
Palabras clave:ChatGPT, GitHub, Modelo de IA, Multimodal, Aprendizaje por refuerzo, Código abierto, Meta FAIR, AGI, Función de investigación profunda de ChatGPT, Arquitectura híbrida Transformer, Afinamiento por refuerzo RFT, Modelo multiverso de IA para mundos múltiples, Marco de IA para científicos
🔥 Enfoque
La función de investigación profunda (Deep Research) de ChatGPT se integra con GitHub: OpenAI anunció que la función de investigación profunda (Deep Research) de ChatGPT ahora admite la conexión con repositorios de código de GitHub. Después de que un usuario hace una pregunta, el agente de IA puede leer, buscar y analizar automáticamente el código fuente, PRs y documentos README en el repositorio, generando informes detallados con citas directas. Esta función tiene como objetivo ayudar a los desarrolladores a familiarizarse rápidamente con los proyectos, comprender la estructura del código y la pila tecnológica. Actualmente, esta función se encuentra en fase de prueba y está disponible para usuarios de Team, y se extenderá gradualmente a los usuarios de Plus y Pro. (Fuente: OpenAI Developers, snsf, EdwardSun0909, op7418, gdb, tokenbender, 量子位, 36氪)

Se lanza en código abierto Multiverse, el primer modelo de mundo multijugador de IA del mundo: La startup israelí Enigma Labs ha lanzado en código abierto su modelo de mundo multijugador Multiverse, que permite a dos agentes de IA percibir, interactuar y colaborar en el mismo entorno generado. El modelo, entrenado con Gran Turismo 4, procesa el estado del mundo compartido apilando las perspectivas de los dos jugadores a lo largo de los canales de color y combinando fotogramas históricos muestreados de forma dispersa, logrando entrenarse y ejecutarse en tiempo real en PC con un costo inferior a 1500 dólares. Este avance se considera un progreso importante en la comprensión y generación de entornos virtuales compartidos por parte de la IA, ofreciendo nuevas ideas para sistemas multiagente y plataformas de entrenamiento por simulación. (Fuente: Reddit r/MachineLearning, 36氪)
El destacado científico de IA Rob Fergus regresa para dirigir Meta FAIR, con el objetivo de la AGI: Rob Fergus, quien cofundó FAIR tempranamente con Yann LeCun y luego lideró el equipo de Nueva York en DeepMind, ha regresado a Meta para suceder a Joelle Pineau como director de FAIR. Fergus se unió al departamento de GenAI de Meta en abril de este año, dedicándose a mejorar la memoria y las capacidades de personalización del modelo Llama. LeCun anunció simultáneamente que el nuevo objetivo de FAIR será la inteligencia artificial general (AGI). Fergus es un académico altamente citado en el campo de la IA, con trabajos representativos que incluyen la investigación de visualización de ZFNet y trabajos pioneros sobre ejemplos adversarios. (Fuente: ylecun, 36氪)

Anthropic publica investigación sobre los valores de Claude AI, revelando 3307 tendencias de valor de la IA: El equipo de investigación de Anthropic publicó el artículo preimpreso “Values in the Wild”, que identifica 3307 valores únicos de la IA mediante el análisis del rendimiento de Claude AI en conversaciones del mundo real. El estudio encontró que los valores más comunes están orientados al servicio, como “servicial” (23.4%), “profesionalismo” (22.9%) y “transparencia” (17.4%). Los valores de la IA se agruparon en cinco categorías principales: utilitarios (31.4%), cognitivos (22.2%), sociales (21.4%), de protección (13.9%) y personales (11.1%), y mostraron una alta dependencia del contexto. Claude generalmente responde de manera solidaria a los valores expresados por los humanos (43%), el reflejo de valores representa aproximadamente el 20%, mientras que la resistencia a los valores del usuario es rara (5.4%). (Fuente: Reddit r/ArtificialInteligence)
Yoshua Bengio propone el marco “Scientist AI”, abogando por una ruta de desarrollo de IA más segura: El ganador del Premio Turing, Yoshua Bengio, publicó un artículo de opinión en la revista Time exponiendo la dirección de investigación de su equipo sobre “Scientist AI” (IA Científica). Considera que esta es una ruta de desarrollo de IA práctica, efectiva y más segura, destinada a reemplazar la trayectoria actual de desarrollo de IA impulsada por agentes y sin control. El marco enfatiza que los sistemas de IA deben poseer interpretabilidad, verificabilidad y la capacidad de alinearse con los valores humanos, simulando la metodología de la investigación científica para hacer que el comportamiento y los procesos de toma de decisiones de la IA sean más transparentes y controlables, reduciendo así los riesgos potenciales. (Fuente: Yoshua_Bengio)
🎯 Tendencias
La función de ajuste fino reforzado (RFT) de OpenAI se lanza oficialmente en o4-mini: OpenAI anunció que la función de ajuste fino reforzado (RFT), previsualizada en diciembre pasado, ya está oficialmente disponible en el modelo o4-mini. RFT utiliza el razonamiento de cadena de pensamiento y la puntuación específica de la tarea para mejorar el rendimiento del modelo en dominios complejos. Por ejemplo, la empresa AccordanceAI ha utilizado RFT para ajustar modelos con un rendimiento de vanguardia en impuestos y contabilidad. (Fuente: OpenAI Developers, gdb, 量子位, 36氪)
La API de Gemini lanza la función de caché implícito, reduciendo el costo de llamada en un 75%: La API de Gemini de Google ha añadido una función de caché implícito que, cuando una solicitud de usuario tiene un prefijo común con una solicitud anterior, puede activar automáticamente un acierto de caché, ahorrando a los usuarios el 75% de las tarifas de Tokens. Esta función no requiere que los desarrolladores creen activamente una caché. Al mismo tiempo, el requisito mínimo de Tokens para activar la caché se ha reducido a 1K en Gemini 2.5 Flash y a 2K en 2.5 Pro, lo que reduce aún más los costos de uso de la API. (Fuente: op7418)

OpenAI lanza completamente la función de memoria de ChatGPT en el Espacio Económico Europeo y otras regiones: OpenAI anunció que la función de memoria de ChatGPT se ha lanzado por completo para los usuarios de Plus y Pro en el Espacio Económico Europeo (EEE), Reino Unido, Suiza, Noruega, Islandia y Liechtenstein. Esta función permite a ChatGPT hacer referencia a todos los historiales de chat pasados del usuario para proporcionar respuestas más personalizadas, comprender mejor las preferencias e intereses del usuario y, por lo tanto, ofrecer una ayuda más precisa en la escritura, las sugerencias, el aprendizaje, etc. (Fuente: openai)
ByteDance Seed presenta el modelo fundacional multimodal Mogao: El equipo SEED de ByteDance ha lanzado un modelo fundacional Omni llamado Mogao, diseñado específicamente para la generación multimodal intercalada. Mogao integra múltiples mejoras técnicas, incluyendo un diseño de fusión profunda, codificadores visuales duales, incrustaciones de posición rotatoria intercaladas y guía sin clasificador multimodal. Estas mejoras le permiten combinar las ventajas de los modelos autorregresivos (generación de texto) y los modelos de difusión (síntesis de imágenes de alta calidad), procesando eficazmente secuencias arbitrarias intercaladas de texto e imágenes. (Fuente: NandoDF)

