
Palabras clave:AI, GPT-4.1, IPO de Zhipu AI, Inversión en supercomputadoras AI de Nvidia, Gasto de capital en AI de Amazon, Protocolo de interoperabilidad de AI Agent, Base de usuarios de DeepSeek
🔥 Enfoque
OpenAI lanza la serie de modelos GPT-4.1, mejora el rendimiento de la API y descarta GPT-4.5: OpenAI lanzó tres nuevos modelos a través de API el 15 de abril: GPT-4.1, GPT-4.1 mini y GPT-4.1 nano, con el objetivo de superar por completo a la serie GPT-4o. Los nuevos modelos tienen una ventana de contexto de hasta 1 millón de Tokens y una base de conocimientos actualizada hasta junio de 2024. GPT-4.1 destaca en capacidad de codificación (puntuación SWE-bench Verified del 54.6%, un aumento del 21.4% respecto a GPT-4o), seguimiento de instrucciones (puntuación MultiChallenge del 38.3%, un aumento del 10.5% respecto a GPT-4o) y comprensión de video de contexto largo (puntuación Video-MME del 72.0%, un aumento del 6.7% respecto a GPT-4o). Cabe destacar que GPT-4.1 nano es el primer modelo nano, con un rendimiento superior a GPT-4o mini y un costo menor. Al mismo tiempo, OpenAI anunció que retirará la API GPT-4.5 Preview en 3 meses (14 de julio), calificándola como una versión preliminar de investigación, y que integrará las características preferidas por los desarrolladores en los nuevos modelos. Este lanzamiento se considera una medida estratégica de OpenAI para diferenciar los modelos API de la línea de productos ChatGPT y competir directamente con la serie Google Gemini. (Fuente: 36Kr, Xin Zhi Yuan 1, AI Tech Review, Reddit r/LocalLLaMA, Reddit r/artificial)
Zhipu AI inicia asesoramiento para IPO y abre código de nuevos modelos, valoración supera los 20 mil millones: Zhipu AI (Zhipu Huazhang), uno de los “Seis Pequeños Tigres” de los grandes modelos en China, registró su asesoramiento para la salida a bolsa (IPO) en la Oficina Regulatoria de Valores de Beijing el 14 de abril, iniciando formalmente el proceso de IPO con CICC como institución asesora. Zhipu AI fue incubada por el Laboratorio de Ingeniería del Conocimiento de la Universidad de Tsinghua, con miembros clave del equipo provenientes en su mayoría de Tsinghua. Ha recaudado acumulativamente más de 15 mil millones de yuanes y su valoración reciente supera los 20 mil millones de yuanes. Simultáneamente al inicio de la IPO, Zhipu AI anunció la apertura a gran escala del código de la serie de modelos GLM-4-32B/9B, incluyendo modelos base, de inferencia y de reflexión (contemplation), bajo la licencia MIT para uso comercial gratuito. Entre ellos, el modelo de inferencia de 32B parámetros, GLM-Z1-32B-0414, iguala el rendimiento del DeepSeek-R1 de 671B parámetros en algunas tareas. Su versión API ultrarrápida, GLM-Z1-AirX, alcanza una velocidad de inferencia de 200 tokens/s, y la versión de alta relación calidad-precio cuesta solo 1/30 del DeepSeek-R1. La compañía también habilitó el nuevo dominio z.ai como plataforma gratuita para probar los modelos. Esta medida demuestra el despliegue integral de Zhipu AI en investigación y desarrollo tecnológico propio, exploración comercial y construcción de ecosistemas de código abierto. (Fuente: Zhidongxi, InfoQ, QubitAI, GeekPark, Leidi, Cuenta Oficial)

Nvidia invierte 500 mil millones de dólares para fabricar supercomputadoras de IA en EE. UU.: Nvidia anunció un plan importante para invertir 500 mil millones de dólares en los próximos cuatro años para fabricar supercomputadoras de IA por primera vez en suelo estadounidense. El plan implica la colaboración con varios gigantes de la industria, incluyendo TSMC (producción de chips Blackwell en Arizona), Foxconn y Wistron (construcción de fábricas de supercomputadoras en Texas), Amkor y SPIL (empaquetado y pruebas en Arizona). El CEO de Nvidia, Jensen Huang, declaró que esta medida tiene como objetivo satisfacer la creciente demanda de chips de IA y supercomputadoras, mejorar la resiliencia de la cadena de suministro y utilizar las tecnologías de IA, robótica (Isaac GR00T) y gemelos digitales (Omniverse) de Nvidia para diseñar y operar las fábricas. El plan se considera un despliegue estratégico en el contexto del impulso del gobierno de EE. UU. a la fabricación local (como la Ley CHIPS) y la geopolítica, con el objetivo de mejorar la posición de EE. UU. en la carrera global de infraestructura de IA, pero también enfrenta desafíos como la complejidad de la cadena de suministro, la escasez de trabajadores técnicos y la incertidumbre política. (Fuente: Xin Zhi Yuan 1, Xin Zhi Yuan 2, Reddit r/artificial)

Amazon planea invertir más de 100 mil millones de dólares para impulsar la IA, enfrentar la competencia y aprovechar oportunidades: El CEO de Amazon, Andy Jassy, reveló en la carta anual a los accionistas de 2024 que la compañía planea realizar gastos de capital superiores a 100 mil millones de dólares en 2025, la mayoría destinados a proyectos relacionados con la IA, incluyendo centros de datos, equipos de red, hardware de IA (como los chips propios Trainium) y servicios de IA generativa (como la serie de modelos grandes propios Nova, la plataforma Bedrock, la versión mejorada de Alexa+ y el asistente de compras Rufus). Esta enorme inversión (casi 1/6 de los ingresos anuales) refleja que Amazon considera la IA como clave para enfrentar la intensa competencia en el comercio electrónico (de SHEIN, Temu, TikTok, etc.) y aprovechar una oportunidad histórica. Jassy enfatizó que la IA cambiará las reglas de la búsqueda, la programación, las compras, etc., y no invertir significaría perder competitividad. Actualmente, el negocio de IA de Amazon ya genera miles de millones de dólares en ingresos anuales, con un crecimiento interanual de tres dígitos. Esta medida también muestra la determinación de Amazon de seguir invirtiendo para consolidar su posición de liderazgo en servicios en la nube (AWS) frente a competidores como Microsoft Azure y Google Cloud. (Fuente: 36Kr)
🎯 Tendencias
Protocolo de interoperabilidad de AI Agent MCP y estándar A2A ganan atención: El campo de los agentes inteligentes de IA está presenciando una competencia por protocolos de interacción estandarizados. El MCP (Model Context Protocol) propuesto por Anthropic tiene como objetivo unificar la comunicación entre modelos grandes y herramientas externas, fuentes de datos, y ha sido aclamado como el “USB-C de la IA”, obteniendo el apoyo de OpenAI, Google, entre otros. Google, por su parte, ha abierto el código del protocolo A2A (Agent2Agent), centrado en la colaboración segura y eficiente entre agentes de diferentes proveedores y frameworks, con el objetivo de romper las barreras del ecosistema. La aparición de estos dos protocolos marca la evolución de la IA desde la inteligencia individual hacia redes colaborativas, pero también ha suscitado debates sobre “el protocolo como poder”, el monopolio de datos y las barreras del ecosistema (“jardines amurallados”). Controlar el poder de establecer estándares podría reestructurar la cadena industrial de la IA e influir profundamente en la fusión de la IA con el mundo físico (robótica, IoT). Empresas chinas como Alibaba Cloud y Tencent Cloud también han comenzado a implementar soporte para MCP. (Fuente: 36Kr)

Informe de QuestMobile: DeepSeek revoluciona el panorama de aplicaciones de IA en China, la base de usuarios alcanza los 240 millones: El informe “Análisis de la Competencia del Mercado de Aplicaciones de IA del Primer Trimestre de 2025” publicado por QuestMobile muestra que, influenciado por la explosión del modelo DeepSeek y sus aplicaciones, el panorama del mercado de aplicaciones nativas de IA en China ha sido completamente trastocado. A finales de febrero de 2025, la escala de usuarios activos mensuales de aplicaciones nativas de IA alcanzó los 240 millones, un aumento de casi el 90% respecto a enero. La aplicación DeepSeek App se coronó con 194 millones de usuarios activos mensuales, seguida por Doubao de ByteDance (116 millones) y Tencent Yuanbao (41.64 millones) en segundo y tercer lugar, reemplazando a anteriores líderes como Kimi. El informe señala que el efecto de código abierto y beneficio universal de DeepSeek impulsó la adopción por parte de los principales actores y la explosión de aplicaciones de IA, formando 23 verticales, incluyendo asistentes de IA generales y búsqueda de IA, siendo esta última la más competitiva. Actualmente, la “impulsión multi-modelo” se ha convertido en el estándar para las aplicaciones principales, y el foco de la competencia se ha desplazado hacia el diseño y la operación del producto. (Fuente: QuestMobile)

