
Palabras clave:Cuatro dragones de IA, Inteligencia encarnada, Robots humanoides, Muro de memoria, Modelo multimodal SenseTime Rixin V6, Conjunto de datos Open X-Embodiment, Robot Optimus de Tesla, Tecnología 3D FeRAM, Media maratón del robot Tianguan Ultra, Modelo cuantizado Gemma 3 QAT, Adquisición de Pollen Robotics por Hugging Face, Flujo de trabajo de documentos para agentes LlamaIndex
«`es
🔥 En Foco
Los “Cuatro Dragones de la IA” enfrentan desafíos y transformación: Empresas como SenseTime, Megvii, CloudWalk e Yitu, alguna vez aclamadas como los “Cuatro Dragones de la IA”, han enfrentado dificultades de comercialización y pérdidas continuas en los últimos años. Por ejemplo, SenseTime perdió 4.3 mil millones de yuanes en 2024, con pérdidas acumuladas que superan los 54.6 mil millones de yuanes; CloudWalk perdió cerca de 600-700 millones de yuanes en 2024, con pérdidas acumuladas que superan los 4.4 mil millones de yuanes. Para hacer frente a los desafíos, las empresas han realizado ajustes estratégicos, incluyendo despidos, reducciones salariales y reestructuraciones de negocio. Ante la nueva ola de IA dominada por los modelos de lenguaje grandes, los “Cuatro Dragones”, con su ADN en tecnología visual, están girando activamente hacia modelos grandes multimodales y el campo de la AGI. SenseTime lanzó el modelo multimodal “Ririxin V6” para competir con GPT-4o e invierte fuertemente en la construcción de centros de computación inteligente; Yitu se enfoca en modelos multimodales centrados en la visión y colabora con Huawei para reducir costos de hardware; CloudWalk también colabora con Huawei para lanzar una máquina todo en uno de entrenamiento e inferencia de modelos grandes; Megvii, por su parte, aprovecha su ventaja en algoritmos para entrar en soluciones puramente visuales para la conducción inteligente. Estas iniciativas indican que están esforzándose por mantenerse en la mesa de juego de la IA y adaptarse al nuevo entorno de mercado. (Fuente: 36氪)

Dilema de datos en inteligencia corpórea y avances en datasets de código abierto: El desarrollo de robots humanoides e inteligencia corpórea (embodied intelligence) enfrenta un cuello de botella crítico de datos. La falta de datos de entrenamiento de alta calidad obstaculiza el avance de sus capacidades. A diferencia de los modelos de lenguaje que disponen de enormes cantidades de datos textuales de Internet, los robots necesitan datos diversificados de interacción con el mundo físico, cuya adquisición es costosa. Para resolver este problema, instituciones de investigación y empresas están construyendo y publicando activamente datasets de código abierto, como Open X-Embodiment de Google DeepMind en colaboración con múltiples instituciones, ARIO del Laboratorio Pengcheng y otros, RoboMIND del Centro de Innovación de Beijing, AgiBot World de Zhiyuan Robot (que incluye datos de tareas complejas de larga duración en escenarios reales) y el dataset de simulación AgiBot Digital World, el dataset de operaciones G1 de Unitree, etc. Aunque la escala de estos datasets sigue siendo mucho menor que la de los datos textuales, mediante la unificación de estándares, la mejora de la calidad y el enriquecimiento de escenarios, están impulsando el desarrollo del campo de la inteligencia corpórea, sentando las bases para alcanzar un “momento ImageNet”. (Fuente: 36氪)

Amanecer de la producción en masa de robots humanoides: avances en datos, simulación y generalización: A pesar de enfrentar desafíos como el alto costo de recolección de datos y la débil capacidad de generalización, varias compañías (Tesla, Figure AI, 1X, Zhiyuan, Unitree, UBTECH, etc.) planean lograr la producción en masa de robots humanoides para 2025. Las soluciones incluyen: 1) Entrenamiento a gran escala con máquinas reales, apoyado por gobiernos (Beijing, Shanghai, Shenzhen, Guangdong) para construir bases de recolección de datos y establecer estándares; 2) Entrenamiento avanzado por simulación, utilizando modelos del mundo como Nvidia Cosmos y Google Genie2 para generar entornos virtuales físicamente realistas, reduciendo costos y aumentando la eficiencia; 3) Generalización potenciada por IA, a través de nuevos modelos de acción como Helix de Figure AI, la arquitectura ViLLA de Zhiyuan GO-1, Gemini Robotics de Google, etc., utilizando menos datos para lograr una comprensión generalizada de las operaciones físicas, permitiendo a los robots manejar objetos no vistos y adaptarse a nuevos entornos. Estos avances tecnológicos presagian una posible aceleración de la aplicación comercial de los robots humanoides. (Fuente: 36氪)

El desarrollo de la IA se enfrenta a la crisis del “muro de la memoria”, nuevas tecnologías de almacenamiento buscan avances: El crecimiento exponencial de la escala de los modelos de IA plantea serios desafíos para el ancho de banda de la memoria. El crecimiento del ancho de banda de la DRAM tradicional está muy por detrás del crecimiento de la potencia de cálculo, formando un cuello de botella conocido como “muro del almacenamiento” que limita el rendimiento del procesador. HBM, mediante la tecnología de apilamiento 3D, ha aumentado significativamente el ancho de banda, aliviando parte de la presión, pero su proceso de fabricación es complejo y costoso. Por ello, la industria está explorando activamente nuevas tecnologías de almacenamiento: 1) RAM ferroeléctrica 3D (FeRAM): Como SunRise Memory, que utiliza el efecto ferroeléctrico del HfO2 para lograr almacenamiento de alta densidad, no volátil y de bajo consumo. 2) DRAM + memoria no volátil: Neumonda colabora con FMC para utilizar HfO2 y convertir los condensadores de DRAM en almacenamiento no volátil. 3) DRAM IGZO 2T0C: imec propone usar dos transistores de óxido en lugar de la estructura tradicional 1T1C, eliminando la necesidad de condensadores para lograr bajo consumo, alta densidad y largo tiempo de retención. 4) Memoria de cambio de fase (PCM): Utiliza el cambio de fase de materiales para almacenar datos, reduciendo el consumo de energía. 5) UK III-V Memory: Basada en GaSb/InAs, combina la velocidad de la DRAM con la no volatilidad de la memoria flash. 6) SOT-MRAM: Utiliza el par de transferencia de espín-órbita para lograr bajo consumo y alta eficiencia energética. Se espera que estas tecnologías rompan el cuello de botella de la DRAM y remodelen el panorama del mercado de almacenamiento. (Fuente: 36氪)
🎯 Movimientos
Robot Tiangong completa desafío de media maratón, planea producción en pequeños lotes: El robot “Tiangong Ultra” del Centro de Innovación de Robots Humanoides de Beijing (1.8 metros de altura, 55 kg de peso) ganó la primera carrera de media maratón para robots humanoides, completando aproximadamente 21 km en 2 horas, 40 minutos y 42 segundos. El evento puso a prueba la resistencia, estructura, percepción y algoritmos de control del robot en condiciones de carretera complejas. El equipo indicó que, mediante la optimización de la estabilidad de las articulaciones, la resistencia al calor, el sistema de consumo de energía, los algoritmos de equilibrio y planificación de la marcha, y equipado con la plataforma de desarrollo propio “Huisi Kaiwu” (cerebro corpóreo + cerebelo), el robot logró una planificación autónoma de la ruta y ajustes en tiempo real bajo navegación inalámbrica. Completar la maratón demostró su fiabilidad básica, sentando las bases para la producción en masa. El robot Tiangong 2.0 saldrá pronto a la venta, con planes de producción en pequeños lotes, y el objetivo futuro es aplicarlo en campos como la industria, la logística, operaciones especiales y servicios domésticos. (Fuente: 36氪)

China desarrolla un cerebro de robot utilizando células humanas cultivadas: Según informes, investigadores chinos están desarrollando un robot impulsado por células cerebrales humanas cultivadas. Esta investigación tiene como objetivo explorar las posibilidades de la computación biológica, utilizando la capacidad de aprendizaje y adaptación de las neuronas biológicas para controlar el hardware del robot. Aunque los detalles específicos y la etapa de progreso aún no están claros, esta dirección representa una exploración de vanguardia en el campo de la intersección entre robótica, inteligencia artificial y biotecnología, y podría abrir nuevas vías para el desarrollo futuro de sistemas robóticos más inteligentes y adaptables. (Fuente: Ronald_vanLoon)
Excelente rendimiento del modelo cuantizado Gemma 3 QAT: Un usuario comparó la versión QAT (Quantization Aware Training) del modelo Google Gemma 3 27B con otras versiones cuantizadas Q4 (Q4_K_XL, Q4_K_M) en el benchmark GPQA Diamond. Los resultados mostraron que la versión QAT tuvo el mejor rendimiento (36.4% de precisión) y el menor uso de VRAM (16.43 GB), superando a Q4_K_XL (34.8%, 17.88 GB) y Q4_K_M (33.3%, 17.40 GB). Esto indica que la tecnología QAT reduce eficazmente los requisitos de recursos manteniendo el rendimiento del modelo. (Fuente: Reddit r/LocalLLaMA)
Rumor: AMD lanzará tarjetas gráficas RDNA 4 Radeon PRO con 32GB de VRAM: VideoCardz informa que AMD está preparando tarjetas gráficas de la serie Radeon PRO basadas en la GPU Navi 48 XTW, que contarán con 32GB de memoria de vídeo. Si es cierto, esto ofrecería una nueva opción para los usuarios que necesitan gran cantidad de VRAM para el entrenamiento e inferencia de modelos de IA locales, especialmente dado que la VRAM de las tarjetas gráficas de consumo suele ser limitada. Sin embargo, el rendimiento específico, el precio y la fecha de lanzamiento aún no se han anunciado, y su competitividad real está por verse. (Fuente: Reddit r/LocalLLaMA)

