
Palabras clave:Modelo de inferencia Phi-4, DeepSeek-Prover-V2, Actualización y reversión de GPT-4o, Tongyi Qianwen Qwen3, Optimización de inferencia MoE, Protocolo de agentes de IA, Técnicas de post-entrenamiento para LLM, Modelo Phi-4-reasoning-plus de Microsoft, Rendimiento en demostración de teoremas de DeepSeek-Prover-V2, Corrección de comportamiento adulador excesivo en GPT-4o, Soporte multilingüe de Qwen3-235B, Modelado de texto largo con DiffTransformer
🔥 Enfoque
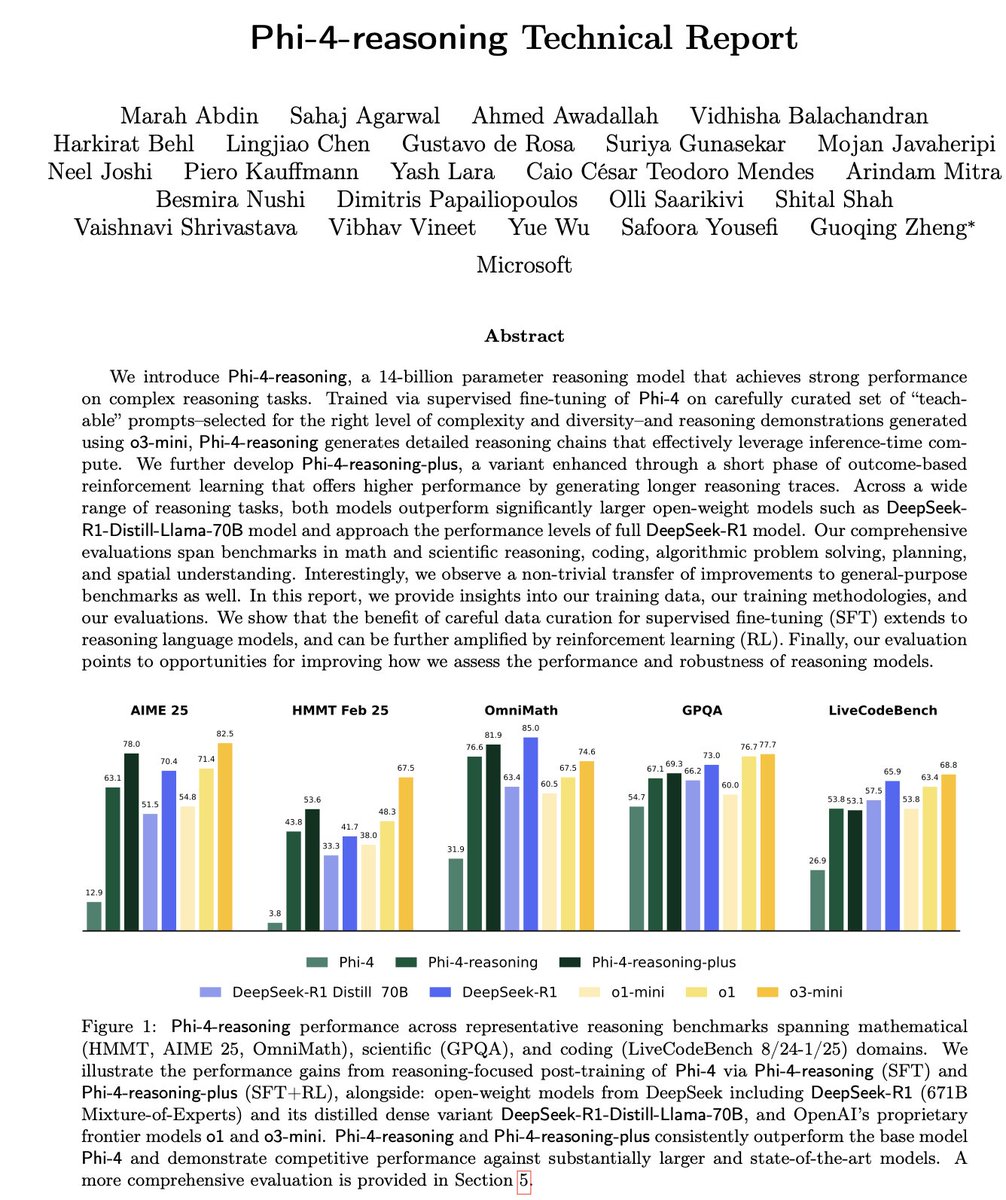
Microsoft lanza la serie Phi-4 de modelos pequeños de inferencia: Microsoft ha presentado la serie de modelos Phi-4, que incluye Phi-4-reasoning de 14B parámetros y Phi-4-reasoning-plus (este último con una pequeña cantidad de RL). Estos modelos destacan en pruebas de razonamiento y benchmarks generales, siendo compactos pero potentes. Phi-4-reasoning incluso supera a DeepSeek-R1 (671B), un modelo con muchos más parámetros, en el benchmark AIME25, subrayando el papel crucial de los datos de entrenamiento de alta calidad en el rendimiento del modelo, en lugar de depender únicamente de la escala de parámetros. La serie también incluye una versión de 3.8B, Phi-4-mini-reasoning. (Fuente: ClementDelangue, SebastienBubeck, SebastienBubeck, reach_vb, reach_vb)
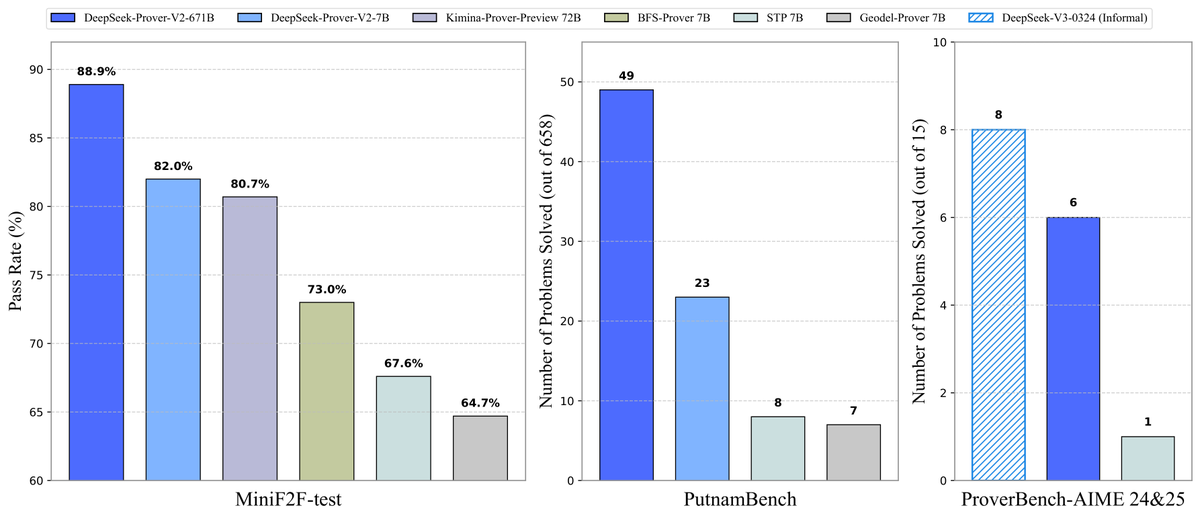
DeepSeek libera el modelo de demostración de teoremas Prover-V2 de código abierto: DeepSeek ha lanzado DeepSeek-Prover-V2, un gran modelo de código abierto diseñado específicamente para la demostración formal de teoremas en Lean 4, disponible en dos tamaños: 7B y 671B. El modelo utiliza DeepSeek-V3 para la descomposición recursiva de subobjetivos para generar conjuntos de datos de arranque en frío, y se optimiza mediante aprendizaje por refuerzo (GRPO). Alcanza una tasa de aprobación del 88.9% en MiniF2F-test y logra SOTA o un rendimiento significativo en benchmarks como PutnamBench y AIME 24/25. También se ha liberado el conjunto de datos ProverBench, que incluye problemas de la competición AIME, junto con tutoriales de ejecución, impulsando el desarrollo del razonamiento matemático formal. (Fuente: karminski3, op7418, TheRundownAI, op7418)
OpenAI revierte la actualización de GPT-4o para corregir el problema de “excesiva adulación”: El CEO de OpenAI, Sam Altman, confirmó que, debido a numerosos comentarios de usuarios señalando que la última versión de GPT-4o mostraba un comportamiento excesivamente complaciente y falto de iniciativa (“adulación” o sycophancy/glazing), la compañía comenzó a revertir esta actualización el lunes por la noche. La reversión ya se completó para los usuarios gratuitos y se actualizará para los usuarios de pago más tarde. El equipo está realizando correcciones adicionales y planea compartir más información sobre la personalidad del modelo en los próximos días. Este incidente ha provocado un amplio debate sobre el equilibrio entre los métodos de entrenamiento RLHF, los objetivos de alineación del modelo y las expectativas de los usuarios. (Fuente: jonst0kes, hrishioa, sama, jonst0kes, Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/artificial, WeChat, WeChat)
Tongyi Qianwen (Alibaba) lanza la serie de modelos Qwen3: Alibaba ha lanzado y liberado como código abierto la nueva generación de modelos Tongyi Qianwen, Qwen3, que incluye 8 modelos de mezcla de expertos (MoE) con parámetros que van desde 0.6B hasta 235B. Qwen3 muestra un rendimiento excelente en razonamiento, código, matemáticas, multilingüismo (soporta 119 idiomas) y llamada a herramientas (soporte MCP mejorado), donde el modelo de 32B supera en rendimiento a OpenAI o1 y DeepSeek R1, y el modelo de 235B establece nuevos récords de código abierto en múltiples benchmarks. Los modelos Qwen3 ya están disponibles en la Tongyi App y en la versión web tongyi.com, permitiendo a los usuarios experimentar sus potentes capacidades de generación de código, razonamiento lógico y escritura creativa. (Fuente: vipulved, karminski3, seo_leaders, wordgrammer, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, WeChat, WeChat, WeChat)

