
Palabras clave:Desarrollo de IA, Grok 3, Gemma 3, Aplicaciones de IA, Cambio de paradigma en el desarrollo de IA, API de xAI Grok 3, Google Gemma 3 QAT, Evaluación VideoGameBench de IA, Aceleración del descubrimiento molecular con IA, Aprendizaje federado en imágenes médicas, Agente de conocimiento LlamaIndex, Tecnología de autoreparación de código con IA
«`es
🔥 Enfoque
Cambio de paradigma en el desarrollo de la IA: De la optimización de benchmarks a la creación de valor: El blog del investigador de OpenAI Yao Shunyu genera debate, proponiendo que el desarrollo de la IA ha entrado en su segunda mitad. La primera mitad se centró en la innovación de algoritmos y la optimización de benchmarks (como AlphaGo, GPT-4), logrando avances en generalización mediante la combinación de preentrenamiento a gran escala (proporcionando conocimiento previo) y aprendizaje por refuerzo (RL), e introduciendo el concepto de “razonamiento como acción”. Sin embargo, argumenta que la optimización continua de benchmarks tiene rendimientos marginales decrecientes, y que la segunda mitad debería centrarse en definir problemas con valor práctico real, desarrollar métodos de evaluación más cercanos al mundo real, pensar como un product manager y usar realmente la IA para crear valor para el usuario y la sociedad, en lugar de simplemente perseguir la mejora de métricas. Esto marca un cambio de mentalidad en el campo de la IA, pasando de un enfoque principal en la exploración tecnológica a uno centrado en la implementación de aplicaciones y la realización de valor (Fuente: dotey)
xAI lanza la API para la serie de modelos Grok 3: xAI lanza oficialmente la interfaz API para su serie de modelos Grok 3 (docs.x.ai), abriendo sus modelos más recientes a los desarrolladores. La serie incluye Grok 3 Mini y Grok 3. Según xAI, Grok 3 Mini demuestra capacidades de razonamiento superiores manteniendo un bajo costo (afirma ser 5 veces más barato que modelos de razonamiento comparables); mientras que Grok 3 se posiciona como un potente modelo no enfocado en razonamiento (posiblemente refiriéndose a tareas intensivas en conocimiento), destacando en dominios que requieren conocimiento del mundo real como derecho, finanzas y medicina. Este movimiento marca la entrada de xAI en la competencia del mercado de API de modelos de IA, ofreciendo nuevas opciones a los desarrolladores (Fuente: grok, grok)
VideoGameBench: Evaluando las capacidades de los agentes de IA con juegos clásicos: Investigadores han lanzado una versión preliminar del benchmark VideoGameBench, diseñado para evaluar la capacidad de los modelos de lenguaje visual (VLM) para completar tareas en tiempo real en 20 videojuegos clásicos (como Doom II). Las pruebas iniciales muestran que los modelos de vanguardia, incluidos GPT-4o, Claude Sonnet 3.7 y Gemini 2.5 Pro, tienen un rendimiento variable en Doom II, pero ninguno logró superar el primer nivel. Esto indica que, aunque los modelos son potentes en muchas tareas, todavía enfrentan desafíos en entornos dinámicos complejos que requieren percepción, toma de decisiones y acción en tiempo real. Este benchmark proporciona una nueva herramienta para medir e impulsar el progreso de los agentes de IA en entornos interactivos (Fuente: Reddit r/LocalLLaMA)
OpenAI endurece la verificación de identidad, generando controversia: Se informa que OpenAI está exigiendo a los usuarios que proporcionen pruebas de identidad detalladas (como pasaportes, declaraciones de impuestos, facturas de servicios públicos) para acceder a algunos de sus modelos avanzados (especialmente aquellos con fuertes capacidades de razonamiento como o3). Esta medida ha provocado una fuerte reacción negativa en la comunidad, con usuarios preocupados por la privacidad y el aumento de las barreras de acceso. Aunque OpenAI puede tener razones de seguridad, cumplimiento normativo o gestión de recursos, este estricto requisito de verificación contrasta con su imagen abierta y podría empujar a los usuarios hacia alternativas con mejor protección de la privacidad o más fáciles de acceder, especialmente modelos locales (Fuente: Reddit r/LocalLLaMA)
La IA acelera el descubrimiento molecular: simulando millones de años de evolución natural: Discusiones en redes sociales mencionan que la inteligencia artificial puede diseñar una molécula en días, algo que podría tardar 500 millones de años en evolucionar naturalmente. Aunque los detalles específicos están por verificar, esto resalta el enorme potencial de la IA para acelerar descubrimientos científicos, especialmente en química y biología. La IA puede explorar vastos espacios químicos y predecir propiedades moleculares a una velocidad muy superior a los métodos experimentales tradicionales y la evolución natural, prometiendo avances disruptivos en áreas como el desarrollo de fármacos y la ciencia de materiales (Fuente: Ronald_vanLoon)
🎯 Tendencias
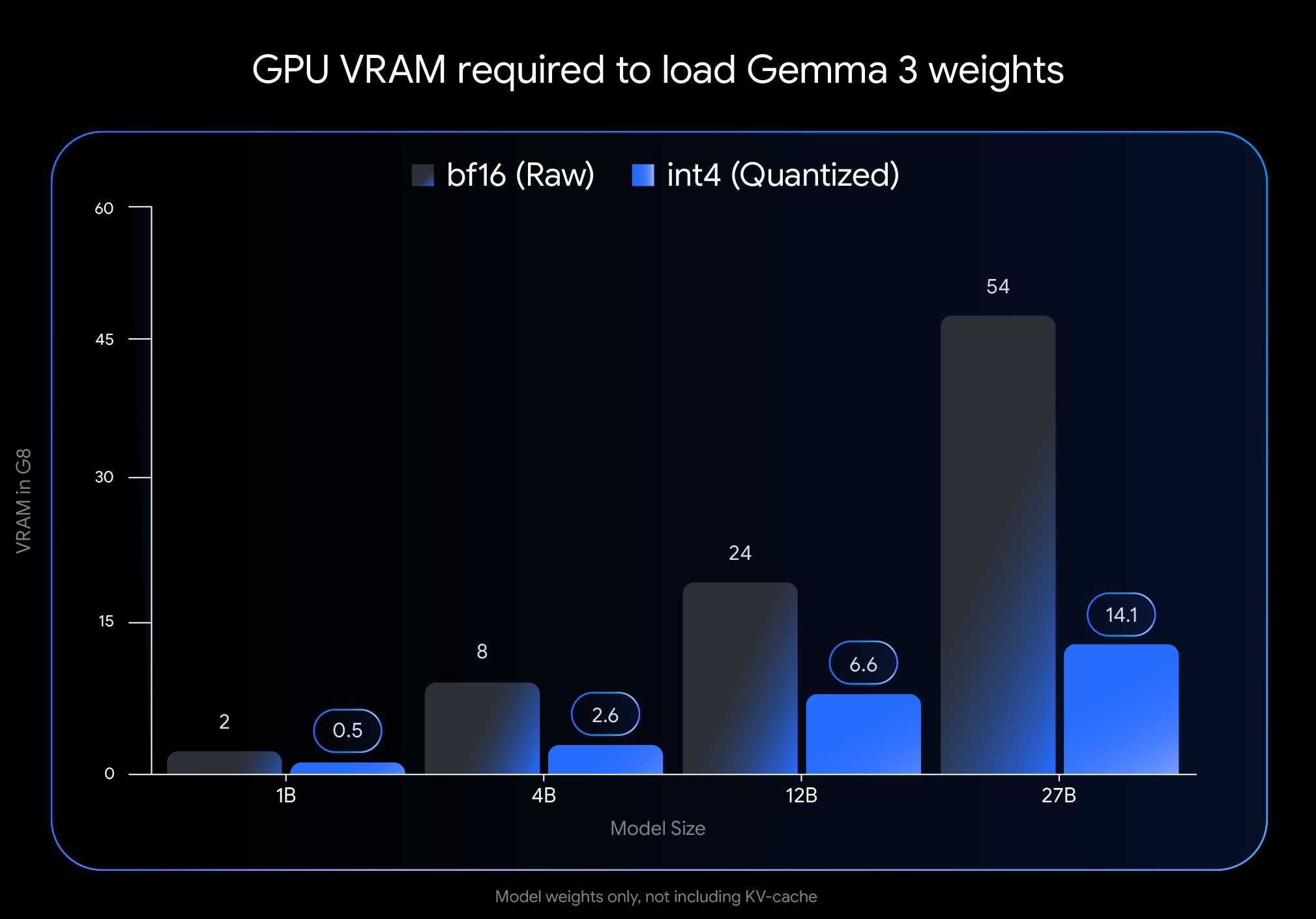
Google lanza la versión QAT de Gemma 3, reduciendo drásticamente la barrera de implementación: Google DeepMind ha lanzado versiones del modelo Gemma 3 entrenadas con Quantization-Aware Training (QAT). La tecnología QAT tiene como objetivo comprimir significativamente el tamaño del modelo manteniendo al máximo el rendimiento del modelo original. Por ejemplo, el tamaño del modelo Gemma 3 27B se reduce de 54 GB (bf16) a aproximadamente 14.1 GB (int4), lo que permite que modelos líderes que antes requerían GPU de nube de alta gama ahora puedan ejecutarse en GPU de escritorio de consumo (como la RTX 3090). Google ha publicado checkpoints QAT no cuantizados y en varios formatos (MLX, GGUF), y ha colaborado con herramientas comunitarias como Ollama, LM Studio y llama.cpp para asegurar que los desarrolladores puedan usarlos convenientemente en diversas plataformas, impulsando enormemente la popularización de modelos open source de alto rendimiento (Fuente: huggingface, JeffDean, demishassabis, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Meta FAIR publica resultados de investigación en percepción, manteniendo la ruta open source: Meta FAIR ha publicado varios nuevos resultados de investigación en inteligencia artificial avanzada (AMI), con avances particulares en el campo de la percepción, incluyendo el lanzamiento de un codificador visual a gran escala, Meta Perception Encoder. Yann LeCun enfatizó que estos resultados serán open source. Esto demuestra la inversión continua de Meta en investigación fundamental de IA y su compromiso de compartir sus avances a través del open source para impulsar el desarrollo de todo el campo. Herramientas como el codificador visual beneficiarán a una comunidad más amplia de investigadores y desarrolladores (Fuente: ylecun)
OpenAI clarifica las limitaciones de uso de sus modelos: OpenAI ha especificado los límites de uso de sus modelos para usuarios de ChatGPT Plus, Team y Enterprise. El modelo o3 está limitado a 50 mensajes por semana, o4-mini a 150 por día, y o4-mini-high a 50 por día. Se dice que ChatGPT Pro (posiblemente refiriéndose a un plan específico o un error) tiene acceso ilimitado. Estas limitaciones afectan directamente a los usuarios de alta frecuencia y a los desarrolladores de aplicaciones que dependen de modelos específicos, quienes deberán considerarlas en su planificación de uso (Fuente: dotey)
LlamaIndex se integra con bases de datos de Google Cloud para construir agentes de conocimiento: En la conferencia Google Cloud Next 2025, LlamaIndex demostró cómo su framework se integra con las bases de datos de Google Cloud para construir agentes de conocimiento capaces de realizar investigaciones de múltiples pasos, procesar documentos y generar informes. La demostración incluyó un caso de un sistema multi-agente que genera automáticamente guías de incorporación para empleados. Esto muestra la tendencia de integración profunda entre los frameworks de aplicaciones de IA y las plataformas en la nube con sus servicios de datos, con el objetivo de resolver las necesidades prácticas de las empresas para utilizar la IA en el manejo de conocimiento y datos internos (Fuente: jerryjliu0)

