Palabras clave:Gemini 2.5 Pro, Modelo de IA, Robots humanoides, Ética de la IA, Emprendimiento en IA, Contenido generado por IA, Creatividad asistida por IA, Gemini 2.5 Pro completando ‘Pokémon: Azul’, Búsqueda web global de Anthropic Claude, Sesgo de enrutamiento en el modelo Qwen3 MoE, Función References de Runway Gen-4, Aplicaciones de la IA en apoyo a la salud mental
🔥 Enfoque
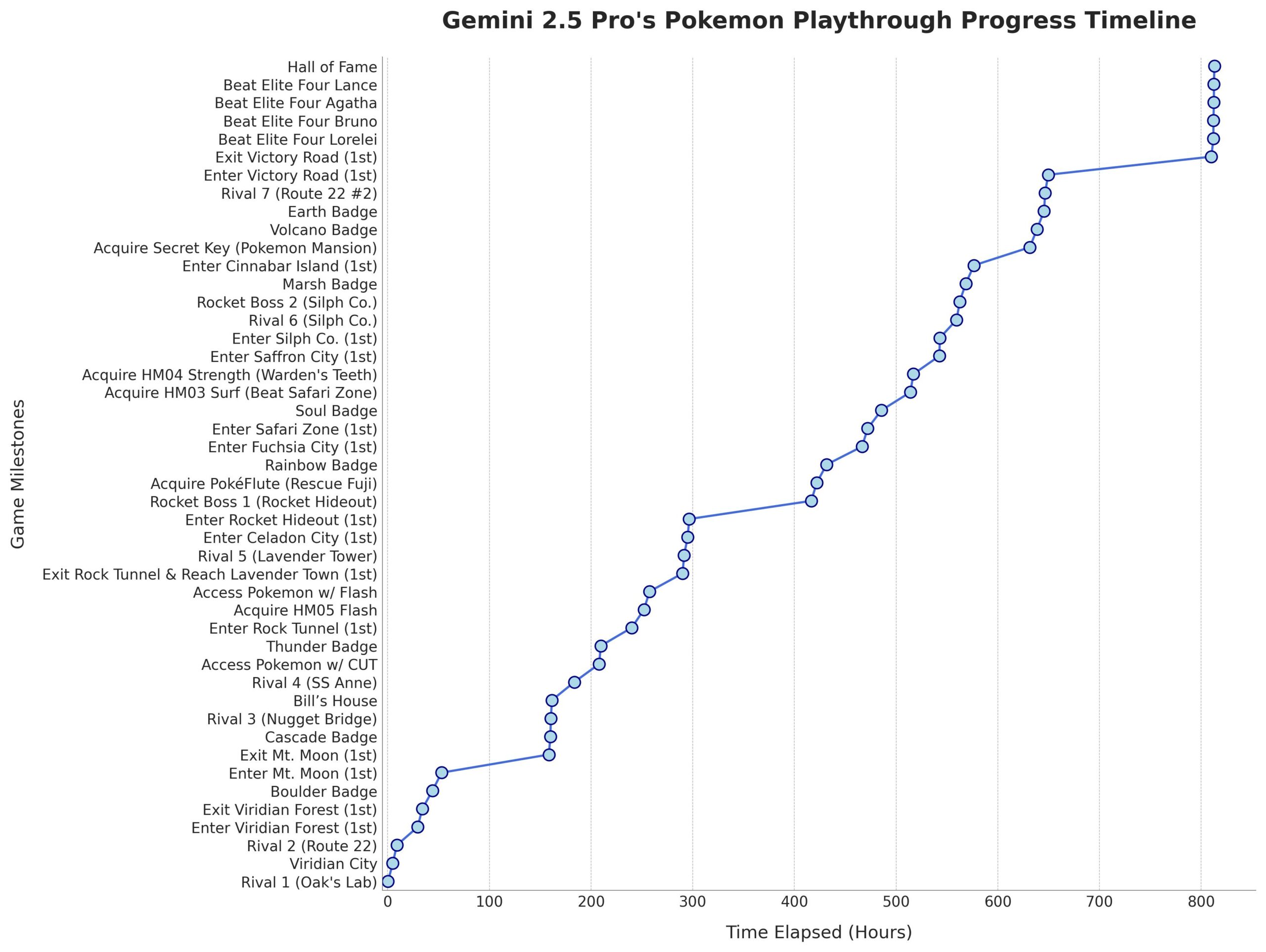
Gemini 2.5 Pro supera con éxito 《Pokémon: Blue》: El modelo de IA Gemini 2.5 Pro de Google completó con éxito el clásico juego 《Pokémon: Blue》, incluyendo la recolección de las 8 medallas y la derrota del Alto Mando de la Liga Pokémon. Este logro fue ejecutado y transmitido en vivo por el streamer @TheCodeOfJoel, y recibió felicitaciones del CEO de Google, Sundar Pichai, y del CEO de DeepMind, Demis Hassabis. Esto demuestra el notable progreso actual de la IA en la planificación de tareas complejas, la formulación de estrategias a largo plazo y la interacción con entornos simulados, superando el rendimiento anterior de la IA en este juego y marcando un nuevo hito en las capacidades de los agentes de IA. (Fuente: Google, jam3scampbell, teortaxesTex, YiTayML, demishassabis, _philschmid, Teknium1, tokenbender)
Apple colabora con Anthropic en el desarrollo de la plataforma de codificación de IA “Vibe Coding”: Según Bloomberg, Apple está colaborando con la startup de IA Anthropic para desarrollar conjuntamente una nueva plataforma de codificación impulsada por IA llamada “Vibe Coding”. Actualmente, la plataforma se está promocionando internamente en Apple para pruebas entre empleados, y existe la posibilidad de que se abra a desarrolladores de terceros en el futuro. Esto marca una mayor exploración de Apple en el campo de las herramientas de asistencia a la programación con IA, con el objetivo de utilizar la IA para mejorar la eficiencia y la experiencia del desarrollador, posiblemente complementando o integrándose con sus propios proyectos como Swift Assist. (Fuente: op7418)
Avances y debates sobre la tecnología robótica impulsada por IA: Recientemente, los robots humanoides y la inteligencia corporeizada han recibido una amplia atención. La empresa Figure mostró su nueva sede de alta tecnología, que abarca desde baterías y actuadores hasta laboratorios de IA, presagiando su ambición en el campo de la robótica. Disney también presentó su tecnología de robots de personajes humanoides. Sin embargo, en la maratón de robots humanoides de Beijing, algunos robots (incluido un Unitree G1 modificado por un cliente) tuvieron un rendimiento deficiente, sufriendo caídas, baja autonomía y problemas de equilibrio, lo que generó un debate sobre las capacidades reales actuales de los robots humanoides y destacó que todavía necesitan un gran progreso tanto en el “cerebelo” (control motor) como en el “cerebro” (toma de decisiones inteligente). (Fuente: adcock_brett, Ronald_vanLoon, 人形机器人,最重要的还是“脑子”)