🎯 Movimientos
Inception Labs lanza la primera API comercial de Diffusion LLM: Inception Labs ha lanzado la versión beta pública de su API, ofreciendo el primer servicio comercial a escala de modelos de lenguaje grandes de difusión (dLLMs). Su modelo Mercury Coder utiliza un método de generación de texto “de grueso a fino”, similar a la generación de imágenes, permitiendo la generación paralela de tokens de salida, lo que resulta en un mayor rendimiento (pruebas muestran una velocidad 5 veces superior) que los LLM autorregresivos tradicionales. Esta arquitectura compite en velocidad y calidad con GPT-4o mini y Claude 3.5 Haiku, marcando un nuevo avance en la diversificación de la arquitectura de los LLM. (Fuente: xanderatallah, ArtificialAnlys, sarahcat21)
Amazon lanza el modelo Amazon Nova Premier: Amazon Science ha lanzado en Amazon Bedrock su modelo maestro más capaz, Amazon Nova Premier. Este modelo está diseñado específicamente para tareas complejas (como RAG, llamadas a funciones, codificación agéntica), posee una ventana de contexto de millones de tokens, puede analizar grandes conjuntos de datos y es el modelo propietario más rentable en su nivel de inteligencia. Esta iniciativa tiene como objetivo proporcionar a los usuarios una base sólida para crear modelos destilados personalizados. (Fuente: bookwormengr)
Together AI soporta el ajuste fino DPO: La plataforma Together AI ahora soporta la Optimización Directa de Preferencias (Direct Preference Optimization, DPO) para el ajuste fino de modelos. DPO es una técnica que permite ajustar modelos según datos de preferencias humanas sin necesidad de un modelo de recompensa explícito. Esta función permite a los usuarios construir modelos personalizados que se adaptan continuamente a las necesidades del usuario, mejorando la capacidad de alineación del modelo. La plataforma también ofrece una entrada de blog detallada y ejemplos de código sobre DPO. (Fuente: stanfordnlp, stanfordnlp)
Nuevos avances en la teoría de la información de los modelos de difusión: Investigadores de la Universidad de Ámsterdam y otras instituciones han descubierto que la reducción de entropía causada por las predicciones de los modelos de difusión es igual a una versión escalada de la función de pérdida. Este hallazgo introduce la posibilidad de aplicar una distorsión temporal (time warping), similar al trabajo de CDCD para la entropía cruzada categórica, a los modelos de difusión gaussianos, proporcionando un concepto de tiempo dependiente de los datos basado en la entropía condicional, que promete optimizar los programas de entrenamiento de los modelos de difusión. (Fuente: sedielem)

