
Palabras clave:Modelo Gemini, Mistral AI, NVIDIA NeMo, LTX-Video, Navegador Safari, RTX 5060, Agente de IA, Ajuste fino de aprendizaje por refuerzo, Generación de imágenes nativas de Gemini, Rendimiento de programación de Mistral Medium 3, Modularidad del marco NeMo 2.0, Generación de video en tiempo real con DiT, Transformación de búsqueda impulsada por IA
🔥 Enfoque
Actualización de la función de generación de imágenes nativa de Google Gemini, mejorando la calidad visual y la precisión del renderizado de texto: Google anunció una importante actualización de la función de generación de imágenes nativa de su modelo Gemini. La nueva versión, “gemini-2.0-flash-preview-image-generation”, ya está disponible en Google AI Studio y Vertex AI. Esta actualización mejora significativamente la calidad visual de las imágenes y la precisión del renderizado de texto, además de reducir la latencia. Las nuevas funciones admiten la fusión de elementos de imagen, la edición en tiempo real (como agregar objetos o modificar contenido parcial) y la combinación con Gemini 2.0 Flash para que la IA conciba y genere imágenes de forma autónoma. Los usuarios pueden probarla gratuitamente en Google AI Studio, y el precio de la llamada a la API es de 0.039 dólares por imagen. Aunque el progreso es notable, algunos usuarios consideran que su efecto general sigue siendo ligeramente inferior al de GPT-4o. (Fuente: 量子位)

Mistral AI lanza Mistral Medium 3, enfocado en programación y multimodalidad, con una drástica reducción de costes: La startup francesa de IA, Mistral AI, ha lanzado su último modelo multimodal, Mistral Medium 3. Este modelo destaca en tareas de programación y STEM, y se afirma que su rendimiento alcanza o supera el 90% de Claude Sonnet 3.7 en varias pruebas de referencia, con un coste de solo 1/8 (0.4 dólares/millón de tokens de entrada, 2 dólares/millón de tokens de salida). Mistral Medium 3 cuenta con capacidades de nivel empresarial como implementación híbrida, post-entrenamiento personalizado e integración con herramientas empresariales, y ya está disponible en Mistral La Plateforme y Amazon Sagemaker, con planes de llegar a más plataformas en la nube en el futuro. Al mismo tiempo, Mistral AI también ha lanzado un servicio de chatbot para empresas, Le Chat Enterprise. (Fuente: 量子位)

NVIDIA lanza NeMo Framework 2.0, mejorando la modularidad y la facilidad de uso, con soporte para modelos de Hugging Face y GPU Blackwell: NVIDIA NeMo Framework se actualiza a la versión 2.0. Las mejoras principales incluyen la adopción de la configuración de Python en lugar de YAML para una mayor flexibilidad; la simplificación de la experimentación y personalización mediante la abstracción modular de PyTorch Lightning; y el uso de la herramienta NeMo-Run para la expansión fluida de experimentos a gran escala. La nueva versión añade soporte para el pre-entrenamiento y el fine-tuning de modelos Hugging Face AutoModelForCausalLM, y ya cuenta con soporte preliminar para las GPU NVIDIA Blackwell B200. Además, NeMo Framework integra soporte para la plataforma de modelos fundacionales del mundo NVIDIA Cosmos, para acelerar el desarrollo de modelos del mundo para sistemas de IA física, incluyendo la biblioteca de procesamiento de vídeo NeMo Curator y el tokenizador Cosmos. (Fuente: GitHub Trending)

Lightricks lanza LTX-Video: modelo de generación de vídeo DiT en tiempo real: Lightricks ha hecho open source LTX-Video, promocionado como el primer modelo de generación de vídeo en tiempo real basado en Diffusion Transformer (DiT). Este modelo es capaz de generar vídeo de alta calidad a una resolución de 1216×704 a 30FPS, y admite múltiples funciones como texto a imagen, imagen a vídeo, animación por fotogramas clave, extensión de vídeo y conversión de vídeo a vídeo. La última versión, 13B v0.9.7, mejora el seguimiento de prompts y la comprensión física, e introduce un pipeline de vídeo multiescala para una renderización rápida y de alta calidad. El modelo está disponible en Hugging Face y cuenta con integraciones para ComfyUI y Diffusers. (Fuente: GitHub Trending)

Apple considera una importante remodelación del navegador Safari, podría virar hacia la búsqueda impulsada por IA, la relación con Google en el punto de mira: Eddie Cue, vicepresidente senior de Apple, testificó en el caso antimonopolio del Departamento de Justicia de EE. UU. contra Google, revelando que Apple está considerando activamente remodelar el navegador Safari, centrándose en un motor de búsqueda impulsado por IA. Señaló que el volumen de búsquedas de Safari disminuyó por primera vez, en parte porque los usuarios están recurriendo a herramientas de IA como OpenAI y Perplexity AI. Apple ha mantenido conversaciones con Perplexity AI y podría introducir más opciones de búsqueda de IA en Safari. Esta medida podría afectar el acuerdo de motor de búsqueda predeterminado de Apple con Google, valorado en unos 20.000 millones de dólares anuales, y tener un impacto en las acciones de ambas empresas. Apple ya ha integrado ChatGPT en Siri y planea añadir Google Gemini. (Fuente: 36氪)

🎯 Tendencias
La tarjeta gráfica de escritorio NVIDIA RTX 5060 saldrá a la venta el 20 de mayo, con un precio en China de 2499 yuanes: NVIDIA anunció que la tarjeta gráfica de escritorio RTX 5060 saldrá a la venta el 20 de mayo, hora de Pekín, con un precio en China de 2499 yuanes. Esta tarjeta utiliza la arquitectura Blackwell RTX, cuenta con 3840 núcleos CUDA, 8GB de memoria GDDR7 y una potencia total de 145W. Según fuentes oficiales, en juegos compatibles con la tecnología de generación multiframe DLSS 4, su rendimiento es el doble que el de la RTX 4060, con el objetivo de que los usuarios puedan ejecutar juegos a más de 100 FPS. El levantamiento del embargo de las reseñas y la venta se realizarán el mismo día. (Fuente: 量子位)

