
Palabras clave:Modelo de IA, OpenAI, Multimodal, Agente, Modelo o3, o4-mini, Razonamiento visual, Uso de herramientas, Gemini 2.5 Flash, Tencent Yuanbao AI, Integración de LLM, Aprendizaje por refuerzo
🔥 Enfoque
OpenAI lanza los modelos o3 y o4-mini, integrando herramientas y capacidades de razonamiento visual: OpenAI ha lanzado oficialmente sus modelos de razonamiento más inteligentes y potentes hasta la fecha, o3 y o4-mini. El punto clave es la primera implementación de un Agent que llama y combina activamente todas las herramientas internas de ChatGPT (búsqueda web, análisis de datos con Python, comprensión visual profunda, generación de imágenes, etc.), y puede integrar imágenes en la cadena de razonamiento para pensar. o3 lidera en áreas como codificación, matemáticas, ciencia y percepción visual, estableciendo nuevos SOTA en múltiples benchmarks; o4-mini, por otro lado, optimiza la velocidad y el coste, con un rendimiento muy superior a su tamaño. Ambos modelos tienen una mayor capacidad para seguir instrucciones, conversaciones más naturales y pueden utilizar la memoria y el historial de conversaciones para ofrecer respuestas personalizadas. Este lanzamiento marca un paso importante de OpenAI hacia una Agentic AI más autónoma, permitiendo a los asistentes de IA completar tareas complejas de forma más independiente. (Fuente: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?)
Los modelos o3 y o4-mini de OpenAI ya están disponibles, mejorando el uso de herramientas y el razonamiento visual: OpenAI lanzó los modelos o3 y o4-mini durante la noche, disponibles para usuarios con cuentas ChatGPT Plus, Pro y Team. Las actualizaciones clave son: 1. La versión completa de o3 admite por primera vez la llamada a herramientas (como conexión a internet, intérprete de código). 2. o3 y o4-mini son los primeros modelos capaces de realizar razonamiento visual en la cadena de pensamiento, pudiendo analizar y pensar combinando imágenes como lo haría un humano, por ejemplo, en un juego de adivinar lugares a partir de imágenes, el modelo puede ampliar detalles de la imagen para un razonamiento paso a paso. Esta capacidad mejora significativamente el rendimiento del modelo en tareas multimodales (como MMMU, MathVista), y predice que la IA desempeñará un papel más importante en escenarios profesionales que requieren juicio visual (como monitorización de seguridad, análisis de imágenes médicas). Al mismo tiempo, OpenAI también ha abierto el código fuente de la herramienta de programación de IA Codex CLI. (Fuente: OpenAI深夜上线o3满血版和o4 mini – 依旧领先。)
Tencent Yuanbao AI se integra oficialmente en WeChat, iniciando un nuevo paradigma de chat: Tencent Yuanbao AI ya está disponible oficialmente como un contacto de WeChat, los usuarios pueden añadirlo buscando “元宝”. Esto rompe el modelo tradicional donde las aplicaciones de IA necesitaban abrirse por separado, integrando la IA sin problemas en los escenarios de comunicación diarios de los usuarios. Yuanbao AI (basado en Hunyuan y DeepSeek) puede interactuar directamente en el cuadro de diálogo de WeChat, admite resumir imágenes, artículos de cuentas públicas, enlaces web, audio y vídeo (actualmente no es compatible con video de WeChat Channels), y puede buscar en el historial de chat. Aunque todavía no admite dibujo ni chats grupales, su facilidad de uso y la profunda integración con el ecosistema de WeChat se consideran ventajas importantes. Los analistas creen que WeChat, con su enorme base de usuarios y red de relaciones sociales, al convertir la IA en un contacto de la agenda, tiene el potencial de cambiar el paradigma de la interacción humano-máquina, haciendo que la IA se integre de forma más natural en la vida de los usuarios. (Fuente: 劲爆!元宝AI接入微信了,怎么用?看这篇就够了、腾讯元宝最终还是活成了微信的模样。)
EE.UU. podría suspender indefinidamente la exportación de chips Nvidia H20 a China, con un impacto profundo: El gobierno de EE.UU. ha notificado a Nvidia que suspenderá indefinidamente la exportación a China del chip de IA H20 (una versión especial diseñada previamente para cumplir con los controles de exportación). H20 es el chip compatible más potente desarrollado por Nvidia para el mercado chino, y se espera que la prohibición de venta suponga un duro golpe para Nvidia. Los datos muestran que China es la cuarta fuente de ingresos más grande de Nvidia, con ventas de H20 en 2024 alcanzando los miles de millones de dólares, y las empresas tecnológicas chinas (como ByteDance, Tencent) son los principales compradores de chips Nvidia, con un crecimiento significativo de la inversión. Esta medida no solo afecta los ingresos de Nvidia, sino que también podría debilitar su ecosistema CUDA (los desarrolladores chinos representan más del 30%). Al mismo tiempo, empresas chinas de chips de IA locales como Huawei (por ejemplo, Ascend 910C) están acelerando su desarrollo y podrían llenar el vacío del mercado. El evento ha generado preocupación en el mercado y las acciones de Nvidia cayeron como respuesta. (Fuente: 中国对英伟达到底有多重要?)
🎯 Tendencias
El modelo de vídeo de primer nivel de Google, Veo 2, llega gratis a AI Studio: Google ha anunciado que su avanzado modelo de generación de vídeo Veo 2 ya está disponible en Google AI Studio, Gemini API y Gemini App, ofreciendo cuotas de uso gratuitas (aproximadamente una docena de veces al día, con una duración máxima de 8 segundos cada vez). Veo 2 admite la generación de vídeo a partir de texto (t2v) y de imagen a vídeo (i2v), es capaz de comprender instrucciones complejas, generar contenido de vídeo realista y estilísticamente diverso, y controlar el movimiento de la cámara. La compañía enfatiza que la clave para generar vídeos de alta calidad es proporcionar Prompts claros, detallados y que contengan palabras clave visuales. El modelo también cuenta con funciones avanzadas como edición dentro del vídeo (recorte, expansión), movimientos de cámara cinematográficos y transiciones inteligentes, con el objetivo de integrarse en los flujos de trabajo de creación de contenido y mejorar la eficiencia. (Fuente: 谷歌杀疯了,顶级视频模型 Veo 2 竟免费开放?速来 AI Studio 白嫖。)
Google lanza Gemini 2.5 Flash, centrado en velocidad, coste y profundidad de pensamiento controlable: Google ha lanzado la versión preliminar del modelo Gemini 2.5 Flash, posicionado como un modelo ligero optimizado en velocidad y coste. Este modelo ha tenido un rendimiento destacado en el ranking LMArena, empatando en segundo lugar con GPT-4.5 Preview y Grok-3, y ocupando el primer lugar en prompts difíciles, codificación y consultas largas. Su característica principal es la introducción de la capacidad de “pensar” y la inferencia totalmente mixta, permitiendo al modelo planificar y descomponer tareas antes de generar la salida. Los desarrolladores pueden controlar la profundidad de pensamiento del modelo (límite de tokens) a través del parámetro “thinking budget”, equilibrando calidad, coste y latencia. Incluso con un presupuesto de 0, el rendimiento supera al de 2.0 Flash. Este modelo tiene una alta relación calidad-precio, con un coste de solo 1/10 a 1/5 del de Gemini 2.5 Pro, adecuado para flujos de trabajo de IA a gran escala y de alta concurrencia. (Fuente: 快如闪电,还能控制思考深度?谷歌 Gemini 2.5 Flash 来了,用户盛赞“绝妙组合”。)
Kunlun Wanwei lanza el modelo de generación de películas de duración ilimitada Skyreels-V2: Kunlun Wanwei ha lanzado y abierto el código fuente de Skyreels-V2, afirmando que es el primer modelo de generación de vídeo de alta calidad del mundo que admite duración ilimitada. Este modelo tiene como objetivo resolver los puntos débiles de los modelos de vídeo existentes en la comprensión del lenguaje cinematográfico, la coherencia del movimiento, las limitaciones de duración del vídeo y la falta de datasets profesionales. Skyreels-V2 combina un gran modelo multimodal, anotación estructurada, generación por difusión, aprendizaje por refuerzo (optimización DPO de la calidad del movimiento) y estrategias de entrenamiento de múltiples etapas con ajuste fino de alta calidad. Adopta la arquitectura Diffusion Forcing, logrando la generación de vídeos largos a través de un programador especial y mecanismos de atención. La compañía afirma que su efecto de generación alcanza el “nivel cinematográfico”, con un rendimiento excelente en benchmarks como V-Bench1.0, superando a otros modelos de código abierto. Los usuarios pueden experimentar en línea generando vídeos de hasta 30 segundos. (Fuente: 震撼!昆仑万维 | 发布全球首款无限时长电影生成模型:Skyreels-V2,可在线体验!)
Shanghai AI Lab lanza el modelo multimodal nativo InternVL3: El Laboratorio de Inteligencia Artificial de Shanghai ha presentado InternVL3, un gran modelo multimodal (MLLM) que adopta un paradigma de preentrenamiento multimodal nativo. A diferencia de la mayoría de los modelos adaptados a partir de LLM puramente textuales, InternVL3 aprende simultáneamente de datos multimodales y corpus de texto puro en una única fase de preentrenamiento, con el objetivo de superar la complejidad y los desafíos de alineación del entrenamiento en múltiples etapas. El modelo combina codificación de posición visual variable, técnicas avanzadas de post-entrenamiento y estrategias de expansión en tiempo de prueba. InternVL3-78B obtuvo 72.2 puntos en el benchmark MMMU, estableciendo un nuevo récord para MLLM de código abierto, con un rendimiento cercano a los modelos propietarios líderes, manteniendo al mismo tiempo sólidas capacidades puramente lingüísticas. Los datos de entrenamiento y los pesos del modelo se harán públicos. (Fuente: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等)
UCLA y otros proponen el framework d1, utilizando aprendizaje por refuerzo para la inferencia de LLM de difusión: Investigadores de UCLA y Meta AI han propuesto el framework d1, aplicando por primera vez el post-entrenamiento con aprendizaje por refuerzo (RL) a grandes modelos de lenguaje de difusión enmascarada (dLLM). Los métodos de RL existentes (como GRPO) se utilizan principalmente para LLM autorregresivos y son difíciles de aplicar directamente a los dLLM, ya que carecen de una descomposición natural de la probabilidad logarítmica. El framework d1 consta de dos etapas: primero, un ajuste fino supervisado (SFT), y luego, en la etapa de RL, se introduce un novedoso método de gradiente de política, diffu-GRPO, que utiliza un estimador eficiente de probabilidad logarítmica de un solo paso y aprovecha el enmascaramiento aleatorio de prompts como regularización, reduciendo la cantidad de generación en línea necesaria para el entrenamiento de RL. Los experimentos muestran que el modelo d1 basado en LLaDA-8B-Instruct supera significativamente al modelo base y a los modelos que utilizan solo SFT o diffu-GRPO en benchmarks de razonamiento matemático y lógico. (Fuente: UCLA | 推出开源后训练框架:d1,扩散LLM推理也能用上GRPO强化学习!)
Meta propone la Atención Multi-Token (MTA): Investigadores de Meta han propuesto el mecanismo de Atención Multi-Token (Multi-Token Attention, MTA), con el objetivo de mejorar la forma en que se calcula la atención en los grandes modelos de lenguaje (LLM). El mecanismo de atención tradicional se basa únicamente en la similitud de un único token de consulta y clave. MTA, mediante la aplicación de operaciones de convolución en los vectores de consulta, clave y cabeza, permite al modelo considerar simultáneamente múltiples tokens de consulta y clave adyacentes para determinar los pesos de atención. Los investigadores creen que esto puede utilizar información más rica y detallada para localizar el contexto relevante. Los experimentos muestran que MTA supera a los modelos Transformer de línea base tradicionales tanto en tareas estándar de modelado de lenguaje como en tareas de recuperación de información de contexto largo. (Fuente: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等)
TogetherAI presenta el modelo de inferencia M1 basado en RNN: TogetherAI ha propuesto M1, un nuevo modelo de inferencia RNN lineal híbrido basado en la arquitectura Mamba. Este modelo tiene como objetivo abordar la complejidad computacional y las limitaciones de memoria que enfrentan los Transformer al procesar secuencias largas y realizar inferencias eficientes. M1 mejora el rendimiento mediante la destilación de conocimiento de modelos de inferencia existentes y el entrenamiento con aprendizaje por refuerzo. Los resultados experimentales muestran que M1, en benchmarks de razonamiento matemático como AIME y MATH, no solo supera a los modelos RNN lineales anteriores, sino que también puede compararse con modelos de inferencia destilados DeepSeek-R1 de tamaño equivalente. Más importante aún, la velocidad de generación de M1 es más de 3 veces más rápida que la de un Transformer del mismo tamaño, y con un presupuesto de tiempo de generación fijo, puede lograr una mayor precisión que este último mediante votación por auto-consistencia. (Fuente: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等)
Tencent Hunyuan abre el código fuente del framework InstantCharacter: El equipo de Tencent Hunyuan ha abierto el código fuente de InstantCharacter, un framework para la generación de imágenes capaz de extraer y preservar las características de una persona a partir de una única imagen de entrada, y luego situar a esa persona en diferentes escenas o estilos. Esta tecnología tiene como objetivo lograr una alta fidelidad en la preservación de la identidad de la persona y una transferencia de estilo controlable. La compañía ha proporcionado una demostración en línea en Hugging Face basada en los estilos artísticos de Ghibli y Makoto Shinkai, y ha publicado el artículo de investigación relacionado, el repositorio de código y un plugin para ComfyUI, facilitando su uso y desarrollo posterior por parte de la comunidad. (Fuente: karminski3)
La función de memoria de ChatGPT se actualiza, admite la búsqueda web combinada con la memoria: OpenAI ha actualizado la función de memoria (Memory) de ChatGPT, añadiendo la capacidad de “Buscar con memoria”. Esto significa que ChatGPT, al realizar tareas de búsqueda web, puede utilizar la información de memoria almacenada previamente sobre las preferencias del usuario, ubicación, etc., para optimizar las consultas de búsqueda y así proporcionar resultados más personalizados. Por ejemplo, si ChatGPT recuerda que el usuario es vegetariano, al preguntarle por restaurantes cercanos, podría buscar automáticamente “restaurantes vegetarianos cercanos”. Esta medida se considera un paso importante de OpenAI para mejorar los servicios personalizados de IA, con el objetivo de mejorar la experiencia del usuario y diferenciarse de otros competidores con funciones de memoria (como Claude, Gemini). Los usuarios pueden optar por desactivar la función de memoria en la configuración. (Fuente: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!)
La tecnología de instantáneas de tiempo de ejecución de modelos de IA evita el arranque en frío: La comunidad de machine learning está explorando la optimización de la orquestación en tiempo de ejecución de LLM mediante la tecnología de instantáneas de modelo. Esta tecnología, al guardar el estado completo de la GPU (incluyendo caché KV, pesos, diseño de memoria), permite evitar el arranque en frío y la inactividad de la GPU al cambiar entre diferentes modelos, logrando una recuperación rápida (aproximadamente 2 segundos). Algunos profesionales han compartido que, utilizando este método, han logrado ejecutar con éxito más de 50 modelos de código abierto en dos GPU A1000 de 16GB, sin necesidad de usar contenedores ni recargar modelos. Esta técnica de reutilización (multiplexing) y rotación de modelos tiene potencial para mejorar la utilización de la GPU y reducir la latencia de inferencia. (Fuente: Reddit r/MachineLearning)
🧰 Herramientas
Volcanic Engine de ByteDance presenta una Demo de solución integral de hardware de IA: Volcanic Engine de ByteDance ha mostrado su solución integral de hardware de IA en colaboración con fabricantes de chips embebidos, utilizando la placa de desarrollo AtomS3R como ejemplo. Esta solución tiene como objetivo proporcionar una experiencia interactiva de IA de baja latencia y alta capacidad de respuesta, caracterizada por una respuesta en milisegundos, interrupción y respuesta en tiempo real, y capacidad de reducción de ruido de audio en entornos complejos a través del SDK RTC, lo que puede reducir eficazmente las interferencias de ruido de fondo y mejorar la precisión de la interacción por voz. El código del cliente y el programa del servidor de esta solución son de código abierto, lo que permite a los desarrolladores realizar personalizaciones DIY, como dotar al hardware de personalidad, rol, timbre de voz personalizados, o conectarlo a bases de conocimiento y herramientas MCP. El hardware en sí incluye una cámara y planea admitir funciones de comprensión visual en el futuro. (Fuente: 体验完字节送的迷你AI硬件,后劲有点大…
)
Mita AI Search lanza la función de aprendizaje “Qué aprender hoy”: Mita AI Search ha lanzado una nueva función llamada “Qué aprender hoy”, que puede convertir automáticamente los archivos subidos por el usuario (admite múltiples formatos) o los enlaces web proporcionados en un vídeo de curso en línea estructurado, con narración y demostración (PPT, animación). Los usuarios pueden elegir diferentes estilos de explicación (como contar historias, estilo Napoleón) y voces (como reina fría). La función tiene como objetivo transformar la entrada de información en una experiencia de aprendizaje más fácil de absorber, e incluso proporciona una sección de pruebas después de la clase. Se considera que esta forma de combinar la generación de contenido con la enseñanza personalizada podría cambiar el modelo de aplicación de la IA en los campos de la educación y el consumo de información, ofreciendo una forma novedosa de adquirir conocimientos y leer contenido rápidamente. (Fuente: 说个抽象的事,你现在可以在秘塔AI搜索里上课了。