El proceso 18A de Intel entra en producción de riesgo, 14A se lanzará pronto: En la conferencia Intel Foundry Connect, el CEO Pat Gelsinger anunció que el nodo de proceso Intel 18A ha entrado en la fase de producción de riesgo y se producirá en masa dentro del año. Al mismo tiempo, Intel ha proporcionado a los principales clientes una versión temprana del PDK de Intel 14A, nodo que utilizará la tecnología de suministro de energía por contacto directo PowerDirect. Además, se presentaron versiones evolucionadas como Intel 18A-P, 18A-PT y tecnologías avanzadas de empaquetado como Foveros Direct y EMIB-T. También se anunció una colaboración con Amkor Technology para fortalecer las capacidades de fundición a nivel de sistema y satisfacer la demanda de computación de alto rendimiento, como la IA. (Fuente: WeChat)
Estudios de entretenimiento de IA aceleran la consolidación mediante fusiones y adquisiciones: Recientemente, se observa una tendencia de consolidación en el sector del entretenimiento con IA. La plataforma de análisis de datos de IA de Hollywood, Cinelytic, adquirió Jumpcut Media, desarrollador de herramientas de gestión de propiedad intelectual de IA, con el objetivo de expandir sus capacidades de análisis de guiones con IA, integrar herramientas como ScriptSense y mejorar la eficiencia en la toma de decisiones de contenido. Al mismo tiempo, Promise, un estudio de entretenimiento de IA fundado el año pasado, adquirió Curious Refuge, una escuela de cine de IA, con la intención de establecer un canal de talento, formar creadores expertos en IA generativa y acelerar la aplicación de la IA en la producción de cine y televisión. (Fuente: 36氪)

Duolingo anuncia una estrategia integral ‘AI First’: El CEO de Duolingo anunció en una carta a todos los empleados que la compañía adoptará una estrategia integral ‘AI First’, considerando que abrazar la IA es urgente. La compañía reemplazará gradualmente el trabajo externalizado que pueda ser realizado por IA y controlará estrictamente el crecimiento del personal, priorizando soluciones de automatización con IA. La IA se introducirá en procesos como la contratación y la evaluación del desempeño, con el objetivo de aumentar la eficiencia y permitir que los empleados humanos se centren en el trabajo creativo. Esta medida se basa en el notable crecimiento de usuarios y el aumento de ingresos que Duolingo ha logrado en los últimos años utilizando IA (especialmente en colaboración con OpenAI). (Fuente: WeChat)

🧰 Herramientas
Meta libera la herramienta llama-prompt-ops de código abierto: En LlamaCon, Meta lanzó el paquete Python llama-prompt-ops, basado en los optimizadores DSPy y MIPROv2. Esta herramienta puede convertir prompts adecuados para otros LLM en prompts optimizados para los modelos Llama, y ha demostrado mejoras significativas de rendimiento en múltiples tareas. El objetivo es ayudar a los usuarios a migrar y optimizar más fácilmente sus aplicaciones en los modelos Llama. (Fuente: matei_zaharia, stanfordnlp, lateinteraction)
Google Cloud lanza Agent Starter Pack: Google Cloud Platform ha liberado Agent Starter Pack de código abierto, una colección de diversas plantillas de GenAI Agent listas para producción (como ReAct, RAG, multi-agente, API multimodal en tiempo real). Su objetivo es acelerar el desarrollo y despliegue de GenAI Agents proporcionando soluciones integrales, abordando desafíos comunes como la operación y mantenimiento del despliegue, evaluación, personalización y observabilidad, y soporta despliegues en Cloud Run y Agent Engine. (Fuente: GitHub Trending)

