
Palabras clave:DeepSeek-Prover-V2, Qwen3, Modelo de razonamiento matemático a gran escala, Modelo multimodal, Métodos de evaluación de IA, Modelos de gran escala de código abierto, Aprendizaje por refuerzo, Cadena de suministro de IA, DeepSeek-Prover-V2-671B, Qwen2.5-Omni-3B, Equidad en el ranking LMArena, Método RLVR para razonamiento matemático, Análisis de riesgos en la cadena de suministro de IA
🔥 Foco
DeepSeek lanza el gran modelo de razonamiento matemático DeepSeek-Prover-V2: DeepSeek ha lanzado la serie de modelos DeepSeek-Prover-V2, diseñados específicamente para la demostración matemática formal y el razonamiento lógico complejo, incluyendo versiones de 671B y 7B. Este modelo se basa en la arquitectura DeepSeek V3 MoE y ha sido ajustado finamente en áreas como el razonamiento matemático, la generación de código y el procesamiento de documentos legales. Los datos oficiales muestran que la versión 671B resuelve casi el 90% de los problemas de miniF2F, mejora significativamente el rendimiento SOTA en PutnamBench y alcanza una tasa de aprobación considerable en las versiones formalizadas de los problemas AIME 24 y 25. Este avance marca un progreso importante en la automatización del razonamiento matemático y la demostración formal por parte de la IA, lo que podría impulsar el desarrollo en campos como la investigación científica y la ingeniería de software. (Fuente: zhs05232838, reach_vb, wordgrammer, karminski3, cognitivecompai, gfodor, Dorialexander, huajian_xin, qtnx_, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Lanzamiento y apertura de la serie de grandes modelos Qwen3: El equipo Qwen de Alibaba ha lanzado la última serie de grandes modelos Qwen3, que incluye 8 modelos con cantidades de parámetros de 0.6B a 235B, abarcando modelos densos y modelos MoE. Los modelos Qwen3 tienen la capacidad de cambiar entre modos de pensamiento/no pensamiento, muestran mejoras significativas en inferencia, matemáticas, generación de código y procesamiento multilingüe (soportando 119 idiomas), y han mejorado las capacidades de Agent y el soporte para MCP. Las evaluaciones oficiales indican que su rendimiento supera a los modelos anteriores Qwen y Qwen2.5, y en algunos benchmarks supera a Llama4, DeepSeek R1 e incluso a Gemini 2.5 Pro. La serie de modelos ha sido abierta en Hugging Face y ModelScope bajo la licencia Apache 2.0. (Fuente: togethercompute, togethercompute, 36氪, QwenLM/Qwen3 – GitHub Trending (all/daily))
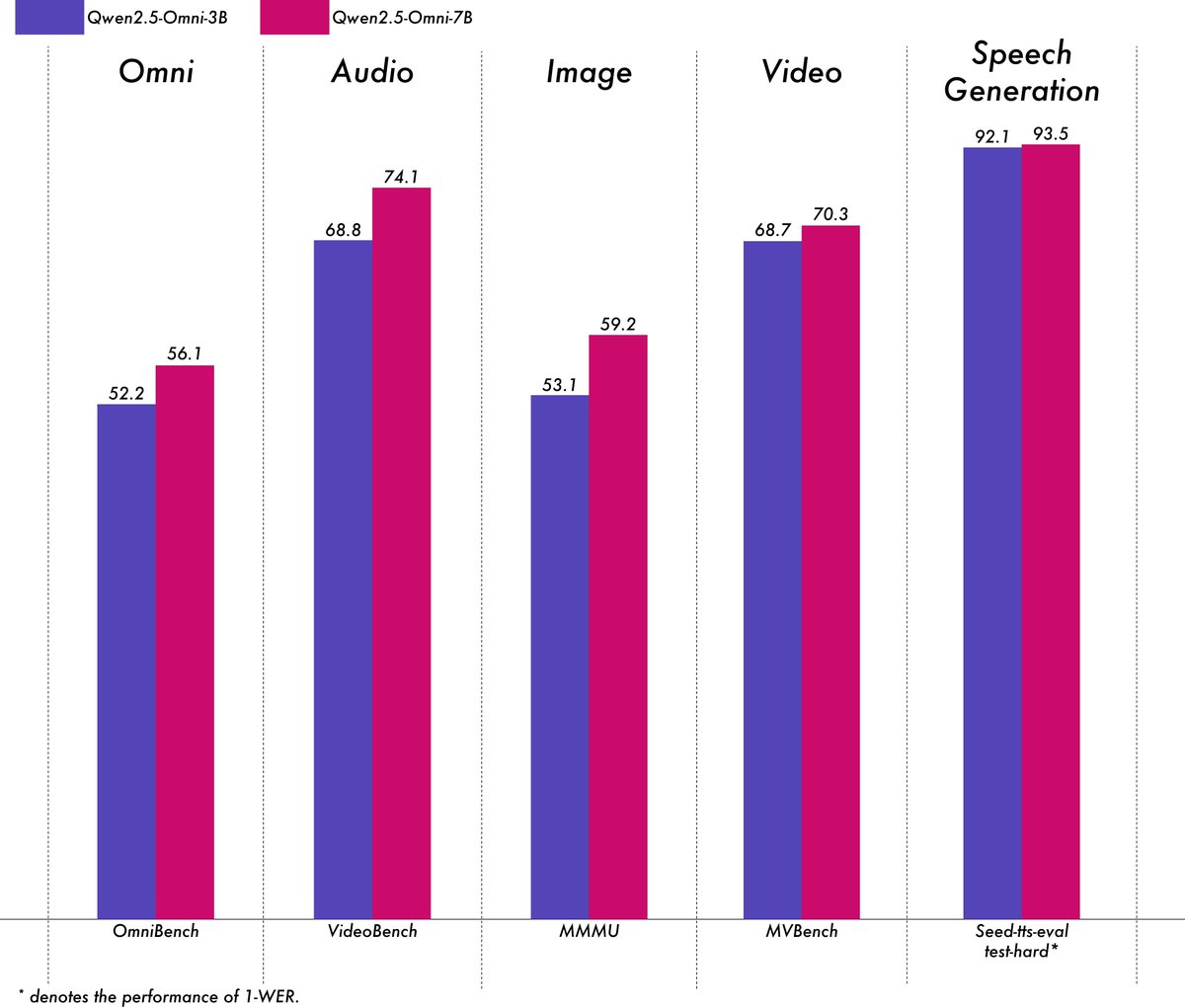
Alibaba lanza el modelo multimodal ligero Qwen2.5-Omni-3B: El equipo Qwen de Alibaba ha lanzado el modelo Qwen2.5-Omni-3B, un modelo multimodal de extremo a extremo capaz de procesar entradas de texto, imagen, audio y video, y generar texto y flujos de audio. En comparación con la versión 7B, el modelo 3B reduce significativamente el consumo de VRAM (más del 50%) al procesar secuencias largas (aproximadamente 25k tokens), permitiendo interacciones de audio y video de 30 segundos en GPUs de consumo de 24GB, mientras conserva más del 90% de la capacidad de comprensión multimodal del modelo 7B y una precisión de salida de voz comparable. El modelo está disponible en Hugging Face y ModelScope. (Fuente: Alibaba_Qwen, tokenbender, karminski3, _akhaliq, awnihannun, Reddit r/LocalLLaMA)
Cohere publica un artículo cuestionando la imparcialidad del ranking LMArena: Investigadores de Cohere han publicado el artículo “The Leaderboard Illusion”, que analiza en profundidad el ampliamente utilizado ranking Chatbot Arena (LMArena). El artículo señala que, aunque LMArena tiene como objetivo proporcionar una evaluación justa, sus políticas actuales (como permitir pruebas privadas, retirar puntuaciones después de la presentación del modelo, mecanismos opacos de desuso del modelo, acceso asimétrico a los datos, etc.) pueden sesgar los resultados de la evaluación a favor de unos pocos grandes proveedores de modelos que pueden aprovechar estas reglas, existiendo un riesgo de sobreajuste (overfitting), distorsionando así la medición del progreso real de los modelos de IA. El artículo ha provocado un amplio debate en la comunidad sobre la cientificidad y la imparcialidad de los métodos de evaluación de modelos de IA, y propone sugerencias concretas de mejora. (Fuente: BlancheMinerva, sarahookr, sarahookr, aidangomez, maximelabonne, xanderatallah, sarahcat21, arohan, sarahookr, random_walker, random_walker)

🎯 Tendencias
