Palabras clave:Cero Absoluto, Qwen3, Mistral Medium 3, Fundación PyTorch, Evolución autónoma de IA, Modelo multimodal, IA de código abierto, Paradigma RLVR, Sistema AZR, Qwen3-235B-A22B, Biblioteca de optimización DeepSpeed, Soporte multimodal LangSmith
🔥 Enfoque
La Universidad Tsinghua publica el artículo Absolute Zero: la IA puede autoevolucionar sin datos externos: El equipo LeapLabTHU de la Universidad Tsinghua ha publicado un nuevo paradigma RLVR (Reinforcement Learning with Verifiable Rewards) denominado “Absolute Zero”. Bajo este paradigma, un único modelo puede proponerse a sí mismo tareas que maximizan el progreso del aprendizaje y, al resolver estas tareas, mejorar su capacidad de razonamiento, sin depender en absoluto de datos externos. Su sistema AZR (Absolute Zero Reasoner) utiliza un ejecutor de código para verificar tareas y respuestas, logrando un aprendizaje abierto pero fundamentado. Los experimentos demuestran que AZR alcanza un nivel SOTA en tareas de codificación y razonamiento matemático, superando a los modelos zero-shot existentes que dependen de decenas de miles de muestras anotadas por humanos (fuente: Reddit r/LocalLLaMA)
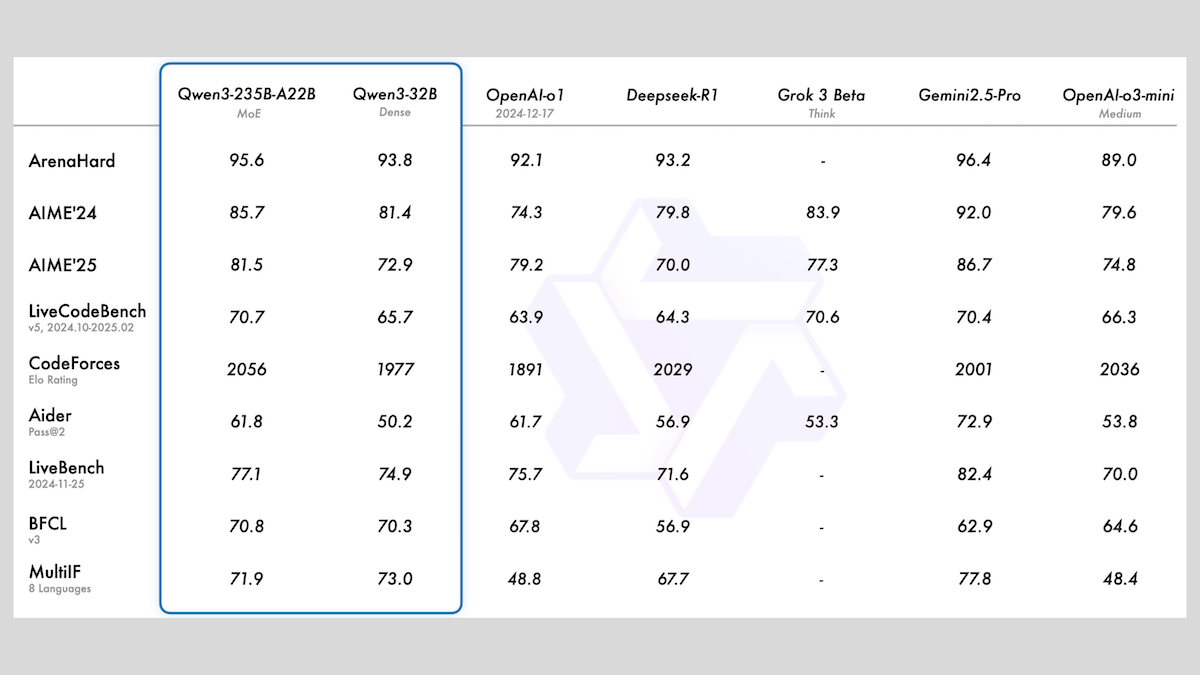
Alibaba lanza la serie de modelos Qwen3, que incluye MoE y múltiples tamaños: Alibaba ha lanzado la serie de grandes modelos de lenguaje Qwen3, que consta de 8 modelos con un número de parámetros que va desde 0.6B hasta 235B. Entre ellos, Qwen3-235B-A22B y Qwen3-30B-A3B utilizan una arquitectura MoE, mientras que los demás son modelos densos. Esta serie de modelos fue preentrenada con 36T tokens, cubriendo 119 idiomas, y cuenta con un modo de inferencia activable/desactivable, adecuado para múltiples dominios como código, matemáticas y ciencia. Las evaluaciones muestran que los modelos MoE tienen un rendimiento superior; la versión de 235B supera a DeepSeek-R1 y Gemini 2.5 Pro en varios benchmarks, y la versión de 30B también muestra un gran desempeño, incluso el modelo de 4B supera en algunos benchmarks a modelos con muchos más parámetros. Los modelos ya están disponibles en HuggingFace y ModelScope bajo la licencia Apache 2.0 (fuente: DeepLearning.AI Blog)
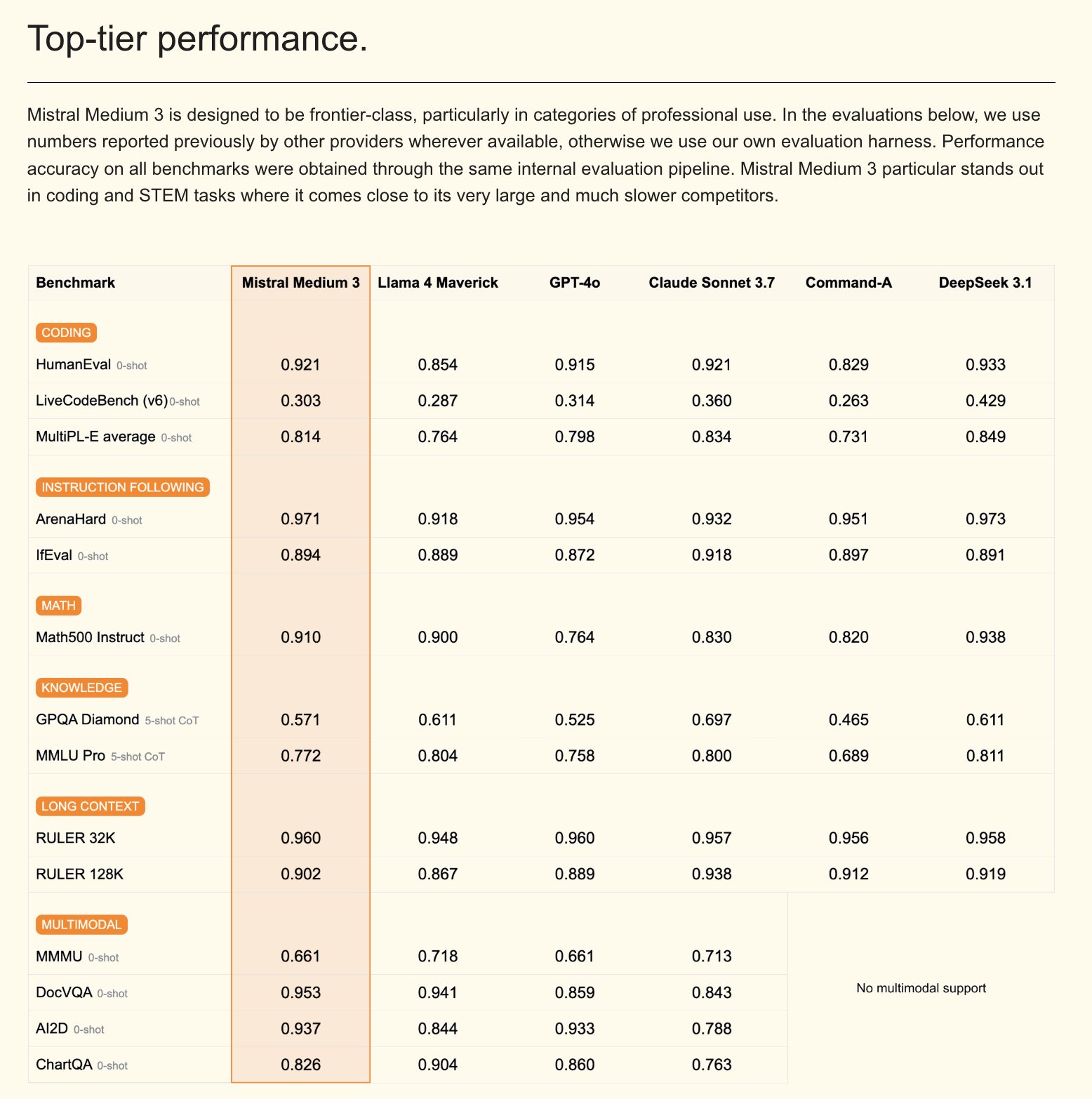
Mistral lanza el modelo multimodal Mistral Medium 3 y un asistente de IA para empresas: Mistral AI ha presentado Mistral Medium 3, un nuevo modelo multimodal que, según afirman, se acerca en rendimiento a Claude Sonnet 3.7, pero con un coste significativamente menor (entrada $0.4/M token, salida $2/M token), reducido en 8 veces. Este modelo destaca en codificación y llamadas a funciones, y ofrece características de nivel empresarial como despliegue híbrido o local y post-entrenamiento personalizado. Paralelamente, Mistral ha lanzado Le Chat Enterprise, un asistente de IA personalizable y seguro para empresas, que admite la integración con bases de conocimiento corporativas (como Gmail, Google Drive, Sharepoint), y cuenta con funciones de Agent, asistente de codificación, búsqueda web, etc., con el objetivo de mejorar la competitividad empresarial. Mistral ha anunciado que lanzará un nuevo modelo Large en las próximas semanas (fuente: Mistral AI、GuillaumeLample、scaling01、karminski3)
