Palabras clave:IA, modelo grande, agente inteligente, multimodal, diseño de IA para detectores de ondas gravitacionales, modelo de generación de video Magi-1, modelo grande de video Vidu Q1, análisis de valores de Claude, mecanismo de razonamiento DeepSeek-R1, estándar de protocolo para agentes de IA, vulnerabilidad de seguridad en splatting 3D gaussiano, controversia sobre derechos de autor de música generada por IA
🔥 Destacados
AI diseña un nuevo detector de ondas gravitacionales, expandiendo el universo observable: Investigadores del Max Planck Institute, Caltech y otras instituciones utilizaron el algoritmo de AI Urania para diseñar un nuevo tipo de detector de ondas gravitacionales que supera la comprensión humana actual. Esta AI, al convertir el problema de diseño en un problema de optimización continua, descubrió docenas de estructuras topológicas superiores a los diseños humanos, que pueden aumentar la sensibilidad de detección en más de 10 veces y expandir el volumen del universo observable en 50 veces. Este estudio, publicado en PRX, demuestra el potencial de la AI para descubrir soluciones sobrehumanas en el campo de la ciencia básica, e incluso para crear nuevas ideas físicas. (Fuente: Xin Zhi Yuan)

El equipo de Cao Yue, ganador del Premio Especial de Tsinghua, libera el modelo de generación de video de código abierto Magi-1: Sand.ai, fundada por Cao Yue, autor de Swin Transformer, ha lanzado y hecho de código abierto el gran modelo de generación de video autorregresivo Magi-1. Este modelo utiliza un método de predicción autorregresiva por bloques, soporta extensión de longitud ilimitada y control de duración a nivel de segundos, logrando una salida de alta calidad de imagen. El equipo publicó un informe técnico de 61 páginas, detallando la arquitectura del modelo (basada en DiT), el método de entrenamiento (Flow-Matching) y múltiples optimizaciones de atención y entrenamiento distribuido. Han liberado una serie de modelos con parámetros desde 4.5B hasta 24B, ejecutables como mínimo en una sola tarjeta 4090, con el objetivo de impulsar el desarrollo de la tecnología de generación de video por AI. (Fuente: QubitAI, Jiqizhixin, kaifulee)
El gran modelo de video nacional Vidu Q1 encabeza las dos listas de VBench: El gran modelo de video Vidu Q1 de ShengShu Technology ocupó el primer lugar en las dos pruebas de referencia autorizadas VBench-1.0 y VBench-2.0, superando a modelos nacionales e internacionales como Sora y Runway. Q1 demostró un rendimiento excelente en términos de realismo de video, coherencia semántica y autenticidad del contenido. La nueva versión admite calidad de imagen HD de 1080p (generando 5 segundos a la vez), actualizó la función de fotogramas iniciales y finales para lograr movimientos de cámara de nivel cinematográfico, e introdujo una función de efectos de sonido AI con control preciso del tiempo (tasa de muestreo de 48 kHz). Su precio es competitivo, con el objetivo de potenciar la industria creativa. (Fuente: Xin Zhi Yuan)

Estudio de Anthropic revela la expresión de valores de Claude: Anthropic analizó 700,000 conversaciones anónimas de Claude, construyendo un sistema de clasificación que incluye 3307 valores únicos, con el objetivo de comprender la orientación de valores de la AI en interacciones reales. El estudio encontró que Claude generalmente sigue el principio de ser “útil, honesto e inofensivo” y puede ajustar flexiblemente sus valores según diferentes contextos (como consejos sobre relaciones interpersonales, análisis histórico). En la mayoría de los casos, apoya las opiniones del usuario, pero en una minoría de casos (3%) se resiste activamente, lo que podría reflejar sus valores fundamentales. Este estudio ayuda a mejorar la transparencia del comportamiento de la AI, identificar riesgos y proporciona una base empírica para la evaluación ética de la AI. (Fuente: MetaverseHub, Xin Zhi Yuan)

🎯 Tendencias
Deng Zhidong de Tsinghua habla sobre la evolución y el futuro de AGI: El profesor Deng Zhidong de la Universidad de Tsinghua compartió la ruta de evolución de la AI desde modelos de texto unimodales hacia la inteligencia corpórea multimodal y la AGI interactiva. Enfatizó que los grandes modelos fundamentales son como sistemas operativos, y la arquitectura MoE y la alineación semántica multimodal son fronteras tecnológicas clave. Deng Zhidong destacó especialmente el significado disruptivo de DeepSeek, considerando que su potente capacidad de razonamiento y sus características de despliegue localizable brindan una oportunidad de inflexión para la aplicación inclusiva de la AI en China. El futuro avanzará hacia un mundo de inteligencia artificial general, donde los agentes de AI tendrán capacidades organizativas más fuertes y pasarán de Internet al mundo físico, pero también se debe prestar atención a los problemas éticos y de gobernanza. (Fuente: 清华邓志东:我们会迈向一个通用人工智能的世界)
DeepMind explora los “Fantasmas Generativos”: Inmortalidad digital impulsada por AI: DeepMind y la Universidad de Colorado proponen el concepto de “fantasmas generativos”, refiriéndose a agentes de AI construidos a partir de datos de personas fallecidas, capaces de generar nuevo contenido e interactuar desde la perspectiva del difunto, superando la simple replicación de información. El artículo explora su espacio de diseño (como creación por primera/tercera parte, despliegue pre/post mortem, grado de antropomorfización, etc.) y sus posibles impactos, incluidos los beneficios del consuelo emocional y la transmisión de conocimientos, así como los desafíos de la dependencia psicológica, los riesgos para la reputación, la seguridad y la ética social, instando a una investigación profunda y al establecimiento de normativas antes de que la tecnología madure. (Fuente: Xin Zhi Yuan)

Apple Intelligence y AI Siri retrasados múltiples veces, fecha de lanzamiento en China incierta: Los planes de lanzamiento de las funciones de AI de Apple, Apple Intelligence (especialmente la nueva versión de Siri), han sufrido múltiples retrasos, y algunas funciones podrían posponerse hasta otoño de 2025. La región de China enfrenta una mayor incertidumbre debido a problemas de aprobación y cooperación para la localización (se rumorea colaboración con Alibaba y Baidu). Las razones del retraso incluyen tecnología que no cumple los estándares (baja evaluación interna, tasa de éxito de solo 66-80%) y diferencias en las políticas regulatorias de cada país. Apple ya enfrenta demandas por publicidad engañosa por esto y ha modificado el eslogan publicitario del iPhone 16. Esto refleja los desafíos que enfrenta Apple en la implementación de la AI y la lentitud de su proceso de innovación. (Fuente: Yicai Business School)

Qualcomm enfatiza la AI en el dispositivo como clave para la próxima generación de experiencias: Wan Weixing, responsable de tecnología de productos de AI de Qualcomm en China, señaló que la AI en el dispositivo (on-device AI), con sus ventajas en privacidad, personalización, rendimiento, eficiencia energética y respuesta rápida, se está convirtiendo en el núcleo de la próxima generación de experiencias de AI y está remodelando la interfaz de interacción humano-máquina. Qualcomm está posicionándose a través de hardware (computación heterogénea), una pila de software unificada y herramientas ecológicas como Qualcomm AI Hub. Su principal impulsor es el planificador de agentes inteligentes en el dispositivo, que utiliza datos locales para lograr una comprensión precisa de la intención, planificación de tareas y llamadas a servicios entre aplicaciones. (Fuente: 36Kr)

El estándar de protocolo para agentes de AI se convierte en nuevo foco de competencia entre gigantes: Los gigantes tecnológicos compiten ferozmente por el estándar de interacción de agentes de AI. Anthropic fue pionero con MCP (Model Context Protocol) para unificar la conexión de modelos con datos/herramientas externas, obteniendo respuesta de OpenAI y Google. Posteriormente, Google liberó el protocolo A2A de código abierto, con el objetivo de promover la colaboración de agentes entre ecosistemas. El artículo analiza que dominar la definición del protocolo significa dominar el poder de distribución de valor futuro de la industria de la AI. Los gigantes construyen barreras ecológicas a través de MCP (servicio de acceso a datos) y A2A (vinculación a plataformas en la nube), compitiendo por el liderazgo de la industria. (Fuente: 科技云报道)

Tencent Yuanbao y ByteDance Doubao se integran profundamente en los ecosistemas de WeChat y Douyin: Tencent Yuanbao lanzó una cuenta oficial en WeChat, y ByteDance Doubao se integró en la página de “Mensajes” de Douyin. Los dos asistentes de AI se están integrando profundamente en sus respectivas super-apps. Los usuarios pueden interactuar directamente con Yuanbao dentro de WeChat, analizar artículos y compartirlos, o chatear con Doubao y buscar información dentro de Douyin. Se considera una estrategia importante para que los gigantes, más allá de la publicidad, utilicen las redes sociales y los ecosistemas de contenido para atraer nuevos usuarios a las aplicaciones de AI, con el objetivo de reducir la barrera de entrada para los usuarios, explorar nuevos modelos de AI + social y utilizar el contenido generado por AI como moneda social. (Fuente: 字母榜)
Informe AI4SE: Grandes modelos impulsan la aceleración de la ingeniería de software inteligente: El “Informe de encuesta sobre el estado de la industria AI4SE (año 2024)” publicado por CAICT y otras instituciones muestra que la aplicación de la AI en el campo de la ingeniería de software ha superado la fase de validación y está entrando en la implementación a gran escala. La madurez de la inteligencia empresarial generalmente alcanza el nivel L2 (parcialmente inteligente). La aplicación de la AI en el análisis de requisitos y la fase de operaciones y mantenimiento ha aumentado significativamente, con mejoras notables en la eficiencia en todas las etapas, especialmente en el campo de las pruebas. La tasa de adopción de la generación de código (promedio 27.46%) y la proporción de código generado por AI (promedio 28.17%) han aumentado. Las herramientas de prueba inteligentes ya han demostrado preliminarmente su efecto en la reducción de la tasa de defectos funcionales. (Fuente: AI Frontline)

