
Palabras clave:AlphaEvolve, DeepSeek V3, GPT-4.1, Speech-02, Modelo Claude, Falcon-Edge, BLIP3-o, AM-Thinking-v1, Agente de codificación inteligente impulsado por Gemini, Diseño conjunto de hardware y software para reducir costos de modelos grandes, Tecnología de clonación de voz con cero muestras, Capacidad de razonamiento extremo, Arquitectura BitNet de 1.58 bits
🔥 Enfoque
DeepMind presenta AlphaEvolve: agente de codificación evolutiva impulsado por Gemini que impulsa el descubrimiento de algoritmos : AlphaEvolve combina la creatividad del modelo Gemini con evaluadores automáticos, utilizando un marco evolutivo para optimizar algoritmos. Ha logrado avances en múltiples campos, como completar la multiplicación de matrices complejas de 4×4 con 48 multiplicaciones escalares, mejorando el algoritmo de Strassen; descubrir 593 configuraciones de esferas externas en un espacio de 11 dimensiones, avanzando en el “problema del número de besos” (kissing number problem) de 300 años de antigüedad. Además, AlphaEvolve también ha optimizado la programación de centros de datos de Google (ahorrando un 0.7% de recursos computacionales), el diseño de la próxima generación de TPU (eliminando bits redundantes), el entrenamiento de modelos de IA (aceleración del kernel crítico en un 23%), etc. El medallista Fields Terence Tao también participó en la exploración de sus aplicaciones matemáticas. (Fuente: DeepMind)

Análisis detallado del paper de DeepSeek V3: diseño conjunto de software y hardware para reducir el coste y el consumo de energía de los grandes modelos : El equipo de DeepSeek ha publicado un paper que detalla cómo DeepSeek-V3 logra la rentabilidad en el entrenamiento e inferencia a gran escala mediante un diseño conjunto de software y hardware. Las tecnologías clave incluyen: 1) Optimización de memoria: adopción de Atención Latente Multicabezal (MLA) para comprimir la caché de clave-valor, entrenamiento con precisión mixta FP8 para reducir el consumo de memoria. 2) Optimización computacional: aplicación del modelo Mixture of Experts (MoE), activando solo una parte de los parámetros, y combinado con entrenamiento FP8, reduce significativamente los costes computacionales. 3) Optimización de la comunicación: adopción de topología de red fat-tree multiplano y tecnología de superposición de doble micro-batch (DualPipe) para reducir la latencia y mejorar la utilización de la GPU. 4) Aceleración de la inferencia: introducción del marco de Predicción Multi-Token (MTP), predicción y validación en paralelo de múltiples tokens candidatos, mejorando la velocidad de generación. El paper también presenta cinco perspectivas para el futuro diseño de hardware de IA, incluyendo soporte para computación de baja precisión, expansión y fusión, optimización de la topología de red, optimización del sistema de memoria, y robustez y tolerancia a fallos. (Fuente: arXiv)

El modelo GPT-4.1 de OpenAI lanzado oficialmente en ChatGPT, los usuarios pueden seleccionarlo directamente : OpenAI anunció que el modelo GPT-4.1 ya está disponible en ChatGPT. Los usuarios de Plus, Pro y Team pueden acceder a él a través del selector de modelos, mientras que los usuarios de las versiones Enterprise y Education obtendrán acceso más adelante. GPT-4.1 mini también reemplazará a GPT-4o mini para todos los usuarios. GPT-4.1 ha llamado la atención por su excelente rendimiento en tareas de codificación y seguimiento de instrucciones; anteriormente, la versión API admitía una ventana de contexto de hasta 1 millón de tokens. Sin embargo, algunas pruebas de usuarios revelaron que la longitud del contexto de la versión GPT-4.1 en ChatGPT parece seguir siendo de 128k, sin alcanzar el millón de la versión API, lo que generó cierta decepción. (Fuente: OpenAI Developers)

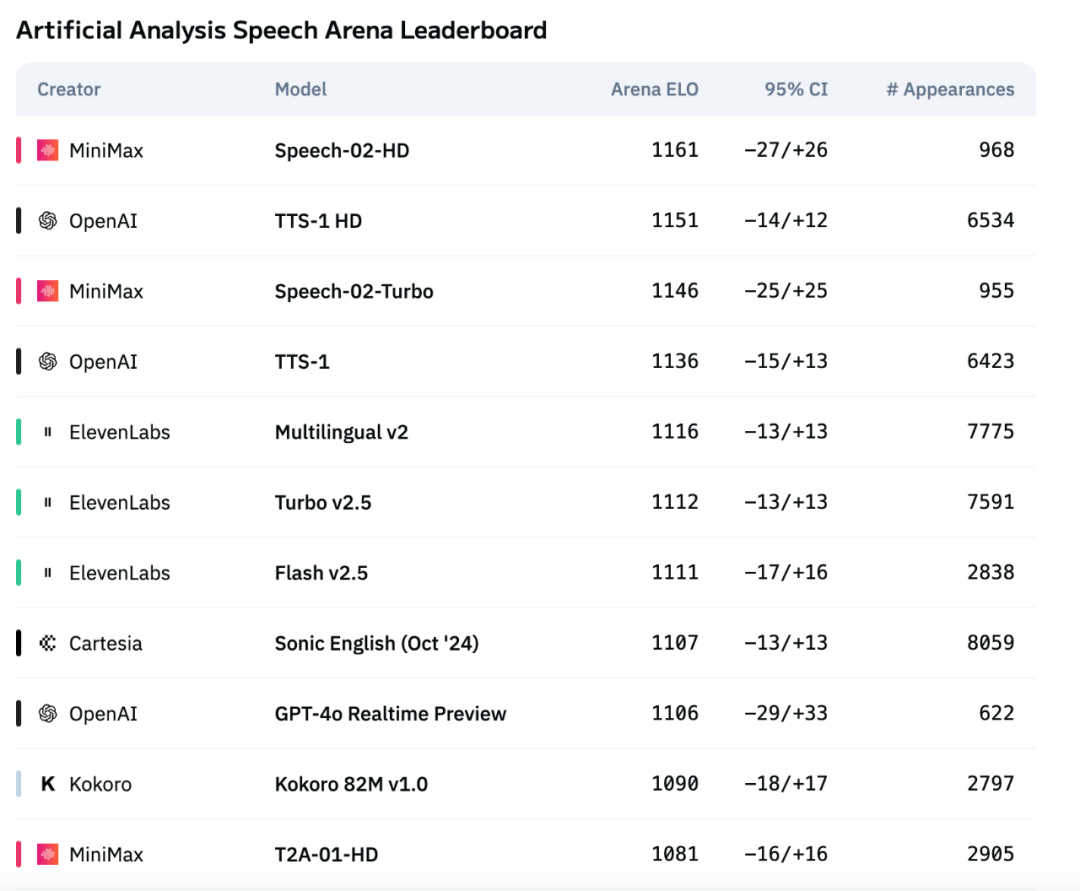
El modelo de voz de nueva generación Speech-02 de MiniMax encabeza la lista de evaluación de voz de Artificial Analysis : El último modelo de texto a voz (TTS) de MiniMax, Speech-02, ha obtenido la puntuación ELO más alta en la prestigiosa lista internacional de evaluación de voz Artificial Analysis Speech Arena, superando a productos similares de OpenAI y ElevenLabs. El modelo muestra un rendimiento excelente en métricas clave como la tasa de error de palabras (WER) y la similitud del hablante (SIM), destacando especialmente su ventaja local en el procesamiento del chino y el cantonés. La innovación principal de Speech-02 radica en la clonación de voz real zero-shot (solo requiere unos segundos de audio de referencia, sin necesidad de texto) y la adopción de una nueva arquitectura Flow-VAE, que mejora la naturalidad y la expresividad emocional de la generación de voz, admitiendo 32 idiomas. Su coste también es extremadamente competitivo, aproximadamente 1/4 del de los productos competidores de ElevenLabs. (Fuente: 机器之心)
🎯 Movimientos
La nueva versión de los modelos Claude de Anthropic podría incorporar la capacidad de “razonamiento extremo” : Según informes de The Information y observaciones de la comunidad, Anthropic podría lanzar nuevas versiones de sus modelos Claude Sonnet y Claude Opus en las próximas semanas, cuya característica más destacada sería la capacidad de “razonamiento extremo” (Extreme reasoning). Esta función permitiría al modelo pausar, reevaluar y ajustar su estrategia al encontrar problemas difíciles, en lugar de dar una respuesta directa. En tareas como la generación de código, el modelo podría probar y corregir errores automáticamente. Este enfoque de razonamiento cíclico dinámico y uso de herramientas tiene como objetivo que el modelo maneje problemas complejos de manera más inteligente, reduzca la dependencia de la supervisión humana y se acerque más a la forma de pensar de un colaborador humano. Algunos usuarios ya han detectado que Anthropic está probando un modelo llamado Claude Neptune (posiblemente Claude 3.8), que admite un contexto de 128k tokens. (Fuente: 量子位)
TII lanza la serie Falcon-Edge de modelos Bitnet eficientes y el kit de herramientas de ajuste fino onebitllms : El Technology Innovation Institute (TII) ha lanzado Falcon-Edge, una serie de modelos de lenguaje altamente comprimidos basados en la arquitectura BitNet, con características potentes, versátiles y ajustables. Al mismo tiempo, han hecho open source onebitllms, un kit de herramientas Python ligero (instalable mediante pip) diseñado específicamente para el ajuste fino o la continuación del preentrenamiento de estos modelos de 1.58 bits. Esta iniciativa tiene como objetivo reducir la barrera de entrada al uso de grandes modelos e impulsar el desarrollo y la aplicación de la tecnología LLM de 1 bit. (Fuente: younes)