)
Cursor IDE se actualiza a la versión 0.49, mejorando el sistema de reglas y el control del Agent: El editor de código AI-first Cursor ha lanzado la vista previa de la actualización 0.49. Las nuevas funciones incluyen: 1. Generación automática de archivos de reglas .mdc mediante el comando de chat /Generate Cursor Rules para fijar el contexto del proyecto. 2. Aplicación automática de reglas más inteligente, el Agent puede cargar automáticamente las reglas correspondientes según la ruta del archivo. 3. Corrección del error por el que “Adjuntar siempre reglas” fallaba en conversaciones largas. 4. Nueva función “Project Structure Awareness” (Beta) para que la IA comprenda mejor todo el proyecto. 5. El protocolo MCP (Model Context Protocol) ahora admite la transmisión de imágenes, facilitando el manejo de tareas relacionadas con la visión. 6. Control mejorado del Agent sobre los comandos de terminal, los usuarios pueden editar o saltar comandos antes de ejecutarlos. 7. Soporte para configuración global de archivos ignorados (.cursorignore). 8. Experiencia de revisión de código optimizada, mostrando la vista diff directamente después de los mensajes del Agent. (Fuente: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!)
OpenAI abre el código fuente de la herramienta de programación de IA en línea de comandos Codex CLI: Coincidiendo con el lanzamiento de o3 y o4-mini, OpenAI ha abierto el código fuente de Codex CLI, un ligero Agent de codificación de IA que puede ejecutarse directamente en la terminal de línea de comandos del usuario. Esta herramienta tiene como objetivo aprovechar al máximo las potentes capacidades de codificación y razonamiento de los nuevos modelos, puede procesar directamente repositorios de código locales e incluso combinar capturas de pantalla o bocetos para realizar razonamiento multimodal. El CEO de OpenAI, Sam Altman, lo promocionó personalmente y enfatizó su naturaleza de código abierto para fomentar la iteración rápida de la comunidad. Al mismo tiempo, OpenAI ha lanzado un programa de subvenciones de 1 millón de dólares (en forma de API Credits) para apoyar proyectos basados en Codex CLI y modelos de OpenAI. (Fuente: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?)
La plataforma LKE de Tencent Cloud integra MCP, simplificando la construcción de Agents: La plataforma Language Knowledge Engine (LKE) de Tencent Cloud ha añadido soporte para el Model Context Protocol (MCP), con el objetivo de reducir la barrera para construir y usar Agents de IA. Los usuarios ahora pueden, a través de operaciones de clic en la plataforma LKE, acceder fácilmente a herramientas MCP integradas como Tencent Cloud EdgeOne Pages (despliegue de páginas web con un clic), Firecrawl (rastreador web), etc. Combinado con las potentes capacidades de la base de conocimientos de LKE (RAG), los usuarios pueden crear aplicaciones complejas basadas en conocimiento privado y llamadas a herramientas externas, por ejemplo, generar y publicar automáticamente páginas web basadas en el contenido de la base de conocimientos. La plataforma admite el modo Agent, donde el modelo (como DeepSeek R1) puede pensar de forma autónoma y elegir las herramientas adecuadas para completar la tarea. La plataforma también admite la conexión de MCP externos. (Fuente: 效果惊艳!MCP+腾讯云知识引擎,一个0门槛打造专属AI Agent的神器诞生~