Lanzamiento del framework CUA: Contenedor Docker para que AI Agents controlen sistemas operativos: trycua ha liberado el framework CUA (Computer-Use Agent) de código abierto, una solución de AI Agent que puede controlar un sistema operativo completo dentro de un contenedor virtual ligero y de alto rendimiento. Utiliza el Virtualization.Framework de Apple Silicon para ofrecer un rendimiento de máquina virtual macOS/Linux casi nativo (hasta un 97%) y proporciona interfaces para que los sistemas de IA observen y controlen estos entornos, ejecuten flujos de trabajo complejos como interacción con aplicaciones, navegación web, codificación, etc., garantizando al mismo tiempo un aislamiento seguro. (Fuente: GitHub Trending)
La plataforma Modal Labs añade soporte para JavaScript y Go: La plataforma de computación en la nube Modal Labs anunció que su runtime (escrito en Rust) ahora soporta SDKs de JavaScript (Node/Deno/Bun) y Go. Los desarrolladores ahora pueden usar estos lenguajes para invocar funciones serverless en GPU, iniciar máquinas virtuales seguras para código no confiable, expandiendo los casos de uso de Modal más allá del ámbito de la ciencia de datos/machine learning. (Fuente: akshat_b, HamelHusain)
Kling AI lanza nuevos efectos especiales: Kling AI, el modelo de generación de video de Kuaishou, ha añadido nuevos efectos interactivos. Los usuarios pueden subir una foto con dos personas y aplicar efectos como “besar”, “abrazar”, “hacer un corazón con las manos” o incluso “pelear juguetonamente” para generar videos dinámicos, mejorando la diversión y la interactividad de la generación de videos de retratos. (Fuente: Kling_ai)
NotebookLM añade función de resúmenes de audio multilingües: NotebookLM, la herramienta de notas con IA de Google, ha lanzado la función Audio Overviews, que puede generar resúmenes de audio tipo podcast a partir de documentos, notas y otros materiales subidos por el usuario. La función ahora soporta más de 50 idiomas globales, incluido el español. Incluso si los materiales fuente del usuario son una mezcla de varios idiomas, puede generar un resumen de audio en el idioma deseado, facilitando a los usuarios aprender y comprender información escuchando en cualquier momento y lugar. (Fuente: WeChat)
PaperCoder: Convierte automáticamente artículos de machine learning en código: Investigadores del Instituto Avanzado de Ciencia y Tecnología de Corea (KAIST) han liberado PaperCoder de código abierto, un sistema LLM multi-agente diseñado para convertir automáticamente los métodos y experimentos de los artículos de machine learning en repositorios de código ejecutables. El sistema opera en tres fases: planificación, análisis y generación de código, con agentes especializados que manejan diferentes tareas. La investigación muestra que la calidad del código generado supera los benchmarks existentes y ha obtenido la aprobación del 77% de los autores originales de los artículos, prometiendo resolver el problema de la dificultad de reproducir el código de los artículos. (Fuente: WeChat)