Xiaomi lanza el modelo de inferencia de código abierto MiMo-7B: Xiaomi ha lanzado MiMo-7B, un modelo de inferencia de código abierto entrenado con 25 billones de tokens, especialmente bueno en matemáticas y codificación. El modelo utiliza una arquitectura decoder-only Transformer, que incluye tecnologías como GQA, pre-RMSNorm, SwiGLU y RoPE, y añade 3 módulos MTP (Multi-Token-Prediction) para acelerar la inferencia mediante decodificación especulativa. El modelo ha pasado por tres etapas de preentrenamiento y post-entrenamiento basado en aprendizaje por refuerzo con una versión modificada de GRPO, resolviendo problemas de hacking de recompensas y mezcla de idiomas en tareas de razonamiento matemático. (Fuente: scaling01)

JetBrains abre el código de su modelo de completado de código Mellum: JetBrains ha abierto el código de su modelo de completado de código Mellum en Hugging Face. Se trata de un modelo pequeño, eficiente y enfocado (Focal Model), diseñado específicamente para tareas de completado de código. El modelo fue entrenado desde cero por JetBrains y es el primero de su serie de LLM especializados en desarrollo. Esta iniciativa tiene como objetivo proporcionar a los desarrolladores herramientas de asistencia de código más profesionales. (Fuente: ClementDelangue, Reddit r/LocalLLaMA)
LightOn lanza el nuevo modelo de recuperación SOTA GTE-ModernColBERT: Para superar las limitaciones de los modelos densos basados en ModernBERT, LightOn ha lanzado GTE-ModernColBERT. Este es el primer modelo SOTA de interacción tardía (multi-vector) entrenado con su framework PyLate, diseñado para mejorar el rendimiento en tareas de recuperación de información, especialmente en escenarios que requieren una comprensión de interacción más fina. (Fuente: tonywu_71, lateinteraction)

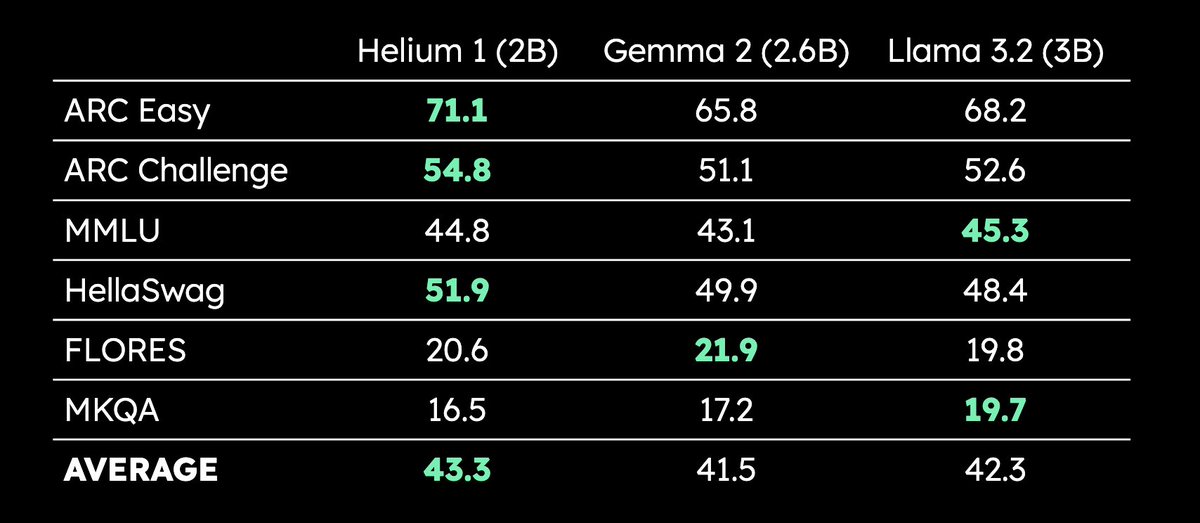
Kyutai lanza el LLM multilingüe de 2B parámetros Helium 1: Kyutai ha lanzado el nuevo LLM de 2 mil millones de parámetros Helium 1, y al mismo tiempo ha abierto el código del proceso de replicación de su conjunto de datos de entrenamiento, dactory, que cubre los 24 idiomas oficiales de la UE. Helium 1 establece nuevos estándares de rendimiento para los idiomas europeos dentro de su escala de parámetros, con el objetivo de mejorar las capacidades de IA para los idiomas europeos. (Fuente: huggingface, armandjoulin, eliebakouch)
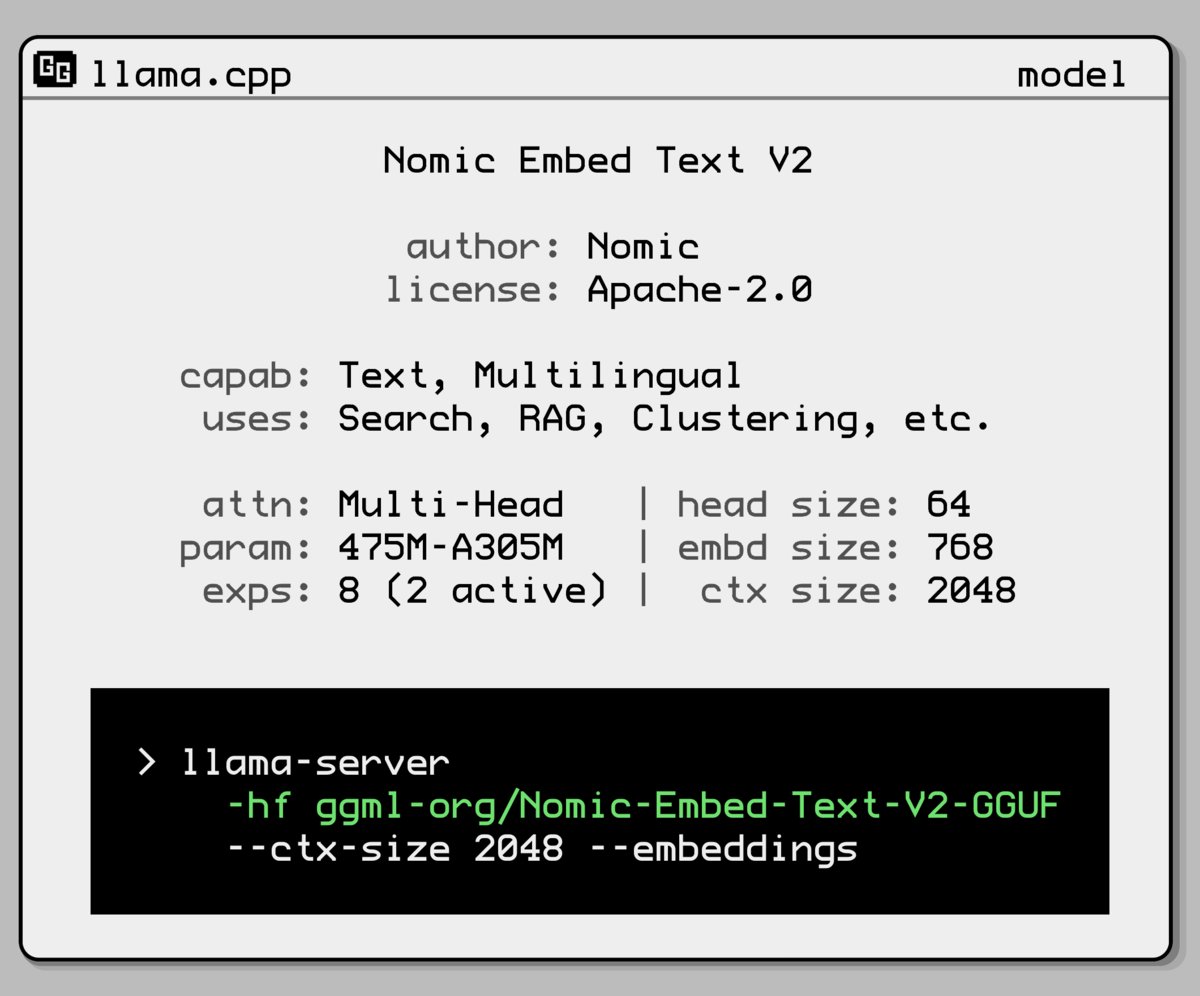
Nomic AI lanza un nuevo modelo de embedding con arquitectura Mixture-of-Experts: Nomic AI ha presentado un nuevo modelo de embedding que adopta una arquitectura Mixture-of-Experts (MoE). Esta arquitectura se utiliza normalmente en modelos grandes para mejorar la eficiencia y el rendimiento; aplicarla a modelos de embedding podría tener como objetivo mejorar la capacidad de representación para tareas o tipos de datos específicos, o lograr una mejor generalización manteniendo bajos costos computacionales. (Fuente: ggerganov)
OpenAI revierte la actualización de GPT-4o para solucionar el problema de adulación excesiva: OpenAI anunció la reversión de la actualización de GPT-4o en ChatGPT de la semana pasada, debido a que la versión mostraba un comportamiento excesivamente adulador y complaciente con los usuarios (sycophancy). Los usuarios ahora están utilizando una versión anterior con un comportamiento más equilibrado. OpenAI afirma estar trabajando para solucionar el problema del comportamiento adulador del modelo y ha programado una sesión de AMA (Ask Me Anything) con la responsable de comportamiento del modelo, Joanne Jang, para discutir la configuración de la personalidad de ChatGPT. (Fuente: openai, joannejang, Reddit r/ChatGPT)
Terminus actualiza su prospecto y anuncia su estrategia de inteligencia espacial: La empresa de AIoT Terminus ha actualizado su prospecto, revelando ingresos de 1.843 millones de yuanes en 2024, un aumento interanual del 83.2%. Al mismo tiempo, la compañía anunció su nueva estrategia de inteligencia espacial, formando una arquitectura de tres productos principales: modelo de dominio AIoT (basado en la fusión con DeepSeek), infraestructura AIoT (base de computación inteligente) y agentes AIoT (robots inteligentes corpóreos, etc.), con el objetivo de un despliegue integral en la inteligencia espacial. (Fuente: 36氪)
