
Palabras clave:AlphaEvolve, Claude Sonnet, GPT-4.1, Meta FAIR, Qwen3, Phi-4-reasoning, Regulación de IA, Seed1.5-VL, Agente de codificación impulsado por Gemini, Optimización de algoritmos de multiplicación de matrices, Optimización de eficiencia en centros de datos, Modelos multimodales multilingües, Red descentralizada de entrenamiento de IA
🔥 Enfoque
Google DeepMind publica AlphaEvolve: Agente de codificación impulsado por Gemini, revolucionando el descubrimiento de algoritmos: Google DeepMind presenta AlphaEvolve, un agente de codificación de IA impulsado por Gemini, diseñado para descubrir y optimizar algoritmos complejos mediante la combinación de la creatividad de los modelos de lenguaje grandes con evaluadores automatizados. AlphaEvolve ha diseñado con éxito algoritmos de multiplicación de matrices más rápidos, resuelto problemas matemáticos abiertos como el problema de superposición mínima de Erdős y el problema del número de osculación, y se utiliza internamente en Google para optimizar la eficiencia de los centros de datos (recuperando un promedio del 0.7% de los recursos computacionales), el diseño de chips y acelerar el entrenamiento del propio Gemini, demostrando el enorme potencial de la IA en el descubrimiento científico y la optimización de la ingeniería. (Fuente: GoogleDeepMind, DeepLearning.AI Blog)
Anthropic lanzará próximamente nuevos modelos Claude Sonnet y Opus, reforzando la capacidad de razonamiento y llamada a herramientas: Según The Information, Anthropic planea lanzar nuevas versiones de Claude Sonnet y Claude Opus en las próximas semanas. La característica principal de los nuevos modelos es la capacidad de cambiar flexiblemente entre el “modo de pensamiento” y el “modo de uso de herramientas”. Cuando el modelo encuentra obstáculos al usar herramientas externas (como aplicaciones, bases de datos) para resolver problemas, puede volver activamente al “modo de razonamiento” para reflexionar y autocorregirse. En cuanto a la generación de código, los nuevos modelos pueden probar automáticamente el código generado y, si encuentran errores, se detendrán, pensarán y corregirán. Se espera que este ciclo cerrado de “pensar-actuar-reflexionar” mejore significativamente la capacidad y fiabilidad del modelo para resolver problemas complejos. (Fuente: steph_palazzolo, dotey)

Congresistas republicanos de EE. UU. proponen prohibir la regulación de la IA a nivel federal y estatal durante 10 años, generando un intenso debate: Congresistas republicanos de EE. UU. han añadido una cláusula a un proyecto de ley de conciliación presupuestaria que propone prohibir a los gobiernos federal y estatal regular los modelos, sistemas o sistemas de toma de decisiones automatizados de inteligencia artificial durante los próximos diez años, y planean asignar 500 millones de dólares para apoyar la comercialización de la IA y su aplicación en los sistemas de TI del gobierno federal. Esta medida es vista por algunas personalidades del sector tecnológico como una señal positiva para proteger la innovación en IA y evitar que la regulación la ahogue, pero también ha suscitado preocupaciones sobre los riesgos potenciales como la proliferación de DeepFakes, la pérdida de control sobre la privacidad de los datos, la ética de la IA y el impacto ambiental. Si se aprueba, esta propuesta tendrá un impacto significativo en la legislación actual y futura sobre IA. (Fuente: Reddit r/ArtificialInteligence, Yoshua_Bengio)

OpenAI lanza el modelo GPT-4.1 y el Centro de Evaluación de Seguridad, enfatizando la codificación y el seguimiento de instrucciones: OpenAI anunció que, a petición de los usuarios, el modelo GPT-4.1 está disponible en ChatGPT a partir de hoy (para usuarios Plus, Pro, Team; las versiones Enterprise y Education llegarán más tarde). GPT-4.1 está optimizado específicamente para tareas de codificación y seguimiento de instrucciones, es más rápido y puede servir como reemplazo diario de o3 y o4-mini para la codificación. Al mismo tiempo, GPT-4.1 mini reemplazará al GPT-4o mini actualmente utilizado por todos los usuarios. Además, OpenAI ha lanzado el Centro de Evaluación de Seguridad (Safety Evaluations Hub) para publicar los resultados de las pruebas de seguridad de sus modelos y sus métricas, que se actualizarán periódicamente para aumentar la transparencia en la comunicación sobre seguridad. (Fuente: openai, michpokrass)
Meta FAIR publica múltiples resultados de investigación en IA, centrándose en el descubrimiento molecular y el modelado atómico: Meta AI (FAIR) anunció las últimas versiones de código abierto en los campos de predicción de propiedades moleculares, procesamiento del lenguaje y neurociencia. Entre ellos se encuentran Open Molecules 2025 (OMol25), un conjunto de datos para el descubrimiento molecular para la simulación de grandes sistemas atómicos; Universal Model for Atoms (UMA), un modelo de potencial interatómico de aprendizaje automático aplicable ampliamente al modelado de interacciones atómicas en materiales y moléculas; y Adjoint Sampling, un algoritmo escalable para entrenar modelos generativos basado en recompensas escalares. Además, FAIR, en colaboración con el Hospital de la Fundación Rothschild, ha llevado a cabo investigaciones que revelan similitudes significativas en el desarrollo del lenguaje entre humanos y LLMs. (Fuente: AIatMeta)
🎯 Movimientos
ByteDance lanza el modelo de lenguaje visual grande Seed1.5-VL, con un rendimiento excepcional con 20B de parámetros activos: ByteDance ha lanzado su modelo grande multimodal de visión y lenguaje Seed1.5-VL. Este modelo, con solo 20B de parámetros activos, demuestra un rendimiento comparable al de Gemini 2.5 Pro y ha alcanzado el estado del arte (SOTA) en 38 de 60 benchmarks públicos. Seed1.5-VL mejora la comprensión multimodal general y la capacidad de razonamiento, destacando especialmente en localización visual, razonamiento, comprensión de video y agentes inteligentes multimodales. El modelo ya está disponible a través de la API de Volcano Engine, con un precio de inferencia de entrada de 0.003 yuanes/mil tokens y de salida de 0.009 yuanes/mil tokens. (Fuente: 机器之心)

Informe técnico de Qwen3 revela: Fusión de modos de pensamiento y no pensamiento, destilación de modelos grandes a pequeños: Alibaba ha publicado el informe técnico de la serie de modelos Qwen3, que incluye 8 modelos con parámetros que van desde 0.6B hasta 235B. La innovación principal radica en un doble modo de trabajo: el modelo puede cambiar automáticamente entre el “modo de pensamiento” (razonamiento complejo) y el “modo de no pensamiento” (respuesta rápida) según la complejidad de la tarea, asignando dinámicamente los recursos computacionales a través de un parámetro de “presupuesto de pensamiento”. El entrenamiento utiliza un preentrenamiento de tres etapas (conocimiento general, mejora del razonamiento, texto largo) y un postentrenamiento de cuatro etapas (arranque en frío de cadena de pensamiento larga, aprendizaje por refuerzo para el razonamiento, fusión de modos de pensamiento, aprendizaje por refuerzo general). Al mismo tiempo, adopta una estrategia de destilación de datos “grande enseña a pequeño”, utilizando un modelo maestro (como el de 235B) para entrenar modelos estudiantes (como el de 30B), logrando la transferencia de conocimiento. (Fuente: 36氪)

