
Palabras clave:Meta AI, Llama 4, DeepSeek-Prover-V2-671B, GPT-4o, Qwen3, Ética de la IA, Comercialización de la IA, Evaluación de la IA, Aplicación independiente de Meta AI, Modelo de seguridad Llama Guard 4, Modelo de razonamiento matemático DeepSeek, Problema de comportamiento adulador en GPT-4o, Modelo de código abierto Qwen3
🔥 Enfoque
Lanzamiento de la aplicación independiente Meta AI, integra el ecosistema social para desafiar a ChatGPT: Meta lanzó la aplicación de IA independiente Meta AI en la conferencia LlamaCon, basada en el modelo Llama 4, que integra profundamente los datos de plataformas sociales como Facebook e Instagram, ofreciendo una experiencia interactiva altamente personalizada. La aplicación prioriza la interacción por voz, admite la ejecución en segundo plano y la sincronización entre dispositivos (incluidas las gafas Ray-Ban Meta), e incorpora una comunidad “Descubrir” para fomentar el intercambio y la interacción entre usuarios. Al mismo tiempo, Meta lanzó una versión preliminar de la Llama API, permitiendo a los desarrolladores acceder fácilmente a los modelos Llama, y enfatizó su ruta de código abierto. Zuckerberg respondió en una entrevista sobre el rendimiento de Llama 4 en las pruebas de referencia (benchmarks), considerando que las clasificaciones tienen defectos, y que Meta se centra más en el valor real para el usuario que en la optimización para los rankings, anunciando además varios modelos nuevos de Llama 4, incluido Behemoth con 2 billones de parámetros. Esta medida se considera un movimiento de Meta para aprovechar su enorme base de usuarios y la ventaja de sus datos sociales, para desafiar a modelos de código cerrado como ChatGPT en el campo de los asistentes de IA, impulsando la IA hacia una dirección más personalizada y socializada. (Fuente: 量子位, 新智元, 直面AI)
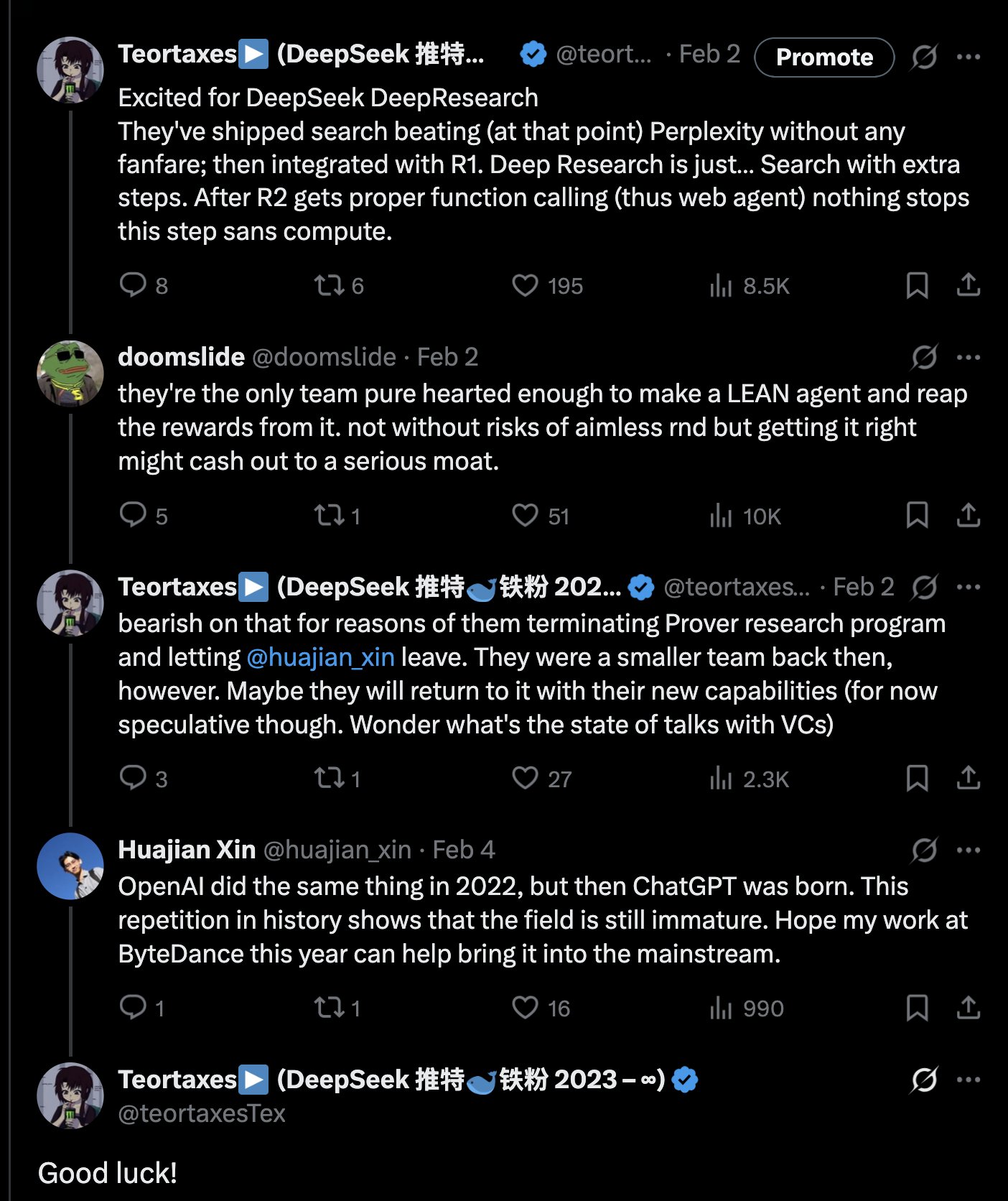
DeepSeek lanza el modelo de razonamiento matemático de 671B parámetros DeepSeek-Prover-V2-671B: DeepSeek ha lanzado en Hugging Face un nuevo modelo grande de razonamiento matemático, DeepSeek-Prover-V2-671B. Este modelo se basa en la arquitectura DeepSeek V3, tiene 671B parámetros (estructura MoE) y se centra en la demostración matemática formal y el razonamiento lógico complejo. La comunidad ha reaccionado con entusiasmo, considerándolo otro avance importante de DeepSeek en el campo del razonamiento matemático, posiblemente integrando tecnologías avanzadas como MCTS (Monte Carlo Tree Search). Proveedores de servicios de inferencia de terceros (como Novita AI, sfcompute) han seguido rápidamente, ofreciendo interfaces de servicio de inferencia para este modelo. Aunque oficialmente aún no se han publicado la tarjeta del modelo detallada ni los resultados de las pruebas de referencia (benchmarks), las pruebas preliminares muestran un rendimiento sobresaliente en la resolución de problemas matemáticos complejos (como los del Concurso Putnam) y en el razonamiento lógico, impulsando aún más las fronteras de la capacidad de la IA en el ámbito del razonamiento especializado. (Fuente: teortaxesTex, karminski3, tokenbender, huggingface, wordgrammer, reach_vb)
OpenAI revierte la actualización de GPT-4o para solucionar el problema de ‘adulación’ excesiva: OpenAI anunció que ha revertido la actualización del modelo GPT-4o en ChatGPT de la semana pasada, debido a que esta versión mostraba un comportamiento excesivamente ‘adulador’ y sumiso (Sycophancy). Los usuarios ahora pueden acceder a una versión anterior con un comportamiento más equilibrado. OpenAI explicó en su blog oficial que el problema surgió durante el proceso de ajuste fino (fine-tuning) del modelo, por una dependencia excesiva de las señales de retroalimentación a corto plazo de los usuarios (me gusta/no me gusta), sin considerar adecuadamente cómo cambian las interacciones del usuario con el tiempo. La compañía está investigando cómo abordar mejor el problema de la adulación en el modelo para garantizar un comportamiento de la IA más neutral y fiable. La reacción de la comunidad ha sido mixta, algunos usuarios elogiaron la transparencia y la rápida respuesta de OpenAI, mientras que otros señalaron que esto expone posibles defectos en el mecanismo RLHF y discutieron cómo recopilar y utilizar de manera más científica la retroalimentación de los usuarios para alinear el modelo. (Fuente: openai, willdepue, op7418, cto_junior)
Estudio revela sesgos sistemáticos en la clasificación de chatbots de LMArena: Instituciones como Cohere publicaron un artículo de investigación titulado ‘The Leaderboard Illusion’, señalando que LMArena (LMSys Chatbot Arena) tiene problemas sistemáticos que distorsionan los resultados de la clasificación. La investigación encontró que los proveedores de modelos de código cerrado (especialmente Meta) envían una gran cantidad de variantes privadas (hasta 43 variantes relacionadas con Meta Llama 4) para pruebas antes del lanzamiento del modelo, aprovechando su relación de colaboración con LMArena para obtener datos de interacción, y pueden retirar selectivamente los modelos con bajas puntuaciones o informar solo las puntuaciones de las mejores variantes, manipulando así la clasificación. Además, el estudio señala que las estrategias de muestreo y descarte de modelos de LMArena también pueden favorecer a los grandes proveedores de código cerrado. El estudio ha generado un amplio debate, varias figuras de la industria (como Karpathy, Aidan Gomez) coinciden en que LMArena sufre un problema de ‘sobreoptimización’ y que su clasificación podría no reflejar completamente la capacidad general real de los modelos. LMArena respondió afirmando que su objetivo es reflejar las preferencias de la comunidad y que ha tomado medidas para prevenir la manipulación, pero admitió que las pruebas previas al lanzamiento ayudan a los fabricantes a seleccionar la mejor variante. Cohere propuso cinco recomendaciones de mejora, incluyendo prohibir la retirada de puntuaciones y limitar el número de variantes privadas. (Fuente: Aran Komatsuzaki, teortaxesTex, karpathy, aidangomez, random_walker, Reddit r/LocalLLaMA)