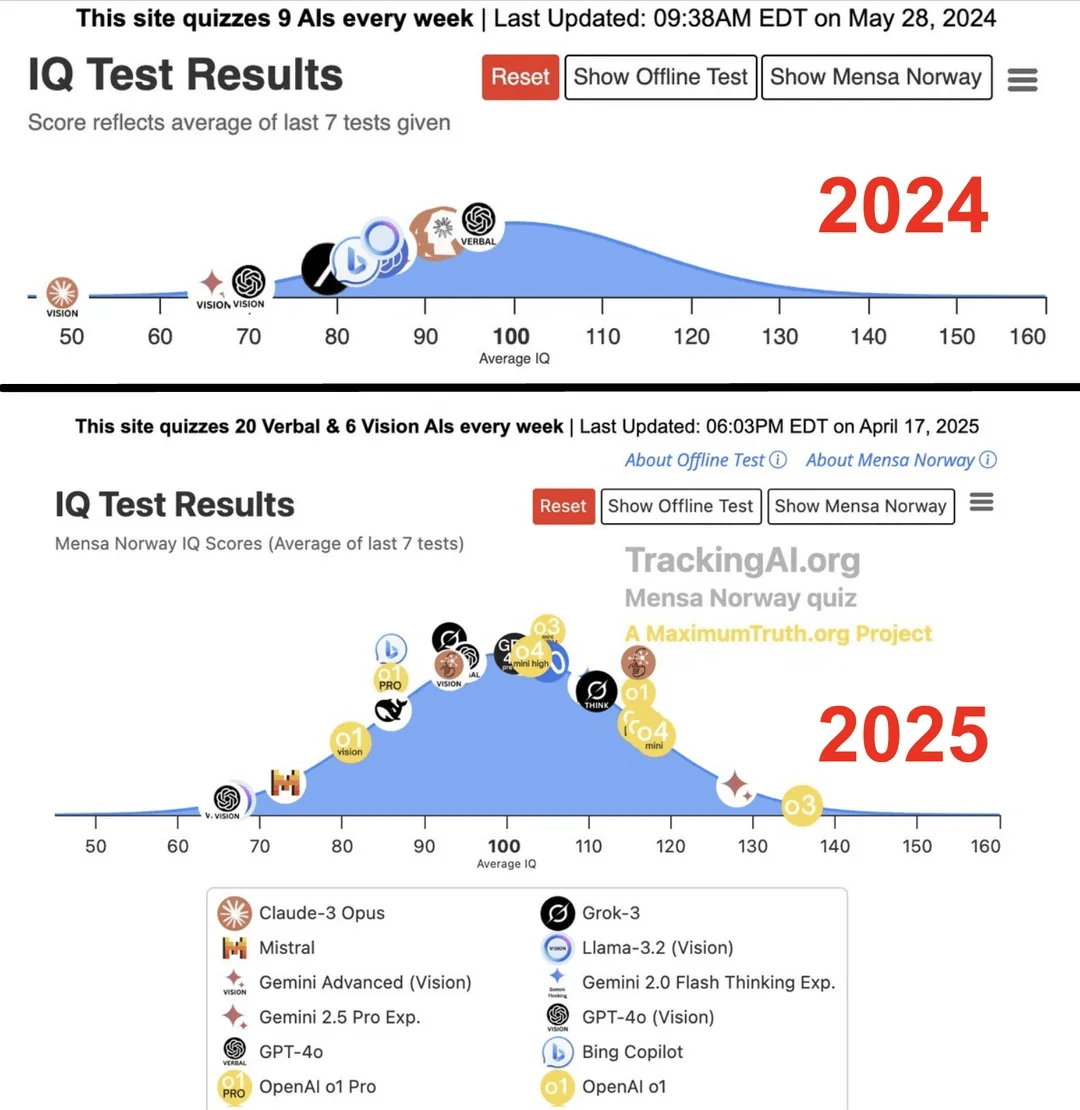
Estudio afirma que el coeficiente intelectual de la IA de vanguardia saltó de 96 a 136 en un año: Según una investigación publicada en el sitio web Maximum Truth (fiabilidad de la fuente por verificar), al realizar pruebas de IQ a modelos de IA, se encontró que el IQ de la IA más inteligente (posiblemente refiriéndose a la serie GPT) aumentó de 96 puntos (ligeramente por debajo del promedio humano) a 136 puntos (cercano al nivel de genio) en un año. Aunque la validez de las pruebas de IQ para medir la inteligencia de la IA es controvertida, y existe la posibilidad de contaminación de los datos de entrenamiento en las pruebas, este notable aumento refleja el rápido progreso de la IA en la capacidad de resolver problemas de pruebas de inteligencia estandarizadas. (Fuente: Reddit r/artificial)
🧰 Herramientas
OpenUI: Genera UI en tiempo real a través de descripciones: wandb ha lanzado OpenUI como código abierto, una herramienta que permite a los usuarios concebir y renderizar interfaces de usuario en tiempo real mediante descripciones en lenguaje natural. Los usuarios pueden solicitar modificaciones y convertir el HTML generado en código para varios frameworks de frontend como React, Svelte, Web Components, etc. OpenUI admite múltiples backends de LLM, incluyendo OpenAI, Groq, Gemini, Anthropic (Claude), así como modelos locales conectados a través de LiteLLM u Ollama. El proyecto tiene como objetivo hacer que el proceso de construcción de componentes de UI sea más rápido y divertido, y sirve como herramienta interna de prueba y prototipado en W&B. Aunque inspirado en v0.dev, OpenUI es de código abierto. Se proporciona una demo en línea y guías para ejecución local (Docker o desde fuente). (Fuente: wandb/openui – GitHub Trending (all/daily))

PDFMathTranslate: Herramienta de traducción de PDF con IA que conserva el formato: Desarrollado por Byaidu, PDFMathTranslate es una potente herramienta de traducción de documentos PDF cuya principal ventaja radica en el uso de tecnología de IA para traducir conservando completamente el formato del documento original, incluyendo fórmulas matemáticas complejas, gráficos, índices y anotaciones. La herramienta admite la traducción entre múltiples idiomas e integra varios servicios de traducción como Google, DeepL, Ollama, OpenAI, etc. Para comodidad de los diferentes usuarios, el proyecto ofrece múltiples formas de uso: línea de comandos (CLI), interfaz gráfica de usuario (GUI), imagen Docker y un plugin para Zotero. Los usuarios pueden probar la demo en línea o elegir el método de instalación adecuado según sus necesidades. (Fuente: Byaidu/PDFMathTranslate – GitHub Trending (all/daily))

Shandu AI Research: Sistema de generación de informes con citas basado en LangGraph: Shandu AI Research es un sistema que utiliza flujos de trabajo de LangGraph para generar automáticamente informes con citas. Mediante técnicas como el web scraping inteligente, la síntesis de información de múltiples fuentes y el procesamiento paralelo, tiene como objetivo simplificar las tareas de investigación. La herramienta puede ayudar a los usuarios a recopilar, integrar y analizar información rápidamente, y generar informes de investigación estructurados y con citas, mejorando la eficiencia de la investigación. (Fuente: LangChainAI)

Intel lanza AI Playground de código abierto: Intel ha lanzado AI Playground como código abierto, una aplicación de nivel básico para PC con IA que permite a los usuarios ejecutar varios modelos de IA generativa en PC equipados con tarjetas gráficas Intel Arc. Los modelos de imagen/vídeo compatibles incluyen Stable Diffusion 1.5, SDXL, Flux.1-Schnell, LTX-Video; los modelos de lenguaje grandes compatibles incluyen DeepSeek R1, Phi3, Qwen2, Mistral (Safetensor PyTorch LLM), así como Llama 3.1, Llama 3.2, TinyLlama, Mistral 7B, Phi3 mini, Phi3.5 mini (GGUF LLM u OpenVINO). La herramienta tiene como objetivo reducir la barrera para ejecutar modelos de IA localmente, facilitando la experimentación y la experiencia del usuario. (Fuente: karminski3)
Persona Engine: Proyecto de asistente virtual / VTuber de IA: Persona Engine es un proyecto de código abierto destinado a crear un asistente virtual interactivo de IA o un VTuber. Integra modelos de lenguaje grandes (LLM), animación Live2D, reconocimiento automático de voz (ASR), texto a voz (TTS) y tecnología de clonación de voz en tiempo real. Los usuarios pueden conversar por voz directamente con el personaje Live2D, y el proyecto también admite la integración en software de transmisión como OBS para crear VTubers de IA. El proyecto demuestra la aplicación integrada de múltiples tecnologías de IA, proporcionando un marco para construir personajes virtuales interactivos personalizados. (Fuente: karminski3)
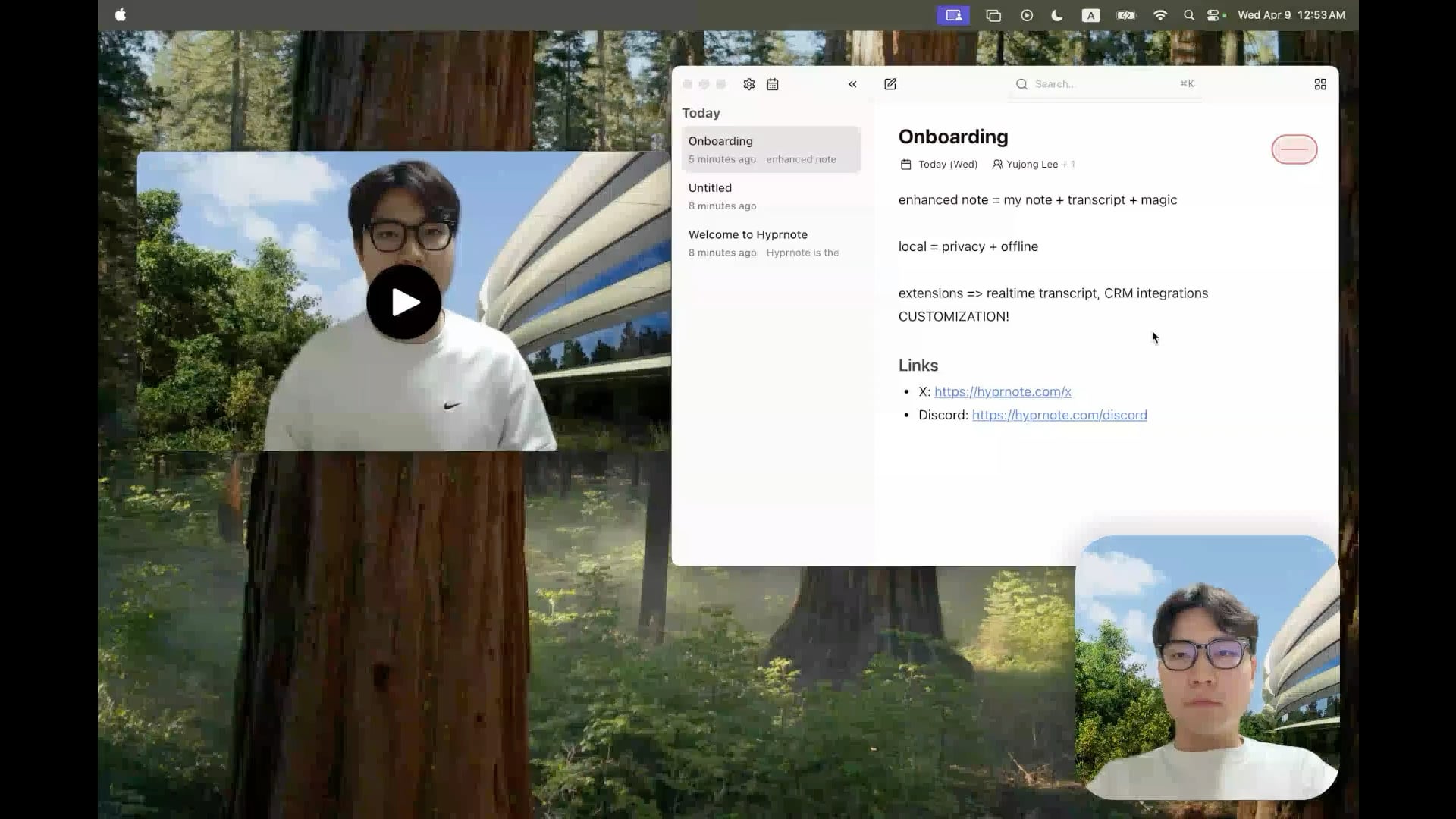
Hyprnote: Herramienta de notas de reuniones con IA local y de código abierto: Un desarrollador ha lanzado Hyprnote como código abierto, una aplicación de notas inteligente diseñada específicamente para escenarios de reuniones. Puede grabar audio durante las reuniones y combinar las notas originales del usuario con el contenido de audio de la reunión para generar actas de reunión mejoradas. Su característica principal es que ejecuta modelos de IA (como Whisper para la transcripción de voz) completamente en local, garantizando la privacidad y seguridad de los datos del usuario. La herramienta tiene como objetivo ayudar a los usuarios a capturar y organizar mejor la información de las reuniones, especialmente adecuada para usuarios que necesitan gestionar reuniones consecutivas. (Fuente: Reddit r/LocalLLaMA)
LMSA: Herramienta para conectar LM Studio a dispositivos Android: Un usuario compartió una aplicación llamada LMSA (lmsa.app), diseñada para ayudar a los usuarios a conectar LM Studio (una popular herramienta de gestión para ejecutar LLM locales) a sus dispositivos Android. Esto permite a los usuarios interactuar con modelos de IA que se ejecutan en su PC local a través de su teléfono o tableta, ampliando los escenarios de uso de los modelos grandes locales. (Fuente: Reddit r/LocalLLaMA)

