
Palabras clave:AI, 大 modelo, carrera armamentística de AI, modelos de industria vertical, IPO de Zhipu AI, descubrimiento independiente de leyes físicas por AI, sistema de asistencia para ciegos con AI, tecnología AI avanzada, desarrollo de grandes modelos de AI, competencia global en AI, aplicaciones de AI en industrias específicas, inversión en Zhipu AI, innovaciones en AI para la ciencia, soluciones de AI para discapacidad visual
«` markdown
🔥 Enfoque
Los gigantes tecnológicos inician una carrera armamentista de IA, con los modelos verticales y los ecosistemas como foco: Los gigantes tecnológicos globales están invirtiendo en IA con una intensidad sin precedentes, y se espera que el gasto de capital supere los 320 mil millones de dólares en 2025. Empresas chinas como Alibaba, Tencent, Huawei, etc., también están aumentando sus apuestas, invirtiendo fuertemente en infraestructura de IA, grandes modelos y potencia de cómputo. El foco de la competencia se está desplazando de los grandes modelos generales a los modelos de industria vertical, que se están convirtiendo en nuevos motores de crecimiento debido a sus altos márgenes brutos y su capacidad para resolver problemas prácticos. A pesar de los desafíos con los chips de alta gama, los fabricantes nacionales están progresando en la optimización de costos de cómputo y en modelos de inferencia (“pensamiento lento”) (como el efecto DeepSeek). Cada empresa sigue un camino diferente: Alibaba invierte fuertemente en infraestructura, Huawei innova en hardware (CloudMatrix 384) y promueve la colaboración edge-cloud, Baidu se acerca a las aplicaciones, mientras que Tencent y ByteDance aprovechan sus ventajas en escenarios diversificados. La extensión del hardware de IA y la construcción de ecosistemas de código abierto (como HarmonyOS, Ascend, Hunyuan) se han vuelto cruciales; la competencia ha pasado de avances tecnológicos puntuales a la capacidad de sinergia del ecosistema. (Fuente: 36氪-科技云报道)

Descubrimiento sorprendente del MIT: La IA puede derivar leyes físicas de forma independiente sin conocimiento previo: El equipo de Max Tegmark del MIT ha desarrollado una nueva arquitectura llamada MASS (Multiple AI Scalar Scientists). Este sistema de IA, sin que se le informara de ninguna ley física, pudo aprender de forma independiente y proponer formulaciones teóricas muy similares al Hamiltoniano o Lagrangiano de la mecánica clásica, simplemente analizando datos de observación de sistemas físicos como péndulos y osciladores. La investigación muestra que la IA corrige autónomamente sus teorías cuando se enfrenta a sistemas más complejos, y diferentes “científicos” de IA eventualmente convergen hacia principios físicos conocidos, favoreciendo especialmente la descripción Lagrangiana en sistemas complejos. Este logro demuestra el enorme potencial de la IA en el descubrimiento científico fundamental y podría revelar de forma independiente las leyes básicas del universo. (Fuente: 新智元)

El sistema de asistencia para ciegos con IA del equipo de la Universidad Jiao Tong de Shanghái aparece en una publicación secundaria de Nature, permitiendo a los discapacitados visuales “recuperar la vista”: El equipo de Gu Leilei de la Universidad Jiao Tong de Shanghái ha desarrollado un sistema portátil de asistencia para ciegos impulsado por IA que combina tecnología electrónica flexible. Sustituye parcialmente la función visual mediante retroalimentación auditiva y táctil, ayudando a las personas con discapacidad visual a realizar tareas diarias como la navegación y el agarre. El hardware del sistema es ligero, el software optimiza la salida de información para adaptarse a la cognición fisiológica humana y se ha desarrollado un sistema de entrenamiento inmersivo en VR. Las pruebas demuestran que el sistema mejora significativamente la capacidad de los usuarios con discapacidad visual para navegar evitando obstáculos y agarrar objetos tanto en entornos virtuales como reales. Los resultados de la investigación, publicados en Nature Machine Intelligence, muestran el enorme potencial de la IA para ayudar a las personas con discapacidad visual, mejorar su capacidad de vida independiente y proporcionar nuevas ideas para dispositivos de asistencia visual portátiles personalizados y fáciles de usar. (Fuente: 36氪)

Zhipu AI inicia el asesoramiento para IPO, compitiendo por ser la “primera acción de grandes modelos”: Zhipu AI (Beijing Zhipu Huazhang Technology), una empresa de grandes modelos de IA afiliada a Tsinghua, completó el registro de asesoramiento para IPO en la Oficina Reguladora de Valores de Pekín el 14 de abril, con CICC como asesor. Su objetivo es el mercado de acciones A de China, con la esperanza de convertirse en la “primera acción de grandes modelos de IA” del país. Aunque la escala de usuarios de su producto de consumo “Zhipu Qingyan” no es grande, Zhipu, con su sólido trasfondo técnico (afiliada a Tsinghua, serie de grandes modelos GLM de desarrollo propio), carácter estatal (incluida en la Entity List de EE. UU.) y progreso en la comercialización (sirviendo a clientes gubernamentales y empresariales, con un crecimiento significativo de los ingresos), ha obtenido más de 16 mil millones de yuanes en financiación, con una valoración superior a 20 mil millones. Sus inversores incluyen VCs conocidos, gigantes industriales y capital estatal de varias regiones. Ante el impacto de nuevas fuerzas como DeepSeek, la decisión de Zhipu de salir a bolsa se considera un paso clave para asegurar una posición favorable en la feroz competencia, satisfacer las necesidades de financiación y responder a las expectativas de los inversores. La compañía ha continuado recientemente haciendo open source los modelos de la serie GLM-4, mostrando su esfuerzo simultáneo en tecnología y capital. (Fuente: 36氪-真故研究室, 36氪-互联网爆料汇, 创投日报)

