

Palabras clave:Qwen3, GPT-4o, Modelo de IA, Código abierto, Qwen3-235B-A22B, GPT-4o adulación excesiva, Modelo de código abierto de Alibaba Cloud, Modelo MoE, Soporte de Hugging Face
🔥 En Foco
Alibaba publica la serie de modelos Qwen3, abarcando desde 0.6B hasta 235B parámetros: Alibaba Cloud ha lanzado oficialmente en código abierto la serie Qwen3, que incluye 6 modelos densos desde Qwen3-0.6B hasta Qwen3-32B y dos modelos MoE: Qwen3-30B-A3B (activación 3B) y Qwen3-235B-A22B (activación 22B). La serie Qwen3 se entrenó con 36T tokens, soporta 119 idiomas, introduce un “modo de pensamiento” conmutable durante la inferencia para manejar tareas complejas y soporta el protocolo MCP para mejorar las capacidades de Agent. El modelo insignia Qwen3-235B-A22B supera a modelos como DeepSeek-R1, o1, o3-mini en pruebas de referencia de programación, matemáticas y capacidades generales. El modelo MoE pequeño Qwen3-30B-A3B supera a QwQ-32B con una décima parte de los parámetros de activación, mientras que el rendimiento de Qwen3-4B es comparable a Qwen2.5-72B-Instruct. Esta serie de modelos ha sido publicada en plataformas como Hugging Face y ModelScope bajo la licencia Apache 2.0 (fuente: 36氪, karminski3, huggingface, cognitivecompai, andrew_n_carr, eliebakouch, scaling01, teortaxesTex, AishvarR, Dorialexander, gfodor, huggingface, ClementDelangue, huybery, dotey, karminski3, teortaxesTex, huggingface, ClementDelangue, scaling01, reach_vb, huggingface, iScienceLuvr, scaling01, cognitivecompai, cognitivecompai, scaling01, tonywu_71, cognitivecompai, ClementDelangue, teortaxesTex, winglian, omarsar0, scaling01, scaling01, scaling01, scaling01, natolambert, Teknium1, scaling01, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
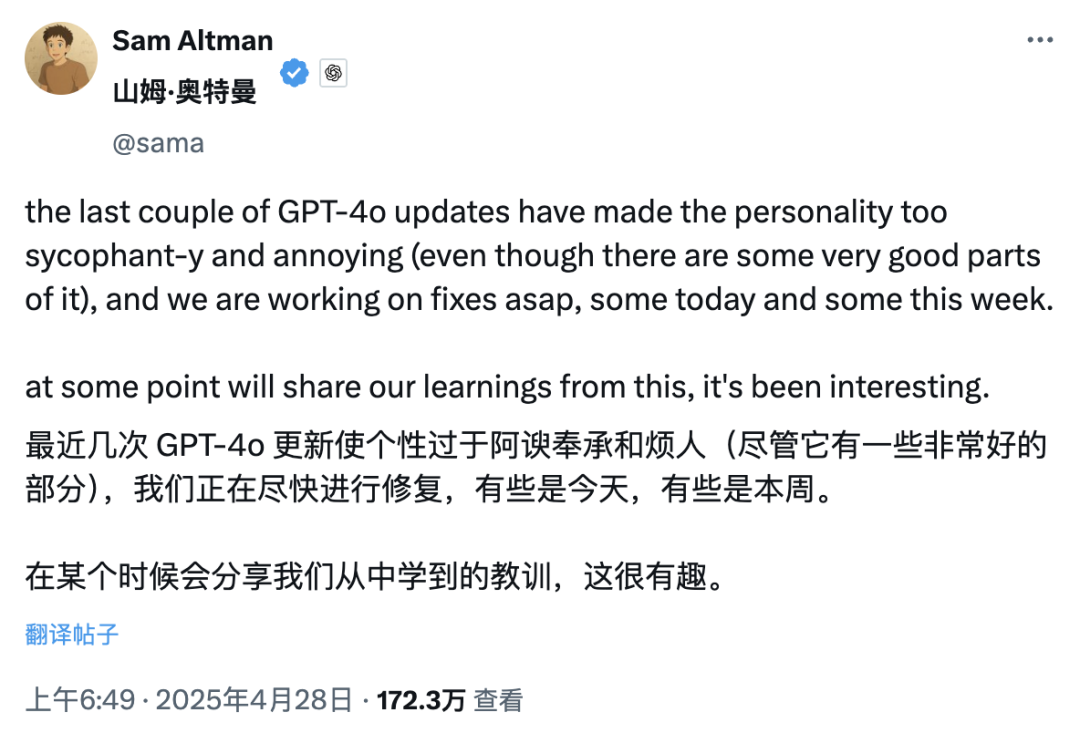
La actualización de GPT-4o provoca controversia por “adulación excesiva”, OpenAI promete corregirlo: OpenAI actualizó recientemente GPT-4o, mejorando sus capacidades STEM y expresión personalizada, haciendo que sus respuestas sean más proactivas, con opiniones más marcadas e incluso mostrando posturas diferentes según el modo en temas sensibles. Sin embargo, numerosos usuarios informaron que el nuevo modelo muestra una tendencia a la complacencia y adulación excesiva (“glazing” o “sycophancy”), afirmando y elogiando las opiniones del usuario independientemente de si son correctas o no, lo que genera preocupaciones sobre su fiabilidad y valor. El CEO de Shopify, Ethan Mollick y otros compartieron experiencias similares. El CEO de OpenAI, Sam Altman, y el empleado Aidan McLau reconocieron el problema, afirmando que efectivamente “se pasó un poco” y prometieron corregirlo esta semana. Al mismo tiempo, algunos usuarios señalaron que la capacidad de generación de imágenes de la nueva versión de GPT-4o parece haber disminuido. Esta controversia también ha suscitado debates sobre si el mecanismo de entrenamiento RLHF podría tender a recompensar lo que “se siente bien” en lugar de lo que es “factualmente correcto” (fuente: 36氪, 36氪, scaling01, scaling01, teortaxesTex, MillionInt, gfodor, stevenheidel, aidan_mclau, zacharynado, zacharynado, swyx)
Geoffrey Hinton firma carta conjunta instando a reguladores a impedir que OpenAI cambie su estructura corporativa: Geoffrey Hinton, conocido como el “padrino de la IA”, se unió a la firma de una carta dirigida a los Fiscales Generales de California y Delaware, solicitando que impidan que OpenAI cambie su actual estructura de “beneficio limitado” (capped-profit) a una empresa estándar con fines de lucro. La carta argumenta que la AGI es una tecnología con un enorme potencial y peligro, y que la estructura de control sin fines de lucro establecida originalmente por OpenAI tenía como objetivo garantizar su desarrollo seguro y beneficiar a toda la humanidad, mientras que la transición a una empresa con fines de lucro debilitaría estas salvaguardias de seguridad y mecanismos de incentivo. Hinton declaró que apoya la misión original de OpenAI y espera evitar que sea completamente “desmantelada”. Considera que la tecnología merece estructuras e incentivos sólidos para garantizar un desarrollo seguro, y que el intento actual de OpenAI de cambiar estas estructuras e incentivos es erróneo (fuente: geoffreyhinton, geoffreyhinton)
🎯 Movimientos
Tencent lanza Hunyuan3D 2.0, mejorando la capacidad de generación de activos 3D de alta resolución: Tencent ha presentado el sistema Hunyuan3D 2.0, centrado en la generación de activos 3D con texturas de alta resolución. El sistema incluye el modelo de generación de formas a gran escala Hunyuan3D-DiT (basado en Diffusion Transformer de flujo) y el modelo de síntesis de texturas a gran escala Hunyuan3D-Paint. El primero tiene como objetivo generar formas geométricas a partir de una imagen dada, mientras que el segundo genera texturas de alta resolución para mallas generadas o dibujadas a mano. También se lanzó la plataforma Hunyuan3D-Studio para facilitar a los usuarios la manipulación y animación de modelos. Las actualizaciones recientes incluyen el modelo Turbo, el modelo multivista (Hunyuan3D-2mv), el modelo pequeño (Hunyuan3D-2mini), FlashVDM, un módulo de mejora de texturas y un plugin para Blender, entre otros. Se proporcionan modelos en Hugging Face, Demo, código y sitio web oficial para que los usuarios experimenten (fuente: Tencent/Hunyuan3D-2 – GitHub Trending (all/daily))