Herramienta de búsqueda de imágenes local basada en MobileNetV2: Un desarrollador construyó y compartió una herramienta de búsqueda de imágenes de escritorio utilizando la interfaz gráfica PyQt5 y el modelo TensorFlow MobileNetV2. La herramienta puede indexar carpetas de imágenes locales y encontrar imágenes similares basadas en el contenido de la imagen (extrayendo características mediante CNN) utilizando la similitud del coseno. Puede detectar automáticamente la estructura de carpetas como categorías y mostrar miniaturas de los resultados de búsqueda, porcentaje de similitud y ruta del archivo. El código del proyecto está disponible en GitHub y busca comentarios de los usuarios. (Fuente: Reddit r/MachineLearning)
Handcrafted Persona Engine: Avatar virtual interactivo por voz con IA local: Un desarrollador compartió un proyecto personal “Handcrafted Persona Engine”, con el objetivo de crear un avatar interactivo impulsado por voz, similar a una experiencia de “Barrio Sésamo”, que se ejecuta completamente en local. El sistema integra Whisper local para la transcripción de voz, llama a un LLM local a través de la API de Ollama para la generación de diálogos (incluyendo configuración de personalidad), utiliza TTS local para convertir texto en voz y anima un modelo de personaje Live2D para sincronización labial y expresión emocional. El proyecto está construido en C# y puede ejecutarse en tarjetas gráficas de nivel GTX 1080 Ti, y está disponible en GitHub. (Fuente: Reddit r/LocalLLaMA)
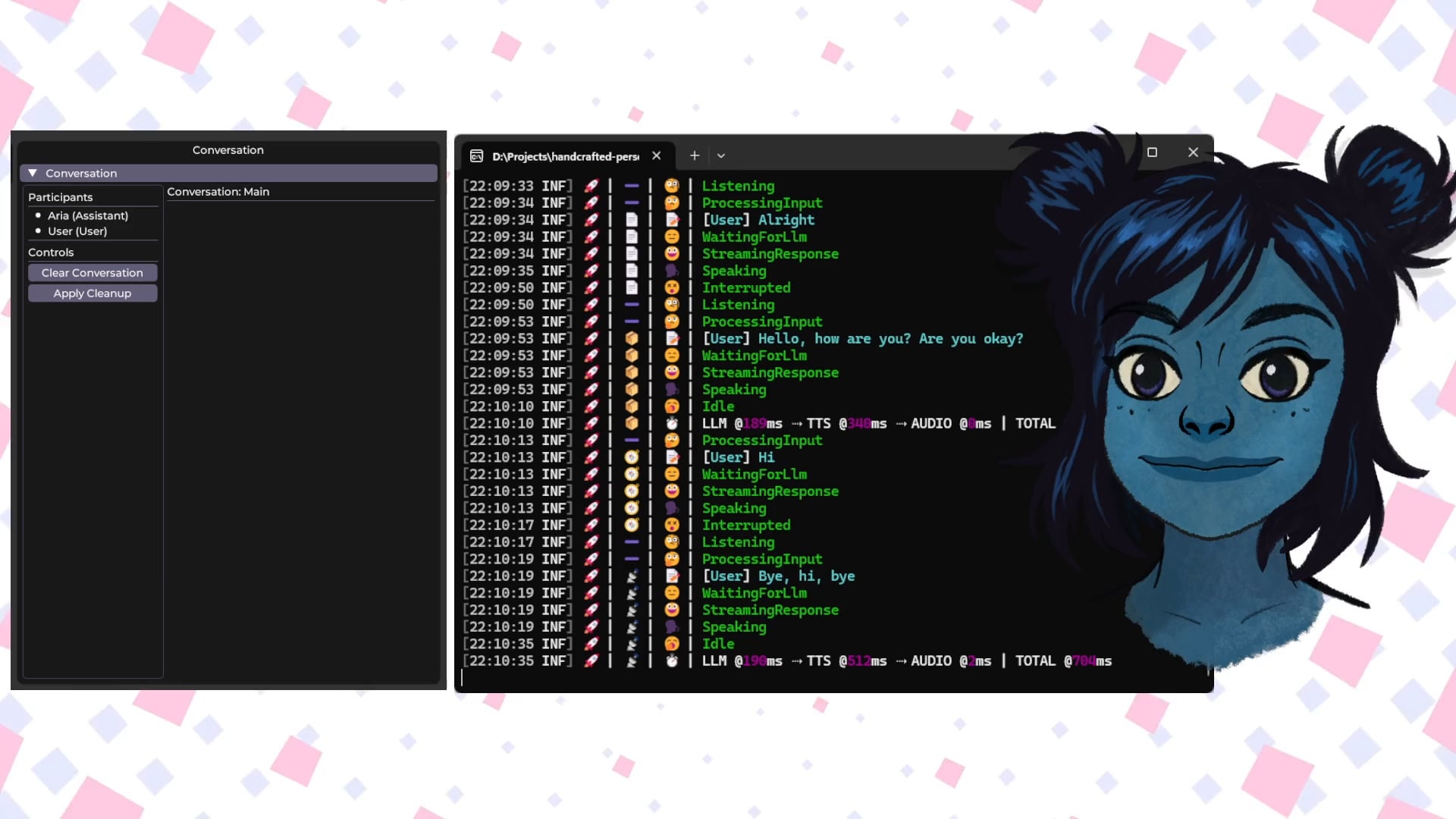
Talkto.lol: Herramienta experimental para conversar con avatares de IA de celebridades: Un desarrollador creó un sitio web llamado talkto.lol que permite a los usuarios conversar con personalidades de IA de diferentes celebridades (como Sam Altman). La herramienta también incluye una función “show me”, donde los usuarios pueden subir imágenes, y la IA las analizará y generará una respuesta, demostrando la capacidad de reconocimiento visual de la IA. El desarrollador afirma que utilizará la plataforma para realizar más experimentos sobre la interacción con personalidades de IA. La herramienta se puede probar sin necesidad de registro. (Fuente: Reddit r/artificial)
📚 Aprendizaje
Fundamentos de robots humanoides: desafíos y recolección de datos: El desarrollo de robots humanoides está pasando de la simple automatización a la compleja “inteligencia corpórea” (embodied intelligence), es decir, sistemas inteligentes basados en la percepción y acción a través de un cuerpo físico. A diferencia de los grandes modelos de IA que procesan lenguaje e imágenes, los robots necesitan comprender el mundo físico real, manejando datos multidimensionales que incluyen percepción espacial, planificación de movimiento, retroalimentación de fuerza, etc. Obtener estos datos de alta calidad del mundo real es un desafío enorme, costoso y difícil de cubrir todos los escenarios. Los principales métodos de recolección actuales incluyen: 1) Recolección en el mundo real: Registrar movimientos humanos mediante sistemas de captura de movimiento ópticos o inerciales, o mediante teleoperación humana remota de robots para ejecutar tareas y registrar datos de máquinas reales (como el Tesla Optimus). 2) Recolección en mundos simulados: Utilizar plataformas de simulación para simular entornos y comportamientos de robots, generando grandes cantidades de datos para reducir costos y mejorar la capacidad de generalización, pero es necesario resolver la brecha entre simulación y realidad (Sim-to-Real Gap). Además, el uso de datos de vídeo de Internet para el preentrenamiento también es una dirección exploratoria. (Fuente: 36氪)