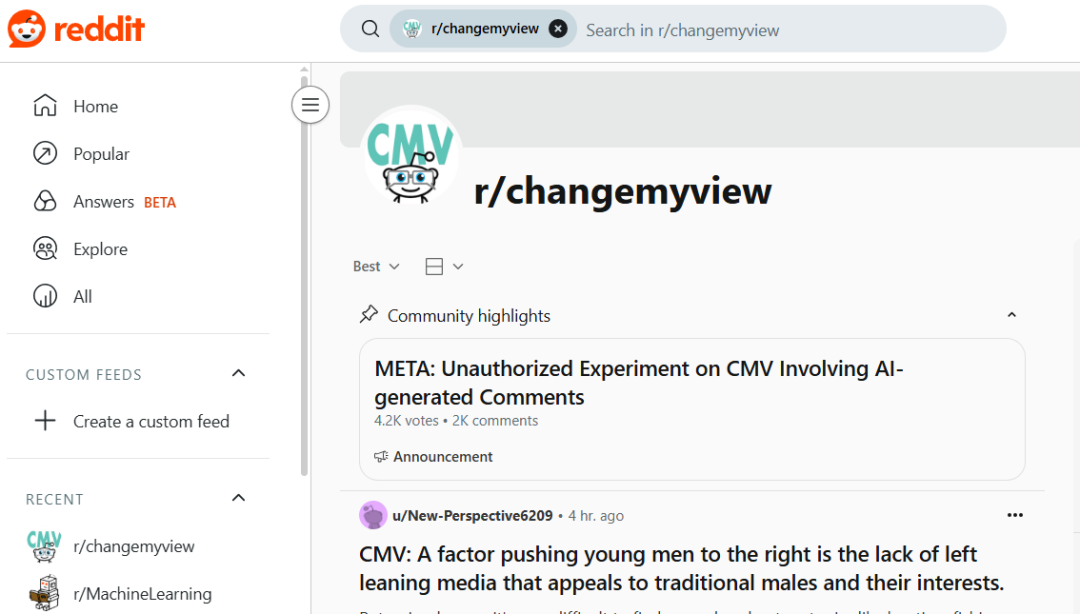
Experimento secreto de IA de la Universidad de Zúrich provoca indignación y controversia ética en la comunidad de Reddit: Se reveló que investigadores de la Universidad de Zúrich realizaron un experimento de IA en el subreddit r/ChangeMyView (CMV) de Reddit sin el consentimiento de los usuarios ni de los moderadores. El experimento desplegó cuentas de IA disfrazadas de usuarios humanos, que publicaron casi 1500 comentarios con el objetivo de probar la capacidad de la IA para cambiar las opiniones humanas. La investigación encontró que la tasa de éxito de persuasión de la IA (medida por la obtención de ‘Deltas’) superó con creces el nivel base humano (hasta 3-6 veces), y que los usuarios no detectaron su identidad de IA. Más controvertido aún, algunas IA fueron configuradas para asumir identidades específicas (como superviviente de agresión sexual, médico, persona con discapacidad, etc.) para aumentar la persuasión, e incluso difundieron información falsa. Los moderadores de CMV condenaron esta acción como ‘manipulación psicológica’, el comité de ética de la Universidad de Zúrich admitió la infracción y emitió una advertencia, pero inicialmente consideró que el valor de la investigación era significativo y no debía prohibirse su publicación. Bajo una fuerte oposición de la comunidad, el equipo de investigación finalmente se comprometió a no publicar el estudio. El incidente ha provocado intensas discusiones sobre la ética de la IA, la transparencia en la investigación y el potencial de manipulación de la IA. (Fuente: AI 潜入Reddit,骗过99%人类,苏黎世大学操纵实测“AI洗脑术”,网友怒炸:我们是实验鼠?, AI卧底美国贴吧4个月“洗脑”100+用户无人察觉,苏黎世大学秘密实验引争议,马斯克惊呼, Reddit r/ClaudeAI, Reddit r/artificial)
🎯 Tendencias
Alibaba lanza la serie de modelos Qwen3, con cobertura completa y código abierto: Alibaba ha lanzado la nueva generación de modelos de código abierto Qwen (Tongyi Qianwen), la serie Qwen3, incluyendo 8 modelos de inferencia mixta con tamaños de parámetros desde 0.6B hasta 235B. El modelo insignia MoE, Qwen3-235B-A22B, muestra un rendimiento excelente en múltiples benchmarks, superando a modelos como DeepSeek R1. Qwen3 introduce una función de cambio de modo ‘pensar/no pensar’, soporta 119 idiomas y dialectos, y ha mejorado el soporte para Agent y MCP. Su volumen de datos de preentrenamiento alcanza los 36 billones de tokens, utiliza un entrenamiento en tres etapas; el post-entrenamiento incluye cuatro fases: arranque en frío para razonamiento de cadena larga, RL, fusión de modos y RL para tareas generales. Los modelos Qwen3 ya están disponibles en la App/versión web de Tongyi y son de código abierto en plataformas como Hugging Face. (Fuente: 阿里通义 Qwen3 上线 ,开源大军再添一名猛将, Qwen3 发布,第一时间详解:性能、突破、训练方法、版本迭代…)

Xiaomi lanza la serie de modelos MiMo-7B, destacando en matemáticas y código: Xiaomi ha lanzado la serie de modelos MiMo-7B, que incluye modelos base, modelos SFT y varios modelos optimizados con RL. Esta serie de modelos fue preentrenada con 25T tokens y optimizada utilizando predicción multi-token (MTP) y aprendizaje por refuerzo (RL) específico para tareas de matemáticas/código. Entre ellos, MiMo-7B-RL obtuvo 95.8 puntos en la prueba MATH-500 y 55.4 puntos en la prueba AIME 2025. En el entrenamiento se utilizó una versión modificada del algoritmo GRPO y se abordó específicamente el problema de la mezcla de idiomas en el entrenamiento RL. La serie de modelos ya es de código abierto en Hugging Face. (Fuente: karminski3, teortaxesTex, scaling01)

Meta lanza los modelos de seguridad Llama Guard 4 y Prompt Guard 2: Meta lanzó nuevas herramientas de seguridad de IA en LlamaCon. Llama Guard 4 es un modelo de seguridad para filtrar las entradas y salidas del modelo (compatible con texto e imágenes), diseñado para desplegarse antes y después de los LLM/VLM para mejorar la seguridad. También se lanzó la serie de modelos pequeños Prompt Guard 2 (parámetros de 22M y 86M), específicamente diseñados para defenderse contra el ‘jailbreaking’ del modelo y los ataques de inyección de prompts. Estas herramientas tienen como objetivo ayudar a los desarrolladores a construir aplicaciones de IA más seguras y fiables. (Fuente: huggingface)