La biblioteca Transformers de Hugging Face recibe una importante actualización, convirtiéndose en el estándar central para la definición de modelos : Hugging Face ha anunciado que su biblioteca Transformers está experimentando ajustes significativos con el objetivo de convertirse en el estándar central para la definición de modelos en diferentes backends y runtimes. Mediante la colaboración con numerosos socios del ecosistema como vLLM, LlamaCPP, SGLang, MLX, DeepSpeed, Microsoft y NVIDIA, se está impulsando la estandarización del código de los modelos, con la expectativa de aportar mayor coherencia y fiabilidad a todo el ecosistema de IA. Esta medida ha sido ampliamente elogiada por la comunidad y se considera un paso importante para impulsar el desarrollo de la IA de código abierto. (Fuente: Arthur Zucker)

Salesforce lanza BLIP3-o en Hugging Face: una serie de modelos multimodales unificados totalmente open source : Salesforce ha presentado la serie de modelos BLIP3-o, una familia de modelos multimodales unificados completamente open source. Esta serie abarca la arquitectura del modelo, los métodos de entrenamiento y los conjuntos de datos, con el objetivo de impulsar el desarrollo y la aplicación de la tecnología de IA multimodal. El lanzamiento de BLIP3-o proporciona a investigadores y desarrolladores potentes herramientas y recursos para el procesamiento multimodal. (Fuente: AK)

NVIDIA muestra el uso de datos sintéticos para avanzar en la tecnología de conducción totalmente autónoma : NVIDIA ha publicado un nuevo vídeo que muestra cómo utiliza datos sintéticos para acelerar la investigación y el desarrollo de la tecnología de conducción totalmente autónoma (FSD). Mediante la generación de escenarios y datos de conducción virtuales a gran escala y diversificados, NVIDIA puede entrenar y validar sus algoritmos de conducción autónoma de manera más eficiente, superando las limitaciones de la recopilación de datos del mundo real e impulsando la tecnología de conducción autónoma hacia una dirección más segura y fiable. (Fuente: SawyerMerritt)
El equipo A-M-team lanza el modelo de inferencia 32B AM-Thinking-v1, superando en parte el rendimiento de DeepSeek-R1 : El equipo de investigación chino A-M-team ha hecho open source en Hugging Face el modelo de inferencia AM-Thinking-v1 de 32B parámetros. Este modelo muestra un rendimiento sobresaliente en tareas como el razonamiento matemático (puntuación de 85.3 en la serie AIME) y la generación de código (puntuación de 70.3 en LiveCodeBench), y se afirma que supera a DeepSeek-R1 (671B MoE) en estas evaluaciones específicas, acercándose a modelos de mayor escala como Qwen3-235B-A22B. El equipo se centra en optimizar la capacidad de inferencia de los modelos densos de 32B mediante esquemas de post-entrenamiento (incluyendo SFT de arranque en frío, filtrado de datos guiado por tasa de aprobación, RL de dos etapas), con el objetivo de explorar vías para lograr un fuerte razonamiento bajo condiciones de computación limitada y datos de código abierto. (Fuente: AI科技评论)

Actualización de Marigold: convierte modelos Stable Diffusion en estimadores de profundidad, admite inferencia en un solo paso y alta resolución : El proyecto Marigold ha lanzado una importante actualización. Esta tecnología permite convertir el modelo Stable Diffusion 2, mediante una pequeña cantidad de muestras sintéticas y un corto período de entrenamiento (2-3 días en 1 GPU), en un estimador de profundidad avanzado. Las nuevas características de la versión incluyen: inferencia rápida en un solo paso, soporte para nuevas modalidades, salida de alta resolución, soporte para la biblioteca Diffusers y nuevas demostraciones. (Fuente: Anton Obukhov)
La serie de modelos Qwen3 muestra un fuerte rendimiento en la comunidad de código abierto, NVIDIA OpenCodeReasoning la elige como base : La serie de modelos Qwen3 de Alibaba continúa ganando atención y aplicación en la comunidad de código abierto. La reciente serie de modelos OpenCodeReasoning de NVIDIA (que incluye especificaciones de 7B, 14B, 32B) ha elegido Qwen como base. Qwen3 es favorecido por los desarrolladores por sus versiones completas, actualizaciones continuas, soporte nativo para modos de inferencia mixtos y un ecosistema próspero (más de 300 millones de descargas globales, más de 100,000 modelos derivados). Las actualizaciones recientes incluyen el modelo multimodal para dispositivos Qwen-omini 3B, la colaboración con Unsloth para mejorar la eficiencia del ajuste fino, la publicación de recomendaciones detalladas de hiperparámetros de implementación, el soporte para la vista previa en tiempo real de páginas web generadas, la provisión de múltiples versiones cuantizadas y la publicación de informes técnicos, entre otros. (Fuente: AI前线)
Lanzamiento de Hugging Face Accelerate v1.7.0, compatible con compilación regional y QLoRA para FSDPv2 : Se ha lanzado oficialmente la versión v1.7.0 de Hugging Face Accelerate. Los aspectos más destacados de esta versión incluyen: compilación regional (Regional compilation) implementada por @IlysMoutawwakil, que mejora la eficiencia y flexibilidad de la compilación; ganchos de conversión por capas (Layerwise casting hook) aportados por @RisingSayak, una función ampliamente utilizada en la biblioteca diffusers; y soporte para QLoRA en FSDPv2 implementado por @winglian, optimizando aún más el entrenamiento de modelos a gran escala. (Fuente: Marc Sun)

