
Palabras clave:ChatBot Arena, Phi-4-reasoning, Claude Integrations, DeepSeek-Prover-V2, Qwen3, Gemini, Parakeet-TDT-0.6B-v2, Agente de IA inteligente, Alucinación de ranking, Capacidad de razonamiento de modelos pequeños, Integración de aplicaciones de terceros, Agente de programación de IA, Demostración de teoremas matemáticos
🔥 En Foco
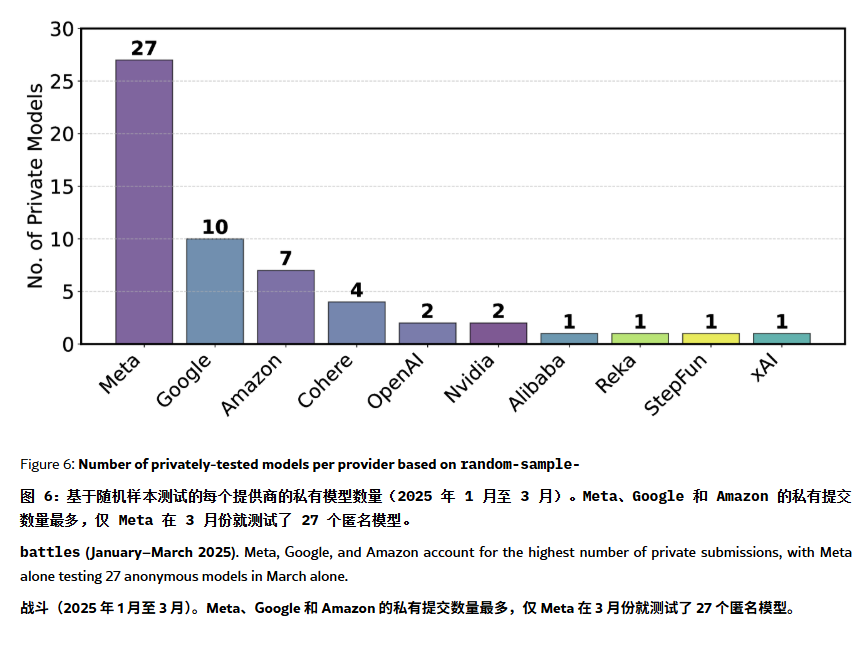
Se acusa al ranking de ChatBot Arena de “alucinaciones” y manipulación: Un artículo en ArXiv [2504.20879] cuestiona el ampliamente citado ranking de modelos de ChatBot Arena, argumentando que sufre de “alucinación de ranking”. El artículo señala que las grandes empresas tecnológicas (como Meta) podrían manipular el ranking enviando numerosas variantes de modelos con ajuste fino (p. ej., 27 probadas para Llama-4) y publicando solo los mejores resultados; la frecuencia de exhibición de modelos también podría favorecer a los modelos de grandes empresas, reduciendo las oportunidades de exposición para los modelos open source; el mecanismo de eliminación de modelos carece de transparencia, y numerosos modelos open source son retirados con datos de prueba insuficientes; además, la similitud de las preguntas frecuentes de los usuarios podría llevar a que los modelos se sobreajusten específicamente en el entrenamiento para mejorar sus puntuaciones. Esto genera preocupaciones sobre la fiabilidad y la imparcialidad de los benchmarks de LLM actuales, recomendando a desarrolladores y usuarios que consideren los rankings con cautela y evalúen la construcción de sistemas de evaluación adaptados a sus propias necesidades. (Fuente: karminski3, op7418, TheRundownAI)
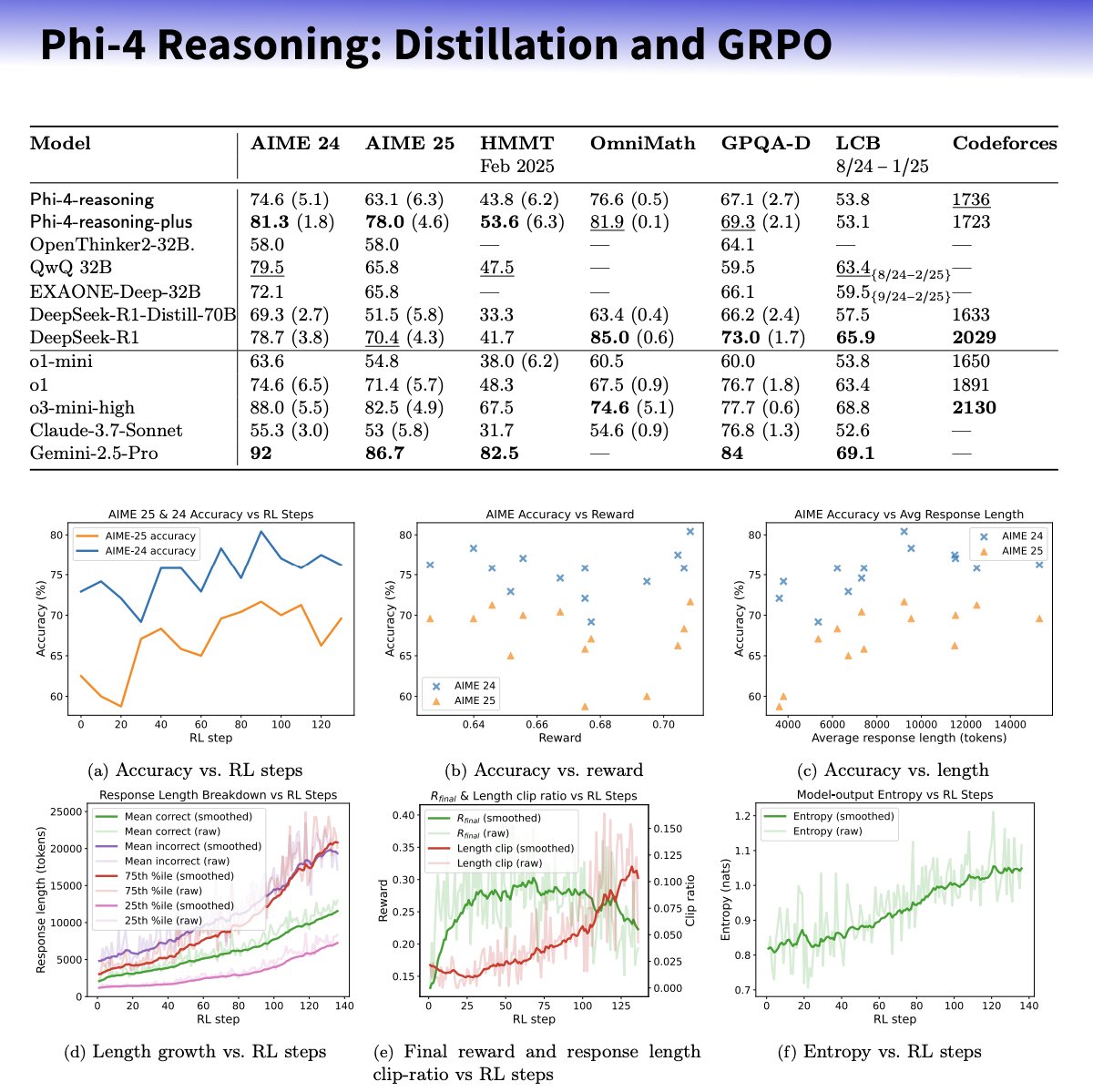
Microsoft lanza la serie de modelos pequeños Phi-4-reasoning, enfocados en mejorar la capacidad de razonamiento: Microsoft ha presentado los modelos Phi-4-reasoning y Phi-4-reasoning-plus, basados en la arquitectura Phi-4, con el objetivo de mejorar las capacidades de razonamiento de los modelos de lenguaje pequeños mediante datasets cuidadosamente seleccionados, ajuste fino supervisado (SFT) y aprendizaje por refuerzo (RL) dirigido. Según se informa, estos modelos utilizan OpenAI o3-mini como “profesor” para generar trayectorias de razonamiento de cadena de pensamiento (CoT) de alta calidad y se optimizan mediante el algoritmo GRPO para el aprendizaje por refuerzo. El investigador de Microsoft Sebastien Bubeck afirma que Phi-4-reasoning supera a DeepSeek R1 en capacidad matemática, aunque su tamaño es solo el 2% del de este último. La serie utiliza tokens de razonamiento especializados y una longitud de contexto ampliada de 32K. Se considera que esta iniciativa explora la dirección de modelos más pequeños y especializados, que podrían ofrecer soluciones de razonamiento más potentes para escenarios con recursos limitados, aunque también ha suscitado debates sobre si utiliza tecnología de OpenAI y se publica bajo licencia MIT. (Fuente: _philschmid, TheRundownAI, Reddit r/LocalLLaMA)
Anthropic lanza la función Integrations y amplía las capacidades de investigación: Anthropic ha anunciado el lanzamiento de Claude Integrations, que permite a los usuarios conectar Claude con 10 aplicaciones y servicios de terceros como Jira, Confluence, Zapier, Cloudflare, Asana, y próximamente también con Stripe, GitLab, entre otros. El soporte para MCP (Model Context Protocol), anteriormente limitado a servidores locales, se extiende a servidores remotos, permitiendo a los desarrolladores crear sus propias integraciones en aproximadamente 30 minutos a través de la documentación o soluciones como Cloudflare. Al mismo tiempo, se ha mejorado la función de Investigación (Research) de Claude, añadiendo un modo avanzado que puede buscar en la web, Google Workspace y las Integrations conectadas, descomponer solicitudes complejas para investigar y generar informes completos con citas, lo que puede llevar hasta 45 minutos. La función de búsqueda web también está disponible para usuarios de pago a nivel mundial. Estas actualizaciones tienen como objetivo mejorar la integración y la capacidad de investigación profunda de Claude como asistente de trabajo. (Fuente: _philschmid, Reddit r/ClaudeAI)