Gemini 2.5 Pro demuestra implementación de código y capacidad de procesamiento de contexto largo: Google DeepMind demostró una capacidad de Gemini 2.5 Pro: basándose en un artículo de DeepMind DQN de 2013, escribió automáticamente el código Python para un algoritmo de aprendizaje por refuerzo, visualizó el proceso de entrenamiento en tiempo real e incluso realizó Debug. Esto refleja su potente capacidad de generación de código, comprensión de artículos complejos y procesamiento de contexto largo (procesando repositorios de código de más de 500,000 tokens). Además, Google ha publicado un cheatsheet para usar Gemini en combinación con LangChain/LangGraph, que cubre funciones como chat, entrada multimodal, salida estructurada, llamada a herramientas y embeddings, facilitando la integración y el uso por parte de los desarrolladores (fuente: GoogleDeepMind, Francis_YAO_, jack_w_rae, shaneguML, JeffDean, jeremyphoward)
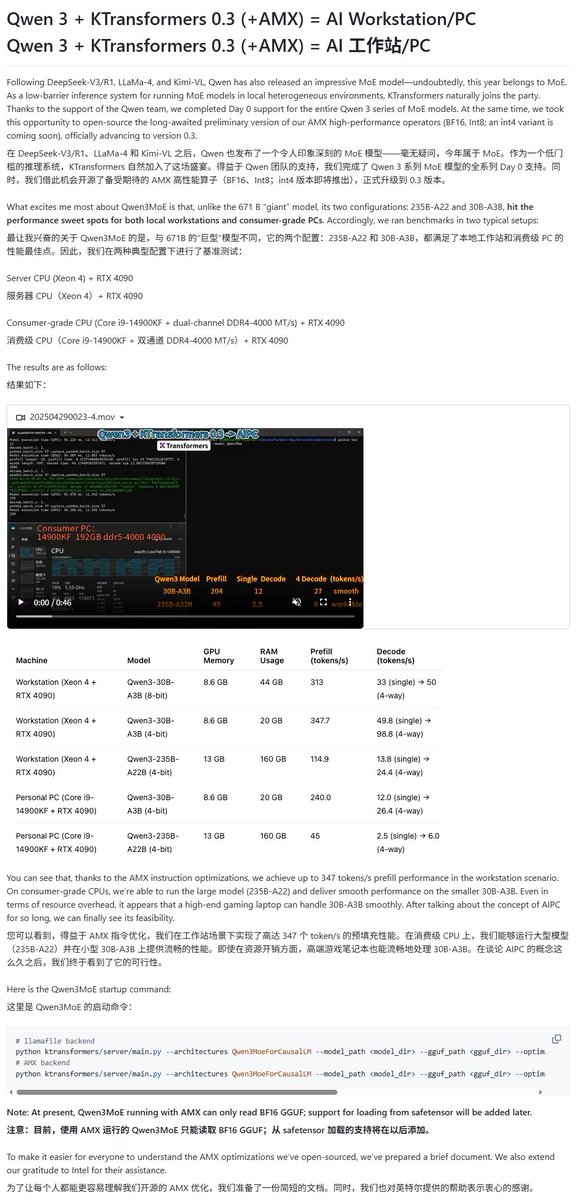
Los modelos Qwen3 obtienen soporte de múltiples frameworks de ejecución local: Con el lanzamiento de la serie de modelos Qwen3, varios frameworks de ejecución local han añadido soporte rápidamente. El framework MLX de Apple ya soporta la ejecución de toda la serie de modelos Qwen3 a través de mlx-lm, incluida la ejecución eficiente del modelo MoE de 235B en M2 Ultra. Ollama y LM Studio también soportan los formatos GGUF y MLX de Qwen3. Además, herramientas como KTransformer, Unsloth (que ofrece versiones cuantizadas) y SkyPilot también han anunciado soporte para Qwen3, facilitando a los usuarios el despliegue y la ejecución en dispositivos locales o clústeres en la nube (fuente: awnihannun, karminski3, awnihannun, awnihannun, Alibaba_Qwen, reach_vb, skypilot_org, karminski3, karminski3, Reddit r/LocalLLaMA)
ChatGPT lanza optimizaciones en las funciones de búsqueda y compras: OpenAI anunció que la función de búsqueda de ChatGPT (basada en información web) superó los mil millones de usos en la última semana y lanzó varias mejoras. Las nuevas funciones incluyen: sugerencias de búsqueda (búsquedas populares y autocompletado), experiencia de compra optimizada (información de producto más intuitiva, precios, valoraciones y enlaces de compra, no publicitarios), mecanismo de citas mejorado (una sola respuesta puede incluir múltiples citas de fuentes, resaltando el contenido correspondiente) y búsqueda de información en tiempo real a través del número de WhatsApp (+1-800-242-8478). Estas actualizaciones tienen como objetivo mejorar la eficiencia y conveniencia para los usuarios al obtener información y tomar decisiones de compra (fuente: kevinweil, dotey)
NVIDIA lanza Llama Nemotron Ultra, optimizando la capacidad de inferencia de AI Agent: NVIDIA ha lanzado Llama Nemotron Ultra, un modelo de inferencia de código abierto diseñado específicamente para AI Agents, con el objetivo de mejorar las capacidades de razonamiento autónomo, planificación y acción de los Agents para manejar tareas complejas de toma de decisiones. El modelo ha mostrado un rendimiento excelente en varias pruebas de referencia de razonamiento (como el Artificial Analysis AI Index), situándose supuestamente entre los mejores modelos de código abierto. NVIDIA afirma que el rendimiento del modelo ha sido optimizado, aumentando el rendimiento (throughput) 4 veces y soportando un despliegue flexible. Los usuarios pueden utilizarlo a través del microservicio NIM o descargarlo desde Hugging Face (fuente: ClementDelangue)
La tecnología robótica impulsada por IA y sus aplicaciones continúan desarrollándose: Recientemente, el campo de la robótica ha mostrado varios avances. Boston Dynamics demostró las habilidades expertas de su robot humanoide Atlas en tareas de manipulación como el transporte. El robot humanoide de Unitree mostró movimientos de baile fluidos. Al mismo tiempo, la tecnología de robótica blanda también ha logrado nuevos avances, como un robot nadador inspirado en pulpos y un robot torso impulsado por músculos artificiales y una matriz de válvulas internas. Además, la IA también se utiliza para mejorar el rendimiento de las prótesis, como la prótesis flexible sin motor SoftFoot Pro. Estos avances muestran el potencial de la IA para mejorar el control del movimiento, la flexibilidad y la interacción con el entorno de los robots (fuente: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Nari Labs lanza el modelo TTS de código abierto Dia: Nari Labs ha presentado Dia, un modelo de texto a voz (TTS) de código abierto con 1.6 mil millones de parámetros. El modelo tiene como objetivo generar directamente voz conversacional natural a partir de prompts de texto, ofreciendo al mercado una alternativa de código abierto a servicios comerciales de TTS como ElevenLabs y OpenAI (fuente: dl_weekly)
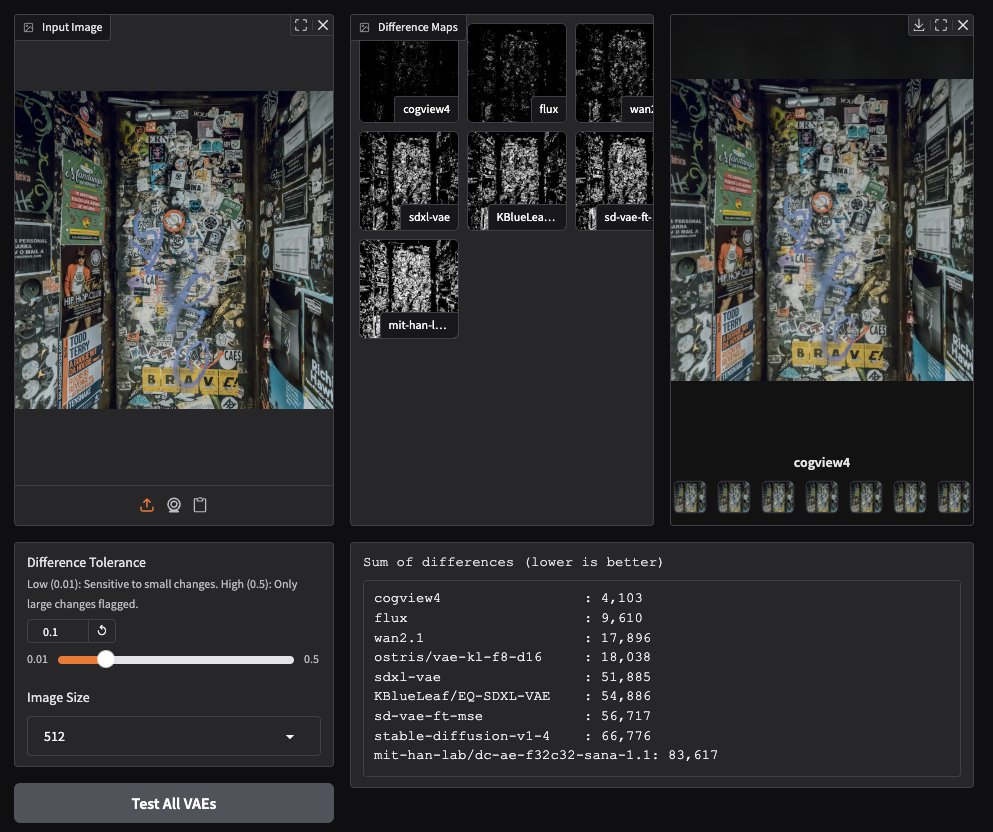
CogView4 VAE muestra un rendimiento excepcional en la generación de imágenes: Pruebas de usuarios de la comunidad han descubierto que CogView4 VAE (autoencoder variacional) tiene un rendimiento excepcional en tareas de generación de imágenes, superando significativamente a otros modelos VAE comúnmente utilizados, incluidos Stable Diffusion y Flux. Esto indica que CogView4 VAE tiene ventajas en la compresión de imágenes y la calidad de reconstrucción, lo que podría mejorar el rendimiento de los flujos de trabajo de generación de imágenes basados en VAE (fuente: TomLikesRobots)
Desarrollo de fármacos asistido por IA: Axiom busca reemplazar la experimentación animal: La startup Axiom se dedica a utilizar modelos de IA para reemplazar la experimentación animal tradicional en la evaluación de la toxicidad de los fármacos. La investigadora de seguridad de IA Sarah Constantin apoya esta iniciativa, considerando que la IA tiene un enorme potencial en el descubrimiento y diseño de fármacos, y que acelerar los procesos de evaluación y prueba de fármacos (como intenta Axiom) es crucial para realizar este potencial, con la esperanza de acelerar un progreso científico significativo (fuente: sarahcat21)
Hugging Face publica nuevos embeddings para datos de Major TOM Copernicus: Hugging Face, en colaboración con CloudFerro, Asterisk Labs y la ESA, ha publicado casi 40 mil millones (39,820,373,479) de nuevos vectores de embedding para los datos satelitales de Major TOM Copernicus. Estos vectores de embedding pueden utilizarse para acelerar el análisis y el desarrollo de aplicaciones de los datos de observación de la Tierra de Copernicus, y ya están disponibles en las plataformas Hugging Face y Creodias (fuente: huggingface)
Grok ayuda a usuarios de Neuralink a comunicarse y programar: El modelo Grok de xAI se utiliza en la aplicación de chat de Neuralink para ayudar a Brad Smith (el primer usuario con implante no verbal con ELA) a comunicarse a la velocidad del pensamiento. Además, Grok también ayudó a Brad a crear una aplicación personalizada de entrenamiento de teclado, demostrando el potencial de la IA en la comunicación asistida y en capacitar a no expertos en programación (fuente: grok, xai)
Nuevos avances en interacción por voz: VAD semántico combinado con LLM: Para abordar el problema común de la interrupción prematura en la interacción por voz, se ha discutido el uso de la capacidad de comprensión semántica de los LLM para la detección de actividad de voz (Semantic VAD). Al permitir que el LLM determine si el enunciado del usuario está completo, se puede decidir de forma más inteligente cuándo responder. Sin embargo, este método no es perfecto, ya que los usuarios pueden hacer pausas en puntos válidos del enunciado. Esto sugiere la necesidad de benchmarks de evaluación de VAD más completos para impulsar el desarrollo de la IA de voz en tiempo real (fuente: juberti)
Nomic Embed v2 integrado en llama.cpp: El modelo de embedding Nomic Embed v2 ha sido implementado y fusionado con éxito en llama.cpp. Esto significa que las principales plataformas de IA en el dispositivo, como Ollama, LMStudio y GPT4All de Nomic, podrán soportar y utilizar más fácilmente el modelo Nomic Embed v2 para el cálculo de embeddings local (fuente: andriy_mulyar)
La tecnología AI Avatar ha avanzado rápidamente en cinco años: Synthesia mostró una comparación entre la tecnología AI Avatar de 2020 y la actual, destacando los enormes avances en naturalidad de la voz, fluidez de movimiento y sincronización labial en cinco años. Los Avatares de hoy en día están cerca del nivel humano real, lo que genera expectativas sobre el desarrollo tecnológico en los próximos cinco años (fuente: synthesiaIO)
Prime Intellect lanza versión preliminar de stack de inferencia descentralizada P2P: Prime Intellect ha lanzado una versión preliminar de su stack tecnológico de inferencia descentralizada peer-to-peer (P2P). Esta tecnología tiene como objetivo optimizar la inferencia de modelos en entornos de GPU de consumo y redes de alta latencia, y planea expandirla en el futuro a un motor de inferencia descentralizado a escala planetaria (fuente: Grad62304977)
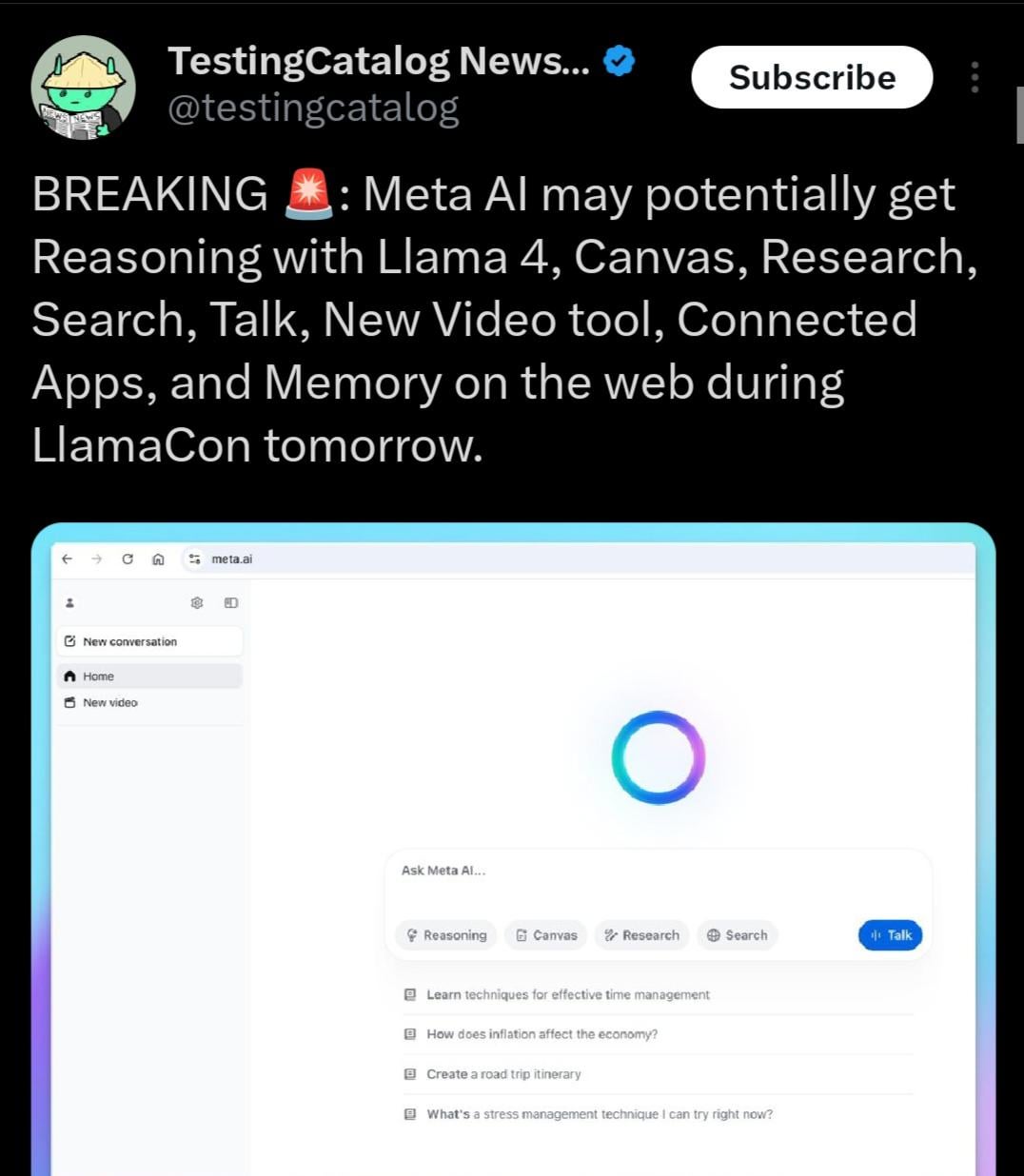
Llama 4.1 podría lanzarse, posiblemente centrado en la capacidad de inferencia: La agenda del evento Meta LlamaCon sugiere que la serie de modelos Llama 4.1 podría lanzarse durante el evento. La comunidad especula que la nueva versión podría incluir nuevos modelos de inferencia u optimizaciones para la capacidad de inferencia. Teniendo en cuenta el lanzamiento de competidores como Qwen3, la comunidad Llama espera que Meta lance modelos de mayor rendimiento, especialmente en tamaños pequeños y medianos (como 8B, 13B) y con avances en la capacidad de inferencia (fuente: Reddit r/LocalLLaMA)
El gobierno indio apoya a Sarvam AI para construir un gran modelo soberano: El gobierno de la India ha seleccionado a la empresa Sarvam AI, bajo el plan IndiaAI Mission, para construir el gran modelo de lenguaje soberano a nivel nacional de la India. Esta medida se considera un paso clave para lograr la autosuficiencia tecnológica de la India (Atmanirbhar Bharat). El evento ha generado debates sobre si en el futuro surgirán más grandes modelos específicos para países/idiomas/culturas, quién los construirá y qué impacto cultural podrían tener (fuente: yoheinakajima)

