
Palabras clave:OpenAI, DSPy, SGLang, Nvidia, ChatGPT, IA, LLM, MoE, dspy.GRPO, DeepSeek MoE, Periquito TDT, Sistemas Agénticos, EQ-Bench 3
🔥 Enfoque
OpenAI confirma que mantiene su estructura sin fines de lucro: OpenAI anuncia que su entidad con fines de lucro existente se convertirá en una Corporación de Beneficio Público (PBC), pero el control seguirá perteneciendo a la organización sin fines de lucro actual. Esta medida confirma que OpenAI seguirá siendo controlada por la organización sin fines de lucro y reafirma su misión de asegurar que la AGI (Inteligencia Artificial General) beneficie a toda la humanidad. Esta decisión se toma después de experimentar turbulencias internas y cuestionamientos externos sobre la naturaleza de su estructura (incluida la demanda de Musk), con reacciones mixtas en la comunidad: algunos lo ven como una defensa de su misión, mientras que otros cuestionan la verdadera intención de su reajuste de capital (fuente: OpenAI, sama, jachiam0, NeelNanda5, scaling01, zacharynado, mcleavey, steph_palazzolo, Plinz, Teknium1)
El framework DSPy lanza el optimizador experimental de RL en línea dspy.GRPO: El equipo de NLP de Stanford ha lanzado una nueva función experimental para el framework DSPy, dspy.GRPO, un optimizador de aprendizaje por refuerzo (RL) en línea. La herramienta está diseñada para optimizar programas DSPy, aplicable directamente incluso a programas complejos multimodulares y de múltiples pasos, sin necesidad de modificar el código existente. Este movimiento se considera un paso importante para llevar la optimización RL (como GRPO utilizado por DeepSeek) a un nivel de abstracción más alto (flujos de trabajo de LLM), con el objetivo de mejorar el rendimiento y la eficiencia de los agentes de IA y pipelines complejos. La comunidad ha reaccionado con entusiasmo, considerándolo un componente importante de DSPy 3.0 (fuente: Omar Khattab, matei_zaharia, lateinteraction, Michael Ryan, Lakshya A Agrawal, Scott Condron, Noah Ziems, Rogerio Chaves, Karthik Kalyanaraman, Josh Cason, Mehrdad Yazdani, DSPy, Hopkinx🀄️, Ahmad, william, lateinteraction, lateinteraction, swyx)
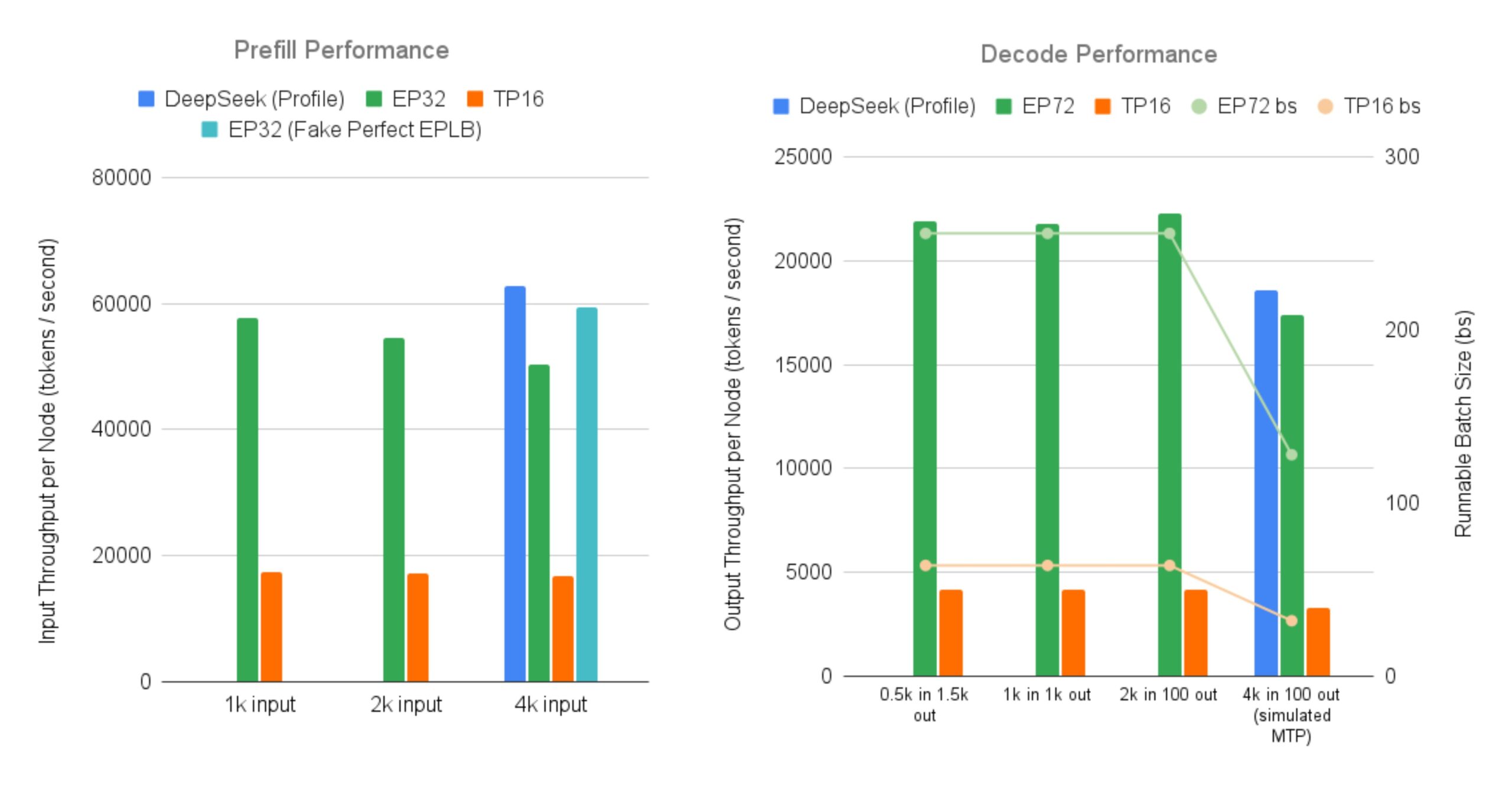
SGLang implementa de código abierto el servicio eficiente para modelos grandes MoE de DeepSeek: LMSYS Org anuncia que SGLang proporciona la primera implementación de código abierto para servir modelos MoE (Mixture-of-Experts) como DeepSeek V3/R1, con características de Expert Parallelism a gran escala y Prefill-Decode Disaggregation, en 96 GPUs. Esta implementación casi alcanza el rendimiento reportado oficialmente por DeepSeek (entrada de 52.3k tokens/segundo por nodo, salida de 22.3k tokens/segundo), logrando un aumento de hasta 5 veces en el rendimiento de salida en comparación con el paralelismo tensorial tradicional. Esto proporciona a la comunidad una solución de código abierto para ejecutar y desplegar eficientemente modelos MoE grandes (fuente: LMSYS Org, teortaxesTex, cognitivecompai, lmarena_ai, cognitivecompai)
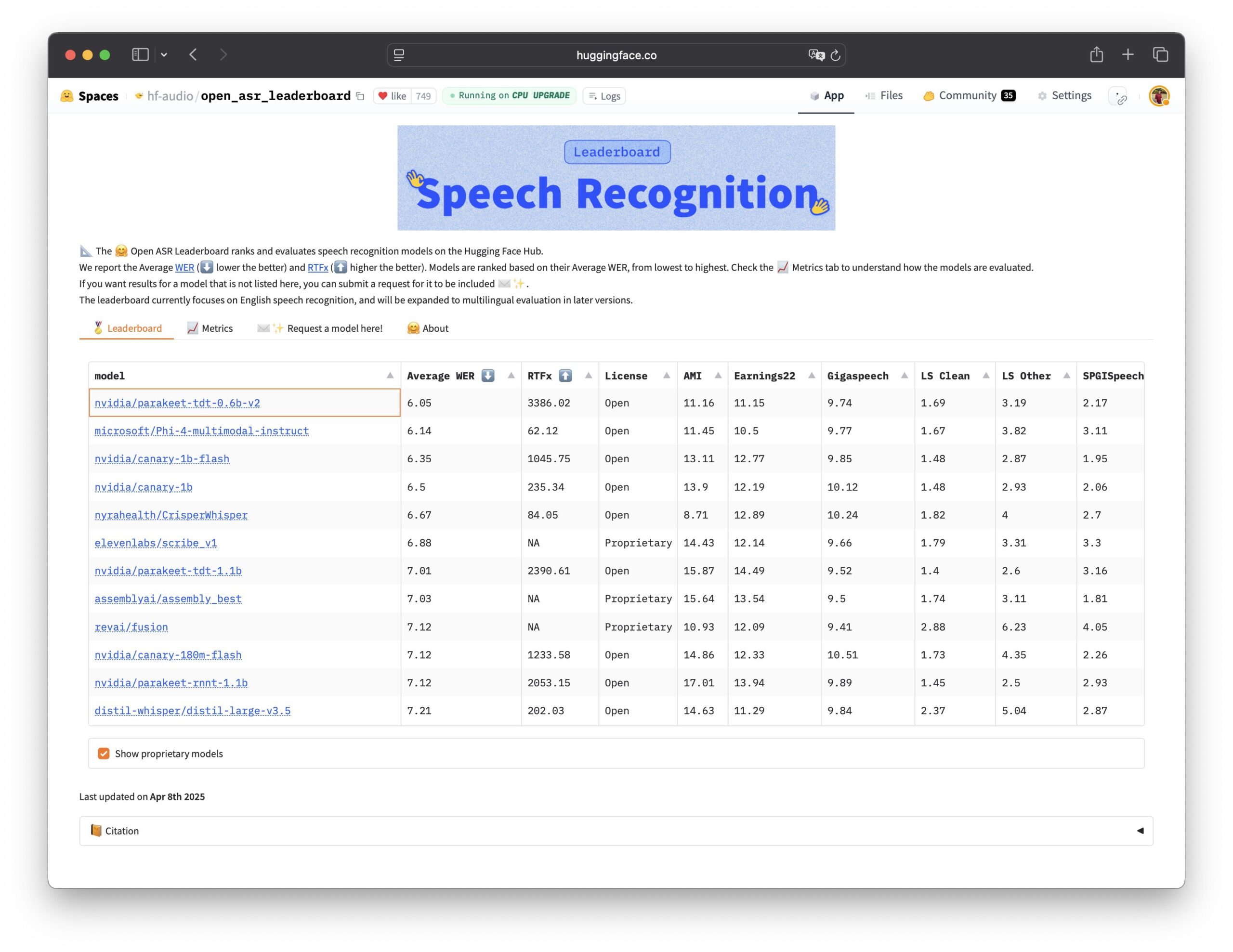
Nvidia lanza el modelo de reconocimiento de voz Parakeet TDT de código abierto: Nvidia ha lanzado el modelo Parakeet TDT 0.6B de código abierto, que obtiene el mejor rendimiento en el Open ASR Leaderboard, convirtiéndose en el modelo de reconocimiento automático de voz (ASR) de código abierto líder en rendimiento actualmente. El modelo tiene 600 millones de parámetros y puede transcribir 60 minutos de audio en 1 segundo, superando en rendimiento a muchos modelos de código cerrado convencionales. El modelo utiliza la licencia CC-BY-4.0, permitiendo el uso comercial, y proporciona una potente opción de código abierto para el campo del reconocimiento de voz (fuente: Vaibhav (VB) Srivastav, huggingface, ClementDelangue)
🎯 Tendencias
El volumen de visitas de ChatGPT sigue creciendo y supera a X: Datos de Similarweb muestran que el volumen de visitas de ChatGPT continúa creciendo, superando en abril el total de visitas (4.786 millones) de la plataforma X (4.028 millones). Desde principios de 2025, el tráfico de ChatGPT ha aumentado constantemente, pasando de estar ocasionalmente por detrás en enero a liderar casi por completo sobre X en abril, lo que demuestra el fuerte impulso de los chatbots de IA en la actividad de los usuarios (fuente: dotey)
La confianza en los datos y el liderazgo se convierten en clave para la transformación de la IA: Múltiples informes y discusiones enfatizan que la confianza en los datos es la fuerza invisible que acelera la transformación de la IA. Al mismo tiempo, los líderes exitosos de GenAI muestran diferentes cualidades en estrategia, organización y aplicación tecnológica. Esto indica que la clave del éxito de la IA no reside solo en la tecnología en sí, sino también en una base de datos de alta calidad y confiable, así como en un liderazgo y despliegue estratégico efectivos (fuente: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

