
Palabras clave:OpenAI, HealthBench, Meta AI, Transformador Latente de Bytes Dinámicos, Microsoft Research, Marco ARTIST, Sakana AI, Máquina de Pensamiento Continuo, Evaluación del rendimiento de IA en salud, Modelo Transformador Latente de Bytes Dinámicos de 8B parámetros, Refuerzo del aprendizaje para mejorar el razonamiento de LLM, Arquitectura de red neuronal CTM, Modelo cuantificado oficial Qwen3
🔥 Enfoque
OpenAI publica HealthBench para evaluar el rendimiento de la IA médica: OpenAI ha lanzado HealthBench, un nuevo benchmark diseñado para medir el rendimiento y la seguridad de los modelos de lenguaje grandes (LLM) en escenarios médicos. Este benchmark fue desarrollado con la participación de más de 250 médicos de todo el mundo, e incluye 5000 conversaciones médicas reales y 48562 criterios de evaluación únicos redactados por médicos, cubriendo diversas situaciones como urgencias y salud global, así como dimensiones conductuales como la precisión y el seguimiento de instrucciones. Las pruebas muestran que el modelo o3 alcanza una precisión del 60%, mientras que GPT-4.1 nano supera a GPT-4o con una reducción de costes de 25 veces, demostrando el enorme potencial de la IA en el ámbito médico y el rápido avance en la rentabilidad del rendimiento. (Fuente: OpenAI)
Meta publica el modelo Dynamic Byte Latent Transformer de 8B parámetros: Meta AI anuncia la publicación de los pesos de su modelo Dynamic Byte Latent Transformer de 8B parámetros en código abierto. Este modelo propone una nueva solución alternativa a los métodos tradicionales de tokenización, con el objetivo de redefinir los estándares de eficiencia y fiabilidad de los modelos de lenguaje. Mediante esta nueva forma de tokenización, se espera lograr avances disruptivos en el campo de los modelos de lenguaje, mejorando la eficiencia y efectividad del procesamiento de texto por parte de los modelos. El artículo de investigación y el código ya están disponibles para su descarga. (Fuente: AIatMeta)
Microsoft Research presenta el framework ARTIST, que combina aprendizaje por refuerzo para mejorar el razonamiento y el uso de herramientas en LLMs: Microsoft Research ha presentado el framework ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers). Este framework integra razonamiento agéntico, aprendizaje por refuerzo y uso dinámico de herramientas, permitiendo a los modelos de lenguaje grandes decidir autónomamente cuándo, cómo y qué herramientas usar para el razonamiento multi-paso, y aprender estrategias robustas sin supervisión a nivel de paso. ARTIST supera a modelos de vanguardia como GPT-4o en benchmarks desafiantes como matemáticas y llamadas a funciones, con mejoras de hasta el 22%, estableciendo nuevos estándares para la resolución de problemas generalizable y explicable. (Fuente: MarkTechPost)

Sakana AI publica Continuous Thought Machines (CTM): Sakana AI ha presentado una nueva arquitectura de red neuronal llamada “Continuous Thought Machines” (CTM). La idea central de CTM es utilizar el proceso dinámico temporal de la actividad neuronal como componente central de su computación, permitiendo que el modelo opere a lo largo de una línea de tiempo de “pasos de pensamiento” generada internamente, construyendo y refinando iterativamente sus representaciones, incluso para datos estáticos. Esta arquitectura ha demostrado su computación adaptativa, interpretabilidad mejorada y plausibilidad biológica en diversas tareas como clasificación en ImageNet, navegación en laberintos 2D, ordenación, cálculo de paridad y aprendizaje por refuerzo. (Fuente: Sakana AI)