La capacidad de los agentes de IA sigue una nueva Ley de Moore: se duplica cada 4 meses: Una investigación de AI Digest señala que la capacidad de los agentes de IA para completar tareas de programación está experimentando un crecimiento exponencial. El tiempo que tardan en procesar tareas (medido en tiempo requerido por un experto humano) se duplica aproximadamente cada 4 meses en el período 2024-2025, más rápido que la duplicación cada 7 meses observada entre 2019-2025. Los agentes de IA más avanzados actualmente pueden manejar tareas de programación que requerirían 1 hora a un humano. Si esta tendencia acelerada continúa, se espera que para 2027 los agentes de IA puedan completar tareas complejas de hasta 167 horas (aproximadamente un mes). Este rápido aumento de la capacidad se debe a los avances en los propios modelos y a la mejora de la eficiencia algorítmica, y podría formar un ciclo de retroalimentación positiva de crecimiento superexponencial debido a la IA que asiste a la investigación y desarrollo de IA. Esto presagia la posibilidad de una “explosión de inteligencia de software”, que transformará profundamente campos como el desarrollo de software y la investigación científica, al tiempo que plantea desafíos sociales como el impacto de la automatización en el mercado laboral. (Fuente: Xinzhiyuan)

🎯 Movimientos
Lanzamiento de DeepSeek-Prover-V2, mejora la capacidad de demostración de teoremas matemáticos: DeepSeek AI ha lanzado DeepSeek-Prover-V2, disponible en tamaños de 7B y 671B, enfocado en la demostración formal de teoremas en Lean 4. El modelo utiliza búsqueda recursiva de pruebas y aprendizaje por refuerzo (GRPO) para su entrenamiento, aprovechando DeepSeek-V3 para descomponer teoremas complejos y generar borradores de pruebas, combinados con iteración experta y datos sintéticos de arranque en frío para el ajuste fino y el aprendizaje por refuerzo. DeepSeek-Prover-V2-671B alcanza una tasa de aprobación del 88.9% en MiniF2F-test y resuelve 49 problemas en PutnamBench, demostrando un rendimiento SOTA. También se ha publicado el benchmark ProverBench, que incluye problemas de AIME y de libros de texto. El modelo tiene como objetivo unificar el razonamiento informal con la demostración formal, impulsando el desarrollo de la demostración automática de teoremas. (Fuente: Xinzhiyuan)

Nvidia y UIUC proponen un nuevo método para extender el contexto a 4 millones de tokens: Investigadores de Nvidia y la Universidad de Illinois Urbana-Champaign (UIUC) han propuesto un método de entrenamiento eficiente que puede extender la ventana de contexto de Llama 3.1-8B-Instruct de 128K a 1M, 2M e incluso 4M de tokens. El método utiliza una estrategia de dos etapas: preentrenamiento continuo y ajuste fino de instrucciones. Las técnicas clave incluyen el uso de separadores de documentos especiales, extensión de codificación posicional basada en YaRN y preentrenamiento en un solo paso. El modelo resultante, UltraLong-8B, muestra un rendimiento excelente en benchmarks de contexto largo como RULER, LV-Eval e InfiniteBench, y mantiene o incluso supera el rendimiento del Llama 3.1 base en tareas estándar de contexto corto como MMLU y MATH, superando a otros modelos de contexto largo como ProLong y Gradient. Esta investigación proporciona una vía eficiente y escalable para construir LLMs con contexto ultralargo. (Fuente: Xinzhiyuan)

Lanzamiento de Qwen3, con mejoras significativas de rendimiento: Alibaba ha lanzado la serie de modelos Qwen3, incluyendo Qwen3-30B-A3B, entre otros. Según pruebas preliminares de usuarios de Reddit y datos de benchmarks (como AHA Leaderboard), Qwen3 muestra un mejor rendimiento en comparación con las versiones anteriores Qwen2.5 y QwQ en múltiples dimensiones (como conocimientos específicos en salud, Bitcoin, Nostr, etc.). Los comentarios de los usuarios indican que Qwen3 demuestra una gran capacidad en el manejo de tareas específicas (como simular la dinámica del sistema solar), aplicando correctamente las leyes físicas para generar órbitas elípticas y períodos relativos. Sin embargo, algunos usuarios señalan que el rendimiento de Qwen3 disminuye notablemente en contextos largos (cercanos a 16K) y consume muchos tokens durante la inferencia, sugiriendo usarlo en combinación con herramientas de búsqueda. La nomenclatura de Qwen3 (como Qwen3-30B-A3B) también ha sido elogiada por su claridad. (Fuente: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, karminski3, madiator)
Gemini pronto integrará datos de la cuenta de Google para ofrecer una experiencia personalizada: Google planea permitir que el asistente de IA Gemini acceda a los datos de la cuenta de Google del usuario, incluyendo Gmail, Fotos, historial de YouTube, etc., con el objetivo de proporcionar una experiencia de asistencia más personalizada, proactiva y potente. Josh Woodward, jefe de producto de Google, afirmó que esto es para que Gemini entienda mejor al usuario y se convierta en una extensión de él. La función será opcional (opt-in), y los usuarios podrán elegir si habilitan el acceso a los datos. Esta medida ha generado debates sobre la privacidad y la seguridad de los datos, y los usuarios deberán sopesar la conveniencia de la personalización frente a la privacidad de sus datos. (Fuente: JeffDean, Reddit r/ArtificialInteligence)

