHub. Este proyecto demuestra el potencial de aplicar grandes modelos de lenguaje al control autónomo de drones, lo que ha generado discusiones sobre la IA en la automatización y posibles aplicaciones militares. (Fuente: karminski3)
Qwen Web Dev: Genera e implementa sitios web con una sola indicación: El equipo Qwen de Alibaba anunció mejoras en su herramienta Qwen Web Dev, que permite a los usuarios generar un sitio web con solo una indicación (prompt) y desplegarlo con un solo clic. Esta herramienta tiene como objetivo reducir la barrera de entrada al desarrollo web, permitiendo a los usuarios transformar sus ideas en sitios web accesibles de manera más conveniente y compartirlos con el mundo. (Fuente: Alibaba_Qwen, huybery)
SuperGo.AI: Herramienta de interfaz única que integra ocho modelos LLM: Un entusiasta de la IA ha desarrollado una herramienta llamada SuperGo.AI, que integra ocho LLM con diferentes roles (como Supercerebro de IA, Imaginación de IA, Ética de IA, Universo de IA, etc.) en una única interfaz. Estos roles de IA pueden percibirse e interactuar entre sí, y los usuarios pueden seleccionar los modos “Creativo”, “Científico” y “Mixto” para obtener respuestas combinadas. La herramienta tiene como objetivo ofrecer una novedosa experiencia de colaboración multi-IA y actualmente no tiene muro de pago. (Fuente: Reddit r/artificial)
Kokoro-JS: Implementa texto a voz (TTS) local ilimitado: Kokoro-JS es una herramienta de texto a voz 100% local y 100% de código abierto, que funciona descargando un modelo de IA de aproximadamente 300MB en el navegador. El texto introducido por el usuario no se envía a ningún servidor, garantizando la privacidad y la disponibilidad sin conexión. La herramienta tiene como objetivo proporcionar funciones de TTS ilimitadas. (Fuente: Reddit r/LocalLLaMA)
📚 Aprendizaje
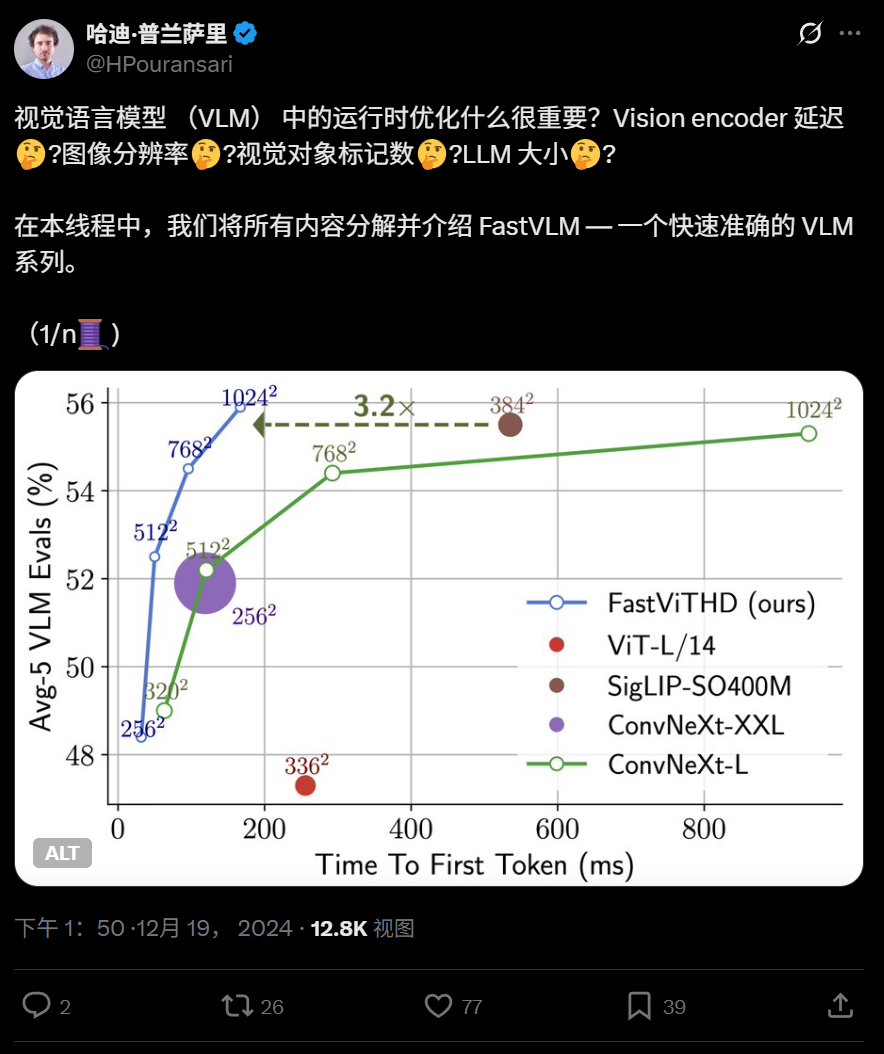
Apple lanza el modelo de lenguaje visual eficiente FastVLM de código abierto, optimizado para ejecución en dispositivos: Apple ha lanzado FastVLM, un modelo de lenguaje visual de código abierto diseñado específicamente para una ejecución eficiente en dispositivos como el iPhone. FastVLM introduce un nuevo codificador visual híbrido, FastViTHD, que combina capas convolucionales con módulos Transformer, y utiliza técnicas de pooling multiescala y submuestreo para reducir significativamente el número de tokens visuales necesarios para procesar imágenes (16 veces menos que un ViT tradicional), logrando una velocidad de salida del primer token 85 veces más rápida. Este modelo es compatible con los principales LLM y ya se ofrece una aplicación de demostración para iOS/macOS basada en el framework MLX, adecuada para dispositivos de borde y tareas de imagen y texto en tiempo real. (Fuente: WeChat)