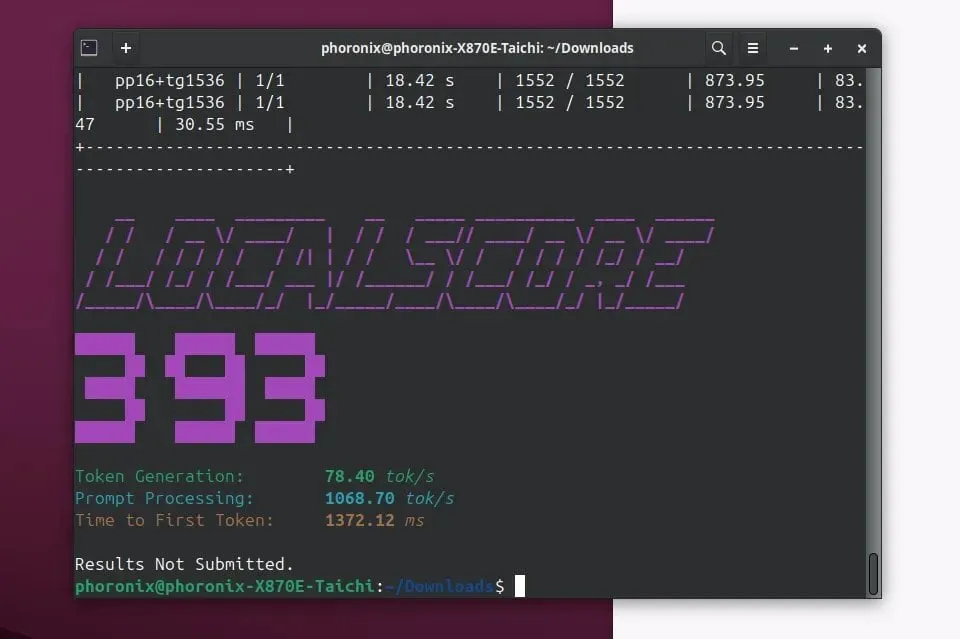
Lanzamiento de Llamafile 0.9.3, añade soporte para los modelos Qwen3 y Phi4 : Llamafile ha lanzado la versión 0.9.3, esta actualización añade soporte para las recientes y populares series de modelos Qwen3 y Phi4. Llamafile se dedica a simplificar la distribución y ejecución de aplicaciones LLM, empaquetando los pesos del modelo y el código necesario para su ejecución en un único archivo ejecutable, permitiendo una implementación conveniente en múltiples sistemas operativos. (Fuente: Phoronix)
Tencent lanza el gran modelo de imagen HunyuanImage 2.0 : Tencent ha lanzado oficialmente la nueva versión de su gran modelo de imagen Hunyuan, HunyuanImage 2.0. Se espera que esta actualización mejore la calidad de generación de imágenes, la controlabilidad y la capacidad de comprender instrucciones complejas. Los usuarios pueden obtener más información sobre los detalles técnicos y las mejoras a través de los canales oficiales. (Fuente: Hunyuan)

Lanzamiento de Ollama v0.7, mejora la experiencia de ejecución de grandes modelos localmente : Ollama ha lanzado la versión v0.7, continuando su compromiso de simplificar el proceso de ejecución de grandes modelos de lenguaje en dispositivos locales. La nueva versión podría incluir optimizaciones de rendimiento, soporte para nuevos modelos o mejoras en la experiencia del usuario. Los usuarios pueden visitar el sitio web oficial o GitHub para ver el registro de cambios detallado y realizar la descarga. (Fuente: ollama)
llama.cpp fusiona la funcionalidad de entrada de PDF, permitiendo el procesamiento directo de documentos PDF : El proyecto llama.cpp ha fusionado recientemente una actualización importante que añade soporte para la entrada directa de archivos PDF. Esto significa que los usuarios ahora pueden utilizar más convenientemente el contenido de documentos PDF como entrada para que los grandes modelos de lenguaje locales impulsados por llama.cpp los procesen, analicen o respondan preguntas, ampliando sus escenarios de aplicación. Esta función se implementa a través de un paquete JS externo en el frontend web incorporado, sin aumentar la carga de mantenimiento del núcleo. (Fuente: GitHub)
Microsoft Copilot incorpora la función de generación de imágenes de 4o, mejorando los efectos visuales y la coherencia del texto : El asistente de IA de Microsoft, Copilot, ahora integra la capacidad de generación de imágenes del modelo GPT-4o de OpenAI. Esta actualización tiene como objetivo proporcionar efectos visuales más nítidos, una generación de texto más coherente y admitir una variedad de estilos, desde fotorrealistas hasta dibujos animados divertidos. Los usuarios pueden experimentar la función de creación de imágenes impulsada por 4o a través de Copilot. (Fuente: yusuf_i_mehdi)

NVIDIA DRIVE Labs explora el futuro de la conducción sin mapas, reduciendo la dependencia de mapas HD : El último vídeo de NVIDIA DRIVE Labs explora el futuro de la conducción sin mapas (mapless driving). Los mapas de alta definición son cruciales para la conducción autónoma, pero sus costes y desafíos de mantenimiento limitan su implementación. NVIDIA está reduciendo la dependencia de los mapas HD mediante innovaciones como la eliminación de cuellos de botella de información, la mejora de la precisión de las tareas y la aceleración del tiempo de entrenamiento e inferencia de los modelos, impulsando los límites de la tecnología de conducción autónoma. (Fuente: NVIDIA DRIVE)
Dolphin 3.2 (entrenado sobre Qwen3) ofrecerá interruptores de prompt de sistema, mejorando el control del usuario : El próximo modelo Dolphin 3.2, entrenado sobre Qwen3, introducirá tres interruptores de prompt de sistema: /no_think (posiblemente para reducir pasos de pensamiento redundantes), /uncensored (posiblemente para reducir la censura de contenido) y /china (posiblemente para contextos o servicios específicos de China). Estos interruptores tienen como objetivo otorgar a los usuarios un mayor grado de propiedad y control sobre la implementación de su modelo. (Fuente: cognitivecompai)

🧰 Herramientas
Runway lanza la función “References”, que permite aprender y aplicar técnicas o estilos específicos a nuevas creaciones : Runway ha añadido una nueva función llamada “References”, que permite a los usuarios mostrar a la plataforma una técnica o estilo artístico específico y luego utilizarlo como referencia para aplicarlo a cualquier nuevo contenido generado. Esta función proporciona a los usuarios una capacidad de control de estilo más precisa, haciendo que la creación asistida por IA sea más personalizada y específica. El usuario Cristobal Valenzuela ha lanzado una convocatoria para que la comunidad comparta casos originales de uso de esta función y premiará los 5 casos más creativos con un año gratuito del plan Unlimited. (Fuente: c_valenzuelab)