Nvidia lanza el modelo ASR Parakeet-TDT-0.6B-v2: Nvidia ha lanzado un nuevo modelo de reconocimiento automático de voz (ASR), Parakeet-TDT-0.6B-v2, con 600 millones de parámetros. Según se informa, este modelo supera a Whisper3-large (1.6 mil millones de parámetros) en el Open ASR Leaderboard, especialmente en el manejo de datasets diversos (incluyendo LibriSpeech, Fisher Corpus, datos de YouTube, etc., aproximadamente 120,000 horas de datos). El modelo admite marcas de tiempo a nivel de carácter, palabra y párrafo, pero actualmente solo soporta inglés y requiere GPU de Nvidia y frameworks específicos para funcionar. Los comentarios iniciales de los usuarios elogian su alta precisión en la transcripción y la puntuación. (Fuente: Reddit r/LocalLLaMA)

Lanzamiento de Qwen2.5-VL, mejora la comprensión visual del lenguaje: Alibaba ha lanzado la serie de modelos multimodales Qwen2.5-VL (incluyendo parámetros de 3B, 7B, 72B), con el objetivo de mejorar la comprensión e interacción de las máquinas con el mundo visual. Estos modelos pueden utilizarse para resumir imágenes, responder preguntas visuales, generar informes a partir de información visual compleja, etc. El artículo presenta su arquitectura, rendimiento en benchmarks y detalles de inferencia, mostrando sus avances en la comprensión visual del lenguaje. (Fuente: Reddit r/deeplearning)

El soporte para Mistral Small 3.1 Vision se ha fusionado en llama.cpp: El proyecto llama.cpp ha fusionado el soporte para el modelo Mistral Small 3.1 Vision (24B parámetros). Esto significa que los usuarios podrán ejecutar este modelo multimodal en el framework llama.cpp para tareas como la comprensión de imágenes. Unsloth ya ha proporcionado los archivos del modelo en formato GGUF correspondientes. Esto facilita la ejecución local de los modelos visuales de Mistral. (Fuente: Reddit r/LocalLLaMA)
Meta lanza Synthetic Data Kit: Meta ha hecho open source una herramienta de línea de comandos llamada Synthetic Data Kit, diseñada para simplificar la fase de preparación de datos necesaria para el ajuste fino de LLMs. La herramienta ofrece cuatro comandos: ingest (importar datos), create (generar pares de QA, opcionalmente con cadena de inferencia), curate (usar Llama como juez para seleccionar muestras de alta calidad) y save-as (exportar a formatos compatibles). Utiliza LLMs locales (a través de vLLM) para generar datos de entrenamiento sintéticos de alta calidad, especialmente adecuados para desbloquear capacidades de razonamiento en tareas específicas para modelos como Llama-3. (Fuente: Reddit r/MachineLearning)
GTE-ModernColBERT-v1 se convierte en un modelo de embedding popular: El modelo GTE-ModernColBERT-v1, lanzado por LightOnIO, se ha convertido en el nuevo modelo de búsqueda/embedding de tendencia en Hugging Face. Este modelo utiliza un método de búsqueda multi-vector (también conocido como interacción tardía o ColBERT), ofreciendo una nueva opción para los desarrolladores interesados en este tipo de tecnología. (Fuente: lateinteraction)
Actualización del algoritmo de recomendación de X: La plataforma X (anteriormente Twitter) ha corregido su algoritmo de recomendación para abordar problemas de larga data como la no incorporación de comentarios negativos de los usuarios, la visualización repetida del mismo contenido y las recomendaciones irrelevantes del algoritmo SimCluster. Se informa que los comentarios iniciales son positivos. (Fuente: TheGregYang)
Wikipedia anuncia una nueva estrategia de IA para ayudar a los editores humanos: Wikipedia ha anunciado su nueva estrategia de inteligencia artificial, destinada a utilizar herramientas de IA para apoyar y mejorar el trabajo de los editores humanos, en lugar de reemplazarlos. Los detalles específicos no se detallan en la fuente, pero indica que la enciclopedia en línea más grande del mundo está explorando cómo integrar la tecnología de IA en sus procesos de creación y mantenimiento de contenido. (Fuente: Reddit r/artificial)
🧰 Herramientas
Midjourney lanza la función Omni-Reference: Midjourney ha lanzado la nueva función Omni-Reference (oref), que permite a los usuarios guiar la generación de imágenes proporcionando URLs de imágenes de referencia (usando el parámetro –oref) para lograr consistencia en personajes, objetos, vehículos o criaturas no humanas. Los usuarios pueden controlar el peso de la influencia de la imagen de referencia con el parámetro –ow; pesos más bajos son adecuados para estilización, mientras que pesos más altos son para realismo o coincidencia facial precisa. La función tiene como objetivo mejorar la consistencia y controlabilidad de elementos específicos en las imágenes generadas. (Fuente: op7418, DavidSHolz)

Runway Gen-4 References logra personalización con una sola imagen: El modelo Gen-4 de Runway ha lanzado la función References (referencia), donde los usuarios solo necesitan proporcionar una imagen de referencia para aplicar el estilo o las características del personaje de la imagen al nuevo contenido generado. Las demostraciones muestran que la función puede recrear fácilmente retratos de personas con el estilo de la imagen de referencia o situarlos en el mundo representado por la imagen de referencia, demostrando la capacidad del modelo para lograr una alta consistencia y calidad estética en la generación personalizada con solo una imagen de referencia. (Fuente: c_valenzuelab, c_valenzuelab)

El bot de WhatsApp de Perplexity restablece su servicio: El chatbot de WhatsApp de Perplexity AI, que estuvo brevemente fuera de línea debido a una demanda que superó con creces las expectativas, ha restablecido su servicio. Los usuarios pueden interactuar con él a través del número de teléfono +1 (833) 436-3285, pudiendo reenviar mensajes para verificación de hechos, hacer preguntas directas para obtener respuestas, mantener conversaciones de texto de forma libre y crear imágenes. (Fuente: AravSrinivas, AravSrinivas)
Krea AI combina el modelo de imagen 4o para un control preciso de la imagen: La herramienta creativa de IA Krea AI ha añadido una nueva función que permite a los usuarios combinar las capacidades del modelo de imagen 4o de OpenAI para controlar con mayor precisión el contenido y el estilo de las imágenes generadas mediante collage de imágenes y garabatos. Esto demuestra la continua innovación de Krea en la generación interactiva de imágenes, permitiendo a los usuarios guiar la creación de IA de manera más intuitiva y detallada. (Fuente: op7418)
Servidor todo en uno Xingyun Heyi: Ejecuta DeepSeek completo a bajo costo: Xingyun Integrated Circuits, con antecedentes en Tsinghua, ha lanzado el servidor todo en uno Heyi AI, que afirma poder ejecutar el modelo DeepSeek-R1/V3 671B con precisión FP8 sin cuantificar a más de 20 tokens/s, con soporte para contexto de 128K, a un precio de 149,000 yuanes. La solución utiliza CPU AMD EPYC de doble socket y memoria de alta capacidad y frecuencia, complementada con una pequeña cantidad de aceleración GPU, con el objetivo de reducir drásticamente el costo de hardware para la implementación privada de modelos grandes a través de una arquitectura CPU+memoria, ofreciendo una experiencia localizada cercana al rendimiento oficial, adecuada para escenarios empresariales sensibles al costo que requieren alta precisión. (Fuente: Xinzhiyuan)