HIT y UPenn proponen PointKAN, mejorando el análisis de nubes de puntos 3D basado en KAN: Investigadores del Instituto de Tecnología de Harbin (Shenzhen) y la Universidad de Pensilvania han presentado PointKAN, una nueva arquitectura para la percepción 3D basada en Kolmogorov-Arnold Networks (KANs). PointKAN reemplaza las funciones de activación fijas en los MLP tradicionales por funciones de activación aprendibles, mejorando la capacidad de aprender características geométricas complejas. Incluye un módulo de afinidad geométrica y un módulo de extracción de características locales en paralelo. El equipo también propuso una versión PointKAN-elite, que adopta la estructura Efficient-KANs, utiliza funciones racionales como funciones base y comparte parámetros por grupos, reduciendo significativamente la cantidad de parámetros y la complejidad computacional, al tiempo que demuestra un rendimiento SOTA en tareas de clasificación, segmentación parcial y aprendizaje con pocas muestras. (Fuente: 量子位)

La Universidad de Pittsburgh propone el framework PhyT2V para mejorar el realismo físico de los vídeos generados por IA: El Laboratorio de Sistemas Inteligentes de la Universidad de Pittsburgh ha desarrollado el framework PhyT2V, con el objetivo de mejorar la consistencia física del contenido generado por modelos de texto a vídeo (T2V). Este método no requiere reentrenamiento del modelo ni datos externos a gran escala. A través de un razonamiento en cadena (CoT) guiado por grandes modelos de lenguaje (LLM) y un mecanismo iterativo de autocorrección, analiza y optimiza las indicaciones de texto en múltiples rondas según reglas físicas. PhyT2V es capaz de identificar reglas físicas, desajustes semánticos y generar indicaciones corregidas, mejorando así la capacidad de generalización de los principales modelos T2V (como CogVideoX, OpenSora) en escenarios físicos realistas (sólidos, fluidos, gravedad, etc.), especialmente en escenarios fuera de distribución, con mejoras de hasta 2.3 veces en los indicadores de sentido común físico (PC) y cumplimiento semántico (SA). (Fuente: WeChat)
Últimas investigaciones sobre LLM: multimodalidad, alineación en tiempo de prueba, agentes, optimización de RAG, etc. Los avances de investigación de LLM de la semana incluyen: 1. La Universidad de Washington propone QALIGN, un método de alineación en tiempo de prueba que no requiere modificar el modelo ni acceder a los logits, logrando una mejor alineación en la generación de texto mediante MCMC. 2. UCLA preentrena Clinical ModernBERT, extendiendo la longitud del contexto del codificador del dominio biomédico a 8192 tokens. 3. Skoltech propone un método ligero de recuperación RAG autoadaptativo e independiente del LLM basado en información externa (popularidad de entidades, tipo de pregunta). 4. PSU define el problema de atribución automatizada de fallos en sistemas multiagente de LLM y desarrolla conjuntos de datos y métodos de evaluación. 