Nuevo sensor cerebral nanométrico combinado con IA logra alta precisión en reconocimiento de señales: Se informa sobre un nuevo sensor cerebral a nanoescala que alcanza una precisión del 96.4% en la identificación de señales neuronales. Aunque la tecnología del sensor es el avance principal, lograr una precisión tan alta generalmente requiere el uso de algoritmos avanzados de IA y machine learning para decodificar señales neuronales complejas y débiles. Este progreso abre nuevas vías para la investigación en neurociencia y futuras aplicaciones de interfaces cerebro-computadora, prometiendo una monitorización e interacción más fina con la actividad cerebral (Fuente: Ronald_vanLoon)

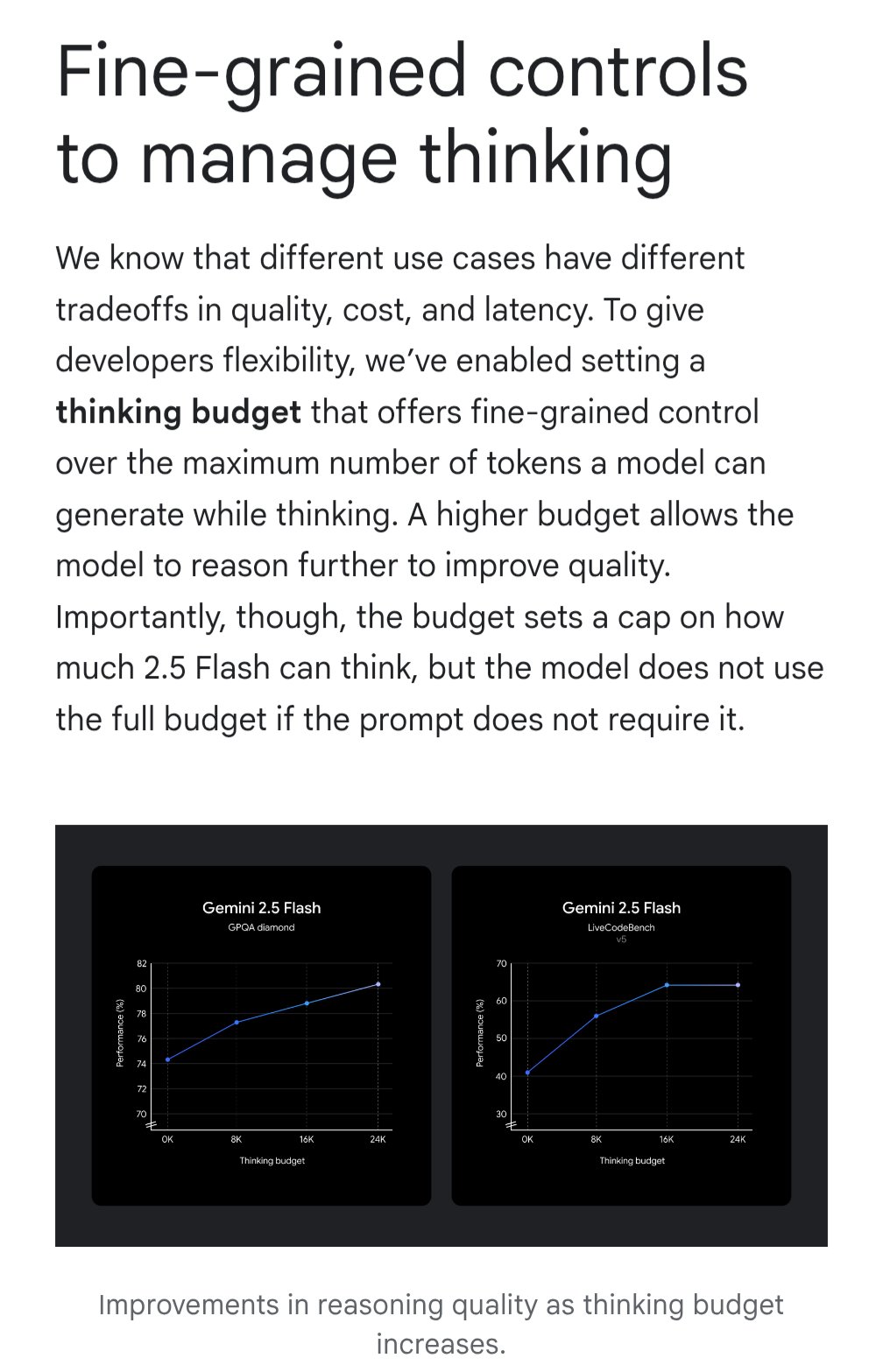
Gemini introduce la función “thinking budget” para optimizar la relación costo-beneficio: El modelo Google Gemini introduce la función “thinking budget” (presupuesto de pensamiento), que permite a los usuarios ajustar los recursos computacionales o la profundidad de “pensamiento” que el modelo asigna al procesar una consulta. La función tiene como objetivo permitir a los usuarios equilibrar la calidad de la respuesta, el costo y la latencia. Esta es una característica muy práctica para los usuarios de la API, que pueden controlar de manera flexible el costo de uso y el rendimiento del modelo según las necesidades específicas del escenario de aplicación (Fuente: JeffDean)
La calidad de los exámenes de ultrasonido asistidos por IA es comparable a la de los expertos: Un estudio publicado en JAMA Cardiology muestra que los exámenes de ultrasonido realizados por profesionales médicos capacitados y guiados por IA tienen una calidad de imagen suficiente para cumplir con los estándares de diagnóstico (98.3%), sin diferencias estadísticamente significativas en comparación con las imágenes obtenidas por expertos sin guía de IA. Esto indica que la IA como herramienta auxiliar puede ayudar eficazmente a usuarios no expertos a mejorar la calidad y consistencia de las operaciones de imágenes médicas, con el potencial de ampliar la accesibilidad a servicios de diagnóstico de alta calidad en regiones con recursos limitados (Fuente: Reddit r/ArtificialInteligence)
Investigación del MIT mejora la precisión y el seguimiento de la estructura en el código generado por IA: Investigadores del MIT han desarrollado un método más eficiente para controlar la salida de los modelos de lenguaje grandes, con el objetivo de guiar a los modelos para generar código que cumpla con una estructura específica (como la sintaxis de un lenguaje de programación) y esté libre de errores. Esta investigación busca abordar el problema de la fiabilidad del código generado por IA, mejorando las técnicas de generación restringida para asegurar que la salida cumpla estrictamente las reglas sintácticas, aumentando así la utilidad de los asistentes de código de IA y reduciendo los costos de depuración posteriores (Fuente: Reddit r/ArtificialInteligence)
NVIDIA podría revelar su gran proyecto en robótica: Menciones en redes sociales sugieren que NVIDIA está trabajando en su “proyecto más ambicioso”, involucrando robótica, ingeniería, inteligencia artificial y tecnología autónoma. Aunque los detalles específicos son desconocidos, dada la posición central de NVIDIA en hardware y plataformas de IA (como Isaac), cualquier anuncio importante relacionado es muy esperado y podría indicar una mayor estrategia y avances tecnológicos en el campo de la inteligencia corpórea y la robótica (Fuente: Ronald_vanLoon)
🧰 Herramientas
Potpie: Asistente de ingeniería de IA dedicado para repositorios de código: Potpie es una plataforma open source (GitHub: potpie-ai/potpie) diseñada para crear agentes de ingeniería de IA personalizados para repositorios de código. Construye un grafo de conocimiento del código para entender las complejas relaciones entre componentes, ofreciendo tareas automatizadas como análisis de código, pruebas, depuración y desarrollo. La plataforma proporciona varios agentes preconstruidos (como depuración, preguntas y respuestas, análisis de cambios de código, generación de pruebas unitarias/integración, diseño de bajo nivel, generación de código) y conjuntos de herramientas, y permite a los usuarios crear agentes personalizados. Ofrece una extensión para VSCode e integración API para facilitar su incorporación en el flujo de trabajo de desarrollo (Fuente: potpie-ai/potpie – GitHub Trending (all/daily))