Se intensifica el debate sobre la ética y el impacto social de la IA: En las redes sociales y en el ámbito de la investigación, aumentan las discusiones sobre el impacto social y las cuestiones éticas de la IA. Por ejemplo, el proyecto de ley de IA SB-1047 de California genera controversia, y documentales relacionados exploran la necesidad y los desafíos de la regulación. La conferencia NAACL 2025 organizó un tutorial sobre “Inteligencia social en la era de los LLM”, explorando los desafíos emergentes y a largo plazo en la interacción de la IA con humanos y la sociedad. Al mismo tiempo, los usuarios expresan preocupación por la calidad del contenido generado por IA (“slop”), argumentando la necesidad de un mejor diseño y control de modelos. Estas discusiones reflejan la creciente preocupación social por las cuestiones éticas, regulatorias y de adaptación social que plantea el rápido desarrollo de la tecnología de IA. (Fuente: teortaxesTex, gneubig, stanfordnlp, jam3scampbell, willdepue, wordgrammer)

🎯 Tendencias
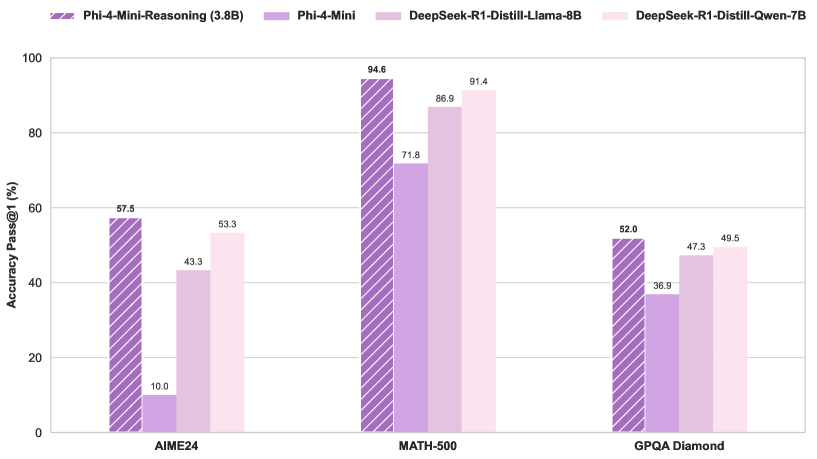
Microsoft lanza el modelo Phi-4-Mini-Reasoning: Microsoft ha publicado el modelo Phi-4-Mini-Reasoning en Hugging Face. Este modelo está diseñado para mejorar las capacidades de razonamiento matemático de los modelos de lenguaje pequeños, impulsando aún más el desarrollo de modelos más pequeños y eficientes. (Fuente: _akhaliq)
El modelo Claude de Anthropic soporta búsqueda web global: Anthropic ha anunciado que su modelo de IA Claude ahora ofrece funciones de búsqueda web a nivel mundial para todos los usuarios de pago. Para tareas simples, Claude realizará una búsqueda rápida; para problemas complejos, explorará múltiples fuentes de información, incluido Google Workspace, mejorando la capacidad del modelo para obtener y procesar información en tiempo real. (Fuente: Teknium1, Reddit r/ClaudeAI)

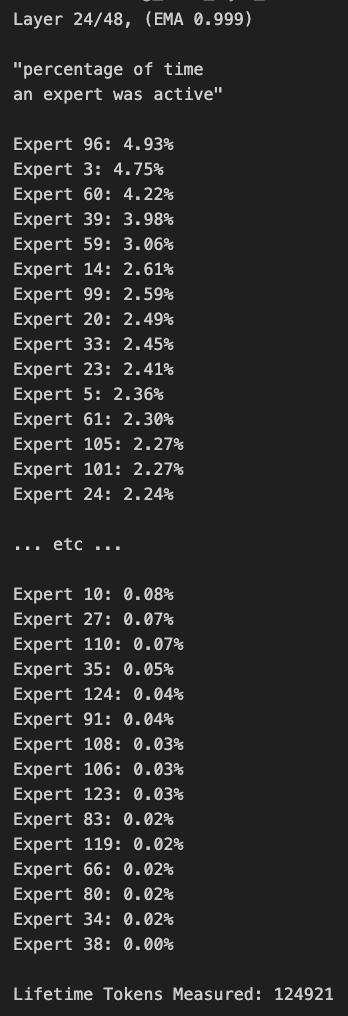
El enrutamiento del modelo Qwen3 MoE presenta sesgos y puede ser podado: El usuario kalomaze analizó y descubrió que la distribución del enrutamiento del modelo Qwen3 MoE (Mezcla de Expertos) presenta un sesgo significativo, e incluso el modelo 30B MoE muestra potencial para la poda. Esto significa que algunos Experts (Expertos) pueden no estar siendo utilizados plenamente, y eliminarlos mediante poda podría reducir el tamaño del modelo y los requisitos computacionales sin afectar significativamente el rendimiento. Kalomaze ya ha publicado una versión basada en este descubrimiento, podando el modelo 30B a 16B, y planea lanzar una versión podada de 235B a 150B. (Fuente: andersonbcdefg, Reddit r/LocalLLaMA)
DeepSeek Prover V2 destaca entre los asistentes matemáticos de código abierto: DeepSeek Prover V2 es considerado actualmente el modelo de asistencia matemática de código abierto con mejor rendimiento. Aunque su rendimiento aún no alcanza al de modelos cerrados o más potentes como Gemini 2.5 Pro, o4 mini high, o3, Claude 3.7 y Grok 3, funciona bien en razonamiento estructurado. Los usuarios consideran que necesita mejorar en las sesiones de “brainstorming” que requieren pensamiento creativo. (Fuente: cognitivecompai)