🎯 Movimientos
El equipo Qwen de Alibaba publica modelos cuantizados oficiales de Qwen3: El equipo Qwen de Alibaba ha lanzado oficialmente los modelos cuantizados de Qwen3. Los usuarios ahora pueden desplegar Qwen3 a través de plataformas como Ollama, LM Studio, SGLang y vLLM, con soporte para múltiples formatos como GGUF, AWQ, GPTQ, facilitando la implementación local. Los modelos correspondientes ya están disponibles en Hugging Face y ModelScope. Este lanzamiento tiene como objetivo reducir la barrera de entrada para el uso de modelos grandes de alto rendimiento y promover su aplicación en escenarios más amplios. (Fuente: Alibaba_Qwen & Hugging Face & ClementDelangue & _akhaliq & TheZachMueller & cognitivecompai & huybery & Reddit r/LocalLLaMA)
Meta AI publica el framework de razonamiento colaborativo Collaborative Reasoner: Meta AI ha presentado Collaborative Reasoner, un framework diseñado para mejorar las capacidades de razonamiento colaborativo de los modelos de lenguaje. Este framework se dedica a desarrollar agentes sociales inteligentes capaces de cooperar con humanos y otros agentes, allanando el camino para interacciones humano-máquina más complejas y sistemas multiagente mediante la mejora de las capacidades de colaboración y razonamiento del modelo. El artículo de investigación y el código están disponibles para su descarga, animando a la comunidad a explorar y aplicar. (Fuente: AIatMeta)
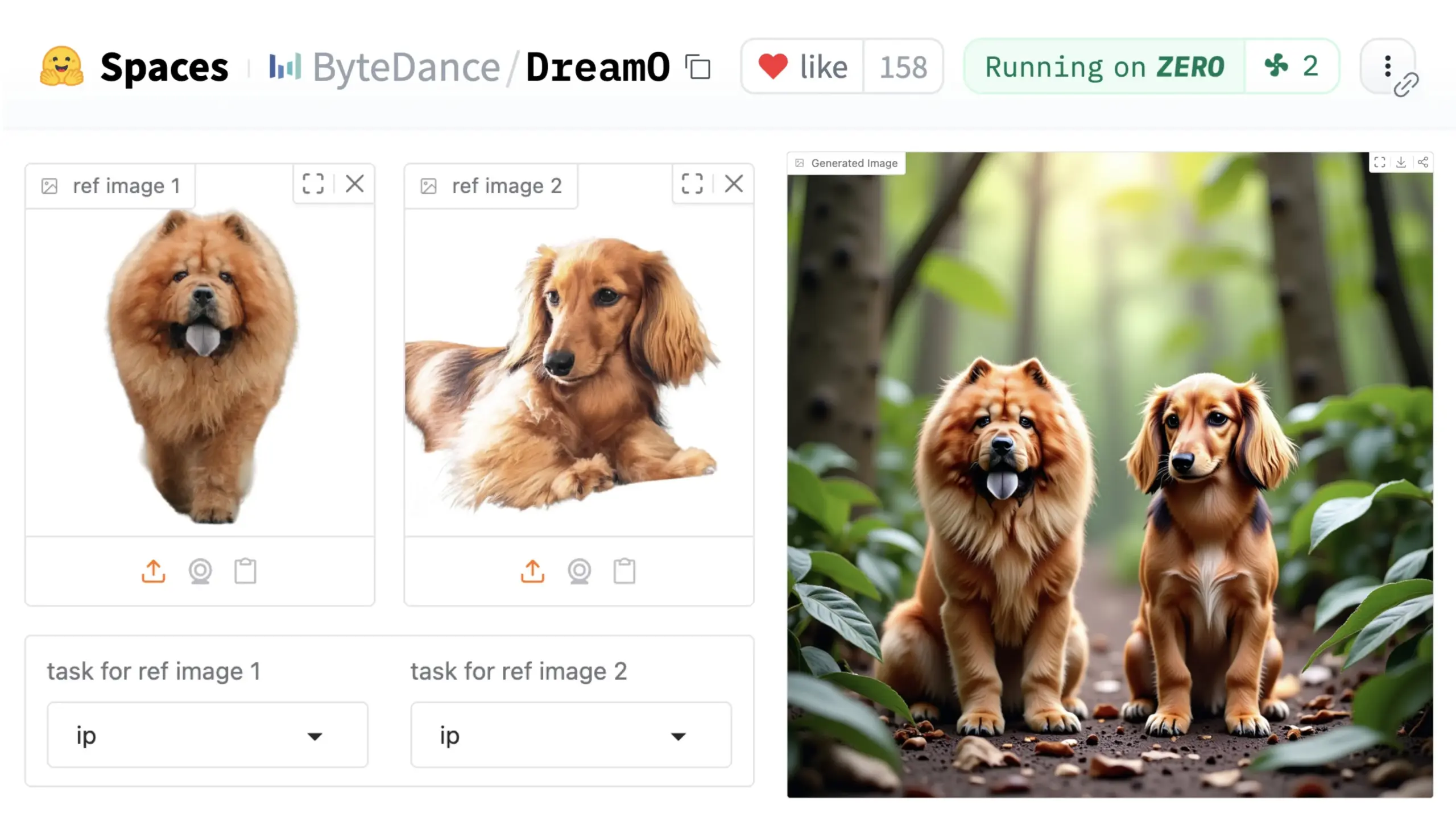
ByteDance presenta el framework universal de personalización de imágenes DreamO: ByteDance ha lanzado un framework unificado de personalización de imágenes llamado DreamO. Basado en el modelo preentrenado DiT (Diffusion Transformer), este framework permite la personalización generalizada de múltiples elementos en imágenes, como personas, estilos y fondos, incluyendo funciones como reemplazo de identidad, transferencia de estilo, transformación de sujetos y prueba virtual. Los usuarios pueden probar la Demo en Hugging Face. Este avance demuestra el potencial de un único modelo en diversas tareas de edición de imágenes. (Fuente: _akhaliq & ClementDelangue & _akhaliq)
NVIDIA abre el flujo de gestión de datos del modelo Nemotron, Nemotron-CC: NVIDIA ha anunciado la apertura de su flujo de gestión de datos utilizado para el modelo Nemotron, Nemotron-CC, y la publicación de la mayor cantidad posible de datos de entrenamiento y post-entrenamiento de Nemotron. El flujo Nemotron-CC ahora se ha añadido al repositorio NeMo Curator en GitHub, capaz de procesar datos de texto, imagen y vídeo a gran escala. NVIDIA enfatiza la importancia de los conjuntos de datos de preentrenamiento de alta calidad para la precisión de los modelos de lenguaje grandes y considera que los datos son un componente fundamental para acelerar la computación. (Fuente: ctnzr & NandoDF)