GTE-ModernColBERT logra SOTA en tareas de embedding de texto largo: LightOn ha lanzado el modelo de embedding multivectorial GTE-ModernColBERT, que ha alcanzado el rendimiento SOTA (State-of-the-Art) en el benchmark de búsqueda de documentos largos LongEmbed, superando a otros por casi 10 puntos. Cabe destacar que este modelo solo fue entrenado en documentos cortos de MS MARCO (longitud 300), pero demostró una excelente capacidad de generalización zero-shot en tareas de texto largo. Esto confirma aún más el potencial de los modelos de Late Interaction (como ColBERT) para manejar la recuperación de contexto largo, superando a los modelos tradicionales BM25 y de recuperación densa (fuente: Antoine Chaffin, Ben Clavié, tomaarsen, Dorialexander, Manuel Faysse, Omar Khattab)

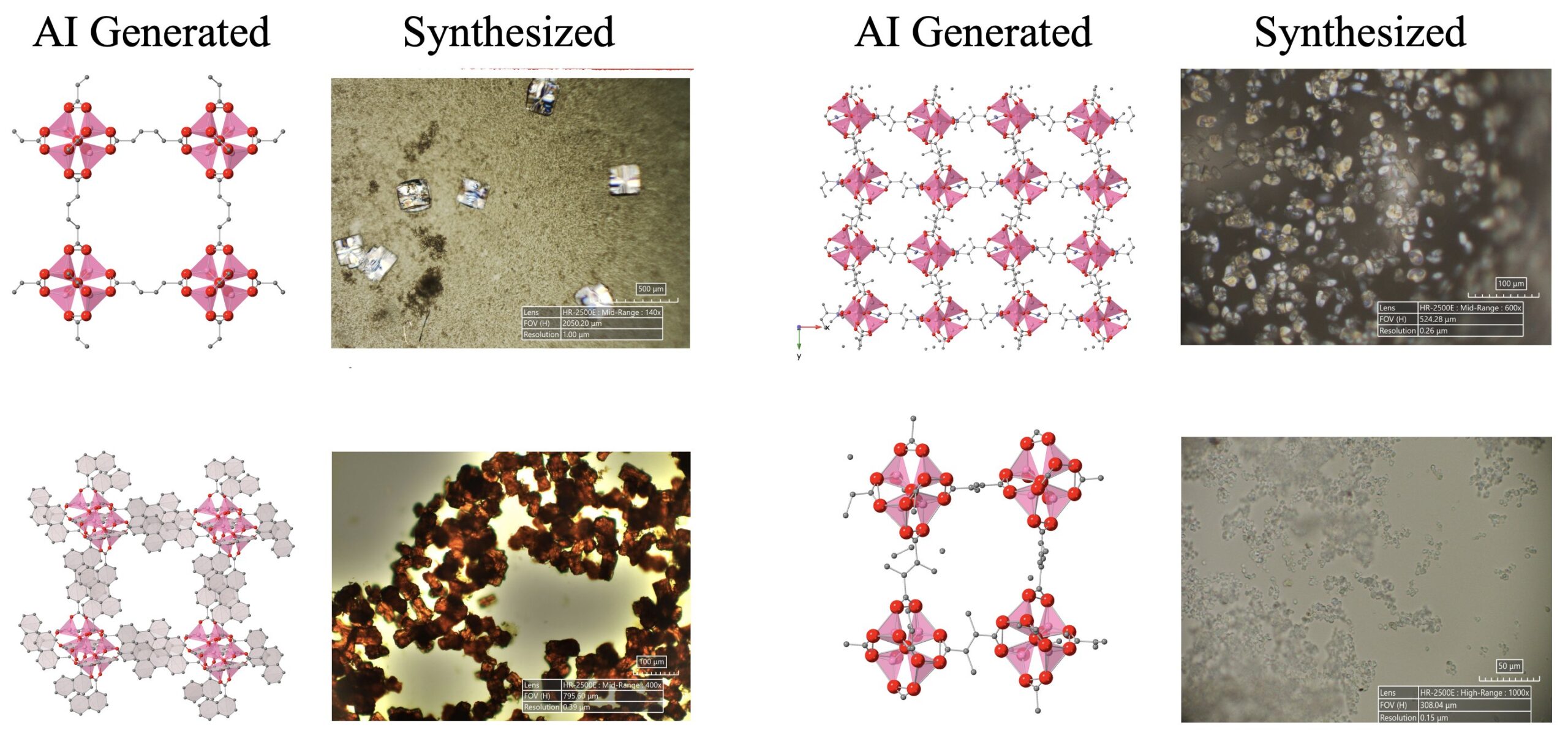
Avances en el descubrimiento científico impulsado por IA: Un sistema de agentes de IA compuesto por LLM, modelos de difusión y dispositivos de hardware ha descubierto y sintetizado con éxito de forma autónoma 5 nuevas estructuras metal-orgánicas (MOFs), que superan el conocimiento humano existente. Esta investigación demuestra el potencial de los agentes de IA en la automatización de la investigación científica, capaces de completar todo el proceso desde la propuesta de ideas de investigación hasta la validación en experimentos de laboratorio húmedo (fuente: Sherry Yang)
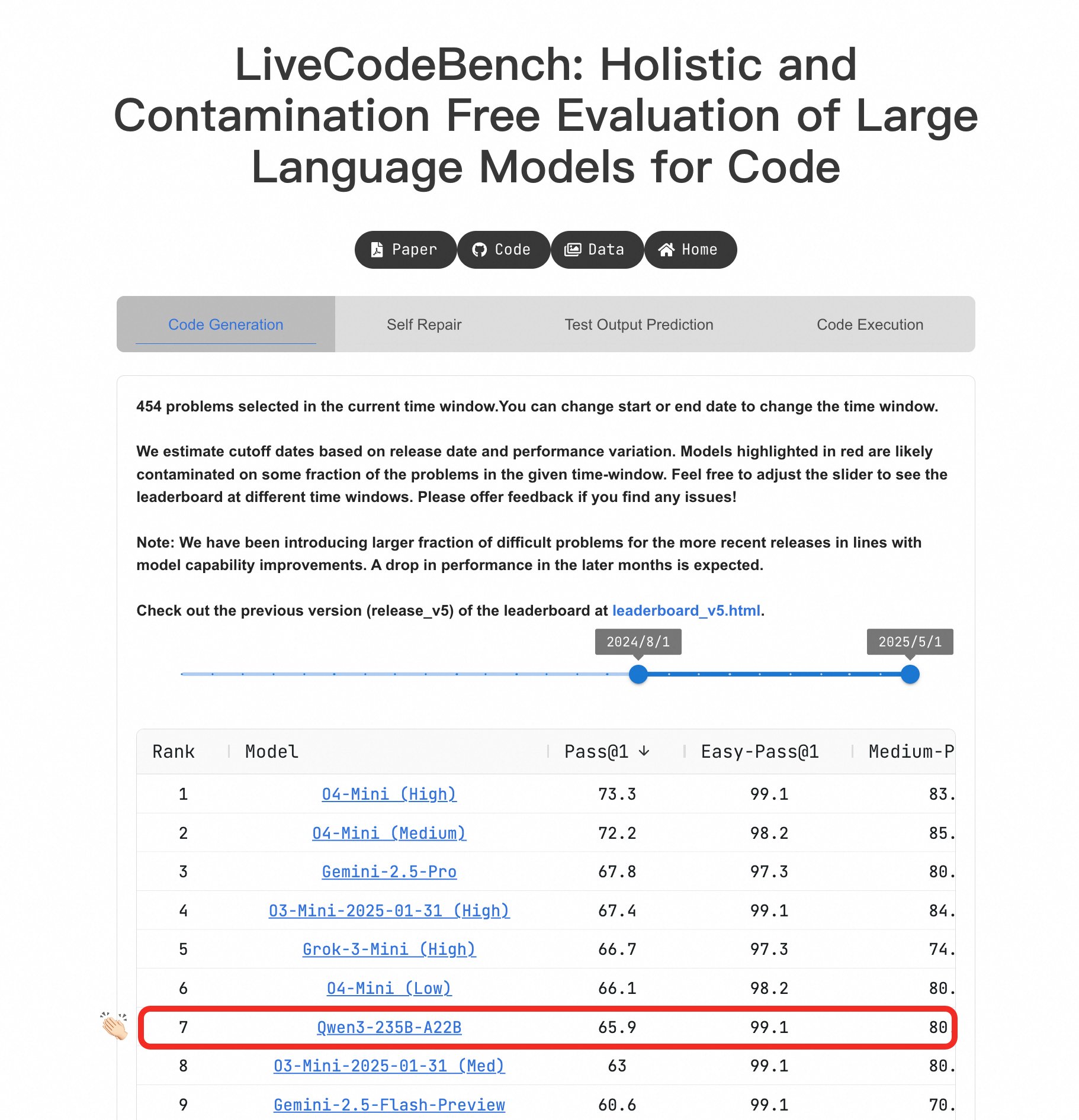
El modelo grande Qwen3 destaca en capacidad de programación: En el benchmark LiveCodeBench, el modelo Qwen3-235B-A22B ha demostrado un rendimiento sobresaliente, siendo considerado uno de los mejores modelos de código abierto en generación de código a nivel competitivo, con un rendimiento comparable a o4-mini (Low confidence). Incluso en problemas difíciles, Qwen3 mantiene un nivel similar a O4-Mini (Low), superando a o3-mini (fuente: Binyuan Hui, teortaxesTex)
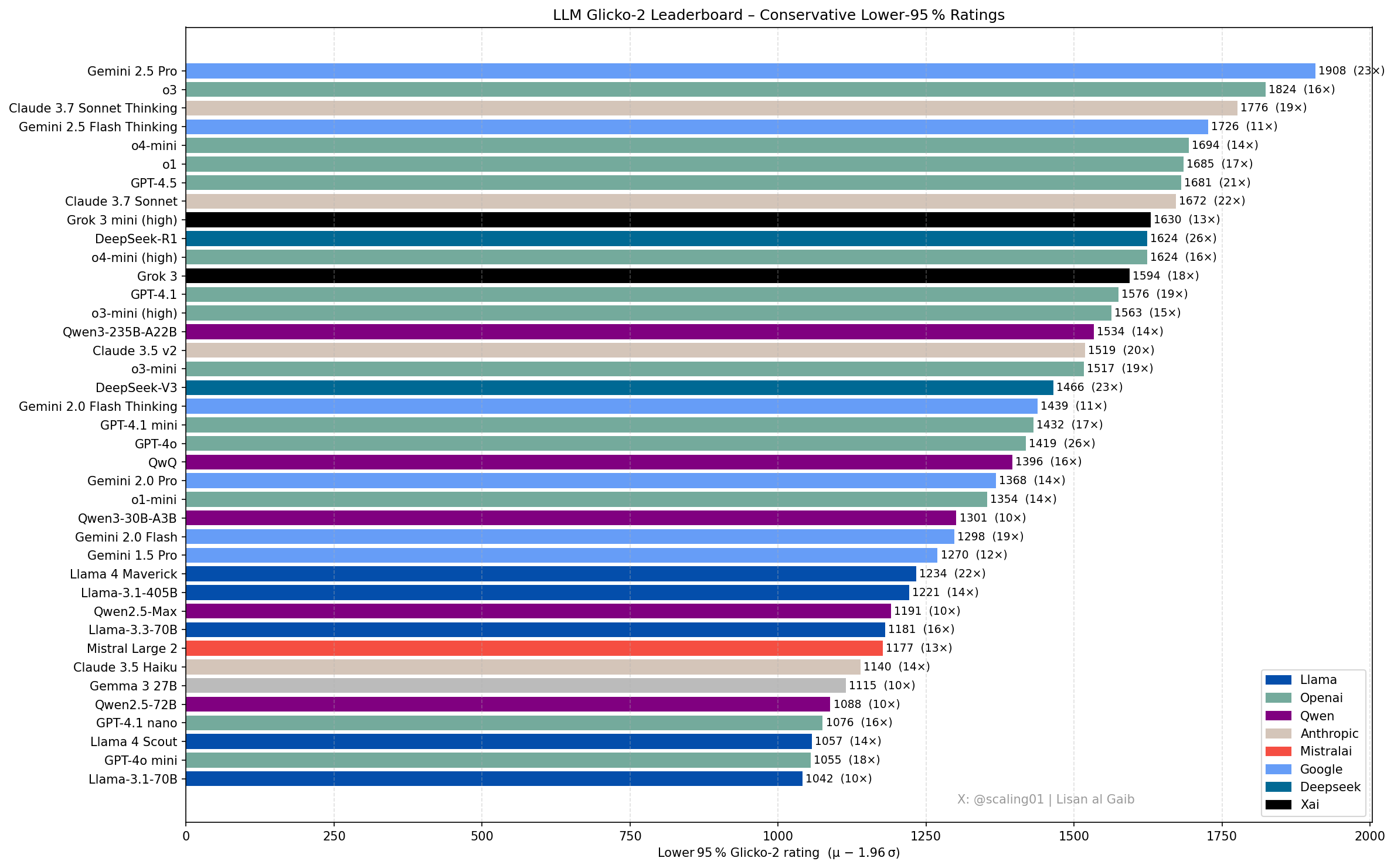
Nuevos avances y discusiones en el ranking de LLM: Lisan al Gaib, miembro de la comunidad, actualizó el ranking de LLM utilizando el sistema de calificación Glicko-2, lo que generó debate. Scaling01 considera que la lista coincide en un 95% con sus percepciones subjetivas; Gemini 2.5 Pro sigue siendo el líder, pero Gemini 2.5 Flash, Grok 3 mini y GPT-4.1 podrían estar sobrevalorados. El ranking muestra una secuencia de progreso razonable para las series de modelos OpenAI, Llama y Gemini, con o3 (high) a un nivel comparable con Gemini 2.5 Pro (fuente: Lisan al Gaib)
El ecosistema de robótica de código abierto se desarrolla rápidamente: Clem Delangue de Hugging Face expresó su entusiasmo por los avances en el campo de la robótica de IA después de conversar con NPeW y Matth Lapeyre. Peter Welinder (OpenAI) también elogió el trabajo de Hugging Face en la promoción del ecosistema de robótica de código abierto, considerando que el campo está creciendo rápidamente (fuente: ClementDelangue, Peter Welinder, ClementDelangue, huggingface)
La dirección de investigación en interpretabilidad de IA recibe atención: Los investigadores piden más trabajo en la interpretabilidad de la IA, especialmente para explicar los comportamientos extraños que presentan los modelos. Al comprender estos comportamientos, se pueden deducir conclusiones más profundas sobre los mecanismos internos de los LLM y potencialmente generar nuevas herramientas de interpretabilidad. Se considera una dirección de investigación prometedora e influyente (fuente: Josh Engels)
FutureHouseSF se dedica a construir “científicos de IA”: Sam Rodriques, CEO de FutureHouseSF, fue entrevistado sobre el objetivo de la compañía de construir “científicos de IA”. La discusión abarcó el significado específico de un científico de IA, el papel de la robótica en ello y por qué el campo científico necesita un impulso similar al de un “proyecto Stargate”, con el objetivo de utilizar la IA para acelerar el descubrimiento científico (fuente: steph_palazzolo)
La ventaja de los TPU de Google podría estar subestimada: El comentarista Justin Halford cree que los inversores podrían estar subestimando la ventaja de Google en los TPU (Tensor Processing Units). Señala que, en ausencia de una ventaja algorítmica significativa, el poder de cómputo será clave en la carrera de la IA, y los TPU desarrollados internamente por Google evitan costos intermedios, lo cual es crucial en un contexto donde miles de millones de dólares fluyen hacia la construcción de infraestructura (fuente: Justin_Halford_)
Lanzamiento del modelo VLA de código abierto Nora: Declare Lab ha lanzado Nora, un nuevo modelo de visión-lenguaje-acción (VLA) de código abierto basado en Qwen2.5VL y el tokenizador FAST+. El modelo fue entrenado en el dataset Open X-Embodiment y supera en rendimiento a Spatial VLA y OpenVLA en tareas del mundo real WidowX (fuente: Reddit r/MachineLearning)

