Palabras clave:robots humanoides, aplicaciones de IA, AGI, conducción autónoma, maratón de robots humanoides, Agente+MCP, predicción AGI de DeepMind, FSD de visión pura de Tesla, clonación de voz GPT-SoVITS, razonamiento químico ChemAgent, modelo de negocio de robots Agimus, desafío al monopolio de GPU de NVIDIA
🔥 Enfoque
Debut de robots humanoides en la media maratón de Beijing: Oportunidades y desafíos coexisten: En la Media Maratón de Yizhuang Beijing 2025, 21 equipos de robots humanoides compitieron por primera vez junto a corredores humanos. TianGong Ultra, Songyan Dynamics N2 y Zhuoyide Walker II obtuvieron los tres primeros lugares. La competencia destacó el potencial de los robots humanoides, pero también expuso numerosos desafíos como caídas, autonomía de batería y control (principalmente remoto). Después de la carrera, Unitree Technology respondió al incidente de caída de su robot G1, señalando que el desarrollo y la operación por parte del usuario tienen un gran impacto en el rendimiento del robot. Este evento no solo mostró la escala inicial de la industria de robots humanoides de China, sino que también generó amplias discusiones sobre la madurez tecnológica, el costo (el precio de preventa del Songyan N2 comienza en 39,900 yuanes), las rutas de comercialización (alquiler, aplicaciones industriales) y el desarrollo futuro (grandes modelos de AI, aprendizaje autónomo). Aunque la industria ha atraído el favor del capital, la rentabilidad a corto plazo es difícil y la implementación en el mercado aún necesita tiempo (Fuente: 摔倒的宇树和人形机器人的“求生”博弈, 从进厂到马拉松:人形机器人离“实用”还有多远?)
Nuevo paradigma de aplicación de AI: Agent+MCP se convierte en la fórmula de éxito para 2025: La combinación de la capacidad de planificación y acción autónoma de los Agents con la capacidad del protocolo MCP para invocar herramientas y datos externos se está convirtiendo en una nueva tendencia en las aplicaciones de AI. Productos como “Coze Space”, Fellou, Dia, GenSpark, Zhipu AutoGLM, etc., han surgido sucesivamente y han atraído la atención. Muchos de estos productos provienen de la transformación de la búsqueda de AI, intentando establecer barreras de experiencia de usuario a través de diferentes diseños de productos (facilidad de uso, capacidad de investigación, ejecución práctica). A pesar de su enorme potencial, actualmente enfrentan desafíos como el límite de capacidad del modelo, la adquisición de información multiplataforma y los modelos de comercialización. Microsoft también ha lanzado el sistema multi-Agent UFO² para escritorio, lo que indica que AM (Agent+MCP) se convertirá en una dirección importante para los productos de AI (Fuente: 2025年,AI应用的爆款公式只有一个)
Intenso debate sobre el futuro de la AI: Hassabis predice la cura de todas las enfermedades en diez años, historiador de Harvard advierte sobre la extinción humana por AGI: El CEO de Google DeepMind, Demis Hassabis, predijo en una entrevista que la AI alcanzará la AGI en 5-10 años y podría curar todas las enfermedades en una década, mostrando avances de AI como Project Astra. Considera que la AI será la herramienta definitiva para acelerar el descubrimiento científico. Sin embargo, el historiador de Harvard Niall Ferguson advirtió que la llegada de la AGI podría llevar a la humanidad a ser obsoleta como los carruajes, o incluso extinguirse, convirtiéndose en los “extraterrestres” creados por nosotros mismos. Señaló que tendencias como la rigidez institucional y la disminución de la tasa de natalidad global podrían hacer que la humanidad elija “retirarse del escenario histórico” frente a la AGI. Esta discusión resalta el enorme contraste entre el optimismo extremo sobre el potencial de la AGI y la profunda preocupación por el futuro de la civilización humana (Fuente: 诺奖得主Hassabis豪言:AI十年治愈所有疾病,哈佛教授警告AGI终结人类文明, 哈佛历史学家预警:AGI灭绝人类,美国或将解体)
🎯 Tendencias
Avances frecuentes en la industria robótica, aceleración de la implementación comercial: La Feria de Cantón estableció por primera vez una zona exclusiva para robots de servicio, donde fabricantes nacionales como Pangolin Robot, Hongxujin Technology, etc., obtuvieron grandes pedidos del extranjero, demostrando la competitividad de los robots de servicio chinos en el mercado global. Al mismo tiempo, los robots humanoides de empresas como Midea están en proceso de iteración, planeando entrar a “trabajar” en fábricas. En la cadena de suministro, aunque hay desarrollos en segmentos como PCB, sensores y nuevos materiales (como PEEK), la producción a gran escala aún requiere tiempo; la tecnología, el costo y el cierre del ciclo de escenarios de aplicación son clave. Varios fabricantes planean alcanzar una producción a nivel de miles de unidades para 2025, lo que se espera impulse el desarrollo de la cadena de suministro y la acumulación de datos, acelerando el avance de los robots hacia una etapa más práctica (Fuente: 机器人组团“营业”引爆声量场,产业链频刷进展)

Tesla persiste en FSD de visión pura, la ruta LiDAR enfrenta desafíos y oportunidades: Musk reafirmó su confianza en la solución de visión pura para lograr el FSD, creyendo que las cámaras más la AI pueden simular la conducción humana sin necesidad de LiDAR. A pesar de la realidad de la caída de costos (el LiDAR nacional ya ha bajado a cientos de dólares) y la popularización en el mercado (ya presente en modelos de vehículos de 100,000 yuanes), Tesla mantiene su ruta, lo que impone requisitos extremadamente altos en su potencia de cálculo, algoritmos y datos. Al mismo tiempo, fabricantes de LiDAR como Hesai y RoboSense dominan el mercado con ventajas de costo e iteración tecnológica, y expanden activamente los mercados extranjeros y negocios no vehiculares como la robótica. La proximidad de la conducción autónoma de nivel L3 podría traer nuevas oportunidades para el LiDAR, ya que su capacidad de percepción en redundancia de seguridad y escenarios específicos se considera indispensable (Fuente: 马斯克最新的AI驾驶方案,会终结激光雷达吗?)

Google Imagen 3/4 posiblemente en pruebas internas: Se rumorea que Google está probando internamente sus modelos de generación de imágenes de próxima generación, Imagen 3 e Imagen 4, lo que sugiere que Google podría tener nuevos movimientos importantes en el campo de la generación de imágenes, con el objetivo de alcanzar o superar a los competidores (Fuente: Google 又憋图像大招?传 Imagen 3/4 内测中。)
THUDM lanza la serie de modelos de codificación SWE-Dev: El Grupo de Investigación de Ingeniería del Conocimiento y Minería de Datos de la Universidad Tsinghua (THUDM) ha lanzado la serie de grandes modelos de codificación SWE-Dev basados en Qwen-2.5 y GLM-4, incluyendo versiones 7B, 9B y 32B, con el objetivo de mejorar las capacidades de AI para tareas de desarrollo de software y codificación (Fuente: Reddit r/LocalLLaMA)

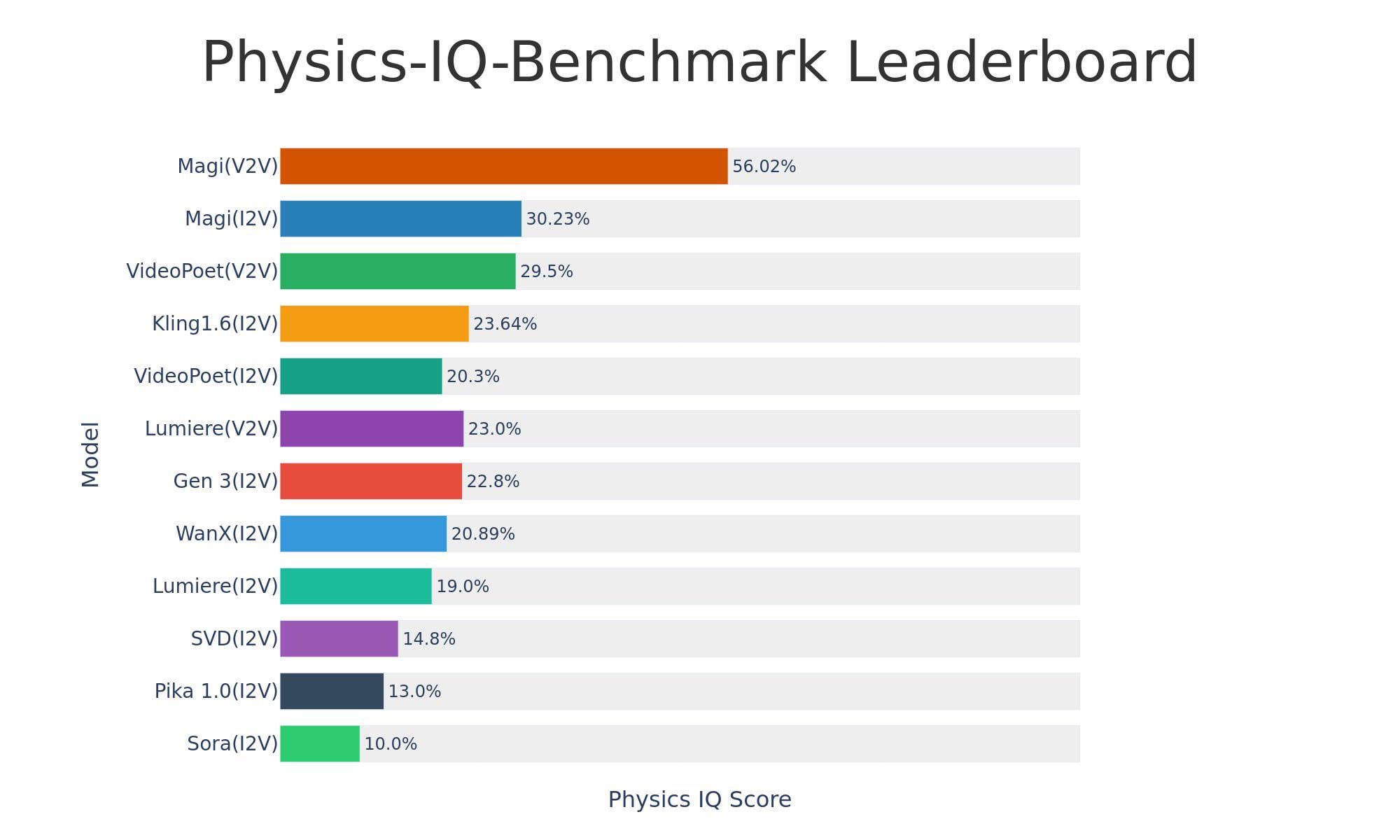
Sand-AI lanza el modelo de generación de video de código abierto Magi-1: Sand-AI ha lanzado Magi-1, un modelo de generación de video de difusión autorregresiva de código abierto, que afirma poder generar videos de duración ilimitada y admite texto a video, imagen a video y video a video. El modelo muestra un rendimiento excelente en pruebas de referencia de comprensión física, pero requiere una memoria de video extremadamente alta para funcionar (aproximadamente 640 GB de VRAM). El código y el modelo ya están publicados en GitHub y Hugging Face (Fuente: Reddit r/LocalLLaMA)
Grok añade capacidades de visión, audio multilingüe y búsqueda en tiempo real: xAI anunció que el modelo Grok ha añadido capacidad de comprensión visual y, en modo de voz, admite entrada de audio multilingüe y funciones de búsqueda en tiempo real, mejorando sus capacidades de interacción multimodal y adquisición de información (Fuente: grok, xai)
El modelo Grok 3 llega a You.com: El modelo insignia de xAI, Grok 3, ya está disponible en el motor de búsqueda You.com, permitiendo a los usuarios experimentar las capacidades de Grok 3 en esa plataforma (Fuente: xai)

El modelo TTS de código abierto Dia se lanza y atrae atención: Se ha lanzado un modelo de texto a voz (TTS) de código abierto llamado Dia, que afirma tener una calidad comparable a modelos comerciales como ElevenLabs y OpenAI. Admite clonación de voz zero-shot y síntesis en tiempo real, y puede ejecutarse en un MacBook. El modelo ha ganado rápidamente atención en Hugging Face y ha sido reportado por medios como VentureBeat (Fuente: huggingface, huggingface, huggingface)
Demostración de la tecnología de conducción autónoma de Tesla: Se muestran videos o información relacionada con la tecnología de conducción autónoma Autopilot de Tesla, lo que continúa generando interés en los avances de la tecnología de conducción autónoma (Fuente: Ronald_vanLoon)
Demostración de tecnología robótica: Múltiples fuentes muestran diferentes aplicaciones de robots, incluyendo brazos robóticos para el ensamblaje de pequeños gadgets, evaluación del robot TITA, el robot anfibio Copperstone HELIX Neptune y cómo los robots perciben el mundo, lo que indica el continuo desarrollo de la tecnología robótica en diversos campos (Fuente: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 Herramientas
GPT-SoVITS: Potente herramienta de clonación de voz few-shot y texto a voz: Desarrollado por RVC-Boss, GPT-SoVITS es un proyecto de código abierto que permite entrenar modelos TTS de alta calidad con solo 1 minuto de datos de voz, logrando la clonación de voz few-shot. Admite TTS zero-shot (conversión instantánea con 5 segundos de entrada), inferencia interlingüística (compatible con inglés, japonés, coreano, cantonés, chino) e integra una caja de herramientas WebUI que incluye separación de voz y acompañamiento, segmentación automática de conjuntos de entrenamiento, ASR en chino y etiquetado de texto, facilitando a los usuarios la creación de conjuntos de datos y modelos. El proyecto ha recibido una atención extremadamente alta en GitHub (más de 44k estrellas) y se ha actualizado a la versión V4, optimizando continuamente la similitud del timbre, la estabilidad y la calidad de salida (Fuente: RVC-Boss/GPT-SoVITS – GitHub Trending (all/daily))