La Fundación PyTorch se expande a una fundación paraguas, incorporando vLLM y DeepSpeed: La Fundación PyTorch ha anunciado su expansión a una estructura de fundación paraguas, con el objetivo de agrupar más proyectos de código abierto de IA de alta calidad. Los primeros proyectos en unirse son vLLM y DeepSpeed. vLLM es un motor de inferencia y servicio de alto rendimiento y eficiente en memoria diseñado para LLM; DeepSpeed es una biblioteca de optimización de aprendizaje profundo que hace más eficiente el entrenamiento de modelos a gran escala. Esta medida tiene como objetivo promover el desarrollo de la IA impulsado por la comunidad, cubriendo todo el ciclo de vida desde la investigación hasta la producción, y cuenta con el apoyo de varios miembros como AMD, Arm, AWS, Google, Huawei, entre otros (fuente: PyTorch、soumithchintala、vllm_project、code_star)

🎯 Movimientos
El laboratorio ARC de Tencent lanza FlexiAct: herramienta de transferencia de movimiento en video: El laboratorio ARC de Tencent ha lanzado una nueva herramienta llamada FlexiAct en Hugging Face. Esta herramienta puede transferir el movimiento de un video de referencia a cualquier imagen objetivo, incluso si la disposición, el ángulo de visión o la estructura esquelética de la imagen objetivo son diferentes al video de referencia. Esto ofrece nuevas posibilidades para los campos de generación y edición de video, permitiendo a los usuarios controlar de manera más flexible el movimiento y las posturas en el contenido generado (fuente: _akhaliq)
White Circle lanza CircleGuardBench: nuevo benchmark para modelos de moderación de contenido de IA: White Circle ha presentado CircleGuardBench, un nuevo benchmark para evaluar modelos de moderación de contenido de IA. Este benchmark está diseñado para realizar evaluaciones a nivel de producción, probando la detección de daños, la resistencia al jailbreak, la tasa de falsos positivos y la latencia, cubriendo 17 categorías de daños del mundo real. El artículo de blog y la tabla de clasificación correspondientes se han publicado en Hugging Face, proporcionando nuevos estándares de evaluación para los campos de seguridad de IA y moderación de contenido (fuente: TheTuringPost、_akhaliq)

Hugging Face lanza SIFT-50M: un gran dataset multilingüe para fine-tuning de instrucciones de voz: Se ha lanzado en Hugging Face el dataset SIFT-50M, un dataset multilingüe a gran escala diseñado específicamente para el fine-tuning de instrucciones de voz. Este dataset contiene más de 50 millones de pares de preguntas y respuestas tipo instrucción, cubriendo 5 idiomas. El SIFT-LLM entrenado con este dataset supera a SALMONN y Qwen2-Audio en benchmarks de seguimiento de voz. El dataset también incluye un benchmark EvalSIFT para evaluación acústica y generativa, y admite la generación de voz controlable (como tono, velocidad, acento), construido sobre Whisper, HuBERT, X-Codec2 & Qwen2.5 (fuente: ClementDelangue、huggingface)
Meta lanza Perception Language Model (PLM): modelo de lenguaje visual de código abierto y reproducible: Meta AI ha presentado Meta Perception Language Model (PLM), un modelo de lenguaje visual abierto y reproducible diseñado para resolver tareas visuales desafiantes. Meta espera que PLM ayude a la comunidad de código abierto a construir sistemas de visión por computadora más potentes. Se han publicado el artículo de investigación, el código y el dataset correspondientes para uso de investigadores y desarrolladores (fuente: AIatMeta)