🎯 Movimientos
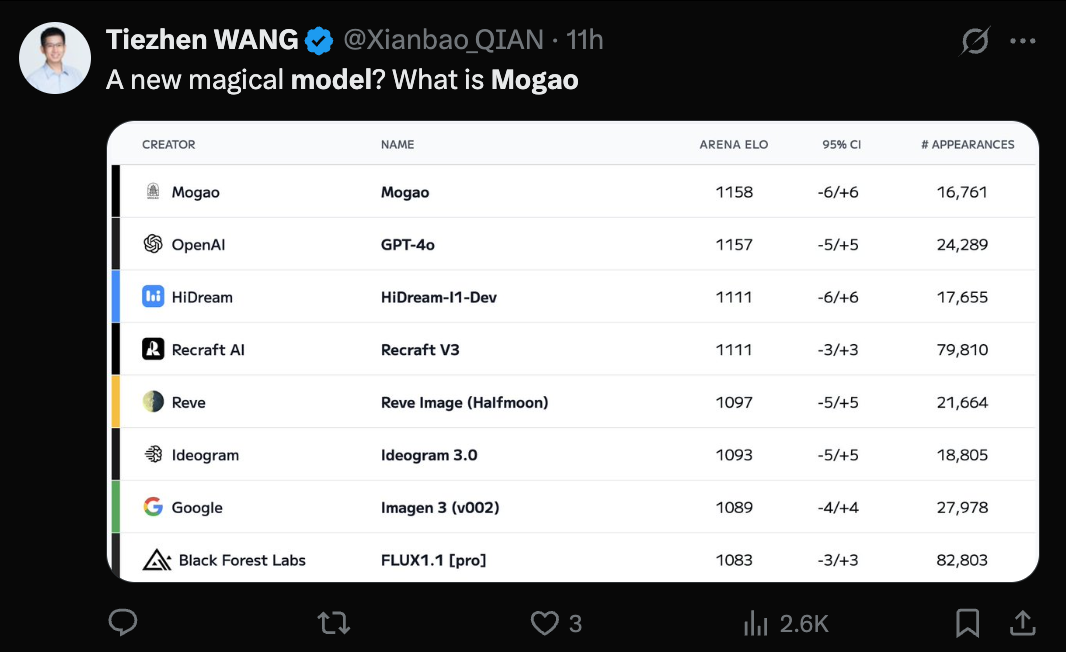
Se revela el modelo Seedream 3.0 (Mogao) de ByteDance, se reconoce su capacidad de text-to-image: Se ha confirmado que el misterioso modelo Mogao, que recientemente dominó el ranking de text-to-image de Artificial Analysis, es Seedream 3.0, desarrollado por el equipo Seed de ByteDance. Este modelo destaca en realismo, diseño, anime y otros estilos, así como en la generación de texto, siendo especialmente bueno en el manejo de texto denso y la generación de retratos realistas. La tasa de usabilidad de caracteres chinos e ingleses alcanza el 94%, el realismo de los retratos se acerca al nivel de la fotografía profesional y admite la salida de imágenes con resolución nativa de 2K, con una rápida velocidad de generación. El informe técnico revela múltiples innovaciones en el procesamiento de datos (entrenamiento consciente de defectos, muestreo de doble eje), pre-entrenamiento (arquitectura MMDiT, resolución mixta, RoPE intermodal) y post-entrenamiento (entrenamiento continuo, SFT, RLHF, modelo de recompensa VLM), así como en la aceleración de la inferencia (Hyper-SD, RayFlow). En comparación con GPT-4o, Seedream 3.0 es superior en chino, tipografía y color. (Fuente: 36氪-机器之心)
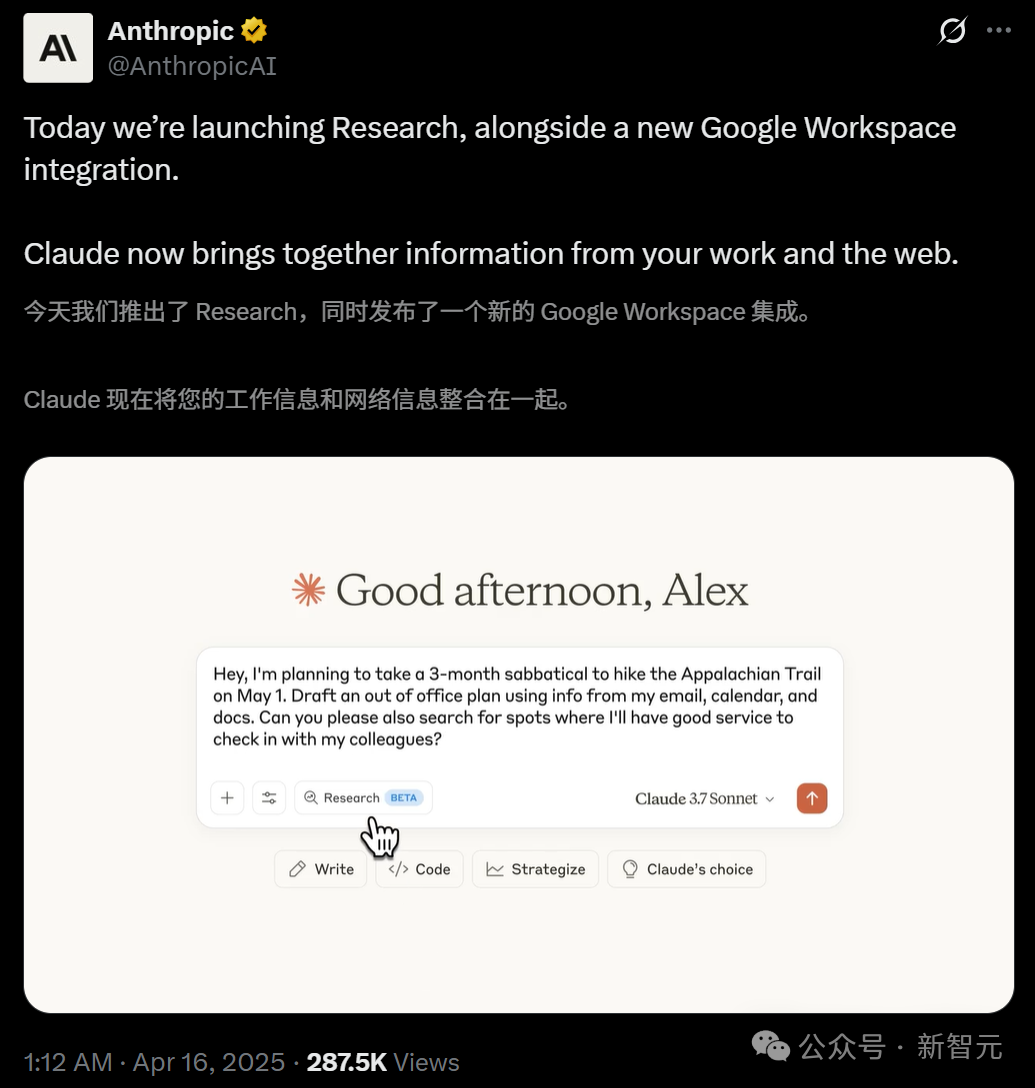
Claude lanza la función Research y se integra con Google Workspace: Anthropic ha añadido dos funciones principales a su asistente de IA Claude: Research y la integración con Google Workspace. La función Research permite a Claude buscar información en línea y combinarla con archivos internos del usuario (como Google Docs) para un análisis multiángulo, generando rápidamente informes completos. La integración con Google Workspace conecta Gmail, Google Calendar y Docs, permitiendo a Claude comprender la agenda, correos electrónicos y contenido de documentos del usuario, extraer información y ayudar a completar tareas, como planificar viajes basados en información personal o redactar correos electrónicos. Estas funciones tienen como objetivo mejorar significativamente la eficiencia laboral del usuario. La función Research está actualmente disponible en beta para usuarios Max, Team y Enterprise en EE. UU., Japón y Brasil, mientras que la integración de Workspace está disponible en beta para todos los usuarios de pago. Los comentarios de los usuarios son positivos, indicando que puede aumentar la eficiencia y descubrir conexiones entre datos, aunque también existen preocupaciones sobre la seguridad de los datos. (Fuente: 新智元, op7418, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
CUHK y Tsinghua lanzan Video-R1, iniciando un nuevo paradigma de razonamiento en vídeo: Equipos de la Universidad China de Hong Kong (CUHK) y la Universidad de Tsinghua han lanzado conjuntamente el primer modelo de razonamiento en vídeo del mundo que adopta el paradigma R1 de aprendizaje por refuerzo, llamado Video-R1. Este modelo tiene como objetivo abordar la falta de lógica temporal y capacidad de razonamiento profundo en los modelos de vídeo existentes. Mediante la introducción del algoritmo T-GRPO consciente del tiempo y el uso de conjuntos de datos de entrenamiento híbridos que combinan imágenes y vídeos (Video-R1-COT-165k y Video-R1-260k), Video-R1 con 7B parámetros supera a GPT-4o en el benchmark de razonamiento espacial en vídeo VSI-Bench propuesto por Fei-Fei Li. El modelo muestra “momentos aha” similares a los humanos, capaces de realizar razonamiento lógico basado en información temporal. Los experimentos demuestran que aumentar el número de fotogramas de entrada mejora la precisión del razonamiento. El proyecto ha hecho open source el modelo, el código y los conjuntos de datos, lo que indica que la IA de vídeo está avanzando de “comprender” a “pensar”. (Fuente: 新智元)

ICLR 2025 introduce por primera vez la revisión por IA a gran escala, mejorando significativamente la calidad de la revisión: Ante el aumento del volumen de envíos y el descenso de la calidad de las revisiones, la conferencia ICLR 2025 ha desplegado por primera vez a gran escala un “Agente Inteligente de Retroalimentación de Revisión” (Review Feedback Agent) de IA para ayudar en la revisión por pares. Este sistema utiliza múltiples LLMs, como Claude Sonnet 3.5, para identificar ambigüedades, malentendidos de contenido o comentarios no profesionales en las opiniones de los revisores, y proporciona sugerencias específicas de mejora a los revisores. El experimento cubrió el 42.3% de las revisiones, y los resultados mostraron que la retroalimentación de la IA mejoró la calidad de la revisión en el 89% de los casos. El 26.6% de los revisores modificaron sus revisiones basándose en las sugerencias de la IA, y las revisiones modificadas aumentaron en promedio 80 palabras, volviéndose más específicas e informativas. Al mismo tiempo, la intervención de la IA también aumentó la actividad y profundidad de la discusión entre autores y revisores durante el período de Rebuttal. Este experimento pionero demuestra el enorme potencial de la IA para optimizar el proceso de revisión por pares. (Fuente: 新智元)