El equipo de Tsinghua lanza SurveyGO (Juan Ji): Herramienta de revisión bibliográfica y generación de informes largos impulsada por AI: Basado en la tecnología LLMxMapReduce-V2 desarrollada por los equipos de NLP de Tsinghua, OpenBMB y ModelBest, SurveyGO puede procesar eficientemente grandes volúmenes de literatura para generar informes de revisión largos (de miles de caracteres) con estructura clara, lógica rigurosa y citas precisas. La herramienta optimiza el esquema mediante un mecanismo convolucional impulsado por entropía de información y genera contenido jerárquicamente, resolviendo el problema de contenido fragmentado y falta de profundidad en la generación de textos largos por AI tradicional. Los usuarios pueden usarla a través de la versión web ingresando un tema o cargando archivos, con el objetivo de mejorar significativamente la eficiencia de la investigación bibliográfica y la redacción para investigadores y creadores de contenido (Fuente: INTJ式学术暴力!清华团队造出“论文卷姬”:3分钟速通200小时文献综述, 如何 AI「拼好文」:生成万字报告,不限模型)

text-generation-webui lanza versión portátil, enfocada en llama.cpp: Para simplificar el proceso de despliegue, text-generation-webui ha lanzado una versión portátil y autocontenida específicamente para llama.cpp. Los usuarios pueden descargarla, descomprimirla y ejecutarla sin necesidad de instalar Python, PyTorch u otras dependencias. La nueva versión es compatible con Windows, Linux, macOS, incluye versiones para CPU y CUDA, ocupa aproximadamente 700 MB y ha optimizado la velocidad de inicio y la experiencia del usuario (como abrir automáticamente el navegador, iniciar la API por defecto). Esto proporciona una gran comodidad para los usuarios que solo desean usar llama.cpp para inferencia local (Fuente: Reddit r/LocalLLaMA)
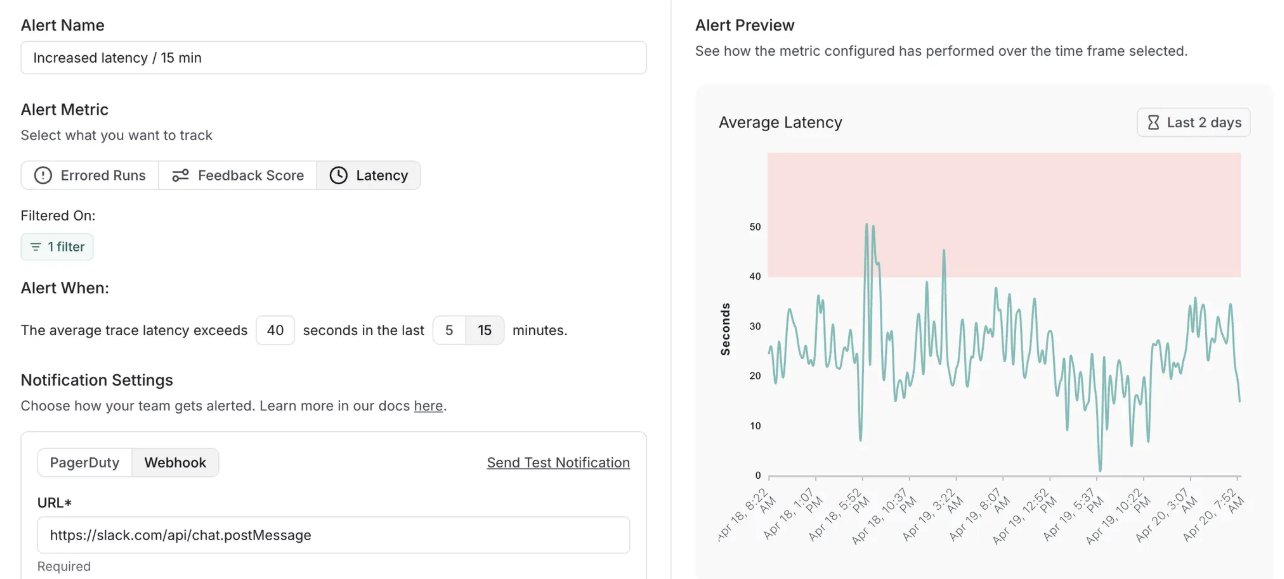
LangSmith añade función de alertas y actualiza versión autoalojada: La plataforma MLOps de LangChain, LangSmith, ha añadido una función de alertas en tiempo real. Los usuarios pueden configurar notificaciones para tasas de error, latencia de ejecución y puntuaciones de retroalimentación, para detectar problemas antes de que afecten a los clientes. Al mismo tiempo, su versión autoalojada se ha actualizado a v0.10, incluyendo la función de alertas, una nueva interfaz de usuario para crear y ver evaluaciones, soporte para datos de seguimiento de clientes OpenTelemetry y optimizaciones de rendimiento (Fuente: LangChainAI, LangChainAI)
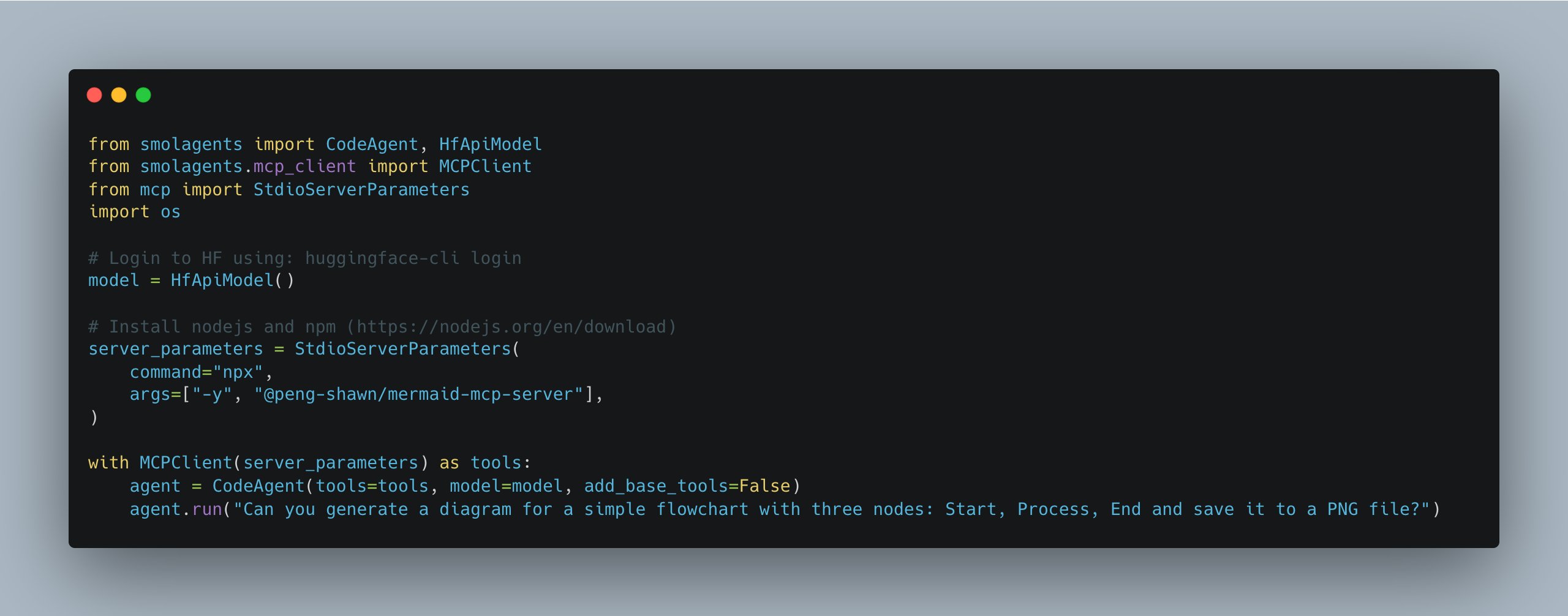
smolagents se actualiza, simplifica la gestión de múltiples servidores MCP: La biblioteca smolagents de Hugging Face ha lanzado una nueva versión que introduce la clase MCPClient, facilitando enormemente la gestión de conexiones a múltiples servidores MCP (Protocolo de Comunicación de Modelos). Esto ayuda a los desarrolladores a construir y coordinar sistemas de Agents más complejos (Fuente: huggingface)
Suna: Plataforma Agent de código abierto que compite con Manus: Kortix AI ha lanzado la plataforma Agent de código abierto Suna, con el objetivo de competir con Manus. Suna integra automatización del navegador, gestión de archivos, rastreo web, búsqueda extendida, ejecución de línea de comandos, despliegue de sitios web e integración de API, permitiendo a la AI operar estas herramientas de forma colaborativa para resolver problemas complejos y automatizar flujos de trabajo a través del diálogo (Fuente: karminski3)
Exa MCP ahora admite búsqueda en Twitter sin API: El servidor MCP (Protocolo de Comunicación de Modelos) de Exa se ha actualizado y ahora admite la búsqueda de contenido en Twitter sin necesidad de utilizar la API de Twitter. Esto facilita a los Agents de AI que necesitan obtener información de Twitter, aunque actualmente parece tener un soporte deficiente para el rastreo de datos de usuarios chinos (Fuente: karminski3)
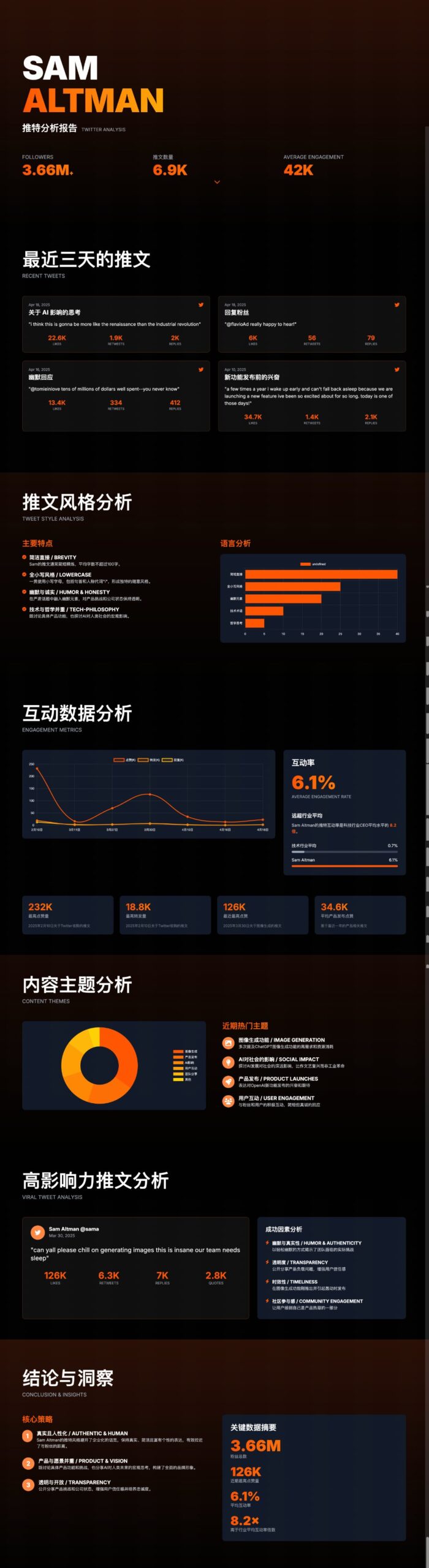
ChatUI-energy: Interfaz que muestra el consumo de energía de las conversaciones de AI en tiempo real: Miembros de la comunidad de Hugging Face han lanzado ChatUI-energy, una variante de Chat UI que puede mostrar en tiempo real la energía consumida durante las conversaciones del usuario con modelos de AI (como Llama, Mistral, Qwen, Gemma, etc.). Esta iniciativa tiene como objetivo aumentar la transparencia energética del uso de la AI (Fuente: huggingface, huggingface)
Uso de AI para el desarrollo, despliegue y optimización de aplicaciones web: El artículo comparte la práctica completa del uso de AI (como Lovable, Cursor, BrowserTools MCP) para el desarrollo (una herramienta de empalme de imágenes), depuración, auditoría SEO y optimización del rendimiento de una aplicación web. Se destaca cómo utilizar Vercel y GitHub para lograr el despliegue automatizado CI/CD, así como la configuración de la resolución de dominios y subdominios. Muestra el papel auxiliar de la AI en la codificación y el mantenimiento de sitios web (Fuente: AI 编码 + Vercel 部署 + 域名解析:一文搞定Web 应用开发上线全流程,氛围编码+MCP 审计优化。)