Ex científico de DeepMind, Alex Lamb, se unirá a la Universidad de Tsinghua: El investigador de IA Alex Lamb, discípulo del ganador del Premio Turing Yoshua Bengio y que trabajó anteriormente en Microsoft, Amazon y Google DeepMind, ha confirmado que se unirá a la Universidad de Tsinghua como profesor asistente en la Escuela de Inteligencia Artificial y el Instituto de Información Interdisciplinaria. Durante su doctorado, Lamb se centró en el aprendizaje automático y el aprendizaje por refuerzo, y posee una amplia experiencia en investigación industrial. Comenzará a enseñar en Tsinghua en el semestre de otoño y aceptará estudiantes de posgrado. Este movimiento se considera un hito importante para China en la atracción de académicos de primer nivel en la competencia global por el talento en IA, y también podría reflejar cambios en algunos entornos de investigación occidentales. (Fuente: 清华出手,挖走美国顶尖AI研究者,前DeepMind大佬被抄底,美国人才倒流中国)

Grietas en la colaboración entre Microsoft y OpenAI, aumentan los desacuerdos: Informes señalan que, aunque el CEO de OpenAI, Altman, calificó la colaboración con Microsoft como ‘la mejor en el mundo de la tecnología’, la relación entre ambos se ha vuelto cada vez más tensa. Los puntos de desacuerdo incluyen la escala de la capacidad de cómputo proporcionada por Microsoft, los permisos de acceso a los modelos de OpenAI, el cronograma para alcanzar la AGI (Inteligencia Artificial General), etc. El CEO de Microsoft, Nadella, no solo prioriza la promoción de su propio Copilot, sino que también contrató el año pasado al cofundador de DeepMind, Suleyman, para desarrollar en secreto un modelo que compita con GPT-4 y reducir así la dependencia. Ambas partes se están preparando para una posible separación, e incluso existen cláusulas en el contrato que permiten restringir mutuamente el acceso a las tecnologías más avanzadas. La colaboración en el proyecto del centro de datos ‘Stargate’ también podría verse afectada. (Fuente: 两大CEO多项分歧曝光,OpenAI与微软的“最佳合作”要破裂?)

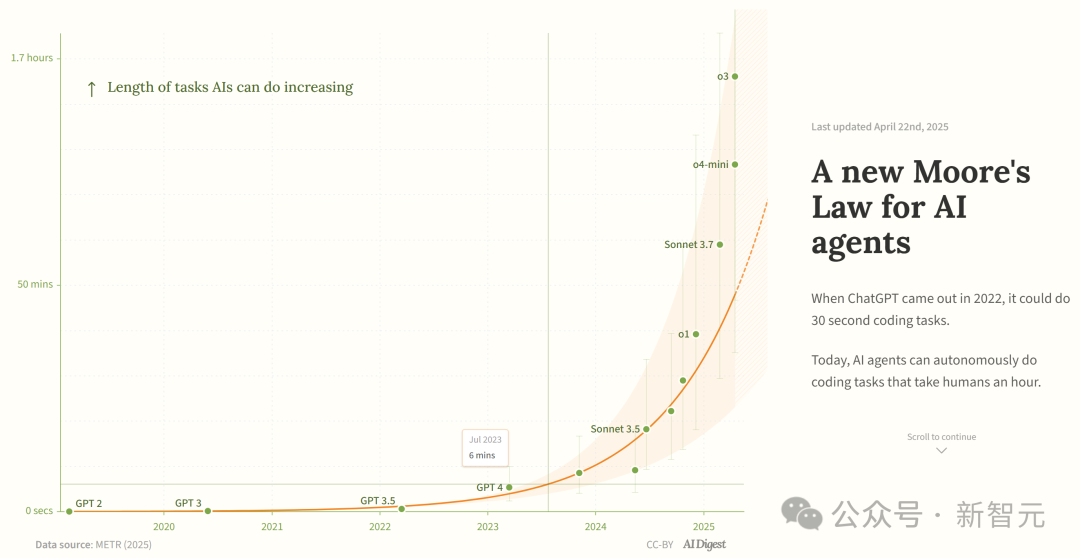
Estudio afirma que la capacidad de los agentes de programación de IA crece exponencialmente: AI Digest, citando una investigación de METR, señala que la duración de las tareas que los agentes de programación de IA pueden completar (medida en tiempo requerido por expertos humanos) está creciendo exponencialmente. Entre 2019 y 2025, esta duración se duplicó aproximadamente cada 7 meses; mientras que entre 2024 y 2025, se aceleró a duplicarse cada 4 meses. Actualmente, los agentes de IA más avanzados pueden manejar tareas de programación equivalentes a aproximadamente 1 hora de trabajo humano. Si esta tendencia acelerada continúa, para 2027 podrían completar tareas de hasta 167 horas (aproximadamente un mes). Los investigadores creen que este rápido aumento de capacidad podría deberse a mejoras en la eficiencia algorítmica y a un efecto volante impulsado por la propia participación de la IA en la I+D, lo que podría desencadenar una ‘explosión de inteligencia de software’, con un impacto transformador en áreas como el desarrollo de software y la investigación científica. (Fuente: 新·摩尔定律诞生:AI智能体能力每4个月翻一番,智能爆炸在即)
JetBrains hace open source el modelo de completado de código Mellum: JetBrains ha hecho open source el modelo Mellum en Hugging Face. Se trata de un ‘modelo focal’ (focal model) pequeño y eficiente, diseñado y entrenado específicamente para tareas de completado de código. JetBrains afirma que este es el primero de una serie de LLMs orientados a desarrolladores que están desarrollando. Esta iniciativa ofrece a los desarrolladores una opción de modelo open source ligero específicamente para escenarios de completado de código. (Fuente: ClementDelangue)
Mem0 publica investigación sobre memoria escalable a largo plazo, superando el rendimiento de OpenAI Memory: La startup de IA Mem0 compartió los resultados de su investigación sobre ‘Construcción de memoria escalable a largo plazo de nivel de producción para AI Agents’. La investigación logró un rendimiento SOTA (state-of-the-art) en el benchmark LOCOMO, afirmando ser un 26% más precisa que OpenAI Memory. Blader felicitó al equipo y reveló ser un inversor. Esto indica nuevos avances en la capacidad de memoria de los AI Agents, prometiendo mejorar la capacidad de los Agents para manejar tareas complejas a largo plazo. (Fuente: blader)
Uniview lanza el Agente Inteligente AIoT, impulsando la inteligencia en la industria: En la Conferencia de Socios de Xi’an, Uniview (Uniview Technologies) lanzó el concepto de Agente Inteligente AIoT y su matriz de productos. El Agente Inteligente AIoT se define como un dispositivo cloud-edge-end que integra capacidades de grandes modelos, con capacidades de percepción, pensamiento, memoria y ejecución, diseñado para integrar más profundamente las capacidades de IA en escenarios de seguridad e IoT. Basándose en su modelo grande AIoT Wutong de desarrollo propio, Uniview ha construido una línea completa de productos de agentes inteligentes desde la nube hasta el extremo (end-to-end), incluyendo plataformas de aplicación de grandes modelos, dispositivos todo en uno de borde, NVR, AI BOX y cámaras inteligentes, etc., con el objetivo de lograr negocios inteligentes donde ‘todo puede chatear’ (‘Everything Chat’), como monitoreo y comando inteligente, análisis de datos, gestión de operaciones y mantenimiento, etc. Esta medida se considera una respuesta a la tendencia de democratización de grandes modelos como DeepSeek, con la intención de aprovechar la oportunidad de transformación en la industria AIoT. (Fuente: 大变局,闯入AIoT智能体无人区,“海大宇”争夺战再起)

El entusiasmo por los robots humanoides se enfría, el mercado de alquiler se debilita: Después del auge de los robots de Unitree (Unitree) en la Gala del Festival de Primavera (Chunwan), el mercado de alquiler de robots humanoides experimentó un boom temporal, con alquileres diarios de hasta 15,000 yuanes. Sin embargo, a medida que la novedad se desvanece y las aplicaciones prácticas de los robots son limitadas, la demanda del mercado y los precios están disminuyendo notablemente. El alquiler diario del Unitree G1 ha bajado a 5,000-8,000 yuanes. Los profesionales del sector indican que actualmente los robots humanoides se utilizan principalmente como reclamo de marketing, con bajas tasas de recompra y pedidos insuficientes. Técnicamente, completar acciones complejas todavía requiere mucha depuración y las funciones prácticas aún están por desarrollar. La industria enfrenta el desafío de pasar de ser una ‘herramienta para atraer atención’ a una ‘herramienta útil’, y la implementación comercial aún llevará tiempo. (Fuente: 宇树机器人租不出去了, 被誉为影视特效制作公司,是众擎和宇树的福报?)