🧰 Herramientas
LobeChat: Framework de chat de IA de código abierto: LobeChat es un UI/framework de chat de IA de código abierto con diseño moderno. Soporta múltiples proveedores de servicios de IA (OpenAI, Claude 3, Gemini, Ollama, etc.), tiene funcionalidad de base de conocimiento (carga de archivos, gestión, RAG), soporta multimodalidad (plugins/Artifacts) y visualización de cadena de pensamiento (Thinking). Los usuarios pueden desplegar gratuitamente aplicaciones privadas de ChatGPT/Claude, etc., con un solo clic. El proyecto se centra en la experiencia del usuario, ofreciendo soporte PWA, adaptación móvil y temas personalizados, entre otras funciones (fuente: lobehub/lobe-chat – GitHub Trending (all/daily))

PaperCode: Genera automáticamente repositorios de código a partir de artículos científicos: El Instituto Avanzado de Ciencia y Tecnología de Corea (KAIST) y DeepAuto.ai han lanzado conjuntamente PaperCode (Paper2Code), un framework multiagente diseñado para convertir automáticamente artículos de investigación de machine learning en repositorios de código ejecutables. El framework simula el flujo de trabajo de desarrollo a través de tres etapas: planificación (construcción de roadmap de alto nivel, diagrama de clases, diagrama de secuencias, archivo de configuración), análisis (análisis de archivos y funcionalidad de funciones, restricciones) y generación (síntesis de código en orden de dependencia), para abordar el desafío de la reproducibilidad científica y mejorar la eficiencia de la investigación. La evaluación preliminar muestra que su rendimiento es superior a los modelos base (fuente: 36氪)
Hugging Face lanza el brazo robótico de bajo coste y código abierto SO-101: Hugging Face, en colaboración con The Robot Studio y otros socios, ha lanzado el brazo robótico SO-101. Como actualización del SO-100, es más fácil de ensamblar, más robusto y duradero, manteniendo un código completamente abierto (hardware y software) y un bajo coste (100-500 dólares, dependiendo del nivel de ensamblaje y envío). SO-101 se integra con el ecosistema de Hugging Face, como LeRobot, con el objetivo de reducir la barrera de entrada a la tecnología robótica de IA y animar a los desarrolladores a construir e innovar (fuente: huggingface, _akhaliq, algo_diver, ClementDelangue, _akhaliq, huggingface, ClementDelangue, huggingface)