5. La Universidad de Fudan propone un marco de restricciones multidimensionales y un proceso de generación automatizada de instrucciones para mejorar la capacidad de seguimiento de instrucciones de los LLM. 6. a-m-team lanza AM-Thinking-v1 (32B) de código abierto, con capacidad de codificación matemática comparable a DeepSeek-R1-671B. 7. Xiaomi lanza MiMo-7B, que mediante la optimización del preentrenamiento y el post-entrenamiento, muestra un rendimiento excelente en tareas de inferencia. 8. MiniMax propone el modelo TTS autorregresivo MiniMax-Speech, compatible con la clonación de voz zero-shot en 32 idiomas. 9. ByteDance construye el modelo de lenguaje visual Seed1.5-VL, con un rendimiento destacado en tareas multimodales y centradas en agentes. 10. El primer modelo de lenguaje de 32B parámetros del mundo, INTELLECT-2, logra el entrenamiento por aprendizaje reforzado distribuido, proponiendo el framework PRIME-RL. (Fuente: WeChat)
Talleres de AAAI 2025 se centran en el razonamiento neuronal, el descubrimiento matemático y la IA para acelerar la ciencia y la ingeniería: Los talleres de AAAI 2025 discutieron principalmente la aplicación de la IA en el campo científico. Entre ellos, el taller “Razonamiento Neuronal y Descubrimiento Matemático” enfatizó que las redes neuronales de caja negra pueden usarse para proponer conjeturas matemáticas y generar nuevas geometrías, pero también señaló su incapacidad para alcanzar un razonamiento lógico a nivel simbólico y abogó por enfoques interdisciplinarios. Otro taller, “IA para Acelerar la Ciencia y la Ingeniería” (cuarta edición, con el tema de la IA en las biociencias), se centró en modelos fundamentales para el diseño terapéutico, modelos generativos para el descubrimiento de fármacos, diseño de anticuerpos en bucle cerrado en el laboratorio, aprendizaje profundo en genómica e inferencia causal en aplicaciones biológicas, entre otros temas, y exploró los desafíos y oportunidades de los modelos generativos en las biociencias. (Fuente: aihub.org)

Google y Anthropic muestran desacuerdo en la investigación sobre interpretabilidad de la IA, la interpretabilidad mecanicista enfrenta desafíos: La naturaleza de “caja negra” de la IA limita su aplicación en muchos campos críticos. Google DeepMind anunció recientemente una reducción en la prioridad de la investigación sobre “interpretabilidad mecanicista” (mechanistic interpretability), argumentando que la ingeniería inversa de los mecanismos internos de la IA mediante métodos como los autoencoders dispersos (SAE) enfrenta numerosos problemas, como la falta de referencias objetivas, la cobertura incompleta de conceptos, la distorsión de características, etc., y que las técnicas SAE existentes no han logrado identificar los “conceptos” necesarios en tareas críticas. Por otro lado, el CEO de Anthropic, Dario Amodei, aboga por fortalecer la investigación en este campo y se muestra optimista sobre la posibilidad de lograr una “resonancia magnética de la IA” en los próximos 5-10 años. Esta controversia pone de manifiesto los profundos desafíos para comprender y controlar el comportamiento de la IA. (Fuente: 36氪)

