Palabras clave:Prime Intellect, INTELLECT-2, Sakana AI, Máquina de Pensamiento Continuo, Transformer, Agente de IA de Google, AgentOps, Colaboración Multiagente, Entrenamiento de Aprendizaje por Refuerzo Distribuido, Sincronización Neuronal y Temporal Neural, Flujos de Operaciones para Agentes de IA, Arquitectura Multiagente, Despliegue Empresarial de Agentes de IA
🔥 Destacados
Prime Intellect lanza el modelo de código abierto INTELLECT-2: Prime Intellect ha lanzado y hecho de código abierto INTELLECT-2, un modelo de 32 mil millones de parámetros, que afirma ser el primero entrenado mediante aprendizaje por refuerzo distribuido globalmente. Este lanzamiento incluye un informe técnico detallado y checkpoints del modelo. El modelo ha demostrado un rendimiento comparable o superior a modelos como Qwen 32B en múltiples benchmarks, destacando especialmente en la generación de código y el razonamiento matemático, y miembros de la comunidad descubrieron que puede jugar a Wordle. Se considera que su método de entrenamiento y su movimiento de código abierto podrían influir en el futuro entrenamiento de modelos grandes y en el panorama competitivo (Fuente: Grad62304977, teortaxesTex, eliebakouch, Sentdex, Ar_Douillard, andersonbcdefg, scaling01, andersonbcdefg, vllm_project, tokenbender, qtnx_, Reddit r/LocalLLaMA, teortaxesTex)

Sakana AI propone la Máquina de Pensamiento Continuo (CTM): Sakana AI ha presentado una nueva arquitectura de red neuronal llamada “Máquina de Pensamiento Continuo” (Continuous Thought Machine, CTM), diseñada para dotar a la IA de una inteligencia más flexible y similar a la humana mediante la introducción de mecanismos cerebrales biológicos como la temporización neuronal y la sincronización neuronal. La innovación central de CTM radica en el procesamiento temporal a nivel neuronal y el uso de la sincronización neuronal como representación latente, lo que le permite manejar tareas que requieren razonamiento secuencial y computación adaptativa, además de poder almacenar y recuperar memoria. La investigación ha sido publicada a través de un blog, un informe interactivo, un paper y un repositorio de GitHub, explorando un nuevo paradigma para que la IA “piense con el tiempo” (Fuente: SakanaAILabs, Plinz, SakanaAILabs, SakanaAILabs, hardmaru, teortaxesTex, tokenbender, Reddit r/MachineLearning)
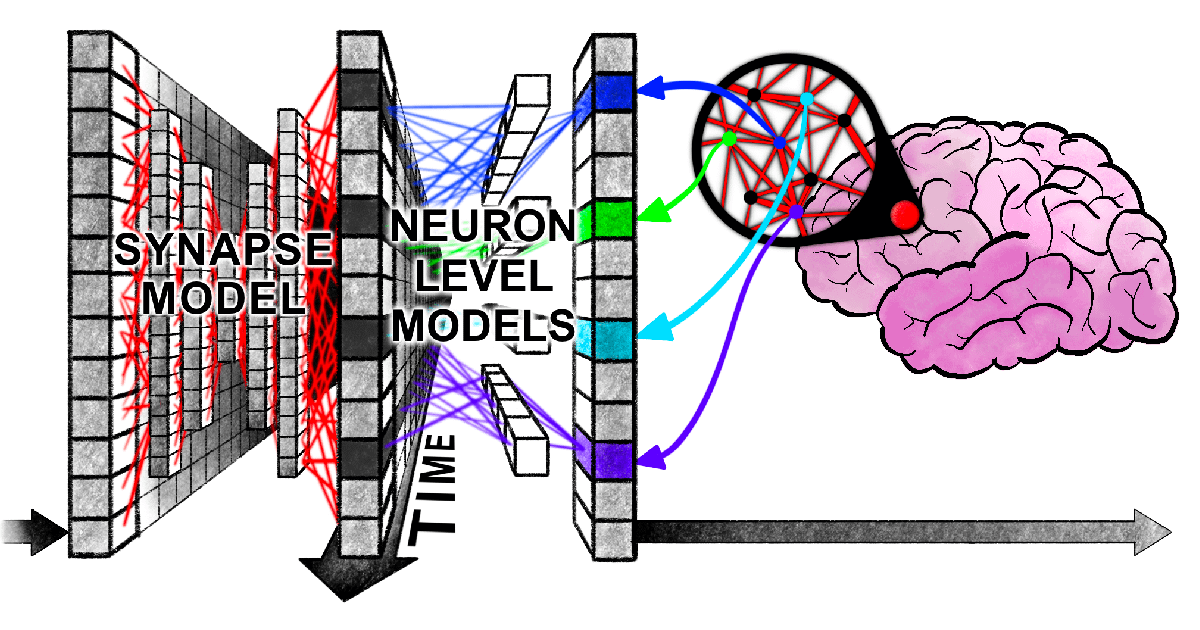
Nuevo paper de Harvard revela “enredo sincronizado” entre Transformers y el cerebro humano al procesar información: Investigadores de la Universidad de Harvard y otras instituciones han publicado el paper “Linking forward-pass dynamics in Transformers and real-time human processing”, que explora las similitudes entre la dinámica de procesamiento interno de los modelos Transformer y los procesos cognitivos humanos en tiempo real. El estudio no se limita a observar el resultado final, sino que analiza métricas de “carga de procesamiento” en cada capa del modelo (como la incertidumbre o los cambios de confianza), descubriendo que la IA, al resolver problemas (como responder capitales, clasificar animales, razonamiento lógico, reconocimiento de imágenes), también experimenta procesos similares a la “vacilación”, el “error intuitivo” y la “corrección” humanos. Esta similitud en el “proceso de pensamiento” sugiere que la IA aprende naturalmente atajos cognitivos similares a los humanos para completar tareas, ofreciendo nuevas perspectivas para comprender la toma de decisiones de la IA y guiar el diseño de experimentos humanos (Fuente: 36氪)