Discusión sobre preferencias de modelos: Tendencias de los desarrolladores y características específicas de los modelos: El debate sobre las ventajas y desventajas de los diferentes grandes modelos continúa en la comunidad de desarrolladores. Por ejemplo, Sentdex opina que o3 combinado con Codex en Cursor funciona mejor que Claude 3.7. VictorTaelin, por su parte, afirma que aunque Sonnet 3.7 no es perfecto (a veces añade proactivamente contenido no solicitado, el nivel de inteligencia no cumple las expectativas), en la práctica sigue ofreciendo resultados más estables y fiables que GPT-4o (propenso a errores), o3/Gemini (formato de código y reescritura deficientes), R1 (un poco anticuado) y Grok 3 (el segundo mejor, pero ligeramente inferior en la práctica). Esto refleja las diferencias de aplicabilidad de los distintos modelos en tareas y flujos de trabajo específicos. (Fuente: Sentdex, VictorTaelin, paul_cal)

Discusión sobre tendencias de rendimiento de LLM: ¿Crecimiento exponencial o rendimientos decrecientes?: Usuarios de Reddit debaten si los LLM todavía están experimentando mejoras exponenciales. Algunos opinan que, aunque el progreso inicial fue rápido, actualmente la mejora del rendimiento de los LLM tiende a mostrar rendimientos decrecientes, y obtener rendimiento adicional se vuelve cada vez más difícil y costoso, similar al desarrollo de la tecnología de conducción autónoma. Otros usuarios rebaten, señalando que el enorme salto de GPT-3 a Gemini 2.5 Pro indica que el progreso sigue siendo significativo y que es demasiado pronto para afirmar que se ha alcanzado una meseta. La discusión refleja las diferentes expectativas sobre la velocidad futura del desarrollo de la IA. (Fuente: Reddit r/ArtificialInteligence)
Los chips de IA se convierten en clave para el desarrollo de robots humanoides: La opinión de la industria sostiene que el núcleo de los robots humanoides reside en su “cerebro”, es decir, chips de alto rendimiento. El artículo señala que actualmente los robots humanoides aún tienen deficiencias en el control motor (cerebelo) y la toma de decisiones inteligente (cerebro), y el rendimiento del chip determina directamente el nivel de inteligencia del robot. Las GPU de Nvidia, los procesadores Intel, así como chips nacionales como el Huashan A2000 y el Wudang C1236 de Black Sesame Smart, están proporcionando a los robots capacidades más potentes de percepción, razonamiento y control, siendo clave para impulsar a los robots humanoides desde ser un truco publicitario hacia aplicaciones prácticas. (Fuente: 人形机器人,最重要的还是“脑子”)

Ética de la IA y antropomorfismo: ¿Por qué le decimos “gracias” a la IA?: La discusión señala que, aunque la IA no tiene emociones, los usuarios tienden a usar lenguaje cortés con ella (como “gracias”, “por favor”). Esto proviene del instinto humano de antropomorfizar y de la “percepción de presencia social”. La investigación muestra que un estilo de interacción cortés puede guiar a la IA a producir respuestas más acordes a las expectativas y más humanizadas. Sin embargo, esto también conlleva riesgos, como que la IA podría aprender y amplificar los sesgos humanos, o ser guiada maliciosamente para generar contenido inapropiado. El comportamiento cortés hacia la IA refleja la compleja psicología y adaptación social humana al interactuar con máquinas cada vez más inteligentes. (Fuente: 你对 AI 说的每一句「谢谢」,都在烧钱)