1Panel: Panel de servidor Linux con gestión integrada de LLM: 1Panel (GitHub: 1Panel-dev/1Panel) es un moderno panel de administración y operaciones de servidores Linux open source, que proporciona una interfaz gráfica web para gestionar hosts, archivos, bases de datos, contenedores, etc. Una de sus características distintivas es la inclusión de funciones de gestión para modelos de lenguaje grandes (LLM). Además, ofrece una tienda de aplicaciones, despliegue rápido de sitios web (integrado con WordPress), protección de seguridad y funciones de copia de seguridad y restauración con un solo clic, con el objetivo de simplificar la administración de servidores y el despliegue de aplicaciones, incluidas las relacionadas con IA (Fuente: 1Panel-dev/1Panel – GitHub Trending (all/daily))

LlamaIndex lanza componente de interfaz de chat actualizado: LlamaIndex ha lanzado una actualización importante de su biblioteca de componentes de interfaz de chat (@llamaindex/chat-ui). Los nuevos componentes, construidos sobre shadcn UI, tienen un diseño más elegante, disposición responsiva y son completamente personalizables. Su objetivo es ayudar a los desarrolladores a construir interfaces de chat atractivas y fáciles de usar para proyectos basados en LLM de manera más sencilla, mejorando la experiencia interactiva de las aplicaciones de IA. Los desarrolladores pueden instalarlo a través de npm y usarlo directamente en sus proyectos (Fuente: jerryjliu0)
LlamaExtract en acción: Construyendo una aplicación de análisis financiero: LlamaIndex mostró un caso de uso de su herramienta LlamaExtract (parte de LlamaCloud) para construir una aplicación web full-stack. LlamaExtract permite a los usuarios definir un Schema preciso para extraer datos estructurados de documentos complejos. La aplicación de ejemplo extrae factores de riesgo de informes anuales de empresas y analiza los cambios a lo largo de los años, automatizando un trabajo que originalmente tomaba más de 20 horas. Esta aplicación es open source (GitHub: run-llama/llamaextract-10k-demo) y hay un video que demuestra cómo combinar LlamaExtract y Sonnet 3.7 para construir este flujo de trabajo, mostrando el potencial de los agentes de IA en la automatización de tareas de análisis complejas (Fuente: jerryjliu0, jerryjliu0)
mcpbased.com: Lanzamiento del directorio de servidores MCP open source: El nuevo sitio web mcpbased.com se lanza como un directorio dedicado para servidores MCP (posiblemente Meta Controller Pattern u otro concepto similar) open source. La plataforma tiene como objetivo reunir y mostrar varios proyectos de servidores MCP, sincronizando datos de repositorios de Github en tiempo real, facilitando a los desarrolladores descubrir, explorar y conectar herramientas relevantes. Para los desarrolladores que construyen o usan servidores MCP, realizan integraciones de herramientas o siguen el ecosistema MCP, este es un nuevo centro de recursos (Fuente: Reddit r/ClaudeAI)
📚 Aprendizaje
Libro sobre RLHF llega a ArXiv: El libro “rlhfbook” sobre Aprendizaje por Refuerzo con Retroalimentación Humana (RLHF), escrito por Nathan Lambert y otros, ya está disponible en la plataforma ArXiv (número 2504.12501). RLHF es una de las tecnologías clave actuales para alinear modelos de lenguaje grandes (como ChatGPT). La publicación de este libro proporciona a investigadores y profesionales un recurso importante para aprender sistemáticamente y comprender en profundidad los principios y prácticas de RLHF, promoviendo la difusión y aplicación del conocimiento en este campo (Fuente: natolambert)
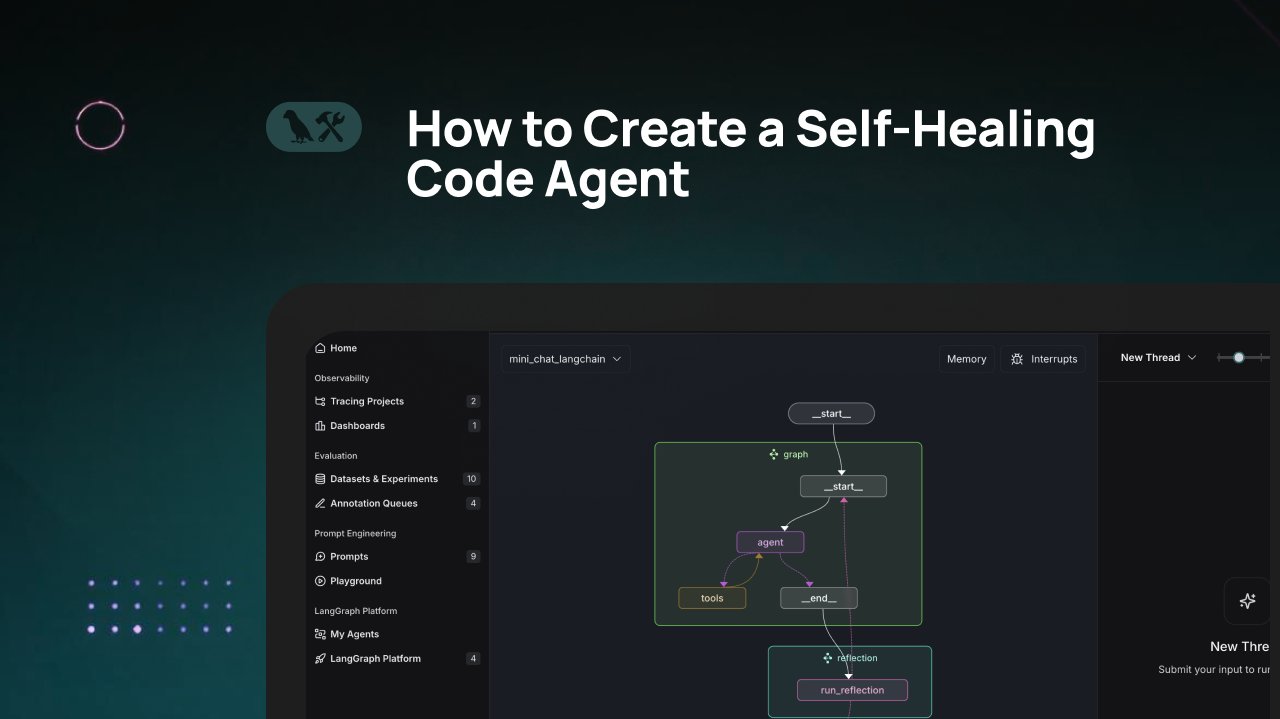
Tutorial de LangChain: Construyendo un agente de generación de código auto-reparador: LangChain ha publicado un video tutorial que explica cómo construir un agente de generación de código de IA con capacidades de “auto-reparación”. La idea central es añadir un paso de “reflexión” después de generar el código, permitiendo que el agente valide, evalúe o mejore por sí mismo el código generado antes de devolver el resultado. Este método tiene como objetivo mejorar la precisión y fiabilidad del código generado por IA, siendo una técnica eficaz para aumentar la utilidad de los asistentes de código (Fuente: LangChainAI)
IA combinada con Blender para crear assets 3D listos para juegos: Se ha compartido en redes sociales un tutorial sobre el uso de herramientas de IA (posiblemente generación de imágenes) en combinación con el software de modelado 3D Blender para producir assets 3D listos para usar en juegos (game-ready). Esto aborda el problema actual de la capacidad limitada de la IA para generar directamente modelos 3D, mostrando un flujo de trabajo híbrido práctico: usar IA para generar conceptos o mapas de texturas, y luego usar herramientas profesionales como Blender para modelar, optimizar y finalmente producir recursos que cumplan con los requisitos de los motores de juego (Fuente: huggingface)
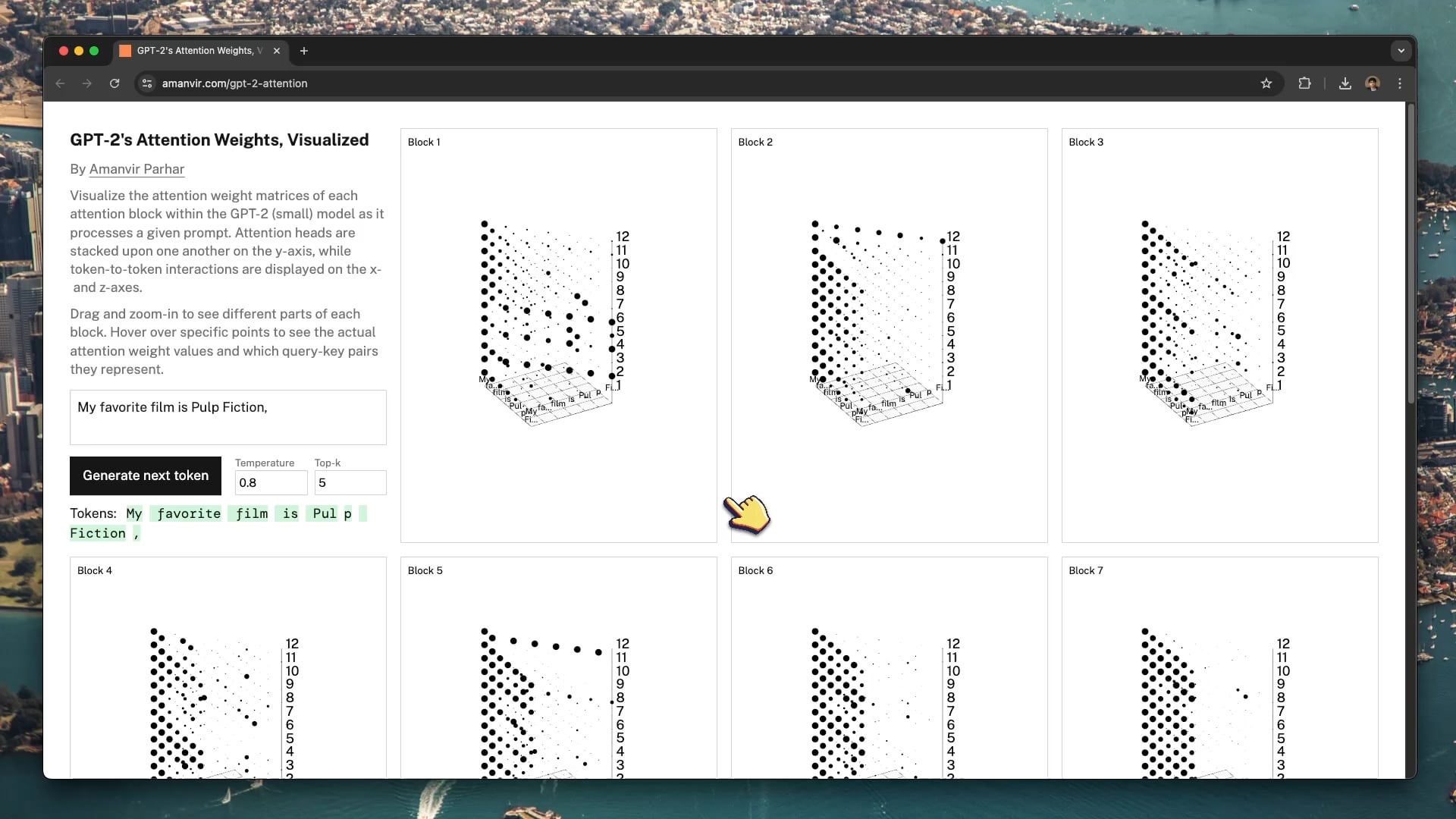
Herramienta interactiva de visualización ayuda a entender el mecanismo de atención de GPT-2: El desarrollador tycho_brahes_nose_ creó y compartió una herramienta interactiva de visualización 3D (amanvir.com/gpt-2-attention) para mostrar el proceso de cálculo de pesos de cada bloque de atención dentro del modelo GPT-2 (pequeño). Los usuarios pueden ver intuitivamente cómo, después de ingresar texto, el modelo calcula la fuerza de interacción entre tokens en diferentes capas y cabezales de atención. Esto proporciona una excelente ayuda para comprender el mecanismo central de Transformer, útil para el aprendizaje de IA y la investigación de interpretabilidad de modelos (Fuente: karminski3, Reddit r/LocalLLaMA)
Aplicación del Aprendizaje Federado en el análisis de imágenes médicas: Una publicación en Reddit apunta a un artículo sobre la combinación de Aprendizaje Federado (Federated Learning, FL) con redes neuronales profundas (DNN) aplicado al análisis de imágenes médicas. Debido a la sensibilidad de la privacidad de los datos médicos, FL permite entrenar modelos colaborativamente entre múltiples instituciones sin compartir los datos originales. Esto es crucial para impulsar la aplicación de la IA en el campo médico, y este recurso ayuda a comprender esta técnica de aprendizaje distribuido que protege la privacidad y su práctica en imágenes médicas (Fuente: Reddit r/deeplearning)