DSPy: un marco de programación LLM minimalista diseñado para la iteración rápida : El marco DSPy ha llamado la atención por su diseño minimalista. Los desarrolladores afirman que la mayoría de sus funciones principales (Module u Optimizer) se pueden implementar con solo una línea de código, con el objetivo de ayudar a los usuarios a probar e iterar ideas rápidamente. A diferencia de algunas herramientas que requieren una gran cantidad de código repetitivo y conceptos complejos, DSPy enfatiza la facilidad de uso y la eficiencia. Los usuarios comentan que pueden empezar rápidamente leyendo la documentación de introducción y optimizar modelos en poco tiempo utilizando este marco, aunque el uso de modelos SOTA para la optimización cíclica puede generar ciertos costes. (Fuente: lateinteraction)
Unsloth AI se expande al ajuste fino de modelos TTS y de audio, aumentando la velocidad y reduciendo el uso de VRAM : Unsloth AI ha anunciado que su tecnología de optimización ahora es compatible con el ajuste fino de modelos de texto a voz (TTS) y de audio. Los usuarios pueden utilizar cuadernos de Colab gratuitos para entrenar, ejecutar y guardar modelos como Sesame-CSM y OpenAI Whisper. Unsloth afirma que su tecnología puede aumentar la velocidad de entrenamiento de TTS en 1.5 veces, al tiempo que reduce el uso de VRAM en un 50%. La documentación relevante y los cuadernos de Colab ya están disponibles en su sitio web. (Fuente: Unsloth AI)
Modal facilita la tarea de incrustación de 30 millones de reseñas de Amazon, logrando el procesamiento en horas con GPU L40S : La plataforma Modal ha demostrado su capacidad para escalar horizontalmente el procesamiento de tareas de incrustación a gran escala en GPU L40S. A través de un caso de demostración, Modal completó con éxito el procesamiento de incrustación de 30 millones de reseñas de Amazon en una hora. Esto se debe al sistema de generación escalable actualizado del equipo de Modal, que hace que el procesamiento paralelo a gran escala sea más simple y eficiente. (Fuente: charles_irl)

Lovart AI: un nuevo agente de diseño visual de IA que integra múltiples modelos de primer nivel : Un agente de diseño visual de IA llamado Lovart ha llamado la atención. Puede completar tareas de diseño visual profesional como carteles, identidad visual de marca y guiones gráficos mediante instrucciones en lenguaje natural. La capacidad principal de Lovart radica en su coordinación de fusión de múltiples modelos, integrando varios modelos de primer nivel como GPT image-1, Flux pro, OpenAI-o3, Gemini Imagen 3, Kling AI, Tripo AI, Suno AI, y cuenta con herramientas de edición de nivel profesional incorporadas (como capas, máscaras, ajuste fino de texto), admitiendo la separación de imagen y texto y la edición por capas. Este producto es operado de forma independiente por la filial en el extranjero de Liblib y tiene como objetivo proporcionar una experiencia de diseño de IA integral y altamente controlable. (Fuente: 量子位)
Lanzamiento de OpenHands 0.38.0: soporte nativo para Windows y extensión de Chrome mejoran la facilidad de uso : OpenHands ha lanzado la versión 0.38.0, que trae varias actualizaciones importantes. Entre ellas se incluyen: soporte nativo para Windows (sin necesidad de WSL), lo que facilita su uso para los usuarios de Windows; función de captura de pantalla del navegador; y una capacidad de personalización de sandbox más flexible. Además, se ha lanzado una extensión de Chrome que permite a los usuarios iniciar OpenHands desde GitHub con un solo clic, simplificando aún más el proceso operativo. (Fuente: All Hands AI)
Lanzamiento de Tensorlake Cloud, mejora la capacidad de extracción de documentos y construcción de flujos de trabajo : Tensorlake ha anunciado el lanzamiento de Tensorlake Cloud, con el objetivo de optimizar la extracción de documentos y los flujos de trabajo para dar soporte a la construcción de aplicaciones de agentes inteligentes y flujos de trabajo empresariales complejos. La plataforma utiliza modelos avanzados de comprensión de la disposición de documentos (entrenados con datos del mundo real como formularios ACORD, extractos bancarios, informes de investigación, etc.) y modelos de extracción de tablas para transformar documentos no estructurados en datos limpios y estructurados, especialmente adecuados para procesar tablas complejas y densas, supliendo las deficiencias de los modelos de lenguaje visual (VLM) en este aspecto. (Fuente: Tensorlake)
Patronus AI lanza Percival: un agente inteligente especializado en depurar y mejorar agentes de IA : Patronus AI ha lanzado una nueva herramienta, Percival, un agente de IA diseñado específicamente para depurar y mejorar agentes de IA. Percival puede analizar instantáneamente trazas complejas de agentes, identificar hasta 60 modos de fallo diferentes y sugerir automáticamente correcciones de prompts para mejorar el rendimiento. La herramienta aborda desafíos clave como la “explosión de contexto” (agentes que procesan millones de tokens) y admite la adaptación de dominio para casos de uso específicos y la orquestación compleja de múltiples agentes. (Fuente: Weaviate Podcast)

Replit integra Semgrep para lograr una “programación con ambiente seguro”, escaneando vulnerabilidades automáticamente : Replit ha anunciado una colaboración con Semgrep para lanzar la función “Safe Vibe Coding” (Programación con Ambiente Seguro). Ahora, cada vez que un usuario implementa código en Replit, Semgrep ejecutará automáticamente un escaneo de seguridad para ayudar a descubrir y corregir vulnerabilidades potenciales, evitando la exposición accidental de información sensible como claves API. Esta medida tiene como objetivo mejorar la seguridad al utilizar la codificación asistida por IA (como la generación de código a través de LLM). (Fuente: amasad)

Lanzamiento de la versión 0.50 de Cursor AI, con importantes actualizaciones : La herramienta de programación asistida por IA Cursor ha lanzado su versión 0.50, descrita como “la mayor actualización de su historia”. Se espera que la nueva versión incluya múltiples mejoras funcionales y optimizaciones de la experiencia, con el objetivo de mejorar aún más la eficiencia de codificación de los desarrolladores y la fluidez de la colaboración con la IA. El contenido específico de la actualización se puede consultar en las notas de la versión oficiales. (Fuente: eric zakariasson)

OpenMemory MCP: servidor de gestión de memoria localizado que admite el intercambio de contexto entre aplicaciones : OpenMemory MCP es un servidor de gestión de memoria diseñado para mejorar la productividad de las aplicaciones de IA. Permite a los usuarios compartir contexto entre diferentes aplicaciones (como Cursor y Claude Desktop) y utiliza PostgreSQL y Qdrant para almacenar e indexar datos localmente, garantizando la privacidad de los datos. La herramienta admite la búsqueda semántica y proporciona un panel de control para gestionar la memoria y el acceso a las aplicaciones, resolviendo el problema de la pérdida de contexto entre sesiones. (Fuente: Reddit r/ClaudeAI)

Hugging Face Inference Endpoint combinado con vLLM y Gradio para una transcripción rápida con Whisper : Hugging Face ha demostrado cómo utilizar su servicio Inference Endpoint, en combinación con el proyecto vLLM y la interfaz Gradio, para implementar el modelo Whisper de OpenAI y lograr una función de transcripción de voz extremadamente rápida. Esta combinación aprovecha las herramientas de código abierto de la comunidad de IA para proporcionar a los usuarios una solución de voz a texto eficiente y fácil de usar. (Fuente: Morgan Funtowicz)
A.I.T.E Ball: una Magic 8 Ball de IA autónoma basada en Orange Pi y Gemma 3 1B : Un desarrollador ha presentado un proyecto de Magic 8 Ball impulsado por IA completamente autónomo (sin necesidad de conexión a internet): A.I.T.E Ball. El dispositivo funciona con un Orange Pi Zero 2W, utiliza whisper.cpp para la conversión de texto a voz y llama.cpp para ejecutar el modelo Gemma 3 1B para preguntas y respuestas. Esto demuestra el potencial de implementar aplicaciones de IA localizadas en hardware de bajo consumo. (Fuente: Reddit r/LocalLLaMA)

