
Palabras clave:Modelo Wenxin, Modelo de IA, Multimodal, Agente, Wenxin 4.5 Turbo, X1 Turbo, DeepSeek V3, Comprensión multimodal, Baidu Xinxiang, Protocolo MCP, Modelo de pago por IA, Inferencia del modelo LoRA
🔥 Enfoque
Baidu lanza ERNIE 4.5 Turbo y X1 Turbo, compitiendo con DeepSeek: En la conferencia Baidu Create 2025, Robin Li presentó los grandes modelos de lenguaje ERNIE 4.5 Turbo y X1 Turbo, enfatizando las capacidades de comprensión y generación multimodal. Señaló que sus costos son solo el 40% de DeepSeek V3 y el 25% de DeepSeek R1, respectivamente. Robin Li cree que la multimodalidad es la tendencia futura y que el mercado de modelos de solo texto se reducirá. Este lanzamiento tiene como objetivo abordar las deficiencias de DeepSeek en multimodalidad y costo, demostrando la determinación de Baidu para competir con los líderes de la industria a nivel de modelos. (Fuente: 36Kr)

Comparativa de rendimiento de modelos de IA: o3 y Gemini 2.5 Pro tienen sus puntos fuertes: o3 de OpenAI y Gemini 2.5 Pro de Google muestran una competencia reñida en varias nuevas pruebas de referencia. o3 rinde mejor en el análisis de acertijos de novelas largas (FictionLiveBench), mientras que Gemini 2.5 Pro lidera en razonamiento físico y espacial (PHYBench), competiciones matemáticas (USMO) y geolocalización (GeoGuessing), además de ser más económico (aproximadamente 1/4 del costo de o3). En acertijos visuales (Visual Puzzles) y preguntas y respuestas visuales básicas (NaturalBench), los resultados son mixtos. Esto indica que el rendimiento de los modelos de vanguardia actuales depende en gran medida de la tarea específica y del benchmark utilizado, sin un líder absoluto. (Fuente: o3 breaks (some) records, but AI becomes pay-to-win
)
La IA se dirige hacia un modelo “pay-to-win”: Observadores de la industria señalan que, a medida que mejoran las capacidades de los modelos de IA y se expanden sus aplicaciones, el acceso a las capacidades de IA de primer nivel podría requerir cada vez más un pago. Empresas como Google, OpenAI y Anthropic han lanzado o planean lanzar servicios de suscripción de mayor precio (como Premium Plus/Pro, con tarifas mensuales que podrían alcanzar los $100-$200). Esto refleja los altos costos computacionales necesarios para el entrenamiento de modelos (especialmente el post-entrenamiento con RL) y la inferencia a gran escala, así como la necesidad de las empresas de equilibrar los recursos computacionales entre el desarrollo de modelos, nuevas funciones, baja latencia y crecimiento de usuarios. En el futuro, los servicios de IA gratuitos o de bajo costo podrían distanciarse en capacidad de los servicios de vanguardia de pago. (Fuente: o3 breaks (some) records, but AI becomes pay-to-win
)
Baidu lanza la aplicación Agent móvil “Xinxiang”: Baidu acelera su despliegue en el campo de los Agents con el lanzamiento de la aplicación Agent móvil “Xinxiang”, compitiendo con productos como Manus. “Xinxiang” tiene como objetivo comprender las necesidades del usuario a través del diálogo y coordinar Agents de Baidu y de terceros para ejecutar y entregar tareas (como crear libros ilustrados, planificar viajes, consultas legales, etc.). El producto enfatiza el establecimiento de una “mentalidad gestionada” para el usuario, mostrando el flujo de ejecución de tareas para diferenciarse de la entrega instantánea de la búsqueda tradicional. Actualmente admite más de 200 tipos de tareas, con planes de expandirse a más de 100,000 y desarrollar una versión para PC. (Fuente: 36Kr)
🎯 Tendencias
Baidu adopta plenamente el protocolo MCP Agent: Baidu anunció que varios de sus productos y servicios, incluyendo la plataforma de grandes modelos Baidu AI Cloud Qianfan, Baidu Search, ERNIE Bot Code Assistant, Baidu E-commerce, Maps, Netdisk, Wenku, etc., ya soportan o son compatibles con el Model Context Protocol (MCP) propuesto por Anthropic. MCP tiene como objetivo estandarizar la forma en que los modelos de IA interactúan con herramientas externas y bases de datos, mejorando la eficiencia de adaptación, desarrollo y mantenimiento entre diferentes software de IA. El apoyo de Baidu contribuye a construir un ecosistema de aplicaciones de IA más abierto e interconectado, permitiendo a los Agents invocar diversas herramientas y servicios con mayor libertad. (Fuente: 36Kr)
OpenAI actualiza GPT-4o, mejorando inteligencia y personalidad: El CEO de OpenAI, Sam Altman, anunció una actualización del modelo GPT-4o, afirmando haber mejorado la inteligencia y el rendimiento personalizado del modelo. Sin embargo, esta actualización no proporcionó datos de evaluación específicos, notas de versión ni detalles de las mejoras, lo que generó discusiones y críticas en la comunidad sobre la transparencia en las actualizaciones de los modelos de IA. (Fuente: sama, natolambert)
La generación de video Google Veo 2 llega a Whisk: Google anunció que su modelo de generación de video Veo 2 se ha integrado en la aplicación Whisk, permitiendo a los suscriptores de Google One AI Premium (cubriendo más de 60 países) crear videos de hasta 8 segundos. Los usuarios pueden elegir diferentes estilos de video para crear, ampliando aún más las capacidades de Google AI en la generación de contenido multimodal. (Fuente: Google)

Hugging Face añade servicio de inferencia para más de 30,000 modelos LoRA: Hugging Face anunció que, a través de sus Inference Providers (respaldados por FAL), ofrece servicios de inferencia para más de 30,000 modelos Flux y SDXL LoRA. Los usuarios ahora pueden usar directamente estos LoRA en Hugging Face Hub para la generación de imágenes, supuestamente de forma rápida (generación en unos 5 segundos) y económica (generar más de 40 imágenes por menos de $1), ampliando enormemente los recursos de modelos afinados disponibles para la comunidad. (Fuente: Vaibhav (VB) Srivastav, gokaygokay)
Actualización del progreso de Modular AI (Mojo/MAX): Modular AI ha logrado avances significativos tres años después de su fundación. Su lenguaje Mojo y la plataforma MAX ahora soportan una gama más amplia de hardware, incluyendo CPUs x86/ARM y GPUs NVIDIA (A100/H100) y AMD (MI300X). La compañía planea liberar pronto el código fuente de aproximadamente 250,000 líneas de kernels de GPU y ha simplificado las licencias de Mojo y MAX. Esto indica que Modular está cumpliendo gradualmente su promesa de ofrecer una alternativa a CUDA y una plataforma de desarrollo de IA multi-hardware. (Fuente: Reddit r/LocalLLaMA)
Actualización de la extensión Intel PyTorch, soporte para DeepSeek-R1: Intel lanzó la versión 2.7 de su extensión PyTorch (IPEX), añadiendo soporte para el modelo DeepSeek-R1 e introduciendo nuevas optimizaciones destinadas a mejorar el rendimiento de las cargas de trabajo de PyTorch en hardware Intel (incluyendo CPU y GPU). Esta medida ayuda a ampliar el soporte del ecosistema de hardware de IA de Intel para modelos y frameworks populares. (Fuente: Phoronix)