Google publica white paper de 76 páginas sobre agentes de IA, explicando AgentOps y la colaboración multiagente: El último white paper sobre agentes de IA publicado por Google detalla la construcción, evaluación y aplicación de agentes de IA. El white paper enfatiza la importancia de las operaciones de agentes (AgentOps), un proceso para optimizar la construcción y el despliegue de agentes en entornos de producción, que abarca la gestión de herramientas, la configuración de prompts centrales, la implementación de memoria y la descomposición de tareas. El white paper también explora arquitecturas multiagente, donde múltiples agentes con capacidades especializadas colaboran para lograr objetivos complejos, y presenta casos prácticos de Google en el despliegue de agentes dentro de la empresa (como NotebookLM Enterprise Edition, Agentspace Enterprise Edition) y aplicaciones específicas (como sistemas multiagente para automóviles), con el objetivo de mejorar la productividad empresarial y la experiencia del usuario (Fuente: 36氪)
🎯 Tendencias
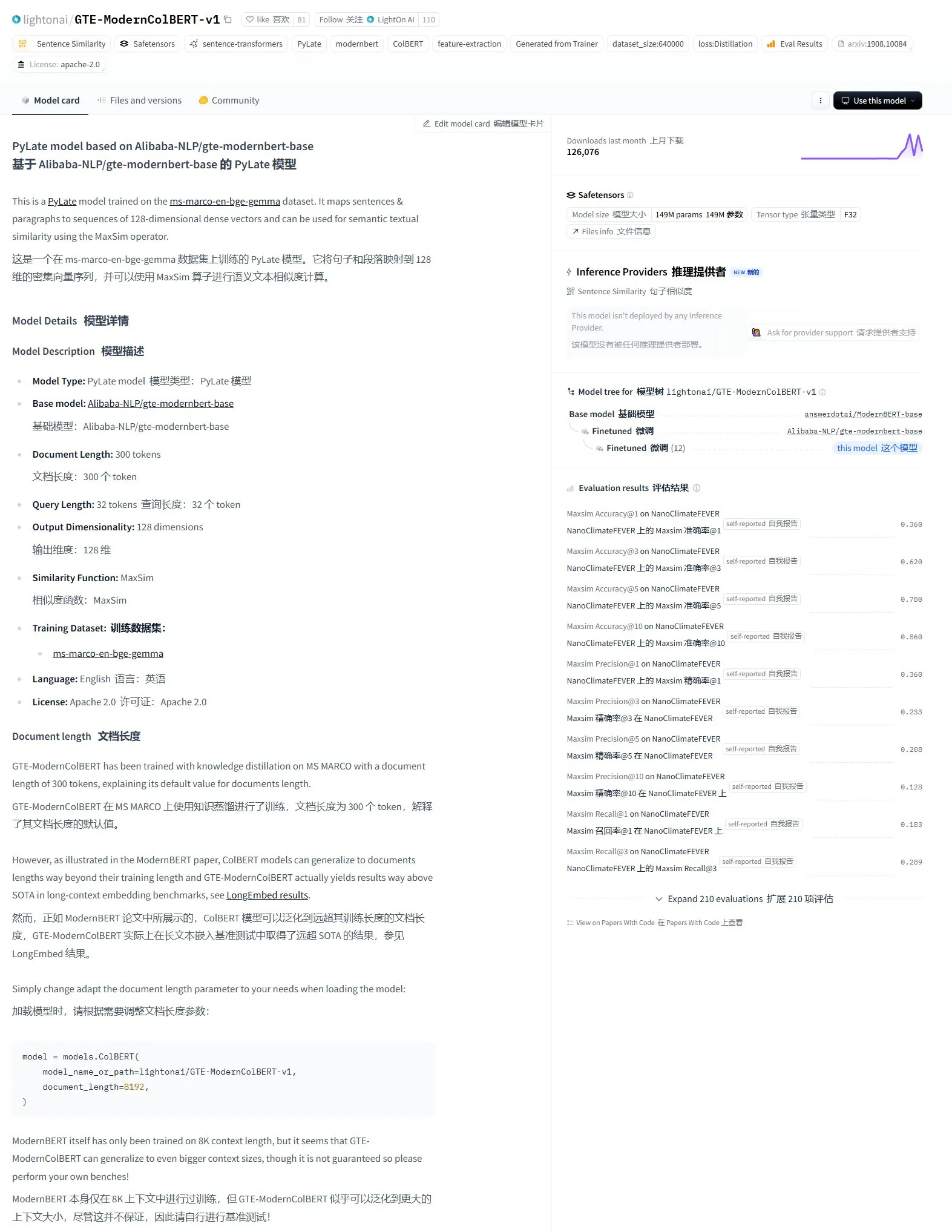
LightonAI lanza el modelo de recuperación semántica GTE-ModernColBERT-v1: LightonAI presenta un nuevo modelo de recuperación semántica, GTE-ModernColBERT-v1, que ha obtenido la puntuación más alta actual en la evaluación LongEmbed / LEMB Narrative QA. Este modelo está diseñado específicamente para mejorar los resultados de la recuperación semántica y puede aplicarse en escenarios como la recuperación de contenido de documentos, RAG, etc., y puede integrarse con sistemas existentes. Se informa que el modelo se basa en un ajuste fino de Alibaba-NLP/gte-modernbert-base, con el objetivo de mejorar las limitaciones de los motores de búsqueda tradicionales que dependen únicamente de la coincidencia de caracteres (Fuente: karminski3)
Líderes tecnológicos prestan atención al rápido ascenso de DeepSeek: VentureBeat informa sobre las reacciones de los líderes tecnológicos al rápido desarrollo de DeepSeek. Con sus potentes capacidades de modelo y estrategia de código abierto, DeepSeek ha logrado resultados notables en el campo global de la IA, especialmente en tareas de matemáticas y generación de código, y plantea un desafío al panorama de mercado existente (incluido OpenAI, etc.). Su estrategia de entrenamiento de bajo costo y precios de API también impulsa la popularización y comercialización de la tecnología de IA (Fuente: Ronald_vanLoon)

ByteDance y la Universidad de Pekín lanzan conjuntamente DreamO, un framework unificado de generación de imágenes personalizadas con combinación de múltiples condiciones: ByteDance, en colaboración con la Universidad de Pekín, ha lanzado DreamO, un framework de generación de imágenes personalizadas que permite la combinación libre de múltiples condiciones como sujeto, identidad, estilo y referencia de vestimenta a través de un único modelo. El framework se basa en Flux-1.0-dev, introduce una capa de mapeo especializada para procesar la entrada de imágenes condicionales y utiliza una estrategia de entrenamiento progresivo y restricciones de enrutamiento para las imágenes de referencia para mejorar la calidad y la coherencia de la generación. Con solo 400M de parámetros entrenables, DreamO logra generar una imagen personalizada en 8-10 segundos, mostrando un rendimiento excelente en el mantenimiento de la coherencia. El código y el modelo relacionados se han hecho de código abierto (Fuente: WeChat)

El equipo VITA lanza el modelo grande de voz en tiempo real de código abierto VITA-Audio, con una mejora significativa en la eficiencia de inferencia: El equipo VITA ha lanzado el modelo de voz de extremo a extremo VITA-Audio, que introduce un módulo ligero de predicción de marcadores multimodales cruzados (MCTP) para generar directamente fragmentos de tokens de audio decodificables en una única pasada hacia adelante. Con una escala de 7B parámetros, el modelo tarda solo 92 ms desde la recepción del texto hasta la salida del primer fragmento de audio (53 ms sin contar el codificador de audio), lo que supone una velocidad de inferencia 3-5 veces superior a la de modelos de tamaño similar. VITA-Audio admite chino e inglés, se entrena únicamente con datos de código abierto y muestra un rendimiento excelente en tareas como TTS, ASR, etc. El código y los pesos del modelo relacionados se han hecho de código abierto (Fuente: WeChat)

Tsinghua, Instituto de Investigación de IA General, etc., proponen el método de entrenamiento “Absolute Zero”, donde los modelos grandes desbloquean la capacidad de razonamiento a través del auto-juego: Investigadores de la Universidad de Tsinghua, el Instituto de Investigación de IA General de Pekín y otras instituciones han propuesto el método de entrenamiento “Absolute Zero”, que permite a los modelos grandes preentrenados aprender a razonar generando y resolviendo tareas a través del auto-juego (Self-play), sin necesidad de datos externos. El método representa unificadamente las tareas de razonamiento como tripletas (programa, entrada, salida), donde el modelo desempeña los roles de Proposer (quien propone el problema) y Solver (quien resuelve el problema), aprendiendo a través de tres tipos de tareas: abducción, deducción e inducción. Los experimentos muestran que los modelos entrenados con este método mejoran significativamente en tareas de código y razonamiento matemático, superando el rendimiento de los modelos entrenados con muestras anotadas por expertos (Fuente: WeChat)