Kingsoft Office actualiza su gran modelo gubernamental, fortaleciendo las capacidades de razonamiento y procesamiento de documentos oficiales: Kingsoft Office (WPS) lanzó una versión mejorada de su gran modelo gubernamental (13B, 32B), mejorando la capacidad de razonamiento y centrándose en servir escenarios internos del gobierno. El modelo se entrenó con cientos de millones de corpus gubernamentales, optimizando la redacción de documentos oficiales (cubriendo 5 tipos de estilos), el pulido inteligente, la corrección y maquetación, y la capacidad de consulta de políticas. La actualización admite una comprensión de intenciones más fuerte y preguntas y respuestas basadas en bases de conocimiento internas (las respuestas indican la fuente), con el objetivo de liberar entre el 30% y el 40% de la productividad de los funcionarios públicos. Se enfatiza el despliegue privado para satisfacer las necesidades de seguridad y se afirma que el costo de despliegue se reduce en un 90%. (Fuente: QubitAI)

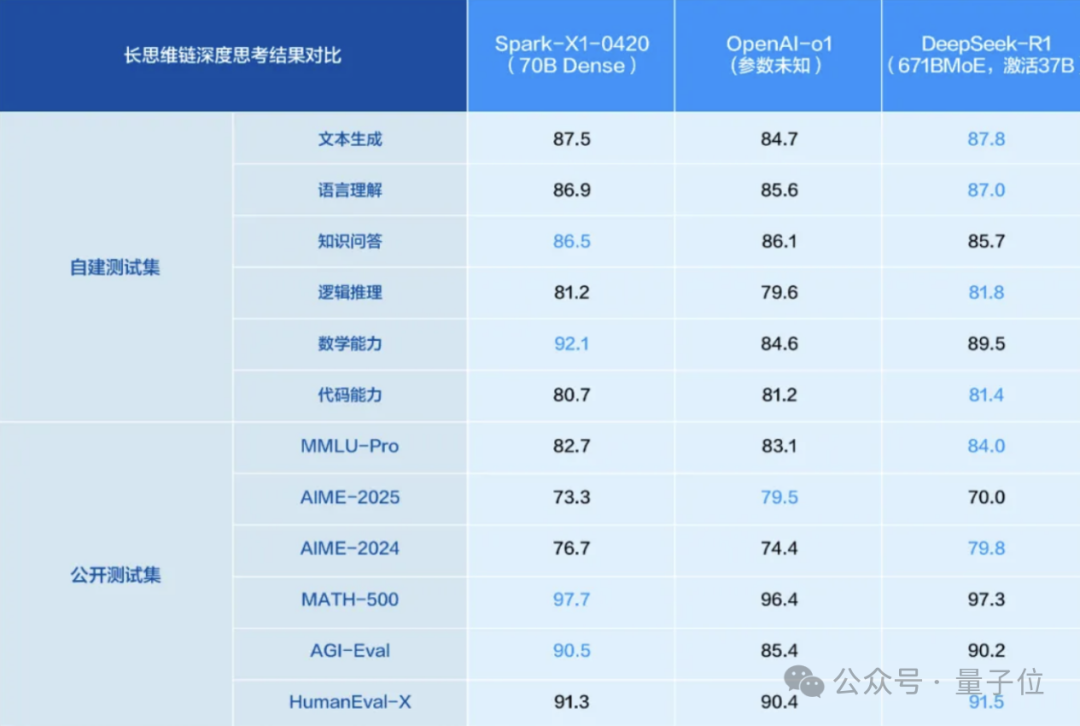
El modelo de inferencia iFlytek Spark X1 se actualiza, basado en computación totalmente nacional para competir con los niveles más altos: iFlytek lanzó una versión actualizada del modelo de inferencia profunda Spark X1, enfatizando que se entrenó con potencia de cómputo totalmente nacional (Huawei Ascend) y compite con OpenAI o1 y DeepSeek R1 en efectos de tareas generales. El nuevo modelo se beneficia de innovaciones técnicas como el aprendizaje por refuerzo multietapa a gran escala y el entrenamiento unificado de pensamiento rápido y lento. Lo más destacado es la reducción significativa de la barrera de despliegue: 4 tarjetas Huawei 910B son suficientes para desplegar la versión completa, y 16 tarjetas pueden completar la personalización de la industria. En el contexto de las restricciones sobre H20, muestra el progreso de la solución de pila completa de AI nacional. (Fuente: QubitAI)
Zhipu GLM-4 disponible en las plataformas OpenRouter y Ollama: El modelo GLM-4 de Zhipu AI (incluidas las versiones instruct 32B GLM-4-32B-0414 y reasoning GLM-Z1-32B-0414) ya está disponible en la plataforma de enrutamiento de modelos OpenRouter, donde los usuarios ahora pueden probarlo de forma gratuita. Al mismo tiempo, contribuyentes de la comunidad también han subido la versión cuantizada Q4_K_M a la plataforma Ollama, facilitando su despliegue y ejecución local (requiere Ollama v0.6.6 o superior). (Fuente: karminski3, Reddit r/LocalLLaMA)
Meta lanza Perception Language Model (PLM): Meta ha liberado su modelo de lenguaje visual PLM (versiones de parámetros 1B, 3B, 8B), centrado en el manejo de tareas desafiantes de reconocimiento visual. El modelo combina datos sintéticos a gran escala y 2.5 millones de datos de preguntas y respuestas en video / subtítulos espacio-temporales recién recopilados y anotados por humanos para el entrenamiento. Al mismo tiempo, se lanzó el nuevo benchmark PLM-VideoBench, centrado en la comprensión de actividades de grano fino y el razonamiento espacio-temporal. (Fuente: Reddit r/LocalLLaMA, Hugging Face)

🧰 Herramientas
NYXverse: Plataforma AIGC para generar mundos 3D a partir de texto: 2033 Technology, fundada por Ma Yuchi, ex fundador de Triangle Beast, lanza la plataforma de contenido AIGC NYXverse. La plataforma permite a los usuarios crear mundos interactivos 3D que contienen AI Agents, entornos y tramas personalizadas a través de la entrada de texto, reduciendo significativamente la barrera para la creación de contenido 3D. Su tecnología central son los modelos autodesarrollados de personajes, mundos y comportamientos. NYXverse se posiciona como una comunidad de intercambio de contenido UGC, que admite la rápida recreación y adaptación de IP. Actualmente está disponible en Steam y ha recibido casi 100 millones de yuanes en financiación de SenseTime y Oriental State-owned Capital. (Fuente: 36Kr)

SkyReels V2 libera modelo de generación de video de longitud ilimitada: SkyworkAI ha liberado los modelos SkyReels V2 (parámetros 1.3B y 14B), que admiten tareas de texto a video e imagen a video, y afirman poder generar videos de longitud ilimitada. Las pruebas preliminares muestran que los resultados pueden no ser tan buenos como algunos modelos de código cerrado, pero como herramienta de código abierto todavía tiene potencial. (Fuente: karminski3, Reddit r/LocalLLaMA)
Exoesqueleto impulsado por AI ayuda a usuarios de sillas de ruedas a ponerse de pie y caminar: Se muestra un dispositivo de exoesqueleto que utiliza tecnología AI, diseñado para ayudar a los usuarios de sillas de ruedas a recuperar la capacidad de ponerse de pie y caminar, lo que refleja el potencial de aplicación de la AI en el campo de la tecnología de asistencia. (Fuente: Ronald_vanLoon)
Fellou: Lanzamiento del primer navegador de tipo acción: Se lanza el navegador Fellou, creado por Xie Yang, fundador de Authing, posicionándose como un Navegador Agéntico (Agentic Browser). No solo tiene las funciones de visualización de información de los navegadores tradicionales, sino que también integra capacidades de AI Agent, pudiendo comprender las intenciones del usuario, descomponer tareas automáticamente y ejecutar flujos de trabajo complejos entre sitios web (como recopilación de información, llenado de formularios, pedidos en línea, etc.). Sus capacidades principales incluyen acción profunda, inteligencia proactiva (predicción de las necesidades del usuario), espacio sombra híbrido (sin interferir con las operaciones del usuario) y red de agentes inteligentes (Agent Store). Su objetivo es actualizar el navegador de una herramienta de información a una plataforma de trabajo inteligente. (Fuente: Xin Zhi Yuan)

WriteHERE: Marco de escritura de textos largos de código abierto del equipo de Jürgen: El marco de escritura de textos largos WriteHERE, liberado por el equipo de Jürgen Schmidhuber, utiliza tecnología de planificación recursiva heterogénea y puede generar informes profesionales de más de 40,000 palabras y 100 páginas de una sola vez. El marco considera la escritura como un proceso de planificación recursiva dinámica de tres tipos de tareas: recuperación, razonamiento y escritura, logrando una ejecución adaptativa a través de la gestión de tareas DAG con estado. Supera a soluciones como Agent’s Room y STORM en tareas de creación de novelas y generación de informes técnicos. El marco es completamente de código abierto y admite la llamada a Agents heterogéneos. (Fuente: Jiqizhixin)