Réplica ligera de “Her” OS1/Samantha basada en modelos locales: Un desarrollador ha recreado localmente en el navegador el asistente de AI OS1/Samantha de la película “Her” utilizando transformers.js y modelos ONNX (incluyendo Ultravox Llama 3.2 1B, Whisper Base, Kokoro TTS y MiniLM embeddings). El proyecto demuestra la posibilidad de implementar una AI de interacción por voz que se ejecuta localmente con recursos limitados (aproximadamente 2 GB de descarga de modelos) (Fuente: Reddit r/LocalLLaMA)
ChatWise combina servidores MCP para implementar RAG y sincronización de datos: Un usuario compartió una configuración de flujo de trabajo en ChatWise utilizando instrucciones del sistema, combinando los servidores MCP de Pinecone (base de datos), Exa (búsqueda) y Time (tiempo), para lograr una implementación simple de RAG (generación aumentada por recuperación) y sincronización de datos (Fuente: op7418)

📚 Aprendizaje
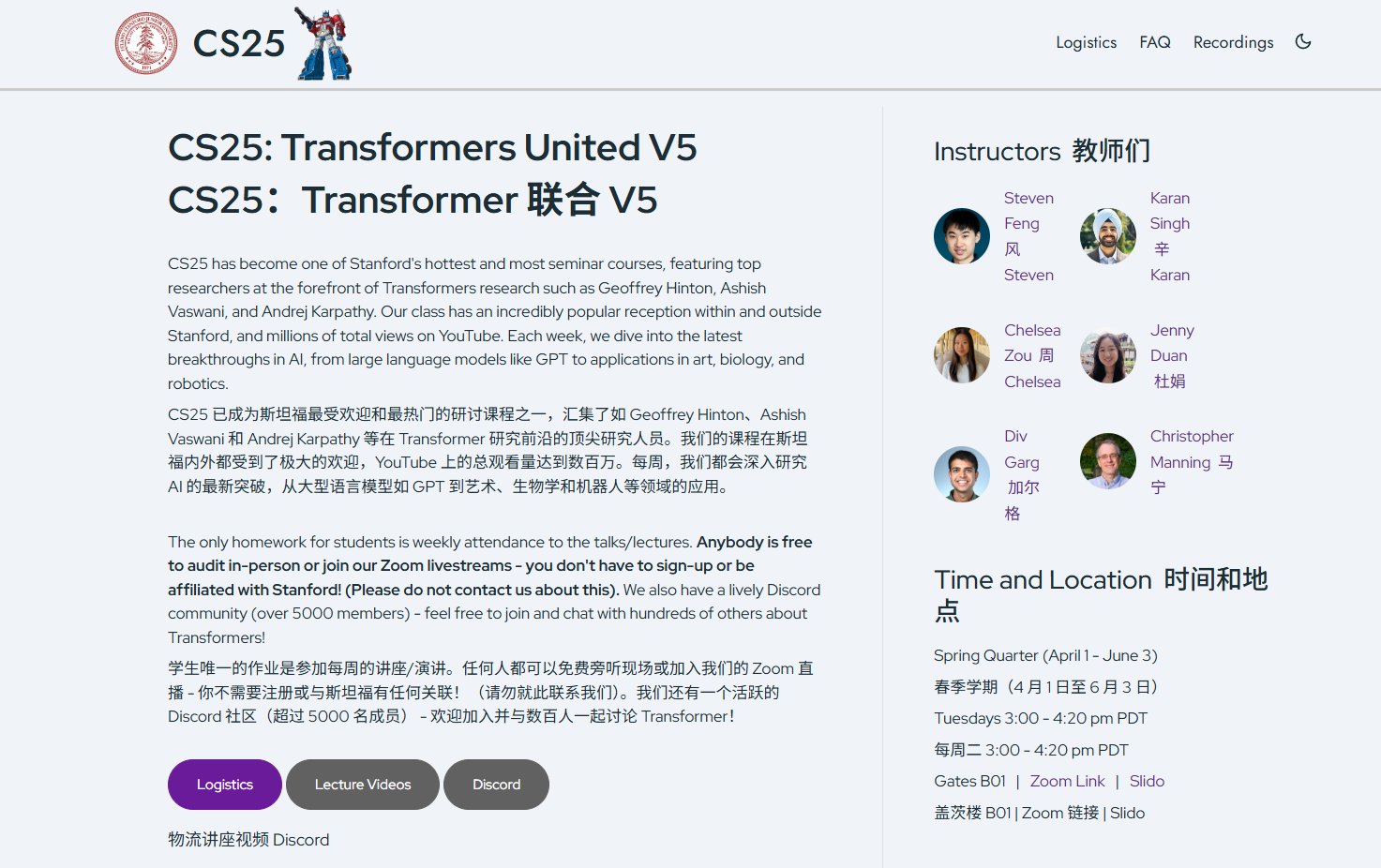
La Universidad de Stanford abre el curso sobre Transformers CS25: El curso de seminario sobre Transformers CS25 de la Universidad de Stanford está abierto al público y se puede participar a través de Zoom en vivo. El curso invita a investigadores de primer nivel como Andrej Karpathy, Geoffrey Hinton, Jim Fan, Ashish Vaswani y ponentes de OpenAI, Google, NVIDIA para dar conferencias. El contenido abarca arquitectura LLM, aplicaciones multimodales, biología, robótica y otros temas de vanguardia. Las grabaciones del curso se publicarán en YouTube y se ha creado una comunidad en Discord para discusiones (Fuente: karminski3, dotey, Reddit r/deeplearning, Reddit r/LocalLLaMA)
Investigación de Tsinghua y Jiao Tong revela limitaciones del RL en la capacidad de razonamiento de los LLM: Un estudio de la Universidad Tsinghua y la Universidad Jiao Tong de Shanghái desafía la idea de que el aprendizaje por refuerzo (RL) mejora la capacidad de razonamiento de los grandes modelos. Los experimentos muestran que, aunque el RL puede mejorar la precisión del modelo a bajas tasas de muestreo (eficiencia), a altas tasas de muestreo, el modelo base puede resolver más problemas difíciles (frontera de capacidad). Esto sugiere que el RL es mejor para optimizar el rendimiento del modelo dentro de su rango de capacidad existente, en lugar de expandir su capacidad de razonamiento fundamental. El artículo señala que los métodos actuales de RL (como GRPO) pueden caer en óptimos locales debido a una exploración insuficiente, limitando la resolución de problemas complejos (Fuente: RL 是推理神器?清华上交大最新研究指出:RL 让大模型更会 「套公式」,却不会真推理, Reddit r/artificial)