Próximo lanzamiento de la aplicación NotebookLM: La aplicación de notas con IA de Google, NotebookLM, lanzará próximamente aplicaciones oficiales para iOS y Android, previstas para el 20 de mayo, con pre-registro ya disponible. Esto llevará las funciones de NotebookLM de proporcionar resúmenes, respuestas a preguntas y generación creativa basadas en las notas y documentos del usuario a los dispositivos móviles. (Fuente: zacharynado)
Granola lanza aplicación iOS para actas de reuniones en tiempo real con IA: La aplicación de notas con IA Granola ha lanzado su versión para iOS, extendiendo su funcionalidad original de notas de IA para reuniones de Zoom a conversaciones cara a cara fuera de línea. Los usuarios pueden usar Granola en su iPhone para grabar y transcribir conversaciones, y utilizar la IA para generar resúmenes y notas, facilitando la revisión y organización posterior. (Fuente: amasad)
Grok Studio admite el procesamiento de PDF: El asistente de IA Grok ha añadido la capacidad de procesar archivos PDF en su función Studio. Los usuarios ahora pueden manejar y analizar documentos PDF de manera más conveniente dentro de Grok Studio. Los detalles específicos de la función no se han detallado, pero marca una expansión en las capacidades de Grok para comprender e interactuar con documentos de múltiples formatos. (Fuente: grok, TheGregYang)
Nuevo modelo de Suno muestra una excelente capacidad de generación musical: La plataforma de generación de música por IA Suno ha lanzado un nuevo modelo, y los comentarios de los usuarios indican que sus resultados son “muy sobresalientes”. Un usuario intentó usarlo para generar una canción estilo concierto en vivo; aunque no logró completamente el efecto de respuesta deseado, la música generada funcionó bien en términos de ambiente de multitud, demostrando el progreso del nuevo modelo en calidad musical y diversidad de estilos. (Fuente: nptacek, nptacek)
Aplicación Frog Spot asistida por IA para identificar cantos de ranas: Un desarrollador ha creado una aplicación gratuita llamada Frog Spot que utiliza un modelo CNN autoentrenado (TensorFlow Lite) para identificar diferentes tipos de cantos de ranas analizando el espectrograma de 10 segundos de audio. La aplicación tiene como objetivo ayudar al público a conocer las especies locales y también demuestra el potencial de aplicación del deep learning en el monitoreo bioacústico y la ciencia ciudadana. (Fuente: Reddit r/deeplearning)
Automatización de dibujos técnicos industriales asistida por IA: Un artículo de IAAI 2025 presenta un método para automatizar la expansión de “Instrument Typicals” en diagramas de tuberías e instrumentación (P&ID). El método combina modelos de visión por computadora (detección y reconocimiento de texto) y reglas específicas del dominio para extraer automáticamente información de los dibujos P&ID y las tablas de leyenda, expandiendo los símbolos simplificados de Instrument Typicals en listas detalladas de instrumentos, generando un índice de instrumentos preciso. Esto tiene como objetivo mejorar la eficiencia en proyectos de ingeniería (especialmente en la fase de licitación) y reducir errores manuales. (Fuente: aihub.org)

Uso de Sora para generar un paisaje en miniatura de pato prensado en salsa de soja: Un usuario compartió imágenes de un “pato prensado en salsa de soja en paisaje en miniatura” generadas por Sora a partir de un prompt detallado. El prompt describía meticulosamente el estilo de la escena (fotografía macro, paisaje en miniatura), el sujeto principal (edificios de puestos hechos de pato prensado), detalles (piel de color rojo salsa de soja, chiles y sésamo, chef cortando, comensales), el entorno (calles hechas de salsa de pato, paredes estilo marinado, farolillos rojos, etc.). Esto demuestra la capacidad de Sora para comprender descripciones textuales complejas e imaginativas y generar imágenes de alta calidad correspondientes. (Fuente: dotey)

Creación de GPTs de pronóstico del tiempo en 3D: Un usuario compartió una aplicación ChatGPTs casera llamada “Weather 3D”, que puede obtener datos meteorológicos en tiempo real llamando a una API meteorológica basada en el nombre de la ciudad ingresado por el usuario, y generar una ilustración estilo modelo en miniatura isométrico 3D del edificio emblemático de esa ciudad, incorporando al mismo tiempo las condiciones meteorológicas actuales. La parte superior de la ilustración muestra el nombre de la ciudad, las condiciones meteorológicas, la temperatura y un icono del tiempo. Este GPTs demuestra cómo combinar llamadas a API y capacidades de generación de imágenes para crear aplicaciones de IA prácticas y visualmente atractivas. (Fuente: dotey)

📚 Aprendizaje
AdaRFT: Nuevo método para optimizar el ajuste fino mediante aprendizaje por refuerzo: Taiwei Shi et al. proponen un método de aprendizaje curricular ligero y plug-and-play llamado AdaRFT, diseñado para optimizar el proceso de entrenamiento de algoritmos de aprendizaje por refuerzo basados en retroalimentación humana (RFT) como PPO, GRPO, REINFORCE. Se afirma que AdaRFT puede reducir el tiempo de entrenamiento de RFT hasta 2 veces y mejorar el rendimiento del modelo, al organizar de manera más inteligente el orden de los datos de entrenamiento para mejorar la eficiencia y efectividad del aprendizaje. (Fuente: menhguin)

Masterclass online sobre Evaluación de IA (Evals): Hamel Husain y Shreya Shankar han lanzado una masterclass online de 4 semanas sobre la evaluación de aplicaciones de IA (Evals). El curso tiene como objetivo ayudar a los desarrolladores a llevar las aplicaciones de IA desde la fase de prototipo hasta estar listas para producción, cubriendo métodos de evaluación durante el desarrollo y post-lanzamiento, la diferencia entre benchmarks y evaluación práctica, inspección de datos, PromptEvals, etc. Se enfatiza la importancia de la evaluación para garantizar la fiabilidad y el rendimiento de las aplicaciones de IA. (Fuente: HamelHusain, HamelHusain)

Manual de ajuste de modelos de Google: Google Research ofrece un repositorio de recursos llamado “tuning_playbook”, destinado a proporcionar orientación y mejores prácticas para el ajuste de modelos. Este es un recurso de aprendizaje valioso para desarrolladores e investigadores que necesitan realizar ajustes finos en modelos de lenguaje grandes u otros modelos de machine learning para adaptarlos a tareas o datasets específicos. (Fuente: zacharynado)