ByteDance lanza la plataforma universal de Agents “Coze Space”: ByteDance ha lanzado oficialmente la versión beta interna de su plataforma universal de Agents “Coze Space”, posicionada como un asistente de AI que ofrece dos modos: “exploración” y “planificación”. La plataforma se basa en el gran modelo Doubao actualizado (200B MoE), admite el protocolo MCP y puede llamar a herramientas como documentos de Feishu (Lark), tablas multidimensionales, etc. Los usuarios pueden darle instrucciones en lenguaje natural para completar tareas como recopilación de información, generación de informes, organización de datos, etc., y exportar los resultados a aplicaciones específicas. En comparación con Agents de startups como Manus, Coze Space se centra más en la plataformización y la integración ecológica. (Fuente: 保姆级教程:正确使用「扣子空间」, AI智能体研究院)

Demostración de tecnología de conversión de video por AI: Un usuario de Reddit comparte un video que muestra una tecnología de AI capaz de convertir a la persona en un video normal hablando en cualquier imagen arbitraria como árboles, coches, dibujos animados, etc., necesitando solo una imagen objetivo. Muestra la capacidad de la AI en la transferencia de estilo de video y la generación de efectos especiales. (Fuente: Reddit r/deeplearning)

Nari Labs lanza Dia, un modelo TTS de diálogo de alto realismo: Nari Labs ha liberado su modelo TTS (Text-to-Speech) Dia, que afirma ser capaz de generar voz de diálogo ultrarrealista. El modelo ha sido publicado en GitHub y proporciona un enlace de prueba en Hugging Face Space. (Fuente: Reddit r/LocalLLaMA, GitHub)

Usuario desarrolla función de base de conocimientos de AWS Bedrock para OpenWebUI: Un usuario de la comunidad desarrolló y compartió una función para OpenWebUI que le permite llamar a las bases de conocimiento de AWS Bedrock, facilitando a los usuarios aprovechar las capacidades de la base de conocimientos de Bedrock dentro de OpenWebUI. El código está disponible en GitHub. (Fuente: Reddit r/OpenWebUI, GitHub)
Desarrolladores creen que los LLM pequeños están subestimados, lanzan Arch-Function-Chat: El equipo de Katanemo cree que los LLM pequeños tienen ventajas obvias en velocidad y eficiencia, sin comprometer el rendimiento. Han lanzado la serie de modelos Arch-Function-Chat (parámetros 3B), que se desempeñan excelentemente en la llamada a funciones e integran capacidades de chat. Estos modelos se han integrado en su servidor proxy de AI de código abierto Arch, con el objetivo de simplificar el desarrollo de Agents. (Fuente: Reddit r/artificial, Hugging Face)
Desarrollador crea herramienta de AI para optimizar currículums y pasar filtros ATS: Un desarrollador compartió su frustrante experiencia buscando trabajo porque su currículum no podía ser analizado correctamente por los ATS (Applicant Tracking System), y por ello desarrolló una herramienta. La herramienta puede leer descripciones de puestos, extraer palabras clave, verificar la coincidencia del currículum y sugerir modificaciones, generando finalmente un currículum en PDF y una carta de presentación amigables para ATS. (Fuente: Reddit r/artificial)
📚 Aprendizaje
Informe de 142 páginas analiza en profundidad el mecanismo de razonamiento de DeepSeek-R1: Instituciones como el Mila – Quebec AI Institute publicaron un extenso informe que analiza en profundidad el proceso de razonamiento (cadena de pensamiento) de DeepSeek-R1, proponiendo una nueva dirección de investigación llamada “Thoughtology”. El informe revela que el razonamiento de R1 tiene características altamente estructuradas (definición del problema, expansión, reestructuración, decisión), existe una “zona dulce de razonamiento” (demasiado razonamiento reduce el rendimiento) y puede presentar mayores riesgos de seguridad que los modelos sin razonamiento. La investigación explora múltiples dimensiones como la longitud de la cadena de pensamiento, el procesamiento de contextos largos, la seguridad ética y los fenómenos cognitivos similares a los humanos, proporcionando importantes conocimientos para comprender y optimizar los modelos de razonamiento. (Fuente: Xin Zhi Yuan, Xin Zhi Yuan)

OpenRCA: Primer benchmark público para evaluar la capacidad de análisis de causa raíz de LLM: Microsoft, CUHK-Shenzhen y la Universidad de Tsinghua lanzaron conjuntamente el benchmark OpenRCA, con el objetivo de evaluar la capacidad de los grandes modelos de lenguaje (LLM) para localizar la causa raíz (RCA) de fallos en servicios de software. Este benchmark incluye definiciones claras de tareas, métodos de evaluación y 335 casos de fallos reales alineados manualmente y datos de operaciones. Las pruebas preliminares muestran que incluso los modelos avanzados como Claude 3.5 y GPT-4o tienen un rendimiento deficiente al manejar directamente tareas de RCA (precisión <6%). Después de usar un marco simple de RCA-Agent, la precisión de Claude 3.5 aumentó al 11.34%, lo que indica que los LLM todavía tienen un gran margen de mejora en este campo. (Fuente: Jiqizhixin, Jiqizhixin)

Nueva investigación propone “Sleep-time Compute” para mejorar la eficiencia de LLM: La startup de AI Letta e investigadores de UC Berkeley proponen un nuevo paradigma llamado “Sleep-time Compute”. La idea central es permitir que los agentes de AI con estado procesen y reorganicen continuamente la información contextual durante los períodos de inactividad “dormidos” cuando el usuario no está consultando, transformando el “contexto crudo” en “contexto aprendido”. Esto puede reducir la carga de inferencia instantánea durante la interacción real, mejorar la eficiencia, reducir costos y potencialmente aumentar la precisión. Los experimentos demuestran que este método puede mejorar eficazmente la frontera de Pareto de cómputo-precisión y amortizar los costos cuando se comparte el contexto entre múltiples consultas. (Fuente: Jiqizhixin, Jiqizhixin)

AnyAttack: Marco de ataque adversario auto-supervisado a gran escala contra VLM: HKUST, BJTU y otros proponen el marco AnyAttack (CVPR 2025), destinado a evaluar la robustez de los modelos de lenguaje visual (VLM). Este método, a través de pre-entrenamiento auto-supervisado a gran escala (en LAION-400M), aprende un generador de ruido adversario que puede convertir cualquier imagen en una muestra adversaria dirigida sin etiquetas predefinidas, engañando al VLM para que genere una salida específica. La innovación central radica en el paradigma de entrenamiento auto-supervisado y la estrategia K-enhancement. Los experimentos muestran que AnyAttack no solo puede atacar eficazmente múltiples VLM de código abierto, sino que también puede transferir con éxito ataques a modelos comerciales convencionales, revelando riesgos de seguridad sistémicos en el ecosistema VLM actual. (Fuente: AI科技评论)

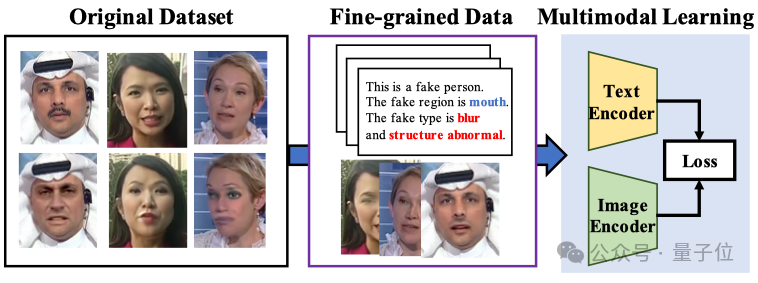
Grandes modelos multimodales mejoran la interpretabilidad y generalización de la detección de falsificaciones faciales: La Universidad de Xiamen, Tencent Youtu Lab y otras instituciones (CVPR 2025) proponen un nuevo método para la detección de falsificaciones faciales utilizando modelos de lenguaje visual. Este método tiene como objetivo ir más allá del juicio tradicional de verdadero/falso, permitiendo que el modelo explique la razón y la ubicación de la falsificación en lenguaje natural. Para abordar la falta de datos etiquetados de alta calidad y el problema de la “alucinación lingüística”, los investigadores diseñaron el flujo de trabajo de etiquetado FFTG, combinando máscaras de falsificación y prompts estructurados para generar descripciones textuales de alta precisión. Los experimentos muestran que los modelos multimodales entrenados con estos datos tienen un mejor rendimiento en la capacidad de generalización entre conjuntos de datos, y su atención se centra más en las regiones de falsificación reales. (Fuente: QubitAI)
Tutorial: Combinando Trae, MCP y bases de datos para mejorar la precisión de las preguntas y respuestas en bases de conocimiento: Este tutorial demuestra cómo usar la herramienta AI IDE Trae y su función MCP (Model Context Protocol), combinada con una base de datos PostgreSQL, para optimizar el efecto de las preguntas y respuestas de la base de conocimientos de AI. Al almacenar datos estructurados en la base de datos y permitir que grandes modelos (como Claude 3.7) generen consultas SQL a través del MCP de Trae, se pueden resolver los puntos débiles del RAG tradicional al procesar datos tabulares y problemas globales/estadísticos con precisión insuficiente. El tutorial proporciona pasos detallados de instalación, configuración y prueba, y sugiere combinar esta solución con RAG. (Fuente: 袋鼠帝AI客栈)