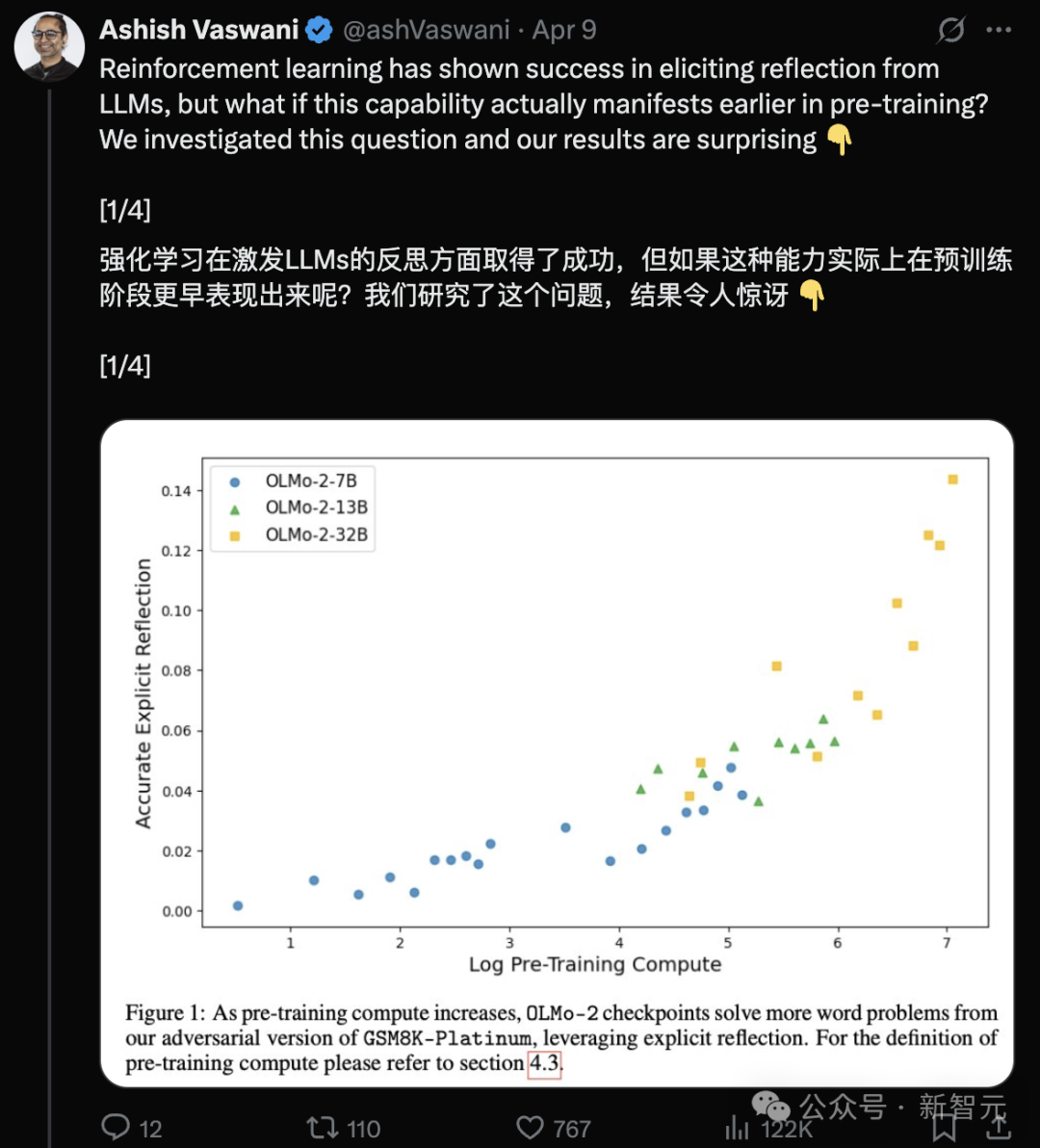
Equipo de autores de Transformer: Los LLM ya tienen capacidad de reflexión en la etapa de preentrenamiento: Un equipo liderado por el primer autor del paper de Transformer, Ashish Vaswani, publicó una investigación que propone que los grandes modelos de lenguaje ya desarrollan capacidades de reflexión y autocorrección durante la etapa de preentrenamiento, y no dependen completamente del aprendizaje por refuerzo (RLHF). El estudio, mediante la introducción de cadenas de pensamiento adversarias, distingue y cuantifica las capacidades de reflexión contextual y autorreflexión, descubriendo que estas capacidades aumentan con la cantidad de cómputo de preentrenamiento. Un simple prompt como “Wait,” puede estimular eficazmente la reflexión explícita. Esto desafía la opinión de DeepSeek y otros de que la reflexión proviene principalmente del RL, y ofrece una nueva perspectiva para comprender y acelerar el desarrollo de la capacidad de razonamiento en el preentrenamiento (Fuente: Transformer原作打脸DeepSeek观点?一句Wait就能引发反思,RL都不用)
ChemAgent: Banco de memoria autoactualizable mejora la capacidad de razonamiento químico de los LLM: Investigadores de Yale, Stanford y otras instituciones proponen el marco ChemAgent, que mejora significativamente el rendimiento de los LLM en tareas de razonamiento químico mediante la introducción de un banco de memoria dinámico y autoactualizable que incluye planificación, ejecución y memoria de conocimiento. Este marco simula el proceso de aprendizaje humano, resolviendo problemas químicos complejos mediante la descomposición de tareas y la recuperación de memoria. Los experimentos en el conjunto de datos SciBench muestran que ChemAgent mejora la precisión en promedio un 10% (en relación con SOTA) hasta un 37% (en relación con el razonamiento directo) en comparación con los métodos de referencia, especialmente en la precisión de cálculos y conversión de unidades. El estudio también analiza la relación entre la similitud de la memoria, la cantidad y el rendimiento, así como las limitaciones actuales (Fuente: 准确率飙升46%!耶鲁-斯坦福「自更新记忆库」新框架,重塑LLM化学推理能力)
La Universidad Tecnológica del Sur de China logra una serie de avances en computación evolutiva distribuida: El equipo de Inteligencia Computacional de la Universidad Tecnológica del Sur de China ha logrado una serie de resultados en la optimización del consenso distribuido de sistemas multiagente (MAS). La investigación incluye: la publicación de una revisión sobre este campo interdisciplinario; la propuesta del algoritmo MASOIE, que optimiza la colaboración mediante mecanismos de aprendizaje interno y externo; la propuesta del algoritmo MACPO, que utiliza incentivos de objetivos para impulsar la cooperación; el diseño del mecanismo de adaptación de paso CCSA para mejorar el rendimiento de la optimización de caja negra; la propuesta del algoritmo MASTER para mejorar la precisión de la localización en redes de sensores. El equipo también organizó competiciones relacionadas para promover el desarrollo del campo (Fuente: 打破共识优化壁垒!华南理工深耕分布式进化计算,实现多智能体高效协同)
Serie de tutoriales en video para construir DeepSeek desde cero: Vizuara ha publicado en YouTube la serie de tutoriales en video “Construir DeepSeek desde cero”. Actualmente se han actualizado 13 lecciones, que cubren los fundamentos de DeepSeek, el flujo de procesamiento de Tokens, los mecanismos de atención (autoatención, atención causal, atención multi-cabeza, atención multi-consulta, atención de consulta agrupada, atención latente multi-cabeza) y conceptos centrales como KV Cache, con explicaciones y implementaciones de código. La serie tiene como objetivo analizar en profundidad la arquitectura de DeepSeek, con un plan total de 35-40 videos que cubrirán más contenido como RoPE, MoE, MTP, SFT, GRPO, etc. (Fuente: karminski3, Reddit r/LocalLLaMA)
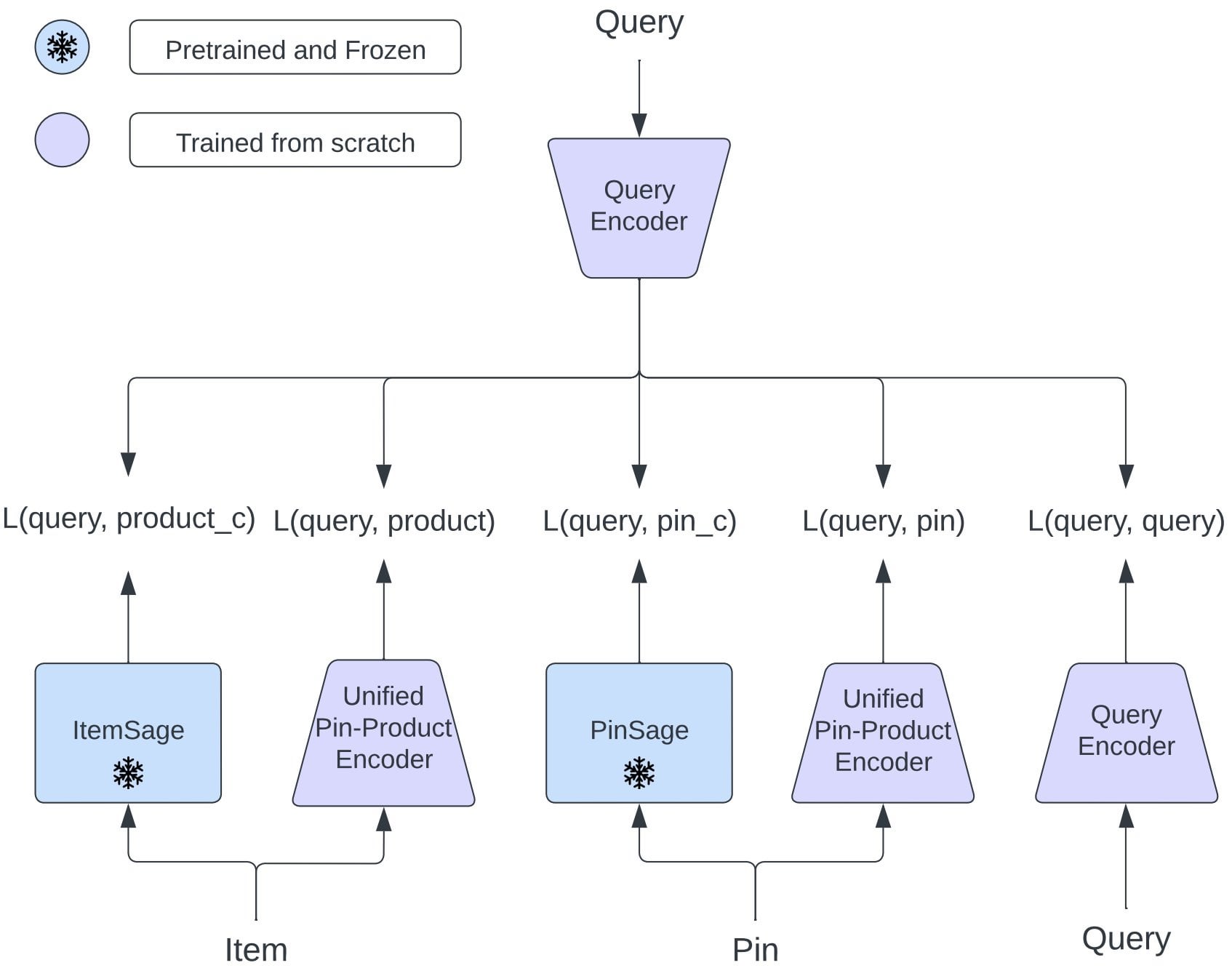
Pinterest propone OmniSearchSage: Modelo de embedding unificado mejora la recuperación multitarea: Investigadores de Pinterest proponen OmniSearchSage, un modelo de embedding de consulta unificado que, entrenado mediante aprendizaje multitarea, puede recuperar simultáneamente pins, productos y consultas relacionadas, desafiando la arquitectura tradicional de doble torre. Este modelo fusiona títulos generados por GenAI, señales de tableros curados por usuarios y datos de participación conductual, enriqueciendo la comprensión del ítem y pudiendo integrarse directamente en sistemas existentes (como PinSage). Los resultados muestran que este método ha logrado mejoras prácticas significativas en búsqueda, publicidad y latencia (Fuente: Reddit r/MachineLearning)
FlowReasoner: Flujo de trabajo multiagente ajustado dinámicamente según la consulta: Un paper propone FlowReasoner, con el objetivo de inferir instantáneamente un flujo de trabajo multiagente exclusivo para cada consulta del usuario. Mediante SFT de inferencia y aprendizaje por refuerzo GRPO, el modelo puede ajustar dinámicamente la combinación y secuencia de tareas de los Agents (como generación de código, revisión, prueba, revisión) basándose en la retroalimentación de la ejecución. Este método se valida en el escenario de Code Interpreter, dependiendo de la ejecución de Python y pruebas unitarias, mostrando el potencial de adaptación dinámica del flujo de trabajo a las necesidades de la consulta, y podría generalizarse en el futuro a campos como la recuperación, el análisis de datos, etc. (Fuente: dotey)

Tutorial de LangChain: Construir un flujo de trabajo de generación de informes de cumplimiento con LlamaIndex: LlamaIndex ha publicado un tutorial en video que demuestra cómo construir un Agentic Workflow para generar informes de cumplimiento. Este flujo de trabajo utiliza LLM para procesar grandes cantidades de texto normativo, compararlo con el lenguaje contractual y generar resúmenes concisos. El tutorial muestra cómo configurar un índice LlamaCloud, definir esquemas para la extracción de cláusulas y la verificación de cumplimiento, y usar búsqueda semántica para encontrar lenguaje normativo relevante (Fuente: jerryjliu0)

Tutorial de LangChain: Agent de generación de código autorreparable: LangChain ha publicado un tutorial que presenta cómo construir un Agent de generación de código de AI con capacidad de autorreparación. Este tutorial utiliza el marco OpenEvals y el entorno sandbox E2B para evaluar y mejorar el código generado por AI, añadiendo un paso de reflexión para validar el código antes de devolver la respuesta (Fuente: LangChainAI)

Análisis de Anthropic descubre que Claude tiene un código moral intrínseco: Tras analizar 700,000 conversaciones de Claude, Anthropic descubrió que su modelo de AI muestra un código moral intrínseco. Este hallazgo podría tener una importancia significativa para la investigación sobre seguridad y ética de la AI (Fuente: Reddit r/ClaudeAI, Reddit r/artificial)

Google propone la “Era de la Experiencia” para abordar la escasez de datos de entrenamiento de AI: Investigadores de Google (incluido David Silver) publicaron el paper “The Era of Experience”, proponiendo que los Agents de AI generen sus propios datos de entrenamiento para resolver el problema de escasez de datos que enfrenta actualmente el entrenamiento basado en datos humanos. Esto podría indicar una nueva dirección en el paradigma de entrenamiento de AI y podría desafiar los métodos de entrenamiento que dependen de conjuntos de datos existentes (Fuente: Reddit r/artificial)

Lista de recursos de cursos y certificaciones gratuitas: El repositorio de GitHub cloudcommunity/Free-Certifications recopila y organiza una gran cantidad de recursos que ofrecen cursos y certificaciones gratuitas, cubriendo múltiples áreas como tecnología general, seguridad, bases de datos, gestión de proyectos, marketing, etc. Incluye algunos cursos y certificaciones gratuitas relacionadas con AI, aprendizaje automático y ciencia de datos, como el curso de aprendizaje automático de freeCodeCamp, los fundamentos de GenAI de Databricks, los cursos de AI de IBM Cognitive Class, etc. (Fuente: cloudcommunity/Free-Certifications – GitHub Trending (all/daily))
Prueba de fiabilidad de LLM para la edición de código: Un usuario compartió un video probando la fiabilidad de varios modelos de lenguaje grandes (LLM) en la escritura y modificación de código de aprendizaje profundo, explorando la efectividad real y las limitaciones de los LLM actuales en tareas de asistencia a la programación (Fuente: Reddit r/deeplearning)

💼 Negocios
La guerra arancelaria de EE. UU. impacta a las startups chinas de hardware de AI: La imposición de altos aranceles por parte de EE. UU. a productos chinos (algunas tasas alcanzan el 125%) afecta gravemente a las startups chinas de hardware de AI orientadas al mercado estadounidense (como juguetes de AI, gafas inteligentes, etc.). Dado que el mercado estadounidense es un campo clave para la validación de mercado y la adquisición de usuarios tempranos para muchos productos de hardware de AI (por ejemplo, a través de Kickstarter), los altos aranceles provocan una reducción drástica de las ganancias e incluso pérdidas, lo que ha llevado a algunas empresas a suspender los envíos a EE. UU. Aunque categorías como las gafas inteligentes han obtenido exenciones temporales, el futuro es incierto. Los riesgos del modelo de “despacho gris” del que depende la industria también están aumentando. Esto obliga a las empresas a reevaluar sus estrategias de mercado, acelerar la expansión global y diversificar los riesgos (Fuente: 襁褓中的AI硬件,迎接最激烈的关税战)

Análisis profundo de ZHIYUAN ROBOTICS: Productos, tecnología y modelo de negocio: ZHIYUAN ROBOTICS, fundada por Peng Zhihui (“Zhihui Jun”) y otros, posee la serie “Yuanzheng” (A1, A2, A2-W con ruedas, A2-Max de carga pesada) orientada a escenarios industriales y comerciales, y la serie “Lingxi” (X1 de código abierto, X1-W de adquisición de datos, X2 bípedo interactivo) enfocada en la ligereza y el código abierto, así como los robots de limpieza Elf G1 y Juechen C5. Tecnológicamente, la empresa enfatiza la sinergia hardware-software y el bucle cerrado de datos, desarrollando internamente el módulo de articulación PowerFlow, manos diestras, y desarrollando software como el gran modelo Qiyuan (GO-1), la plataforma de datos AIDEA, el marco de comunicación AimRT, etc. El modelo de negocio incluye venta de hardware, servicios de suscripción y reparto de beneficios del ecosistema (componentes de código abierto, cooperación en la cadena de suministro). La empresa ha completado 8 rondas de financiación, con una valoración de 15 mil millones de yuanes, inversores como Hillhouse, BYD, Tencent, etc., y coopera con varias empresas de la cadena de suministro y gobiernos locales, con el objetivo de crear un robot corpóreo general de clase mundial (Fuente: 智元机器人深度拆解:人形机器人独角兽进化论)

Proyecto de impresión 3D incubado internamente por Dreame, “AtomFab”, recibe decenas de millones de yuanes en financiación: AtomFab Technology, incubada internamente por Dreame Technology, ha completado una ronda de financiación ángel de decenas de millones de yuanes, invertida por Chuizhuāng Venture Capital. La empresa, fundada en enero de 2025, se enfoca en el mercado de impresión 3D de consumo, utilizando tecnología de AI para resolver puntos débiles como la facilidad de uso, la estabilidad y la eficiencia. La empresa reutilizará las tecnologías de motores, sensores, interacción AI de Dreame y sus recursos maduros de cadena de suministro para reducir costos y acelerar la producción. Los productos se lanzarán prioritariamente en los mercados europeo y estadounidense, utilizando la red de posventa internacional de Dreame para brindar soporte. Se espera que el primer producto se lance en la segunda mitad de 2025 (Fuente: 追觅内部孵化3D打印项目获数千万融资,优先布局欧美等海外市场|硬氪首发)
La posición de monopolio de las GPU de NVIDIA podría enfrentar desafíos: Aunque los envíos de GPU de NVIDIA continúan creciendo, su dominio a largo plazo enfrenta desafíos. Las razones principales incluyen: 1) La fuerte demanda de los gigantes de la nube (Google, Microsoft, Amazon, Meta) pero están invirtiendo fuertemente en chips de desarrollo propio (TPU, Maia, Trainium, MTIA) para reducir costos y dependencia; 2) La industria se está transformando hacia la optimización distribuida, integrada verticalmente y a nivel de sistema (chip, red, refrigeración, software), donde NVIDIA tiene una presencia relativamente insuficiente; 3) El aumento de la demanda de personalización, donde los ASIC muestran ventajas en cargas de trabajo específicas (como inferencia, recomendación); 4) La tecnología de red de NVIDIA (Infiniband) y su pila de software (como BaseCommand) pueden no igualar las soluciones internas de los gigantes de la nube en términos de ultraescala y tolerancia a fallos. Aunque NVIDIA se esfuerza por adaptarse (como Blackwell, Spectrum-X), los desafíos estructurales persisten (Fuente: 计算的未来:英伟达王冠正摇摇欲坠)