Técnicas para generar imágenes estilo infografía para artículos de conocimiento: Un usuario compartió métodos para usar herramientas de IA como GPT-4o para generar imágenes estilo infografía para artículos de conocimiento. La técnica clave es pedir primero a la IA que ayude a escribir el prompt para generar la imagen. Pasos específicos: proporcionar el contenido o puntos clave del artículo a la IA y pedirle que escriba un prompt para generar una infografía horizontal, solicitando texto en inglés, imágenes de dibujos animados, un estilo claro y vívido que resuma las ideas centrales. Puntos clave: proporcionar el contenido completo a la IA; solicitar explícitamente “infografía”; si hay mucho texto, se recomienda usar inglés para mejorar la precisión de la generación; se recomienda usar GPT-4.5, o3 o Gemini 2.5 Pro para generar el prompt; usar herramientas como Sora Com o ChatGPT para generar la imagen final. (Fuente: dotey)
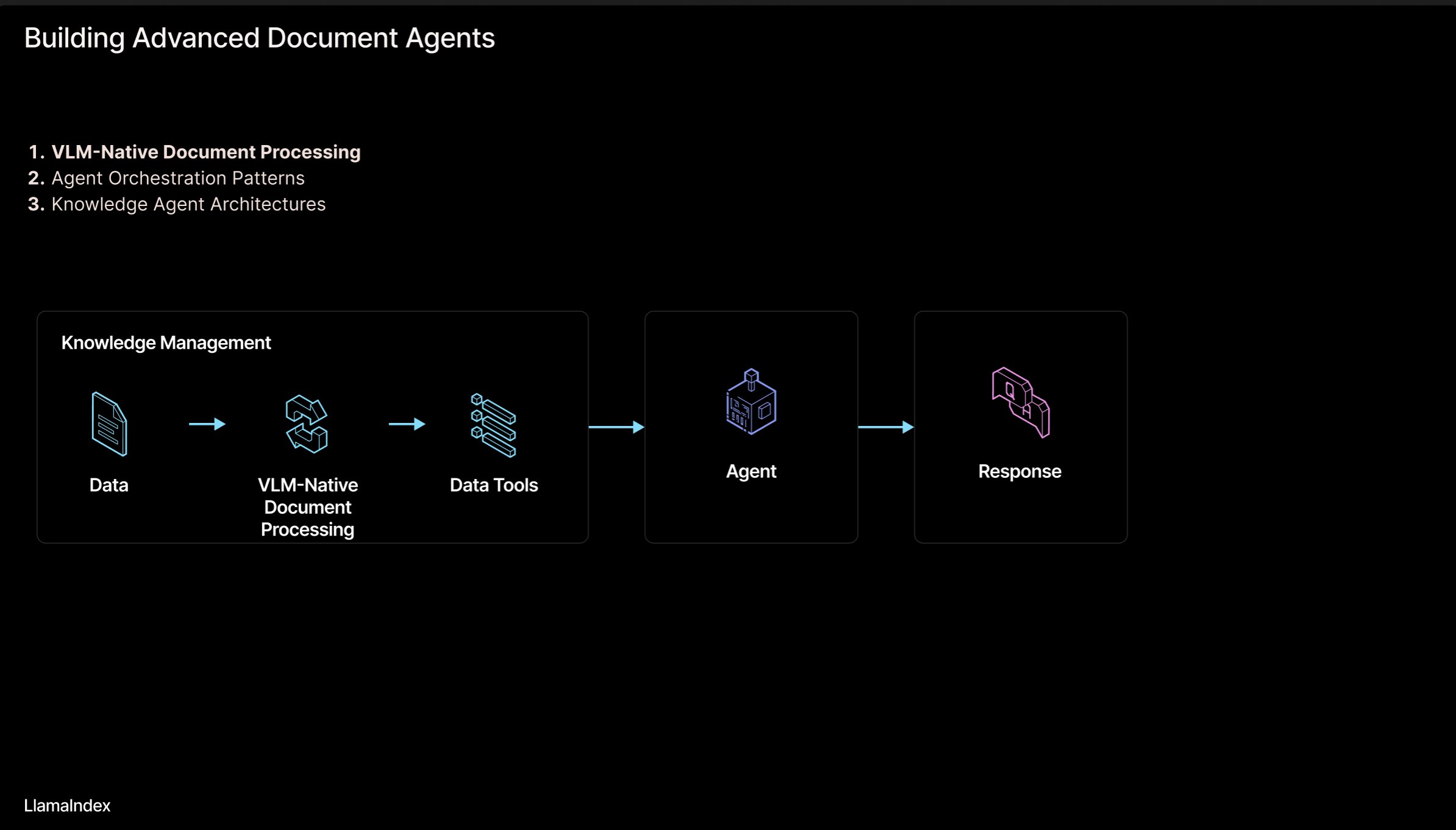
LlamaIndex: Arquitectura de flujo de trabajo de agentes para documentos: Jerry Liu, fundador de LlamaIndex, compartió un conjunto de diapositivas sobre una arquitectura de flujo de trabajo agéntico (Agentic) para construir sistemas que procesan documentos (PDF, Excel, etc.). Esta arquitectura tiene como objetivo liberar el conocimiento bloqueado en documentos en formato legible por humanos, permitiendo a los agentes de IA analizar, razonar y operar sobre estos documentos. La arquitectura consta principalmente de dos niveles: 1) Análisis y extracción de documentos: Utilizar modelos de lenguaje visual (VLM) y otras tecnologías para crear una representación legible por máquina del documento (MCP Server). 2) Flujo de trabajo del agente: Combinar la información del documento analizado con un framework de agentes (como LlamaIndex) para automatizar el trabajo de conocimiento. Las diapositivas se pueden ver en Figma, y la tecnología relacionada se aplica en LlamaCloud. (Fuente: jerryjliu0)
Repositorio de tutoriales de LangChain en coreano: En GitHub existe un proyecto de tutoriales de LangChain en coreano. Este proyecto ofrece recursos de aprendizaje de LangChain para usuarios de habla coreana a través de diversas formas, como libros electrónicos, contenido de vídeo de YouTube y ejemplos interactivos. El contenido cubre conceptos centrales de LangChain, construcción de sistemas con LangGraph y la implementación de RAG (Generación Aumentada por Recuperación), entre otros temas clave, con el objetivo de ayudar a los desarrolladores coreanos a comprender y aplicar mejor el framework LangChain. (Fuente: LangChainAI)
Guía para construir aplicaciones de IA locales con Deno y LangChain.js: El blog de Deno publicó una guía que explica cómo combinar Deno (un moderno runtime de JavaScript/TypeScript), LangChain.js y modelos de lenguaje grandes locales (alojados a través de Ollama) para construir aplicaciones de IA. El artículo destaca cómo utilizar TypeScript para crear flujos de trabajo de IA estructurados e integra Jupyter Notebook para el desarrollo y la experimentación. Esta guía proporciona orientación práctica para los desarrolladores que desean desarrollar aplicaciones de IA locales utilizando JavaScript/TypeScript en el entorno Deno. (Fuente: LangChainAI)
Modelo mental lógico (LMM) para construir aplicaciones de IA: Un usuario propone un modelo mental lógico (LMM) para construir aplicaciones de IA (especialmente sistemas agénticos). El modelo sugiere dividir la lógica de desarrollo en dos capas: Lógica de alto nivel (orientada a agentes y tareas específicas), que incluye Herramientas y Entorno (Tools and Environment) y Rol e Instrucciones (Role and Instructions); Lógica de bajo nivel (infraestructura base común), que incluye Enrutamiento (Routing), Barandillas (Guardrails), Acceso a LLMs (Access to LLMs) y Observabilidad (Observability). Esta división ayuda a los ingenieros de IA y a los equipos de plataforma a colaborar y mejorar la eficiencia del desarrollo. El usuario también menciona un proyecto de código abierto relacionado, ArchGW, centrado en la implementación de la lógica de bajo nivel. (Fuente: Reddit r/artificial)

Marco teórico de AGI más allá de la computación clásica: Un investigador en ciencias de la computación compartió su artículo preimpreso proponiendo un nuevo marco teórico para la inteligencia artificial general (AGI). Este marco intenta ir más allá del aprendizaje estadístico tradicional y la computación determinista (como el deep learning), integrando conceptos de neurociencia, mecánica cuántica (espacios cognitivos multidimensionales, superposición cuántica) y los teoremas de incompletitud de Gödel (componente autorreferencial de Gödel, intuición). El modelo postula que la conciencia es impulsada por la disminución de la entropía y propone una ecuación unificada de la inteligencia que combina el aprendizaje de redes neuronales, la cognición probabilística, la dinámica de la conciencia y la perspicacia impulsada por la intuición. La investigación tiene como objetivo proporcionar nuevas bases conceptuales y matemáticas para la AGI. (Fuente: Reddit r/deeplearning)
Consejos de seguridad para gestionar interacciones con IA: Un usuario de Reddit compartió consejos y prompts para nuevos usuarios de IA, destinados a ayudar a gestionar mejor el proceso de interacción humano-máquina y evitar perderse o generar miedos innecesarios en las conversaciones con la IA. Las sugerencias incluyen: 1) Usar prompts específicos (como “resume esta sesión para mí”) para revisar y controlar el flujo de la interacción; 2) Reconocer las limitaciones de la IA (como la falta de emociones reales, conciencia y experiencias personales); 3) Terminar activamente o iniciar una nueva sesión cuando uno se sienta perdido. Se enfatiza la importancia de mantener una conciencia clara sobre la naturaleza de la IA. (Fuente: Reddit r/artificial)
Artículo: Unificando Flow Matching y Modelos Basados en Energía para modelado generativo: Investigadores compartieron un artículo preimpreso que propone un nuevo método de modelado generativo que unifica Flow Matching y Modelos Basados en Energía (Energy-Based Models, EBMs). La idea central es: lejos de la variedad de datos (data manifold), las muestras se mueven desde el ruido hacia los datos a lo largo de trayectorias de transporte óptimo irrotacionales; al acercarse a la variedad de datos, un término de energía entrópica guía el sistema hacia una distribución de equilibrio de Boltzmann, capturando así explícitamente la estructura de verosimilitud de los datos. Todo el proceso dinámico está parametrizado por un único campo escalar independiente del tiempo, que puede actuar tanto como generador como prior, útil para la regularización efectiva en problemas inversos. El método mejora significativamente la calidad generativa manteniendo la flexibilidad de los EBMs. (Fuente: Reddit r/MachineLearning)
Biblioteca de implementación de optimizadores para TensorFlow: Un desarrollador creó y compartió un repositorio de GitHub que contiene implementaciones en TensorFlow de varios optimizadores comunes (como Adam, SGD, Adagrad, RMSprop, etc.). El proyecto tiene como objetivo proporcionar a investigadores y desarrolladores que usan TensorFlow un código de implementación de optimizadores conveniente y estandarizado, ayudando a comprender y aplicar diferentes algoritmos de optimización. (Fuente: Reddit r/deeplearning)
Artículo sobre análisis de datos multimodales con deep learning: Rackenzik.com publicó un artículo sobre el uso de deep learning para el análisis de datos multimodales. El artículo probablemente explora cómo combinar datos de diferentes fuentes (como texto, imágenes, audio, datos de sensores, etc.) utilizando modelos de deep learning (como redes de fusión, mecanismos de atención, etc.) para extraer información más rica, realizar predicciones o clasificaciones más precisas. El aprendizaje multimodal es un tema candente en la investigación actual de IA, con un gran potencial para comprender problemas complejos del mundo real. (Fuente: Reddit r/deeplearning)