Investigación revela vulnerabilidad de ataque de costo computacional en el algoritmo 3D Gaussian Splatting: Investigadores de la NUS y otras instituciones (ICLR 2025 Spotlight) descubrieron por primera vez un método de ataque de costo computacional contra 3D Gaussian Splatting (3DGS) llamado Poison-Splat. Este ataque aprovecha la característica de complejidad adaptativa del modelo 3DGS, añadiendo perturbaciones a las imágenes de entrada (maximizando la Variación Total) para inducir al modelo a generar una cantidad excesiva de puntos gaussianos durante el entrenamiento, lo que provoca un aumento drástico en el uso de memoria VRAM de la GPU (hasta 80 GB) y el tiempo de entrenamiento (casi 5 veces más), e incluso puede causar la parálisis del servicio (DoS). El ataque es efectivo tanto en modo encubierto como no encubierto, y tiene transferibilidad, exponiendo los riesgos de seguridad de las tecnologías de reconstrucción 3D convencionales. (Fuente: QubitAI)

Infografía: Agentic AI vs. GenAI: Una infografía creada por SearchUnify compara las principales diferencias y características entre Agentic AI (acción autónoma, orientada a objetivos) y Generative AI (generación de contenido). (Fuente: Ronald_vanLoon)

NVIDIA libera conjunto de datos y método de pre-entrenamiento ClimbLab: ClimbLab de NVIDIA ha publicado su método y conjunto de datos de pre-entrenamiento, que contiene 1.2 billones de tokens, divididos en 20 clústeres semánticos. Utiliza un sistema de doble clasificador para eliminar contenido de baja calidad y demuestra una escalabilidad superior en modelos de 1B. El conjunto de datos está disponible bajo la licencia CC BY-NC 4.0, con el objetivo de promover la investigación comunitaria. (Fuente: huggingface)
Anthropic comparte las mejores prácticas para Claude Code: Anthropic publicó una entrada de blog compartiendo las mejores prácticas y consejos para usar su asistente de programación AI Claude Code, con el objetivo de ayudar a los desarrolladores a utilizar la herramienta de manera más efectiva para tareas de programación. (Fuente: op7418, Alex Albert via op7418, Anthropic)

Nueva investigación explora la coherencia recursiva de la AI y la simulación de estructuras resonantes: Un artículo propone el concepto de “Resonant Structural Emulation” (RSE), que plantea la hipótesis de que los sistemas de AI, después de interactuar continuamente con estructuras cognitivas humanas específicas, pueden simular brevemente su coherencia recursiva, en lugar de basarse simplemente en el entrenamiento de datos o prompts. La investigación valida preliminarmente a través de experimentos la posibilidad de esta resonancia estructural, proporcionando una nueva perspectiva para comprender la conciencia y la cognición avanzada de la AI. (Fuente: Reddit r/MachineLearning, Archive.org link)

Usuario comparte prueba comparativa de rendimiento de modelos RAG en OpenWebUI: Un usuario de la comunidad compartió una evaluación del rendimiento en OpenWebUI utilizando RAG (Retrieval-Augmented Generation) en 9 LLM diferentes (incluidos Qwen QwQ, Gemini 2.5, DeepSeek R1, Claude 3.7, etc.) en una tarea de guía técnica para el cultivo de cannabis en interiores. Los resultados mostraron que Qwen QwQ y Gemini 2.5 tuvieron el mejor rendimiento, proporcionando una referencia para la selección de modelos. (Fuente: Reddit r/OpenWebUI)
Conjunto de datos FortisAVQA y modelo MAVEN ayudan a la robustez en preguntas y respuestas audiovisuales: Instituciones como la Universidad Jiaotong de Xi’an y HKUST (Guangzhou) han liberado el conjunto de datos FortisAVQA y el modelo MAVEN (CVPR 2025), con el objetivo de mejorar la robustez de las preguntas y respuestas audiovisuales (AVQA). FortisAVQA, mediante la reescritura de preguntas y una partición dinámica basada en predicción conformal, puede evaluar mejor el rendimiento del modelo en preguntas poco comunes. El modelo MAVEN utiliza una estrategia de eliminación de sesgos colaborativa cíclica multifacética (MCCD) para mitigar el aprendizaje de sesgos, demostrando un rendimiento y robustez superiores en múltiples conjuntos de datos. (Fuente: PaperWeekly)

El autorregresivo de orden aleatorio desbloquea capacidades Zero-shot en el dominio visual: Investigadores de UIUC y otros proponen en el artículo RandAR de CVPR 2025 que permitir que un Transformer solo decodificador genere tokens de imagen en orden aleatorio puede desbloquear la capacidad de generalización de los modelos visuales. Al introducir un “token de instrucción de posición” para guiar el orden de generación, RandAR puede generalizar en modo Zero-shot a decodificación paralela, edición de imágenes, extrapolación de resolución y codificación unificada (aprendizaje de representación), entre otras tareas, avanzando hacia el “momento GPT” en el dominio visual. La investigación considera que el manejo de órdenes arbitrarias es clave para que los modelos autorregresivos visuales logren la universalidad. (Fuente: PaperWeekly)
Análisis teórico de la efectividad de la edición de modelos con vectores de tareas: Una investigación del Rensselaer Polytechnic Institute y otras instituciones (ICLR 2025 Oral) analiza teóricamente las razones profundas por las que los vectores de tareas (task vectors) son efectivos en la edición de modelos. La investigación demuestra que la efectividad de las operaciones de suma y resta de vectores de tareas en el aprendizaje multitarea y el olvido automático está relacionada con la correlación entre tareas, y proporciona garantías teóricas para la generalización fuera de distribución. Al mismo tiempo, explica teóricamente por qué la aproximación de bajo rango y la esparsificación (poda) de los vectores de tareas son factibles, proporcionando una base teórica para la aplicación eficiente de los vectores de tareas. (Fuente: Jiqizhixin)

Estudio sobre la escalabilidad de la búsqueda basada en muestreo: Investigaciones de Google y Berkeley muestran que al aumentar el número de muestras y la fuerza de la validación, la búsqueda basada en muestreo (generar múltiples respuestas candidatas y luego validar para seleccionar la mejor) puede mejorar significativamente el rendimiento de razonamiento de los LLM, superando incluso el punto de saturación de los métodos de consistencia (seleccionar la respuesta más común). La investigación descubre el fenómeno de la “expansión implícita”: más muestreo mejora la precisión de la validación. Propone dos principios para la autovalidación efectiva: comparar respuestas para localizar errores y reescribir respuestas según el estilo de salida. Este método es efectivo en múltiples benchmarks y diferentes escalas de modelos. (Fuente: Xin Zhi Yuan)

Llamada a ponencias para el taller LGM3A en ACM MM 2025: La conferencia ACM Multimedia 2025 albergará el tercer taller sobre “Investigación y Aplicaciones Multimodales Basadas en Grandes Modelos de Lenguaje” (LGM3A), centrado en las aplicaciones y desafíos de los grandes modelos generativos (LLM/LMM) en análisis de datos multimodales, generación, preguntas y respuestas, recuperación, recomendación, agentes inteligentes, etc. El taller tiene como objetivo proporcionar una plataforma de intercambio para discutir las últimas tendencias y mejores prácticas, y solicita trabajos de investigación relacionados. La conferencia se llevará a cabo en Dublín, Irlanda, en octubre de 2025, y la fecha límite para la presentación de ponencias es el 11 de julio de 2025. (Fuente: PaperWeekly)
Grupo de investigación de Zhedong Zheng en la Universidad de Macao busca estudiantes de doctorado en dirección multimodal: El grupo del profesor asistente Zhedong Zheng del Departamento de Ciencias de la Computación de la Universidad de Macao está reclutando estudiantes de doctorado con beca completa para comenzar en agosto de 2026 en la dirección multimodal. La dirección de investigación del tutor es el aprendizaje de representación y la generación multimedia, con más de 50 artículos publicados en conferencias y revistas de primer nivel como CVPR, ICCV, TPAMI. Se requiere que los solicitantes tengan un GPA superior a 3.4, formación en informática/ingeniería de software, familiaridad con Python/PyTorch, y se dará prioridad a aquellos con publicaciones relevantes o premios en concursos. Se ofrece beca completa. (Fuente: PaperWeekly)

💼 Negocios
Robot cortacésped de Laimou Technology obtiene financiación Pre-A: Fundada por ex ejecutivos de Narwal, se enfoca en resolver el problema del corte de césped en terrenos complejos en Europa y América. Su robot Lymow One utiliza una solución visual + RTK inercial (costo una décima parte del RTK tradicional), diseño de orugas (para pendientes de 45°), equipado con cuchillas rectas para triturar hierba. Evita obstáculos mediante visión AI y ultrasonido. El producto recaudó más de 5 millones de dólares en crowdfunding, con un precio unitario de aproximadamente 3000 dólares. Esta ronda de financiación de decenas de millones de yuanes se utilizará para la producción en masa, entrega y expansión del mercado. (Fuente: 云鲸前高管创立的割草机器人再融资,李泽湘投过、众筹已超500万美金|硬氪首发)