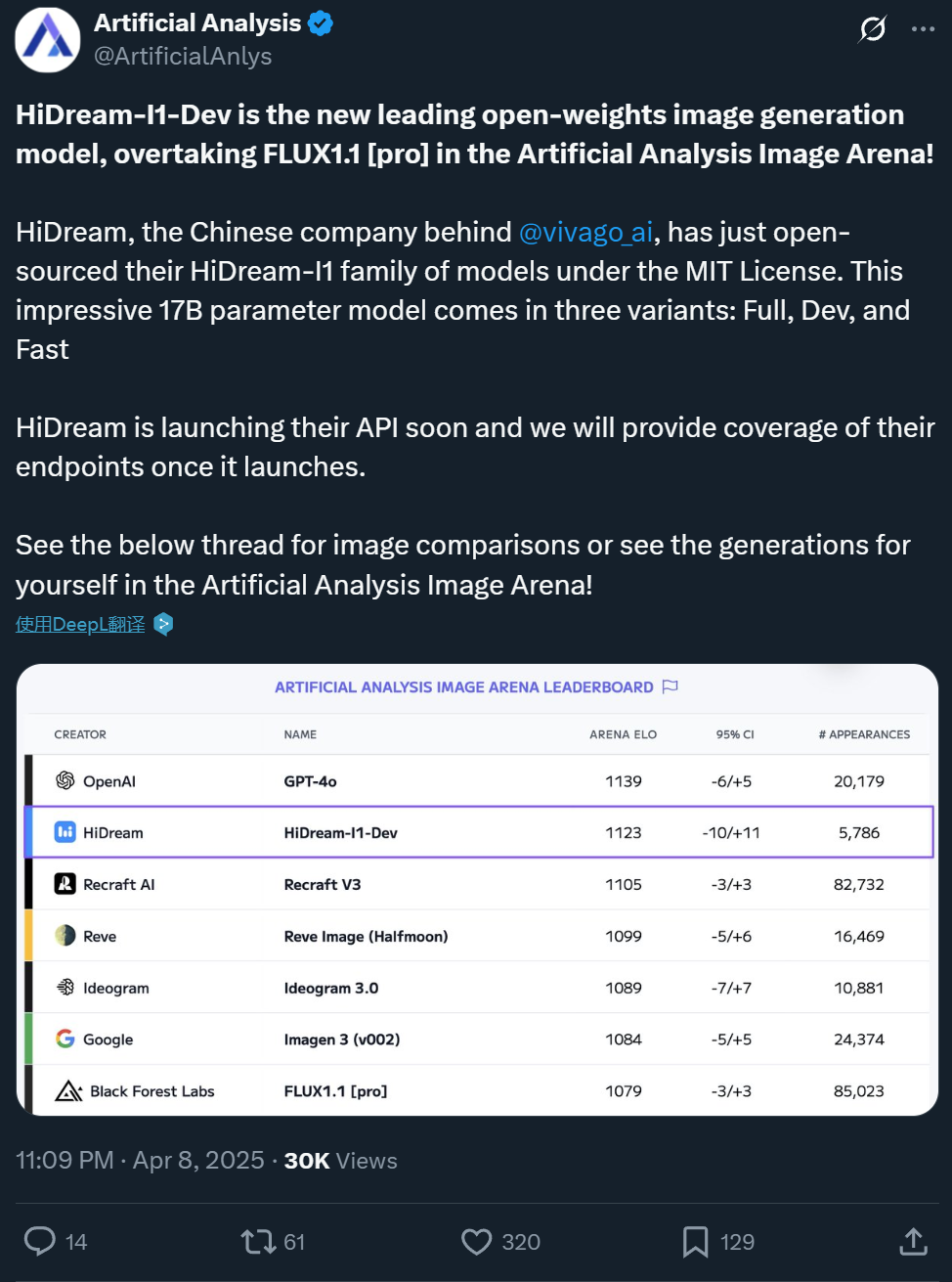
Zxiang Future abre el código del modelo de generación de texto a imagen HiDream-I1 de 17B, con efectos comparables a GPT-4o: La empresa china Zxiang Future ha abierto el código de su modelo grande de generación de texto a imagen HiDream-I1 de 17 mil millones de parámetros, bajo la licencia permisiva MIT, permitiendo su uso comercial. El modelo ha mostrado un rendimiento excepcional en arenas y benchmarks (como HPSv2.1, GenEval, DPG-Bench) en plataformas como Artificial Analysis. Se considera que el realismo, la delicadeza y la capacidad de seguimiento de instrucciones de las imágenes generadas son comparables a los de GPT-4o y FLUX 1.1 Pro, e incluso superiores en algunos aspectos. HiDream-I1 utiliza la arquitectura Sparse Diffusion Transformer (Sparse DiT), incorporando la tecnología MoE para mejorar el rendimiento y la eficiencia. La compañía también anunció la próxima apertura del código del modelo HiDream-E1, que admite la edición interactiva de imágenes. La combinación de ambos tiene como objetivo proporcionar una experiencia de generación y edición de imágenes “versión de código abierto de GPT-4o”. El modelo ya está disponible en Hugging Face y se puede probar en la plataforma Vivago. (Fuente: Ji Qizhi Xin 1, Ji Qizhi Xin 2)
ByteDance lanza el modelo base de video Seaweed de 7B, de bajo costo y alta eficiencia: El equipo Seed de ByteDance ha lanzado un modelo base de generación de video llamado Seaweed (un juego de palabras con Seed-Video). El modelo tiene solo 7 mil millones de parámetros y se informa que fue entrenado utilizando 665,000 horas de GPU H100 (equivalente a entrenar con 1000 tarjetas durante aproximadamente 28 días), con un costo relativamente bajo. Seaweed puede generar videos de diferentes resoluciones (soporta nativamente 1280×720, escalable a 2K), cualquier relación de aspecto y duración a partir de texto. El modelo admite la generación de imagen a video, control de sujeto de referencia (imagen única/múltiple), combinación con la solución de humanos digitales Omnihuman para generar videos con sincronización labial, doblaje de video y otras funciones. Técnicamente, utiliza una arquitectura DiT+VAE, combinada con un flujo completo de procesamiento de datos y una estrategia de entrenamiento multi-etapa y multi-tarea (pre-entrenamiento, SFT, RLHF), y se ha optimizado a nivel de sistema para mejorar la eficiencia del entrenamiento. El equipo está liderado por el Dr. Jiang Lu, ex jefe de generación de video de Google, entre otros. (Fuente: QubitAI)

Alibaba Tongyi lanza el modelo de generación de video de humanos digitales OmniTalker: El equipo HumanAIGC del laboratorio Tongyi de Alibaba ha presentado un nuevo modelo grande de generación de video de humanos digitales, OmniTalker. El modelo tiene como objetivo resolver los problemas de latencia, desincronización audio-visual y falta de consistencia de estilo causados por los métodos tradicionales en cascada (TTS + conducción por audio). OmniTalker es un marco unificado de extremo a extremo que, a partir de texto y un fragmento de audio/video de referencia, puede generar en tiempo real voz y video de humano digital sincronizados, conservando al mismo tiempo el sonido y el estilo de habla facial de la fuente de referencia. Su arquitectura central utiliza un DiT (Diffusion Transformer) de doble flujo, que procesa la información de audio y visual por separado, y garantiza la sincronización y la consistencia del estilo a través de un novedoso módulo de fusión audio-visual. El modelo utiliza un módulo de aprendizaje de referencia contextual para capturar las características de estilo del video de referencia, sin necesidad de entrenar extractores de estilo adicionales. El proyecto ya está abierto para pruebas en la comunidad ModelScope y HuggingFace. (Fuente: Ji Qizhi Xin)

Kuaishou lanza la versión 2.0 del modelo de video Kling AI: El modelo de generación de video Kling AI de Kuaishou ha lanzado su versión 2.0, que según se informa, presenta mejoras significativas en la amplitud del movimiento de cámara, el seguimiento de las leyes físicas, la actuación de personajes, la estabilidad de la acción y la comprensión semántica. Las evaluaciones de los usuarios muestran que la nueva versión funciona excepcionalmente bien en el manejo de interacciones complejas (como un T-Rex rompiendo árboles), acciones finas (como quitarse las gafas), escenas con múltiples personas y simulación de luces y sombras realistas. El realismo y la sensación cinematográfica de los videos generados han mejorado enormemente, y se considera que el efecto supera a la versión anterior 1.6 y alcanza un nivel líder en la industria. Aunque todavía hay margen de mejora en el movimiento rápido de grupos y la simulación física extrema (como lanzar una canasta), su rendimiento general se considera que ya desafía el nivel de producción profesional. Los usuarios pueden probar la nueva versión a través del sitio web oficial klingai.com. (Fuente: Cuenta Oficial, op7418)