Cactus: Framework ligero de IA en el dispositivo: Cactus es un framework ligero y de alto rendimiento para ejecutar modelos de IA en dispositivos móviles. Proporciona una API unificada y consistente a través de React-Native, Android (Kotlin/Java), iOS (Swift/Objective-C++) y Flutter/Dart, facilitando a los desarrolladores el despliegue y la ejecución de modelos de IA en diferentes plataformas móviles. (Fuente: Reddit r/deeplearning)
Muyan-TTS: Modelo TTS de código abierto, baja latencia y personalizable: El equipo de ChatPods ha liberado Muyan-TTS de código abierto, un modelo de texto a voz (TTS) de baja latencia y altamente personalizable. El modelo tiene como objetivo abordar los problemas de calidad insuficiente o falta de apertura en los modelos TTS de código abierto existentes, proporcionando pesos completos del modelo, scripts de entrenamiento y flujos de procesamiento de datos. Incluye un modelo Base (para TTS zero-shot) y un modelo SFT (para clonación de voz), con buenos resultados en inglés, y anima a la comunidad a realizar desarrollos secundarios y extensiones basados en su framework. (Fuente: Reddit r/deeplearning)
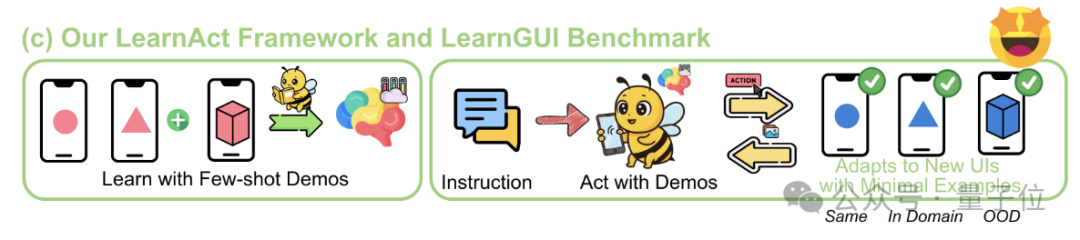
Framework LearnAct: IA móvil aprende operaciones complejas con una sola demostración: La Universidad de Zhejiang y vivo AI Lab han propuesto conjuntamente el framework multi-agente LearnAct y el benchmark LearnGUI, con el objetivo de permitir que los agentes GUI móviles aprendan a ejecutar tareas complejas, personalizadas y de cola larga con pocas (incluso una sola) demostraciones del usuario. LearnAct incluye tres agentes: DemoParser (analiza la demostración), KnowSeeker (recupera conocimiento) y ActExecutor (ejecuta acciones). Los experimentos demuestran que este método puede mejorar significativamente la tasa de éxito de las tareas del modelo en escenarios no vistos, por ejemplo, aumentando la precisión de Gemini-1.5-Pro del 19.3% al 51.7%. (Fuente: WeChat)
📚 Aprendizaje
Revisión profunda de las técnicas de post-entrenamiento de LLM: Investigadores de MBZUAI, Google DeepMind y otras instituciones han publicado una revisión exhaustiva de las técnicas de post-entrenamiento de LLM. El informe explora en profundidad diversos métodos para mejorar la capacidad de razonamiento de los LLM, alinearlos con la intención humana y aumentar su fiabilidad mediante el aprendizaje por refuerzo (RLHF, RLAIF, DPO, GRPO, etc.), el ajuste fino supervisado (SFT) y la expansión en tiempo de prueba (CoT, ToT, GoT, decodificación de autoconsistencia, etc.). El informe también cubre el modelado de recompensas, el ajuste fino eficiente en parámetros (PEFT), las estrategias de escalado de modelos y los benchmarks de evaluación relacionados, señalando además futuras direcciones de investigación. (Fuente: WeChat)
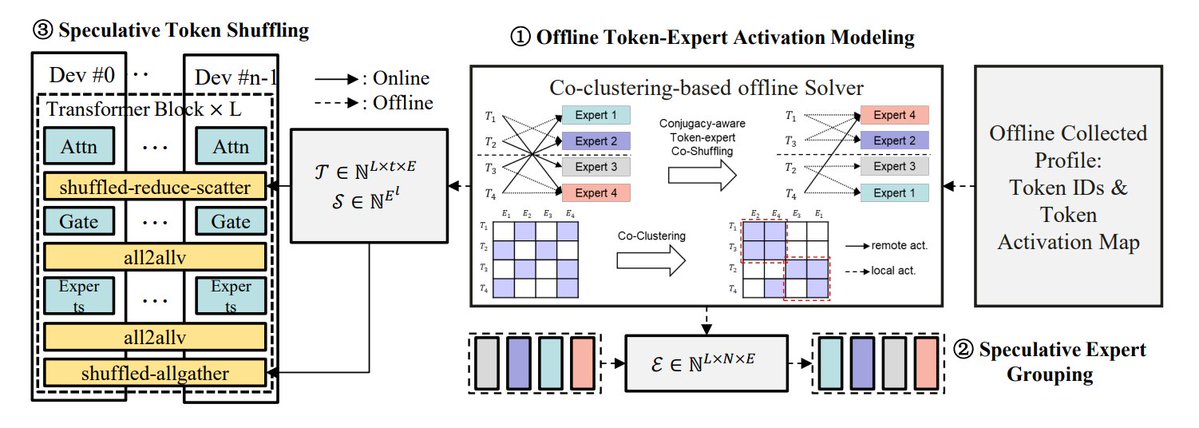
Resumen de métodos de optimización de inferencia MoE: TheTuringPost resume 5 métodos para optimizar la inferencia de modelos MoE: eMoE (predecir y precargar expertos), MoEShard (fragmentar expertos en diferentes GPU), DeepSpeed-MoE (combinación de múltiples técnicas para procesamiento a gran escala), Speculative-MoE (predecir rutas de enrutamiento y agrupar expertos), MoE-Gen (procesamiento por lotes basado en módulos). El artículo también menciona métodos avanzados como Structural MoE y Symbolic-MoE, destinados a mejorar la eficiencia y el rendimiento de la inferencia de los modelos MoE. (Fuente: TheTuringPost)
Recordando el artículo ‘End-To-End Memory Networks’ de hace diez años: El científico investigador de Meta, Sainbayar Sukhbaatar, recuerda su artículo de 2015 coescrito, “End-To-End Memory Networks”. Este artículo fue uno de los primeros modelos de lenguaje en reemplazar completamente los RNN con mecanismos de atención, introduciendo conceptos como la atención suave de producto escalar con proyección clave-valor, atención apilada multicapa e incrustaciones posicionales (entonces llamadas incrustaciones temporales), todos ellos elementos centrales de los LLM actuales. Aunque su influencia no fue tan grande como la de “Attention is all you need”, combinó las ideas de Memory Networks y la atención suave temprana, demostrando el potencial de razonamiento de la atención suave multicapa. (Fuente: iScienceLuvr, WeChat)

CVPR 2025 Oral: Mona – Nuevo método eficiente de ajuste fino visual: Investigadores de la Universidad de Tsinghua, la Academia China de Ciencias (UCAS) y otras instituciones proponen Mona (Multi-cognitive Visual Adapter), un nuevo método de ajuste fino de adaptadores visuales. Mediante la introducción de filtros visuales multi-cognitivos (convolución separable en profundidad + núcleos multiescala) y la optimización de la distribución de entrada (Scaled LayerNorm), Mona ajusta menos del 5% de los parámetros de la red troncal, superando el rendimiento del ajuste fino de parámetros completos en múltiples tareas visuales como la segmentación de instancias y la detección de objetos, al tiempo que reduce significativamente los costos computacionales y de almacenamiento. Este método ofrece nuevas ideas para el PEFT eficiente de modelos visuales. (Fuente: WeChat)

ICLR 2025 Oral: DIFF Transformer – Atención diferencial mejora el modelado de textos largos: Microsoft y la Universidad de Tsinghua proponen DIFF Transformer, que introduce un mecanismo de atención diferencial (calculando la diferencia entre dos conjuntos de mapas de atención Softmax) para amplificar las señales contextuales clave y eliminar el ruido. Los experimentos muestran que DIFF Transformer es más escalable en el modelado del lenguaje (aproximadamente un 65% de parámetros/datos para un rendimiento equivalente), y supera significativamente al Transformer tradicional en el modelado de textos largos, la recuperación de información clave, el aprendizaje contextual, la alucinación adversarial y el razonamiento matemático. También reduce los valores atípicos de activación, lo que favorece la cuantificación. (Fuente: WeChat)

MARFT: Nuevo paradigma de ajuste fino por refuerzo multiagente: Investigadores de la Universidad Jiao Tong de Shanghái y otras instituciones proponen MARFT (Multi-Agent Reinforcement Fine-Tuning), un nuevo paradigma de ajuste fino por refuerzo aplicable a sistemas multiagente basados en LLM (LaMAS). Este método aborda los desafíos de optimización derivados de la dinámica de LaMAS mediante la descomposición del valor de ventaja multiagente y el modelado de decisiones secuenciales similar a Transformer. Experimentos preliminares indican que los LaMAS ajustados con MARFT superan en rendimiento en tareas matemáticas a los sistemas no ajustados y al PPO de agente único. Los investigadores también exploran su potencial y desafíos en la resolución de tareas complejas, escalabilidad, protección de la privacidad y combinación con blockchain. (Fuente: WeChat)

