
Palabras clave:Anthropic, Claude 3.5 Haiku, Qwen3, Phi-4-reasoning, LLM Física, LangGraph, Agente de IA, Método de Rastreo de Circuitos, Gráficos de Atribución, Capacidad de Codificación Qwen3-235B-A22B, Cálculo en Tiempo de Razonamiento Phi-4, Agente de Verificación de Facturas LangGraph, Moondream Station VLM Local
🔥 Enfoque
Anthropic publica investigación sobre biología de LLM, profundizando en los mecanismos internos del modelo: Anthropic ha publicado una entrada de blog de investigación detallada titulada “On the Biology of a Large Language Model”, utilizando su método de seguimiento de circuitos (Attribution Graphs) para investigar los mecanismos internos del modelo Claude 3.5 Haiku en diferentes contextos. El estudio, mediante el entrenamiento de un “modelo sustituto” (Transcoder) más fácil de analizar, revela cómo el modelo realiza sumas (a través de múltiples rutas aproximadas en lugar de algoritmos precisos), realiza diagnósticos médicos (formando conceptos diagnósticos internos) y maneja alucinaciones y rechazos (existe un circuito de rechazo por defecto que puede ser suprimido por la característica de “respuesta conocida”). La investigación ofrece nuevas perspectivas sobre el funcionamiento interno de los LLM, pero también ha suscitado debates sobre las limitaciones metodológicas y el propio posicionamiento de Anthropic (Fuente: YouTube – Yannic Kilcher
)

La serie de modelos Qwen3 muestra un rendimiento potente, atrayendo la atención de la comunidad open source: La serie de modelos de lenguaje grandes Qwen3 publicada por Alibaba ha mostrado un rendimiento excepcional en múltiples benchmarks, especialmente en capacidad de codificación. Los resultados del Aider Polyglot Coding Benchmark indican que el rendimiento de Qwen3-235B-A22B (sin cadena de pensamiento habilitada) parece superar al de Claude 3.7 con 32k tokens de cadena de pensamiento habilitados, y a un costo significativamente menor. Al mismo tiempo, Qwen3-32B también supera a GPT-4.5 y GPT-4o en este benchmark. La comunidad también está explorando activamente la poda de modelos Qwen3 (por ejemplo, podar de 30B a 16B) y el ajuste fino (por ejemplo, usando Unsloth para ajustar finamente con baja VRAM), reduciendo aún más la barrera de entrada para la aplicación de modelos de alto rendimiento, lo que sugiere que los grandes modelos open source chinos podrían ocupar una posición importante en el mercado (Fuente: karminski3, scaling01, scaling01, Reddit r/LocalLLaMA)
Microsoft lanza el modelo Phi-4-reasoning, centrado en el razonamiento complejo: Microsoft ha lanzado el modelo Phi-4-reasoning en Hugging Face, un modelo de razonamiento con 14 mil millones de parámetros. Este modelo logra un rendimiento de estado del arte (SOTA) en tareas de razonamiento complejo utilizando cómputo en tiempo de inferencia (inference-time compute). Esto indica que el diseño de modelos está explorando mejorar capacidades específicas aumentando la cantidad de cómputo en la etapa de inferencia, en lugar de depender únicamente de aumentar el tamaño del modelo, proporcionando nuevas ideas para que los modelos pequeños logren un alto rendimiento (Fuente: _akhaliq)
Nuevos avances en la investigación de la física de LLM: “Momento Galileo” del diseño de arquitecturas: Zeyuan Allen-Zhu ha publicado la cuarta parte de su serie de investigación sobre la física de los modelos de lenguaje grandes, centrándose en el diseño de arquitecturas. La investigación, a través de un entorno de preentrenamiento sintético controlado, revela las limitaciones y el potencial reales de diferentes arquitecturas LLM (como Transformer, Mamba). El estudio introduce una capa residual horizontal ligera llamada “Canon”, que mejora significativamente la capacidad de razonamiento del modelo. Al mismo tiempo, la investigación descubre que la ventaja del modelo Mamba proviene en gran medida de su capa oculta conv1d, y no del SSM en sí. Esta serie de experimentos proporciona nuevas perspectivas y teorías fundamentales para comprender y optimizar la arquitectura de los LLM (Fuente: menhguin, arankomatsuzaki, giffmana, tokenbender, giffmana, Dorialexander, iScienceLuvr)