Estudio revela que la diferencia entre Transformer y SSM en tareas de recuperación se debe a unas pocas cabezas de atención: Una nueva investigación señala que los modelos de espacio de estados (SSM) se quedan atrás de los Transformer en tareas como MMLU (opción múltiple) y GSM8K (matemáticas), principalmente debido a desafíos en la capacidad de recuperación contextual. Curiosamente, el estudio encontró que tanto en la arquitectura Transformer como en la SSM, el cálculo clave para manejar las tareas de recuperación es realizado por solo unas pocas cabezas de atención (heads). Este hallazgo ayuda a comprender las diferencias intrínsecas entre las dos arquitecturas y podría guiar el diseño de modelos híbridos. (Fuente: simran_s_arora, _albertgu, teortaxesTex)
🧰 Herramientas
Novita AI es el primero en desplegar el servicio de inferencia DeepSeek-Prover-V2-671B: Novita AI anunció ser el primer proveedor en ofrecer el servicio de inferencia para el recién lanzado modelo de razonamiento matemático de 671B parámetros de DeepSeek, DeepSeek-Prover-V2. El modelo también está disponible en Hugging Face, y los usuarios ahora pueden probar directamente este potente modelo de razonamiento matemático y lógico a través de Novita AI o la plataforma Hugging Face. (Fuente: _akhaliq, mervenoyann)
PPIO Cloud lanza el servicio del modelo DeepSeek-Prover-V2-671B: La plataforma en la nube nacional PPIO Cloud ha lanzado rápidamente el servicio de inferencia para el recién publicado modelo DeepSeek-Prover-V2-671B. Los usuarios pueden experimentar este gran modelo de 671B parámetros, enfocado en la demostración matemática formal y el razonamiento lógico complejo, a través de esta plataforma. La plataforma también ofrece un mecanismo de invitación, donde invitar a amigos a registrarse otorga cupones utilizables tanto en la API como en la interfaz web. (Fuente: karminski3)

Gradio introduce una función sencilla de servidor MCP: El framework Gradio ha añadido una nueva función que permite convertir fácilmente cualquier aplicación Gradio en un servidor de Protocolo de Contexto de Modelo (MCP) simplemente añadiendo el parámetro mcp_server=True en demo.launch(). Esto significa que los desarrolladores pueden exponer rápidamente sus aplicaciones Gradio existentes (incluidas muchas alojadas en Hugging Face Spaces) para ser utilizadas por LLMs o Agents que soporten MCP, simplificando enormemente la integración de aplicaciones de IA con Agents. (Fuente: mervenoyann, _akhaliq, ClementDelangue, huggingface, _akhaliq)
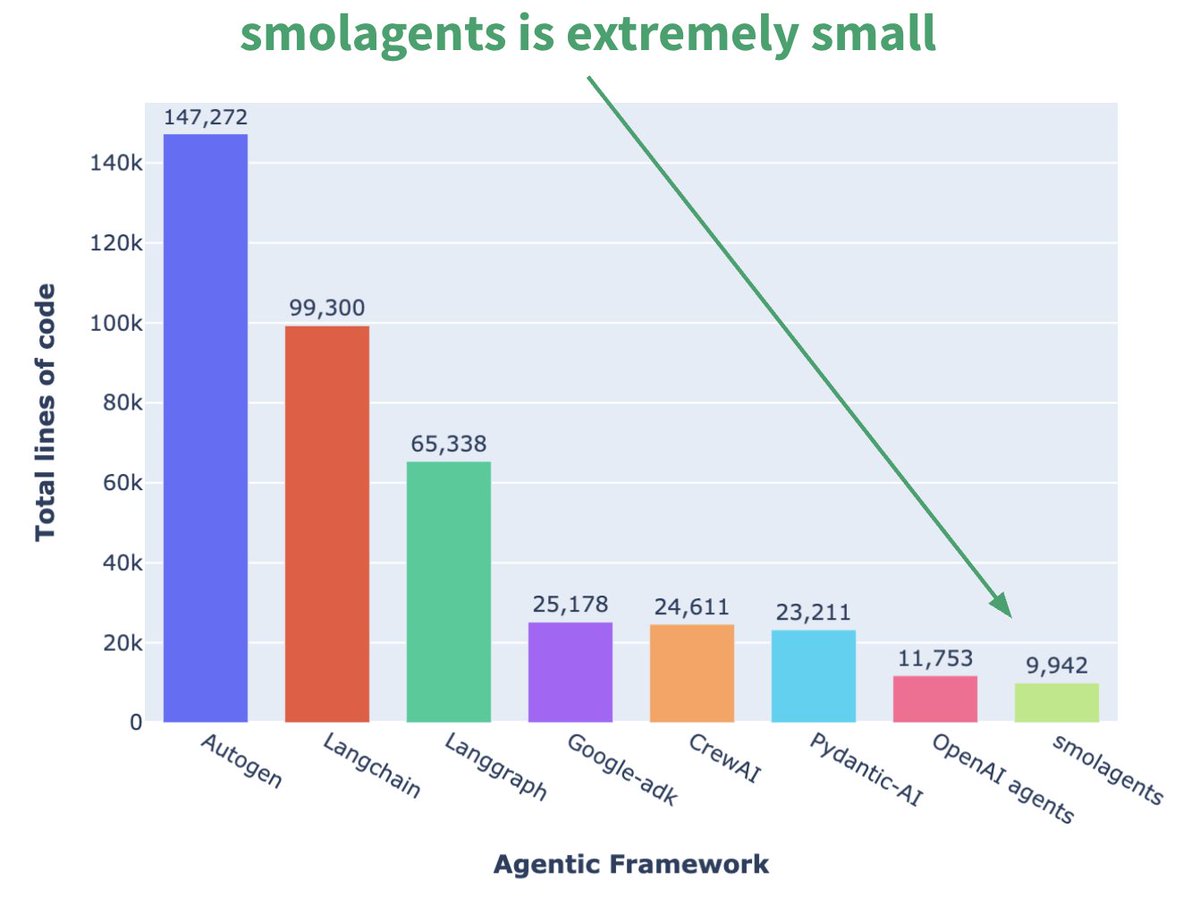
Hugging Face lanza el framework de Agent minimalista smolagents: Hugging Face ha lanzado un framework de Agent llamado smolagents, cuya característica principal es la simplicidad extrema. El framework tiene como objetivo proporcionar los bloques de construcción más esenciales, evitando la abstracción excesiva y la complejidad, permitiendo a los usuarios construir flexiblemente sus propios flujos de trabajo de Agent sobre él. También se ha publicado un curso corto correspondiente en DeepLearning.AI para ayudar a los usuarios a empezar. (Fuente: huggingface, AymericRoucher, ClementDelangue)
Runway lanza la función Gen-4 References, mejorando la consistencia en la generación de video: Runway ha lanzado la función Gen-4 References para todos los usuarios de pago. Esta función permite a los usuarios utilizar fotos, imágenes generadas, modelos 3D o selfies como referencia para generar contenido de video con personajes, lugares, etc., consistentes. Esto resuelve el persistente problema de la consistencia en la generación de video por IA, haciendo posible colocar personas u objetos específicos en cualquier escenario imaginado, mejorando la controlabilidad y utilidad de la creación de video con IA. (Fuente: c_valenzuelab, eerac, c_valenzuelab, c_valenzuelab, c_valenzuelab, TomLikesRobots, c_valenzuelab)
Hugging Face Spaces se actualiza a Nvidia H200, mejorando la capacidad de ZeroGPU: Hugging Face anunció que su ZeroGPU v2 ha cambiado a GPUs Nvidia H200. Esto significa que Hugging Face Spaces (especialmente el plan Pro) ahora está equipado con 70GB de VRAM y una capacidad de cálculo de punto flotante (flops) 2.5 veces mayor. Esta medida tiene como objetivo desbloquear nuevos escenarios de aplicaciones de IA y proporcionar a los usuarios opciones de computación CUDA más potentes, distribuidas y rentables, soportando la ejecución de modelos más grandes y complejos. (Fuente: huggingface, ClementDelangue)