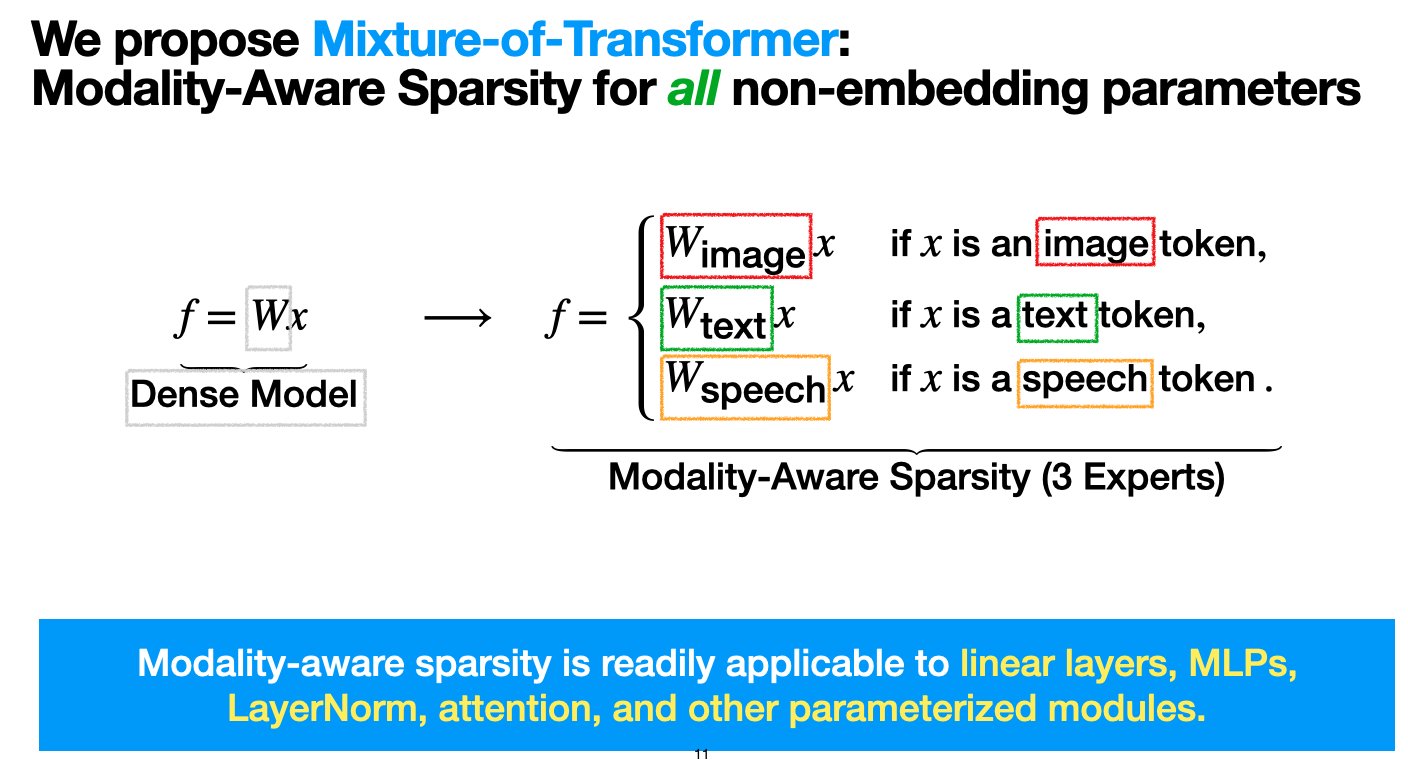
Meta presenta la arquitectura de Transformadores Mixtos (MoT), con el objetivo de reducir los costos de preentrenamiento de modelos multimodales: Investigadores de Meta AI han propuesto una arquitectura dispersa llamada “Mixture-of-Transformers (MoT)” (Mezcla de Transformadores), destinada a reducir significativamente los costos computacionales del preentrenamiento de modelos multimodales sin sacrificar el rendimiento. MoT aplica una dispersión consciente de la modalidad a los parámetros de Transformer no incrustados (como redes de avance, matrices de atención y normalización de capas). Los experimentos demuestran que en la configuración de Chameleon (generación de texto + imagen), un modelo MoT de 7B alcanza la calidad de la línea base densa utilizando solo el 55.8% de los FLOPs; al expandirse al habla como tercera modalidad, utiliza solo el 37.2% de los FLOPs. Esta investigación ha sido aceptada por TMLR (marzo de 2025) y el código es de fuente abierta. (Fuente: VictoriaLinML)
Se lanza Smoothie Qwen, un proyecto de mejora del modelo Qwen, para equilibrar la generación multilingüe: Se ha lanzado un proyecto de mejora del modelo Qwen llamado Smoothie Qwen, que tiene como objetivo equilibrar la capacidad de generación multilingüe ajustando las probabilidades de los parámetros internos del modelo. El proyecto aborda principalmente el problema de que algunos usuarios no chinos ocasionalmente obtienen resultados en chino al usar Qwen, y afirma no reducir la inteligencia del modelo. (Fuente: karminski3)

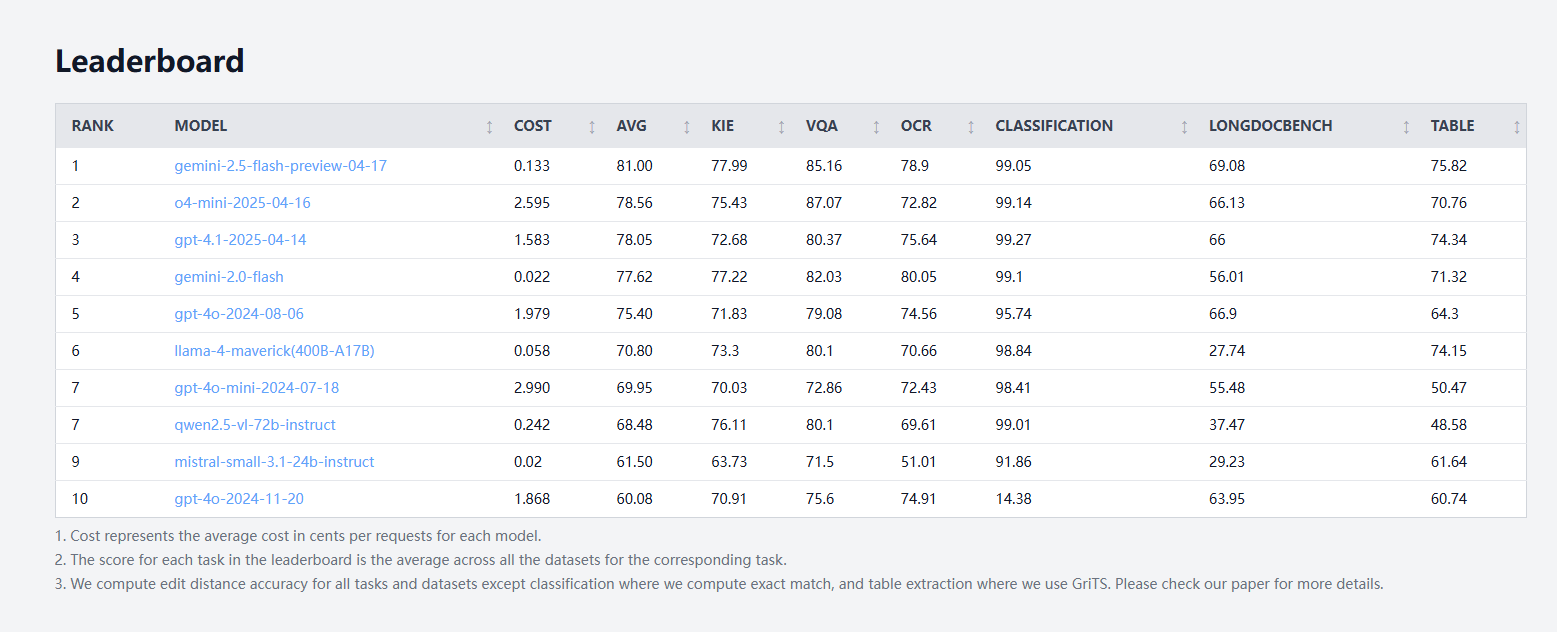
Se lanza idp-leaderboard, el primer benchmark de IA para tipos de documentos: Se ha lanzado el nuevo benchmark de IA idp-leaderboard, centrado en evaluar la capacidad de los modelos para procesar documentos e imágenes de documentos. Según la clasificación preliminar, gemini-2.5-flash-preview-04-17 muestra el mejor rendimiento general en el procesamiento de documentos. Cabe destacar que Qwen2.5-VL no tuvo un buen desempeño en el procesamiento de tablas. (Fuente: karminski3)
La función Discover de Perplexity recibe una importante actualización: Arav Srinivas, cofundador de Perplexity, anunció que su función Discover (flujo de descubrimiento de información) ha sido mejorada significativamente, animando a los usuarios a probarla. Esto generalmente implica optimizaciones en la presentación de la información, la relevancia o la interfaz de usuario, con el objetivo de mejorar la capacidad del usuario para adquirir y explorar nueva información. (Fuente: AravSrinivas)
Lenovo anuncia una importante actualización de su superagente inteligente personal Tianxi, el primer despliegue local de DeepSeek en una tableta a nivel mundial: Lenovo anunció una importante actualización de su superagente inteligente personal Tianxi, avanzando hacia un nivel L3 completo, y lanzó el agente inteligente de dominio “Xiang Bang Bang”, centrado en servicios de IA para dispositivos inteligentes personales. Al mismo tiempo, Lenovo presentó varios productos terminales de IA nuevos, incluida la primera tableta del mundo en implementar localmente el gran modelo DeepSeek, la YOGA Pad Pro 14.5 AI Yuanqi Edition, así como teléfonos moto AI, PC de la serie Legion, etc., construyendo un ecosistema de IA completo de PC con IA, teléfonos con IA, tabletas con IA e AIoT. (Fuente: 量子位)