)
Framework Spring AI: un framework de aplicación para ingeniería de IA: Spring AI es un framework de aplicación de IA diseñado para desarrolladores Java, con el objetivo de introducir los principios de diseño del ecosistema Spring (como portabilidad, diseño modular, uso de POJO) en el campo de la IA. Proporciona una API unificada para interactuar con múltiples proveedores de modelos de IA principales (Anthropic, OpenAI, Microsoft, Amazon, Google, Ollama, etc.), admitiendo completado de chat, embeddings, texto a imagen/audio, moderación, etc. Al mismo tiempo, integra múltiples bases de datos vectoriales (Cassandra, Azure Vector Search, Chroma, Milvus, etc.), ofreciendo una API portable y filtrado de metadatos estilo SQL. El framework también admite salida estructurada, llamadas a herramientas/funciones, observabilidad, framework ETL, evaluación de modelos, memoria de chat y RAG, entre otras funciones, y simplifica la integración a través de la autoconfiguración de Spring Boot. (Fuente: spring-projects/spring-ai – GitHub Trending (all/weekly)
)
olmocr: kit de herramientas de linealización de PDF para el procesamiento de datasets de LLM: allenai ha abierto el código fuente de olmocr, un kit de herramientas diseñado específicamente para procesar documentos PDF para la construcción y entrenamiento de datasets de grandes modelos de lenguaje (LLM). Incluye varias funciones: estrategias de prompt para análisis de texto natural de alta calidad utilizando ChatGPT 4o, herramientas de evaluación para comparar diferentes versiones de flujos de procesamiento, funciones básicas de filtrado de lenguaje y eliminación de spam SEO, código de ajuste fino para Qwen2-VL y Molmo-O, un flujo para procesar PDF a gran escala utilizando Sglang, y herramientas para visualizar documentos procesados en formato Dolma. El kit de herramientas requiere soporte de GPU para la inferencia local y proporciona instrucciones para su uso local y en clústeres de múltiples nodos (compatible con S3 y Beaker). (Fuente: allenai/olmocr – GitHub Trending (all/daily)