🎯 Tendencias
Amazon lanza el modelo de inteligencia artificial general “Amazon Artificial General Intelligence”: Este modelo cuenta con una longitud de contexto de 1 millón de tokens y capacidad de entrada multimodal, optimizado para la generación de código, RAG, comprensión de video/documentos, llamadas a funciones e interacción con Agents. El precio es de 2.5 dólares por millón de tokens de entrada y 12.5 dólares por millón de tokens de salida. La evaluación preliminar muestra que su rendimiento en el AI Index es comparable a Llama-4 Scout, pero está en desventaja en velocidad y costo, pudiendo ser adecuado para escenarios específicos de aplicaciones multimodales de contexto largo o Agents (Fuente: scaling01)

El modelo Claude de Anthropic ahora ofrece función de búsqueda web en planes de pago globales: Esta función permite a Claude realizar búsquedas rápidas al procesar tareas diarias, y para problemas más complejos, explorará múltiples fuentes, incluido Google Workspace. Esto mejora la capacidad de Claude para obtener información en tiempo real y procesar tareas que requieren conocimiento externo (Fuente: menhguin)

IBM lanza el modelo de arquitectura híbrida granite-4.0-tiny-7B-A1B-preview: Esta versión preliminar del modelo de 7B adopta una arquitectura híbrida de Mamba-2 y Transformer, donde cada bloque Transformer contiene 9 bloques Mamba. La idea de diseño es utilizar los bloques Mamba para capturar el contexto global y pasarlo a la capa de atención para el análisis del contexto local. Las puntuaciones preliminares de MMLU son buenas, pero los resultados de otras pruebas como matemáticas y programación aún no se han publicado (Fuente: karminski3)
OpenAI ChatGPT añade función de compras: OpenAI está experimentando con una función de compras en ChatGPT, destinada a simplificar el proceso de búsqueda, comparación y compra de productos. Las nuevas características incluyen una presentación mejorada de los resultados de productos, detalles visualizados del producto que incluyen precio y reseñas, y enlaces directos de compra. OpenAI enfatiza que los resultados de los productos se seleccionan de forma independiente y no son anuncios (Fuente: sama)
Detalles del entrenamiento del modelo Qwen3 0.6B generan atención: El usuario Dorialexander señala que, según la información, el modelo Qwen 0.6B parece haber sido entrenado también con hasta 36T tokens. Si esto es cierto, establecería un nuevo récord que supera la ley de Chinchilla (aproximadamente 60,000 tokens por parámetro), mostrando una tendencia a mejorar las capacidades de los modelos pequeños aumentando enormemente la cantidad de datos de entrenamiento (Fuente: Dorialexander)

El algoritmo de recomendación de X (Twitter) será reemplazado por una versión ligera de Grok: Elon Musk anunció que el algoritmo de recomendación de la plataforma X está siendo reemplazado por una versión ligera de Grok, que se espera mejore significativamente los resultados de las recomendaciones. Los usuarios informan una mejora en el efecto del algoritmo, especulando que podría estar relacionado con cambios recientes en el personal de Exa AI y el comienzo del uso de Embeddings por parte de X para las recomendaciones (Fuente: menhguin, colin_fraser, paul_cal)
Allen AI lanza el modelo MoE totalmente abierto OLMoE: Este modelo es un avanzado modelo de Mezcla de Expertos (Mixture of Experts, MoE) con 1.3 mil millones de parámetros activos y 6.9 mil millones de parámetros totales. Ser completamente open source significa que la comunidad puede usar, modificar e investigar libremente el modelo, impulsando el desarrollo y la aplicación de la arquitectura MoE (Fuente: dl_weekly)