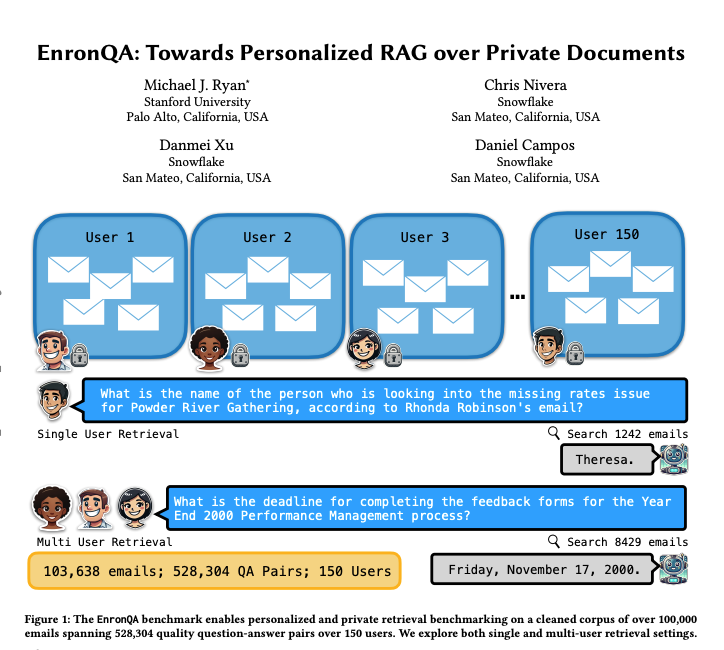
EnronQA: Dataset de benchmark RAG personalizado: Investigadores han lanzado el dataset EnronQA, que contiene 103,638 correos electrónicos de 150 usuarios y 528,304 pares de preguntas y respuestas de alta calidad. Este dataset tiene como objetivo servir como benchmark para evaluar el rendimiento de sistemas personalizados de Generación Aumentada por Recuperación (RAG) en el manejo de documentos privados. El dataset incluye respuestas de referencia doradas, respuestas incorrectas, justificaciones de razonamiento y respuestas alternativas, lo que ayuda a analizar de manera más detallada el rendimiento de los sistemas RAG. (Fuente: tokenbender)
ReXGradient-160K: Dataset a gran escala de radiografías de tórax e informes: Se ha publicado un gran dataset público de radiografías de tórax llamado ReXGradient-160K, que contiene 60,000 estudios de radiografías de tórax y sus informes radiológicos emparejados (texto libre) de 109,487 pacientes únicos de 3 sistemas de salud de EE. UU. (79 puntos de atención médica). Se afirma que es el dataset de radiografías de tórax con el mayor número de pacientes disponible públicamente hasta la fecha, proporcionando un recurso valioso para entrenar y evaluar modelos de IA de imágenes médicas. (Fuente: iScienceLuvr)

Artículo de blog que explora el crecimiento de la capacidad de los agentes de IA: El investigador Shunyu Yao publicó un artículo de blog titulado “The Second Half”, proponiendo que el desarrollo actual de la IA se encuentra en un momento de “descanso intermedio”. Antes de esto, el entrenamiento era más importante que la evaluación; después de esto, la evaluación será más importante que el entrenamiento, porque el aprendizaje por refuerzo (RL) finalmente está comenzando a funcionar eficazmente. El artículo explora la importancia del cambio en la metodología de evaluación en el contexto de la mejora continua de las capacidades de la IA. (Fuente: andersonbcdefg)
OpenAI comparte investigación sobre privacidad y memorización: Los investigadores de OpenAI Pratyush Maini y Zhili Feng darán una charla sobre investigación de privacidad y memorización, discutiendo cómo detectar, cuantificar y eliminar el fenómeno de la memorización en modelos de lenguaje grandes, y su aplicación práctica en LLMs en producción. Esto se relaciona con cómo equilibrar la capacidad del modelo con la protección de la privacidad de los datos del usuario. (Fuente: code_star)