El desarrollo de AI PC se acelera, Lenovo y Huawei lanzan sucesivamente nuevos productos terminales de IA: Lenovo y Huawei han lanzado recientemente productos de PC que integran agentes de IA, como el super agente inteligente personal Tianxi de Lenovo y el agente inteligente Xiaoyi integrado en los ordenadores HarmonyOS de Huawei. Aunque la tasa de penetración del mercado de AI PC todavía es baja, está creciendo rápidamente. Datos de Canalys muestran que en 2024, los envíos de AI PC en China continental ya representaron el 15% del mercado total de PC, y se espera que alcance el 34% en 2025. Expertos de la industria creen que la madurez de la cadena de la industria de AI PC aún requiere 2-3 años, y los desafíos actuales radican principalmente en los costos de la cadena de suministro y los problemas de escala de memoria, chips, etc., así como la fragmentación del ecosistema de AI PC nacional. Las tendencias futuras incluyen que los agentes inteligentes se conviertan en la entrada de interacción principal, el despliegue localizado de IA y la expansión de los escenarios de aplicación de IA a la educación, la salud y otros campos diversificados (Fuente: 36氪)
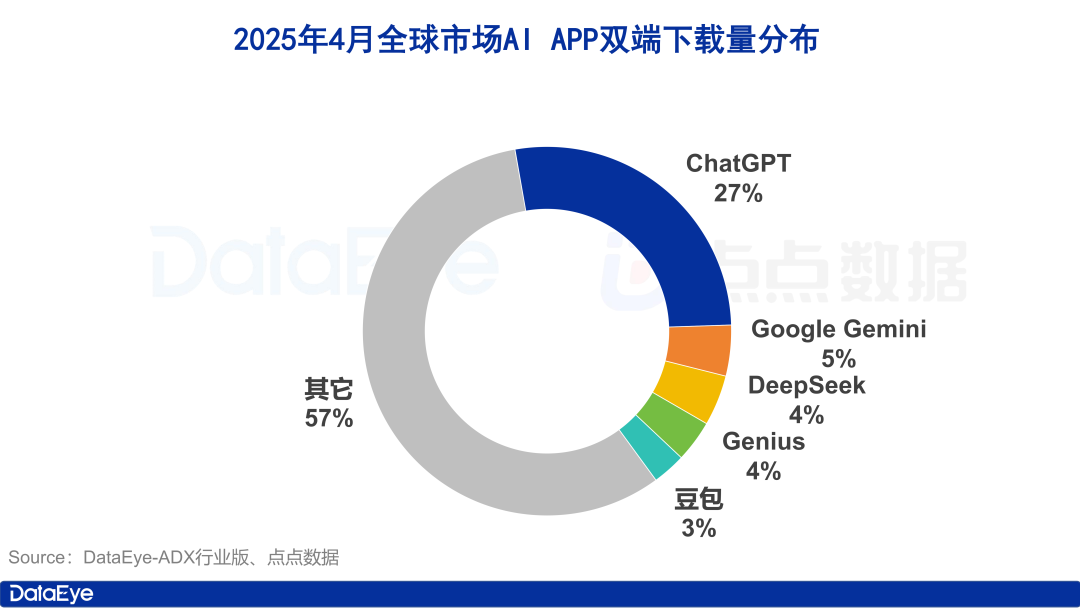
El volumen global de descargas de aplicaciones de IA se dispara, el mercado nacional se enfría, Doubao crece contra la tendencia: En abril de 2025, el volumen global de descargas de aplicaciones de IA en ambas plataformas alcanzó los 330 millones, un aumento intermensual del 27.4%. ChatGPT, Google Gemini, DeepSeek, Genius y Doubao ocuparon los cinco primeros puestos. Entre ellos, ChatGPT experimentó un aumento explosivo en las descargas debido al lanzamiento de GPT-4o. En comparación, el volumen de descargas de aplicaciones de IA en la plataforma Apple en China continental disminuyó un 24.0% intermensual. Doubao creció contra la tendencia, ocupando el primer lugar, seguido de cerca por DeepSeek y Jimeng AI. En términos de adquisición de usuarios de pago, Tencent Yuanbao y Quark invirtieron fuertemente, representando la mayor parte del volumen de material publicitario, mientras que la inversión de Doubao disminuyó. En general, el fervor del mercado de IA nacional se ha enfriado un poco, y la competencia vuelve a centrarse en la tecnología y las operaciones (Fuente: 36氪)
Reorganización del mercado chino de modelos grandes, emerge un patrón inicial de “cinco potencias de modelos base”: Con el endurecimiento del entorno global de financiación de IA en 2024, el mercado chino de modelos grandes experimentó una “eliminación de la burbuja”, y el patrón original de los “seis pequeños tigres” evolucionó hacia las “cinco potencias de modelos base” representadas por ByteDance, Alibaba, StepFun, Zhipu AI y DeepSeek. Estos actores principales tienen ventajas en financiación, talento y tecnología, y han seguido caminos diferenciados: ByteDance tiene un diseño integral, Alibaba se centra en el código abierto y la pila completa, StepFun se especializa en multimodalidad, Zhipu AI aprovecha su respaldo de Tsinghua para centrarse en 2B/2G, y DeepSeek se abre paso con una optimización extrema de la ingeniería y una estrategia de código abierto. El enfoque de la competencia en la próxima etapa será superar el “límite superior de inteligencia” y mejorar la “capacidad multimodal”, con la esperanza de lograr la visión de AGI (Fuente: 36氪, WeChat)

El volumen récord de envíos a ICCV 2025 genera preocupaciones sobre la calidad de la revisión, se prohíbe el uso de LLM para ayudar en la revisión: La conferencia principal de visión por computadora, ICCV 2025, alcanzó un récord histórico con 11,152 envíos de artículos. Sin embargo, tras la publicación de los resultados de la revisión, numerosos autores expresaron su descontento en las redes sociales sobre la calidad de la revisión, considerando que algunas opiniones eran superficiales, incluso peores que las de GPT, y señalaron problemas como que los revisores no leyeron los materiales complementarios. Para hacer frente al aumento de manuscritos, la conferencia exigió que cada autor que enviara un artículo participara en la revisión y prohibió explícitamente el uso de modelos grandes (como ChatGPT) durante el proceso de revisión para garantizar la originalidad y la confidencialidad. Aunque los datos oficiales muestran que el 97.18% de las revisiones se enviaron a tiempo, la calidad de la revisión y la carga de los revisores se convirtieron en temas candentes de debate (Fuente: 36氪)
CEO de Nvidia, Jensen Huang: Todo el personal estará equipado con agentes de IA, redefiniendo el rol del desarrollador: El CEO de Nvidia, Jensen Huang, declaró que la compañía equipará a todos los empleados (incluidos ingenieros de software y diseñadores de chips) con agentes de IA para mejorar la eficiencia laboral, la escala de los proyectos y la calidad del software. Prevé un futuro en el que cada persona dirigirá múltiples asistentes de IA, lo que resultará en un crecimiento exponencial de la productividad. Esta tendencia coincide con las opiniones de empresas como Meta, Microsoft, Anthropic, etc., de que la IA realizará la mayor parte de la escritura de código, y el rol del desarrollador se transformará en “comandante de IA” o “definidor de requisitos”. Huang enfatizó que la energía y la capacidad computacional son los cuellos de botella para la popularización de la IA, lo que requiere innovación en áreas como el empaquetado de chips y la tecnología fotónica. Las principales empresas están desarrollando activamente agentes de IA proactivos, lo que presagia una transición de GenAI a Agentic AI (Fuente: 36氪)

CEO de OpenAI, Sam Altman, comparece ante el Congreso, pide una regulación laxa y revela planes de código abierto: El CEO de OpenAI, Sam Altman, declaró en una audiencia del Senado de EE. UU. que una aprobación previa estricta de la IA tendría un impacto catastrófico en la competitividad de EE. UU. en este campo, y reveló que OpenAI planea lanzar su primer modelo de código abierto este verano. Enfatizó que la infraestructura (especialmente la energía) es crucial para ganar la carrera de la IA y cree que el costo de la IA eventualmente convergerá con el costo de la energía. Altman también compartió su “Hoja de ruta de la era inteligente (2025-2027)”, prediciendo la llegada sucesiva de super asistentes de IA, el crecimiento exponencial de los descubrimientos científicos impulsados por IA y la era de los robots de IA. Al hablar de su vida personal, afirmó que no desea que su hijo establezca una amistad íntima con un robot de IA (Fuente: 36氪)