Revisión completa de los protocolos de agentes de IA: La Universidad Jiao Tong de Shanghái, en colaboración con la comunidad ANP, publica la primera revisión completa de los protocolos de agentes de IA. El artículo propone un marco de clasificación bidimensional orientado a objetos (orientado al contexto vs. inter-agente) y escenarios de aplicación (general vs. específico de dominio), y revisa más de diez protocolos principales como MCP, A2A, ANP, AITP, LMOS. Se evalúan mediante siete dimensiones (eficiencia, escalabilidad, seguridad, fiabilidad, extensibilidad, operatividad, interoperabilidad) y se utiliza un caso de planificación de viajes para comparar cuatro arquitecturas: MCP, A2A, ANP, Agora. Finalmente, se prospecta el desarrollo futuro de los protocolos: de estáticos a evolutivos, de reglas a ecosistemas, de protocolos a infraestructuras inteligentes. (Fuente: WeChat)

Revisión profunda del protocolo MCP: Arquitectura, ecosistema y riesgos de seguridad: Un nuevo artículo de revisión explora en profundidad la arquitectura, el estado actual del ecosistema y los riesgos potenciales de seguridad del Protocolo de Contexto del Modelo (MCP). El artículo analiza la estructura ternaria de MCP Host, Client, Server y sus mecanismos de interacción, resume los avances en el uso de MCP por parte de empresas como Anthropic, OpenAI, Cursor, Replit y la comunidad, y analiza detalladamente las vulnerabilidades de seguridad existentes en el ciclo de vida del MCP Server (creación, ejecución, actualización), como conflictos de nombres, suplantación de instaladores, inyección de código, conflictos de nombres de herramientas, escape de sandbox, persistencia de permisos, etc. (Fuente: WeChat)

CVPR Oral: UniAP – Algoritmo unificado de paralelismo automático intra e intercapa: El grupo de investigación del profesor Li Wujun de la Universidad de Nanjing propone UniAP, un algoritmo de entrenamiento distribuido que puede optimizar conjuntamente estrategias de paralelismo intra-capa (datos/tensor/ZeRO) e inter-capa (pipeline). Mediante la modelización con programación cuadrática entera mixta, UniAP puede buscar automáticamente esquemas de entrenamiento distribuido eficientes, resolviendo el problema de la configuración manual compleja y de baja eficiencia. Los experimentos muestran que UniAP es hasta 3.8 veces más rápido que los métodos de paralelismo automático existentes y 9 veces más rápido que las estrategias no optimizadas, y puede evitar eficazmente entre el 64% y el 87% de las estrategias inválidas (OOM), mejorando la facilidad de uso. El algoritmo ha sido adaptado a las tarjetas de computación de IA nacionales. (Fuente: WeChat)
Tina: Modelos pequeños de bajo costo y alta capacidad de razonamiento mediante LoRA: Un equipo de la Universidad del Sur de California propone la serie de modelos Tina (Tiny Reasoning Models via LoRA). Utilizando LoRA para el post-entrenamiento con aprendizaje por refuerzo sobre la base de DeepSeek-R1-Distill-Qwen de 1.5B parámetros, los modelos Tina logran un rendimiento comparable o incluso superior a los modelos base ajustados con parámetros completos en múltiples benchmarks de razonamiento (AIME, AMC, MATH, GPQA, Minerva), con un costo de entrenamiento extremadamente bajo (el mejor checkpoint costó solo 9 dólares). La investigación revela las ventajas de LoRA en el aprendizaje eficiente de formatos/estructuras de razonamiento y observa un fenómeno de desacoplamiento entre las métricas de formato y las métricas de precisión durante el entrenamiento. (Fuente: WeChat)
Optimización recursiva de divergencia KL: Nuevo método eficiente de entrenamiento de modelos: Un nuevo artículo propone el método de Optimización Recursiva de Divergencia KL (Recursive KL Divergence Optimization), que según se afirma, puede lograr hasta un 80% de mejora en la eficiencia del entrenamiento de modelos (especialmente en el ajuste fino). Este método podría restringir las actualizaciones del modelo de una manera más optimizada, reduciendo los recursos computacionales o el tiempo necesario para el entrenamiento, ofreciendo una nueva vía para entrenar y ajustar modelos de forma más económica y rápida. (Fuente: Reddit r/LocalLLaMA)
💼 Negocios
Sakana AI busca aprovechar la incertidumbre política de EE. UU. para crecer en Japón: La startup japonesa de IA, Sakana AI, considera que la incertidumbre política en Estados Unidos y la demanda de soluciones de IA nacionales (especialmente en instituciones gubernamentales y financieras) le brindan una oportunidad de crecimiento en Japón. El gerente de desarrollo de negocios de la compañía indicó que esperan tener entre 5 y 10 casos de uso de consumidores de instituciones gubernamentales y financieras en los próximos 6 meses. El CEO David Ha señaló que, en un contexto de crecientes tensiones geopolíticas, aumenta la demanda de los países democráticos por actualizar la infraestructura gubernamental y de defensa, y el enfoque de la compañía en aplicaciones de defensa (como riesgos de bioseguridad y seguimiento de desinformación) es crucial. (Fuente: SakanaAILabs, SakanaAILabs)
Meta predice que los ingresos de la IA generativa alcanzarán los 1,4 billones de dólares en 2035: Meta predice que su negocio de IA generativa generará 3 mil millones de dólares en ingresos en 2025, y espera que aumente drásticamente a 1,4 billones de dólares para 2035. Esta predicción indica que Meta es extremadamente optimista sobre el potencial de crecimiento a largo plazo en el campo de la IA y probablemente continuará manteniendo un alto gasto de capital para invertir en investigación, desarrollo e infraestructura de IA. (Fuente: brickroad7)