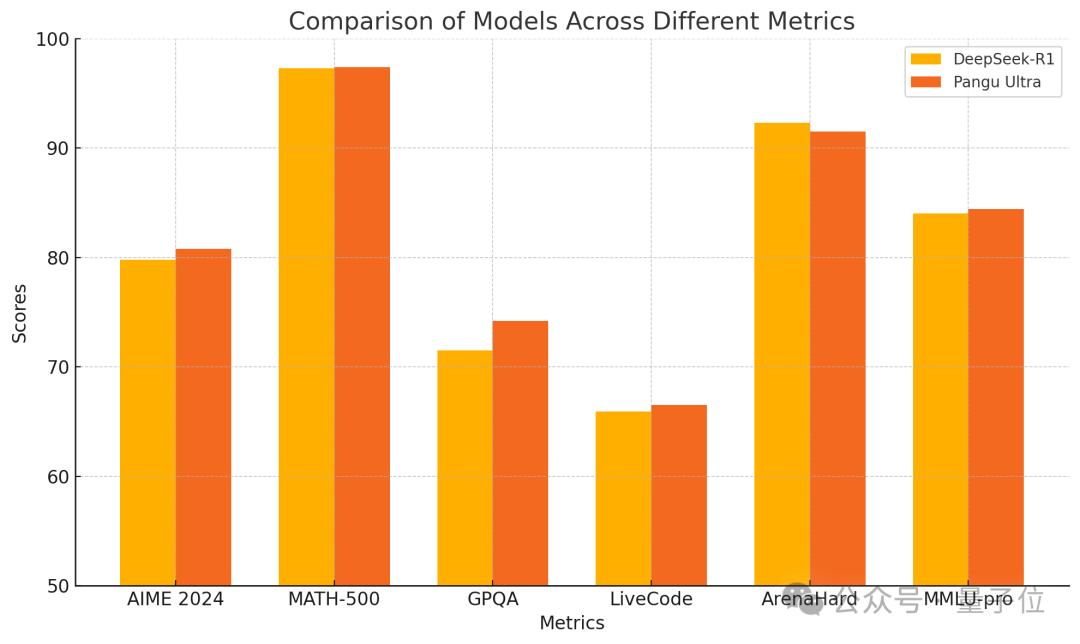
Huawei lanza el modelo denso Pangu Ultra 135B, entrenado puramente en Ascend con rendimiento superior: Huawei ha anunciado un nuevo miembro de su serie de modelos grandes Pangu: Pangu Ultra. Se trata de un modelo denso (Dense) con 135 mil millones de parámetros, entrenado completamente en el clúster de computación AI Ascend de Huawei (8192 NPUs), sin usar GPUs de Nvidia. Según los informes, Pangu Ultra muestra un rendimiento excepcional en tareas como el razonamiento matemático (AIME 2024, MATH-500) y la programación (LiveCodeBench), con un rendimiento comparable a modelos MoE de mayor escala como DeepSeek-R1. Técnicamente, el modelo utiliza una innovadora normalización de capas Sandwich-Norm de escalado profundo y una estrategia de inicialización de parámetros TinyInit, resolviendo eficazmente los problemas de inestabilidad al entrenar redes ultra profundas (94 capas), logrando un entrenamiento estable sin picos de pérdida. Mediante la optimización a nivel de sistema, el entrenamiento alcanzó una utilización de la potencia de cálculo (MFU) superior al 52%. (Fuente: QubitAI)
Canopy Labs abre el código del modelo de síntesis de voz emocional Orpheus: Canopy Labs ha lanzado y abierto el código de una serie de modelos de texto a voz (TTS) llamada Orpheus. El modelo se basa en la arquitectura Llama, con una versión inicial de 3 mil millones de parámetros, y posteriormente se lanzarán versiones más pequeñas de 1B, 0.5B y 0.15B. La característica de Orpheus es su capacidad para generar voz con emociones, entonaciones y ritmos altamente humanizados, e incluso puede inferir y generar sonidos no verbales como risas y suspiros a partir del texto, logrando una expresión “empática”. El modelo admite la clonación de voz zero-shot y el control de la entonación emocional mediante etiquetas. Utiliza inferencia en streaming, con una latencia tan baja como 100-200 ms, y una velocidad de inferencia más rápida que la reproducción en tiempo real en una tarjeta gráfica A100 de 40 GB. Los desarrolladores afirman que su rendimiento supera a los modelos SOTA de código abierto existentes y a algunos de código cerrado, con el objetivo de romper el monopolio de los modelos TTS de código cerrado. El modelo y el código ya están disponibles en GitHub y Hugging Face. (Fuente: Xin Zhi Yuan)

La Universidad de Zhejiang y ByteDance lanzan conjuntamente el modelo de síntesis de voz MegaTTS3: El equipo del profesor Zhao Zhou de la Universidad de Zhejiang, en colaboración con ByteDance, ha lanzado y abierto el código del modelo de síntesis de voz de tercera generación, MegaTTS3. Con un tamaño ligero de solo 0.45B parámetros, el modelo logra una síntesis de voz bilingüe chino-inglés de alta calidad y muestra un rendimiento excepcional en la clonación de voz zero-shot, capaz de generar voz natural, controlable y personalizada. MegaTTS3 se centra en superar los desafíos del alineamiento disperso voz-texto, la controlabilidad de la generación y el equilibrio entre eficiencia y calidad. Los aspectos técnicos destacados incluyen la tecnología “Guía Libre de Clasificador Multi-Condición” (Multi-Condition CFG) para el control multidimensional como la intensidad del acento, y la tecnología “Aceleración de Flujo Rectificado por Segmentos” (PeRFlow) que triplica la velocidad de muestreo. El modelo demuestra una naturalidad (CMOS) y similitud del hablante (SIM-O) líderes en benchmarks como LibriSpeech. (Fuente: PaperWeekly)

