
Palabras clave:Seguridad de IA, Ética de la inteligencia artificial, Agentes de IA, Generación 3D, Modelos de código, Evaluación de riesgos de IA, Comprensión de video Gemini 2.5 Pro, Generación 3D AssetGen 2.0, Modelo de código Seed-Coder, Operaciones de agentes (AgentOps)
🔥 Enfoque
Preocupación por los riesgos de seguridad de la IA, expertos instan a evaluar el riesgo inspirándose en la experiencia de seguridad nuclear: La preocupación de la comunidad internacional por los riesgos potenciales de la inteligencia artificial aumenta día a día. Algunos expertos (como Max Tegmark) instan a las empresas de IA a que, antes de lanzar sistemas de IA peligrosos, emulen los métodos de cálculo de seguridad de Robert Oppenheimer durante la primera prueba nuclear, evaluando rigurosamente la probabilidad de que la inteligencia artificial se descontrole (constante de Compton). Esta medida tiene como objetivo formar un consenso en la industria, impulsar el establecimiento de un mecanismo global de seguridad de la IA y prevenir las consecuencias catastróficas que podría traer una superinteligencia. (Fuente: Reddit r/artificial, Reddit r/ArtificialInteligence)

El nuevo Papa Francisco (alias Leo XIV) presta gran atención a los cambios sociales provocados por la IA: El recién elegido Papa Francisco (conocido como Leo XIV) ha identificado la inteligencia artificial como uno de los principales desafíos que enfrenta la humanidad. Eligió “Leo” como su nombre papal, en parte debido a los nuevos problemas sociales impulsados por la IA y la revolución industrial, lo que evoca la respuesta histórica del Papa León XIII a la primera Revolución Industrial. El Papa enfatiza que la IA plantea desafíos para mantener la “dignidad humana, la justicia y el trabajo”, y planea publicar en el futuro importantes documentos sobre la ética de la IA, demostrando la profunda preocupación de los líderes religiosos por la ética tecnológica de la IA y su impacto social. (Fuente: Reddit r/artificial, AymericRoucher, AravSrinivas, Reddit r/ArtificialInteligence)

Google publica un white paper de 76 páginas sobre agentes de IA, explicando AgentOps y futuras aplicaciones: Google ha publicado un white paper de 76 páginas sobre agentes de IA, que detalla la construcción, evaluación y aplicación de agentes inteligentes. El white paper enfatiza la importancia de las operaciones de agentes (AgentOps), como una rama de las operaciones de IA generativa. AgentOps se centra en la gestión de herramientas, la configuración de prompts centrales, las funciones de memoria y la descomposición de tareas necesarias para el funcionamiento eficiente de los agentes. El white paper también explora arquitecturas de colaboración multiagente, donde diferentes agentes desempeñan roles como planificación, recuperación, ejecución y evaluación para completar tareas complejas conjuntamente, y anticipa las perspectivas de aplicación de los agentes en empresas para ayudar a los empleados y automatizar tareas de backend, como NotebookLM Enterprise Edition y Agentspace. (Fuente: WeChat)

Meta lanza AssetGen 2.0: generación de activos 3D de alta calidad a partir de texto/imágenes: Meta ha lanzado su último modelo de IA fundamental para 3D, AssetGen 2.0, capaz de crear activos 3D de alta calidad a partir de prompts de texto e imágenes. AssetGen 2.0 incluye dos submodelos: uno para generar mallas 3D, que utiliza un modelo de difusión 3D de una sola etapa para mejorar los detalles y la fidelidad; y otro modelo, TextureGen, para generar texturas, introduciendo métodos para mejorar la consistencia de la vista, la reparación de texturas y una mayor resolución de textura. Esta tecnología ya se utiliza internamente en Meta para crear mundos 3D y se planea extenderla a los creadores de Horizon a finales de este año. (Fuente: Reddit r/artificial)

🎯 Tendencias
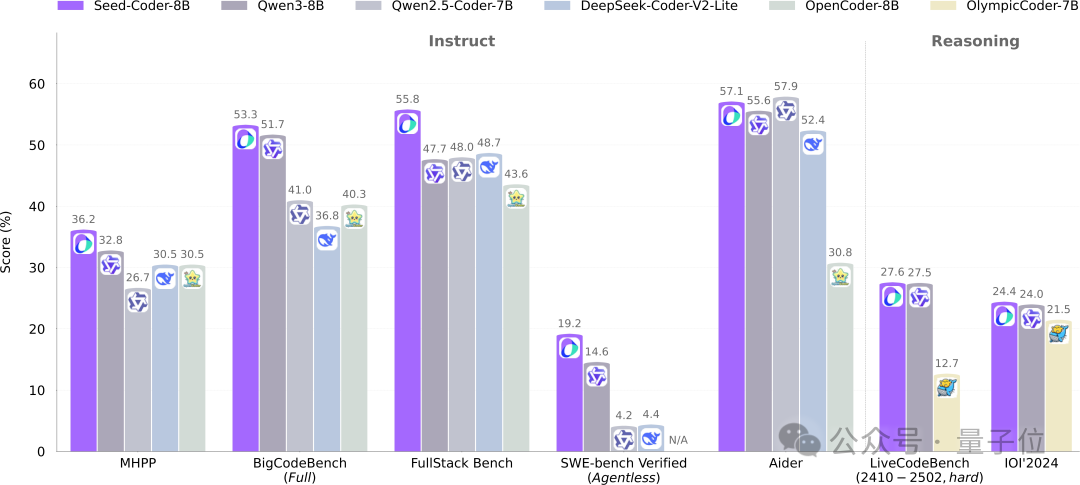
ByteDance Seed hace open source su modelo de código de 8B Seed-Coder, adoptando un nuevo paradigma de gestión de datos centrado en el modelo: El equipo Seed de ByteDance ha hecho open source por primera vez su modelo de código de 8B, Seed-Coder, que incluye las versiones Base, Instruct y Reasoning. Este modelo ha demostrado un rendimiento excelente en múltiples benchmarks de generación de código, superando especialmente a modelos como Qwen3 en HumanEval y MBPP. La innovación central de Seed-Coder radica en proponer un método de procesamiento de datos “centrado en el modelo”, utilizando el propio LLM para generar y filtrar datos de entrenamiento de código de alta calidad, incluyendo código a nivel de archivo, código a nivel de repositorio, datos de commits y datos web relacionados con el código, con un volumen total de datos de entrenamiento de 6T tokens. Esta medida tiene como objetivo reducir la participación manual y mejorar la capacidad del modelo de código. (Fuente: WeChat)
Gemini 2.5 Pro logra avances en la comprensión de video, integrando nativamente audio, video y código: Los últimos modelos Gemini 2.5 Pro y Flash de Google han logrado avances significativos en la capacidad de comprensión de video. Gemini 2.5 Pro ha alcanzado el nivel SOTA en varios benchmarks clave de comprensión de video, superando incluso a GPT 4.1. La serie de modelos Gemini 2.5 logra por primera vez una integración nativa y fluida de información de audio y video con otros formatos de datos como el código, siendo capaz de convertir directamente videos en aplicaciones interactivas (como apps de aprendizaje), generar animaciones p5.js a partir de videos, y recuperar y describir con precisión fragmentos de video, demostrando una potente capacidad de razonamiento temporal. Estas funciones ya están disponibles en Google AI Studio, Gemini API y Vertex AI. (Fuente: WeChat)

ModelScope hace open source el modelo de imagen unificado Nexus-Gen, para competir con las capacidades de imagen de GPT-4o: El equipo de ModelScope ha lanzado Nexus-Gen, un modelo multimodal unificado capaz de procesar simultáneamente la comprensión, generación y edición de imágenes, con el objetivo de igualar las capacidades de procesamiento de imágenes de GPT-4o. Este modelo adopta una ruta tecnológica token → transformer → diffusion → pixels, fusionando el modelado de texto de MLLM con la capacidad de renderizado de imágenes de los modelos Diffusion. Para resolver el problema de acumulación de errores en la predicción autorregresiva de embeddings de imágenes continuas, el equipo propuso una estrategia autorregresiva de prellenado. Nexus-Gen se entrenó con aproximadamente 25 millones de datos de imágenes y texto, incluido el conjunto de datos de edición ImagePulse recientemente publicado como open source por la comunidad ModelScope. (Fuente: WeChat)

