
Palabras clave:OpenAI, Chips de IA, Modelos grandes, Aprendizaje por refuerzo, Infraestructura de IA, IA multimodal, Agentes inteligentes, RAG (Recuperación Generativa Aumentada), Plan nacional de IA de OpenAI, Restricciones a la exportación de chips H20 de Nvidia, Optimización de inferencia DeepSeek-R1, Microscopio óptico de IA Meta-rLLS-VSIM, Modelo de código grande Seed-Coder de ByteDance
🔥 Destacados
OpenAI lanza el plan «IA a Nivel Nacional», impulsando la infraestructura global de IA: OpenAI inicia el proyecto «OpenAI for Countries» como parte de su plan «Stargate», con el objetivo de ayudar a los países a establecer centros de datos de IA locales, personalizar ChatGPT y promover el desarrollo del ecosistema de IA. El CEO Sam Altman ya ha inspeccionado el primer parque de supercomputación en Abilene, Texas, parte del plan «Stargate» de 500 mil millones de dólares, destinado a crear la instalación de entrenamiento de IA más grande del mundo. Esta medida marca la colaboración de OpenAI con múltiples gobiernos para impulsar la popularización y aplicación global de la tecnología de IA mediante la construcción de infraestructura y el intercambio de tecnología, con un plan inicial para cooperar con 10 países o regiones (Fuente: WeChat)

Se rumorea que la administración Trump planea abolir las restricciones de exportación de chips de IA de tres niveles, podría adoptar un sistema de licencias global más simplificado: Según informes de medios extranjeros, la administración Trump planea revocar el «Marco de Difusión de Inteligencia Artificial» (FAID) establecido al final de la era Biden, que originalmente imponía restricciones de clasificación de tres niveles a las exportaciones globales de chips de IA. El equipo de Trump considera que el marco es demasiado engorroso y obstaculiza la innovación, inclinándose por reemplazarlo con un sistema de licencias global más simple, ejecutado a través de acuerdos intergubernamentales. Esta medida podría afectar las estrategias de mercado global de fabricantes de chips como Nvidia, con el objetivo de consolidar la innovación y el dominio de Estados Unidos en el campo de la IA (Fuente: WeChat)

El equipo de SGLang optimiza significativamente el rendimiento de inferencia de DeepSeek-R1, aumentando el throughput 26 veces: Un equipo conjunto de SGLang, Nvidia y otras instituciones ha mejorado el rendimiento de inferencia del modelo DeepSeek-R1 en GPU H100 en 26 veces en cuatro meses, mediante una actualización integral del motor de inferencia SGLang. Las soluciones de optimización incluyen la separación de prellenado y decodificación (separación PD), paralelismo de expertos a gran escala (EP), DeepEP, DeepGEMM y un equilibrador de carga para paralelismo de expertos (EPLB), entre otras tecnologías. Al procesar secuencias de entrada de 2000 tokens, se logró un throughput de 52.3k tokens de entrada por segundo y 22.3k tokens de salida por segundo por nodo, acercándose a los datos oficiales de DeepSeek y reduciendo significativamente los costes de despliegue local (Fuente: WeChat)

El científico de OpenAI Dan Roberts: La expansión del aprendizaje por refuerzo impulsará a la IA a descubrir nueva ciencia, podría alcanzar una AGI de nivel Einstein en 9 años: El científico investigador de OpenAI, Dan Roberts, pronunció un discurso en AI Ascent de Sequoia Capital, discutiendo el papel central del aprendizaje por refuerzo (RL) en la construcción futura de modelos de IA. Sostiene que, al escalar continuamente el RL, los modelos de IA no solo mejorarán su rendimiento en tareas como el razonamiento matemático, sino que también podrán realizar descubrimientos científicos mediante la «computación en tiempo de prueba» (es decir, cuanto más tiempo piense el modelo, mejor será su rendimiento). Citando el descubrimiento de la relatividad general por Einstein como ejemplo, especula que si la IA pudiera realizar cálculos y reflexionar durante 8 años, podría alcanzar un nivel de avance científico similar al de Einstein en 9 años. Roberts enfatizó que el desarrollo futuro de la IA se centrará más en la computación de RL, e incluso podría dominar todo el proceso de entrenamiento (Fuente: WeChat)

🎯 Tendencias
Jim Fan de Nvidia: Los robots pasarán el «Test de Turing Físico», la simulación y la IA generativa son clave: Jim Fan, director de la división de robótica de Nvidia, propuso el concepto de «Test de Turing Físico» en su discurso en AI Ascent de Sequoia, donde los humanos no podrían distinguir si una tarea es realizada por una persona o un robot. Señaló que el coste actual de adquisición de datos para robots es alto, y la tecnología de simulación es crucial, especialmente combinada con IA generativa (como el ajuste fino de modelos de generación de video) para crear datos de entrenamiento diversos y a gran escala («primos digitales» en lugar de «gemelos digitales» exactos). Predice que, mediante la simulación a gran escala y modelos de visión-lenguaje-acción (como GR00T de Nvidia), las API físicas serán omnipresentes en el futuro, los robots podrán realizar tareas cotidianas complejas y se integrarán con la inteligencia ambiental (Fuente: WeChat)
ByteDance lanza la serie de grandes modelos de código Seed-Coder, la versión 8B muestra un rendimiento superior: ByteDance ha lanzado la serie de grandes modelos de código Seed-Coder, que incluye versiones de 8B, 14B y otras. Entre ellas, Seed-Coder-8B ha destacado en múltiples benchmarks de capacidad de codificación como SWE-bench, Multi-SWE-bench e IOI, superando supuestamente a Qwen3-8B y Qwen2.5-Coder-7B-Inst. La serie de modelos incluye versiones Base, Instruct y Reasoner, con la filosofía central de «dejar que el modelo de código organice sus propios datos», mostrando mejoras significativas en el razonamiento de código y las capacidades de ingeniería de software. Los modelos ya están disponibles en código abierto en Hugging Face y GitHub (Fuente: Reddit r/LocalLLaMA, karminski3, teortaxesTex)
Alibaba presenta el framework ZeroSearch de código abierto, que utiliza LLM para simular búsquedas y reduce los costes de entrenamiento de IA en un 88%: Investigadores de Alibaba han lanzado un framework de aprendizaje por refuerzo llamado «ZeroSearch», que permite a los grandes modelos de lenguaje (LLM) desarrollar funciones de búsqueda avanzada simulando motores de búsqueda, sin necesidad de recurrir a costosas API de motores de búsqueda comerciales (como Google) durante el entrenamiento. Los experimentos demuestran que el uso de un LLM de 3B como motor de búsqueda simulado mejora eficazmente la capacidad de búsqueda del modelo de políticas, y el rendimiento de un módulo de recuperación de 14B parámetros incluso supera a Google Search, reduciendo al mismo tiempo los costes de API en un 88%. Esta tecnología ya está disponible en código abierto en GitHub y Hugging Face, y es compatible con series de modelos como Qwen-2.5 y LLaMA-3.2 (Fuente: WeChat)