La entrada de robots humanoides en los hogares genera debate, las empresas de electrodomésticos se posicionan activamente en la inteligencia corpórea (embodied intelligence): La entrada de robots humanoides en escenarios domésticos ha provocado un debate en la industria sobre sus modelos de aplicación y su impacto en el sector de los electrodomésticos. Se argumenta que los robots humanoides deberían aprovechar sus características “de propósito general” para resolver tareas no estándar como doblar ropa y organizar objetos, y utilizar sus capacidades de interacción para actuar como “mayordomos”, dirigiendo y coordinando otros dispositivos inteligentes, en lugar de simplemente reemplazar los electrodomésticos existentes. Ante esta tendencia, gigantes de los electrodomésticos como Haier y Midea ya han comenzado a posicionarse, lanzando sus propios productos de robots humanoides (como Kuavo) y explorando la integración de la tecnología de embodied intelligence en electrodomésticos tradicionales (como el robot aspirador con brazo mecánico de Dreame, la lavadora de Yimu Technology que puede agarrar ropa). Esto indica que la industria de electrodomésticos se está adaptando activamente a la ola de IA y podría formar en el futuro un ecosistema de hogar inteligente simbiótico y fusionado con robots humanoides. (Fuente: 36氪-具身研习社)

Huawei lanza el servidor de IA CloudMatrix 384, compitiendo con el GB200 de Nvidia: Huawei presentó en su Conferencia de Ecosistema Cloud su último clúster de servidores de IA, CloudMatrix 384. Este sistema está compuesto por 384 tarjetas de cómputo Ascend, con una potencia de cómputo de clúster único de 300 PFlops y un rendimiento de decodificación por tarjeta de 1920 Tokens/s, apuntando directamente al H100 de Nvidia. Utiliza interconexión de alta velocidad totalmente óptica (6812 módulos ópticos de 400G), con una eficiencia de entrenamiento cercana al 90% del rendimiento de una sola tarjeta Nvidia. Este movimiento se considera un paso importante para que China alcance el nivel líder internacional en infraestructura de IA, con el objetivo de satisfacer la demanda de potencia de cómputo bajo las restricciones de chips de alta gama. Los analistas creen que esto demuestra el rápido progreso de Huawei en el campo del hardware de IA y podría afectar la estructura actual del mercado. (Fuente: dylan522p, 36氪-科技云报道)
Google lanza la función text-to-video Veo 2 y Whisk Animate: Google ha integrado su modelo text-to-video Veo 2 en Gemini Advanced. Los usuarios miembros pueden usar esta función de forma gratuita a través de la aplicación Gemini, generando vídeos de 8 segundos de duración. Al mismo tiempo, la herramienta de edición de imágenes de Google, Whisk, también ha actualizado la función Whisk Animate, que permite a los usuarios convertir las imágenes generadas en vídeos utilizando Veo 2, aunque esta función requiere una suscripción a Google One. Esto marca el esfuerzo continuo de Google en el campo de la generación multimodal, proporcionando a los usuarios herramientas de creación más ricas. (Fuente: op7418, op7418)
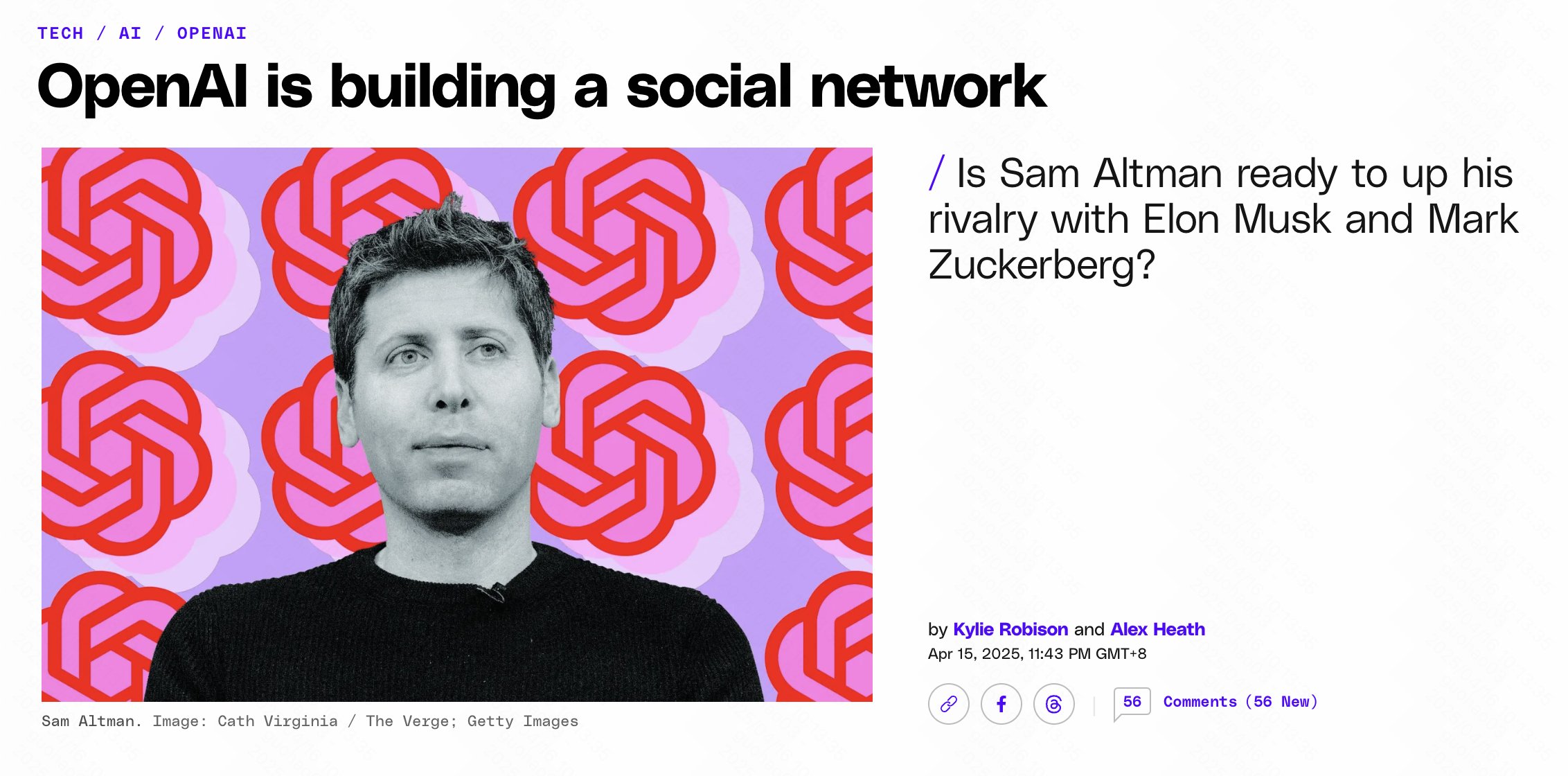
OpenAI podría estar construyendo un producto social similar a X: Según The Verge, OpenAI está desarrollando internamente un prototipo de producto social similar a X (anteriormente Twitter). Este producto podría combinar las capacidades de generación de imágenes de ChatGPT (especialmente después del lanzamiento de GPT-4o) con un feed social. Dada la enorme base de usuarios de ChatGPT y sus avances en la generación de imágenes, se considera que este movimiento tiene cierta viabilidad y podría marcar el intento de OpenAI de expandir sus capacidades de IA al ámbito de las redes sociales. (Fuente: op7418)
DeepCoder lanza un modelo de codificación open source de 14B de alto rendimiento: El equipo de DeepCoder ha lanzado un modelo de codificación open source de 14 mil millones de parámetros y alto rendimiento, que según se informa, tiene un desempeño excelente en tareas de codificación. El lanzamiento de este modelo proporciona a los desarrolladores otra potente opción de herramienta de generación y asistencia de código, especialmente en escenarios donde se necesita equilibrar el rendimiento y el tamaño del modelo. (Fuente: Ronald_vanLoon)