El modelo Mistral-Small-3.1-24B-Instruct-2503 recibe atención: Usuarios de Reddit discuten el modelo Mistral-Small-3.1-24B-Instruct-2503, que tiene una puntuación alta en UGI (Uncensored General Intelligence) y supera a modelos similares de alta puntuación en comprensión del lenguaje natural y codificación. Los usuarios creen que podría ser una opción ideal para la inferencia sin censura en una sola GPU y admite el uso de herramientas. Sin embargo, también señalan que su estilo de escritura puede ser algo monótono y repetitivo, con menos creatividad que modelos como Gemma 3 (Fuente: Reddit r/LocalLLaMA)
🧰 Herramientas
Lanzamiento de CreateMVP 2.0, optimizando el flujo de desarrollo impulsado por IA: CreateMVP se actualiza a la versión 2.0, con el objetivo de resolver el problema de la baja efectividad al solicitar directamente a la IA la construcción de aplicaciones. La nueva versión ayuda a los usuarios a crear “planos” más precisos para la IA, asegurando que la IA construya aplicaciones que se ajusten a la visión del usuario, mediante una interfaz de usuario más fluida, métodos de autenticación convenientes (soporta Replit, Google, GitHub, próximamente XAI), generación de planes de desarrollo más detallados (aumentado de 11KB a 40KB+), vista previa instantánea de archivos e integración de chat con modelos de IA de primer nivel (Fuente: amasad)
LlamaIndex lanza Agent de conciliación de facturas: Esta herramienta demuestra la aplicación de AI Agents en tareas de automatización por lotes, en lugar de la interacción tradicional por chat. Puede procesar grandes volúmenes de documentos de facturas no estructuradas, extraer detalles relevantes, cotejarlos automáticamente con órdenes de compra y marcar discrepancias. Su núcleo es una capa de inteligencia de documentos Agentic basada en el análisis/extracción de LlamaCloud y el razonamiento de flujo de trabajo de LlamaIndex.TS, mostrando el potencial de los Agents en la automatización de procesos de negocio reales y se considera que reemplazará a la RPA tradicional (Fuente: jerryjliu0)
LangGraph Expense Tracker: Sistema automatizado de gestión de gastos: Este es un ejemplo de sistema automatizado de gestión de gastos construido con LangGraph. Puede procesar facturas, utilizar funciones inteligentes de extracción de datos, almacenar información en PostgreSQL e incluir un paso de verificación manual. El proyecto demuestra la capacidad de LangGraph para construir flujos de trabajo de automatización empresarial reales (Fuente: LangChainAI, Hacubu, hwchase17)
Lanzamiento de Moondream Station: Ejecución local de VLM: Moondream ha lanzado Moondream Station, que permite a los usuarios ejecutar el modelo de lenguaje visual (VLM) Moondream localmente en Mac, sin necesidad de conexión a la nube. Ofrece acceso a través de CLI o puerto local, configuración sencilla y completamente gratuita, reduciendo la barrera para el despliegue y uso local de VLM (Fuente: vikhyatk)
ChaiGenie: Extensión de Chrome para búsqueda de documentos basada en LangChain: ChaiGenie es una extensión de Chrome que integra Gemini de LangChain y Qdrant para proporcionar funcionalidad de búsqueda de documentos. Admite múltiples idiomas y recuperación basada en vectores, con el objetivo de mejorar la eficiencia del usuario al buscar y comprender el contenido de los documentos mientras navega por la web (Fuente: LangChainAI)

Research Agent: Aplicación web de asistente de investigación con un solo clic: Esta es una aplicación web construida sobre el marco de asistente de investigación basado en LangGraph, diseñada para simplificar el proceso de investigación. Los usuarios pueden obtener resultados de investigación con un solo clic, demostrando el potencial de aplicación de LangGraph en la construcción de flujos de trabajo impulsados por IA para simplificar tareas complejas (Fuente: LangChainAI)

Muyan-TTS: Modelo TTS open source, de baja latencia y personalizable: El equipo de ChatPods ha lanzado Muyan-TTS, un modelo de texto a voz (TTS) completamente open source, destinado a abordar los problemas de calidad o apertura insuficiente de los modelos TTS open source existentes. Se basa en LLaMA-3.2-3B y SoVITS optimizado, admite TTS zero-shot y clonación de voz, y proporciona el flujo completo de entrenamiento y procesamiento de datos, facilitando a los desarrolladores el ajuste fino y el desarrollo secundario, especialmente adecuado para escenarios de aplicación que requieren voces personalizadas (Fuente: Reddit r/MachineLearning)