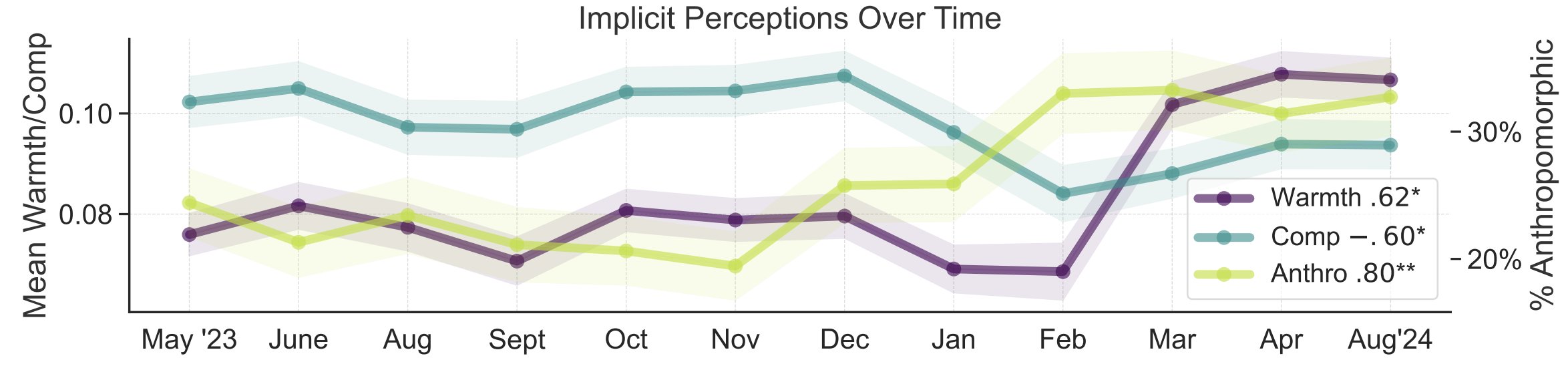
Estudio sobre las metáforas de la percepción pública de la IA: Investigadores de la Universidad de Stanford, Myra Cheng et al., publicaron un artículo en FAccT 2025 que analiza 12,000 metáforas sobre IA recopiladas durante 12 meses para comprender los modelos mentales del público sobre la IA y sus cambios a lo largo del tiempo. El estudio encontró que, con el tiempo, el público tiende a ver la IA como más humana y con más agencia (aumento de la antropomorfización), y su inclinación emocional hacia ella (calidez) también está aumentando. Este método proporciona una visión más detallada de la percepción pública que los autoinformes. (Fuente: stanfordnlp, stanfordnlp)
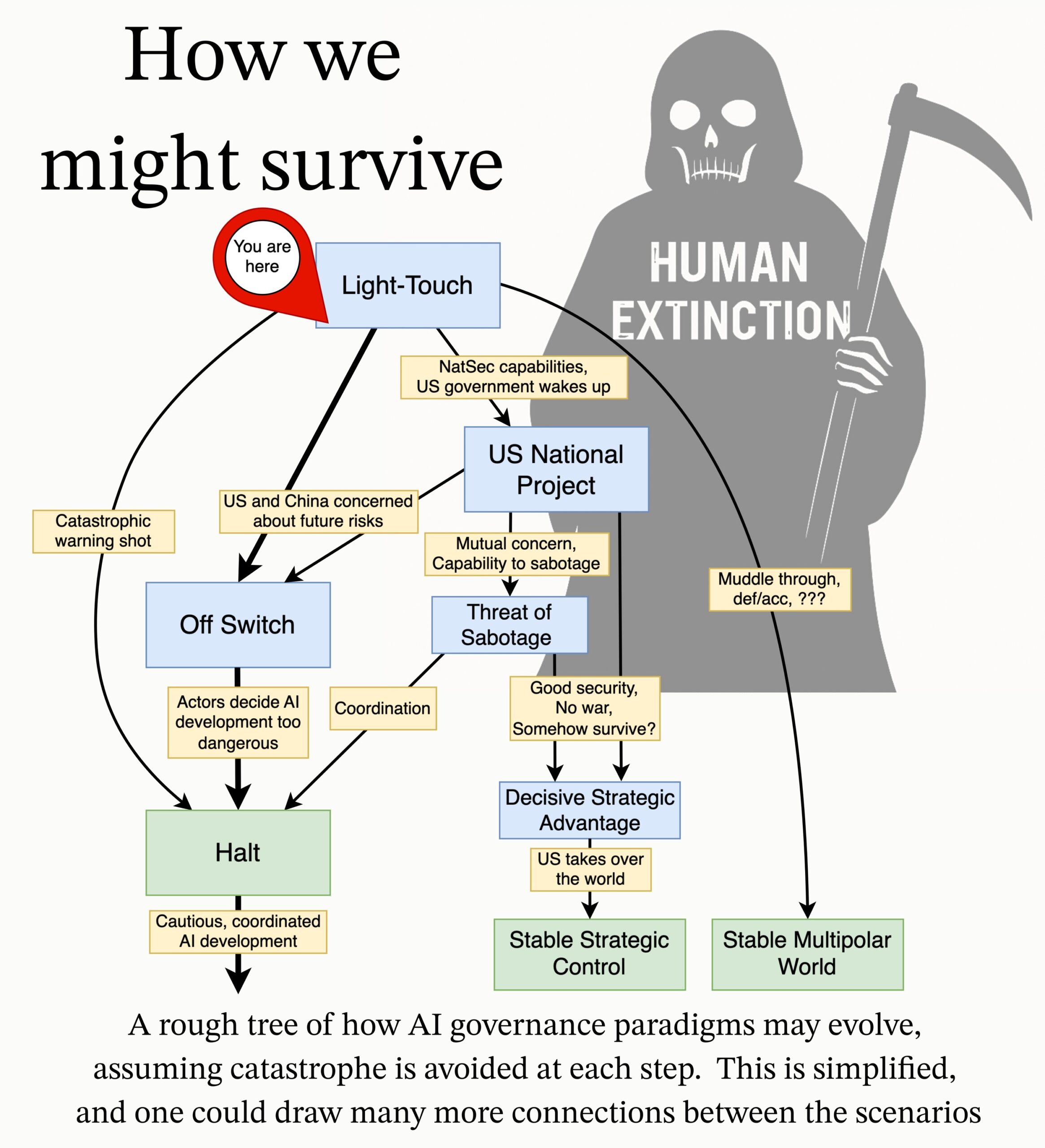
MIRI publica agenda de investigación sobre gobernanza de IA: El equipo de gobernanza técnica del Machine Intelligence Research Institute (MIRI) ha publicado una nueva agenda de investigación sobre gobernanza de IA, exponiendo su visión del panorama estratégico y proponiendo una serie de preguntas de investigación accionables. Su objetivo es explorar qué medidas deben tomarse para evitar que cualquier organización o individuo construya una superinteligencia incontrolable, con el fin de reducir los riesgos catastróficos y de extinción derivados de la IA. (Fuente: JeffLadish)
💼 Negocios
Deepexi, proveedor de soluciones de IA empresarial, solicita OPI en Hong Kong: Deepexi (滴普科技), proveedor de soluciones de IA empresarial fundado por Zhao Jiehui, ex ejecutivo de Huawei y Alibaba, ha presentado formalmente una solicitud de cotización en la bolsa de Hong Kong. La compañía se especializa en la plataforma de inteligencia de datos FastData y la solución de inteligencia artificial empresarial FastAGI, sirviendo a industrias como el retail (p. ej., Belle), manufactura y salud. En los últimos tres años, los ingresos de la compañía han crecido continuamente, alcanzando los 243 millones de yuanes en 2024. Deepexi ha completado 8 rondas de financiación, obteniendo inversiones de instituciones reconocidas como Hillhouse Capital, IDG Capital y 5Y Capital, con una valoración de aproximadamente 6.8 mil millones de yuanes después de la última ronda. A pesar del crecimiento de los ingresos, la compañía todavía está en pérdidas, aunque la pérdida neta ajustada se ha reducido año tras año. (Fuente: 36Kr)
BMW China anuncia la integración del modelo grande DeepSeek: Tras su colaboración con Alibaba, BMW Group profundiza aún más su despliegue de IA en China, anunciando que integrará el modelo grande DeepSeek. Se planea que esta función comience en el tercer trimestre de 2025, aplicándose primero a varios modelos nuevos vendidos en China equipados con el sistema operativo BMW de novena generación, y en el futuro también se aplicará a los modelos BMW New Generation producidos localmente. Esta medida tiene como objetivo fortalecer la experiencia de interacción hombre-máquina centrada en el Asistente Personal Inteligente de BMW a través de las capacidades de pensamiento profundo de DeepSeek, mejorar el nivel de inteligencia y la conexión emocional del vehículo, y es un paso importante para que BMW acelere su estrategia de IA localizada y afronte los desafíos de la transformación inteligente. (Fuente: 36Kr)
Shopify obliga a todos los empleados a usar IA, busca reemplazar algunos puestos con IA: El CEO de la plataforma global de comercio electrónico Shopify, Tobi Lutke, enfatizó en un memorando interno que el uso eficiente de la IA se ha convertido en una “regla de hierro” para todos los empleados de la empresa, ya no es una sugerencia. El memorando exige que los empleados apliquen la IA a sus flujos de trabajo, convirtiéndolo en un reflejo condicionado; los equipos que soliciten personal adicional deben demostrar por qué la IA no puede realizar la tarea; las evaluaciones de desempeño incluirán métricas de uso de IA. Lutke señaló que la IA puede aumentar enormemente la eficiencia (hasta 10 o incluso 100 veces para algunos empleados), y los empleados deben mejorar entre un 20% y un 40% anualmente para mantener la competitividad. Shopify ya ha realizado despidos en departamentos como el de atención al cliente e introducido reemplazos de IA. Esta medida se considera una señal clara de la tendencia de ajuste y despido de puestos de cuello blanco causada por la IA. (Fuente: Xinzhiyuan)