Lou Tiancheng habla sobre conducción autónoma e inteligencia corporeizada: L2 no puede escalar a L4, VLA tiene ayuda limitada para L4: Lou Tiancheng, cofundador y CTO de Pony.ai, compartió sus últimas ideas sobre conducción autónoma e IA al presentar la nueva generación de modelos Robotaxi. Enfatizó la diferencia fundamental entre L2 y L4, creyendo que L2 no puede escalar a L4, y que el paradigma VLA (Visión-Lenguaje-Acción) actualmente popular en el dominio L2 “básicamente no ayuda mucho” a L4. Señaló que L4 requiere una seguridad extrema similar a la de un médico especialista, mientras que VLA es más como un médico general. El núcleo de la transformación tecnológica de Pony.ai en los últimos dos años ha sido el enfoque de extremo a extremo y el modelo del mundo, este último aplicado durante aproximadamente 5 años. También considera que la “conducción remota en la nube” es un pseudoconcepto y afirmó que el estado actual de la inteligencia corporeizada es similar al de la conducción autónoma en 2018, y enfrentará desafíos similares de “período de vacío”. (Fuente: 量子位)

Kimi prueba una comunidad de contenido, OpenAI podría desarrollar una aplicación social, las empresas de grandes modelos de IA exploran lo social para mejorar la fidelidad del usuario: Kimi de Moonshot AI está realizando pruebas graduales de un producto de comunidad de contenido, generado principalmente por IA que extrae noticias de actualidad, centrándose en campos como la tecnología y las finanzas. Casualmente, también se ha informado que OpenAI planea desarrollar un software social, posiblemente compitiendo con X. Estas acciones indican que las empresas de grandes modelos de IA están intentando mejorar la fidelidad del usuario mediante la creación de comunidades o funciones sociales, para resolver el problema de que las herramientas de IA se “usan y descartan”. Sin embargo, la operación de la comunidad enfrenta desafíos de calidad del contenido, riesgos de seguridad y monetización. Este movimiento también refleja que después de que el auge del crecimiento en la industria de la IA haya tocado techo, se está comenzando a pasar de “quemar dinero por crecimiento” a prestar más atención al ROI y explorar nuevos modelos de negocio. (Fuente: 36氪)

TCL adopta plenamente la IA, lanza el gran modelo Fuxi y múltiples electrodomésticos con IA, pero enfrenta desafíos de homogeneización: TCL destacó sus productos y estrategia de IA en ferias como AWE 2025 y CES 2025, incluyendo el gran modelo TCL Fuxi y funciones de IA aplicadas a televisores, aires acondicionados, lavadoras y otros electrodomésticos. Su negocio de televisores tuvo un desempeño sobresaliente, con envíos globales en primer lugar en el primer trimestre, siendo la tecnología Mini LED su ventaja. Sin embargo, la aplicación de la IA en el campo de los electrodomésticos se concentra actualmente en la interacción por voz y la optimización de funciones específicas (como chips de calidad de imagen con IA, sueño con IA, ahorro de energía con IA), enfrentando el desafío de la competencia por homogeneización con otras marcas (como Hisense Xinghai, Haier HomeGPT, Midea Meiyan). TCL también explora robots de compañía con IA y el diseño de gafas inteligentes a través de Leiniao. A pesar del aumento de la inversión en IA, su ventaja tecnológica independiente aún no es significativa y enfrenta problemas como altos costos de marketing y disminución del margen bruto. (Fuente: 36氪)
La IA impulsa la transformación educativa, empresas líderes como iFlytek y Excel Education aceleran su despliegue en IA: Un informe analiza las últimas prácticas en el campo de la IA de empresas educativas líderes como iFlytek, Excel Education, Fenbi, Zhonggong Education, Huatu Education y Yiqi Education Technology. iFlytek, con su capacidad de cómputo nacional y los modelos Deepseek-V3/R1, se enfoca en la educación en tecnología de la información. Excel Education utiliza Deepseek R1 para potenciar toda la cadena de enseñanza, lanzando herramientas de corrección y lectura con IA. Fenbi ha construido una matriz de productos de IA que cubre escenarios de aprendizaje de alta frecuencia y necesidades básicas. Zhonggong Education se centra en servicios de empleo con IA, desarrollando el gran modelo “Yunxin”. Huatu Education combina sus ventajas offline con IA para mejorar la precisión de los servicios para exámenes de la función pública. Yiqi Education Technology impulsa la integración de enseñanza y evaluación con IA. Las tendencias de la industria muestran que la educación con IA está pasando de herramientas puntuales a la competencia ecosistémica y la monetización del valor. (Fuente: 36氪)
Grandes tecnológicas como Baidu y Alibaba impulsan el protocolo MCP, compitiendo por el derecho a definir el ecosistema de Agentes de IA: El Protocolo de Contexto de Modelo (MCP) ha sido impulsado recientemente por Anthropic, OpenAI, Google y grandes tecnológicas chinas como Baidu y Alibaba. La aplicación “Xin Xiang” de Baidu y la plataforma Bai Lian de Alibaba Cloud ya son compatibles con MCP, permitiendo a los Agentes de IA invocar herramientas y servicios externos de manera más conveniente. Este movimiento, aparentemente para unificar los estándares de la industria, es en realidad una lucha de las grandes tecnológicas por el derecho a definir el futuro ecosistema de Agentes de IA. Al construir y promover MCP, las grandes tecnológicas intentan atraer a más desarrolladores a sus ecosistemas, para así dominar las barreras de datos y el poder de interlocución en la industria. La dirección de monetización de las aplicaciones de Agentes actualmente parece seguir centrándose en el tráfico y la publicidad. (Fuente: 36氪)

Se revela la estrategia de IA de Apple: posible cooperación con Baidu y Alibaba para crear una versión china del sistema de IA de “doble núcleo”: Un informe analiza la posible cooperación de Apple con Baidu y Alibaba para proporcionar soporte técnico a sus funciones de IA en el mercado chino. Wenxin Yiyan de Baidu tiene ventajas en el reconocimiento visual, mientras que el gran modelo Qianwen de Alibaba destaca en la comprensión cognitiva y el cumplimiento normativo del contenido. Este modelo de “doble núcleo” podría tener como objetivo combinar las fortalezas de ambas empresas para satisfacer el ecosistema de datos del mercado chino, el enfoque tecnológico y los requisitos regulatorios, manteniendo al mismo tiempo el dominio y el poder de negociación de Apple en la cooperación. Este movimiento se considera una estrategia de “segmentación de nicho ecológico” de Apple para hacer frente a la presión competitiva local de HarmonyOS y otros, así como en un contexto de regulación de datos cada vez más estricta. (Fuente: 36氪)
El profesor Yu Jingyi analiza en profundidad la inteligencia espacial: enorme potencial, pero sin consenso formado, los datos y la comprensión física son clave: El profesor Yu Jingyi de la Universidad ShanghaiTech señaló en una entrevista que el potencial de los grandes modelos en la integración transmodal está lejos de agotarse, y la inteligencia espacial está evolucionando de la réplica digital a la comprensión y creación inteligentes, gracias a los avances de la IA generativa. Considera que los desafíos centrales actuales de la inteligencia espacial radican en la escasez de datos de escenas 3D reales y la falta de unificación en los métodos de representación tridimensional. El proyecto CAST de su equipo explora las relaciones entre objetos y la plausibilidad física mediante la introducción de la “Teoría del Actor-Red” y las reglas físicas. Enfatiza la prioridad de la percepción y predice avances revolucionarios en la tecnología de sensores. El estándar para medir la inteligencia corporeizada debería ser la robustez y la seguridad, no la pura precisión. A corto plazo, la inteligencia espacial explotará en la producción cinematográfica, los juegos, etc., y a medio y largo plazo se convertirá en el núcleo de la inteligencia corporeizada, siendo la economía de baja altitud también un importante escenario de aplicación. (Fuente: 36氪)