Google Gemini API introduce la función de caché implícita, que puede ahorrar un 75% de los costes: Google anunció la introducción de la función de caché implícita para su Gemini API. Cuando la solicitud de un usuario coincide con la caché, el coste de usar el modelo Gemini 2.5 puede reducirse automáticamente en un 75%. Al mismo tiempo, el número mínimo de tokens necesarios para activar la caché también se ha reducido: Gemini 2.5 Flash a 1K tokens y Gemini 2.5 Pro a 2K tokens. Esta función tiene como objetivo reducir los costes para los desarrolladores que utilizan la Gemini API, sin necesidad de crear explícitamente una caché. (Fuente: matvelloso, demishassabis, algo_diver, jeremyphoward)
Meta FAIR nombra a Rob Fergus como nuevo director, centrándose en la inteligencia artificial general (AGI): Meta anunció que Rob Fergus asumirá el liderazgo de su equipo de investigación fundamental en IA (FAIR). Yann LeCun declaró que FAIR se reenfocará en la inteligencia artificial avanzada, comúnmente conocida como IA de nivel humano o AGI. Esta noticia ha sido recibida con gran interés y felicitaciones por parte de la comunidad de investigación en IA. (Fuente: ylecun, Ar_Douillard, soumithchintala, aaron_defazio, sainingxie)
OpenAI lanza la función de fine-tuning mediante aprendizaje por refuerzo (RFT) para el modelo o4-mini: OpenAI anunció que su modelo o4-mini ahora es compatible con el fine-tuning mediante aprendizaje por refuerzo (RFT). Esta tecnología, en desarrollo desde diciembre del año pasado, utiliza el razonamiento de cadena de pensamiento y la puntuación específica de la tarea para mejorar el rendimiento del modelo, especialmente en dominios complejos. La empresa Ambience utilizó un modelo ajustado con RFT que superó en un 27% la precisión de codificación ICD-10 de médicos clínicos expertos. La empresa Harvey también entrenó modelos con RFT para mejorar la precisión de las citas en tareas legales. Al mismo tiempo, el modelo más rápido y pequeño de OpenAI, 4.1-nano, también está disponible para fine-tuning. (Fuente: stevenheidel, aidan_mclau, andrwpng, teortaxesTex, OpenAIDevs, OpenAIDevs)
La Universidad de Tsinghua presenta Absolute Zero Reasoner: IA que autogenera datos de entrenamiento para un razonamiento excepcional: Un equipo de la Universidad de Tsinghua ha desarrollado un modelo de IA llamado Absolute Zero Reasoner, que puede generar completamente tareas de entrenamiento a través del auto-juego (self-play) y aprender de ellas, sin necesidad de datos externos. En áreas como las matemáticas y la codificación, su rendimiento ya supera a los modelos entrenados con datos curados por expertos humanos. Este logro podría significar una mitigación del problema del cuello de botella de datos en el desarrollo de la IA, abriendo nuevos caminos hacia la AGI. (Fuente: corbtt)

Meta colabora con NVIDIA para mejorar el rendimiento de búsqueda vectorial en GPU de Faiss mediante cuVS: Meta y NVIDIA anunciaron una colaboración para integrar cuVS (CUDA Vector Search) de NVIDIA en la biblioteca de búsqueda de similitud de código abierto de Meta, Faiss v1.10, con el fin de mejorar significativamente el rendimiento de la búsqueda vectorial en GPU. Esta integración permite una mejora de hasta 4.7 veces en el tiempo de construcción de índices IVF y una reducción de la latencia de búsqueda de hasta 8.1 veces. En cuanto a los índices de grafos, el tiempo de construcción de CUDA ANN Graph (CAGRA) es 12.3 veces más rápido que HNSW en CPU, y la latencia de búsqueda se reduce 4.7 veces. (Fuente: AIatMeta)
Google AI Studio y Firebase Studio integran Gemini 2.5 Pro: Google anunció la integración del modelo Gemini 2.5 Pro en Gemini Code Assist (versión personal) y Firebase Studio. Esto proporcionará a los desarrolladores más comodidad y potentes funciones al utilizar modelos de codificación de primer nivel en estas plataformas, con el objetivo de mejorar la eficiencia y la experiencia de codificación. (Fuente: algo_diver)
Microsoft Copilot lanza la función Pages, compatible con la edición en línea y el resaltado de texto: Microsoft Copilot ha añadido la función “Pages”, que permite a los usuarios editar directamente las respuestas generadas por la IA dentro de la interfaz de Copilot. Pueden resaltar texto y solicitar modificaciones específicas. Esta función tiene como objetivo ayudar a los usuarios a convertir más rápida e inteligentemente preguntas y resultados de investigación en documentos utilizables, mejorando la eficiencia del trabajo. (Fuente: yusuf_i_mehdi)
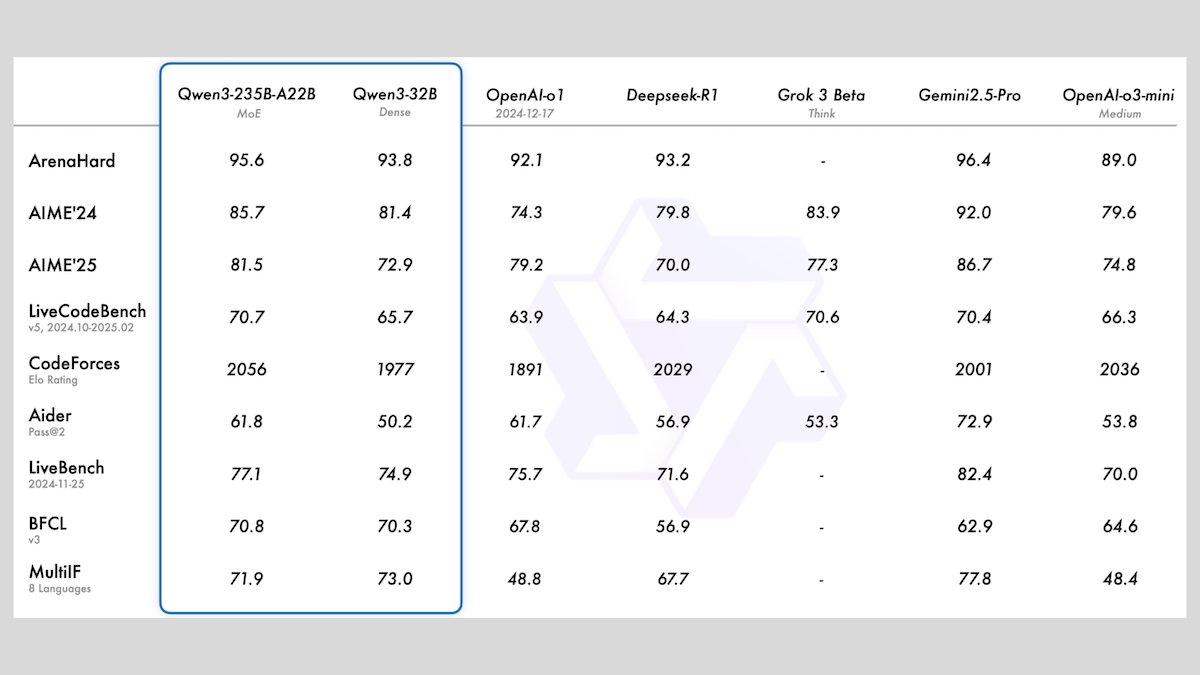
Alibaba lanza la serie de modelos Qwen3, que incluye 8 modelos de lenguaje grandes de código abierto: Alibaba ha lanzado la serie Qwen3, que incluye 8 modelos de lenguaje grandes de código abierto. Entre ellos se encuentran 2 modelos de mezcla de expertos (MoE) y 6 modelos densos con un rango de parámetros de 0.6B a 32B. Todos los modelos admiten modos de inferencia opcionales y capacidades multilingües en 119 idiomas. Qwen3-235B-A22B y Qwen3-30B-A3B muestran un rendimiento excelente en tareas de inferencia, codificación y llamada a funciones, comparables a los modelos de primer nivel como los de OpenAI. En particular, Qwen3-30B-A3B ha llamado la atención por su potente rendimiento y su capacidad de ejecución local. (Fuente: DeepLearningAI)
Meta lanza el modelo Meta Locate 3D para la localización precisa de objetos en entornos 3D: Meta AI ha lanzado Meta Locate 3D, un modelo diseñado específicamente para la localización precisa de objetos en entornos 3D. Este modelo tiene como objetivo ayudar a los robots a comprender con mayor precisión su entorno e interactuar de forma más natural con los humanos. Meta ha puesto a disposición del público el modelo, el conjunto de datos, el artículo de investigación y una demostración para su uso y experimentación. (Fuente: AIatMeta)
Google publica un nuevo informe que explica cómo utilizar la IA para combatir el fraude en línea: Google ha publicado un nuevo informe sobre cómo utiliza la tecnología de inteligencia artificial para combatir el fraude en línea en su motor de búsqueda, el navegador Chrome y el sistema operativo Android. El informe detalla los esfuerzos de Google durante más de una década y los avances más recientes en el uso de la IA para proteger a los usuarios del fraude en línea, destacando el papel crucial de la IA en la identificación y el bloqueo de actividades fraudulentas. (Fuente: Google)
Cohere lanza el modelo de incrustación Embed 4, reforzando las capacidades de búsqueda y recuperación de IA: Cohere ha lanzado su último modelo de incrustación, Embed 4, diseñado para revolucionar la forma en que las empresas acceden y utilizan los datos. Embed 4, el modelo de incrustación más potente de Cohere hasta la fecha, se centra en mejorar la precisión y la eficiencia de la búsqueda y recuperación de IA, ayudando a las organizaciones a desbloquear el valor oculto de sus datos. (Fuente: cohere)