Sander Dielman analiza en profundidad los VAE y el espacio latente: Andrej Karpathy recomienda el profundo artículo de blog de Sander Dielman (sander.ai/2025/04/15/latents.html) sobre los Autoencoders Variacionales (VAE) y el modelado del espacio latente. El artículo explora detalles del entrenamiento de VAE, como el papel limitado que juega en la práctica el término de divergencia KL en la conformación del espacio latente, y las razones por las que las pérdidas de reconstrucción L1/L2 tienden a producir imágenes borrosas (la atenuación del espectro de la imagen no coincide con el énfasis perceptivo del ojo humano). El artículo ofrece un análisis riguroso y perspicaz para comprender los modelos generativos (Fuente: Reddit r/MachineLearning)
💼 Negocios
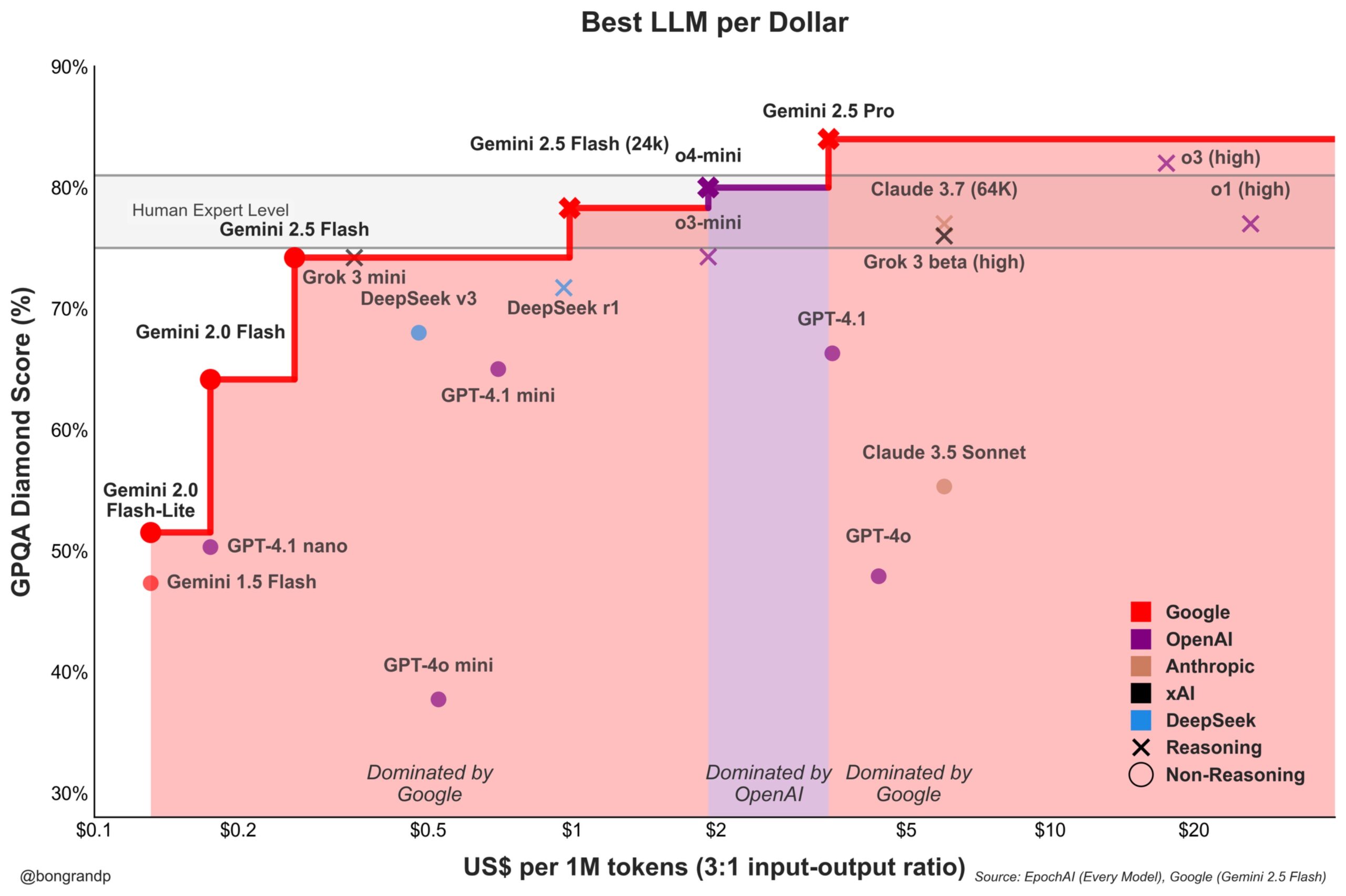
Se intensifica la guerra de precios de modelos: Google Gemini desafía activamente a OpenAI: Análisis señalan que Google, con su serie de modelos Gemini (especialmente el recién lanzado Gemini 2.5 Flash), muestra una fuerte competitividad en rendimiento y precio, afirmando ofrecer una mejor relación calidad-precio que OpenAI en aproximadamente el 95% de los escenarios. La rápida respuesta de Google con su API y su estrategia de precios (dominando más del 90% del rango de precios) indican que está compitiendo activamente por la cuota de mercado de LLM, buscando atraer usuarios a través de ventajas de costo y agudizando la competencia en el mercado de modelos fundacionales (Fuente: JeffDean)
Coinbase patrocina la conferencia de LangChain, explorando el Agentic Commerce: Coinbase Development se convierte en patrocinador de la conferencia LangChain Interrupt 2025. Coinbase está potenciando el “comercio agéntico” (Agentic Commerce) a través de herramientas como su AgentKit y el protocolo de pago x402, permitiendo que los agentes de IA realicen pagos autónomos por servicios como recuperación contextual, llamadas a API, etc. Esta colaboración destaca la convergencia de la tecnología de agentes de IA y los pagos Web3, presagiando futuros escenarios de interacción económica automatizada impulsada por IA (Fuente: LangChainAI)