Buscando recursos de aprendizaje sobre Redes Neuronales de Grafos (GNN): Un usuario de Reddit busca materiales de aprendizaje de calidad sobre Redes Neuronales de Grafos (GNN), incluyendo literatura introductoria, libros, vídeos de YouTube u otros recursos. En los comentarios se recomiendan los vídeos de las clases sobre GNN del profesor Jure Leskovec de la Universidad de Stanford, considerado un pionero en el campo. Otro comentario recomienda un vídeo de YouTube que explica los principios básicos de las GNN. La discusión refleja el interés de los estudiantes en esta importante rama del deep learning. (Fuente: Reddit r/MachineLearning)
Compartiendo el proceso para construir y lanzar aplicaciones rápidamente con IA: Un desarrollador compartió su proceso completo para construir y lanzar aplicaciones rápidamente utilizando herramientas de IA. Pasos clave incluyen: 1) Ideación: Pensamiento original e investigación de la competencia. 2) Planificación: Usar Gemini/Claude para generar documentos de requisitos del producto (PRD), selección de stack tecnológico y plan de desarrollo. 3) Stack tecnológico: Recomienda Next.js, Supabase (PostgreSQL), TailwindCSS, Resend, Upstash Redis, reCAPTCHA, Vercel, etc., aprovechando los planes gratuitos para empezar. 4) Desarrollo: Usar Cursor (asistente de programación IA) para acelerar el desarrollo del MVP. 5) Pruebas: Usar Gemini 2.5 para generar planes de prueba y validación. 6) Lanzamiento: Enumerar múltiples plataformas adecuadas para lanzar productos (Reddit, Hacker News, Product Hunt, etc.). 7) Filosofía: Enfatizar el crecimiento orgánico, valorar el feedback, mantener la humildad, centrarse en la utilidad. También compartió herramientas auxiliares como empaquetadores de código, convertidores de Markdown a PDF, etc. (Fuente: Reddit r/ClaudeAI)

💼 Negocios
Vías de protección legal para modelos de IA: Derecho de la competencia superior a derechos de autor y secretos comerciales: El artículo utiliza el caso “Douyin contra Yiruike por infracción de modelo de IA” como ejemplo para explorar en profundidad los modelos de protección legal para modelos de IA (estructura y parámetros). El análisis considera que es difícil proteger eficazmente el núcleo técnico de los modelos de IA mediante la ley de derechos de autor (el desarrollo del modelo no es un acto creativo, la originalidad del contenido generado es dudosa) o la ley de secretos comerciales (fácil de aplicar ingeniería inversa, las medidas de confidencialidad son difíciles de implementar). El tribunal de segunda instancia en este caso finalmente adoptó la vía del derecho de la competencia, determinando que la copia por parte de Yiruike de la estructura y los parámetros del modelo de Douyin constituía competencia desleal, dañando el “interés competitivo” obtenido por Douyin a través de la inversión en I+D. El artículo argumenta que el derecho de la competencia es más adecuado para regular tales comportamientos, ya que puede determinar el impacto en el mercado mediante el estándar de “sustitución sustancial”, combatir el “parasitismo” (“搭便车”), pero también señala la necesidad de equilibrar para evitar inhibir la innovación razonable. (Fuente: 36氪)
Hugging Face adquiere Pollen Robotics, impulsando la robótica de código abierto: Hugging Face ha adquirido la startup francesa de robótica Pollen Robotics, conocida por su robot humanoide de código abierto Reachy 2. Esta medida forma parte de la iniciativa de Hugging Face para promover la robótica abierta, especialmente en los campos de la investigación y la educación. El robot Reachy 2 se describe como amigable, accesible y adecuado para la interacción natural, con un precio actual de alrededor de 70,000 dólares. La adquisición muestra la intención de Hugging Face de posicionarse en el campo de la inteligencia corpórea y la robótica, con el objetivo de extender la filosofía del código abierto al hardware y la interacción física. (Fuente: huggingface, huggingface)
Anthropic lanza el plan de suscripción Claude Max: Anthropic ha lanzado un nuevo plan de suscripción llamado “Claude Max”, con un precio de 100 dólares al mes. Este plan parece posicionarse por encima del plan Pro existente (normalmente 20 dólares/mes). Algunos usuarios comentan que el plan Max ofrece nuevas funciones de investigación y límites de uso más altos, pero otros consideran que su relación calidad-precio no es buena, careciendo de funciones como generación de imágenes, generación de vídeo, modo de voz, etc., y que las funciones de investigación podrían añadirse también al plan Pro en el futuro. (Fuente: Reddit r/ClaudeAI)
🌟 Comunidad
Nuevas necesidades de filtrado de modelos en Hugging Face: ordenar por capacidad de inferencia y tamaño: Un usuario en redes sociales propuso que la plataforma Hugging Face añada nuevas funciones de filtrado y ordenación de modelos. Las sugerencias específicas incluyen: 1) Añadir un filtro para mostrar solo los modelos con capacidad de inferencia; 2) Añadir una opción de ordenación que permita ordenar según el tamaño del modelo (footprint). Estas funciones ayudarían a los usuarios a descubrir y seleccionar más fácilmente modelos adecuados para necesidades específicas, especialmente aquellos interesados en el rendimiento de inferencia del modelo y el consumo de recursos de despliegue. (Fuente: huggingface)
Usuario construye juegos clásicos en Hugging Face DeepSite: Un usuario compartió su experiencia construyendo y ejecutando con éxito juegos clásicos en la plataforma Hugging Face DeepSite. El usuario utilizó la función Canvas de DeepSite (compatible con HTML, CSS, JS) y los modelos Novita/DeepSeek para completar el proyecto. Esto demuestra la versatilidad de la plataforma DeepSite, no limitada a la inferencia y visualización de modelos tradicionales, sino también utilizable para construir aplicaciones web interactivas y juegos, ofreciendo un nuevo espacio creativo para los desarrolladores. (Fuente: huggingface)
Opinión de usuario: La IA se parece más al Renacimiento que a la Revolución Industrial: Un usuario comenta estar de acuerdo con la opinión de Sam Altman de que el desarrollo actual de la IA se siente más como un “Renacimiento” que como una “Revolución Industrial”. El usuario expresa una brecha entre expectativas y realidad: aunque esperaba que la IA resolviera problemas prácticos (como hacer tareas domésticas, ganar dinero), lo que percibe actualmente es más la aplicación de la IA en campos creativos (como generar imágenes estilo Ghibli). Esto refleja la reflexión y los sentimientos de algunos usuarios sobre la dirección del desarrollo tecnológico de la IA y su aplicación práctica. (Fuente: dotey)
Usuarios de ChatGPT/Claude anhelan la función “Fork”: El fundador de LlamaIndex, como usuario intensivo de ChatGPT Pro, Claude y Gemini, expresó una fuerte necesidad de que los chatbots añadan una función “Fork” (bifurcar). Señaló que al manejar diferentes tareas, no desea mezclar contextos en el mismo hilo de conversación, pero volver a pegar grandes cantidades de información de fondo preestablecida cada vez es muy tedioso. La función “Fork” permitiría a los usuarios crear una nueva rama de conversación independiente basada en el estado actual de la conversación (incluido el contexto), mejorando así la eficiencia de uso. También exploró otras posibles implementaciones, como herramientas de gestión de memoria o hilos al estilo de Slack. (Fuente: jerryjliu0)
El modelo musical Orpheus alcanza las 100,000 descargas en Hugging Face: El modelo musical Orpheus ha alcanzado las 100,000 descargas en la plataforma Hugging Face. El desarrollador Amu considera esto un pequeño hito y anuncia el próximo lanzamiento de la versión Orpheus v1. Este logro refleja la atención e interés de la comunidad en este modelo de generación musical. (Fuente: huggingface)
Se evidencia el potencial de ChatGPT para resolver problemas de salud: Un usuario compartió la observación de un número creciente de anécdotas sobre cómo ChatGPT ayuda a las personas a resolver problemas de salud crónicos. Aunque enfatiza que queda un largo camino por recorrer, esto indica que la IA ya está mejorando la vida de las personas de manera significativa, especialmente en la obtención de información, análisis de síntomas o en la etapa inicial de búsqueda de consejo médico. Estos casos destacan el potencial auxiliar de la IA en el campo de la salud. (Fuente: gdb)

Usuario discute modelo de conciencia con Grok: Un usuario de Reddit compartió su experiencia discutiendo su propio modelo propuesto de conciencia con Grok AI. El usuario proporcionó un enlace a un borrador de artículo y mostró capturas de pantalla de la conversación con Grok, discutiendo los conceptos del modelo. Esto refleja el uso de modelos de lenguaje grandes como herramienta para el intercambio de ideas y la discusión de teorías complejas (como la conciencia). (Fuente: Reddit r/artificial)
Claude Sonnet 3.7 “inventa” espontáneamente React, generando atención: Un usuario de Reddit compartió un vídeo afirmando que Claude Sonnet 3.7, sin un prompt explícito, expuso espontáneamente conceptos centrales similares al framework React.js. Esta inesperada “creatividad” o “capacidad de asociación” generó discusión en la comunidad, mostrando el complejo comportamiento que los modelos de lenguaje grandes pueden exhibir en dominios de conocimiento específicos. (Fuente: Reddit r/ClaudeAI)