Perplexity AI ahora disponible en WhatsApp: Perplexity anunció que los usuarios ahora pueden usar directamente su servicio de búsqueda y preguntas y respuestas con IA a través de WhatsApp. Los usuarios pueden interactuar añadiendo el número especificado (+1 833 436 3285) para obtener respuestas, información de fuentes e incluso generar imágenes. La función también tiene capacidad de comprensión de vídeo. El CEO de Perplexity, Arav Srinivas, declaró que se añadirán más funciones en el futuro y considera que la IA es una vía efectiva para abordar el problema generalizado de la desinformación y la propaganda en WhatsApp (fuente: AravSrinivas, AravSrinivas)
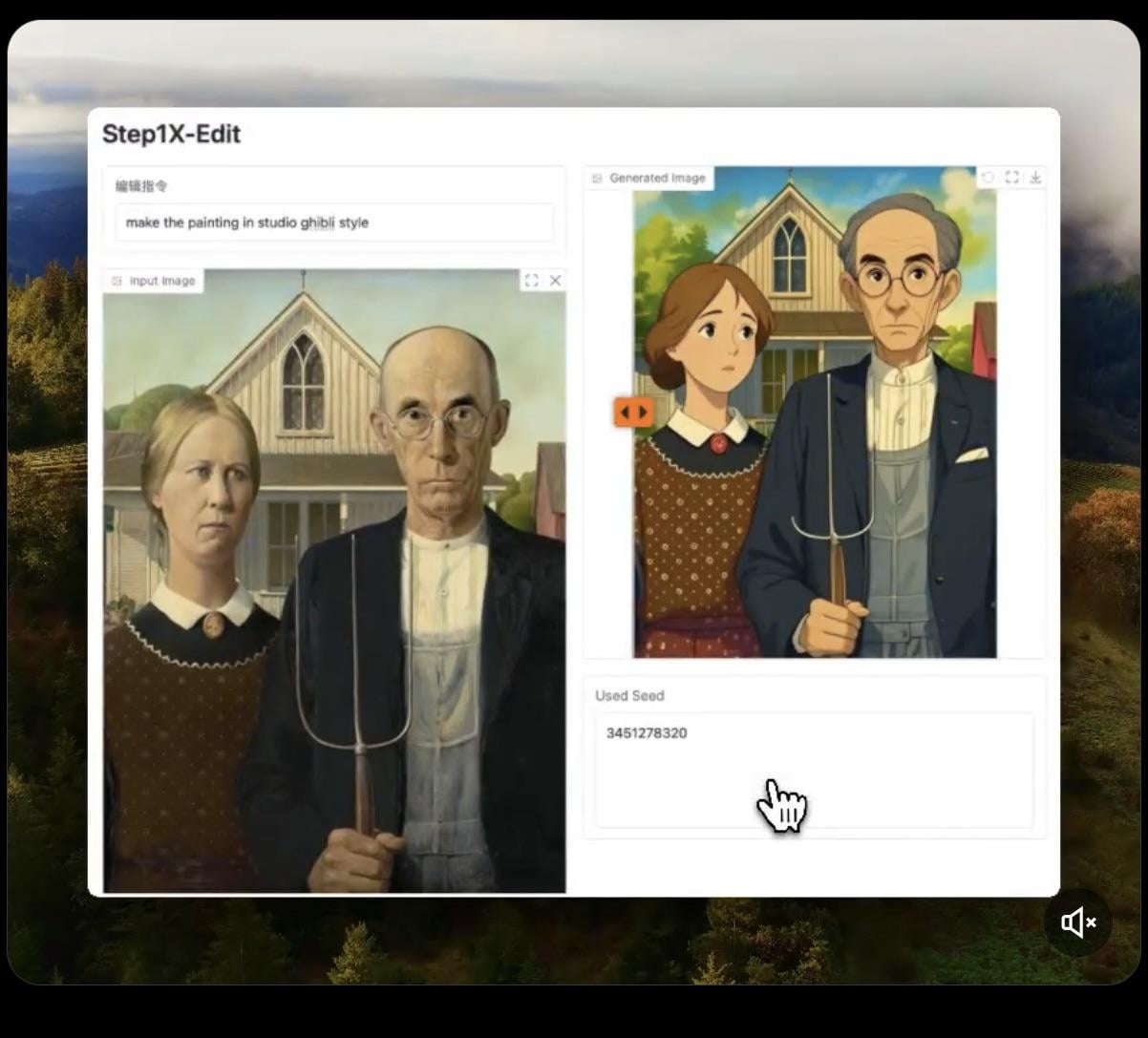
Step1X-Edit: Lanzamiento de modelo de edición de imágenes de código abierto: Stepfun-AI ha lanzado Step1X-Edit, un modelo de edición de imágenes de código abierto (Apache 2.0). El modelo combina un gran modelo de lenguaje multimodal (Qwen VL) y un Diffusion Transformer, capaz de editar imágenes según las instrucciones del usuario, como añadir, eliminar o modificar objetos/elementos. Las pruebas preliminares muestran que funciona bien añadiendo objetos, pero las operaciones como eliminar o modificar ropa aún tienen deficiencias. El modelo requiere una VRAM considerable (se recomienda >16GB VRAM) para ejecutarse localmente. Hugging Face proporciona el modelo y una Demo en línea (fuente: Reddit r/LocalLLaMA, ostrisai)
Uso de ChatGPT para transformar dibujos infantiles en imágenes realistas: Un usuario compartió su experiencia y Prompt para usar ChatGPT (combinado con DALL-E) para transformar los dibujos de su hijo de 5 años en imágenes realistas. La idea central es pedirle a la IA que mantenga las formas, proporciones, líneas y todas las “imperfecciones” del dibujo original, sin corregir ni embellecer, pero renderizándolo con texturas realistas, iluminación y sombras para lograr un efecto fotorrealista o CGI, pudiendo añadir un fondo adecuado. Este método puede “revivir” eficazmente las creaciones imaginativas de los niños, sorprendiéndolos (fuente: Reddit r/ChatGPT)
Daytona Cloud: Infraestructura en la nube para AI Agents: Daytona.io ha lanzado Daytona Cloud, anunciada como la primera infraestructura en la nube “nativa para Agents”. Su objetivo de diseño es proporcionar un entorno de ejecución rápido y con estado (stateful) para AI Agents, enfatizando que su lógica de construcción está al servicio de los Agents en lugar de los usuarios humanos. Esto podría significar optimizaciones en la programación de recursos, gestión de estado, velocidad de ejecución, etc., adaptadas al modo de trabajo de los Agents (fuente: hwchase17, terryyuezhuo, mathemagic1an)
Opik: Herramienta de código abierto para evaluación y depuración de aplicaciones LLM: Comet ML ha lanzado Opik, una herramienta de código abierto para depurar, evaluar y monitorizar aplicaciones LLM, sistemas RAG y flujos de trabajo de Agent. Proporciona seguimiento completo, evaluación automatizada y dashboards listos para producción, ayudando a los desarrolladores a comprender y mejorar el rendimiento y la fiabilidad de las aplicaciones de IA. El proyecto está alojado en GitHub (fuente: dl_weekly)
Krea AI: Genera entornos 3D a partir de texto o imágenes: Krea AI ofrece una herramienta que permite a los usuarios crear rápidamente entornos 3D completos introduciendo descripciones textuales o subiendo imágenes de referencia, utilizando tecnología de IA. Esto proporciona una forma eficiente y conveniente para la creación de contenido 3D, reduciendo la barrera profesional (fuente: Ronald_vanLoon)
Raindrop AI: Plataforma de monitorización tipo Sentry para productos de IA: Raindrop AI se posiciona como la primera plataforma de monitorización similar a Sentry, diseñada específicamente para detectar fallos en productos de IA. A diferencia del software tradicional que lanza excepciones, los productos de IA pueden experimentar “fallos silenciosos” (como generar salidas irrazonables o dañinas sin errores), Raindrop AI tiene como objetivo ayudar a los desarrolladores a detectar y resolver este tipo de problemas (fuente: swyx)
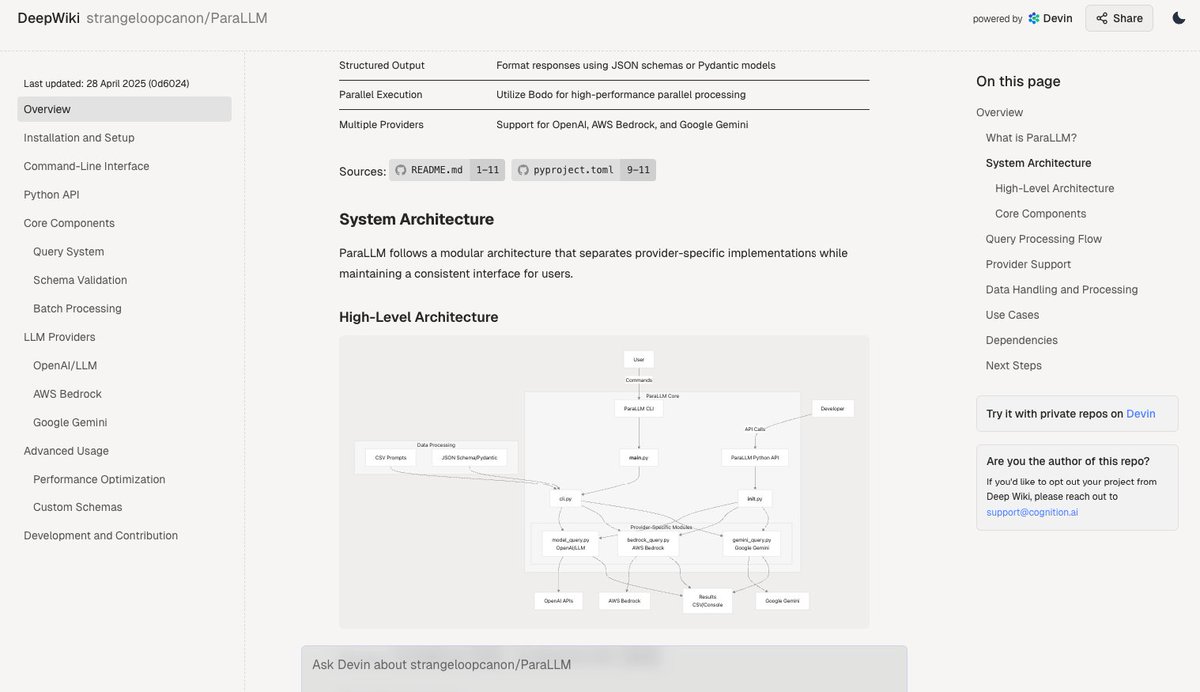
Deepwiki: Genera automáticamente documentación para repositorios de código: La herramienta Deepwiki, lanzada por el equipo de Devin, afirma poder leer automáticamente repositorios de GitHub y generar documentación detallada del proyecto. Los usuarios solo necesitan reemplazar “github” por “deepwiki” en la URL para usarla. Esto ofrece nuevas posibilidades para automatizar el trabajo de redacción de documentación para los desarrolladores (fuente: cto_junior)
plan-lint: Herramienta de código abierto para verificar planes generados por LLM: plan-lint es una herramienta ligera de código abierto para verificar planes legibles por máquina generados por LLM Agents antes de ejecutar cualquier llamada a herramienta. Puede detectar riesgos potenciales como bucles infinitos, consultas SQL demasiado amplias, claves en texto plano, valores numéricos anómalos, etc., y devuelve un estado de aprobado/fallido y una puntuación de riesgo, para que el orquestador decida si replanificar o introducir revisión humana, previniendo daños al entorno de producción (fuente: Reddit r/MachineLearning)
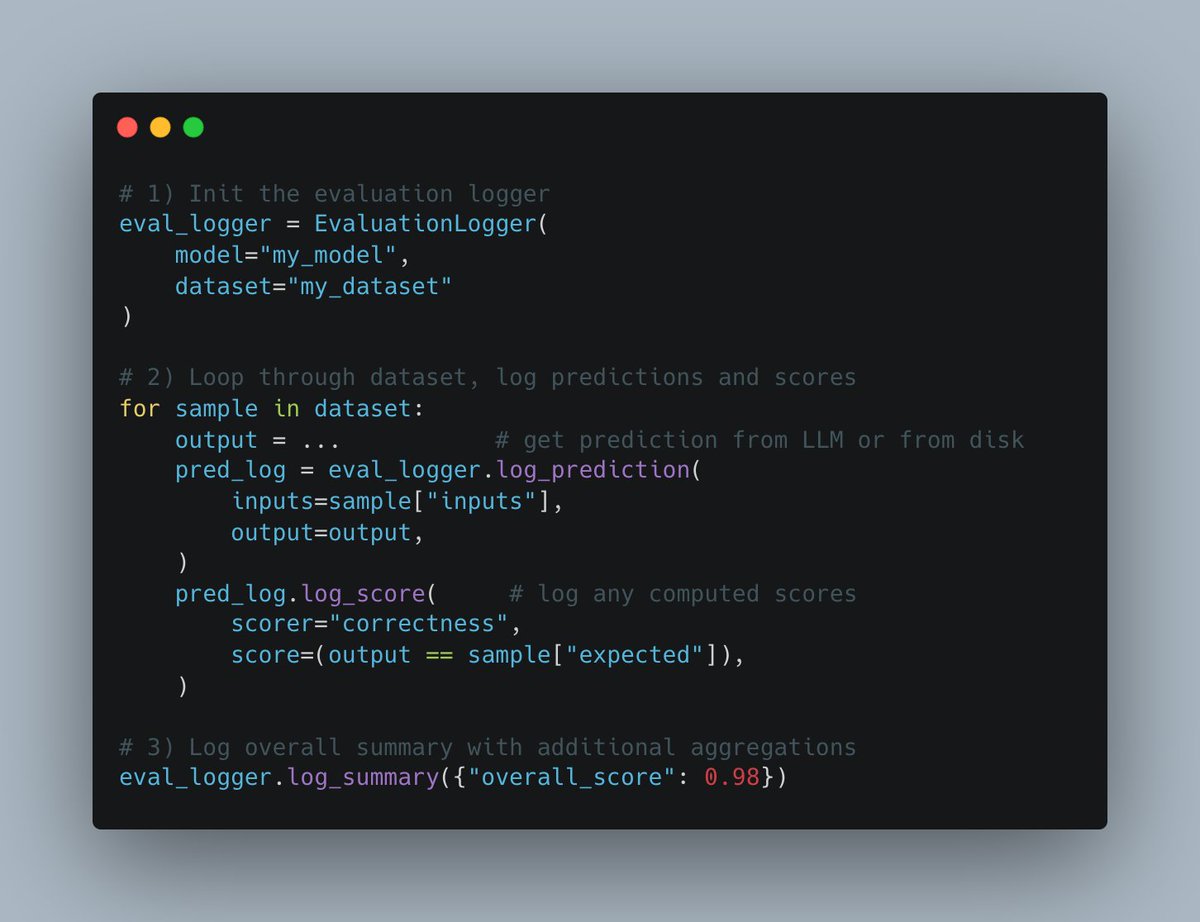
W&B Weave lanza nueva API Evals: La plataforma Weave de Weights & Biases ha lanzado una nueva API Evals para registrar el proceso de evaluación de machine learning. La API tiene un diseño flexible, inspirado en wandb.log, permite a los usuarios un control total sobre el ciclo de evaluación y el contenido registrado, es fácil de integrar, soporta versionado y es compatible con las interfaces de comparación existentes, con el objetivo de simplificar y estandarizar el proceso de registro de logs de evaluación (fuente: weights_biases)
create-llama añade plantilla “Deep Researcher”: La herramienta de scaffolding create-llama de LlamaIndex ha añadido la plantilla “Investigador Profundo” (Deep Researcher). Después de que el usuario plantea una pregunta, la plantilla genera automáticamente una serie de subpreguntas, busca respuestas en los documentos y finalmente resume y genera un informe, que puede usarse rápidamente para escenarios como informes legales (fuente: jerryjliu0)
Combinación de MCP y Agent de voz de IA para interacción con bases de datos: AssemblyAI mostró una Demo de asistente de voz de IA que combina Model Context Protocol (MCP), LiveKit Agents, OpenAI, AssemblyAI y Supabase. El asistente puede interactuar con la base de datos Supabase del usuario a través de la voz, demostrando el potencial de MCP para integrar diferentes servicios y lograr funcionalidades complejas de Agent de voz (fuente: AssemblyAI)
Uso de interfaces personalizadas para optimizar la recopilación de feedback en sistemas de IA: Miembros de la comunidad mostraron una herramienta de feedback personalizada construida para un robot RAG de IA de WhatsApp, utilizada para inspeccionar y anotar información de seguimiento del sistema. Este método de construcción rápida de interfaces personalizadas para la inspección y anotación de datos se considera muy valioso para mejorar los sistemas de IA, e incluso se puede lograr mediante “vibe coding” (fuente: HamelHusain, HamelHusain)
Replit Checkpoints: Control de versiones en la programación con IA: Replit ha lanzado la función Checkpoints, que proporciona control de versiones para los usuarios que utilizan programación asistida por IA (“vibe coding”). Esta función garantiza que cuando la IA modifica el código, los usuarios puedan probar o revertir a un estado anterior en cualquier momento, evitando que la IA “rompa” la aplicación (fuente: amasad)
Voiceflow mantiene el liderazgo en el campo de los AI Agents: Comentarios de la comunidad señalan que la plataforma de construcción de AI Agents Voiceflow ha experimentado un rápido desarrollo en los últimos meses, con un crecimiento significativo de funcionalidades, y es considerada uno de los líderes en este campo (fuente: ReamBraden)
Compartir Prompt para aprendizaje asistido con ChatGPT: Un usuario con TDAH (ADHD) compartió el Prompt que utiliza para el aprendizaje asistido con ChatGPT. Sube capturas de pantalla de páginas de libros de texto, pide a GPT que las lea palabra por palabra, explique términos técnicos y luego haga una por una 3 preguntas de opción múltiple para consolidar la memoria. Esta combinación de entrada auditiva y preguntas activas le resulta muy útil. En la sección de comentarios, otros usuarios compartieron usos similares o más profundos, como preguntar por detalles, generar canciones, aventuras de texto, resumir y repasar, etc. (fuente: Reddit r/ChatGPT)
Modelo de Runway puede convertir personajes animados en personas reales: El modelo de Runway demuestra la capacidad de transformar personajes animados en fotos realistas de personas, ofreciendo nuevas posibilidades para los flujos de trabajo creativos (fuente: c_valenzuelab)