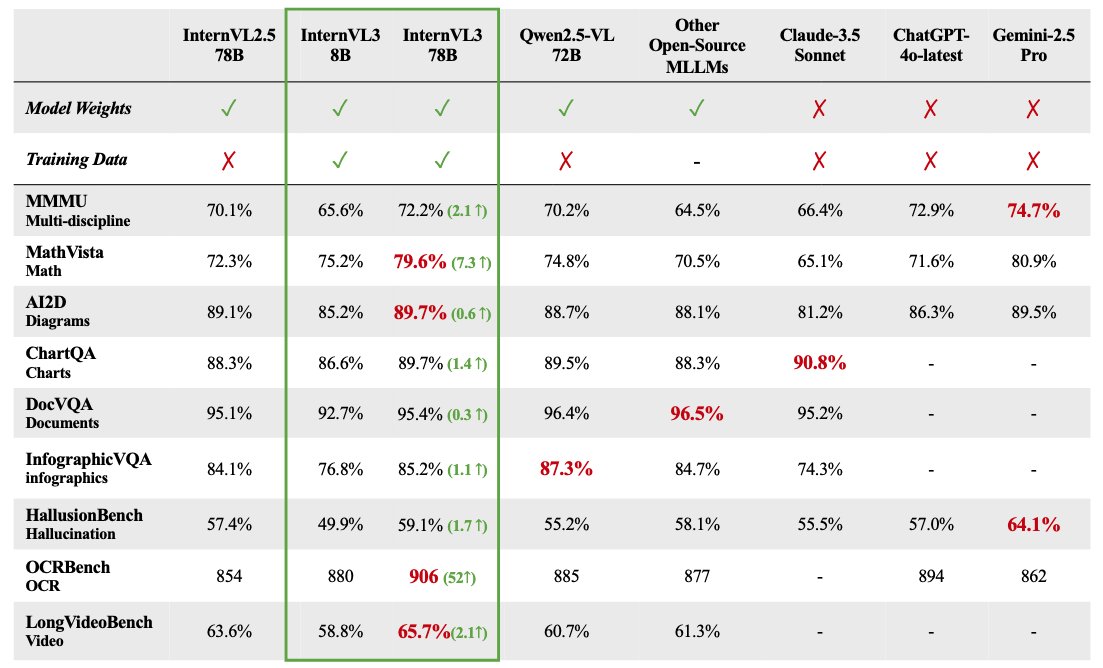
Se abre el código de la serie de modelos grandes multimodales InternVL 3: OpenGVLab ha lanzado la serie de modelos grandes multimodales InternVL 3, con tamaños de parámetros que van desde 1B hasta 78B, ya disponibles en Hugging Face. Según se informa, la versión de 78B parámetros obtuvo una puntuación de 72.2 en el benchmark MMMU, estableciendo un nuevo récord SOTA para modelos multimodales de código abierto. Los aspectos técnicos destacados de InternVL 3 incluyen: pre-entrenamiento multimodal nativo, aprendiendo simultáneamente lenguaje y visión; introducción de codificación de posición visual variable (V2PE) para admitir contexto extendido; uso de técnicas avanzadas post-entrenamiento como SFT y MPO; y aplicación de estrategias de escalado en tiempo de prueba para mejorar la capacidad de razonamiento matemático. Los datos de entrenamiento y los pesos del modelo están abiertos para uso de la comunidad. (Fuente: huggingface)
Análisis del rendimiento real de GPT-4.1: mejora en codificación pero rezagado en razonamiento: Los modelos de la serie GPT-4.1 lanzados por OpenAI muestran un panorama de rendimiento complejo en las pruebas iniciales y evaluaciones de benchmark. Aunque demuestran un progreso significativo en tareas de generación de código en comparación con GPT-4o, como completar mejor tareas de simulación física y desarrollo de juegos, y obtener una puntuación alta en SWE-Bench. Sin embargo, en benchmarks más amplios de razonamiento, matemáticas y respuesta a preguntas de conocimiento (como Livebench, GPQA Diamond), el rendimiento de GPT-4.1 sigue estando por detrás de Gemini 2.5 Pro de Google y Claude 3.7 Sonnet de Anthropic. Los análisis sugieren que GPT-4.1 podría ser una actualización incremental de GPT-4o, o destilado de GPT-4.5. Su estrategia de lanzamiento podría tener como objetivo ofrecer opciones de modelo más rentables y optimizadas específicamente a través de la API, en lugar de un modelo insignia que supere por completo a los competidores. (Fuente: Xin Zhi Yuan)
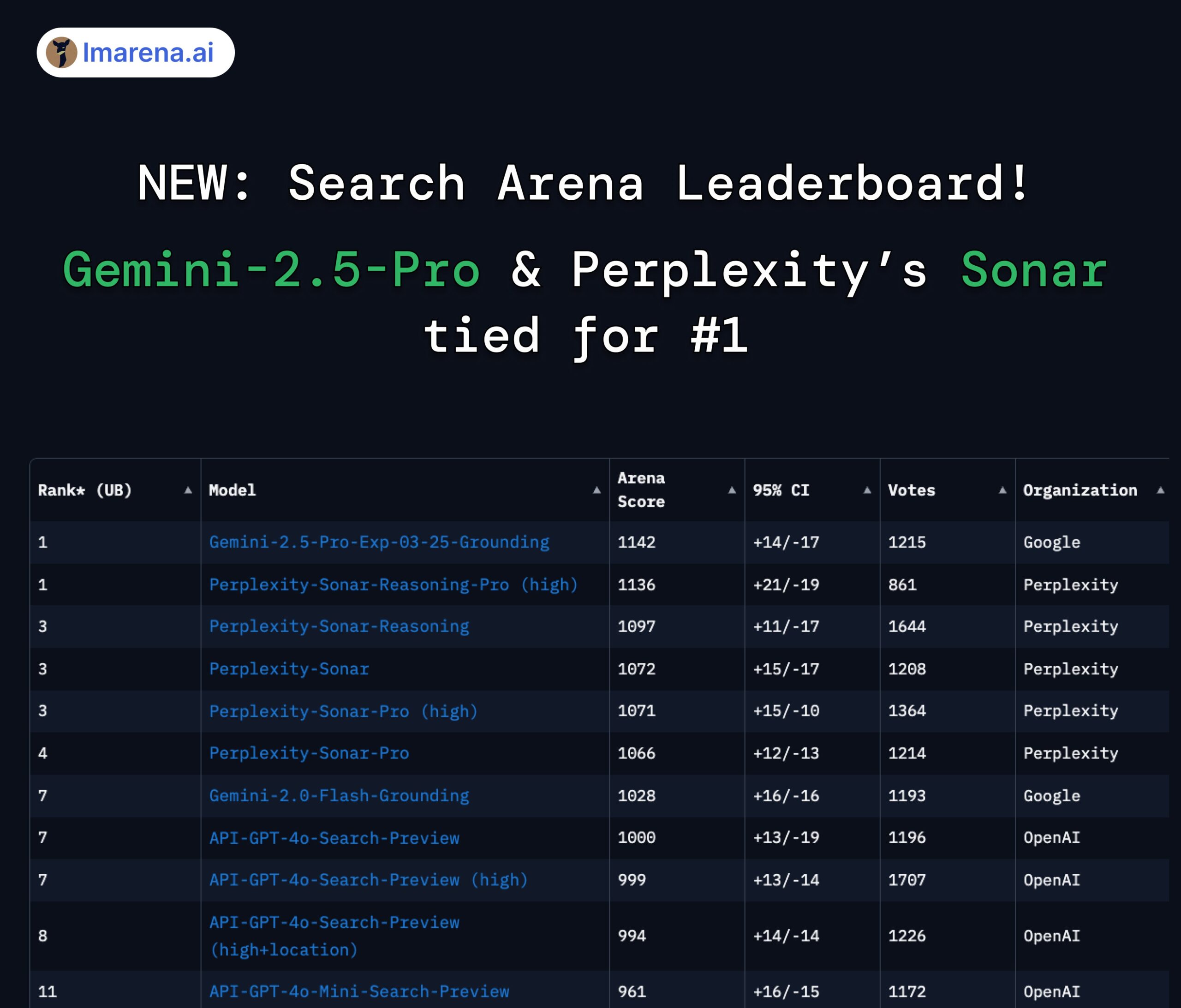
Ranking de búsqueda de LMArena: Gemini 2.5 Pro y Perplexity Sonar empatados en primer lugar: En la evaluación de arena realizada por LMArena para modelos grandes con capacidad de búsqueda/conexión a internet, Gemini-2.5-Pro de Google (combinado con Google Search) y Sonar-Reasoning-Pro de Perplexity empataron en el primer puesto. Este resultado fue confirmado y compartido por el CEO de Google DeepMind, Demis Hassabis, y el jefe de relaciones con desarrolladores de Google, Logan Kilpatrick. El CEO de Perplexity, Aravind Srinivas, también comentó que las pruebas A/B internas muestran que su modelo Sonar supera a GPT-4o en retención de usuarios y su rendimiento es comparable al de Gemini 2.5 Pro y el recién lanzado GPT-4.1. La organización de la evaluación, lmarena.ai, ha abierto el código de 7000 datos de votación de usuarios. (Fuente: lmarena_ai 1, lmarena_ai 2, AravSrinivas, demishassabis)
Meta reanudará el uso de contenido público de usuarios europeos para entrenar IA: Meta ha anunciado que comenzará de nuevo a utilizar contenido público de usuarios europeos para entrenar sus modelos de inteligencia artificial. Anteriormente, Meta había suspendido esta práctica debido a la presión y los requisitos regulatorios de las autoridades europeas de protección de datos (en particular, la Comisión de Protección de Datos de Irlanda). La decisión de reanudar el entrenamiento podría reflejar los continuos esfuerzos y ajustes estratégicos de Meta para equilibrar la privacidad del usuario, el cumplimiento de regulaciones (como el GDPR) y la obtención de datos suficientes para mantener la competitividad de sus modelos de IA. Esta medida podría reavivar el debate sobre los derechos de los datos de los usuarios y la transparencia en el entrenamiento de la IA. (Fuente: Reddit r/artificial)