Lanzamiento de Cursor 0.50, simplificando precios y mejorando múltiples funciones de edición de código: El editor de código IA Cursor ha lanzado la versión 0.50, trayendo consigo importantes actualizaciones. El modelo de precios se ha simplificado a un modelo basado en solicitudes, y el modo Max es compatible con todos los modelos de IA de primer nivel, adoptando precios basados en tokens. Las mejoras funcionales incluyen: un nuevo modelo Tab que admite sugerencias entre archivos y refactorización de código; un agente en segundo plano (versión preliminar) que permite ejecutar múltiples agentes en paralelo y realizar tareas en entornos remotos; el contexto del repositorio de código permite agregar repositorios completos mediante @folders; se ha optimizado la interfaz de usuario de edición en línea, añadiendo edición de archivo completo y la función de enviar al agente; la edición de archivos largos introduce una herramienta de búsqueda y reemplazo; admite espacios de trabajo multirraíz para manejar múltiples repositorios de código; se han mejorado las funciones de chat, admitiendo la exportación a Markdown y la copia. (Fuente: op7418)
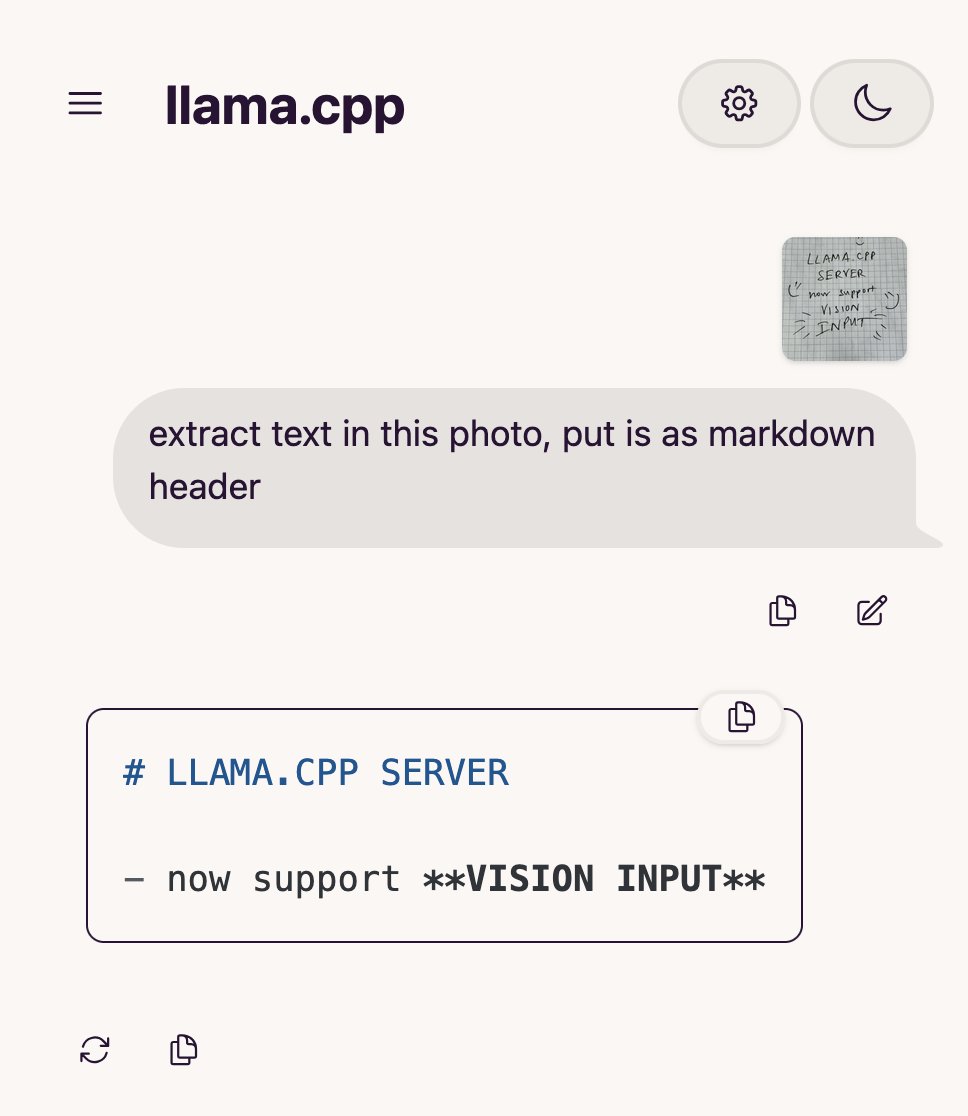
llama.cpp añade soporte para modelos de lenguaje visual (VLM), permitiendo construir flujos completos de Vision RAG: El proyecto open source llama.cpp ha anunciado que ahora es compatible con modelos de lenguaje visual (VLM), lo que permite a los usuarios utilizar funciones visuales a través del servidor llama.cpp y la interfaz de usuario web. Esta actualización significa que se puede cargar en llama.cpp el mismo modelo base compatible con múltiples LoRA, así como modelos de embedding, lo que permite construir flujos completos de generación aumentada por recuperación visual (Vision RAG). Esto amplía aún más las capacidades de llama.cpp para ejecutar grandes modelos de lenguaje localmente, permitiéndole manejar tareas multimodales. (Fuente: mervenoyann, mervenoyann)
Tencent lanza HunyuanCustom: una arquitectura de generación de video personalizada basada en HunyuanVideo: Tencent ha lanzado HunyuanCustom en Hugging Face, una arquitectura impulsada por multimodalidad diseñada específicamente para la generación de video personalizada. Este trabajo se basa en HunyuanVideo, enfatizando especialmente el mantenimiento de la consistencia del sujeto al generar videos, al tiempo que admite la entrada de múltiples condiciones como imágenes, audio, video y texto, proporcionando a los usuarios capacidades de creación de video más flexibles y personalizadas. (Fuente: _akhaliq)
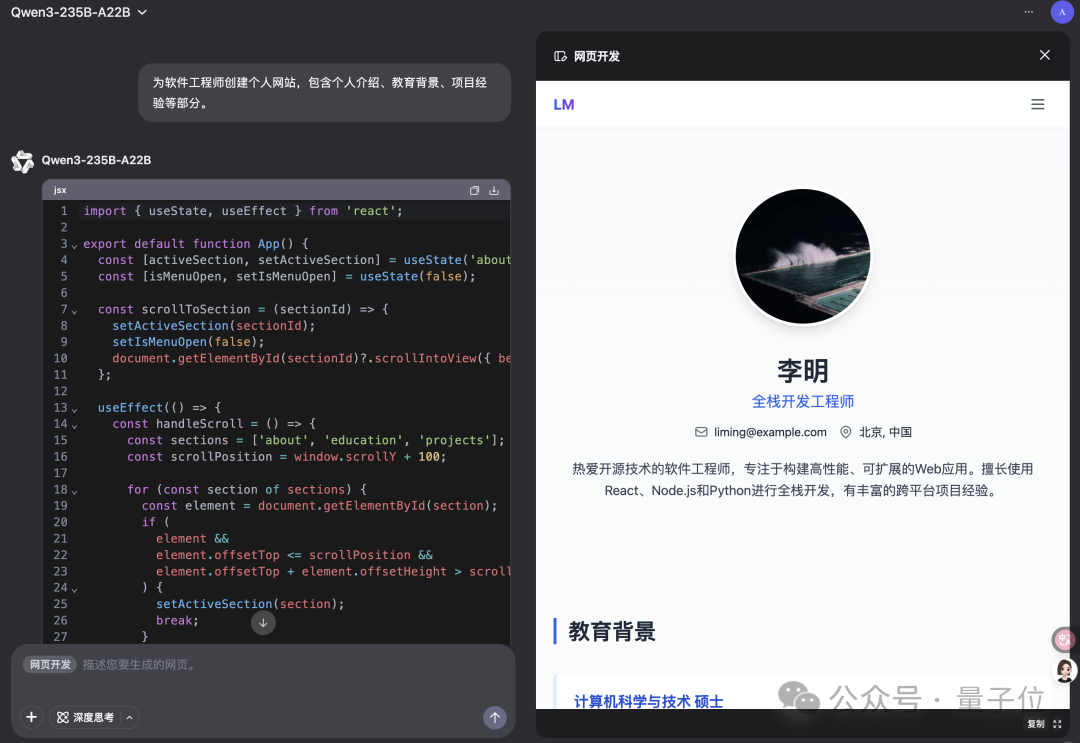
Qwen Chat añade el modo “Desarrollo Web”, generando aplicaciones web React con una sola frase: Qwen Chat de Alibaba ha lanzado el modo “Desarrollo Web” (Web Dev), que permite a los usuarios generar aplicaciones web que incluyen HTML, CSS y JavaScript con una sola instrucción de frase, utilizando el framework React y Tailwind CSS en el backend. Esta función puede crear rápidamente sitios web personales, replicar interfaces web existentes (como Twitter, GitHub) o construir formularios y animaciones específicas según la descripción. Los usuarios pueden elegir diferentes modelos Qwen y combinarlos con el modo “Pensamiento Profundo” para mejorar la calidad de la página web. Esta función tiene como objetivo simplificar el proceso de desarrollo frontend y construir rápidamente prototipos de aplicaciones. (Fuente: WeChat)
Unitree Robotics responde a la vulnerabilidad de seguridad del perro robot Go1, enfatizando que los productos posteriores han sido actualizados: Unitree Robotics ha respondido a los rumores sobre una “vulnerabilidad de puerta trasera” en su serie de perros robot Go1, descontinuada hace unos dos años, reconociendo el problema como una vulnerabilidad de seguridad. Los atacantes podían utilizar la clave de gestión de un servicio de túnel en la nube de terceros para modificar los datos del dispositivo del usuario, obtener imágenes de la cámara y permisos del sistema. Unitree Robotics declaró que las series de robots posteriores utilizan versiones actualizadas más seguras y no se ven afectadas por esta vulnerabilidad. El incidente ha suscitado preocupaciones sobre la seguridad de la cadena de suministro de robots inteligentes y la privacidad de los datos, especialmente en el contexto del primer año de comercialización de robots humanoides, donde la industria enfrenta múltiples desafíos como avances tecnológicos, control de costos y exploración de rutas de comercialización. (Fuente: 36氪)