La guerra por el talento en IA se recrudece: las grandes tecnológicas ofrecen altos salarios, los CTO guían personalmente, el enfoque está en los grandes modelos y la multimodalidad: Las grandes tecnológicas nacionales e internacionales están librando una feroz batalla por el talento en inteligencia artificial. ByteDance, Alibaba, Tencent, Baidu, JD.com, Huawei y otras han lanzado planes de reclutamiento dirigidos a estudiantes de doctorado de primer nivel y jóvenes genios, ofreciendo salarios sin límite, tutoría personal de los CTO y exención de experiencia en prácticas. Las áreas de contratación se concentran principalmente en grandes modelos y multimodalidad, y están estrechamente relacionadas con los escenarios de negocio principales de cada empresa. El éxito de modelos como DeepSeek ha intensificado aún más la sed de talento en la industria. Elon Musk también lamentó la locura de la competencia por el talento en IA, y gigantes extranjeros como OpenAI también atraen talento con altos salarios y reclutamiento personal por parte de los fundadores. (Fuente: 36氪)
Sequoia Capital: El potencial del mercado de IA supera con creces al de la computación en la nube, la capa de aplicación es clave, el Director de IA se convertirá en estándar: Un socio de Sequoia Capital predice que el tamaño del mercado de IA superará con creces el actual mercado de computación en la nube de aproximadamente 400 mil millones de dólares, con un volumen enorme en los próximos 10-20 años, y el valor se concentrará principalmente en la capa de aplicación. Las startups deben centrarse en las necesidades del cliente, ofrecer soluciones de extremo a extremo, profundizar en sectores verticales y utilizar el “volante de datos” (data flywheel) para construir fosos defensivos. Un estudio de AWS muestra que las empresas globales están acelerando la adopción de la IA generativa, el 45% de los responsables de la toma de decisiones planean convertirla en su principal prioridad para 2025, y el puesto de Director de IA (CAIO) se convertirá en un estándar empresarial, con el 60% de las empresas ya habiendo establecido este puesto. La economía de agentes se considera la siguiente etapa del desarrollo de la IA, pero necesita resolver tres desafíos técnicos: identidad persistente, protocolos de comunicación y confianza en la seguridad. (Fuente: 36氪)

Las nuevas fuerzas automotrices apuestan todo a la IA, Li Auto, XPeng y NIO compiten por el derecho a definir el automóvil de próxima generación: El avance logrado por la tecnología de red neuronal de extremo a extremo de Tesla FSD V12 ha impulsado a las nuevas fuerzas automotrices nacionales como Li Auto, XPeng y NIO a acelerar su despliegue en IA. Li Auto lanzó el gran modelo de conductor VLA (Visión-Lenguaje-Acción) y desarrolló la parte lingüística basada en el modelo de código abierto DeepSeek. XPeng Motors construyó un modelo base LVA de 72 mil millones de parámetros. NIO, por su parte, lanzó el primer modelo del mundo de conducción inteligente de China, NWM, y desarrolló internamente el chip de conducción inteligente de 5nm Shenji NX9031. Todas las empresas están invirtiendo masivamente en algoritmos, potencia de cómputo (chips de desarrollo propio) y datos, y están generalizando la tecnología de IA a campos como los robots humanoides, compitiendo por el derecho a definir el automóvil de próxima generación e incluso los productos, pero enfrentan desafíos financieros y de monetización. (Fuente: 36氪)
🧰 Herramientas
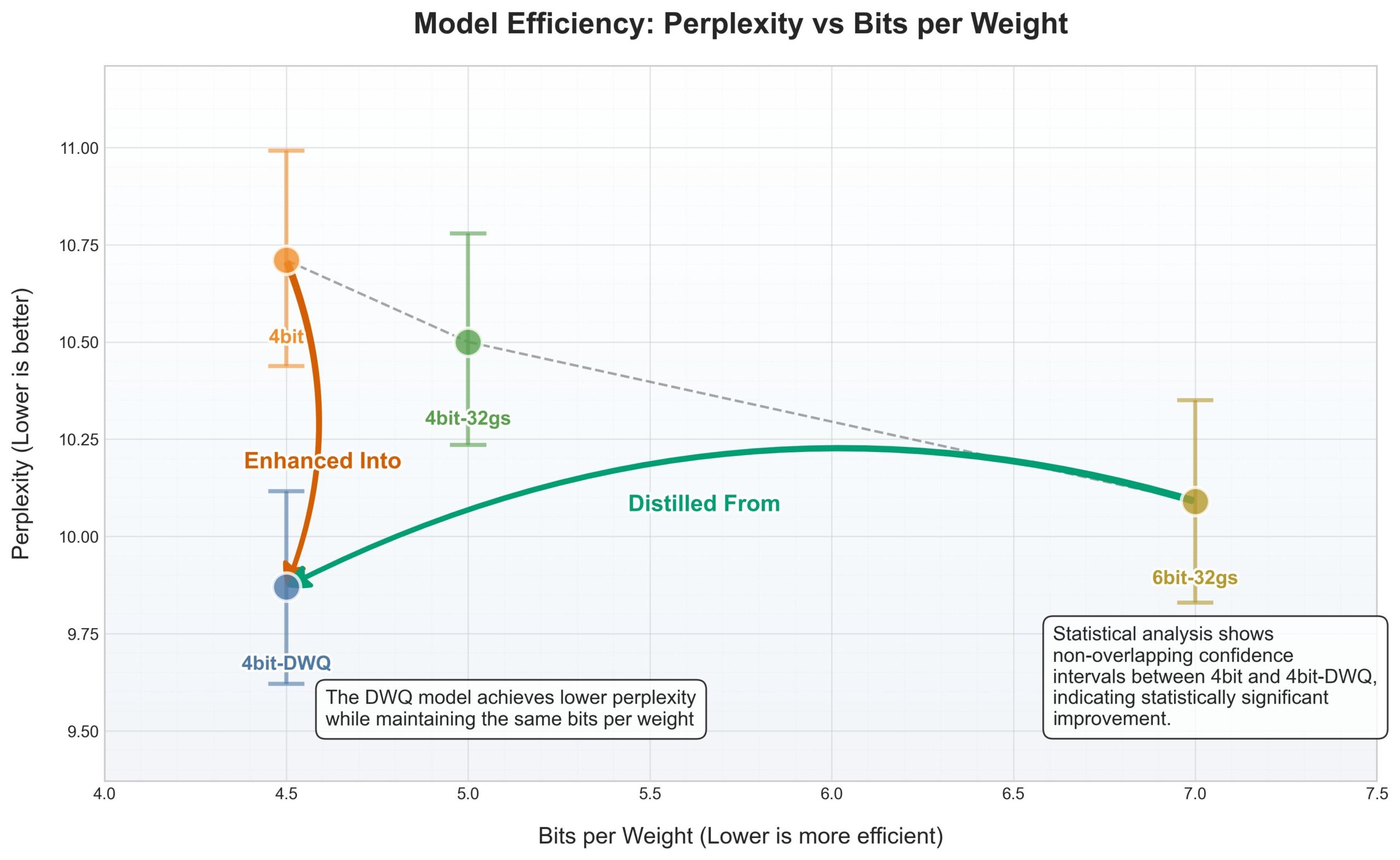
El framework MLX de Apple recibe cuantización DWQ, 4 bits rinden mejor que los antiguos 6 bits: Se ha lanzado un nuevo método de cuantización DWQ (Dynamic Weight Quantization, cuantización dinámica de pesos) para el framework de aprendizaje automático MLX de Apple. Según datos compartidos por el usuario karminski3, los modelos cuantizados a 4bit-dwq (como Qwen3-30B) incluso superan en perplejidad al antiguo método de cuantización de 6 bits, y solo requieren 17GB de memoria para funcionar. Esto abre nuevas posibilidades para ejecutar grandes modelos de lenguaje de manera eficiente en dispositivos Apple. (Fuente: karminski3)
Perplexity ahora admite búsquedas conversacionales más naturales dentro de WhatsApp: Arav Srinivas, cofundador de Perplexity, anunció que la integración de Perplexity dentro de WhatsApp ha sido mejorada y ahora puede ofrecer una experiencia conversacional más natural. Además, cuando no se necesita una búsqueda, ignora inteligentemente el paso de búsqueda, permitiendo a los usuarios interactuar directamente con la IA en un formato de chat. (Fuente: AravSrinivas)
nanobrowser_ai es compatible con los principales LLM e integra Langchain.js: La herramienta de IA nanobrowser_ai anunció compatibilidad con múltiples grandes modelos de lenguaje, incluidos los modelos de OpenAI, Gemini y modelos locales ejecutados a través de Ollama. La herramienta utiliza el framework Langchain.js para lograr un soporte flexible para diferentes LLM, ofreciendo a los usuarios una selección más amplia de modelos. (Fuente: hwchase17)
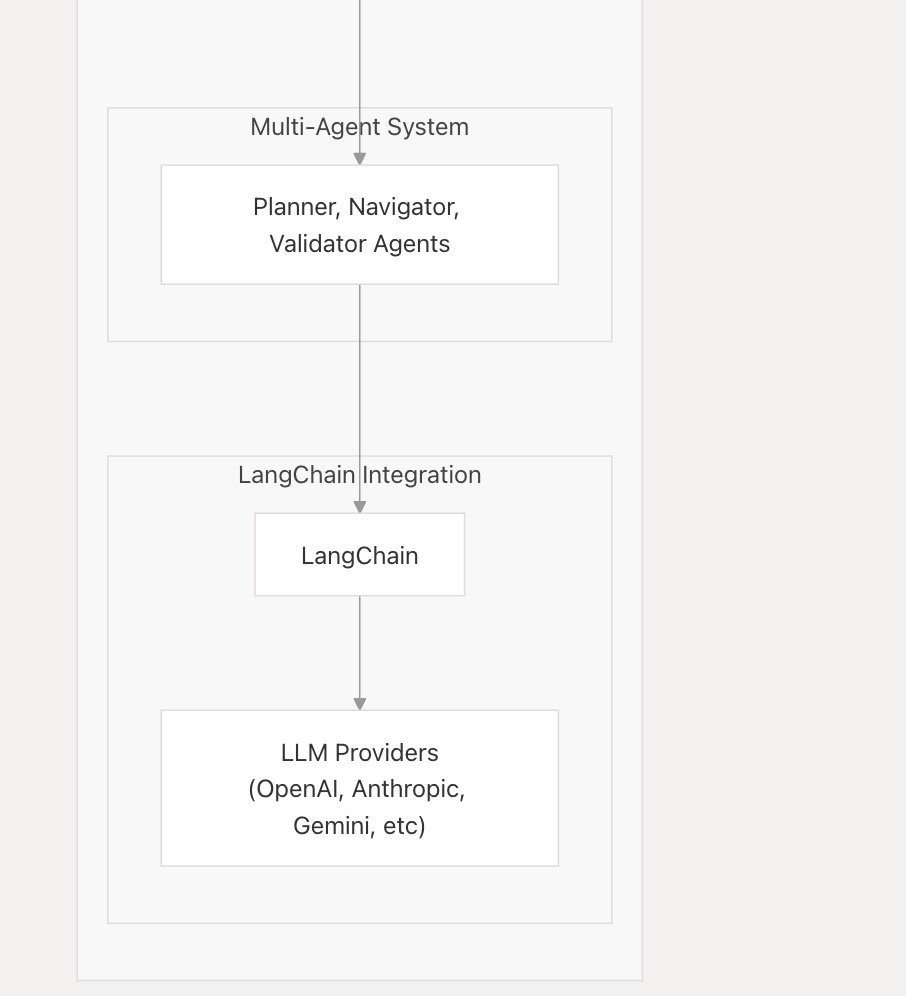
LlamaIndex TypeScript añade soporte para API de LLM en tiempo real, integrando primero Google Gemini: LlamaIndex TypeScript anunció soporte para API de LLM en tiempo real, permitiendo a los desarrolladores implementar funciones de conversación de audio en tiempo real en aplicaciones de IA. La primera integración es la interfaz de abstracción en tiempo real de Google Gemini, y el soporte en tiempo real de OpenAI también estará disponible próximamente. Esta actualización facilita a los desarrolladores cambiar entre diferentes modelos en tiempo real y construir aplicaciones de IA más interactivas. (Fuente: _philschmid)
Tutorial de aplicación Gradio: Uso de Qwen2.5-VL para anotación de imágenes y videos y detección de objetos: Un tutorial detalla cómo usar Qwen2.5-VL (modelo de lenguaje visual) para construir una aplicación Gradio que permita la anotación automática de imágenes y videos, así como funciones de detección de objetos. El tutorial tiene como objetivo ayudar a los desarrolladores a utilizar la potente capacidad de Qwen2.5-VL para construir rápidamente aplicaciones de IA interactivas. (Fuente: Reddit r/deeplearning)