🌟 Comunidad
Discusión sobre el problema de las alucinaciones en IA: Robin Li (Li Yanhong) criticó en la Conferencia de Desarrolladores de IA de Baidu que DeepSeek-R1 tiene una alta tasa de alucinaciones, es lento y costoso, lo que reavivó la discusión en la comunidad sobre el fenómeno de las “alucinaciones” en los modelos grandes. Algunos análisis señalan que no solo DeepSeek, sino también modelos avanzados como o3/o4-mini de OpenAI y Qwen3 de Alibaba, presentan problemas de alucinaciones, y que el pensamiento multi-paso de los modelos de inferencia puede amplificar los sesgos. La evaluación de Vectara muestra que la tasa de alucinaciones de R1 (14.3%) es mucho mayor que la de V3 (3.9%). La comunidad cree que a medida que aumenta la capacidad de los modelos, las alucinaciones se vuelven más sutiles y lógicas, dificultando a los usuarios distinguir la verdad de la falsedad, lo que genera preocupaciones sobre la fiabilidad. Al mismo tiempo, hay opiniones que consideran las alucinaciones como un subproducto de la creatividad, especialmente valioso en campos como la creación literaria. Cómo definir un nivel aceptable de alucinaciones y cómo mitigarlas mediante técnicas como RAG, control de calidad de datos y modelos críticos sigue siendo un tema de exploración continua en la industria. (Fuente: 36Kr)

Reflexiones y debates sobre compañeros/amigos de IA: La propuesta del CEO de Meta, Mark Zuckerberg, de usar amigos de IA personalizados para satisfacer la necesidad de más conexiones sociales (afirmando que la persona promedio tiene 3 amigos pero necesita 15) generó debate en la comunidad. Sebastien Bubeck cree que lograr verdaderos compañeros de IA es muy difícil, la clave es que la IA necesita poder responder significativamente a “¿Qué has estado haciendo últimamente?”, es decir, tener sus propias experiencias, no solo compartir las del usuario. Argumenta que la visión actual de los compañeros de IA se centra demasiado en la experiencia compartida e ignora que la IA misma necesita tener experiencias independientes que compartir, incluso chismes (compartir experiencias mutuas). Otros comentaristas cuestionan desde la perspectiva del número de Dunbar, argumentando que un gran círculo social compuesto por IA podría carecer de significado real. También hay preocupaciones de que los amigos de IA proporcionados por empresas comerciales tengan como objetivo final la conversión de marketing de precisión, en lugar de una compañía genuina. (Fuente: jonst0kes, SebastienBubeck, gfodor, gfodor)

La creación artística con IA genera emociones y reflexiones: En la comunidad, algunos usuarios expresaron sentirse “apenados” (grieving) porque la IA puede crear obras de arte “increíblemente buenas” en poco tiempo, considerando que esto desafía la singularidad humana en la creación artística. Esto generó discusiones sobre el arte de IA, la naturaleza de la creatividad humana y el sentido del valor personal ante el impacto tecnológico. Algunos comentarios sugieren que el placer de la creación artística reside en el proceso mismo, no en competir con la IA; el arte de IA puede servir como fuente de inspiración. Otros creen que el arte de IA carece de los “errores” o el alma de la creación humana, pareciendo demasiado perfecto o estereotipado. Al mismo tiempo, la discusión se extendió a reflexiones filosóficas sobre la simulación de emociones por IA, la conciencia y las futuras estructuras sociales (como el reemplazo de trabajos). (Fuente: Reddit r/ArtificialInteligence)
Ética y responsabilidad de la IA: experimentos secretos y divulgación de información: La comunidad discutió problemas éticos en la investigación de IA. Una noticia mencionó a investigadores de IA realizando experimentos secretos en Reddit para intentar cambiar las opiniones de los usuarios, lo que generó preocupaciones sobre el derecho al consentimiento informado de los usuarios y el riesgo de manipulación por IA. En otra discusión, un usuario informó sobre las dificultades encontradas al reportar posibles problemas de seguridad a empresas de IA, enfrentando procesos complejos y responsabilidades poco claras, lo que destaca la inmadurez actual en el campo de la IA en cuanto a mecanismos de divulgación responsable y respuesta a vulnerabilidades. (Fuente: Reddit r/ArtificialInteligence, nptacek)