Peking University/StepStar/Lightelligence proponen InfiniteHBD: una arquitectura de dominio de alto ancho de banda para GPU de nueva generación que reduce costos y aumenta la eficiencia: En respuesta a las limitaciones de las arquitecturas de dominio de alto ancho de banda (HBD) existentes en términos de escalabilidad, costo y tolerancia a fallos, equipos de la Universidad de Pekín, StepStar y Lightelligence han propuesto la arquitectura InfiniteHBD. Esta arquitectura se centra en un módulo de conmutación óptica (OCSTrx) y, al integrar capacidades de conmutación óptica de bajo costo (OCS) en el módulo de conversión optoelectrónica, logra una topología K-Hop Ring dinámicamente reconfigurable a escala de centro de datos y aislamiento de fallos a nivel de nodo. El costo unitario de InfiniteHBD es solo el 31% del de NVL-72, la tasa de desperdicio de GPU es casi nula y la MFU (utilización de FLOPs del modelo) mejora hasta 3.37 veces en comparación con NVIDIA DGX, ofreciendo una solución superior para el entrenamiento de modelos grandes a gran escala. El paper ha sido aceptado en SIGCOMM 2025. (Fuente: WeChat)

OceanBase lanza PowerRAG, abrazando completamente la IA y construyendo una base de datos integrada Data×AI: En su conferencia de desarrolladores, OceanBase lanzó PowerRAG, un producto de aplicación orientado a la IA, con el objetivo de proporcionar capacidades de desarrollo RAG listas para usar, conectando datos, plataformas, interfaces y capas de aplicación. El CTO Yang Chuanhui detalló la estrategia de IA de OceanBase: construir capacidades Data×AI, evolucionando de una base de datos integrada a una base de datos integrada. OceanBase mejorará las capacidades vectoriales, optimizará la recuperación fusionada, logrará la actualización dinámica del almacenamiento de conocimiento empresarial, e integrará profundamente el post-entrenamiento y el ajuste fino de modelos. Ya se ha adaptado a plataformas de agentes principales como Dify, FastGPT y al protocolo MCP. Su rendimiento vectorial ha demostrado ser líder en las pruebas VectorDBBench, y mediante el algoritmo de cuantización BQ, ha reducido significativamente los requisitos de memoria. (Fuente: WeChat)

💼 Negocios
Fondos de Shanghai State-owned Capital Investment invierten en empresas de chips de IA como SINOENG, Enflame Technology y Biren Technology: Shanghai State-owned Capital Investment Co., Ltd. (Shanghai Guotou) firmó recientemente acuerdos de inversión con tres empresas de semiconductores: SINOENG, Enflame Technology y Biren Technology. Anteriormente, su fondo matriz de IA líder ya había liderado la financiación previa a la salida a bolsa de Biren Technology. Shanghai Guotou declaró que desplegará activamente inversiones en áreas como modelos fundamentales, chips de computación e inteligencia incorporada. SINOENG se especializa en IP de semiconductores, especialmente en tecnología Chiplet; su fundador, Zeng Keqiang, fue anteriormente vicepresidente de Synopsys China. Enflame Technology y Biren Technology son ambas empresas de diseño de chips GPU. Esta medida muestra el enfoque de Shanghai Guotou en la parte superior de la cadena de la industria de la IA, especialmente en el campo de los chips de computación. (Fuente: 36氪)