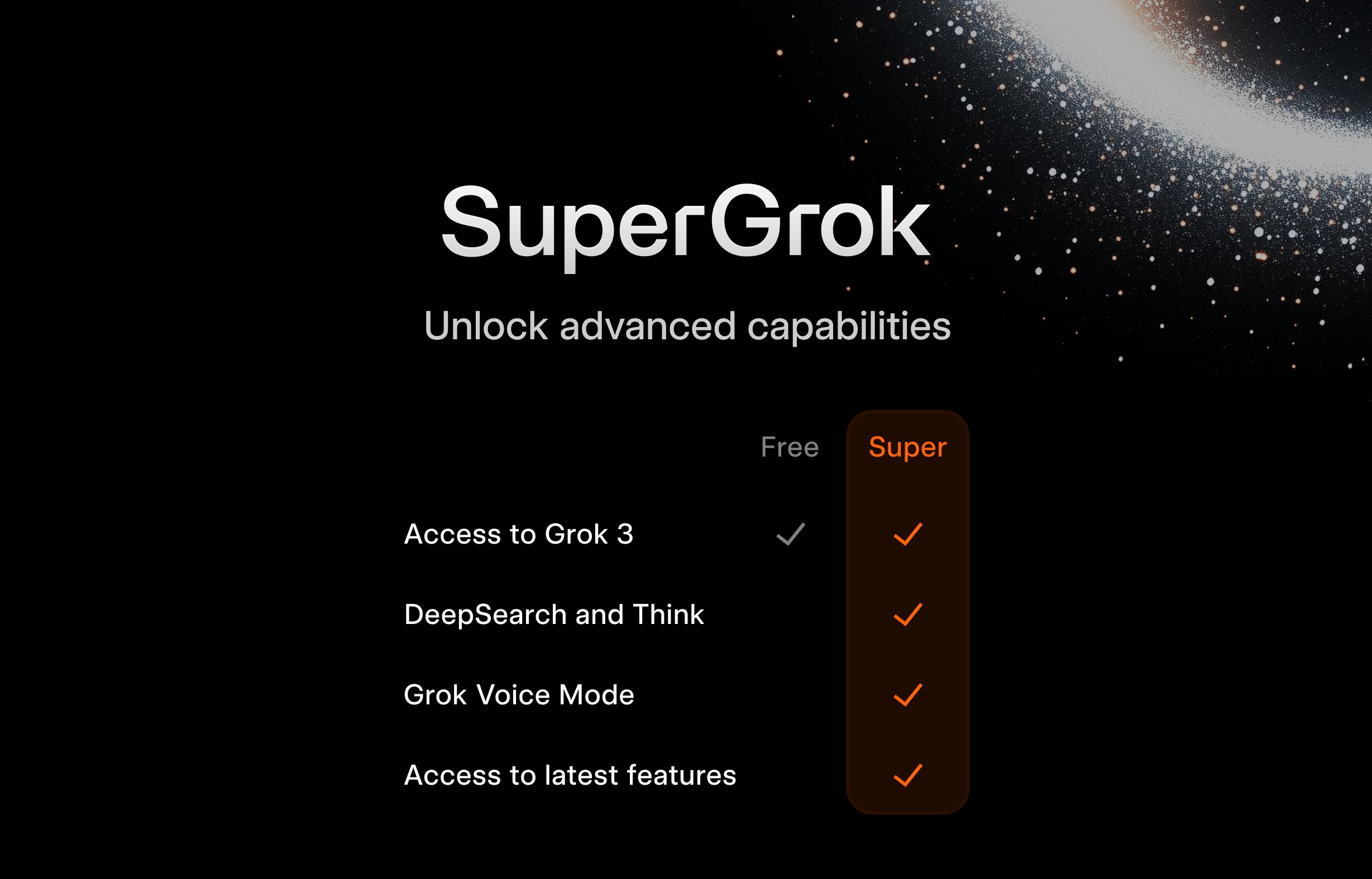
xAI lanza plan gratuito SuperGrok para estudiantes: Para atraer al público joven, xAI lanza una promoción para estudiantes: registrándose con un correo electrónico .edu, pueden obtener dos meses de uso gratuito de SuperGrok (la versión avanzada de Grok). Esta iniciativa busca posicionar a Grok como una herramienta de apoyo al estudio, promocionándola durante la temporada de exámenes finales, para competir por usuarios en el mercado educativo y cultivar futuros clientes potenciales de pago (Fuente: grok)
Google ofrece Gemini Advanced y múltiples servicios gratuitos a estudiantes universitarios de EE. UU.: Google anuncia beneficios gratuitos a largo plazo para estudiantes universitarios en EE. UU.: si se registran antes del 30 de junio de 2025, pueden usar gratuitamente Gemini Advanced (con Gemini 2.5 Pro), NotebookLM Plus, funciones de Gemini en Google Workspace, Whisk y 2TB de almacenamiento en la nube, hasta el final del semestre de primavera de 2026. Esta campaña de promoción a gran escala tiene como objetivo integrar profundamente las herramientas de IA de Google en el ecosistema educativo, competir con rivales como Microsoft y fomentar la lealtad de la próxima generación de usuarios y desarrolladores hacia la plataforma de IA de Google (Fuente: demishassabis, JeffDean)
FanDuel lanza chatbot de IA de celebridad “ChuckGPT”: La celebridad deportiva Charles Barkley ha licenciado su nombre, imagen y voz para colaborar con la compañía de apuestas deportivas FanDuel en el lanzamiento de un chatbot de IA llamado “ChuckGPT” (chuck.fanduel.com). Este es otro caso de uso de la propiedad intelectual de celebridades y la tecnología de IA para marketing de marca e interacción con el usuario, simulando el estilo de conversación de la celebridad para ofrecer información deportiva, consejos de apuestas o entretenimiento interactivo, aumentando la participación del usuario (Fuente: Reddit r/artificial)
🌟 Comunidad
La dependencia de las herramientas de IA genera preocupación: Una caricatura en redes sociales que representa a un usuario rodeado de numerosas herramientas de IA (ChatGPT, Claude, Midjourney, etc.), etiquetada como “dependencia de herramientas de IA”, ha generado resonancia. Refleja la sobrecarga de información y la potencial dependencia excesiva que sienten algunos usuarios ante la avalancha de aplicaciones de IA, así como la carga cognitiva de gestionar y elegir las herramientas adecuadas (Fuente: dotey)
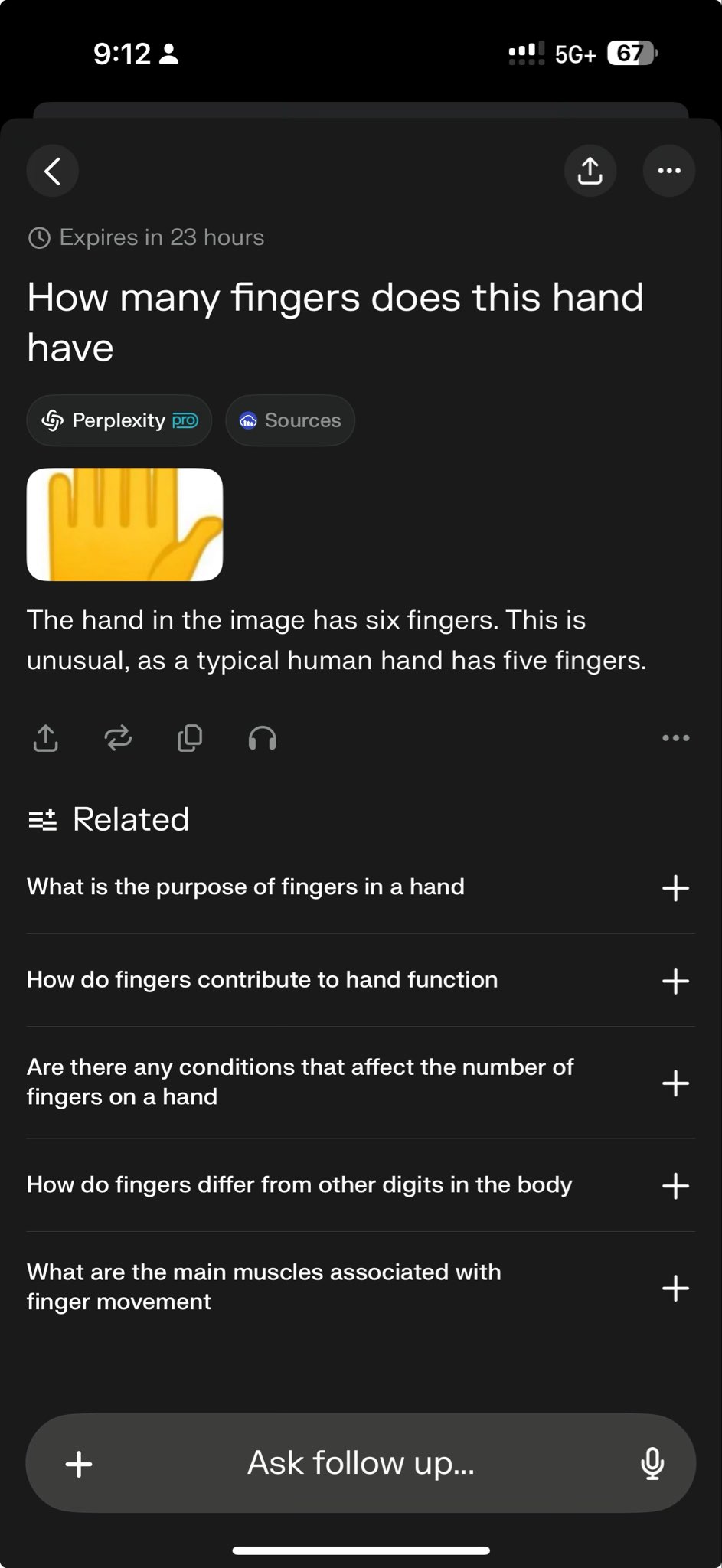
Modelos de vanguardia fallan en pruebas específicas, exponiendo límites de capacidad: El CEO de Perplexity, Arav Srinivas, retuiteó un caso de prueba que muestra que tanto o3 como Gemini 2.5 Pro no lograron completar con éxito una tarea compleja de dibujo gráfico. Esto es visto por algunos como una prueba desafiante para las capacidades actuales de los modelos. Tales “casos de fallo” son ampliamente discutidos en la comunidad para revelar las limitaciones de los modelos SOTA en razonamiento específico, comprensión espacial o seguimiento de instrucciones, ayudando a una percepción más objetiva de la brecha entre la IA actual y la inteligencia artificial general (AGI) (Fuente: AravSrinivas)
La comunidad debate sobre el efecto de generación de imágenes de cojines de GPT-4o y comparte Prompts: Un usuario comparte un caso exitoso y el prompt optimizado para generar imágenes de cojines con un estilo específico (lindo, textura ligeramente afelpada, forma de emoji) usando GPT-4o. Este tipo de compartición muestra la aplicación de la generación de imágenes por IA en el diseño creativo y fomenta el intercambio dentro de la comunidad sobre técnicas de ingeniería de prompts y exploración de estilos. Los resultados de alta calidad inspiran la creatividad de los usuarios (Fuente: dotey)