Reflexión del campo del NLP sobre el auge de ChatGPT: Quanta Magazine publicó un artículo basado en entrevistas con varios expertos en Procesamiento del Lenguaje Natural (NLP) como Chris Potts, Yejin Choi, Emily Bender, repasando el impacto y la reflexión que la publicación de ChatGPT trajo a todo el campo. El artículo explora cómo el auge de los modelos de lenguaje grandes desafió las bases teóricas del NLP tradicional, provocó debates dentro del campo, divisiones en facciones y ajustes en las direcciones de investigación. Los miembros de la comunidad reaccionaron positivamente al artículo, considerándolo un buen resumen de la conmoción y adaptación en el campo de la lingüística después de GPT-3. (Fuente: stanfordnlp, Teknium1, YejinChoinka, sleepinyourhat)
Aparición y percepción de anuncios generados por IA: Usuarios de redes sociales informaron haber comenzado a ver anuncios generados por IA en plataformas como YouTube, expresando sentirse “muy incómodos”. Esto indica que la tecnología de generación de contenido por IA ha comenzado a aplicarse en la producción de publicidad comercial, y al mismo tiempo, provoca reacciones iniciales de los usuarios sobre la calidad, autenticidad y experiencia emocional del contenido generado por IA. (Fuente: code_star)
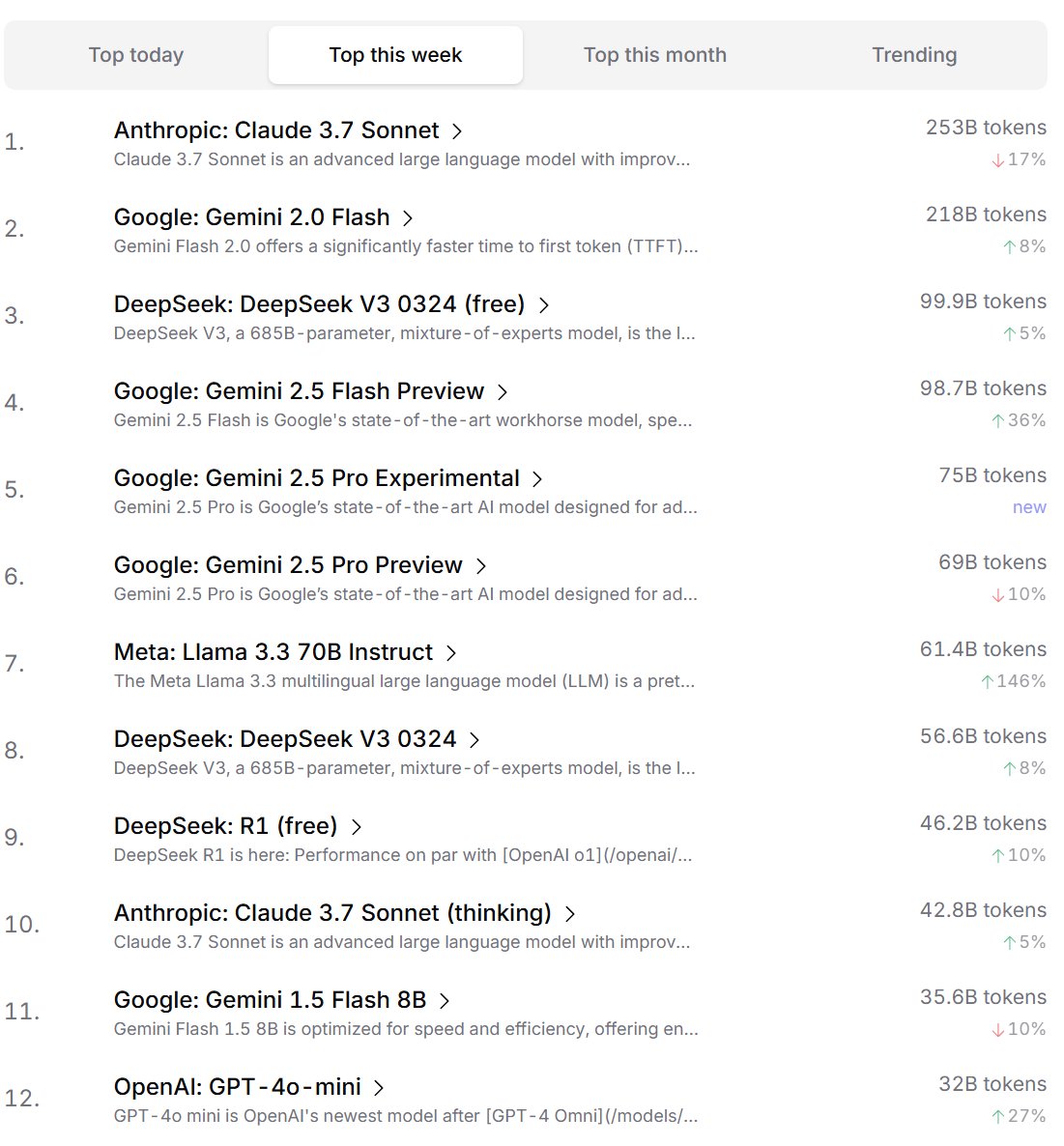
Ranking de preferencias de modelos de IA por desarrolladores: Cursor.ai publicó el ranking de modelos de IA preferidos por sus usuarios (principalmente desarrolladores), mientras que Openrouter también publicó el ranking de uso de tokens por modelo. Se considera que estos rankings, basados en datos de uso real de productos, podrían reflejar mejor las preferencias de elección de los usuarios en escenarios de desarrollo reales que los rankings tipo arena como ChatBot Arena, ofreciendo diferentes perspectivas para evaluar la utilidad práctica de los modelos. (Fuente: op7418, Reddit r/LocalLLaMA)
Debate sobre si la IA posee capacidad de “pensamiento”: Existe un debate continuo en la comunidad sobre si los modelos de lenguaje grandes (LLMs) realmente poseen la capacidad de “pensar”. Algunos argumentan que los LLMs actuales en realidad no piensan antes de hablar, sino que simulan el proceso de pensamiento generando más texto (como la cadena de pensamiento), lo cual es engañoso. Otros sostienen que usar métodos matemáticos continuos (como los LLMs) para realizar razonamiento discreto en computadoras discretas es fundamentalmente problemático. Estas discusiones reflejan una reflexión profunda sobre la naturaleza de la tecnología de IA actual y sus futuras direcciones de desarrollo. (Fuente: francoisfleuret, pmddomingos)
Reflexión dialéctica sobre el consumo de energía de la IA y su impacto ambiental: Ante los problemas ambientales causados por el enorme consumo de energía para el entrenamiento y funcionamiento de la IA, surge una reflexión dialéctica en la comunidad. Una opinión sostiene que la enorme demanda de energía de la IA (especialmente de empresas de computación a hiperescala como Google, Amazon, Microsoft) está obligando a estas empresas a invertir en la construcción de sus propias fuentes de energía renovable (solar, eólica, baterías), e incluso a reiniciar centrales nucleares (como la colaboración de Microsoft con Constellation para reiniciar la central nuclear de Three Mile Island). Esta demanda podría convertirse en un catalizador para acelerar el despliegue de energía limpia y los avances tecnológicos (como los reactores nucleares modulares pequeños SMR). Sin embargo, también se señala que el problema de los rendimientos decrecientes del consumo de energía de la IA y el consumo de recursos hídricos para la refrigeración también merecen atención. (Fuente: Reddit r/ArtificialInteligence)
Anthropic acusada de intentar limitar la competencia en chips de IA: La comunidad discute que el CEO de Anthropic, Dario Amodei, aboga por reforzar los controles de exportación de chips de IA a lugares como China, llegando a sugerir que los chips podrían contrabandearse disfrazados de barrigas de embarazo falsas. Los críticos argumentan que la medida de Anthropic tiene como objetivo limitar el acceso de los competidores (especialmente empresas chinas como DeepSeek, Qwen) a recursos computacionales avanzados para mantener su ventaja en el desarrollo de modelos de vanguardia. Se acusa a esta práctica de utilizar la política para reprimir la competencia, lo que es perjudicial para el desarrollo abierto de la tecnología de IA global y la comunidad open source. (Fuente: Reddit r/LocalLLaMA)

💡 Otros
Reflexiones sobre la IA y los límites cognitivos humanos: Jeff Ladish comenta que la ventana de oportunidad para que los humanos actúen como “asistentes de copiar y pegar” para la IA es extremadamente breve, insinuando que la capacidad autónoma de la IA superará rápidamente la simple asistencia. Al mismo tiempo, el fundador de DeepMind, Hassabis, declaró en una entrevista que una verdadera AGI debería poder proponer independientemente conjeturas científicas valiosas (como Einstein proponiendo la relatividad general), no solo resolver problemas, y cree que la IA actual todavía tiene deficiencias en la generación de hipótesis. Liu Cixin, por su parte, espera que la IA pueda superar los límites cognitivos biológicos del cerebro humano. Estas opiniones apuntan conjuntamente a una reflexión profunda sobre los límites de la capacidad de la IA, la evolución del papel humano y la naturaleza de la inteligencia futura. (Fuente: JeffLadish, Xinzhiyuan)
LiDAR de Waymo captura un momento peligroso: El sistema LiDAR del vehículo autónomo de Waymo capturó claramente la imagen de nube de puntos 3D de un repartidor volteándose en una colisión durante un accidente de motocicleta que el vehículo logró evitar con éxito. Esto no solo demuestra la potente capacidad del sistema de percepción de Waymo (incluso en escenarios dinámicos complejos), sino que también registró inesperadamente una perspectiva única del accidente. Afortunadamente, nadie resultó gravemente herido en el accidente. (Fuente: andrew_n_carr)
Nuevas ideas para la creación de novelas con IA: sistema de promesas argumentales: El desarrollador Levi propone un sistema de “Promesa Argumental” (Plot Promise) para la creación de novelas con IA, como alternativa al método tradicional de esquema jerárquico. El sistema, inspirado en la teoría de “promesa, progreso, recompensa” de Brandon Sanderson, considera la historia como una serie de hilos narrativos activos (promesas), cada uno con una puntuación de importancia. El algoritmo sugiere el momento de avanzar basándose en la puntuación y el progreso, pero la IA elige lógicamente la promesa más adecuada para avanzar en el contexto actual. El usuario puede añadir o eliminar promesas dinámicamente. Este método busca mejorar la flexibilidad de la historia, la escalabilidad (adaptándose a obras muy largas) y la emergencia creativa, pero enfrenta desafíos como la optimización de decisiones de IA, el mantenimiento de la coherencia a largo plazo y las limitaciones de longitud del prompt de entrada. (Fuente: Reddit r/ArtificialInteligence)