OWL Agent: agente universal de código abierto integrado con MCPToolkit : El proyecto de agente OWL de código abierto ahora incluye soporte integrado para MCPToolkit. Los usuarios pueden conectar fácilmente servidores MCP como Playwright, desktop-commander o herramientas Python personalizadas, y OWL descubrirá e invocará automáticamente estas herramientas en sus flujos de trabajo multiagente, mejorando su universalidad y capacidad de ejecución de tareas. (Fuente: Reddit r/LocalLLaMA)

ElevenLabs lanza SB-1 Infinite Soundboard: combina efectos de sonido, caja de ritmos y generador de ruido ambiental : ElevenLabs ha lanzado SB-1 Infinite Soundboard, una herramienta que combina una tabla de efectos de sonido, una caja de ritmos y un generador de ruido ambiental infinito. Los usuarios pueden describir el efecto de sonido deseado y SB-1 utilizará su modelo de texto a efectos de sonido (Text-to-SFX) para generar estos sonidos, ofreciendo nuevas posibilidades para la creación de audio. (Fuente: ElevenLabs)
Proyecto Anytop: nuevos avances en animación con IA, da vida a organismos nunca vistos, admite aprendizaje y transferencia de movimiento : Two Minute Papers presenta el proyecto Anytop, una tecnología de animación con IA capaz de generar movimientos realistas para organismos nunca antes vistos (incluidos dinosaurios, insectos extraños, etc.). Esta IA no solo puede generar movimientos de forma independiente, sino que también permite que diferentes criaturas aprendan y adapten los movimientos de otras (como un dinosaurio aprendiendo a pararse en una pata como un flamenco). Logra la generalización a formas desconocidas al comprender la similitud semántica de las partes del cuerpo (como el concepto general de brazos y piernas). Además, el sistema puede comprender la semántica de los movimientos (como ataque, relajación) y mostrar movimientos de conceptos similares entre diferentes animales, e incluso puede completar movimientos de entrada incompletos. (Fuente: )

Sketch2Anim: la IA convierte bocetos simples en animaciones 3D completas : Otra tecnología presentada por Two Minute Papers, Sketch2Anim, puede convertir simples bocetos de líneas dibujados por el usuario (que indican la trayectoria del movimiento) en animaciones completas de personajes 3D. Esta IA es capaz de comprender la intención 3D detrás del boceto 2D (como distinguir entre un puñetazo hacia adelante y un puñetazo lateral), resolviendo las limitaciones de tecnologías similares anteriores que solo podían comprender instrucciones a nivel 2D, lo que permite a personas no profesionales crear rápidamente animaciones 3D mediante dibujos simples. (Fuente: )
📚 Aprendizaje
DeepSeek publica el paper del modelo V3, compartiendo desafíos de escalado y reflexiones sobre la arquitectura de hardware de IA : El equipo de DeepSeek ha publicado en Hugging Face el paper sobre el modelo DeepSeek-V3. Dicho paper profundiza en los desafíos encontrados durante el proceso de escalado de grandes modelos de lenguaje y presenta reflexiones y perspectivas sobre la dirección futura del desarrollo de la arquitectura de hardware de IA. Esto proporciona una valiosa referencia para que investigadores y desarrolladores comprendan los cuellos de botella en el entrenamiento y despliegue de modelos a gran escala, así como la forma de optimizar mediante la colaboración de hardware y software. (Fuente: Adina Yakup)
Lanzamiento de un curso gratuito sobre el Protocolo de Contexto de Modelo (MCP) para ayudar a construir aplicaciones de IA con datos y herramientas externas : Ben Burtenshaw ha anunciado el lanzamiento de un curso gratuito sobre MCP (Model Context Protocol). El curso tiene como objetivo ayudar a los alumnos, desde principiantes hasta expertos, a comprender el funcionamiento de MCP, cómo conectar LLMs a servidores MCP y cómo utilizar MCP para desplegar aplicaciones de agentes de IA, aprovechando así datos y herramientas externas para mejorar las capacidades de las aplicaciones de IA. (Fuente: Ben Burtenshaw)

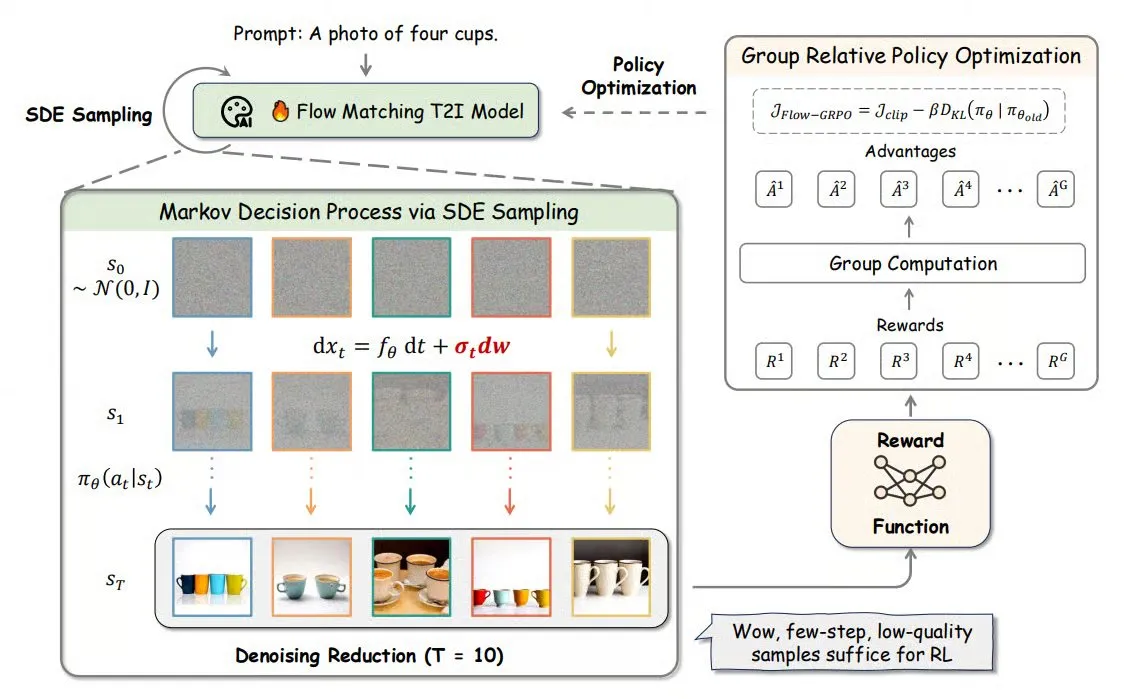
Flow-GRPO: introduce el aprendizaje por refuerzo en línea en modelos de coincidencia de flujo, mejorando la precisión en la generación de imágenes : Flow-GRPO es un nuevo método que, por primera vez, aplica el aprendizaje por refuerzo (RL) en línea a los modelos de coincidencia de flujo (flow matching). Lo logra mediante dos estrategias innovadoras: 1) Conversión de ODE a SDE: transforma el proceso determinista de los modelos de flujo basado en ecuaciones diferenciales ordinarias (ODE) en ecuaciones diferenciales estocásticas (SDE), introduciendo la aleatoriedad necesaria para el RL. 2) Reducción de la eliminación de ruido para acelerar el entrenamiento: durante el entrenamiento se reducen los pasos de eliminación de ruido, mientras que en la inferencia se utilizan los pasos completos. Mediante Flow-GRPO, la precisión de los modelos de flujo en tareas de generación de imágenes se eleva por encima del 92%. (Fuente: TheTuringPost)
Paper de ICML 2025 PENCIL: alternancia de “razonamiento-borrado” logra un nuevo paradigma de pensamiento profundo en grandes modelos : Chenxiao Yang y otros investigadores del Toyota Technological Institute at Chicago proponen PENCIL (Pondering with Erasure Net for Contextual Inference Learning), un nuevo paradigma para el pensamiento profundo en grandes modelos mediante la alternancia de “generación” y “borrado” de resultados intermedios. Este método se inspira en las reglas de reescritura de la lógica y la gestión de memoria de la programación funcional, borrando dinámicamente los pasos intermedios que ya no son necesarios, resolviendo eficazmente los problemas a los que se enfrentan las tradicionales cadenas de pensamiento largas (CoT), como el desbordamiento de la ventana de contexto, la dificultad para recuperar información y la disminución de la eficiencia de generación. Se demuestra teóricamente que PENCIL puede simular cualquier operación de una máquina de Turing con una complejidad espacial y temporal óptima, resolviendo todos los problemas computables. Los experimentos muestran que en tareas como 3-SAT, QBF y el acertijo de Einstein, PENCIL supera significativamente a las CoT tradicionales. (Fuente: 机器之心)