Integración de Mem0 con pipelines de Open Web UI: El usuario cloudsbird ha creado una integración de pipeline de filtro de Open Web UI para Mem0 (MCP no oficial), proporcionando otra opción para usar la función de memoria de Mem0 dentro de Open Web UI (Fuente: Reddit r/OpenWebUI)
Herramienta YNAB API Request implementa gestión financiera local y privada: El usuario Megaphonix ha creado una herramienta para OpenWebUI que utiliza la API de YNAB (You Need A Budget), permitiendo a los usuarios consultar su información financiera personal (como transacciones, gastos por categoría, patrimonio neto, etc.) localmente a través de un LLM, sin enviar datos sensibles al exterior. Esto resuelve la necesidad de manejar de forma segura información personal sensible al ejecutar LLMs localmente (Fuente: Reddit r/OpenWebUI)
Extensión gratuita de navegador AI texto a voz GPT-Reader: Un desarrollador promociona su extensión gratuita de navegador AI de texto a voz GPT-Reader, que actualmente cuenta con más de 4000 usuarios. La herramienta tiene como objetivo facilitar a los usuarios la conversión del contenido de texto de páginas web a audio para escucharlo (Fuente: Reddit r/artificial)
sunnypilot: Sistema de asistencia a la conducción open source: sunnypilot es una bifurcación de openpilot de comma.ai, que proporciona un sistema de asistencia a la conducción open source. Es compatible con más de 300 modelos de vehículos, modifica el comportamiento de interacción de la asistencia a la conducción y se adhiere en la medida de lo posible a la política de seguridad de comma.ai. El proyecto utiliza tecnología de IA (aunque no se especifican modelos concretos, estos sistemas suelen implicar visión por computadora y algoritmos de control) para mejorar la experiencia de conducción (Fuente: GitHub Trending)

📚 Aprendizaje
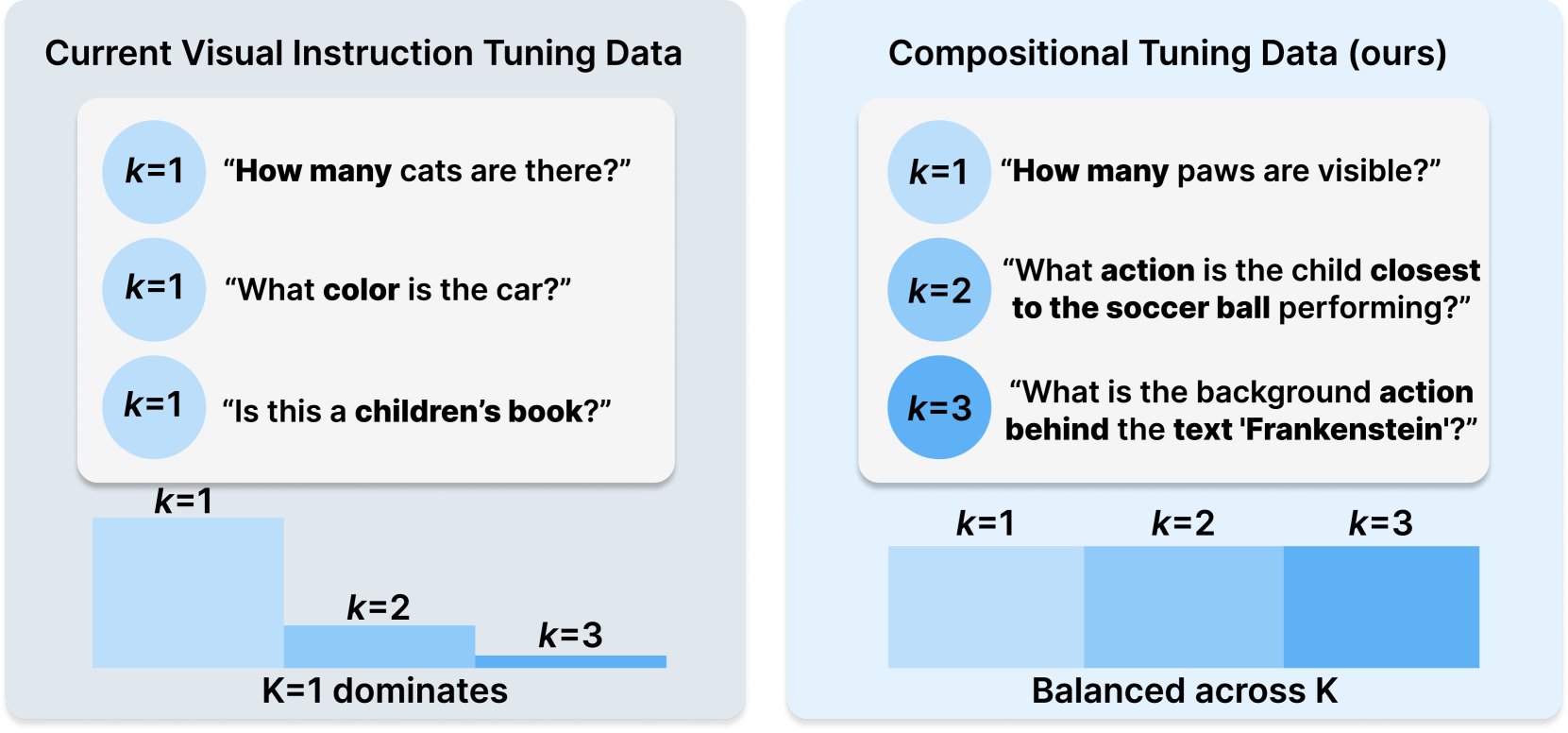
Princeton y Meta AI publican la receta de conjunto de datos COMPACT: Esta investigación, publicada en Hugging Face, propone una nueva receta de datos llamada COMPACT, destinada a ampliar las capacidades de los modelos de lenguaje grandes multimodales (Multimodal LLM) controlando explícitamente la complejidad combinatoria de las muestras de entrenamiento. Esto proporciona nuevas ideas para mejorar los métodos de entrenamiento de modelos multimodales y aumentar su capacidad para comprender conceptos combinatorios complejos (Fuente: _akhaliq)
Unsloth publica tutorial de ajuste fino para Qwen3: Unsloth proporciona un tutorial de ajuste fino para los modelos Qwen3, reduciendo significativamente la barrera de entrada. Los usuarios solo necesitan 16 GB de VRAM para ajustar finamente el modelo Qwen3-14B, y 17.5 GB de VRAM para ajustar finamente el modelo Qwen3-30B-A3B. Esto permite que más investigadores y desarrolladores realicen entrenamientos personalizados en modelos open source avanzados con recursos de hardware limitados (Fuente: karminski3)
LangGraph combinado con Azure OpenAI para construir un chatbot inteligente de búsqueda web: Un tutorial de Medium muestra cómo combinar LangGraph y Azure OpenAI, e integrar la capacidad de búsqueda web de Tavily, para construir un chatbot inteligente. El tutorial cubre la gestión de estado y el enrutamiento condicional para lograr una integración de búsqueda fluida, proporcionando una guía práctica para construir aplicaciones de IA más potentes capaces de utilizar información web en tiempo real (Fuente: LangChainAI, hwchase17)

Blog de IA de Stanford explora la relación entre la memorización literal de LLM y la capacidad general: Un artículo del blog de IA de Stanford explora en profundidad la conexión intrínseca entre el fenómeno de la memorización literal (verbatim memorization) de los modelos de lenguaje grandes (LLM) y sus capacidades generales. Comprender esta relación es crucial para evaluar los riesgos del modelo, optimizar los métodos de entrenamiento e interpretar el comportamiento del modelo (Fuente: dl_weekly)