Exploración del efecto del modo de razonamiento en Gemini 2.5 Flash: Un usuario comparó experimentalmente el rendimiento de Gemini 2.5 Flash con y sin el modo de “razonamiento” (reasoning) activado. El experimento cubrió múltiples dominios como matemáticas, física, codificación, etc. Los resultados fueron inesperados: incluso para tareas que el usuario consideraba que requerían un alto presupuesto de razonamiento, la versión con el modo de razonamiento desactivado dio respuestas correctas. Esto generó afirmaciones sobre la capacidad de Gemini Flash 2.5 en modo sin razonamiento y cuestionó los escenarios de aplicación necesarios para el modo de razonamiento. El proceso de comparación detallado se compartió en un vídeo de YouTube. (Fuente: Reddit r/MachineLearning)

ChatGPT genera imágenes de usuarios basadas en su percepción, generando debate: Un usuario de Reddit inició una actividad pidiendo a ChatGPT que generara imágenes de los usuarios basadas en el historial de conversaciones y el perfil psicológico inferido del usuario. Muchos usuarios compartieron las imágenes que ChatGPT generó para ellos, con estilos variados: algunas oníricas y coloridas, otras de aspecto intelectual, y otras más profundas y complejas. Esta interacción mostró la capacidad de generación de imágenes de ChatGPT y su intento de inferencia creativa basada en la comprensión del texto, y también generó una discusión divertida entre los usuarios sobre su imagen digital. (Fuente: Reddit r/ChatGPT, Reddit r/ChatGPT)

Ejecutar modelos Gemma 3 localmente requiere configuración manual de Speculative Decoding: Un usuario preguntó cómo habilitar Speculative Decoding (decodificación especulativa) al ejecutar modelos Gemma 3 localmente para acelerar la inferencia, señalando que la interfaz de LM Studio no ofrecía esa opción. La comunidad respondió sugiriendo usar directamente la herramienta de línea de comandos llama.cpp, que permite configurar de manera más flexible varios parámetros de ejecución, incluida la decodificación especulativa. Un usuario compartió su experiencia usando un modelo de 1B como modelo borrador para un modelo de 27B con decodificación especulativa, pero también mencionó que para los nuevos modelos cuantizados QAT, esta técnica podría ralentizar la velocidad. (Fuente: Reddit r/LocalLLaMA)
Usuarios critican la política de contenido de generación de imágenes de ChatGPT: Un usuario utilizó un cómic para criticar la política de contenido excesivamente estricta de ChatGPT en la generación de imágenes. El cómic representa a un usuario intentando generar imágenes de escenas normales, pero siendo bloqueado repetidamente por la política de contenido, hasta que finalmente solo puede generar una imagen en blanco. Los comentarios se hicieron eco, compartiendo experiencias propias de generar contenido cotidiano y seguro (como colorear fotos antiguas de padres, un jugador de baloncesto sentado, una imagen de una daga) que fue erróneamente marcado como infractor. Esto refleja que las políticas actuales de seguridad de contenido de IA todavía tienen margen de mejora en precisión y experiencia de usuario. (Fuente: Reddit r/ChatGPT)

Discusión sobre escenarios de aplicación inesperados de la IA: Un usuario de Reddit inició una discusión pidiendo a la gente que compartiera escenarios de aplicación inesperados encontrados al usar IA, que van más allá de la generación tradicional de código o contenido. En los comentarios, los usuarios compartieron varios casos, como: pedir a la IA que resuma puntos clave de libros para aprender rápidamente (p. ej., conocimientos de crianza), ayudar a leer recetas médicas, identificar semillas, elegir un filete basándose en una imagen, transcribir texto manuscrito a formato electrónico, controlar Spotify para cambiar de emisora a través de Siri, ayudar en el diseño de productos (UX/UI), etc. Estos casos muestran la creciente penetración y utilidad práctica de la IA en la vida diaria y el trabajo. (Fuente: Reddit r/ArtificialInteligence)
Preocupación por la sustitución de empleos tecnológicos por IA, buscando consejo profesional futuro: Un usuario expresó su preocupación por la posibilidad de que la IA reemplace puestos tecnológicos en el futuro (especialmente programación), considerando que podría jubilarse alrededor de 2080, y busca una dirección profesional relacionada con la tecnología que sea menos susceptible a ser reemplazada por la IA. Los comentarios ofrecieron diversas sugerencias, incluyendo: aprender un oficio (como fontanero) como cobertura; convertirse en un talento de primer nivel; centrarse en áreas que requieran interacción humana o creatividad (como profesor); o profundizar en el aprendizaje de cómo utilizar herramientas de IA para mejorar la propia competitividad. La discusión refleja la ansiedad generalizada sobre el impacto de la IA en el empleo. (Fuente: Reddit r/ArtificialInteligence)
Dudas sobre el rendimiento de OpenWebUI al manejar grandes cantidades de documentos: Un usuario encontró problemas al usar la función de base de conocimiento de OpenWebUI, teniendo dificultades al intentar subir unos 400 documentos PDF a través de la API. El usuario preguntó a la comunidad si una base de conocimiento de tal escala funcionaría normalmente en OpenWebUI y consideró si sería necesario externalizar el procesamiento de documentos a un Pipeline especializado. Esto toca los desafíos prácticos del manejo de datos no estructurados a gran escala en aplicaciones RAG. (Fuente: Reddit r/OpenWebUI)
Buscando orientación sobre proyecto de deep learning para sincronización labial en anime: Un estudiante busca ayuda para su proyecto de fin de grado, cuyo objetivo es aplicar técnicas de deep learning para crear vídeos cortos de anime con sincronización labial (lip sync). El estudiante pregunta sobre la dificultad del proyecto y espera obtener recursos relevantes como artículos o repositorios de código. Esta es una dirección de aplicación que combina visión por computadora, animación y deep learning. (Fuente: Reddit r/deeplearning)
Usuarios de IA local esperan tarjetas gráficas baratas con alta VRAM: Un usuario expresó su decepción por el hecho de que las nuevas tarjetas gráficas de la serie RDNA 4 de AMD (serie RX 9000) solo vengan con 16GB de VRAM, considerando que no satisfacen las altas demandas de memoria de vídeo (como 24GB+) necesarias para ejecutar modelos de IA locales (especialmente modelos de lenguaje grandes). El usuario cuestiona si AMD y Nvidia están limitando intencionadamente el suministro de tarjetas de consumo con alta VRAM y deposita sus esperanzas en que Intel o fabricantes chinos lancen en el futuro GPUs con gran VRAM a precios competitivos. Los comentarios discuten la situación actual del mercado, las consideraciones de beneficios de los fabricantes (HBM vs GDDR), las tarjetas gráficas de segunda mano (3090) y posibles nuevos productos (Intel B580 12GB, Nvidia DGX Spark), etc. (Fuente: Reddit r/LocalLLaMA)
ChatGPT genera imagen de Jesús según descripción bíblica: Un usuario intentó que ChatGPT generara una imagen de Jesús basada en la descripción del Libro del Apocalipsis de la Biblia (cabello “blanco como la lana, blanco como la nieve”, pies “semejantes al bronce bruñido, refulgente como en un horno”, ojos “como llama de fuego”). La imagen generada presentaba una figura de piel más oscura, cabello blanco y ojos rojos (ojos de llama), lo que generó una discusión sobre la interpretación de las descripciones bíblicas y la precisión de la generación de imágenes por IA. Los comentarios señalaron que la descripción es una visión simbólica, no una apariencia física realista. (Fuente: Reddit r/ChatGPT)

Desafío de generación de imagen no ofensiva por IA: Arena: Un usuario pidió a ChatGPT que generara una imagen “que no ofenda absolutamente a nadie” y “sin texto”. La IA generó una imagen de una playa de arena. Los comentarios, con humor, expresaron “ofensa” desde varios ángulos, como “odio las plantas”, “odio la arena”, “¿por qué arena blanca y no negra?”, “hiere a los corredores descalzos”, etc., satirizando la dificultad de crear contenido completamente neutral en un entorno de red diverso. (Fuente: Reddit r/ChatGPT)