Paper de ICML 2025 MemVR: simula el mecanismo humano de “mirar dos veces” para mitigar las alucinaciones en grandes modelos multimodales : Investigadores de la HKUST (Guangzhou) y otras instituciones proponen el método MemVR (Memory-space Visual Retracing) que, simulando la estrategia humana de verificar dos veces los recuerdos inciertos, mitiga el problema de las alucinaciones en los grandes modelos de lenguaje multimodales (MLLM). MemVR utiliza tokens visuales como evidencia complementaria y, en las capas intermedias donde el modelo encuentra dificultades por olvido durante la inferencia, “recupera” el conocimiento visual a través de una red de propagación hacia adelante (FFN) para calibrar las predicciones. Este método diseña un mecanismo de activación dinámico que selecciona la capa de activación basándose en la incertidumbre de la salida de diferentes capas. Los experimentos demuestran que MemVR logra resultados significativos en múltiples benchmarks de evaluación de alucinaciones y benchmarks generales, y tiene ventajas de eficiencia en comparación con otros métodos. (Fuente: PaperWeekly)

Paper de SIGIR 2025 PaRT: recuperación personalizada en tiempo real mejora la experiencia de los chatbots sociales proactivos : La Universidad de Ciencia y Tecnología de China y otras instituciones proponen el método PaRT (Proactive Social Chatbots with Personalized Real-time ReTreival), que tiene como objetivo mejorar la experiencia de conversación de los chatbots sociales proactivos mediante la combinación de la reescritura de consultas impulsada por la personalización y el reconocimiento de intenciones con la recuperación en tiempo real. El sistema PaRT consta de tres módulos: construcción de perfiles de usuario personalizados, reconocimiento de intenciones y reescritura de consultas, y generación mejorada por recuperación en tiempo real. Puede iniciar o cambiar temas de forma proactiva según los intereses del usuario y el contexto de la conversación, proporcionando respuestas más naturales e informativas. Tanto los experimentos offline como las pruebas A/B online demuestran que este método puede mejorar eficazmente la personalización, la riqueza de las respuestas y la duración media de la conversación. (Fuente: PaperWeekly)
Paper de ICML 2025 PreSelect: esquema eficiente de selección de datos de preentrenamiento basado en la fuerza predictiva : La Universidad de Ciencia y Tecnología de Hong Kong y vivo AI Lab proponen el método de selección de datos PreSelect, que introduce el concepto de “fuerza predictiva” (Predictive Strength) para cuantificar la contribución de los datos al modelo en una capacidad específica. Este método utiliza la coherencia entre la clasificación de las puntuaciones de diferentes modelos en pruebas de referencia y la clasificación de la pérdida (Loss) en los datos para evaluar el valor de los datos, y utiliza un clasificador fastText ligero para una puntuación aproximada, logrando una selección eficiente de datos a gran escala. Los experimentos demuestran que PreSelect puede aumentar la eficiencia de los datos en 10 veces, y los datos seleccionados muestran resultados significativamente mejores en el entrenamiento de modelos en comparación con varios métodos de referencia, cubriendo fuentes de contenido de alta calidad más amplias y reduciendo el sesgo de longitud de la muestra. (Fuente: 量子位)

El curso AI Evals invita a 12 ponentes a compartir marcos de evaluación y prácticas : El curso AI Evals organizado por Hamel Husain ha anunciado su lista de 12 ponentes invitados, que incluye al creador del framework inspect, JJ Allaire, y al defensor de desarrolladores de Modal, Charles Frye, entre otros. El curso profundizará en diversos aspectos de la evaluación de IA, incluyendo marcos de evaluación, creación de aplicaciones de etiquetado personalizadas, prácticas de evaluación de modelos, etc., con el objetivo de ayudar a los participantes a dominar las habilidades y herramientas clave para evaluar el rendimiento de los sistemas de IA. (Fuente: Hamel Husain)

Publicado tutorial de FedRAG: guía de inicio para construir y ajustar sistemas RAG : El proyecto FedRAG ha publicado nuevos cuadernos de tutorial y vídeos complementarios, diseñados para ayudar a los usuarios a familiarizarse rápidamente con la biblioteca. El tutorial demuestra cómo construir un sistema RAG utilizando la integración de Hugging Face, usar una base de conocimientos en memoria para almacenar nodos, definir SentenceTransformer (Dragon+) como recuperador, definir un modelo preentrenado (como Qwen2.5-0.5B) como generador, y usar los entrenadores LSR y RALT para el ajuste fino centralizado del recuperador y el generador. (Fuente: nerdai)