Sakana AI y Mitsubishi UFJ Bank alcanzan una asociación integral para desarrollar IA específica para la banca: La startup japonesa de IA Sakana AI anunció la firma de un acuerdo de asociación de varios años con Mitsubishi UFJ Bank (MUFG). Sakana AI desarrollará agentes de IA especializados para las operaciones bancarias de MUFG, con el objetivo de impulsar la transformación del negocio bancario y la aplicación práctica de la IA. Al mismo tiempo, el cofundador y COO de Sakana AI, Ren Ito, actuará como asesor de MUFG para ayudar al banco a implementar su estrategia de IA. Esta colaboración marca un paso importante para Sakana AI en la aplicación de tecnología avanzada de IA para resolver problemas específicos del sector financiero japonés. (Fuente: SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs)

La cofundadora de 01.AI (零一万物), Gu Xuemei, deja la empresa para emprender; el enfoque comercial de la compañía se desplaza hacia el B2B: Gu Xuemei, cofundadora de 01.AI y responsable del preentrenamiento de modelos y productos para el consumidor (C-end), dejó la empresa hace varios meses y recientemente está preparando su propio emprendimiento. 01.AI confirmó el asunto y agradeció su contribución. Desde 2025, el enfoque comercial de 01.AI se ha desplazado de las aplicaciones AI ToC y las API de modelos hacia escenarios B2B como personas digitales, personalización e implementación de modelos. Sus productos C-end, como la herramienta de oficina para el mercado nacional “Wanzhi”, han cesado sus operaciones debido a un volumen de usuarios inferior al esperado, y la comercialización del producto de rol para el extranjero, Mona, tampoco ha sido ideal. Anteriormente, el cofundador Dai Zonghong también había dejado la empresa para emprender. (Fuente: 36氪)

🌟 Comunidad
La detección de AIGC en tesis genera controversia, se cuestiona su precisión y afecta la graduación de estudiantes: Este año, muchas universidades han introducido la detección de AIGC como parte de la revisión de tesis de graduación, con el objetivo de evitar que los estudiantes abusen de la escritura con IA. Sin embargo, esta medida ha generado una amplia controversia. Los estudiantes informan que el contenido que escribieron ellos mismos a menudo se identifica erróneamente como generado por IA, mientras que después de la revisión asistida por IA, el grado de sospecha aumenta. Incluso hay pruebas que muestran que el “Prefacio al Pabellón del Príncipe Teng” (《滕王阁序》) tiene un grado de sospecha de generación por IA del 99.2%. Las propias herramientas de detección de AIGC son impulsadas por IA, y su principio se basa en analizar las características