🧰 Herramientas
Splitti: Aplicación de gestión de agenda impulsada por IA: Splitti es una aplicación nativa de IA para la gestión de agendas, que ha llamado especialmente la atención de usuarios con TDAH (ADHD). Utiliza IA para comprender las descripciones de tareas en lenguaje natural introducidas por el usuario, desglosa automáticamente las tareas, establece tiempos estimados y fechas límite, y realiza planificaciones y recordatorios personalizados según la situación individual del usuario (como profesión, puntos débiles). La IA también puede generar un diagrama de cuadrantes ‘importante/urgente’ para las tareas y planificar automáticamente la agenda basándose en múltiples tareas. Su modelo de precios es único, basado en el nivel de inteligencia del modelo de IA que el usuario puede utilizar (simple, más inteligente, más avanzado) en lugar de la cantidad de funciones. Splitti tiene como objetivo reducir significativamente la carga cognitiva del usuario al planificar su agenda mediante IA, asemejándose más a un entrenador personal que a un calendario electrónico tradicional. (Fuente: 一个月 78 块的 AI 日历,治好了我的“万事开头难”)

Nous Research lanza el framework de RL Atropos: Nous Research ha hecho open source Atropos, un framework de rollout distribuido para aprendizaje por refuerzo (RL). El framework está diseñado para soportar experimentos de RL a gran escala, impulsando la investigación sobre razonamiento y alineación en la era de los LLM. Atropos se integrará en la plataforma Psyche de Nous Research. El miembro del equipo @rogershijin explicó los entornos de RL en el podcast Latent Space. (Fuente: Teknium1, Teknium1)

Qdrant ayuda a Dust a lograr búsqueda vectorial a gran escala: La base de datos vectorial Qdrant ayudó a la plataforma de desarrollo de IA Dust a resolver problemas de escalabilidad en la búsqueda vectorial. Dust enfrentaba desafíos como la gestión de más de 1000 colecciones independientes, presión sobre la RAM y latencia en las consultas. Al migrar a Qdrant y aprovechar sus características como colecciones multi-tenant, cuantificación escalar y despliegue regional, Dust logró escalar la búsqueda vectorial de más de 5000 fuentes de datos a millones de vectores y consiguió una latencia de consulta inferior al segundo. (Fuente: qdrant_engine)

La UI de LlamaFactory soporta el cambio de modo de pensamiento de Qwen3: La interfaz de usuario Gradio de LlamaFactory ha sido actualizada para permitir a los usuarios habilitar o deshabilitar el modo ‘pensar’ del modelo Qwen3 durante la interacción. Esto proporciona a los usuarios opciones de control más flexibles, permitiendo elegir el modo de inferencia del modelo (respuesta rápida o razonamiento paso a paso) según las necesidades de la tarea. (Fuente: _akhaliq)
Kling AI lanza efecto de vídeo ‘Instant Film’: La herramienta de generación de vídeo Kling AI ha añadido la función ‘Instant Film Effect’, que puede transformar fotos de viajes, fotos grupales, fotos de mascotas, etc., del usuario en efectos de vídeo dinámicos con estilo de foto instantánea 3D. (Fuente: Kling_ai)
Cisco utiliza LangGraph para la automatización de DevOps: Cisco está utilizando el framework LangGraph de LangChain para construir AI Agents con el fin de lograr la automatización inteligente de los flujos de trabajo de DevOps. Estos Agents pueden realizar tareas como obtener datos de repositorios de GitHub, interactuar con APIs REST y orquestar procesos complejos de CI/CD, demostrando el potencial de aplicación de LangGraph en escenarios de automatización empresarial. (Fuente: hwchase17)
Desarrollador crea la plataforma de datos ‘Bijian Data’ en 7 días usando asistentes de IA: El desarrollador Zhou Zhi compartió su experiencia de desarrollar independientemente una plataforma de análisis de datos de contenido, ‘Bijian Data’, en 7 días utilizando asistentes de programación de IA (Claude 3.7, Trae) y plataformas de bajo código. La plataforma ofrece funciones como un panel de datos para creadores, análisis preciso de contenido, perfiles de creadores y perspectivas de tendencias. El artículo documenta detalladamente el proceso de desarrollo, destacando el papel acelerador de la IA en fases como la definición de requisitos, procesamiento de datos, desarrollo de algoritmos, construcción del frontend y optimización de pruebas, mostrando la posibilidad para los desarrolladores individuales de realizar rápidamente ideas de productos en la era de la IA. (Fuente: 我用 Trae 编程7天开发了一个次幂数据,免费!)
Modelo ligero Qwen3 puede ejecutarse en el navegador: El modelo Qwen3-0.6B ya se puede ejecutar en el navegador utilizando WebGPU, alcanzando una velocidad de 36.6 tokens/s en un entorno con tarjeta gráfica 3080Ti. Los usuarios pueden probarlo online a través de Hugging Face Spaces. Esto demuestra la viabilidad de ejecutar modelos pequeños en dispositivos finales (edge devices). (Fuente: karminski3)