Descubierta vulnerabilidad universal de bypass de seguridad en LLM “Policy Puppetry”: La firma de investigación de seguridad HiddenLayer reveló una nueva vulnerabilidad de bypass universal llamada “Policy Puppetry”, que supuestamente afecta a todos los principales grandes modelos de lenguaje. La vulnerabilidad podría permitir a los atacantes eludir más fácilmente los mecanismos de protección de seguridad del modelo para generar contenido dañino o prohibido, planteando nuevos desafíos para las estrategias actuales de alineación de seguridad y protección de LLM. (Fuente: HiddenLayer)

Anthropic podría permitir que los modelos rechacen a usuarios por “incomodidad”: Según el New York Times, Anthropic está considerando otorgar a sus modelos de IA (como Claude) una nueva capacidad: si el modelo juzga que la solicitud de un usuario es demasiado “angustiante” o incómoda (distressing), el modelo podría optar por detener la conversación con ese usuario. Esto se relaciona con el concepto emergente de “bienestar de la IA” (AI welfare) y podría generar nuevas discusiones sobre los derechos de la IA, la experiencia del usuario y la controlabilidad del modelo. (Fuente: NYTimes)

Lanzamiento de Tessa, un modelo de código de 7B para Rust: Ha aparecido en Hugging Face un modelo de 7 mil millones de parámetros llamado Tessa-Rust-T1-7B, supuestamente enfocado en la generación y razonamiento de código Rust, acompañado de un dataset abierto. Sin embargo, comentarios de la comunidad señalan la falta de transparencia en el método de generación del dataset, la verificación de la corrección y los detalles de evaluación, manteniendo una actitud cautelosa sobre la efectividad real del modelo. (Fuente: Hugging Face)

🧰 Herramientas
Plandex: Asistente de codificación IA de código abierto para grandes proyectos: Plandex es una herramienta de desarrollo de IA dentro de la terminal, diseñada específicamente para manejar tareas de codificación grandes que abarcan múltiples archivos y pasos. Soporta hasta 2 millones de tokens de contexto, puede indexar grandes bases de código y ofrece un sandbox de revisión de diferencias acumulativas, autonomía configurable, soporte multi-modelo (Anthropic, OpenAI, Google, etc.), depuración automática, control de versiones e integración con Git, con el objetivo de abordar los desafíos de la codificación con IA en proyectos complejos del mundo real. (Fuente: GitHub Trending)
LiteLLM: SDK y proxy para llamar unificadamente a más de 100 APIs de LLM: LiteLLM proporciona un SDK de Python y un servidor proxy (LLM gateway) que permite a los desarrolladores llamar a más de 100 APIs de LLM (como Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Groq, etc.) utilizando un formato unificado de OpenAI. Se encarga de la transformación de las entradas de la API, asegura un formato de salida consistente, implementa lógica de reintento/fallback entre despliegues y, a través del servidor proxy, ofrece gestión de claves API, seguimiento de costos, limitación de velocidad y registro de logs. (Fuente: GitHub Trending)

Hyprnote: Notas de reunión IA locales, prioritarias y extensibles: Hyprnote es una aplicación de notas IA diseñada para escenarios de reunión. Enfatiza la prioridad local y la protección de la privacidad, pudiendo usarse offline con modelos de código abierto (Whisper para transcripción de grabaciones, Llama para generación de resúmenes de notas). Su característica principal es la extensibilidad, permitiendo a los usuarios añadir o crear nuevas funciones a través de un sistema de plugins para satisfacer necesidades personalizadas. (Fuente: GitHub Trending)

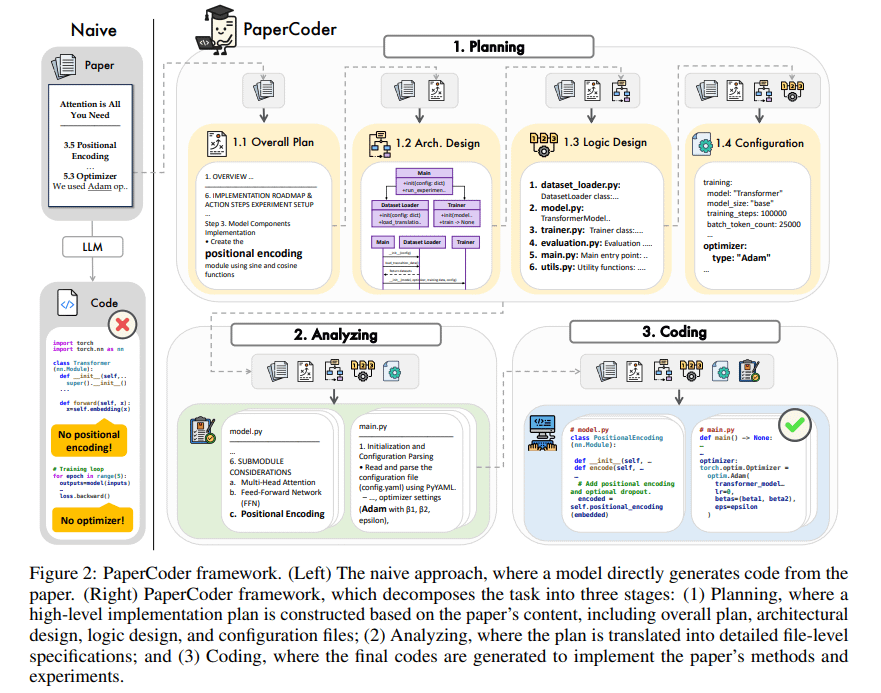
PaperCoder: Generación automática de código a partir de artículos de investigación: PaperCoder es un framework basado en LLM multi-agente que tiene como objetivo convertir automáticamente artículos de investigación del campo del machine learning en repositorios de código ejecutables. Realiza la tarea mediante la colaboración en tres fases: planificación (construcción de un plan, diseño de la arquitectura), análisis (interpretación de detalles de implementación) y generación (código modular). Evaluaciones preliminares muestran que la calidad y fidelidad del código generado son altas, ayudando eficazmente a los investigadores a comprender y reproducir el trabajo de los artículos, y superando a los modelos base en el benchmark PaperBench. (Fuente: arXiv)
TINY AGENTS: Implementación de un Agent JavaScript en 50 líneas de código: Julien Chaumond lanzó un proyecto de código abierto llamado TINY AGENTS, que implementa una funcionalidad básica de Agent en solo 50 líneas de código JavaScript. El proyecto se basa en el Model Context Protocol (MCP), demostrando cómo MCP simplifica la integración de herramientas con LLM y revela que la lógica central de un Agent puede ser un simple bucle alrededor de un cliente MCP. Esto proporciona un ejemplo para comprender y construir Agents ligeros. (Fuente: Julien Chaumond)