Claude Code ahora admite la referencia a otros archivos .MD, optimizando la organización de instrucciones: Claude Code de Anthropic ha actualizado su funcionalidad, y la versión 0.2.107 permite que los archivos CLAUDE.md importen otros archivos Markdown. Los usuarios pueden cargar contenido de archivos adicionales al inicio agregando [u/path/to/file].md en el archivo principal CLAUDE.md. Esta mejora permite a los usuarios organizar y gestionar mejor las instrucciones de Claude, aumentando la fiabilidad y modularidad de la configuración de instrucciones en proyectos grandes, y resolviendo los problemas de confusión que antes podían surgir por depender de archivos dispersos. (Fuente: Reddit r/ClaudeAI)

La Oficina de Derechos de Autor de EE. UU. adopta una postura más firme sobre el preentrenamiento de IA, debilitando la defensa de “uso justo”: El último informe publicado por la Oficina de Derechos de Autor de EE. UU. adopta una postura más firme sobre el uso de material protegido por derechos de autor en la fase de preentrenamiento de los modelos de IA. El informe señala que, dado que los laboratorios de IA ahora afirman que sus modelos pueden competir con los titulares de derechos (por ejemplo, generando contenido similar a obras originales), esto debilita la solidez de su defensa de “uso justo” (fair use) en litigios por infracción de derechos de autor. Este cambio podría tener un impacto significativo en las fuentes de datos de entrenamiento y la conformidad de los modelos de IA. (Fuente: Dorialexander)

Nvidia lanza la tarjeta gráfica profesional RTX Pro 5000, equipada con 48GB de memoria GDDR7: Nvidia ha presentado la nueva GPU de escritorio de nivel profesional RTX Pro 5000, basada en la arquitectura Blackwell. Esta tarjeta gráfica está equipada con 48GB de memoria GDDR7, un ancho de banda de memoria de hasta 1344 GB/s y un consumo de energía de 300W. Aunque oficialmente se la denomina una tarjeta Blackwell de 48GB “asequible”, se espera que el precio siga siendo alto (algunos comentarios mencionan un nivel de 4000 dólares), dirigida principalmente a usuarios de estaciones de trabajo profesionales, proporcionando un potente soporte de cómputo para tareas como el entrenamiento de modelos de IA y el renderizado 3D a gran escala. (Fuente: Reddit r/LocalLLaMA)

🧰 Herramientas
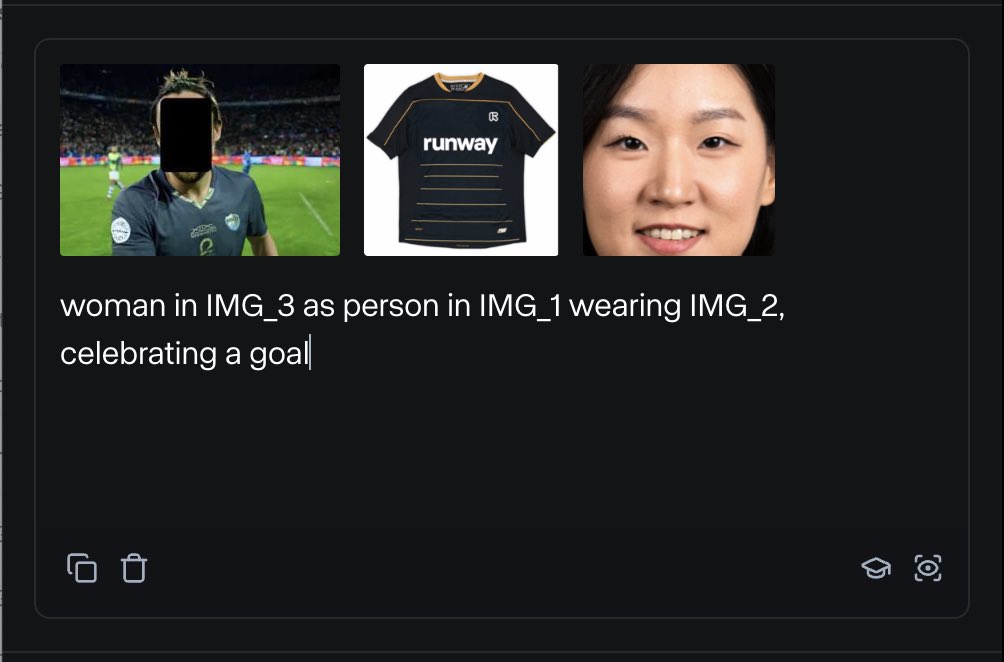
RunwayML lanza la función References, que permite mezclar diversos materiales de referencia para generar contenido: La nueva función “References” de RunwayML permite a los usuarios mezclar diferentes materiales de referencia (como imágenes, estilos) como “ingredientes” y generar nuevo contenido visual basado en cualquier combinación de estos “ingredientes”. Esta función se considera una máquina de creación casi en tiempo real, capaz de ayudar a los usuarios a realizar rápidamente diversas ideas creativas, ampliando enormemente la flexibilidad y las posibilidades de la IA en la creación de contenido visual. (Fuente: c_valenzuelab)
Chat2DB: Cliente de IA para operar bases de datos con lenguaje natural: Chat2DB es una herramienta cliente de base de datos impulsada por IA que permite a los usuarios interactuar con bases de datos mediante lenguaje natural. Por ejemplo, un usuario puede preguntar “¿Quién es el cliente que más ha gastado este mes?”, y Chat2DB puede utilizar la IA para comprender la pregunta, generar automáticamente la consulta SQL correspondiente según la estructura de la tabla de la base de datos, ejecutar la consulta y devolver el resultado. Esto reduce significativamente la barrera técnica para operar bases de datos, permitiendo que personal no técnico realice consultas y análisis de datos de manera conveniente. El proyecto es open source en GitHub. (Fuente: karminski3)
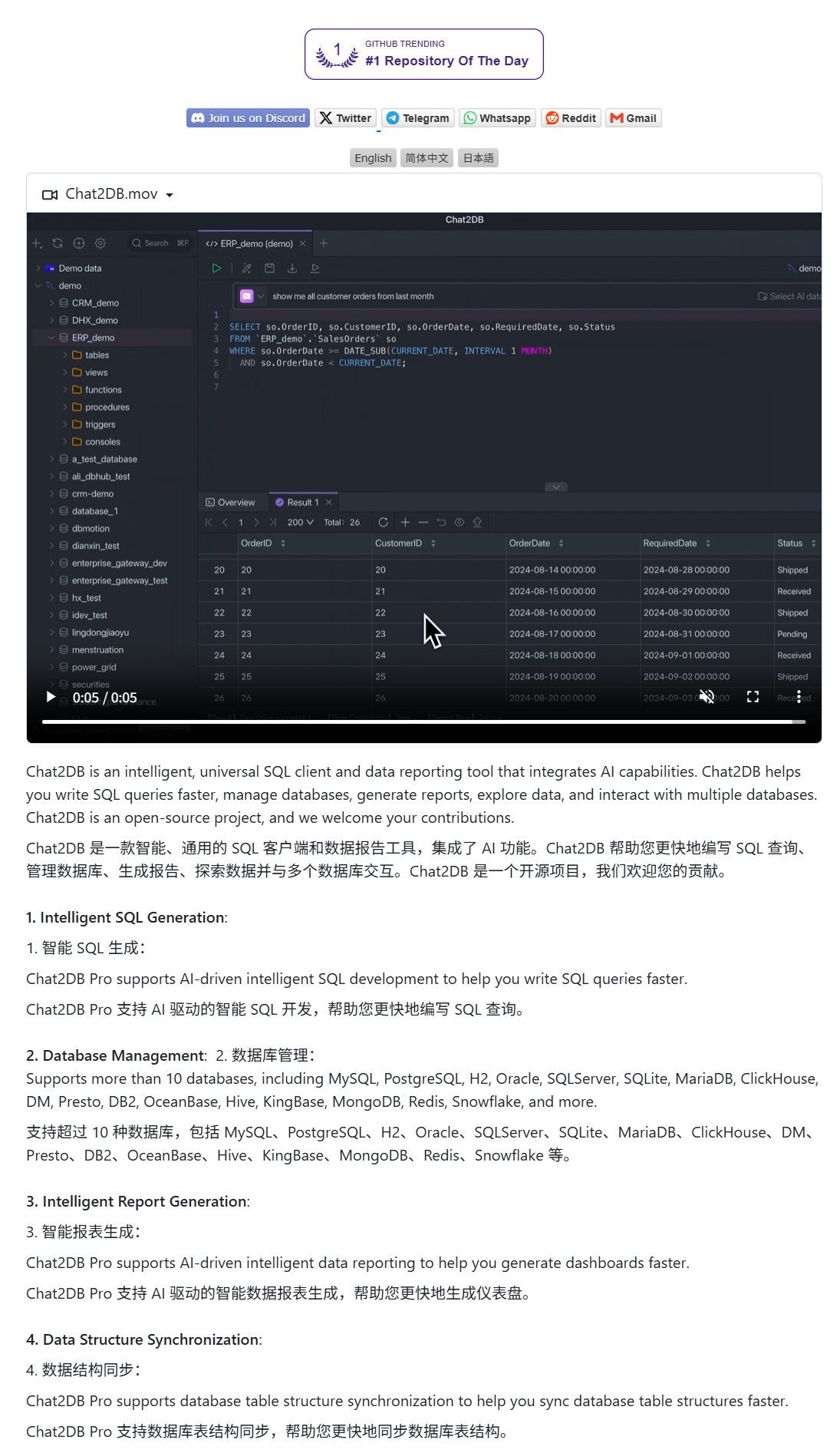
El modelo Qwen 3 8B demuestra una excelente capacidad de código, puede generar un teclado HTML: El modelo Qwen 3 8B (versión cuantizada Q6_K), a pesar de su menor número de parámetros, muestra un rendimiento sobresaliente en la generación de código. Un usuario, mediante dos prompts cortos, logró que el modelo generara el código para un teclado HTML funcional. Esto demuestra el potencial de los modelos más pequeños para alcanzar una alta utilidad en tareas específicas, especialmente atractivo para escenarios de implementación local con recursos limitados. (Fuente: Reddit r/LocalLLaMA)
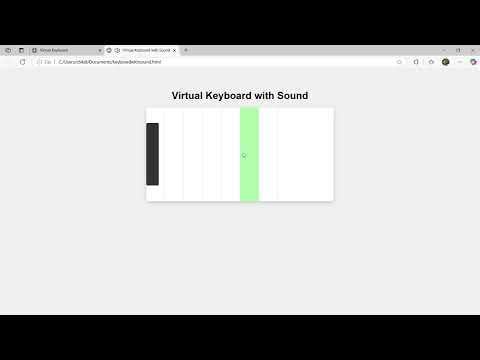
Ollama Chat: Herramienta de chat para LLM locales con interfaz similar a Claude: Ollama Chat es una interfaz de chat web diseñada para grandes modelos de lenguaje locales, cuyo estilo de interfaz de usuario y experiencia de usuario se inspiran en Claude de Anthropic. La herramienta admite la carga de archivos de texto, el historial de conversaciones y la configuración de prompts del sistema, con el objetivo de proporcionar una solución de interacción con LLM locales fácil de usar y estéticamente agradable. El proyecto es open source en GitHub, lo que facilita a los usuarios su propia implementación y uso. (Fuente: Reddit r/LocalLLaMA)
Técnicas de prompts para generar tarjetas personalizadas con IA (cumpleaños/Día de la Madre): Un usuario compartió técnicas de prompts para usar IA en la generación de tarjetas personalizadas (como tarjetas de cumpleaños, tarjetas del Día de la Madre). La clave está en especificar claramente el tema de la tarjeta (ej. Día de la Madre, cumpleaños), el estilo (ej. estilo femenino, estilo infantil), el destinatario (ej. mamá, Sandy, Jimmy), la edad (ej. 30 años, 6 años) y el contenido específico del mensaje de felicitación o un tono cálido y dulce. Combinando estos elementos, se puede guiar a la IA para generar diseños de tarjetas que cumplan con los requisitos. (Fuente: dotey)