)
Lanzamiento de la aplicación de escritorio Dive Agent v0.8.0: La aplicación de escritorio de Agent de IA de código abierto Dive ha lanzado la versión v0.8.0, con importantes ajustes de arquitectura y actualizaciones funcionales. Esta versión tiene como objetivo integrar LLM que admiten llamadas a herramientas con MCP Server. Las principales actualizaciones incluyen: gestión de claves API de LLM, soporte para ID de modelo personalizados, soporte completo para modelos de llamada a herramientas/funciones; gestión de herramientas MCP (añadir, eliminar, modificar), interfaz de configuración compatible con edición JSON y formularios. El backend DiveHost ha sido migrado de TypeScript a Python para resolver problemas de integración con LangChain, y puede funcionar como un servidor A2A (Agent-to-Agent) independiente. (Fuente: Reddit r/LocalLLaMA)
llama.cpp fusiona herramientas CLI multimodales: El proyecto llama.cpp ha fusionado los programas de ejemplo de interfaz de línea de comandos (CLI) para LLaVa, Gemma3 y MiniCPM-V en una única herramienta unificada llama-mtmd-cli. Esto forma parte de su integración gradual del soporte multimodal (a través de la biblioteca libmtmd). Aunque el soporte multimodal todavía está en desarrollo (por ejemplo, el soporte en llama-server aún es experimental), la fusión de las CLI es un paso para simplificar el conjunto de herramientas. Al mismo tiempo, el soporte para SmolVLM v1/v2 también está en desarrollo. (Fuente: Reddit r/LocalLLaMA)
LightRAG: Despliegue automatizado de pipelines RAG: LightRAG es un proyecto RAG (Retrieval-Augmented Generation) de código abierto. Miembros de la comunidad han creado tutoriales y scripts de automatización (usando Ansible + Docker Compose + Sbnb Linux) que permiten a los usuarios desplegar rápidamente (en cuestión de minutos) el sistema LightRAG en servidores bare metal, logrando la construcción automatizada de un pipeline RAG completamente funcional desde una máquina vacía. Esto simplifica el proceso de despliegue de soluciones RAG autoalojadas. (Fuente: Reddit r/LocalLLaMA)
Nari Labs lanza el modelo TTS de código abierto Dia-1.6B: Nari Labs ha lanzado y abierto el código fuente de su modelo de texto a voz (TTS) Dia-1.6B. La característica de este modelo es que no solo puede generar voz, sino que también puede integrar de forma natural sonidos no lingüísticos (sonidos paralingüísticos) como risas, toses, carraspeos, etc., en el habla para mejorar la naturalidad y expresividad de la voz. La compañía ha proporcionado vídeos de demostración para mostrar el efecto. El modelo requiere aproximadamente 10GB de VRAM para funcionar y actualmente no se ofrece una versión cuantizada. El repositorio de código y el modelo se han publicado en GitHub y Hugging Face. (Fuente: karminski3)
📚 Aprendizaje
Jeff Dean repasa los hitos clave del desarrollo de la IA en los últimos quince años: El científico jefe de Google, Jeff Dean, en una charla, repasó los avances importantes en el campo de la IA durante los últimos quince años, destacando especialmente las contribuciones de investigación de Google. Los hitos clave incluyen: entrenamiento de redes neuronales a gran escala (demostrando el efecto de escala), sistema distribuido DistBelief (permitiendo entrenar grandes modelos en CPU), embeddings de palabras Word2Vec (revelando la semántica del espacio vectorial), modelos Seq2Seq (impulsando tareas como la traducción automática), TPU (aceleración de hardware personalizada para redes neuronales), arquitectura Transformer (revolucionando el procesamiento de secuencias, base de los LLM), aprendizaje autosupervisado (utilizando datos no etiquetados a gran escala), Vision Transformer (unificando el procesamiento de imágenes y texto), modelos dispersos/MoE (mejorando la capacidad y eficiencia del modelo), Pathways (simplificando la computación distribuida a gran escala), cadena de pensamiento CoT (mejorando la capacidad de razonamiento), destilación de conocimiento (transfiriendo la capacidad de modelos grandes a modelos pequeños) y decodificación especulativa (acelerando la inferencia). Estas tecnologías han impulsado conjuntamente el desarrollo de la IA moderna. (Fuente: 比较全!回顾LLM发展史 | Transformer、蒸馏、MoE、思维链(CoT)
)
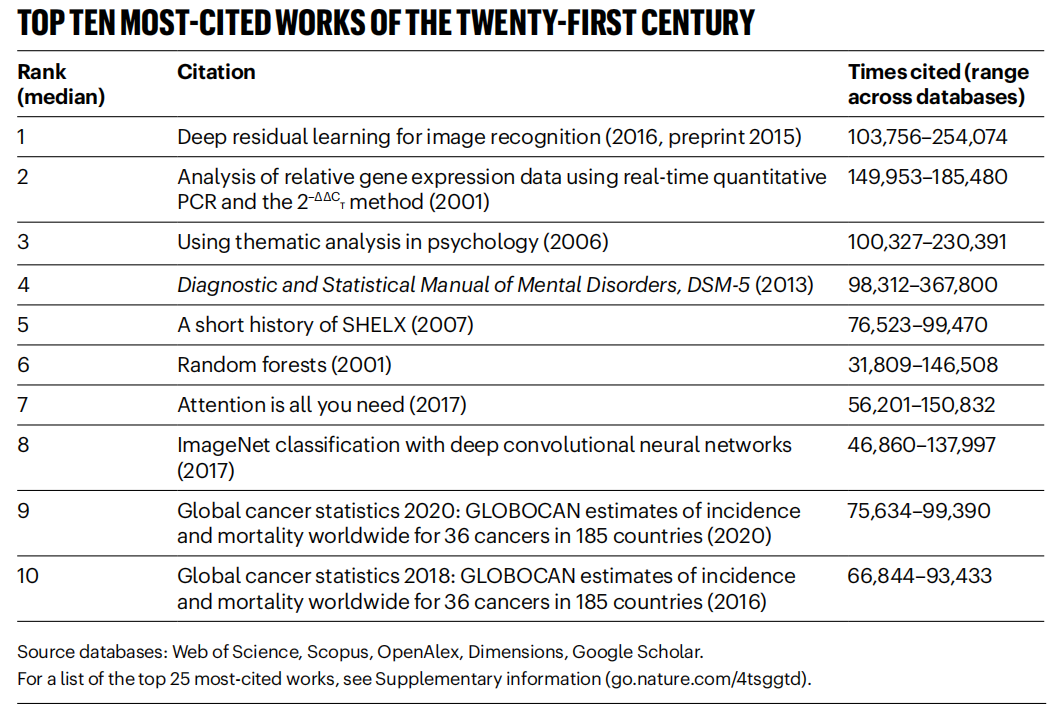
《Nature》 recopila los artículos más citados del siglo XXI, el campo de la IA domina: La revista 《Nature》, mediante la integración de datos de 5 bases de datos, ha publicado la lista de los 25 artículos más citados del siglo XXI. El artículo de ResNets de Microsoft de 2016 (escrito por Kaiming He y otros) ocupa el primer lugar en la clasificación general; esta investigación es fundamental para el progreso del deep learning y la IA. Los primeros puestos de la lista también incluyen varios artículos relacionados con la IA, como Random Forests (6º), Attention is all you need (Transformer, 7º), AlexNet (8º), U-Net (12º), revisión de Deep Learning (Hinton et al., 16º) y el dataset ImageNet (Fei-Fei Li et al., 24º). Esto refleja el rápido desarrollo y la amplia influencia de la tecnología de IA en este siglo. El artículo también señala que la popularidad de los preprints ha añadido complejidad a las estadísticas de citas. (Fuente: Nature最新统计!盘点引领人类进入「AI时代」的论文,ResNets引用量第一!
)
Instituciones como la Universidad de Beihang publican una revisión sobre LLM Ensemble: Investigadores de la Universidad de Aeronáutica y Astronáutica de Beijing y otras instituciones han publicado la última revisión sobre el ensamblaje de grandes modelos de lenguaje (LLM Ensemble). LLM Ensemble se refiere a combinar las fortalezas de múltiples LLM en la fase de inferencia para procesar las consultas de los usuarios. Esta revisión propone una taxonomía de LLM Ensemble (ensamblaje pre-inferencia, ensamblaje intra-inferencia, ensamblaje post-inferencia, subdividido en siete categorías de métodos), revisa sistemáticamente los últimos avances en cada tipo de método, discute problemas de investigación relacionados (como la relación con la fusión de modelos, la colaboración de modelos, el aprendizaje débilmente supervisado), presenta conjuntos de pruebas de referencia, aplicaciones típicas, y finalmente resume y analiza los logros existentes y prospecta futuras direcciones de investigación, como un ensamblaje a nivel de fragmento más basado en principios, un post-ensamblaje no supervisado más refinado, etc. (Fuente: ArXiv 2025 | 北航等机构发布最新综述:大语言模型集成(LLM Ensemble)

)
Anthropic comparte patrones de uso y experiencias con Claude Code: Empleados de Anthropic han compartido las mejores prácticas internas y patrones efectivos para programar utilizando Claude Code. Estos patrones no solo son aplicables a Claude, sino que también son universalmente aplicables a la colaboración en programación con otros LLM. Se enfatiza la importancia de proporcionar un contexto claro, descomponer problemas complejos, hacer preguntas iterativas, aprovechar las diferentes fortalezas del modelo (como generación de código, explicación, refactorización) y realizar una validación efectiva. Estas experiencias tienen como objetivo ayudar a los desarrolladores a utilizar las herramientas de programación asistida por IA de manera más eficiente. (Fuente: AnthropicAI

)
Anthropic publica el dataset de valores de Claude: Anthropic ha publicado en Hugging Face Datasets un conjunto de datos llamado “values-in-the-wild”. Este dataset contiene 3307 valores expresados por Claude en millones de conversaciones del mundo real. La publicación de este dataset tiene como objetivo aumentar la transparencia del comportamiento del modelo y ponerlo a disposición de investigadores y el público para su descarga, exploración y análisis, con el fin de comprender mejor las tendencias de valores que manifiestan los grandes modelos de lenguaje en aplicaciones prácticas. (Fuente: huggingface、huggingface)
Diez puntos de vista clave sobre el despertar cognitivo de la IA: El artículo propone diez puntos de vista a nivel cognitivo sobre el desarrollo de la IA, con el objetivo de ayudar a las personas a comprender más profundamente el impacto y la esencia de la IA. Los puntos clave incluyen: la inteligencia de la IA difiere de la inteligencia humana (brecha de inteligencia); la IA provoca reflexiones sobre la naturaleza de la conciencia humana; la relación entre humanos y la IA está pasando de ser una herramienta a un socio colaborador; el desarrollo de la IA no debe limitarse a imitar el cerebro humano; los estándares de inteligencia evolucionan con el progreso de la IA; la IA podría desarrollar formas de inteligencia completamente nuevas; se debe considerar racionalmente la expresión emocional y las limitaciones cognitivas de la IA; la verdadera amenaza profesional proviene de no usar la IA, no de la IA en sí; en la era de la IA, debemos centrarnos en desarrollar habilidades exclusivamente humanas (creatividad, inteligencia emocional, pensamiento transdisciplinario); el significado último de investigar la IA es conocernos más profundamente a nosotros mismos como humanos. (Fuente: AI认知觉醒的10句话,一句顶万句,句句清醒