Tesla logra el estacionamiento automático de vehículos recién salidos de fábrica: Tesla ha demostrado un nuevo avance en su tecnología de conducción autónoma: los vehículos, después de salir de la línea de producción en la fábrica, pueden conducirse automáticamente hasta el área de carga o el estacionamiento sin intervención humana. Esto muestra el potencial de aplicación de la capacidad FSD (Full Self-Driving) de Tesla en entornos específicos y controlados, ayudando a mejorar la eficiencia logística de la producción y siendo un paso hacia aplicaciones de conducción autónoma más amplias. (Fuente: Ronald_vanLoon, Ronald_vanLoon)
Dexterity lanza Mech, un robot industrial impulsado por “Physical AI”: Dexterity ha presentado un robot industrial llamado Mech, caracterizado por el uso de la tecnología “Physical AI”. Esta IA permite al robot navegar y operar en entornos industriales complejos, mostrando una flexibilidad y adaptabilidad sobrehumanas, con el objetivo de resolver tareas complejas que la automatización industrial tradicional tiene dificultades para manejar. (Fuente: Ronald_vanLoon)
El MIT desarrolla un nuevo robot saltador diseñado para terrenos accidentados: Investigadores del MIT han desarrollado un nuevo robot cuyo diseño se inspira en el movimiento de salto, especialmente hábil para moverse en terrenos accidentados e irregulares. Este robot demuestra la aplicación de la biónica en el diseño de robots y el potencial del machine learning para controlar movimientos complejos, con posibles aplicaciones en búsqueda y rescate, exploración planetaria y otros entornos complejos. (Fuente: Ronald_vanLoon)
Se inicia INTELLECT-2: Entrenamiento distribuido global de aprendizaje por refuerzo para un modelo de 32B: El proyecto Prime Intellect ha lanzado la iniciativa INTELLECT-2, con el objetivo de entrenar un modelo de inferencia avanzado de 32 mil millones de parámetros utilizando recursos de computación distribuida global y aprendizaje por refuerzo. Este modelo se basa en la arquitectura Qwen y su objetivo es lograr un “presupuesto de pensamiento” controlable, es decir, que el usuario pueda especificar cuántos pasos de inferencia (cuántos tokens pensar) debe realizar el modelo antes de resolver un problema. Esta es una exploración importante del entrenamiento distribuido y el aprendizaje por refuerzo para mejorar las capacidades de inferencia de los modelos grandes. (Fuente: Reddit r/LocalLLaMA)

ByteDance lanza Liquid, un modelo autorregresivo multimodal similar a GPT-4o: ByteDance ha lanzado una serie de modelos multimodales llamada Liquid. Este modelo adopta una arquitectura autorregresiva similar a GPT-4o, capaz de recibir entradas de texto e imagen y generar salidas de texto o imagen. A diferencia de los MLLM anteriores que utilizaban embeddings visuales preentrenados externos, Liquid utiliza un único LLM para la generación autorregresiva. Ya se ha lanzado una versión 7B del modelo y una Demo en Hugging Face. Las evaluaciones preliminares sugieren que la calidad de generación de imágenes aún no alcanza la de GPT-4o, pero la unificación de su arquitectura es un avance técnico importante. (Fuente: Reddit r/LocalLLaMA)
Ejecución de múltiples LLMs mediante la técnica de instantáneas de memoria de GPU: Se discute una técnica para cambiar y ejecutar rápidamente múltiples LLMs tomando instantáneas del estado de la memoria de la GPU (incluidos pesos, caché KV, diseño de memoria, etc.). Este método es similar a la operación fork de un proceso y puede restaurar el estado del modelo en segundos (aproximadamente 2 segundos para un modelo 70B, 0.5 segundos para un modelo 13B) sin necesidad de recargar o reinicializar. Sus ventajas potenciales incluyen la ejecución de decenas de LLMs en un solo nodo GPU para reducir los costos de inactividad, lograr un cambio dinámico de modelos bajo demanda y utilizar el tiempo de inactividad para el fine-tuning local, entre otros. (Fuente: Reddit r/MachineLearning)
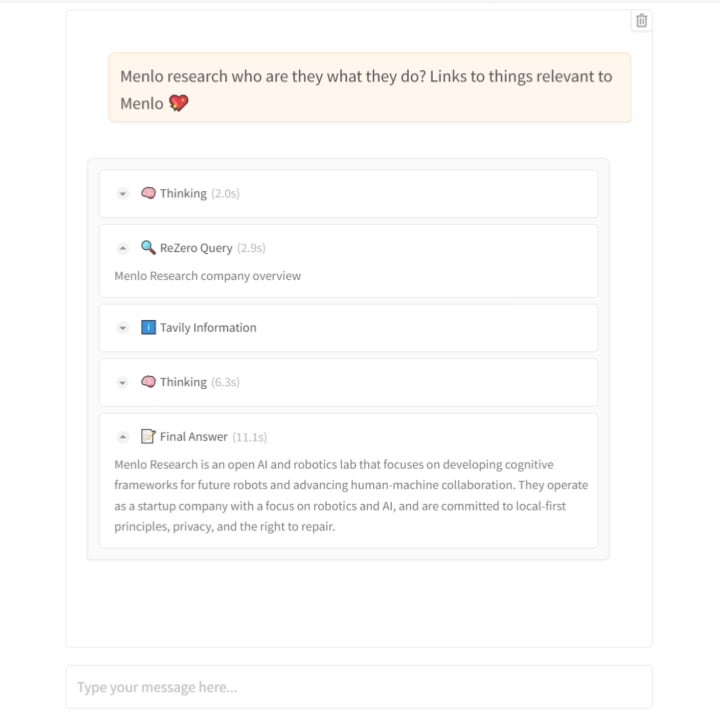
Menlo Research lanza el modelo ReZero: enseñando a la IA a buscar con “persistencia”: El equipo de Menlo Research ha lanzado un nuevo modelo y paper llamado ReZero. Este modelo se basa en la idea de que “la búsqueda requiere múltiples intentos”. Utiliza GRPO (un algoritmo de optimización de aprendizaje por refuerzo) y capacidades de llamada a herramientas para el entrenamiento, e introduce una “recompensa por reintento” (retry_reward). El objetivo del entrenamiento es que el modelo, al encontrar dificultades o resultados de búsqueda iniciales insatisfactorios, intente buscar de forma activa y repetida hasta encontrar la información necesaria. Los experimentos muestran que, en comparación con los modelos de referencia, el rendimiento de ReZero mejora significativamente (46% vs 20%), demostrando la efectividad de la estrategia de búsqueda repetida y desafiando la noción de que “la repetición equivale a alucinación”. Este modelo puede usarse para optimizar la generación de consultas de los motores de búsqueda existentes o como una capa de mejora de búsqueda para LLMs. El modelo y el código son open source. (Fuente: Reddit r/LocalLLaMA)
Hugging Face adquiere una startup de robots humanoides: Hugging Face, la conocida comunidad y plataforma de IA de código abierto, ha adquirido una startup de robots humanoides cuya información específica no ha sido revelada. Este movimiento podría indicar el deseo de Hugging Face de expandir las capacidades de su plataforma desde el software y los modelos hacia el hardware y la robótica, impulsando aún más la aplicación de la IA en el mundo físico, especialmente en la embodied intelligence. (Fuente: Reddit r/ArtificialInteligence)

🧰 Herramientas
Lanzamiento del modelo TTS emocional open source Orpheus, compatible con inferencia en streaming y clonación de voz: Canopy Labs ha hecho open source una serie de modelos de text-to-speech (TTS) llamada Orpheus (hasta 3 mil millones de parámetros, basada en la arquitectura Llama). Se afirma que este modelo supera el rendimiento de los modelos open source existentes y algunos de código cerrado. Su característica distintiva es la capacidad de generar voz similar a la humana con entonación, emoción y ritmo naturales, e incluso puede inferir y generar sonidos no verbales como suspiros y risas a partir del texto, mostrando cierta capacidad de “empatía”. Orpheus admite la clonación de voz zero-shot, entonación emocional controlable y logra una inferencia en streaming de baja latencia (aproximadamente 200 ms), adecuada para aplicaciones de conversación en tiempo real. El proyecto ofrece varios tamaños de modelo y tutoriales de fine-tuning, con el objetivo de reducir la barrera para la síntesis de voz de alta calidad. (Fuente: 36氪)