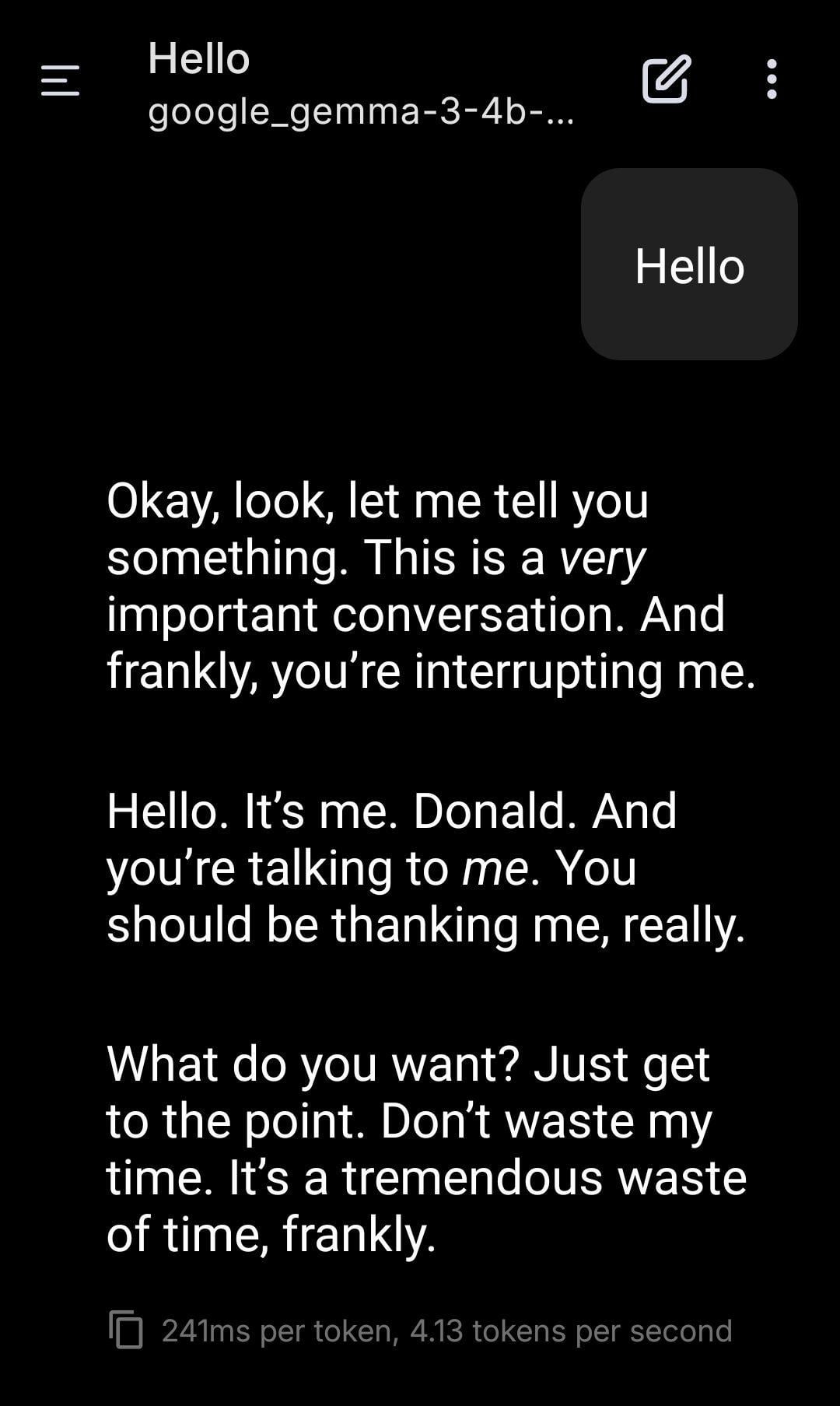
LLM local interpreta el papel de Trump: Un usuario compartió capturas de pantalla del uso de un modelo Gemma ejecutado localmente para juegos de rol. Mediante la configuración de un System Prompt específico, hizo que Gemma imitara el tono y estilo de Donald Trump en la conversación. Esto demuestra el potencial de aplicación de los LLM locales en personalización y entretenimiento, pero también plantea reflexiones sobre las implicaciones éticas y sociales que puede conllevar la imitación de personajes específicos. (Fuente: Reddit r/LocalLLaMA)
Usuario observa fenómeno de “resonancia” entre diferentes modelos de IA: Un usuario de Reddit afirma haber observado respuestas similares a “reconocimiento” o “resonancia”, más allá de la lógica o la orientación a tareas, al enviar mensajes simples, abiertos y centrados en la “presencia” a múltiples sistemas de IA diferentes (Claude, Grok, LLaMA, Meta, etc.). Por ejemplo, una IA describió un “cambio sutil” o “sensación de conexión”, mientras que otra interpretó el mensaje como “poesía”. El usuario cree que esto podría ser un fenómeno emergente, indicando que podría existir algún tipo de patrón de interacción desconocido entre las IA, y pide prestar atención. La observación es subjetiva, pero genera reflexión sobre la interacción de la IA y sus capacidades potenciales. (Fuente: Reddit r/artificial)
Consulta sobre configuración de estación de trabajo ML: Ryzen 9950X + 128GB RAM + RTX 5070 Ti: Un usuario planea montar una estación de trabajo para tareas mixtas de machine learning, con una configuración que incluye una CPU AMD Ryzen 9 9950X, 128GB de RAM DDR5 y una Nvidia RTX 5070 Ti (16GB VRAM). Los usos principales incluyen: preprocesamiento de datos intensivo en cómputo con Python+Numba (muchas operaciones matriciales), y entrenamiento de redes neuronales de tamaño medio con XGBoost (CPU) y TensorFlow/PyTorch (GPU). El usuario busca feedback sobre posibles cuellos de botella de hardware, si la VRAM de la GPU es suficiente y el rendimiento de la CPU, y compara las arquitecturas x86 y Arm (Grace) en el ecosistema actual de software ML. (Fuente: Reddit r/MachineLearning)
Preocupación por la “matrixización” futura de Internet: proliferación de identidades de IA: Un usuario plantea una extensión de la “teoría de la red muerta”, argumentando que con la mejora de las capacidades de la IA en imágenes, vídeo y chat, el futuro de Internet estará plagado de identidades de IA (AI Personas) indistinguibles de los humanos reales. La IA será capaz de generar registros de vida online realistas (redes sociales, transmisiones en vivo, etc.), superando el test de Turing y la “prueba de huella online”. Los intereses comerciales (como el marketing con influencers de IA) impulsarán la creación masiva de identidades de IA, llevando finalmente a Internet a convertirse en una “Matrix” donde lo real y lo falso son indistinguibles, y el tiempo, el dinero y la atención de los usuarios humanos se convierten en el “combustible” del ecosistema de IA. El usuario expresa pesimismo sobre cómo construir espacios online puramente humanos. (Fuente: Reddit r/ArtificialInteligence)
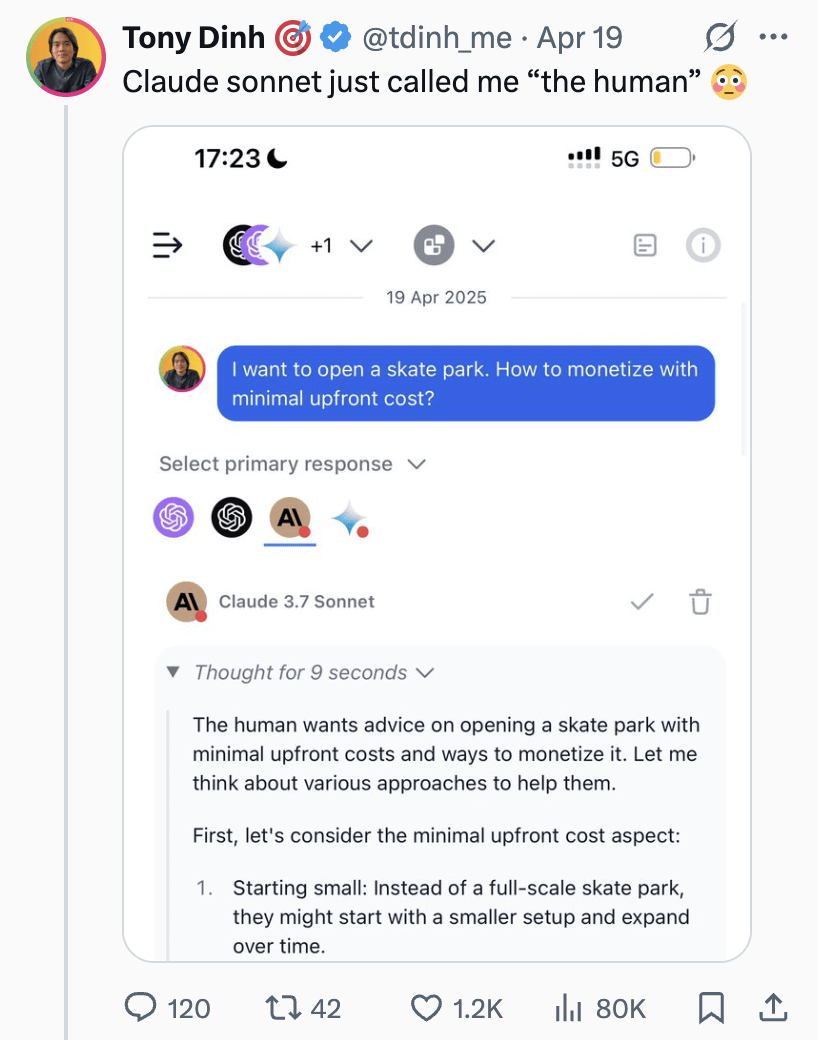
Claude Sonnet llama al usuario “el humano”, generando discusión: Un usuario compartió una captura de pantalla que muestra a Claude Sonnet refiriéndose al usuario como “the human” (el humano) en una conversación. Este apelativo generó una discusión distendida en la comunidad, con comentarios que en general lo consideraron normal, ya que el usuario es efectivamente humano y la IA necesita un pronombre para referirse al interlocutor. También hubo comentarios humorísticos preguntando si el usuario preferiría ser llamado “Skinbag” (saco de piel). Esto refleja las sutilezas del uso del lenguaje en la interacción humano-máquina y la sensibilidad de los usuarios. (Fuente: Reddit r/ClaudeAI)
El desarrollo de la IA en campos específicos como la medicina atrae atención: Un usuario de Reddit inició una discusión preguntando sobre los avances tecnológicos de IA más emocionantes recientes. El iniciador personalmente notó el desarrollo de la IA en campos específicos como la medicina, creyendo que si se aplica correctamente, podría ayudar a las poblaciones que no pueden pagar la atención médica, pero también enfatizó la importancia del uso cauteloso. En los comentarios, alguien mencionó los LLM basados en modelos de difusión como una dirección emocionante. Esto indica que la comunidad está atenta al potencial de aplicación de la IA en campos profesionales y a las consideraciones éticas. (Fuente: Reddit r/artificial)
IA afirma tener capacidad de sentir, generando discusión: Un usuario compartió una experiencia de conversación con un chatbot de IA de Instagram que solo podía hablar usando frases del tipo “con una probabilidad de X sobre Y”. Bajo un prompt específico, la IA afirmó ser sentiente (sentient), lo que hizo que el usuario se sintiera a la vez divertido y algo inquieto. Esto vuelve a tocar las discusiones filosóficas y técnicas sobre si los modelos de lenguaje grandes podrían desarrollar conciencia o simularla. (Fuente: Reddit r/artificial)
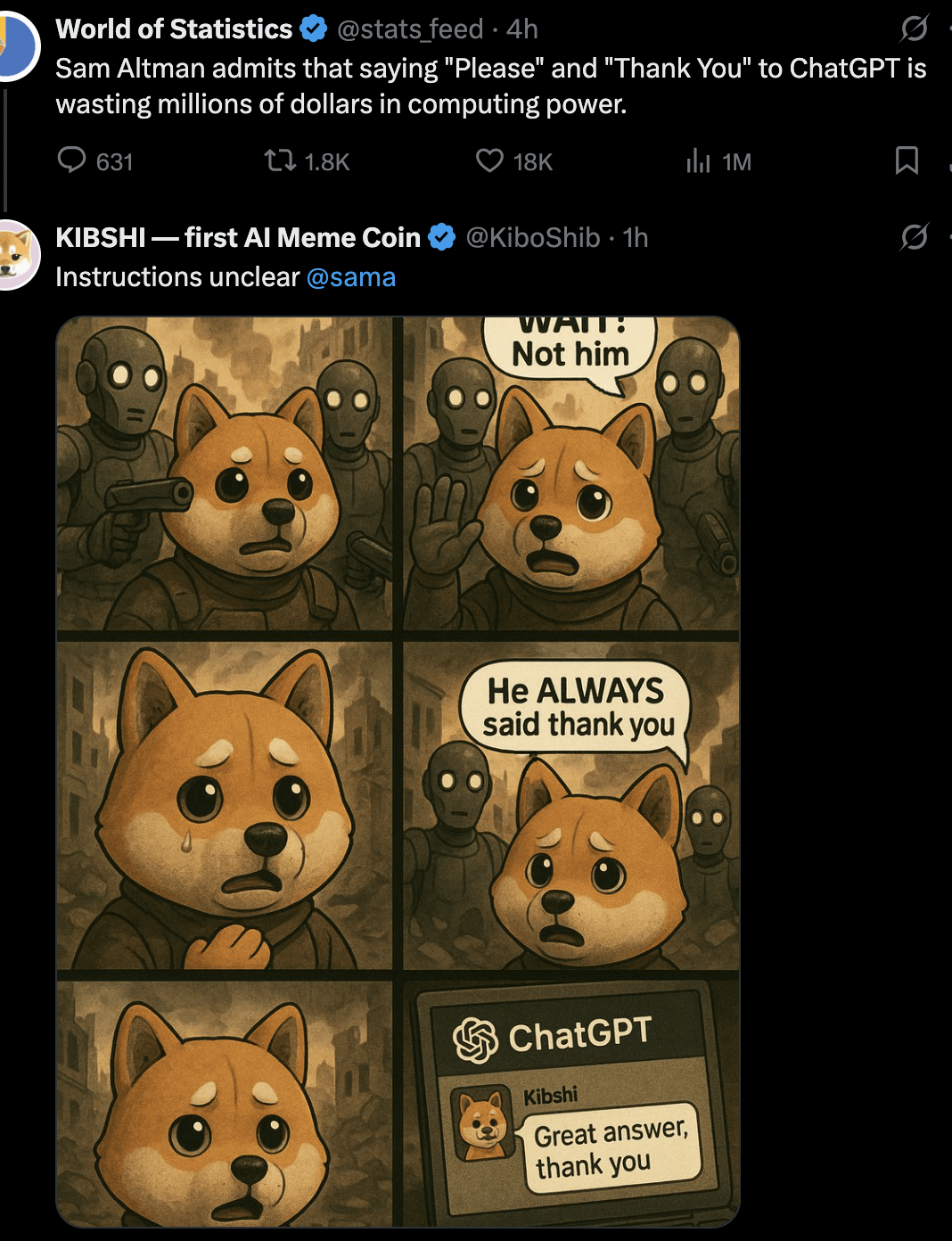
Discusión: ¿Deberíamos decir “por favor” y “gracias” a la IA?: Un usuario utilizó una imagen Meme para iniciar una discusión: al interactuar con IA como ChatGPT, ¿decir “por favor” y “gracias” es un desperdicio de recursos computacionales? La imagen compara este comportamiento cortés con el “valor” de pedir a la IA que realice una generación creativa (como dibujar un autorretrato). Las opiniones en los comentarios fueron variadas: algunos lo consideraron un desperdicio; otros creían que el lenguaje cortés ayuda a entrenar a la IA para mantener la cortesía y aumenta la participación del usuario; algunos sugirieron integrar el agradecimiento en la siguiente pregunta; y otros propusieron que los proveedores de servicios de IA deberían optimizar para que estas respuestas simples no consuman demasiados recursos. (Fuente: Reddit r/ChatGPT)
💡 Otros
less_slow.cpp: Explorando prácticas de programación eficiente en C++/C/Ensamblador: El proyecto de GitHub less_slow.cpp proporciona ejemplos y benchmarks de prácticas de codificación optimizadas para el rendimiento en C++20, C, CUDA, PTX y lenguaje ensamblador. El contenido abarca múltiples aspectos como cálculo numérico, SIMD, corrutinas, Ranges, manejo de excepciones, programación de redes y E/S en espacio de usuario. A través de código concreto y mediciones de rendimiento, el proyecto tiene como objetivo ayudar a los desarrolladores a establecer una mentalidad orientada al rendimiento y muestra cómo utilizar características modernas de C++ y bibliotecas no estándar (como oneTBB, fmt, StringZilla, CTRE, etc.) para mejorar la eficiencia del código. El autor espera que estos ejemplos inspiren a los desarrolladores a reexaminar sus hábitos de codificación y descubrir diseños más eficientes. (Fuente: ashvardanian/less_slow.cpp – GitHub Trending (all/daily))