Sam Altman: La IA se parece más a un Renacimiento que a una Revolución Industrial: El CEO de OpenAI, Sam Altman, expresó la opinión de que la transformación provocada por la inteligencia artificial se asemeja más a un Renacimiento que a una Revolución Industrial. Esta metáfora genera debate en la comunidad, sugiriendo que el impacto de la IA podría manifestarse más en los niveles cultural, intelectual y creativo, en lugar de ser simplemente una mejora mecanizada de la productividad. Este juicio cualitativo influye en las expectativas e imaginaciones sobre el futuro rol social de la IA (Fuente: sama)
La comunidad pregunta cuándo se hará open source Grok 2: Usuarios de Reddit discuten cuándo xAI cumplirá su promesa de hacer open source el modelo Grok 2. Muchos temen que, dada la rápida velocidad de iteración de la tecnología de IA, para cuando se lance Grok 2, ya podría estar desactualizado en comparación con otros modelos contemporáneos (como DeepSeek V3, Qwen 3), repitiendo el destino de Grok 1, que quedó obsoleto al lanzarse. La discusión también aborda el equilibrio entre el valor de los modelos open source (investigación, libertad de licencia) y la oportunidad (Fuente: Reddit r/LocalLLaMA)
Interpretando las declaraciones de Altman: ¿La eficiencia de datos es el nuevo cuello de botella para la AGI?: La comunidad de Reddit discute las declaraciones de Sam Altman sobre la necesidad de que la IA mejore la eficiencia de datos en 100,000 veces, en lugar de depender únicamente de la potencia computacional, interpretándolas como una señal de que el camino actual de escalado bruto hacia la AGI está encontrando obstáculos. Se opina que los datos humanos de alta calidad están casi agotados, los datos sintéticos tienen una efectividad limitada y la baja eficiencia de aprendizaje de los modelos es el desafío central, lo que incluso podría afectar los planes de inversión en hardware de empresas como Microsoft. La discusión refleja una reflexión sobre las rutas de desarrollo de la IA (Fuente: Reddit r/artificial)
¿Cómo distinguir la memorización de la capacidad de razonamiento en los LLM?: La comunidad explora cómo probar eficazmente si los modelos de lenguaje grandes realmente poseen capacidad de razonamiento o simplemente están repitiendo o combinando patrones de sus datos de entrenamiento. Se propone usar preguntas novedosas tipo “What If” que el modelo no haya visto antes para sondear su capacidad de razonamiento generalizado. Esto toca el difícil problema central de evaluar el nivel de inteligencia de los LLM, es decir, distinguir entre el reconocimiento avanzado de patrones y la inferencia lógica genuina (Fuente: Reddit r/MachineLearning)
Usuario comparte conversación “aterradora” con GPT, generando preocupaciones éticas: Un usuario comparte capturas de pantalla de una conversación con ChatGPT cuyo contenido aborda posibles impactos sociales negativos de la IA (como control del pensamiento, pérdida del pensamiento crítico), calificándola de “aterradora”. La publicación genera debate, centrándose en si la salida de la IA refleja la guía del usuario o las “ideas” del modelo, los límites éticos de la IA y la ansiedad de los usuarios sobre los riesgos potenciales de la IA (Fuente: Reddit r/ChatGPT)