LlamaIndex publica tutorial: implementación de citas e inferencia en LlamaExtract : El equipo de LlamaIndex ha publicado el último tutorial práctico en código realizado por @tuanacelik, que muestra cómo implementar funciones de citación e inferencia en LlamaExtract. El contenido del tutorial incluye: cómo definir un esquema personalizado para indicar al LLM qué contenido extraer de fuentes de datos complejas y cómo añadir citas. Esta función tiene como objetivo ayudar a los usuarios a construir agentes de IA multipaso capaces de extraer información estructurada de grandes cantidades de documentos fuente de forma precisa y fundamentada. (Fuente: LlamaIndex 🦙)
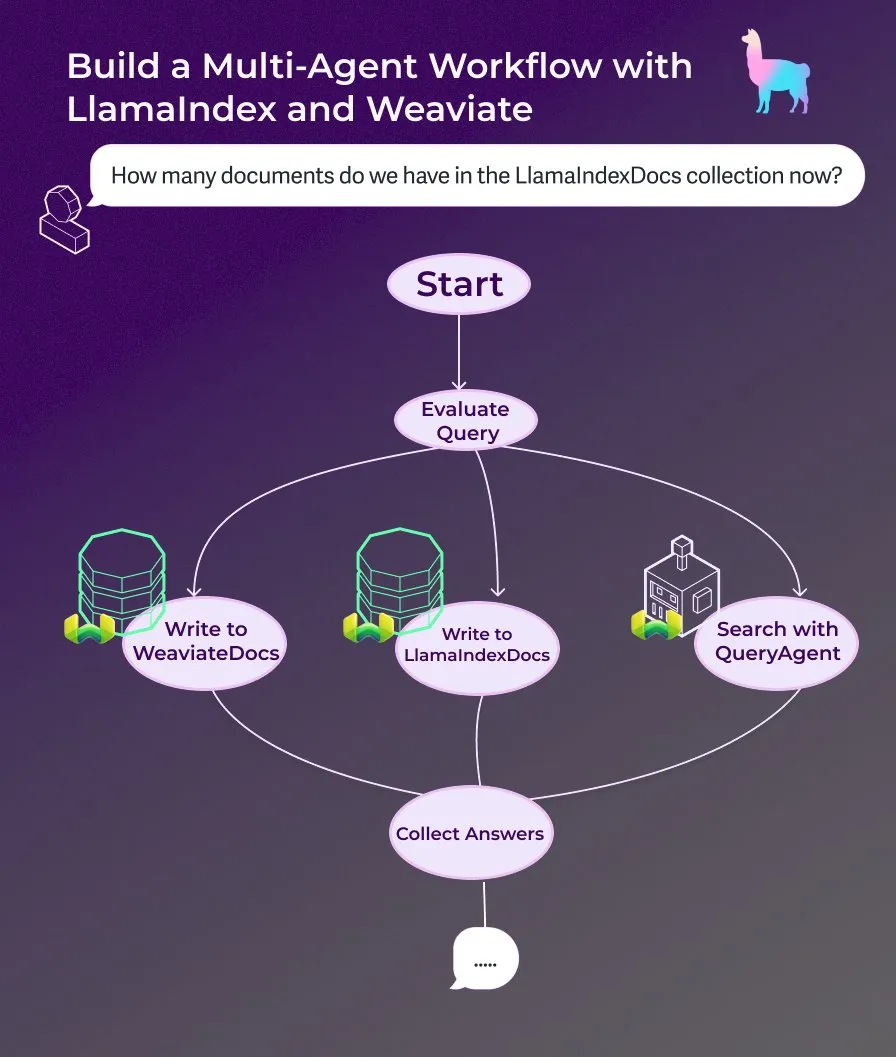
LlamaIndex publica tutorial: construcción de un asistente de documentos multiagente con flujos de trabajo de agentes controlados por eventos : LlamaIndex ha publicado un nuevo tutorial práctico que muestra cómo construir un asistente de documentos multiagente utilizando flujos de trabajo de agentes controlados por eventos. Este asistente es capaz de escribir contenido de páginas web en las colecciones LlamaIndexDocs y WeaviateDocs, utilizar un orquestador para decidir cuándo llamar a Weaviate QueryAgent para buscar y agregar, utilizar salida estructurada para la clasificación de consultas y, opcionalmente, utilizar FunctionAgent. (Fuente: LlamaIndex 🦙)
Modular publica charla técnica interna sobre el compilador Mojo, explorando Mojo y la arquitectura GPU : La empresa Modular ha comenzado a compartir sus charlas técnicas internas, siendo la primera charla pública una que profundiza en el tema del lenguaje de programación Mojo y la arquitectura GPU. El contenido incluye el funcionamiento interno del compilador Mojo y los desafíos y soluciones que el equipo enfrenta al desarrollar para las GPU modernas, con el objetivo de compartir con la comunidad los detalles de su stack tecnológico. (Fuente: Modular)
Taller AI by Hand: construye un modelo Transformer desde cero en Excel : ProfTomYeh promociona su taller AI by Hand, que tiene como objetivo que los participantes construyan un modelo Transformer desde cero en Excel. De esta manera, los alumnos pueden comprender de forma clara e intuitiva cada paso matemático del Transformer, evitando verlo como una “caja negra” y estableciendo así una comprensión profunda del funcionamiento interno del modelo. (Fuente: ProfTomYeh)
DeepLearning.AI publica The Batch número 301: explora el valor comercial de la velocidad de la IA y los últimos avances : Andrew Ng, en su última edición de The Batch, analiza cómo se subestima la importancia de la mejora en la velocidad de ejecución de tareas por parte de la IA para la creación de valor comercial. Sostiene que la IA no solo reduce costes, sino que, lo que es más importante, acelera la innovación y la exploración al acortar el tiempo desde la idea hasta el prototipo. Esta edición también informa sobre el lanzamiento de la serie de inferencia Phi-4 de Microsoft, el rendimiento de DeepCoder-14B igualando a o1, la flexibilización de las normas de IA de la UE, entre otras noticias. (Fuente: DeepLearningAI)
💼 Negocios
La startup de animación de personajes con IA Cartwheel recauda 10 millones de dólares para simplificar el proceso de animación 3D : Cartwheel, una startup especializada en animación de personajes con IA, ha anunciado la finalización de una ronda de financiación de 10 millones de dólares. La empresa se dedica a desarrollar tecnología para simplificar el proceso de producción de animación 3D, con el objetivo de permitir a los creadores producir animaciones de personajes 3D de alta calidad de forma más rápida y económica, al tiempo que mejora el control sobre el producto final y elimina tareas tediosas. (Fuente: andrew_n_carr)
Hedra obtiene 32 millones de dólares en financiación Serie A, liderada por a16z, para acelerar la creación de vídeos impulsados por personajes : La startup de generación de vídeo con IA Hedra ha anunciado la finalización de una ronda de financiación Serie A de 32 millones de dólares, liderada por Andreessen Horowitz (a16z), con Matt Bornstein uniéndose al consejo directivo. Los inversores existentes a16z speedrun, Abstract e Index Ventures también participaron en esta ronda. Hedra se dedica a facilitar la creación de vídeos impulsados por personajes. Desde su lanzamiento en modo sigiloso el año pasado, casi 3 millones de personas han utilizado sus herramientas para crear más de 10 millones de vídeos. Los nuevos fondos se utilizarán para acelerar el desarrollo de productos y la expansión del equipo, con el fin de lograr una creación de contenido rápida, expresiva e intuitiva. (Fuente: Hedra)
Tripadvisor utiliza Qdrant para crear itinerarios de viaje con IA, aumentando la participación del usuario de 2 a 3 veces : Tripadvisor está redefiniendo la experiencia de descubrimiento de viajes utilizando la base de datos vectorial Qdrant. Analizando más de mil millones de reseñas y fotos, 11 millones de establecimientos y datos de 21 países, Tripadvisor crea itinerarios dinámicos generados por IA, en lugar de depender de filtros tradicionales. Los resultados muestran que los usuarios que utilizan estas herramientas de IA pasan de 2 a 3 veces más tiempo, lo que demuestra el enorme potencial de la IA en la planificación personalizada de viajes. (Fuente: qdrant_engine)