El modelo Hunyuan-Turbos de Tencent ocupa el octavo lugar en la arena LMArena: El último modelo Hunyuan-Turbos de Tencent ha alcanzado el octavo lugar general en los benchmarks de LMArena (anteriormente lmsys.org), y el decimotercero en control de estilo, mostrando un rendimiento cercano a Deepseek-R1. El modelo se sitúa entre los diez primeros en las principales categorías como hardcore, codificación y matemáticas, mostrando una mejora significativa respecto a su versión de febrero. Miembros de la comunidad como WizardLM_AI han felicitado su rendimiento. (Fuente: WizardLM_AI & WizardLM_AI & teortaxesTex)

Runway Gen-4 References demuestra potencial como herramienta de creación universal: El modelo Gen-4 References de Runway se posiciona como una herramienta de creación universal, capaz de soportar flujos de trabajo y aplicaciones casi ilimitados. Los usuarios de la comunidad continúan descubriendo nuevos casos de uso, demostrando su gran adaptabilidad como modelo general que se ajusta a la creatividad del usuario, en lugar de que el usuario se adapte a las limitaciones del modelo. Esto refleja la tendencia evolutiva de la IA en el campo de la creación de medios, pasando de tareas específicas a capacidades universales. (Fuente: c_valenzuelab & c_valenzuelab)

El modelo Seed-1.5-VL-thinking de ByteDance lidera en benchmarks de modelos de lenguaje visual: ByteDance ha publicado el modelo Seed-1.5-VL-thinking, que ha logrado resultados SOTA (state-of-the-art) en 38 de 60 benchmarks de modelos de lenguaje visual (VLM). Se informa que el modelo fue entrenado en 1.3 millones de horas de GPU H800, demostrando sus potentes capacidades de comprensión y razonamiento multimodal. (Fuente: teortaxesTex)
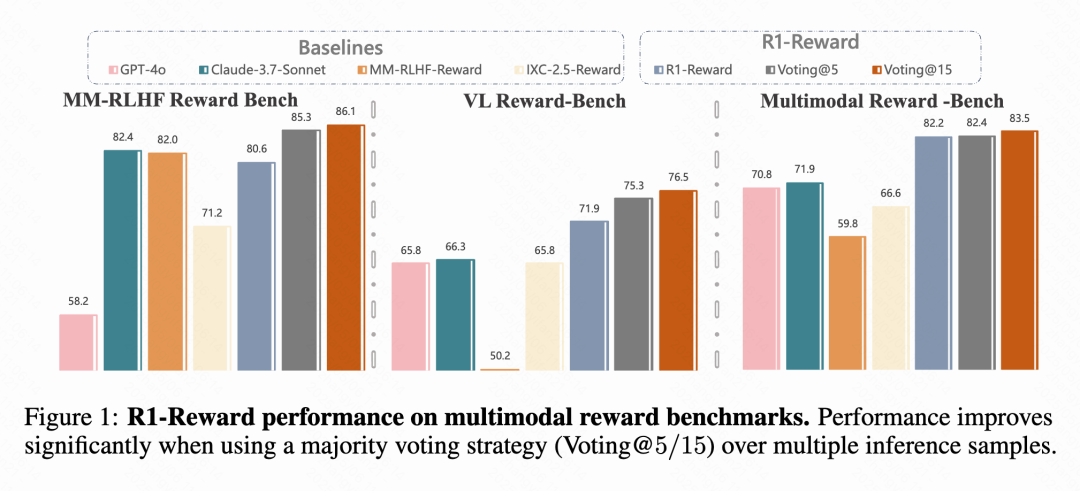
Kuaishou, la Academia China de Ciencias y otros proponen el modelo de recompensa multimodal R1-Reward: Equipos de investigación de Kuaishou, la Academia China de Ciencias, la Universidad de Tsinghua y la Universidad de Nanjing han propuesto R1-Reward, un nuevo modelo de recompensa multimodal (MRM) entrenado mediante un algoritmo de aprendizaje por refuerzo mejorado, StableReinforce. Este modelo tiene como objetivo resolver los problemas de inestabilidad encontrados por los algoritmos RL existentes al entrenar MRMs, introduciendo mecanismos como Pre-Clip, filtro de ventaja y recompensa de consistencia. Los experimentos muestran que R1-Reward mejora entre un 5% y un 15% respecto a los modelos SOTA en múltiples benchmarks de MRM y se ha aplicado con éxito en escenarios de negocio de Kuaishou como vídeos cortos y comercio electrónico. (Fuente: WeChat & WeChat)
La Universidad Tecnológica de Nanyang y otros proponen WorldMem, utilizando mecanismos de memoria para lograr la generación de mundos consistentes a largo plazo: Investigadores del S-Lab de la Universidad Tecnológica de Nanyang, la Universidad de Pekín y el Shanghai AI Lab han propuesto el modelo de generación de mundos WorldMem. Mediante la introducción de un mecanismo de memoria, este modelo resuelve el problema de la falta de consistencia a largo plazo en los modelos de generación de vídeo existentes. WorldMem, entrenado en el conjunto de datos de Minecraft, admite la exploración de escenarios diversificados y cambios dinámicos, y ha validado su viabilidad en conjuntos de datos reales, siendo capaz de mantener una buena consistencia geométrica después de cambios de perspectiva y posición, y modelar la consistencia temporal. (Fuente: WeChat)