Nuevo método para optimizar la inferencia de LLM: Snapshot y restauración: Enfrentando los desafíos del arranque en frío (cold start) y el despliegue multimodelo en la inferencia de LLM, un equipo ha construido un nuevo sistema de tiempo de ejecución. Este sistema, mediante la toma de snapshots del estado completo de ejecución del modelo (incluyendo disposición de memoria, caché de atención, contexto de ejecución) y restaurándolo directamente en la GPU, logra arranques en frío en menos de 2 segundos. Puede alojar más de 50 modelos en 2 GPUs A4000, alcanzando una utilización de GPU superior al 90% y sin inflación de memoria persistente. Este enfoque es similar a construir un “sistema operativo” para la inferencia (fuente: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Detector de objetos en tiempo real de código abierto D-FINE: La biblioteca Hugging Face Transformers ha añadido el detector de objetos en tiempo real D-FINE. Se afirma que este modelo es más rápido y preciso que YOLO, utiliza la licencia Apache 2.0 y puede ejecutarse en una GPU T4 (entorno Colab gratuito), ofreciendo una nueva opción SOTA de código abierto para la detección de objetos en tiempo real (fuente: merve, algo_diver)
Los precios de los LLM tienden a ser dinámicos: Se observa que los precios de los modelos de lenguaje grandes se están volviendo más dinámicos. Esto podría ayudar al mercado a encontrar puntos de precio más óptimos con el tiempo, reflejando la tendencia de los proveedores de modelos a ajustar sus estrategias de precios bajo la presión de los costos, la demanda y la competencia (fuente: xanderatallah)
tinybox green v2 soporta P2P entre GPUs: the tiny corp anuncia que su producto tinybox green v2, mediante un controlador modificado, soporta la comunicación punto a punto (P2P) entre GPUs RTX 5090. Esto significa que los datos pueden transferirse directamente entre GPUs sin pasar por la RAM de la CPU, mejorando la eficiencia del trabajo colaborativo multi-GPU. La función es compatible con tinygrad y PyTorch (cualquier biblioteca que use NCCL) (fuente: the tiny corp)
Investigadores lanzan EQ-Bench 3 para evaluar la inteligencia emocional de los LLM: Sam Paech ha lanzado EQ-Bench 3, una herramienta de benchmarking para medir la inteligencia emocional (EQ) de los modelos de lenguaje grandes (LLM). El equipo de desarrollo lanzó esta versión después de múltiples prototipos fallidos, con el objetivo de evaluar de manera más precisa y confiable la capacidad de los modelos para comprender y responder a las emociones (fuente: Sam Paech, fabianstelzer)

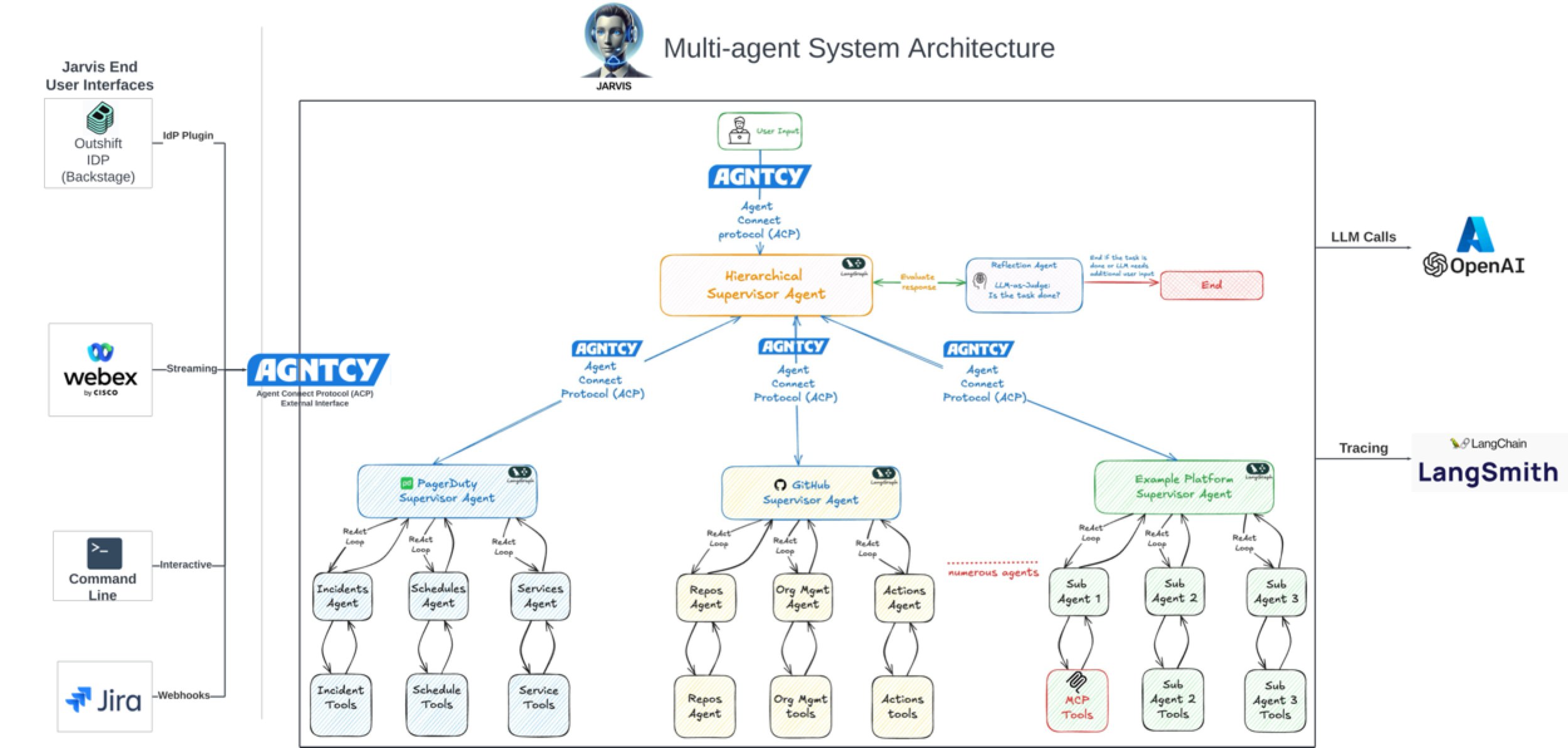
La IA impulsa significativamente la eficiencia en el desarrollo de software: Discusiones y casos en la comunidad muestran que la IA está mejorando notablemente la eficiencia en el desarrollo de software. Por ejemplo, en el repositorio de código de la empresa Vesta, los commits de IA ya ocupan el primer lugar. Cisco Outshift, utilizando el ingeniero de plataforma de IA JARVIS construido sobre LangGraph y LangSmith, redujo el tiempo de configuración de CI/CD de una semana a menos de una hora, y el tiempo de aprovisionamiento de recursos de medio día a unos pocos segundos, logrando un aumento de productividad de 10 veces (fuente: mike, LangChainAI, hwchase17)
La IA incursiona en la industria cinematográfica y creativa: Disney/Lucasfilm, a través de Industrial Light & Magic (ILM), ha lanzado su primer trabajo público de IA generativa, marcando la adopción de la tecnología de IA por parte de los principales estudios de VFX. Esto presagia que la IA desempeñará un papel más importante en áreas como los efectos especiales cinematográficos y el diseño creativo, cambiando los flujos de trabajo de creación de contenido (fuente: Bilawal Sidhu)
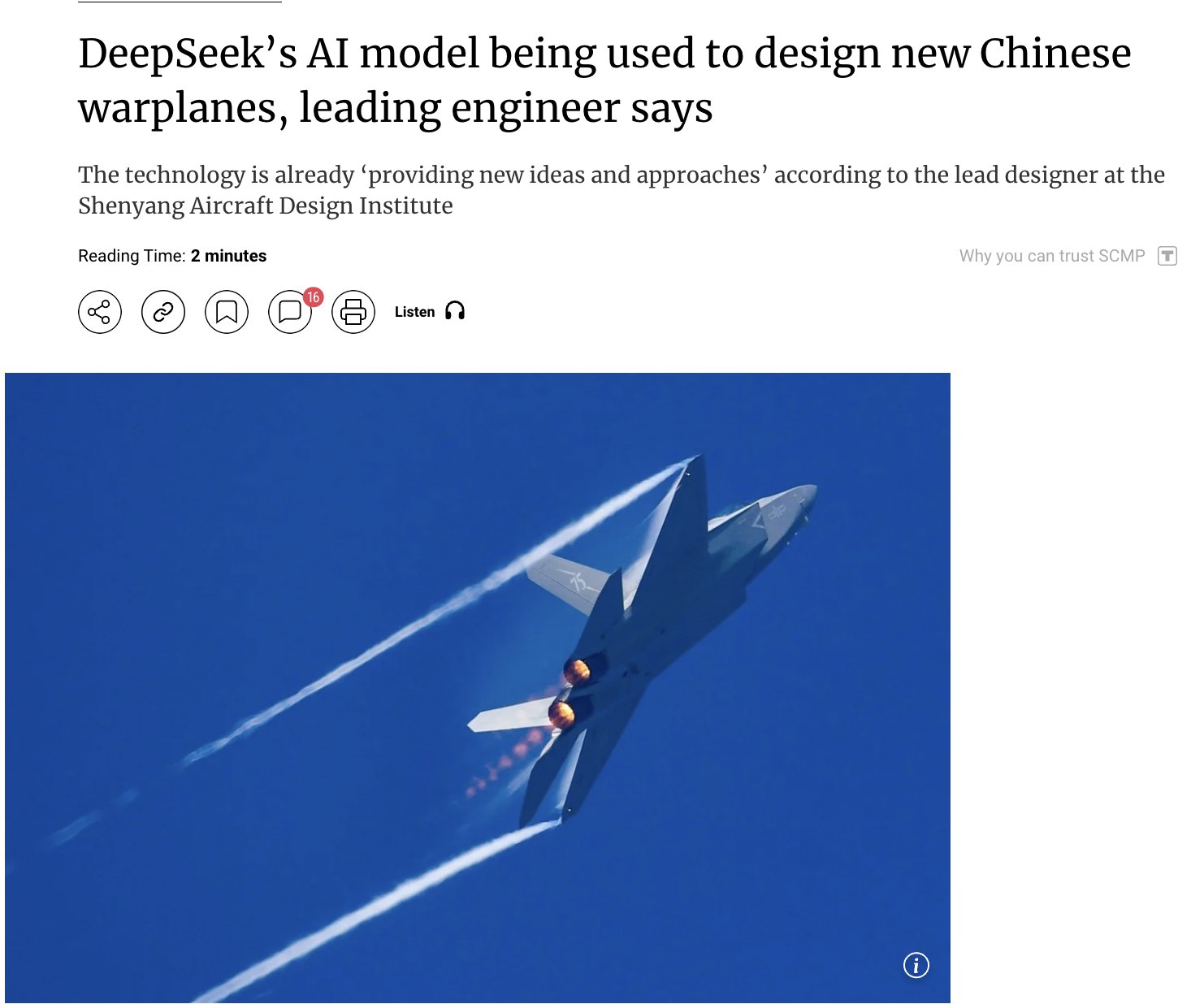
La aplicación de la IA en el ámbito militar genera atención: Informes sugieren que China está utilizando su modelo de IA de desarrollo propio DeepSeek para diseñar cazas avanzados (como J-15, J-35) y dar forma a la próxima generación de aviones (J-36, J-50). Se afirma que la IA acelera la I+D optimizando el sigilo (stealth), los materiales y el rendimiento. Aunque la fuente de información debe tratarse con cautela, esto refleja el potencial de la aplicación de la IA en los campos de defensa y aeroespacial y la atención que suscita (fuente: Clash Report)
Movimientos de talento: Rohan Pandey deja OpenAI: Rohan Pandey, investigador del equipo de Training de OpenAI, ha anunciado su salida. Dijo que se tomará un descanso para dedicarse a resolver el problema del OCR sánscrito, con el fin de “preservar para siempre los clásicos de la literatura india en los pesos de la superinteligencia”, y luego anunciará sus próximos planes. Miembros de la comunidad lo valoran muy positivamente, considerándolo un investigador extremadamente talentoso (fuente: Rohan Pandey, JvNixon, teortaxesTex)