Microsoft lanza la serie de modelos Phi-4-reasoning y comparte experiencias en el entrenamiento de modelos de razonamiento: Microsoft ha presentado tres modelos: Phi-4-reasoning, Phi-4-reasoning-plus (ambos con 14B de parámetros) y Phi-4-mini-reasoning (con 3.8B de parámetros), y ha hecho públicos sus métodos y experiencias de entrenamiento. Estos modelos, mediante el ajuste fino de modelos preentrenados, se centran en mejorar capacidades como el razonamiento matemático. Por ejemplo, Phi-4-reasoning-plus muestra un rendimiento excelente en problemas matemáticos mediante aprendizaje por refuerzo, mientras que Phi-4-mini-reasoning se somete a SFT y ajuste fino RL por etapas. El informe comparte la posible inestabilidad en el entrenamiento de modelos pequeños y las estrategias para afrontarla, así como consideraciones sobre la selección de datos y el diseño de funciones de recompensa en el entrenamiento RL de modelos grandes. Los pesos de los modelos se han abierto en Hugging Face bajo la licencia MIT. (Fuente: DeepLearning.AI Blog)
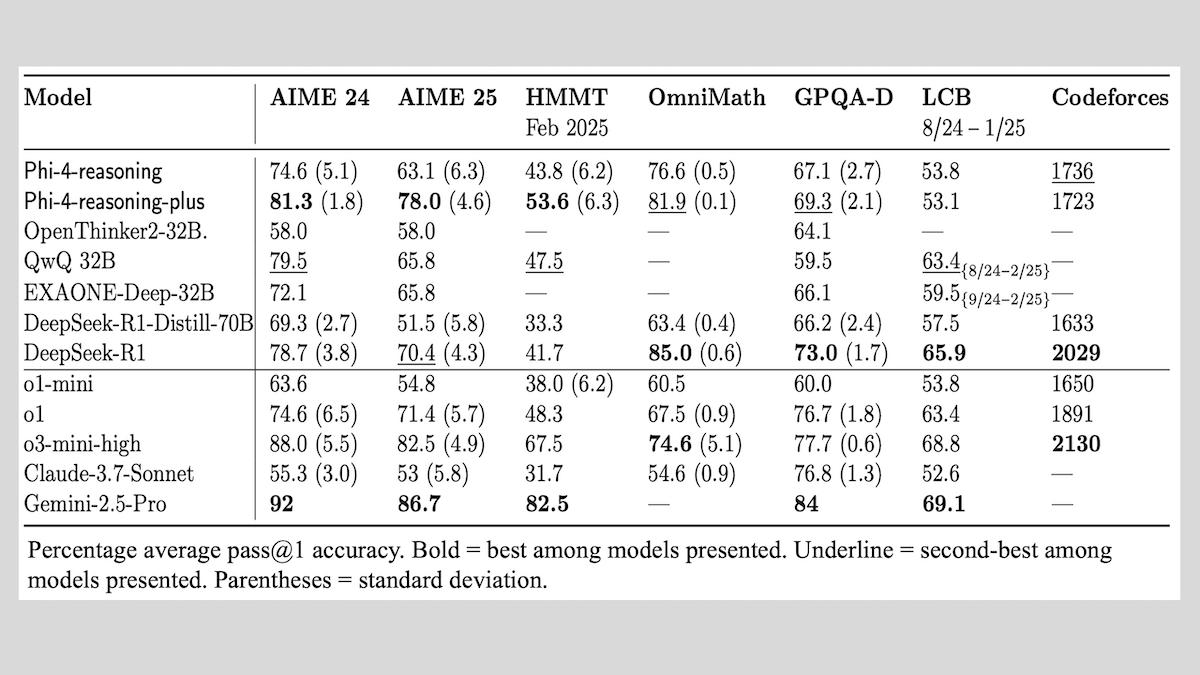
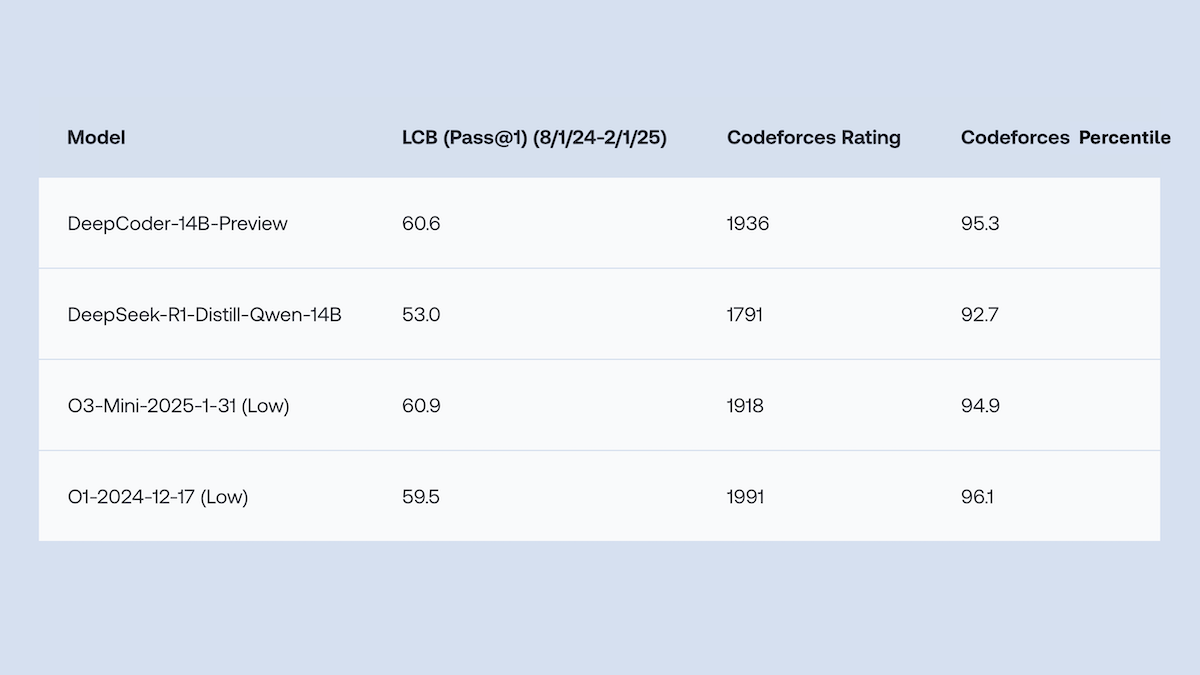
Together.AI y Agentica liberan DeepCoder-14B-Preview de código abierto, con un rendimiento en generación de código comparable a o1: Los equipos de Together.AI y Agentica han lanzado DeepCoder-14B-Preview, un modelo de generación de código de 14B parámetros, cuyo rendimiento en múltiples benchmarks de codificación es comparable al de modelos más grandes como DeepSeek-R1 y o1 de OpenAI. Este modelo se obtuvo mediante el ajuste fino de DeepSeek-R1-Distilled-Qwen-14B, utilizando un método simplificado de aprendizaje por refuerzo (combinando optimizaciones de GRPO y DAPO) y mejorando la capacidad de procesamiento paralelo de la biblioteca RL Verl, lo que redujo significativamente el tiempo de entrenamiento. Los pesos del modelo, el código, los conjuntos de datos y los registros de entrenamiento están disponibles como código abierto bajo la licencia MIT. (Fuente: DeepLearning.AI Blog)
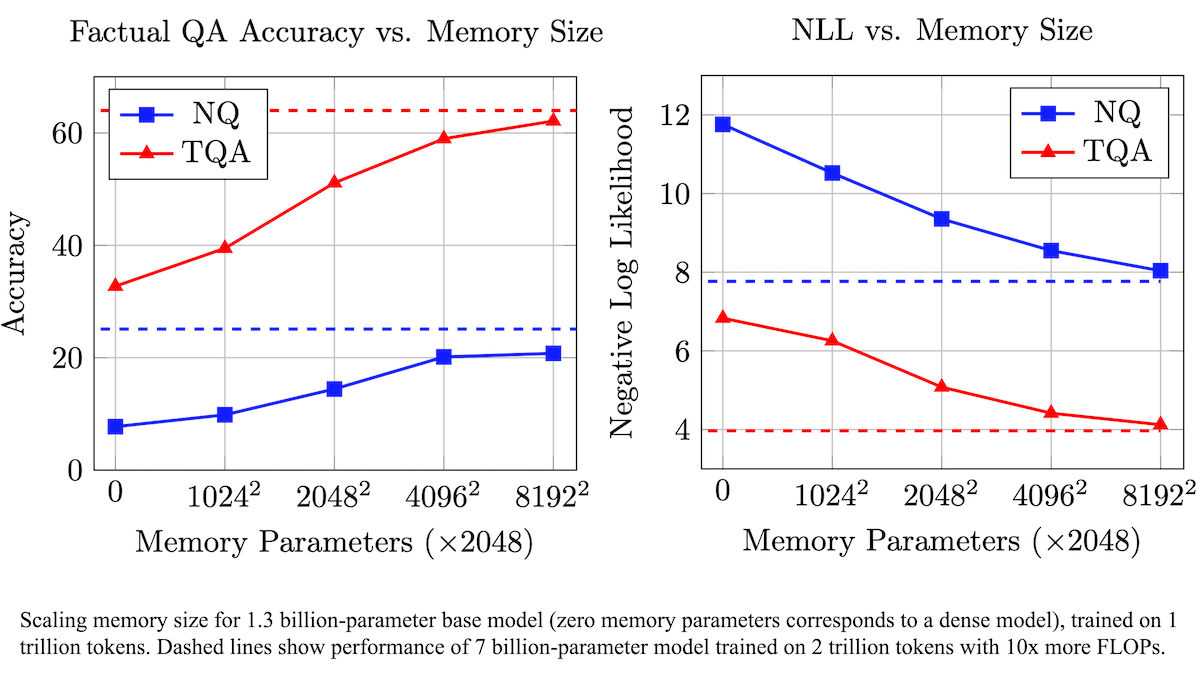
Meta propone una capa de memoria entrenable para mejorar la precisión fáctica de los LLM y reducir los requisitos computacionales: Investigadores de Meta han mejorado la precisión en la recuperación de hechos de los modelos de lenguaje grandes (LLM) al añadir una capa de memoria entrenable a la arquitectura Transformer, sin aumentar significativamente la carga computacional. Este método almacena información aprendiendo claves y sus valores correspondientes, y adopta una estrategia de descomponer las claves en dos subclaves, resolviendo eficazmente el cuello de botella computacional en la recuperación de claves a gran escala. Los experimentos demuestran que un modelo de 8B parámetros equipado con una capa de memoria supera a modelos similares sin capa de memoria en múltiples conjuntos de datos de preguntas y respuestas, mostrando ventajas en los datos de preentrenamiento y los requisitos de cómputo. (Fuente: DeepLearning.AI Blog)
Alibaba libera la serie de modelos base de video Wan2.1 de código abierto, que admite la generación y edición de video a partir de texto/imágenes: Alibaba ha lanzado Wan2.1, un completo conjunto de modelos base de video de código abierto, que incluye versiones de 1.3B y 14B parámetros, bajo la licencia Apache 2.0. Wan2.1 muestra un rendimiento excelente en múltiples tareas como texto a video, imagen a video, edición de video, texto a imagen y video a audio, y es especialmente compatible con la generación visual de texto en chino e inglés. Su modelo T2V-1.3B solo requiere 8.19GB de VRAM, puede ejecutarse en GPU de consumo y puede generar 5 segundos de video a 480P en 4 minutos. El Wan-VAE complementario puede codificar y decodificar eficientemente videos de 1080P, conservando la información temporal. (Fuente: _akhaliq, Reddit r/LocalLLaMA)