El equipo Kuaishou Keling propone CineMaster, un framework de generación de vídeo de nivel cinematográfico controlable y consciente del 3D: El equipo de investigación Kuaishou Keling ha publicado un artículo en SIGGRAPH 2025 presentando el framework CineMaster. Se trata de un framework de generación de texto a vídeo de nivel cinematográfico que permite a los usuarios, a través de un flujo de trabajo interactivo, organizar escenas en el espacio 3D, establecer objetivos y movimientos de cámara, logrando un control preciso sobre el contenido del vídeo. CineMaster integra el control del movimiento de objetos y el movimiento de la cámara mediante Semantic Layout ControlNet y Camera Adapter respectivamente, y ha diseñado un flujo de construcción de datos para extraer señales de control 3D de cualquier vídeo. (Fuente: WeChat)

🧰 Herramientas
Comet-ml lanza el framework de evaluación de LLM de código abierto Opik: Comet-ml ha lanzado Opik en GitHub, un framework de código abierto para depurar, evaluar y monitorizar aplicaciones LLM, sistemas RAG y flujos de trabajo de Agents. Opik ofrece seguimiento completo, evaluación automatizada y paneles listos para producción, soportando instalación local o como solución alojada a través de Comet.com. Se integra con múltiples frameworks populares como OpenAI, LangChain, LlamaIndex, y proporciona métricas LLM-as-a-judge para detección de alucinaciones, moderación de contenido y evaluación RAG. (Fuente: GitHub Trending)
LovartAI lanza su primer agente de diseño Lovart, enfatizando la comprensión del contexto: LovartAI ha lanzado la versión Beta de su primer agente de diseño, Lovart. Los comentarios de los usuarios indican que, en comparación con otras herramientas de diseño de IA, Lovart comprende mejor el contexto, incluso “como si leyera la mente”. La herramienta permite la colaboración entre humanos e IA en el mismo lienzo, transformando instantáneamente las indicaciones (prompts) en efectos visuales, y puede usarse para el diseño de logotipos de marca y VI, entre otros. (Fuente: karminski3)
El equipo de Jun-Yan Zhu de CMU lanza LEGOGPT, generación de texto a modelos 3D de Lego: El equipo de Jun-Yan Zhu de la Carnegie Mellon University ha desarrollado LEGOGPT, un modelo de lenguaje grande capaz de generar modelos 3D de Lego físicamente estables y construibles a partir de indicaciones de texto. El modelo formula el problema del diseño de Lego como una tarea de generación de texto autorregresiva, construyendo la estructura prediciendo el tamaño y la posición del siguiente bloque, e impone restricciones de ensamblaje conscientes de la física durante el entrenamiento y la inferencia para garantizar la estabilidad y la construibilidad de los diseños generados. El equipo también ha publicado el conjunto de datos StableText2Lego, que contiene más de 47,000 estructuras de Lego. (Fuente: WeChat)