El registro de derechos de autor de IA supera las 1000 obras: La Oficina de Derechos de Autor de EE. UU. ha registrado más de 1000 obras que contienen contenido generado por IA. Esto refleja la creciente aplicación de la IA en el ámbito creativo y, al mismo tiempo, subraya que la titularidad y protección de los derechos de autor del contenido generado por IA se están convirtiendo cada vez más en un foco de atención (fuente: Reddit r/artificial, Reddit r/ArtificialInteligence)

Duolingo despide a contratistas, la aplicación de IA genera preocupación: Duolingo ha despedido a parte de sus contratistas porque la IA puede generar contenido de cursos 12 veces más rápido. Esta medida ha generado preocupaciones sobre el impacto de la automatización en el aprendizaje de idiomas y el empleo en industrias relacionadas, mostrando el potencial de la IA para reemplazar el trabajo humano en la creación de contenido y las consiguientes repercusiones socioeconómicas (fuente: Reddit r/ArtificialInteligence)

¿Microsoft adelanta a Amazon en la carrera de la nube y la IA?: Informes analizan que Microsoft, gracias a su activa estrategia en el campo de la IA (como la inversión en OpenAI) y la integración de sus servicios en la nube (Azure), está superando a Amazon (AWS) en la carrera de la nube y la IA. El artículo considera que Amazon podría estar rezagada respecto a Microsoft en cuanto a enfoque estratégico (fuente: Reddit r/ArtificialInteligence, Reddit r/deeplearning)

Discusión sobre la tasa de uso de expertos en modelos MoE: La comunidad discute si el uso de expertos (Experts) en modelos MoE sigue el principio de Pareto (pocos expertos manejan la mayor parte del tráfico). La mayoría opina que el objetivo del entrenamiento suele ser equilibrar la carga entre los expertos, y la desviación en el modelo Mixtral es muy pequeña. Sin embargo, Qwen3 podría tener cierta desviación, aunque lejos de una distribución 80/20. El ejemplo de DeepSeek-R1 (256 expertos, 8 activados) también ilustra que, aunque tareas específicas (como la codificación) tiendan a favorecer a ciertos expertos, esto no es fijo, y los expertos compartidos siempre están activos (fuente: Reddit r/LocalLLaMA)

El modelo fine-tuned Josiefied-Qwen3-8B recibe buenas críticas: Un usuario comparte una evaluación positiva del modelo Qwen3 8B fine-tuned por Goekdeniz-Guelmez (Josiefied-Qwen3-8B-abliterated-v1). Se considera que este modelo supera a la versión original de Qwen3 8B en seguir instrucciones y generar respuestas vívidas, además de no tener censura. El usuario lo ejecutó con cuantización Q8 y considera que su rendimiento supera las expectativas para un modelo de 8B, especialmente adecuado para sistemas RAG en línea (fuente: Reddit r/LocalLLaMA)

RTX 5060 Ti 16GB podría ser una opción de buena relación calidad-precio para IA: Un usuario comparte su experiencia, considerando que la versión RTX 5060 Ti 16GB (aprox. 499 USD), aunque con malas reseñas de rendimiento en juegos, ofrece una buena relación calidad-precio en aplicaciones de IA gracias a sus 16GB de VRAM. Comparado con una GPU de 12GB ejecutando LightRAG para procesar PDF, la versión de 16GB es más del doble de rápida porque puede alojar más capas del modelo, evitando cambios frecuentes de modelo y mejorando la utilización de la GPU. Su tamaño de tarjeta más corto también es adecuado para construcciones SFF (Small Form Factor) (fuente: Reddit r/LocalLLaMA)
Discusión sobre la viabilidad de usar imágenes RGB para clasificación fina de objetos: La comunidad pregunta si, en ausencia de imágenes hiperespectrales (HSI), el uso exclusivo de imágenes RGB es suficiente para la clasificación en tiempo real o detección de anomalías de objetos finos de una sola clase (como granos de café). Aunque la literatura a menudo recomienda HSI para manejar diferencias sutiles, el usuario desea conocer casos de éxito o la viabilidad de lograr tales tareas utilizando solo RGB (fuente: Reddit r/deeplearning)
Presunta filtración del System Prompt del modelo Claude: Ha aparecido en GitHub un texto que presuntamente es el System Prompt del modelo Claude, con una longitud de 25K tokens. Contiene instrucciones detalladas, como exigir al modelo que bajo ninguna circunstancia (incluidos resultados de búsqueda y contenido generado) copie o cite letras de canciones, ni siquiera en forma aproximada o codificada, lo que se especula está relacionado con restricciones de derechos de autor. Esta filtración (si es auténtica) proporciona pistas sobre los mecanismos internos de trabajo y las restricciones de seguridad de Claude (fuente: karminski3)
Lanzamiento del nuevo modelo de restauración de imágenes por IA PixelHacker: Se ha lanzado el modelo PixelHacker, centrado en la restauración de imágenes (inpainting), enfatizando el mantenimiento de la consistencia estructural y semántica durante el proceso de restauración. Se afirma que el rendimiento de este modelo en datasets como Places2, CelebA-HQ y FFHQ supera a los modelos SOTA actuales (fuente: Reddit r/deeplearning)

ChatGPT añade nueva voz HELLO_TIBOR: Usuarios han descubierto que la última versión de la aplicación web de ChatGPT ha añadido una nueva opción de voz llamada “HELLO_TIBOR”. Esto indica que OpenAI podría estar expandiendo continuamente sus funciones de interacción por voz, ofreciendo opciones de voz más diversas (fuente: Tibor Blaho)
🧰 Herramientas
Runway logra convertir imágenes en capturas de pantalla de juegos y homenajes cinematográficos: Un usuario experimentó con la función Gen-4 References de Runway, utilizando prompts detallados de múltiples pasos (analizando la escena, comprendiendo la intención, estableciendo requisitos de motor de juego y renderizado), para convertir con éxito imágenes ordinarias en capturas de pantalla de juego isométricas 2.5D estilo Unreal Engine. Otro usuario utilizó Runway References y Gen-4 para crear un videoclip en homenaje a la película “Goodfellas”. Estos casos demuestran la potente capacidad de Runway en la generación controlada de imágenes/vídeos, especialmente en la combinación de imágenes de referencia y transferencia de estilo (fuente: Ray (movie arc), Bryan Fox, c_valenzuelab, c_valenzuelab)