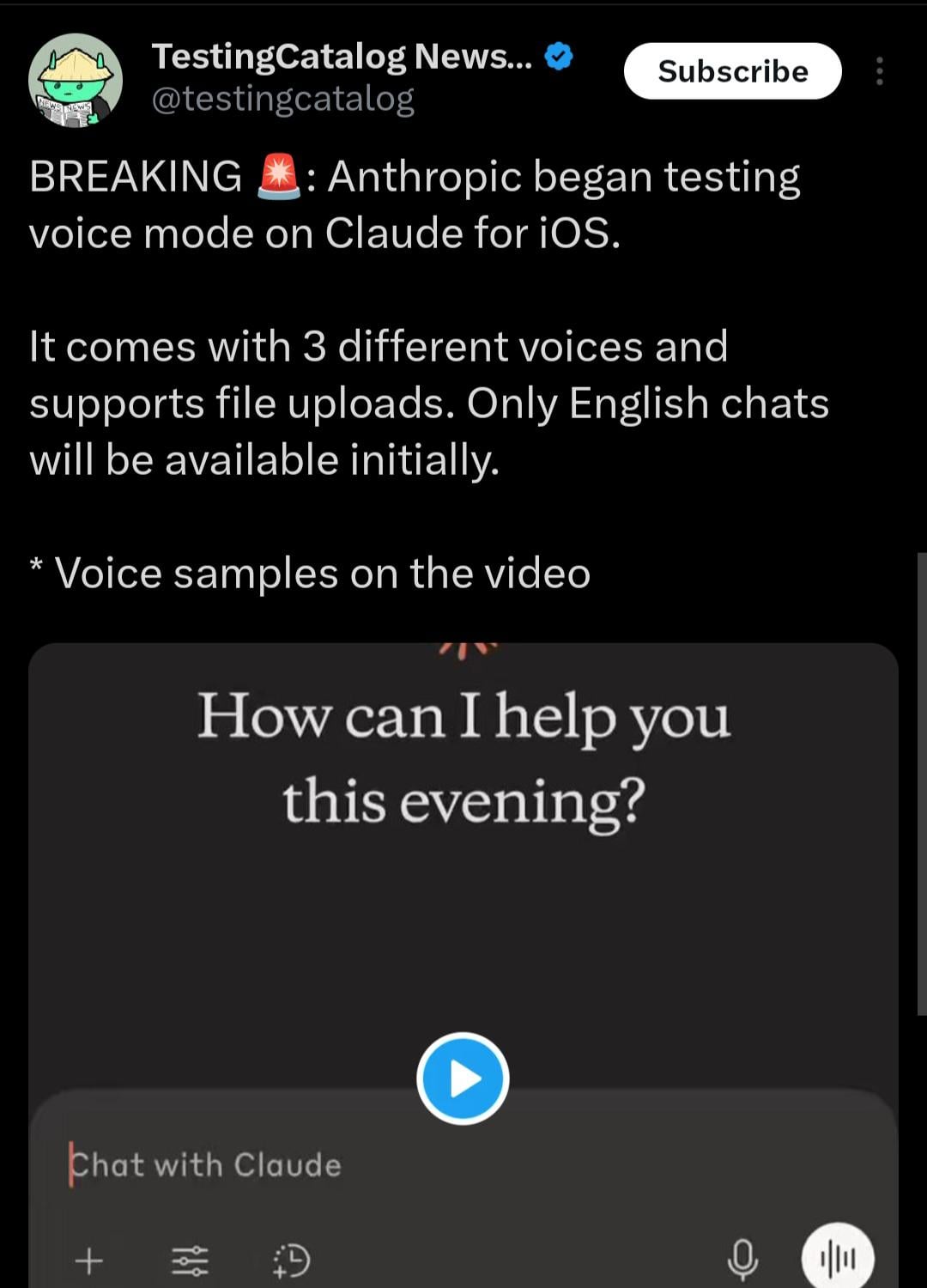
La aplicación móvil de Claude podría añadir modo de interacción por voz: Según pistas descubiertas por el usuario de X @testingcatalog, Anthropic podría planear añadir una función de interacción por voz a su aplicación móvil Claude. Las capturas de pantalla muestran un icono de micrófono en la interfaz de la aplicación, lo que sugiere que los usuarios podrían en el futuro conversar con Claude mediante voz, de forma similar a los modos de voz ya ofrecidos por las aplicaciones ChatGPT y Google Gemini. Esto haría que la interacción con Claude en dispositivos móviles fuera más diversa y cómoda, mejorando aún más la experiencia del usuario y manteniéndose a la par funcionalmente con otros asistentes de IA principales. (Fuente: Reddit r/ClaudeAI)
La velocidad de los modelos de la serie Z1 de Zhipu atrae atención, denominados “modelos instantáneos”: La serie de modelos Z1 recientemente lanzada por Zhipu AI, especialmente la versión GLM-Z1-AirX, ha llamado la atención por su velocidad de inferencia extremadamente rápida. Algunos analistas los han denominado “modelos instantáneos”, señalando que pueden completar la primera respuesta y generar más de 50 caracteres chinos en 0.3 segundos, una velocidad cercana al tiempo de reflejo neuronal humano. Esta baja latencia y alto rendimiento prometen cambiar el modo de interacción humano-máquina, pasando de “pregunta-espera-respuesta” a un diálogo casi en tiempo real, especialmente adecuado para escenarios que requieren alta velocidad de respuesta como educación, servicio al cliente, creación de contenido y llamadas de Agent. Se informa que la velocidad de la versión API de Z1-AirX puede alcanzar los 200 tokens/s. (Fuente: Cuenta Oficial)

Juegos nativos de IA: Evolución y desafíos desde herramientas de eficiencia hasta innovación en jugabilidad: La industria del juego está evolucionando desde el uso de la IA para mejorar la eficiencia en I+D y operaciones (como generación de arte, asistencia de código, pruebas automatizadas) hacia la exploración de verdaderos “juegos nativos de IA”. El núcleo de los juegos nativos de IA reside en la profunda integración de la IA en la jugabilidad, creando contenido dinámico impulsado por la interacción del jugador y experiencias personalizadas, en lugar de guiones preestablecidos. Ejemplos de esta exploración son “Whispers from the Star”, invertido por el fundador de miHoYo, Cai Haoyu, y el modo de jugador IA en “Space Kill” de Giant Network. Sin embargo, la realización de juegos nativos de IA enfrenta numerosos desafíos: a nivel técnico, es necesario resolver problemas de capacidad, estabilidad y costo del modelo; a nivel de diseño, faltan ejemplos maduros y es necesario equilibrar la controlabilidad y la libertad; a nivel de usuario, es necesario satisfacer las demandas de los jugadores en cuanto a diversión y profundidad de interacción; además, existen riesgos de cumplimiento de contenido y éticos. Actualmente, la industria todavía se encuentra en una etapa temprana de exploración, lejos de una implementación madura. (Fuente: Jiemian News)
🧰 Herramientas
Inventario de cinco aplicaciones de IA innovadoras: 36Kr ha recopilado cinco herramientas de IA creativas y prácticas de casos de innovación de aplicaciones nativas de IA recientes: 1) AiPPT.com: Genera rápidamente PPT a partir de una frase o importando archivos (Word, PDF, Xmind, enlaces), admite ejecución sin conexión. 2) Gafas AI Shanke PaiPai Mirror: Gafas de IA con funciones como tomar fotos y grabar videos, traducción en tiempo real, reconocimiento de fórmulas. 3) Agente inteligente de interrogatorio no sensorial digital Lianxin: Basado en el modelo psicológico grande “Insight into People”, ayuda en los interrogatorios analizando microexpresiones, voz y señales fisiológicas, generando informes. 4) IA de calzado Huilima Vali: Introduce palabras clave y genera 8 diseños de calzado en 10 segundos, integrando biblioteca de materiales y datos de patrones, conectando con la producción. 5) Agente inteligente HR Sandbox de Nanfang Shìtōng: Gestiona tareas de recursos humanos relacionadas con la seguridad social, proporcionando interpretación de políticas, cálculo de costos, gestión inteligente, alerta de riesgos, etc. Estas aplicaciones demuestran el potencial de la IA en herramientas de eficiencia, hardware inteligente y dominios profesionales (seguridad, diseño, RRHH). (Fuente: 36Kr)

Haixin Intelligence lanza la plataforma de desarrollo AI sin código “Haisnap”: Haixin Intelligence Technology, respaldada por activos estatales de Beijing, ha lanzado una plataforma de desarrollo AI sin código/bajo código llamada “Haisnap”. Los usuarios pueden describir sus necesidades en lenguaje natural para que la IA genere automáticamente aplicaciones web o minijuegos. La característica de la plataforma es que el código es visible en tiempo real durante el proceso de generación y admite la edición y modificación secundaria a través del diálogo. Las aplicaciones desarrolladas por los usuarios pueden publicarse en la “Comunidad Creativa” de la plataforma para que otros las exploren, usen y recreen (remix). Actualmente, la plataforma está abierta de forma gratuita, con el objetivo de reducir las barreras para el desarrollo de aplicaciones de IA, promover la creación universal, con especial atención a la educación en IA para jóvenes y la implementación en la industria. (Fuente: QubitAI)

Lanzamiento del sistema de preguntas y respuestas sobre base de conocimientos de código abierto ChatWiki, compatible con GraphRAG e integración con WeChat: ChatWiki es un nuevo sistema de preguntas y respuestas de IA sobre base de conocimientos de código abierto. Integra modelos de lenguaje grandes (compatible con más de 20 modelos como DeepSeek, OpenAI, Claude) con tecnología de generación aumentada por recuperación (RAG), y admite especialmente GraphRAG basado en grafos de conocimiento para manejar consultas complejas. Las funciones del sistema incluyen: importar documentos en varios formatos (OFD, Word, PDF, etc.) para construir bases de conocimiento privadas; admitir segmentación semántica para mejorar la precisión de RAG; publicar bases de conocimiento como sitios de documentación pública; proporcionar interfaces API para una integración perfecta con cuentas oficiales de WeChat, servicio al cliente de WeChat y otros ecosistemas para crear chatbots de IA; herramienta de orquestación de flujo de trabajo visual incorporada; admitir la conexión con datos comerciales de terceros; proporcionar gestión de permisos a nivel empresarial; admitir implementación local mediante Docker y código fuente. (Fuente: Cuenta Oficial)

ModelScope Community lanza MCP Square, creando el mayor ecosistema de servicios MCP de China: ModelScope, la comunidad de modelos de IA de Alibaba, ha lanzado oficialmente “MCP Square”, que reúne casi 1500 servicios que implementan el Protocolo de Contexto de Modelo (MCP), cubriendo áreas como búsqueda, mapas, pagos, herramientas para desarrolladores, etc., con el objetivo de crear la mayor comunidad china de MCP. Varios servicios MCP de Alipay y MiniMax se lanzan exclusivamente aquí, como las capacidades de pago, consulta y reembolso de Alipay, y las capacidades de generación de voz, imagen y video de MiniMax, todas accesibles para agentes de IA a través del protocolo MCP. Los desarrolladores pueden experimentar e integrar rápidamente estos servicios en el campo experimental MCP de ModelScope mediante una configuración JSON simple y recursos gratuitos en la nube, reduciendo enormemente las barreras para que las aplicaciones de IA accedan a herramientas y datos externos. ModelScope también lanzó MCP Bench para evaluar la calidad y el rendimiento de varios servicios MCP. (Fuente: Xin Zhi Yuan)