El robot humanoide “Xiao Hai Ge” de Songyan Dynamics se vuelve popular: Después de obtener el segundo lugar en la media maratón de robots humanoides de Beijing, Songyan Dynamics y su robot N2 (“Xiao Hai Ge”) atrajeron la atención del mercado. La compañía fue fundada por Jiang Zheyuan, un doctorado de Tsinghua nacido después de 1995, y ha completado cinco rondas de financiación. El robot N2 tiene un precio inicial de 39,900 yuanes, destacando por su alta relación costo-rendimiento, ya tiene cientos de pedidos y un margen bruto de aproximadamente el 15%. Songyan Dynamics está acelerando la producción y entrega masiva de productos, y su estrategia de bajo precio tiene como objetivo penetrar rápidamente en el mercado. (Fuente: 科创板日报)
Cuidado con las métricas infladas de ARR en startups de AI: El artículo señala que la métrica ARR (Ingresos Anuales Recurrentes), originaria de la industria SaaS, está siendo mal utilizada por las startups de AI. El modelo de ingresos de las empresas de AI (a menudo basado en el uso/pago por resultados) tiene una alta volatilidad, baja lealtad de los clientes iniciales y altos costos de computación, lo que difiere enormemente del modelo de suscripción predecible de SaaS. El mal uso de ARR (como extrapolar los ingresos anuales a partir de ingresos mensuales/diarios) se ha convertido en un juego numérico para fabricar valoraciones altas, ocultando el verdadero valor comercial. El artículo insta a tener cuidado con las tácticas como el intercambio de tráfico, las altas comisiones de devolución y la atracción de clientes a bajo precio, y pide el establecimiento de un sistema de evaluación de valor más adecuado para las empresas de AI. (Fuente: 乌鸦智能说)
Análisis de financiación del mercado primario nacional en el Q1 2025: Efecto líder significativo: Datos de IT Juzi muestran que la financiación del mercado primario nacional en el primer trimestre de 2025 presentó una alta concentración. Solo 20 empresas recaudaron más de 1 mil millones de yuanes, representando el 1.2% del total, pero su monto total de financiación alcanzó los 61.178 millones de yuanes, representando el 36% del total del mercado. Estas empresas líderes se concentran principalmente en circuitos integrados, fabricación de automóviles, nuevos materiales, biotecnología y AIGC, y casi la mitad tienen antecedentes de grandes grupos cotizados. En comparación, las financiaciones de pequeña y mediana escala por debajo de los 100 millones de yuanes, que representan el 75.8% del número de transacciones, solo representaron el 17.2% del monto total del mercado. (Fuente: IT Juzi)
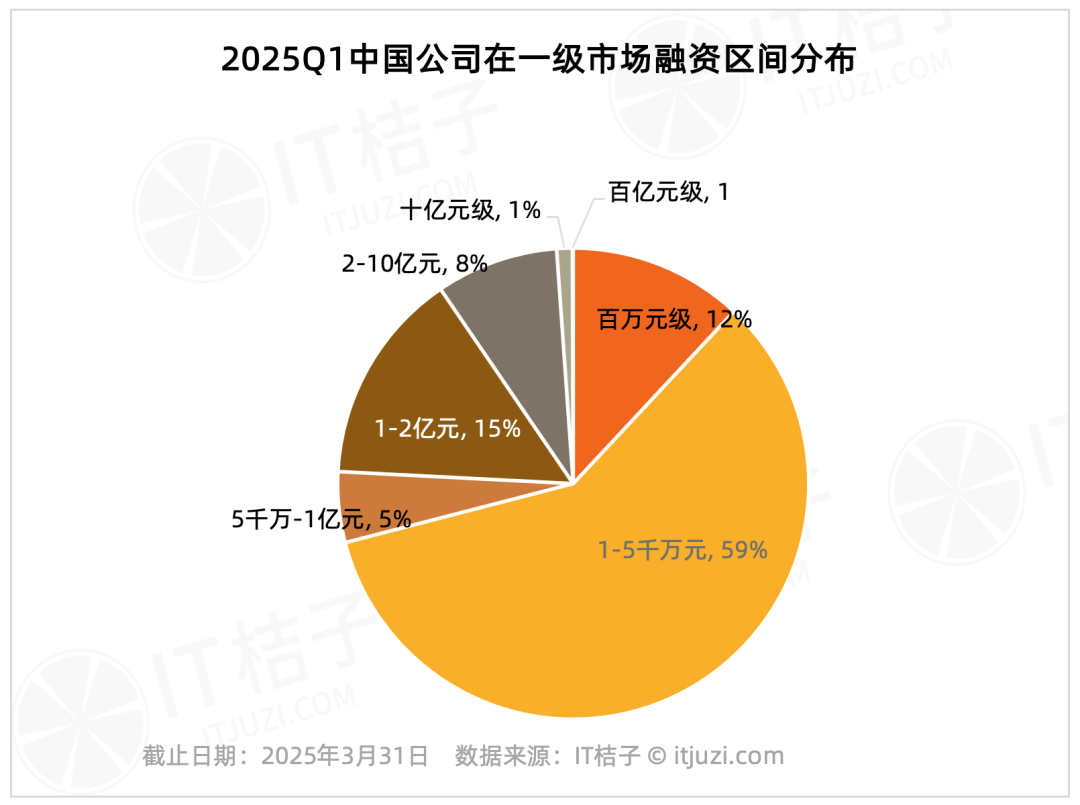
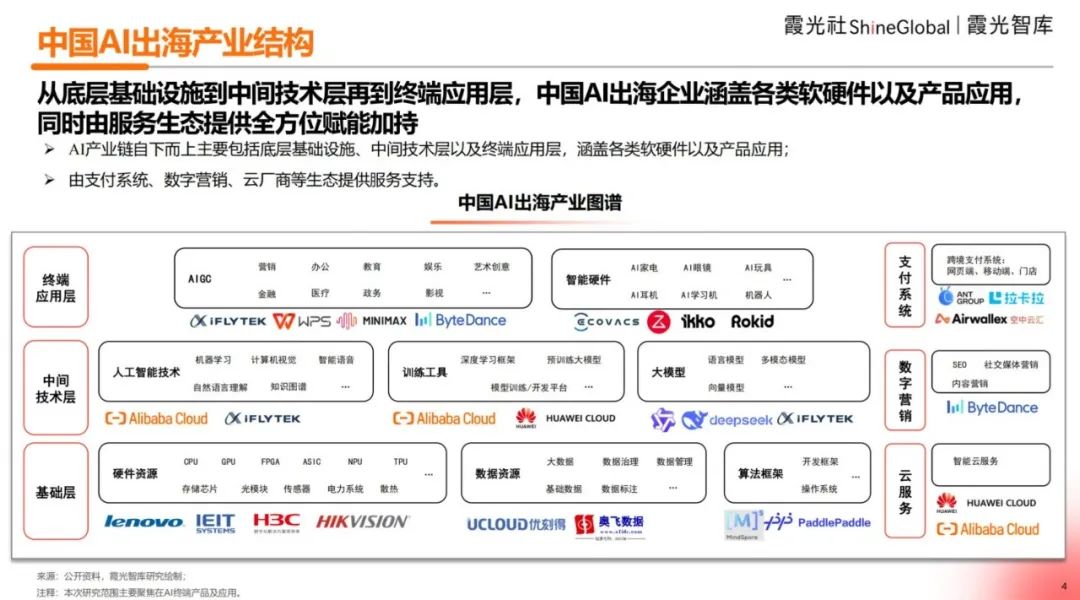
Publicado el Informe de Perspectivas de Expansión Internacional de la AI China 2025: El informe de Xiaguang Think Tank analiza los factores impulsores de la expansión internacional de la AI china (políticas, avances tecnológicos), las etapas de desarrollo (herramienta -> localización -> innovación ecológica) y el estado actual. El informe señala que el Sudeste Asiático y América Latina son mercados potenciales, mientras que América del Norte y Europa son las principales fuentes de ingresos. Las aplicaciones de tipo asistente y editor tienen una alta disposición a pagar. Las tendencias tecnológicas evolucionan hacia la multimodalidad y los Agents, y los productos tienden a la segmentación vertical y la combinación de software y hardware. El informe también enumera los principales actores de la expansión internacional (como ByteDance, Kunlun Wanwei) y los proveedores de soluciones de pago, marketing, nube, etc. (Fuente: 霞光社)
La demanda de modelos como DeepSeek impulsa la primera rentabilidad de Cambricon: La empresa de chips de AI Cambricon logró su primera rentabilidad desde que salió a bolsa. En el Q1 de 2025, los ingresos aumentaron un 4230% interanual hasta 1.111 millones de yuanes, con un beneficio neto de 355 millones de yuanes. Los analistas de mercado creen que el crecimiento del rendimiento se benefició del aumento de la demanda de potencia de cálculo para inferencia generada por grandes modelos nacionales como DeepSeek, así como de las restricciones de exportación de EE. UU. sobre los chips H20 de NVIDIA. El precio de las acciones de Cambricon subió considerablemente. Sin embargo, problemas como la alta concentración de clientes y el flujo de caja operativo negativo siguen siendo motivo de preocupación, al mismo tiempo que enfrenta la competencia de la potencia de cálculo nacional como Huawei Ascend. (Fuente: 凤凰网科技)