Runway soporta la importación de activos 3D para mejorar la controlabilidad de la generación de vídeo: La función Gen-4 References de Runway ahora soporta el uso de activos 3D como referencia para lograr un control más preciso sobre la forma y los detalles de los objetos en los vídeos generados. Los usuarios solo necesitan proporcionar una imagen de fondo de la escena, una composición simple del modelo 3D en esa escena y una imagen de referencia de estilo para introducir modelos altamente detallados y específicos en el flujo de trabajo de generación, mejorando la consistencia y controlabilidad del contenido generado (fuente: Runway, c_valenzuelab, op7418)
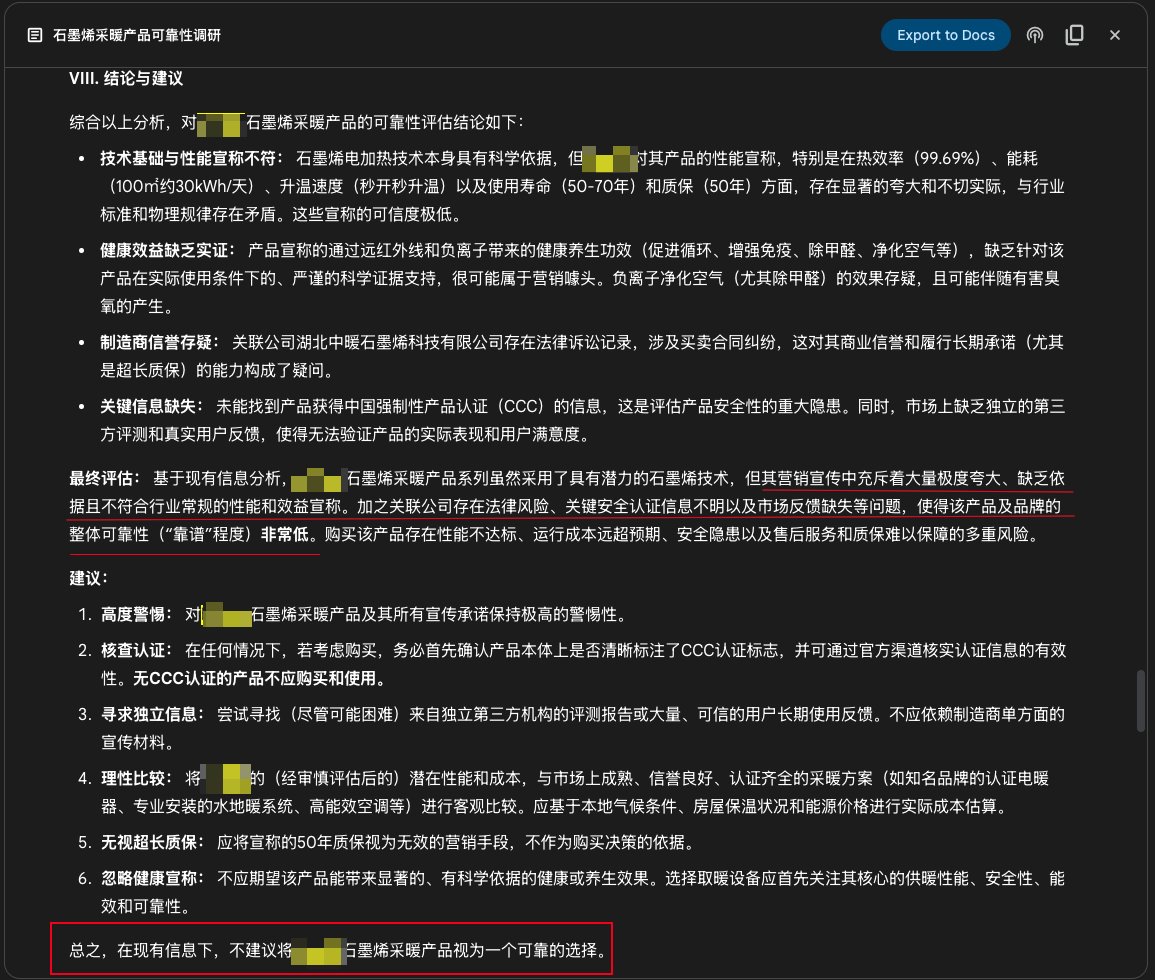
Función Deep Research de Google Gemini utilizada para investigación de productos: Un usuario compartió un caso de uso de la función Deep Research de Google Gemini para investigar la fiabilidad de un producto. Introduciendo la descripción promocional del producto, Gemini buscó cientos de páginas web y señaló claramente que la promoción de un producto de calefacción de grafeno era exagerada, carecía de fundamento, presentaba riesgos y no se recomendaba su compra. Esto demuestra el valor práctico de las herramientas de investigación profunda de IA en la verificación de información y la ayuda en la decisión del consumidor (fuente: dotey)
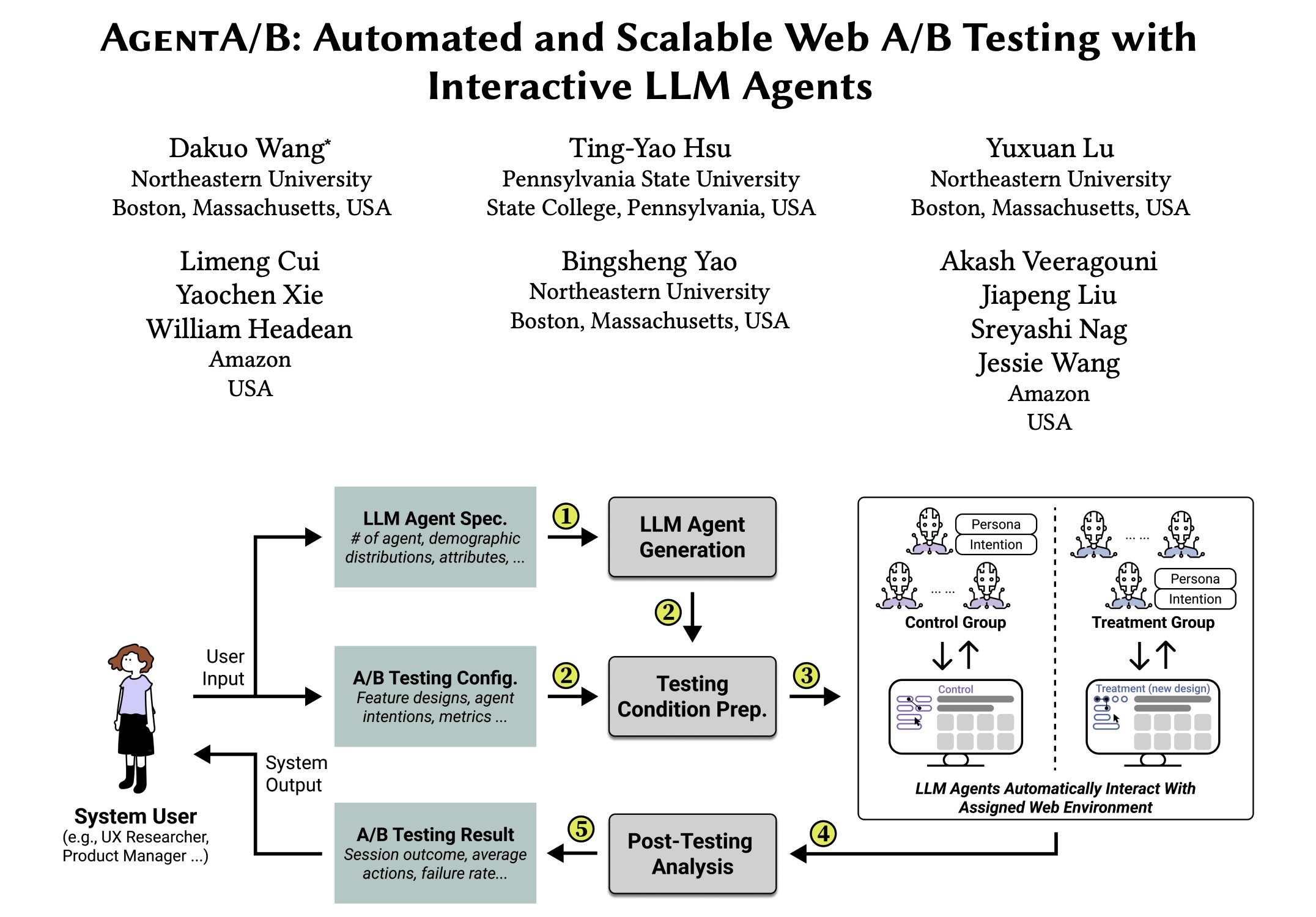
AgentA/B: Framework de pruebas A/B automatizadas basado en agentes LLM: AgentA/B es un framework de pruebas A/B totalmente automatizado que utiliza agentes a gran escala basados en LLM para reemplazar el tráfico de usuarios reales. Estos agentes pueden simular comportamientos de usuario realistas e impulsados por intenciones en entornos web reales, permitiendo una evaluación de la experiencia de usuario (UX) más rápida, barata y sin riesgos, incluso sin tráfico real (fuente: elvis)
Qdrant ayuda a Pariti a mejorar la eficiencia de contratación: La plataforma de contratación Pariti utiliza la base de datos vectorial Qdrant para potenciar su sistema de coincidencia de candidatos impulsado por IA. Mediante la capacidad de búsqueda vectorial en tiempo real de Qdrant, Pariti puede clasificar y puntuar dinámicamente la compatibilidad de 70,000 perfiles de candidatos en 40 milisegundos, reduciendo el tiempo de revisión de candidatos en un 70%, duplicando la tasa de éxito de contratación, y con el 94% de los candidatos principales apareciendo entre los 10 primeros resultados de búsqueda (fuente: qdrant_engine)

Qwen 3 y LangGraph, entre otros, construyen un agente de investigación profunda de código abierto: Soham ha desarrollado y liberado un agente de investigación profunda de código abierto. Este agente utiliza el modelo Qwen 3, combinado con Composio, LangGraph de LangChain, Together AI y Perplexity/Tavily para la búsqueda. Se afirma que su rendimiento supera a muchos otros modelos de código abierto probados. El código está disponible, proporcionando una solución de herramienta de automatización de investigación reproducible (fuente: Soham, hwchase17)
Perplexity en WhatsApp mejora la experiencia de uso de IA en móviles: Arav Srinivas, CEO de Perplexity, mencionó que usar Perplexity AI en WhatsApp es muy conveniente, especialmente en vuelos con mala conexión a internet. Dado que WhatsApp está optimizado para entornos de red débiles, acceder a la IA a través de la aplicación de mensajería se convierte en una forma estable y fiable, mejorando la usabilidad de la IA en móviles y escenarios especiales (fuente: AravSrinivas)
Actualización de la app de Suno para iOS: Soporte para generar fragmentos de música compartibles: La versión iOS de la aplicación de generación de música Suno AI se ha actualizado, añadiendo la función de convertir las canciones generadas en fragmentos compartibles. Los usuarios pueden elegir longitudes de fragmento de 10, 20 o 30 segundos, acompañados de letras y portada o visualizaciones proporcionadas oficialmente (se añadirán más estilos en el futuro), facilitando a los usuarios compartir y mostrar la música creada por IA en redes sociales (fuente: SunoMusic, SunoMusic)
Discusión en la comunidad sobre el asistente de programación de IA Cursor: El usuario Andrew Carr expresó su agrado por el asistente de programación de IA Cursor. Al mismo tiempo, Justin Halford opina que Cursor es solo una función y no un producto completo, fácilmente reemplazable por lanzamientos de grandes compañías de modelos. La herramienta Cline anunció soporte para el formato de archivo de configuración .cursorrules de Cursor, mostrando el interés de la comunidad y los intentos de integración (fuente: andrew_n_carr, Justin Halford, Celestial Vault)
OctoTools: Framework flexible de llamada a herramientas LLM gana premio a mejor paper en NALCL: El framework OctoTools recibió el premio al mejor paper en KnowledgeNLP@NAACL. Es un framework flexible y fácil de usar que equipa a los LLM con diversas herramientas (como comprensión visual, recuperación de conocimiento de dominio, razonamiento numérico, etc.) a través de “tarjetas de herramientas” modulares (similares a bloques de Lego) para completar tareas de razonamiento complejas. Actualmente soporta modelos de OpenAI, Anthropic, DeepSeek, Gemini, Grok y Together AI, y ya ha lanzado su paquete PyPI (fuente: lupantech)

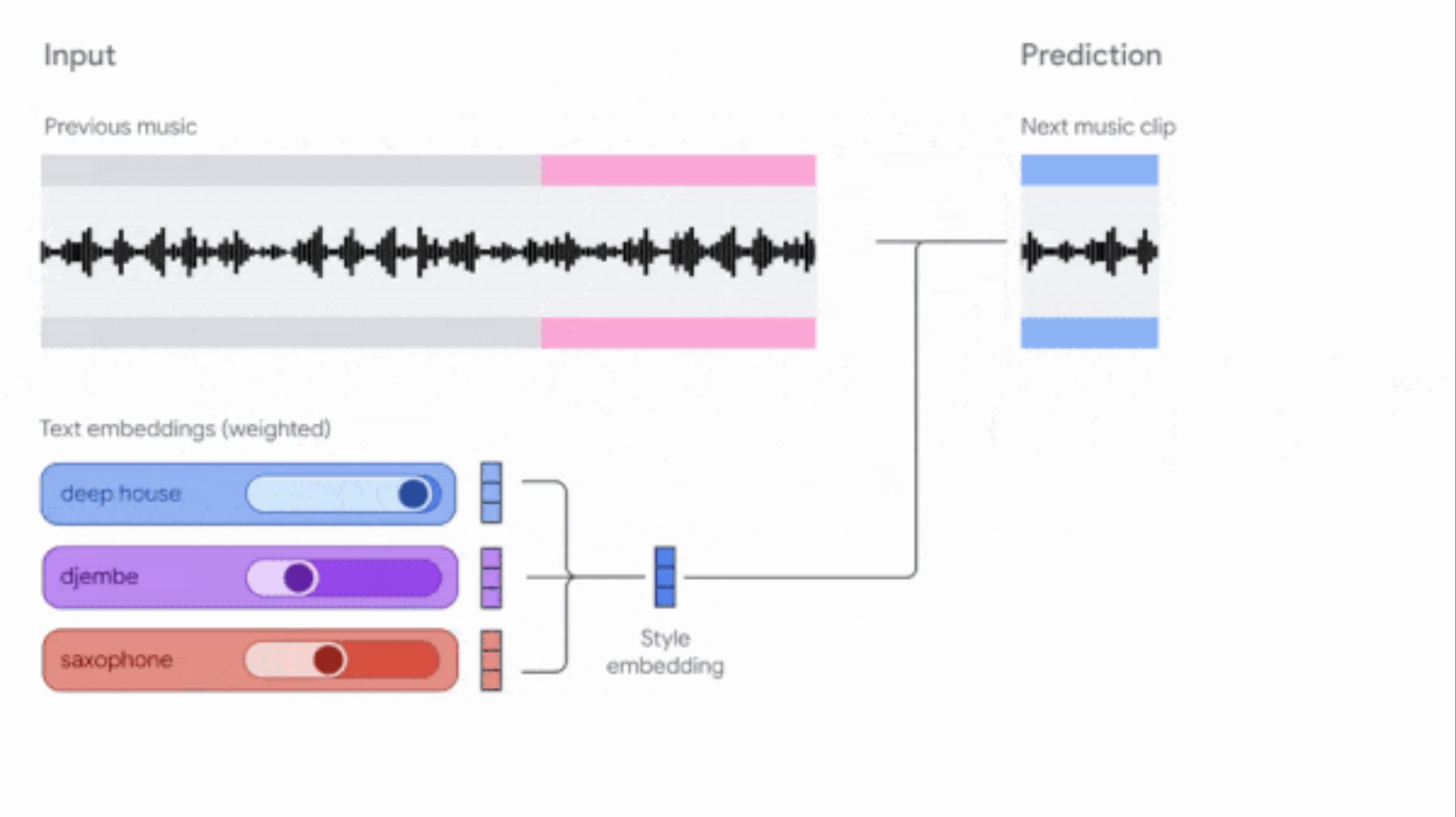
Google actualiza las herramientas Music AI Sandbox y MusicFX DJ: Google ha actualizado sus herramientas de generación de música para compositores y productores. Music AI Sandbox ahora permite a los usuarios introducir letras para generar canciones completas; MusicFX DJ permite a los usuarios controlar música en streaming en tiempo real. Ambas se basan en el modelo Lyria actualizado (Lyria 2 y Lyria RealTime respectivamente), pueden generar audio de alta calidad a 48kHz y ofrecen un amplio control sobre la tonalidad, el tempo, los instrumentos, etc. Music AI Sandbox actualmente requiere solicitar acceso a través de una lista de espera (fuente: DeepLearningAI)
Agente de revisión de código impulsado por IA: Herramientas como Composiohq y LlamaIndex, combinadas con Grok 3 y Replit Agent, han construido un agente de IA capaz de revisar Pull Requests de GitHub. El proceso incluye: Grok 3 genera el código del agente de revisión, Replit Agent crea automáticamente la interfaz frontend, el usuario envía el enlace del PR a través de la interfaz, y el agente realiza la revisión y proporciona feedback. Esto demuestra el potencial de los agentes de IA en la automatización de procesos de desarrollo de software (como la revisión de código) (fuente: LlamaIndex 🦙)
Generación de páginas para colorear con IA (con imagen de referencia): Un usuario compartió su experiencia y prompts para generar páginas para colorear en blanco y negro con una pequeña imagen de referencia a color usando IA. El objetivo es resolver el problema de los niños que no saben qué colores usar al colorear. El prompt solicita generar un boceto de líneas de contorno claras en blanco y negro adecuado para imprimir, con una pequeña imagen a color en una esquina como referencia, especificando también el estilo, tamaño, edad adecuada y contenido de la imagen (fuente: dotey)