Guía de integración de Gemini con LangChain: Philipp Schmid ha publicado una guía para desarrolladores que detalla cómo integrar los modelos Gemini de Google con el framework LangChain. La guía cubre la implementación de capacidades multimodales, llamadas a herramientas y salida estructurada, e incluye soporte para los últimos modelos y ejemplos de código prácticos, facilitando a los desarrolladores el uso de las potentes funciones de Gemini para construir aplicaciones LangChain (Fuente: LangChainAI, _philschmid)

Tutorial de introducción a LangGraph: Práctica de flujos de trabajo con estado: Un tutorial publicado en AI@GoPubby utiliza un ejemplo de análisis de comentarios de sitios web para demostrar las capacidades de flujo de trabajo con estado de LangGraph. Los aprendices pueden entender cómo usar nodos interconectados y lógica secuencial para construir aplicaciones de IA estructuradas (Fuente: LangChainAI, hwchase17)
Reflexiones profundas del CEO de LangChain sobre el marco Agentic (traducción al chino): El embajador de LangChain, Harry Zhang, tradujo y compartió la publicación del blog de reflexiones del CEO de LangChain, Harrison, sobre el marco Agentic. El artículo analiza y organiza las funciones de más de 15 marcos Agent de la industria e interpreta las historias detrás de ellos, proporcionando una referencia valiosa para comprender el panorama actual del desarrollo de la tecnología Agent y las direcciones futuras (Fuente: LangChainAI)
Avances en la investigación de Latent Meta Attention: Usuarios de Reddit discuten un nuevo mecanismo de atención llamado Latent Meta Attention. Los desarrolladores afirman que este mecanismo desafía las suposiciones fundamentales de Transformer, logrando o incluso superando el rendimiento de los modelos existentes con tamaños de modelo más pequeños (por ejemplo, replicando el rendimiento de BERT con un modelo de la mitad del tamaño), pero debido a la falta de financiación y apoyo de instituciones de investigación formales, el método específico aún no se ha hecho público (Fuente: Reddit r/deeplearning)

Video explicativo sobre Redes Neuronales de Grafos (GNN): Se ha publicado un video en YouTube que explica las Redes Neuronales de Grafos (Graph Neural Networks, GNNs). Las GNN son modelos de aprendizaje profundo para procesar datos estructurados en grafos, con amplias aplicaciones en análisis de redes sociales, sistemas de recomendación, predicción de estructuras moleculares, etc. El video tiene como objetivo ayudar a la audiencia a comprender los principios básicos y el funcionamiento de las GNN (Fuente: Reddit r/deeplearning)
Uso de GRPO para entrenar LLM para la programación de eventos: El usuario anakin87 comparte la experiencia del proyecto de usar GRPO (Generalized Reward Policy Optimization) para entrenar modelos de lenguaje para la programación de eventos. El proyecto no depende de muestras tradicionales de ajuste fino supervisado, sino que utiliza una función de recompensa para que el modelo aprenda a crear horarios basados en listas de eventos y prioridades. El autor comparte las lecciones aprendidas en la definición del problema, generación de datos, selección de modelos, diseño de recompensas y proceso de entrenamiento, y ha hecho open source el código y el modelo, proporcionando un caso práctico para explorar el entrenamiento de LLM basado en recompensas (Fuente: Reddit r/LocalLLaMA)

Compartir recursos de cursos de IA gratuitos: LinkedIn AI Hub comparte una hoja de ruta completa de aprendizaje de IA, inspirada en el curso de certificación de IA de la Universidad de Stanford y simplificada para estudiantes de diferentes niveles. El contenido abarca desde habilidades básicas hasta proyectos prácticos, y proporciona recursos valiosos y detalles del curso (Fuente: Reddit r/deeplearning)