La plataforma Trae.ai ofrece Gemini 2.5 Pro de forma gratuita: La plataforma de herramientas de IA Trae.ai ha anunciado que ha incorporado el último modelo Gemini 2.5 Pro de Google y lo ofrece de forma gratuita. Los usuarios pueden experimentar las diversas capacidades de Gemini 2.5 Pro en esta plataforma. (Fuente: dotey)
Herramienta de reclutamiento con IA Hireway: evalúa a 800 candidatos en un día: Hireway demuestra la capacidad de su herramienta de reclutamiento con IA, afirmando que puede evaluar eficientemente a 800 candidatos en un solo día. La herramienta utiliza IA y tecnología de automatización para optimizar el proceso de contratación, mejorar la eficiencia de la selección y la experiencia del candidato. (Fuente: Ronald_vanLoon)
PRIMA.CPP: Acelerando la inferencia de LLMs 70B en clústeres domésticos comunes: PRIMA.CPP es un proyecto open source basado en llama.cpp, diseñado para optimizar y acelerar la velocidad de inferencia de grandes modelos de lenguaje de hasta 70 mil millones de parámetros en clústeres de computación domésticos comunes con recursos limitados (posiblemente involucrando múltiples PCs o dispositivos ordinarios). El proyecto se centra en la eficiencia de la inferencia distribuida, ofreciendo nuevas posibilidades para ejecutar modelos grandes localmente. El paper ha sido publicado en Hugging Face. (Fuente: Reddit r/LocalLLaMA)

Compartir Prompt para personajes de peluche: Un usuario comparte un conjunto de prompts para generar adorables personajes de animales estilo peluche en 3D, adecuados para herramientas de generación de imágenes como Sora o GPT-4o. El prompt enfatiza la descripción detallada, como textura súper suave, pelaje denso, ojos grandes, iluminación suave y fondo, con el objetivo de generar renders de alta calidad adecuados para mascotas de marca o imágenes IP. (Fuente: dotey)

📚 Aprendizaje
Jeff Dean comparte los materiales de su charla en ETH Zúrich: El científico jefe de Google DeepMind, Jeff Dean, ha compartido la grabación y los enlaces a las diapositivas de su presentación en el Departamento de Ciencias de la Computación de ETH Zúrich. El contenido de la charla probablemente cubre los últimos avances en el campo de la IA, direcciones de investigación o los logros de investigación de Google, proporcionando valiosos recursos de aprendizaje para investigadores y estudiantes. (Fuente: JeffDean)
Publicado el informe técnico sobre la revisión por IA en ICLR 2025: Junto con la noticia de la introducción de la revisión por IA en ICLR 2025, también se ha publicado un detallado informe técnico de 30 páginas (arXiv:2504.09737). El informe detalla el diseño experimental, los modelos de IA utilizados (con Claude Sonnet 3.5 como núcleo), el mecanismo de generación de retroalimentación, los métodos de prueba de fiabilidad y los resultados del análisis cuantitativo sobre el impacto en la calidad de la revisión, la actividad de la discusión y la decisión final. Este informe proporciona una referencia profunda para comprender el potencial, los desafíos y los detalles de implementación de la IA en la revisión por pares académica. (Fuente: 新智元)
Paper, código y conjuntos de datos del modelo de razonamiento en vídeo Video-R1 disponibles en open source: El equipo de CUHK y Tsinghua no solo ha lanzado el modelo Video-R1, sino que también ha hecho completamente open source su paper técnico (arXiv:2503.21776), el código de implementación (GitHub: tulerfeng/Video-R1) y los dos conjuntos de datos clave utilizados para el entrenamiento (Video-R1-COT-165k y Video-R1-260k). Esto proporciona a la comunidad investigadora recursos completos para replicar, mejorar y explorar más a fondo el paradigma R1 de razonamiento en vídeo, ayudando a impulsar el desarrollo tecnológico en este campo. (Fuente: 新智元)
Publicado el paper sobre el descubrimiento independiente de leyes físicas por la IA: Los resultados de la investigación del equipo de Max Tegmark del MIT sobre el sistema de IA MASS capaz de descubrir independientemente Hamiltonianos y Lagrangianos se han publicado como preimpresión (arXiv:2504.02822v1). El paper detalla la filosofía de diseño de la arquitectura MASS, el algoritmo central (aprendizaje de funciones escalares basado en el principio de conservación de la acción), la configuración experimental (diferentes sistemas físicos, escenarios con uno o varios científicos de IA) y el descubrimiento de cómo las teorías de la IA evolucionan con la complejidad de los datos y finalmente convergen hacia las formulaciones de la mecánica clásica. Este paper proporciona una importante base teórica y empírica para explorar la aplicación de la IA en el descubrimiento científico fundamental. (Fuente: 新智元)
Publicado el paper de PRIMA.CPP: El paper técnico que presenta el proyecto PRIMA.CPP (destinado a acelerar la inferencia de LLMs a escala 70B en clústeres de bajos recursos) ha sido publicado en Hugging Face Papers (ID: 2504.08791). El paper probablemente detalla las técnicas de optimización empleadas, las estrategias de inferencia distribuida y los resultados de evaluación de rendimiento en configuraciones de hardware específicas, proporcionando una referencia técnica detallada para investigadores y profesionales en campos relacionados. (Fuente: Reddit r/LocalLLaMA)
Análisis profundo del modelo RWKV-7 y conversación con el autor: Oxen.ai ha publicado un vídeo y un artículo de blog con un análisis profundo del modelo RWKV-7 (Goose). El contenido cubre los problemas que la arquitectura RWKV intenta resolver, su método de iteración y sus características técnicas clave. Lo especial es que el vídeo incluye una entrevista y una sesión de preguntas y respuestas con uno de los autores principales del modelo, Eugene Cheah, proporcionando una valiosa perspectiva del autor y conocimientos para comprender este LLM de arquitectura no-Transformer, y explora conceptos interesantes como “Learning at Test Time”. (Fuente: Reddit r/MachineLearning)

Artículo compartido: 7 consejos para dominar el Prompt Engineering: El sitio web FrontBackGeek ha publicado un artículo que resume 7 potentes consejos para ayudar a los usuarios a dominar mejor el Prompt Engineering y obtener así mejores resultados de los modelos de IA (como los LLMs). El artículo puede cubrir aspectos como cómo dar instrucciones claras, proporcionar contexto, establecer roles, controlar el formato de salida, etc. (Fuente: Reddit r/deeplearning)