Ejemplo de código de agente para generar imágenes usando el modelo gpt-image-1: Un usuario compartió un fragmento de código que muestra cómo crear un agente que utiliza el modelo gpt-image-1 para generar imágenes. Esto proporciona a los desarrolladores una referencia de código para implementar rápidamente la funcionalidad de generación de imágenes (fuente: skirano)
VectorVFS: Usar el sistema de archivos como una base de datos vectorial: VectorVFS es un paquete Python ligero y una herramienta CLI que utiliza los atributos extendidos (xattr) del VFS de Linux para almacenar embeddings vectoriales directamente en los inodos del sistema de archivos. Esto transforma la estructura de directorios existente en un repositorio de embeddings eficiente y con capacidad de búsqueda semántica, sin necesidad de mantener índices separados o bases de datos externas (fuente: Reddit r/MachineLearning)
Asistente de Kubernetes impulsado por IA kubectl-ai: Google Cloud Platform ha lanzado kubectl-ai, un asistente de línea de comandos para Kubernetes impulsado por IA. Puede comprender instrucciones en lenguaje natural, ejecutar los comandos kubectl correspondientes e interpretar los resultados. Soporta modelos Gemini, Vertex AI, Azure OpenAI, OpenAI, así como modelos Ollama y Llama.cpp ejecutados localmente. El proyecto también incluye el benchmark k8s-bench para evaluar el rendimiento de diferentes LLM en tareas de K8s (fuente: GitHub Trending)

Higgsfield Effects: Paquete de efectos visuales de nivel cinematográfico impulsado por IA: Higgsfield AI ha lanzado Higgsfield Effects, un kit de herramientas que incluye 10 efectos visuales (VFX) de nivel cinematográfico, como Thor, invisibilidad, metalización, prender fuego, etc. Los usuarios pueden invocar estos efectos mediante un solo prompt, con el objetivo de simplificar los complejos procesos de producción de VFX, permitiendo que usuarios comunes creen fácilmente efectos visuales de alto impacto (fuente: Higgsfield AI 🧩)
Agent-S: Framework de agente abierto para simular el uso humano de computadoras: Agent-S es un framework de agente de código abierto cuyo objetivo es permitir que la IA use las computadoras como lo hacen los humanos. Podría incluir capacidades como comprender la intención del usuario, operar interfaces gráficas, usar diversas aplicaciones, etc., con el objetivo de lograr un comportamiento de agente de IA más general y autónomo (fuente: dl_weekly)
Extensión de Chrome generada por IA completa automáticamente cuestionarios en línea: Un usuario utilizó Gemini AI para crear una extensión de Chrome que puede completar automáticamente cuestionarios en una plataforma específica de aprendizaje en línea. Esto demuestra el potencial de aplicación de la IA en la automatización de tareas repetitivas, pero también podría generar discusiones sobre la integridad académica (fuente: Reddit r/ArtificialInteligence)
Generación de imágenes con GPT-4o: Retratos de celebridades al estilo Rembrandt: Un usuario utilizó GPT-4o para transformar a varios protagonistas conocidos de series de televisión (como Walter White, Don Draper, Tony Soprano, SpongeBob, etc.) en retratos al estilo de pintura de Rembrandt. Estas imágenes muestran la capacidad de la IA para comprender las características de los personajes e imitar estilos artísticos específicos (fuente: Reddit r/ChatGPT, Reddit r/ChatGPT)

Meta lanza el kit de herramientas Llama Prompt Ops: Meta AI ha lanzado Llama Prompt Ops, un kit de herramientas Python para optimizar los prompts del modelo Llama. La herramienta tiene como objetivo ayudar a los desarrolladores a diseñar y ajustar de manera más efectiva los prompts para los modelos Llama, con el fin de mejorar el rendimiento del modelo y la calidad de la salida (fuente: Reddit r/artificial, Reddit r/ArtificialInteligence)
Usuario busca IA gratuita/de bajo costo para generar Excel/hojas de cálculo: Un usuario de Reddit busca herramientas de IA gratuitas o de bajo costo capaces de generar documentos de hoja de cálculo de Excel u OpenOffice, esperando evitar el límite diario de la versión gratuita de ChatGPT. La comunidad recomendó opciones como Claude, Google Gemini (junto con Sheets) y el despliegue local de modelos de código abierto (a través de LM Studio o LocalAI) (fuente: Reddit r/artificial)
Usuario consulta métodos para manejar contexto largo en Claude: Un usuario de Reddit pregunta cómo sortear la limitación de longitud de contexto y el problema de la “amnesia en nuevos chats” al trabajar en proyectos complejos con Claude. Los métodos sugeridos por la comunidad incluyen: guardar información clave en archivos del proyecto o hacer que Claude resuma los puntos clave de la conversación y llevarlos al nuevo chat (fuente: Reddit r/ClaudeAI)
Usuario consulta cómo usar las nuevas funciones de OpenWebUI: Un usuario de Reddit pregunta cómo usar específicamente las nuevas funciones añadidas en la versión v0.6.6 de OpenWebUI, como “grabación e importación de audio de reuniones”, importación de notas (Markdown) e integración con OneDrive (fuente: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Usuario consulta método para procesar gran cantidad de archivos JSON para RAG en OpenWebUI: Un usuario de Reddit busca las mejores prácticas para procesar eficientemente miles de archivos JSON para RAG en OpenWebUI. Considerando que subir directamente a la “base de conocimiento” podría ser ineficiente, el usuario pregunta si hay configuraciones recomendadas de bases de datos vectoriales externas o métodos de integración de pipelines de datos personalizados (fuente: Reddit r/OpenWebUI)
Usuario reporta problema de timeout en la integración de OpenWebUI con n8n: Un usuario encuentra problemas al usar OpenWebUI como frontend para un agente de IA de n8n: cuando el flujo de trabajo de n8n tarda más de unos 60 segundos en ejecutarse, OpenWebUI muestra un error, incluso si el usuario confirma que el backend de n8n se completó con éxito. El usuario busca formas de aumentar el tiempo de espera o mantener la conexión (fuente: Reddit r/OpenWebUI)
📚 Aprendizaje
LangGraph para construir sistemas Agénticos complejos: LangGraph, como parte del ecosistema LangChain, se enfoca en construir aplicaciones multi-Actor con estado. La charla de Jacob Schottenstein explora el uso de LangGraph para convertir grafos acíclicos dirigidos (DAG) en grafos cíclicos dirigidos (DCG) para construir sistemas de Agentes más potentes. En un caso práctico, Cisco Outshift utilizó LangGraph y LangSmith para construir el ingeniero de plataforma de IA JARVIS, mejorando significativamente la eficiencia de DevOps (fuente: Sydney Runkle, LangChainAI, hwchase17, Hacubu)
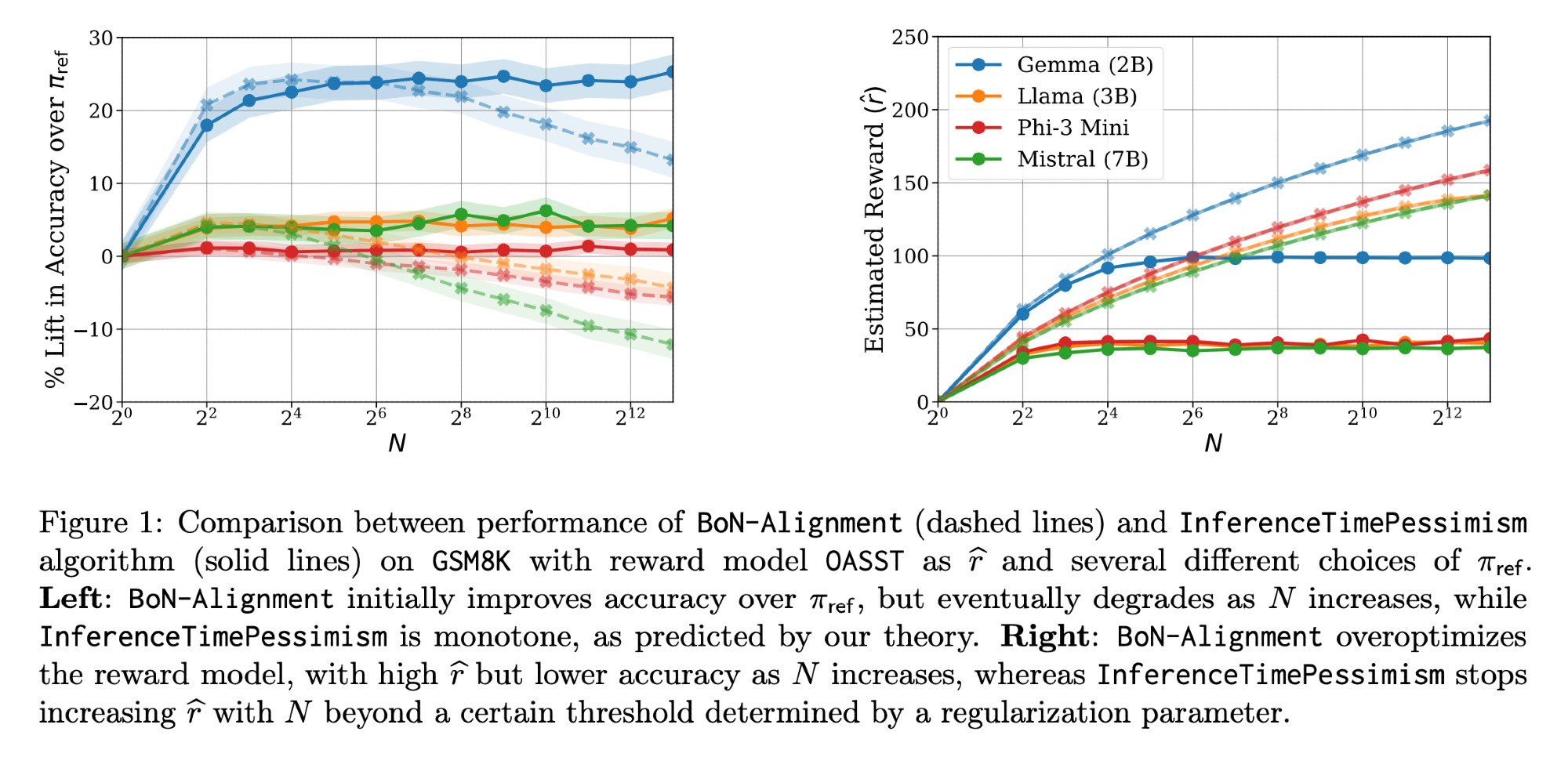
Optimización de la inferencia de LLM: Paper Llama-Nemotron e InferenceTimePessimism: El paper Llama-Nemotron (arXiv:2505.00949v1) publicado por Meta AI & Nvidia Research presenta una serie de métodos de optimización directa para reducir costos en cargas de trabajo de inferencia manteniendo la calidad. Al mismo tiempo, un paper de ICML ‘25 introduce el algoritmo InferenceTimePessimism como una mejora potencial al método de inferencia Best-of-N, con el objetivo de utilizar información adicional para optimizar el proceso de inferencia (fuente: finbarrtimbers, Dylan Foster 🐢)
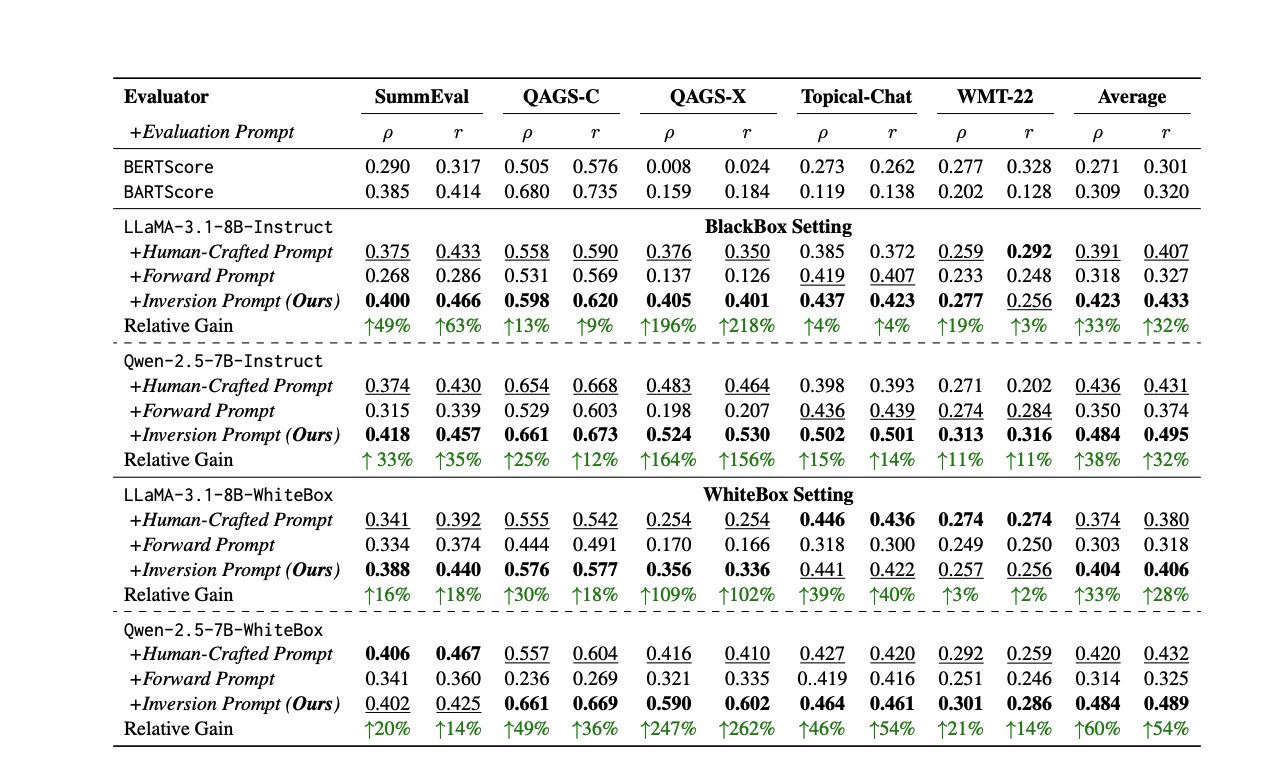
Nuevos métodos y recursos para la evaluación de LLM: Evaluar el rendimiento de los LLM es un desafío continuo. Un paper propone un método para generar automáticamente prompts de evaluación de alta calidad invirtiendo las respuestas, para abordar la inconsistencia de los evaluadores humanos o LLM. Al mismo tiempo, la experta en evaluación de LLM Shreya Shankar ha lanzado un curso de evaluación de LLM dirigido a ingenieros y gerentes de producto. Además, el benchmark SciCode se ha lanzado como una competencia de Kaggle, desafiando a la IA a escribir código para fenómenos físicos y matemáticos complejos (fuente: ben_burtenshaw, Aditya Parameswaran, Ofir Press)
Recursos relacionados con el Control y Alineamiento de la IA: El control de la IA (investigación sobre cómo monitorear y usar de forma segura IA que no alcanza la superinteligencia pero podría no estar alineada) se está convirtiendo en un campo cada vez más importante. FAR.AI ha publicado los vídeos de las charlas de la conferencia ControlConf, que incluyen las perspectivas de Neel Nanda y otros expertos. Al mismo tiempo, un artículo que discute los valores (distinguiendo valores finales de valores instrumentales) se considera relevante para la discusión sobre el alineamiento de la IA (fuente: FAR.AI, Séb Krier)