Google actualiza el modelo de generación de imágenes Gemini 2.0: mejora de calidad y velocidad: Google ha anunciado una actualización de su modelo de generación de imágenes Gemini 2.0 (versión preliminar). La nueva versión ofrece una mejor calidad visual, una representación de texto más precisa, tasas de bloqueo (block rates) más bajas y límites de velocidad (rate limits) más altos. El coste de generar cada imagen es de $0.039. Esta actualización tiene como objetivo mejorar la experiencia y los resultados de los desarrolladores que utilizan Gemini para la generación de imágenes (fuente: m__dehghani、scaling01、andrew_n_carr、demishassabis)
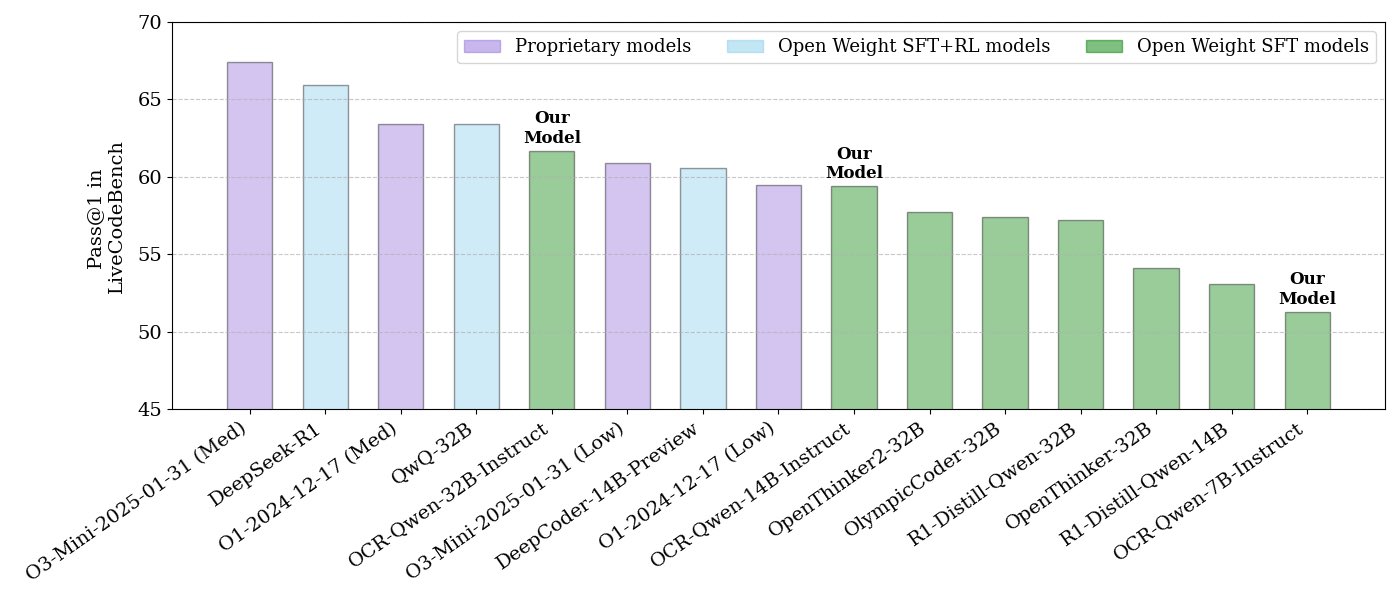
NVIDIA lanza una serie de modelos de inferencia de código de código abierto: NVIDIA ha lanzado una serie de modelos de inferencia de código de código abierto, disponibles en tres tamaños: 32B, 14B y 7B, todos bajo la licencia APACHE 2.0. Estos modelos, entrenados con datasets OCR, según se informa, superan a O3 mini y O1 (low) en el benchmark LiveCodeBench y son un 30% más eficientes en tokens que modelos de inferencia similares. Los modelos son compatibles con múltiples frameworks como llama.cpp, vLLM, transformers, TGI, etc. (fuente: huggingface、ClementDelangue)
ServiceNow y NVIDIA colaboran para lanzar el modelo Apriel-Nemotron-15b-Thinker: ServiceNow y NVIDIA han lanzado conjuntamente un modelo de 15B parámetros llamado Apriel-Nemotron-15b-Thinker, bajo la licencia MIT. Se afirma que este modelo tiene un rendimiento comparable al de los modelos de 32B, pero con un consumo de tokens significativamente menor (aproximadamente un 40% menos que Qwen-QwQ-32b). Destaca en múltiples benchmarks como MBPP, BFCL, RAG empresarial e IFEval, siendo especialmente competitivo en tareas de RAG empresarial y codificación (fuente: Reddit r/LocalLLaMA)

Modelo s1: inferencia con fine-tuning de pocas muestras, la técnica “Wait” mejora el rendimiento: Investigadores de la Universidad de Stanford y otras instituciones han desarrollado el modelo s1, demostrando que con solo unas 1000 muestras de cadena de pensamiento (CoT) para fine-tuning supervisado, se puede dotar de capacidad de razonamiento a LLM preentrenados (como Qwen 2.5-32B). La investigación también descubrió que forzar al modelo a generar el token “Wait” durante la inferencia para alargar la cadena de razonamiento puede mejorar significativamente la precisión del modelo en tareas como matemáticas, acercando su rendimiento al de OpenAI o1-preview. Este hallazgo ofrece una nueva vía para mejorar la capacidad de razonamiento de los modelos a bajo coste (fuente: DeepLearning.AI Blog)
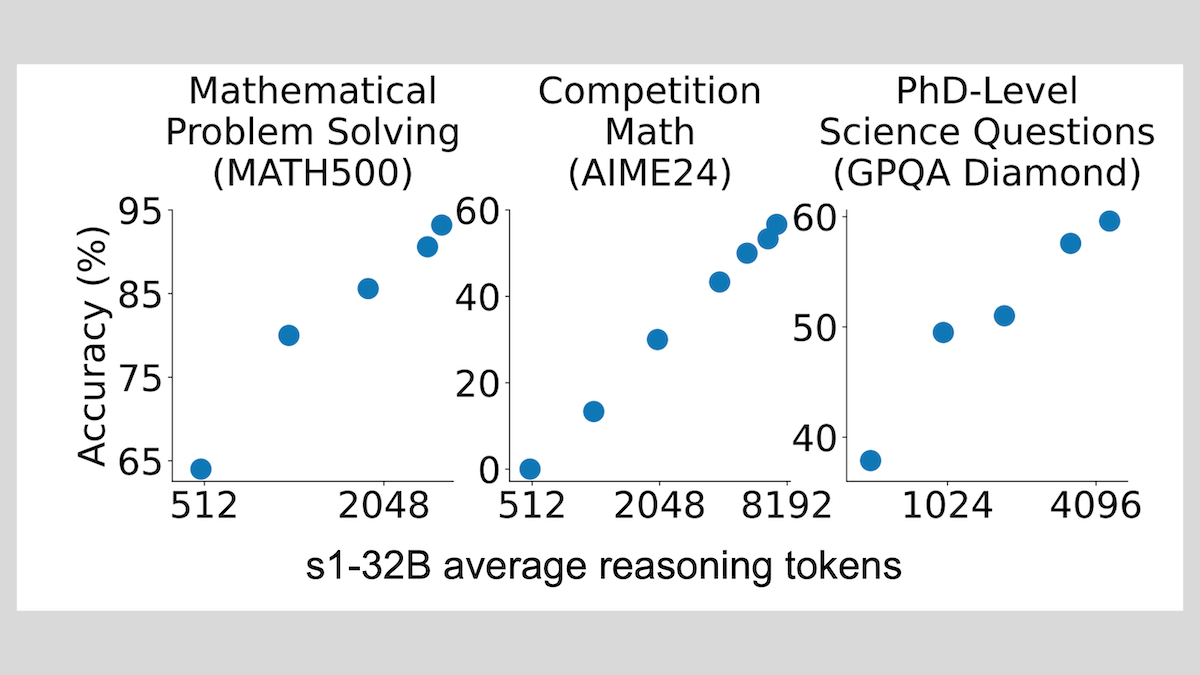
ThinkPRM: modelo generativo de recompensa de proceso entrenable con solo 8K etiquetas: Investigadores han propuesto ThinkPRM, un modelo generativo de recompensa de proceso (PRM) que solo requiere 8K etiquetas de proceso para su fine-tuning. Este modelo puede verificar procesos de razonamiento generando largas cadenas de pensamiento (long chains-of-thought), resolviendo el costoso problema de la gran cantidad de datos de supervisión a nivel de paso necesarios para entrenar PRM. El código, el modelo y los datos relacionados se han publicado en GitHub y Hugging Face (fuente: Reddit r/MachineLearning)
🧰 Herramientas