lingüísticas del texto y compararlas con los patrones de escritura de la IA, pero su precisión es cuestionable; una herramienta temprana de OpenAI solo tenía una precisión del 26%. Esta incertidumbre no solo causa problemas y gastos adicionales a los estudiantes (diferentes sitios de detección dan resultados distintos y los servicios de reducción de similitud son de pago), sino que también plantea reflexiones sobre la naturaleza de las herramientas de IA: la IA imita la escritura humana, y luego se usa IA para detectar si un texto humano se parece a la IA, lo que presenta una paradoja lógica. (Fuente: 36氪)

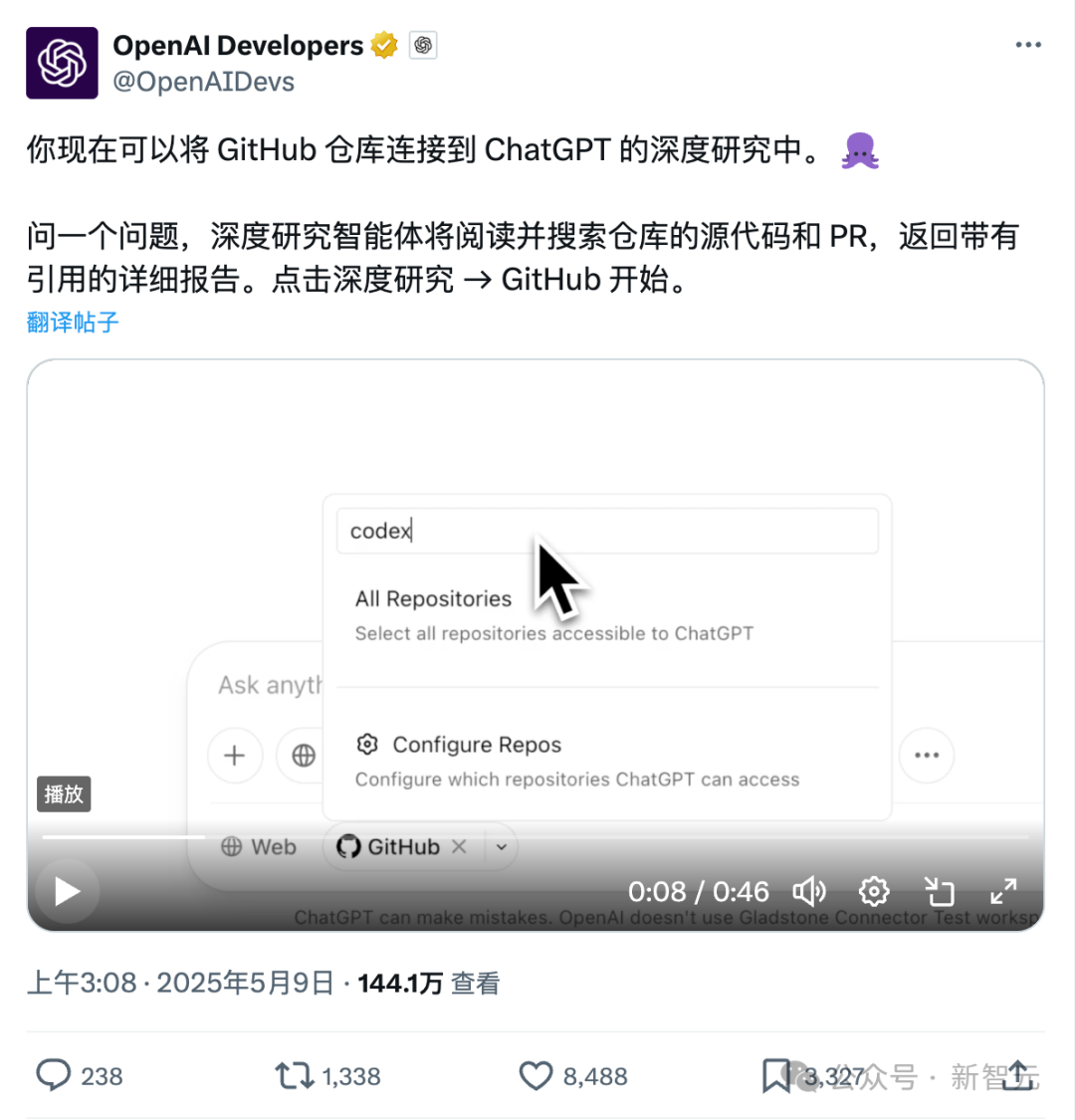
Nueva función de ChatGPT para conectar directamente con GitHub: investigación profunda de repositorios de código y documentos especializados: La función Deep Research de ChatGPT, lanzada recientemente, ha añadido la capacidad de conectarse directamente a repositorios de GitHub. Los usuarios pueden autorizar a ChatGPT para acceder a sus repositorios públicos o privados para realizar análisis profundos de código, resumir la arquitectura funcional, identificar el stack tecnológico, evaluar la calidad del código y analizar la idoneidad del proyecto, entre otras cosas. Esta función no se limita al código; los usuarios pueden subir documentos de diversos tipos como PDF, Word, etc., al repositorio de GitHub y utilizar ChatGPT para una investigación profunda de material en dominios específicos, lo que equivale a una combinación de RAG+MCP de alcance limitado. Esta función está actualmente disponible para usuarios Plus y, al limitar el alcance de la investigación, se espera que mejore la profesionalidad y precisión de los informes de investigación y reduzca las alucinaciones. (Fuente: 36氪)
La competencia en el mercado de Agentes de IA se intensifica, Manus abre el registro completamente, grandes empresas como ByteDance y Baidu entran en el juego: Manus, conocido como el “Agente Todopoderoso”, anunció el 12 de mayo la apertura completa del registro, permitiendo a los usuarios obtener cuotas de uso sin esperas. Al mismo tiempo, circulan rumores en el mercado de que Manus está llevando a cabo una nueva ronda de financiación con una valoración de 1.500 millones de dólares. Desde su lanzamiento en marzo, Manus ha desencadenado una oleada de proyectos de tipo Agente, pero también enfrenta desafíos como la disminución del tráfico y la aparición de productos competidores. ByteDance ha lanzado Coze Space, Baidu ha lanzado “Miaoda” (秒哒) y “Xinxiang” (心响), y el Agente de diseño Lovart también ha comenzado sus pruebas. El mercado de Agentes está pasando de la validación temprana de conceptos a una competencia integral en funciones de producto, modelos de negocio y crecimiento de usuarios. (Fuente: 36氪)