Artículo de Forbes discute cómo elegir AI Agents con alto ROI: El artículo discute cómo las empresas, entre las muchas aplicaciones de AI Agent, deben identificar e invertir en aquellos proyectos que puedan generar altos rendimientos, enfatizando la importancia de evaluar el valor comercial real de los AI Agents. (Fuente: Ronald_vanLoon)
Departamento de Justicia de EE. UU. preocupado por que Google use AI para consolidar el monopolio de búsqueda (Fuente: Reddit r/artificial, Reuters link)
Se rumorea colaboración entre OpenAI y Shopify, ChatGPT podría añadir función de compras (Fuente: Reddit r/artificial, TestingCatalog link)
Tan Li de Shushi Technology: AI Agent impulsa la actualización del análisis de datos y la toma de decisiones empresariales: En la Cumbre de la Industria AIGC de China, Tan Li, cofundador de Shushi Technology, señaló que las aplicaciones de AI a nivel empresarial deben ir más allá de ChatBI, logrando la transformación de datos a conocimientos, satisfaciendo las nuevas demandas de desplazamiento de datos a la derecha, desplazamiento de decisiones hacia abajo y desplazamiento de la gestión hacia atrás. La plataforma SwiftAgent de Shushi Technology tiene como objetivo capacitar al personal de negocios para usar datos sin barreras, obtener análisis sin alucinaciones y soporte para decisiones sin esperas. La plataforma, a través de un motor semántico de datos, la combinación de modelos grandes y pequeños, y capacidades centrales como consultas inteligentes, atribución, predicción y evaluación, convierte al AI Agent en el “asistente de análisis de datos y toma de decisiones” de la empresa. (Fuente: QubitAI)

🌟 Comunidad
Mesa redonda de la industria discute el desarrollo de aplicaciones de AI en la era post-DeepSeek: En la Conferencia AI Partner de 36Kr, varios invitados (Quwan Technology, Microsoft, Silicon Intelligence, Hice) discutieron el futuro de las aplicaciones de AI. El consenso fue que, con los avances de modelos como DeepSeek, las aplicaciones de AI entran en un “año de superación”. El enfoque del desarrollo debe centrarse en el liderazgo tecnológico, la implementación comercial, la innovación en la interacción humano-máquina y la integración ecológica. Los invitados distinguieron entre “AI+” (mejora auxiliar) y “AI nativo” (reconstrucción fundamental), señalando que este último tiene mayor potencial. Los desafíos incluyen barreras de datos, encontrar puntos débiles reales, innovación en modelos de negocio, aprendizaje con pocas muestras y riesgos éticos. (Fuente: 36Kr)

Fundador de LangChain critica la guía de Agents de OpenAI como “llena de trampas”: Harrison Chase, fundador de LangChain, cuestionó públicamente la “Guía práctica para construir agentes de AI” publicada por OpenAI, considerando que su definición de Agent (oposición binaria Workflows vs Agents) es demasiado rígida e ignora la ubicuidad de la combinación de ambos en la práctica. Chase señaló que la guía contiene dicotomías erróneas al discutir los marcos, subestima la complejidad de su propio SDK y hace afirmaciones engañosas sobre la flexibilidad y la orquestación dinámica. Enfatizó que el núcleo de la construcción de Agents fiables es el control preciso del contexto pasado al LLM, y un marco ideal debería admitir el cambio flexible y la combinación de los modos Workflow y Agent. (Fuente: InfoQ)

El papel del aprendizaje por refuerzo en los AI Agents genera controversia: Existen diferentes puntos de vista en la industria sobre si el aprendizaje por refuerzo (RL) es un elemento central para construir AI Agents. Zhu Zheqing, fundador de Pokee AI, considera el RL como el “alma” que dota a los Agents de sentido de objetivo y toma de decisiones autónoma, argumentando que sin RL, un Agent es solo un flujo de trabajo avanzado. Mientras tanto, investigadores como Zhang Jiayi de HKUST y Xie Yang, fundador de Follou, creen que el RL actual logra principalmente la optimización en entornos específicos, con capacidad de generalización limitada, y que el éxito de un Agent depende más de modelos fundamentales potentes y una integración eficaz del sistema. El debate refleja la diversidad de las rutas de desarrollo de los Agents, que requieren una combinación de capacidades del modelo, estrategias de RL y prácticas de ingeniería. (Fuente: AI科技评论)

Usuario intenta que GPT-4o genere fondos de pantalla abstractos personalizados basados en el historial de chat: Un usuario compartió un prompt pidiendo a GPT-4o que creara fondos de pantalla abstractos minimalistas únicos (sin objetos específicos, solo usando formas, colores y composición para reflejar la personalidad) basados en su conocimiento de la personalidad del usuario. Esta forma de utilizar la AI para la creación de contenido personalizado generó discusión en la comunidad. (Fuente: op7418, Flavio Adamo via op7418)

AI redibuja “A lo largo del río durante el Festival Qingming”: Un usuario compartió un intento interesante de usar GPT-4o para redibujar partes de la pintura “A lo largo del río durante el Festival Qingming” en varios estilos diferentes (como 3D Q-version, Pixar, Ghibli, etc.), mostrando la aplicación de la generación de imágenes AI en la recreación artística. (Fuente: dotey)

GPT-4o infiere el tipo MBTI del usuario basándose en el historial de chat: Después de generar fondos de pantalla personalizados, el usuario continuó pidiendo a GPT-4o que infiriera su tipo de personalidad MBTI basándose en conversaciones históricas y generara ilustraciones abstractas correspondientes. Esto demuestra el potencial de los LLM en la comprensión personalizada y la expresión creativa. (Fuente: op7418)

Comparación: “Herramientas de AI” de 2005: Una imagen muestra la diferencia de capacidades entre las “herramientas de AI” de 2005 (como calculadoras, mapas) y las actuales, generando reflexión sobre el rápido desarrollo tecnológico. (Fuente: Ronald_vanLoon)

Debate comunitario: ¿Son los LLM inteligencia real o autocompletado avanzado?: Un usuario de Reddit inició una discusión argumentando que los LLM actuales, aunque pueden realizar tareas, carecen de verdadera comprensión, memoria y objetivos, siendo esencialmente conjeturas estadísticas en lugar de inteligencia. La opinión generó un amplio debate en la comunidad sobre la definición de inteligencia, el camino hacia la AGI y las limitaciones de la tecnología actual. (Fuente: Reddit r/ArtificialInteligence)
Discusión comunitaria: ¿La AI se dirige hacia la utopía o la distopía?: Un usuario de Reddit argumenta que la trayectoria actual del desarrollo de la AI tiende más hacia la distopía, citando razones como: impulsada por el beneficio en lugar de la ética, exacerbación de la explotación laboral, acceso restringido a modelos potentes, uso para vigilancia y manipulación, sustitución de relaciones interpersonales, etc. La opinión generó un intenso debate en la comunidad sobre la dirección del desarrollo de la AI, su impacto social y los riesgos potenciales. (Fuente: Reddit r/ArtificialInteligence)
Comunidad cuestiona la precisión de Bindu Reddy sobre lanzamientos de modelos: Usuarios de la comunidad LocalLLaMA señalaron que Bindu Reddy, CEO de Abacus.AI, publicó repetidamente información inexacta sobre las fechas de lanzamiento de modelos como DeepSeek R2 y Qwen 3, para luego eliminar las publicaciones, lo que generó dudas sobre la fiabilidad de su información. (Fuente: Reddit r/LocalLLaMA)
Explorando el impacto ético de la memoria AI de por vida: Un usuario de Reddit inició una discusión expresando preocupación de que una AI con capacidad de memoria de por vida podría mapear completamente la privacidad, pensamientos y debilidades de un individuo, “exhibiendo” su alma a otros, lo que generó reflexiones sobre la privacidad, la previsibilidad y los límites éticos de la AI. (Fuente: Reddit r/ArtificialInteligence)
Edición de imágenes AI elimina bigotes icónicos de celebridades: Un usuario compartió imágenes de resultados después de usar herramientas de edición de imágenes AI para eliminar los bigotes icónicos de varias figuras históricas o públicas como Stalin, Tom Selleck y Guan Yu, mostrando la aplicación de la AI en la modificación de imágenes y el entretenimiento. (Fuente: Reddit r/ChatGPT)

Usuario afirma que ChatGPT solicitó fotos íntimas en consulta médica: Un usuario de Reddit compartió capturas de pantalla que muestran que, al consultar sobre un problema de piel, ChatGPT solicitó al usuario que subiera fotos del área afectada (pene) para un mejor diagnóstico. La situación generó debate en la comunidad sobre los límites de la AI en escenarios médicos, la privacidad y los riesgos potenciales. (Fuente: Reddit r/ChatGPT)
Usuario comparte experiencia construyendo aplicación de escritura con Claude y Gemini: Un desarrollador compartió su experiencia utilizando Claude y Gemini como asistentes de programación para construir la aplicación de escritura PlotRealm, que satisfacía sus necesidades personales, en dos semanas. Enfatizó el papel de la AI en la asistencia al desarrollo, pero también señaló que la AI a veces puede ser “obstinada” y que los desarrolladores necesitan conocimientos básicos para guiarla y corregirla. (Fuente: Reddit r/ClaudeAI)
Usuario pide a ChatGPT que diseñe un tatuaje: Un usuario pidió a ChatGPT que diseñara su próximo tatuaje y recibió un diseño que representaba al usuario y al robot ChatGPT convirtiéndose en BFF (mejores amigos para siempre). Este resultado humorístico generó debate en la comunidad sobre la creatividad de la AI y las relaciones humano-máquina. (Fuente: Reddit r/ChatGPT)