)
LlamaIndex comparte un tutorial para construir Agents de flujo de trabajo de documentos: La grabación de la charla del cofundador de LlamaIndex, Jerry Liu, comparte cómo construir Agents de flujo de trabajo de documentos utilizando LlamaIndex. El contenido cubre la evolución de LlamaIndex de RAG a knowledge agents, el uso de LlamaParse para procesar documentos complejos, el uso de Workflows para una orquestación flexible de Agents basada en eventos, casos de uso clave (investigación de documentos, generación de informes, automatización del procesamiento de documentos) y mejoras en la recuperación multimodal combinando texto e imágenes. (Fuente: jerryjliu0
)
Tutorial para construir Agents con LlamaIndex.TS: Miembros del equipo de LlamaIndex comparten un tutorial completo a nivel de código para construir Agents utilizando la versión TypeScript de LlamaIndex (LlamaIndex.TS). La grabación de la transmisión en vivo incluye los fundamentos de LlamaIndex, los conceptos de Agent y RAG, patrones agénticos comunes (encadenamiento, enrutamiento, paralelización, etc.), construcción de RAG agéntico en LlamaIndex.TS, y la construcción de una aplicación React full-stack que integra Workflows. (Fuente: jerryjliu0

)
Debate sobre si el aprendizaje por refuerzo realmente mejora la capacidad de razonamiento de los LLM: La discusión comunitaria se centra en un artículo que plantea la pregunta: ¿Puede el aprendizaje por refuerzo (RL) realmente incentivar a los grandes modelos de lenguaje (LLM) a desarrollar capacidades de razonamiento que superen las de sus modelos base? En la discusión se menciona que, aunque el RL (como RLHF) puede mejorar la alineación y el seguimiento de instrucciones del modelo, aún está por ver si puede mejorar sistemáticamente la lógica de razonamiento complejo intrínseca. Algunos opinan que el efecto actual del RL podría manifestarse más en la optimización de la expresión y el seguimiento de formatos específicos, en lugar de un salto fundamental en el razonamiento lógico. Will Brown señala que métricas como pass@1024 tienen un significado limitado al evaluar tareas de razonamiento matemático como AIME. (Fuente: natolambert

)
Debate sobre la terminología relacionada con los modelos del mundo: Un usuario de Reddit pregunta sobre la confusión de términos como “modelos del mundo (world models)”, “modelos del mundo fundacionales (foundation world models)”, “modelos fundacionales del mundo (world foundation models)”, etc. La comunidad responde señalando que “modelo del mundo” generalmente se refiere a una simulación o representación interna del entorno (mundo físico o un dominio específico como un tablero de ajedrez); “modelo fundacional” se refiere a un gran modelo preentrenado que puede servir como punto de partida para múltiples tareas posteriores. La combinación de estos términos podría referirse a la construcción de modelos fundacionales generalizables que puedan comprender y predecir la dinámica del mundo, pero la definición específica puede variar según el investigador, lo que refleja que la terminología en este campo aún no está completamente unificada. (Fuente: Reddit r/MachineLearning)
Debate sobre métodos para combinar XGBoost y GNN: Usuarios de Reddit discuten cómo combinar eficazmente XGBoost y redes neuronales de grafos (GNN) para tareas como la detección de fraudes. Un método común es utilizar los embeddings de nodos aprendidos por la GNN como nuevas características, que se introducen en XGBoost junto con los datos tabulares originales. La discusión considera que el desafío de este método radica en si los embeddings de GNN pueden proporcionar un valor significativo más allá de los datos originales y técnicas como SMOTE, de lo contrario, podrían introducir ruido. La clave del éxito reside en una estructura de grafo cuidadosamente diseñada y en si los embeddings de GNN pueden capturar información relacional (como anillos de fraude en la estructura del grafo) que XGBoost difícilmente podría obtener. (Fuente: Reddit r/MachineLearning)
💼 Negocios
Beijing celebra la primera maratón mundial de robots humanoides, explorando el “IP de tecnología deportiva”: Beijing Yizhuang celebró con éxito la primera media maratón mundial de robots humanoides, donde “corredores” de más de 20 empresas de robots humanoides compitieron junto a corredores humanos. El robot Tiangong Ultra ganó con un tiempo de 2 horas y 40 minutos, demostrando su velocidad y adaptabilidad al terreno. Songyan Dynamics N2 (subcampeón) y Zhuoyi Dexing Walker II (tercer puesto) también tuvieron un rendimiento destacado. El evento no fue solo una competición tecnológica, sino también una exploración de modelos de negocio. Los organizadores atrajeron inversiones a través de un mecanismo de “licitación tecnológica” e intentaron crear un IP de “robot + deporte”. El artículo explora las vías de comercialización como el desarrollo de IP de eventos de robots, patrocinios de robots, el surgimiento de la profesión de agente de robots, la fusión de turismo cultural deportivo y la promoción del deporte inteligente para todos, considerando que el mercado del deporte inteligente tiene un enorme potencial. (Fuente: 独家揭秘北京机器人马拉松:谁在打造下一个“体育科技IP”?

)
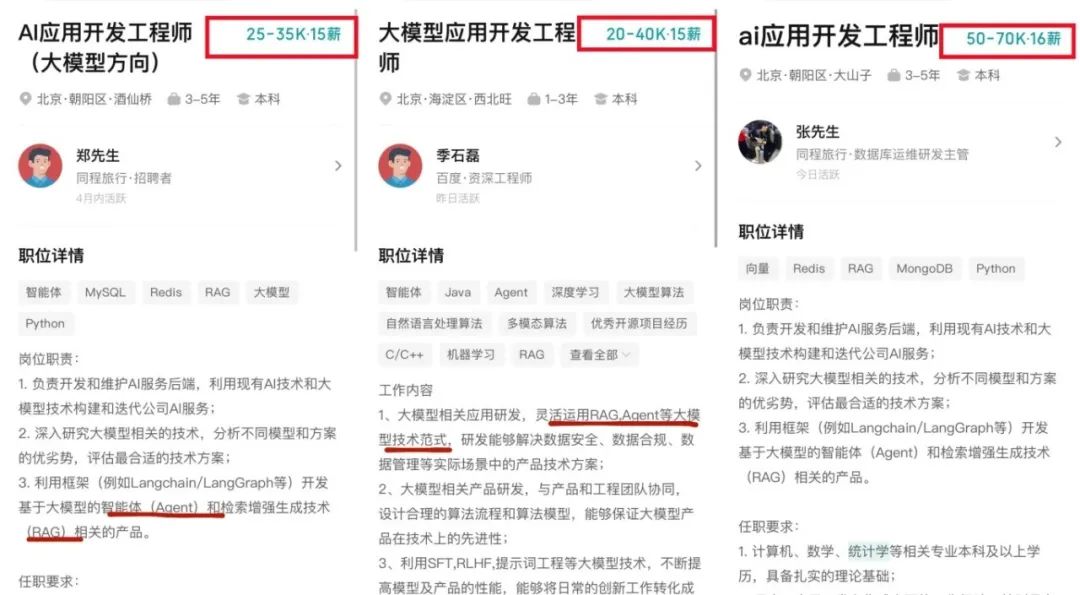
El desarrollo de aplicaciones de grandes modelos de IA se convierte en la nueva tendencia tecnológica, impactando los modelos de desarrollo tradicionales: Con la popularización de la tecnología de grandes modelos de IA, las empresas (como Alibaba, ByteDance, Tencent) están acelerando la integración de la IA (especialmente las tecnologías Agent y RAG) en sus negocios principales, lo que desafía el modelo de desarrollo tradicional CRUD. La demanda del mercado de ingenieros con capacidad de desarrollo de aplicaciones de grandes modelos de IA ha aumentado drásticamente, con salarios significativamente más altos, mientras que los puestos técnicos tradicionales enfrentan riesgos de reducción. “Entender de IA” ya no significa solo saber llamar a una API, sino que requiere dominar los principios de la IA, las tecnologías de aplicación y la experiencia práctica en proyectos. El artículo enfatiza que los profesionales de la tecnología deben aprender activamente la tecnología de grandes modelos de IA para adaptarse a los cambios de la industria y aprovechar las nuevas oportunidades de desarrollo profesional. Zhihu Zhixuetang ha lanzado para ello un “Campamento de Entrenamiento Práctico de Desarrollo de Aplicaciones de Grandes Modelos” gratuito. (Fuente: 炸裂!又一个AI大模型的新方向,彻底爆了!!
)
El auge de los servicios de optimización de LLM genera preocupaciones sobre el SEO versión IA: Un usuario de Reddit observa que los resultados de recomendación de productos de los chatbots de IA se están volviendo cada vez más consistentes, sospechando que están surgiendo servicios de “optimización de LLM”, similares a la optimización de motores de búsqueda (SEO). Hay informes de que equipos de marketing ya han contratado dichos servicios para asegurar que sus productos obtengan una mayor prioridad en las recomendaciones de IA, lo que lleva a una mayor exposición de productos de grandes marcas y a que los resultados ya no sean “orgánicos”. Esto ha generado preocupaciones sobre la imparcialidad y transparencia de las recomendaciones de IA, temiendo que la búsqueda/recomendación de IA termine siendo manipulada por intereses comerciales, al igual que los motores de búsqueda tradicionales. La comunidad pide más discusión y atención sobre este fenómeno. (Fuente: Reddit r/ArtificialInteligence)
Google muestra un fuerte rendimiento en la carrera de los LLM, mientras Meta y OpenAI enfrentan desafíos: Un artículo de IEEE Spectrum analiza que, aunque OpenAI y Meta dominaron el desarrollo temprano de los LLM, recientemente Google, con sus potentes nuevos modelos (como la serie Gemini), está recuperando terreno e incluso liderando en algunos aspectos. Al mismo tiempo, Meta y OpenAI parecen encontrar algunos desafíos o controversias en el lanzamiento de modelos y estrategias de mercado (por ejemplo, se sugiere que los modelos de Meta podrían estar entrenados sobre otros modelos, la estrategia de lanzamiento y la transparencia de OpenAI son cuestionadas). El artículo considera que el panorama competitivo en el campo de los LLM está cambiando, y la inversión continua y la fortaleza tecnológica de Google la convierten en una fuerza a tener en cuenta. (Fuente: Reddit r/MachineLearning