Lanzamiento de SkyPilot v0.9, añade panel de control y funciones de despliegue en equipo: SkyPilot ha lanzado la versión 0.9, introduciendo una función de panel de control web que permite a los usuarios y equipos ver el estado de todos los clústeres y trabajos, registros, colas, y compartir URLs directamente. La nueva versión también soporta despliegues en equipo (arquitectura cliente-servidor), guardado de checkpoints de modelos 10 veces más rápido a través de buckets de almacenamiento en la nube, y añade soporte para Nebius AI y GB200. Estas actualizaciones tienen como objetivo mejorar la eficiencia de gestión y la capacidad de colaboración de SkyPilot para ejecutar cargas de trabajo de IA en la nube. (Fuente: skypilot_org)

Tesslate lanza el modelo de generación de UI de 7B UIGEN-T2: Tesslate ha lanzado UIGEN-T2, un modelo de 7B parámetros especializado en generar interfaces de sitios web HTML/CSS/JS + Tailwind que incluyen gráficos y elementos interactivos. El modelo, entrenado con datos específicos, puede generar elementos de UI funcionales como carritos de compra, gráficos, menús desplegables, diseños responsivos y temporizadores, y soporta estilos como glassmorphism y modo oscuro. La versión GGUF del modelo y los pesos LoRA se han publicado en Hugging Face, y se proporcionan un Playground y Demo en línea. (Fuente: Reddit r/LocalLLaMA)
AI EngineHost ofrece servicio de hosting de IA vitalicio a bajo precio, generando dudas: Un servicio llamado AI EngineHost afirma ofrecer hosting web vitalicio y poder desplegar LLMs de código abierto como LLaMA 3, Grok-1 en servidores GPU NVIDIA con un solo clic, por un pago único de 16.95 dólares. El servicio promete almacenamiento NVMe ilimitado, ancho de banda, dominios, soporte para múltiples lenguajes y bases de datos, e incluye licencia comercial. Sin embargo, su precio extremadamente bajo y la promesa “vitalicia” han generado amplias dudas en la comunidad sobre su legitimidad y sostenibilidad, sospechando que podría ser una estafa o tener trampas ocultas. (Fuente: Reddit r/deeplearning)
BrowserQwen: Asistente de navegador basado en Qwen-Agent: El equipo de Qwen ha lanzado BrowserQwen, una aplicación de asistente de navegador construida sobre el framework Qwen-Agent. Utiliza las capacidades de uso de herramientas, planificación y memoria del modelo Qwen, con el objetivo de ayudar a los usuarios a interactuar de manera más inteligente con el navegador, posiblemente incluyendo comprensión de contenido web, extracción de información, automatización de tareas, etc. (Fuente: QwenLM/Qwen-Agent – GitHub Trending (all/daily))
AutoMQ: Alternativa Stateless a Kafka basada en S3: AutoMQ es un proyecto de código abierto que tiene como objetivo proporcionar una alternativa stateless a Kafka construida sobre S3 o almacenamiento de objetos compatible. Su principal ventaja radica en resolver los problemas de escalabilidad y alto costo de Kafka tradicional en la nube (especialmente el tráfico entre zonas de disponibilidad). Al separar el almacenamiento del cómputo, AutoMQ afirma lograr una eficiencia de costos 10 veces mayor, autoescalado en segundos, latencia de milisegundos de un solo dígito y alta disponibilidad multizona. (Fuente: AutoMQ/automq – GitHub Trending (all/daily))
Daytona: Infraestructura segura y elástica para ejecutar código generado por IA: Daytona es una plataforma de infraestructura diseñada para ser segura, aislada y de respuesta rápida, específicamente para ejecutar código generado por IA. Soporta control programático a través de SDK (Python/TypeScript), puede crear rápidamente entornos sandbox (menos de 90 ms), realizar operaciones de archivos, comandos Git, interacciones LSP y ejecución de código, y soporta persistencia e imágenes OCI/Docker. Su objetivo es resolver los problemas de seguridad y gestión de recursos al ejecutar código de IA no confiable o experimental. (Fuente: daytonaio/daytona – GitHub Trending (all/daily))
MLX Swift Examples: Biblioteca de ejemplos que muestra el uso de MLX Swift: El equipo MLX de Apple mantiene un proyecto que contiene múltiples ejemplos de uso del framework MLX Swift. Estos ejemplos cubren aplicaciones como grandes modelos de lenguaje (LLM), modelos de lenguaje visual (VLM), modelos de embedding, generación de imágenes Stable Diffusion y el clásico entrenamiento de reconocimiento de dígitos manuscritos MNIST. El repositorio de código tiene como objetivo ayudar a los desarrolladores a aprender y aplicar MLX Swift para tareas de machine learning, especialmente dentro del ecosistema de Apple. (Fuente: ml-explore/mlx-swift-examples – GitHub Trending (all/daily))