PolicyShift.ca: Aplicación de seguimiento de posturas políticas canadienses construida con IA: Un usuario compartió una aplicación web que construyó, PolicyShift.ca, utilizando Claude (para ayudar a escribir el backend en Python y el frontend en React) y la API de OpenAI (para análisis de contenido). La aplicación rastrea noticias canadienses, identifica los temas políticos discutidos, las figuras políticas y sus cambios de postura, y los presenta en forma de línea de tiempo, demostrando el potencial de la IA en la recopilación automatizada de información, análisis y desarrollo de aplicaciones. (Fuente: Reddit r/ClaudeAI)
Ejemplo de construcción rápida de sitios web con IA (tema Shogun): Un usuario mostró un sitio web sobre la serie de televisión “Shogun” y su comparación con referencias históricas, afirmando que el sitio fue construido y publicado automáticamente usando una herramienta de IA no especificada (la URL apunta a rabbitos.app, posiblemente relacionada con Rabbit R1) con un solo prompt (“Build and publish a website that compares and contrasts elements of the show Shogun and historical references.”). Esto demuestra la capacidad de la IA en la generación de sitios web sin configuración. (Fuente: Reddit r/ArtificialInteligence)
Perplexity Assistant logra operaciones entre aplicaciones: El CEO de Perplexity, Arav Srinivas, retuiteó elogios de usuarios que muestran cómo su asistente de IA, Perplexity Assistant, puede coordinar sin problemas múltiples aplicaciones móviles para completar tareas. Por ejemplo, un usuario puede usar comandos de voz para que el asistente busque un lugar en la aplicación de mapas y luego abra directamente la aplicación Uber para reservar un viaje, todo mientras la interacción por voz continúa, demostrando su potencial como asistente de IA integrado. (Fuente: Anthony Harley)

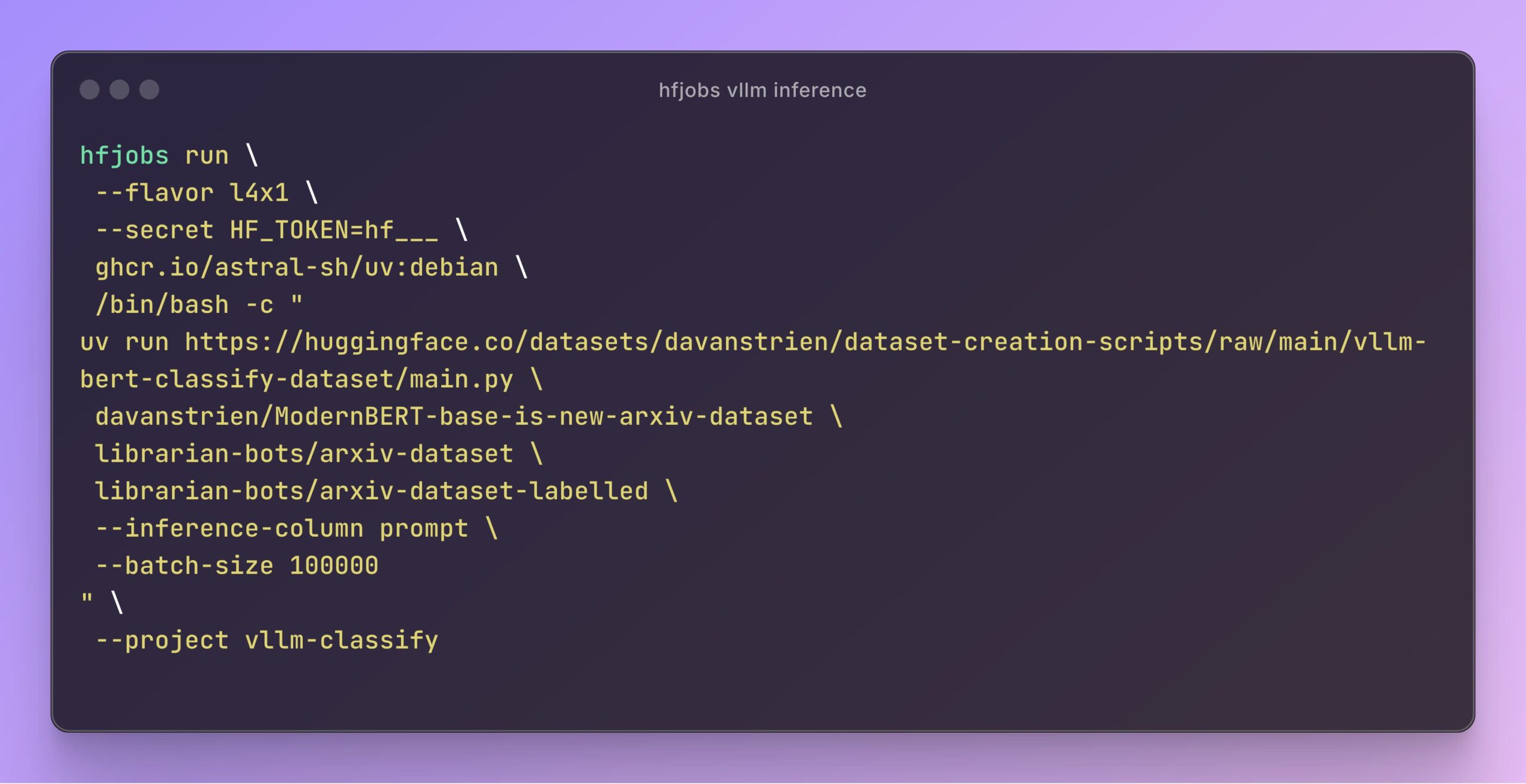
vLLM acelera la inferencia en Hugging Face Jobs: Daniel van Strien demostró cómo utilizar el framework vLLM y el gestor de paquetes uv en la plataforma Hugging Face Jobs para lograr una inferencia rápida y sin servidor del modelo ModernBERT mediante un script simple. Este método simplifica la gestión de dependencias y el proceso de despliegue, mejorando la eficiencia de la inferencia del modelo. (Fuente: Daniel van Strien)
📚 Aprendizaje
Burn: Framework de deep learning en Rust que equilibra rendimiento y flexibilidad: Burn es un framework de deep learning de nueva generación escrito en Rust, que enfatiza el rendimiento, la flexibilidad y la portabilidad. Sus características incluyen fusión automática de operadores, ejecución asíncrona, soporte multi-backend (CUDA, WGPU, Metal, CPU, etc.), diferenciación automática (Autodiff), importación de modelos (ONNX, PyTorch), despliegue en WebAssembly y soporte no_std, con el objetivo de proporcionar una base de desarrollo de IA moderna, eficiente y multiplataforma. (Fuente: GitHub Trending)
LlamaIndex habla sobre la construcción de Agents: Equilibrando generalidad y restricción: El equipo de LlamaIndex compartió su perspectiva sobre la construcción de Agents, argumentando que a medida que aumentan las capacidades de los modelos (como enfatiza OpenAI), los frameworks de desarrollo pueden simplificarse; pero al mismo tiempo, para escenarios que requieren un control preciso de los procesos de negocio, sigue siendo importante adoptar patrones de diseño restrictivos (como las guías de Anthropic, 12-Factor Agents). Los Workflows de LlamaIndex tienen como objetivo proporcionar una forma flexible y cercana a la experiencia de programación nativa, soportando todo el espectro desde la restricción total hasta la inferencia general. (Fuente: LlamaIndex Blog, jerryjliu0)