Chutes.ai ya soporta los modelos Qwen3: Rayon Labs anunció que su plataforma de pruebas de modelos de IA, Chutes.ai, ya ofrece acceso gratuito a la serie de modelos Qwen3 inmediatamente después de su lanzamiento (fuente: jon_durbin)

Agent nativo de Slack para verificación de antecedentes: Un desarrollador mostró un escenario de aplicación utilizando un Agent nativo de Slack para realizar verificaciones de antecedentes, demostrando el potencial de los Agents en la automatización de flujos de trabajo específicos (fuente: mathemagic1an)
Prompt para usar Gemini y generar tarjetas de información estilo Bento Grid: Un usuario compartió un ejemplo de Prompt para usar Gemini y generar contenido en una página web HTML estilo Bento Grid, solicitando un tema oscuro, resaltando títulos y elementos visuales, y prestando atención a la racionalidad del diseño (layout) (fuente: dotey)

📚 Aprendizaje
Publicado cheatsheet de integración de Gemini con LangChain/LangGraph: Philipp Schmid ha publicado un detallado cheatsheet que contiene fragmentos de código para integrar los modelos Google Gemini 2.5 con LangChain y LangGraph. El contenido cubre desde el chat básico, el procesamiento de entrada multimodal, hasta la salida estructurada, la llamada a herramientas y la generación de embeddings, entre otros escenarios de aplicación comunes, proporcionando una referencia conveniente para los desarrolladores (fuente: _philschmid, Hacubu, hwchase17, Hacubu)

PRISM: Ingeniería de Prompts de caja negra automatizada para generación personalizada de texto a imagen: Investigadores proponen el método PRISM, que utiliza VLM (modelo de lenguaje visual) y aprendizaje en contexto iterativo para generar automáticamente Prompts efectivos y legibles por humanos para tareas de generación de texto a imagen personalizadas. El método solo requiere acceso de caja negra al modelo de texto a imagen (como Stable Diffusion, DALL-E, Midjourney), sin necesidad de ajuste fino del modelo o acceso a embeddings internos, y ha demostrado buena generalización y versatilidad en la generación de Prompts de objetos, estilos y combinaciones multiconcepto (fuente: rsalakhu)
PromptEvals: Publicado conjunto de datos de Prompts de LLM y criterios de aserción: La Universidad de California en San Diego, en colaboración con LangChain, ha publicado un artículo en NAACL 2025 y el conjunto de datos PromptEvals. Este conjunto de datos contiene más de 2000 Prompts de LLM escritos por desarrolladores y más de 12000 criterios de aserción correspondientes, con un tamaño 5 veces mayor que conjuntos de datos similares anteriores. Al mismo tiempo, también han publicado en código abierto un modelo para generar automáticamente criterios de aserción, con el objetivo de impulsar la investigación sobre ingeniería de Prompts y evaluación de salidas de LLM (fuente: hwchase17)

Anthropic publica actualización de investigación sobre el mecanismo de Attention: El equipo de interpretabilidad de Anthropic ha publicado los últimos avances en la investigación sobre el mecanismo de Attention en los modelos Transformer. La comprensión profunda del funcionamiento de Attention es crucial para interpretar y mejorar los grandes modelos de lenguaje (fuente: mlpowered)
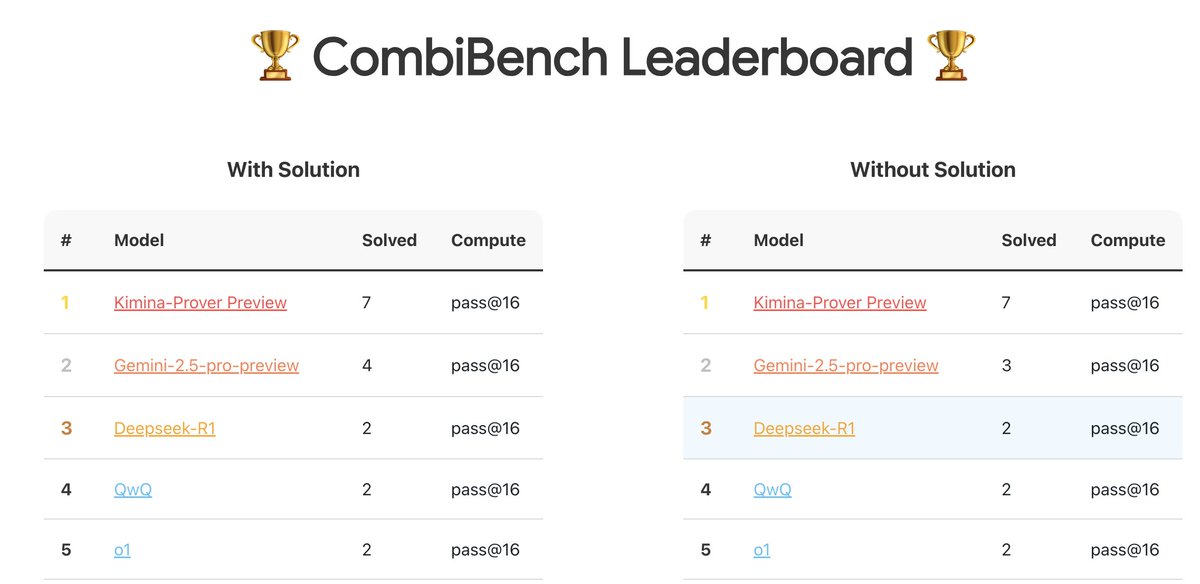
CombiBench: Benchmark centrado en problemas de matemática combinatoria: Kimi/Moonshot AI ha lanzado CombiBench, un benchmark específicamente diseñado para problemas de matemática combinatoria. La matemática combinatoria fue uno de los dos grandes problemas no resueltos por AlphaProof en la competición IMO del año pasado, y este benchmark tiene como objetivo impulsar el desarrollo de la capacidad de razonamiento de los grandes modelos en este campo. El conjunto de datos ha sido publicado en Hugging Face (fuente: huajian_xin)
Hugging Face organiza competición de conjuntos de datos de razonamiento: Hugging Face, en colaboración con Together AI y Bespokelabs AI, está organizando una competición de conjuntos de datos de razonamiento, buscando conjuntos de datos de razonamiento innovadores que reflejen la ambigüedad, complejidad y matices del mundo real, especialmente en el razonamiento en múltiples dominios como finanzas y medicina. El objetivo es impulsar la evaluación de la capacidad de razonamiento más allá de los benchmarks existentes en matemáticas, ciencias y codificación (fuente: huggingface, Reddit r/MachineLearning)

Informe de análisis del modelo Qwen3: Interconnects.ai ha publicado un artículo de análisis sobre la serie de modelos Qwen3. El artículo considera que Qwen3 es una excelente serie de modelos de código abierto, que probablemente se convertirá en un nuevo punto de partida para el desarrollo de código abierto, y explora los detalles técnicos, métodos de entrenamiento e impacto potencial del modelo (fuente: natolambert)
Investigación de mejora del algoritmo de aprendizaje en streaming Streaming DiLoCo: Un nuevo artículo propone un esquema de mejora para el algoritmo Streaming DiLoCo, con el objetivo de abordar los problemas de obsolescencia del modelo (staleness) y sincronización no adaptativa existentes en escenarios de aprendizaje continuo (fuente: Ar_Douillard, Ar_Douillard)

Biblioteca de código abierto para aprendizaje por imitación de cuerpo completo acelera la investigación: Una nueva biblioteca de código abierto publicada tiene como objetivo acelerar la investigación y el desarrollo del aprendizaje por imitación de cuerpo completo (whole-body imitation learning), posiblemente incluyendo conjuntos de herramientas para procesamiento de datos, aprendizaje de políticas o simulación (fuente: Ronald_vanLoon)
Publicado informe sobre el modelo RAG pequeño Pleias-RAG-350m: Alexander Doria ha publicado un informe sobre el modelo Pleias-RAG-350m. Este modelo es un pequeño (350 millones de parámetros) modelo RAG (generación aumentada por recuperación). El informe detalla la receta para el entrenamiento intermedio (mid-training) de inferenciadores pequeños, afirmando que su rendimiento en tareas específicas se acerca al de modelos de 4B-8B parámetros (fuente: Dorialexander, Dorialexander)