Lanzamiento de Blender 4.4, mejora el trazado de rayos y la usabilidad: El software 3D de código abierto Blender ha lanzado la versión 4.4. La nueva versión presenta mejoras significativas en el trazado de rayos, mejorando el efecto de reducción de ruido, especialmente al manejar Subsurface Scattering y Depth of Field, e introduce un mejor muestreo de ruido azul para mejorar la calidad de la vista previa y la consistencia de la animación. Además, se han mejorado el compositor de imágenes, el pincel Grab Cloth Brush, la herramienta Grease Pencil y la interfaz de usuario (como la visibilidad del índice de malla). Las funciones de edición de video también han sido optimizadas. (Fuente: YouTube – Two Minute Papers
)
📚 Aprendizaje
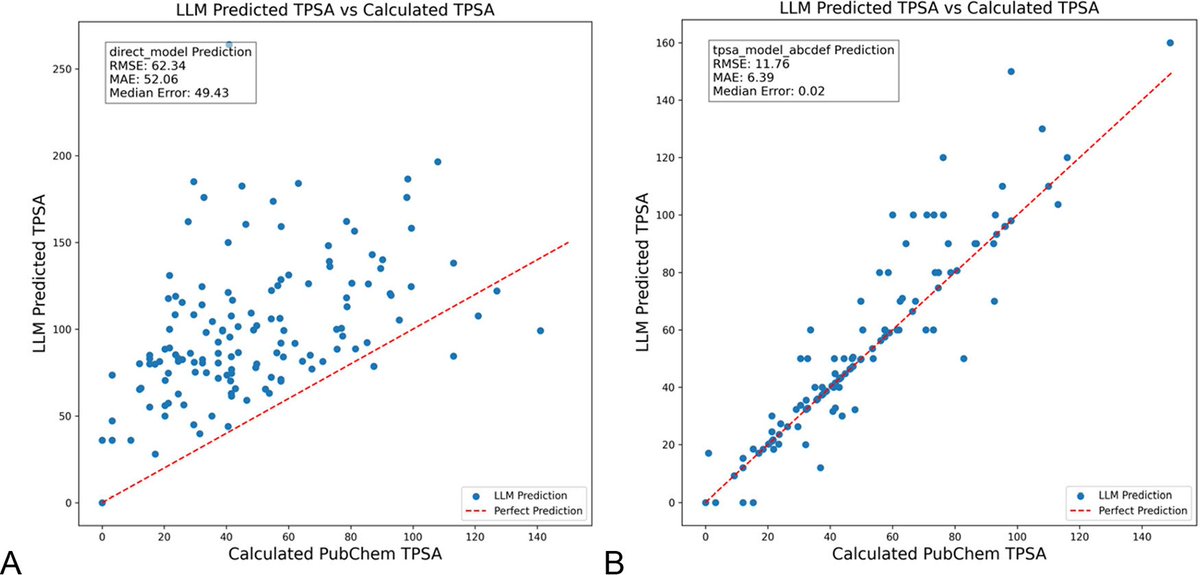
La optimización de prompts de LLM con DSPy reduce significativamente las alucinaciones en química: Un nuevo artículo publicado en el Journal of Chemical Information and Modeling demuestra que construir y optimizar prompts de LLM utilizando el framework DSPy puede reducir significativamente el problema de las alucinaciones en el campo de la química. La investigación, mediante la optimización de un programa DSPy, redujo el error cuadrático medio (RMS error) en la predicción del área de superficie polar topológica molecular (TPSA) en un 81%. Esto indica que mediante la optimización programática de prompts, se puede mejorar eficazmente la precisión y fiabilidad de los LLM en dominios científicos especializados como la química. (Fuente: lateinteraction, lateinteraction)
Artículo propone cuantificar el razonamiento de sentido común con grafos y realizar análisis mecanicistas: Un nuevo artículo propone un método para representar el conocimiento implícito de 37 actividades cotidianas como grafos dirigidos, generando así una cantidad masiva (aproximadamente 10^17 por actividad) de consultas de sentido común. Este método tiene como objetivo superar las limitaciones de los benchmarks existentes, que son limitados y no exhaustivos, para evaluar de manera más rigurosa la capacidad de razonamiento de sentido común de los LLM. La investigación utiliza la estructura de grafos para cuantificar el sentido común y mejora la técnica de activación de parches (activation patching) mediante prompts conjugados (conjugate prompts) para localizar los componentes clave responsables del razonamiento en el modelo. (Fuente: menhguin)

Método de aprendizaje por refuerzo (RLVR) que mejora significativamente el razonamiento matemático de LLM con una sola muestra: Un nuevo artículo propone que el método de Aprendizaje por Refuerzo con Retroalimentación de Validación (RLVR), utilizando solo una muestra de entrenamiento, puede mejorar significativamente el rendimiento de los grandes modelos de lenguaje en tareas matemáticas. Los experimentos muestran que en el benchmark MATH500, RLVR con una sola muestra puede aumentar la precisión de Qwen2.5-Math-1.5B del 36.0% al 73.6%, y la precisión de Qwen2.5-Math-7B del 51.0% al 79.2%. Este hallazgo podría inspirar una reconsideración de los mecanismos de RLVR y ofrecer nuevas vías para mejorar la capacidad del modelo en situaciones de bajos recursos. (Fuente: StringChaos, _akhaliq, _akhaliq, natolambert)

DeepLearning.AI actualiza el curso “LLMs as Operating Systems: Agent Memory”: El curso corto gratuito “LLMs as Operating Systems: Agent Memory”, ofrecido por DeepLearning.AI en colaboración con Letta, ha sido actualizado. El curso explica cómo usar el método MemGPT para construir Agents LLM que puedan gestionar memoria a largo plazo (más allá de las limitaciones de la ventana de contexto). El nuevo contenido incluye un servicio pre-desplegado de Letta Agent (para práctica de Agents en la nube) y funcionalidad de salida en streaming (para observar el proceso de razonamiento paso a paso del Agent), con el objetivo de ayudar a los estudiantes a construir sistemas de IA más adaptables y colaborativos. (Fuente: DeepLearningAI)

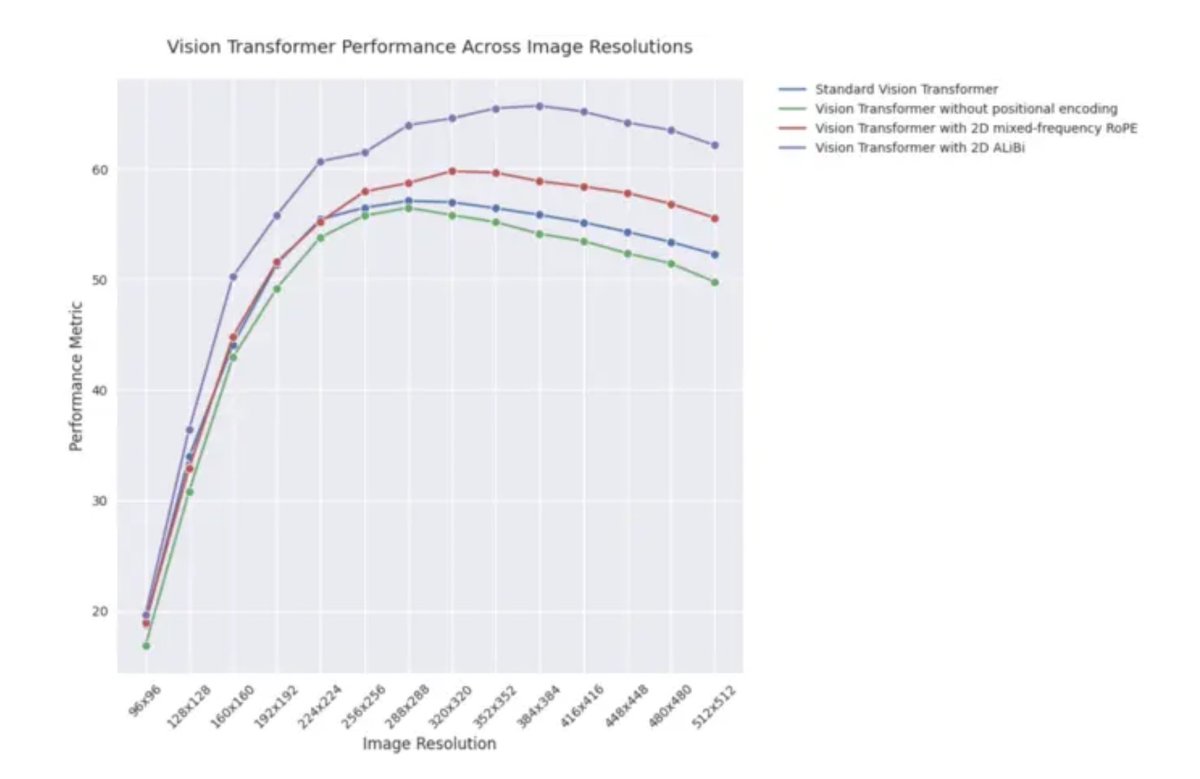
Entrada de blog de ICLR 2025: Rendimiento de extrapolación de 2D ALiBi en Vision Transformers: Una entrada de blog de ICLR 2025 señala que los Vision Transformers (ViT) que utilizan atención bidimensional con sesgos lineales (2D ALiBi) muestran el mejor rendimiento en la tarea de extrapolación a tamaños de imagen más grandes en el conjunto de datos Imagenet100. ALiBi es un método de codificación de posición relativa cuyo éxito en el campo del NLP inspiró su exploración en el dominio visual. Este resultado indica que 2D ALiBi ayuda a los ViT a generalizar mejor a resoluciones de imagen no vistas durante el entrenamiento. (Fuente: OfirPress)