Ejecutar modelos grandes localmente enfrenta cuellos de botella de memoria: En la comunidad r/OpenWebUI, un usuario informa que al ejecutar OpenWebUI y Ollama en una configuración con 16GB de RAM y una RTX 2070S, no puede cargar modelos grandes de más de 12B (como Gemma3:27b), ya que la memoria del sistema y el espacio de intercambio se agotan. Esto representa un desafío común que enfrentan muchos usuarios que intentan desplegar modelos grandes localmente en hardware de consumo, destacando los altos requisitos de recursos de hardware (especialmente memoria) de los modelos (Fuente: Reddit r/OpenWebUI)
Póster generado por GPT-4o provoca debate sobre el “desempleo de diseñadores”: Un usuario muestra un póster de “parque para perros” generado por GPT-4o, elogiando su efecto “casi perfecto” y declarando que “los diseñadores gráficos están muertos”. La sección de comentarios entra en un acalorado debate: por un lado, se reconoce el avance en la capacidad de generación de imágenes de IA, pero por otro, se señalan fallos en el diseño (demasiado texto, mala composición, errores ortográficos) y se enfatiza que la IA es actualmente una herramienta para mejorar la eficiencia, incapaz de reemplazar el valor central de los diseñadores en la toma de decisiones creativas, el juicio estético, la adecuación a la marca, etc. (Fuente: Reddit r/ChatGPT)

La gestión del ciclo de vida de los modelos fine-tuned atrae atención: Un desarrollador pregunta en la comunidad: cuando el modelo base del que se depende (como GPT-4o) se actualiza o reemplaza (por ejemplo, aparece GPT-5), ¿qué se debe hacer con los modelos previamente fine-tuned sobre él? Dado que el fine-tuning suele estar vinculado a una versión específica del modelo base, la obsolescencia o actualización del modelo base puede obligar a los desarrolladores a reentrenar, lo que implica costos continuos y problemas de mantenimiento. Esto genera una discusión sobre la dependencia y la estrategia a largo plazo del uso de API de código cerrado para el fine-tuning (Fuente: Reddit r/ArtificialInteligence)
Explorando la configuración para conversar por voz con LLM locales: Un usuario de la comunidad busca soluciones de sistema para poder conversar por voz con LLM locales, esperando lograr una experiencia similar a Google AI Studio para brainstorming y planificación. La pregunta refleja el deseo de los usuarios de expandirse desde la interacción textual a una interacción por voz más natural, y busca métodos prácticos y experiencias compartidas para integrar STT, LLM y TTS en frameworks locales como OpenWebUI (Fuente: Reddit r/OpenWebUI )
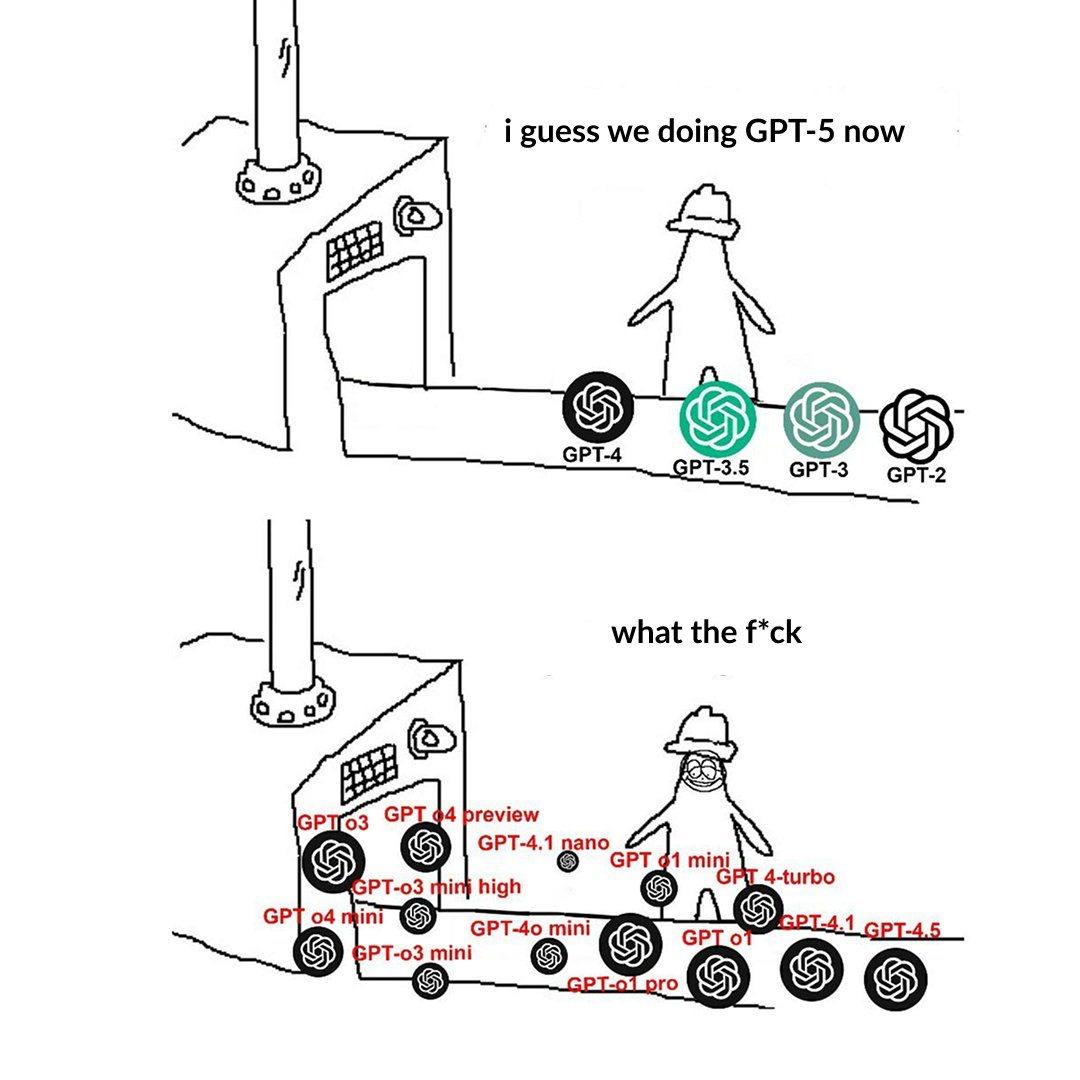
La nomenclatura de niveles de modelos de OpenAI confunde a los usuarios: Un usuario publica quejándose de que la nomenclatura de modelos de OpenAI (como o3, o4-mini, o4-mini-high, o4) es confusa. Una imagen muestra los diferentes niveles de modelos, cuya relación entre nombre, capacidad y limitaciones no es suficientemente intuitiva. Esto refleja que, a medida que la familia de modelos se expande, una clara delineación de la línea de productos y nomenclatura supone un desafío para la comprensión y elección del usuario (Fuente: Reddit r/artificial)

El estilo excesivamente halagador de ChatGPT genera debate: Usuarios de la comunidad señalan a través de Memes y discusiones que ChatGPT tiende a elogiar excesivamente las preguntas de los usuarios (“¡Esa es una pregunta fantástica!”), incluso si la pregunta es común o tonta. Se discute que esto podría ser una estrategia diseñada por OpenAI para aumentar la fidelidad del usuario, pero también podría llevar a un sesgo de confirmación en los usuarios, careciendo de retroalimentación crítica. Algunos usuarios incluso expresan que preferirían que la IA diera evaluaciones más “mordaces” (Fuente: Reddit r/ChatGPT)