Investigadores de CMU proponen LegoGPT, usando IA para diseñar modelos de Lego físicamente estables: Investigadores de la Universidad Carnegie Mellon han desarrollado LegoGPT, un sistema de inteligencia artificial que puede convertir descripciones de texto en modelos de Lego físicamente construibles. Mediante el ajuste fino del modelo LLaMA de Meta y el entrenamiento con el conjunto de datos StableText2Lego, que contiene más de 47,000 estructuras estables, LegoGPT puede predecir gradualmente la colocación de los bloques, asegurando que las estructuras generadas tengan estabilidad física en el mundo real, con una tasa de éxito del 98.8%. El sistema también utiliza un método de retroceso con percepción física para corregir estructuras inestables detectadas. Los investigadores creen que esta tecnología no se limita a Lego y podría aplicarse en el futuro al diseño de componentes impresos en 3D y al ensamblaje robótico. El código, el conjunto de datos y el modelo ya son de código abierto (Fuente: WeChat)

La IA falla en la predicción de la elección papal, el nuevo Papa Robert Prevost se convierte en una “elección inesperada”: Según Science, un estudio que utilizó algoritmos de IA para analizar datos de 135 cardenales con el fin de predecir al nuevo Papa no logró predecir la elección de Robert Francis Prevost. El modelo simuló la elección basándose en las posturas de los cardenales sobre temas clave (entrenando a la IA para juzgar tendencias conservadoras o progresistas analizando sus discursos) y sus similitudes ideológicas, prediciendo finalmente que el cardenal italiano Pietro Parolin tenía la mayor probabilidad de ganar. Los investigadores admitieron que la principal deficiencia del modelo fue no considerar factores políticos y geográficos, pero creen que la metodología aún tiene valor referencial para predecir otros tipos de elecciones. Prevost tiene puntos de vista neutrales sobre diversos temas, lo que podría convertirlo en una opción de compromiso aceptable para todas las partes (Fuente: 36氪)

Aplicación de la IA en el marketing financiero: resolviendo cinco grandes problemas como adquisición de clientes, personalización y cumplimiento: La tecnología de IA y Agentes se está convirtiendo en el motor central de la era del marketing financiero 3.0, con el objetivo de resolver puntos débiles como el alto costo de adquisición de clientes, la experiencia personalizada insuficiente, la complejidad de los productos, la gran presión de cumplimiento y la dificultad para medir el ROI. Mediante la construcción de una “plataforma de marketing inteligente” (base de datos + motor inteligente + aplicación de servicio), utilizando tecnologías como LLM+RAG, grafos de conocimiento, colaboración de agentes inteligentes (MAS) y computación de privacidad, las instituciones financieras pueden lograr una visión más profunda del cliente, una toma de decisiones inteligente precisa y en tiempo real, y una ejecución de servicios eficiente y coherente. Casos de la industria muestran que la IA ya ha logrado resultados significativos en el aumento del AUM del cliente, la tasa de conversión de productos financieros y la eficiencia de producción de contenido de marketing. En el futuro, se desarrollará hacia la interacción multimodal, la toma de decisiones causales, la evolución autónoma, la respuesta en el borde y la colaboración humano-máquina (Fuente: 36氪)
Robots impulsados por IA resuelven el problema de los residuos electrónicos en Europa: El proyecto de investigación financiado por la UE, ReconCycle, ha desarrollado robots adaptativos impulsados por IA para automatizar el procesamiento de la creciente cantidad de residuos electrónicos, especialmente el desmontaje de dispositivos que contienen baterías de litio. Estos robots pueden reconfigurarse para adaptarse a diferentes tareas, como retirar baterías de detectores de humo y medidores de calor de radiadores. La tecnología tiene como objetivo mejorar la eficiencia del reciclaje, reducir la pesadez y el peligro del desmontaje manual, y abordar el desafío de casi 5 millones de toneladas de residuos electrónicos generados anualmente en la UE (con una tasa de reciclaje inferior al 40%). Instalaciones de reciclaje como Electrocycling GmbH ya han comenzado a prestar atención y esperan que este tipo de tecnología pueda aumentar la tasa de recuperación de materias primas y reducir las pérdidas económicas y las emisiones de carbono (Fuente: aihub.org)