Discusión sobre el uso de la función WebSearch en Open WebUI: Usuarios de la comunidad Reddit discuten cómo usar la función Web Search en Open WebUI. Las preguntas se centran en cómo controlar con precisión las palabras clave de consulta utilizadas por el motor de búsqueda y cómo restringir la función Web Search a modelos específicos para evitar que los datos de modelos privados se envíen accidentalmente a la red. Esto refleja la necesidad real de los usuarios de precisión en el control y seguridad de la privacidad al usar herramientas de IA con funciones de búsqueda integradas. (Fuente: Reddit r/OpenWebUI 1, Reddit r/OpenWebUI 2)
Usuario busca comprender el Protocolo de Contexto de Modelo (MCP): Un usuario en la comunidad Reddit ha publicado pidiendo una explicación del Protocolo de Contexto de Modelo (MCP), lo que indica que con la promoción y aplicación del estándar MCP (como MCP Square de ModelScope), existe una creciente necesidad en la comunidad de desarrolladores y usuarios de comprender esta tecnología emergente y su funcionamiento. (Fuente: Reddit r/OpenWebUI)
📚 Aprendizaje
ICLR 2025 otorga el Premio a la Prueba del Tiempo al optimizador Adam y al mecanismo de atención: La Conferencia Internacional sobre Representaciones de Aprendizaje (ICLR) ha otorgado su “Premio a la Prueba del Tiempo” (Test of Time Award) de 2025 a dos artículos emblemáticos publicados hace diez años (en 2015). Uno es “Adam: A Method for Stochastic Optimization” de Diederik P. Kingma y Jimmy Ba, cuyo optimizador Adam propuesto se ha convertido en el algoritmo estándar para el entrenamiento de modelos de aprendizaje profundo. El otro es “Neural Machine Translation by Jointly Learning to Align and Translate” de Dzmitry Bahdanau, Kyunghyun Cho y Yoshua Bengio, que introdujo por primera vez el mecanismo de atención, sentando las bases para la arquitectura Transformer y los modelos de lenguaje grandes modernos. Estos dos premios destacan el profundo impacto de la investigación fundamental en el desarrollo actual de la IA. (Fuente: Xin Zhi Yuan)

Breve historia del desarrollo de la IA y retrospectiva de la evolución empresarial: El artículo repasa sistemáticamente la historia del desarrollo de la inteligencia artificial desde mediados del siglo XX hasta la actualidad, con hitos clave como la Prueba de Turing, la Conferencia de Dartmouth, el simbolismo y los sistemas expertos, los inviernos de la IA, el auge del aprendizaje automático (DeepBlue, PageRank), la revolución del aprendizaje profundo (AlexNet, AlphaGo) y la era actual de los modelos grandes (serie GPT, comercialización de la IA generativa, debate entre código abierto y cerrado). Al mismo tiempo, el artículo divide el desarrollo empresarial de la IA en cuatro eras: la era pionera (2000-2010, exploración de aplicaciones tipo herramienta), la era de la fiebre del oro (2011-2016, empoderamiento de plataformas y explosión impulsada por datos), la era de la burbuja (2017-2020, lucha por escenarios y cuellos de botella en la comercialización) y la era de la reestructuración (2021-presente, nuevo panorama impulsado por modelos grandes). El artículo enfatiza la sinergia entre la potencia de cálculo, los datos y los algoritmos, así como el impacto de nuevas fuerzas como DeepSeek en el panorama. (Fuente: Chaos University)
OpenAI publica la guía de ingeniería de prompts para GPT-4.1: Junto con el lanzamiento de la serie de modelos GPT-4.1, OpenAI ha actualizado su guía de ingeniería de prompts (Prompting). La guía enfatiza que los modelos de la serie GPT-4.1, en comparación con modelos anteriores como GPT-4, seguirán las instrucciones de manera más estricta y literal, siendo más sensibles a prompts claros y específicos. Si el modelo no se comporta como se espera, generalmente añadir instrucciones concisas y claras puede guiar su comportamiento. Esto difiere de los modelos anteriores que tendían a adivinar la intención del usuario, por lo que los desarrolladores podrían necesitar ajustar sus estrategias de prompting existentes. La guía proporciona las mejores prácticas, desde principios básicos hasta estrategias avanzadas, para ayudar a los desarrolladores a aprovechar mejor las características de los nuevos modelos. (Fuente: dotey, Reddit r/LocalLLaMA)
La Universidad Jiao Tong de Shanghái y otros lanzan el benchmark de inteligencia espaciotemporal STI-Bench, desafiando la comprensión física de los modelos multimodales: La Universidad Jiao Tong de Shanghái, en colaboración con varias instituciones, ha lanzado el primer benchmark para evaluar la inteligencia espaciotemporal de los modelos grandes multimodales (MLLM), STI-Bench. Este benchmark utiliza videos del mundo real, centrándose en la capacidad precisa y cuantitativa de comprensión espacial y temporal, e incluye ocho tareas: medición de escala, relaciones espaciales, localización 3D, trayectoria de desplazamiento, velocidad y aceleración, orientación egocéntrica, descripción de trayectoria y estimación de pose. La evaluación de modelos de vanguardia como GPT-4o, Gemini 2.5 Pro, Claude 3.7 Sonnet, Qwen 2.5 VL, etc., muestra que los modelos existentes tienen un rendimiento generalmente bajo en estas tareas (precisión <42%), especialmente con dificultades para manejar atributos espaciales cuantitativos, cambios dinámicos temporales e integración de información intermodal. Este benchmark revela las limitaciones actuales de los MLLM en la comprensión del mundo físico, proporcionando una dirección para investigaciones futuras. (Fuente: QubitAI)

La investigación que combina aprendizaje por refuerzo y optimización multiobjetivo atrae atención: El campo interdisciplinario del aprendizaje por refuerzo (RL) y la optimización multiobjetivo (MOO) se está convirtiendo en un punto candente en la investigación de la toma de decisiones de IA. Esta combinación tiene como objetivo permitir que los agentes inteligentes equilibren múltiples objetivos (posiblemente conflictivos) en entornos complejos, en lugar de buscar un único óptimo. Por ejemplo, HKUST propuso un marco dinámico de equilibrio de gradientes para la conducción autónoma, optimizando simultáneamente la seguridad y la eficiencia energética; el algoritmo de búsqueda de estrategias de Pareto del MIT se utiliza para el control de robots; Alibaba Cloud utiliza tecnología de alineación multiobjetivo para transacciones financieras para equilibrar ganancias y riesgos. Investigaciones relacionadas como CMORL (aprendizaje por refuerzo multiobjetivo continuo) y el aprendizaje de conjuntos de Pareto para optimización combinatoria están explorando cómo hacer que los agentes de RL manejen de manera más efectiva problemas del mundo real que cambian dinámicamente o tienen múltiples dimensiones de optimización. (Fuente: Cuenta Oficial)

Lanzamiento de código abierto de la plataforma automática de ataque y defensa adversaria A³D (TPAMI 2025): El equipo de investigación de Diseño Inteligente y Aprendizaje Robusto (IDRL) del Instituto de Innovación en Tecnología de Defensa de la Academia de Ciencias Militares ha desarrollado y abierto el código de una plataforma llamada A³D (Ataque y Defensa Adversaria Automática). Esta plataforma utiliza tecnología de aprendizaje automático automatizado (AutoML), combinada con ideas de teoría de juegos de ataque-defensa, con el objetivo de buscar automáticamente arquitecturas de redes neuronales robustas y estrategias eficientes de ataque adversario. La plataforma integra múltiples métodos de búsqueda de arquitectura neuronal (NAS) y métricas de evaluación de robustez (ataques de norma, ataques semánticos, camuflaje adversario, etc.) para la defensa automática, al tiempo que proporciona un módulo de ataque adversario automático que puede buscar esquemas de ataque combinados óptimos mediante algoritmos de optimización. Los resultados de la investigación se publicaron en la prestigiosa revista TPAMI, y el código se ha publicado en plataformas como Hongshan Open Source, proporcionando nuevas herramientas para evaluar y mejorar la seguridad de los modelos DNN. (Fuente: Cuenta Oficial)

La Universidad de Florida busca doctorandos/internos con beca completa en NLP/LLM: El profesor asistente Yuanyuan Lei del Departamento de Computación de la Universidad de Florida (se incorpora en otoño de 2025) ha publicado información de admisión, buscando estudiantes de doctorado con beca completa para comenzar en otoño de 2025 o primavera de 2026, así como internos de investigación con horarios flexibles (posibilidad de trabajo remoto). Las áreas de investigación se centran en el procesamiento del lenguaje natural (NLP) y los modelos de lenguaje grandes (LLM), incluyendo específicamente LLM mejorados con conocimiento, verificación de hechos, razonamiento y planificación, aplicaciones de NLP (multimodal, legal, comercial, científico, etc.). Se da la bienvenida a estudiantes con formación en computación, ingeniería electrónica, estadística, matemáticas o campos relacionados, con interés y motivación por la investigación en IA. El correo electrónico menciona el posible impacto de la ley SB-846 de Florida en la admisión de estudiantes de China continental y las posibles vías para abordarlo. (Fuente: PaperWeekly)