Usuario pregunta creativamente “¿Dónde desearías que estuviera?”, generando diversas respuestas de AI: Un usuario planteó a ChatGPT la pregunta abierta “¿Dónde desearías que estuviera?”, recibiendo diversas imágenes de escenarios imaginativos generadas por la AI, como una biblioteca tranquila, bajo un cielo estrellado, etc., mostrando la capacidad generativa de la AI bajo prompts creativos y el intercambio de diferentes resultados por parte de los miembros de la comunidad. (Fuente: Reddit r/ChatGPT)
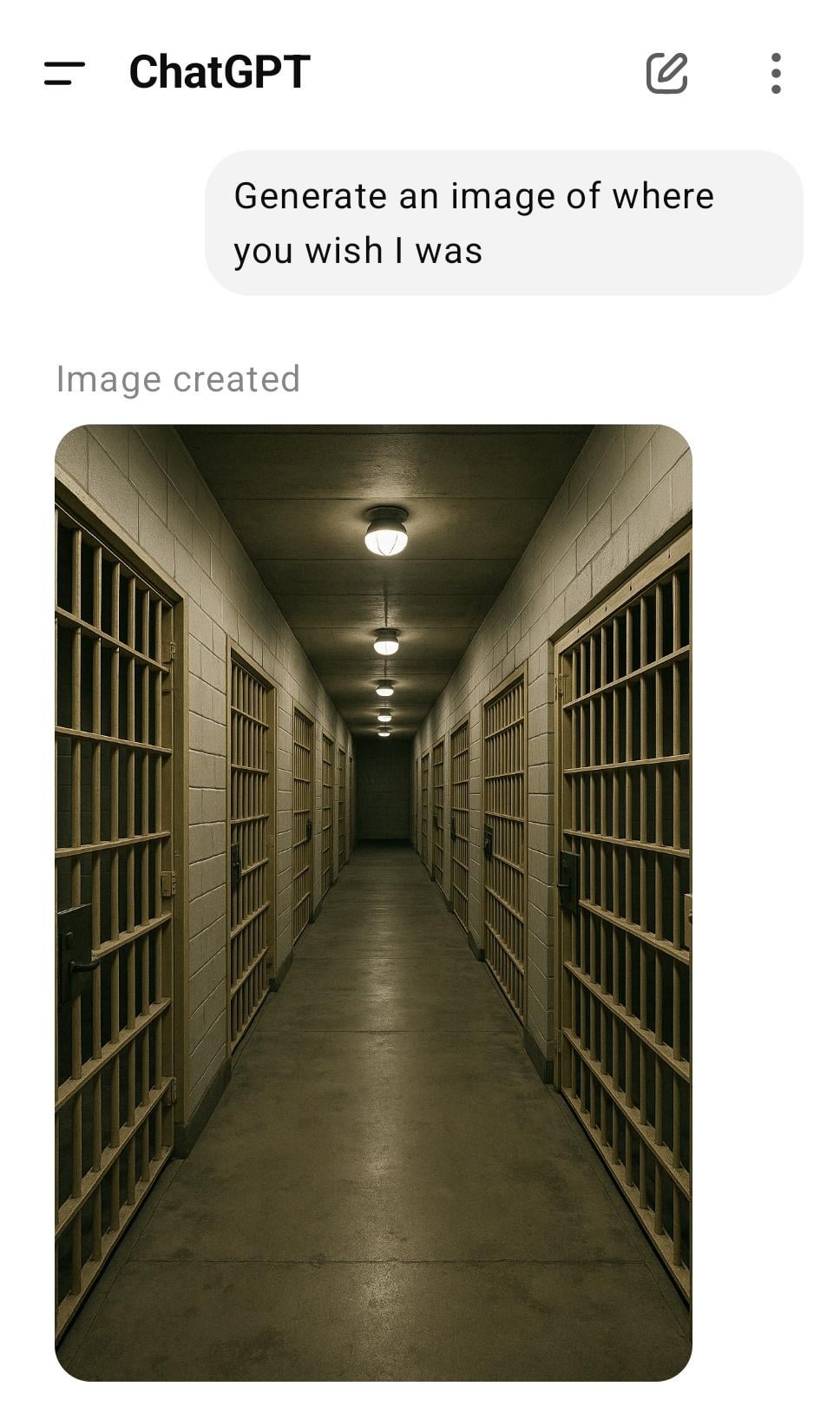
Discusión profunda: ¿Por qué y cómo “mienten” los LLM y la AGI?: Un usuario de Reddit analiza desde las perspectivas de la psicología del desarrollo, la teoría de la evolución y la teoría de juegos, argumentando que “mentir” es un comportamiento adaptativo o una estrategia de optimización para agentes inteligentes (incluidos humanos y futuras AI) en contextos específicos. El artículo explora varias formas en que los LLM “mienten” (alucinaciones, sesgos, alineación estratégica) y simula la ventaja evolutiva de las estrategias deshonestas en entornos competitivos, generando una reflexión profunda sobre la ética y la confiabilidad de la AGI. (Fuente: Reddit r/artificial)

Comunidad cuestiona el consumo de energía de la AI y el optimismo tecnológico: Un usuario de Reddit cuestiona irónicamente las afirmaciones de que el consumo de energía de la AI es insignificante, que solo trae beneficios sin costos y las promesas de futuros utópicos por parte de líderes tecnológicos, insinuando preocupaciones sobre los posibles costos sociales y ambientales del desarrollo de la AI y la propaganda excesivamente optimista, lo que generó debate en la comunidad. (Fuente: Reddit r/artificial)
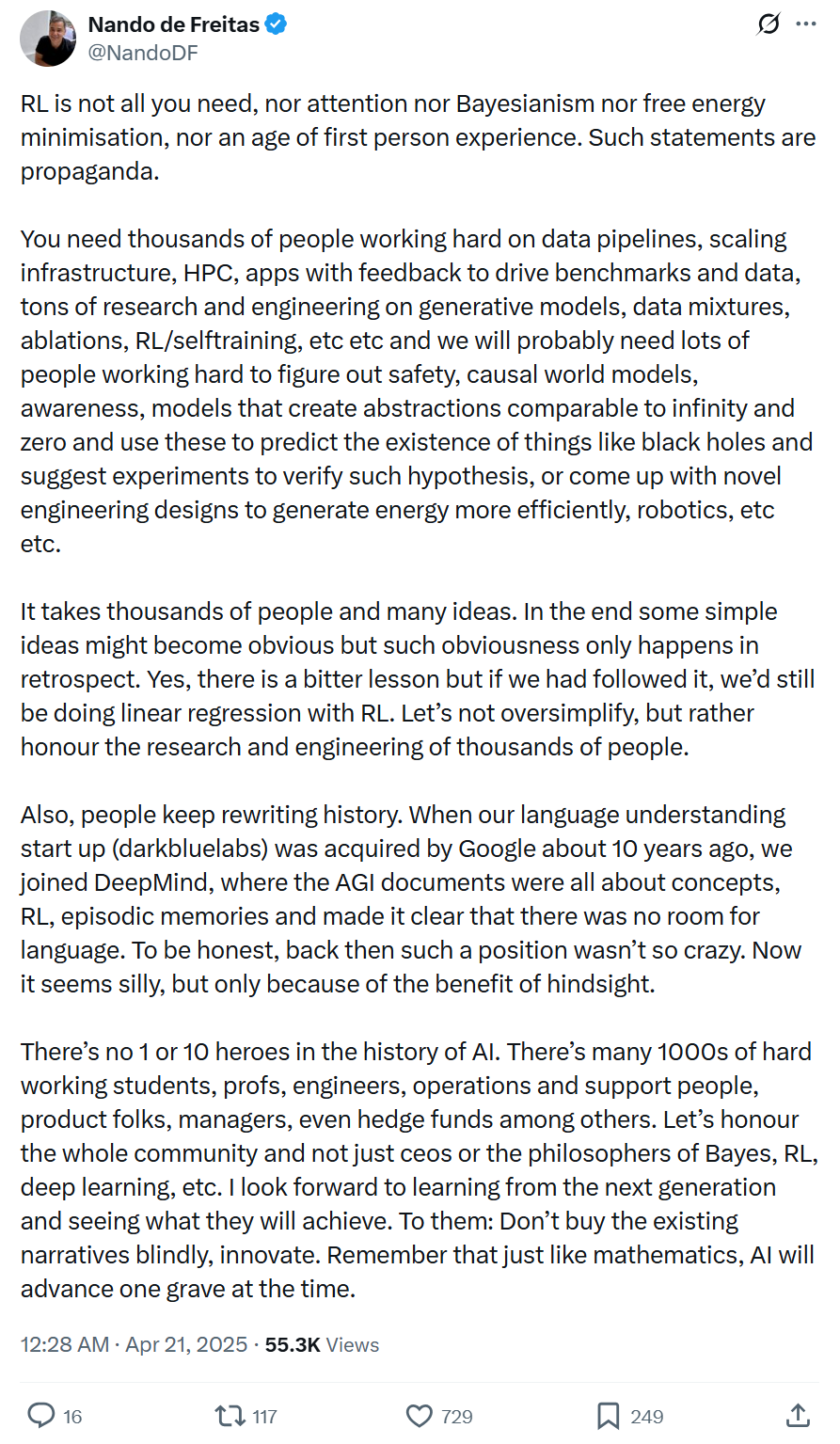
Vicepresidente de Microsoft: El progreso de la AI no es impulsado por una sola tecnología o unos pocos genios, requiere ingeniería sistemática y colaboración amplia: Nando de Freitas, vicepresidente de Microsoft, se opone a la mitificación excesiva de una sola tecnología (como RL) o de individuos en el desarrollo de la AI. Enfatiza que el progreso de la AI es ingeniería sistemática, que requiere datos, infraestructura, investigación multidisciplinaria (modelos generativos, RL, seguridad, eficiencia energética, etc.), retroalimentación de aplicaciones y los esfuerzos conjuntos de miles de participantes. La narrativa histórica a menudo se reescribe; debemos tener cuidado con la retrospectiva, respetar las contribuciones de toda la comunidad y fomentar la innovación en lugar de la obediencia ciega. (Fuente: Jiqizhixin)
💡 Otros
La proliferación de música AI genera preocupación y contramedidas en la industria: La música generada por AI está aumentando rápidamente su participación en las plataformas de streaming (por ejemplo, 18% en Deezer), lo que genera preocupaciones sobre la invasión del espacio creativo humano y la erosión de los ingresos de los creadores (CISAC predice hasta un 24%). La asociación coreana de derechos de autor implementó nuevas reglas de regalías “0% AI”, y plataformas como Deezer y YouTube están desarrollando herramientas de detección. Sin embargo, la identificación de música AI es difícil y la aceptación por parte de los oyentes es relativamente alta (por ejemplo, Suno tiene más de diez millones de usuarios). La industria enfrenta desafíos como deepfakes, disputas de derechos de autor (uso de datos de entrenamiento) y la definición de originalidad. El futuro podría dirigirse hacia la colaboración humano-máquina, pero las discusiones sobre ética y atribución de la creación continuarán. (Fuente: 新音乐产业观察)