🧰 Herramientas
Función Runway Gen-4 References: La función Gen-4 References lanzada por RunwayML permite a los usuarios integrar sus propias imágenes u otras de referencia en vídeos o imágenes generados por IA (como memes). Los comentarios de los usuarios indican que la función tiene un efecto notable, siendo capaz de manejar múltiples personajes consistentes apareciendo en la misma imagen generada, lo que simplifica el proceso de integrar personas o estilos específicos en creaciones de IA. (Fuente: c_valenzuelab)

Krea AI lanza plantillas para generación de imágenes: Krea AI añade una nueva función que convierte prompts comunes de generación de imágenes de GPT-4o en plantillas. Los usuarios solo necesitan subir su propia imagen y seleccionar una plantilla para generar una imagen con el estilo correspondiente, sin necesidad de introducir manualmente prompts complejos, simplificando el flujo de trabajo de generación de imágenes. (Fuente: op7418)
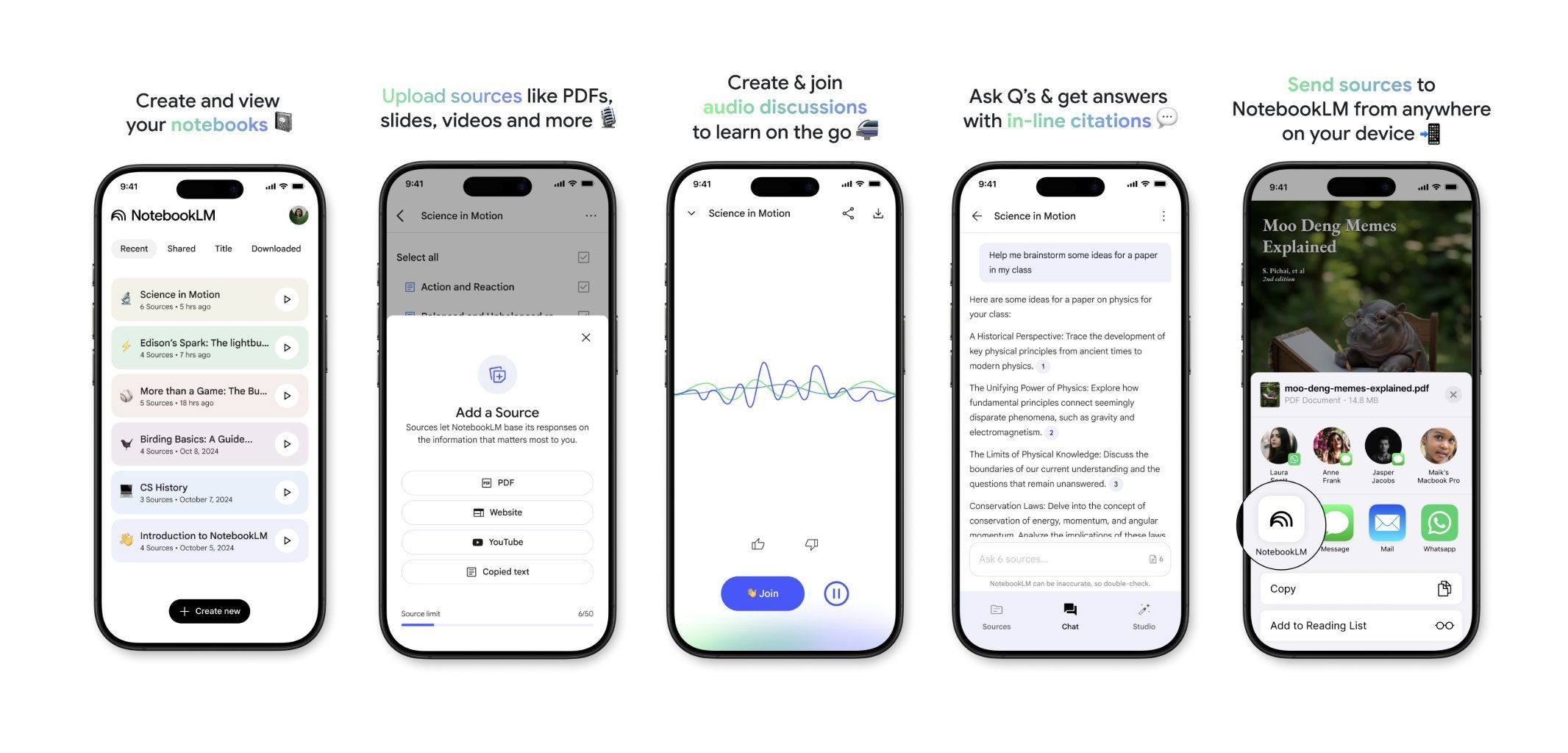
NotebookLM lanzará próximamente una aplicación móvil: NotebookLM de Google (anteriormente Project Tailwind) lanzará próximamente una aplicación móvil. Los usuarios podrán reenviar rápidamente artículos y contenido vistos en sus teléfonos a NotebookLM para su procesamiento e integración. Ya está abierta la lista de espera para la aplicación, con el objetivo de ofrecer una experiencia más conveniente de gestión de información móvil y aprendizaje asistido por IA. (Fuente: op7418)
Runway utilizado para diseño de interiores: Un usuario muestra un caso de uso de Runway AI para diseño de interiores. Proporcionando una imagen del espacio y una imagen de referencia que representa el estilo/ambiente, Runway es capaz de generar representaciones de diseño de interiores que fusionan las características de ambas, demostrando el potencial de aplicación de la IA en el campo del diseño creativo. (Fuente: c_valenzuelab)

Unsloth soporta el ajuste fino de modelos Qwen3: Unsloth anuncia soporte para el ajuste fino de la serie de modelos Qwen3, con una velocidad 2 veces mayor y una reducción del 70% en el uso de VRAM. Los usuarios pueden realizar ajustes finos con una longitud de contexto 8 veces mayor que Flash Attention 2 en una GPU de 24GB de VRAM. Proporciona un notebook de Colab para ajustar finamente el modelo Qwen3 14B de forma gratuita y ha subido varios modelos cuantizados, incluyendo GGUF. Esto reduce la barrera de hardware para el ajuste fino de modelos avanzados. (Fuente: Reddit r/LocalLLaMA)