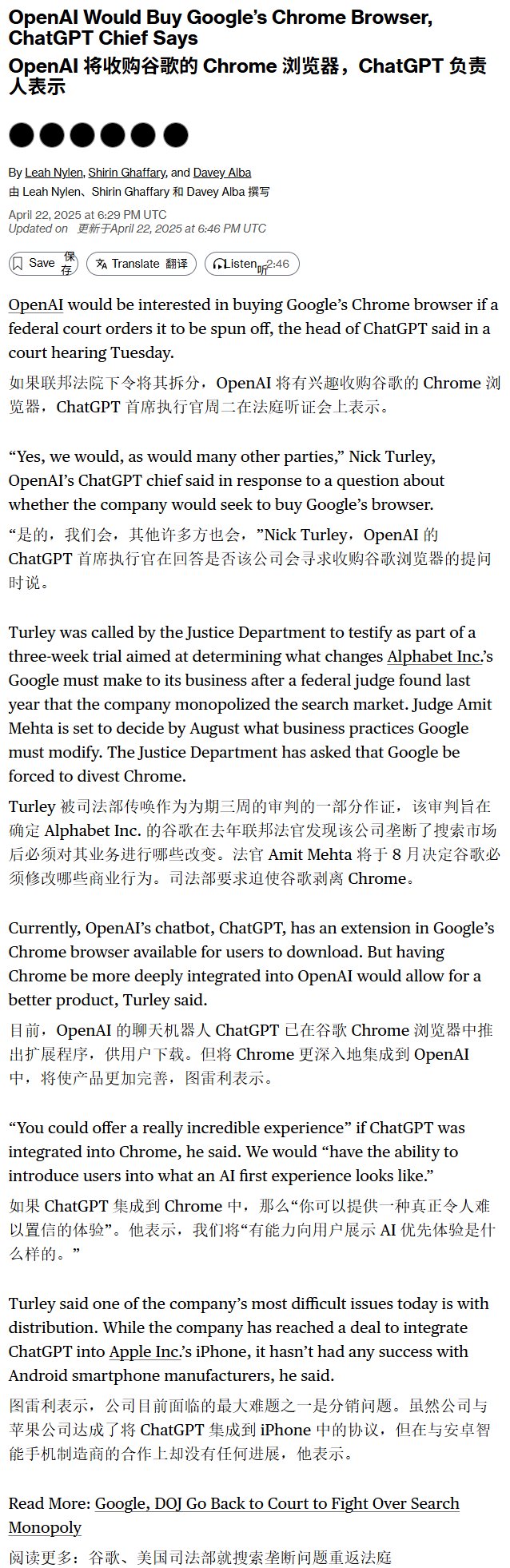
Rumor: OpenAI interesada en adquirir el navegador Chrome: Según Bloomberg, si Google se viera obligada a dividir su negocio de búsqueda por orden de un tribunal federal de EE. UU. debido a un caso antimonopolio, OpenAI podría estar interesada en adquirir su negocio del navegador Chrome. Esto refleja el interés potencial de las empresas de AI en controlar las entradas de los usuarios y las fuentes de datos, pero actualmente es solo un rumor y depende del progreso del caso antimonopolio de Google (Fuente: karminski3)
Estrategias para lograr resultados comerciales con GenAI: Un artículo de Forbes explora cómo las empresas pueden ir más allá de la etapa experimental y obtener resultados comerciales reales utilizando la inteligencia artificial generativa (GenAI), proponiendo 9 estrategias para ayudar a las empresas a integrar GenAI en sus procesos comerciales para mejorar la eficiencia y la innovación (Fuente: Ronald_vanLoon)

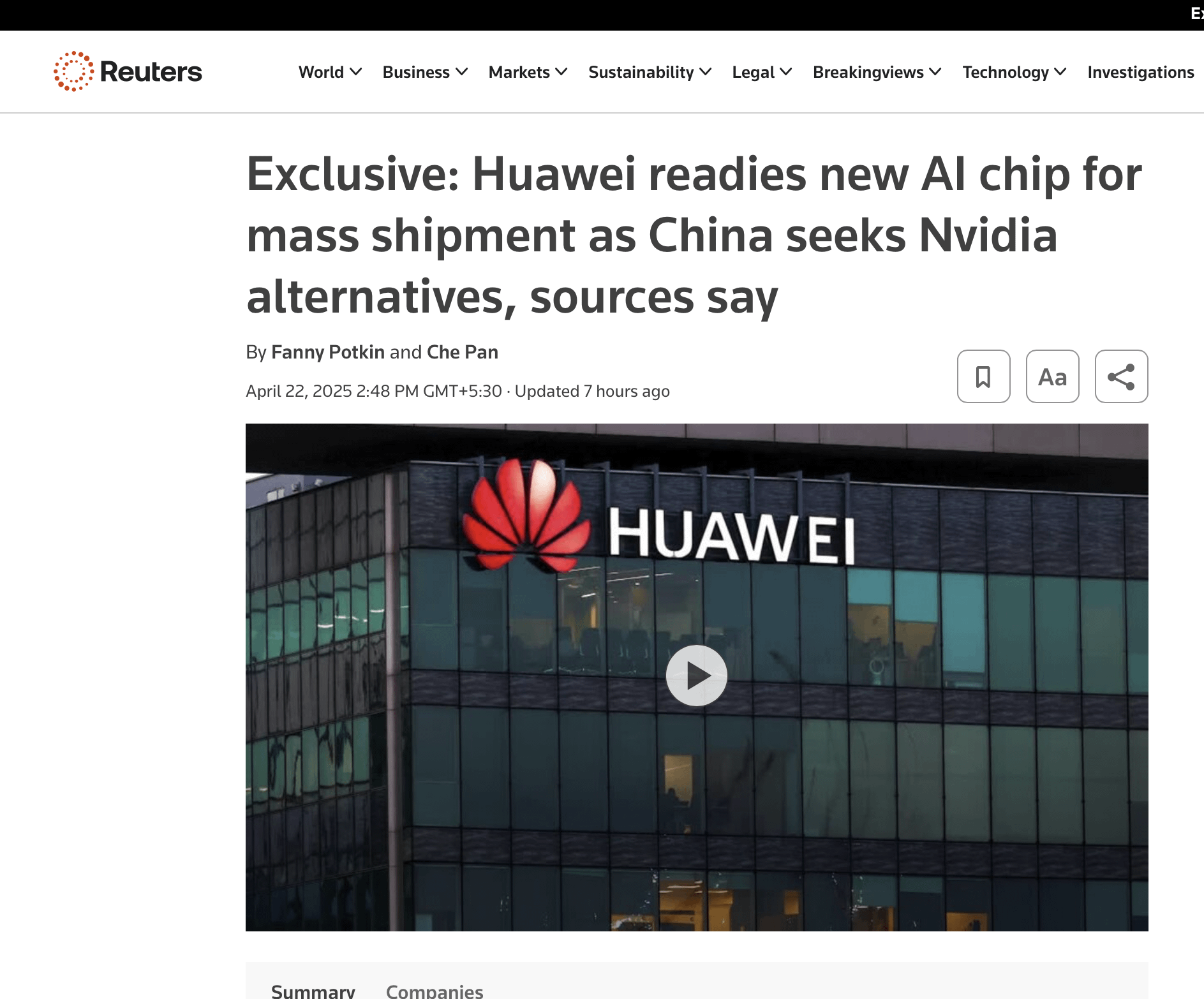
El nuevo chip de Huawei podría competir con NVIDIA: Discusiones en redes sociales mencionan que el nuevo chip lanzado por Huawei podría representar una competencia para NVIDIA en el campo de la AI, lo que podría influir en el panorama de las negociaciones entre China y EE. UU. sobre chips y aranceles (Fuente: Reddit r/ArtificialInteligence)
🌟 Comunidad
La fiebre del oro de DeepSeek y la reflexión: La popularidad de DeepSeek ha generado numerosos intentos comerciales a su alrededor, incluida la creación de contenido (producción masiva de guiones de videos cortos, textos publicitarios), el pago por conocimiento (venta de tutoriales de uso, cursos de monetización) y servicios de operación delegada. Sin embargo, muchos de los que lo intentaron descubrieron que el contenido producido en masa con AI es muy homogéneo, fácilmente limitado o prohibido por las plataformas, y difícil de convertir realmente en beneficios efectivos. El artículo señala que los verdaderos beneficiarios suelen ser los “intermediarios” que venden cursos o servicios aprovechando la asimetría de información, en lugar de los usuarios directos. Al mismo tiempo, DeepSeek también ha mostrado problemas como servidores ocupados y respuestas estereotipadas, lo que ha generado discusiones sobre su valor de aplicación y limitaciones (Fuente: DeepSeek走红三个月,第一批想靠它赚钱的怎么样了?)

Desarrollador de herramienta de trampa con AI obtiene financiación, generando controversia ética: Chungin Lee, un estudiante de 21 años de la Universidad de Columbia, fue suspendido por desarrollar Interview Coder, una herramienta de AI para hacer trampa en entrevistas técnicas. Menos de un mes después, fundó la empresa Cluely con un compañero, expandiendo la herramienta a exámenes, ventas, reuniones y otros escenarios, y obtuvo 5.3 millones de dólares en financiación inicial. Argumentan que no es trampa, sino usar la tecnología para mejorar la eficiencia, y que en el futuro todos usarán asistencia de AI. El asunto ha generado una gran controversia: los partidarios lo ven como una innovación audaz, mientras que los críticos temen que socave la equidad, difumine los límites de la capacidad e incluso lo comparan con tramas de “Black Mirror”. El incidente ha provocado intensos debates sobre la ética de la AI, la equidad educativa y la definición de capacidad (Fuente: 21岁学生开发AI作弊工具被哥大停学,转身拿下530万美元融资,网友:《黑镜》成真, 靠开发AI作弊神器成名,21岁小伙遭学校开除不足一月后,转身拿下530万美元融资)

Endurecimiento de la política de visas de EE. UU., posible fuga de talento de AI: Recientemente, el gobierno de EE. UU. ha revocado masivamente los registros SEVIS y las visas de estudiantes internacionales (incluidos estudiantes de doctorado en AI), por razones que van desde infracciones menores hasta errores del sistema (posiblemente relacionados con el cribado por AI), y el proceso carece de transparencia y oportunidades de apelación. El profesor de Caltech Yisong Yue y otros temen que esta medida esté dañando el atractivo de EE. UU. para el talento de AI de primer nivel, y muchos investigadores en instituciones como OpenAI y Google ya están considerando irse. Esto podría hacer retroceder los proyectos de AI de EE. UU. y debilitar su ventaja en AI. Ya hay estudiantes que han demandado conjuntamente al gobierno y han obtenido una orden de restricción temporal (Fuente: 加州AI博士一夜失身份,谷歌OpenAI学者掀「离美潮」,38万岗位消失AI优势崩塌)

Discusión sobre el estado actual del desarrollo de modelos de código abierto: La comunidad discute las últimas novedades sobre los grandes modelos de código abierto, mencionando la expectativa por Qwen 3, la lenta adopción de Llama 4, el aparente estancamiento de los modelos de inferencia, la subestimación de los modelos multimodales y el continuo dominio de China en el campo del código abierto. Los participantes enfatizan que la comprensión del “estancamiento de la inferencia” debe distinguir entre código abierto y cerrado, y señalan que se trata más bien de desafíos relacionados con la diversidad de modelos y la extensión del RL (Fuente: natolambert)
Elogios a la capacidad de búsqueda del modelo o3 de OpenAI: Un usuario elogia la potente capacidad de búsqueda del modelo o3 de OpenAI, capaz de encontrar información muy específica sin necesidad de mucho contexto adicional, con una experiencia de interacción similar a la de hablar con un colega (Fuente: gdb)
Significado e impacto del TTS de código abierto: Al discutir el modelo Dia TTS, miembros de la comunidad enfatizan que su rendimiento de alta calidad demuestra que entrenar modelos TTS SOTA ya no requiere miles de millones de dólares de inversión. El efecto compuesto de la industria de la AI facilita cada vez más el entrenamiento, y el poder del código abierto está acelerando la democratización de la tecnología (Fuente: huggingface, huggingface)
Meta organiza LlamaCon 2025 para celebrar la comunidad de código abierto: Meta anunció que organizará el evento LlamaCon 2025, con el objetivo de celebrar la comunidad de código abierto de Llama y sus logros, y compartirá los últimos avances y planes futuros para los modelos y herramientas de Llama (Fuente: AIatMeta)