La codificación asistida por IA cambia el flujo de trabajo de los desarrolladores, aumenta la productividad pero requiere cautela ante la dependencia excesiva: Un usuario de Reddit compartió cómo los asistentes de código de IA han cambiado significativamente su experiencia de codificación, especialmente al tratar con grandes proyectos heredados y comprender código complejo. Las herramientas de IA pueden explicar el código línea por línea, ofrecer sugerencias, resaltar problemas potenciales, resumir archivos, buscar fragmentos y generar comentarios, como tener un experto disponible las 24 horas. Los comentarios señalan que la IA puede realizar codificación repetitiva, mejorar la eficiencia, guiar hacia nuevos métodos, agregar comentarios e incluso ayudar a los desarrolladores a completar tareas que exceden su capacidad, reduciendo días de trabajo a horas. Sin embargo, esto también plantea interrogantes sobre la evolución de las habilidades de los desarrolladores y la dependencia de las herramientas de IA. (Fuente: Reddit r/artificial)
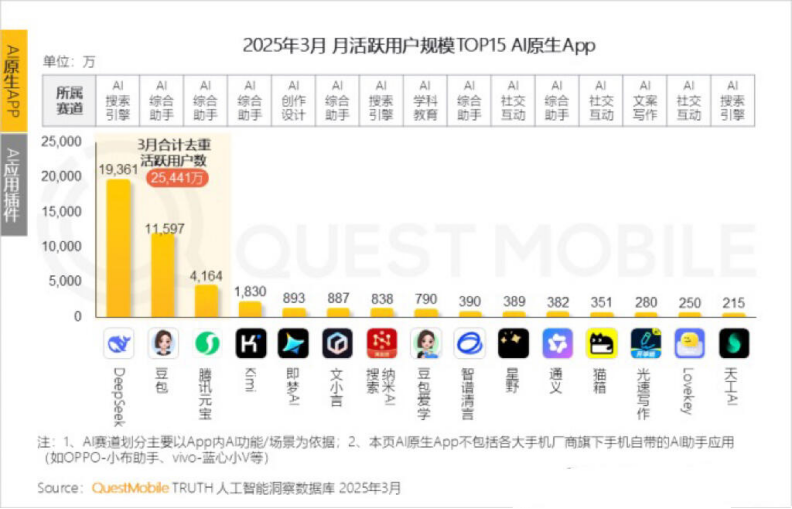
Los usuarios activos mensuales de Kimi disminuyen, Moonshot AI (月之暗面) busca avances en nichos verticales y una transformación hacia lo social: Kimi Chat, de Moonshot AI, vio caer sus usuarios activos mensuales de 36 millones en octubre del año pasado a 18.2 millones en marzo de este año según datos de QuestMobile, descendiendo al cuarto lugar. Para mejorar la retención de usuarios, Kimi está expandiéndose desde un modelo grande general hacia nichos verticales, como la colaboración con Caixin Media para mejorar la calidad de búsqueda de contenido financiero, la incursión en la búsqueda médica con IA y la introducción de contenido de vídeo de Bilibili. Al mismo tiempo, Kimi ha lanzado un desafío de “check-in” en Xiaohongshu, intentando llegar a más usuarios C-end a través de plataformas sociales. Su interfaz de usuario también se está ajustando hacia la multimodalidad, un estilo similar a Doubao y la comunitarización. Enfrentando a competidores como DeepSeek y la entrada de grandes empresas en aplicaciones de IA, el posicionamiento de liderazgo tecnológico de Kimi se ve afectado, la presión de comercialización aumenta y está buscando activamente nuevos puntos de crecimiento. (Fuente: 36氪)
Debate sobre si la IA debería referirse a sí misma en primera persona: Un usuario de Reddit inició un debate, argumentando que el hecho de que LLMs como ChatGPT se refieran a sí mismos como “yo” o al usuario como “tú” podría ser inapropiado, ya que son esencialmente “cosas” y no “personas”. Sugirió que usaran la tercera persona, como “ChatGPT le ayudará…”, para evitar dar a los usuarios la impresión de que son entidades personificadas, lo que podría generar peligros potenciales o problemas éticos. En los comentarios, algunos consideraron que la tercera persona, por el contrario, implicaría autoconciencia, mientras que otros sintieron que la tercera persona sonaba tonta y desagradable. La discusión refleja la reflexión de los usuarios sobre el posicionamiento de la identidad de la IA y las formas de interacción humano-máquina. (Fuente: Reddit r/ArtificialInteligence)