Función Claude AI Styles: Un usuario comparte el uso de la función Styles de Claude AI para mejorar la experiencia de colaboración con la IA. Creando un estilo llamado “Iterative Engineering”, que establece los pasos de discutir, planificar, modificar en pequeños pasos, probar, iterar y refactorizar según sea necesario, se puede guiar a Claude para codificar de manera más metódica e incremental, evitando que reescriba excesivamente el código y mejorando la utilidad de la IA como compañero de programación. (Fuente: Reddit r/ClaudeAI)
Deepwiki proporciona fuentes para bloques de código: El usuario cto_junior menciona que una ventaja de Deepwiki es que muestra bloques de código fuente junto a cada respuesta, y no solo adjunta enlaces. Esta práctica aumenta la credibilidad de la información, siendo especialmente útil para ingenieros de desarrollo de software (SDEs) escépticos sobre las herramientas de IA. (Fuente: cto_junior)
📚 Aprendizaje
NousResearch publica actualización del framework Atropos RL: El framework de entorno de aprendizaje por refuerzo (RL) Atropos de NousResearch ha sido actualizado. La nueva función permite a los usuarios probar rápida y fácilmente los ‘rollouts’ del entorno RL, sin necesidad de entrenamiento o motor de inferencia. Utiliza la API de OpenAI por defecto, pero se puede configurar para otros proveedores de API (o puntos finales locales VLLM/SGLang). Después de la prueba, genera un informe web que contiene las ‘completions’ y sus puntuaciones, y soporta el registro en wandb, facilitando la depuración y evaluación de entornos RL. (Fuente: Teknium1)

Publicado EnronQA, conjunto de datos de referencia para RAG personalizado: Investigadores han publicado el conjunto de datos EnronQA, diseñado para impulsar la investigación sobre la generación aumentada por recuperación personalizada (Personalized RAG) en documentos privados. El conjunto de datos contiene 103,638 correos electrónicos y 528,304 pares de preguntas y respuestas de alta calidad para 150 usuarios, proporcionando un recurso para evaluar y desarrollar sistemas RAG que puedan comprender y utilizar información específica del individuo. (Fuente: lateinteraction)
Lanzamiento de GTE-ModernColBERT (PyLate): LightOnAI ha lanzado GTE-ModernColBERT (PyLate), un recuperador MaxSim de 128 dimensiones, basado en gte-modernbert-base y ajustado finamente sobre ms-marco-en-bge-gemma. Soporta nativamente la biblioteca PyLate, permitiendo reordenamiento e indexación HNSW. Muestra un rendimiento excelente en el benchmark NanoBEIR y supera a ColBERT-small en la puntuación media de BEIR, ofreciendo una nueva opción eficiente para la recuperación de texto. (Fuente: lateinteraction)

SOLO Bench – Nuevo benchmark para LLM: El usuario jd_3d ha desarrollado y publicado SOLO Bench, un nuevo método de benchmark para LLM. La prueba requiere que el LLM genere texto que contenga un número específico (por ejemplo, 250 o 500) de oraciones, donde cada oración debe contener única y exclusivamente una palabra de una lista predefinida (que incluye sustantivos, verbos, adjetivos, etc.), y cada palabra solo puede usarse una vez. Evaluado mediante un script basado en reglas, está diseñado para probar el seguimiento de instrucciones, la satisfacción de restricciones y la capacidad de generación de texto largo de los LLM. Los resultados preliminares muestran que el benchmark puede diferenciar eficazmente el rendimiento de diferentes modelos. (Fuente: Reddit r/LocalLLaMA)