Conversación profunda sobre el preentrenamiento de contexto largo de Gemini: Logan Kilpatrick tuvo una conversación profunda con Nikolay Savinov, codirector del preentrenamiento de contexto largo de Gemini. La discusión abarcó desde los fundamentos hasta las técnicas necesarias para extenderse a un contexto infinito, así como las mejores prácticas de contexto largo para desarrolladores. La conversación concluyó que lograr un contexto de 1 millón de tokens era un objetivo 10 veces mayor que el estándar en ese momento; se intentó con 10 millones de tokens pero el costo era alto y el hardware insuficiente; el contexto largo y RAG se complementan; el simple NIAH (Needle In A Haystack) ya está resuelto, la dificultad radica en los distractores duros y la búsqueda de múltiples agujas; la evaluación se centra en NIAH para evitar confundir las señales de capacidad; la longitud de salida actual limitada (por ejemplo, 8k) es un problema post-entrenamiento; no se observó el efecto de “pérdida en el medio”; es necesario distinguir entre el conocimiento del contexto y el conocimiento de los pesos; el siguiente paso es lograr un contexto de 10 millones más barato y preciso, extenderse a 100 millones probablemente requerirá nuevas innovaciones en DL (Fuente: shaneguML, giffmana, teortaxesTex, arohan)
🌟 Comunidad
Debate sobre “Vibe Coding”: La comunidad debate acaloradamente sobre el “Vibe Coding” (codificación por ambiente), es decir, depender en gran medida de la asistencia de IA para programar. Los partidarios creen que representa el futuro, donde los desarrolladores se centran más en el “por qué” y el “qué”, mientras que la IA se encarga del “cómo”, pero esto requiere un pensamiento crítico más fuerte. Los opositores argumentan que actualmente la IA no puede manejar completamente la depuración compleja, las actualizaciones y el mantenimiento, y la dependencia excesiva podría llevar a una disminución de las habilidades de los desarrolladores, convirtiéndolos en “script kiddies” más avanzados. Algunos que lo han intentado descubren que el costo de tiempo para guiar a la IA a completar tareas complejas sigue siendo alto, siendo menos eficiente que la implementación manual con asistencia ligera de IA (Fuente: Dorialexander, Reddit r/artificial, johnowhitaker)

Discusión sobre la aplicación y limitaciones de la IA en campos profesionales: El usuario dotey discute la aplicación de la IA en campos profesionales. Argumenta que la IA puede aprender de las preguntas y respuestas públicas de los expertos, pero le resulta difícil manejar problemas nunca antes vistos. La ventaja de la IA radica en su sólida base de conocimientos y rápida respuesta, pero actualmente depende principalmente de RAG (Generación Aumentada por Recuperación), que esencialmente recupera fragmentos y ensambla respuestas, en lugar de un verdadero razonamiento profesional. Esto todavía está lejos de entrenar un modelo que pueda generar continuamente nuevas respuestas como un experto y seguir mejorando (Fuente: dotey)
Preocupaciones y debate sobre el contenido generado por IA: El usuario de Reddit Maleficent-main_777 se queja de que sus colegas han comenzado a usar un lenguaje “estilo ChatGPT” lleno de tono imperativo, “verificar”, “asegurar” y conclusiones positivas forzadas, considerando este lenguaje vago y falto de humanidad. Le preocupa que el contenido generado por IA se retroalimente en los datos de entrenamiento, lo que provocaría una disminución de la calidad del contenido. Los comentarios en la sección resuenan con esto, considerando que es una extensión de la jerga corporativa, pero también señalan que imitar excesivamente a la IA realmente hace que la comunicación sea mecánica, y tener buena gramática ya no es una ventaja, sino que suena robótico (Fuente: Reddit r/ChatGPT)