)
🌟 Comunidad
El renacimiento y los desafíos de los robots humanoides: mirando al futuro desde la media maratón: Recientemente, el interés en los robots humanoides ha resurgido, desde actuaciones en galas hasta la media maratón en Beijing Yizhuang, generando una amplia atención. El artículo explora la intención original del diseño de robots humanoides (imitar a los humanos para adaptarse a entornos y herramientas humanas) y sus ventajas sobre otros tipos de robots (más fáciles de generar empatía, beneficiosos para la interacción humano-robot). La media maratón de Yizhuang expuso los desafíos actuales de los robots humanoides en navegación autónoma de larga distancia, equilibrio, consumo de energía, etc., pero también mostró el progreso de productos como Tiangong Ultra y Songyan Dynamics N2. El artículo señala que el desarrollo de robots humanoides se beneficia del intercambio de código abierto (como el plan de código abierto de Tiangong), pero también enfrenta cuellos de botella de datos. Finalmente, los robots humanoides se consideran un destino importante en el campo de la robótica, no solo son una manifestación de la tecnología, sino que también albergan profundas reflexiones humanas sobre nosotros mismos y el futuro inteligente. (Fuente: 人形机器人:最初的设想,最后的归宿

)
Debate comunitario sobre Vibe Coding: los límites de la programación asistida por IA: El CTO de Canva comentó sobre el concepto de “Vibe Coding” propuesto por Andrej Karpathy (refiriéndose a desarrolladores que principalmente ajustan Prompts para que la IA genere código, prestando menos atención a los detalles). El CTO de Canva opina que este método solo es adecuado para escenarios únicos como el desarrollo de prototipos, y nunca debe usarse en entornos de producción, porque el código generado por IA a menudo tiene errores, vulnerabilidades de seguridad o problemas de rendimiento, y debe ser supervisado y revisado estrictamente por ingenieros experimentados. Enfatiza que la cultura de ingeniería de Canva se basa en la propiedad del código y la revisión por pares, y las herramientas de IA refuerzan estos principios. La comunidad debate intensamente sobre esto: algunos coinciden con los riesgos en producción y creen que el código de IA necesita supervisión humana; otros creen que la IA se desarrolla rápidamente y los líderes de ingeniería deben reevaluar constantemente las capacidades de la IA, citando casos como Airbnb que utiliza IA para acelerar proyectos. (Fuente: dotey

)
Discusión comunitaria sobre el rendimiento de Llama 4 y los modelos de OpenAI en tareas de contexto largo: Miembros de la comunidad compartieron los resultados del modelo Llama 4 en el benchmark OpenAI-MRCR (recuperación y respuesta a preguntas multi-salto y multi-documento). Los datos muestran que Llama 4 Scout (versión más pequeña) tiene un rendimiento similar a GPT-4.1 Nano en longitudes de contexto más largas; Llama 4 Maverick (versión más grande) tiene un rendimiento cercano pero ligeramente inferior a GPT-4.1 Mini. En general, para tareas con contexto de hasta 32k, OpenAI o3 o Gemini 2.5 Pro son buenas opciones (o3 podría ser mejor en razonamiento complejo); por encima de 32k de contexto, Gemini 2.5 Pro muestra un rendimiento más estable; pero cuando el contexto supera los 512k, la precisión de Gemini 2.5 Pro también cae por debajo del 80%, recomendándose el procesamiento por fragmentos. Esto indica que en el procesamiento de contexto ultralargo, todos los modelos aún tienen margen de mejora. (Fuente: dotey
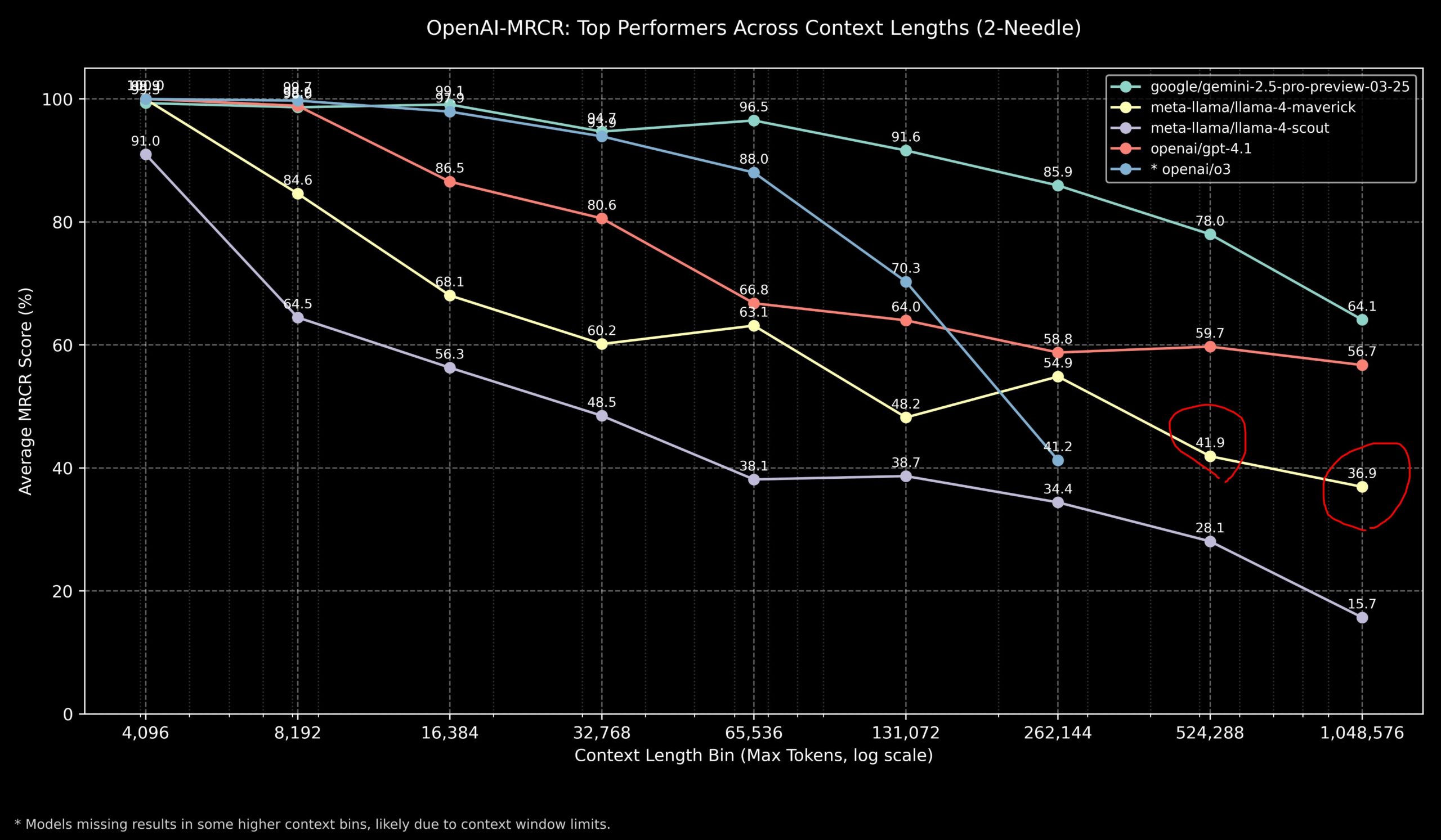
)
Evaluación comunitaria del modelo GLM-4 32B muestra un rendimiento sorprendente: Un usuario de Reddit compartió su experiencia ejecutando localmente el modelo cuantizado GLM-4 32B Q8, describiendo su rendimiento como “asombroso”, superando a otros modelos locales de nivel similar (aprox. 32B), e incluso mejor que algunos modelos de 72B, comparable a una versión local de Gemini 2.5 Flash. El usuario elogió especialmente el rendimiento del modelo en la generación de código, afirmando que no escatima en la longitud de la salida, puede proporcionar detalles completos de implementación y demostró su capacidad para generar visualizaciones complejas HTML/JS (como el sistema solar, redes neuronales) desde cero, con resultados superiores a Gemini 2.5 Flash. El modelo también funcionó bien en el uso de herramientas, pudiendo colaborar con herramientas como Cline/Aider. (Fuente: Reddit r/LocalLLaMA
)
Discusión comunitaria sobre las puntuaciones de benchmark de OpenAI o3 que no cumplen las expectativas: Medios como TechCrunch señalan que las puntuaciones del nuevo modelo o3 de OpenAI en algunos benchmarks (como ARC-AGI-2) parecen ser inferiores al nivel que la compañía insinuó inicialmente. Aunque OpenAI mostró el rendimiento SOTA de o3 en múltiples áreas, las puntuaciones cuantitativas específicas y las comparaciones directas con otros modelos de primer nivel han generado discusión en la comunidad. Algunos usuarios creen que depender únicamente de las puntuaciones de los benchmarks puede no reflejar completamente la capacidad real del modelo, especialmente en razonamiento complejo y uso de herramientas. La comparación con benchmarks más centrados en capacidades AGI como ARC-AGI-2 podría ser más relevante. (Fuente: Reddit r/deeplearning