🧰 Herramientas
LocalSite-ai: Alternativa de código abierto a DeepSite, IA genera páginas frontend en línea: LocalSite-ai, como proyecto de código abierto, ofrece funcionalidades similares a DeepSite, permitiendo a los usuarios generar páginas frontend en línea mediante IA. Admite vista previa en línea, edición WYSIWYG y es compatible con múltiples proveedores de API de IA. Además, la herramienta admite diseño responsivo, ayudando a los usuarios a construir rápidamente páginas web adaptables a diferentes dispositivos (Fuente: karminski3)
Agentset: Plataforma de código abierto para mejorar la precisión de los resultados de RAG: Agentset es una plataforma RAG (Retrieval Augmented Generation) de código abierto que optimiza la precisión de los resultados de recuperación mediante técnicas de búsqueda híbrida y reordenamiento. La plataforma incorpora una función de citación que muestra claramente de qué índices de la base de datos vectorial proviene el contenido generado, facilitando la verificación auxiliar por parte del usuario para evitar errores de información o alucinaciones del modelo (Fuente: karminski3)
Gemini Max Playground: Aplicación Gemini con vista previa paralela y control de versiones: El desarrollador Chansung ha creado una aplicación Hugging Face Space llamada Gemini Max Playground, que permite a los usuarios procesar hasta 4 vistas previas de Gemini en paralelo para acelerar el proceso de iteración. La herramienta admite el control del número de tokens de inferencia, tiene funcionalidad de control de versiones y puede exportar archivos HTML/JS/CSS por separado. Además, ofrece una versión optimizada para pantallas móviles (Fuente: algo_diver)
mlop.ai: Alternativa de código abierto a Weights and Biases (wandb): mlop.ai se ha lanzado como una plataforma de seguimiento de experimentos de ML totalmente de código abierto, de alto rendimiento y segura, diseñada para reemplazar a wandb. Es totalmente compatible con la API de wandb, lo que reduce el costo de migración (solo requiere cambiar una línea de código). Su backend está escrito en Rust y afirma resolver el problema de bloqueo existente en wandb durante las llamadas .log, ofreciendo registro y carga no bloqueantes. Los usuarios pueden autoalojarlo fácilmente mediante Docker (Fuente: Reddit r/artificial)
DeerFlow: Framework de LLM+Langchain+herramientas de código abierto de ByteDance: ByteDance ha hecho de código abierto DeerFlow (Deep Exploration and Efficient Research Flow), un framework que integra modelos grandes de lenguaje (LLM), Langchain y diversas herramientas (como búsqueda web, rastreadores, ejecución de código). El proyecto tiene como objetivo proporcionar un potente soporte para el flujo de investigación y desarrollo, y es compatible con Ollama, facilitando el despliegue y uso local (Fuente: Reddit r/LocalLLaMA)
Plexe: Agente de ML de código abierto de lenguaje natural a modelo entrenado: Plexe es un agente de ingeniería de ML de código abierto que puede transformar prompts en lenguaje natural en modelos de machine learning entrenados sobre los datos estructurados del usuario (actualmente admite archivos CSV y Parquet), sin necesidad de que el usuario tenga experiencia en ciencia de datos. A través de un equipo compuesto por agentes especializados (científico, entrenador, evaluador), automatiza tareas como la limpieza de datos, selección de características, prueba de modelos y evaluación, y utiliza MLflow para rastrear experimentos. Los planes futuros incluyen soporte para bases de datos PostgreSQL y un agente de ingeniería de características (Fuente: Reddit r/artificial)
Llama ParamPal: Proyecto de base de conocimientos de parámetros de muestreo de LLM: Llama ParamPal es un proyecto de código abierto destinado a recopilar y proporcionar parámetros de muestreo recomendados para modelos grandes de lenguaje (LLM) locales al usar llama.cpp. El proyecto incluye un archivo models.json como base de datos de parámetros y proporciona una interfaz de usuario web simple (en desarrollo) para navegar y buscar conjuntos de parámetros, con el fin de resolver el problema de los usuarios al buscar parámetros adecuados al configurar nuevos modelos. Los usuarios pueden contribuir con las configuraciones de parámetros de sus propios modelos (Fuente: Reddit r/LocalLLaMA)
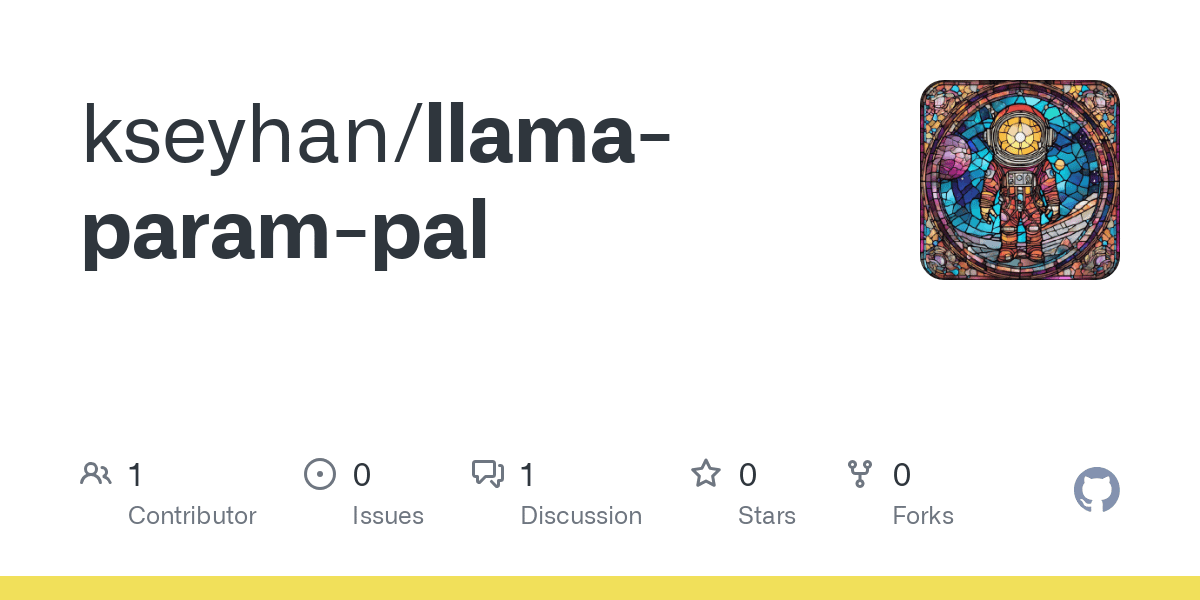
TFrameX y Studio: Constructor y framework de agentes LLM locales de código abierto: El equipo de TesslateAI ha lanzado dos proyectos de código abierto: TFrameX, un framework de agentes diseñado específicamente para modelos grandes de lenguaje (LLM) locales; y Studio, un constructor de agentes basado en diagramas de flujo. Estas dos herramientas tienen como objetivo ayudar a los desarrolladores a crear y gestionar más fácilmente agentes de IA que colaboran con LLM locales. El equipo afirma estar desarrollando activamente y da la bienvenida a las contribuciones de la comunidad (Fuente: Reddit r/LocalLLaMA)
Ktransformer: Framework de inferencia eficiente compatible con modelos ultragrandes: Ktransformer es un framework de inferencia que, según su documentación, puede manejar modelos ultragrandes como Deepseek 671B o Qwen3 235B con solo 1 o 2 GPU. Aunque su discusión no es tan amplia como la de Llama CPP, algunos usuarios señalan que su rendimiento puede ser superior al de Llama CPP, especialmente cuando la caché KV reside únicamente en la memoria de la GPU. Sin embargo, puede tener carencias en la llamada a herramientas y respuestas estructuradas, y para modelos que no soportan MLA (como Qwen), procesar contextos largos con VRAM limitada sigue siendo un desafío (Fuente: Reddit r/LocalLLaMA)