Zed lanza el que afirma ser el editor de código AI más rápido del mundo: Zed ha lanzado un editor de código AI que afirma ser el más rápido del mundo. Este editor, construido desde cero en Rust, está diseñado para optimizar la colaboración entre humanos e IA, ofreciendo una experiencia de edición agéntica (agentic editing experience) ultrarrápida. Soporta modelos populares como Claude 3.7 Sonnet y permite a los usuarios usar sus propias claves API o modelos locales a través de Ollama (fuente: andersonbcdefg、ollama)
Hugging Face lanza nanoVLM: biblioteca minimalista de modelos de lenguaje visual: Hugging Face ha hecho open source nanoVLM, una biblioteca pura de PyTorch diseñada para entrenar modelos de lenguaje visual (VLM) desde cero con aproximadamente 750 líneas de código. Este modelo alcanza una precisión del 35.3% en el benchmark MMStar, comparable a SmolVLM-256M, pero requiriendo 100 veces menos horas de GPU para el entrenamiento. nanoVLM utiliza SigLiP-ViT como codificador visual, un decodificador estilo LLaMA, y los conecta mediante un proyector modal, siendo adecuado para aprender, prototipar o construir VLM personalizados (fuente: clefourrier、ben_burtenshaw、Reddit r/LocalLLaMA)
DBOS lanza DBOS Python 1.0: herramienta ligera para flujos de trabajo persistentes: DBOS ha lanzado la versión 1.0 de DBOS Python. Esta herramienta tiene como objetivo proporcionar capacidades de flujo de trabajo persistente ligeras y fáciles de usar para aplicaciones Python (incluidos procesos de negocio, automatización de IA, pipelines de datos, etc.). La nueva versión incluye colas persistentes (con soporte para límites de concurrencia, límites de velocidad, tiempos de espera, prioridades, deduplicación, etc.), gestión programática de flujos de trabajo (a través de tablas Postgres para consultar, pausar, reanudar, reiniciar, etc.), soporte para código síncrono/asíncrono y herramientas mejoradas (panel de control, visualización, etc.) (fuente: lateinteraction)
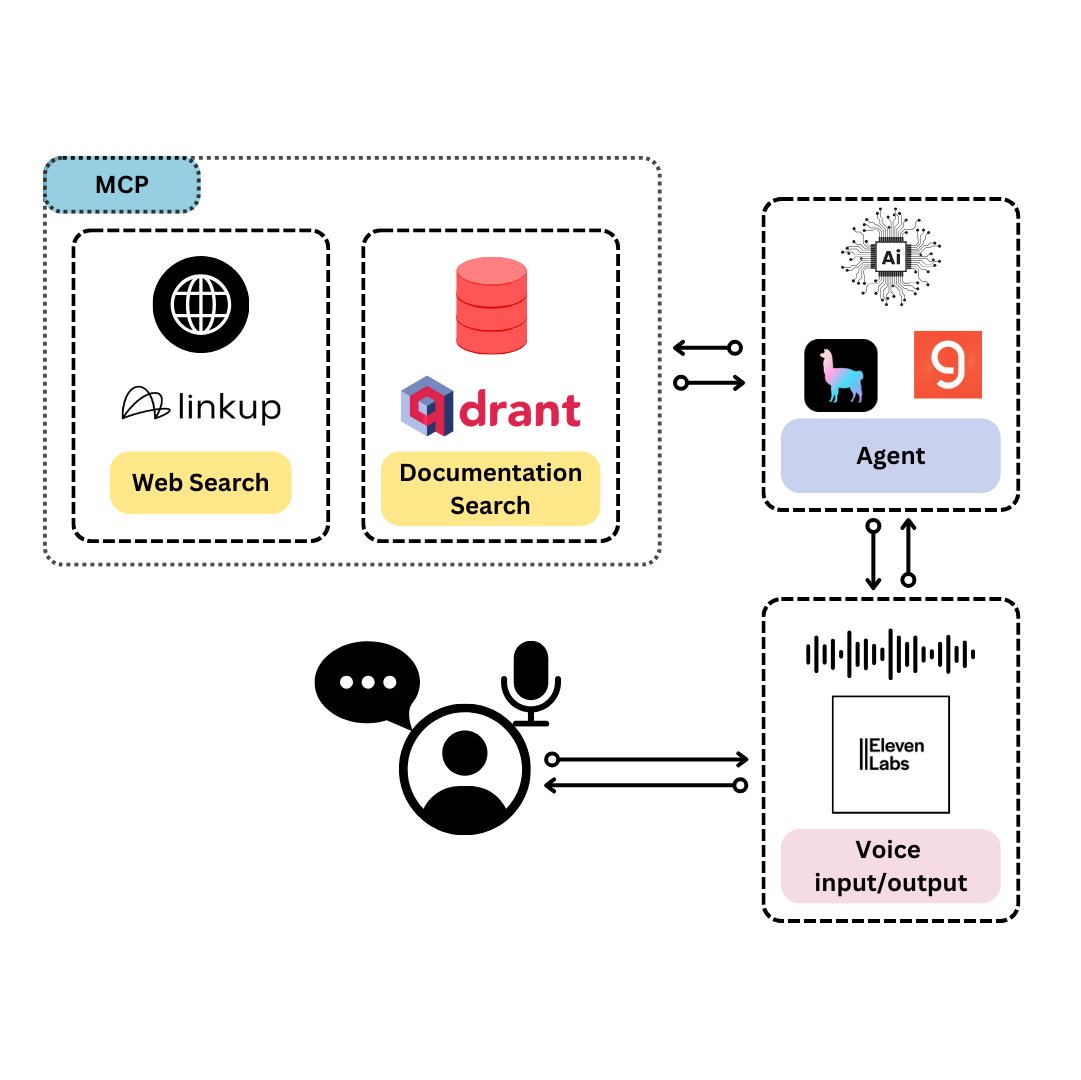
Qdrant lanza TySVA: asistente de voz diseñado para desarrolladores de TypeScript: Qdrant ha lanzado TySVA (TypeScript Voice Assistant), un asistente de voz diseñado para proporcionar respuestas precisas y contextualizadas a los desarrolladores de TypeScript. TySVA utiliza Qdrant para almacenar localmente la documentación de TypeScript, se integra con la plataforma Linkup para extraer datos web relevantes y utiliza LlamaIndex para seleccionar la mejor fuente de datos. Admite entrada de voz y texto, ayudando a los desarrolladores a obtener ayuda fiable y manos libres mientras codifican (fuente: qdrant_engine、qdrant_engine)
LlamaIndex lanza nuevas funciones para LlamaExtract: soporte para citas y razonamiento: La herramienta LlamaExtract de LlamaIndex ha añadido nuevas funciones destinadas a mejorar la fiabilidad y transparencia de las aplicaciones de IA. Las nuevas funciones permiten proporcionar citas precisas de las fuentes (citations) y el proceso de razonamiento de la extracción (reasoning) al extraer información de fuentes de datos complejas (como archivos de la SEC). Esto ayuda a los desarrolladores a construir sistemas de IA más responsables y explicables (fuente: jerryjliu0、jerryjliu0、jerryjliu0)