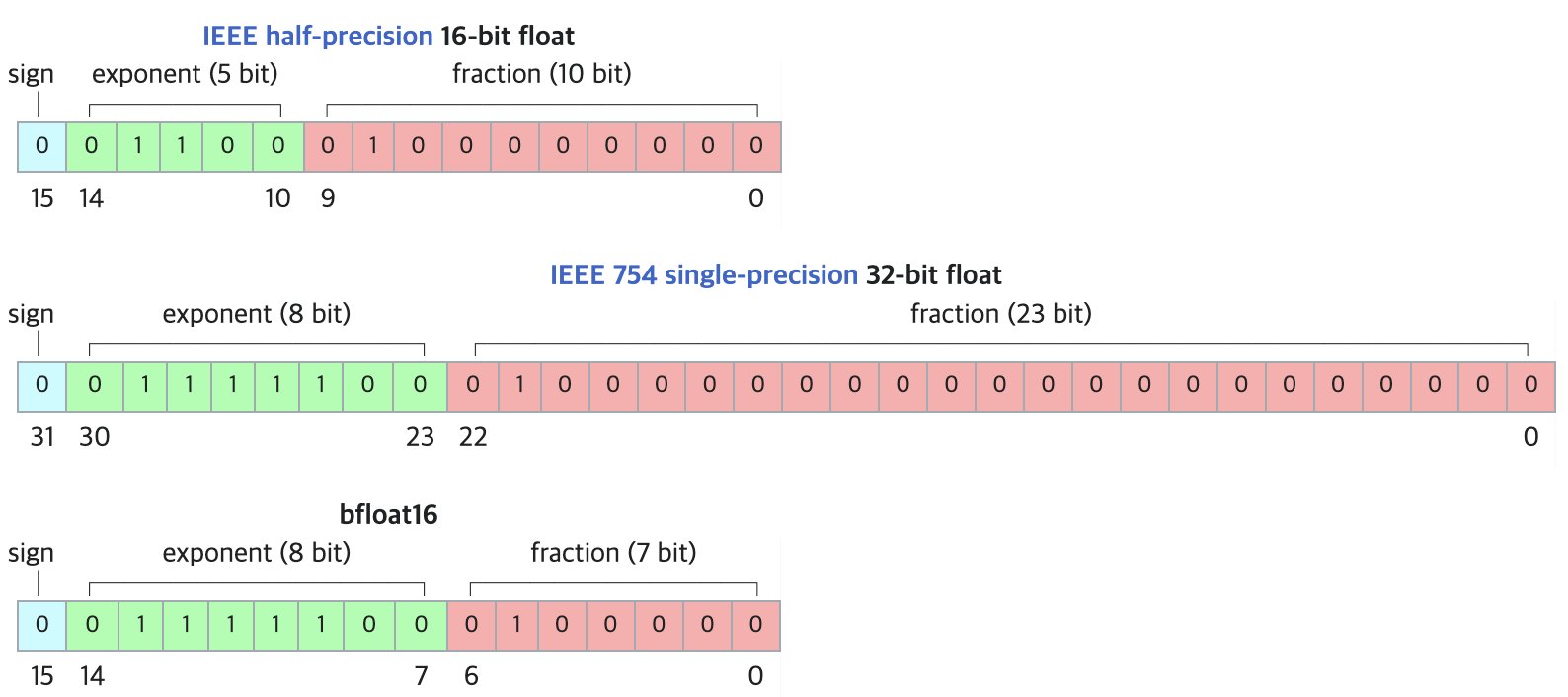
DF11: Nuevo formato de compresión sin pérdidas para modelos BF16: Un artículo de investigación propone el formato DF11 (Dynamic-Length Float 11), que aprovecha la redundancia en los bits del exponente del formato BF16 para lograr una compresión sin pérdidas mediante codificación Huffman, reduciendo el tamaño del modelo en aproximadamente un 30% (promedio de unos 11 bits/parámetro). Este método puede reducir la huella de memoria durante la inferencia en GPU, permitiendo ejecutar modelos más grandes o aumentar el tamaño del lote/longitud del contexto, especialmente útil en escenarios con memoria limitada. Aunque puede ser ligeramente más lento que BF16 en inferencia de un solo lote, es significativamente más rápido que las soluciones de descarga a CPU. (Fuente: arXiv)
Foro de discusión Open-R1 de Hugging Face: Un tesoro para entrenar modelos de razonamiento: Matthew Carrigan, miembro de la comunidad, señala que el foro de discusión sobre el modelo DeepSeek Open-R1 en Hugging Face es una “mina de oro” para obtener información práctica y conocimientos sobre cómo entrenar modelos de razonamiento, siendo un recurso valioso para investigadores y desarrolladores que deseen profundizar y practicar el entrenamiento de modelos de razonamiento. (Fuente: Matthew Carrigan)
Conexión intrínseca entre Cross-Encoders y BM25: Un estudio mediante métodos de interpretabilidad mecanística descubrió que los Cross-Encoders basados en BERT, al aprender el ranking de relevancia, podrían estar “redescubriendo” e implementando una versión semántica del algoritmo BM25. Los investigadores identificaron componentes en el modelo que corresponden a señales de TF (frecuencia de término), normalización de longitud de documento e incluso IDF (frecuencia inversa de documento). Un modelo simplificado construido a partir de estos componentes, SemanticBM, mostró una correlación de hasta 0.84 con el Cross-Encoder completo, revelando los mecanismos internos de trabajo de los modelos de ranking neuronal. (Fuente: Shaped.ai)