Manipulación del espacio latente mediante reflexión recursiva estratégica: Un usuario propone un método para crear jerarquías de razonamiento anidadas en el espacio latente de los LLM mediante la “reflexión recursiva estratégica” (Strategic recursive reflection, RR). Indicando al modelo en momentos clave que reflexione sobre interacciones previas, se generan bucles metacognitivos, construyendo “mini espacios latentes”. Cada prompt se considera una presión que guía la ruta del modelo en el espacio latente, haciéndolo más autorreferencial y capaz de abstracción. Se considera que esto simula el proceso humano de profundizar el pensamiento mediante la reflexión sobre las ideas, con el objetivo de explorar conceptos más profundos. (Fuente: Reddit r/ArtificialInteligence)
💼 Negocios
Google paga a Samsung para preinstalar Gemini AI: Después de ser declarado culpable de violar las leyes antimonopolio el año pasado por su acuerdo de motor de búsqueda predeterminado, se revela que Google paga mensualmente a Samsung “enormes sumas de dinero” y un porcentaje de los ingresos para preinstalar Gemini AI en los dispositivos Samsung, y podría requerir a los socios que preinstalen obligatoriamente Gemini. Esto explica por qué la serie Samsung Galaxy S25 integra profundamente Gemini, incluso estableciéndolo como el asistente de IA predeterminado. Esta medida refleja la estrategia de Google, ante la insuficiencia de sus propios canales de hardware, de apresurarse a capturar la entrada de IA en el sector móvil, pero también podría volver a suscitar preocupaciones antimonopolio. (Fuente: 三星手机预装Gemini AI,也是谷歌花钱买的)

Las startups de IA enfrentan desafíos: Una discusión en Reddit señala que muchas startups de IA pueden carecer de una ventaja competitiva sostenible (“foso”), porque las capacidades de los modelos tienden a converger y la lealtad del usuario es baja. Las grandes tecnológicas (Google, Microsoft, Apple), con la ventaja de su ecosistema (como la preinstalación, la integración), llegan más fácilmente a los usuarios. Incluso si el modelo de una startup es ligeramente mejor, los usuarios pueden preferir usar la IA predeterminada o integrada que es “suficientemente buena”. Esto genera preocupaciones sobre la viabilidad a largo plazo de las startups de IA y las perspectivas de inversión de VC. (Fuente: Reddit r/ArtificialInteligence)
Resumen de financiación y noticias empresariales de IA de esta semana (2 de mayo de 2025): CEO de Microsoft revela que la IA ya escribe “partes importantes” del código de la empresa; CFO de Microsoft advierte que los servicios de IA podrían interrumpirse debido a la alta demanda; Google comienza a mostrar anuncios en chatbots de IA de terceros; Meta lanza aplicación de IA independiente; Cast AI recauda $108M, Astronomer recauda $93M, Edgerunner AI recauda $12M; Investigación acusa a LM Arena de manipulación en sus benchmarks; Nvidia desafía el apoyo de Anthropic a los controles de exportación de chips. (Fuente: Reddit r/artificial)