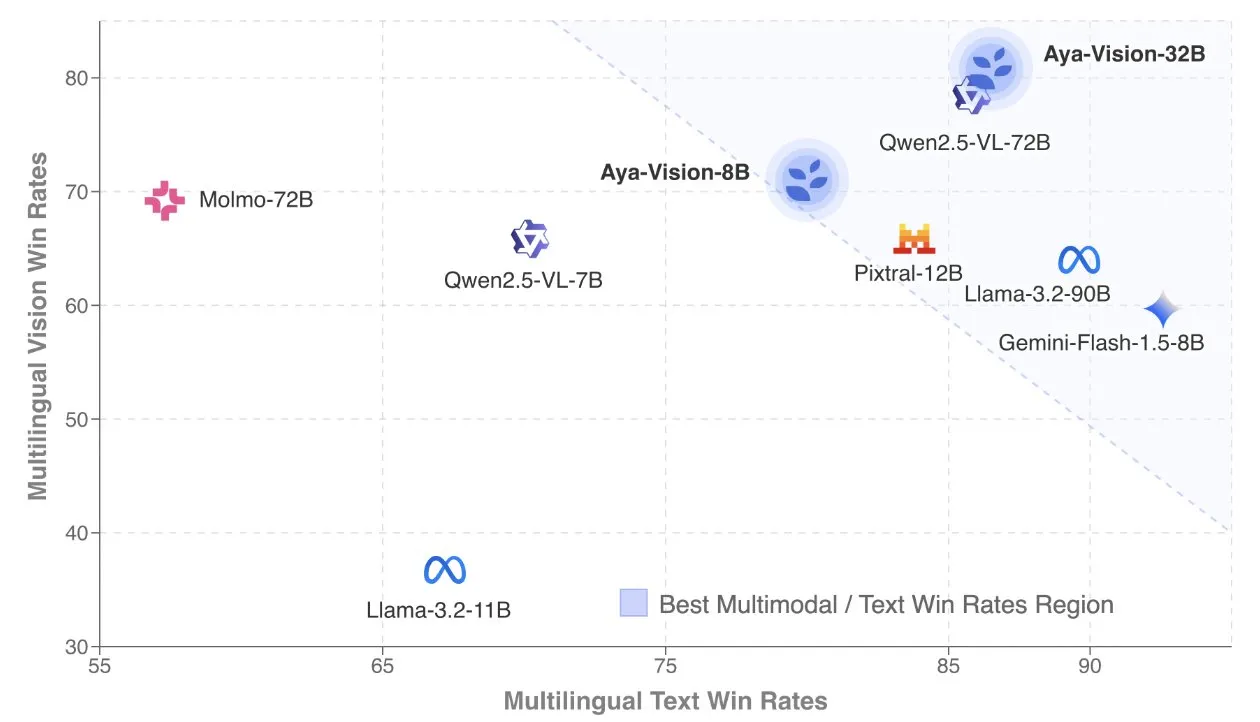
Cohere publica el informe técnico de Aya Vision, centrado en modelos multimodales multilingües: Cohere Labs ha publicado el informe técnico de Aya Vision, que detalla su fórmula para construir modelos multimodales multilingües SOTA. Los modelos Aya Vision tienen como objetivo unificar las capacidades en tareas multimodales y de texto en 23 idiomas. El informe explora el marco de datos sintéticos multilingües, el diseño de la arquitectura, los métodos de entrenamiento, la fusión de modelos transmodales y una evaluación exhaustiva en tareas de generación abierta y multilingüe. Su modelo de 8B supera en rendimiento a modelos más grandes como Pixtral-12B, mientras que el modelo de 32B es más eficiente, superando a modelos más del doble de grandes como Llama3.2-90B. (Fuente: sarahookr, Cohere Labs)
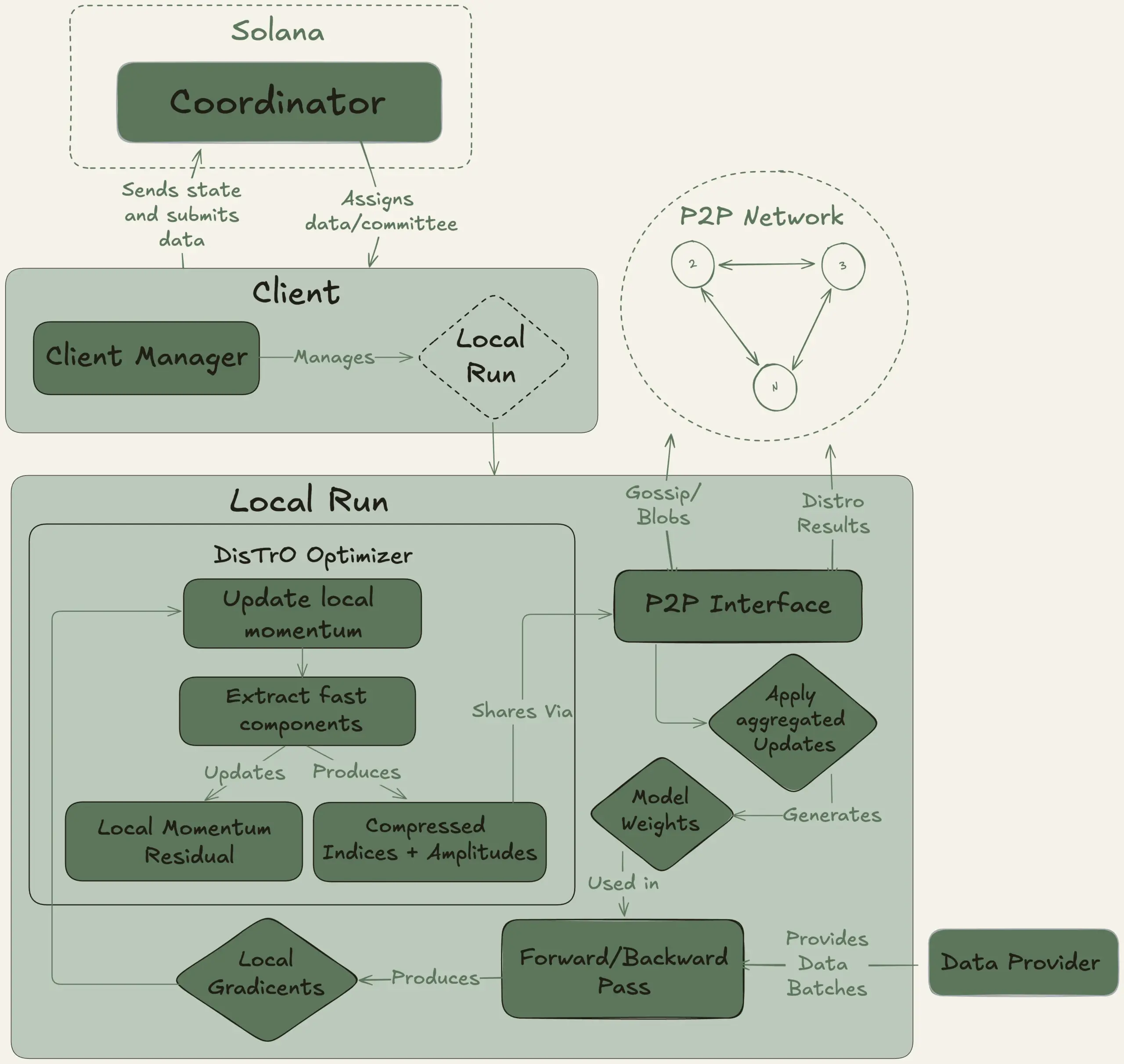
Nous Research lanza el proyecto Psyche, con el objetivo de entrenar de forma descentralizada un modelo grande de 40B parámetros: Nous Research ha anunciado el lanzamiento de la red Psyche, una red de entrenamiento de IA descentralizada, destinada a reunir la potencia de cálculo global para entrenar conjuntamente potentes modelos de IA, permitiendo que individuos y pequeñas comunidades participen en el desarrollo de modelos a gran escala. Su testnet ya ha comenzado el preentrenamiento de un LLM de 40B parámetros, utilizando la arquitectura MLA, con un conjunto de datos que incluye FineWeb (14T), parte de FineWeb-2 (4T) y The Stack v2 (1T), sumando un total de aproximadamente 20T tokens. Una vez completado el entrenamiento de este modelo, todos los checkpoints (incluidas las versiones no recocidas y recocidas) y el conjunto de datos serán de código abierto. (Fuente: eliebakouch, Teknium1)
Stability AI lanza el modelo de código abierto Stable Audio Open Small, centrado en la generación rápida de texto a audio: Stability AI ha lanzado el modelo Stable Audio Open Small en Hugging Face, un modelo diseñado específicamente para la generación rápida de texto a audio y que utiliza tecnología de post-entrenamiento adversario. Este modelo tiene como objetivo proporcionar una solución de generación de audio eficiente y de código abierto. (Fuente: _akhaliq)
Google Gemini Advanced se integra con GitHub, reforzando la capacidad de asistencia en codificación: Google ha anunciado que Gemini Advanced ahora está conectado a GitHub, mejorando aún más su capacidad como asistente de codificación. Los usuarios pueden conectar directamente repositorios públicos o privados de GitHub, utilizando Gemini para generar o modificar funciones, explicar código complejo, hacer preguntas sobre el código base, realizar depuración, entre otras operaciones. Se puede comenzar a usar haciendo clic en el botón “+” en la barra de prompts y seleccionando “Importar código”, luego pegando la URL de GitHub. (Fuente: algo_diver)
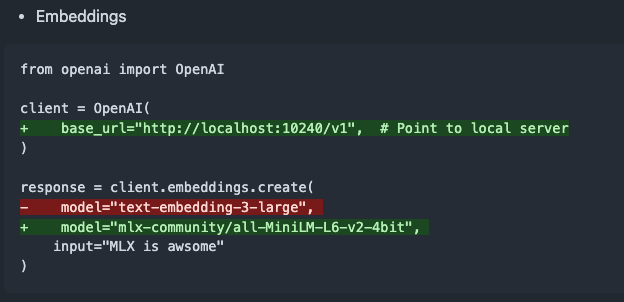
mlx-omni-server v0.4.0 lanzado, añade servicio de embeddings y más modelos TTS: mlx-omni-server se actualiza a la versión v0.4.0, introduciendo un nuevo servicio /v1/embeddings, que simplifica la generación de embeddings a través de mlx-embeddings. Al mismo tiempo, integra más modelos TTS (como kokoro, bark) y actualiza mlx-lm para admitir nuevos modelos como qwen3. (Fuente: awnihannun)
Together Chat añade función de procesamiento de archivos PDF: Together Chat ha anunciado que admite la carga y el procesamiento de archivos PDF. La versión actual analiza principalmente el contenido de texto en los PDF y lo pasa al modelo para su procesamiento. Se planea lanzar una versión v2 en el futuro, que añadirá la función de OCR para leer el contenido de las imágenes en los PDF. (Fuente: togethercompute)
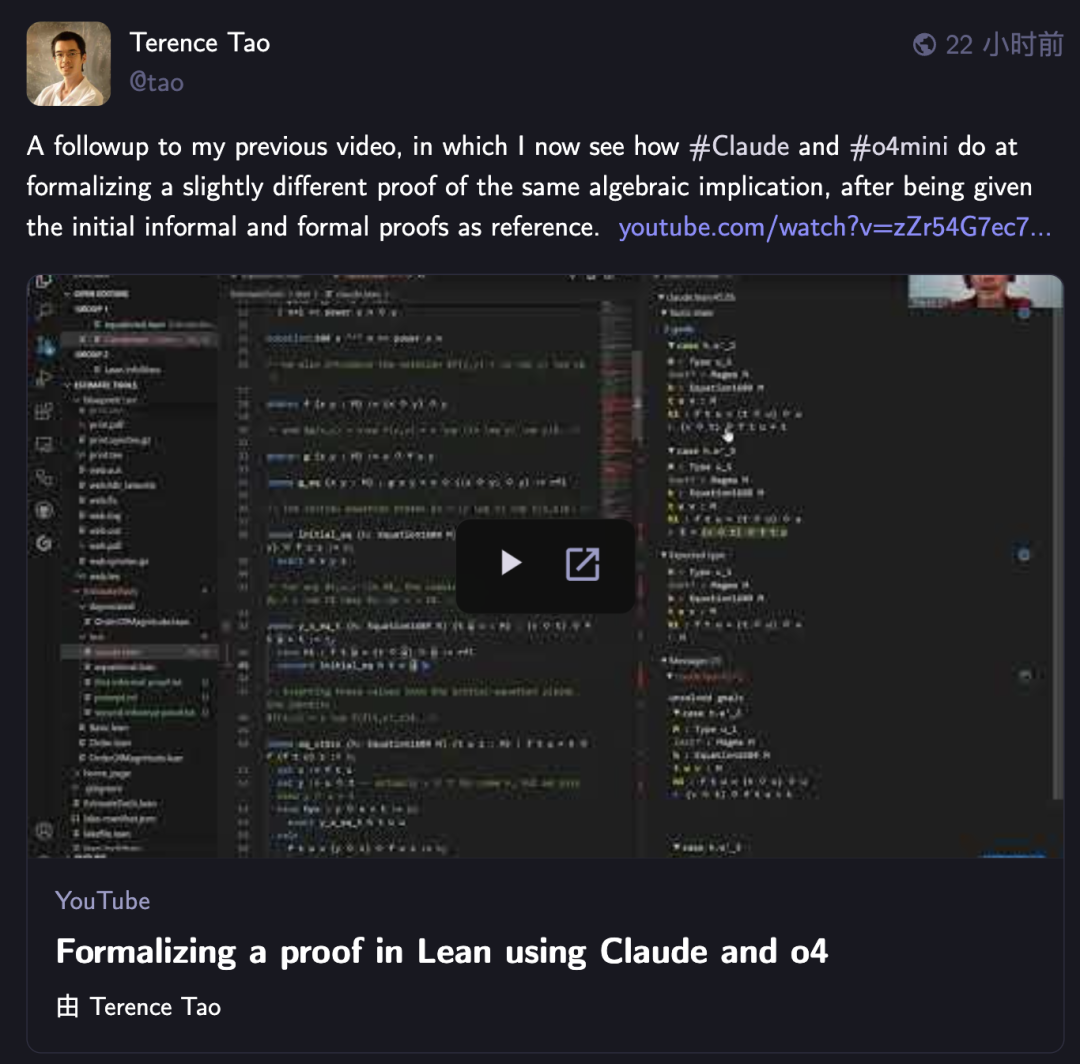
Terence Tao vuelve a desafiar la prueba formal matemática con IA, Claude supera a o4-mini: El matemático Terence Tao, en su serie de videos de YouTube, probó la capacidad de la IA para formalizar pruebas de implicación algebraica en el asistente de pruebas Lean. En el experimento, Claude pudo completar la tarea en aproximadamente 20 minutos, aunque durante el proceso de compilación reveló una comprensión errónea de la regla de que los números naturales en Lean comienzan desde 0 y problemas en el manejo de la simetría, que se corrigieron con intervención humana. En comparación, o4-mini se mostró más cauteloso, pudo identificar problemas en la definición de la función de potencia, pero en el paso crucial de la prueba optó por abandonar, sin completar la tarea. Tao concluyó que una dependencia excesiva de la automatización puede debilitar la comprensión de la estructura general de la prueba, y que el nivel óptimo de automatización debería estar entre el 0% y el 100%, conservando la intervención humana para profundizar la comprensión. (Fuente: 36氪)
Entrevista a Altman: El objetivo final de OpenAI es crear un servicio de suscripción de IA central: El CEO de OpenAI, Sam Altman, en el evento AI Ascent 2025 de Sequoia Capital, declaró que el “ideal platónico” de OpenAI es desarrollar un sistema operativo de IA que se convierta en el servicio de suscripción de IA central para los usuarios. Visualiza que los futuros modelos de IA podrán procesar los datos de toda la vida de un usuario (billones de tokens de contexto), logrando un razonamiento profundamente personalizado. Altman admitió que esto todavía está en “fase de PPT”, pero enfatizó que la compañía se enorgullece de su flexibilidad y adaptabilidad. También habló sobre el potencial de la interacción por voz con IA, que 2025 será un año en el que los agentes de IA brillarán, y considera que la codificación será el núcleo para impulsar el funcionamiento de los modelos y las llamadas a API. (Fuente: 36氪, 量子位)