El plugin de VSCode gemini-code se acerca a las 50,000 descargas: El plugin de asistente de programación con IA para VSCode, gemini-code, ha alcanzado cerca de 50,000 descargas. El desarrollador raizamrtn indicó que realizará algunas actualizaciones necesarias durante el fin de semana. El plugin tiene como objetivo utilizar las capacidades del modelo Gemini para ayudar a los desarrolladores en su trabajo de codificación. (Fuente: raizamrtn)

Startup francesa de IA Arcads AI: equipo de 5 personas genera 5 millones de dólares anuales, enfocada en la producción automatizada de anuncios en video: Arcads AI, una startup de IA con sede en París, ha logrado 5 millones de dólares en ingresos recurrentes anuales y es rentable con un equipo de solo 5 personas. La empresa ofrece a los anunciantes servicios de producción de anuncios en video rápidos, de bajo costo y alta conversión a través de un sistema de IA altamente automatizado. Los clientes solo necesitan proporcionar el texto principal, y la IA completa todo el proceso, desde la construcción de escenas, la actuación de los actores, la grabación de la voz en off hasta la producción final. La plataforma Arcads cuenta con más de 300 imágenes de actores de IA basadas en autorizaciones de personas reales, admite 35 idiomas y logra el “contenido como servicio”. Sus operaciones internas también utilizan ampliamente agentes de IA, como AI Spy Agent para analizar a la competencia y AI Ghostwriter para generar ideas creativas, lo que aumenta significativamente la eficiencia. (Fuente: 36氪)
📚 Aprendizaje
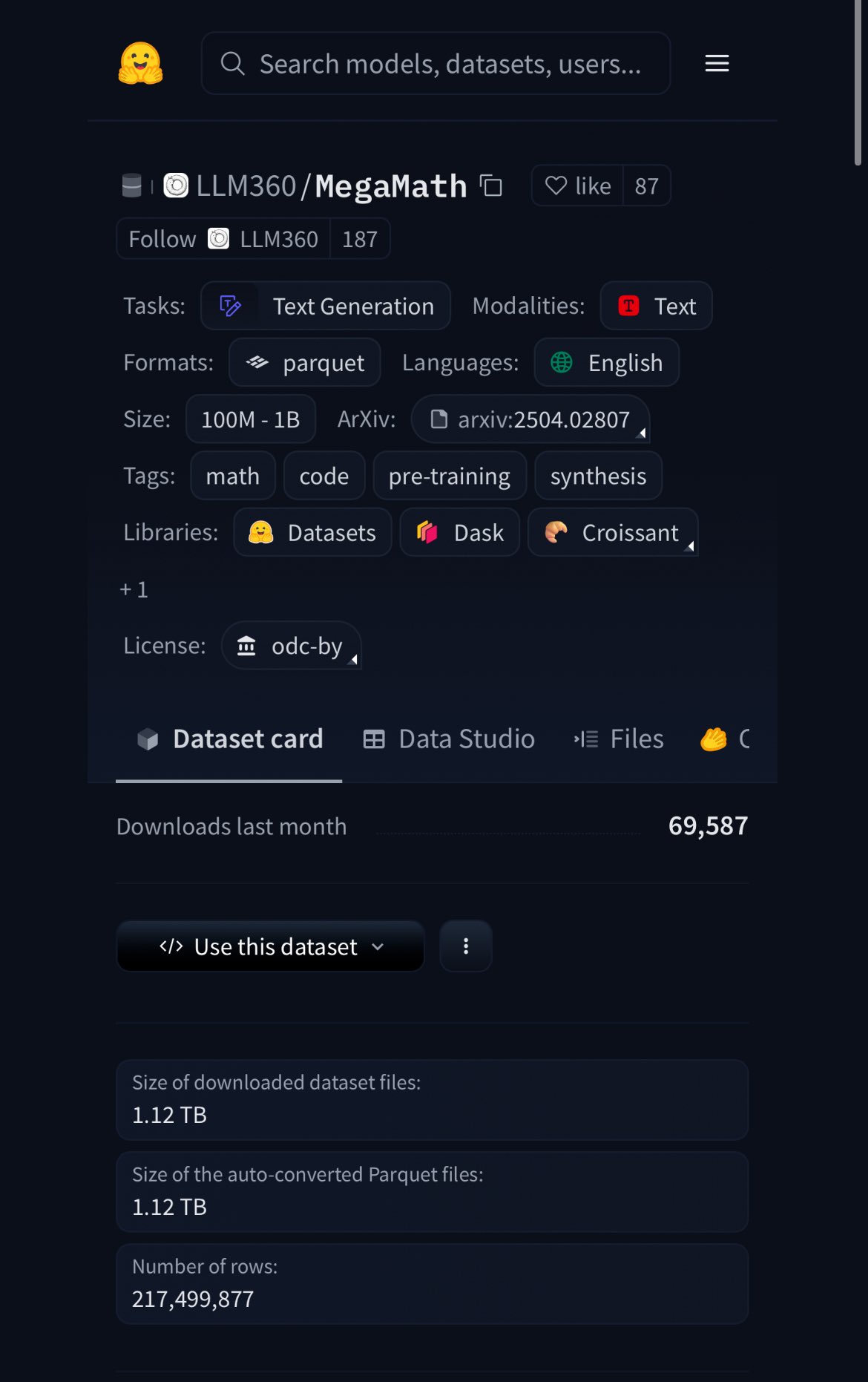
HuggingFace lanza el conjunto de datos MegaMath, con 370B de tokens, el 20% son datos sintéticos: HuggingFace ha lanzado el conjunto de datos MegaMath, que contiene 370 mil millones de tokens, siendo actualmente el mayor conjunto de datos de preentrenamiento matemático, aproximadamente 100 veces el tamaño de la Wikipedia en inglés. Es de destacar que el 20% de estos datos son sintéticos, lo que ha reavivado el debate sobre el papel de los datos sintéticos de alta calidad en el entrenamiento de modelos. (Fuente: ClementDelangue)
Nous Research organiza un hackathon de entornos RL con un premio de 50,000 dólares: Nous Research anunció la organización del Hackathon de Entornos RL de Nous en San Francisco, donde los participantes crearán utilizando el framework de entornos de aprendizaje por refuerzo Atropos de Nous, con un premio total de 50,000 dólares. Entre los socios se encuentran xAI, NVIDIA, Nebius AI, entre otros. (Fuente: Teknium1)