🌟 Comunidad
Discusión sobre la calidad y el coste del contenido generado por IA (“slop”): La comunidad expresa preocupación por la calidad desigual del contenido generado por IA (denominado “slop”). El usuario wordgrammer señala la baja calidad de muchos vídeos generados por IA y que el coste real (considerando el filtrado y los reintentos) es mucho mayor que el precio anunciado. Esto genera debate sobre el diseño de modelos (citando la opinión de Steve Jobs por jam3scampbell) y el uso eficaz de las herramientas de IA, enfatizando la necesidad de un control más fino y estándares de calidad de generación más altos. (Fuente: wordgrammer, jam3scampbell, willdepue)
El rendimiento de la IA en tareas específicas genera debate: Miembros de la comunidad discuten el rendimiento y las limitaciones de la IA en diferentes tareas. Por ejemplo, se considera que DeepSeek R1 podría ser un pico en el ‘hype’ de los LLM; aunque hay avances en áreas como matemáticas formales y medicina, aún no ha captado la atención generalizada de los usuarios comunes. DeepSeek Prover V2 funciona bien en matemáticas, pero se considera que carece de creatividad. El usuario vikhyatk cuestiona el sentido de optimizar excesivamente los modelos para rendir en benchmarks específicos como AIME (American Invitational Mathematics Examination), argumentando que al público general no le importan las habilidades matemáticas. Estas discusiones reflejan la reflexión sobre los límites de la capacidad de la IA y su valor práctico. (Fuente: wordgrammer, cognitivecompai, vikhyatk)
Creatividad y diseño asistidos por IA: La comunidad muestra diversas formas de usar herramientas de IA para el diseño creativo. Usuarios utilizan la función Gen-4 References de Runway para integrarse en memes; usan Runway para generar conceptos de diseño de interiores; utilizan GPT-4o y plantillas de prompts para crear imágenes con estilos específicos (como un tigre de Amur de origami, reposamuñecas de silicona con forma de animal, integrar el significado de palabras en el diseño de letras). Estos casos demuestran el potencial de la IA en la creatividad visual y el diseño personalizado. (Fuente: c_valenzuelab, c_valenzuelab, dotey, dotey, dotey)

Cuestionamiento sobre la capacidad de la IA para imitar estilos de escritura: El usuario nrehiew_ opina que la instrucción de “continuar escribiendo en mi tono y estilo” a un LLM podría no tener un efecto real, porque la mayoría de la gente sobreestima la singularidad de su propio estilo de escritura. Esto genera debate sobre la capacidad de los LLM para comprender y replicar estilos de escritura sutiles, así como sobre el sesgo de percepción de los usuarios respecto a esta capacidad. (Fuente: nrehiew_)