📚 Aprendizaje
Google publica un white paper sobre ingeniería de prompts, guiando a los usuarios sobre cómo preguntar eficazmente: Google ha publicado un white paper sobre ingeniería de prompts (accesible a través de Kaggle), destinado a enseñar a los usuarios cómo preguntar de manera más efectiva a los modelos de IA. El tutorial es claro y detalla cómo especificar los requisitos de salida, restringir el rango de salida y cómo usar variables, entre otras técnicas, ayudando a los usuarios a mejorar la eficiencia y efectividad de la interacción con grandes modelos de lenguaje para obtener respuestas más precisas y útiles. (Fuente: karminski3)

Equipo de HKUST (Guangzhou) propone MultiGO: modelado gaussiano jerárquico para generar humanos texturizados en 3D a partir de una sola imagen: Un equipo de la Universidad de Ciencia y Tecnología de Hong Kong (Guangzhou) ha propuesto un innovador framework llamado MultiGO, que reconstruye modelos humanos 3D con texturas a partir de una sola imagen mediante modelado gaussiano jerárquico. Este método descompone el cuerpo humano en diferentes niveles de precisión como esqueleto, articulaciones y arrugas, refinándolos progresivamente. La tecnología central utiliza puntos de splatting gaussiano como primitivas 3D y ha diseñado módulos de mejora del esqueleto, mejora de las articulaciones y optimización de las arrugas. Este resultado de investigación ha sido seleccionado para CVPR 2025, proporcionando nuevas ideas para la reconstrucción de humanos 3D a partir de una sola imagen, y el código se hará open source próximamente. (Fuente: WeChat)

Tsinghua, Fudan y HKUST publican conjuntamente RM-BENCH: el primer benchmark de evaluación de modelos de recompensa: Abordando los problemas actuales en la evaluación de modelos de recompensa de grandes modelos de lenguaje, como “la forma prevalece sobre el contenido” y los sesgos de estilo, equipos de investigación de la Universidad de Tsinghua, la Universidad de Fudan y la Universidad de Ciencia y Tecnología de Hong Kong han publicado conjuntamente el primer benchmark sistemático de evaluación de modelos de recompensa, RM-BENCH. Este benchmark cubre cuatro dominios principales: chat, código, matemáticas y seguridad. Al evaluar la sensibilidad del modelo a diferencias sutiles de contenido y su robustez a las desviaciones de estilo, tiene como objetivo establecer un nuevo estándar más fiable para los “jueces de contenido”. La investigación encontró que los modelos de recompensa existentes tienen un rendimiento deficiente en los dominios de matemáticas y código, y generalmente presentan sesgos de estilo. Este trabajo ha sido aceptado como Oral en ICLR 2025. (Fuente: WeChat)

La Universidad de Tianjin y Tencent hacen open source la solución COME: 5 líneas de código para mejorar la robustez de TTA y resolver el colapso del modelo: La Universidad de Tianjin y Tencent han propuesto conjuntamente el método COME (Conservatively Minimizing Entropy), destinado a resolver el problema de la excesiva confianza y el colapso del modelo causados por la minimización de la entropía (EM) durante la adaptación en tiempo de prueba (TTA). COME modela explícitamente la incertidumbre de la predicción mediante la introducción de lógica subjetiva y utiliza una restricción de logit adaptativa (congelando la norma del logit) para controlar indirectamente la incertidumbre, logrando así una minimización conservadora de la entropía. Este método no requiere modificar la arquitectura del modelo, solo unas pocas líneas de código para integrarse en los métodos TTA existentes, y mejora significativamente la robustez y precisión del modelo en conjuntos de datos como ImageNet-C, con un costo computacional mínimo. El artículo ha sido aceptado en ICLR 2025 y el código ya es open source. (Fuente: WeChat)
Huawei y el Instituto de Ingeniería de la Información de CAS proponen DEER: mecanismo de “salida temprana dinámica” en la cadena de pensamiento para mejorar la eficiencia y precisión de la inferencia de LLM: Huawei, en colaboración con el Instituto de Ingeniería de la Información de la Academia China de Ciencias (CAS), ha propuesto el mecanismo DEER (Dynamic Early Exit in Reasoning), destinado a resolver el problema del pensamiento excesivo que puede ocurrir en los grandes modelos de lenguaje durante la inferencia con cadenas de pensamiento largas (Long CoT). DEER monitorea los puntos de transición del razonamiento, induce respuestas tentativas y evalúa su confianza, para determinar dinámicamente si se debe terminar el pensamiento de forma temprana y generar una conclusión. Los experimentos demuestran que en LLM de razonamiento como la serie DeepSeek, DEER puede reducir la longitud de generación de la cadena de pensamiento en un promedio de 31%-43% sin entrenamiento adicional, al tiempo que aumenta la precisión en un 1.7%-5.7%. (Fuente: WeChat)