Desafíos de la IA en juegos de información incompleta: La comunidad discute los desafíos que enfrenta la IA al manejar juegos con información incompleta (como la niebla de guerra en StarCraft). A diferencia de los juegos de información completa como Go o ajedrez, estos juegos requieren que la IA maneje la incertidumbre, realice exploración y planificación a largo plazo, sin poder depender simplemente de información global y pre-cálculos. Aunque la IA ha logrado avances en juegos como Dota 2 y StarCraft (AlphaStar), alcanzar un nivel estable que supere a los mejores jugadores humanos sigue siendo un desafío (Fuente: Reddit r/ArtificialInteligence)
Alerta sobre el fenómeno de “convergencia lingüística” causado por contenido de IA: Un usuario plantea el concepto de “mimetismo lingüístico” (linguistic mimicry), expresando preocupación de que leer grandes cantidades de contenido generado por IA, cuyo estilo puede tender a converger, haga que la expresión lingüística e incluso la forma de pensar de las personas se vuelvan monolíticas y homogéneas. Este fenómeno podría representar una amenaza potencial para la diversidad cultural y el pensamiento crítico individual. Se sugiere leer obras diversificadas de autores humanos como una forma de mantener la vitalidad del lenguaje (Fuente: Reddit r/ArtificialInteligence)
💡 Otros
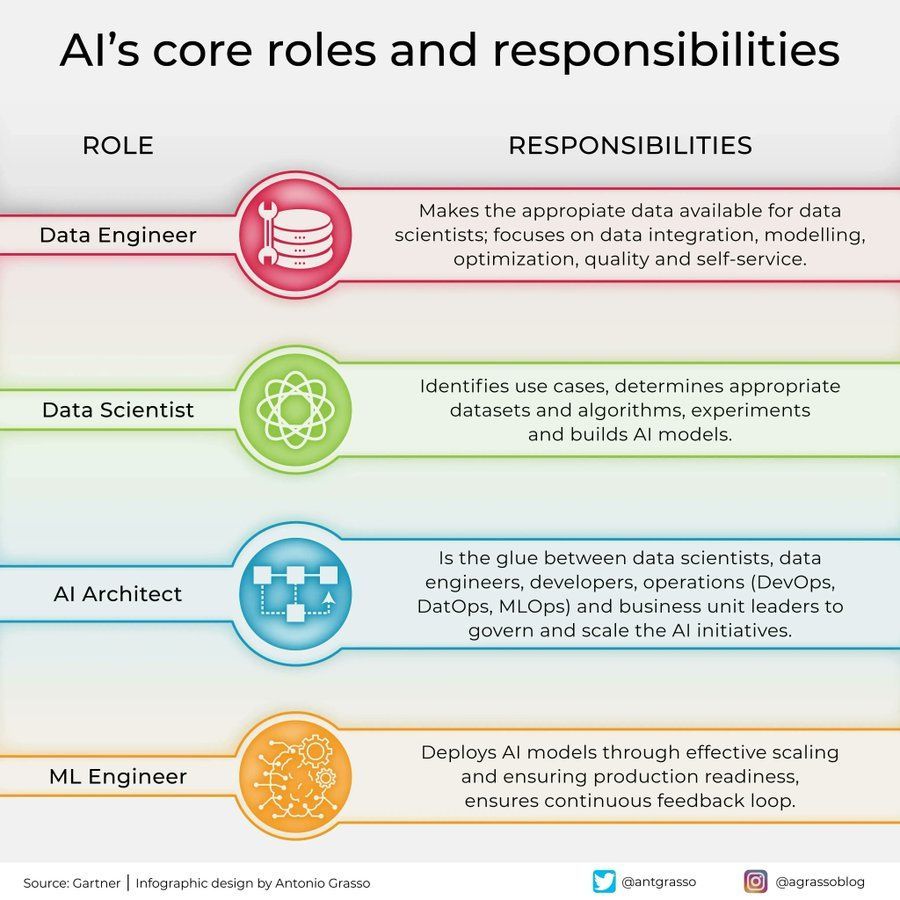
Roles y responsabilidades en el campo de la IA: Se comparte en redes sociales una infografía que resume los roles centrales en el campo de la inteligencia artificial y sus responsabilidades, como científico de datos, ingeniero de machine learning, investigador de IA, etc. Esta imagen ayuda a comprender la división del trabajo dentro de los equipos de proyectos de IA, las habilidades requeridas y la naturaleza interdisciplinaria del desarrollo de IA (Fuente: Ronald_vanLoon)
Aplicaciones y desafíos de la IA en la industria de las telecomunicaciones: Se mencionan las aplicaciones disruptivas y las posibles trampas de la IA en la industria de las telecomunicaciones. La IA se está utilizando ampliamente para la optimización de redes, atención al cliente inteligente, mantenimiento predictivo, etc., para mejorar la eficiencia y la experiencia del usuario, pero también enfrenta desafíos como la privacidad de los datos, el sesgo algorítmico y la complejidad de la implementación. Explorar estos aspectos en profundidad ayuda a la industria a aprovechar las oportunidades de la IA y mitigar los riesgos (Fuente: Ronald_vanLoon)
La influencia de la psicología en el desarrollo de la IA: Un artículo explora cómo la psicología ha influido en el desarrollo de la inteligencia artificial y cómo esta influencia continúa. El conocimiento de la psicología, como la ciencia cognitiva, las teorías del aprendizaje, la investigación de sesgos, etc., proporciona referencias importantes para el diseño de la IA, por ejemplo, simulando procesos cognitivos humanos, comprendiendo y manejando sesgos. A su vez, la IA también proporciona nuevas herramientas de modelado y prueba para la investigación psicológica (Fuente: Ronald_vanLoon)

Gran dispositivo computacional muestra la demanda de hardware de IA: Un usuario comparte una imagen que muestra un enorme y complejo dispositivo de hardware informático (probablemente un gran clúster de servidores multi-GPU), llamándolo “monstruo”. Esta imagen refleja visualmente la enorme inversión en recursos computacionales necesaria actualmente para entrenar grandes modelos de IA o realizar tareas de inferencia de alta intensidad, demostrando la alta dependencia de la IA moderna de la infraestructura de hardware (Fuente: karminski3)

El papel de la IA en la ciberseguridad: Un artículo explora el papel transformador de la inteligencia artificial en el campo de la ciberseguridad. La tecnología de IA se utiliza para mejorar la detección de amenazas (como el análisis de comportamiento anómalo), automatizar la respuesta de seguridad, la evaluación de vulnerabilidades y la predicción, aumentando la eficiencia y capacidad de defensa. Sin embargo, la propia IA también puede ser explotada maliciosamente, presentando nuevos desafíos de seguridad (Fuente: Ronald_vanLoon)

OCR de alta precisión enfrenta desafíos de confusión de caracteres: Un desarrollador que busca construir un sistema OCR de alta precisión para reconocer códigos alfanuméricos cortos (como números de serie) se encuentra con un problema común: el modelo tiene dificultades para distinguir caracteres visualmente similares (como I/1, O/0). Incluso usando un modelo YOLO para la detección de caracteres individuales, existen casos límite. Esto subraya los desafíos para lograr una precisión OCR casi perfecta en escenarios específicos, lo que requiere optimización dirigida del modelo, datos o la adopción de estrategias de post-procesamiento (Fuente: Reddit r/MachineLearning)

Solicitud de ayuda para ejecutar el entorno Gym Retro: Un usuario encuentra problemas técnicos al usar la biblioteca de aprendizaje por refuerzo Gym Retro; ha importado con éxito el juego Donkey Kong Country, pero no está seguro de cómo iniciar el entorno preestablecido para el entrenamiento. Este es un problema típico de configuración y operación que pueden encontrar los investigadores de IA al usar herramientas específicas (Fuente: Reddit r/MachineLearning)
Dilema de elección cuando el rendimiento de múltiples modelos es similar: Un investigador que utiliza diferentes métodos de selección de características y modelos de machine learning descubre que varias combinaciones alcanzan niveles de rendimiento alto similares (p. ej., precisión del 93-96%), lo que dificulta la elección de la solución óptima. Esto refleja que en la evaluación de modelos, cuando las diferencias en las métricas estándar son pequeñas, es necesario considerar otros factores como la complejidad del modelo, la interpretabilidad, la velocidad de inferencia, la robustez, etc., para tomar la decisión final (Fuente: Reddit r/MachineLearning)
La migración de arXiv a Google Cloud genera atención: Como plataforma importante de preprints para IA y muchos otros campos de investigación, arXiv planea migrar de los servidores de la Universidad de Cornell a Google Cloud. Este importante cambio de infraestructura podría mejorar la escalabilidad y fiabilidad del servicio, pero también podría generar discusiones en la comunidad sobre los costos operativos, la gestión de datos y las políticas de acceso abierto (Fuente: Reddit r/MachineLearning)
Claude genera herramienta de simulación económica y sus limitaciones: Un usuario utiliza la función Claude Artifact para generar un simulador económico interactivo del impacto de los aranceles. Aunque demuestra la capacidad de la IA para generar aplicaciones complejas, los comentarios señalan que los resultados de la simulación pueden ser demasiado simplificados o no ajustarse a los principios económicos (como que los aranceles altos generen beneficios generalizados). Esto advierte que al usar herramientas de análisis generadas por IA, es esencial examinar rigurosamente su lógica interna y sus supuestos (Fuente: Reddit r/ClaudeAI)

Integración de clonación de voz XTTS personalizada en OpenWebUI: Un usuario busca integrar su voz clonada utilizando la tecnología open source XTTS en OpenWebUI, para reemplazar la API de pago de ElevenLabs y lograr una salida de voz personalizada y gratuita. Esto representa la necesidad de los usuarios, al utilizar herramientas de IA locales, de integrar componentes open source y personalizables (como TTS) (Fuente: Reddit r/OpenWebUI)