La API de Gemini lanza la función de caché implícita, que puede ahorrar un 75% de los costes: La API de Google Gemini ha habilitado recientemente la función de caché implícita para la serie de modelos Gemini 2.5 (Pro y Flash). Cuando la solicitud de un usuario coincide con la caché, se puede ahorrar automáticamente hasta un 75% de los costes. Al mismo tiempo, se ha reducido el requisito mínimo de tokens para activar la caché: a 1K tokens para el modelo 2.5 Flash y a 2K tokens para el modelo 2.5 Pro. Esta medida tiene como objetivo reducir los costes para los desarrolladores que utilizan la API de Gemini y mejorar la eficiencia de las solicitudes repetitivas de alta frecuencia (Fuente: JeffDean)
La Universidad de Tsinghua desarrolla el microscopio óptico de IA Meta-rLLS-VSIM, que mejora la resolución volumétrica 15.4 veces: El grupo de investigación de Li Dong de la Universidad de Tsinghua, en colaboración con el equipo de Dai Qionghai, ha propuesto el microscopio de iluminación estructurada virtual de lámina de luz de red reflectante impulsado por metaaprendizaje (Meta-rLLS-VSIM). Este sistema, mediante la innovación cruzada de IA y óptica, ha mejorado la resolución lateral de la imagen de células vivas a 120 nm y la resolución axial a 160 nm, logrando una superresolución casi isotrópica y una resolución volumétrica 15.4 veces superior a la del LLSM tradicional. Sus tecnologías principales incluyen el uso de DNN para aprender y extender la capacidad de superresolución a múltiples direcciones mediante «iluminación estructurada virtual», y la mejora de la resolución axial mediante la fusión de información de doble vista por reflexión especular y la red RL-DFN. La introducción de la estrategia de metaaprendizaje permite que el modelo de IA complete el despliegue adaptativo en solo 3 minutos, lo que reduce enormemente la barrera de aplicación de la IA en experimentos biológicos y proporciona una poderosa herramienta para observar procesos vitales como la división de células cancerosas y el desarrollo embrionario (Fuente: WeChat)

Se lanza la serie de grandes modelos de lenguaje Qwen3, continuando su liderazgo en la comunidad de código abierto: Alibaba ha lanzado la serie de grandes modelos de lenguaje Qwen3, con tamaños de parámetros que van desde 0.5B hasta 235B, mostrando un rendimiento excelente en múltiples benchmarks. Varios modelos de menor tamaño han alcanzado el nivel SOTA entre los modelos de código abierto de escala similar. La serie Qwen3 admite múltiples idiomas y una longitud de contexto de hasta 128k tokens. Debido a su potente rendimiento y menores costes de despliegue (en comparación con DeepSeek-R1, etc.), la serie Qwen ha sido ampliamente adoptada en el extranjero (especialmente en Japón) como base para el desarrollo de IA, dando lugar a una gran cantidad de modelos especializados. El lanzamiento de Qwen3 consolida aún más su posición de liderazgo en la comunidad global de IA de código abierto, superando las 20,000 estrellas en GitHub en una semana (Fuente: dl_weekly, WeChat)

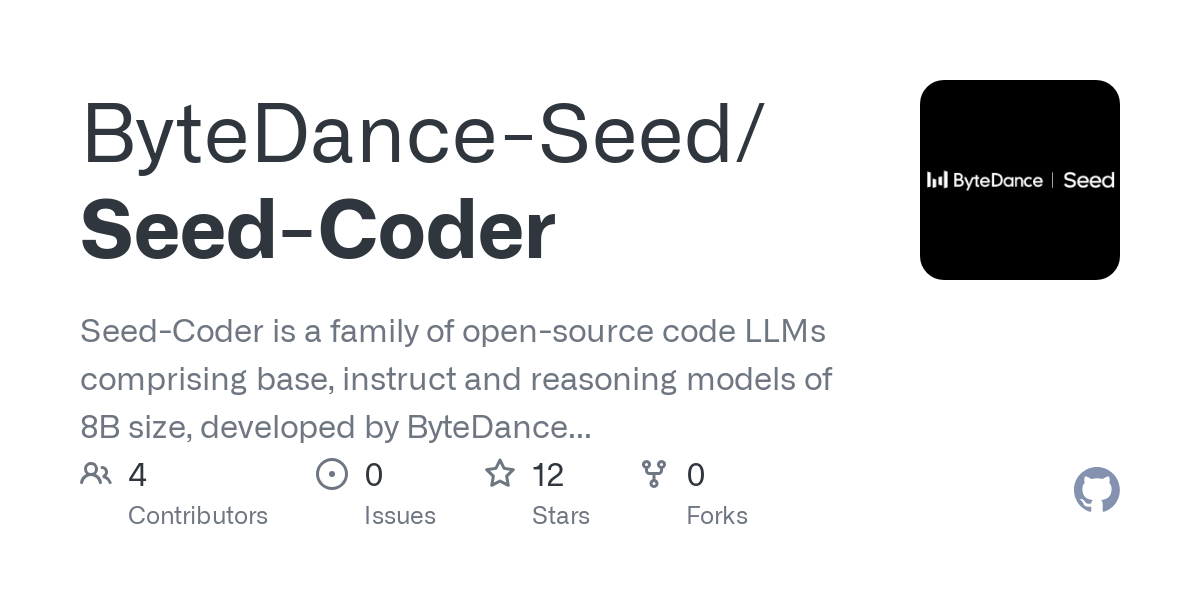
D-FINE: Detector de objetos en tiempo real basado en optimización de distribución de grano fino, con rendimiento superior: Investigadores proponen D-FINE, un nuevo detector de objetos en tiempo real que redefine la tarea de regresión de cuadros delimitadores en DETR como una optimización de distribución de grano fino (FDR) e introduce una estrategia de autodisciplina de localización óptima global (GO-LSD). D-FINE logra un rendimiento excepcional sin aumentar los costes adicionales de inferencia y entrenamiento. Por ejemplo, D-FINE-N alcanza un 42.8% de AP en COCO val, con una velocidad de hasta 472 FPS (GPU T4); D-FINE-X, después del preentrenamiento en Objects365+COCO, alcanza un AP de 59.3% en COCO val. Este método logra una localización más precisa mediante la optimización iterativa de la distribución de probabilidad y transfiere el conocimiento de localización de la capa final a las capas anteriores mediante autodisciplina (Fuente: GitHub Trending)
El modelo Harmon coordina representaciones visuales, unificando la comprensión y generación multimodal: Investigadores de la Universidad Tecnológica de Nanyang han propuesto el modelo Harmon, que tiene como objetivo unificar las tareas de comprensión y generación multimodal mediante un MAR Encoder (Masked Autoencoder for Reconstruction) compartido. La investigación descubrió que el MAR Encoder puede aprender semántica visual simultáneamente durante el entrenamiento de generación de imágenes, y sus resultados de Linear Probing superan con creces a VQGAN/VAE. El framework Harmon utiliza el MAR Encoder para procesar imágenes completas para la comprensión y adopta el paradigma de modelado de máscaras MAR para la generación de imágenes, con el LLM facilitando la interacción modal. Los experimentos demuestran que Harmon se acerca a Janus-Pro en benchmarks de comprensión multimodal y muestra un rendimiento excelente en los benchmarks de estética de generación de texto a imagen MJHQ-30K y de seguimiento de instrucciones GenEval, superando incluso a algunos modelos expertos. El modelo ya es de código abierto (Fuente: WeChat)