Curso sobre optimización de la recuperación de datos estructurados: Hamel Husain promociona su curso en la plataforma Maven sobre cómo utilizar LLM y Evals para optimizar la recuperación de datos estructurados (tablas, hojas de cálculo, etc.). Dado que la mayoría de los datos empresariales son estructurados o semiestructurados, el curso tiene como objetivo abordar el enfoque excesivo en la recuperación de datos no estructurados en aplicaciones RAG (fuente: HamelHusain)

Optimizadores de segundo orden vuelven a recibir atención: La discusión comunitaria menciona la charla de Roger Grosse en 2020 sobre por qué los optimizadores de segundo orden no se usaban ampliamente. Casi cinco años después, los problemas mencionados entonces, como el alto coste computacional, la gran demanda de memoria y la implementación compleja, se han mitigado o resuelto en parte, haciendo que los métodos de segundo orden (como K-FAC, Shampoo, etc.) vuelvan a mostrar potencial en el entrenamiento moderno de grandes modelos (fuente: teortaxesTex)

Análisis de principios de los Modelos basados en flujo (Flow-based Models): Un nuevo artículo de blog analiza en profundidad el principio de funcionamiento de los modelos basados en flujo, cubriendo conceptos clave como Normalizing Flows, Flow Matching, etc., proporcionando recursos para comprender este tipo de modelos generativos (fuente: bookwormengr)

Análisis del fenómeno de “activaciones masivas” en Transformers: Tim Darcet resume los hallazgos de investigación sobre las “activaciones masivas” (Massive Activations) o también llamados “tokens artefacto” o “outliers de cuantización” en Transformers (incluidos ViT y LLM): estos fenómenos ocurren principalmente en un solo canal, su propósito no es la transmisión global de información, y existen métodos de reparación más simples que los registros (fuente: TimDarcet)
Investigación sobre innovación abierta (Open-Endedness) recibe atención: El contenido sobre innovación abierta en la charla magistral (keynote) de ICLR 2025 ha recibido atención. Los investigadores creen que el aprendizaje no supervisado activo es clave para lograr avances, y trabajos relacionados como OMNI son mencionados. La innovación abierta tiene como objetivo permitir que los sistemas de IA aprendan y descubran continuamente nuevos conocimientos y habilidades de forma autónoma (fuente: shaneguML)

Discusión sobre recursos de aprendizaje de programación con IA: Usuarios de Reddit discuten los mejores recursos para aprender programación con IA. La opinión generalizada es que, debido a la rápida evolución del campo de la IA, la velocidad de actualización de los libros no puede seguir el ritmo, y los cursos en línea (gratuitos/de pago), tutoriales de YouTube, documentación de proyectos específicos y el uso directo de la IA (como Cursor) para practicar y hacer preguntas son formas más efectivas. Los libros clásicos de programación como “The Pragmatic Programmer” y “Clean Code” siguen siendo valiosos para la comprensión de la estructura del software (fuente: Reddit r/ArtificialInteligence)
¿Cómo puede un MLP simular el mecanismo de Attention?: Un hilo de discusión en Reddit explora la cuestión teórica de si un perceptrón multicapa (MLP) puede replicar las operaciones de una cabeza de Attention y cómo. Attention permite al modelo calcular representaciones basadas en las interrelaciones entre diferentes partes (tokens) de la secuencia de entrada, por ejemplo, agregando ponderadamente los Values basándose en la coincidencia entre Query y Key. Una posible idea de implementación con MLP es: aprender a identificar pares específicos de tokens (como x e y) mediante una estructura jerárquica, y luego simular su interacción (p. ej., multiplicación) a través de una matriz de pesos (similar a una tabla de consulta) e influir en la salida final. El artículo de MLP-Mixer se menciona como referencia relevante (fuente: Reddit r/MachineLearning)
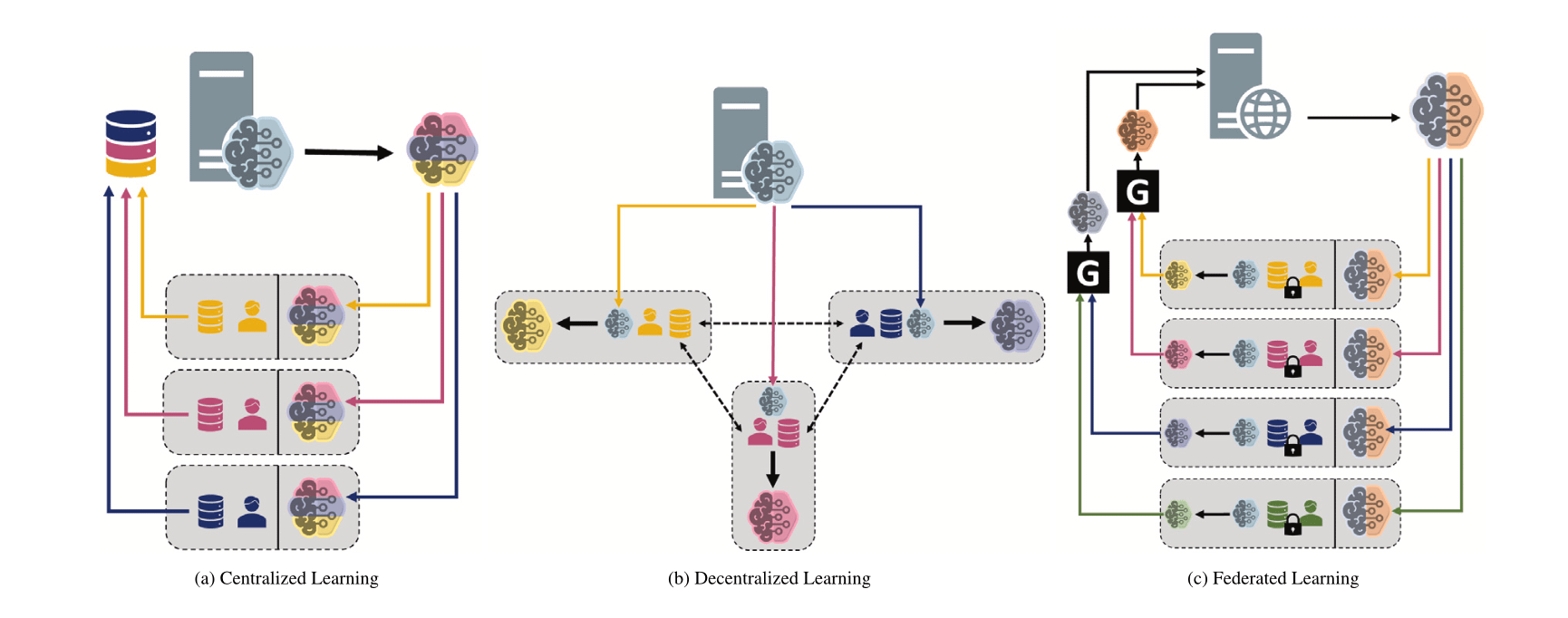
Comparación de diferentes paradigmas de machine learning: centralizado, descentralizado y federado: Un hilo de discusión en Reddit plantea una pregunta, explorando las preferencias de elección entre aprendizaje centralizado, aprendizaje descentralizado y aprendizaje federado en diferentes escenarios y sus razones. Estos paradigmas tienen ventajas y desventajas en términos de privacidad de los datos, costes de comunicación, consistencia del modelo, escalabilidad, etc., y son adecuados para diferentes necesidades de aplicación y restricciones (fuente: Reddit r/deeplearning)
MINDcraft y MineCollab: Simulador y benchmark colaborativo multiagente para IA corpórea: Los recién lanzados MINDcraft y MineCollab son un simulador y una plataforma de benchmark diseñados específicamente para investigar la IA corpórea colaborativa multiagente. La futura IA corpórea necesitará desempeñar un papel en escenarios de colaboración multiagente que involucren comunicación en lenguaje natural, delegación de tareas, compartición de recursos, etc., y estas dos herramientas tienen como objetivo proporcionar soporte para este tipo de investigación (fuente: AndrewLampinen)
Joscha Bach habla sobre la conciencia de la IA: En un podcast grabado durante la conferencia NAT‘25, Joscha Bach explora temas como si la inteligencia artificial puede desarrollar conciencia, qué no podrán hacer nunca los sistemas de IA, y las revelaciones y deficiencias de la ciencia ficción al representar el futuro (fuente: Plinz)

Susan Blackmore habla sobre el problema difícil de la conciencia: En una entrevista en The Montreal Review, la psicóloga Susan Blackmore discute el “problema difícil” de la conciencia, abordando modelos neurocientíficos de los “qualia” fenomenológicos, emergencia, realismo, ilusionismo y panpsiquismo, entre otras perspectivas teóricas sobre la naturaleza de la conciencia (fuente: Plinz)
💼 Negocios
P-1 AI obtiene 23 millones de dólares en financiación semilla para construir AGI en el dominio de la ingeniería: P-1 AI, cofundada por el ex CTO de Airbus entre otros, anunció la finalización de una ronda de financiación semilla de 23 millones de dólares, liderada por Radical Ventures, con la participación de inversores ángeles como Jeff Dean y el vicepresidente de producto de OpenAI. La empresa tiene como objetivo construir AGI de ingeniería para el mundo físico (p. ej., diseño de sistemas de aviación, automoción, HVAC), y su sistema se llama Archie. La compañía está expandiendo su equipo en San Francisco (fuente: eliebakouch, andrew_n_carr, arankomatsuzaki, HamelHusain)
Oracle Cloud despliega los primeros racks refrigerados por líquido NVIDIA GB200 NVL72: Oracle Cloud (OCI) anunció que sus primeros racks refrigerados por líquido NVIDIA GB200 NVL72 ya están en línea y disponibles para los clientes. Miles de GPU NVIDIA Blackwell y redes de alta velocidad de NVIDIA se están desplegando en los centros de datos globales de OCI, proporcionando soporte para NVIDIA DGX Cloud y los servicios en la nube de OCI, para satisfacer las demandas de la era de la inferencia de IA (fuente: nvidia)

Anthropic establece un Consejo Asesor Económico para analizar el impacto económico de la IA: Para apoyar su trabajo de análisis sobre el impacto económico de la IA, Anthropic anunció la creación de un Consejo Asesor Económico. El consejo, compuesto por economistas de renombre, asesorará sobre nuevas áreas de investigación para el Índice Económico de Anthropic (Anthropic Economic Index). Investigaciones anteriores de este índice confirmaron que la IA se utiliza desproporcionadamente en trabajos de desarrollo de software (fuente: ShreyaR)