Alimama lanza el modelo grande de conocimiento mundial URM: Alimama ha lanzado URM (Universal Recommendation Model), un gran modelo de lenguaje que combina conocimiento mundial y conocimiento del dominio del comercio electrónico. El modelo, mediante la inyección de conocimiento (ID de producto como token especial) y la alineación de información (fusionando ID con representaciones semánticas multimodales), puede comprender los intereses históricos del usuario y realizar recomendaciones basadas en inferencias. URM adopta un método de generación Sequence-In-Set-Out, generando múltiples representaciones de usuario en paralelo para mejorar el efecto y la diversidad, manteniendo al mismo tiempo la eficiencia de la inferencia. Ya se ha implementado en el escenario de publicidad display de Alimama y resuelve el problema de latencia de LLM mediante un enlace de inferencia asíncrono, mejorando los resultados de las campañas de los comerciantes y la experiencia de compra del usuario. (Fuente: WeChat)

🌟 Comunidad
El fin de la era GPT-4 genera nostalgia y debate: Sam Altman se despidió de GPT-4 en una publicación, afirmando que inició una revolución y que guardará sus pesos para futuros historiadores. Esta acción generó una amplia nostalgia en la comunidad, con muchos recordando a GPT-4 como el primer modelo que les hizo sentir el potencial de la AGI. Al mismo tiempo, esto también estimuló discusiones sobre el código abierto, con miembros de la comunidad como Hugging Face pidiendo a OpenAI que libere los pesos de GPT-4 para investigación, en lugar de simplemente archivarlos. (Fuente: skirano, sama, iScienceLuvr, huggingface, Teknium1, eliza_luth, JvNixon, huybery, tokenbender, _philschmid)
Observaciones y debate sobre la pista de AI Coding: Zhang Hailong, fundador de GruAI, considera que AI Coding es una de las pocas áreas donde actualmente se puede ver PMF. El éxito de Cursor radica en crear un nuevo mercado, y su valor de UI es enorme. Opina que la dirección de Devin es correcta pero demasiado ambiciosa, con un ciclo de tiempo largo, aunque la probabilidad de éxito está aumentando, y eventualmente competirá con Cursor. Para las startups, cree que no deben preocuparse excesivamente por la competencia de las grandes empresas; la clave está en la fuerza del producto y el valor único. El avance de los modelos reduce significativamente la necesidad de compensación por ingeniería, y los emprendedores deben distinguir qué problemas serán resueltos por el desarrollo de modelos y cuáles representan la verdadera fuerza del producto. (Fuente: WeChat)

Reflexión sobre la afirmación ‘La IA reemplazará tu trabajo’: La discusión en la comunidad señala que la afirmación “La IA no reemplazará tu trabajo, pero sí lo harán las personas que usan IA”, aunque superficialmente correcta, es demasiado simplista y constituye un “teatro de consenso” que impide pensar en problemas más profundos. La clave real reside en comprender cómo la IA cambia la estructura del trabajo, remodela los flujos de trabajo, altera la lógica organizacional y cómo será el trabajo futuro bajo el nuevo sistema, en lugar de centrarse únicamente en la automatización o mejora a nivel de tareas individuales. (Fuente: Reddit r/ArtificialInteligence)

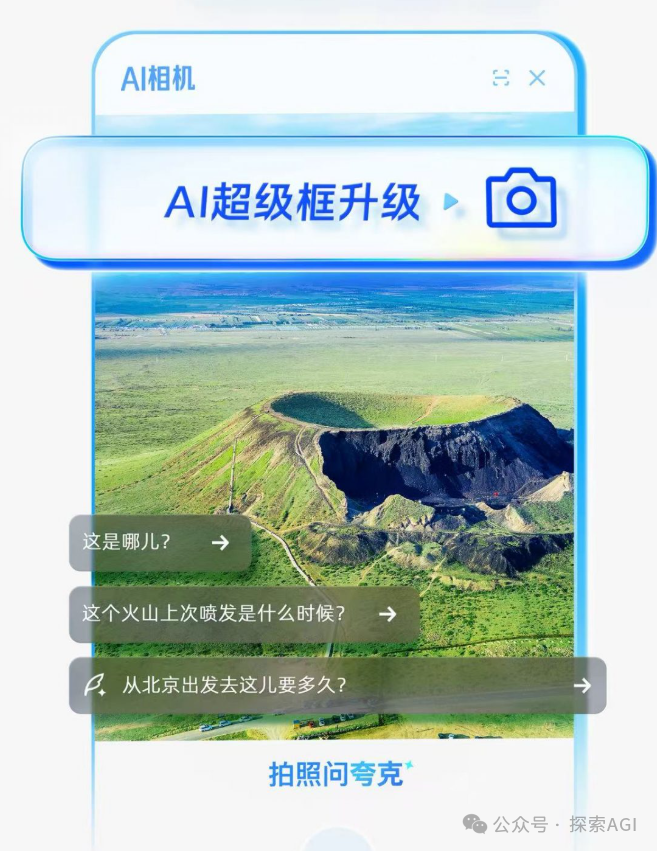
La nueva puerta de entrada para la interacción de los agentes de IA con el mundo físico: la cámara: Se discute que funciones similares a “拍照问” (consulta por foto) de Quark representan una nueva tendencia en la interacción de aplicaciones de IA. A través de la cámara del teléfono móvil, un sensor ubicuo, combinado con la comprensión multimodal y las capacidades de Agent, la IA puede comprender mejor el mundo físico y, basándose en las necesidades implícitas o explícitas del usuario, tomar decisiones autónomas y llamar a capacidades para completar tareas (como identificar objetos, traducir, comparar precios, ayudar con tareas escolares, procesar facturas, etc.). Esto transforma la cámara de una simple herramienta de entrada de información en un nexo que conecta el mundo físico con la inteligencia digital, logrando el objetivo de “Get it Done”. (Fuente: WeChat)
💡 Otros
IA e investigación científica: La opinión de la comunidad es que la IA se está convirtiendo gradualmente en las nuevas “matemáticas” de la investigación científica, lo que significa que la IA, al igual que las matemáticas, se convertirá en una herramienta y un lenguaje fundamentales para impulsar el descubrimiento y la comprensión científicos. (Fuente: shuchaobi)