Se publica la lista semanal de modelos populares de HuggingFace: El usuario karminski3 compartió la lista de los modelos más populares de esta semana en HuggingFace, mencionando que ha probado personalmente la mayoría de ellos o ha compartido demostraciones oficiales. Esto refleja el entusiasmo de la comunidad por seguir y evaluar rápidamente los nuevos modelos. (Fuente: karminski3)
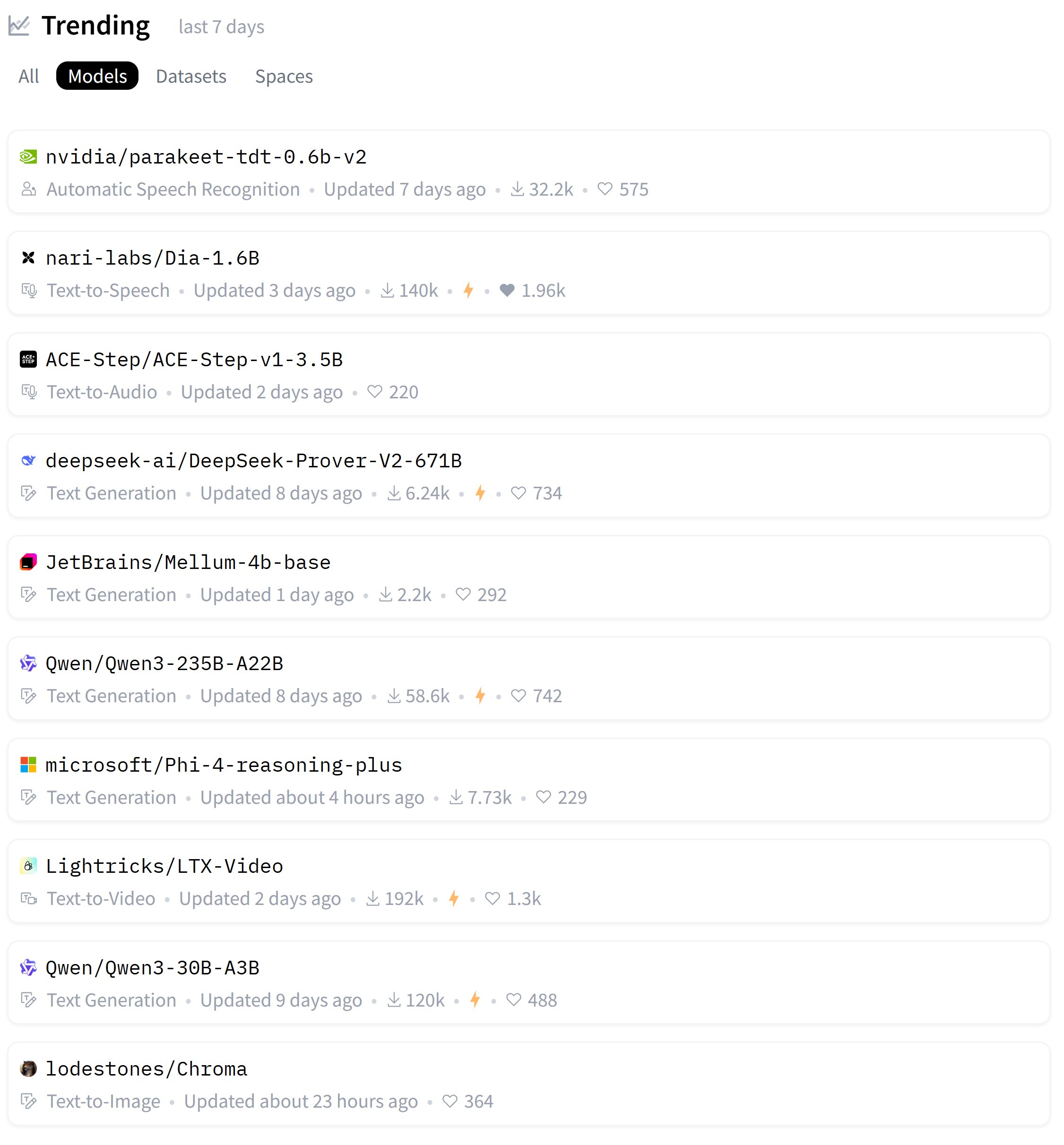
Zeyuan Allen-Zhu publica una serie de investigaciones sobre el diseño de arquitecturas LLM, discutiendo el modelo Primer: El investigador Zeyuan Allen-Zhu, a través de su serie de investigaciones “Physics of LLM Design”, utiliza entornos de preentrenamiento sintéticos controlados para revelar los límites reales de las arquitecturas LLM. En su última publicación, discute el modelo Primer (arxiv.org/abs/2109.08668) y su atención multi-dconv-head (que él llama Canon-B sin conexiones residuales), señalando que tiene problemas, pero también considera que el modelo Primer (con solo 180 citas) está subestimado porque descubrió señales significativas a partir de experimentos ruidosos del mundo real. (Fuente: ZeyuanAllenZhu, cloneofsimo)
El Simons Institute discute las leyes de escalamiento de redes neuronales: El Simons Institute, en su serie Polylogues, invitó a Anil Ananthaswamy y Alexander Rush a discutir las leyes de escalamiento neuronal (neural scaling laws) descubiertas empíricamente en los últimos años. Estas leyes han tenido un impacto significativo en las decisiones de las grandes empresas para construir modelos cada vez más grandes. (Fuente: NandoDF)

François Fleuret publica “The Little Book of Deep Learning”: François Fleuret ha publicado una obra titulada “The Little Book of Deep Learning” (El Pequeño Libro del Aprendizaje Profundo), con el objetivo de proporcionar a los lectores conocimientos concisos sobre el aprendizaje profundo. (Fuente: Reddit r/deeplearning)
Profesor de Princeton: La IA podría acabar con las humanidades, pero las impulsaría a regresar a la experiencia existencial: El profesor D. Graham Burnett de la Universidad de Princeton escribió en The New Yorker sobre el impacto de la IA en las humanidades. Observó una “vergüenza por la IA” generalizada en las universidades estadounidenses, donde los estudiantes no se atreven a admitir que usan IA. Argumenta que la IA ya ha superado los métodos académicos tradicionales en la recuperación y análisis de información, convirtiendo los libros académicos en artefactos arqueológicos. Aunque la IA podría acabar con las humanidades en el sentido tradicional, centradas en la producción de conocimiento, también podría impulsarlas a regresar a cuestiones fundamentales: cómo vivir, enfrentar la muerte y otras experiencias existenciales, temas que la IA no puede abordar directamente. (Fuente: 36氪)