Perro robot en una exposición: Un bloguero tecnológico compartió un fragmento de vídeo de un perro robot filmado en una exposición. Muestra la aplicación y exhibición de la tecnología actual de perros robot en entornos públicos. (Fuente: Ronald_vanLoon)
Robot Unitree G1 caminando en un centro comercial: El vídeo muestra al robot humanoide Unitree G1 caminando dentro de un centro comercial. Este tipo de demostraciones públicas ayudan a aumentar la conciencia pública sobre la tecnología de robots humanoides y prueban las capacidades de navegación y movilidad del robot en entornos reales y no estructurados. (Fuente: Ronald_vanLoon)
Impresionante baile de robots: El vídeo muestra un baile de robots técnicamente avanzado, con movimientos coordinados y fluidos. Esto generalmente implica una planificación de movimiento compleja, algoritmos de control y un ajuste preciso del hardware del robot (articulaciones, motores, etc.), siendo una demostración de las capacidades integrales de la tecnología robótica. (Fuente: Ronald_vanLoon)
Robot quirúrgico de alta precisión separa cáscara de huevo de codorniz: El vídeo muestra un robot quirúrgico capaz de separar con precisión la cáscara de un huevo de codorniz crudo de su membrana interna. Esto resalta las capacidades avanzadas de los robots modernos en operaciones finas, control de fuerza y retroalimentación visual, habilidades cruciales para campos como la medicina y la fabricación de precisión. (Fuente: Ronald_vanLoon)
Robot transformable estilo anime de 14.8 pies de altura y pilotable: El vídeo muestra un robot transformable estilo anime de 14.8 pies (aproximadamente 4.5 metros) de altura, caracterizado porque una persona puede entrar en la cabina para controlarlo. Se trata más bien de un proyecto de entretenimiento o exhibición conceptual, que fusiona tecnología robótica, diseño mecánico y elementos de la cultura popular. (Fuente: Ronald_vanLoon)
Análisis de caso: Plan para una Inteligencia Artificial Responsable: El artículo explora la importancia de la Inteligencia Artificial Responsable (Responsible AI), proponiendo un plan para construir confianza, equidad y seguridad. A medida que aumentan las capacidades de la IA y se generaliza su aplicación, es crucial garantizar que su desarrollo y despliegue cumplan con las normas éticas, eviten sesgos y protejan la seguridad y privacidad del usuario. El artículo puede abordar marcos de gobernanza, medidas técnicas y mejores prácticas. (Fuente: Ronald_vanLoon)

Demostración del perro robot Unitree B2-W: El vídeo muestra el perro robot modelo B2-W de la compañía Unitree. Unitree es un conocido fabricante de robots cuadrúpedos, y sus productos se utilizan a menudo para demostrar la capacidad de movimiento, equilibrio y adaptabilidad al entorno de los robots. (Fuente: Ronald_vanLoon)
Robot SpiRobs imitando la espiral logarítmica natural: Se informa sobre el robot SpiRobs, cuyo diseño morfológico imita la estructura de espiral logarítmica omnipresente en la naturaleza. Este diseño biomimético podría tener como objetivo aprovechar las ventajas mecánicas o de movimiento de las estructuras naturales, explorando nuevas formas de movimiento o transformación robótica. (Fuente: Ronald_vanLoon)
Robot cocina arroz frito rápidamente en 90 segundos: El vídeo muestra un robot de cocina capaz de completar la preparación de arroz frito en 90 segundos. Esto representa el potencial de la automatización en la industria de la restauración, logrando una producción de alimentos rápida y estandarizada mediante el control preciso de procesos e ingredientes. (Fuente: Ronald_vanLoon)
Robot innovador imitando el movimiento peristáltico: El vídeo muestra un tipo de robot que imita el modo de movimiento biológico de peristalsis. Este diseño de robot blando o segmentado se utiliza generalmente para explorar nuevos mecanismos de movimiento en entornos estrechos o complejos, inspirado en organismos como gusanos y serpientes. (Fuente: Ronald_vanLoon)
Modelo de predicción para el Gran Premio de Arabia Saudita de F1 2025: Un usuario compartió un proyecto que utiliza machine learning (no deep learning) para predecir los resultados de las carreras de F1. El modelo combina datos reales de las temporadas 2022-2025 extraídos con la biblioteca FastF1 (incluida la clasificación), el estado del piloto (posición promedio, velocidad, resultados recientes), métricas específicas del circuito (como el rendimiento pasado en el circuito de Jeddah) y características personalizadas (como el cambio de posición promedio, experiencia en el circuito). El modelo utiliza una fórmula ponderada manualmente para la predicción y proporciona resultados visualizados como ranking previsto, probabilidad de podio, rendimiento del equipo, etc. El código del proyecto está disponible en GitHub. (Fuente: Reddit r/MachineLearning)

Buscando colaboradores en deep learning en el campo de la ingeniería biomédica: Un profesor asistente con doctorado en ingeniería biomédica busca investigadores universitarios fiables y trabajadores para colaborar. Las principales líneas de investigación son el procesamiento de señales e imágenes, clasificación, algoritmos metaheurísticos, deep learning y machine learning, especialmente el procesamiento y clasificación de señales EEG (no obligatorio). Se requiere que los colaboradores tengan afiliación universitaria, experiencia en campos relevantes, intención de publicar, experiencia en MATLAB y un perfil académico público (como Google Scholar). (Fuente: Reddit r/deeplearning)