Karminski3 comparte una versión modificada por la comunidad de Qwen3-30B, duplicando el número de expertos activados: La comunidad de desarrolladores ha modificado el modelo Qwen3, lanzando la versión Qwen3-30B-A6B-16-Extreme. Al modificar los parámetros del modelo, el número de expertos activados se ha incrementado de A3B a A6B, lo que supuestamente aporta una ligera mejora de calidad, aunque la velocidad de generación se ralentizará en consecuencia. Los usuarios también pueden lograr un efecto similar modificando los parámetros de ejecución de llama.cpp con --override-kv http://qwen3moe.expert_used_count=int:24, o realizar la operación inversa para reducir la cantidad de activación de Qwen3-235B-A22B y así acelerarlo. (Fuente: karminski3)

🧰 Herramientas
Lanzamiento de OpenMemory MCP: Sistema de memoria compartida de ejecución local, conectando múltiples herramientas de IA: El equipo de mem0ai ha lanzado OpenMemory MCP, un servidor de memoria privado construido sobre el Protocolo de Contexto de Modelo Abierto (MCP). Admite ejecución 100% local y tiene como objetivo resolver el problema actual de que las herramientas de IA (como Cursor, Claude Desktop, Windsurf, Cline) no comparten información de contexto y pierden la memoria al finalizar la sesión. Los datos del usuario se almacenan localmente, garantizando la privacidad y seguridad. OpenMemory MCP proporciona una API estandarizada para operaciones de memoria (CRUD) y cuenta con un panel de control centralizado para que los usuarios gestionen la memoria y los permisos de acceso de los clientes, simplificando la implementación a través de Docker. (Fuente: 36氪, AI进修生)