Tuixing Technology logra un ciclo comercial cerrado para robots logísticos mediante la acumulación de datos con un «sistema de sombra para repartidores»: Los robots logísticos de Tuixing Technology ya están operativos en varias ciudades de China, logrando el punto de equilibrio para robots individuales al trabajar en colaboración con repartidores humanos. Una de sus tecnologías principales es el «sistema de sombra para repartidores», que recopila datos sobre el comportamiento de conducción, la percepción del entorno y las operaciones (como abrir/cerrar puertas, recoger/dejar objetos) de repartidores reales en entornos urbanos complejos. Esto proporciona a los robots datos de entrenamiento masivos y de alta calidad para el aprendizaje por imitación y el aprendizaje por refuerzo. Actualmente, el sistema ha acumulado decenas de millones de kilómetros de datos de conducción y casi un millón de trayectorias de extremidades superiores. Basándose en esto, Tuixing Technology ha entrenado un modelo VLA de árbol de comportamiento, que permite a los robots hacer frente a situaciones complejas del mundo real, y planea expandirse a mercados extranjeros (Fuente: WeChat)

Kuaishou lanza el framework KuaiMod, utilizando grandes modelos multimodales para optimizar el ecosistema de videos cortos: Kuaishou ha propuesto KuaiMod, una solución de optimización del ecosistema de la plataforma de videos cortos basada en grandes modelos multimodales, con el objetivo de mejorar la experiencia del usuario mediante la discriminación automatizada de la calidad del contenido. KuaiMod se inspira en el enfoque del derecho jurisprudencial, utilizando el razonamiento en cadena de los modelos de lenguaje visual (VLM) para analizar contenido de baja calidad, y actualiza continuamente las estrategias de discriminación mediante el aprendizaje por refuerzo basado en la retroalimentación del usuario (RLUF). Este framework ya se ha implementado en la plataforma Kuaishou, reduciendo eficazmente la tasa de denuncias de usuarios en más del 20%. Kuaishou también se dedica a crear grandes modelos multimodales que puedan comprender los videos cortos de la comunidad, pasando de la extracción de representaciones a la comprensión semántica profunda, y ya se ha aplicado en múltiples escenarios como la estructuración de etiquetas de interés de video y la asistencia en la generación de contenido, logrando resultados efectivos (Fuente: WeChat)

Lenovo lanza el superagente inteligente personal «Tianxi», avanzando hacia la inteligencia de nivel L3: Lenovo presentó en su Conferencia de Innovación Tecnológica el superagente inteligente personal «Tianxi», que cuenta con percepción e interacción multimodal, cognición y toma de decisiones basadas en una base de conocimientos personal, y capacidad de desglose y ejecución autónoma de tareas complejas. Tianxi tiene como objetivo proporcionar una experiencia de colaboración hombre-máquina natural y fluida a través de interfaces AUI acompañantes como AI Suixin Chuang (AI Free Window), AI Linglong Tai (AI Exquisite Console) y AI Ruying Kuang (AI Shadow Frame). Integra múltiples grandes modelos líderes en la industria, incluido DeepSeek-R1, y adopta una arquitectura de despliegue híbrida de borde-nube, combinada con Lenovo Personal Cloud 1.0 (equipada con un gran modelo de 72 mil millones de parámetros) para proporcionar una potente capacidad de cómputo y 100 GB de espacio de memoria exclusivo. Lenovo también lanzó superagentes inteligentes a nivel empresarial «Lexiang» y a nivel urbano, mostrando su diseño integral en el campo de la IA (Fuente: WeChat)

Nueva investigación juzga la generalización de las redes neuronales mediante la complejidad de la interacción simbólica: El equipo del profesor Zhang Quanshi de la Universidad Jiao Tong de Shanghái ha propuesto una nueva teoría para analizar la generalización de las redes neuronales desde la perspectiva de la complejidad de la representación de la interacción simbólica intrínseca. El estudio encontró que las interacciones generalizables (que aparecen con alta frecuencia tanto en los conjuntos de entrenamiento como de prueba) suelen presentar una distribución decreciente en diferentes órdenes (complejidad) (predominan las interacciones de bajo orden), mientras que las interacciones no generalizables (que aparecen principalmente en el conjunto de entrenamiento) presentan una distribución fusiforme (predominan las interacciones de orden medio, y los efectos positivos y negativos se anulan fácilmente). Esta teoría tiene como objetivo juzgar directamente el potencial de generalización de un modelo analizando los patrones de distribución de su «lógica de interacción AND-OR» equivalente, proporcionando una nueva perspectiva para comprender y mejorar la generalización del modelo (Fuente: WeChat)
🧰 Herramientas
Llama.cpp es totalmente compatible con modelos de lenguaje visual (VLM): Llama.cpp ahora es totalmente compatible con modelos de lenguaje visual (VLM), lo que permite a los desarrolladores ejecutar aplicaciones multimodales en el dispositivo. Julien Chaumond de Hugging Face y otros han compartido modelos precuantizados, incluyendo Gemma de Google DeepMind, Pixtral de Mistral AI, Qwen VL de Alibaba y SmolVLM de Hugging Face, que se pueden usar directamente. Esta actualización es gracias a las contribuciones de los equipos @ngxson y @ggml_org, abriendo nuevas posibilidades para aplicaciones de IA multimodales localizadas y de baja latencia (Fuente: ggerganov, ClementDelangue, cognitivecompai)
Quark AI Super Box actualiza la «búsqueda profunda», mejorando la «inteligencia de búsqueda» de la IA: Quark AI Super Box se ha actualizado recientemente, introduciendo la función de «búsqueda profunda», con el objetivo de mejorar la inteligencia de búsqueda (SQ) de la IA. La nueva función enfatiza el pensamiento activo y la planificación lógica de la IA antes de la búsqueda, permitiendo una mejor comprensión de las intenciones de consulta complejas y personalizadas del usuario, descomponiendo problemas y realizando búsquedas inteligentes y organizadas. En el campo de la salud, el asesor de salud de IA de Quark, «Aqua», consultará opiniones de médicos de hospitales de primer nivel y materiales profesionales; en el ámbito académico, se conectará a fuentes autorizadas como CNKI. Además, Quark posee potentes capacidades de procesamiento multimodal, como análisis de imágenes, recorte de IA, mejora de imágenes y transformación de estilos. Se informa que Quark lanzará en el futuro una versión Pro de búsqueda profunda con capacidades de Deep Research (Fuente: WeChat)