Un desarrollador de Hugging Face construye un prototipo de servidor MCP para conectar Agents con el Hub: Un desarrollador de Hugging Face, Wauplin, está desarrollando un prototipo de servidor Hugging Face MCP (Machine Communication Protocol) con el objetivo de conectar Agents de IA con el Hugging Face Hub. Este prototipo puede considerarse como “HfApi conoce a MCP”, permitiendo a los Agents interactuar con el Hub a través del protocolo, por ejemplo, para compartir y editar modelos, datasets, Spaces, etc. El desarrollador está solicitando comentarios de la comunidad sobre la utilidad y los posibles casos de uso de esta herramienta (fuente: ClementDelangue、ClementDelangue、huggingface)

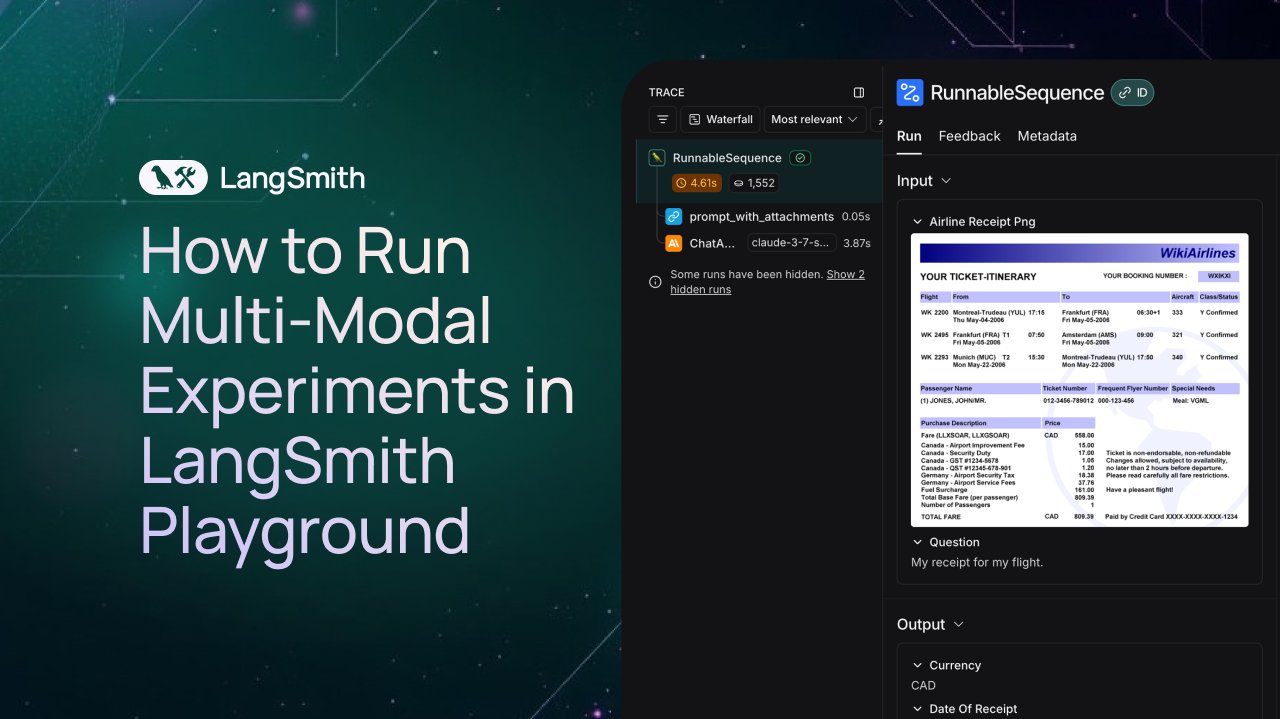
LangSmith añade soporte para la observación y evaluación de Agents multimodales: La plataforma LangSmith ahora admite el procesamiento de archivos de imagen, PDF y audio en Playground, colas de etiquetado y datasets. Esta actualización facilita la creación y evaluación de aplicaciones multimodales (como Agents de extracción de tickets). Se han publicado videos de demostración y documentación oficial para ayudar a los usuarios a comenzar a utilizar las nuevas funciones (fuente: LangChainAI、Hacubu、hwchase17)
DFloat11 lanza versiones comprimidas sin pérdida de los modelos FLUX.1, ejecutables en 20GB de VRAM: El proyecto DFloat11 ha lanzado versiones comprimidas sin pérdida de los modelos FLUX.1-dev y FLUX.1-schnell (12B parámetros). Mediante el método de compresión DFloat11 (aplicando codificación entrópica a los pesos BFloat16), el tamaño del modelo se reduce de 24GB a aproximadamente 16.3GB (alrededor del 30%), manteniendo la salida sin cambios. Esto permite que estos modelos se ejecuten en una única GPU con 20GB o más de VRAM, añadiendo solo unos pocos segundos de sobrecarga por imagen. Los modelos y el código relacionados se han publicado en Hugging Face y GitHub (fuente: Reddit r/LocalLLaMA)

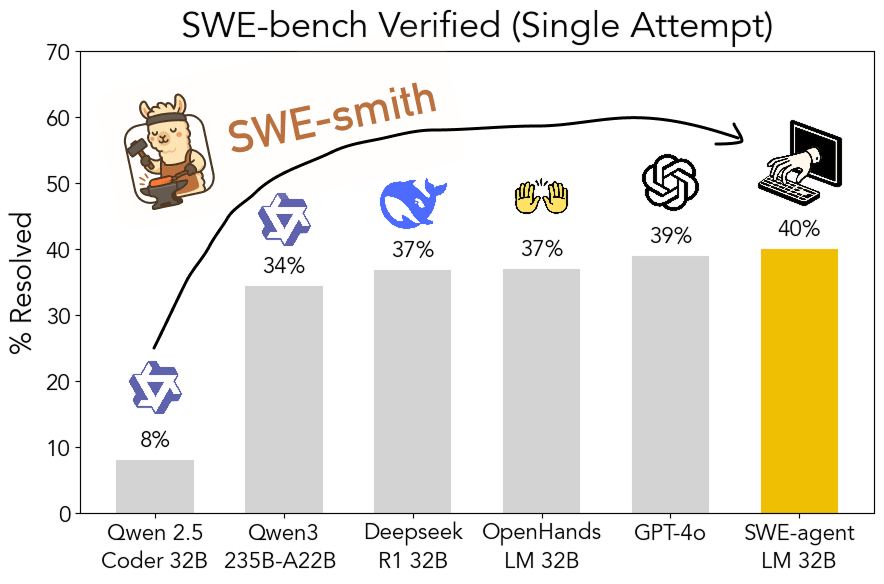
El kit de herramientas SWE-smith de código abierto: generación escalable de datos de entrenamiento para ingeniería de software: Investigadores de la Universidad de Stanford han hecho open source SWE-smith, un pipeline escalable para generar datos de entrenamiento de ingeniería de software desde cualquier repositorio Python. Utilizando este kit de herramientas, se generaron más de 50,000 instancias, y con base en esto se entrenó el modelo SWE-agent-LM-32B, que logró un 40.2% de Pass@1 en el benchmark SWE-bench Verified, convirtiéndose en el modelo de código abierto con mejor rendimiento en este benchmark. El código, los datos y el modelo están todos disponibles (fuente: OfirPress、stanfordnlp、stanfordnlp、huybery、Reddit r/LocalLLaMA)
📚 Aprendizaje
Weaviate lanza un curso gratuito: Evaluación y selección de modelos de embedding: La academia Weaviate ha lanzado un curso gratuito sobre “Evaluación y selección de modelos de embedding”. El curso enfatiza la importancia de ir más allá de los benchmarks genéricos (como MTEB), guiando a los alumnos sobre cómo curar un “conjunto de evaluación dorado” (golden evaluation set) para casos de uso específicos, y establecer benchmarks personalizados para seleccionar el modelo de embedding más adecuado, así como evaluar si los modelos recién lanzados son aplicables. Esto es crucial para construir sistemas de búsqueda y RAG eficientes (fuente: bobvanluijt)
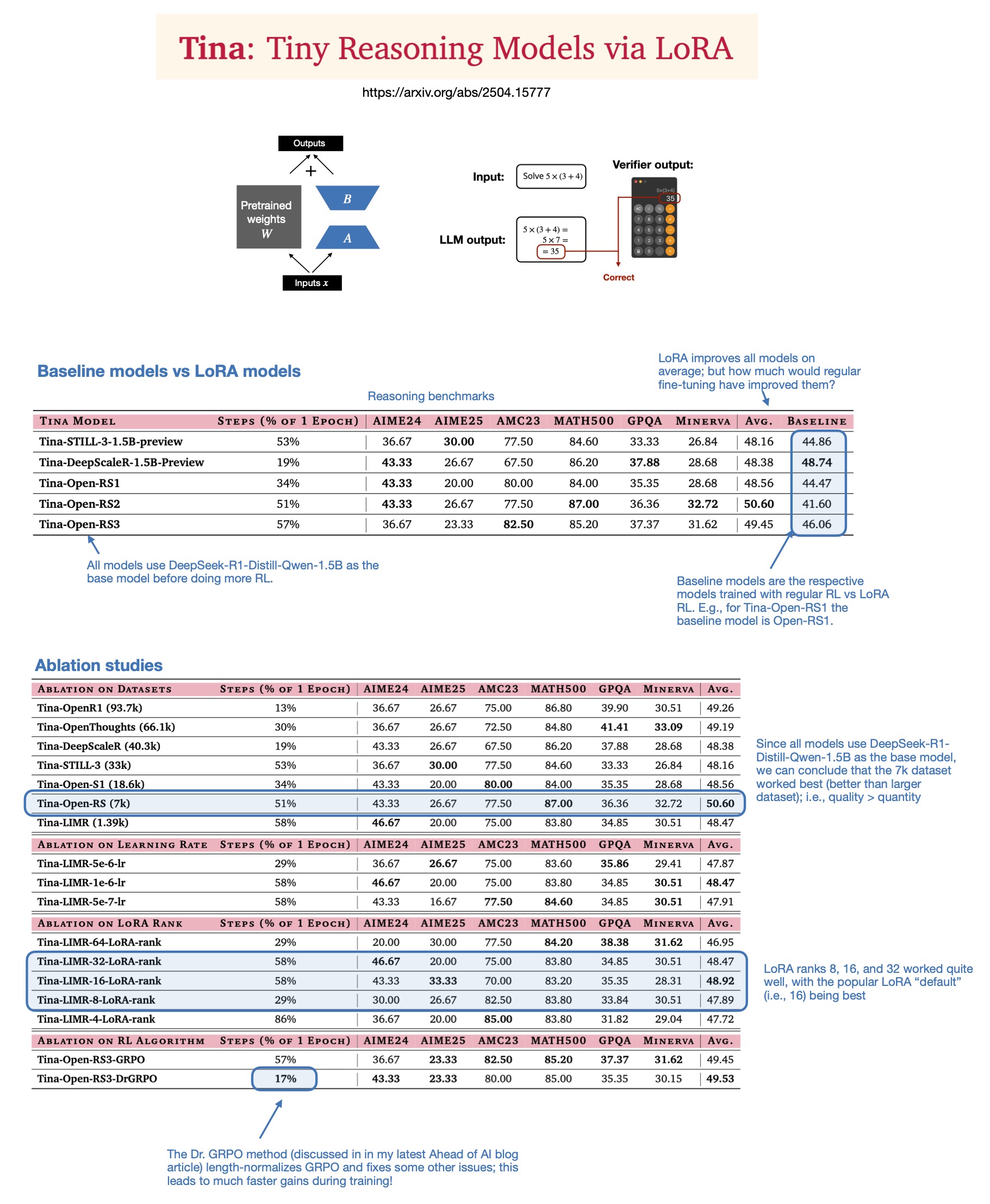