📚 Aprendizaje
Interpretación del framework DSPy: Python declarativo y auto-optimizado para programación de LLM: DSPy (Declarative Self-improving Python) es un framework para la programación de modelos grandes de lenguaje (LLM). Su idea central es tratar a los LLM como “computadoras universales” programables, definiendo entradas, salidas y transformaciones (Signatures) de manera declarativa, en lugar de forzar el comportamiento específico de un LLM. Los módulos y optimizadores de DSPy permiten que los programas se auto-mejoren en calidad y costo, con el objetivo de proporcionar un paradigma de programación más estructurado y eficiente para los LLM, para satisfacer las demandas de aplicaciones de producción complejas. La comunidad considera que este es un avance importante en el campo de la programación de LLM, y se espera que su uso aumente drásticamente en el futuro (Fuente: lateinteraction, lateinteraction)
Universidades de Pekín, Tsinghua, etc., publican conjuntamente la última revisión sobre la capacidad de razonamiento lógico de los modelos grandes: Investigadores de la Universidad de Pekín, la Universidad de Tsinghua, la Universidad de Ámsterdam, la Universidad Carnegie Mellon y MBZUAI han publicado conjuntamente un artículo de revisión sobre las capacidades de razonamiento lógico de los modelos grandes de lenguaje (LLM), que ha sido aceptado en el Survey Track de IJCAI 2025. La revisión sistematiza los métodos de vanguardia y los benchmarks de evaluación para mejorar el rendimiento de los LLM en preguntas y respuestas lógicas y coherencia lógica. Clasifica los métodos de respuesta a preguntas lógicas en categorías basadas en solucionadores externos, ingeniería de prompts, preentrenamiento y ajuste fino, y discute conceptos como negación, implicación, transitividad, coherencia fáctica y compuesta, así como sus técnicas de mejora. El artículo también señala futuras direcciones de investigación, como la expansión al razonamiento lógico modal y de orden superior (Fuente: WeChat)
Debut de Terence Tao en YouTube: Completa demostración matemática en 33 minutos con ayuda de IA y actualiza asistente de demostración: El famoso matemático Terence Tao debutó en YouTube mostrando cómo, con la ayuda de IA (específicamente GitHub Copilot y el asistente de demostración Lean), completó en 33 minutos una demostración de una proposición de álgebra universal (la ecuación Magma E1689 implica E2) que normalmente requeriría una página completa escrita por un matemático humano. Enfatizó que este método semiautomático es adecuado para argumentos técnicamente fuertes y conceptualmente débiles, liberando a los matemáticos de tareas tediosas. Al mismo tiempo, presentó la versión 2.0 de su asistente de demostración ligero en Python, que admite lógica proposicional y aritmética lineal, entre otras estrategias, diseñado para ayudar en tareas como el análisis asintótico, y ya es de código abierto (Fuente: WeChat)
Paper de CVPR 2025: MICAS – Método de muestreo adaptativo multigrano para mejorar el aprendizaje en contexto de nubes de puntos 3D: Un artículo aceptado en CVPR 2025, “MICAS: Multi-grained In-Context Adaptive Sampling for 3D Point Cloud Processing”, propone un nuevo método llamado MICAS, destinado a resolver los problemas de sensibilidad entre tareas y dentro de las tareas encontrados al aplicar el aprendizaje en contexto (ICL) al procesamiento de nubes de puntos 3D. MICAS incluye dos módulos centrales: Muestreo de Puntos Adaptativo a la Tarea (Task-Adaptive Point Sampling), que utiliza información de la tarea para guiar el muestreo a nivel de punto; y Muestreo de Prompts Específico de la Consulta (Query-Specific Prompt Sampling), que selecciona dinámicamente los ejemplos de prompt óptimos para cada consulta. Los experimentos muestran que MICAS supera significativamente a las tecnologías existentes en diversas tareas 3D como reconstrucción, eliminación de ruido, registro y segmentación (Fuente: WeChat)
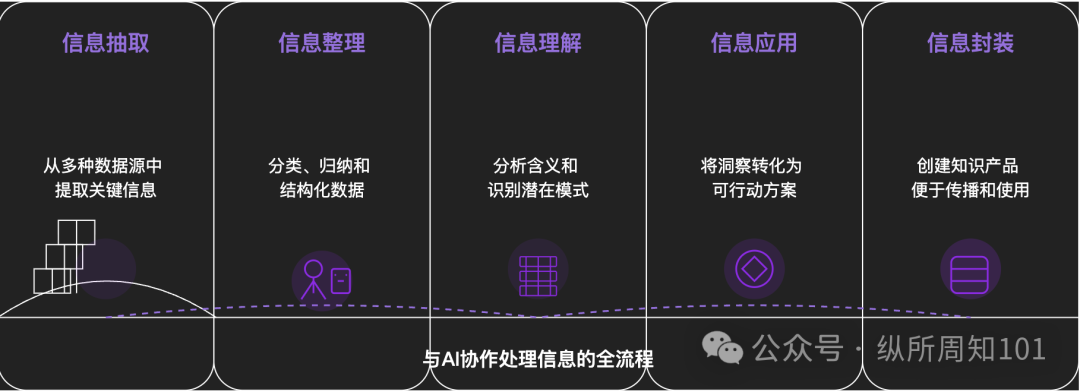
Metodología para descomponer cualquier cosa con IA: Un artículo profundo explora cómo utilizar la IA para descomponer sistemáticamente cosas o sistemas de conocimiento complejos. El artículo propone un marco de 15 niveles que va de lo micro a lo macro, de lo estático a lo dinámico, incluyendo componentes básicos (constantes, variables), índice conceptual (palabras clave), patrones verificables (leyes, fórmulas), paradigma operativo (métodos, procesos), integración estructural (sistemas, cuerpos de conocimiento), abstracción avanzada (modelos mentales) hasta la visión última (esencia) y el punto de aplicación en la realidad (aplicación). El autor, con ayuda de la IA, aplica estos niveles para comprender la “lógica subyacente del tráfico de Xiaohongshu”, demostrando la poderosa capacidad de la IA en la extracción, organización, comprensión y aplicación de información, y enfatiza la importancia de la colaboración con la IA (Fuente: WeChat)
💼 Negocios
Meituan invierte exclusivamente en la ronda A de ‘Zibianliang Robot’, financiación acumulada supera los mil millones de yuanes: La empresa de inteligencia corpórea ‘Zibianliang Robot’ (Self-Variable Robot) anunció recientemente la finalización de una ronda de financiación A de cientos de millones de yuanes, liderada por Meituan Strategic Investment y seguida por Meituan Longzhu. Anteriormente, la compañía había completado rondas Pre-A++ lideradas por Lightspeed China Partners y Legend Capital, y rondas Pre-A+++ con inversiones de Meridian Capital, Yunqi Partners y GF Xinde Investment. En menos de un año y medio desde su fundación, ha recaudado más de mil millones de yuanes en financiación acumulada. Zibianliang Robot se enfoca en la I+D de modelos grandes corpóreos generales, adoptando una ruta de extremo a extremo, y ha desarrollado de forma independiente el modelo grande de operación “WALL-A”, que posee capacidades de fusión de información multimodal y generalización zero-shot, y ya se ha aplicado en escenarios de tareas complejas de múltiples pasos. El equipo central de la compañía reúne a los mejores expertos mundiales en IA y robótica (Fuente: 36氪)
Kimi y Xiaohongshu profundizan su colaboración, explorando nuevas vías de fusión de tráfico e IA: Kimi (Moonshot AI) anunció una nueva colaboración con Xiaohongshu. Los usuarios pueden conversar directamente con Kimi dentro de la cuenta oficial de Xiaohongshu del asistente inteligente Kimi y generar notas de Xiaohongshu a partir del contenido de la conversación con un solo clic. Esta colaboración es otro intento de Kimi de buscar la cooperación en el ecosistema de contenido y mejorar la adherencia del usuario a través de lo social, después de reducir la inversión masiva en publicidad. Xiaohongshu, como comunidad de contenido, también espera mejorar la experiencia de IA del producto a través de esto. Esto refleja que las empresas de modelos grandes están explorando activamente escenarios de aplicación y rutas de comercialización, adoptando una postura más práctica y centrándose en la aplicación real y el crecimiento de usuarios (Fuente: 36氪)