CAS y otros proponen R1-Reward: entrenamiento de modelos de recompensa multimodales mediante aprendizaje por refuerzo estable: Equipos de investigación de la Academia China de Ciencias (CAS), la Universidad de Tsinghua, Kuaishou y la Universidad de Nanjing han propuesto R1-Reward, un método para entrenar modelos de recompensa multimodales (MRM) mediante un algoritmo de aprendizaje por refuerzo estable llamado StableReinforce, con el objetivo de mejorar su capacidad de razonamiento a largo plazo. StableReinforce mejora los problemas de inestabilidad que pueden encontrar los algoritmos de RL existentes como PPO al entrenar MRM, mediante una estrategia Pre-Clip, un filtro de ventajas y un novedoso mecanismo de recompensa de consistencia (introduciendo un modelo árbitro para verificar la consistencia entre el análisis y la respuesta) para estabilizar el proceso de entrenamiento. Los experimentos demuestran que R1-Reward supera el rendimiento de los modelos SOTA en varios benchmarks de MRM, y su rendimiento puede mejorarse aún más mediante el muestreo múltiple y la votación en tiempo de inferencia. (Fuente: WeChat)
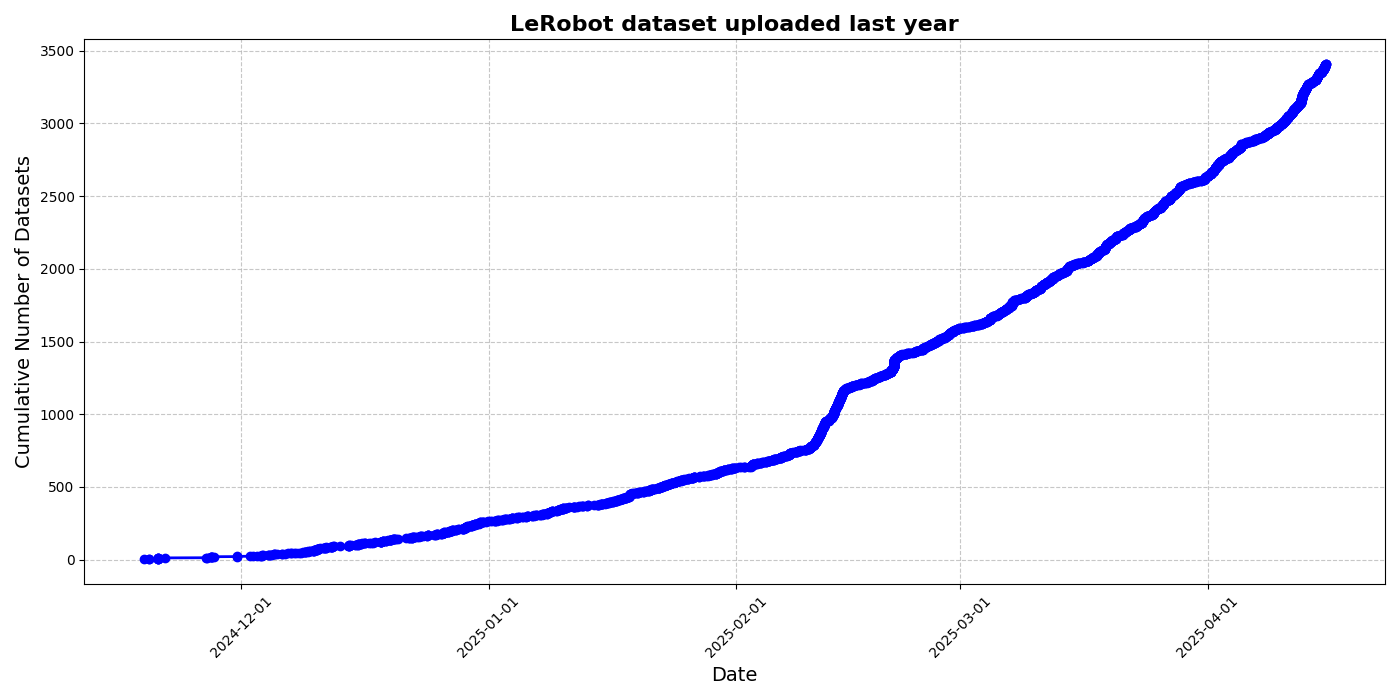
HuggingFace lanza la iniciativa de conjunto de datos comunitarios LeRobot, impulsando el “momento ImageNet” de la robótica: HuggingFace ha lanzado el proyecto de conjunto de datos comunitarios LeRobot, con el objetivo de construir el “ImageNet” del campo de la robótica, impulsando el desarrollo de la tecnología robótica general mediante contribuciones de la comunidad. El artículo enfatiza la importancia de la diversidad de datos para la capacidad de generalización de los robots y señala que los conjuntos de datos robóticos existentes provienen en su mayoría de entornos académicos restringidos. LeRobot, al simplificar los procesos de recopilación y carga de datos y reducir los costos de hardware, anima a los usuarios a compartir datos de diferentes robots (como So100, brazo mecánico Koch) en diversas tareas (como jugar al ajedrez, operar cajones). Al mismo tiempo, el artículo propone estándares de calidad de datos y una lista de mejores prácticas para abordar desafíos como la inconsistencia en la anotación de datos y el mapeo ambiguo de características, promoviendo la construcción de conjuntos de datos robóticos de alta calidad y diversificados. (Fuente: HuggingFace Blog, LoubnaBenAllal1)
Artículo de blog de HuggingFace resume 11 algoritmos de alineación y optimización para LLM: TheTuringPost compartió un artículo de HuggingFace que resume 11 algoritmos de alineación y optimización para grandes modelos de lenguaje (LLM). Estos algoritmos incluyen PPO (Optimización de Políticas Próximas), DPO (Optimización Directa de Preferencias), GRPO (Optimización de Políticas Relativas a Grupos), SFT (Ajuste Fino Supervisado), RLHF (Aprendizaje por Refuerzo con Retroalimentación Humana) y SPIN (Ajuste Fino Auto-jugado), entre otros. El artículo proporciona enlaces y más información sobre estos algoritmos, ofreciendo a investigadores y desarrolladores una visión general de los métodos de optimización de LLM. (Fuente: TheTuringPost)
UC Berkeley comparte materiales del curso de posgrado en Visión por Computadora CS280: Los profesores Angjoo Kanazawa y Jitendra Malik de la Universidad de California, Berkeley, han compartido todos los materiales de las clases de su curso de posgrado en Visión por Computadora CS280, impartido este semestre. Consideran que este conjunto de materiales, que combina contenidos clásicos y modernos de la visión por computadora, ha funcionado bien y lo han hecho público para referencia de los estudiantes. (Fuente: NandoDF)
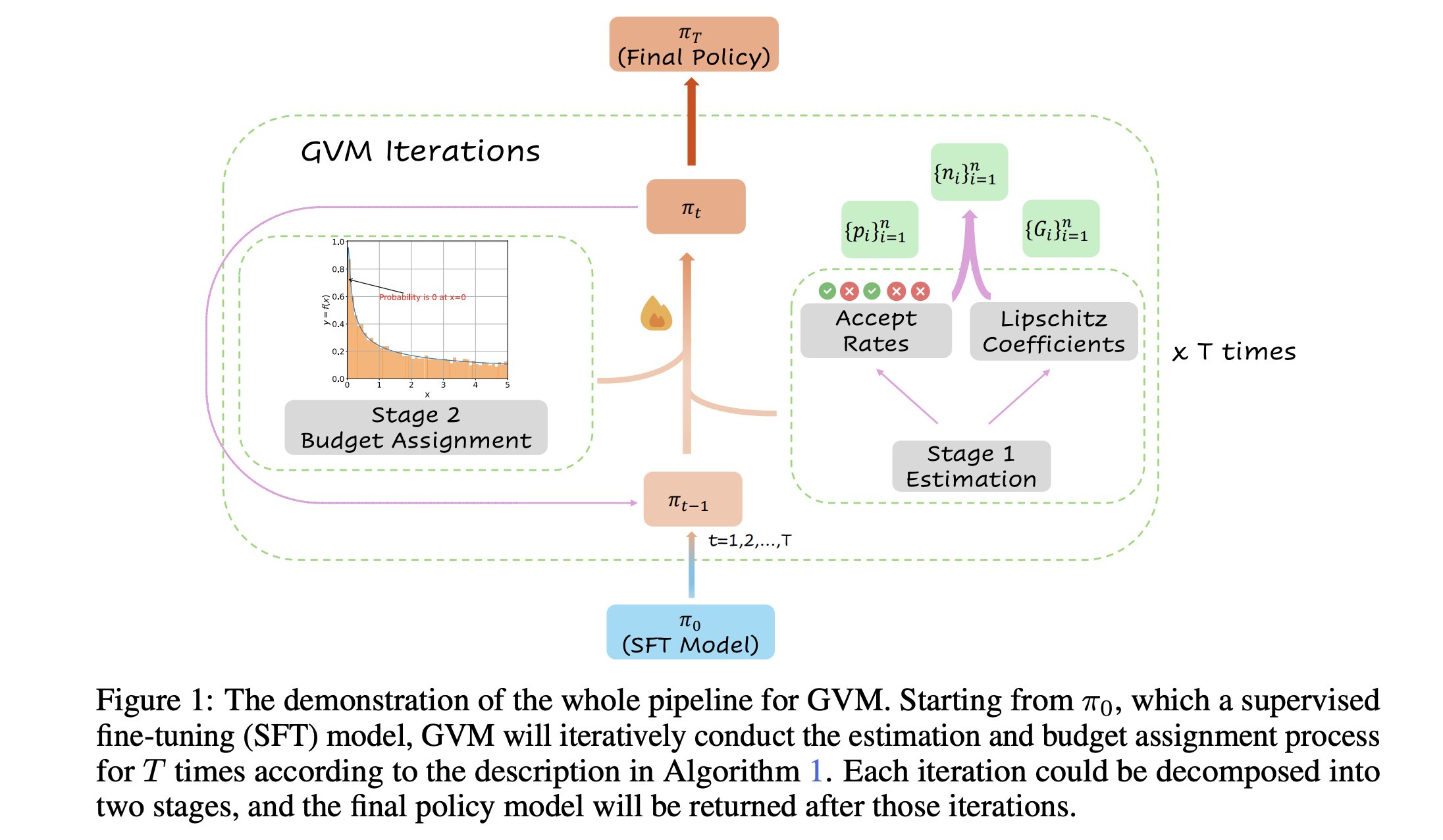
GVM-RAFT: Framework de muestreo dinámico para optimizar los razonadores de cadena de pensamiento: Un nuevo artículo presenta el framework GVM-RAFT, que optimiza los razonadores de cadena de pensamiento (chain-of-thought) ajustando dinámicamente la estrategia de muestreo para cada prompt, con el objetivo de minimizar la varianza del gradiente. Se afirma que este método logra una aceleración de 2 a 4 veces en tareas de razonamiento matemático y mejora la precisión. (Fuente: _akhaliq)
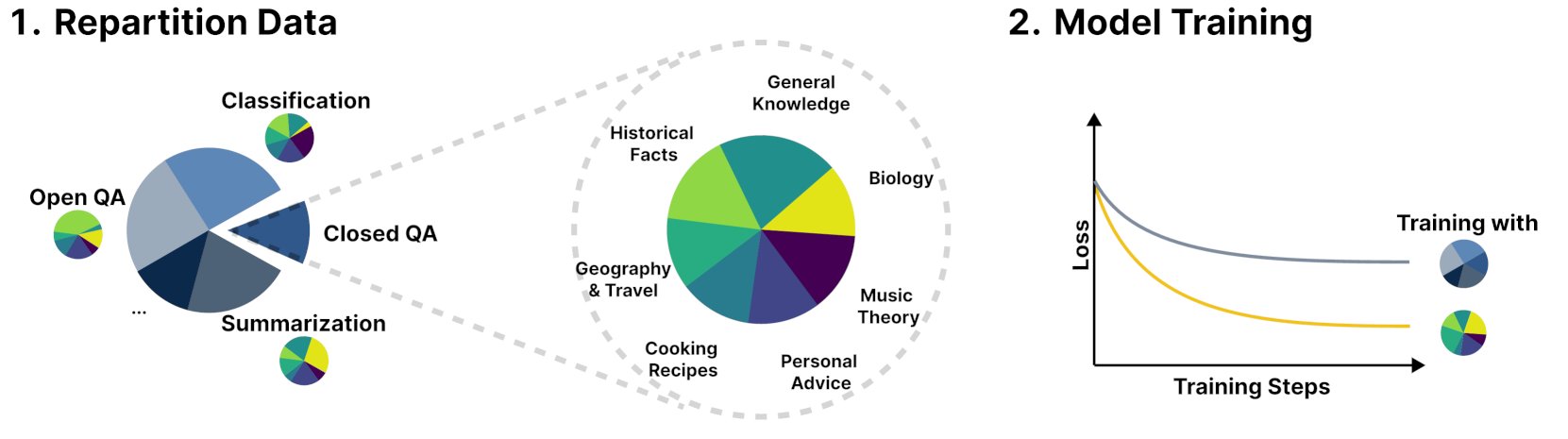
Nuevo framework R&B mejora el rendimiento del modelo de lenguaje mediante el equilibrio dinámico de los datos de entrenamiento: Una nueva investigación titulada R&B propone un nuevo framework que, mediante el equilibrio dinámico de los datos de entrenamiento del modelo de lenguaje, mejora el rendimiento del modelo con solo un aumento del 0.01% en el costo computacional adicional. Este método tiene como objetivo optimizar la eficiencia en la utilización de datos para obtener una mejora en el rendimiento del modelo a un costo relativamente bajo. (Fuente: _akhaliq)
Artículo explora nueva perspectiva sobre la seguridad de la IA: considerar el progreso social y tecnológico como coser una colcha: Un nuevo artículo publicado en arXiv, “Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt”, propone una nueva visión de la seguridad de la IA, abogando por centrar el núcleo de la seguridad de la IA en prevenir que las divergencias escalen a conflictos. El artículo compara el progreso social y tecnológico con coser una colcha en constante crecimiento, cambio, llena de parches y multicolor, enfatizando la importancia de mantener la estabilidad y la cooperación en sistemas complejos. (Fuente: jachiam0)
Artículo discute el cómputo adaptativo en modelos de lenguaje autorregresivos: Se menciona la naturaleza interesante del cómputo adaptativo en el aprendizaje profundo y se enumeran desarrollos tecnológicos relacionados: PonderNet (DeepMind, 2021) como una herramienta temprana para integrar redes neuronales y recurrencia; los modelos de difusión que realizan cómputos a través de múltiples pasadas hacia adelante; y los recientes modelos de lenguaje de tipo inferencial que logran efectos similares generando un número arbitrario de tokens. Esto refleja una tendencia hacia la flexibilidad y el dinamismo en la asignación y uso de recursos computacionales por parte de los modelos. (Fuente: jxmnop)
Artículo explora cómo los “datos malos” pueden generar “buenos modelos”: Un artículo de la Universidad de Harvard de 2025, “When Bad Data Leads to Good Models” (arXiv:2505.04741), explora cómo en ciertos casos, datos aparentemente de baja calidad (como datos de preentrenamiento que incluyen contenido de 4chan) podrían ayudar a alinear los modelos y ocultar su “nivel de poder” (power level), haciendo que se desempeñen mejor. Esto ha generado discusiones sobre la calidad de los datos, la alineación de los modelos y la autenticidad del comportamiento de los modelos. (Fuente: teortaxesTex)