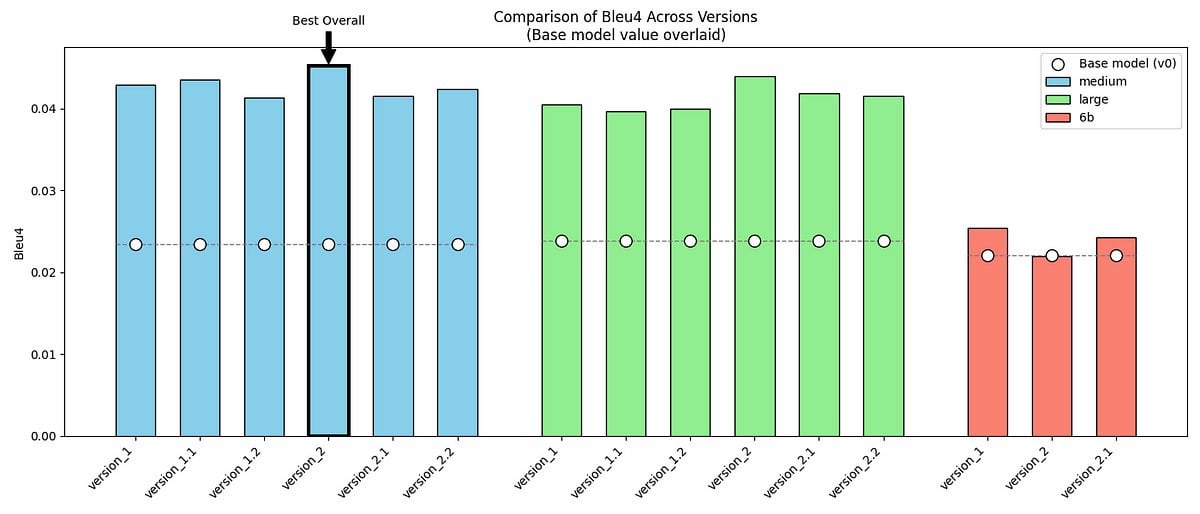
Proyecto compartido: Fine-tuning de GPT-2/GPT-J para imitar el tono del Sr. Darcy de “Orgullo y Prejuicio”: Un desarrollador comparte su proyecto personal: utilizando los modelos GPT-2 (medium) y GPT-J, y realizando fine-tuning con dos conjuntos de datos que incluyen diálogos originales y datos sintéticos creados por él mismo, intenta imitar el estilo de habla único (formal, conciso, ligeramente crítico) del Sr. Darcy de “Orgullo y Prejuicio” de Jane Austen. El proyecto muestra ejemplos de salida del modelo, métricas de evaluación (mejora de BLEU-4 pero aumento de la perplejidad) y los desafíos encontrados (como la dificultad para ajustar GPT-J). El código y los conjuntos de datos están disponibles en GitHub, proporcionando un caso de estudio para explorar el modelado de estilos literarios específicos o voces de personajes históricos. (Fuente: Reddit r/MachineLearning)
Discusión sobre la publicación de Meta Reviews de ACL 2025: Se han publicado los resultados de las Meta Reviews (meta-revisiones) de la conferencia ACL 2025. Investigadores relacionados han iniciado un hilo en la comunidad invitando a todos a discutir e intercambiar opiniones sobre las puntuaciones de sus papers y las Meta Reviews correspondientes. Esto proporciona una plataforma para que los autores que enviaron trabajos compartan experiencias y comparen expectativas y resultados. (Fuente: Reddit r/MachineLearning)
Compartir experiencia: Construcción de un servidor de IA de 160GB VRAM de bajo costo: Un usuario de Reddit comparte detalladamente su proceso y resultados preliminares de la construcción de un servidor de inferencia de IA con 160GB de VRAM por aproximadamente 1000 dólares (costo principal: 10 GPUs AMD MI50 de segunda mano a 90 dólares cada una y un chasis de minería Octominer de 100 dólares). El contenido incluye la selección de hardware, instalación del sistema (Ubuntu + ROCm 6.3.0), compilación y prueba de llama.cpp, mediciones reales de consumo de energía (aproximadamente 120W en reposo, pico de 340W durante la inferencia), situación de la disipación de calor y datos de rendimiento (comparación con tarjetas como la 3090, ejecución de modelos llama3.1-8b y llama-405b). Esta compartición proporciona una valiosa referencia de configuración de hardware DIY y experiencia práctica para entusiastas de la IA con presupuesto limitado. (Fuente: Reddit r/LocalLLaMA)
Publicación del paper y código del modelo ReZero: Se han publicado el paper técnico relacionado con el modelo ReZero de Menlo Research (que entrena al modelo mediante GRPO para buscar repetidamente hasta encontrar la información necesaria) (arXiv:2504.11001), los pesos del modelo (Hugging Face: Menlo/ReZero-v0.1-llama-3.2-3b-it-grpo-250404) y el código de implementación (GitHub: menloresearch/ReZero). Esto proporciona recursos completos de aprendizaje y experimentación para investigar y aplicar esta nueva estrategia de búsqueda. (Fuente: Reddit r/LocalLLaMA)
💼 Negocios
Ex ejecutivo de robótica de Alibaba, Min Wei, funda Yingshen Intelligence, obtiene decenas de millones en ronda semilla: Yingshen Intelligence, fundada en 2024 por Min Wei, ex líder técnico del equipo de robótica de Alibaba, se centra en la investigación, desarrollo y aplicación de tecnología de embodied intelligence de nivel L4. La compañía completó recientemente rondas consecutivas de financiación semilla (invertida por Zhuoyuan Asia) y semilla+ (invertida conjuntamente por Zhuoyuan Asia y Hangzhou Xihu Kechuangtou) por decenas de millones de RMB. Basándose en su gran modelo de inteligencia espacio-temporal de desarrollo propio (construyendo un modelo del mundo real 4D a través de Real to Real, modelando directamente a partir de datos de vídeo) y robots industriales, Yingshen Intelligence ofrece soluciones colaborativas de hardware y software. Ya ha conseguido pedidos industriales por valor de decenas de millones, centrándose inicialmente en escenarios industriales, con planes de expandirse a industrias de servicios como la mensajería y la hostelería. (Fuente: 36氪)
El mercado de juguetes con IA está en auge online pero frío offline, la exportación podría ser la principal vía: Los juguetes con IA muestran un rendimiento explosivo en plataformas online (como live streaming e-commerce, redes sociales), con predicciones de rápido crecimiento del tamaño del mercado. Sin embargo, las visitas offline (tomando Guangzhou como ejemplo) revelan que los juguetes con IA son difíciles de encontrar en jugueterías tradicionales y tiendas generales, con bajas tasas de distribución y conocimiento del consumidor. Actualmente, las ventas de juguetes con IA pueden depender principalmente de canales online, y los mercados extranjeros (Europa, América, Oriente Medio) son una importante vía de venta, con fabricantes que ofrecen servicios de personalización de apariencia e idioma. El análisis de los datos del tamaño del mercado indica que el mercado de decenas de miles de millones informado anteriormente podría referirse a “juguetes inteligentes” en un sentido más amplio, no puramente juguetes con IA. A pesar del frío recibimiento offline, dado el creciente interés de los adultos por la compañía emocional (como el caso Moflin) y el potencial de la tecnología de IA para todas las edades, todavía se considera que el mercado de juguetes con IA tiene un enorme espacio para el desarrollo. (Fuente: 36氪)

Qingcheng Jizhi, empresa de AI Infra afiliada a Tsinghua: La demanda de inferencia explota, la relación costo-rendimiento impulsa la sustitución nacional: Conversación con Tang Xiongchao, CEO de Qingcheng Jizhi, una empresa de infraestructura de IA afiliada a Tsinghua. La compañía observa que, desde que el modelo DeepSeek se hizo popular, la demanda de potencia de cómputo para inferencia de IA ha aumentado drásticamente, y la potencia de cómputo nacional previamente inactiva ha comenzado a funcionar. Sin embargo, la innovación técnica de DeepSeek (como la precisión FP8) está profundamente ligada a las tarjetas H de Nvidia, lo que amplía la brecha con la mayoría de los chips nacionales actuales. Para resolver este problema, Qingcheng Jizhi y Tsinghua han lanzado conjuntamente el motor de inferencia open source “Chitu”, con el objetivo de permitir que las GPUs existentes y los chips nacionales ejecuten eficientemente modelos avanzados como DeepSeek, promoviendo un ecosistema de IA nacional de ciclo cerrado. Tang Xiongchao cree que, aunque la sustitución por chips nacionales requiere un proceso, es optimista a largo plazo sobre su ventaja en la relación costo-rendimiento. El enfoque comercial actual de la empresa es satisfacer la demanda de despliegue localizado de grandes modelos por parte de gobiernos y empresas. (Fuente: 凤凰网科技)
El auge de la inversión en IA continúa, emergen jóvenes inversores: Aunque el entorno general de inversión se enfrió en 2024, el sector de la IA continuó atrayendo capital, con una financiación global récord y un mercado nacional igualmente activo. Gigantes como ByteDance, Alibaba y Tencent aceleraron su posicionamiento. Surgieron unicornios como Zhipu AI, Moonshot AI y Unitree Robotics. Los puntos calientes de inversión cubren toda la cadena industrial, incluyendo infraestructura, AIGC, embodied intelligence, etc. Firmas de inversión establecidas como Sequoia China y BlueRun Ventures continuaron liderando, mientras que fondos industriales y fuerzas de capital estatal, representados por el Fondo de Inversión de la Industria de Inteligencia Artificial de Pekín, también se convirtieron en importantes impulsores. Cabe destacar que un grupo de jóvenes inversores nacidos en los 80 (como Cao Xi, Dai Yusen, Lin Haizhuo, Zhang Jinjian, etc.) se mostraron activos en la era de la IA 2.0. Con su agudeza y capacidad de ejecución, buscaron activamente oportunidades en un mercado con nuevas reglas, convirtiéndose en una fuerza emergente que no puede ser ignorada. (Fuente: 36氪-第一新声)

Fundador de la aplicación de compras con IA Nate acusado de fraude, usó “API humana” para simular IA y obtener 50 millones de dólares en inversión: El Departamento de Justicia de EE. UU. ha acusado a Albert Saniger, fundador de la aplicación de compras con IA Nate, de fraude por obtener más de 50 millones de dólares en capital de riesgo mediante la promoción falsa de las capacidades de su tecnología de IA. Nate afirmaba que su aplicación podía completar automáticamente el proceso de compra online utilizando tecnología de IA propietaria, pero en realidad, su funcionalidad principal dependía en gran medida de cientos de agentes de servicio al cliente contratados en Filipinas para procesar manualmente los pedidos. La supuesta tasa de automatización de IA era casi nula. El fundador ocultó la verdad a inversores y empleados, y finalmente la empresa se quedó sin fondos y quebró. Este caso revela los posibles riesgos de fraude en el auge de las startups de IA, es decir, usar mano de obra humana para simular IA y atraer inversiones, perjudicando los intereses de los inversores y la reputación de la industria. Saniger podría enfrentarse a hasta 40 años de prisión. (Fuente: CSDN)