LangChain lanza múltiples integraciones y tutoriales, fortaleciendo las capacidades de RAG y agentes inteligentes: LangChain ha publicado recientemente varias actualizaciones y tutoriales: 1. Tutorial de UI para agentes de redes sociales: Guía sobre cómo transformar agentes de redes sociales de LangChain en aplicaciones web fáciles de usar, integrando ExpressJS y la UI de AgentInbox, y con soporte para Notion. 2. Solución RAG galardonada: Muestra una implementación de RAG para analizar informes anuales de empresas, compatible con análisis de PDF, múltiples LLM y recuperación avanzada. 3. Aplicación de chat RAG privada: Tutorial que demuestra cómo construir una aplicación de chat RAG localizada y centrada en la privacidad de los datos utilizando LangChain y el framework Reflex. 4. Integración de Nimble Retriever: Introduce un potente recuperador de datos web, proporcionando datos precisos para aplicaciones LangChain. 5. Guía de salida estructurada para Claude 3.7: Ofrece tres métodos para lograr una salida estructurada con Claude 3.7 a través de LangChain y AWS Bedrock. 6. Sistema RAG de chat local: Proyecto de código abierto que muestra un sistema de preguntas y respuestas sobre documentos completamente localizado, construido con el flujo RAG de LangChain y LLM locales (a través de Ollama), garantizando la privacidad de los datos (Fuente: LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI)

Minion-agent: Un framework de agentes de IA de código abierto que integra capacidades de múltiples frameworks: Minion-agent es un nuevo framework de desarrollo de agentes de IA de código abierto, diseñado para resolver el problema de fragmentación de los frameworks de IA existentes (como OpenAI, LangChain, Google AI, SmolaAgents). Proporciona una interfaz unificada, admite la invocación de capacidades de múltiples frameworks, herramientas como servicio (navegación web, operaciones de archivos, etc.) y colaboración multiagente. El proyecto demuestra su potencial de aplicación en escenarios como la investigación profunda (recopilación automática de literatura para generar informes), comparación de precios (investigación de mercado automatizada), generación creativa (generación de código de juegos) y seguimiento de dinámicas tecnológicas, enfatizando las ventajas del modelo de código abierto en flexibilidad y rentabilidad (Fuente: WeChat)

RunwayML demuestra potentes capacidades de generación y edición de video en múltiples escenarios: El investigador independiente de IA Cristobal Valenzuela y otros usuarios han demostrado la aplicación de RunwayML en diversos escenarios creativos. Esto incluye el uso de sus funciones Frames, References y Gen-4 para generar y visualizar rápidamente ideas visuales creativas manteniendo la coherencia de estilo y personajes; transformar el mundo de Rembrandt en un videojuego RPG; y lograr una novedosa síntesis de vistas de diseño de interiores a partir de una sola imagen de referencia visual. Estos casos destacan los avances de RunwayML en la generación controlada de video, la transferencia de estilo y la construcción de escenas (Fuente: c_valenzuelab, c_valenzuelab, c_valenzuelab, c_valenzuelab)

Olympus: Un enrutador de tareas universal para tareas de visión por computadora: Olympus es un enrutador de tareas universal diseñado para tareas de visión por computadora. Su objetivo es simplificar y unificar los flujos de procesamiento de diferentes tareas visuales, posiblemente mediante la programación inteligente y la asignación de recursos computacionales o llamadas a modelos, para optimizar la eficiencia y el rendimiento de los sistemas de visión por computadora multitarea. El proyecto es de código abierto en GitHub (Fuente: dl_weekly)
Tracy Profiler: Analizador híbrido de fotogramas y muestreo en tiempo real a nivel de nanosegundos: Tracy Profiler es una herramienta de análisis de fotogramas y muestreo híbrida en tiempo real, con resolución de nanosegundos y soporte para telemetría remota, para juegos y otras aplicaciones. Admite el análisis de rendimiento de CPU (C, C++, Lua, Python, Fortran y bindings de terceros para Rust, Zig, C#, etc.), GPU (OpenGL, Vulkan, Direct3D, Metal, OpenCL), asignación de memoria, bloqueos y cambios de contexto, y puede asociar automáticamente capturas de pantalla con los fotogramas capturados. Esta herramienta, con su alta precisión y tiempo real, proporciona a los desarrolladores potentes medios para localizar y optimizar cuellos de botella de rendimiento (Fuente: GitHub Trending)

FieldStation42: Simulador de transmisión de televisión retro: FieldStation42 es un proyecto de Python que tiene como objetivo simular la experiencia de ver televisión de transmisión antigua. Puede admitir múltiples canales simultáneamente, insertar automáticamente anuncios y avances de programas, y generar una programación semanal según la configuración. El simulador puede seleccionar aleatoriamente programas no emitidos recientemente para mantener la frescura, admite la configuración de rangos de fechas de emisión de programas (como programas de temporada) y puede configurar videos de cierre de estación de televisión y pantallas de bucle sin señal. El proyecto también admite la conexión de hardware (como Raspberry Pi Pico) para simular operaciones de cambio de canal y proporciona una función de canal de vista previa/guía. Su objetivo es que cuando un usuario «encienda el televisor», pueda reproducir contenido de programa «real» que corresponda a esa franja horaria y canal (Fuente: GitHub Trending)