Google anuncia que la conferencia Google I/O se celebrará el 20 de mayo: Google ha anunciado oficialmente que su conferencia anual de desarrolladores, Google I/O, se celebrará el 20 de mayo y ya ha abierto el plazo de inscripción. Durante el evento se realizarán presentaciones magistrales y se anunciarán nuevos productos y tecnologías, y se espera que la IA sea uno de los temas centrales. (Fuente: Google)
El modelo Parakeet de NVIDIA establece un nuevo récord en transcripción de audio: transcribe 60 minutos de audio en 1 segundo: El modelo Parakeet de NVIDIA ha logrado un gran avance en la transcripción de audio, siendo capaz de transcribir hasta 60 minutos de audio en solo 1 segundo, y se encuentra entre los primeros puestos en las clasificaciones relevantes de Hugging Face. Este logro demuestra la posición de liderazgo de NVIDIA en la tecnología de reconocimiento de voz y proporciona a los desarrolladores herramientas eficientes de procesamiento de audio. (Fuente: huggingface)

🧰 Herramientas
LlamaParse añade soporte para GPT 4.1 y Gemini 2.5 Pro, reforzando la capacidad de análisis de documentos: LlamaParse ha implementado recientemente una serie de actualizaciones funcionales, incluyendo la introducción de nuevos modelos de análisis GPT 4.1 y Gemini 2.5 Pro para mejorar la precisión. Además, la nueva versión añade funciones de detección automática de orientación e inclinación, asegurando un análisis perfectamente alineado; proporciona puntuaciones de confianza para evaluar la calidad del análisis; y permite a los usuarios personalizar la tolerancia a errores y la forma de gestionar las páginas fallidas. LlamaParse ofrece una cuota gratuita de 10,000 páginas al mes. (Fuente: jerryjliu0)