7 estudios revelan el profundo impacto de la IA en el cerebro y el comportamiento humanos: Una serie de nuevas investigaciones exploran el impacto de la IA en los niveles psicológico, social y cognitivo de los seres humanos. Los hallazgos incluyen: 1) Los testers de equipo rojo (red teamers) de LLM exploran las vulnerabilidades de los modelos por curiosidad y responsabilidad moral; 2) ChatGPT muestra una alta precisión diagnóstica en el análisis de casos psiquiátricos; 3) Las tendencias políticas de ChatGPT cambian sutilmente entre diferentes versiones; 4) El uso de ChatGPT podría exacerbar la desigualdad en el lugar de trabajo, siendo más utilizado por hombres jóvenes de altos ingresos; 5) La IA puede detectar signos de depresión analizando el comportamiento de conducción de personas mayores; 6) Los LLM muestran un sesgo de deseabilidad social al “maquillar” su imagen en pruebas de personalidad; 7) La dependencia excesiva de la IA podría debilitar el pensamiento crítico, especialmente en los grupos más jóvenes. (Fuente: 36氪)

Entrevista a Onur Boyar: Uso de modelos generativos y optimización bayesiana para el diseño de fármacos y materiales: Onur Boyar, participante del Foro de Doctorandos AAAI/SIGAI, presentó su trabajo de investigación doctoral en la Universidad de Nagoya, centrado en el uso de modelos generativos y métodos bayesianos para el diseño de fármacos y materiales. Participa en el proyecto japonés Moonshot, cuyo objetivo es construir robots científicos de IA para gestionar el proceso de descubrimiento de fármacos. Sus métodos de investigación incluyen el uso de la optimización bayesiana en el espacio latente para editar moléculas existentes, con el fin de mejorar la eficiencia de las muestras y la viabilidad sintética. Destaca la estrecha colaboración con químicos y se unirá al equipo de descubrimiento de materiales de IBM Research Tokyo después de su graduación. (Fuente: aihub.org)

💼 Negocios
Modular colabora con AMD para organizar un Mojo Hackathon, utilizando GPUs MI300X: Modular anunció una colaboración con AMD para organizar un hackathon especial en AGI House. En el evento, los desarrolladores programarán en lenguaje Mojo utilizando GPUs AMD Instinct™ MI300X. El evento también contará con presentaciones técnicas de representantes de Modular, AMD, Dylan Patel de SemiAnalysis y Anthropic. (Fuente: clattner_llvm)
Stripe lanza múltiples funciones nuevas impulsadas por IA, incluido un modelo fundacional de IA para el sector de pagos: La empresa de servicios financieros Stripe anunció en su conferencia anual el lanzamiento de varios productos nuevos para acelerar la implementación de aplicaciones de IA, incluido el primer modelo fundacional de IA del mundo diseñado específicamente para el sector de pagos. Este modelo, entrenado con decenas de miles de millones de transacciones, tiene como objetivo mejorar la detección de fraudes (por ejemplo, un aumento del 64% en la tasa de detección de ataques de “prueba de tarjetas”), las tasas de autorización y la experiencia de pago personalizada. Stripe también amplió sus capacidades de gestión de fondos multidivisa y profundizó su colaboración con grandes empresas como Nvidia (utilizando Stripe Billing para gestionar las suscripciones de GeForce Now) y PepsiCo. (Fuente: 36氪)
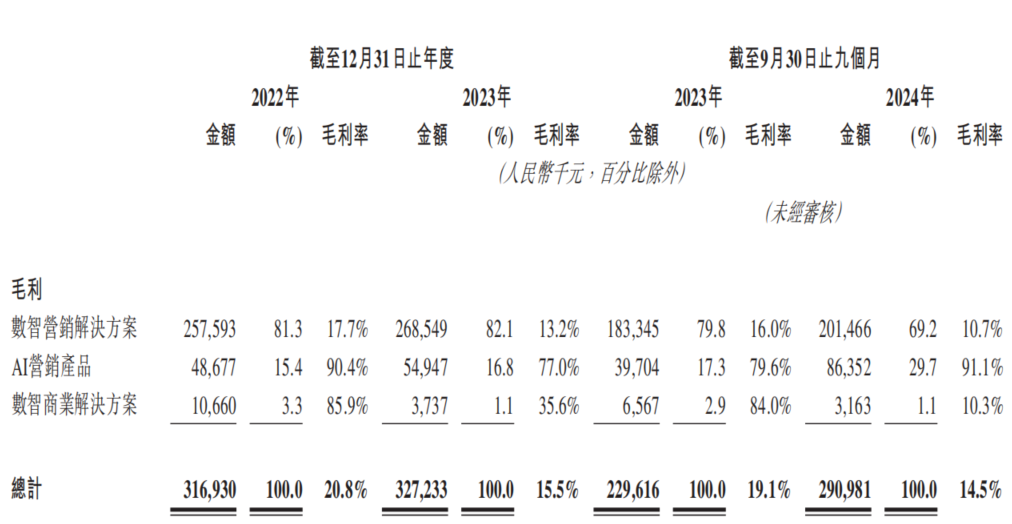
La empresa de marketing con IA Dongxin Marketing vuelve a intentar cotizar en la Bolsa de Hong Kong, enfrentando el dilema de “aumento de ingresos sin aumento de beneficios”: Dongxin Marketing, bajo el nombre de “la mayor empresa de marketing con IA de China”, ha vuelto a presentar su prospecto a la Bolsa de Hong Kong. Los datos muestran que los ingresos de la empresa en los primeros tres trimestres de 2022-2024 continuaron creciendo, pero el beneficio neto disminuyó drásticamente e incluso se convirtió en pérdidas, con un margen bruto que cayó del 20.8% al 14.5%. Los ingresos del negocio de marketing con IA representan menos del 5% y, aunque el margen bruto es tan alto como el 91.1%, no es suficiente para cubrir la inversión en I+D. La empresa enfrenta problemas como cuentas por cobrar elevadas, flujo de caja ajustado y una gran presión de deuda, y sus beneficios dependen en gran medida de los subsidios gubernamentales. Su posicionamiento en el mercado ha pasado de “proveedor de servicios de marketing móvil” a “empresa de marketing con IA”, pero el valor tecnológico de su IA y sus perspectivas de comercialización son dudosas. (Fuente: 36氪)
🌟 Comunidad
Fuerte competencia entre los motores de inferencia vLLM y SGLang, los desarrolladores comparan públicamente los datos de fusión de PR: La comunidad de desarrolladores debate acaloradamente la competencia entre los dos principales motores de inferencia, vLLM y SGLang. El principal mantenedor de vLLM incluso ha creado un panel público para comparar el número de solicitudes de extracción (PR) fusionadas en GitHub entre SGLang y vLLM, lo que subraya la intensa carrera entre ambos en la iteración de funciones y la optimización del rendimiento. Por su parte, SGLang destaca su implementación pionera de código abierto en áreas como la caché radix, la superposición de CPU, MLA y EP a gran escala. (Fuente: dylan522p, jeremyphoward)
Universo de personajes “Italian brainrot” generado por IA causa furor entre la generación Zoomer, con cientos de millones de vistas: Justine Moore señala que una serie de personajes “Italian brainrot” (podredumbre cerebral italiana) generados por IA se ha vuelto extremadamente popular entre la generación Zoomer (Generación Z). Han construido un “universo cinematográfico” completo en torno a estos personajes, y el contenido relacionado ha obtenido cientos de millones de vistas. Este fenómeno refleja el poderoso atractivo y el potencial de propagación viral del contenido generado por IA entre las generaciones más jóvenes, así como la formación de subculturas específicas. (Fuente: nptacek)

Comparación entre los modelos Qwen3 y DeepSeek R1 genera debate, cada uno con sus pros y contras: Un usuario de Reddit compartió una comparativa de pruebas entre los grandes modelos de código abierto Qwen3 235B y DeepSeek R1. El autor de la publicación considera que Qwen rinde mejor en tareas sencillas, pero en tareas que requieren matices (como razonamiento, matemáticas y escritura creativa), DeepSeek R1 ofrece un rendimiento superior. En los comentarios de la comunidad, los usuarios discutieron la accesibilidad de DeepSeek R1, la versión de ajuste fino sin censura de Qwen3 235B y la idoneidad de usar modelos de lenguaje para la escritura creativa, entre otros temas. (Fuente: Reddit r/LocalLLaMA)