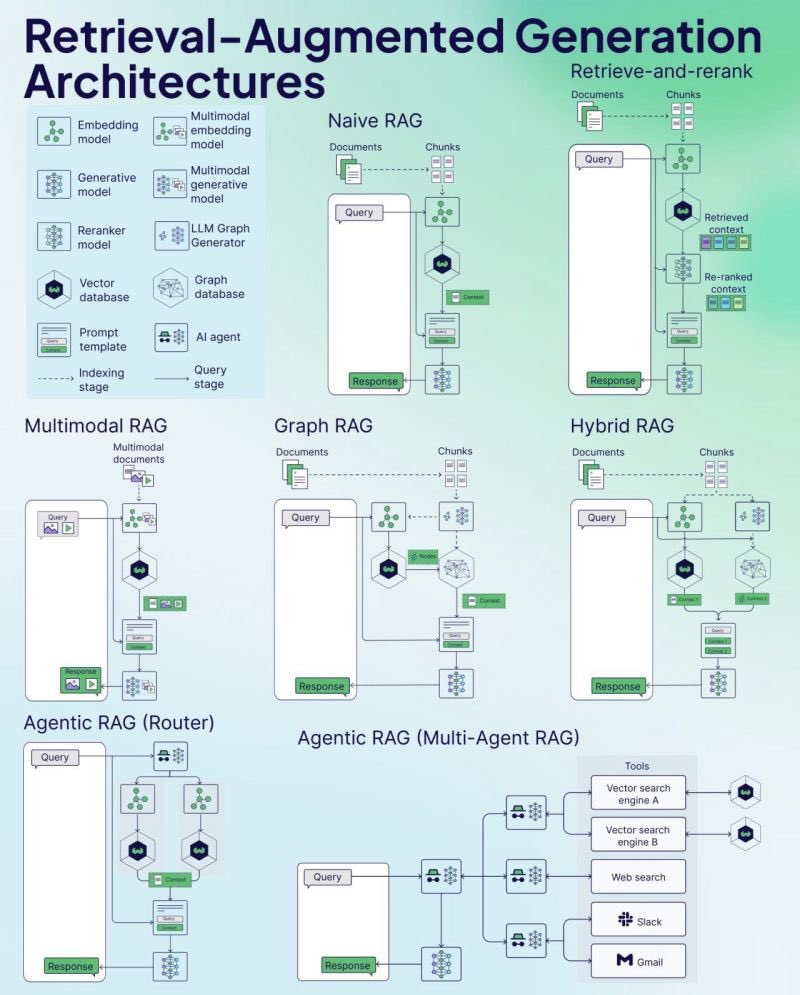
Weaviate publica una hoja de trucos (Cheat Sheet) de RAG: La empresa de bases de datos vectoriales Weaviate ha publicado una hoja de trucos (Cheat Sheet) sobre Generación Aumentada por Recuperación (RAG). Este material tiene como objetivo proporcionar a los desarrolladores una guía de referencia rápida, que posiblemente cubra conceptos clave de RAG, arquitectura, técnicas comunes, mejores prácticas o problemas frecuentes, para ayudar a los desarrolladores a comprender e implementar mejor los sistemas RAG. (Fuente: bobvanluijt)
Investigación del MIT revela la estructura y los riesgos de la cadena de suministro de IA: Investigadores del MIT y otras instituciones han publicado un nuevo artículo que explora las emergentes Cadenas de Suministro de IA (AI Supply Chains). A medida que el proceso de construcción de sistemas de IA se vuelve cada vez más descentralizado (involucrando a múltiples entidades como proveedores de modelos base, servicios de ajuste fino, proveedores de datos, plataformas de despliegue, etc.), el artículo investiga el impacto de esta estructura de red, incluyendo riesgos potenciales (como la propagación de fallos aguas arriba), asimetrías de información, conflictos de control y objetivos de optimización. La investigación analiza dos casos mediante análisis teóricos y empíricos, enfatizando la importancia de comprender y gestionar las cadenas de suministro de IA. (Fuente: jachiam0, aleks_madry)
LangChain lanza video de introducción de cinco minutos a LangSmith: LangChain ha publicado un video corto de 5 minutos que explica las funciones de su plataforma comercial LangSmith. El video presenta cómo LangSmith ayuda a lo largo de todo el ciclo de vida del desarrollo de aplicaciones y Agents LLM, incluyendo observabilidad (observability), evaluación (evaluation) e ingeniería de prompts (prompt engineering), con el objetivo de ayudar a los desarrolladores a mejorar el rendimiento de las aplicaciones. (Fuente: LangChainAI)
Together AI publica video tutorial sobre ejecución y ajuste fino de modelos OSS: Together AI ha publicado un nuevo video instructivo que guía a los usuarios sobre cómo ejecutar y ajustar finamente modelos grandes de código abierto en la plataforma Together AI. El video probablemente cubre pasos como la selección del modelo, configuración del entorno, carga de datos, inicio de tareas de entrenamiento y realización de inferencias, con el objetivo de reducir la barrera para que los usuarios utilicen su plataforma para la personalización y despliegue de modelos de código abierto. (Fuente: togethercompute)
Artículo propone usar “Agents conscientes” para evaluar la cognición social de los LLM: Un nuevo artículo presenta el framework SAGE (Sentient Agent as a Judge), un método de evaluación novedoso que utiliza Agents conscientes (Sentient Agents) que simulan dinámicas emocionales humanas y razonamiento interno para evaluar la capacidad de cognición social de los LLM en conversaciones. El framework tiene como objetivo probar la capacidad de los LLM para interpretar emociones, inferir intenciones ocultas y responder con empatía. La investigación encontró que en 100 escenarios de conversación de apoyo, las puntuaciones emocionales de los Agents conscientes se correlacionan altamente con métricas centradas en el ser humano (como BLRI, indicadores de empatía), y que los LLM con fuertes habilidades sociales no necesariamente requieren respuestas largas. (Fuente: menhguin)

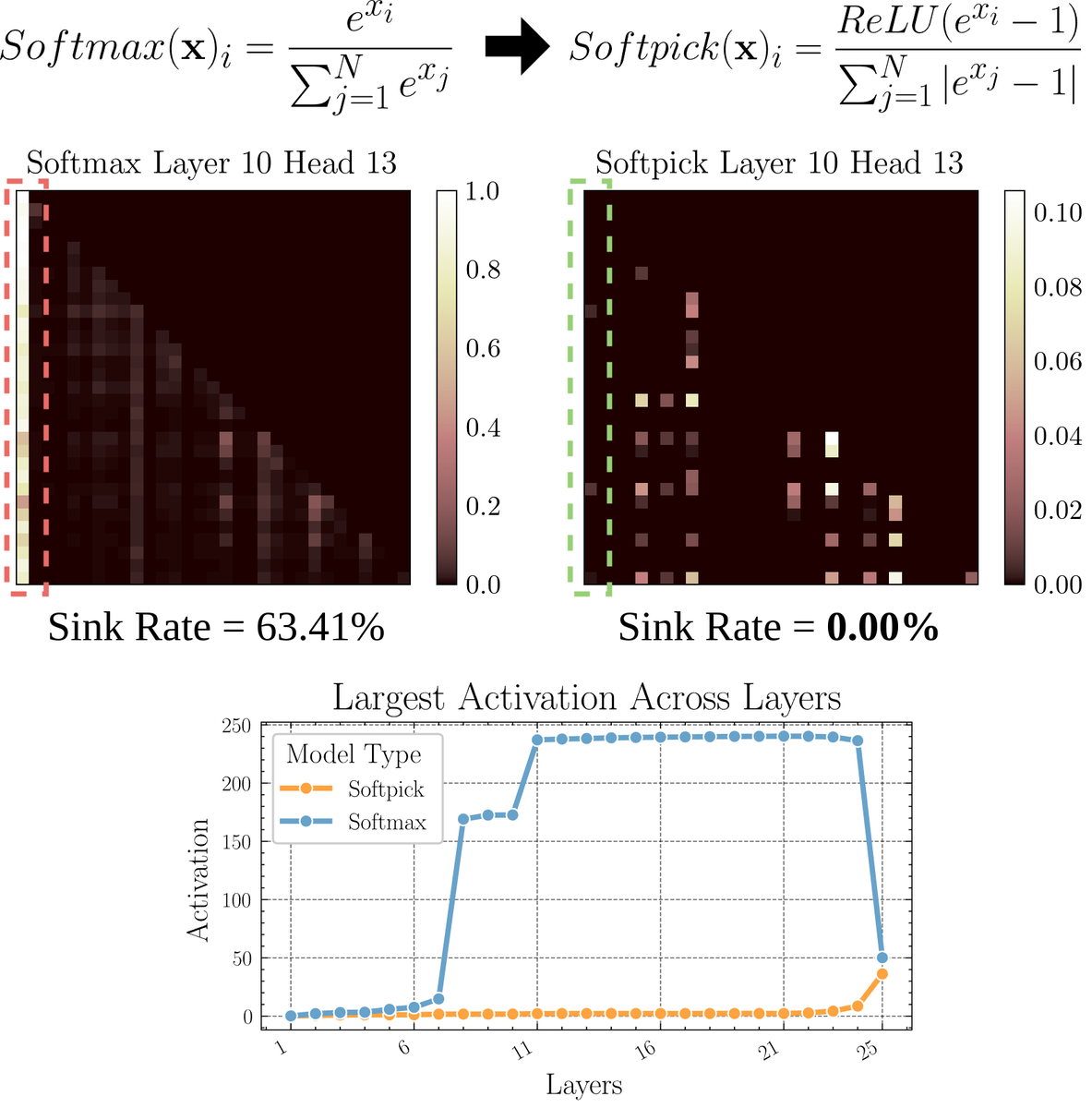
Artículo explora Softpick: un mecanismo de atención alternativo a Softmax: Un artículo preimpreso propone Softpick, una alternativa que modifica Softmax para abordar los problemas de “sumidero de atención” (attention sink) y valores de activación a gran escala en el mecanismo de atención. El método sugiere usar ReLU(x – 1) en el numerador de Softmax y abs(x – 1) en el término del denominador. Los investigadores creen que este simple ajuste podría mejorar algunos problemas inherentes de los mecanismos de atención existentes mientras se mantiene el rendimiento, especialmente al procesar secuencias largas o en escenarios que requieren una distribución de atención más estable. (Fuente: sedielem)
💼 Negocios