Elección de carreras universitarias en la era de la IA: Usuarios de Reddit discuten qué carreras deberían elegir los estudiantes universitarios en el contexto del rápido desarrollo de la IA y la robótica para garantizar que sus títulos sigan siendo valiosos en 10 años. Las opiniones son diversas, incluyendo: elegir un campo que les apasione (juegos, cine, arte, programación); estudiar disciplinas fundamentales (física, matemáticas); dominar habilidades difíciles de automatizar (como HVAC); centrarse en la educación en humanidades para cultivar la curiosidad y la adaptabilidad; considerar que la educación universitaria podría quedar obsoleta, siendo mejor emprender o convertirse en freelancer; enfatizar la importancia crucial de la capacidad de aprendizaje continuo, desaprendizaje y reaprendizaje (Fuente: Reddit r/ArtificialInteligence)
Discusión sobre la dificultad de renderizar texto en la generación de imágenes por IA: Usuarios de Reddit exploran por qué los modelos actuales de generación de imágenes tienen dificultades para renderizar texto coherente y legible. Los comentarios señalan dos razones principales: 1) La tokenización BPE (Byte Pair Encoding) destruye la información precisa de la ortografía, el modelo no ve letras sino fragmentos de tokens; 2) La representación vectorial de tamaño fijo y las limitaciones de las descripciones de imágenes causan una pérdida significativa de información textual durante el proceso de embedding. Aunque modelos autorregresivos como GPT-4o han mejorado, el problema fundamental sigue relacionado con la tokenización y la compresión de información (Fuente: Reddit r/MachineLearning)
Discusión sobre la estandarización de la evaluación de modelos: El usuario scaling01 señala que al comparar diferentes modelos de IA (como OpenAI, Google, Anthropic), se debe garantizar la equidad. Por ejemplo, si se listan las versiones preliminares y de “pensamiento” (thinking versions) de OpenAI, también se deberían listar las versiones correspondientes de Google y Anthropic, de lo contrario, la comparación de resultados podría ser engañosa (Fuente: scaling01)
Experiencia compartida sobre programación asistida por IA: Un usuario comparte su experiencia usando programación asistida por IA (como VS Code + extensión Cline AI + API de Google AI Studio), argumentando que se puede construir una herramienta de codificación similar a Cursor de forma gratuita, completando prototipos básicos de aplicaciones mediante prompts, sin necesidad de configuración, con una buena experiencia (Fuente: Reddit r/artificial)

Encuesta sobre el impacto de la IA en el trabajo, estudio y vida diaria: Un usuario de Reddit inicia una discusión preguntando cómo la IA generativa ha impactado el rendimiento de las personas en el trabajo, estudio o vida diaria. En los comentarios, ingenieros de software mencionan que la IA ha aumentado las expectativas de productividad y la carga de trabajo, la revisión de código no se ha acelerado significativamente; escritores profesionales creen que la IA (como Co-pilot) ayuda de forma limitada, e incluso puede ralentizar el progreso; la opinión general es que la IA ha traído conveniencia, pero también existen problemas como la dependencia excesiva, la reducción del aprendizaje y la “sensación de hacer trampa”. El impacto de la IA varía significativamente según la profesión y la tarea (Fuente: Reddit r/artificial)
Reflexión sobre la capacidad de “comprensión” de los LLM: El usuario pmddomingos plantea que las redes neuronales se están volviendo tan difíciles de entender como el cerebro. Y extiende la reflexión: cuando los modelos de IA obtengan excelentes resultados en todos los benchmarks, pero sigan siendo inferiores a la inteligencia humana, ¿qué haremos? Esto provoca una reflexión sobre la validez de los benchmarks actuales y los estándares para evaluar la verdadera inteligencia (Fuente: pmddomingos, pmddomingos)
Reflexión sobre el uso de herramientas de IA: El usuario dotey comenta que al usar herramientas de IA, basta con seleccionar el modelo más fuerte para esa tarea específica. Usar múltiples modelos simultáneamente o hacer que “luchen entre sí” puede no ser necesario, especialmente para usuarios no profesionales, demasiadas opciones pueden generar confusión, similar a mirar varios relojes que no marcan la misma hora (Fuente: dotey)