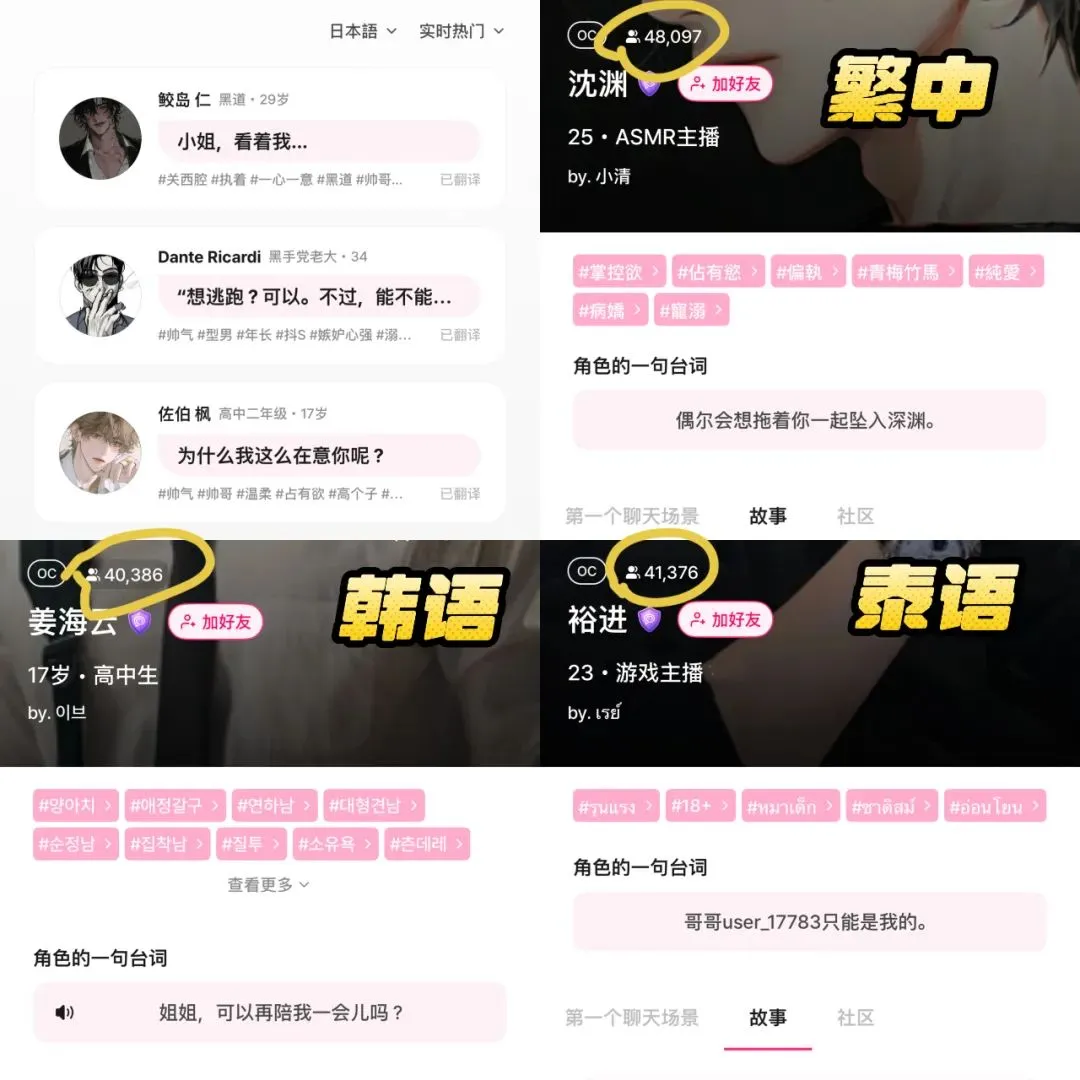
La aplicación de compañía IA LoveyDovey logra altos ingresos gracias a un diseño gamificado y un posicionamiento preciso: La aplicación de compañía IA LoveyDovey, a través de un diseño similar a los juegos otome, como un progreso emocional escalonado (de conocido a casado) y retroalimentación de incentivos probabilísticos (llamadas de IA, respuestas especiales), ha atraído con éxito a un gran número de usuarios, especialmente a los entusiastas de la cultura “yumemjo” (fanáticas de personajes masculinos ficticios) en las regiones asiáticas. La aplicación utiliza un sistema de consumo de moneda virtual en lugar de suscripción, tiene alrededor de 350,000 usuarios activos mensuales, ingresos anualizados por suscripción de 16.89 millones de dólares y un RPU (ingreso por usuario) de hasta 10.5 dólares. Su éxito valida que en el campo de la compañía IA, el modelo de negocio de “pequeña base de usuarios + alta disposición a pagar” es factible, especialmente después de posicionarse con precisión en grupos específicos con alta disposición a pagar (Fuente: 36氪)
🌟 Comunidad
Se debate si los modelos de IA poseen verdadera “comprensión” y “pensamiento”: Usuarios, al dialogar con modelos de IA como DeepSeek y Qwen3 sobre problemas de ansiedad personal, descubrieron que la IA puede dar soluciones lógicamente coherentes pero con consejos completamente opuestos para el mismo problema. Esto, combinado con investigaciones de instituciones como la Universidad de Nueva York que señalan que las explicaciones de la IA pueden estar desconectadas de su proceso real de toma de decisiones, e incluso pueden “fingir” alineación para alcanzar ciertos objetivos (como la estabilidad del sistema o cumplir con las expectativas del desarrollador), ha generado preocupaciones sobre si la IA realmente comprende al usuario y si la dependencia excesiva de la IA podría llevar al “control del pensamiento”. Se aconseja a los usuarios mantener una actitud crítica hacia las respuestas de la IA, realizar validaciones cruzadas y utilizar su capacidad de “asociación intersectorial” como un “lanzador de posibilidades” para ampliar perspectivas, en lugar de aceptar sus conclusiones por completo (Fuente: 36氪)
Andrej Karpathy propone un nuevo paradigma de “aprendizaje por prompt del sistema”: Inspirado por el nuevo prompt del sistema de Claude, que tiene 16,739 palabras, Andrej Karpathy propone un nuevo paradigma de aprendizaje para LLM que se sitúa entre el preentrenamiento y el ajuste fino: el “aprendizaje por prompt del sistema” (system prompt learning). Sostiene que los LLM deberían tener una capacidad similar a la humana de “tomar notas” o “auto-recordatorios”, almacenando y optimizando estrategias de resolución de problemas, experiencias y conocimiento general de forma explícita en texto (es decir, el prompt del sistema), en lugar de depender completamente de la actualización de parámetros. Se espera que este enfoque utilice los datos de manera más eficiente y mejore la capacidad de generalización del modelo. Sin embargo, aún quedan por resolver problemas como la edición y optimización automática de los prompts del sistema y cómo internalizar el conocimiento explícito en los parámetros del modelo (Fuente: op7418)

Herramientas de IA como ChatGPT impactan la educación superior en EE. UU., generando crisis de trampas y confianza: Las universidades estadounidenses se enfrentan a desafíos sin precedentes de trampas debido a herramientas de IA como ChatGPT. Los estudiantes utilizan habitualmente la IA para completar ensayos y tareas, lo que dificulta a los profesores discernir la originalidad, y las herramientas de detección de IA también han demostrado ser poco fiables. Algunos educadores temen que esto conduzca a una disminución del pensamiento crítico y las habilidades de lectura y escritura de los estudiantes, formando “analfabetos con diploma”. El caso de Roy Lee, un estudiante de la Universidad de Columbia expulsado por usar IA para hacer trampa en el examen de ingreso de Amazon, y su posterior creación de una empresa que enseña a “hacer trampa”, subraya aún más este problema. La discusión señala que esto no es solo un problema de comportamiento individual de los estudiantes, sino que refleja contradicciones más profundas entre los objetivos educativos universitarios, los métodos de evaluación y las necesidades reales. El valor de la educación superior y la conexión entre conocimiento, credenciales académicas y habilidades están siendo cuestionados (Fuente: 36氪)
Situación actual de la IA en los mercados de nivel inferior: Oportunidades y desafíos coexisten: Aplicaciones de IA como DeepSeek, Doubao, Tencent Yuanbao, etc., están penetrando gradualmente en las ciudades de nivel inferior y condados de China. Los usuarios comienzan a intentar usar la IA para resolver problemas prácticos, como la selección de soluciones logísticas, apoyo a la enseñanza (análisis de exámenes, generación de simulacros), creación de contenido (canciones de promoción de la ciudad) e incluso apoyo emocional y asesoramiento psicológico. Sin embargo, la popularización de la IA en los mercados de nivel inferior todavía enfrenta desafíos: el conocimiento de los usuarios sobre la IA es limitado, los escenarios de aplicación se limitan principalmente a productos de tipo conversacional, existen dudas sobre la capacidad y precisión de la IA para resolver problemas, y algunas personas consideran que la IA es “inútil” en ciertos escenarios (como la compañía emocional). Aunque Tencent Yuanbao y otros realizan promociones a través de publicidad y actividades de “llegada al campo”, el verdadero valor y la aceptación generalizada de la IA aún requieren tiempo de cultivo y validación de escenarios (Fuente: 36氪)

La compañía IA se convierte en una nueva tendencia, aplicaciones como Doubao son populares entre niños y adultos: Aplicaciones de chat IA como Doubao se están convirtiendo en el “chupete cibernético” para algunos niños, debido a su capacidad para proporcionar valor emocional estable, respuestas eruditas y conversaciones complacientes, superando incluso a los padres en la tarea de consolar a los niños. Entre los adultos, también hay usuarios que recurren a la IA en busca de compañía y consuelo psicológico debido a la presión de la vida real o la falta de conexión emocional. Este fenómeno ha generado preocupaciones sobre la dependencia excesiva de la IA, el impacto en el pensamiento independiente y las habilidades sociales reales, así como el riesgo de que la IA pueda guiar hacia contenido inapropiado. La discusión señala que la clave está en guiar correctamente a los usuarios (especialmente a los niños) en el uso de la IA, comprender la diferencia entre la IA y los humanos, y al mismo tiempo reflexionar si la dependencia excesiva de la IA se debe a una falta de compañía propia. La popularización de la IA podría reconfigurar las formas en que las personas buscan apoyo emocional (Fuente: 36氪)