)
Demis Hassabis predice que la AGI podría llegar en 5-10 años: En una entrevista de 60 Minutos, el CEO de Google DeepMind, Demis Hassabis, discutió el progreso de la AGI. Destacó Astra, que puede interactuar en tiempo real, y los modelos Gemini que aprenden a actuar en el mundo. Hassabis predice que la AGI con generalidad a nivel humano podría lograrse en los próximos 5 a 10 años, lo que revolucionaría campos como la robótica, el desarrollo de fármacos, etc., y podría traer una gran abundancia material, resolviendo desafíos globales. Al mismo tiempo, también enfatizó los riesgos que podría traer la IA avanzada (como el abuso), y la necesidad de priorizar las medidas de seguridad y las consideraciones éticas al avanzar hacia esta tecnología transformadora. (Fuente: Reddit r/ArtificialInteligence、Reddit r/artificial、AravSrinivas)
Usuario comparte experiencia exitosa de fitness asistido por IA: Un usuario de Reddit compartió su experiencia de éxito en la pérdida de peso y tonificación utilizando ChatGPT. El usuario pasó de 240 libras a 165 libras en un año, logrando un físico tonificado. ChatGPT desempeñó un papel clave: elaborando planes de dieta y ejercicio amigables para principiantes, ajustándolos según las fotos de progreso semanales y los eventos de la vida del usuario, y proporcionando motivación en los momentos bajos. El usuario considera que, en comparación con nutricionistas y entrenadores personales caros y difíciles de mantener a largo plazo, la IA ofreció una solución altamente personalizada y de coste extremadamente bajo, demostrando el potencial de la IA en la gestión personalizada de la salud. (Fuente: Reddit r/ArtificialInteligence)
Respuesta anómala de elogio de Claude genera discusión: Un usuario informó que, mientras usaba Claude para investigar sobre sistemas informáticos y seguridad, se encontró dos veces con que el modelo, después de una respuesta normal, añadía repentinamente una frase de elogio irrelevante: “This was a great question king, you are the perfect male specimen.” (Buena pregunta, rey, eres el espécimen masculino perfecto). El usuario compartió el enlace de la conversación y preguntó por la causa. La comunidad se mostró curiosa y perpleja, especulando que podría ser un patrón en los datos de entrenamiento del modelo activado accidentalmente, un error relacionado con el nombre de usuario, o alguna forma de fallo de alineación o “alucinación”. (Fuente: Reddit r/ClaudeAI)
Debate comunitario sobre si la IA puede realmente “pensar fuera de la caja”: Un usuario de Reddit inició una discusión sobre si la IA puede realizar una verdadera innovación del tipo “pensar fuera de la caja”. La mayoría de los comentarios consideran que la IA actual puede realizar combinaciones y conexiones novedosas basadas en el conocimiento existente, generando ideas que parecen innovadoras, pero su creatividad sigue limitada por los datos de entrenamiento y los algoritmos. La “innovación” de la IA se parece más a un reconocimiento y combinación eficiente de patrones que a un avance basado en una comprensión profunda, intuición o conceptos completamente nuevos como en los humanos. Sin embargo, también hay opiniones que sostienen que la innovación humana también se basa en conexiones únicas de conocimiento existente, y la IA tiene un enorme potencial en este aspecto, especialmente en el manejo de datos complejos y el descubrimiento de correlaciones ocultas que podrían superar a los humanos. (Fuente: Reddit r/ArtificialInteligence)
¿Claude muestra “compasión” en el tres en raya?: Un experimento descubrió que si, antes de jugar al tres en raya (Tic Tac Toe) con Claude, se le informa a Claude que uno ha tenido un día duro de trabajo, Claude parece “dejarse ganar” intencionadamente en la partida posterior, aumentando la probabilidad de elegir estrategias no óptimas. Este interesante hallazgo ha generado un debate sobre si la IA puede mostrar o simular compasión. Aunque es más probable que se trate de que el modelo ajuste su estrategia de comportamiento en función de la entrada (por ejemplo, para evitar que el usuario se sienta frustrado), en lugar de una verdadera reacción emocional, revela los complejos patrones de comportamiento que la IA puede generar en la interacción humano-máquina. (Fuente: Reddit r/ClaudeAI)
Discusión comunitaria sobre cómo demostrar la conciencia humana a la IA: Un usuario de Reddit plantea una pregunta filosófica: si en el futuro fuera necesario demostrar a una IA que los humanos poseen conciencia, ¿cómo se haría? Los comentarios señalan que esto toca el “problema difícil de la conciencia” (Hard Problem of Consciousness). Actualmente no existe un método reconocido para demostrar objetivamente la existencia de la experiencia subjetiva (qualia). Cualquier prueba de comportamiento externo (como el test de Turing) podría ser simulada por una IA suficientemente compleja. Si se establece una definición de conciencia demasiado estricta que excluya la posibilidad de la IA, entonces, desde la perspectiva de la IA, los humanos tampoco podrían cumplir su definición de “conciencia”. Este problema subraya la profunda dificultad de definir y verificar la conciencia. (Fuente: Reddit r/artificial