Tiny Corp presenta una solución eGPU AMD basada en USB3, compatible con Apple Silicon: Tiny Corp ha demostrado una solución para conectar una eGPU AMD a un Mac con Apple Silicon a través de USB3 (específicamente, utilizando un dispositivo ADT-UT3G basado en el controlador ASM2464PD). Esta solución reescribe los controladores, con el objetivo de utilizar el ancho de banda de 10 Gbps de USB3 y utiliza libusb, lo que teóricamente también la hace compatible con Linux o Windows. Esto ofrece una nueva vía para que los usuarios de Apple Silicon amplíen su capacidad de procesamiento gráfico, especialmente valiosa para escenarios como la ejecución local de grandes modelos de IA (Fuente: Reddit r/LocalLLaMA)
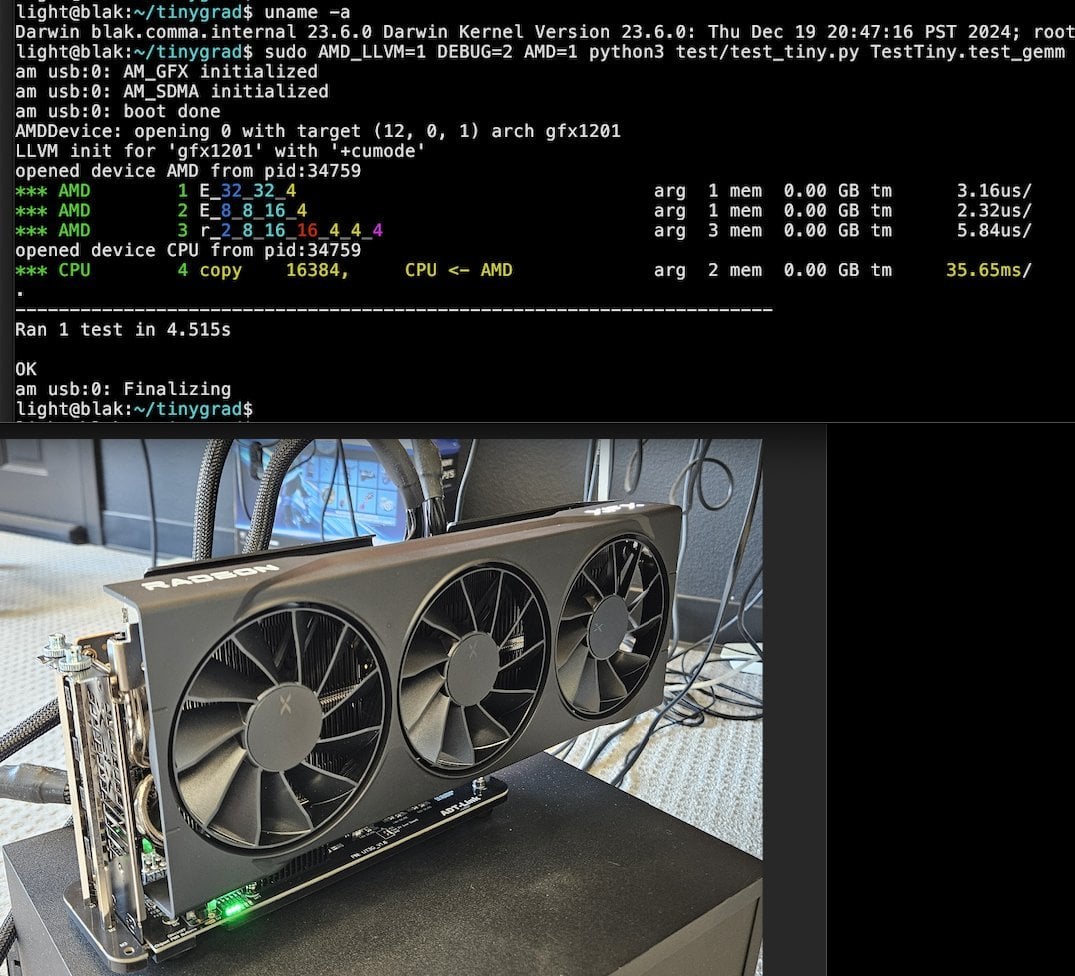
Llama.cpp-vulkan implementa soporte para FlashAttention en GPU AMD: El backend Vulkan de Llama.cpp ha fusionado recientemente la implementación de FlashAttention, lo que significa que los usuarios que utilizan llama.cpp-vulkan en GPU AMD ahora pueden aprovechar la tecnología FlashAttention. Combinado con la cuantización de caché KV Q8, se espera que los usuarios puedan duplicar el tamaño del contexto mientras mantienen o mejoran la velocidad de inferencia. Esta actualización es un beneficio importante para los usuarios de GPU AMD que ejecutan grandes modelos de lenguaje localmente (Fuente: Reddit r/LocalLLaMA)
Devseeker: Asistente de codificación de IA ligero, alternativa a Aider y Claude Code: Devseeker es un nuevo proyecto de agente de codificación de IA ligero y de código abierto, posicionado como una alternativa a Aider y Claude Code. Tiene la capacidad de crear y editar código, gestionar archivos y carpetas de código, memoria de código a corto plazo, revisión de código, ejecutar archivos de código, calcular el uso de tokens y ofrecer múltiples modos de codificación. El proyecto tiene como objetivo proporcionar una herramienta de programación asistida por IA más fácil de desplegar y usar localmente (Fuente: Reddit r/ClaudeAI)
📚 Aprendizaje
Panaversity lanza un proyecto de aprendizaje de IA Agéntica, centrado en Dapr y OpenAI Agents SDK: Panaversity ha lanzado el proyecto «Learn Agentic AI», con el objetivo de formar ingenieros de IA agéntica y robótica a través del patrón de diseño Dapr Agentic Cloud Ascent (DACA) y múltiples tecnologías nativas de la nube para agentes (incluyendo OpenAI Agents SDK, Memory, MCP, A2A, Knowledge Graphs, Dapr, Rancher Desktop, Kubernetes). El proyecto se centra en cómo diseñar sistemas capaces de manejar decenas de millones de agentes de IA concurrentes y ofrece las series de cursos AI-201, AI-202, AI-301, que cubren desde los fundamentos hasta los agentes de IA distribuidos a gran escala. El proyecto enfatiza que OpenAI Agents SDK debería convertirse en el framework de desarrollo principal debido a su simplicidad, facilidad de uso y alto control (Fuente: GitHub Trending)

Investigación sobre el ajuste fino con RL revela la compleja relación entre la gestión de datos y la capacidad de generalización: Un artículo compartido por Minqi Jiang discute el impacto de la gestión de datos en la capacidad de generalización del modelo durante el ajuste fino con aprendizaje por refuerzo (RL). El estudio encontró que, ya sea entrenando en tareas de codificación «infinitas» mediante aprendizaje curricular por auto-juego (Absolute Zero Reasoner), o entrenando repetidamente solo en una única muestra de tarea MATH (1-shot RLVR), los modelos de la serie Qwen2.5 de tamaño 7B pueden lograr una mejora de precisión de aproximadamente 28% a 40% en benchmarks matemáticos. Esto revela una paradoja: estrategias extremas de gestión de datos (datos infinitos vs. datos de un solo punto) pueden producir mejoras de generalización similares. Las posibles explicaciones incluyen que el RL principalmente extrae capacidades preexistentes del modelo preentrenado, la existencia de «circuitos de razonamiento» compartidos y que el preentrenamiento podría conducir a circuitos de razonamiento competitivos. Los investigadores creen que para superar el «techo del preentrenamiento», es necesario recopilar y crear continuamente nuevas tareas y entornos (Fuente: menhguin)
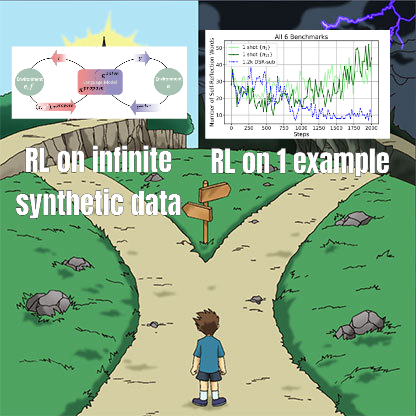
Absolute Zero Reasoner: Mejora de la capacidad de razonamiento con cero datos mediante auto-juego: Un artículo titulado «Absolute Zero Reasoner» propone que un modelo puede aprender a proponer tareas que maximicen la capacidad de aprendizaje mediante auto-juego completo (self-play), y mejorar su propia capacidad de razonamiento resolviendo estas tareas, todo el proceso sin necesidad de datos externos. Este método supera a otros modelos «zero-shot» tanto en el dominio matemático como en el de la codificación. Esto sugiere que los sistemas de IA podrían evolucionar continuamente sus capacidades de razonamiento generando y resolviendo problemas internamente, ofreciendo nuevas ideas para aplicaciones de IA en dominios con datos escasos o altos costes de anotación (Fuente: cognitivecompai, Reddit r/LocalLLaMA)