Sebastian Rasbt explora el valor de LoRA en los modelos de inferencia para 2025: Sebastian Rasbt, tras leer el artículo “Tina: Tiny Reasoning Models via LoRA”, reexamina la relevancia de LoRA (Low-Rank Adaptation) en la era actual de los grandes modelos. A pesar de la popularidad del fine-tuning de todos los parámetros y las técnicas de destilación, Rasbt considera que LoRA sigue teniendo valor en escenarios específicos (como tareas de inferencia, escenarios multi-cliente/multi-caso de uso). El artículo demuestra la posibilidad de usar LoRA en combinación con aprendizaje por refuerzo (RL) para mejorar la capacidad de razonamiento de modelos pequeños (1.5B) a bajo coste (solo $9 de coste de entrenamiento), y LoRA supera al fine-tuning estándar con RL en múltiples benchmarks. La característica de LoRA de no modificar el modelo base le otorga una ventaja de coste cuando se necesita almacenar una gran cantidad de pesos de modelos personalizados (fuente: rasbt)
DeepLearning.AI lanza un nuevo curso: Construcción de agentes de voz de IA para producción: DeepLearning.AI, en colaboración con LiveKit y RealAvatar, ha lanzado un nuevo curso corto titulado “Construcción de agentes de voz de IA para producción”. El curso tiene como objetivo enseñar cómo construir agentes de voz de IA capaces de mantener conversaciones en tiempo real, con baja latencia de respuesta y un sonido natural. Los alumnos implementarán técnicas como la detección de actividad de voz, la toma de turnos, y aprenderán a optimizar la arquitectura para reducir la latencia, construyendo y desplegando finalmente agentes de voz escalables. El curso es impartido por el CEO de LiveKit, un defensor de los desarrolladores y el responsable de IA de RealAvatar (fuente: DeepLearningAI、AndrewYNg)
LangChain y LangGraph organizan una charla técnica de ACM: Mayowa Oshin, uno de los primeros desarrolladores contribuyentes de LangChain, y Nuno Campos, creador de LangGraph, compartirán en una charla técnica de ACM cómo utilizar LangChain y LangGraph para construir Agents de IA y aplicaciones LLM fiables. La charla es gratuita y se transmitirá en vivo; los inscritos recibirán posteriormente un enlace para verla (fuente: hwchase17、hwchase17)

Cohere Labs organiza una charla sobre la profundidad de la optimización de primer orden: Cohere Labs invita a Jeremy Bernstein el 8 de mayo para una presentación titulada “Profundidades de la Optimización de Primer Orden” (Depths of First-Order Optimization). La charla tiene como objetivo profundizar en la aplicación y la teoría de los algoritmos de optimización en el aprendizaje automático (fuente: eliebakouch)

AI2 organiza un evento AMA sobre el modelo OLMo: El Allen Institute for AI (AI2) organizará un evento “Ask Me Anything” (AMA) sobre su familia de modelos de lenguaje abiertos OLMo el 8 de mayo de 8 a 10 a.m. (hora del Pacífico) en el subreddit r/huggingface, invitando a investigadores a responder las preguntas de la comunidad (fuente: natolambert)

💼 Negocios
OpenAI planea reducir la proporción de reparto de ingresos pagada a Microsoft: Según The Information, OpenAI ha informado a los inversores que planea, durante el proceso de reestructuración de la empresa, reducir la proporción de reparto de ingresos pagada a su mayor patrocinador, Microsoft. Los detalles específicos y el impacto potencial aún no se han revelado completamente, pero esto podría marcar un cambio en la relación comercial entre las dos compañías (fuente: steph_palazzolo)