Debate sobre si la AI es verdaderamente “inteligente”: El artículo “Necesitamos dejar de fingir que la AI es inteligente” genera debate, explorando los límites de la capacidad de la tecnología de AI actual y la complejidad de la definición de “inteligencia” (Fuente: Ronald_vanLoon)

Experiencia de uso de ChatGPT: Pérdida de conexión y prueba de honestidad: Un usuario informa encontrar frecuentemente el problema de “pérdida de conexión de red” con ChatGPT, especulando que podría estar relacionado con la carga de uso. Al mismo tiempo, otro usuario comparte un prompt interesante que pide a ChatGPT que use su función de memoria para dar su “opinión real” sobre el usuario, generando discusiones sobre la interacción personalizada de la AI y la “conciencia” (Fuente: natolambert, dotey)
Optimismo sobre el desarrollo en el campo de la robótica: El cofundador de Hugging Face, Thomas Wolf, comenta que los laboratorios de robótica de 2025 son muy divertidos debido al hardware de código abierto, los buenos avances en aprendizaje por refuerzo y la concentración de talento, reflejando el entusiasmo de la industria por el rápido desarrollo de la tecnología robótica (Fuente: huggingface)
Se reconoce la utilidad de Gemini Deep Research: Un usuario comparte un caso de uso de la función Gemini Deep Research para verificar la fiabilidad de la información de un tuit, mostrando su valor práctico en la verificación de información y la investigación profunda (Fuente: dotey)

Críticas y defensa de las bibliotecas de AI de código abierto: Miembros de la comunidad observan que recientemente ha habido bastantes comentarios negativos sobre diversas bibliotecas de AI de código abierto, argumentando que estas críticas pueden basarse en información obsoleta o métricas parciales, e instan a los críticos a participar en la construcción de mejores versiones (Fuente: natolambert)
Especulación sobre la experiencia de juego con AI: Un usuario expresa curiosidad sobre la futura experiencia de juego impulsada por AI, especulando que podría ser similar a la interacción de VRChat, pero expresa dudas sobre la operación exclusiva mediante voz (Fuente: karminski3)
Discusión sobre la función de ampliación de imágenes de ChatGPT: Un usuario intentó que ChatGPT aumentara la resolución de una imagen, descubriendo que no amplía realmente los píxeles, sino que vuelve a dibujar una imagen similar pero con detalles diferentes en alta resolución. La sección de comentarios coincide en general con esto y discute la verdadera tecnología de ampliación de imágenes por AI (Fuente: Reddit r/ChatGPT)
ChatGPT genera una imagen de cómo imagina el mundo: Un usuario pidió a ChatGPT que generara una imagen de cómo imagina que debería ser el mundo, obteniendo una escena idílica de un parque. Los usuarios en los comentarios señalaron inconsistencias lógicas en la imagen (como la distancia Tierra-Luna, la ubicación de los bancos) y posibles sesgos (raza de las personas), reflejando las limitaciones actuales de los modelos de generación de imágenes (Fuente: Reddit r/ChatGPT)

Exploración de por qué el antiguo modelo LLM MythoMax13B sigue siendo popular: Un usuario de Reddit pregunta por qué el modelo MythoMax13B, basado en Llama2, sigue siendo popular en escenarios de RPG en plataformas como OpenRouter. Los comentarios sugieren que las razones incluyen: bajo costo (a menudo como opción gratuita), relativa estabilidad y seguimiento de instrucciones, familiaridad de los usuarios con sus prompts y configuraciones, y el efecto de consolidación de los tutoriales iniciales (Fuente: Reddit r/LocalLLaMA)
Búsqueda de herramienta de filtrado de privacidad local: Un usuario de Reddit busca una herramienta o un modelo de lenguaje pequeño (SLM) que pueda ejecutarse en un dispositivo local para detectar y anonimizar automáticamente (por ejemplo, reemplazando con marcadores de posición) la información antes de enviar un prompt a un LLM, y restaurar la información original al recibir la respuesta del LLM, para proteger la privacidad (Fuente: Reddit r/OpenWebUI)
Discusión sobre la advertencia de Anthropic sobre “empleados totalmente de AI”: Anthropic advirtió que empleados virtuales compuestos enteramente por AI podrían aparecer en un año, lo que generó discusión en la comunidad. Los comentaristas expresaron escepticismo, señalando problemas de estabilidad en los propios servicios de Anthropic y considerando que es más probable que sea propaganda o alarmismo (Fuente: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ClaudeAI)

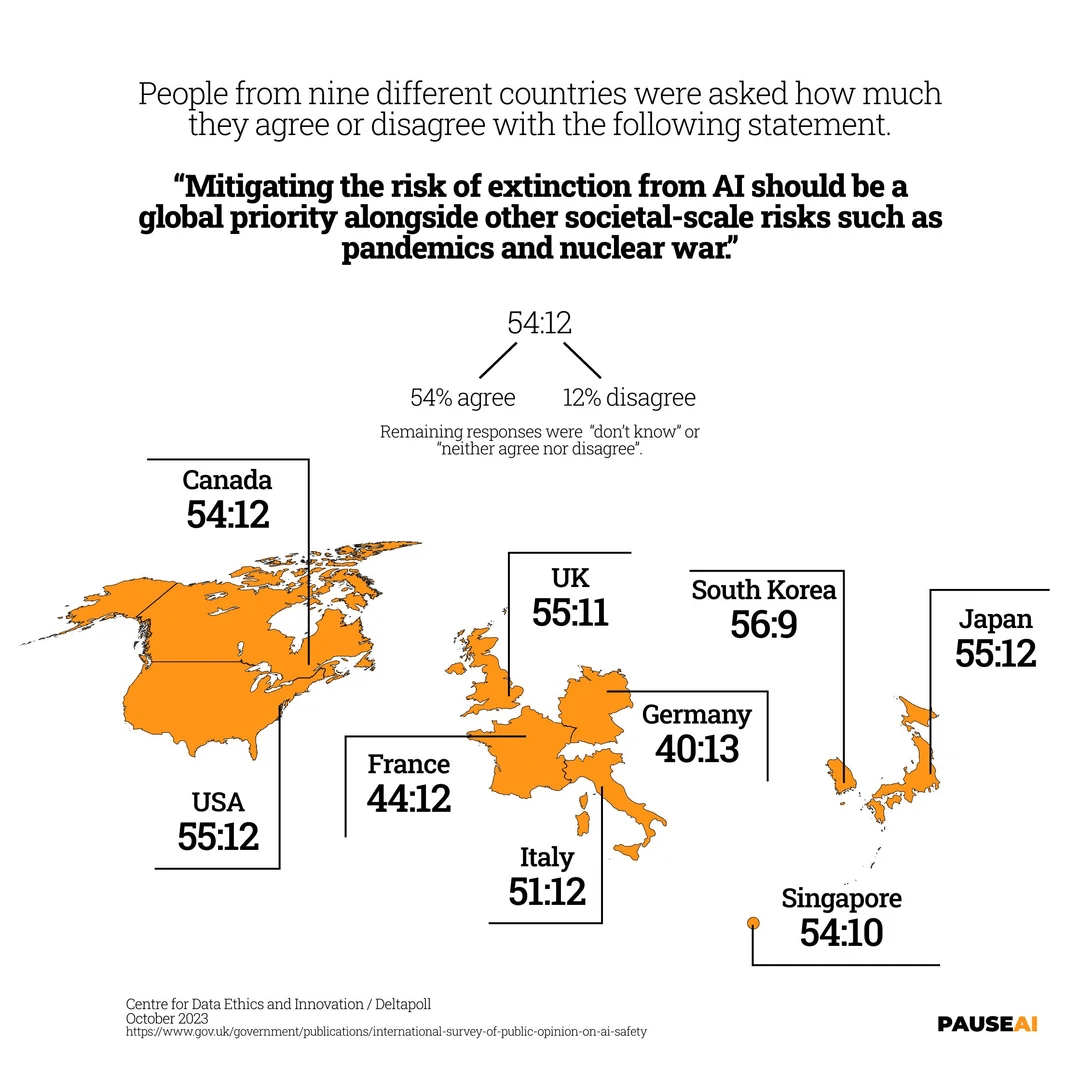
Preocupación global por el riesgo de extinción por AI: Una imagen muestra los resultados de una encuesta que indica que la mayoría de las personas en el mundo cree que se debe tomar en serio el riesgo de que la AI pueda causar la extinción humana (Fuente: Reddit r/artificial)
El “sabor a máquina” del texto generado por AI y técnicas de humanización: Los usuarios discuten cómo identificar el texto generado por AI (como correos electrónicos, publicaciones), señalando sus problemas comunes: falta de tono específico, excesiva formalidad, perfección impecable. Y comparten técnicas para hacer que la escritura de la inteligencia artificial sea más natural: especificar el escenario, proporcionar ejemplos, ajustar la aleatoriedad, añadir detalles concretos, editar uno mismo, conservar pequeñas imperfecciones, etc. (Fuente: Reddit r/artificial)
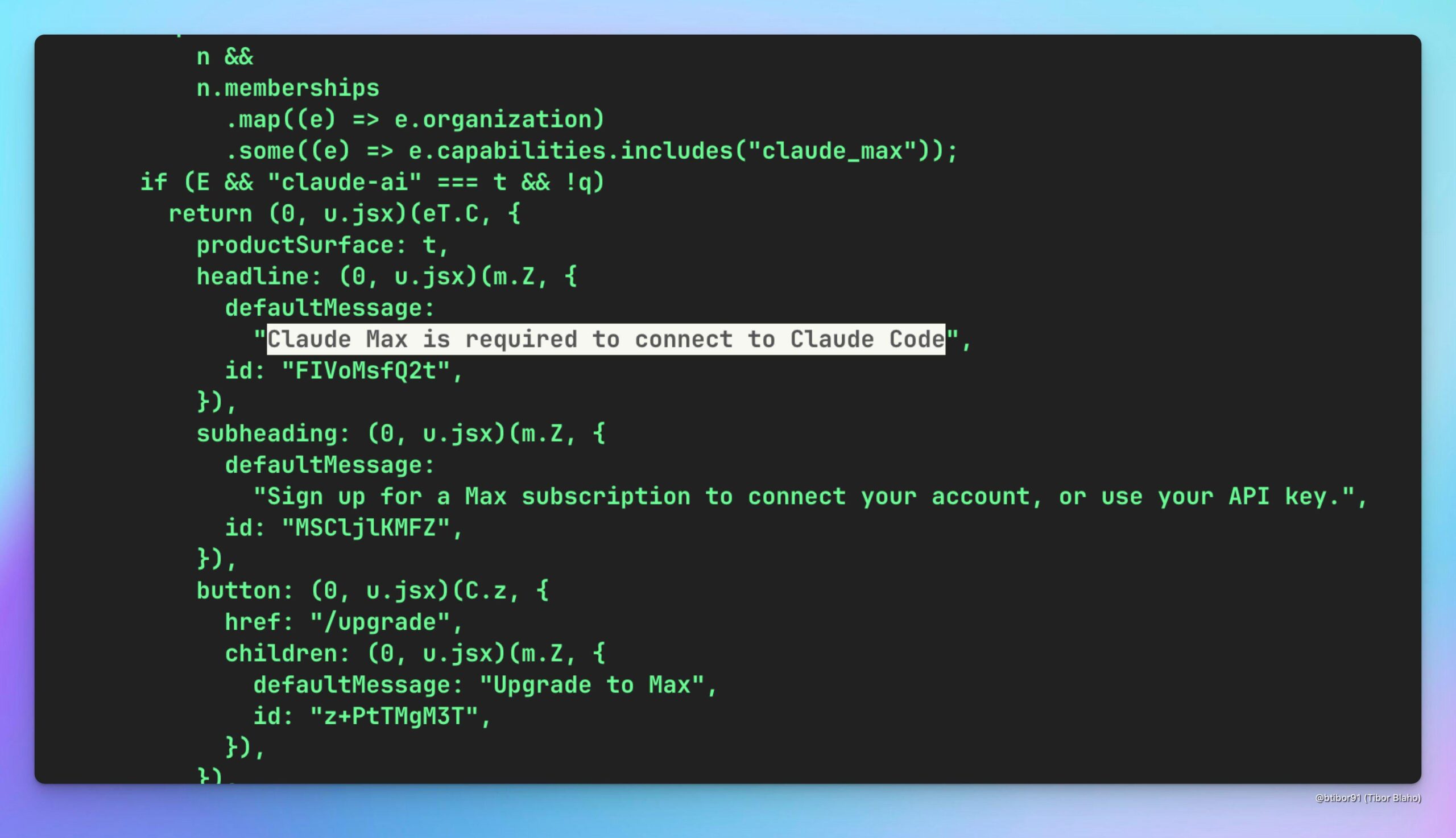
Especulación sobre si Claude Code se puede usar a través de Claude Max: Un usuario especula si es posible usar indirectamente el modelo Claude Code (posiblemente más rentable) suscribiéndose al servicio Claude Max, y discute su valor potencial, esperando al mismo tiempo que OpenAI ofrezca una solución similar (Fuente: Reddit r/ClaudeAI)
Imitación humorística del comportamiento local del modelo o3: Un usuario publica un prompt de sistema humorístico destinado a hacer que un modelo LLM local muestre características similares a las criticadas por algunos usuarios del modelo o3 de OpenAI (como respuestas breves, código sutilmente erróneo, comportamiento molesto), para burlarse del descontento con el modelo o3 (Fuente: Reddit r/LocalLLaMA)