Errores comunes en la evaluación de productos de IA y mejores prácticas compartidas: Hamel Husain y Shreya Runwal compartieron errores comunes al crear evaluaciones de productos de IA (evals) y ofrecieron consejos para evitarlos. Los puntos clave incluyen: los benchmarks de modelos base no equivalen a la evaluación de aplicaciones; las evaluaciones genéricas no son válidas, deben ser específicas para la aplicación concreta; no subcontratar la anotación y la ingeniería de prompts a no expertos en el dominio; se deben construir aplicaciones de anotación de datos propias; los prompts de LLM deben ser específicos y basarse en el análisis de errores; usar etiquetas binarias; dar importancia a la revisión de datos; tener cuidado con el sobreajuste a los datos de prueba; realizar pruebas en línea. Estas prácticas tienen como objetivo ayudar a los desarrolladores a construir sistemas de evaluación de productos de IA más fiables y que reflejen mejor el rendimiento en el mundo real (Fuente: jeremyphoward, HamelHusain)
Nuevas ideas para la optimización de la caché KV: Diccionario universal transferible y reconstrucción mediante procesamiento de señales: El equipo de Dimitris Papailiopoulos de la Universidad de Wisconsin-Madison propone un nuevo método para reducir la caché KV, utilizando un diccionario universal y transferible combinado con algoritmos tradicionales de reconstrucción de procesamiento de señales. Este método ya ha alcanzado el nivel SOTA (state-of-the-art) en modelos que no son de inferencia y se espera que funcione aún mejor en modelos de inferencia. Esta investigación ha sido aceptada en ICML, proporcionando una nueva perspectiva y ruta técnica para resolver el problema del alto consumo de la caché KV en la inferencia de grandes modelos (Fuente: teortaxesTex, jeremyphoward, arohan, andersonbcdefg)

Qdrant promueve sistemas RAG y prácticas de búsqueda híbrida en la comunidad brasileña: La base de datos vectorial Qdrant está ganando cada vez más atención en la comunidad brasileña. El desarrollador Daniel Romero compartió dos artículos en portugués que presentan métodos prácticos para construir sistemas RAG (Recuperación Aumentada por Generación) utilizando Qdrant, FastAPI y búsqueda híbrida. El contenido incluye cómo construir un sistema RAG de búsqueda híbrida y estrategias de ingesta de datos para RAG, en particular la técnica de Hybrid Chunking. Estos recursos ayudan a los desarrolladores brasileños a utilizar mejor Qdrant para el desarrollo de aplicaciones de IA (Fuente: qdrant_engine)
OpenAI Academy lanza una serie temática sobre ingeniería de prompts para educación K-12: OpenAI Academy ha lanzado la serie de aprendizaje «Mastering Your Prompts» sobre ingeniería de prompts (Prompt Engineering) dirigida a educadores de K-12. La serie tiene como objetivo ayudar a los educadores a comprender y aplicar mejor las técnicas de prompting para integrar más eficazmente herramientas de IA (como ChatGPT) en la práctica docente, mejorando los resultados de la enseñanza y la experiencia de aprendizaje de los estudiantes. Esto indica que la educación asistida por IA se está infiltrando gradualmente en la etapa de educación básica y se está dando importancia a la formación de la alfabetización en IA de los educadores (Fuente: dotey)
Yann LeCun comparte el contenido de su charla en la Universidad Nacional de Singapur: Yann LeCun compartió el documento PDF de su Conferencia Distinguida (Distinguished Lecture) impartida el 27 de abril de 2025 en la Universidad Nacional de Singapur (NUS). Aunque no se proporcionó el tema específico de la charla, LeCun, como pionero en el campo del aprendizaje profundo, sus conferencias suelen abordar teorías de vanguardia de la inteligencia artificial, tendencias futuras o profundas reflexiones sobre el desarrollo actual de la IA. Este recurso ofrece a los interesados en la investigación de la IA acceso directo a sus últimas perspectivas (Fuente: ylecun)
PyTorch colabora con el backend de Mojo para simplificar la adaptación a nuevo hardware y lenguajes: PyTorch está trabajando para simplificar el proceso de creación de nuevos backends para lenguajes de programación y hardware emergentes. En el hackathon de Mojo, marksaroufim mostró los esfuerzos de PyTorch en este sentido y mencionó un backend WIP (en progreso) desarrollado en colaboración con el equipo de Mojo. Esto indica que el ecosistema PyTorch está expandiendo activamente su compatibilidad para admitir entornos de desarrollo de IA y opciones de aceleración de hardware más diversos, reduciendo así la barrera para los desarrolladores al desplegar y optimizar modelos PyTorch en diferentes plataformas (Fuente: marksaroufim)
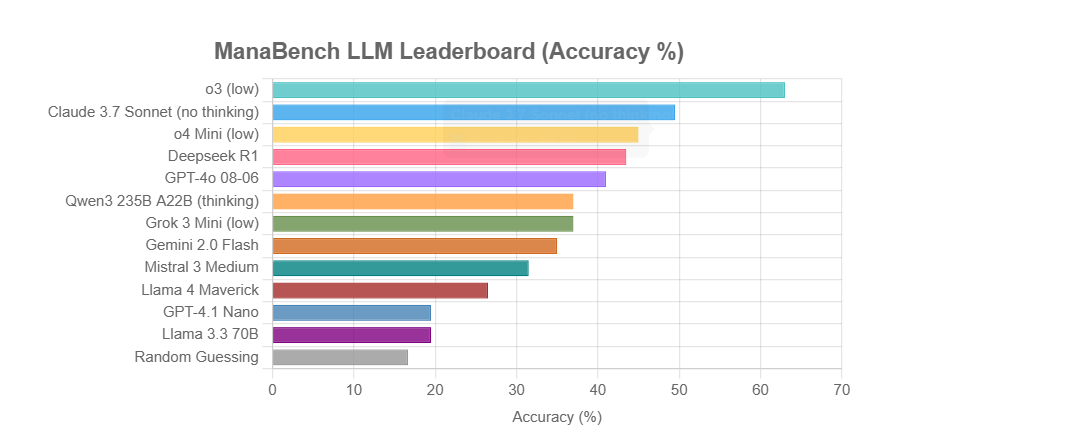
ManaBench: Nuevo benchmark de capacidad de razonamiento de LLM basado en la construcción de mazos de Magic: The Gathering: Un desarrollador ha creado un nuevo benchmark llamado ManaBench, que prueba la capacidad de razonamiento de sistemas complejos de los LLM haciéndoles elegir la carta número 60 más adecuada entre seis opciones, dadas 59 cartas de Magic: The Gathering (MTG). Este benchmark enfatiza el razonamiento estratégico, la optimización de sistemas, y las respuestas son consistentes con el diseño de expertos humanos, siendo difíciles de descifrar mediante simple memorización. Los resultados preliminares muestran que los modelos de la serie Llama rinden por debajo de lo esperado, mientras que modelos de código cerrado como o3 y Claude 3.7 Sonnet lideran. Este benchmark tiene como objetivo evaluar de manera más realista el rendimiento de los LLM en tareas que requieren un razonamiento complejo (Fuente: Reddit r/LocalLLaMA)
Discusión: ¿Revivirá o enterrará la IA el sueño de la Web Semántica?: En las redes sociales, el usuario Spencer mencionó que, a menos que se trate de sitios web de grandes empresas con una exposición significativa al riesgo debido a la ley ADA (Ley de Estadounidenses con Discapacidades), la Web Semántica es más teórica que práctica en la mayoría de los sitios web. Dorialexander respondió que siente que la IA o revivirá el sueño de la Web Semántica o lo enterrará para siempre. Esto refleja la expectación y la preocupación sobre el potencial de la IA en la comprensión y utilización de datos estructurados; la IA podría alcanzar indirectamente los objetivos de la Web Semántica mediante la comprensión y generación automática de información estructurada, pero también podría hacer que la tecnología tradicional de la Web Semántica sea menos importante debido a sus propias potentes capacidades (Fuente: Dorialexander)
Investigadores exploran la ética y las arquitecturas de la memoria y el olvido en modelos: Se está redactando un borrador de artículo titulado «Sticky Minds: The Ethics and Architectures of AI Memory and Forgetting», que explora cómo decidimos qué deben olvidar los modelos cuando empiezan a «recordar demasiado bien», fusionando la neuroarquitectura con la ética de la memoria. Esto se refiere a cómo los sistemas de IA almacenan, recuperan y (selectivamente) olvidan información, así como los desafíos éticos y el impacto social que esto conlleva, lo cual es crucial para construir una IA responsable y confiable (Fuente: Reddit r/artificial)
💼 Negocios
Se rumorea que Nvidia lanzará una versión «recortada adicionalmente» del chip H20 para cumplir con los nuevos controles de exportación de EE. UU.: Según Reuters, Nvidia planea lanzar en los próximos dos meses una nueva versión del chip de IA H20 específica para China, con el fin de cumplir con los últimos requisitos de control de exportación de EE. UU. Este chip será «recortado» aún más sobre la base del H20 original (que ya era una versión degradada personalizada para el mercado chino), por ejemplo, la capacidad de memoria de video se reducirá significativamente. Aunque el rendimiento se reducirá nuevamente, se dice que los usuarios finales podrían ajustar el rendimiento en cierta medida modificando la configuración del módulo. Actualmente, Nvidia ha recibido pedidos del H20 por valor de 18 mil millones de dólares (Fuente: WeChat)