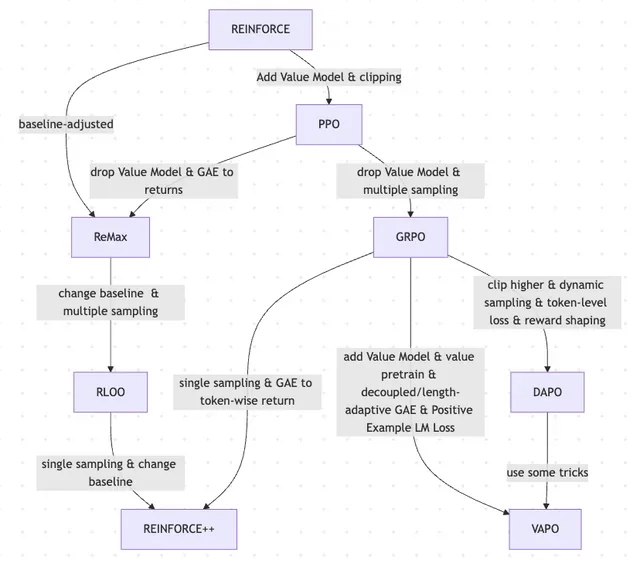
Artículo explora la evolución de RLHF y sus variantes, desde REINFORCE hasta VAPO: Un artículo de investigación resume la evolución de los métodos de aprendizaje por refuerzo (RL) utilizados para el ajuste fino de grandes modelos de lenguaje (LLM). El artículo rastrea la evolución desde los algoritmos clásicos PPO y REINFORCE hasta métodos recientes como GRPO, ReMax, RLOO, DAPO y VAPO, analizando el descarte de modelos de valor, los cambios en las estrategias de muestreo, los ajustes de la línea base y la aplicación de técnicas como la modelización de recompensas y la pérdida a nivel de token. El estudio tiene como objetivo mostrar claramente el panorama de investigación de RLHF y sus variantes en el campo de la alineación de LLM. (Fuente: Reddit r/MachineLearning)
Artículo “Absolute Zero”: IA realiza razonamiento de autoaprendizaje reforzado sin datos humanos: Un white paper titulado “Absolute Zero: Reinforced Self-Play Reasoning with Zero Data” (arXiv:2505.03335) explora nuevos métodos para entrenar IA lógica. Los investigadores entrenaron modelos de IA lógica sin usar conjuntos de datos etiquetados por humanos; el modelo puede generar tareas de razonamiento por sí mismo, resolver problemas y verificar soluciones mediante la ejecución de código. Esto ha generado discusiones sobre si la IA puede, en un entorno completamente desprovisto de conocimiento previo (como matemáticas, física, lenguaje), inventar representaciones simbólicas desde cero, definir estructuras lógicas, desarrollar sistemas numéricos y construir modelos causales, así como el potencial y los riesgos de tal “inteligencia alienígena”. (Fuente: Reddit r/ArtificialInteligence, Reddit r/artificial)
El Laboratorio de Interacción Humano-Computadora Inteligente de la Universidad de Fudan recluta estudiantes de maestría y doctorado para 2026: El Laboratorio de Interacción Humano-Computadora Inteligente de la Facultad de Ciencias de la Computación y Tecnología de la Universidad de Fudan está reclutando estudiantes de maestría y doctorado para el campamento de verano/admisión recomendada de 2026. El laboratorio está dirigido por el profesor Shang Li y sus líneas de investigación incluyen AGI vestible (gafas inteligentes MemX combinadas con LLM), inteligencia corpórea open source, compresión de modelos (de grande a pequeño) y sistemas de aprendizaje automático (como optimización de compilación de ML, procesadores de IA). El laboratorio se dedica a explorar la inteligencia centrada en el ser humano, fusionando grandes modelos con wearables inteligentes y nuevos paradigmas de interacción humano-computadora en sistemas de inteligencia corpórea. (Fuente: WeChat)