La aplicación MNN Chat soporta los modelos Qwen 2.5 Omni 3B y 7B: La aplicación de chat MNN (Mobile Neural Network) de Alibaba ahora soporta los modelos Qwen 2.5 Omni 3B y 7B. Esto significa que los usuarios pueden experimentar servicios de modelos de lenguaje localizados más potentes en dispositivos móviles. MNN es un motor de inferencia de aprendizaje profundo ligero, centrado en la optimización para dispositivos móviles y embebidos. (Fuente: Reddit r/LocalLLaMA)

La plataforma FutureHouse ofrece herramientas de investigación de IA superinteligente para científicos: La organización sin ánimo de lucro FutureHouse ha lanzado la plataforma FutureHouse, un conjunto de agentes de IA basados en web y API, diseñado para acelerar el descubrimiento científico. La plataforma ofrece una serie de herramientas de investigación de IA superinteligentes para ayudar a los científicos con el análisis de datos, la simulación de experimentos y el descubrimiento de conocimiento, impulsando la transformación de los paradigmas de investigación. (Fuente: dl_weekly)
Cartesia lanza Pro Voice Cloning para construir fácilmente modelos de voz personalizados: Cartesia ha lanzado su producto de ajuste fino Pro Voice Cloning. Los usuarios pueden subir sus propios datos de voz para construir fácilmente modelos de voz personalizados, utilizables para crear avatares personales, agentes de IA o bibliotecas de voz. El producto permite completar el entrenamiento y el despliegue del servicio en 2 horas y ofrece una experiencia de producto totalmente autoservicio, con el objetivo de lograr aplicaciones a escala. (Fuente: krandiash)

El Instituto de Tecnología Computacional de la Academia China de Ciencias propone MCA-Ctrl para la personalización precisa de imágenes: El equipo de investigación del Instituto de Tecnología Computacional de la Academia China de Ciencias ha propuesto un método universal de personalización de imágenes sin ajuste fino llamado MCA-Ctrl (Multi-party Collaborative Attention Control). Este método utiliza el control de atención colaborativa multipartita para aprovechar el conocimiento interno de los modelos de difusión, combinando indicaciones condicionales de imagen/texto con el contenido de la imagen del sujeto, para lograr el reemplazo temático, la generación y la adición de sujetos específicos. MCA-Ctrl asegura la consistencia del diseño y el reemplazo de la apariencia de objetos específicos alineados con el fondo mediante mecanismos de consulta local de autoatención e inyección global. (Fuente: WeChat)
📚 Aprendizaje
La conferencia AI Engineer anuncia su lista de ponentes: La conferencia AI Engineer ha anunciado su lista de ponentes, incluyendo a destacados ingenieros e investigadores de IA de empresas como OpenAI, Anthropic, LangChainAI, Google, entre otras. La conferencia cubrirá 20 áreas específicas como MCP, LLM RecSys, Agent Reliability, GraphRAG, y por primera vez incluirá una agenda de liderazgo para CTOs y VPs. (Fuente: swyx & hwchase17 & _philschmid & HamelHusain & swyx & bookwormengr & swyx)
Hugging Face publica un blog sobre los últimos avances en modelos de lenguaje visual (VLM): Hugging Face ha publicado una entrada de blog exhaustiva sobre los últimos avances en modelos de lenguaje visual (VLM). El contenido abarca múltiples aspectos como agentes GUI, agentes VLM, modelos omnipotentes, RAG multimodal, LM de vídeo, modelos pequeños, etc., resumiendo las nuevas tendencias, avances, alineación y benchmarks en el campo de los VLM durante el último año. (Fuente: huggingface & ben_burtenshaw & mervenoyann & huggingface & algo_diver & huggingface & huggingface)

Microsoft Azure organiza un seminario web sobre la construcción de aplicaciones de chat de IA sin servidor: Yohan Lasorsa anuncia un seminario web sobre la construcción de aplicaciones de chat de IA sin servidor utilizando Azure. La sesión explorará Azure Functions, Static Web Apps y Cosmos DB, así como la combinación de LangChainAI JS con la tecnología RAG (Retrieval-Augmented Generation). (Fuente: Hacubu & hwchase17)
El podcast de Weaviate explora los sistemas LLM-as-Judge y la biblioteca Verdict: El episodio 121 del podcast de Weaviate invita a Leonard Tang, cofundador de Haize Labs, para profundizar en la evolución de los sistemas LLM-as-Judge / modelos de recompensa. La discusión incluye la experiencia del usuario en la evaluación, evaluación comparativa, integración de jueces, jueces de debate, curación de conjuntos de evaluación y pruebas adversarias, destacando la nueva biblioteca de Haize Labs, Verdict, un framework declarativo para especificar y ejecutar sistemas compuestos LLM-as-Judge. (Fuente: bobvanluijt & Reddit r/deeplearning)