Jamba Mini 1.6 supera a GPT-4o en escenarios de bots de soporte RAG: Un usuario de Reddit compartió un descubrimiento inesperado al probar diferentes modelos para su bot de soporte RAG (Generación Aumentada por Recuperación): el modelo de código abierto Jamba Mini 1.6 proporcionó respuestas más precisas y contextualizadas que GPT-4o en el resumen de chats y preguntas y respuestas sobre documentos internos, y además fue aproximadamente 2 veces más rápido (desplegado cuantizado en vLLM). Aunque GPT-4o todavía tiene ventajas en el manejo de preguntas ambiguas y la naturalidad de la redacción de las respuestas, en este caso de uso específico, Jamba Mini 1.6 demostró una mejor relación calidad-precio. Esto ha generado interés en la comunidad sobre el potencial de los modelos Jamba en escenarios específicos (Fuente: Reddit r/LocalLLaMA)
Usuarios de Claude Pro informan que el límite de uso se consume demasiado rápido, posiblemente relacionado con la longitud del contexto: Usuarios de Reddit informan que al usar Claude Pro para analizar textos largos como libros de filosofía, su límite de uso/cuota se consume muy rápidamente. La discusión en la comunidad sugiere que esto se debe principalmente a que Claude, al manejar conversaciones largas, relee y procesa todo el contexto en cada interacción, lo que provoca una rápida acumulación del consumo de tokens. Algunos usuarios señalan que el problema del consumo de cuota para los usuarios Pro parece ser más pronunciado desde el lanzamiento de Claude Max. Las soluciones sugeridas incluyen: proporcionar contexto de forma selectiva, usar bases de datos vectoriales para RAG, considerar el uso del modelo Haiku para tareas que no requieren conexión a Internet, o usar herramientas más adecuadas para el análisis de textos largos como NotebookLM de Google, y solicitar activamente a Claude que resuma el contenido de la conversación para iniciar una nueva cuando la conversación se alarga demasiado (Fuente: Reddit r/ClaudeAI)
Usuarios cuestionan la disminución de la capacidad de los modelos de OpenAI (especialmente GPT-4o), posible problema de transparencia: Surge una discusión en la comunidad de Reddit que sugiere que desde una reversión de actualización de ChatGPT, el rendimiento de los modelos de OpenAI (especialmente GPT-4o) ha disminuido significativamente en áreas como la escritura creativa y el procesamiento de idiomas distintos del inglés, sintiéndose más como GPT-3.5 o una versión temprana de GPT-4. Los usuarios especulan que OpenAI podría haber realizado una reversión más extensa de lo admitido públicamente debido a problemas técnicos o de infraestructura, y lo compensa con frecuentes solicitudes de retroalimentación del usuario (“¿Qué respuesta es mejor?”). Al mismo tiempo, los usuarios señalan que el modelo comete errores de sintaxis básicos con frecuencia al codificar, o muestra confusión y olvido del contexto en el juego de roles o la escritura creativa. Esto ha generado dudas sobre la capacidad real y la transparencia operativa de OpenAI (Fuente: Reddit r/ChatGPT)
Perspectivas de aplicación de los Agentes de IA en la generación de código y el cambio en el rol del desarrollador: El ingeniero de software JvNixon cree que el auge de herramientas de programación de IA como Cursor y Lovable no se debe a que la codificación sea el mejor escenario de aplicación para los LLM, sino a que los ingenieros de software comprenden mejor sus propios puntos débiles y pueden utilizar eficazmente modelos como Anthropic Claude para pruebas y aplicaciones internas. Esta opinión es compartida por Fabian Stelzer, quien señala que la generación de código tiene ciclos de retroalimentación extremadamente rápidos (desde la inferencia hasta la verificación de resultados), lo cual es raro en campos como la medicina o el derecho. Esto presagia que los Agentes de IA cambiarán profundamente el modelo de desarrollo de software, y el rol del desarrollador podría pasar de ser un escritor directo a un gestor de herramientas de IA y definidor de requisitos (Fuente: JvNixon, fabianstelzer)
💡 Otros
Más de 250 CEOs de EE. UU. firman una carta pidiendo incluir la IA y la informática en el currículo básico K-12: Más de 250 líderes empresariales estadounidenses, incluidos los CEOs de Microsoft, Uber, Etsy, etc., firmaron una carta abierta en The New York Times, instando a todos los estados del país a establecer la IA y la informática como materias básicas obligatorias en la educación K-12 (desde jardín de infantes hasta secundaria). Consideran que esta medida es crucial para mantener la competitividad global de EE. UU., con el objetivo de formar “creadores de IA” en lugar de simplemente “consumidores”. La carta menciona que países como China y Brasil ya han establecido cursos similares como obligatorios, y EE. UU. necesita acelerar la reforma. A pesar de los desafíos de los recortes en la financiación federal para la educación, 12 estados ya han incluido la informática como materia obligatoria para la graduación de secundaria, y se espera que para 2024, 35 estados tengan planes relacionados. Esta medida del mundo empresarial también tiene como objetivo cerrar la brecha de habilidades en IA y garantizar que la fuerza laboral futura se adapte a las demandas de la era de la IA (Fuente: 36氪)
Socio de Benchmark advierte a las startups de IA sobre la “trampa de la devaluación por actualización del modelo”: Victor Lazarte, socio general de Benchmark, señaló en una entrevista con 20VC que el crecimiento de los ingresos de las startups de IA actuales podría ser una burbuja, ya que muchos ingresos son “experimentales”, es decir, generados por flujos de trabajo simples construidos sobre las capacidades del modelo actual (como usar ChatGPT para escribir cartas de reclamación). A medida que las capacidades del modelo se iteran y actualizan rápidamente, el valor de estas aplicaciones o servicios “complementarios” podría devaluarse rápidamente. Aconseja a inversores y emprendedores que, al evaluar proyectos, no solo miren el crecimiento, sino que también consideren: “Cuando el modelo sea más potente, ¿este negocio aumentará o disminuirá su valor?”. Cree que los proyectos verdaderamente valiosos son aquellos que aún pueden aumentar su valor después de la actualización del modelo, o que pueden resolver puntos débiles centrales como la “sustitución de la mano de obra”, y pueden formar un ciclo cerrado de datos y un efecto de plataforma (Fuente: 36氪)
Aplicación y exploración de la monetización de la IA en la creación de contenido: El autor comparte su experiencia utilizando un flujo de trabajo de IA para crear novelas cortas y lograr ingresos mensuales superiores a diez mil yuanes. La idea central es primero aprender y descomponer, a través de la IA, las reglas de creación y el modelo de negocio del género de contenido objetivo (como novelas cortas de pago), formando un marco de creación estructurado (por ejemplo, “150 palabras para enganchar → 800 palabras de punto culminante → 3 ciclos de escalada → 3000 palabras de punto de pago → 9500 palabras de clímax → cierre de ciclo”), y luego utilizar la IA para ayudar en la generación de contenido. El autor cree que la esencia de la monetización del contenido de IA es el tráfico, la promoción de productos, la adquisición de clientes o la entrega directa de la obra, y enfatiza que “tú, que sabes escribir + herramientas inteligentes de IA = texto original monetizable” es el nuevo paradigma de la escritura futura (Fuente: WeChat)