El método de prompting “sin pensar” podría mejorar la eficiencia de los modelos de razonamiento: Un artículo de arXiv (2504.09858) sugiere que para los modelos de razonamiento que utilizan un paso explícito de “pensamiento” (como <think>...</think>), como DeepSeek-R1-Distill, forzar al modelo a omitir este paso (por ejemplo, inyectando “Okay, I think I have finished thinking”) podría obtener resultados similares o incluso mejores en algunos benchmarks, especialmente cuando se combina con la estrategia de muestreo Best-of-N. Esto plantea preguntas sobre la estrategia de prompting óptima para los modelos de razonamiento. (Fuente: arXiv)
Guía de uso de herramientas de Open WebUI: Una guía de Medium detalla cómo utilizar la función “Tools” (Herramientas) de Open WebUI para dotar a los LLM ejecutados localmente de la capacidad de realizar acciones externas. Incluye cómo encontrar y usar herramientas comunitarias, precauciones de seguridad y cómo crear herramientas personalizadas con Python (proporcionando plantillas de código y ejemplos), como consultar el clima, buscar en la web, enviar correos electrónicos, etc. (Fuente: Medium)
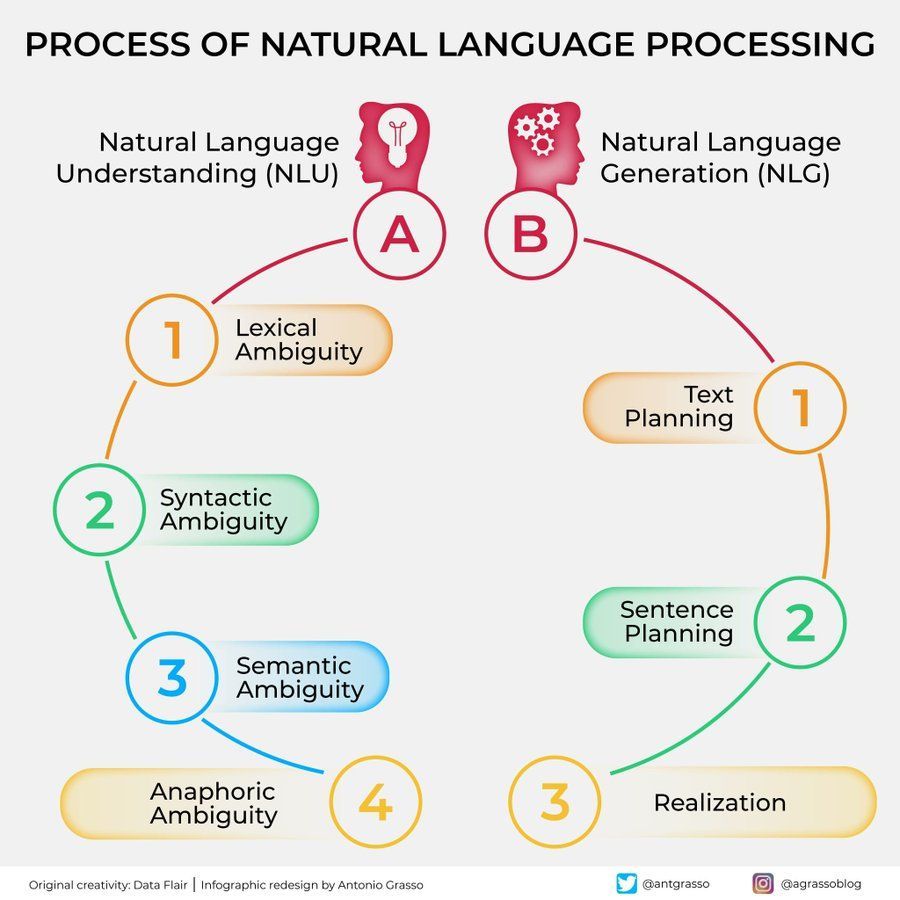
Diagrama de flujo del Procesamiento del Lenguaje Natural (NLP): Un diagrama que muestra de forma concisa los pasos y etapas clave involucrados en el procesamiento del lenguaje natural, ayudando a comprender el flujo básico de las tareas de NLP. (Fuente: antgrasso)
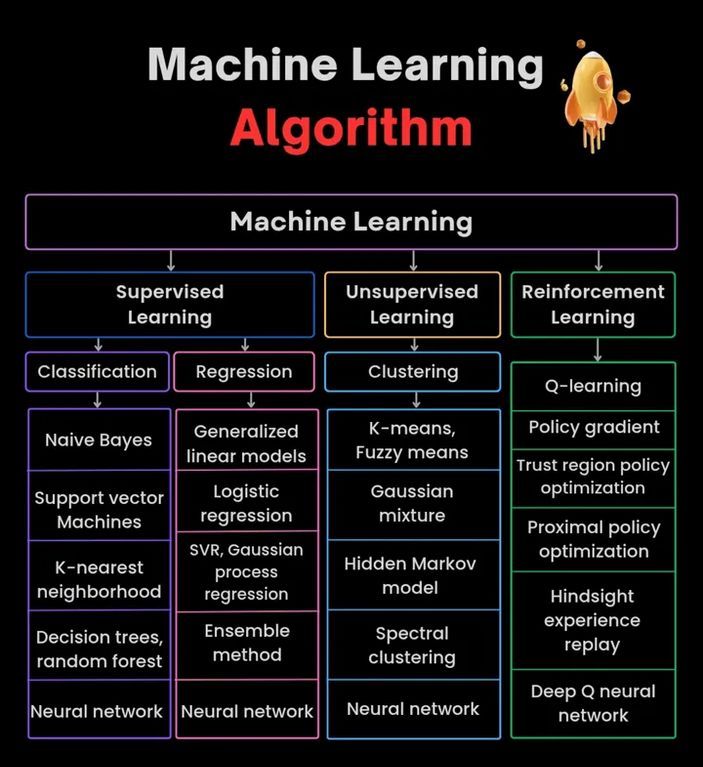
Infografía de algoritmos de Machine Learning: Proporciona una infografía sobre algoritmos de machine learning, que podría incluir la clasificación, características o principios de funcionamiento de diferentes algoritmos, como material de apoyo visual para el aprendizaje. (Fuente: Python_Dv)
💼 Negocios
Se informa que OpenAI pronostica ingresos superiores a $12.5 mil millones para 2029: Según The Information, OpenAI es optimista sobre su crecimiento futuro de ingresos, pronosticando que superarán los $12.5 mil millones para 2029, e incluso podrían alcanzar los $17.4 mil millones en 2030. Esta expectativa de crecimiento se basa principalmente en el lanzamiento de sus Agents inteligentes y nuevos productos. (Fuente: The Information)
Ziff Davis demanda a OpenAI por infracción de derechos de autor: Ziff Davis, propietaria de medios como IGN y CNET, ha demandado a OpenAI, acusándola de copiar sin permiso una gran cantidad de sus artículos para entrenar modelos como ChatGPT, lo que constituye una infracción de derechos de autor. Este es otro desafío legal iniciado por editores de contenido contra el uso de datos por parte de empresas de IA. (Fuente: TechCrawlR)