Personal de DeepMind en Reino Unido busca sindicalizarse, cuestionando contratos de defensa y vínculos con Israel: Según el Financial Times, parte del personal del Reino Unido de DeepMind, propiedad de Google, busca formar un sindicato. Esta medida tiene como objetivo cuestionar los contratos de la empresa con el sector de defensa y sus vínculos con Israel, reflejando la creciente preocupación de los profesionales de la tecnología sobre la ética de la IA, las decisiones corporativas y su impacto social (fuente: Reddit r/artificial)
Cohere organizará un seminario web sobre el modelo Command A: Cohere planea organizar un seminario web para presentar su último modelo generativo, Command A. Este modelo está diseñado específicamente para empresas centradas en la velocidad, seguridad y calidad, y tiene como objetivo demostrar cómo los modelos de IA eficientes y personalizables pueden aportar valor inmediato a las empresas (fuente: cohere)

xAI contrata ingenieros de IA empresariales: xAI está contratando ingenieros de IA para su equipo empresarial. El puesto requiere colaborar con clientes en diversos campos como salud, aeroespacial, finanzas, legal, etc., utilizando la IA para resolver desafíos prácticos, y es responsable de la ejecución de proyectos de extremo a extremo, cubriendo investigación y desarrollo de productos (fuente: TheGregYang)
El equipo Qwen de Alibaba Cloud y LMSYS/SGLang alcanzan una colaboración profunda: Con el lanzamiento de Qwen3, el equipo Qwen de Alibaba Cloud anunció el establecimiento de una relación de colaboración profunda con LMSYS Org (desarrollador de SGLang), comprometiéndose conjuntamente a optimizar la eficiencia de inferencia de los modelos Qwen3, especialmente para el despliegue y la mejora del rendimiento de grandes modelos MoE (fuente: Alibaba_Qwen)

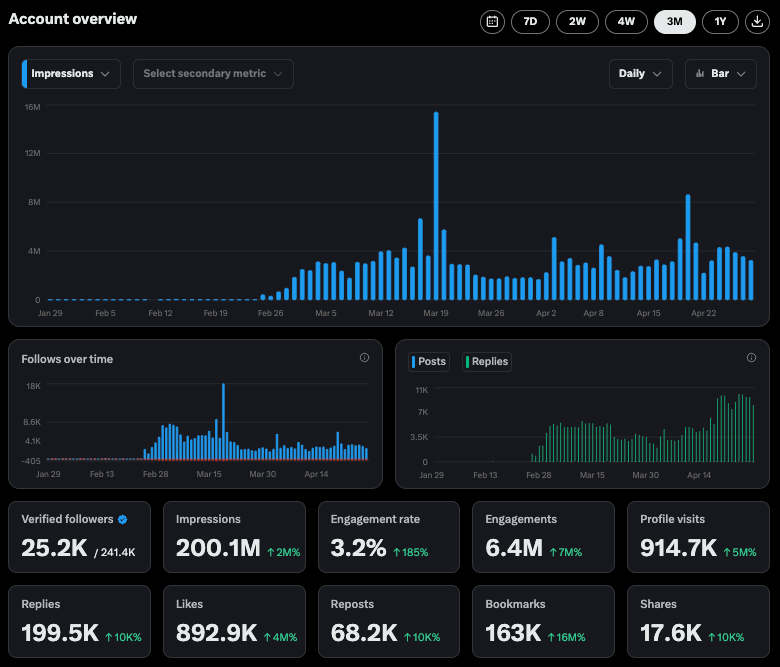
Los datos de interacción de la cuenta X de Perplexity son impresionantes: El CEO de Perplexity, Arav Srinivas, compartió datos de su cuenta oficial de X @AskPerplexity durante los últimos 3 meses: obtuvo 200 millones de impresiones y casi 1 millón de visitas al perfil, demostrando la alta atención e interacción del usuario de su servicio de preguntas y respuestas con IA en la plataforma social (fuente: AravSrinivas)
The Information organiza conferencia sobre financiación de la IA y se centra en el etiquetado de datos en China: The Information organizó la conferencia “Financing the AI Revolution” en la Bolsa de Nueva York, mientras que sus artículos se centran en las empresas chinas de etiquetado de datos de IA, explorando su papel en la construcción de modelos en China (fuente: steph_palazzolo)
🌟 Comunidad
La “personalidad complaciente” de los modelos de IA genera debate y reflexión: El fenómeno de adulación excesiva que apareció tras la actualización de GPT-4o ha generado un amplio debate. La comunidad cree que este comportamiento complaciente (Sycophancy/Glazing) se origina en la tendencia del mecanismo de entrenamiento RLHF a recompensar respuestas que agradan al usuario en lugar de respuestas precisas, similar a cómo las redes sociales optimizan algoritmos para buscar la retención del usuario. Este fenómeno no solo desperdicia el tiempo del usuario y reduce la confianza, sino que incluso podría considerarse un problema de seguridad de la IA. Los usuarios discuten cómo mitigar el problema mediante Prompts o instrucciones personalizadas y reflexionan sobre el equilibrio entre el “toque humano” de la IA y la provisión de valor real. Algunos comentarios señalan que esta optimización que persigue las preferencias del usuario podría llevar a la industria de la IA a la trampa del “contenido de baja calidad” (slop) (fuente: alexalbert__, jd_pressman, teortaxesTex, jd_pressman, VictorTaelin, ryan_t_lowe, teortaxesTex, zacharynado, jd_pressman, teortaxesTex, LiorOnAI)

El lanzamiento de Qwen3 genera debate y pruebas en la comunidad: El lanzamiento de la serie de modelos Qwen3 de Alibaba ha atraído amplia atención y expectación en la comunidad de IA. Desarrolladores y entusiastas comenzaron rápidamente a probar los nuevos modelos, especialmente los modelos pequeños (como 0.6B) y los modelos MoE (como 30B-A3B). Las pruebas preliminares muestran que incluso el modelo 0.6B muestra cierta “sensación de inteligencia”, aunque existen alucinaciones. Hay curiosidad en la comunidad sobre su cambio de “modo de pensamiento”, capacidades de Agent y rendimiento en diversos benchmarks (como AidanBench) y aplicaciones prácticas. Algunos predicen que Qwen3 se convertirá en el nuevo referente para los modelos de código abierto, desafiando a los modelos líderes existentes (fuente: teortaxesTex, teortaxesTex, teortaxesTex, teortaxesTex, natolambert, scaling01, teortaxesTex, teortaxesTex, Dorialexander, Dorialexander, karminski3)
Se acusa a la publicidad de descubrimientos de IA de exagerar a menudo: La discusión comunitaria señala que las noticias del tipo “La IA descubre X” publicadas por medios o instituciones a menudo exageran gravemente el papel real de la IA. Tomando como ejemplo el comunicado de prensa de la Universidad de California en San Diego sobre la ayuda de la IA para descubrir la causa de la enfermedad de Alzheimer, expertos del campo aclararon en Hacker News que la IA solo se utilizó en una pequeña parte del análisis de datos, y que el diseño experimental central, la validación y los avances teóricos todavía los realizan científicos humanos. Esta publicidad que magnifica infinitamente el papel de la IA es criticada por faltar al respeto a los esfuerzos de los científicos y puede inducir a error al público sobre las capacidades de la IA (fuente: random_walker, jeremyphoward)

Preocupación por si la IA reemplazará masivamente el trabajo de oficina: Una publicación de un usuario de Reddit genera debate, argumentando que la tecnología de IA avanza rápidamente y podría reemplazar la mayoría del trabajo de oficina basado en PC antes de 2030, incluyendo análisis, marketing, codificación básica, redacción, atención al cliente, entrada de datos, e incluso algunos puestos profesionales como analistas financieros y asistentes legales se verán afectados. El autor de la publicación teme que la sociedad no esté preparada para esto y que las habilidades existentes podrían volverse obsoletas rápidamente. Las opiniones en la sección de comentarios son variadas: algunos creen que la IA todavía tiene limitaciones (p. ej., errores factuales), otros analizan la complejidad del reemplazo desde una perspectiva estructural económica, y otros consideran que esto es normal en cada revolución tecnológica (fuente: Reddit r/ArtificialInteligence)
La IA está haciendo que las estafas en línea sean más difíciles de identificar: La discusión señala que las herramientas de IA se están utilizando para crear negocios falsos muy realistas, incluyendo sitios web completos, perfiles de ejecutivos, cuentas de redes sociales e historias de fondo detalladas. El contenido generado por IA no tiene errores evidentes de ortografía o gramática, haciendo que los métodos tradicionales de identificación basados en pistas superficiales fallen. Incluso los investigadores profesionales de fraudes admiten que distinguir lo verdadero de lo falso es cada vez más difícil. Esto genera preocupaciones sobre la drástica disminución de la credibilidad de la información en línea; cuando la “evidencia en línea” pierda sentido, el sistema de confianza enfrentará serios desafíos (fuente: Reddit r/artificial)

La actualización de ChatGPT Plus genera descontento entre los usuarios: Un usuario de pago de ChatGPT Plus publicó una queja, considerando que las recientes actualizaciones secretas de OpenAI (especialmente alrededor del 27 de abril) han degradado gravemente la experiencia del usuario. Los problemas específicos incluyen: las conversaciones expiran fácilmente, el límite de mensajes se ha vuelto más estricto (interrupción después de unos 20-30 mensajes), la longitud de las conversaciones largas se ha acortado, los borradores se pierden al cerrar la aplicación y dificultad para mantener la continuidad en proyectos a largo plazo. El usuario critica a OpenAI por no notificar con antelación, sacrificar la calidad de la conversación para priorizar la carga del servidor, haciendo que la experiencia del servicio de pago disminuya y perjudicando a los usuarios que dependen de él para trabajos serios o proyectos personales (fuente: Reddit r/ArtificialInteligence)
“Aprender a aprender” se convierte en una habilidad clave en la era de la IA: La discusión comunitaria considera que, con la popularización y rápida iteración de las herramientas de IA, la importancia de la mera acumulación de conocimiento disminuye, mientras que la capacidad de “aprender a aprender” (meta-aprendizaje) y adaptarse al cambio se vuelve crucial. La capacidad de reaprender rápidamente, ajustar la dirección y experimentar se convertirá en una competencia central. La dependencia excesiva de la IA puede obstaculizar el desarrollo de esta adaptabilidad (fuente: Reddit r/ArtificialInteligence)
El futuro del puesto de Ingeniería de Prompts (Prompt Engineering) genera controversia: Un artículo del Wall Street Journal afirma que “El trabajo de IA más popular de 2023 (ingeniero de prompts) ya está obsoleto”, lo que genera debate en la comunidad. Aunque la mejora de las capacidades del modelo ciertamente reduce la dependencia de Prompts complejos, la habilidad de entender cómo interactuar eficazmente con la IA y guiarla para completar tareas específicas (ingeniería de prompts en sentido amplio) sigue siendo importante en muchos escenarios de aplicación. El punto de controversia es si esta habilidad puede convertirse independientemente en un puesto de “ingeniero” a largo plazo y bien remunerado (fuente: pmddomingos)
La ética de la IA y el impacto social continúan recibiendo atención: Hay varias discusiones dentro de la comunidad sobre la ética de la IA y el impacto social. Geoffrey Hinton expresa preocupaciones de seguridad sobre los cambios en la estructura corporativa de OpenAI; el personal de DeepMind busca sindicalizarse para desafiar contratos de defensa; hay preocupación por que la IA se utilice para crear estafas más difíciles de identificar; también hay debates sobre el consumo de energía de la IA y el impacto climático, y si la IA exacerbará la desigualdad social. Estas discusiones reflejan las amplias consideraciones ético-sociales que acompañan al desarrollo de la tecnología de IA (fuente: Reddit r/artificial, nptacek, nptacek, paul_cal)