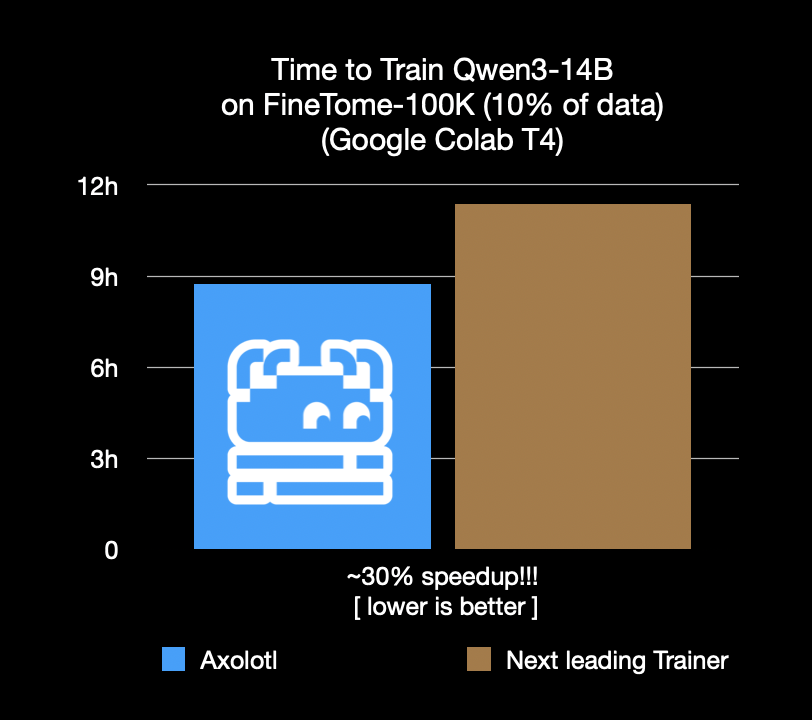
El framework de fine-tuning Axolotl acelera un 30%, ahorrando costes y tiempo: El framework de fine-tuning Axolotl anuncia que en cargas de trabajo reales como FineTome-100k, su velocidad es un 30% más rápida que el siguiente mejor framework. Para equipos de machine learning de tamaño mediano a grande, esto significa un ahorro de miles de dólares al mes. La optimización de este framework tiene como objetivo ayudar a los usuarios a realizar el fine-tuning de modelos de manera más eficiente y económica. (Fuente: Teknium1, winglian, maximelabonne)
Runway lanza el episodio piloto de animación “Mars & Siv: No Vacancy”, mostrando las capacidades del modelo Gen-4: El estudio de IA de Runway ha lanzado el episodio piloto de animación “Mars & Siv: No Vacancy”, creado por Jeremy Higgins y Britton Korbel. Esta obra muestra la aplicación del modelo Gen-4 de Runway en todas las etapas del proceso de producción de animación, desde el concepto hasta el producto final, destacando el potencial de la IA en la generación de contenido creativo. (Fuente: c_valenzuelab, c_valenzuelab)
Replit añade integración con Notion, permitiendo usar contenido de Notion como backend de aplicaciones: Replit anunció una nueva colaboración de integración con Notion, que permite a los desarrolladores utilizar Notion como backend para sus aplicaciones. Los usuarios pueden conectar bases de datos de Notion a proyectos de Replit para mostrar preguntas frecuentes, impulsar chatbots de IA personalizados basados en documentos y registrar tickets de soporte de vuelta en Notion. Esta medida tiene como objetivo combinar las capacidades de organización de backend de Notion con la flexibilidad de creación de frontend de Replit. (Fuente: amasad, amasad, pirroh)
Lanzamiento de Langchain-huggingface v0.2, con soporte para HF Inference Providers: Langchain-huggingface ha lanzado la versión v0.2, que añade soporte para Hugging Face Inference Providers. Esta actualización facilitará el uso de los servicios de inferencia proporcionados por Hugging Face dentro del ecosistema LangChain. (Fuente: LangChainAI, huggingface, ClementDelangue, hwchase17, Hacubu)
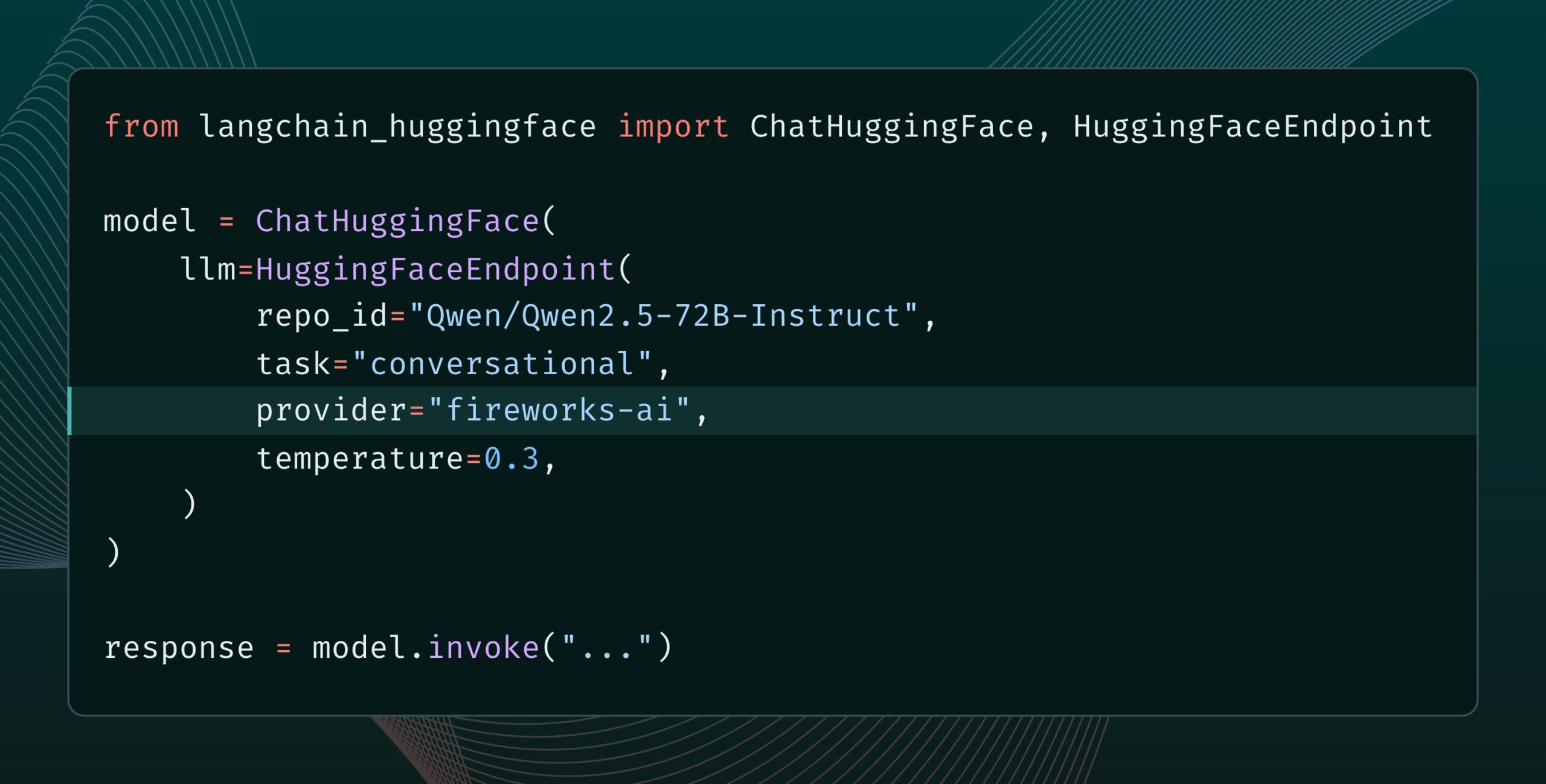
Lanzamiento de smolagents 1.15, añadiendo función de salida en streaming: El framework de agentes de IA smolagents ha lanzado la versión 1.15, introduciendo la función de salidas en streaming (streaming outputs). Los usuarios pueden habilitarla configurando stream_outputs=True al inicializar CodeAgent, lo que hará que todas las interacciones se sientan más fluidas. (Fuente: huggingface, AymericRoucher, ClementDelangue)
Proyecto Better-Qwen3: permite que el modelo Qwen3 cambie automáticamente el modo de pensamiento: Un proyecto de GitHub llamado Better-Qwen3 ha llamado la atención. Este proyecto tiene como objetivo permitir que el modelo Qwen3 controle automáticamente si activa el “modo de pensamiento” según la complejidad de la pregunta del usuario. Para preguntas simples, el modelo responderá directamente; para preguntas complejas, entrará automáticamente en modo de pensamiento para proporcionar una respuesta más profunda. Dirección del proyecto: http://github.com/AaronFeng753/Better-Qwen3 (Fuente: karminski3, Reddit r/LocalLLaMA)
MLX-Audio: biblioteca TTS/STT/STS basada en el framework MLX de Apple: MLX-Audio es una biblioteca de conversión de texto a voz (TTS), voz a texto (STT) y voz a voz (STS) diseñada específicamente para los chips de Apple (Apple Silicon). Desarrollada sobre el framework MLX de Apple, tiene como objetivo proporcionar capacidades eficientes de procesamiento de voz. Esta biblioteca admite múltiples idiomas, personalización de voz, control de velocidad del habla y ofrece una interfaz web interactiva y una API REST. (Fuente: GitHub Trending)
El modelo References de Runway ahora admite la función de expansión de imagen (Outpainting): El modelo References de Runway ahora es compatible con la función de expansión de imagen (outpainting). Los usuarios solo necesitan colocar una imagen en References, seleccionar el formato de salida deseado, dejar el prompt vacío y luego hacer clic en generar para expandir la imagen original. Esta función mejora aún más las capacidades de Runway en la edición y creación de imágenes. (Fuente: c_valenzuelab)