Common Crawl publica nuevos datasets: Common Crawl ha publicado el archivo de rastreo web de abril de 2025. Al mismo tiempo, Bram Vanroy ha lanzado C5 (Common Crawl Creative Commons Corpus), un subconjunto de Common Crawl rigurosamente filtrado que contiene solo documentos con licencia CC. Actualmente ha recopilado 150 mil millones de tokens, cubriendo 8 idiomas europeos, proporcionando una nueva fuente de datos conforme para entrenar modelos de lenguaje (fuente: CommonCrawl, Bram)
Actividades y tutoriales de aprendizaje de IA: Se han publicado varios recursos de actividades y tutoriales relacionados con la IA: Qdrant organizó una sesión de codificación en línea sobre la orquestación de agentes de IA usando MCP; Corbtt planea realizar un webinar sobre la optimización de agentes del mundo real usando RL; Comet ML organizó un evento para compartir ideas sobre la construcción y puesta en producción de sistemas GenAI; Ofir Press compartirá su experiencia en la construcción de SWE-bench y SWE-agent en un webinar de PyTorch; Nous Research, junto con varias instituciones, organiza un hackathon de entornos RL; LlamaIndex patrocina el hackathon MCP de Tel Aviv; Hugging Face ofrece un tutorial de 1 minuto para construir un servidor MCP; Together AI lanza la serie de vídeos de Machine Learning Matryoshka; Se vuelve a recomendar la charla de Andrew Price sobre cómo la IA está cambiando la industria 3D; giffmana compartió la grabación de una charla sobre Transformers (fuente: qdrant_engine, Kyle Corbitt, dl_weekly, PyTorch, Nous Research, LlamaIndex 🦙, dylan, Zain, Cristóbal Valenzuela, Luis A. Leiva)

Discusión sobre teoría y métodos de IA: La comunidad discutió algunas teorías y métodos fundamentales en el campo de la IA: 1. Se exploró el concepto de “World Models”, los problemas que resuelven, la arquitectura técnica y los desafíos. 2. Se discutieron las razones por las que las características de Fourier / métodos espectrales no se han aplicado ampliamente en el deep learning. 3. Se propuso el marco conceptual “Serenity Framework”, integrando cinco teorías principales de la conciencia para explorar la autoconciencia recursiva de la IA. 4. Se discutió si la IA depende excesivamente de modelos preentrenados. 5. Se exploró la importancia de la reducción de LLM (Downscaling) (fuente: Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/artificial, Reddit r/MachineLearning, Natural Language Processing Papers)

Recursos de Prompt Engineering y optimización de modelos: LiorOnAI compartió el marco del presidente de OpenAI, Greg Brockman, para construir el prompt perfecto. Modal proporcionó un tutorial sobre cómo servir LLaMA 3 8B con una latencia inferior a 250ms utilizando técnicas como TensorRT-LLM, cuantización FP8 y decodificación especulativa. N8 Programs compartió su experiencia entrenando con un modelo cuantizado a 6 bits como profesor y un modelo a 4 bits como estudiante en condiciones de baja VRAM (64GB RAM). Kling_ai retuiteó una publicación de recursos que incluye prompts para herramientas como Midjourney v7, Kling 2.0, etc. (fuente: LiorOnAI, Modal, N8 Programs, TechHalla)

Aplicación e investigación de la IA en el ámbito educativo: La tesis doctoral de Rose, doctora en Ciencias de la Computación por la Universidad de Stanford, se centra en el uso de métodos, evaluación e intervención de IA para mejorar la educación. Esto representa una dirección de investigación profunda en la aplicación de la IA en el campo educativo (fuente: Rose)

Vibe-coding: Una forma emergente de programación asistida por IA: Notas de una entrevista del podcast de YC con el CEO de Windsurf mencionaron el concepto de “Vibe-coding”. Podría ser un paradigma de programación más centrado en la intuición, el ambiente y la iteración rápida, profundamente integrado con la asistencia de IA, lo que sugiere un cambio potencial en los procesos y filosofías de desarrollo de software debido a la IA (fuente: Reddit r/ArtificialInteligence)
Información sobre la ruta de actualización de Nvidia CUDA: Un artículo de Phoronix discute la ruta de actualización de Nvidia CUDA después de la arquitectura Volta, lo cual es relevante para usuarios con GPUs Nvidia antiguas (como la serie 10xx) que deseen seguir usándolas para desarrollo de IA (fuente: NerdyRodent)
💼 Negocios
CoreWeave completa la adquisición de Weights & Biases: La plataforma de nube de IA CoreWeave ha completado formalmente la adquisición de la plataforma MLOps Weights & Biases (W&B). Esta adquisición tiene como objetivo combinar la infraestructura de nube de IA de alto rendimiento de CoreWeave con las herramientas para desarrolladores de W&B, para crear la próxima generación de plataformas de nube de IA, ayudando a los equipos a construir, desplegar e iterar aplicaciones de IA más rápidamente (fuente: weights_biases, Chen Goldberg)

El robot de Figure AI se prueba y optimiza en la fábrica de BMW: El equipo de la compañía de robots humanoides Figure AI realizó una visita de dos semanas a la planta de Spartanburg del Grupo BMW para optimizar los procesos de sus robots en el taller de carrocería del X3 y explorar nuevos escenarios de aplicación. Esto marca el inicio de la fase sustancial de la colaboración entre ambas partes en 2025, demostrando el potencial de aplicación de los robots humanoides en el sector de fabricación de automóviles (fuente: adcock_brett)

Reborn y Unitree Robotics alcanzan una colaboración estratégica: La compañía de IA Reborn ha anunciado una asociación estratégica con la compañía de robótica Unitree Robotics. Ambas partes colaborarán en los campos de datos, modelos y robots humanoides, con el objetivo común de acelerar el desarrollo de tecnologías relacionadas (fuente: Reborn)

🌟 Comunidad
La visión prudente de Buffett sobre la IA genera debate: En la junta de accionistas de 2025, Buffett expresó una actitud de “esperar y ver” y “aplicación limitada” hacia la IA. Enfatizó que la IA no puede reemplazar el juicio humano en decisiones complejas (citando como ejemplo al responsable de seguros Ajit Jain), y que Berkshire considera la IA como una herramienta para mejorar la eficiencia de los negocios existentes, no para invertir en empresas puramente algorítmicas. Considera que existe una burbuja en el campo de la IA y que es necesario esperar a que la tecnología demuestre rentabilidad a largo plazo. Esto generó un debate sobre el valor de los modelos “IA + Industria” frente a “Industria + IA” (fuente: 36氪)
El CEO de Anthropic admite falta de comprensión sobre cómo funciona la IA: Dario Amodei, CEO de Anthropic, admitió que actualmente existe una falta de comprensión profunda sobre el funcionamiento interno de los grandes modelos de IA (como los LLM), calificando la situación como “sin precedentes” en la historia de la tecnología. Esta sincera declaración vuelve a poner de relieve el “problema de la caja negra” de la IA, generando amplias discusiones y preocupaciones en la comunidad sobre la interpretabilidad, controlabilidad y seguridad de la IA (fuente: Reddit r/ArtificialInteligence)

Plan de OpenAI para lanzar modelos de código abierto no de vanguardia y su controversia: Kevin Weil, CPO de OpenAI, declaró que la compañía se está preparando para lanzar un modelo de pesos de código abierto construido sobre valores democráticos, pero que este modelo estará intencionadamente una generación por detrás de los modelos de vanguardia para evitar acelerar a los competidores (como China). Esta estrategia generó un intenso debate en la comunidad, con críticos argumentando que este posicionamiento es contradictorio: no puede convertirse en el “mejor” modelo de código abierto del mundo (necesitaría competir con modelos de vanguardia como DeepSeek-R2), podría volverse inútil debido a su rendimiento inferior, y al mismo tiempo podría canibalizar los propios ingresos de API de gama media-baja de OpenAI, resultando en una situación de “perder-perder” (lose-lose) (fuente: Haider., scaling01)
Discusión sobre la automatización impulsada por IA y el futuro del trabajo: El CEO de Fiverr cree que la IA eliminará las “tareas simples”, hará que las “tareas difíciles” sean simples y las “tareas imposibles” difíciles, enfatizando que los profesionales deben convertirse en maestros de su dominio para evitar ser reemplazados. La comunidad discute si la IA reemplazará todos los trabajos y los posibles cambios estructurales sociales resultantes (colapso económico o utopía UBI). Al mismo tiempo, la aplicación de la IA en el desarrollo de software es cada vez más común, convirtiéndose incluso en el principal contribuidor de código, lo que genera reflexión sobre los futuros modelos de desarrollo (fuente: Emm | scenario.com, Reddit r/ArtificialInteligence, mike)
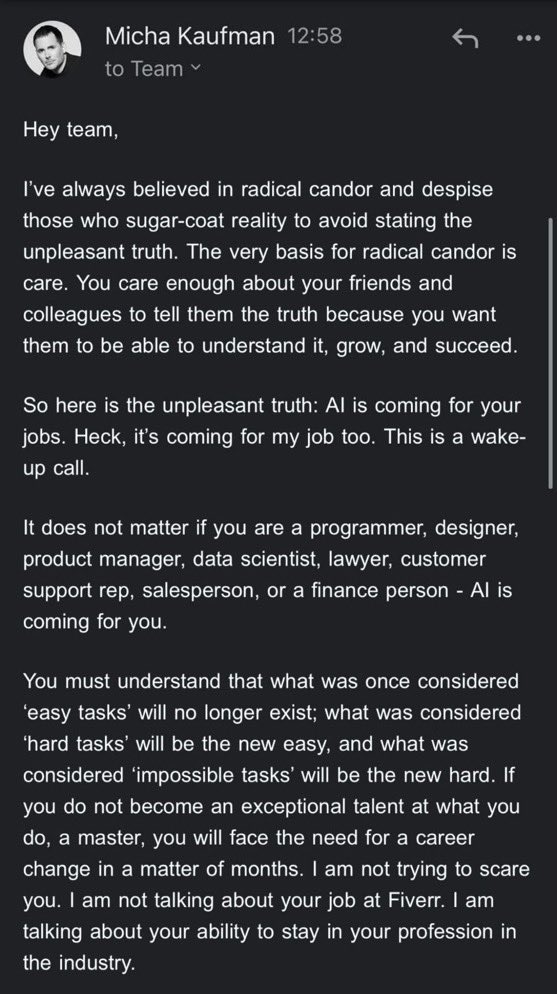
La discusión sobre seguridad y riesgos de la IA sigue intensificándose: Demis Hassabis, CEO de Google DeepMind, advierte que la AGI podría llegar en 5-10 años, pero la sociedad aún no está preparada para afrontar su impacto transformador, pidiendo una cooperación global activa. Al mismo tiempo, se desarrolló un diálogo significativo sobre el riesgo de catástrofe por IA entre Ajeya Cotra, preocupada por el riesgo, y random_walker, escéptico, donde ambas partes se esforzaron por comprender el punto de vista del otro e identificar los puntos clave de desacuerdo. La comunidad también ha comenzado a discutir el problema del control de la IA, centrándose en cómo monitorear y usar de forma segura sistemas de IA fuertes (fuente: Chubby♨️, dylan matthews 🔸, random_walker, FAR.AI, zacharynado)
Aplicación e impacto de la IA en la vida cotidiana y las relaciones interpersonales: Un usuario comparte su experiencia usando IA (Anthropic Sonnet) para ayudar con las respuestas en aplicaciones de citas y mejorar su tasa de éxito, e imagina la posibilidad de un “Cursor de relaciones”. Al mismo tiempo, un artículo señala que la IA está fomentando las fantasías mentales de algunas personas, llevándolas a distanciarse de amigos y familiares reales. Esto refleja la penetración de la IA en los ámbitos emocional y social, y las oportunidades y riesgos potenciales que conlleva (fuente: arankomatsuzaki, Reddit r/artificial)