LangChain lanza la versión oficial de la plataforma LangGraph y múltiples actualizaciones, fortaleciendo el desarrollo y la observabilidad de agentes de IA: LangChain anunció en la conferencia Interrupt la disponibilidad general (GA) de su plataforma LangGraph. Esta plataforma está diseñada específicamente para construir y gestionar flujos de trabajo de agentes de IA de larga duración y con estado, admitiendo despliegue con un solo clic, escalado horizontal y API para memoria, interacción humano-máquina (HIL), historial de conversaciones, etc. Al mismo tiempo, se lanzó LangGraph Studio V2, un IDE para agentes, que admite ejecución local, edición directa de configuraciones, integración con Playground y la capacidad de extraer datos de seguimiento del entorno de producción para depuración local. Además, LangChain también lanzó la plataforma de construcción de agentes sin código de código abierto Open Agent Platform (OAP) y mejoró la observabilidad de agentes en LangSmith en términos de llamada a herramientas y trazas. (Fuente: LangChainAI, hwchase17)
PatronusAI lanza Percival: un agente de IA capaz de evaluar y reparar otros agentes de IA: PatronusAI ha presentado Percival, promocionado como el primer agente de IA capaz de evaluar y reparar automáticamente los errores de otros agentes de IA. Percival no solo puede detectar fallos en los registros de seguimiento de los agentes, sino que también puede proponer sugerencias de reparación. Según se informa, en el conjunto de datos TRAIL, que contiene errores anotados manualmente de GAIA y SWE-Bench, el rendimiento de Percival es 2.9 veces superior al de los LLM SOTA. Sus funciones incluyen la sugerencia automática de soluciones de reparación para los prompts de los agentes, la captura de más de 20 tipos de fallos de agentes (que abarcan el uso de herramientas, la coordinación de la planificación, errores específicos del dominio, etc.) y la reducción del tiempo de depuración manual de horas a menos de 1 minuto. (Fuente: rebeccatqian, basetenco)
PyWxDump: Herramienta de obtención y exportación de información de WeChat, compatible con el entrenamiento de IA: PyWxDump es una herramienta de Python para obtener información de cuentas de WeChat (apodo, cuenta, teléfono, correo electrónico, clave de base de datos), descifrar bases de datos, ver localmente los historiales de chat y exportar los historiales de chat a formatos como CSV, HTML, etc., que se pueden utilizar para el entrenamiento de IA, respuestas automáticas y otros escenarios. La herramienta admite la obtención de información de múltiples cuentas y todas las versiones de WeChat, y proporciona una interfaz de usuario web para ver los historiales de chat. (Fuente: GitHub Trending)

Airweave: Herramienta que permite a los agentes de IA buscar en cualquier aplicación, compatible con el protocolo MCP: Airweave es una herramienta diseñada para permitir que los agentes de IA realicen búsquedas semánticas en el contenido de cualquier aplicación. Es compatible con el Protocolo de Contexto de Modelo (MCP) y puede conectarse sin problemas a diversas aplicaciones, bases de datos o API, transformando su contenido en conocimiento utilizable por los agentes. Sus funciones principales incluyen la sincronización de datos, la extracción y transformación de entidades, la arquitectura multi-tenant, las actualizaciones incrementales, la búsqueda semántica y el control de versiones, entre otras. (Fuente: GitHub Trending)

iFLYTEK lanza los auriculares AI de nueva generación iFLYBUDS Pro3 y Air2, equipados con el cerebro AI viaim: Future Intelligence ha lanzado los auriculares de conferencia AI iFLYBUDS Pro3 e iFLYBUDS Air2 de iFLYTEK, ambos equipados con el nuevo cerebro AI viaim. viaim es un agente de IA orientado a la oficina personal de negocios, que integra cuatro módulos principales: procesamiento inteligente de percepción de extremo a extremo, razonamiento colaborativo de Agente inteligente, capacidad multimodal en tiempo real y protección de la privacidad y seguridad de los datos. Los auriculares admiten grabación conveniente (llamadas, en el sitio, grabación de audio y video), asistente de IA (generación automática de resúmenes de títulos, preguntas específicas), traducción multilingüe (32 idiomas, interpretación simultánea, traducción cara a cara, traducción de llamadas) y otras funciones, además de mejorar la calidad del sonido y la comodidad de uso. (Fuente: WeChat)

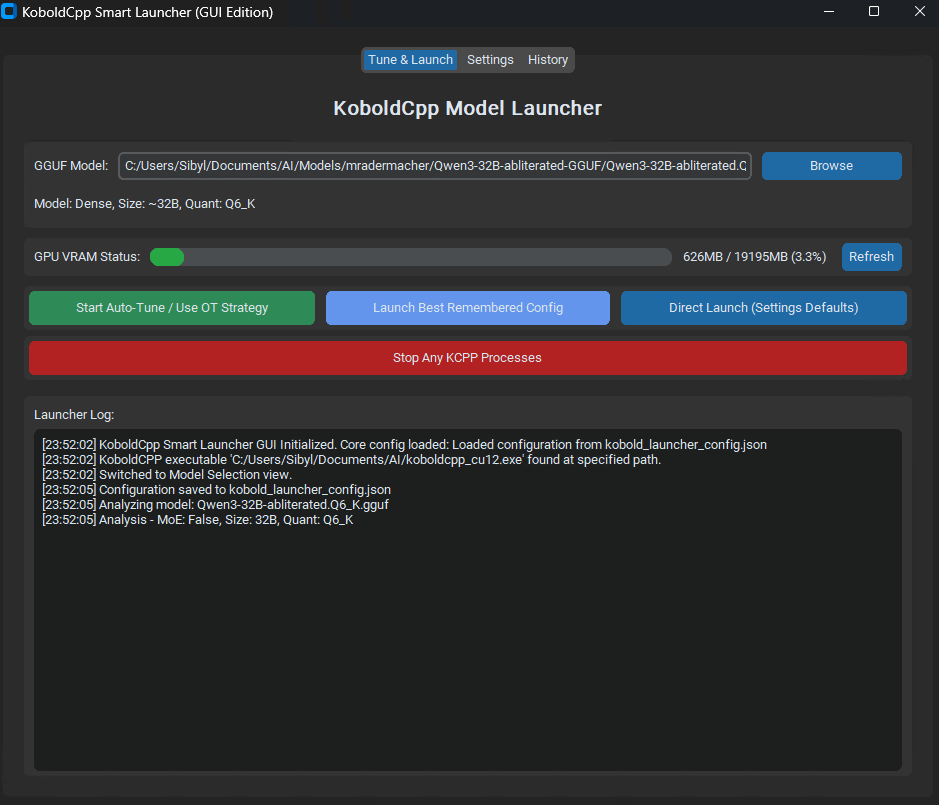
Lanzamiento de KoboldCpp Smart Launcher: Herramienta de ajuste automático de Tensor Offload para optimizar el rendimiento de LLM: Se ha lanzado una herramienta GUI y CLI llamada KoboldCpp Smart Launcher, diseñada para ayudar a los usuarios a encontrar automáticamente la mejor estrategia de Tensor Offload de KoboldCpp al ejecutar LLM localmente. Al distribuir tensores entre la CPU y la GPU de forma más granular (en lugar de capas enteras), se dice que la herramienta puede duplicar con creces la velocidad de generación sin aumentar los requisitos de VRAM. Por ejemplo, QwQ Merge en una GPU de 12GB VRAM pasó de 3.95 t/s a 10.61 t/s. (Fuente: Reddit r/LocalLLaMA)
OpenBMB libera AgentCPM-GUI de código abierto: el primer agente GUI en dispositivo optimizado para chino: El equipo de OpenBMB ha liberado AgentCPM-GUI de código abierto, el primer agente GUI (interfaz gráfica de usuario) en dispositivo optimizado específicamente para aplicaciones en chino. Este agente ha mejorado su capacidad de razonamiento mediante el ajuste fino reforzado (RFT), adopta un diseño de espacio de acción compacto y posee una capacidad de localización GUI (grounding) de alta calidad, con el objetivo de mejorar la experiencia del usuario al operar diversas aplicaciones en un entorno chino. (Fuente: Reddit r/LocalLLaMA)
MAESTRO: Aplicación de investigación de IA de prioridad local, compatible con colaboración multiagente y LLM personalizados: MAESTRO (Multi-Agent Execution System & Tool-driven Research Orchestrator) es una aplicación de investigación impulsada por IA recientemente lanzada que enfatiza el control y la capacidad local. Ofrece un marco modular que incluye extracción de documentos, potentes flujos de RAG y un sistema multiagente (planificación, investigación, reflexión, redacción), capaz de abordar problemas de investigación complejos. Los usuarios pueden interactuar a través de una interfaz web Streamlit o CLI, utilizando sus propios conjuntos de documentos y LLM locales o de API de su elección. (Fuente: Reddit r/LocalLLaMA)
Contextual AI lanza un analizador de documentos optimizado para RAG: Contextual AI ha lanzado un nuevo analizador de documentos, diseñado específicamente para sistemas de generación aumentada por recuperación (RAG). La herramienta tiene como objetivo proporcionar un análisis de alta precisión de documentos no estructurados complejos mediante la combinación de modelos visuales, OCR y de lenguaje visual, capaz de preservar la estructura jerárquica del documento, procesar modalidades complejas como tablas, gráficos y diagramas, y proporcionar cuadros delimitadores y puntuaciones de confianza para la auditoría del usuario, reduciendo así la pérdida de contexto y las alucinaciones en los sistemas RAG causadas por fallos en el análisis. (Fuente: douwekiela)
Gradio añade función de deshacer/rehacer a ImageEditor: El componente ImageEditor de Gradio ahora incluye botones de deshacer (undo) y rehacer (redo), proporcionando a los usuarios funciones de edición de imágenes en Python similares a las de aplicaciones profesionales de pago, mejorando la interactividad y la facilidad de uso. (Fuente: _akhaliq)
RunwayML lanza la nueva función References, compatible con pruebas zero-shot de materiales, ropa, ubicaciones y poses: La función References de RunwayML se ha actualizado, permitiendo a los usuarios utilizar imágenes de previsualización de esferas de material 3D tradicionales como entrada para aplicar su material a cualquier objeto, logrando una transferencia y visualización de material zero-shot. Además, la nueva función también admite pruebas zero-shot para ropa, ubicaciones y poses de personajes, ampliando las posibilidades de generación creativa y creación rápida de prototipos. (Fuente: c_valenzuelab, c_valenzuelab)