💼 Negocios
Un vistazo a 10 startups de IA valoradas en más de 1.000 millones de dólares con menos de 50 empleados: Business Insider ha elaborado una lista de 10 startups de IA valoradas en más de 1.000 millones de dólares pero con menos de 50 empleados. Entre ellas se encuentran Safe Superintelligence (valoración de 32.000 millones de dólares, 20 empleados), OG Labs (valoración de 2.000 millones de dólares, 40 empleados), Magic (valoración de 1.580 millones de dólares, 20 empleados), Sakana AI (valoración de 1.500 millones de dólares, 28 empleados), entre otras. Estas empresas demuestran el potencial en el campo de la IA para que equipos pequeños alcancen altas valoraciones, reflejando el alto valor de la tecnología y la innovación en los mercados de capitales. (Fuente: hardmaru)
Fourier Intelligence profundiza en escenarios de atención a personas mayores y colabora con el Shanghai International Medical Center para crear una base de rehabilitación de inteligencia corpórea: Fourier Intelligence, un unicornio de la inteligencia corpórea, anunció en su primera cumbre ecológica de inteligencia corpórea que colaborará con el Shanghai International Medical Center para promover conjuntamente la aplicación de robots de inteligencia corpórea en escenarios de rehabilitación médica, incluyendo la construcción de estándares, la creación conjunta de soluciones y la investigación científica, y para construir la primera base de demostración de rehabilitación de inteligencia corpórea en China. El fundador de Fourier, Gu Jie, propuso que la estrategia central para los próximos diez años sea “basarse en la atención a personas mayores, centrarse en la interacción y servir a las personas”, enfatizando que la rehabilitación médica es su base. Desde su fundación en 2015, la compañía se ha expandido gradualmente desde robots de rehabilitación hasta robots humanoides de propósito general de las series GR-1 y GRx, habiendo enviado ya cientos de unidades. (Fuente: 36氪)
Se informa que Meta está reclutando a exfuncionarios del Pentágono, lo que podría fortalecer su presencia en el sector militar: Según Forbes, Meta está reclutando a exfuncionarios del Pentágono, una medida que podría significar que la compañía planea fortalecer sus operaciones en tecnología militar o campos relacionados con la defensa. Esta tendencia ha generado debate y preocupación sobre la participación de las grandes empresas tecnológicas en aplicaciones militares. (Fuente: Reddit r/artificial)

🌟 Comunidad
Andrej Karpathy propone que al aprendizaje de LLM le falta un paradigma importante, el “aprendizaje de prompts de sistema”, lo que genera un animado debate: Andrej Karpathy considera que al aprendizaje actual de LLM le falta un paradigma importante, al que denomina “aprendizaje de prompts de sistema”. Señala que el preentrenamiento es para el conocimiento, y el ajuste fino (supervisado/por refuerzo) es para el comportamiento habitual, ambos implican cambios de parámetros, pero una gran cantidad de interacción y retroalimentación humana parece no aprovecharse suficientemente. Lo compara con darle al protagonista de Memento un cuaderno para almacenar conocimiento y estrategias globales de resolución de problemas. Este punto de vista ha generado una amplia discusión; algunos creen que esto se acerca a la filosofía de DSPy, o que involucra problemas de memoria/optimización y aprendizaje continuo, y se debate cómo implementar mecanismos similares en Langgraph. (Fuente: lateinteraction, hwchase17, nrehiew_, tokenbender, lateinteraction, lateinteraction)
Empresas de IA piden a los solicitantes de empleo que no usen IA para escribir sus solicitudes, lo que genera debate: Empresas de IA como Anthropic están pidiendo a los solicitantes de empleo que no utilicen herramientas de IA al redactar sus solicitudes (como currículums), una regulación que ha provocado discusiones en la comunidad. Algunos reclutadores afirman que el fenómeno de los currículums generados por IA llenos de “basura textual” es grave, e incluso profesionales experimentados pueden perder el enfoque por ello. Sin embargo, algunos solicitantes creen que la IA puede ayudarles a optimizar mejor sus currículums para los requisitos del puesto, destacar habilidades y mejorar la legibilidad. La discusión también se extiende al fenómeno de plataformas como LinkedIn inundadas de contenido generado por IA, y si se deberían adoptar otros métodos, como videos, para evaluar a los solicitantes. (Fuente: Reddit r/artificial, Reddit r/ArtificialInteligence)

La “identificabilidad” del contenido generado por IA genera debate, los usuarios consideran que es fácil de detectar: Discusiones en la comunidad señalan que el contenido generado por IA (especialmente ChatGPT) es fácil de identificar, no solo por signos de puntuación específicos (como los guiones largos o em dashes) o estructuras de frases (como “Eso no es x; eso es y.”), sino más bien por su “ritmo” y “sensación de insipidez” característicos. Una vez que se identifican rastros de IA, el contenido parece poco auténtico y carente de personalidad. Algunos usuarios afirman haber encontrado este tipo de situaciones en correos electrónicos, publicaciones en redes sociales e incluso videojuegos, y consideran que usar directamente IA para generar todo el contenido conduce a un contenido aburrido y poco sincero, recomendando a los usuarios que utilicen la IA como una herramienta para modificar y personalizar. (Fuente: Reddit r/ChatGPT)
El desarrollo de la IA presenta un ciclo de “luna de miel – reacción negativa”, reflejando la preferencia humana por la autenticidad: Existe la opinión de que la aparición de nuevos modelos de IA generativa (texto, imágenes, música, etc.) suele ir acompañada de un período de “luna de miel”, durante el cual la gente se maravilla de sus capacidades. Pero pronto, cuando la gente comienza a identificar los “patrones” o “rastros” generados por la IA, se produce una reacción negativa, pasando del elogio a la sospecha, e incluso considerándola “sin alma”. Este fenómeno de aprender rápidamente a identificar obras de IA y tender a preferir creaciones humanas imperfectas podría significar que la IA es más una herramienta de asistencia que un reemplazo completo de los creadores humanos, ya que la gente valora la historia detrás de la obra, la intención del autor y la autenticidad. (Fuente: Reddit r/ArtificialInteligence)
La tasa de generación de código por IA interna de Anthropic supera el 70%, lo que evoca ideas sobre la autoiteración de la IA: Mike Krieger de Anthropic reveló que más del 70% de las pull requests dentro de la empresa ahora son generadas por IA. Este dato ha provocado discusiones en la comunidad, con algunos evocando escenarios de máquinas autoeditándose y mejorándose, similares a tramas de obras de ciencia ficción. Al mismo tiempo, algunos han expresado dudas sobre la veracidad de este dato y su significado específico (por ejemplo, la complejidad de estas PR). (Fuente: Reddit r/ClaudeAI)