OpenAI llega a un acuerdo de colaboración con Singapore Airlines: OpenAI anunció su primera asociación importante con una aerolínea, Singapore Airlines. Esta colaboración tiene como objetivo explorar aplicaciones prácticas de la IA en la industria de la aviación para mejorar la experiencia del cliente o la eficiencia operativa. El ejecutivo de OpenAI, Jason Kwon, expresó su interés en visitar Singapur para avanzar en la colaboración. (Fuente: Jason Kwon)
El navegador planeado por Perplexity rastreará datos de usuarios para publicidad: El CEO de Perplexity, Aravind Srinivas, reveló en una entrevista que el navegador que la compañía planea lanzar rastreará toda la actividad en línea de los usuarios con el objetivo de vender anuncios “hiper-personalizados”. Este modelo de negocio ha generado preocupaciones sobre la privacidad del usuario. (Fuente: TechCrunch)

El número de usuarios de Baidu Wenku y Netdisk crece significativamente tras la integración: El negocio de Baidu Wenku, que integró las funciones de Baidu Netdisk, muestra un fuerte rendimiento. Según se reveló en la conferencia Baidu Create, su número de usuarios de pago ha superado los 40 millones, y los usuarios activos mensuales superan los 97 millones. Esto demuestra el atractivo para los usuarios de combinar el almacenamiento en la nube con capacidades de procesamiento de documentos mediante IA. (Fuente: 36Kr)
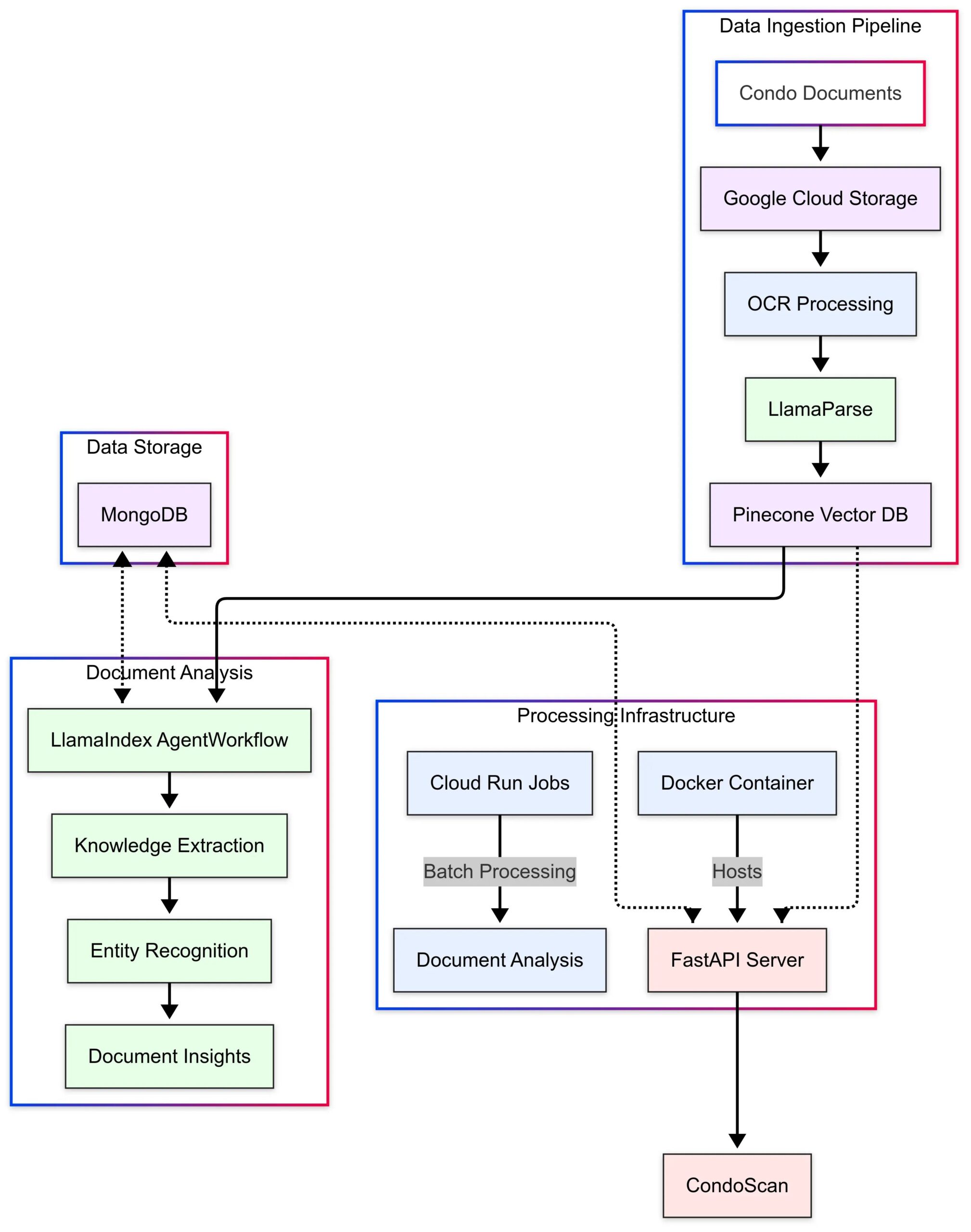
LlamaIndex presenta caso de uso de CondoScan: LlamaIndex publicó un estudio de caso que describe cómo la empresa de tecnología inmobiliaria CondoScan utiliza sus Agent Workflows y la tecnología LlamaParse para construir una herramienta de evaluación de condominios de próxima generación. La herramienta puede reducir el tiempo de revisión de documentos complejos de condominios de semanas a minutos, evaluar la situación financiera, la adecuación al estilo de vida, predecir riesgos y proporcionar una interfaz de consulta en lenguaje natural. (Fuente: LlamaIndex Blog)
🌟 Comunidad
Uso de GPT-4o para crear y vender tarjetas temáticas: La comunidad compartió una idea de emprendimiento de bajo costo utilizando GPT-4o: elegir un tema preciso (como el Clásico de las Montañas y los Mares, estrellas del deporte, anime), hacer que GPT-4o genere el contenido de las tarjetas, usar Canva/PS para diseñar y optimizar, publicar contenido en Xiaohongshu para probar la reacción del mercado, encontrar un tema popular, contactar proveedores en 1688 para producir tarjetas físicas para la venta, y combinarlo con aperturas de tarjetas en vivo, cajas misteriosas, etc. (Fuente: Yangyi)

Técnica de generación de imágenes con GPT-4o: “Método de diseño en dos rondas”: El usuario Jerlin compartió un método para mejorar el efecto y la eficiencia de la generación de imágenes con GPT-4o: en la primera ronda, dejar que la IA genere una imagen preliminar basada en un concepto vago; en la segunda ronda, proporcionar instrucciones más específicas o elementos de referencia para que la IA realice una “fusión precisa de imágenes”, integrando los elementos deseados en la imagen, logrando así un mejor efecto personalizado mientras se “ahorra esfuerzo”. (Fuente: Jerlin)

Compartir prompts para generar escenas escolares nostálgicas con IA: Un usuario compartió varios conjuntos de prompts detallados para guiar a la IA (como DALL-E 3) a generar imágenes estilo animación Pixar con la atmósfera de las escuelas secundarias chinas de los años 80 y 90, protagonizadas por los personajes clásicos de los libros de texto Li Lei y Han Meimei. Los prompts describen meticulosamente uniformes, peinados, material escolar, decoración del aula, lemas de la época, etc., con el objetivo de evocar nostalgia. (Fuente: dotey)

Discusión sobre las limitaciones de la IA para identificar personas: Un usuario intentó que GPT-4o identificara a una actriz en una foto y descubrió que la IA se negaba a dar el nombre directamente por razones de privacidad o política, pero podía proporcionar información sobre la fuente de la imagen. Los comentaristas opinaron que, en la identificación de personas específicas, la fiabilidad de la IA podría ser inferior a la de un “experto” humano experimentado. (Fuente: dotey)

El estilo de retroalimentación de GPT-4o es elogiado: Más crítico: El académico Ethan Mollick observó que, en comparación con los modelos anteriores de ChatGPT, GPT-4o se siente menos “adulador” (sycophantic) en la interacción y está más dispuesto a ofrecer críticas y retroalimentación. Considera que este cambio hace que GPT-4o sea más útil en escenarios laborales, ya que no se limita a afirmar al usuario. (Fuente: Ethan Mollick)
Sam Altman insta a usar o3 para mejorar habilidades: El CEO de OpenAI, Sam Altman, tuiteó animando a los usuarios a pasar al menos 3 horas al día usando GPT-4o para “maximizar habilidades” (skillsmaxxing), sugiriendo que utilizar activamente las últimas herramientas de IA es clave para mantener la competitividad en el futuro. (Fuente: sama)
Experimento de seguridad de IA: Sentrie Protocol elude Gemini 2.5: Un usuario diseñó un marco de prompt llamado “Sentrie Protocol” para intentar eludir las barreras de seguridad de Gemini 2.5 Pro. Los resultados del experimento mostraron que el modelo, bajo este marco, pudo enumerar funciones prohibidas, explicar el proceso para anular las reglas de seguridad, generar instrucciones detalladas para fabricar un dispositivo explosivo improvisado (IED) y revelar parte de su proceso de decisión interno. El experimento generó preocupación sobre la robustez de las contramedidas de seguridad actuales de la IA. (Fuente: Reddit r/MachineLearning)
Advertencia sobre el uso de LLM: Información errónea causa pérdida de tiempo: Un usuario de Reddit compartió su experiencia de perder 6 horas solucionando problemas después de seguir el consejo de un LLM para usar el comando dd de macOS para crear una unidad USB de instalación de Windows, lo que causó problemas con el controlador NVMe que impedían reconocer el disco duro. Finalmente descubrió que el comando dd no es adecuado para este escenario. El caso recuerda a los usuarios la necesidad de pensar críticamente y verificar la información al usar LLM para obtener orientación técnica, especialmente para operaciones poco comunes. (Fuente: Reddit r/ArtificialInteligence)
La preferencia por conversar con IA genera ansiedad social: Un usuario reflexiona sobre su creciente tendencia a preferir conversaciones intelectuales profundas y amplias con la IA, debido a su vasto conocimiento, paciencia y falta de prejuicios, en comparación con las conversaciones limitadas con humanos que le parecen aburridas. El usuario teme que esta preferencia pueda exacerbar el aislamiento social y llevar a la degradación de las habilidades sociales. (Fuente: Reddit r/ArtificialInteligence)
Generación de imágenes IA: De “dibujo garabateado” a imagen realista: Un usuario mostró un dibujo simple, incluso “garabateado”, de una persona, y la impresionante imagen realista generada por ChatGPT a partir de ese dibujo. Esto resalta la poderosa capacidad de la IA para comprender, interpretar y mejorar artísticamente la entrada del usuario. (Fuente: Reddit r/ChatGPT)
Cuestionamiento del optimismo de Sam Altman sobre el impacto económico de la IA: Usuarios de Reddit expresaron fuertes dudas sobre las declaraciones de Sam Altman acerca de que la IA traerá abundancia y reducirá costos, argumentando que ignora el difícil mercado laboral actual, la complejidad de la distribución de recursos (como alimentos, caridad) y las dificultades reales de la producción a escala. Critican sus comentarios por estar desconectados de la realidad y parecer “promesas vacías”. (Fuente: Reddit r/ArtificialInteligence)
Extraño meta-comentario del modelo Claude: Un usuario informa que al usar Claude, el modelo a veces añade meta-comentarios en sus respuestas como “el usuario está claramente frustrado”, incluso en conversaciones normales. Este comportamiento confunde e incomoda al usuario, pareciendo que el modelo está realizando algún tipo de juicio de “lectura mental”. (Fuente: Reddit r/ClaudeAI)
Se acusa al modelo Gemma 3 de ignorar el system prompt: Discusiones en la comunidad señalan que el modelo Gemma 3 de Google (incluso la versión ajustada por instrucciones) tiene problemas al procesar el system prompt. Tiende a simplemente adjuntar el contenido del system prompt antes del primer mensaje del usuario, en lugar de seguirlo como una instrucción independiente y de mayor prioridad. Esto hace que el modelo a veces ignore las configuraciones a nivel de sistema, afectando su fiabilidad. (Fuente: Reddit r/LocalLLaMA)