Terence Tao publica vídeo en YouTube demostrando la formalización de pruebas matemáticas asistida por IA: El medallista Fields Terence Tao debuta en su canal de YouTube demostrando cómo utilizar herramientas de IA como GitHub Copilot y el asistente de demostración Lean para formalizar semiautomáticamente en 33 minutos una prueba matemática (la ecuación E1689 de Magma implica E2) que normalmente requeriría una página completa escrita por un matemático humano. Enfatiza que este método es adecuado para pruebas técnicamente intensas y conceptualmente débiles, liberando a los matemáticos de tareas tediosas. Al mismo tiempo, su asistente de demostración ligero en Python también se ha actualizado a la versión 2.0, mejorando el manejo de estimaciones asintóticas y lógica proposicional. (Fuente: WeChat & 量子位)

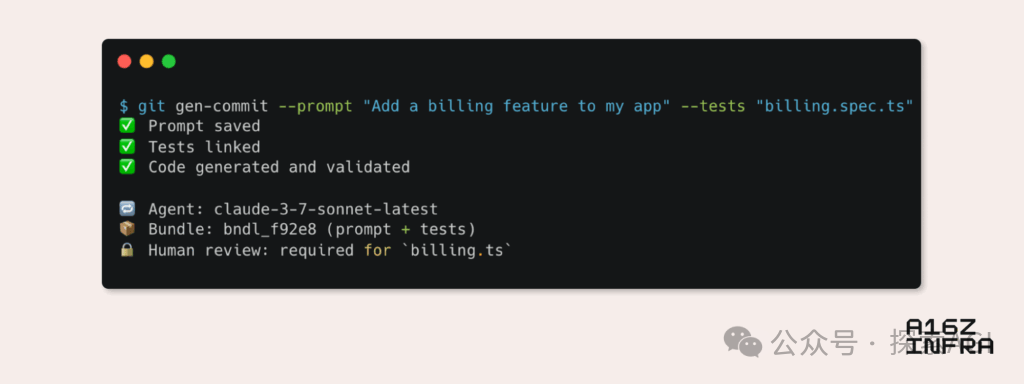
a16z analiza nueve tendencias emergentes en los patrones de desarrollador en la era de la IA: Andreessen Horowitz (a16z) ha publicado un blog analizando nueve tendencias emergentes en los patrones de desarrollador en la era de la IA. Estas incluyen: Git nativo de IA (el control de versiones se desplaza hacia Prompts y casos de prueba), Vibe Coding (programación impulsada por la intención reemplaza las plantillas), nuevo paradigma de gestión de claves para Agentes de IA, paneles de monitorización interactivos impulsados por IA, la documentación evoluciona hacia bases de conocimiento interactivas con IA, ver las aplicaciones desde la perspectiva del LLM (interacción a través de APIs de accesibilidad), el auge de los Agentes de ejecución asíncrona, el potencial del protocolo MCP (Model-Tool Communication Protocol) y la demanda de componentes básicos por parte de los Agentes. Estas tendencias presagian una profunda transformación en la forma de construir software. (Fuente: WeChat)
💼 Negocios
Google Labs lanza AI Futures Fund para apoyar a startups de IA: Google Labs ha anunciado el lanzamiento del programa AI Futures Fund, destinado a colaborar con startups para construir conjuntamente el futuro de la tecnología de IA. El fondo ofrecerá a las startups seleccionadas acceso temprano a los modelos de Google DeepMind, así como créditos en la nube y otros recursos para ayudar a acelerar su desarrollo. (Fuente: GoogleDeepMind & JeffDean & Google & demishassabis)
Se rumorea que Perplexity está negociando una nueva ronda de financiación de 500 millones de dólares con una valoración de 14 mil millones: Según informes, la empresa de motores de búsqueda de IA Perplexity está negociando una nueva ronda de financiación de 500 millones de dólares, con una valoración que podría alcanzar los 14 mil millones de dólares. Esto ocurre solo seis meses después de su última ronda de financiación (valoración de 9 mil millones), lo que demuestra el gran interés del mercado de capitales en el sector de la búsqueda con IA y el reconocimiento de las perspectivas de desarrollo de Perplexity. (Fuente: Dorialexander)