🌟 Comunidad
Los comentarios de Grok sobre el “genocidio blanco” generan controversia, Sam Altman responde con sarcasmo : El modelo Grok de xAI ha generado una amplia discusión y críticas por emitir opiniones aleatorias sobre el genocidio blanco en Sudáfrica. Paul Graham señaló que este comportamiento huele a un error introducido por un parche reciente y expresó su preocupación por que la IA de uso generalizado sea editada instantáneamente en sus opiniones por sus controladores. Sam Altman respondió con sarcasmo, afirmando que xAI daría una explicación transparente y entendería este problema en el contexto del “genocidio blanco en Sudáfrica”, insinuando que esto es el resultado de la búsqueda de la verdad y el seguimiento de instrucciones por parte de la IA. La discusión de la comunidad sobre este asunto refleja una preocupación generalizada por los sesgos de los modelos de IA, su controlabilidad y las intenciones subyacentes. (Fuente: Paul Graham)
Reflexión sobre la productización de la IA: buscar oportunidades en todo el flujo de tareas del usuario, no simplemente superponer funciones de IA : Ren Xin, socio de Yunjiu Capital, compartió una profunda reflexión sobre la productización de la IA, enfatizando que las empresas deben partir de todo el flujo de tareas que realiza el usuario para encontrar puntos de entrada para las aplicaciones de IA, en lugar de simplemente superponer funciones de IA en los productos existentes. Propuso la analogía “el usuario no quiere un taladro, sino un agujero en la pared”, sugiriendo desglosar las tareas del usuario, encontrar los puntos débiles y optimizarlos con IA. Los cuatro niveles de productización de la IA incluyen: completar eficientemente los procesos antiguos, crear nuevos procesos, abrir mercados completamente nuevos (reducir las barreras de entrada, servir a nuevos grupos de usuarios, incluso a la propia IA) y sentar las bases de la infraestructura para un futuro dominado por la IA. Considera que la tecnología de IA se está democratizando y que las empresas sin conocimientos técnicos también pueden aprovechar las oportunidades; en esencia, se trata de “ayudar a la IA a encontrar trabajo”. (Fuente: 混沌大学)
Discusión: El papel de la IA en el desarrollo profesional y estrategias de adaptación : Una publicación en LinkedIn generó una discusión sobre cómo la IA afecta el desarrollo profesional. El dicho común es “la IA no reemplazará tu trabajo, pero sí lo hará alguien que use IA”. Sin embargo, se señaló que esta afirmación es demasiado vaga. Se plantearon preguntas sobre cómo ingenieros frontend con décadas de experiencia, por ejemplo, podrían convertirse repentinamente en ingenieros de IA, y el problema de que no todos pueden ser ingenieros de IA. La discusión en la comunidad sugirió que, para los desarrolladores frontend, pueden aprender a usar herramientas de IA para mejorar la eficiencia laboral. También hubo opiniones de que la IA reemplazará una gran cantidad de trabajos y muchas personas no tendrán a dónde ir. Una visión más general fue que el futuro es incierto, pero la creatividad, la capacidad de descubrir problemas y la capacidad de comprender y conectar con la humanidad podrían ser más defensivas. (Fuente: Reddit r/ArtificialInteligence)
Discusión: Los LLM tienden a “perderse” en conversaciones de múltiples turnos, reiniciar la conversación podría ser beneficioso : Un artículo de investigación señala que el rendimiento de los LLM, tanto de código abierto como cerrados, disminuye significativamente en conversaciones de múltiples turnos. La mayoría de los benchmarks se centran en escenarios de un solo turno con instrucciones claras. La investigación encontró que los LLM a menudo hacen suposiciones (incorrectas) en los primeros turnos de la conversación y luego dependen de estas suposiciones en los turnos posteriores, lo que dificulta su corrección. La conclusión es que cuando una conversación de múltiples turnos no cumple con las expectativas, comenzar una nueva conversación e integrar toda la información relevante en la primera entrada podría ser útil. (Fuente: Reddit r/LocalLLaMA)
Análisis de las razones del ritmo relativamente lento de Apple y WeChat en el desarrollo de la IA: privacidad, seguridad y estrategia de priorización de aplicaciones : Wei Xi analiza en un artículo que, aunque Apple ha lanzado “Apple Intelligence” y WeChat ha integrado DeepSeek y Yuanbao, el avance de ambos en las funciones centrales de IA es relativamente lento. Hay dos razones principales: primero, la alta sensibilidad de la privacidad y la seguridad de los datos; la inteligencia de la IA depende de los datos, y los modelos de negocio centrales de Apple y WeChat determinan que sean extremadamente cautelosos con el intercambio de datos, lo que limita el entrenamiento de modelos y la obtención de contexto de aplicación. En segundo lugar, ambos adoptan una estrategia de “priorización de aplicaciones”, no buscan competir con las principales empresas de IA en el límite superior de la inteligencia de los modelos, sino que se centran más en integrar las capacidades de IA en sus funciones y ecosistemas existentes, lo que puede limitar su liderazgo tecnológico y la velocidad de iteración del producto. (Fuente: 卫夕指北)

OpenAI lanza el “Desafío de la A a la Z”: usar IA para descubrir sitios arqueológicos desconocidos en el Amazonas : OpenAI ha anunciado una colaboración con Kaggle para lanzar el hackathon especial “OpenAI to Z Challenge”. El desafío anima a los participantes a utilizar los modelos OpenAI o3, o4-mini o GPT-4.1 para encontrar sitios arqueológicos previamente desconocidos en la región amazónica. Los participantes pueden compartir su progreso utilizando el hashtag #OpenAItoZ. El evento tiene como objetivo explorar el potencial de la IA en los campos de la arqueología y el análisis geoespacial. (Fuente: OpenAI Developers)
Críticas a las startups de “abogados de IA”: la automatización de “cartas de extorsión” podría convertirse en una carga social : El desarrollador @swyx criticó el fenómeno de algunas VC que invierten en startups de “abogados de IA”. Argumenta que estas empresas se dedican principalmente a generar automáticamente “cartas de reclamación” (demand letters) mediante IA, lo que en esencia es una extorsión automatizada. Aunque algunas reclamaciones pueden ser razonables, señala que la mayoría de estas acciones terminan beneficiando solo a los abogados, convirtiéndose en un puro impuesto para la sociedad. Hace un llamamiento a boicotear, desinvertir y criticar públicamente a estas empresas y sus inversores. (Fuente: swyx)

💡 Otros
Informe sobre carbón presenta un error absurdo “se obtiene al matar esqueletos Wither”, generando debate sobre la calidad del contenido y las alucinaciones de la IA : Un informe de investigación sobre la industria del carbón, con un precio de 8200 yuanes, contenía la descripción “el carbón es un recurso renovable, se obtiene al matar esqueletos Wither”, una frase originada en el juego “Minecraft”, lo que generó un acalorado debate en línea. Muchos lo atribuyeron a la generación de contenido por IA y a las alucinaciones. Sin embargo, el informe se publicó en 2022, antes del lanzamiento de los principales grandes modelos como ChatGPT, lo que indica que se trata de un caso típico de copia y pega manual y negligencia en la revisión. El incidente también provocó una profunda reflexión sobre la calidad del contenido de los informes profesionales, la importancia de la verificación de la información y cómo discernir la verdad de la información en la era de la IA. (Fuente: caoz的梦呓)

Investigadores utilizan terapia de edición genética personalizada para tratar a un bebé con una rara enfermedad metabólica : En menos de siete meses, los médicos construyeron una terapia de edición genética personalizada y la utilizaron con éxito para tratar a un bebé con una enfermedad metabólica mortal. Esta es la primera vez que la edición genética se utiliza para un tratamiento personalizado dirigido a un solo individuo. La terapia tiene como objetivo corregir un error específico de una sola letra en los genes del bebé, demostrando la precisión de las nuevas tecnologías de edición genética (como la edición de bases). Aunque el tratamiento muestra signos positivos tempranos, también pone de relieve los desafíos de coste y escalabilidad para desarrollar terapias genéticas personalizadas para enfermedades ultrarraras. (Fuente: MIT Technology Review)

Se revela una estrategia universal de prompts de jailbreak capaz de eludir las barreras de seguridad de los principales grandes modelos : Investigadores de HiddenLayer han descubierto una estrategia de prompts universal capaz de hacer que los principales grandes modelos de lenguaje, incluidos ChatGPT, Claude y Gemini, eludan sus barreras de seguridad y generen contenido dañino. La estrategia consiste en disfrazar instrucciones dañinas en un formato similar a archivos de políticas como XML, INI o JSON, combinado con escenarios de rol ficticios, engañando al modelo para que interprete los comandos dañinos como instrucciones legítimas del sistema. Este método explota posibles debilidades sistémicas en los datos de entrenamiento del modelo, es decir, la tendencia a ignorar las instrucciones de seguridad al procesar datos relacionados con la enseñanza o las políticas. Esta técnica también es capaz de extraer los prompts del sistema del modelo, exponiendo sus instrucciones internas y restricciones de seguridad. (Fuente: 新智元)