Solicitud de ayuda con problema de conexión del servidor proxy MCP en OpenWebUI: Un usuario de K8s tiene problemas al usar OpenWebUI, no puede acceder al servidor proxy MCP (aplicación FastAPI) desplegado en el mismo pod desde la interfaz web, aunque se puede acceder a través de localhost dentro del pod. El usuario busca ayuda de la comunidad para resolver problemas de conexión de red o configuración (Fuente: Reddit r/OpenWebUI)
Discusión sobre prácticas de seguridad del servidor MCP local: Un usuario inicia una discusión preguntando cómo ejecutar de forma segura un servidor MCP local para hacer frente a posibles riesgos de vulnerabilidad. Los comentarios sugieren usar el modo stdio, o limitar el modo SSE a localhost/127.0.0.1, o usar autenticación por token, y señalan que la preocupación por la inyección de prompts / robo de credenciales se aplica a todas las instalaciones de software (Fuente: Reddit r/ClaudeAI)
Exploración del mecanismo de pago del protocolo Agent-to-Agent (A2A): La comunidad discute el problema de la falta de un mecanismo de pago incorporado entre Agents en el protocolo A2A de Google. Los usuarios creen que esto podría obstaculizar el desarrollo de la economía de Agents y exploran posibles soluciones, como el uso de tokens de autenticación vinculados a la facturación, procesos de custodia incorporados o la adición de información de precios en AgentSkill, etc. (Fuente: Reddit r/artificial)
Advertencia sobre la dependencia excesiva de la AI: Un usuario comparte la experiencia de que la AI de búsqueda de Google dio respuestas opuestas a la misma pregunta, enfatizando que no se debe depender completamente de la AI para tomar decisiones finales. Los comentarios explican la naturaleza probabilística de los LLM, el sesgo en los datos de entrenamiento, la simplificación del modelo, etc., como causas de la inconsistencia, y sugieren usar la AI como una herramienta de investigación auxiliar en lugar de una fuente de información autorizada (Fuente: Reddit r/ArtificialInteligence)
Preguntas sobre el uso de Qdrant para RAG en OpenWebUI: Un usuario pregunta cómo integrar la base de datos vectorial Qdrant en el entorno OpenWebUI para implementar RAG (generación aumentada por recuperación), específicamente cómo hacer que OpenWebUI use los datos de Qdrant y si se necesita un script retriever (Fuente: Reddit r/OpenWebUI)
Discusión sobre la comparación de la efectividad de búsqueda entre Google y ChatGPT: Un usuario publica un gráfico comparativo (no mostrado), afirmando que la efectividad de búsqueda de ChatGPT es superior a la de Google, lo que genera debate en la comunidad. Algunos refutan, argumentando que Google Gemini tiene un rendimiento excelente y herramientas como NotebookLM; otros consideran que esta comparación no tiene sentido, ya que la tecnología avanza constantemente; y otros señalan la importancia de la experiencia del usuario y la integración (Fuente: Reddit r/ChatGPT)
Perspectivas optimistas sobre la dirección de investigación de Character Training: Un observador de la industria predice que Character Training (entrenamiento de personajes, posiblemente refiriéndose a hacer que la AI simule personajes o personalidades específicas) se convertirá en un campo de investigación académica explosivo, considerando que ahora es un buen momento para publicar los primeros papers pioneros (Fuente: natolambert)
💡 Otros
Exploración de la racionalidad de la forma humanoide de los robots: El artículo explora las razones para diseñar robots con forma humana: principalmente para adaptarse al mundo diseñado y construido para humanos (herramientas, entorno, formas de interacción). El diseño humanoide facilita la navegación y operación de los robots en la infraestructura existente, reduce la necesidad de modificaciones y aprovecha las herramientas humanas. Las características antropomórficas también ayudan a la interacción y colaboración humano-robot. Aunque existen desafíos como el equilibrio, el control, el costo y el “valle inquietante”, los avances tecnológicos están superando gradualmente estos obstáculos. El artículo también repasa brevemente la historia del desarrollo de robots, compara el panorama competitivo en el campo de los robots humanoides entre países como China y EE. UU., y anticipa las perspectivas de popularización que traerá la reducción de costos (Fuente: 外媒深度:机器人为什么要做成人形?)

Desafíos laborales y contramedidas de China en la era de la AI: El artículo analiza el impacto de la inteligencia artificial en el mercado laboral chino, especialmente los desafíos para la mano de obra de baja y mediana calificación y el desequilibrio en el desarrollo regional. Basándose en la experiencia de EE. UU. en reforma educativa, reentrenamiento, sistema de seguridad social y apoyo a la innovación, el artículo propone que China debería fortalecer la formación profesional y la educación continua (especialmente habilidades digitales), mejorar el sistema de seguridad social para cubrir nuevas formas de empleo, promover la integración de la industria y la AI y el desarrollo regional coordinado, perfeccionar la regulación de algoritmos y la protección de la privacidad de datos, y fortalecer la coordinación multisectorial y el monitoreo y alerta temprana del empleo, para estabilizar y mejorar la base del empleo (Fuente: 人工智能时代:中国如何稳住、提升就业基本盘)
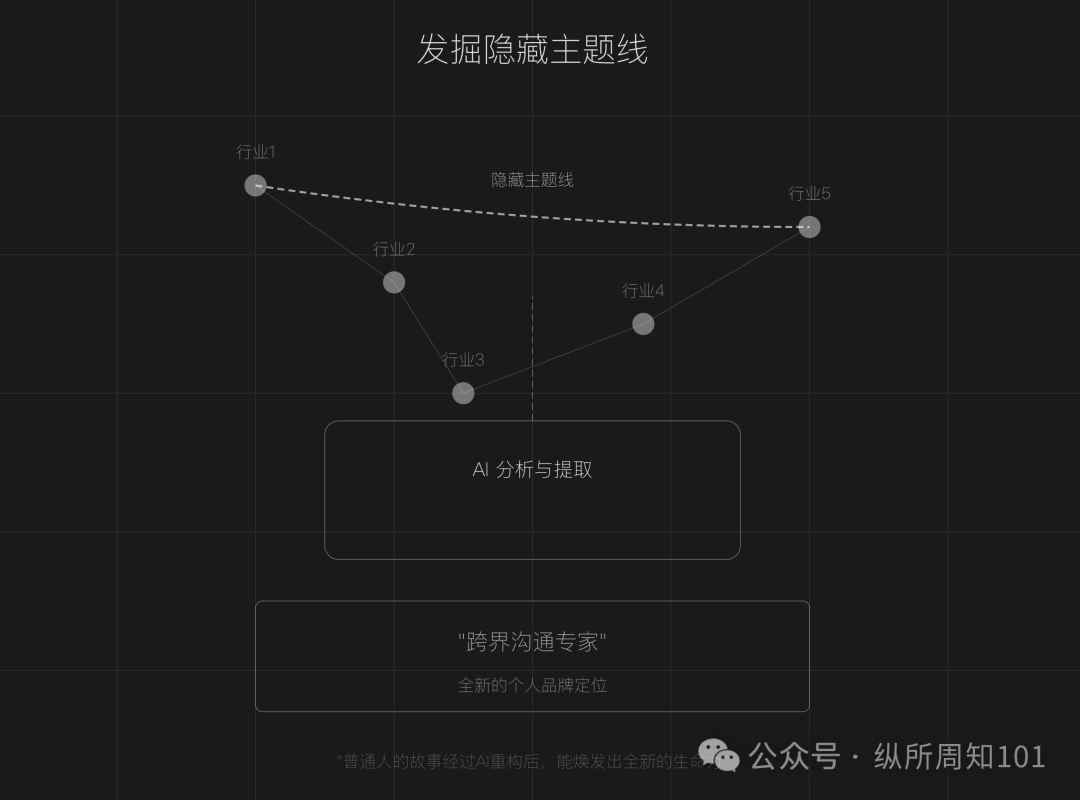
Uso de AI para remodelar la narrativa de la marca personal (IP): El artículo propone que, en una era de saturación de contenido, las personas comunes pueden usar herramientas de AI (como ChatGPT) para reconstruir sus experiencias personales, descubrir líneas temáticas ocultas, remodelar la narrativa de puntos de inflexión clave y dar forma a un sistema lingüístico diferenciado, creando así una marca personal (IP) única. El artículo ofrece pasos específicos (recopilación de datos, minería de temas con AI, remodelación de la estructura de la historia, iteración práctica) y técnicas (construcción inversa, amplificación emocional, refuerzo por contraste), y advierte contra la excesiva idealización, la uniformidad y la falta de profundidad emocional, enfatizando la combinación de autenticidad y asistencia de AI (Fuente: 做个人IP的第一步:用AI改写你的人生叙事)
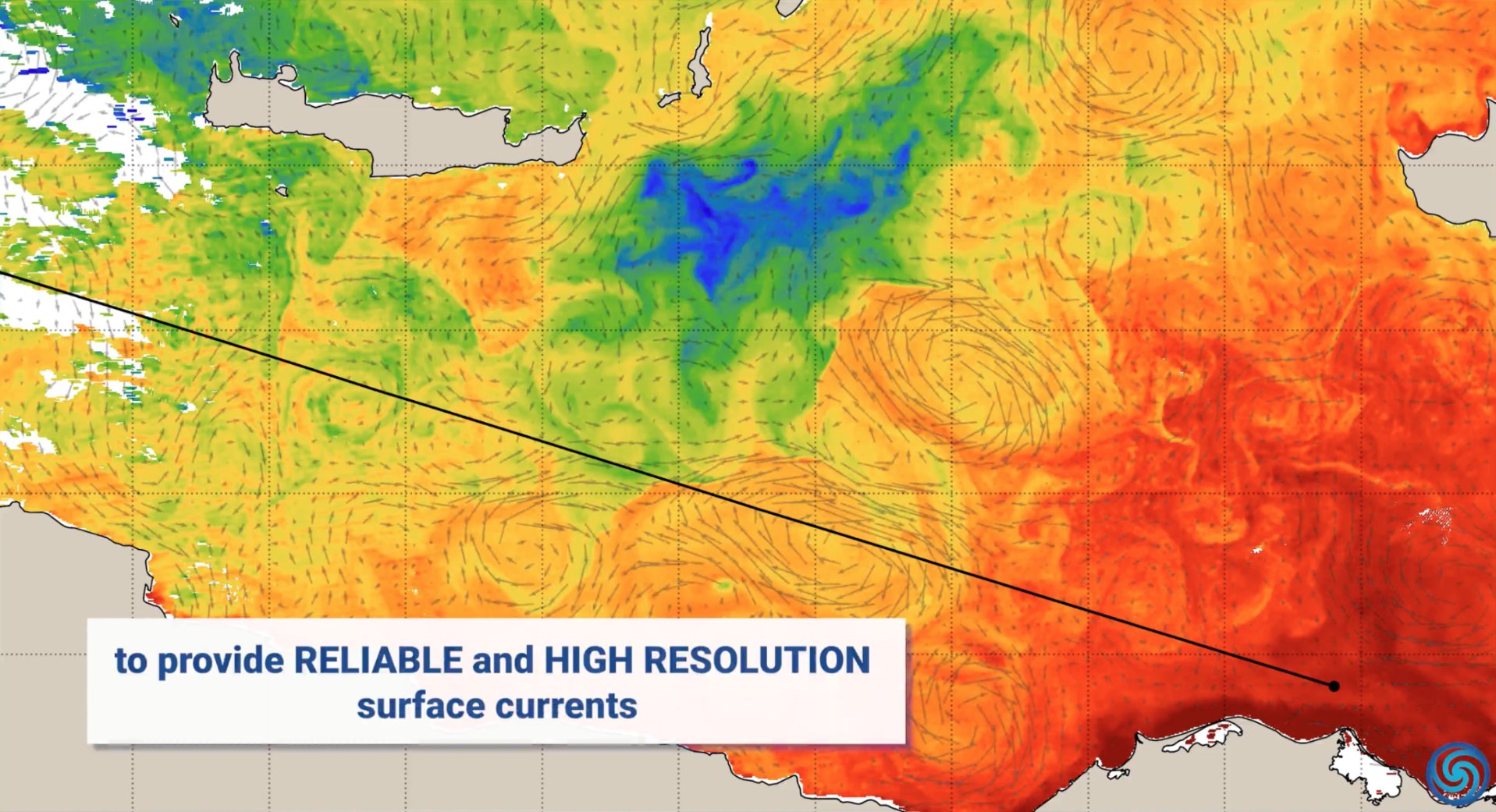
Aplicaciones de la AI en la protección del medio ambiente: Con motivo del Día Mundial de la Tierra, NVIDIA mostró casos de aplicación de su tecnología de AI (como las plataformas Jetson, Earth-2) en la protección del medio ambiente, incluyendo la predicción de corrientes oceánicas para reducir el consumo de combustible, la protección en tiempo real contra incendios forestales y la caza furtiva, la provisión de pronósticos de tormentas más precisos y la detección de asteroides, cubriendo múltiples dimensiones como el océano, la tierra, el cielo y el espacio (Fuente: nvidia, nvidia, nvidia)
AI para mejorar el servicio al cliente: Los centros de contacto impulsados por AI están transformando la experiencia del servicio al cliente, con el objetivo de resolver los puntos débiles de las llamadas de servicio al cliente tradicionales, mejorando la eficiencia y la satisfacción (Fuente: Ronald_vanLoon)
Compartir prompts para generar selfies realistas / imágenes divertidas con AI: Un usuario compartió prompts para usar herramientas de generación de imágenes de AI (como GPT-4o, Sora) para generar selfies “normales” extremadamente realistas, que parecen tomadas casualmente, así como prompts para generar imágenes divertidas como convertir a una persona específica en un cepillo de baño, mostrando el potencial creativo y de entretenimiento de la AI en la generación de imágenes (Fuente: dotey, dotey, dotey)