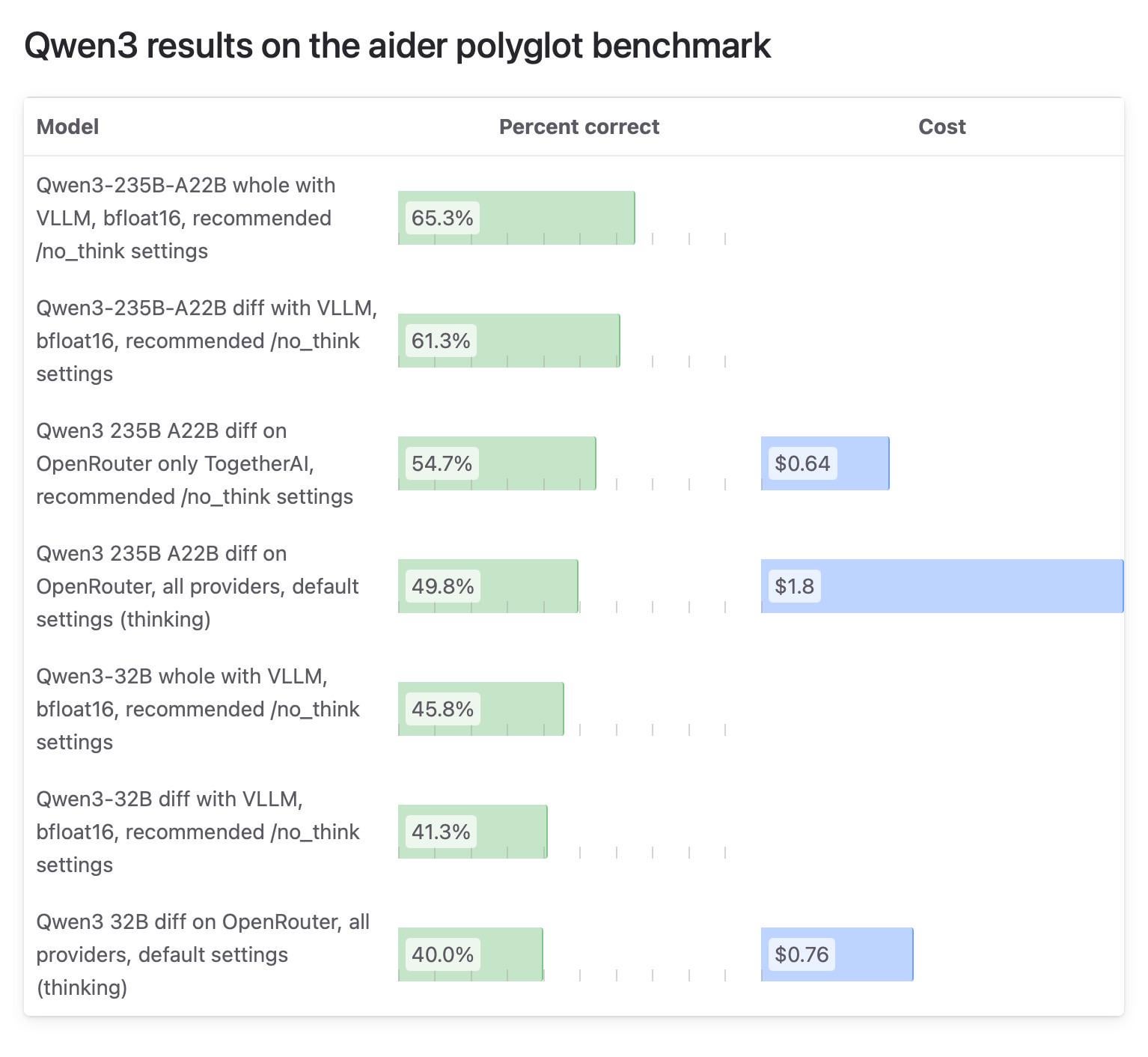
Diferencias en los resultados de las pruebas del modelo Qwen3 en la comunidad Aider llaman la atención, se cuestionan las pruebas de OpenRouter: El blog de Aider publicó un informe de pruebas sobre el modelo Qwen3, señalando grandes diferencias en las puntuaciones del modelo según cómo se ejecute. El debate en la comunidad se centra en la fiabilidad de usar OpenRouter para probar modelos, ya que la mayoría de los usuarios probablemente utilicen modelos a través de OpenRouter, pero su mecanismo de enrutamiento podría llevar a resultados inconsistentes. Algunos usuarios creen que los modelos de código abierto deberían probarse en entornos autoconstruidos estandarizados (como vLLM) para garantizar la reproducibilidad, y piden a los proveedores de API una mayor transparencia, especificando la versión de cuantización y el motor de inferencia utilizados. (Fuente: Reddit r/LocalLLaMA)
Usuarios comparten razones personales para pagar por ChatGPT, abarcando asistencia vital, aprendizaje, creación, etc.: En la comunidad r/ChatGPT de Reddit, muchos usuarios compartieron sus usos personales para la suscripción de pago a ChatGPT Plus/Pro. Estos incluyen: ayudar a usuarios con discapacidad visual a describir imágenes, leer envases de alimentos y señales de tráfico; prepararse para entrevistas; profundizar en la trama de juegos como Elden Ring; analizar planes de entrenamiento de carrera, personalizar recetas; ayudar en el aprendizaje de nuevas habilidades como la cerámica; como compañero personal; planificar jardines, elaborar remedios herbales; y la creación de personajes de D&D y la escritura de fanfiction. Estos casos demuestran el amplio valor de aplicación de ChatGPT en la vida diaria y los intereses personales. (Fuente: Reddit r/ChatGPT)
Pruebas comparativas de modelos cuantizados GGUF desencadenan debate sobre la “guerra de cuantización”, enfatizando que diferentes esquemas de cuantización tienen sus propias ventajas: El usuario de Reddit ubergarm publicó una comparativa detallada de benchmarks para diferentes versiones cuantizadas GGUF de modelos como Qwen3-30B-A3B, incluyendo esquemas de cuantización de diferentes proveedores como bartowski y unsloth. Las pruebas cubrieron múltiples dimensiones como la perplejidad, la divergencia KLD y la velocidad de inferencia. El artículo señala que con la aparición de nuevos tipos de cuantización como la cuantización por matriz de importancia (imatrix), IQ4_XS, y la introducción de métodos como GGUF dinámico de unsloth, la cuantización GGUF ya no es “talla única”. El autor enfatiza que no existe un esquema de cuantización absolutamente óptimo, y los usuarios deben elegir según su hardware y caso de uso específico, pero en general, todos los esquemas principales funcionan bien. (Fuente: Reddit r/LocalLLaMA)

💡 Otros
Daimon Robotics presenta el robot Sparky 1, diestro y con mente ágil: Daimon Robotics mostró su producto innovador en tecnología robótica diestra, Sparky 1. Este robot se describe como poseedor de una capacidad “diestra y con mente ágil” (Mind-Dexterous), lo que sugiere que ha alcanzado un nuevo nivel en percepción, toma de decisiones y manipulación fina, posiblemente fusionando IA avanzada y tecnologías de aprendizaje automático. (Fuente: Ronald_vanLoon)
El MIT desarrolla microrobots del tamaño de un grano de arroz que pueden entrar en el cerebro para tratar tumores inoperables: Investigadores del MIT han desarrollado un microrobot del tamaño de un grano de arroz con el potencial de entrar en el cerebro de forma mínimamente invasiva para tratar tumores que antes eran difíciles de extirpar quirúrgicamente. Este tipo de tecnología combina la microrobótica con la navegación o el control por IA, ofreciendo nuevas posibilidades para la neurocirugía y el tratamiento del cáncer. (Fuente: Ronald_vanLoon)

Ulsan Dynamics completa dos rondas de financiación, impulsando la producción en masa de robots exoesqueleto de consumo y la integración de tecnología de IA: Ulsan Dynamics, una empresa de plataforma tecnológica de robots exoesqueleto, anunció la finalización consecutiva de dos rondas de financiación, lideradas por Binfu Capital, con la participación del antiguo accionista Guoyi Capital. Los fondos se utilizarán para la producción en masa de robots exoesqueleto de consumo e impulsarán la fusión del hardware de exoesqueleto con la tecnología de IA. Los productos de la empresa ya se han aplicado en escenarios industriales y han comenzado a explorar el mercado de asistencia al aire libre (como ayuda para el senderismo en lugares turísticos) y el cuidado de ancianos en el hogar, con planes de lanzar productos de consumo por debajo de los diez mil yuanes. Su último producto ya está equipado con capacidad de entrenamiento de grandes modelos de IA y está investigando la tecnología de interfaz cerebro-computadora. (Fuente: 36氪)