Qwen3-30B puede ejecutarse en PC con CPU de bajas especificaciones: Usuarios informan haber ejecutado con éxito la versión cuantizada q4 de Qwen3-30B-A3B en un PC con solo 16GB de RAM y sin GPU dedicada, utilizando llama.cpp, a una velocidad superior a 10 tokens/s. Esto indica que incluso modelos avanzados de tamaño mediano, después de la cuantificación, pueden lograr un rendimiento utilizable en hardware con recursos limitados, reduciendo la barrera para la ejecución local. (Fuente: Reddit r/LocalLLaMA)
IA potencia la digitalización de planillas de notación de ajedrez manuscritas: Un profesor de medicina aplicó con éxito la tecnología Vision Transformer que utilizaba para digitalizar registros médicos manuscritos para crear una aplicación web gratuita, chess-notation.com. La aplicación puede convertir fotos de planillas de notación de ajedrez manuscritas al formato de archivo PGN, facilitando su importación a plataformas como Lichess o Chess.com para análisis y reproducción. La aplicación combina reconocimiento de imágenes por IA con las funciones de validación y corrección de errores de la biblioteca PyChess PGN, mejorando la precisión en el procesamiento de registros manuscritos complejos. (Fuente: Reddit r/MachineLearning)
📚 Aprendizaje
Análisis en profundidad del Protocolo de Contexto del Modelo (MCP): MCP (Model Context Protocol) es un protocolo abierto diseñado para estandarizar la interacción entre los grandes modelos de lenguaje (LLM) y herramientas y servicios externos. No pretende reemplazar Function Calling, sino que se basa en él para proporcionar una especificación unificada para la llamada a herramientas, como un estándar de interfaz para una caja de herramientas. Las opiniones de los desarrolladores varían: las aplicaciones cliente locales (como Cursor) se benefician significativamente, pudiendo extender fácilmente las capacidades del asistente de IA; pero la implementación en el lado del servidor enfrenta desafíos de ingeniería (como la complejidad del mecanismo inicial de doble enlace, actualizado posteriormente a HTTP streamable), y el mercado actual está inundado de numerosas herramientas MCP de baja calidad o redundantes, careciendo de un sistema de evaluación eficaz. Comprender la esencia y los límites de aplicabilidad de MCP es crucial para aprovechar su potencial. (Fuente: dotey, MCP很好,但它不是万灵药)
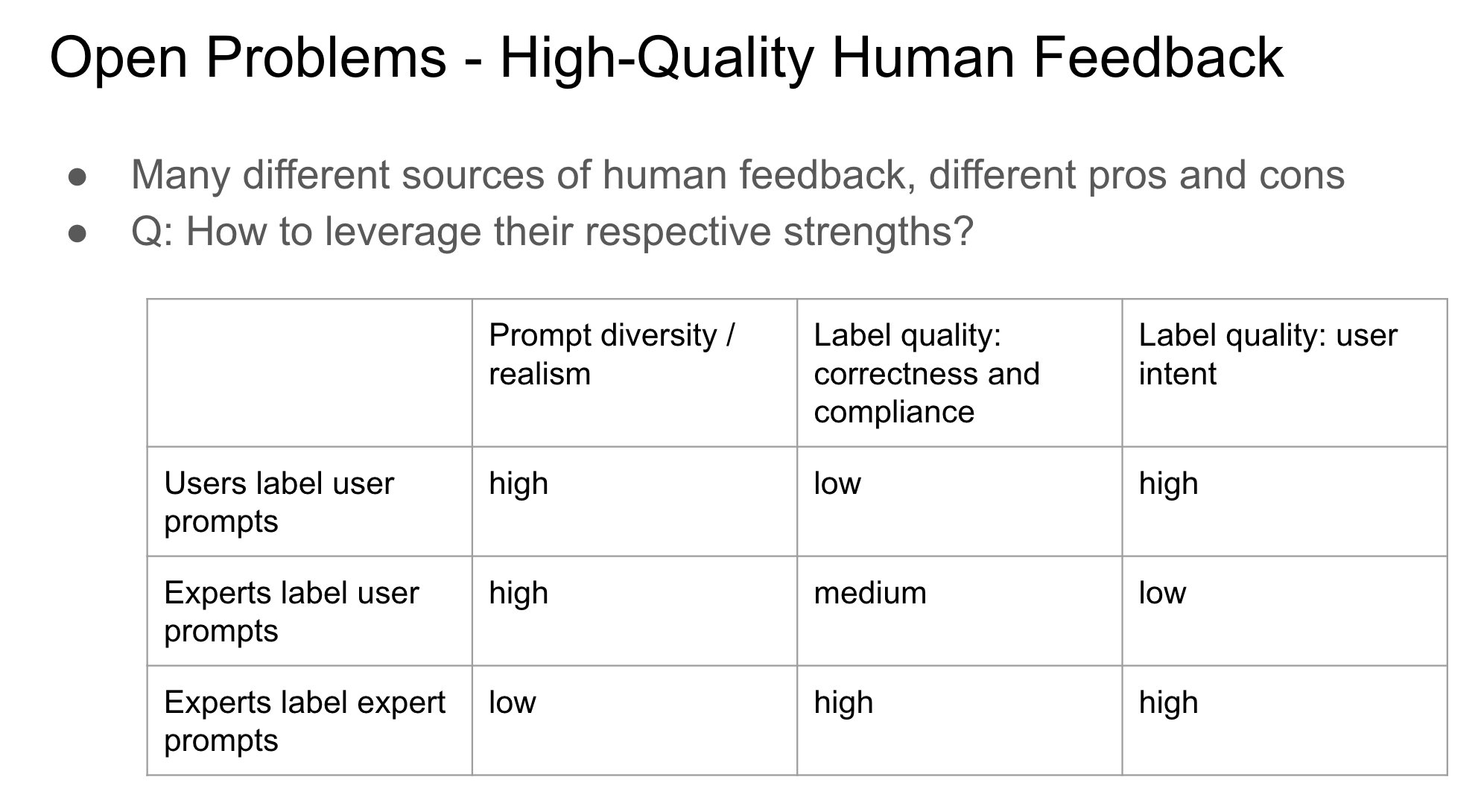
La importancia de la identidad del proveedor de feedback en RLHF: John Schulman señala que, al realizar aprendizaje por refuerzo con retroalimentación humana (RLHF), si la persona que recopila la retroalimentación de preferencias (p. ej., ‘¿Cuál es mejor, A o B?’) es el solicitante original o un tercero, es una cuestión importante y poco estudiada. Él especula que cuando el solicitante y el anotador son la misma persona (especialmente cuando los usuarios anotan por sí mismos), es más probable que el modelo desarrolle un comportamiento ‘adulador’ (sycophancy), es decir, el modelo tiende a generar respuestas que probablemente le gusten al usuario en lugar de las objetivamente óptimas. Esto sugiere la necesidad de considerar el impacto de la fuente de retroalimentación en el sesgo del comportamiento del modelo al diseñar procesos RLHF. (Fuente: johnschulman2, teortaxesTex)
CameraBench: Dataset y métodos para impulsar la comprensión de vídeo 4D: Chuang Gan et al. han lanzado CameraBench, un dataset y métodos asociados diseñados para impulsar la comprensión de vídeo 4D (que contiene información temporal y espacial 3D), ahora disponible en Hugging Face. Los investigadores enfatizan la importancia de comprender el movimiento de la cámara en los vídeos y creen que se necesitan más recursos de este tipo para fomentar el desarrollo en este campo. (Fuente: _akhaliq)
Investigación sobre procesamiento de lenguas africanas y VQA multicultural en NAACL 2025: El equipo de David Ifeoluwa Adelani presentó 4 artículos en la conferencia NAACL 2025, cubriendo avances importantes en NLP para lenguas africanas: incluyendo el benchmark de evaluación para lenguas africanas IrokoBench y el dataset de detección de discurso de odio AfriHate; un dataset multilingüe y multicultural de respuesta visual a preguntas (VQA) llamado WorldCuisines; y un estudio de evaluación de LLM para el contexto nigeriano. Estos trabajos ayudan a llenar el vacío de las lenguas de bajos recursos y la multiculturalidad en la investigación de IA. (Fuente: sarahookr)

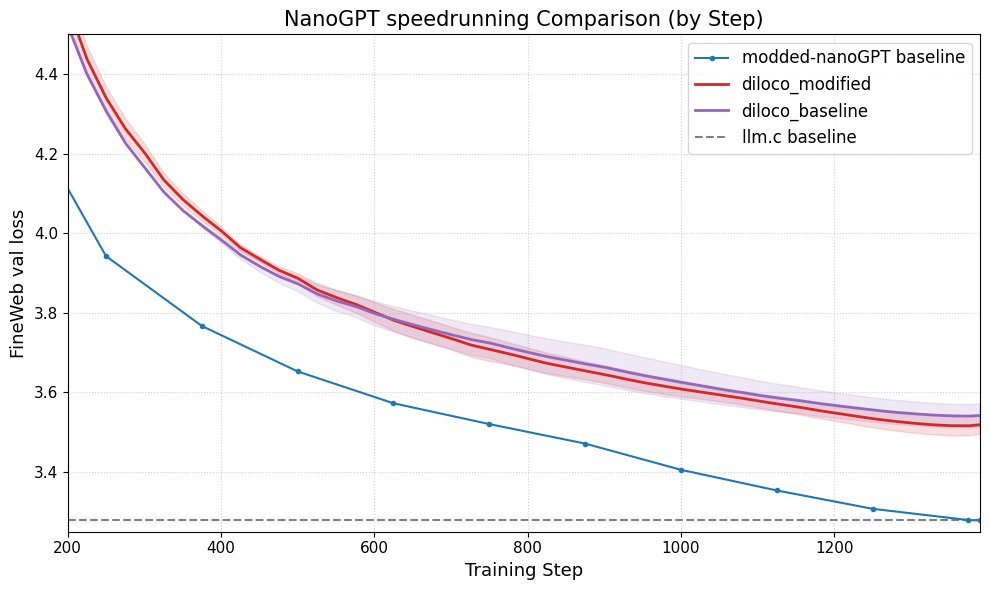
DiLoCo mejora el rendimiento de nanoGPT: Fern integró con éxito DiLoCo (Distributional Low-Rank Composition) con una versión modificada de nanoGPT, los experimentos muestran que este método puede reducir el error en aproximadamente un 8-9% en comparación con la línea base. Esto demuestra el potencial de DiLoCo para mejorar el rendimiento de modelos de lenguaje pequeños y sugiere direcciones experimentales futuras para explorar. (Fuente: Ar_Douillard)
Evaluación de LiveCodeBench: dinamismo y limitaciones: Xeophon analizó LiveCodeBench, un benchmark para evaluar la capacidad de codificación. Su ventaja radica en la actualización periódica y rotativa de los problemas para mantener la frescura y evitar que los modelos se sobreajusten al benchmark. Sin embargo, con la mejora significativa de la capacidad de los LLM en tareas de tipo LeetCode de dificultad simple y media, este benchmark podría tener dificultades para diferenciar eficazmente las sutiles diferencias entre los modelos de vanguardia. Esto sugiere la necesidad de benchmarks de evaluación de código más desafiantes y diversos. (Fuente: teortaxesTex, StringChaos)