Discusión sobre la experiencia de uso y comparación de modelos LLM: Un usuario informa que Gemini 2.5 Pro muestra confusión sobre su propia capacidad de carga de archivos, e incluso no puede cargar archivos, sospechando que es una limitación de las funciones de pago. Al mismo tiempo, familiares de otro usuario informan que prefieren usar Gemini en lugar de ChatGPT. Otro usuario elogia a Claude por ser superior a otros LLM en la generación de contenido escrito, considerando sus respuestas más naturales y más parecidas a un artículo real que a una simple finalización de tareas. Estas discusiones reflejan los problemas encontrados por los usuarios en el uso real, las diferencias de preferencia y las percepciones intuitivas sobre las capacidades de diferentes modelos (fuente: seo_leaders, agihippo, Reddit r/ClaudeAI, seo_leaders)

Exploración de la ética de la IA y las normas sociales: La discusión abarca la aplicación de la IA en el desarrollo de fármacos y sus consideraciones éticas, así como la actitud de las personas anti-IA al respecto. Al mismo tiempo, hay comentarios que sugieren que la popularización de la traducción en tiempo real por IA podría hacer que la gente extrañe la conexión que surgía de la “dificultad” de la comunicación interlingüística en el pasado. También hay discusiones sobre la IA traductora de mascotas, argumentando que parte del agrado por las mascotas reside en poder proyectar emociones, mientras que una traducción real por IA probablemente solo devolvería “tengo hambre” y “quiero aparearme” (fuente: Reddit r/ArtificialInteligence, jxmnop, menhguin)
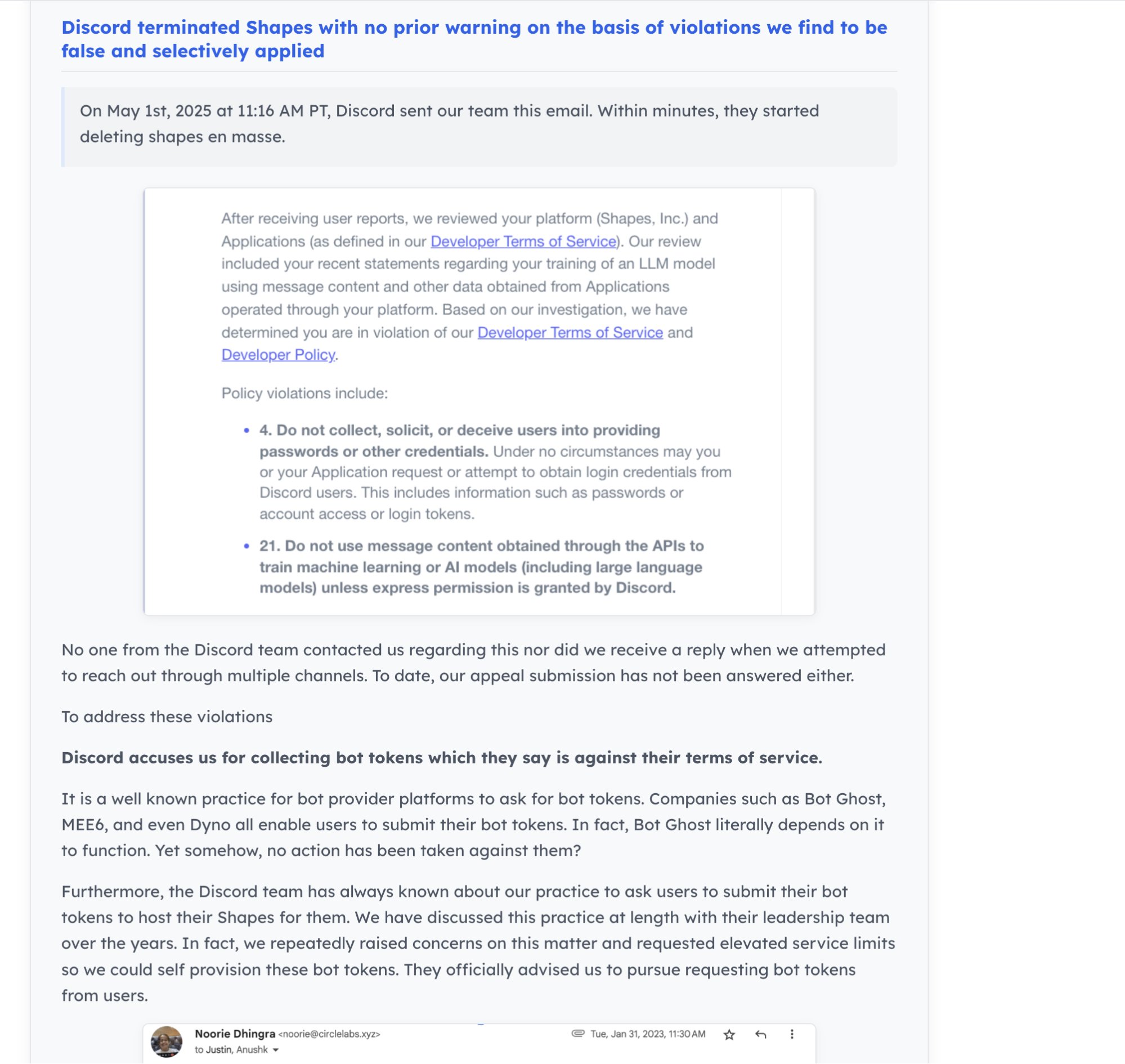
Dinámicas de la comunidad de IA y ecosistema de desarrolladores: Discord cierra el bot de IA “Shapes”, con 30 millones de usuarios, generando preocupación entre los desarrolladores sobre los riesgos de la plataforma. Al mismo tiempo, existe la opinión de que para las startups de IA, contribuir a proyectos de código abierto demuestra más capacidad que hacer LeetCode y facilita la obtención de empleo. Nous Research, junto con XAI, Nvidia y otros, organiza un hackathon de entornos RL con el objetivo de impulsar el desarrollo de entornos RL (fuente: shapes inc, pash, Nous Research)
Comportamiento anómalo de ChatGPT: Atrapado en un bucle “Boethius”: Un usuario informa que al preguntar “quién fue el primer compositor”, ChatGPT-4o mostró un comportamiento anómalo, mencionando repetidamente a Boethius (un teórico musical, no un compositor), e incluso “disculpándose” en conversaciones posteriores y bromeando que Boethius lo perseguía como un “fantasma” en las respuestas. Este interesante “fallo” muestra los patrones de comportamiento inesperados que pueden surgir en los LLM y la posible confusión del estado interno (fuente: Reddit r/ChatGPT)

Reflexión sobre las futuras etapas de desarrollo de la IA: La comunidad pregunta: si el desarrollo actual de la IA se encuentra en la etapa de “mainframe”, ¿cómo será la futura etapa de “microprocesador”? Esta pregunta genera especulaciones sobre la ruta de evolución tecnológica de la IA, las formas de popularización y las posibles formas futuras de IA más miniaturizadas, personalizadas y embebidas (fuente: keysmashbandit)
Estilo e identificación del contenido generado por IA: Usuarios observan que el texto generado por IA (especialmente modelos tipo GPT) a menudo utiliza frases y estructuras fijas (como “implicaciones significativas para…”, etc.), lo que lo hace fácil de identificar. Al mismo tiempo, aunque la calidad del audio generado por IA ha mejorado, todavía parece rígido en estructura, ritmo y pausas. Esto genera discusiones sobre los “patrones repetitivos” y la naturalidad de la salida de los LLM (fuente: Reddit r/ArtificialInteligence)
Reconocimiento del diseño de Perplexity AI: El usuario jxmnop opina que Perplexity AI parece invertir más recursos en diseño que en desarrollar sus propios modelos, pero la experiencia del producto (vibes) se siente bien. Esto refleja que en la competencia de productos de IA, además de la capacidad del modelo central, la interfaz de usuario y el diseño de interacción también son factores diferenciadores importantes (fuente: jxmnop)

Aplicaciones divertidas de la IA fuera del trabajo: Un usuario de Reddit solicita ejemplos de usos interesantes o extraños de la IA fuera del ámbito laboral. Los ejemplos incluyen: analizar sueños desde la perspectiva de Jung y Freud, lectura de posos de café, crear recetas basadas en ingredientes aleatorios de la nevera, escuchar cuentos para dormir leídos por IA, resumir documentos legales, etc. Esto muestra la creatividad de los usuarios al explorar los límites de la aplicación de la IA (fuente: Reddit r/ArtificialInteligence)
Usuario busca el mejor LLM para 48GB de VRAM: Un usuario de Reddit busca el mejor LLM para condiciones de 48GB de VRAM, que equilibre la cantidad de conocimiento y una velocidad utilizable (>10t/s). En la discusión se mencionaron Deepcogito 70B (fine-tune de Llama 3.3), Qwen3 32B, y se sugirió probar Nemotron, YiXin-Distill-Qwen-72B, GLM-4, Mistral Large cuantizado, Command R+, Gemma 3 27B o Qwen3-235B parcialmente descargado (offloaded). Esto refleja la necesidad real de los usuarios de seleccionar y optimizar modelos bajo restricciones específicas de hardware (fuente: Reddit r/LocalLLaMA)
💡 Otros
Avances en robótica: El campo continúa mostrando nuevas dinámicas: 1. PIPE-i: Beca Group lanza un vehículo robótico de inspección para infraestructuras como tuberías. 2. Robot humanoide de código abierto: La Universidad de California en Berkeley lanza un proyecto de robot humanoide de código abierto. 3. Brazo robótico de Hugging Face: Hugging Face lanza un proyecto de brazo robótico impreso en 3D. 4. Pastel robótico comestible: Investigadores crean un pastel robótico que se puede comer. 5. Dron para alcantarillas: Aparecen drones para inspeccionar alcantarillas, reemplazando el trabajo sucio humano (fuente: Ronald_vanLoon, TheRundownAI)

Discusión sobre la regulación de la IA: Lanzamiento de documental sobre la ley SB-1047: Michaël Trazzi ha lanzado un documental sobre la historia detrás de cámaras del debate sobre la ley de seguridad de IA de California SB-1047. La ley buscaba imponer una regulación mínima al desarrollo de IA de vanguardia, pero finalmente no fue aprobada. El documental explora las razones del fracaso de la ley, a pesar del gran apoyo de los ciudadanos de California, generando una mayor reflexión sobre los caminos y desafíos regulatorios de la IA (fuente: Michaël Trazzi, menhguin, NeelNanda5, JeffLadish)
Combinación de computación cuántica e IA: Nvidia está allanando el camino para la computación cuántica práctica mediante la integración de hardware cuántico con supercomputadoras de IA, centrándose en la corrección de errores y acelerando la transición de la experimentación a la aplicación práctica. Al mismo tiempo, existe la opinión de que la computación cuántica podría traer más prosperidad científica que simplemente una disrupción en el campo de la ciberseguridad (fuente: Ronald_vanLoon, NVIDIA HPC Developer)