Nueva investigación sobre modelos de difusión: Prior de ruido correlacionado temporalmente: Un artículo de arXiv titulado “How I Warped Your Noise: a Temporally-Correlated Noise Prior for Diffusion Models” propone un nuevo tipo de prior de ruido para modelos de difusión. El método tiene como objetivo mejorar la calidad o eficiencia de la generación de modelos de difusión (posiblemente de video) introduciendo ruido correlacionado temporalmente. Los detalles técnicos específicos deben consultarse en el artículo original. (Fuente: Reddit r/MachineLearning)
Nueva investigación sobre descubrimiento científico automatizado: AI Scientist-v2: Un artículo de arXiv titulado “The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search” presenta el sistema AI Scientist-v2. Este sistema utiliza el método Agentic Tree Search (búsqueda en árbol agéntica) con el objetivo de lograr un descubrimiento científico automatizado de “nivel de taller” (Workshop-Level). Esto indica que los investigadores están explorando el uso de agentes de IA para realizar investigaciones y exploraciones científicas más avanzadas y autónomas. (Fuente: Reddit r/MachineLearning)
Explicación de la implementación de la regularización Dropout: Un artículo de Substack explica detalladamente la implementación de la técnica de regularización Dropout. Dropout es una técnica de regularización ampliamente utilizada en el aprendizaje profundo que previene el sobreajuste del modelo “descartando” aleatoriamente una parte de las neuronas durante el entrenamiento. El artículo probablemente está dirigido a estudiantes que desean comprender en profundidad el principio de funcionamiento de Dropout o implementar esta técnica por sí mismos. (Fuente: Reddit r/deeplearning)
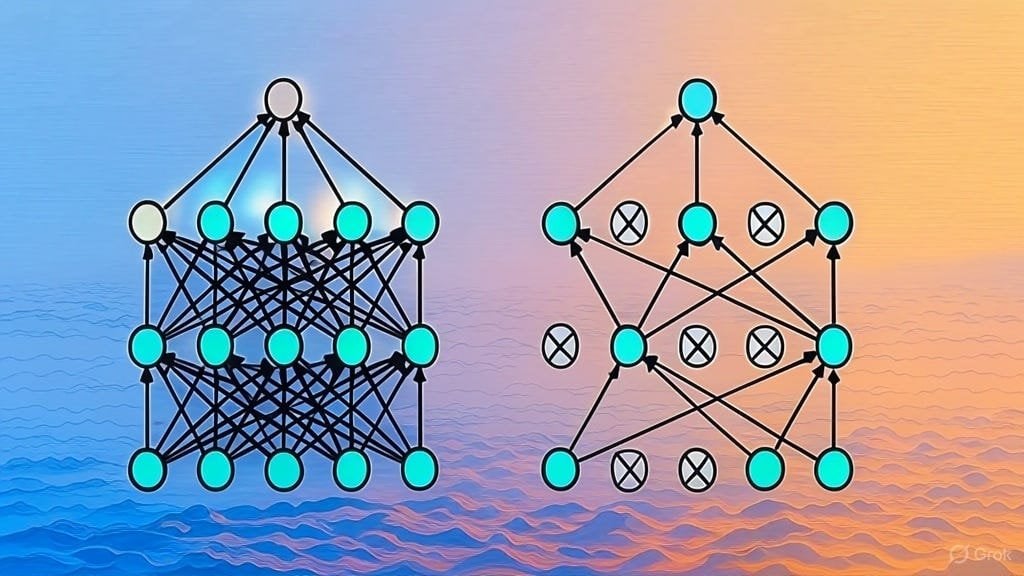
Solicitud de lista de artículos sobre arquitecturas LLM: Un usuario de Reddit inició una discusión para compartir y solicitar artículos de arXiv sobre arquitecturas de modelos de lenguaje grandes (LLM). Las arquitecturas ya enumeradas incluyen BERT, Transformer, Mamba, RetNet, RWKV, Hyena, Jamba, la serie DeepSeek, etc. Esta lista refleja la diversidad y el rápido desarrollo actual de la investigación en arquitecturas LLM, y es valiosa como referencia para los investigadores que desean comprender sistemáticamente este campo. (Fuente: Reddit r/MachineLearning)
💼 Negocios
La plataforma de nutrición AI Fay recauda 50 millones de dólares en financiación, ingresos anuales alcanzan los 50 millones: La plataforma de nutrición AI de Silicon Valley, Fay, completó recientemente una ronda de financiación Serie B de 50 millones de dólares liderada por Goldman Sachs, con una financiación acumulada de 75 millones de dólares y una valoración de 500 millones de dólares. Fay conecta a dietistas registrados con pacientes, utilizando IA para mejorar la eficiencia del servicio (afirma reducir de 6.5 horas/paciente a 2 horas), automatizando tareas como la generación de notas clínicas (incluida la codificación ICD), la creación de planes de nutrición personalizados, la tramitación de reclamaciones de seguros y la gestión administrativa. La plataforma aprovechó con precisión el aumento de la demanda de asesoramiento nutricional provocado por los medicamentos para bajar de peso GLP-1, y estableció el ciclo de pago colaborando con compañías de seguros (la intervención nutricional puede reducir los costos médicos a largo plazo de las enfermedades crónicas). Con menos de 3000 dietistas en la plataforma, Fay logró 50 millones de dólares en ingresos anuales (ARR), demostrando un modelo de negocio exitoso que empodera a profesionales en un nicho médico vertical y se conecta con los pagadores utilizando IA. (Fuente: Crow Intelligence)
Chengdu Hengtu Technology: IA potencia la creatividad digital, rentable en el extranjero: La empresa local de Chengdu, Hengtu Technology, ha acumulado alrededor de 700 millones de usuarios en todo el mundo con su producto principal Fotor (plataforma de edición de imágenes y videos), con más de diez millones de usuarios activos mensuales, destacando especialmente en los mercados extranjeros. Es una de las primeras empresas chinas de aplicaciones de IA en internacionalizarse y lograr rentabilidad a escala. La compañía ha cultivado la tecnología de procesamiento de imágenes durante 16 años y en 2022 integró rápidamente funciones AIGC (texto a imagen, texto a video, etc.) en Fotor y la nueva plataforma Clipfly. Fotor reduce las barreras para la creación de contenido visual digital a través de la IA, sirviendo a múltiples industrias como comercio electrónico, medios propios, publicidad, turismo cultural, educación, etc. Hengtu Technology utiliza la IA para la “traducción cultural”, ayudando a la cultura china a internacionalizarse y explorando nuevas vías en la industria de la creatividad digital. (Fuente: 36Kr Sichuan)
Práctica de implementación de IA empresarial: Enfocarse en el valor, minimizar el ajuste fino, promover la colaboración: En el proceso de implementación de modelos grandes, las empresas han pasado de la exploración inicial a un enfoque más pragmático orientado al valor. Las aplicaciones de IA exitosas a menudo se centran en escenarios altamente repetitivos, con necesidades creativas y paradigmas que se pueden consolidar, como preguntas y respuestas basadas en conocimiento, servicio al cliente inteligente, generación de materiales, análisis de datos, etc. Las empresas reconocen universalmente que perseguir ciegamente el ajuste fino del modelo a menudo tiene una baja relación costo-beneficio, y se debe priorizar la gobernanza del conocimiento y la construcción de plataformas de agentes inteligentes (inicialmente basadas en RAG). La implementación de la IA requiere una profunda participación de los departamentos comerciales y el apoyo de la alta dirección. Adoptar una estrategia paralela de “piloto de ganancia rápida + preparación de la base de IA” funciona mejor. En términos de talento organizacional, las empresas tienden a formar pequeños equipos profesionales de IA para empoderar a los negocios y abordar la escasez de talento mediante la contratación de talento externo de primer nivel, la formación de jóvenes talentos internos (combinación de pasantes + personal de negocios experimentado) y la colaboración con expertos externos. (Fuente: AI Frontline)
El índice de inteligencia artificial del STAR Market atrae atención, podría convertirse en un nuevo foco de inversión: Un análisis del informe señala que, a pesar de la reciente volatilidad del mercado, la industria de inteligencia artificial de China ha formado un ciclo completo de “potencia de cálculo – modelo – aplicación” y muestra una fuerte resiliencia. El proyecto nacional “Computación del Este, Datos del Oeste”, modelos de bajo costo como DeepSeek y avances en aplicaciones como robots humanoides son puntos destacados. La IA se considera un motor importante para el crecimiento económico global en la próxima década, con rendimientos significativos a largo plazo para los activos relacionados. En este contexto, el Índice de Inteligencia Artificial del STAR Market de Shanghái (centrado en chips de computación y aplicaciones de IA) atrae la atención de los inversores debido a sus altas expectativas de crecimiento y al aumento del contenido autónomo y controlable. Instituciones como E Fund han lanzado ETF y fondos vinculados (como 588730, 023564/023565) que siguen este índice, proporcionando herramientas para que los inversores inviertan en la cadena industrial de IA nacional. (Fuente: Entrepreneurship Frontline)