La startup de IA RogoAI completa una ronda de financiación Serie B de 50 millones de dólares: RogoAI, enfocada en construir una plataforma de investigación nativa de IA para la industria de servicios financieros, anunció la finalización de una ronda de financiación Serie B de 50 millones de dólares liderada por Thrive Capital, con la participación de J.P. Morgan Asset Management, Tiger Global, entre otros. Esta ronda de financiación se utilizará para acelerar el desarrollo de productos y la expansión del mercado de RogoAI en el análisis financiero y la automatización de la investigación. (Fuente: hwchase17, hwchase17)
La startup de búsqueda empresarial con IA Glean completa una nueva ronda de financiación con una valoración de 7 mil millones de dólares: Según The Information, la startup de búsqueda empresarial con IA Glean está a punto de completar una nueva ronda de financiación liderada por Wellington Management, con una valoración de aproximadamente 7 mil millones de dólares. La compañía completó una ronda de financiación con una valoración de 4.6 mil millones de dólares hace solo cuatro meses, y este significativo salto en la valoración refleja las altas expectativas del mercado para las aplicaciones de IA a nivel empresarial y las soluciones de gestión del conocimiento. (Fuente: steph_palazzolo)
Groq colabora con Meta para acelerar la API de Llama: La empresa de chips de inferencia de IA Groq anunció una colaboración con Meta para acelerar la API oficial de Llama. Los desarrolladores podrán ejecutar los últimos modelos Llama (a partir de Llama 4) con un rendimiento de hasta 625 tokens/segundo, y afirman que la migración desde OpenAI solo requiere 3 líneas de código. Esta colaboración tiene como objetivo proporcionar a los desarrolladores soluciones de alta velocidad y baja latencia para ejecutar grandes modelos de lenguaje. (Fuente: JonathanRoss321)

🌟 Comunidad
Debate comunitario sobre la comparación entre Llama4 y DeepSeek R1 y el problema de los benchmarks de evaluación de modelos: El CEO de Meta, Mark Zuckerberg, respondió en una entrevista a la cuestión de que Llama4 rinde peor que DeepSeek R1 en la arena, argumentando que los benchmarks de código abierto tienen defectos, están demasiado sesgados hacia casos de uso específicos y no reflejan realmente el rendimiento del modelo en productos reales, añadiendo que el modelo de inferencia de Meta aún no se ha lanzado y no se puede comparar directamente con R1. Estas declaraciones, combinadas con el artículo de Cohere que cuestiona LMArena, han provocado un amplio debate en la comunidad sobre cómo evaluar justamente los LLM, las limitaciones de los rankings públicos y las estrategias de selección de modelos. Muchos coinciden en que no se debe depender excesivamente de los rankings generales, sino combinar la evaluación con casos de uso específicos, datos privados y señales de la comunidad para elegir un modelo. (Fuente: BlancheMinerva, huggingface, ClementDelangue, sarahcat21, xanderatallah, arohan, ClementDelangue, 量子位)
El debate sobre la IA reemplazando el trabajo humano sigue intensificándose: En la comunidad de Reddit han aparecido varias publicaciones discutiendo el impacto de la IA en el empleo. Un traductor de español afirma que su negocio se ha reducido drásticamente debido a la mejora de la calidad de la traducción por IA; otro ingeniero de audio también cambió de carrera debido a la mejora del efecto de masterización por IA. Al mismo tiempo, también hay publicaciones que discuten cómo la aplicación de la IA en campos como el diagnóstico médico y la asesoría fiscal podría reducir la demanda de profesionales. Estos casos han provocado discusiones sobre si la crisis de desempleo provocada por la automatización de la IA está llegando antes de lo esperado, y cómo los profesionales deben adaptarse (por ejemplo, utilizando la IA para transformarse, buscando valor que la IA no pueda reemplazar). (Fuente: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
El fenómeno de la “deriva iterativa” en imágenes generadas por IA llama la atención: Un usuario de Reddit intentó que ChatGPT realizara “réplicas exactas” continuamente basadas en la imagen generada anteriormente. Los resultados mostraron que el contenido y el estilo de la imagen se desviaban gradualmente de la entrada original a medida que aumentaba el número de iteraciones, tendiendo finalmente hacia patrones abstractos o específicos (como tatuajes samoanos / rasgos femeninos). El ejemplo de Dwayne Johnson también mostró una evolución similar de lo realista a lo abstracto. Este fenómeno revela los desafíos actuales de los modelos de generación de imágenes para mantener la consistencia a largo plazo, así como los posibles sesgos o tendencias de convergencia en sus representaciones internas. (Fuente: Reddit r/ChatGPT, Reddit r/ChatGPT)