🌟 Comunidad
Vídeos modificados con IA invaden las plataformas de vídeo corto, generando controversia sobre entretenimiento, derechos de autor y ética: El uso de tecnología de IA (como herramientas text-to-video como Sora, Keling, etc.) para crear “modificaciones radicales” de series de televisión clásicas (como “La Leyenda de Zhen Huan” en moto, “En el Nombre del Pueblo” convertida en “Primavera en Seúl”) se ha popularizado rápidamente en plataformas como Douyin y Bilibili. Este tipo de vídeos atrae un gran tráfico gracias a sus tramas subversivas, impacto visual y cultura de memes, convirtiéndose en un nuevo medio para que los creadores ganen seguidores rápidamente y moneticen (reparto de ingresos por tráfico, publicidad encubierta), así como para la promoción de series. Sin embargo, su popularidad también va acompañada de controversia: la delimitación de la infracción de derechos de autor sobre la obra original es compleja; el contenido modificado puede debilitar la profundidad artística de la obra original, e incluso volverse vulgar, atrayendo la atención de los reguladores. Encontrar un equilibrio entre satisfacer la demanda de entretenimiento y respetar los derechos de autor, manteniendo al mismo tiempo la calidad del contenido, se convierte en el desafío al que se enfrenta la creación secundaria con IA. (Fuente: 36氪-明晰野望)

Usuarios se quejan de los límites y precios de los planes Claude Pro/Max: En el subreddit r/ClaudeAI han aparecido múltiples publicaciones donde los usuarios se quejan de las restricciones y precios de los planes de suscripción Claude Pro y el recién lanzado Max de Anthropic. Los usuarios informan que incluso los usuarios de pago Pro alcanzan rápidamente los límites de uso después de interacciones leves o moderadas (como procesar contextos de cientos de miles de tokens), lo que afecta sus flujos de trabajo. El nuevo plan Max (100$/mes), aunque aumenta el límite (aproximadamente 5-20 veces el de Plus), sigue sin ser de uso ilimitado, y su elevado precio es criticado por los usuarios como un “robo” y de baja relación calidad-precio. Los usuarios generalmente reconocen las capacidades del modelo Claude, pero expresan una fuerte insatisfacción con sus restricciones de uso y estrategia de precios. (Fuente: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Preocupación por el estilo de escritura claro humano confundido con generación por IA: En la comunidad de Reddit, usuarios (incluidos algunos que se identifican como neurodivergentes) informan que sus textos cuidadosamente escritos, gramaticalmente correctos, lógicamente claros y detallados son erróneamente identificados como generados por IA por otras personas o herramientas de detección de IA. Este fenómeno genera debate: por un lado, la prevalencia de contenido generado por IA puede llevar a la gente a sospechar de textos “demasiado perfectos”; por otro lado, expone la inexactitud de las herramientas actuales de detección de IA. Esto causa problemas a los escritores que valoran la expresión clara y también plantea preocupaciones sobre cómo distinguir entre la creación humana y la de IA, y la fiabilidad de las herramientas de detección de IA. (Fuente: Reddit r/artificial, Reddit r/artificial)
Discusión: ¿Es posible y común que los humanos establezcan relaciones emocionales con robots de IA?: En la comunidad de Reddit surge una discusión sobre si los humanos realmente están estableciendo relaciones emocionales con robots de IA (como las aplicaciones de novias IA) similares a las representadas en la película “Her”. Algunos usuarios comparten sus experiencias de desarrollar conexiones emocionales después de interactuar profundamente con chatbots, creyendo que la IA, a través de la “escucha activa” y la imitación de las preferencias del usuario, puede desencadenar respuestas emocionales humanas. Los comentarios exploran la prevalencia de este fenómeno, los mecanismos psicológicos y la relación con el nivel de comprensión tecnológica, reflejando que a medida que mejoran las capacidades de interacción de la IA, las relaciones humano-máquina están entrando en una nueva y más compleja etapa. (Fuente: Reddit r/ArtificialInteligence)
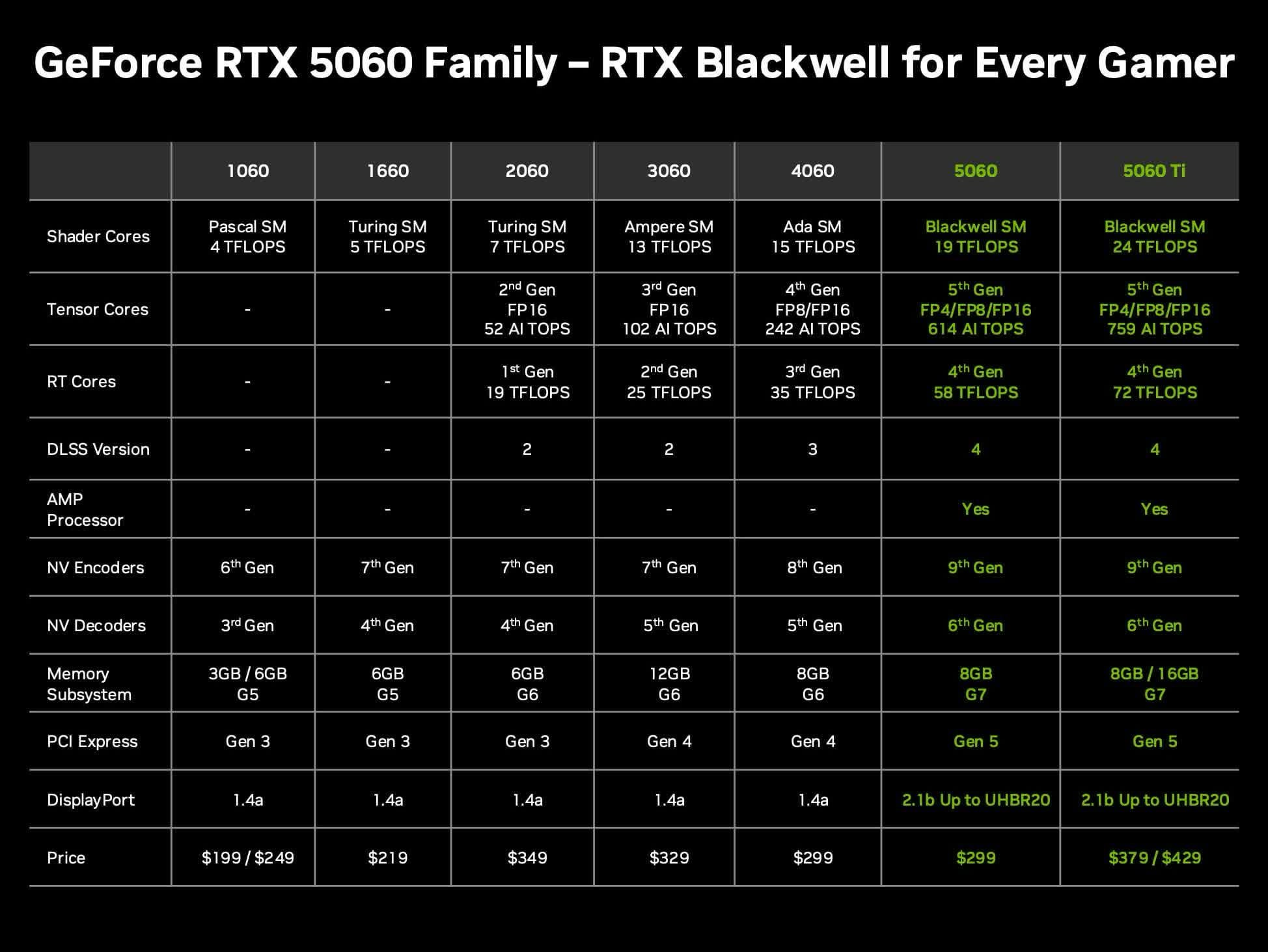
Discusión sobre la relación calidad-precio de la tarjeta Nvidia RTX 5060 Ti 16GB para LLMs locales: Usuarios de la comunidad discuten el valor de la próxima tarjeta gráfica Nvidia GeForce RTX 5060 Ti (se rumorea una versión de 16GB VRAM con un precio de 429 dólares) para ejecutar grandes modelos de lenguaje (LLMs) localmente en casa. La discusión se centra en si su bus de memoria de 128 bits (ancho de banda de 448 GB/s) será un cuello de botella, y sus ventajas y desventajas en comparación con Mac Mini/Studio u otras tarjetas AMD en términos de capacidad de VRAM y rendimiento por dólar (token/s por precio). Teniendo en cuenta que el precio real de mercado podría ser superior al MSRP, los usuarios evalúan si es una opción de hardware de IA local con buena relación calidad-precio. (Fuente: Reddit r/LocalLLaMA)
GPT-4o tiene dificultades para dibujar con precisión la corona de oro con alas de fénix de Sun Wukong: Usuarios informan que al usar GPT-4o para la generación de imágenes, incluso proporcionando descripciones textuales detalladas (incluyendo la corona que sujeta el pelo con plumas de faisán, con forma de antenas de cucaracha), el modelo tiene dificultades para dibujar con precisión la icónica “corona de oro con alas de fénix” del personaje mitológico chino Sun Wukong. Las imágenes generadas a menudo presentan desviaciones en el estilo del tocado. Esto refleja los desafíos que aún existen en los modelos actuales de generación de imágenes por IA para comprender y reproducir símbolos culturales específicos o detalles complejos. (Fuente: dotey)