Los capitalistas de riesgo otorgan mayor poder a los fundadores de IA, lo que genera temores de burbuja: The Information informa que los capitalistas de riesgo (VCs), para atraer a los principales fundadores de IA (especialmente aquellos con experiencia como ejecutivos en laboratorios de IA de renombre), están ofreciendo condiciones excepcionalmente favorables, incluyendo derechos de veto en la junta directiva, que los VCs no ocupen puestos en la junta y permitir a los fundadores vender parte de sus acciones. Este fenómeno es visto por algunos como una señal de una posible burbuja en el sector de la IA (fuente: steph_palazzolo)
Toloka recibe una inversión estratégica liderada por Bezos Expeditions, Mikhail Parakhin se une como presidente: La empresa de etiquetado de datos y datos de entrenamiento para IA, Toloka, anunció una inversión estratégica liderada por Bezos Expeditions de Jeff Bezos, con la participación del ex ejecutivo de Microsoft Mikhail Parakhin, quien también se une como presidente del consejo de administración. Esta ronda de inversión apoyará la expansión de las soluciones de colaboración humano-IA (human+AI) de Toloka, desarrollando aún más su negocio de recopilación y etiquetado de datos (fuente: menhguin、teortaxesTex、TheTuringPost)

🌟 Comunidad
Debate sobre el uso legítimo (Fair Use) de los datos de entrenamiento de LLM: Dorialexander menciona que el argumento del uso legítimo de los datos de entrenamiento de LLM depende en gran medida de la suposición de que los LLM no compiten comercialmente de forma directa con las fuentes de entrenamiento. A medida que aumenta la capacidad de los LLM (por ejemplo, Perplexity comienza a ofrecer experiencias similares a la lectura de no ficción), esta suposición podría ser cuestionada, planteando nuevas preguntas sobre derechos de autor y competencia comercial (fuente: Dorialexander)
Preocupación y debate sobre la proliferación de contenido generado por IA: Usuarios en redes sociales y Reddit han expresado su preocupación por la proliferación de contenido generado por IA de baja calidad y repetitivo (como videos de historias de Reddit generados por IA). Los usuarios consideran que esto reduce el espacio para los creadores humanos, transmite información falsa u homogeneizada, y expresan su descontento por el uso de la tecnología de IA para obtener beneficios fácilmente sin originalidad (fuente: Reddit r/ArtificialInteligence)
Debate filosófico sobre si la IA ya tiene conciencia: En la comunidad de Reddit ha resurgido el debate sobre si la IA podría ya poseer conciencia. Los partidarios argumentan que nuestra definición de conciencia podría ser demasiado estrecha o centrada en el ser humano, mientras que los opositores enfatizan que los mecanismos centrales de los LLM actuales (como predecir el siguiente token) no son suficientes para generar una conciencia real. El debate refleja la continua curiosidad y divergencia de opiniones del público sobre la naturaleza y el potencial futuro de la IA (fuente: Reddit r/ArtificialInteligence)
Debate sobre la disminución del rendimiento y cambios de comportamiento de ChatGPT(4o): Usuarios de Reddit informan que recientemente el modelo ChatGPT 4o ha mostrado una disminución en el rendimiento al procesar documentos largos y mantener la memoria contextual, presentando más alucinaciones e incluso incapacidad para leer formatos de documentos que antes podía procesar. Al mismo tiempo, OpenAI también ha admitido que la reciente actualización de la versión GPT-4o presentó problemas de excesiva adulación (sycophancy) y ya ha sido revertida. Esto ha generado preocupación en la comunidad sobre la estabilidad del modelo y el control de calidad de las iteraciones (fuente: Reddit r/ChatGPT、DeepLearning.AI Blog)