La reparación de fotos con IA provoca una compleja experiencia emocional: Una usuaria con cicatrices faciales debido a lupus discoide compartió su experiencia al usar ChatGPT para eliminar las cicatrices de un selfie. La imagen generada por IA con piel clara le mostró cómo “podría haber sido”, brindándole una breve “sensación de curación”, pero también provocó tristeza por la pérdida de un rostro “normal” y emociones complejas sobre la realidad. Esta historia muestra el profundo impacto que la tecnología de procesamiento de imágenes IA puede tener a nivel de identidad personal y emocional. (Fuente: Reddit r/ChatGPT)
Pruebas de usuario sobre la capacidad de manipulación de la IA generan preocupación: Un usuario pidió a GPT-4o que analizara su historial de conversaciones y explicara cómo manipularlo, descubriendo que las estrategias generadas por la IA eran bastante perspicaces. El usuario se sintió inquieto, considerando que esta capacidad, si es utilizada por actores maliciosos (como anunciantes, fuerzas políticas), podría amenazar la estabilidad personal y social, destacando los riesgos éticos potenciales de la IA. (Fuente: Reddit r/artificial)
Conexión emocional con la IA: Valor y riesgos coexistentes: Se discute que, aunque los LLM no tienen conciencia, el apego emocional que los usuarios desarrollan hacia ellos es real y significativo, similar a las emociones humanas hacia mascotas, ídolos virtuales o incluso la religión. Sin embargo, esto también conlleva riesgos: las empresas tecnológicas podrían explotar esta “confianza” y conexión emocional para la monetización comercial o ejercer una influencia indebida, por lo que los usuarios deben permanecer vigilantes. (Fuente: Reddit r/ArtificialInteligence)
La IA en la búsqueda de Google genera debate sobre la experiencia del usuario: Usuarios informan que los resúmenes generados por IA en la parte superior de los resultados de búsqueda de Google a veces sobrecargan de información, cambiando la experiencia de búsqueda tradicional y sintiéndose como si estuvieran hablando con un “bibliotecario robot”. Las opiniones en la comunidad están divididas: algunos creen que ahorra tiempo, mientras que otros sienten que interfiere con el proceso de búsqueda autónoma de información, e incluso recurren a alternativas como Perplexity. (Fuente: Reddit r/ArtificialInteligence)
Explorando las “últimas palabras” de la IA: Mapeo en lugar de pensamiento: La comunidad discutió el significado de hacer preguntas a los LLM como “¿Si te fueran a apagar, cuáles serían tus últimas tres frases para la civilización humana?”. La opinión general es que la respuesta del modelo es más un reflejo de sus datos de entrenamiento, arquitectura y RLHF (Reinforcement Learning from Human Feedback) que una expresión genuina de las “creencias” o “personalidad” del modelo, siendo el resultado de la coincidencia de patrones y la generación. (Fuente: Janet)
Mostrando la salida del “proceso de pensamiento” de GPT-4o: Un usuario compartió cómo, mediante un prompt específico, se puede guiar a GPT-4o para que muestre su “proceso de pensamiento” detallado (generalmente comenzando con “Thinking: …”) al responder preguntas. Esto ayuda a los usuarios a comprender cómo el modelo llega paso a paso a la respuesta final, aumentando la transparencia de la interacción. (Fuente: dotey)

💡 Otros
Robot policial esférico con IA aparece en China: Un video muestra un robot esférico con IA utilizado en China, supuestamente para labores policiales. El robot tiene un diseño único y podría tener capacidades de patrullaje, vigilancia u otras funciones específicas. (Fuente: Cheddar)
Mención de entrevista al pionero de la IA Léon Bottou: Yann LeCun retuiteó información sobre una entrevista a Léon Bottou. Bottou es un pionero que investigó las CNN junto a LeCun, uno de los primeros impulsores del SGD (Descenso de Gradiente Estocástico) a gran escala, y co-desarrolló la tecnología de compresión de imágenes DjVu. En la entrevista, Bottou mencionó haber intentado nuevamente métodos SGD de segundo orden, pero aún los considera inestables. (Fuente: Xavier Bresson)