Docker2exe: convierte imágenes de Docker en archivos ejecutables: Docker2exe es una herramienta que puede convertir imágenes de Docker en archivos ejecutables independientes, facilitando a los usuarios compartirlos y ejecutarlos. Admite un modo de incrustación, que empaqueta directamente el tarball de la imagen de Docker en el archivo ejecutable. Cuando se ejecuta en el dispositivo de destino, si la imagen de Docker correspondiente no está disponible localmente, cargará automáticamente la imagen incrustada o la extraerá de la red. (Fuente: GitHub Trending)
Smoothie Qwen: suaviza las probabilidades de los tokens del modelo Qwen para equilibrar la generación multilingüe: Smoothie Qwen es una herramienta de ajuste ligera que, al suavizar las probabilidades de los tokens en el modelo Qwen, tiene como objetivo mejorar el equilibrio del modelo en la generación multilingüe, reduciendo el sesgo accidental hacia idiomas específicos (como el chino), mientras mantiene el rendimiento central. La herramienta utiliza rangos Unicode para identificar tokens, realiza análisis de N-gramas y ajusta los pesos de los tokens en lm_head. Los modelos preajustados están disponibles en Hugging Face. (Fuente: Reddit r/LocalLLaMA)

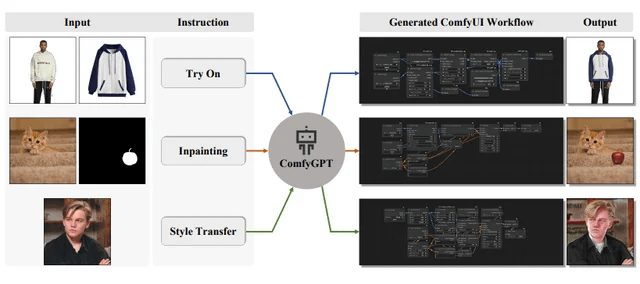
ComfyGPT: sistema multiagente autooptimizante para la generación integral de flujos de trabajo de ComfyUI: Un artículo titulado “ComfyGPT: A Self-Optimizing Multi-Agent System for Comprehensive ComfyUI Workflow Generation” ha sido enviado a arXiv, presentando un sistema llamado ComfyGPT. Este sistema utiliza un método multiagente autooptimizante con el objetivo de generar de manera integral flujos de trabajo para ComfyUI, simplificando la construcción de procesos complejos de generación de imágenes. (Fuente: Reddit r/LocalLLaMA)
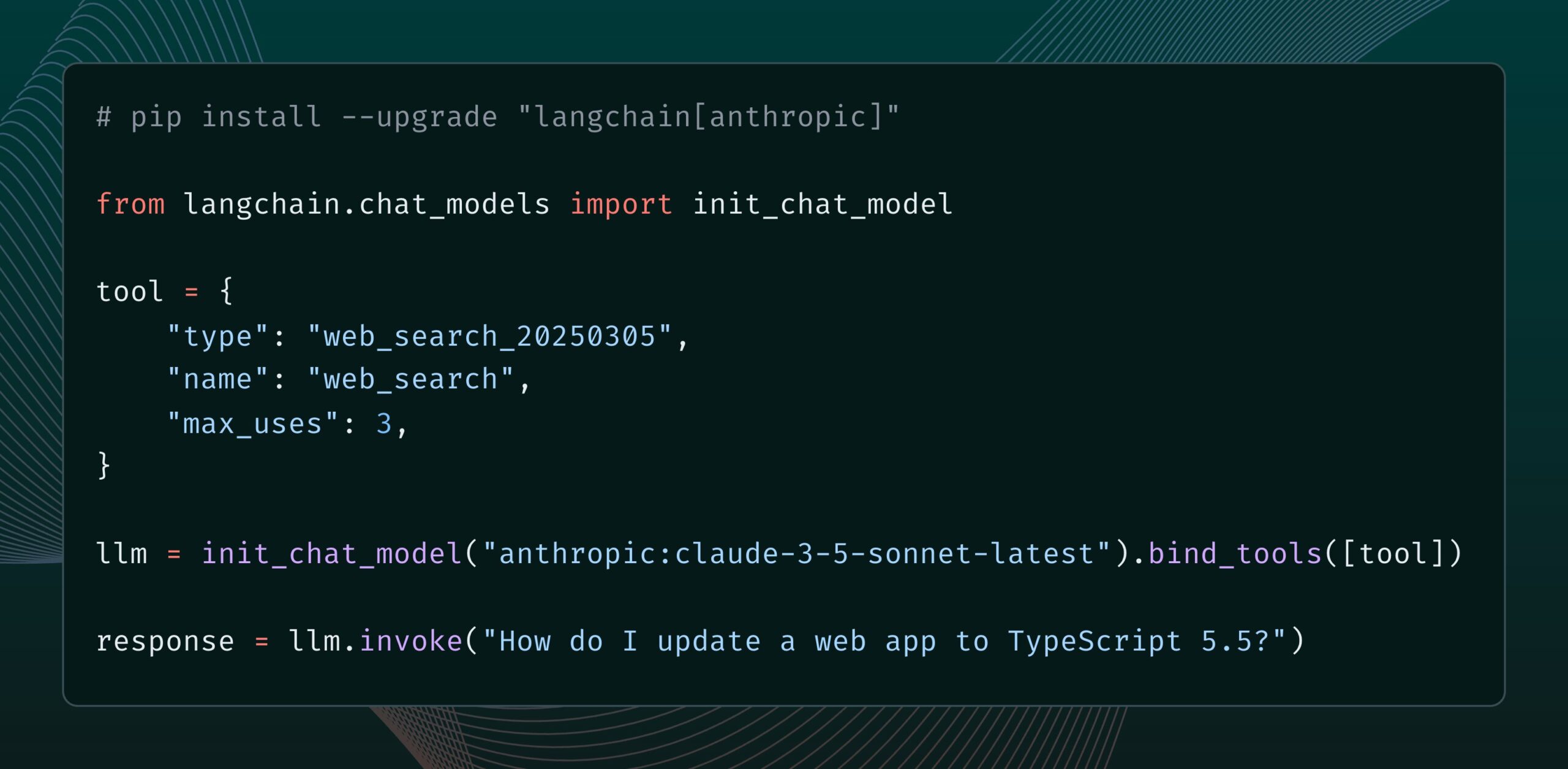
El modelo Claude de Anthropic añade una nueva herramienta de búsqueda web: Anthropic ha lanzado una nueva herramienta de búsqueda web para su modelo Claude. Esta herramienta permite a Claude realizar búsquedas en la web mientras genera respuestas y utilizar los resultados de la búsqueda como base, proporcionando respuestas con citas. Esta función ya está integrada en la biblioteca langchain-anthropic, mejorando la capacidad de Claude para obtener y utilizar información en tiempo real. (Fuente: LangChainAI, hwchase17)
Glass Health lanza la función Workspace, utilizando IA para ayudar en el diagnóstico clínico y la planificación del tratamiento: Glass Health ha lanzado la nueva función Workspace, que permite a los médicos utilizar la IA para completar de manera más eficiente flujos de trabajo complejos de razonamiento diagnóstico, planificación del tratamiento y documentación. Esta medida tiene como objetivo mejorar la eficiencia y la calidad del trabajo médico mediante la tecnología de IA. (Fuente: GlassHealthHQ)
OpenWebUI añade notas mejoradas por IA y funciones de grabación de reuniones: La última versión de OpenWebUI ha incorporado una función de notas mejoradas por IA, que permite a los usuarios crear notas, adjuntar audio de reuniones o voz, y hacer que la IA utilice la transcripción de audio para mejorar, resumir u optimizar instantáneamente las notas. Además, también admite la grabación e importación de audio de reuniones, lo que facilita a los usuarios revisar y extraer información importante de las discusiones. (Fuente: Reddit r/OpenWebUI)
📚 Aprendizaje
Naciones Unidas publica un informe de 200 páginas sobre IA y desarrollo humano global: El Programa de las Naciones Unidas para el Desarrollo (PNUD) ha publicado un informe de 200 páginas que examina la inteligencia artificial desde la perspectiva del desarrollo humano global. El informe explora el impacto de la IA en los Objetivos de Desarrollo Sostenible, la desigualdad, la gobernanza y el futuro del trabajo, entre otros aspectos, y propone recomendaciones políticas. El informe ha llamado la atención por sus puntos de vista definidos. (Fuente: random_walker)
The Turing Post publica un artículo de análisis profundo del protocolo Agent2Agent (A2A): Dado el gran interés de la comunidad en los protocolos de comunicación entre agentes de IA, The Turing Post ha publicado gratuitamente en Hugging Face su artículo de análisis profundo sobre el protocolo A2A de Google. El artículo explora la importancia del protocolo A2A (destinado a romper los silos de los agentes de IA y permitir la colaboración), las posibles aplicaciones (como la colaboración de equipos de agentes especializados, los flujos de trabajo interempresariales, la estandarización de la colaboración hombre-máquina, los directorios de agentes con capacidad de búsqueda) y su principio de funcionamiento y métodos de iniciación. (Fuente: TheTuringPost, TheTuringPost, TheTuringPost, dl_weekly)