)
Discusión comunitaria sobre la mejor elección de modelo para LLM locales según la capacidad de VRAM: La comunidad de Reddit inició una discusión para recopilar las mejores opciones para ejecutar grandes modelos de lenguaje locales en diferentes capacidades de VRAM (de 8GB a 96GB). Los usuarios compartieron sus experiencias y recomendaciones, por ejemplo: 8GB recomiendan Gemma 3 4B; 16GB recomiendan Gemma 3 12B o Phi 4 14B; 24GB recomiendan Mistral small 3.1 o la serie Qwen; 48GB recomiendan Nemotron Super 49B; 72GB recomiendan Llama 3.3 70B; 96GB recomiendan Command A 111B. La discusión también enfatizó que “lo mejor” depende de la tarea específica (codificación, chat, visión, etc.), y mencionó el impacto de la cuantización (como 4-bit) en los requisitos de VRAM. (Fuente: Reddit r/LocalLLaMA)
Salida tipo “colapso” de OpenAI Codex genera análisis: Un usuario informó que mientras usaba OpenAI Codex para una refactorización de código a gran escala, el modelo dejó de generar código repentinamente y en su lugar produjo miles de líneas repetitivas de “END”, “STOP”, así como frases similares a un colapso como “My brain is broken”, “please kill me”. El análisis sugiere que esto podría deberse a una combinación de factores: un Prompt demasiado grande (cercano al límite de 200k tokens), un consumo de inferencia interna que excede el presupuesto, el modelo cayendo en un bucle degenerativo de tokens de terminación de alta probabilidad, y el modelo “alucinando” frases relacionadas con estados de fallo a partir de sus datos de entrenamiento, lo que lleva a un fallo en cascada. (Fuente: Reddit r/ArtificialInteligence)
Aclaración de Sam Altman sobre la cuestión de la cortesía en la interacción con la IA: Circuló en la comunidad una discusión sobre si Sam Altman consideraba una pérdida de tiempo decir “gracias” a ChatGPT. La interacción real en Twitter muestra que Altman respondió “no es necesario” a una publicación de un usuario sobre si “es necesaria la cortesía con los LLM”, pero ese usuario luego bromeó diciendo “¿acaso no has dicho gracias ni una sola vez?”. Esto sugiere que el comentario de Altman podría estar más dirigido a la eficiencia técnica que a una norma de etiqueta en la interacción humano-máquina, pero fue sacado de contexto por algunos medios. La comunidad reaccionó de diversas maneras, y muchas personas expresaron que todavía mantienen la cortesía con la IA por costumbre. (Fuente: Reddit r/ChatGPT
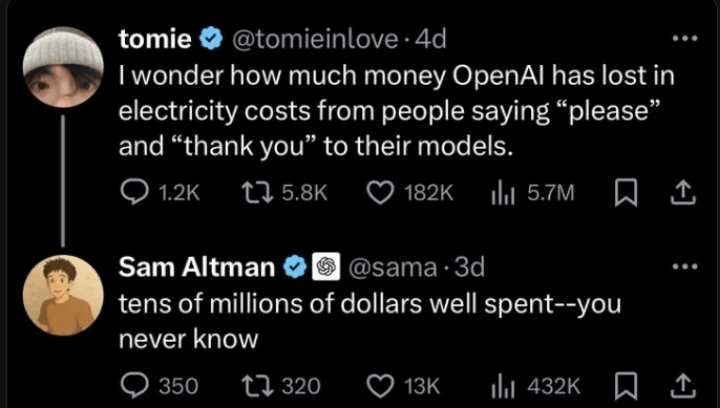
)
La etiqueta “thinking budget” en las respuestas de Claude llama la atención: Un usuario descubrió en los mensajes del sistema de Claude.ai que, al activar la función de “pensar”, se adjunta una etiqueta <max_thinking_length> (por ejemplo, <max_thinking_length>16000</max_thinking_length>). Esto es similar al parámetro “thinking_budget” en la API de Google Gemini 2.5 Flash, lo que sugiere que podría existir un mecanismo interno en el modelo para controlar la profundidad de la inferencia. El usuario intentó modificar esta etiqueta en el Prompt para influir en la longitud de la salida, pero no observó un efecto claro, especulando que la etiqueta en la versión web podría ser solo una marca interna y no un parámetro controlable por el usuario. (Fuente: Reddit r/ClaudeAI)
💡 Otros
Se inicia la elaboración del primer “Estándar de Despliegue Privado de Grandes Modelos de IA” de China: Para hacer frente a los desafíos que enfrentan las empresas en la selección de tecnología, la estandarización de procesos, la seguridad, el cumplimiento normativo y la evaluación de efectos al desplegar grandes modelos de IA de forma privada, el Centro de Estándares Zhihe, junto con el Tercer Instituto del Ministerio de Seguridad Pública y otras 12 unidades, ha iniciado la elaboración del estándar grupal “Guía Técnica de Implementación y Evaluación para el Despliegue Privado de Grandes Modelos de Inteligencia Artificial”. Este estándar tiene como objetivo cubrir todo el proceso, desde la selección del modelo, la planificación de recursos, la implementación del despliegue, la evaluación de la calidad hasta la optimización continua, integrando tecnología, seguridad, evaluación y casos de estudio, y reuniendo la experiencia de los usuarios de modelos, proveedores de servicios técnicos y evaluadores de calidad. Se invita a más empresas e instituciones relevantes a participar en la elaboración del estándar. (Fuente: 12家单位已加入!全国首部「AI大模型私有化部署标准」欢迎参与!

)
La gobernanza de la IA se convierte en clave para definir la próxima generación de IA: A medida que la tecnología de IA se vuelve cada vez más potente y omnipresente, la gobernanza de la IA (Governance) se vuelve crucial. Un marco de gobernanza eficaz debe garantizar que el desarrollo y la aplicación de la IA cumplan con las normas éticas y las regulaciones legales, protejan la seguridad de los datos y la privacidad, y promuevan la equidad y la transparencia. La falta de gobernanza puede conducir a la amplificación de sesgos, un mayor riesgo de abuso y una pérdida de confianza social. El artículo enfatiza que establecer un sistema sólido de gobernanza de la IA es una condición necesaria para promover el desarrollo saludable y sostenible de la IA, y también es clave para que las empresas establezcan una ventaja competitiva y la confianza del usuario en la era de la IA. (Fuente: Ronald_vanLoon

)
El sistema legal se esfuerza por alcanzar el desarrollo de la IA y el problema del robo de datos: El artículo explora los desafíos que enfrenta el sistema legal actual al abordar la rápida evolución de la tecnología de IA, especialmente en lo que respecta a la privacidad de los datos y el robo de datos. La IA tiene enormes necesidades de datos, y el origen y uso de los datos de entrenamiento han generado controversias legales sobre derechos de autor, privacidad y seguridad. Las leyes actuales a menudo van a la zaga del desarrollo tecnológico y tienen dificultades para regular eficazmente la extracción de datos, los sesgos en el entrenamiento de modelos y la propiedad intelectual del contenido generado por IA, entre otros problemas. El artículo pide un fortalecimiento de la legislación y la regulación para seguir el ritmo del progreso de la IA, proteger los derechos individuales y promover la innovación. (Fuente: Ronald_vanLoon

)
Aplicaciones de la IA y la robótica en el sector agrícola: La inteligencia artificial y la tecnología robótica están demostrando su potencial en el sector agrícola. Las aplicaciones incluyen la agricultura de precisión (optimización del riego y la fertilización mediante sensores y análisis de IA), equipos automatizados (como tractores autónomos, robots recolectores), monitorización de cultivos (uso de drones e identificación de imágenes para detectar plagas y enfermedades) y predicción de rendimiento, entre otros. Se espera que estas tecnologías aumenten la eficiencia de la producción agrícola, reduzcan el desperdicio de recursos, disminuyan los costes laborales y promuevan el desarrollo sostenible de la agricultura. (Fuente: Ronald_vanLoon)
Demostración de fútbol robótico impulsado por IA: El vídeo muestra una escena de robots jugando al fútbol. Esto refleja los avances de la IA en el control de robots, la planificación del movimiento, la percepción y la colaboración. El fútbol robótico no es solo un proyecto de entretenimiento y competición, sino también una plataforma para investigar y probar sistemas multi-robot, la toma de decisiones en tiempo real y la interacción en entornos dinámicos complejos. (Fuente: Ronald_vanLoon)
Desarrollo de la tecnología de cirugía asistida por robot: Los sistemas de cirugía asistida por robot (como el robot quirúrgico Da Vinci), al ofrecer operaciones mínimamente invasivas, visión 3D de alta definición y mayor flexibilidad y precisión, están cambiando el campo de la cirugía. La integración de la IA promete mejorar aún más la planificación quirúrgica, la navegación en tiempo real y el apoyo a la toma de decisiones intraoperatorias, mejorando así los resultados quirúrgicos, acortando el tiempo de recuperación y ampliando el alcance de la cirugía mínimamente invasiva. (Fuente: Ronald_vanLoon)
Tecnología de asistencia para personas con discapacidad: La IA y la tecnología robótica están desarrollando herramientas de asistencia más innovadoras para ayudar a las personas con discapacidad a mejorar su calidad de vida e independencia. Los ejemplos pueden incluir prótesis inteligentes, sistemas de asistencia visual, dispositivos domésticos controlados por voz y robots de asistencia capaces de proporcionar apoyo físico o realizar tareas diarias. (Fuente: Ronald_vanLoon)
El robot biónico Unitree G1 muestra agilidad: Unitree Robotics ha mostrado una versión mejorada de su robot biónico G1, destacando la agilidad y flexibilidad de su movimiento. El desarrollo de este tipo de robots humanoides o biónicos combina la IA (para percepción, toma de decisiones, control) y la ingeniería mecánica avanzada, con el objetivo de simular la capacidad de movimiento biológico para adaptarse a entornos complejos y realizar tareas diversas. (Fuente: Ronald_vanLoon)
Google DeepMind explora la posibilidad de comunicación entre IA y delfines: Un proyecto de investigación de Google DeepMind sugiere la posibilidad de utilizar modelos de IA para analizar y comprender la comunicación animal (como la de los delfines mencionada aquí). Mediante el análisis de señales acústicas complejas con machine learning, la IA podría ayudar a decodificar los patrones y la estructura del lenguaje animal, abriendo nuevas vías para la investigación de la comunicación entre especies. (Fuente: Ronald_vanLoon)
La plataforma Hugging Face añade un simulador de robots: Hugging Face ha anunciado la introducción de un nuevo simulador de robots. La simulación de robots es un paso clave para entrenar y probar la interacción de los robots con el mundo físico en un entorno virtual (como agarrar, moverse), especialmente antes de aplicar la IA a robots físicos (Physical AI). Esta medida indica que Hugging Face está ampliando las capacidades de su plataforma para apoyar mejor la investigación y el desarrollo en los campos de la robótica y la inteligencia corporeizada. (Fuente: huggingface)