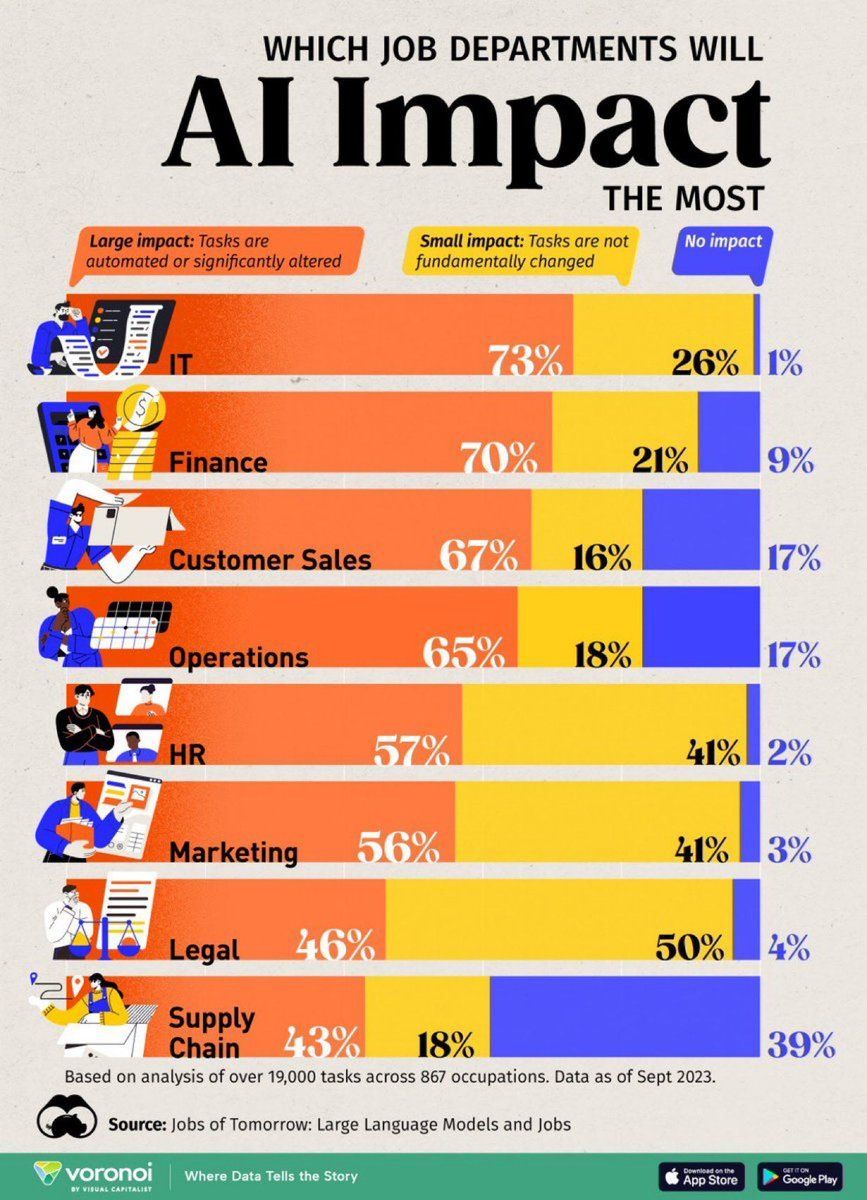
Análisis del impacto de la AI en los puestos de trabajo: Una infografía creada por Visual Capitalist muestra los puestos de trabajo más afectados por la AI, generando atención sobre los cambios en la forma futura del trabajo (Fuente: Ronald_vanLoon)
AI para la detección de defectos en carreteras de Dubái: Dubái adoptará una nueva tecnología de AI para detectar defectos en las carreteras, mostrando el potencial de aplicación de la AI en el mantenimiento de la infraestructura urbana (Fuente: Ronald_vanLoon)
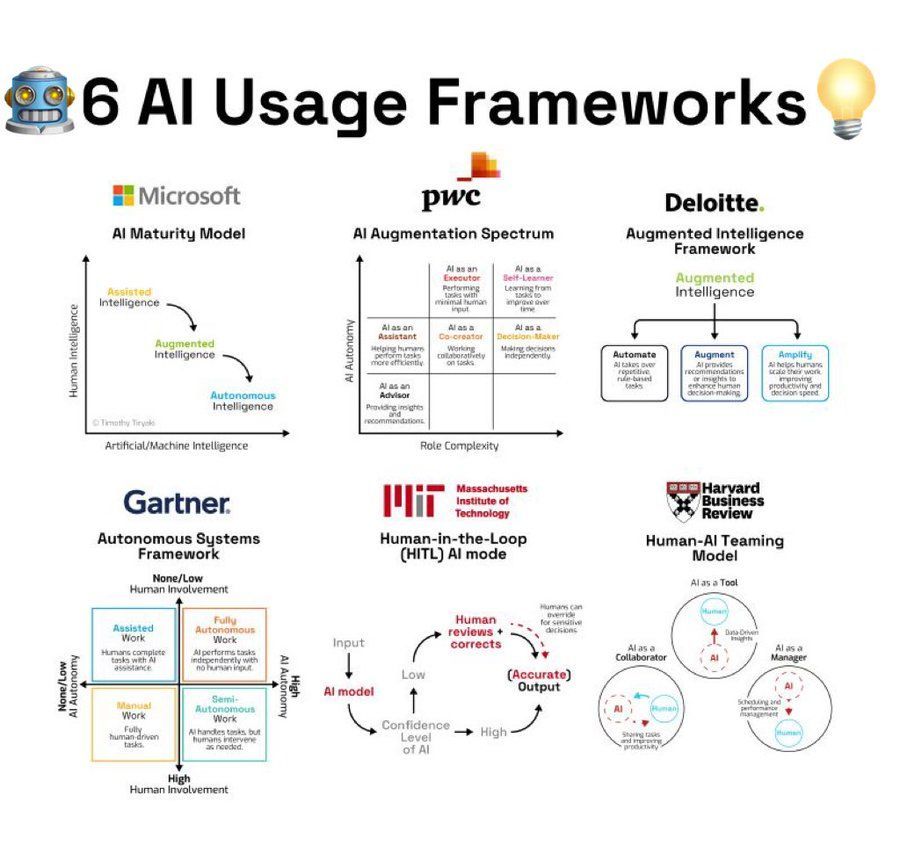
Resumen de marcos de uso de AI: Una infografía resume 6 marcos o metodologías para usar la AI, proporcionando referencias de ideas para usuarios que aplican la AI (Fuente: Ronald_vanLoon)
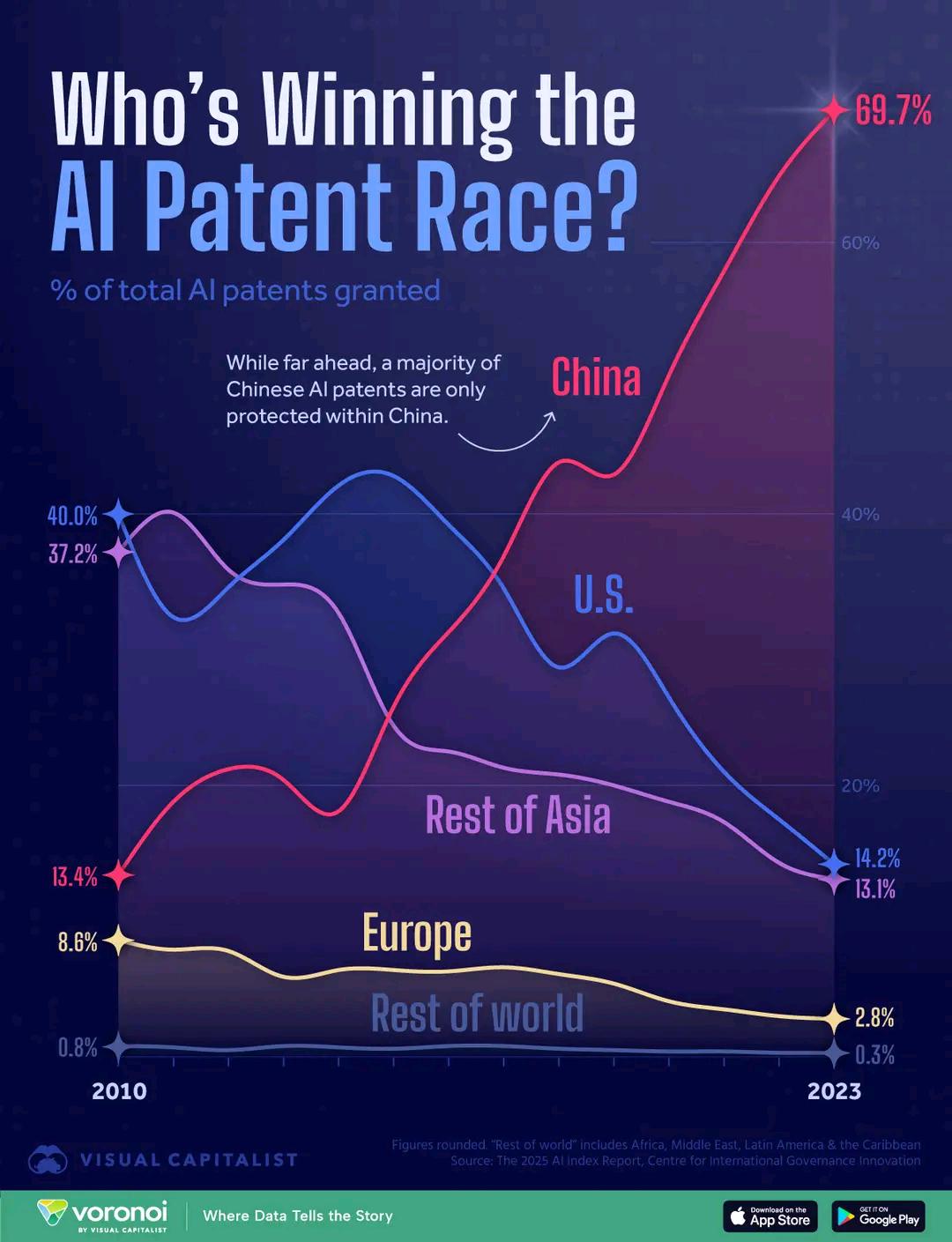
Comparación de países por número de patentes de AI: Un gráfico muestra la comparación del número de patentes en el campo de la AI por país, reflejando las diferencias en la inversión en I+D de AI y la producción entre diferentes países. Los comentarios mencionan que el costo relativamente bajo de solicitar patentes en China podría afectar la interpretación de los datos (Fuente: karminski3)
Brazo biónico ayuda a personas con discapacidad: La empresa Open Bionics instaló un brazo biónico para Grace, una niña de 15 años amputada, mostrando la aplicación de la AI y la tecnología robótica en los campos de la salud médica y la tecnología de asistencia (Fuente: Ronald_vanLoon)
Películas asistidas por AI obtienen elegibilidad para los Oscar, generando atención: La Academia de Artes y Ciencias Cinematográficas de EE. UU. actualizó sus reglas, aclarando que las películas realizadas con herramientas digitales como la AI también son elegibles para competir por los premios Oscar, lo que ha generado amplias discusiones dentro y fuera de Hollywood, centradas en el impacto de la AI en la creación cinematográfica y los estándares de la industria (Fuente: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Lituania establece reglas para el uso de AI en las escuelas: Lituania está desarrollando reglas relacionadas con el uso de la inteligencia artificial en las escuelas, lo que refleja que el sector educativo está comenzando a regular la aplicación de herramientas de AI (Fuente: Reddit r/ArtificialInteligence)