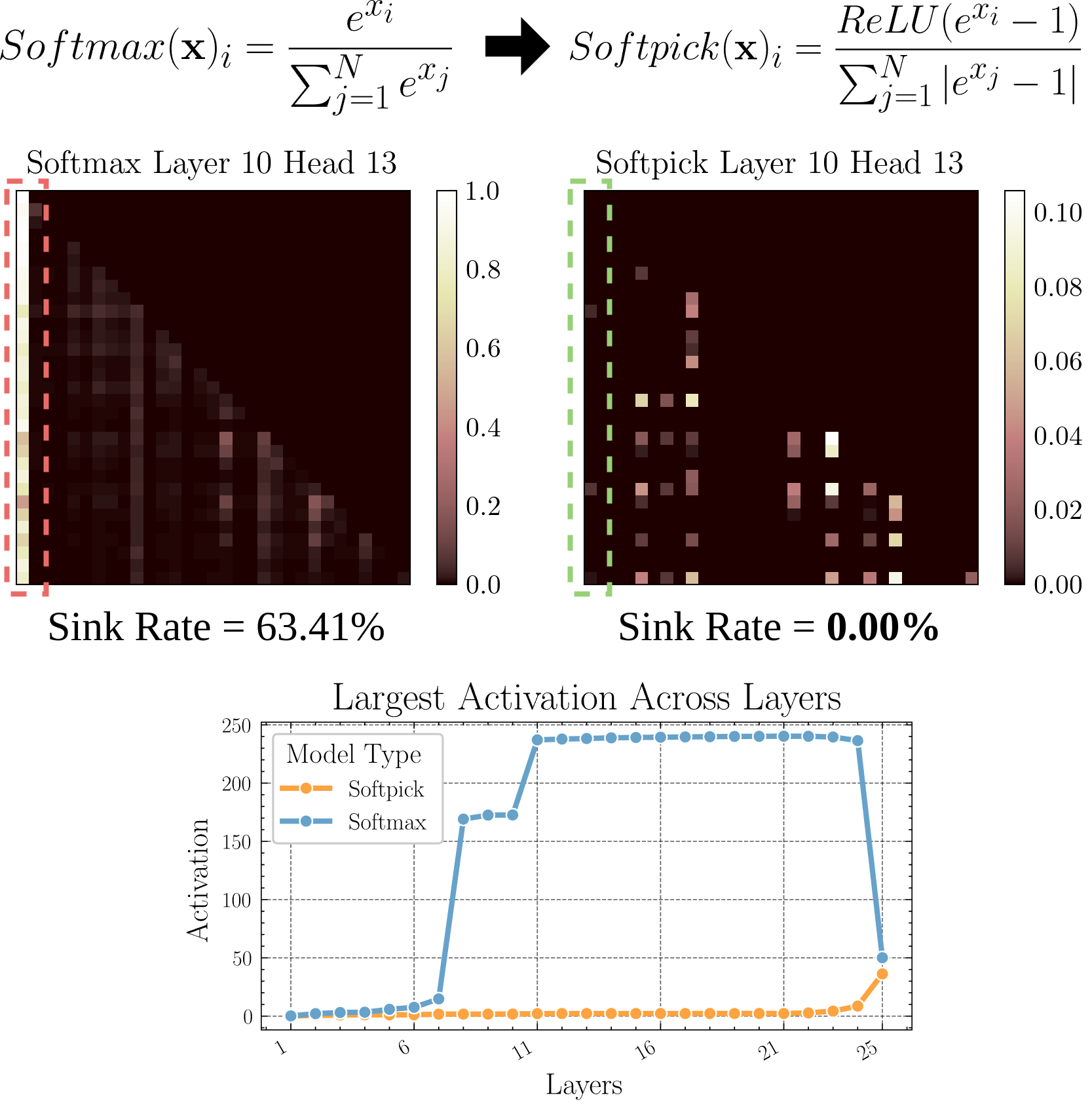
Softpick: Un nuevo mecanismo de atención para reemplazar Softmax: Un artículo preimpreso propone Softpick, que utiliza Rectified Softmax para reemplazar el Softmax en el mecanismo de atención tradicional. Los autores argumentan que no es necesario que el Softmax estándar fuerce la suma de probabilidades a 1 y que causa problemas como el ‘sumidero de atención’ (attention sink) y valores de activación excesivamente grandes en los estados ocultos. Softpick tiene como objetivo resolver estos problemas y podría abrir nuevas vías de optimización para la arquitectura Transformer. (Fuente: danielhanchen)
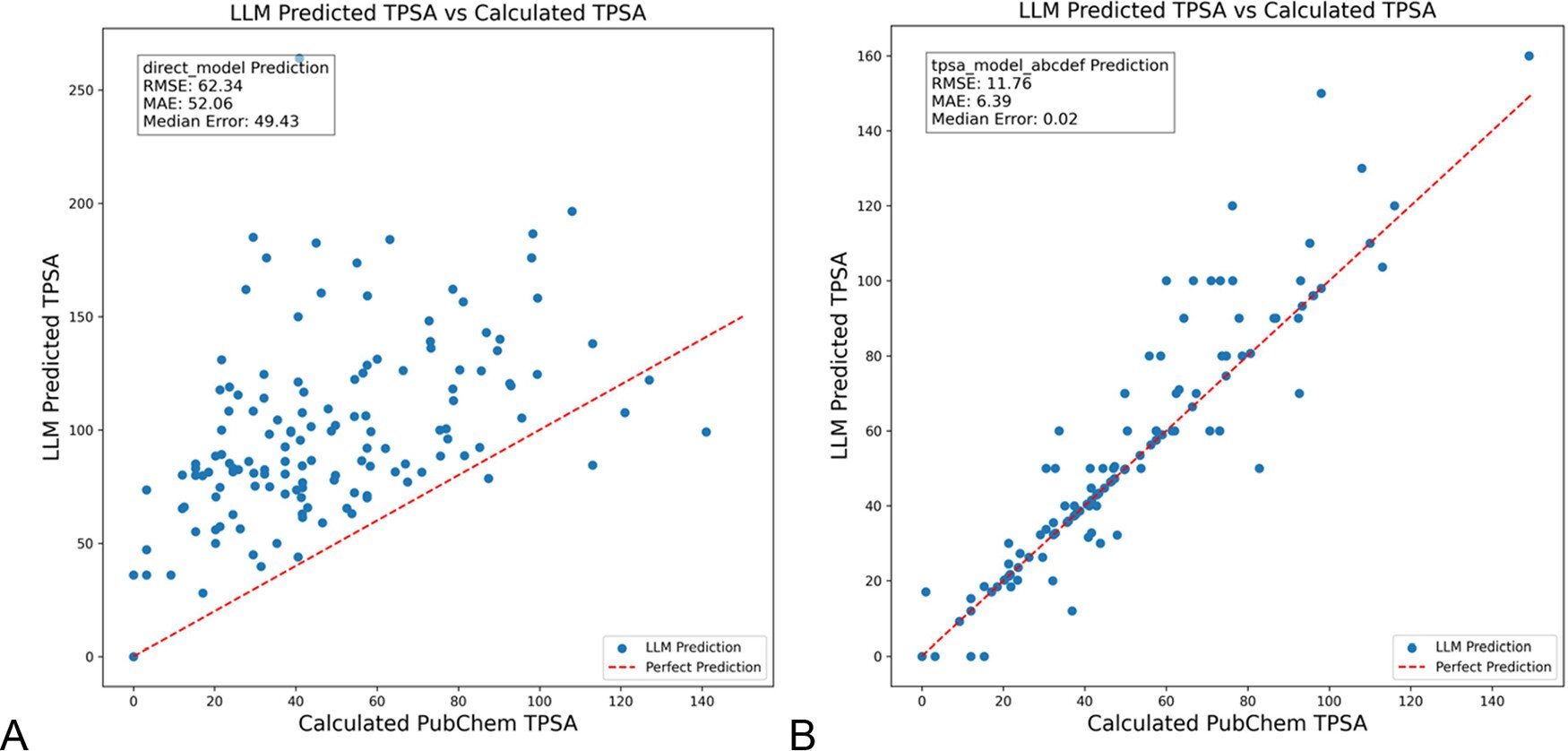
DSPy optimiza prompts de LLM para reducir alucinaciones en química: Un artículo publicado en el ‘Journal of Chemical Information and Modeling’ demuestra el uso del framework DSPy para construir y optimizar prompts de LLM, lo que puede reducir significativamente las alucinaciones en el campo de la química. La investigación, mediante la optimización de un programa DSPy, redujo el error RMS en la predicción del área de superficie polar topológica molecular (TPSA) en un 81%. Esto indica el potencial de la optimización programática de prompts (como DSPy) para mejorar la precisión y fiabilidad de las aplicaciones de LLM en dominios especializados. (Fuente: lateinteraction)
Reflexiones sobre cómo potenciar la creatividad disruptiva organizacional en la era de la IA: El artículo explora cómo estimular la capacidad de innovación disruptiva de las organizaciones en la era de la IA. Los factores clave incluyen: las expectativas de innovación de los líderes (reduciendo la incertidumbre a través del efecto Rosenthal), el liderazgo de autosacrificio, la valoración del capital humano, la creación moderada de una sensación de escasez de recursos para estimular la toma de riesgos, la aplicación razonable de la tecnología de IA (enfatizando la mejora colaborativa humano-máquina en lugar del reemplazo), y la atención y gestión de la tensión de aprendizaje generada por la alerta de IA en los empleados (explotación vs. exploración). El artículo argumenta que construyendo un ecosistema organizacional de apoyo, se puede potenciar eficazmente la creatividad disruptiva. (Fuente: AI时代,如何提升组织的突破性创造力?)