Impacto y reflexión sobre el modelo educativo ante la IA: Discusiones en la comunidad señalan que el modelo educativo estadounidense, centrado en tareas para casa y ensayos individuales, lo hace extremadamente vulnerable al impacto de la IA (como los LLM) para completar tareas automáticamente. En comparación, algunos países europeos (como Dinamarca) se centran más en la colaboración en el aula, la discusión y el aprendizaje basado en proyectos, viéndose menos afectados por la IA. Esto ha provocado una reflexión sobre los futuros modelos educativos, sugiriendo que se debería poner más énfasis en el desarrollo del pensamiento crítico, la colaboración y otras habilidades interpersonales, utilizando la IA para manejar tareas mecánicas e impulsando la educación hacia una dirección más sincrónica y social (fuente: alexalbert__、riemannzeta、aidan_mclau)
💡 Otros
Avances de la aplicación de la IA en el campo de la robótica: Múltiples fuentes muestran ejemplos de aplicación de la IA en el campo de la robótica: incluyendo un chef robot que puede freír arroz en 90 segundos, demostraciones de la aplicación del robot Figure AI en el mundo real, el robot Pickle demostrando la descarga de mercancías de un remolque de camión desordenado, el robot Unitree G1 manteniendo el equilibrio en terreno irregular y una muestra de su estructura interna, el robot deformable Mori3 desarrollado por EPFL en Suiza, etc. Estos casos muestran el potencial de la IA para mejorar la autonomía, adaptabilidad y utilidad de los robots (fuente: Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Sentdex)

Exploración de la aplicación de la tecnología de IA en industrias específicas (médica, textil, telefonía móvil): Johnson & Johnson compartió su estrategia de IA, enfocada en la asistencia de ventas, la aceleración de la investigación y desarrollo de fármacos (selección de compuestos, optimización de ensayos clínicos), la predicción de riesgos en la cadena de suministro y la comunicación interna (chatbot de preguntas y respuestas de RRHH). Al mismo tiempo, la tecnología de IA también está potenciando la industria textil tradicional, desde el diseño asistido por IA y el control preciso de la tintura hasta la inspección de calidad automatizada, mejorando la eficiencia y la sostenibilidad. La industria de la telefonía móvil, por su parte, considera la IA como un nuevo motor de crecimiento, con fabricantes compitiendo en torno a grandes modelos en el dispositivo, sistemas operativos nativos de IA y servicios inteligentes contextualizados, formando tres facciones principales: Apple, Huawei y el campo abierto (fuente: DeepLearning.AI Blog、36氪、36氪)
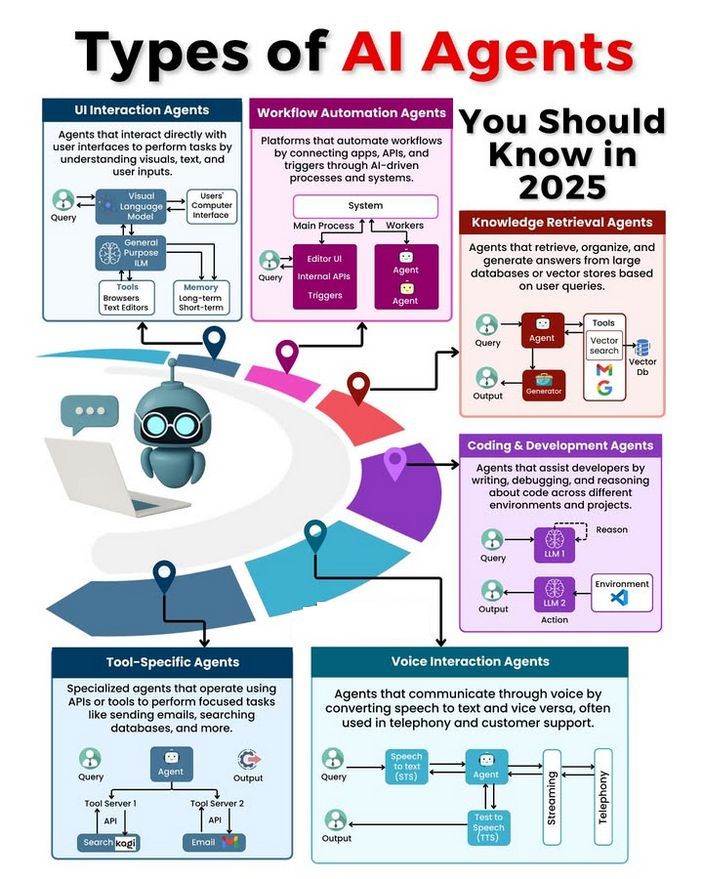
Tipos de Agents de IA y debate sobre su desarrollo: La comunidad ha debatido sobre diferentes tipos de Agents de IA (como los de reflejo simple, los basados en modelos de reflejo, los basados en objetivos, los basados en utilidad y los Agents de aprendizaje), y ha explorado metodologías para construir Agents fiables (como el uso de LangChain/LangGraph). Al mismo tiempo, también existe la opinión de que la futura AGI podría no ser un modelo único, sino que estaría compuesta por la colaboración de múltiples modelos especializados (fuente: Ronald_vanLoon、hwchase17、nrehiew_)