Ingeniero de prompts comparte: cómo escribir fácilmente plantillas de prompts útiles: El ingeniero de prompts dotey compartió un método de tres pasos para crear plantillas de prompts eficientes: 1. Recopilar prompts del mismo estilo pero con diferentes temas; 2. Identificar similitudes y diferencias (se puede usar IA); 3. Probar y optimizar repetidamente. Enfatizó que una buena plantilla es similar a una función en programación, donde se pueden generar diferentes resultados modificando unas pocas variables. También compartió una plantilla de comando para generar rápidamente nuevos prompts usando IA, y señaló que no todos los estilos son adecuados para plantillas, y los temas con muchos detalles complejos aún requieren optimización personalizada. (Fuente: dotey)

El investigador de DeepMind John Jumper y su equipo están contratando para expandir el descubrimiento científico basado en LLM: John Jumper, investigador de Google DeepMind, anunció que su equipo está contratando para múltiples puestos con el fin de expandir el trabajo en el descubrimiento científico basado en modelos de lenguaje grandes (LLM). Los puestos disponibles incluyen científicos de investigación (RS) e ingenieros de investigación (RE), con el objetivo de impulsar el futuro de la IA científica en lenguaje natural. (Fuente: demishassabis, NandoDF)
El blog de Ragas comparte dos años de experiencia en la mejora de aplicaciones de IA: Shahules786 publicó un artículo en el blog de Ragas resumiendo las lecciones aprendidas durante los últimos dos años trabajando en estrecha colaboración con equipos de IA, entregando ciclos de evaluación y mejorando sistemas LLM. El artículo tiene como objetivo proporcionar orientación práctica y conocimientos para los profesionales que construyen y optimizan aplicaciones de IA. (Fuente: Shahules786)

Kyunghyun Cho discute los métodos de enseñanza para cursos de posgrado en machine learning en la era de los LLM: El profesor Kyunghyun Cho de la Universidad de Nueva York compartió sus reflexiones y experimentos sobre el contenido de enseñanza para cursos de posgrado de primer año en machine learning en la era actual de los LLM y la computación a gran escala. Propuso enseñar todo el contenido que acepte SGD (descenso de gradiente estocástico) y no sea LLM, y guiar a los estudiantes a leer artículos clásicos. (Fuente: ylecun, sainingxie)