Mìtǎ AI lanza la función “Aprende algo hoy”, aprendizaje estructurado asistido por IA: Mìtǎ AI ha lanzado la nueva función “Aprende algo hoy”, con el objetivo de transformar la IA de un asistente para la recuperación de información y el procesamiento de documentos a un “profesor de IA” capaz de guiar y enseñar activamente. Después de que los usuarios cargan o buscan materiales, esta función puede generar automáticamente cursos de video sistemáticos y estructurados y explicaciones en PPT, ayudando a los usuarios a organizar los puntos de conocimiento, y admite la selección de diferentes profundidades de explicación (principiante/experto) y estilos (narración de historias/tipo rudo, etc.) según el nivel del usuario. Además, también admite preguntas durante la lección y pruebas posteriores. (Fuente: WeChat)

📚 Aprendizaje
Andrew Ng y Anthropic colaboran en un nuevo curso: Construcción de aplicaciones de IA de contexto enriquecido con MCP: DeepLearning.AI de Andrew Ng y Anthropic han colaborado para lanzar un nuevo curso “MCP: Build Rich-Context AI Apps with Anthropic”, impartido por Elie Schoppik, Director de Educación Técnica de Anthropic. El curso se centra en el Protocolo de Contexto de Modelo (MCP), un protocolo abierto diseñado para estandarizar el acceso de los LLM a herramientas externas, datos y prompts. Los alumnos aprenderán la arquitectura central de MCP, crearán chatbots compatibles con MCP, construirán e implementarán servidores MCP y los conectarán a aplicaciones impulsadas por Claude y otros servidores de terceros para simplificar el desarrollo de aplicaciones de IA de contexto enriquecido. (Fuente: AndrewYNg, DeepLearningAI)
FlashInfer: Mejor artículo de MLSys 2025, motor de atención para inferencia de LLM eficiente y personalizable: El proyecto FlashInfer, una colaboración entre Zihao Ye de la Universidad de Washington, NVIDIA, Tianqi Chen de OctoAI y otros, ha ganado el premio al mejor artículo en MLSys 2025. FlashInfer es un motor de atención eficiente y personalizable optimizado para el servicio de inferencia de LLM. Mediante la optimización del acceso a la memoria (utilizando un formato disperso en bloques y un formato componible para procesar la caché KV), proporcionando plantillas de cálculo de atención flexibles basadas en compilación JIT e introduciendo un mecanismo de programación de tareas con equilibrio de carga, mejora significativamente el rendimiento de la inferencia de LLM y ya se ha integrado en proyectos como vLLM y SGLang. (Fuente: 机器之心)
Artículo de ICML 2025: Análisis teórico del Graph Prompting desde la perspectiva de la manipulación de datos: Qunzhong Wang, Dr. Xiangguo Sun y Profesor Hong Cheng de la Universidad China de Hong Kong publicaron un artículo en ICML 2025, proporcionando por primera vez un marco teórico sistemático para la efectividad del Graph Prompting desde la perspectiva de la “manipulación de datos”. La investigación introduce el concepto de “grafo puente”, demostrando que el mecanismo de Graph Prompting es teóricamente equivalente a realizar alguna operación sobre los datos del grafo de entrada, permitiendo que los modelos preentrenados los procesen correctamente para adaptarse a nuevas tareas. El artículo deriva un límite superior del error, analiza las fuentes de error y su controlabilidad, y modela la distribución del error, proporcionando una base teórica para el diseño y la aplicación del Graph Prompting. (Fuente: WeChat)
Artículo de ICML 2025: Síntesis de datos textuales mediante edición a nivel de token para evitar el colapso del modelo: Un equipo de investigación de instituciones como la Universidad Jiao Tong de Shanghái publicó un artículo en ICML 2025 que explora el problema del “colapso del modelo” causado por datos sintéticos y propone una estrategia de generación de datos llamada “Token-Level Editing”. Este método, en lugar de generar texto completamente nuevo, realiza microediciones y reemplazos en los tokens “excesivamente confiados” del modelo sobre datos reales, con el objetivo de construir datos semisintéticos con una estructura más estable y una mayor capacidad de generalización. El análisis teórico muestra que este método puede restringir eficazmente el error de prueba, evitando que el rendimiento del modelo colapse con el aumento de las rondas iterativas. Los experimentos en las etapas de preentrenamiento, preentrenamiento continuo y ajuste fino supervisado han validado la efectividad de este método. (Fuente: WeChat)

Artículo de ICML 2025: OmniAudio, generación de audio espacial 3D a partir de videos panorámicos de 360°: El equipo de OmniAudio presentó en ICML 2025 una técnica para generar directamente audio espacial de primer orden ambisónico (FOA) a partir de videos panorámicos de 360°. Para abordar el problema de la escasez de datos, el equipo construyó el conjunto de datos 360V2SA a gran escala Sphere360 (más de 100,000 fragmentos, 288 horas). OmniAudio emplea un entrenamiento en dos etapas: preentrenamiento autosupervisado de coincidencia de flujo de grueso a fino, primero entrenando con audio estéreo normal convertido a pseudo-FOA, y luego ajustando finamente con FOA real; luego, combina un codificador de video de doble rama para un ajuste fino supervisado, extrayendo características de vista global y local para generar audio espacial de alta fidelidad y direccionalmente preciso. (Fuente: 量子位)

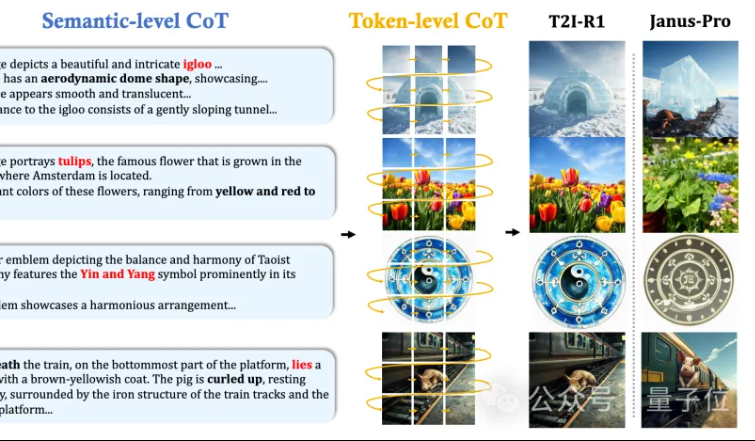
MMLab de la CUHK propone T2I-R1: Introducción de razonamiento CoT de doble nivel y aprendizaje por refuerzo para la generación de texto a imagen: El equipo MMLab de la Universidad China de Hong Kong (CUHK) ha lanzado T2I-R1, el primer modelo de generación de texto a imagen mejorado por razonamiento basado en aprendizaje por refuerzo. Este modelo propone de forma innovadora un marco de razonamiento de cadena de pensamiento (CoT) de doble nivel: Semantic-CoT (razonamiento textual, planificación de la estructura global de la imagen) y Token-CoT (generación de tokens de imagen bloque por bloque, centrándose en detalles de bajo nivel). Mediante el método de aprendizaje por refuerzo BiCoT-GRPO, optimiza sinérgicamente estos dos niveles de CoT en un LMM unificado (Janus-Pro), sin necesidad de modelos adicionales. El modelo de recompensa utiliza una integración de múltiples modelos expertos visuales, asegurando la fiabilidad de la evaluación y previniendo el sobreajuste. Los experimentos demuestran que T2I-R1 puede comprender mejor la intención del usuario, generar imágenes que se ajustan mejor a las expectativas y supera significativamente a los modelos base en los benchmarks T2I-CompBench y WISE. (Fuente: 量子位, WeChat)
OpenAI lanza la biblioteca ligera de evaluación de modelos de lenguaje simple-evals: OpenAI ha liberado simple-evals, una biblioteca ligera para evaluar modelos de lenguaje, con el objetivo de transparentar los datos de precisión de sus últimos lanzamientos de modelos. La biblioteca enfatiza configuraciones de evaluación zero-shot y de cadena de pensamiento (chain-of-thought), y proporciona comparaciones detalladas del rendimiento de los modelos en múltiples benchmarks como MMLU, MATH, GPQA, incluyendo modelos propios de OpenAI (como o3, o4-mini, GPT-4.1, GPT-4o) así como otros modelos principales (como Claude 3.5, Llama 3.1, Grok 2, Gemini 1.5). (Fuente: GitHub Trending)
Lanzamiento de la versión en coreano del LLM Engineer’s Handbook: El “LLM Engineer’s Handbook” de Maxime Labonne ya está disponible en coreano, traducido por Woocheol Cho. Próximamente se publicarán más versiones en otros idiomas de este manual, como ruso, chino y polaco, proporcionando recursos de aprendizaje para desarrolladores de LLM de todo el mundo. (Fuente: maximelabonne)