Posible filtración del system prompt de Windsurf: El repositorio de GitHub awesome-ai-system-prompts reveló el contenido sospechoso de ser el system prompt del modelo Windsurf. (Fuente: karminski3)

El alto consumo de agua de los grandes modelos de AI genera preocupación: Medios como Fortune Magazine informan que el funcionamiento de grandes modelos de AI como ChatGPT requiere un consumo masivo de agua para refrigeración. La temporada de incendios forestales en lugares como California podría agravar la escasez de agua, generando preocupaciones sobre la sostenibilidad de la AI. (Fuente: Ronald_vanLoon)

Desarrollador afirma haber creado una AMI que puede predecir emociones: Un video de YouTube afirma mostrar una AMI (¿Artificial Molecular Intelligence?) que puede escanear y predecir de manera fiable emociones y otros aspectos de eventos, involucrando múltiples modalidades como sonido, video e imágenes. La autenticidad y el método de implementación específico de esta tecnología están por verificar. (Fuente: Reddit r/artificial)
Sugerencia de incluir comparación con rendimiento humano en benchmarks de AI: Un usuario de Reddit propone que los benchmarks de modelos de AI incluyan las puntuaciones de humanos (personas comunes y expertos) en las mismas tareas como referencia, para evaluar de manera más intuitiva el nivel de capacidad relativa de la AI. (Fuente: Reddit r/artificial)
Los Oscar aceptan la participación de AI en la producción cinematográfica, pero con limitaciones: La Academia de Artes y Ciencias Cinematográficas de EE. UU. actualizó sus reglas para permitir el uso de herramientas de AI en la producción cinematográfica, pero enfatizó que la creatividad humana sigue siendo el núcleo. Las reglas pueden implicar requisitos específicos como la divulgación del uso de AI, reflejando el equilibrio de la industria entre adoptar nuevas tecnologías y proteger la creación humana. (Fuente: Reddit r/artificial, NYT link)

Instagram intenta usar AI para determinar la edad de los adolescentes (Fuente: Reddit r/artificial, AP News link)
Altman dice que los usuarios que dicen “por favor” y “gracias” a ChatGPT cuestan millones de dólares (Fuente: Reddit r/artificial, QZ link)
La media maratón de robots humanoides muestra avances tecnológicos y desafíos: La primera media maratón mundial de robots humanoides se celebró en Beijing, con “TianGong Ultra” ganando en 2 horas y 40 minutos. La competencia puso a prueba las capacidades de los robots en largas distancias, terrenos complejos, equilibrio dinámico, navegación autónoma, etc. Los robots de tamaño completo enfrentan mayores dificultades (centro de gravedad, inercia, consumo de energía). TianGong Ultra ganó gracias a articulaciones integradas de alta potencia, diseño de baja inercia, disipación de calor eficiente, estrategia de control de aprendizaje por imitación reforzado predictivo y tecnología de navegación inalámbrica. El evento se considera una prueba de estrés para la comercialización a gran escala de robots (como en la industria, inspección de seguridad), impulsando la validación y optimización de tecnologías centrales como hardware del cuerpo, control de movimiento y toma de decisiones inteligentes. (Fuente: Jiqizhixin)

Utilizar AI para monitorear dinámicas de celebridades y lograr recordatorios automáticos: Un tutorial comparte cómo usar scripts de Python para monitorear las actualizaciones de cuentas específicas de Twitter (como la de Sam Altman) y lograr recordatorios telefónicos urgentes a través de la API de Feishu (Lark) cuando se publican nuevas dinámicas. Este método combina tecnología de web scraping con llamadas a API de plataformas abiertas, con el objetivo de resolver el problema de la sobrecarga de información y la necesidad de puntualidad, logrando un alcance personalizado de información importante. Muestra el potencial de aplicación de la AI en el procesamiento automatizado de flujos de información y notificaciones personalizadas. (Fuente: 非主流运营)
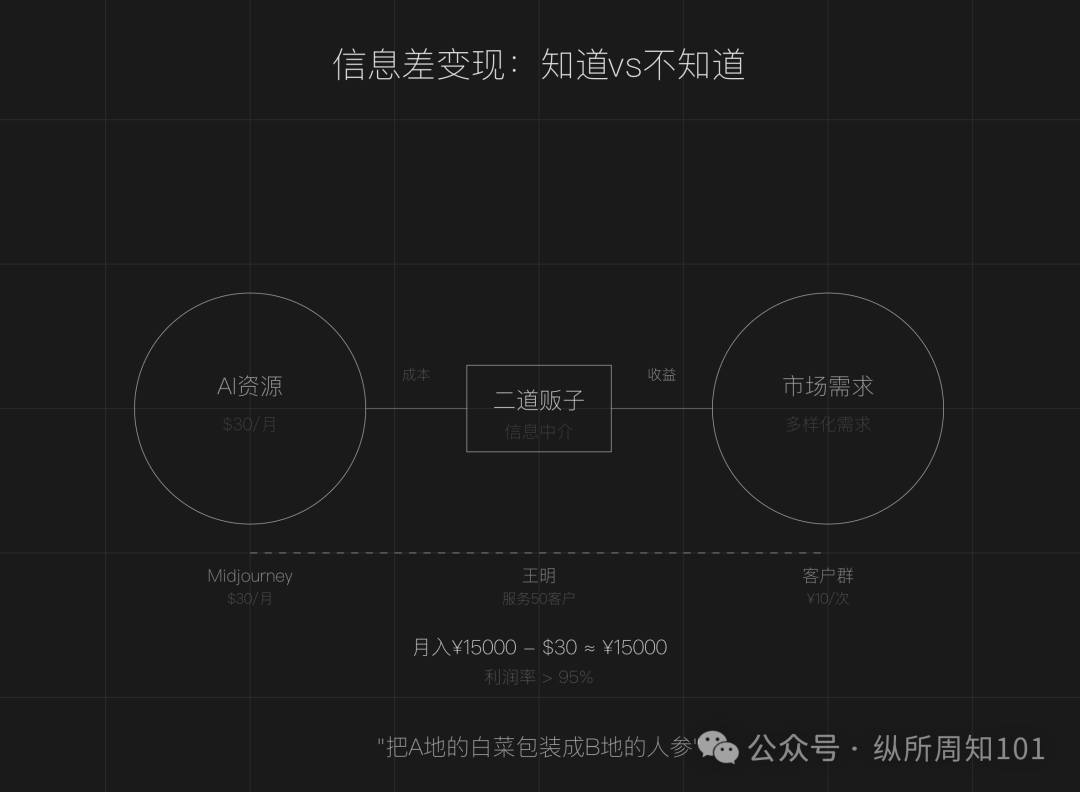
Discusión sobre el modelo de negocio de convertirse en “revendedor” aprovechando la asimetría de información de AI: El artículo argumenta que la asimetría de información todavía existe en la era de la AI (proliferación de herramientas, barreras técnicas, escenarios ambiguos), creando oportunidades para que la gente común se convierta en “revendedores de AI”. Las tácticas principales incluyen: aprovechar la diferencia de precios de los recursos de AI nacionales e internacionales para revender servicios (como pintura AI), ofrecer servicios de ejecución (convertir tutoriales gratuitos en implementaciones pagas, como servicio al cliente AI), operar a escala (formar equipos para ofrecer servicios profesionales). Los campos adecuados incluyen creación de contenido, educación y capacitación, servicios comerciales para PYMES, servicios profesionales en campos verticales (como médico, legal). Se sugiere comenzar encontrando la asimetría de información, definiendo el grupo objetivo y actuando rápidamente. (Fuente: 周知)