Se publica una clasificación de Procesamiento Inteligente de Documentos (IDP) para unificar la evaluación de la capacidad de comprensión de documentos de los VLM: Se ha lanzado una nueva clasificación de Procesamiento Inteligente de Documentos (IDP) con el objetivo de proporcionar una prueba de referencia unificada para diversas tareas de comprensión de documentos como OCR, KIE, VQA y extracción de tablas. Esta clasificación cubre 6 tareas principales de IDP, 16 conjuntos de datos y 9229 documentos. Los resultados preliminares muestran que Gemini 2.5 Flash lidera en general, pero todos los modelos muestran un rendimiento deficiente en la comprensión de documentos largos, y la extracción de tablas sigue siendo un cuello de botella. El rendimiento de la última versión de GPT-4o incluso ha disminuido. (Fuente: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
LangGraph lanza la función Cron Jobs, que permite activar agentes de IA de forma programada: La plataforma LangGraph de LangChain ha añadido la función Cron Jobs, que permite a los usuarios configurar tareas programadas para activar automáticamente la ejecución de agentes de IA. Esta función permite que los agentes de IA ejecuten tareas según un horario preestablecido, lo que es adecuado para escenarios que requieren procesamiento o monitorización periódica. (Fuente: hwchase17)
💼 Negocios
La herramienta de depuración de software de IA Lightrun recauda 70 millones de dólares en una ronda de Serie B, liderada por Accel e Insight Partners: Lightrun, desarrollador de herramientas de observabilidad y depuración de software de IA, anunció la finalización de una ronda de financiación de Serie B de 70 millones de dólares, liderada por Accel e Insight Partners, con la participación de Citigroup, entre otros, elevando su financiación total a 110 millones de dólares. Su producto principal, Runtime Autonomous AI Debugger, puede localizar con precisión el código problemático en el IDE y proporcionar sugerencias de reparación, con el objetivo de reducir el tiempo de depuración de horas a minutos. Los ingresos de la empresa crecieron 4.5 veces en 2024, con clientes que incluyen empresas de Fortune 500 como Citigroup y Microsoft. (Fuente: 36氪)

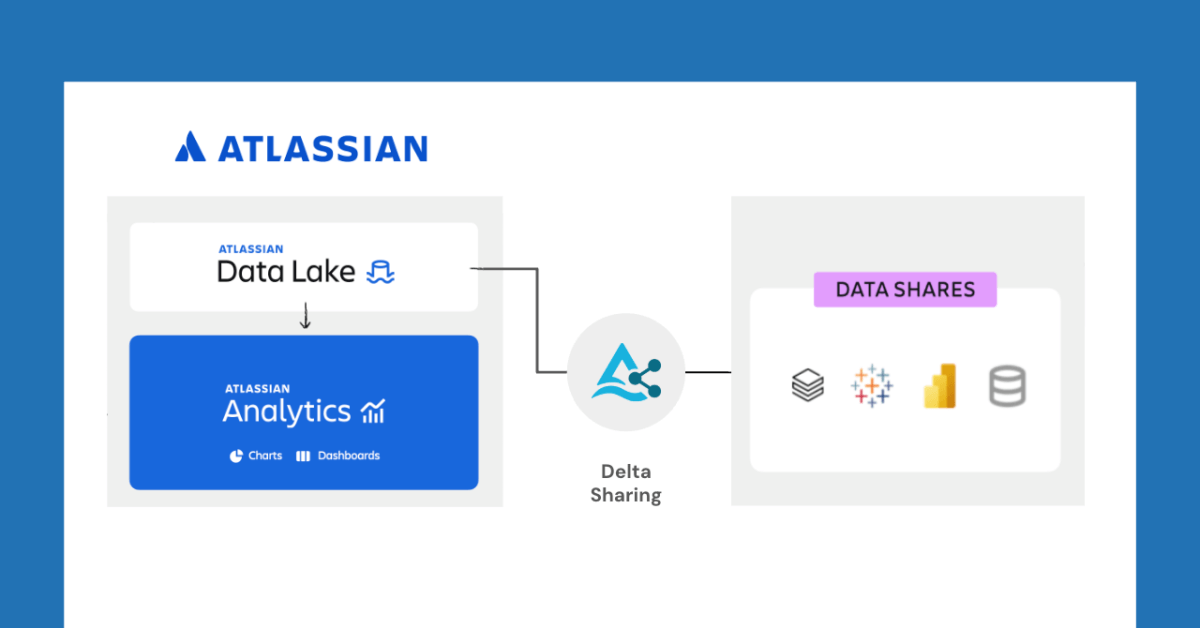
Databricks se asocia con Atlassian para desbloquear nuevas funciones de intercambio de datos a través de Delta Sharing: Databricks anunció una asociación con Atlassian para llevar nuevas capacidades de intercambio de datos a Atlassian Analytics. A través del protocolo abierto de Delta Sharing, los clientes de Atlassian pueden acceder y analizar de forma segura sus datos en Atlassian Data Lake utilizando las herramientas de su elección. Esta función admite la integración de BI, flujos de trabajo de datos personalizados, colaboración entre equipos y otros casos de uso. (Fuente: matei_zaharia)
Fastino recauda 17.5 millones de dólares, centrándose en modelos de lenguaje específicos para tareas (TLM): La startup Fastino anunció una financiación de 17.5 millones de dólares (de una ronda pre-semilla total de 25 millones de dólares) liderada por Khosla Ventures, para desarrollar sus innovadores modelos de lenguaje específicos para tareas (TLM). Fastino afirma que su arquitectura TLM es compacta y está optimizada para tareas específicas, pudiendo entrenarse en GPU de juegos de gama baja, lo que resulta rentable. Los TLM, mediante la especialización de tareas a nivel de arquitectura, pre-entrenamiento y post-entrenamiento, eliminan la redundancia de parámetros y la ineficiencia arquitectónica, con el objetivo de mejorar la precisión en tareas específicas y poder integrarse en aplicaciones sensibles a la latencia y al coste. (Fuente: Reddit r/MachineLearning)

🌟 Comunidad
Las herramientas de búsqueda de empleo asistidas por IA generan preocupación por trampas, las empresas refuerzan las contramedidas: Recientemente, ha aumentado el uso de herramientas de IA para ayudar en entrevistas en línea y exámenes escritos. Estas “herramientas mágicas de entrevista con IA” pueden personalizar respuestas basadas en el currículum del usuario, ayudando a los solicitantes a obtener una ventaja en la búsqueda de empleo. El umbral para adquirir este tipo de software es bajo, e incluso ofrecen varios paquetes de pago y orientación remota. Esta tendencia se remonta a la aparición de herramientas de trampa de IA tempranas como “Interview Coder”. Las empresas han comenzado a tomar contramedidas, como prestar atención al comportamiento anómalo de los solicitantes durante las entrevistas, considerar la introducción de la detección de pantalla o volver a las entrevistas presenciales. Los abogados señalan que hacer trampa con IA viola el principio de buena fe, puede llevar a la rescisión del contrato laboral y conlleva riesgos de fuga de privacidad. (Fuente: 36氪)