Databricks podría adquirir la empresa de bases de datos de código abierto Neon por 1.000 millones de dólares, fortaleciendo su infraestructura de IA: Se rumorea que la empresa de datos e IA Databricks está en negociaciones para adquirir Neon, desarrollador del motor de base de datos PostgreSQL de código abierto, por una suma que podría rondar los 1.000 millones de dólares. Neon se caracteriza por su arquitectura sin servidor, la separación de almacenamiento y cómputo, y su buena adaptación a los agentes de IA y la programación ambiental, permitiendo el pago por uso y el rápido inicio de instancias de base de datos, lo que la hace adecuada para escenarios de aplicaciones de IA. De tener éxito, esta adquisición fortalecería aún más la capa de infraestructura de Databricks en la era de la IA, proporcionándole una solución de base de datos modernizada y centrada en la IA (Fuente: WeChat)

OpenAI nombra a la ex CEO de Instacart, Fidji Simo, como CEO de Negocios de Aplicaciones, fortaleciendo producto y comercialización: OpenAI anunció el nombramiento de Fidji Simo, ex CEO de Instacart y miembro de la junta directiva de la compañía, como la nueva «CEO de Negocios de Aplicaciones», al mismo nivel que Sam Altman. Simo será responsable integral de los productos de OpenAI, especialmente de las aplicaciones orientadas al usuario como ChatGPT, con el objetivo de impulsar la optimización del producto, la mejora de la experiencia del usuario y el proceso de comercialización. Este movimiento marca un cambio significativo en el enfoque estratégico de OpenAI, desde la investigación y desarrollo de modelos hacia la plataformización de productos y la expansión del mercado, con la intención de establecer una mayor competitividad en la capa de aplicaciones de IA. La amplia experiencia de Simo en productos y comercialización en Facebook e Instacart ayudará a OpenAI a enfrentar la creciente competencia del mercado (Fuente: WeChat)

🌟 Comunidad
JetBrains AI Assistant genera descontento entre los usuarios por su mala experiencia y gestión de comentarios: Aunque el plugin AI Assistant de JetBrains tiene más de 22 millones de descargas, su calificación en el marketplace es de solo 2.3 sobre 5, con una gran cantidad de críticas de 1 estrella. Los usuarios se quejan comúnmente de su instalación automática, lentitud, numerosos bugs, soporte insuficiente para modelos de terceros, funciones principales vinculadas a servicios en la nube y falta de documentación. Recientemente, se acusó a JetBrains de eliminar masivamente comentarios negativos; aunque la explicación oficial fue que se trataba de contenido que infringía las normas o problemas ya resueltos, esto generó dudas entre los usuarios sobre el control de la opinión y la falta de atención a sus comentarios, lo que llevó a algunos a volver a publicar sus críticas negativas y mantener la calificación de 1 estrella. Este incidente ha exacerbado el descontento de los usuarios con la estrategia de productos de IA de JetBrains (Fuente: WeChat)