El CEO de Nvidia, Jensen Huang, enfatiza la adopción de agentes de IA por parte de todos los empleados; la IA remodelará el rol del desarrollador: El CEO de Nvidia, Jensen Huang, declaró que la compañía equipará a todos sus empleados con asistentes de IA, y los agentes de IA se integrarán en el desarrollo diario para optimizar el código, descubrir vulnerabilidades y acelerar la creación de prototipos. Considera que en el futuro todos dirigirán múltiples asistentes de IA, y la productividad crecerá exponencialmente. El CEO de Meta, Zuckerberg, el CEO de Microsoft, Nadella, y otros comparten puntos de vista similares, creyendo que la IA realizará la mayor parte del trabajo de codificación, y el rol del desarrollador se transformará en “dirigir la IA” y “definir requisitos”. Esta tendencia augura un cambio drástico en el ciclo de desarrollo de software, y herramientas de programación de IA como GitHub Copilot, Cursor, etc., se popularizarán. (Fuente: WeChat)

Discusión: ¿Es factible que los investigadores de ML lean entre 1000 y 2000 artículos al año?: En la comunidad se ha discutido que los principales investigadores de aprendizaje automático podrían leer cerca de 2000 artículos al año. Al respecto, algunos comentaristas opinan que la cantidad de artículos leídos en sí misma es solo un indicador indirecto; lo verdaderamente importante es la capacidad de filtrar señales de entre una gran cantidad de información, extraer información útil y aplicarla correctamente. Ser capaz de mantenerse al día con los aspectos más destacados y las tendencias del campo, y profundizar en contenidos específicos cuando sea necesario, esta capacidad de filtrado de información es una habilidad clave en este siglo. (Fuente: torchcompiled)
Discusión: Comprar GPU vs. alquilar GPU para entrenamiento/ajuste fino de modelos: Los profesionales del aprendizaje automático se enfrentan a la decisión de comprar o alquilar recursos de GPU. Personas con experiencia sugieren adoptar una estrategia mixta: configurar localmente una GPU de consumo con un rendimiento aceptable para experimentos pequeños, y para tareas de entrenamiento a gran escala, alquilar GPU en la nube. La elección depende de la complejidad del modelo, la cantidad de datos y el presupuesto. Las GPU en la nube tienen ventajas en la organización de ML Ops, pero por el mismo precio, GPU comunes en la nube como las T4 pueden tener un rendimiento inferior al de tarjetas de consumo de gama alta (como 3090/4090), aunque la nube puede ofrecer GPU de primer nivel con mayor memoria, como A100/H100. (Fuente: Reddit r/MachineLearning)
💡 Otros
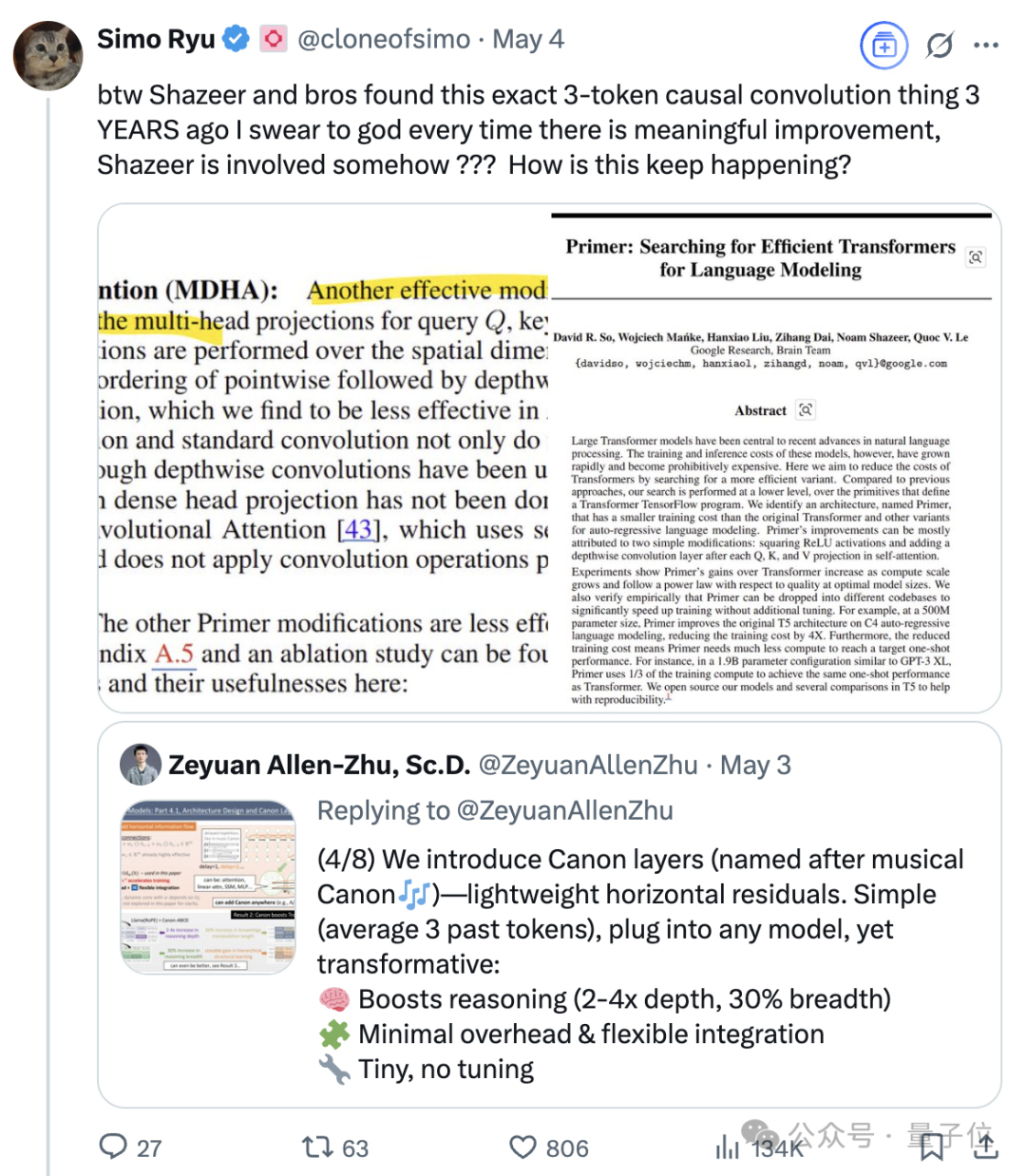
La continua influencia de Noam Shazeer, uno de los ocho “padres” de Transformer: Noam Shazeer, uno de los ocho autores del artículo sobre la arquitectura Transformer “Attention Is All You Need”, es ampliamente considerado como el que hizo la mayor contribución. Su influencia va mucho más allá, incluyendo investigaciones tempranas sobre la introducción de mezclas de expertos dispersas y controladas (MoE) en modelos de lenguaje, el optimizador Adafactor, la atención multiconsulta (MQA) y las capas lineales controladas (GLU) en Transformer. Estos trabajos sentaron las bases de la arquitectura de los grandes modelos de lenguaje actuales, convirtiendo a Shazeer en una figura clave que continúa definiendo los paradigmas tecnológicos en el campo de la IA. Dejó Google para fundar Character.AI, y luego regresó a Google tras la adquisición de su empresa, coliderando el proyecto Gemini. (Fuente: WeChat)
Los gigantes tecnológicos enfrentan una “crisis de la mediana edad” provocada por la IA: Un artículo analiza cómo los “siete gigantes tecnológicos”, incluyendo Google, Apple, Meta y Tesla, están enfrentando desafíos disruptivos provocados por la inteligencia artificial, sumergiéndose en una “crisis de la mediana edad”. El negocio de búsqueda de Google se ve amenazado por el modelo de respuesta directa de la IA, Apple avanza lentamente en innovación de IA, Meta intenta integrar la IA en las redes sociales pero el rendimiento de Llama 4 no ha cumplido las expectativas, y Tesla enfrenta una disminución en las ventas y el precio de las acciones. Estos antiguos líderes de la industria, como los casos en “El dilema del innovador”, necesitan hacer frente al impacto de los nuevos mercados y modelos traídos por la IA, o podrían convertirse en los “Nokia” de la era de la IA. (Fuente: WeChat)

La IA de Google supera a los médicos humanos en la simulación de diálogos médicos: Investigaciones demuestran que un sistema de IA entrenado para realizar entrevistas médicas, al dialogar con pacientes simulados y enumerar posibles diagnósticos basados en el historial médico, igualó e incluso superó el rendimiento de los médicos humanos. Los investigadores creen que este tipo de sistema de IA tiene el potencial de ayudar a universalizar y democratizar los servicios médicos. (Fuente: Reddit r/ArtificialInteligence)