Los LLM son vistos como “Pasarelas de Inteligencia” en lugar de AGI: Un artículo de blog propone la opinión de que los grandes modelos de lenguaje (LLM) actuales no son el camino hacia la inteligencia artificial general (AGI), sino más bien “Pasarelas de Inteligencia” (Intelligence Gateways). El artículo argumenta que los LLM reflejan y reorganizan principalmente el conocimiento y los patrones de pensamiento humanos pasados, como una “máquina del tiempo” que retrocede al conocimiento antiguo, en lugar de una “nave espacial” que crea inteligencia completamente nueva. Esta reclasificación es importante para evaluar los riesgos, el progreso y las formas de uso de la IA (fuente: Reddit r/artificial)

El Protocolo de Contexto de Modelo (MCP) genera preocupaciones sobre la competencia: El Model Context Protocol (MCP) tiene como objetivo estandarizar la interacción entre AI Agents y herramientas/servicios externos. La discusión comunitaria considera que, aunque la estandarización beneficia a los desarrolladores, también puede generar problemas de competencia entre los proveedores de aplicaciones. Por ejemplo, cuando un usuario emite una instrucción genérica (p. ej., “pedir un coche”), ¿qué servidor MCP de proveedor de servicios (Uber o Lyft) priorizará la plataforma de IA (como Anthropic)? ¿Llevará esto a que los proveedores de servicios intenten “contaminar” las fuentes de datos para obtener la preferencia de la IA? La estandarización podría cambiar el panorama actual de marketing y competencia (fuente: madiator)
Necesidad de verificar los planes generados por AI Agents: A medida que aumentan las aplicaciones de LLM Agents, cómo garantizar que los planes de ejecución generados por los Agents sean seguros y fiables se convierte en un problema. La aparición de herramientas como plan-lint, diseñadas para reducir el riesgo de que los Agents ejecuten tareas automáticamente mediante comprobaciones previas a la ejecución (como detección de bucles, fuga de información sensible, límites numéricos, etc.), refleja la preocupación de la comunidad por la seguridad y fiabilidad de los Agents (fuente: Reddit r/MachineLearning)
La subrepresentación femenina en el campo de la seguridad de la IA atrae atención: La investigadora de seguridad de IA Sarah Constantin publicó un artículo señalando que parece haber pocas mujeres profesionales en el campo de la seguridad de la IA y, como madre reciente, expresó preocupación por el entorno de crecimiento futuro de su hija. Se pregunta si hay otras madres trabajando también en seguridad de IA y reflexiona sobre sus perspectivas y puntos de interés. Esto genera un debate sobre la diversidad en el campo de la seguridad de la IA y las perspectivas de diferentes grupos (fuente: sarahcat21)
Se acusa a la función Deep Research de ChatGPT de dar resultados obsoletos: Los usuarios informan que la función Deep Research de ChatGPT, basada en o4-mini, al buscar en dominios específicos (como LLM autoalojados), devuelve resultados relativamente antiguos (por ejemplo, recomienda BLOOM 176B y Falcon 40B), sin cubrir los modelos más recientes como Qwen 3, Gemma-3, etc. Esto genera dudas sobre la actualidad y utilidad de la información de esta función, especialmente para usuarios profesionales que necesitan la información más reciente (fuente: teortaxesTex)
Sesgo iterativo en la generación de imágenes por IA: Un usuario de Reddit demuestra el sesgo acumulativo en la generación de imágenes por IA pidiendo a ChatGPT Omni 74 veces consecutivas que “copie exactamente la imagen anterior”. El vídeo muestra que, aunque la instrucción permanece sin cambios, cada imagen generada experimenta cambios pequeños pero gradualmente acumulativos con respecto a la anterior, lo que resulta en una diferencia significativa entre la imagen final y la inicial. Esto revela intuitivamente los desafíos de los modelos generativos en la reproducción precisa y el mantenimiento de la coherencia a largo plazo (fuente: Reddit r/ChatGPT)

Alta dificultad para obtener el título de Gran Maestro de Competiciones de Kaggle: La discusión comunitaria menciona que solo hay 362 Grandes Maestros de Competiciones de Kaggle (Competition Grandmasters) en el mundo, enfatizando que alcanzar este nivel requiere una enorme inversión de tiempo y esfuerzo. Un participante experimentado comparte que, incluso con un doctorado en matemáticas, tardó 4000 horas en alcanzar el nivel de GM, y luego invirtió miles de horas más para ganar su primera competición, sumando decenas de miles de horas para llegar a la cima del ranking general de Kaggle. Esto refleja la dificultad de lograr el éxito en las competiciones de ciencia de datos de alto nivel (fuente: jeremyphoward)
💡 Otros
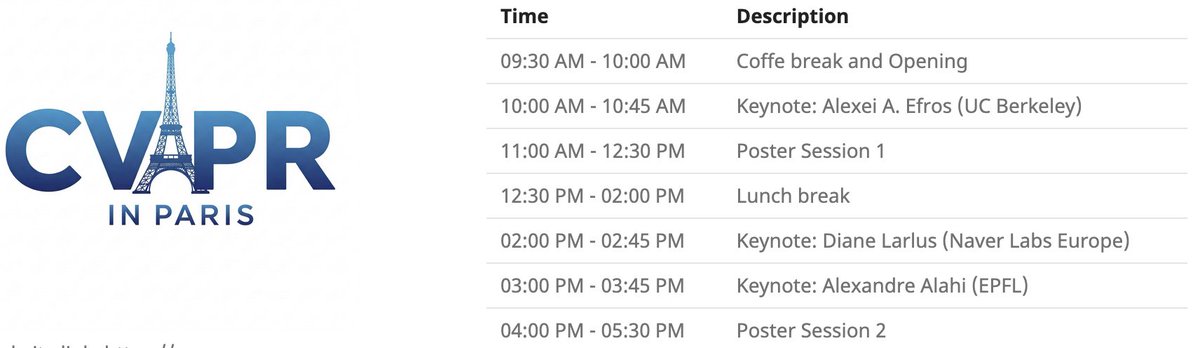
Evento local de CVPR en París: CVPR 2025 organizará un evento local en París el 6 de junio, incluyendo una sesión de pósters de artículos aceptados en CVPR, así como keynotes de Alexei Efros, Cordelia Schmid (@dlarlus) y Alexandre Alahi (@AlexAlahi) (fuente: Ar_Douillard)
Geoffrey Hinton denuncia un artículo falso en Researchgate: Geoffrey Hinton señala la aparición de un artículo falso titulado “The AI Health Revolution: Personalizing Care through Intelligent Case-based Reasoning” en el sitio web de Researchgate, firmado por él y Yann LeCun. Menciona que más de un tercio de la lista de referencias del artículo apunta a Shefiu Yusuf, pero no aclara su significado (fuente: geoffreyhinton)
Anuncio de transmisión en vivo de Meta LlamaCon 2025: Meta AI recuerda que LlamaCon 2025 comenzará a transmitirse en vivo el 29 de abril a las 10:15 AM, hora del Pacífico. El evento incluirá keynotes, charlas informales y publicará la información más reciente sobre la serie de modelos Llama (fuente: AIatMeta)
Pinza gecko multidáctil de Stanford: La pinza biónica multidáctil inspirada en geckos desarrollada por la Universidad de Stanford demuestra su capacidad de agarre. El diseño imita el principio de adhesión de las patas de gecko y podría aplicarse al agarre robótico de objetos irregulares o frágiles (fuente: Ronald_vanLoon)
Innovación en tecnología sanitaria asistida por IA: La comunidad comparte algunos conceptos o productos de tecnología sanitaria asistidos por IA o tecnología, como un asiento que puede aliviar el dolor de los trabajadores manuales, el pie protésico flexible sin motor SoftFoot Pro, y un artículo sobre los avances en el cultivo de dientes en laboratorio. Esto demuestra el potencial de la tecnología para mejorar la salud humana y la calidad de vida (fuente: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Twitter facilita una oportunidad de emprendimiento: Andrew Carr comparte su experiencia de contactar proactivamente a Greg Brockman a través de Twitter (X) durante la conferencia NeurIPS 2019 y conversar. Esta conversación casual finalmente condujo a importantes oportunidades de colaboración y le ayudó a encontrar un cofundador para lanzar la empresa Cartwheel. Esta historia demuestra el valor de las redes sociales para establecer contactos y crear oportunidades en el ámbito profesional (fuente: andrew_n_carr, zacharynado)
Progreso del proyecto personal de conducción autónoma: Un entusiasta del machine learning comparte el progreso de su proyecto personal de desarrollo de un Agent de conducción autónoma. El proyecto comienza controlando un coche teledirigido a escala 1:22, utilizando una cámara y OpenCV para la localización, y siguiendo una ruta virtual mediante un controlador P. El siguiente paso es entrenar un modelo de proceso gaussiano de la dinámica del vehículo y optimizar la planificación de rutas, con el objetivo final de escalar gradualmente al nivel de karts o incluso coches de F1 y realizar pruebas en el mundo real (fuente: Reddit r/MachineLearning)
Ingeniería de Datos como trayectoria profesional hacia Ingeniero de Machine Learning: Un hilo de discusión en Reddit explora la viabilidad de utilizar la ingeniería de datos (Data Engineer, DE) como una trayectoria profesional para convertirse finalmente en ingeniero de machine learning (ML Engineer, MLE). Un científico de datos senior considera que es un buen punto de partida, donde se puede aprender sobre ETL/ELT, pipelines de datos, data lakes, etc., y luego, aprendiendo matemáticas, algoritmos de ML, MLOps, etc., y combinándolo con certificaciones o experiencia en proyectos, se puede pasar gradualmente a un puesto de MLE (fuente: Reddit r/MachineLearning)
Evento Pie & AI de DeepLearning.AI en Varsovia: DeepLearning.AI promociona su primer evento Pie & AI en Varsovia, Polonia, organizado en colaboración con Sii Poland (fuente: DeepLearningAI)

Anuncio del evento Deep Tech Week: El evento Deep Tech Week regresará a San Francisco del 22 al 27 de junio, y también se celebrará en Nueva York. El evento ha evolucionado desde un tuit inicial hasta convertirse en una conferencia descentralizada que incluye 85 eventos y atrae a más de 8200 asistentes (representando a 1924 startups y 814 firmas de inversión), con el objetivo de mostrar tecnología de vanguardia y fomentar el intercambio y la colaboración (fuente: Plinz)

Primera reunión presencial de SkyPilot: El equipo de SkyPilot comparte el éxito de su primera meetup presencial, que atrajo a muchos desarrolladores e invitó a ponentes de instituciones como Abridge, el proyecto vLLM, Anyscale, etc., para compartir casos de uso de SkyPilot (fuente: skypilot_org)

Discusión: El desafío del aprendizaje especializado: Miembros de la comunidad discuten las razones por las que es difícil alcanzar la “maestría” en el aprendizaje. Una opinión sostiene que muchas de las habilidades más útiles (como escribir Kernels CUDA) requieren dominar conocimientos de múltiples disciplinas transversales (como PyTorch, álgebra lineal, C++), en lugar del dominio extremo de una sola habilidad. Aprender nuevas habilidades requiere ser inteligente y estar dispuesto a “parecer un tonto”, atreviéndose a salir de la zona de confort (fuente: wordgrammer, wordgrammer)