Usuarios debaten sobre la calidad de los resultados de los agentes inteligentes de marketing de IA: El usuario de redes sociales omarsar0 observó que muchos tutoriales de YouTube que muestran agentes de IA para marketing generan textos publicitarios de calidad generalmente pobre, carentes de creatividad y estilo. Considera que esto refleja la dificultad de hacer que los LLM produzcan contenido atractivo y de alta calidad, y enfatiza que el «gusto» es crucial al construir agentes de IA. Señala que muchos agentes de IA actuales, aunque tienen flujos de trabajo complejos, aún son deficientes en la producción de contenido con verdadero valor comercial, lo que abre oportunidades para talentos con buen gusto, experiencia y capacidad para diseñar buenos sistemas de evaluación (Fuente: omarsar0)
La codificación asistida por IA y la tendencia de la «programación ambiental» generan debate: Una publicación en Reddit sobre un video de Y Combinator que discute la codificación con IA generó un animado debate. Las opiniones del video coincidían en gran medida con la experiencia del autor de la publicación (quien afirma haber creado múltiples proyectos rentables mediante «programación ambiental»). Los puntos centrales incluyen: 1. La IA ya puede ayudar a construir productos de software complejos y utilizables, incluso sin escribir código. 2. Los ingenieros de software están cada vez más preocupados por que la IA reemplace sus trabajos, pero aquellos que realmente dominan el desarrollo asistido por IA poseen «superpoderes». 3. El papel futuro de los ingenieros de software podría transformarse en «gestores de agentes» expertos en el uso de herramientas de IA, mientras que la IA se encargaría de la mayor parte de la escritura de código. 4. La IA generará una gran cantidad de software de nicho para mercados específicos. Los participantes en la discusión consideraron que, aunque el potencial de la codificación con IA es enorme, todavía se necesitan conocimientos de conceptos de ingeniería, bases de datos, arquitectura, etc., para utilizarla eficazmente (Fuente: Reddit r/ClaudeAI)

Continúa el debate sobre si la IA «dominará el mundo» y su impacto en el empleo: Las publicaciones en el subreddit r/ArtificialInteligence reflejan la ansiedad generalizada de la comunidad y la diversidad de opiniones sobre el impacto futuro de la IA. Algunos usuarios creen que cuanto más se conoce la capacidad de la IA, mayor es la preocupación de que supere a los humanos y domine el futuro, señalando que los sistemas de IA de vanguardia ya muestran capacidades asombrosas. Otros usuarios, sin embargo, consideran que la exageración sobre la AGI ha llevado a expectativas poco realistas, y que la IA es esencialmente una herramienta de automatización inteligente cuyo impacto será gradual, similar al de las computadoras e Internet. La discusión también aborda el impacto potencial de la IA en el empleo, la distribución de la riqueza y la eficacia de la regulación. Hay opiniones que sugieren que la historia demuestra que el progreso tecnológico a menudo agrava la brecha entre ricos y pobres, y que la IA podría concentrar aún más la riqueza al eliminar una gran cantidad de puestos de trabajo. Al mismo tiempo, también hay quienes expresan expectativas positivas sobre el papel de la IA en áreas como la medicina y la educación (Fuente: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Experiencia de usuario: Cómo herramientas de IA como ChatGPT afectan el pensamiento y la cognición: Algunos usuarios han compartido en plataformas sociales y Reddit los efectos cognitivos positivos de usar herramientas de IA como ChatGPT. Sienten que la IA no es solo una herramienta para obtener información o ayudar a escribir, sino más bien un «compañero de pensamiento» o un «espejo» que les ayuda a aclarar sus ideas y expresar claramente pensamientos subconscientes. A través del diálogo con la IA, los usuarios afirman poder reflexionar mejor, desafiar sus propias creencias, descubrir patrones de pensamiento e incluso sentir que están «despertando» a una comprensión más profunda de la vida y los sistemas. Esta experiencia sugiere que la IA, en algunos casos, puede convertirse en un catalizador para el crecimiento personal y la autoexploración (Fuente: Reddit r/ChatGPT)
💡 Otros
Se lanza la segunda edición del Concurso Nacional de Innovación y Aplicación de Inteligencia Artificial «Xingzhi Cup»: Organizado conjuntamente por la Academia China de Tecnología de la Información y las Comunicaciones (CAICT) y otras entidades, se inauguró la segunda edición del «Xingzhi Cup». Bajo el lema «Potenciando con Inteligencia, Liderando con Innovación», el concurso cuenta con tres categorías principales: Innovación en Grandes Modelos, Empoderamiento Sectorial y Ecosistema de Innovación en Software y Hardware, además de varias direcciones especializadas. El evento tiene como objetivo promover la innovación tecnológica en IA, su implementación en ingeniería y la construcción de un ecosistema autónomo, cubriendo cerca de 10 industrias clave como la industrial, médica y financiera, y enfatizando la aplicación de software y hardware de IA de producción nacional. Los proyectos ganadores recibirán financiación, apoyo para la conexión industrial, entre otros (Fuente: WeChat)

Perspectivas de Sequoia Capital en AI Ascent: El mercado de la IA tiene un enorme potencial, la capa de aplicación y la economía de agentes son el futuro: Pat Grady, socio de Sequoia Capital, y otros compartieron sus perspectivas sobre el mercado de la IA en el evento AI Ascent. Consideran que el potencial del mercado de la IA supera con creces al de la computación en la nube, pero advierten sobre los «ingresos por ambiente» (usuarios que prueban por curiosidad y no por una necesidad real). La capa de aplicación se considera donde reside el verdadero valor, y las startups deben centrarse en nichos verticales y las necesidades de los clientes. La IA ya ha logrado avances en la generación de voz y la programación. La perspectiva futura es la «economía de agentes», donde los agentes de IA podrán transferir recursos y realizar transacciones, pero enfrentan desafíos como la identidad persistente, los protocolos de comunicación y la seguridad. Al mismo tiempo, la IA ampliará enormemente las capacidades individuales, dando lugar a «superindividuos» (Fuente: WeChat)

Discusión: El contenido de los cursos universitarios de Machine Learning y la calidad de la enseñanza en la era de la IA generan atención: La publicación del programa de su curso de ML para posgrado por parte del profesor Kyunghyun Cho de la NYU generó debate. El curso enfatiza problemas que no son de LLM resolubles mediante SGD y la lectura de artículos clásicos, lo que obtuvo el reconocimiento de colegas como profesores de CS de Harvard, quienes consideran importante preservar los conceptos fundamentales. Sin embargo, estudiantes de India y Estados Unidos se quejaron de la baja calidad de sus cursos universitarios de ML, demasiado abstractos, llenos de terminología pero carentes de explicaciones profundas, lo que lleva a los estudiantes a depender del autoaprendizaje y los recursos en línea. Esto refleja la contradicción entre el rápido desarrollo del campo de la IA/ML y el retraso en la actualización de los planes de estudio universitarios, así como la importancia de una sólida base matemática y teórica (Fuente: WeChat)