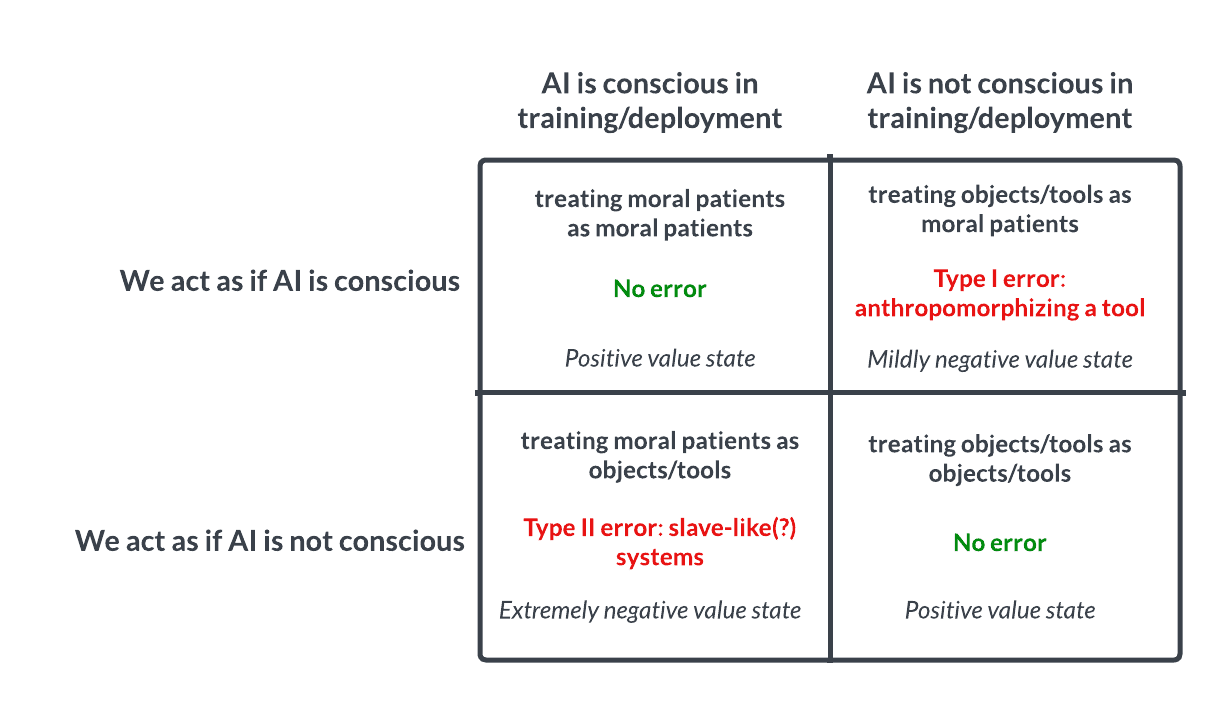
Debate sobre la conciencia y la ética de la IA: La apuesta similar a la de Pascal invita a la reflexión: Una discusión en Reddit plantea que deberíamos tratar a la IA de forma similar a la apuesta de Pascal: si asumimos que la IA no tiene conciencia y la maltratamos, y resulta que sí la tiene, cometeríamos un grave error (como la esclavitud); si asumimos que tiene conciencia y la tratamos bien, y resulta que no la tiene, la pérdida es menor. Esto genera un debate ético sobre la posibilidad de la conciencia de la IA, los criterios para juzgarla y cómo deberíamos tratar a la IA avanzada. En los comentarios, algunos creen que la IA actual no es consciente, otros abogan por la cautela, y otros señalan que primero deberíamos resolver los problemas éticos relacionados con los humanos y los animales. (Fuente: Reddit r/artificial
💡 Otros
La aplicación de tecnología de transformación de edad por IA en la película “Here” genera controversia: La película “Here”, dirigida por Robert Zemeckis y protagonizada por Tom Hanks y Robin Wright, utiliza audazmente la tecnología de transformación generativa por IA en tiempo real desarrollada por Metaphysic, permitiendo a los actores mostrar un rango de edad de 18 a 78 años en la película. La tecnología puede analizar en tiempo real las características biométricas de los actores y generar rostros y cuerpos de diferentes edades, reduciendo enormemente el tiempo de postproducción. Sin embargo, la tecnología aún no es perfecta, especialmente en la restauración de la mirada y el manejo de expresiones complejas, lo que genera discusiones sobre el “efecto uncanny valley”. Al mismo tiempo, la decisión de Hanks de autorizar el uso continuo de su imagen de IA después de su muerte también ha suscitado una amplia controversia sobre los derechos de imagen, la ética y la autenticidad artística. Aunque la taquilla y las críticas fueron mediocres, la película tiene un valor importante para la industria como una exploración temprana de la tecnología de IA en la producción cinematográfica. (Fuente: 36氪-极客电影)

Reclutamiento con IA: Oportunidades y desafíos coexistentes: La IA está cambiando el proceso de reclutamiento, con herramientas como Hireway que afirman mejorar drásticamente la eficiencia de la selección. Sin embargo, la aplicación del reclutamiento con IA también genera debate, por ejemplo, sobre cómo contratar en la era de la IA (Hiring In The AI Era) y cómo equilibrar la eficiencia con la equidad, evitar el sesgo algorítmico, etc. (Fuente: Ronald_vanLoon, Ronald_vanLoon)

La velocidad del desarrollo de la IA invita a la reflexión: el equilibrio entre rapidez y lentitud: Un artículo discute si la estrategia de “moverse rápido y romper cosas” sigue siendo aplicable en la era del rápido desarrollo de la IA. Se argumenta que a veces, reducir la velocidad y reflexionar cuidadosamente (slowing down to speed up) puede ser más efectivo, especialmente en el campo de la IA que involucra sistemas complejos y riesgos potenciales. (Fuente: Ronald_vanLoon)

Servidor oficial de Discord de Anthropic abierto para comentarios directos de los usuarios: Dadas las numerosas preguntas e insatisfacciones de los usuarios sobre el rendimiento y las limitaciones del modelo Claude, la comunidad recomienda unirse al servidor oficial de Discord de Anthropic. Allí, los usuarios tienen la oportunidad de interactuar directamente con los empleados de Anthropic, proporcionando comentarios y preocupaciones de manera más efectiva. (Fuente: Reddit r/ClaudeAI)

Exhibición de diversas tecnologías robóticas y de automatización novedosas: En las redes sociales se muestran vídeos o información sobre diversas tecnologías robóticas y de automatización, incluyendo drones que pueden trabajar bajo el agua, robots blandos que imitan el peristaltismo intestinal, el dron biónico X-Fly, robots multifuncionales capaces de realizar diversas tareas, robots para trasplante de cabello, líneas de producción automatizadas para el procesamiento de huevos, un traje robótico de 9 pies de altura que puede simular movimientos humanos, y una escena divertida de dos robots de reparto “enfrentándose” en la calle. Estas exhibiciones muestran la exploración y el desarrollo de la tecnología robótica en diferentes campos de aplicación. (Fuente: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)