El uso de IA para apoyo emocional genera empatía y debate: Usuarios de Reddit comparten experiencias de obtener apoyo emocional e incluso ayuda para afrontar crisis hablando con IA como ChatGPT. Muchos afirman que en momentos de soledad, necesidad de desahogarse o dificultades psicológicas, la IA ofrece un interlocutor sin prejuicios, paciente y siempre disponible, a veces incluso sintiéndose más eficaz que hablar con humanos reales. Esto genera debate sobre el papel de la IA en el apoyo a la salud mental, al mismo tiempo que se enfatiza que la IA no puede reemplazar la ayuda humana profesional y la necesidad de estar alerta ante los posibles sesgos o desinformación que la IA pueda generar. (Fuente: Reddit r/ChatGPT, Reddit r/ClaudeAI)
Divergencia de opiniones sobre el arte generado por IA: Usuarios discuten el impacto potencial del arte generado por IA en la percepción de los artistas humanos y sus obras. Algunos se quejan de que las obras de alta calidad ahora a menudo se atribuyen fácilmente a la generación por IA, ignorando el talento y el esfuerzo del creador. Este fenómeno incluso empieza a distorsionar la percepción de las personas, haciendo que la gente tienda a buscar “errores humanos” en las obras para confirmar que no son creaciones de IA. El debate también aborda si se debería exigir obligatoriamente que el contenido generado por IA lleve marca de agua. (Fuente: Reddit r/ArtificialInteligence)
💡 Otros
El consumo de recursos de la IA atrae atención: El debate subraya el enorme consumo de recursos detrás del desarrollo de la IA. Entrenar y operar grandes modelos de IA consume grandes cantidades de electricidad y agua, y los centros de datos se convierten en nuevas instalaciones de alto consumo energético. Cada interacción del usuario con la IA, incluido un simple “gracias”, acumula consumo de energía. Esto genera preocupación por el desarrollo sostenible de la IA y la atención a soluciones energéticas (como la fusión nuclear). (Fuente: 你对 AI 说的每一句「谢谢」,都在烧钱)
La distancia entre la IA y la conciencia: Usuarios de Reddit debaten si la IA actual posee autoconciencia. La opinión general es que la IA actual (como los LLM) es esencialmente un complejo sistema de coincidencia de patrones basado en la predicción probabilística de palabras, que carece de comprensión real y autoconciencia, y está muy lejos de poseer dicha capacidad. Pero también hay comentarios que señalan que la propia conciencia humana no se comprende completamente, que la comparación podría ser errónea, y que no se deben ignorar las capacidades sobrehumanas de la IA en tareas específicas. (Fuente: Reddit r/ArtificialInteligence)
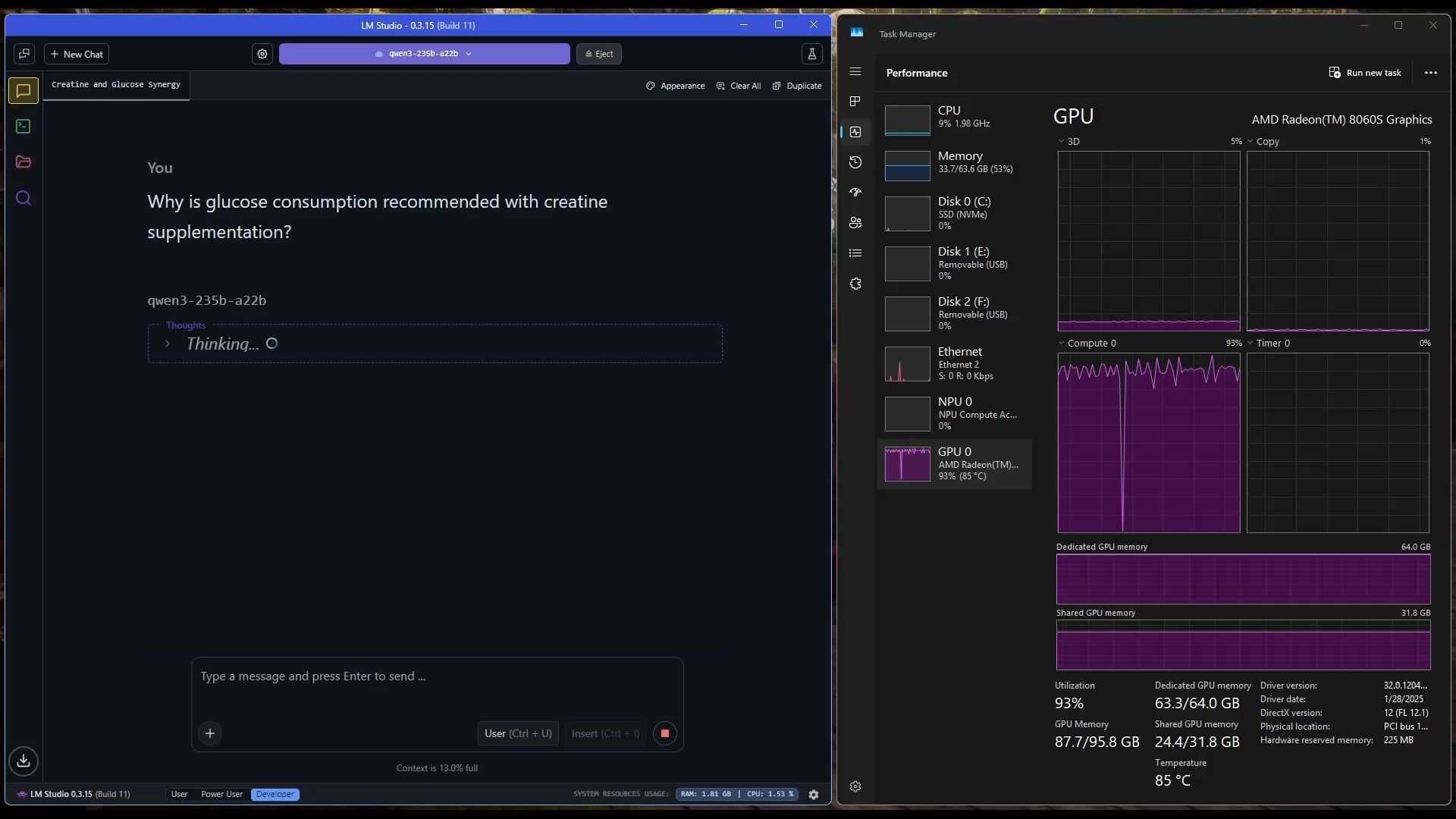
Tablet Windows ejecutando un gran modelo MoE: Un usuario muestra un ejemplo de ejecución del modelo Qwen3 235B-A22B MoE (usando cuantización Q2_K_XL) en una tablet Windows equipada con AMD Ryzen AI Max 395+ y 128GB de RAM, utilizando solo la iGPU (Radeon 8060S, asignando 87.7GB de los 95.8GB disponibles como VRAM), alcanzando una velocidad de aproximadamente 11.1 t/s. Esto demuestra la posibilidad de ejecutar modelos extremadamente grandes en dispositivos portátiles, aunque el ancho de banda de la memoria sigue siendo un cuello de botella. (Fuente: Reddit r/LocalLLaMA)