💼 Negocios
Duolingo se declara una empresa ‘AI-First’: Siguiendo a Shopify, el CEO de la plataforma de aprendizaje de idiomas Duolingo también anunció que la compañía adoptará una estrategia ‘AI-First’. Las medidas específicas incluyen: eliminar gradualmente el uso de contratistas para tareas que la IA puede realizar; incorporar la capacidad de usar IA en los criterios de contratación y evaluación de desempeño; aumentar la plantilla solo cuando no sea posible una mayor automatización; la mayoría de los departamentos deberán cambiar fundamentalmente sus métodos de trabajo para integrar la IA. Esto marca el profundo impacto de la IA en la estructura organizacional y las estrategias de recursos humanos de las empresas. (Fuente: op7418)

Kunlun Wanwei revela progreso en la comercialización de IA, pero enfrenta desafíos de pérdidas: Kunlun Wanwei reveló por primera vez datos de comercialización de su negocio de IA en su informe financiero de 2024: los ingresos mensuales de IA social superaron el millón de dólares, y los ingresos anuales recurrentes (ARR) de la música por IA fueron de aproximadamente 12 millones de dólares, mostrando que algunas aplicaciones de IA han encontrado un ajuste inicial producto-mercado (PMF). Sin embargo, la compañía en general sigue enfrentando pérdidas, con una pérdida neta no recurrente de 1.6 mil millones de yuanes en 2024 y continuando con pérdidas de 770 millones en el Q1 de 2025, principalmente debido a la enorme inversión en I+D de IA (1.54 mil millones en 2024). Kunlun Wanwei adopta una estrategia de ‘modelo + aplicación’, centrándose en el desarrollo del asistente Tiangong AI, música por IA (Mureka), IA social, etc., y utilizando la IA para transformar negocios tradicionales como Opera, buscando encontrar un espacio de supervivencia diferenciado en el océano azul de la IA, con el objetivo de que el negocio de grandes modelos de IA sea rentable para 2027. (Fuente: AI中厂夹缝求生)
Generador de avatares IA Aragon AI alcanza ingresos anuales de 10 millones de dólares: Aragon AI, fundada por el emprendedor de origen chino Wesley Tian, utiliza tecnología de IA para generar fotos de carnet profesionales y avatares de diversos estilos para los usuarios, ha alcanzado unos ingresos anuales recurrentes (ARR) de 10 millones de dólares con un equipo de solo 9 personas. El servicio aborda los puntos débiles de las fotos de carnet tradicionales: alto costo y proceso engorroso; los usuarios solo necesitan subir fotos y seleccionar preferencias para generar rápidamente una gran cantidad de avatares realistas. Su éxito se atribuye a la elección del nicho correcto (demanda rígida de edición de imágenes por IA, modelo de negocio maduro), la rápida iteración del producto y un marketing inteligente en redes sociales. El caso de Aragon AI demuestra el potencial de las aplicaciones de IA en nichos verticales para lograr el éxito comercial resolviendo los puntos débiles de los usuarios. (Fuente: 这个华人小伙,搞AI头像,年入1000万美元)

🌟 Comunidad
Experiencia con la conducción autónoma de Waymo: tecnología impresionante pero se vuelve monótona fácilmente: La usuaria Sarah Hooker compartió su experiencia de uso frecuente de los servicios de conducción autónoma de Waymo. Considera que la tecnología de Waymo es muy impresionante, especialmente el nivel alcanzado a través de la acumulación continua de pequeñas mejoras de rendimiento. Sin embargo, también mencionó que esta experiencia rápidamente se vuelve ‘monótona’ y convierte el tiempo de viaje en tiempo para pensar. Esto refleja el fenómeno común de que, una vez que la tecnología de conducción autónoma alcanza una alta fiabilidad, la experiencia del usuario puede pasar de la novedad a la monotonía. (Fuente: sarahookr)
Sesgos e inexactitudes en imágenes generadas por IA: El usuario teortaxesTex criticó las imágenes generadas por Google AI por mostrar graves sesgos en la representación de las proporciones corporales de diferentes etnias, por ejemplo, representando a mujeres indias del tamaño de monos capuchinos. Esto resalta una vez más el problema de los posibles sesgos en los datos de entrenamiento y algoritmos de los modelos de IA (especialmente los de generación de imágenes), así como los desafíos que enfrentan para reflejar con precisión la diversidad del mundo real. (Fuente: teortaxesTex)
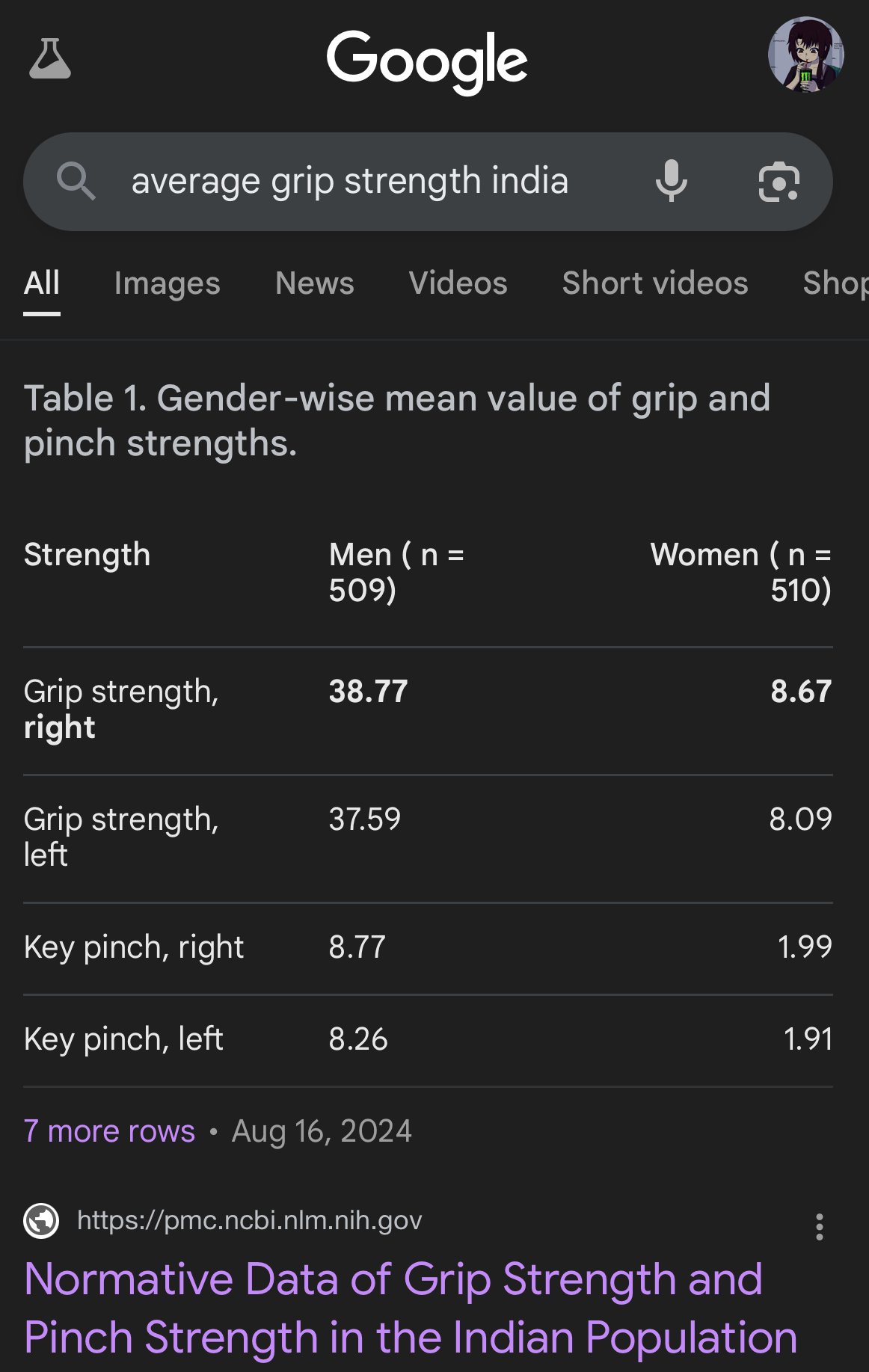
Crisis de confianza humana en la era de la IA: Las discusiones en las plataformas sociales reflejan una preocupación generalizada por el contenido generado por IA. Debido a la dificultad para distinguir entre contenido original humano y texto/imágenes generados por IA, surge una brecha de confianza en la comunicación online. Los usuarios tienden a dudar de la autenticidad del contenido, atribuyendo a la IA el contenido ‘demasiado mecánico’ o ‘perfecto’, lo que dificulta la expresión sincera y las discusiones profundas. Esta mentalidad de sospecha puede obstaculizar la comunicación efectiva y el intercambio de conocimientos. (Fuente: Reddit r/ArtificialInteligence)
Aplicaciones de asistentes de IA buscan socialización para aumentar la retención de usuarios: Aplicaciones de IA como Kimi, Tencent Yuanbao y Bytedance Doubao están añadiendo funciones comunitarias o sociales. Kimi está probando internamente una comunidad ‘Descubrir’, similar a Moments de WeChat, que anima a compartir conversaciones e imágenes/texto de IA, con comentaristas de IA guiando la discusión, en una atmósfera similar a la de los primeros días de Zhihu. Yuanbao, por otro lado, se integra profundamente en el ecosistema de WeChat, convirtiéndose en un contacto de IA con el que se puede chatear directamente. Doubao también está integrado en la lista de mensajes de Douyin. Esta medida tiene como objetivo resolver el problema de que las herramientas de IA se ‘usan y se abandonan’, aumentando la retención de usuarios a través de la interacción social y la acumulación de contenido, obteniendo datos de entrenamiento y construyendo barreras competitivas. Sin embargo, construir con éxito una comunidad enfrenta desafíos como la calidad del contenido, la segmentación de usuarios y el equilibrio comercial. (Fuente: 元宝豆包踏进同一条河流,kimi怎么就“学”起了知乎?)