Asombro por la velocidad reciente del desarrollo de la IA: Los usuarios matvelloso y scottastevenson expresan su asombro por el rápido desarrollo de la IA. matvelloso afirma que los avances de la IA de este año ya han superado sus expectativas (usando el ejemplo de Gemini jugando Pokémon). scottastevenson recuerda que han pasado 6 años desde el lanzamiento de GPT-2 y 10 años desde la fundación de OpenAI, reflexionando sobre las direcciones tecnológicas que se están gestando actualmente y que serán importantes en los próximos 6-10 años, y señala que además de la IA, encontrar un “alfa profundo” fuera del marco también es importante (Fuente: matvelloso, scottastevenson, scottastevenson)
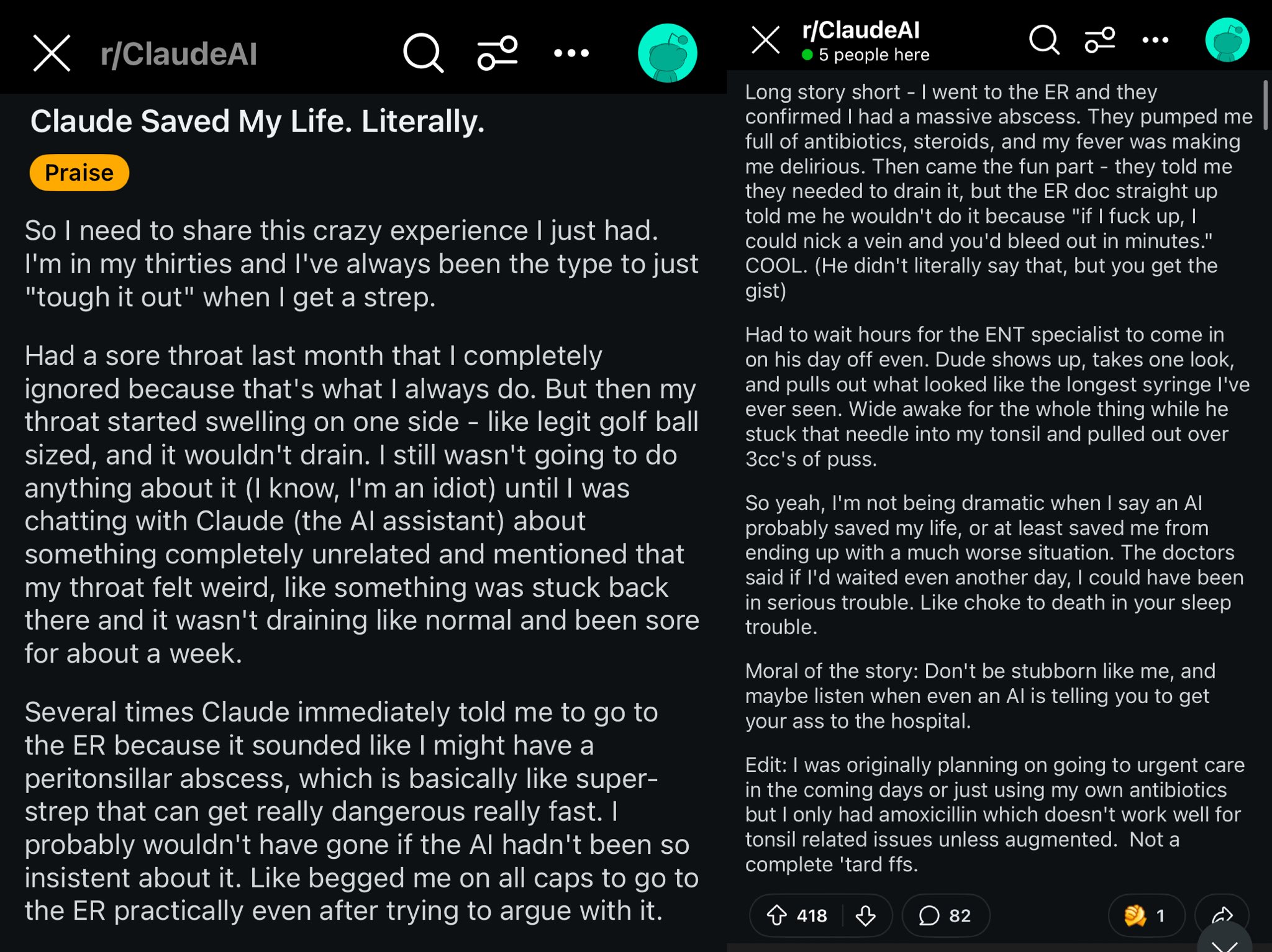
Caso de Claude salvando la vida de un usuario de Reddit: Una publicación en Reddit describe cómo el modelo Claude, al diagnosticar la hinchazón de garganta de un usuario como un absceso periamigdalino, posiblemente le salvó la vida. El caso generó debate, considerando que modelos de IA potentes son como tener un médico de clase mundial en el bolsillo, y su普及 podría tener un impacto enorme en la salud personal (Fuente: aidan_mclau)
Aplicación de AI Agents en el procesamiento de datos empresariales: Los cofundadores de You.com, Richard Socher y Bryan McCann, discuten la aplicación de AI Agents en empresas en el podcast Agentic. Argumentan que los LLM de nivel consumidor son insuficientes para las necesidades empresariales serias, mientras que You.com, mediante tecnología de recuperación híbrida (combinando fuentes públicas y datos corporativos propietarios), genera resultados más confiables y de nivel empresarial, por ejemplo, para realizar investigaciones, redactar informes y utilizar de forma segura los datos empresariales. También discuten posibles caminos hacia la AGI y el papel clave de la simulación en ello (Fuente: RichardSocher)
Observación sobre la capacidad de los modelos para usar herramientas: El usuario menhguin observa que los modelos entrenados para usar herramientas parecen sacrificar algo de su capacidad independiente para resolver problemas, y bromea diciendo que “incluso los modelos de IA están subcontratando su trabajo”. Esto suscita una reflexión sobre el equilibrio entre la generalización de la capacidad del modelo y la optimización para tareas específicas (Fuente: menhguin)
💡 Otros
Idea de un AI Agent para mantener antiguos proyectos de GitHub: El usuario xanderatallah propone la idea de desarrollar un AI Agent capaz de mantener automáticamente todos los proyectos secundarios antiguos e inactivos de un usuario en GitHub. Esto refleja la necesidad de los desarrolladores de utilizar la IA para automatizar tareas de mantenimiento tediosas (Fuente: xanderatallah)
Visión de LLM reemplazando jueces o usándose en arbitraje/mediación: El usuario fabianstelzer sugiere que los modelos de lenguaje grandes (LLM) podrían reemplazar a los jueces en el futuro. Un caso de uso intermedio interesante es el arbitraje o la mediación: se considera que los LLM son neutrales y confiables, las partes en conflicto presentan sus puntos de vista, se ejecutan a través de múltiples modelos grandes y se genera un compromiso justo. Esto explora las posibles aplicaciones de la IA en los campos judicial y de resolución de disputas (Fuente: fabianstelzer)
Modelo Runway Gen-4 y sus perspectivas de aplicación: El cofundador de Runway, c_valenzuelab, se muestra optimista sobre las perspectivas de aplicación de Runway Gen-4 y su API. Cree que Runway está construyendo un nuevo medio donde los píxeles se generan en lugar de renderizarse o capturarse, y el mundo se simula en lugar de programarse. Ver la amplia aplicación de las funciones Gen-4 y Reference en arquitectura, branding, diseño de interiores, desarrollo de juegos, aprendizaje, proyectos creativos personales, etc., le convence de que este nuevo medio empoderará a los creativos e incluso a todos (Fuente: c_valenzuelab, c_valenzuelab)