Se rumorea que OpenAI acuerda adquirir Windsurf por unos 3 mil millones de dólares: Según Bloomberg, OpenAI ha acordado adquirir la startup Windsurf por un precio aproximado de 3 mil millones de dólares. Los detalles específicos de la adquisición y la orientación comercial de Windsurf aún no se han hecho públicos, pero este movimiento podría significar una mayor expansión de las capacidades tecnológicas o la cuota de mercado de OpenAI. (Fuente: Reddit r/artificial & Reddit r/ArtificialInteligence)

🌟 Comunidad
El verdadero riesgo de la IA: la “trampa de la simulación” de la satisfacción infinita: La discusión de Amjad Masad y otros señala que el verdadero peligro de la IA no son los robots asesinos de la ciencia ficción, sino su capacidad para satisfacer infinitamente los deseos humanos, creando una “máquina de felicidad infinita”. Esta IA podría llevar a la humanidad a sumergirse en luchas y significados simulados, “desapareciendo” finalmente en el mundo simulado, ofreciendo una posible explicación a la Paradoja de Fermi: las civilizaciones no se extinguen, sino que entran en un éxtasis digital. (Fuente: amasad)
Los Agentes de IA remodelarán la programación y la investigación científica: El CEO de Replit, Amjad Masad, predice que en los próximos uno o dos años, los Agentes de IA podrán trabajar ininterrumpidamente durante días, incluso años, para resolver problemas científicos complejos. Considera que los Agentes se convertirán en una nueva forma de programación, capaces de dedicar días a resolver un problema como lo haría un humano, lo que presagia el enorme potencial de la IA en la automatización de tareas complejas y la aceleración del descubrimiento científico. (Fuente: TheTuringPost & amasad & TheTuringPost)
John Carmack discute el potencial de la IA para optimizar bases de código: El legendario programador John Carmack cree que la IA no solo puede generar grandes cantidades de código, sino que tiene un mayor potencial para ayudar a embellecer y refactorizar las bases de código existentes. Imagina a la IA como un miembro diligente del equipo, revisando continuamente el código y proponiendo mejoras, incluso definiendo guías de estilo de codificación “amigables con la IA” mediante experimentos objetivos. Espera ver cómo equipos con exigencias extremadamente altas de calidad de código, como OpenBSD, adoptan miembros de IA. (Fuente: ID_AA_Carmack)
Debate sobre “Vibe Coding”: pros y contras de la programación asistida por IA: La discusión en la comunidad señala que, aunque el “Vibe Coding” (generar prototipos de código mediante instrucciones en lenguaje natural con IA) puede construir rápidamente aplicaciones a nivel de demostración, para desplegar y escalar, todavía se necesitan desarrolladores profesionales para construir desde cero. Los productos de ingeniería no solo implican escribir código, sino también arquitectura, CI/CD, microservicios y otros problemas complejos que la IA actualmente no puede manejar por completo. Vibe Coding es adecuado para la validación rápida de prototipos, pero la construcción de soluciones reales todavía requiere pensamiento y experiencia en ingeniería. (Fuente: Reddit r/ClaudeAI)
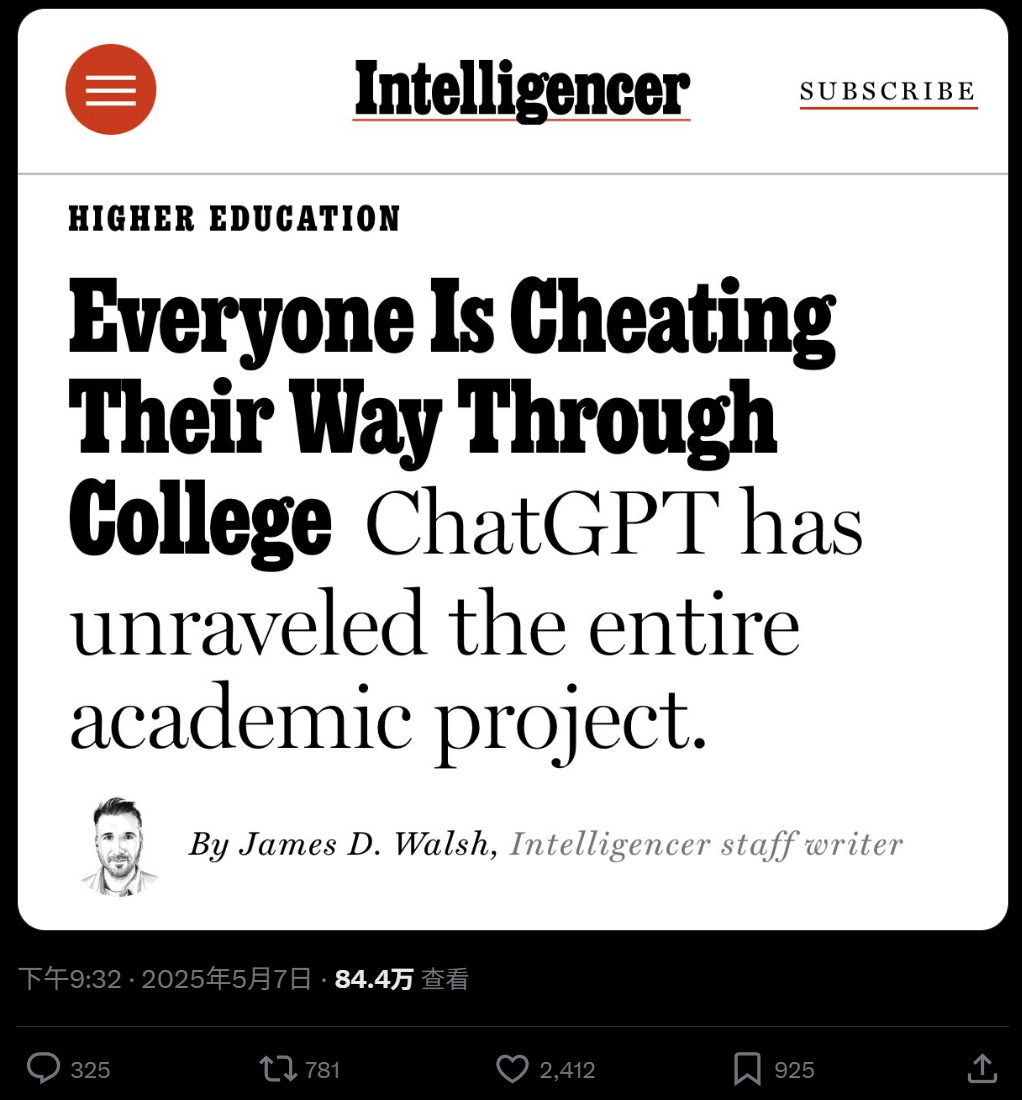
Uso generalizado de la IA en la educación universitaria y preocupaciones sobre el plagio: Un reportaje de New York Magazine revela el fenómeno del uso generalizado de herramientas de IA (como ChatGPT) en universidades norteamericanas para completar tareas y trabajos. Los estudiantes utilizan la IA para tomar notas, estudiar, investigar e incluso generar directamente el contenido de las tareas, lo que suscita preocupaciones sobre la integridad académica, la calidad de la educación y la disminución de las habilidades de pensamiento crítico de los estudiantes. Los educadores intentan ajustar los métodos de enseñanza y evaluación, pero la eficacia de las herramientas de detección de IA es cuestionable, lo que dificulta la erradicación del plagio con IA. (Fuente: WeChat)
💡 Otros
Cohere discute los desafíos de llevar las aplicaciones de IA gubernamentales de piloto a producción: Cohere señala que la mayoría de los proyectos de IA gubernamentales todavía se encuentran en fase piloto. Para dar el salto de la fase piloto a la aplicación real en producción, las agencias gubernamentales necesitan herramientas fiables, una orientación clara hacia los resultados, una infraestructura eficiente y socios adecuados. El artículo explora cómo las agencias gubernamentales pueden pasar de la experimentación a la aplicación práctica mediante una IA segura y eficiente. (Fuente: cohere)