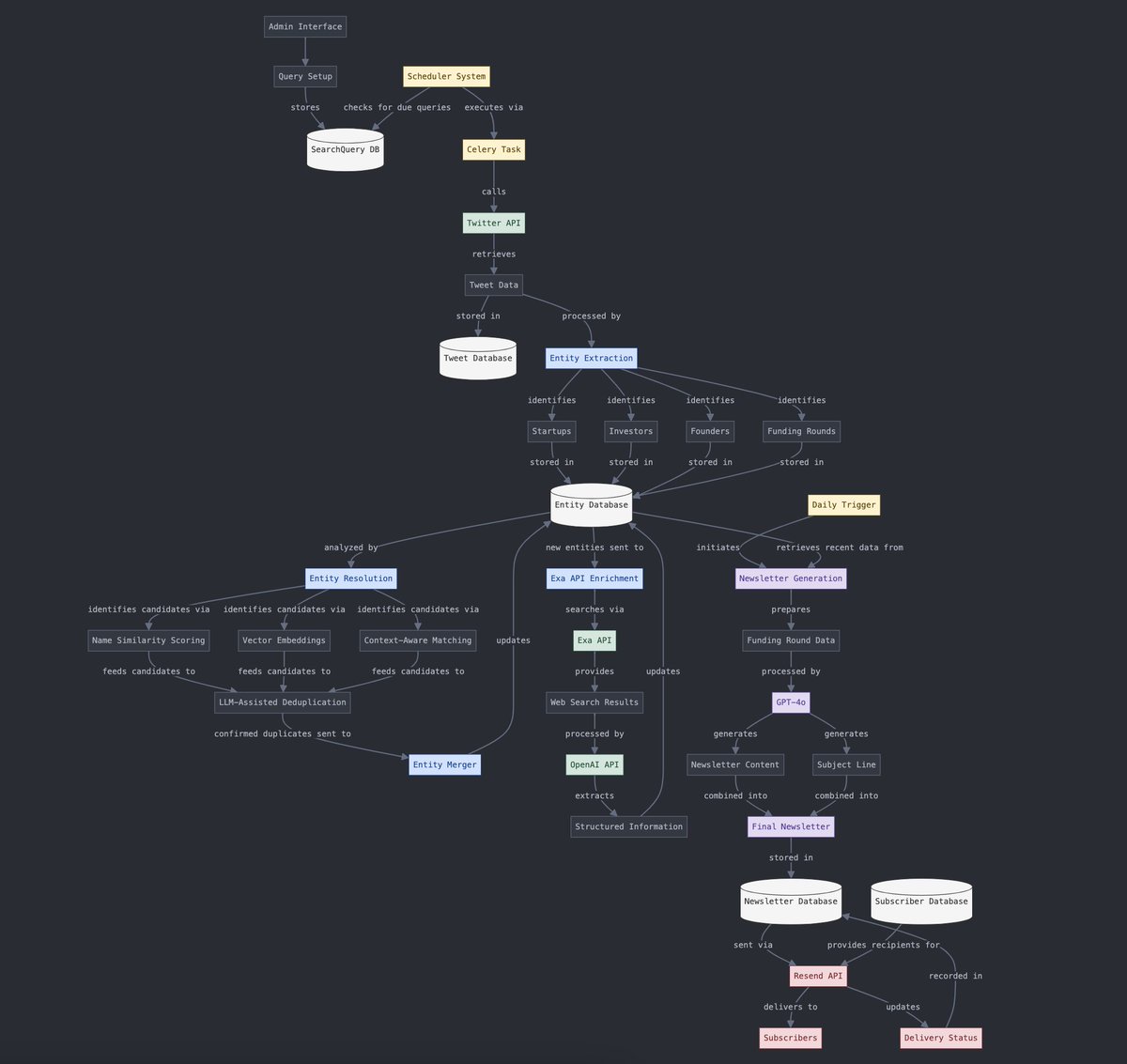
Conversión de datos estructurados y no estructurados: Yohei Nakajima demuestra el uso de la IA para convertir datos no estructurados de tuits en datos estructurados, para luego reconvertirlos en un boletín diario no estructurado, lo que refleja la aplicación de la IA en el procesamiento de información y los flujos de trabajo de generación de contenido. (Fuente: yoheinakajima)
El futuro de la combinación de IA y VR: La discusión en la comunidad contempla el potencial de combinar IA y VR, imaginando un futuro en el que sea posible generar y manipular directamente objetos 3D en un “espacio de pizarra blanca” de VR mediante lenguaje natural o pensamiento, logrando una creación impulsada por la cognición. Se considera a Meta un actor clave en el impulso de esta dirección. (Fuente: Reddit r/ArtificialInteligence)