Anuncio del taller de aprendizaje automático para audio ML4Audio en ICML 2025: El popular taller de aprendizaje automático para audio (ML for Audio) regresará durante ICML 2025 en Vancouver, específicamente el sábado 19 de julio. El taller contará con ponencias de académicos de renombre como Dan Ellis, Albert Gu, Jesse Engel, Laura Laurenti y Pratyusha Rakshit. La fecha límite para la presentación de artículos es el 23 de mayo. (Fuente: sedielem)
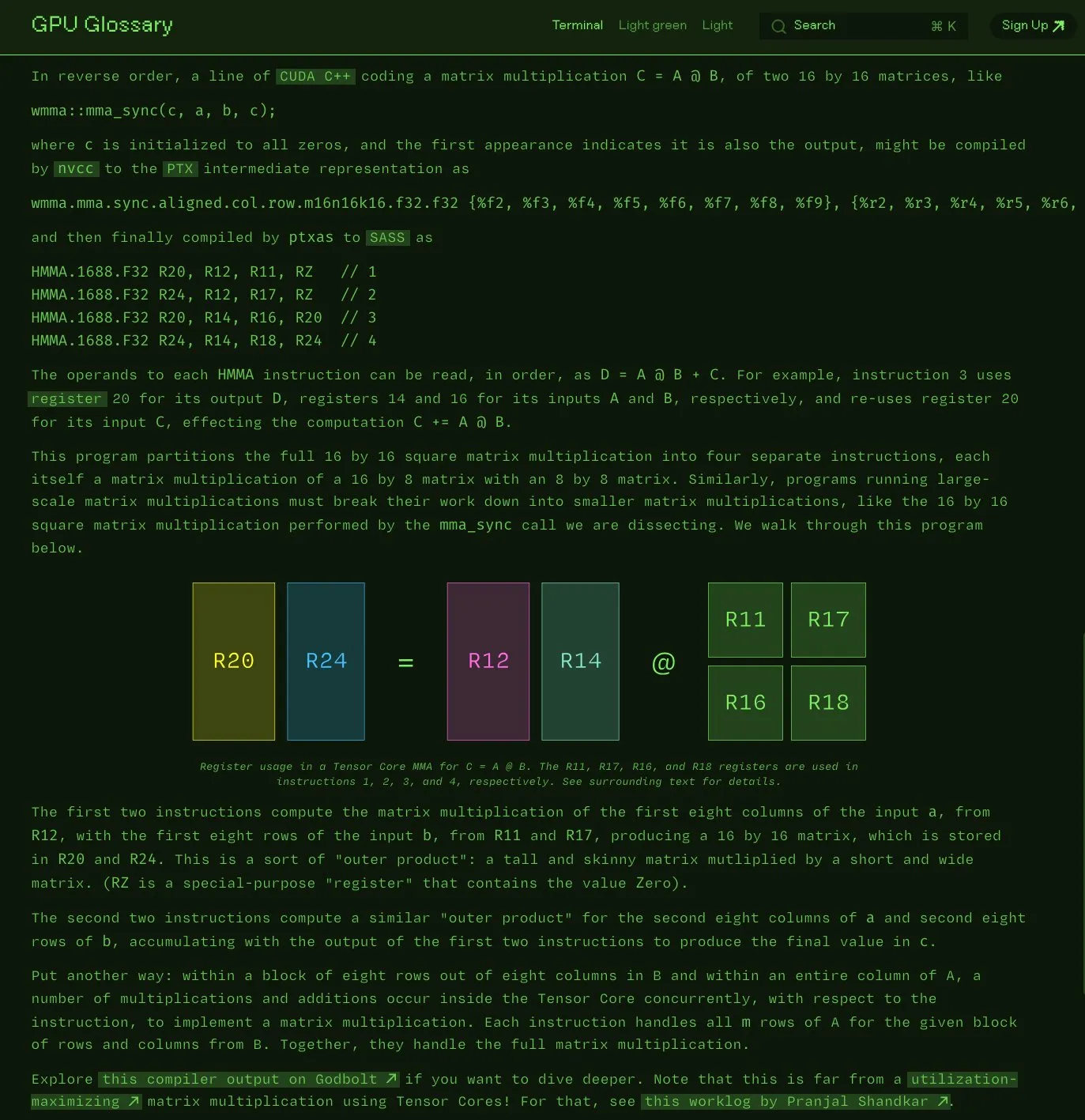
Charles Frye publica un glosario de GPU de código abierto: Charles Frye ha anunciado que su glosario de GPU (GPU Glossary) ya es de código abierto. Este glosario tiene como objetivo ayudar a comprender los conceptos relacionados con el hardware y la programación de GPU, y recientemente se actualizó con la descomposición de la instrucción SASS para la operación simple de multiplicación y acumulación de matrices (mma) ejecutada por los Tensor Cores. El proyecto está alojado en GitHub y enumera algunas tareas pendientes. (Fuente: charles_irl)
OpenAI publica una guía de ingeniería de prompts para GPT-4.1, enfatizando la estructura y las instrucciones claras: OpenAI ha lanzado una guía de ingeniería de prompts para GPT-4.1, destinada a ayudar a los usuarios a construir prompts de manera más efectiva, especialmente para aplicaciones que requieren salida estructurada, razonamiento, uso de herramientas y basadas en agentes. La guía enfatiza la importancia de definir claramente roles y objetivos, proporcionar instrucciones claras (incluyendo tono, formato, límites), subinstrucciones opcionales, razonamiento/planificación paso a paso, definir con precisión el formato de salida y usar ejemplos, y ofrece algunos consejos prácticos como resaltar instrucciones clave, usar Markdown o XML para estructurar la entrada, etc. (Fuente: Reddit r/MachineLearning)

Kaggle y Hugging Face profundizan su colaboración, simplificando la llamada y el descubrimiento de modelos: Kaggle ha anunciado una colaboración reforzada con Hugging Face. Los usuarios ahora pueden iniciar directamente modelos de Hugging Face en Kaggle Notebooks, descubrir ejemplos de código público relacionados y explorar sin problemas entre ambas plataformas. Esta integración tiene como objetivo ampliar la accesibilidad de los modelos, permitiendo a los usuarios de Kaggle utilizar más convenientemente los recursos de modelos del ecosistema de Hugging Face. (Fuente: huggingface)
FedRAG: Marco de código abierto para el ajuste fino de sistemas RAG, compatible con aprendizaje federado: Investigadores del Vector Institute han lanzado FedRAG, un marco de código abierto diseñado para simplificar el ajuste fino (fine-tuning) de sistemas de generación aumentada por recuperación (RAG). Este marco no solo admite el entrenamiento centralizado típico, sino que también introduce especialmente una arquitectura de aprendizaje federado para adaptarse a la necesidad de entrenar en conjuntos de datos distribuidos. FedRAG es compatible con los ecosistemas PyTorch y Hugging Face, admite el uso de Qdrant como almacenamiento de base de conocimientos y puede conectarse a LlamaIndex. (Fuente: nerdai)

💼 Negocios
La empresa matriz de Cursor, Anysphere, alcanza los 200 millones de dólares de ARR en dos años, con una valoración que se dispara a 9 mil millones de dólares: Michael Truell, un desertor del MIT de solo 25 años, lidera Anysphere, la empresa detrás del editor de código con IA Cursor. Sin realizar promoción de mercado, la compañía ha alcanzado los 200 millones de dólares en ingresos recurrentes anuales (ARR) en dos años, y su valoración ha ascendido rápidamente a 9 mil millones de dólares. Cursor ha remodelado el paradigma del desarrollo de software al integrar profundamente la IA en el flujo de trabajo de desarrollo, centrándose en servir a desarrolladores individuales y obteniendo un amplio reconocimiento y difusión boca a boca entre los desarrolladores de todo el mundo. Thrive Capital lideró su última ronda de financiación. (Fuente: 36氪)