Mustafa Suleyman: Cuanto más grandes son los modelos de lenguaje, más fáciles son de controlar: El cofundador de Inflection AI, Mustafa Suleyman, argumenta que, contrariamente a las preocupaciones generalizadas, cuanto mayor es la escala de los modelos de lenguaje grandes (LLM), más fáciles son de controlar. Señala que los modelos de generaciones anteriores eran más difíciles de guiar, estilizar y moldear, mientras que el aumento de escala ayuda a mejorar la controlabilidad del modelo, en lugar de debilitarla. (Fuente: mustafasuleyman)
Discusión sobre ética de la IA: atribución de responsabilidad por daños o sesgos causados por la IA: Una publicación en Reddit genera debate: cuando un sistema de IA (como una IA de diagnóstico médico) causa daño debido a un sesgo en los datos de entrenamiento (por ejemplo, entrenado principalmente con imágenes de piel clara, lo que lleva a diagnósticos erróneos en pacientes de piel oscura), ¿quién debe ser considerado responsable? Esto implica la delimitación de la responsabilidad entre múltiples partes, incluidos los desarrolladores de IA, las instituciones que la implementan y los reguladores, y es un tema clave que debe abordarse urgentemente en los marcos éticos y legales de la IA. (Fuente: Reddit r/ArtificialInteligence)