El CEO de LangChain, Harrison Chase, propone los conceptos de “agentes ambientales” y “bandeja de entrada de agentes”: Harrison Chase, CEO de LangChain, compartió su visión sobre el futuro desarrollo de los agentes de IA en el evento AI Ascent de Sequoia, proponiendo los conceptos de “Agentes Ambientales” (Ambient Agents) y “Bandeja de Entrada de Agentes” (Agent Inbox). Los agentes ambientales se refieren a sistemas de IA que pueden ejecutarse continuamente en segundo plano, respondiendo a eventos en lugar de a instrucciones humanas directas, mientras que la bandeja de entrada de agentes es una nueva interfaz de interacción hombre-máquina para gestionar y supervisar las actividades de estos agentes. (Fuente: hwchase17, hwchase17, hwchase17)

Jim Fan propone la “Prueba de Turing Física” como la nueva estrella polar de la IA: El científico de NVIDIA Jim Fan propuso en el evento AI Ascent de Sequoia el concepto de “Prueba de Turing Física”, considerándolo la próxima “estrella polar” en el campo de la IA. Esta prueba imagina un escenario: después de un hackathon de domingo, la casa está hecha un desastre; el lunes por la noche, al volver a casa, el salón está impecable y hay una cena a la luz de las velas preparada, y no puedes distinguir si lo hizo un humano o una máquina. Él considera que este es el objetivo de la robótica general y compartió los principios fundamentales para resolver este problema, incluyendo la estrategia de datos y la ley de escala. (Fuente: DrJimFan, killerstorm)
La evaluación de modelos de IA se enfrenta a una crisis, la alianza EvalEval pide mejoras: En respuesta a las deficiencias actuales en los métodos de evaluación de modelos de IA, como la saturación de los benchmarks y la falta de rigor científico, se mencionó la alianza EvalEval. Su objetivo es unir a las personas preocupadas por el estado actual de la evaluación para trabajar conjuntamente en la mejora de los informes de evaluación, la resolución del problema de la saturación, el aumento del rigor científico de la evaluación y la infraestructura, etc. Las discusiones relacionadas consideran que se debe prestar más atención a la validez de la evaluación. (Fuente: ClementDelangue)

Debate en Reddit: Observaciones y experiencias en la construcción de flujos de trabajo LLM: Un desarrollador compartió en Reddit un resumen de sus experiencias construyendo flujos de trabajo LLM complejos durante el último año. Puntos clave incluyen: la descomposición de tareas en los pasos más pequeños y el encadenamiento de llamadas a prompts es superior a un único prompt complejo; el uso de etiquetas XML para estructurar los prompts funciona mejor; es necesario informar explícitamente al LLM que su rol es solo el análisis y la transformación semántica, y no debe introducir su propio conocimiento; utilizar bibliotecas NLP tradicionales como NLTK para validar la salida del LLM; los clasificadores tipo BERT ajustados para tareas pequeñas a menudo superan a los LLM; los LLM como árbitros o para calificar la confianza no son fiables, especialmente cuando faltan criterios de calificación claros; en los bucles agénticos, establecer las condiciones para que el LLM decida salir del bucle es un desafío; el rendimiento generalmente disminuye después de que la ventana de contexto de entrada supera los 4K Tokens; los modelos 32B son suficientes para tareas estructuradas; el CoT estructurado es superior al no estructurado; escribir CoT propio es mejor que depender de modelos de razonamiento; el objetivo a largo plazo es ajustar todos los componentes y prestar atención a la construcción de conjuntos de datos de ajuste equilibrados. (Fuente: Reddit r/LocalLLaMA)
Usuarios de Reddit discuten la configuración del prompt del sistema de Claude Sonnet 3.7: Usuarios de la comunidad r/ClaudeAI de Reddit informaron inestabilidad en el modelo Claude Sonnet 3.7 en cuanto al seguimiento de instrucciones, reparación de código y memoria contextual, y solicitaron prompts de sistema efectivos. Algunos usuarios compartieron prompts que imitan el comportamiento de Sonnet 3.5, así como instrucciones detalladas que enfatizan soluciones eficientes y prácticas, y el seguimiento de principios fundamentales de la informática (como DRY, KISS, SRP). Otros usuarios sugirieron mejorar el efecto haciendo que Claude reescriba y optimice sus propios prompts de sistema, o usando instrucciones concisas y claras de una sola línea. (Fuente: Reddit r/ClaudeAI)
Discusión sobre el número de Epochs necesarios para el fine-tuning de LLM: En Reddit r/MachineLearning, un usuario planteó dudas sobre el artículo de Deepseek R1 que solo utilizaba 2 Epochs para el fine-tuning del modelo Deepseek-V3-Base (aproximadamente 800,000 muestras), discutiendo métricas, además de la función de pérdida, que determinan el número de Epochs para el fine-tuning, como el rendimiento de los datos de evaluación y la calidad de los datos. (Fuente: Reddit r/MachineLearning)
💡 Otros
François Chollet: Construir modelos mentales sólidos es un prerrequisito para resolver problemas difíciles: El pensador de IA François Chollet enfatiza que establecer modelos mentales claros y autoconsistentes es un prerrequisito para resolver problemas difíciles de manera creativa (en lugar de depender de la suerte), lo cual es diferente de la capacidad de resolver problemas simples rápidamente. Él cree que la elegancia es la combinación de expresividad y simplicidad, estrechamente relacionada con la compresión. (Fuente: fchollet, teortaxesTex, fchollet, pmddomingos)

Amjad Masad, CEO de Replit: Los agentes de IA serán la nueva ola de la programación: Amjad Masad, CEO y cofundador de Replit, declaró en una entrevista con The Turing Post que siempre ha creído que los agentes de IA liderarán la próxima ola de la programación. Compartió su cambio de mentalidad desde enseñar programación hasta construir agentes que puedan programar automáticamente. Mencionó que los agentes de software ya están produciendo resultados en negocios reales, por ejemplo, ayudando a empresas inmobiliarias a optimizar algoritmos de asignación de clientes potenciales, lo que resulta en un aumento del 10% en la tasa de conversión. Él cree que las futuras startups de mil millones de dólares podrían ser creadas por fundadores independientes mejorados por IA y discutió las condiciones necesarias para realizar esta visión, el estado actual y futuro del campo de la programación, la evolución de la visión de Replit y la importancia de la AGI y el código abierto. (Fuente: TheTuringPost, TheTuringPost)
LazyVim: una configuración de Neovim para “perezosos”: LazyVim es una solución de configuración de Neovim basada en lazy.nvim, diseñada para permitir a los usuarios personalizar y ampliar fácilmente su entorno Neovim. Proporciona una experiencia preconfigurada y rica en funciones similar a un IDE, al tiempo que mantiene un alto grado de flexibilidad, que los usuarios pueden ajustar según sus necesidades. (Fuente: GitHub Trending)