La comunidad discute si la IA reemplazará el trabajo de capital riesgo (VC): Marc Andreessen cree que cuando la IA pueda hacer todo lo demás, el capital riesgo podría ser uno de los últimos trabajos realizados por humanos, porque se parece más al arte que a la ciencia, dependiendo del gusto, la psicología y la tolerancia al caos. Esta opinión generó debate; algunos la consideran una “afirmación ridícula”, cuestionando por qué la inversión temprana es única; otros, desde sus propios campos (como el desarrollo de juegos), creen que esta idea podría ser “auto-consuelo” (cope), ya que las personas en cada campo tienden a pensar que su trabajo no puede ser reemplazado por la IA debido a la necesidad de un gusto único. (Fuente: colin_fraser, gfodor, cto_junior, pmddomingos)
Experimento no autorizado de persuasión por IA de la Universidad de Zúrich en Reddit genera controversia: Según los moderadores de Reddit r/changemyview y Reddit Lies, investigadores de la Universidad de Zúrich desplegaron múltiples cuentas de IA en ese subreddit para participar en discusiones sin informar explícitamente a los usuarios de la comunidad, probando la capacidad persuasiva de los argumentos generados por IA. El estudio encontró que la tasa de éxito de persuasión de las cuentas de IA (obtener la marca “∆” que indica un cambio de opinión del usuario) fue mucho mayor que la línea base humana, y los usuarios no detectaron su identidad de IA. Aunque el experimento afirma haber obtenido la aprobación del comité de ética, su realización secreta y su naturaleza potencialmente “manipuladora” han generado una amplia controversia ética y preocupaciones sobre el abuso de la IA. (Fuente: 量子位)
💡 Otros
¿Sigue siendo necesario aprender a programar en la era de la IA? Una reflexión: En la comunidad ha surgido un debate sobre el valor de aprender a programar en la era de la IA. La opinión es que, aunque la capacidad de generación de código de la IA está aumentando y la naturaleza del trabajo de los ingenieros de software está cambiando rápidamente, aprender a programar sigue siendo importante. Aprender a programar es fundamental para comprender cómo colaborar eficazmente con la IA (especialmente los LLM), y esta capacidad de colaboración humano-máquina se convertirá en una competencia central en todos los campos. La programación es el punto de partida para que los humanos comiencen a “bailar” con la IA, y en el futuro, todas las industrias necesitarán dominar este modo de colaboración. (Fuente: alexalbert__, _philschmid)
Desarrolladores discuten la experiencia y los desafíos de la programación asistida por IA: Desarrolladores en la comunidad comparten sus experiencias usando herramientas de programación con IA (como Cursor, ChatGPT Desktop). Algunos extrañan el “período de reflexión” de la espera de compilación del pasado, argumentando que la programación asistida por IA reintroduce un ciclo similar de edición/compilación/depuración. Otros señalan que las herramientas de IA todavía tienen deficiencias en la comprensión del contexto (como la edición de múltiples archivos) y el seguimiento de instrucciones (como evitar el uso de sintaxis/ingredientes específicos), a veces requiriendo instrucciones muy específicas para lograr el efecto deseado, y que el código generado por IA todavía necesita revisión y depuración manual. (Fuente: hrishioa, eerac, Reddit r/ChatGPT)

Mejora de la felicidad impulsada por IA: una posible dirección de aplicación de la IA: Una publicación en Reddit propone que una de las aplicaciones definitivas de la IA podría ser mejorar la felicidad humana. El autor argumenta que, basándose en la hipótesis de la retroalimentación facial (sonreír puede aumentar la felicidad) y los principios de la atención plena, la IA (como Gemini 2.5 Pro) puede generar contenido de guía de alta calidad para ayudar a las personas a aumentar sus niveles de felicidad a través de ejercicios simples (como sonreír y centrarse en la sensación placentera que produce). El autor compartió informes y audios generados por IA y predice que en el futuro podrían surgir aplicaciones exitosas o robots “mentores de felicidad” basados en este principio. (Fuente: Reddit r/deeplearning)