💡 Otros
El MIT retira de urgencia un paper de IA muy seguido, citando dudas sobre la autenticidad de los datos y la investigación: El Instituto Tecnológico de Massachusetts (MIT) ha retirado el paper “Inteligencia Artificial, Descubrimiento Científico e Innovación de Productos”, escrito por Aidan Toner-Rogers, estudiante de doctorado en economía. El paper había ganado mucha atención por proponer que las herramientas de IA podrían mejorar significativamente la eficiencia innovadora de los científicos de élite, pero también exacerbar la “brecha entre ricos y pobres” en la investigación y reducir la felicidad de los investigadores comunes, y había recibido elogios de profesores de renombre, incluidos premios Nobel. El MIT declaró que, tras recibir una denuncia sobre la integridad de la investigación y realizar una investigación interna, había perdido la confianza en el origen, la fiabilidad, la validez de los datos y la autenticidad de la investigación, y había solicitado a arXiv y al Quarterly Journal of Economics que retiraran el artículo. El autor ha dejado el MIT, y los profesores relacionados también emitieron declaraciones desvinculándose. Se informa que durante la investigación, el autor compró dominios falsos para hacerse pasar por correos electrónicos de grandes empresas, fue descubierto y demandado. (Fuente: 36氪)

Imágenes generadas por IA utilizadas en estafas en línea, generando alerta entre los usuarios: Un usuario de Reddit compartió ejemplos de imágenes de personas generadas por IA que aparecen en redes sociales como Facebook para promocionar productos. Estas imágenes a menudo presentan elementos ilógicos en las personas y escenas (como modelos entrando y saliendo de cajas de manera extraña, personas no relacionadas en el fondo, etc.), pero la consistencia de la imagen del personaje es relativamente alta. Los comentaristas señalaron que este tipo de contenido generado por IA ya se ha utilizado en estafas, advirtiendo a los usuarios que estén atentos. Bloggers como Pleasant Green también han producido videos que exponen este tipo de fraudes. (Fuente: Reddit r/ChatGPT)
Discusión sobre la imitación de estilos y extracción de prompts en imágenes generadas por IA: Los usuarios discutieron cómo hacer que modelos de IA (como DALL-E 3) imiten estilos artísticos específicos (como el estilo Pixar combinado con el estilo Designer Toy de Salvador Dalí) para crear retratos de personajes, y compartieron prompts detallados, enfatizando las características del personaje, el fondo, la iluminación y los conceptos centrales (como la sombra como proyección espiritual). Además, otros usuarios proporcionaron plantillas de prompts para extraer parámetros de estilo de las imágenes y exportarlos en formato JSON, con el objetivo de ayudar a los usuarios a realizar ingeniería inversa de los estilos de imagen, aunque la reproducción precisa sigue siendo difícil. (Fuente: dotey, dotey)