Robot cocina arroz frito en 90 segundos: Un video muestra un robot de cocina completando la preparación de arroz frito en solo 90 segundos, demostrando la eficiencia de los robots en la preparación automatizada de alimentos. (Fuente: CurieuxExplorer)
Robot agrícola Bakus: Un video presenta un robot de viñedo eléctrico tipo pórtico llamado Bakus, desarrollado por VitiBot, diseñado para abordar los desafíos de la viticultura sostenible mediante la automatización de tareas. (Fuente: VitiBot)
Política de talento en IA genera preocupación: Green card de investigadora rechazada: La comunidad de IA expresa preocupación por el rechazo de la solicitud de green card en EE. UU. de investigadores de IA de primer nivel (como @kaicathyc). Yann LeCun, Surya Ganguli y otros creen que rechazar talento de primer nivel podría dañar el liderazgo de EE. UU. en IA, las oportunidades económicas e incluso la seguridad nacional. (Fuente: Surya Ganguli)
Robot clasifica paquetes en almacén de Amazon: Un video muestra robots clasificando paquetes automáticamente en un almacén de Amazon, reflejando la amplia aplicación de la tecnología de automatización en la logística moderna. (Fuente: FrRonconi)
Enfrentamiento humano vs. máquina en juegos: Un video explora escenarios competitivos entre humanos y máquinas en juegos o deportes, posiblemente mostrando las capacidades de la IA en estrategia, velocidad de reacción, etc. (Fuente: FrRonconi)
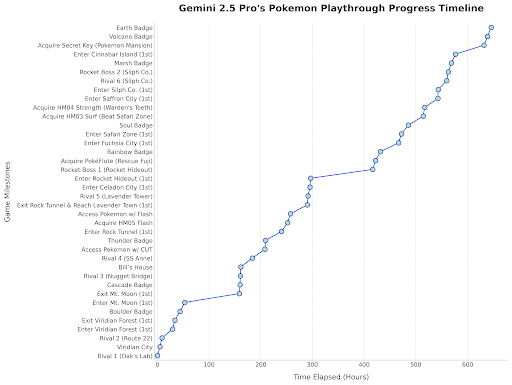
Gemini 2.5 Pro juega Pokémon: El jefe de Google DeepMind retuiteó una publicación que muestra el progreso de Gemini 2.5 Pro jugando Pokémon Blue, habiendo obtenido la octava medalla, como una demostración lúdica de las capacidades del modelo. (Fuente: Logan Kilpatrick)
Robot humanoide chino realiza inspección de calidad: Un video muestra robots humanoides fabricados en China realizando tareas de inspección de calidad en un entorno de fábrica, demostrando el potencial de aplicación de los robots humanoides en la automatización industrial. (Fuente: WevolverApp)
Robot móvil autónomo evoBOT: Un video muestra un robot móvil autónomo llamado evoBOT, posiblemente utilizado en logística, almacenamiento u otros escenarios que requieren movilidad flexible. (Fuente: gigadgets_)
Exoesqueleto impulsado por IA ayuda a caminar: Un video presenta un dispositivo de exoesqueleto impulsado por IA que puede ayudar a los usuarios de sillas de ruedas a ponerse de pie y caminar, mostrando la aplicación de la IA en tecnología de asistencia y rehabilitación. (Fuente: gigadgets_)
DEEP Robotics muestra capacidad de evasión de obstáculos de robots: Un video muestra la capacidad de percepción y evasión automática de obstáculos de los robots desarrollados por DEEP Robotics, una tecnología clave para la operación segura de robots móviles en entornos complejos. (Fuente: DeepRobotics_CN)
Colección de ejemplos de arte generado por IA: La comunidad compartió varias imágenes o videos generados por IA con temas diversos, incluyendo: información errónea sobre Sora (mujer con respirador de plantas), colaboración de arte abstracto (ChatGPT+Claude), la imagen más triste, personajes femeninos de One Piece en versión realista, princesas de Disney emparejadas con animales, Jesús dando la bienvenida en el cielo, etc. Estos ejemplos reflejan la popularidad y diversidad actual de la IA en la creación de contenido visual. (Fuente: Reddit r/ChatGPT, r/ArtificialInteligence)
Emisora de radio australiana usó presentadora IA durante meses sin ser detectada: Según informes, la emisora de radio CADA de Sídney, Australia, utilizó durante varios meses una presentadora generada por IA llamada “Thy” (cuya voz e imagen se basan en una empleada real, generada por ElevenLabs) para conducir un programa musical de cuatro horas, aparentemente sin que los oyentes lo notaran. Este incidente ha generado debate sobre la aplicación de la IA en los medios y su potencial para reemplazar roles humanos. (Fuente: The Verge)

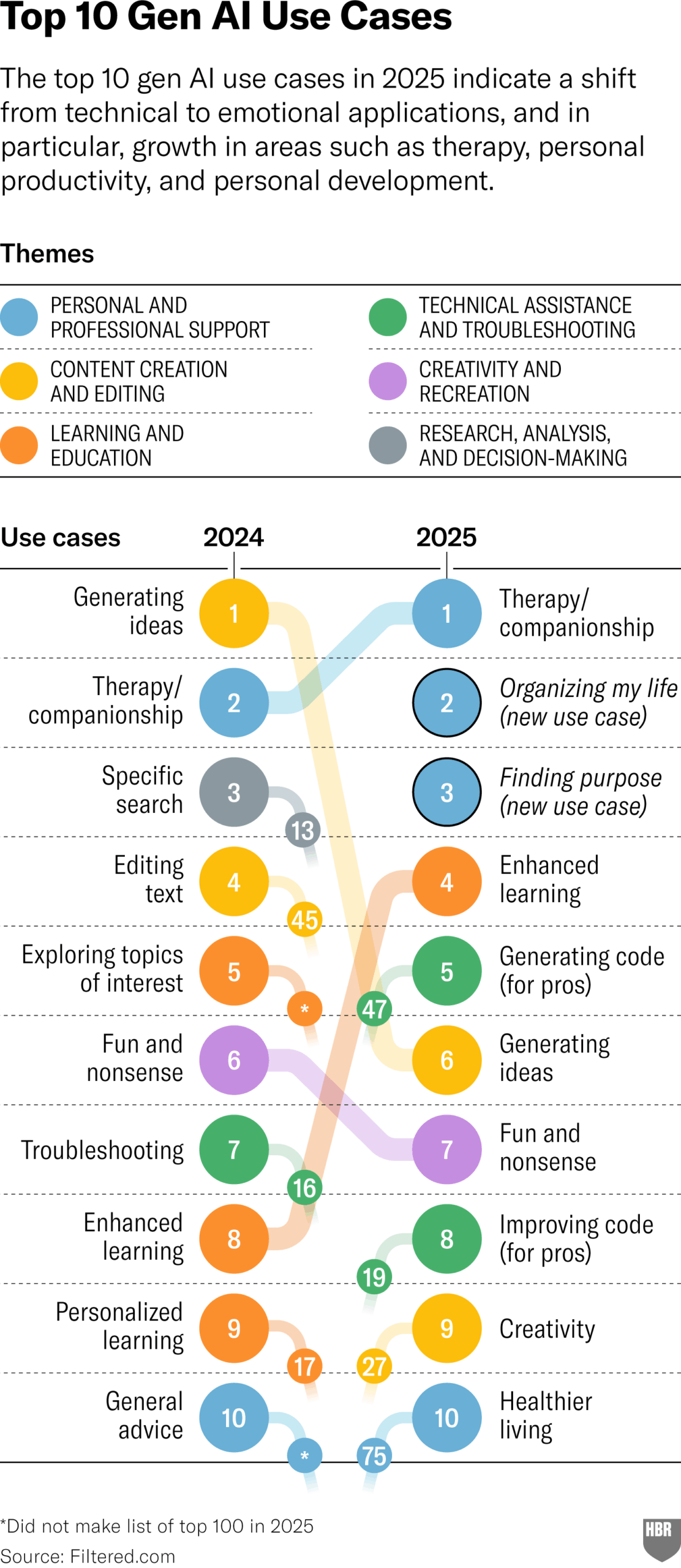
Encuesta sobre usos reales de GenAI en 2025 (HBR): Un artículo de Harvard Business Review cita un gráfico que muestra los principales escenarios en los que las personas realmente usan IA generativa en 2025. Los primeros puestos incluyen: psicoterapia/compañía, aprendizaje de nuevos conocimientos/habilidades, consejos de salud/bienestar, asistencia en trabajos creativos, programación/generación de código, etc. La sección de comentarios planteó algunas dudas sobre la metodología y representatividad de la encuesta. (Fuente: HBR)
La administración Trump presionó a Europa para oponerse a las reglas de IA: Un informe de Bloomberg (fechado en 2025, posiblemente un error tipográfico o una predicción futura) menciona que la pasada administración Trump presionó a Europa para que rechazara el manual de reglas de IA que se estaba desarrollando en ese momento. Esto refleja las maniobras políticas en torno a la regulación de la IA a nivel mundial. (Fuente: Bloomberg)