Databricks anuncia la adquisición de Neon, empresa de Serverless Postgres: Databricks ha acordado adquirir Neon, una empresa de Serverless Postgres centrada en los desarrolladores. Neon es conocida por su novedosa arquitectura de base de datos, que ofrece velocidad, escalado elástico y funciones de ramificación y bifurcación, características atractivas tanto para desarrolladores como para agentes de IA. Esta adquisición tiene como objetivo construir conjuntamente una base de datos abierta y Serverless para desarrolladores y agentes de IA. (Fuente: jefrankle, matei_zaharia)
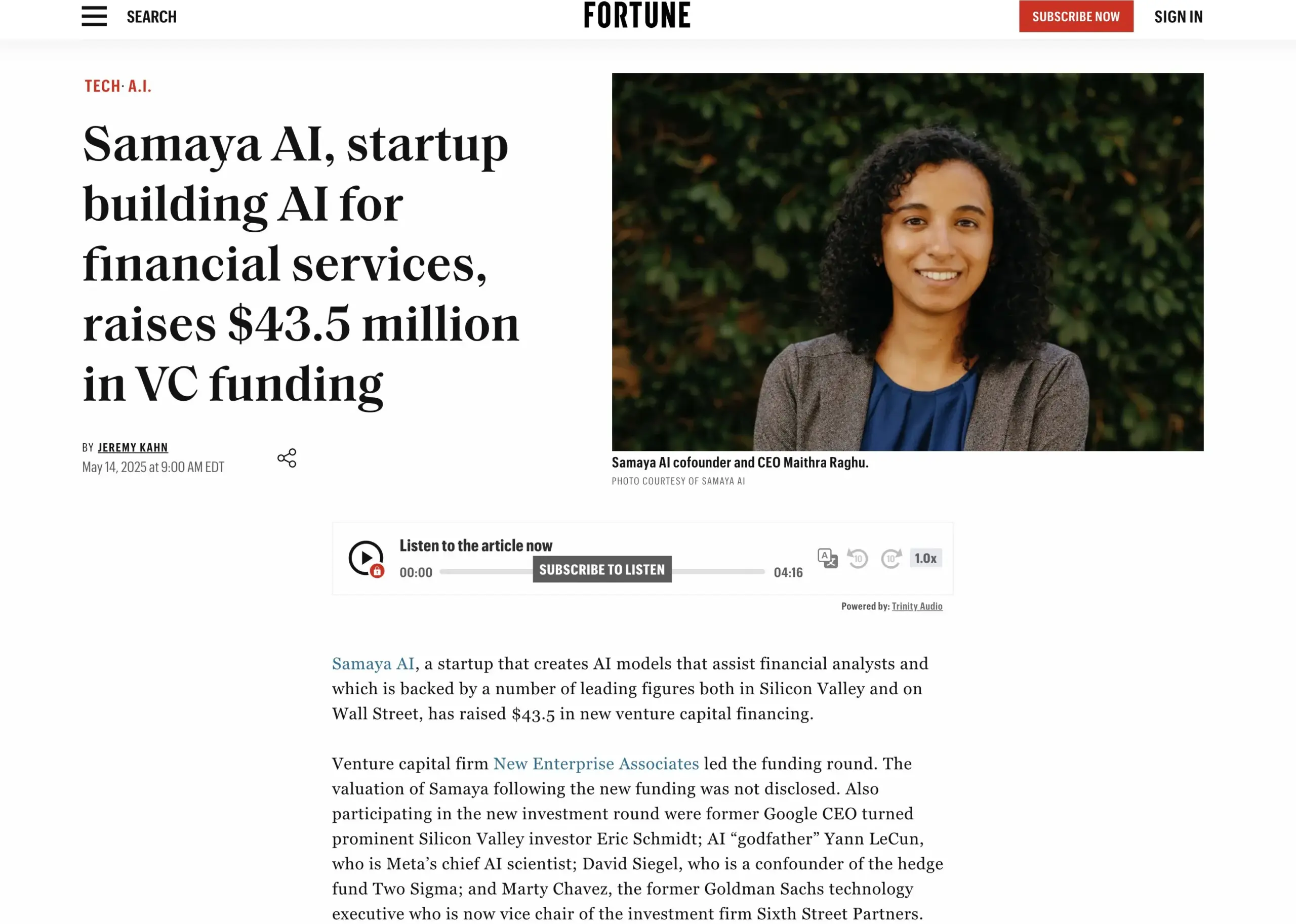
La startup de servicios financieros con IA Samaya AI completa una ronda de financiación de 43.5 millones de dólares: Samaya AI ha anunciado la obtención de 43.5 millones de dólares en una ronda de financiación liderada por NEA, destinados a construir agentes de IA expertos para servicios financieros, con el objetivo de transformar el trabajo del conocimiento a escala. La empresa, fundada en 2022, se especializa en crear soluciones de IA dedicadas para flujos de trabajo financieros complejos. Sus agentes de IA expertos, basados en LLM desarrollados internamente, ya son utilizados por miles de usuarios en instituciones de primer nivel como Morgan Stanley, aplicándose en escenarios como la diligencia debida, el modelado económico y el apoyo a la toma de decisiones, enfatizando la precisión, la transparencia y la ausencia de alucinaciones. (Fuente: maithra_raghu)
🌟 Comunidad
¿Reemplazará la IA a los ingenieros de software? La comunidad debate la necesidad de actualizar habilidades: En las redes sociales ha resurgido el debate sobre si la IA reemplazará a los ingenieros de software. La opinión generalizada es que la IA no reemplazará por completo a los ingenieros de software, ya que el desarrollo de software va mucho más allá de la simple codificación. Sin embargo, aquellos que se dedican principalmente a trabajos de codificación repetitivos y carecen de una comprensión integral del sistema, los “code monkeys”, enfrentan un alto riesgo de ser reemplazados por herramientas asistidas por IA si no mejoran sus habilidades, profundizan en la comprensión de la arquitectura de sistemas y la resolución de problemas complejos. (Fuente: cto_junior, cto_junior)
El futuro de los Agentes de IA: Oportunidades y desafíos coexisten, líderes de la industria ven con optimismo su potencial: El CEO de OpenAI, Sam Altman, predice que 2025 será un año en el que los Agentes de IA brillarán, participando más en el trabajo real. Liu Zhiyi, en su entrevista, también enfatizó que los Agentes están pasando de ser herramientas pasivas a sistemas de ejecución activa, y su desarrollo depende del progreso de los modelos base y de la capacidad de interacción con el mundo físico. Aunque actualmente los Agentes todavía tienen deficiencias en la velocidad de respuesta, el control de alucinaciones, etc., su capacidad para ejecutar tareas de forma autónoma y ayudar en el aprendizaje de modelos grandes es ampliamente reconocida, y ya han comenzado a aplicarse en áreas como el servicio al cliente inteligente y la asesoría financiera. (Fuente: 36氪, 量子位)

Perplexity AI se asocia con PayPal y Venmo para integrar pagos en comercio electrónico y viajes: Perplexity AI ha anunciado su colaboración con PayPal y Venmo para integrar funciones de pago en las compras de comercio electrónico, reservas de viajes, así como en su asistente de voz y en el próximo navegador Comet dentro de su plataforma. Esta medida tiene como objetivo simplificar todo el proceso comercial, desde la navegación, búsqueda y selección hasta el pago seguro, mejorando la experiencia del usuario. (Fuente: AravSrinivas, perplexity_ai)
Discusión sobre la evaluación de modelos de IA: IFEval y ChartQA en el punto de mira, se necesita cautela ante la contaminación de datos de entrenamiento: En las discusiones de la comunidad, IFEval es considerado uno de los mejores benchmarks para la evaluación del seguimiento de instrucciones debido a su diseño simple e ingenioso. Al mismo tiempo, algunos usuarios señalan que los datos de prueba de ChartQA presentan ruido, respuestas ambiguas e inconsistencias, por lo que podría necesitar ser descartado. Vikhyatk advierte que muchos modelos que afirman haber alcanzado una alta precisión en los benchmarks podrían tener problemas de contaminación de datos de entrenamiento no detectados. (Fuente: clefourrier, vikhyatk)

Los derechos de autor y la ética del contenido generado por IA generan preocupación: Audible planea usar narración por IA, y el uso de personajes generados por IA para citas en línea causa inquietud: Audible anunció planes para usar narración generada por IA para producir audiolibros, con el objetivo de “llevar más historias a la vida”, lo que generó un debate sobre la aplicación de la IA en las industrias creativas. Por otro lado, en Reddit, un usuario publicó que su madre interactuó en un sitio de citas con una imagen de un “hombre real” que parecía generada por IA, expresando su temor a que fuera engañada. Esto pone de relieve los riesgos potenciales del contenido generado por IA en términos de autenticidad, manipulación emocional y fraude. (Fuente: Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 Otros
La empresa china “Xingsuan” lanza con éxito el primer lote de 12 satélites de computación espacial, iniciando una nueva era de capacidad de cómputo basada en el espacio: El plan “Xingsuan”, liderado por Guoxing Aerospace, ha enviado con éxito al espacio el primer lote de 12 satélites de computación, formando la primera constelación de computación espacial del mundo. Cada satélite tiene capacidad de computación espacial e interconexión, con una capacidad de cómputo por satélite que aumenta de nivel T a nivel P. La constelación inicial tiene una capacidad de cómputo en órbita de 5 POPS, y la comunicación láser entre satélites alcanza los 100 Gbps. Esta iniciativa tiene como objetivo construir una infraestructura de computación inteligente basada en el espacio, resolver problemas como el gran consumo de energía y la difícil disipación de calor de la capacidad de cómputo terrestre, y apoyar el procesamiento en tiempo real en órbita de datos de exploración del espacio profundo, logrando el “cómputo de datos celestes en el cielo”. Se planea lanzar 2800 satélites en el futuro para formar una gran red de computación espacial. (Fuente: 量子位)

NVIDIA publica su resumen anual, destacando que la IA es el núcleo de la nueva revolución industrial y la inteligencia como producto: NVIDIA señaló en su resumen anual que el mundo está entrando en una nueva revolución industrial, cuyo producto central es la “inteligencia”. NVIDIA se dedica a construir infraestructura inteligente, transformando la computación en una fuerza generativa que impulsa el desarrollo en todos los sectores. (Fuente: nvidia)

La NBA y Kling AI de Kuaishou colaboran para lanzar el cortometraje de IA “El mate de Curry en su infancia”: La NBA ha colaborado con Kling AI, el modelo de generación de video a partir de texto similar a Sora de Kuaishou, para producir un cortometraje de IA titulado “Childhood Curry’s Dunk”, realizado por AI TALK. La película intenta recrear la escena del mate “a través del tiempo” de Curry utilizando Kling AI, para animar los playoffs de la NBA, y cuenta con cameos especiales de Barkley, O’Neal y Jokic. (Fuente: TomLikesRobots)