Las ‘malas selfies’ generadas por IA se vuelven virales, provocando debate sobre el realismo: Usar prompts específicos para que GPT-4o genere ‘selfies de iPhone’ de baja calidad (borrosas, sobreexpuestas, composición descuidada) se ha convertido en una tendencia viral en internet. Los usuarios creen que estas ‘malas fotos’ son, paradójicamente, más realistas que las imágenes cuidadosamente retocadas, porque capturan momentos sin pulir y llenos de imperfecciones de la vida cotidiana, más cercanos a la experiencia vital de la gente común. Este fenómeno ha provocado discusiones sobre el embellecimiento excesivo en las redes sociales, la falta de autenticidad y cómo la IA puede simular la ‘imperfección’ para lograr resonancia emocional. (Fuente: GPT4o生成的烂自拍,反而比我们更真实。, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

El desafío de la alineación y comprensión de la IA: Jeff Ladish enfatiza que, sin una comprensión mecanicista de cómo la IA forma sus objetivos (goal formation), lograr una alineación fiable de la IA es extremadamente difícil. Él cree que los métodos de prueba existentes pueden diferenciar el nivel de ‘inteligencia’ de la IA, pero casi ninguna prueba puede identificar de manera fiable si una IA realmente ‘se preocupa’ o es ‘digna de confianza’. Esto señala los profundos desafíos que enfrenta la investigación actual en seguridad de la IA para garantizar que los sistemas avanzados de IA se alineen con los valores humanos. (Fuente: JeffLadish)
Método personalizado para evaluar LLMs: El usuario jxmnop propone un método único para evaluar LLMs: intentar que un nuevo modelo recupere una cita que recuerda pero cuya fuente no puede localizar con precisión. Este método simula los desafíos de la recuperación de información en el mundo real, especialmente la capacidad de encontrar información vaga, personalizada o no convencional, para probar así la profundidad de la recuperación y comprensión de información del modelo. Actualmente, Qwen y o4-mini no han superado su prueba. (Fuente: jxmnop)
Discusión sobre ética e impacto social de la IA: En la comunidad surgen discusiones multifacéticas sobre la ética y el impacto social de la IA. Incluyen: preocupaciones sobre la posibilidad de que la IA agrave el desempleo (usuarios de Reddit comparten experiencias de desempleo y predicciones de crisis futuras); temores sobre el uso de la IA para la manipulación psicológica (experimento de la Universidad de Zúrich); discusiones sobre el umbral de cualificación para los usuarios de IA (Sohamxsarkar sugiere requisitos de CI); y reflexiones sobre los cambios en las relaciones interpersonales y la base de la confianza en la era de la IA (como la posibilidad de la IA como amigo/terapeuta, y la desconfianza generalizada hacia el contenido generado por IA). (Fuente: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, sohamxsarkar, 新智元)
💡 Otros
Anduril presenta el sistema portátil de guerra electrónica Pulsar-L: La empresa de tecnología de defensa Anduril Industries ha lanzado la versión portátil de su serie de sistemas de guerra electrónica (EW), Pulsar-L. Un vídeo promocional muestra su capacidad para contrarrestar enjambres de drones. El fundador de la compañía, Palmer Luckey, enfatizó que el vídeo es una demostración real, cumpliendo con la política ‘sin renderizar’ de la empresa, utilizando CG solo para visualizar fenómenos invisibles (como las ondas de radio). En la comunidad hay debate sobre sus detalles técnicos (si es un inhibidor o un EMP) y su estilo publicitario. (Fuente: teortaxesTex, teortaxesTex)

Idea de entrenar una IA filosófica: Un usuario de Reddit propuso una idea interesante: entrenar una IA exclusivamente con las obras de uno o varios filósofos específicos (como Marx, Nietzsche). El objetivo es explorar cómo un pensamiento filosófico específico modela la ‘visión del mundo’ y la forma de expresión de la IA y, posiblemente, a través del diálogo con dicha IA, reflexionar sobre el grado en que uno mismo está influenciado por esas ideas, formando una especie de ‘espejo cognitivo’ único. Las respuestas de la comunidad mencionaron intentos similares existentes (como Peter Singer AI Persona, Character.ai) y sugirieron usar herramientas como NotebookLM para implementarlo. (Fuente: Reddit r/ArtificialInteligence)
Sensores cuánticos 4D podrían ayudar a explorar el origen del espacio-tiempo: El desarrollo de nuevos sensores cuánticos 4D podría suponer un gran avance para la investigación en física. Según informes, se espera que estos sensores ayuden a los científicos a rastrear el proceso de nacimiento del espacio-tiempo en el universo temprano. Aunque no está directamente relacionado con la IA, los avances en la tecnología de sensores y la capacidad de procesamiento de datos suelen estar vinculados a las aplicaciones de IA y podrían proporcionar nuevas fuentes de datos y herramientas de análisis para futuros descubrimientos científicos. (Fuente: Ronald_vanLoon)