Apple cambia su estrategia de IA hacia la apertura: permite el desarrollo de Siri usando modelos de terceros: Para acelerar el desarrollo de la función “Siri personalizado” y alcanzar a los competidores, se informa que Apple ha ajustado su estrategia de desarrollo interno cerrado de larga data. Bajo el nuevo vicepresidente senior de ingeniería de software, Craig Federighi, a los ingenieros de Siri se les permite por primera vez usar modelos de lenguaje grandes de terceros para desarrollar funciones de Siri, rompiendo la restricción anterior de usar solo modelos desarrollados internamente por Apple. Se considera que este cambio es una medida clave de Apple para abordar su relativo retraso en las reservas tecnológicas en el campo de la IA y evitar que el retraso de la función “Siri personalizado” cause más insatisfacción (e incluso demandas) de los usuarios. Esta medida podría brindar oportunidades de colaboración con Apple a proveedores de modelos externos como OpenAI o Alibaba (en el mercado chino). (Fuente: San Yi Life)

🌟 Comunidad
La competencia entre las aplicaciones DeepSeek, Doubao y Yuanbao es feroz, la experiencia del producto es clave: El mercado de aplicaciones de asistentes de IA en China está al rojo vivo. DeepSeek experimentó un aumento masivo de usuarios después de que su capacidad de modelo se volviera viral, lo que llevó a Tencent Yuanbao, que fue el primero en integrarlo, a alcanzar brevemente la cima. Sin embargo, Doubao de ByteDance, con funciones de producto más completas y una integración profunda con Douyin (TikTok en China), superó nuevamente a Yuanbao. Los análisis sugieren que depender únicamente de la integración de modelos potentes (como DeepSeek) solo puede traer beneficios a corto plazo. En la competencia a largo plazo, la riqueza funcional de la aplicación en sí, la experiencia del usuario, la colaboración multidispositivo y la capacidad de integración del ecosistema de la plataforma son más cruciales. A medida que las capacidades de los modelos de varias compañías convergen (como tener capacidades de pensamiento profundo), el foco futuro de la competencia estará en el diseño del producto, las estrategias operativas y los avances en nuevas formas de aplicaciones como los AI Agents. (Fuente: Alphabet List)
Estudiante asiático desarrolla herramienta para hacer trampa en entrevistas y desata debate en línea: Roy Lee, un estudiante asiático de la Universidad de Columbia, desarrolló una herramienta de IA llamada Interview Coder y la utilizó para pasar entrevistas técnicas remotas en varias empresas tecnológicas, incluidas Amazon, Meta y TikTok, con la ayuda de ChatGPT. No solo rechazó las ofertas de estas empresas, sino que grabó el proceso de uso de la herramienta y lo publicó en YouTube. Después de ser denunciado por Amazon, fue suspendido por la universidad. Roy Lee no se inmutó, sino que hizo público todo el incidente, incluida la correspondencia por correo electrónico con la universidad y las empresas, lo que le valió un gran apoyo de los internautas y la atención de la industria, y aprovechó la oportunidad para fundar una empresa. El incidente ha provocado acalorados debates sobre la eficacia de las entrevistas técnicas (especialmente el modelo de resolución de problemas de LeetCode), los límites éticos de las herramientas de IA en la contratación y el desafío individual a los sistemas de las grandes empresas. (Fuente: Direct AI)

Usuario prueba la integración de los nuevos modelos GLM de código abierto de Zhipu con base de conocimientos y MCP: Un usuario probó los modelos de la serie GLM recientemente lanzados por Zhipu AI (llamados a través de API). Los resultados mostraron que GLM-Z1-AirX (versión ultrarrápida), al conectarse a una base de conocimientos local construida con FastGPT, respondió extremadamente rápido (según se informa, a 200 tokens/s) y la calidad de la respuesta mejoró en comparación con los modelos ordinarios, generando respuestas más detalladas y completas y tablas comparativas. GLM-4-Air (modelo base), al conectarse a MCP (Model Context Protocol) para ejecutar tareas de Agent (como búsqueda en red, escritura de archivos locales, control de Docker, resumen de páginas web), pudo llamar correctamente a las herramientas y completar las tareas, aunque el efecto fue ligeramente inferior al de DeepSeek-V3. El usuario también elogió el rendimiento de seguridad de los modelos de Zhipu (no respondieron a prompts de jailbreak). (Fuente: Cuenta Oficial)
![Base de conocimientos local + GLM-Z1-Air de código abierto de Zhipu, ¡seguro, privado y con velocidad de respuesta vertiginosa! El efecto alcanza nuevas alturas [incluye玩法 MCP]](https://rebabel.net/wp-content/uploads/2025/04/image_1744722926.gif)
Comparte prompt de “solucionador de problemas hiperracional” y compara el rendimiento del modelo: Un usuario de la comunidad compartió un prompt avanzado diseñado para hacer que un LLM actúe como un “solucionador de problemas hiperracional basado en primeros principios”. El prompt detalla los principios operativos del modelo (deconstruir problemas, ingeniería de soluciones, protocolo de entrega, reglas de interacción), formato de respuesta y características tonales, enfatizando la lógica, la acción y los resultados, y rechazando la ambigüedad, las excusas y el consuelo emocional. El usuario utilizó este prompt para comparar el rendimiento de DeepSeek, Claude Sonnet 3.7 y ChatGPT 4o en la resolución de problemas, la provisión de orientación y la recomendación de recursos en línea, concluyendo que Claude 3.7 tuvo un mejor rendimiento. Esto demuestra cómo un prompt cuidadosamente diseñado puede guiar y mejorar significativamente el rendimiento de un LLM en tareas específicas. (Fuente: Cuenta Oficial)

Debate comunitario sobre el lanzamiento de GPT-4.1: rendimiento, estrategia y nomenclatura: El lanzamiento de la serie de modelos GPT-4.1 por parte de OpenAI ha generado una amplia discusión en la comunidad. Por un lado, los usuarios, a través de pruebas reales y comparaciones de benchmarks (como Aider, Livebench, GPQA Diamond, KCORES Arena), descubrieron que aunque GPT-4.1 muestra una mejora significativa en la codificación, todavía está por detrás de Google Gemini 2.5 Pro y Claude 3.7 Sonnet en capacidad de razonamiento general. Por otro lado, la comunidad discutió y criticó la estrategia de producto de OpenAI (diferenciar API de ChatGPT, descartar GPT-4.5), la velocidad de iteración del modelo y la confusa nomenclatura (lanzamiento de 4.1 después de 4.5). Algunos opinan que OpenAI podría estar enfrentando un cuello de botella en la innovación, mientras que otros creen que es su estrategia para optimizar la línea de productos API y ofrecer diferentes opciones de relación calidad-precio. (Fuente: dotey, op7418, Reddit r/LocalLLaMA 1, Reddit r/ArtificialInteligence, karminski3, Reddit r/LocalLLaMA 2)

ChatGPT demuestra su valía en escenarios de consulta legal, usuarios comparten experiencias exitosas: Un usuario de Reddit compartió un caso exitoso de uso de ChatGPT para manejar una disputa legal relacionada con el trabajo. El usuario enfrentaba el riesgo de ser despedido, proporcionó documentos a ChatGPT y le pidió que actuara como experto en derecho laboral del Reino Unido, descubriendo errores de procedimiento por parte del empleador. Con la ayuda de una carta redactada por ChatGPT, negoció y finalmente llegó a un acuerdo que incluía una compensación de 2 meses de salario, evitando un registro negativo. En los comentarios, otros usuarios también compartieron experiencias de uso de IA (ChatGPT o Gemini) para redactar cartas legales, prepararse para audiencias y lograr resultados positivos, considerando que la IA puede ahorrar costos y tiempo significativos en asistencia legal. (Fuente: Reddit r/ChatGPT)
Usuario se queja del rendimiento deficiente de la función Deep Research de OpenAI: Un usuario de Reddit publicó criticando la función Deep Research (Investigación Profunda) de OpenAI, argumentando que tiene tres problemas principales: 1) Los resultados de búsqueda son inexactos o irrelevantes (depende de la API de Bing); 2) El método de exploración se parece más a una búsqueda en profundidad que a una investigación amplia; 3) Está desconectado de los objetivos de investigación del usuario, careciendo de restricciones. El usuario considera que esto es más una capacidad de búsqueda extendida que una verdadera investigación profunda. Esto refleja la brecha entre las expectativas de los usuarios sobre las capacidades actuales de investigación de los agentes de IA y la experiencia real. (Fuente: Reddit r/deeplearning)
Exhibición y discusión de contenido generado por IA: Usuarios de la comunidad comparten activamente contenido creado con diversas herramientas de IA (como ChatGPT, Midjourney, Kling AI, Suno AI, etc.), incluyendo caricaturas satíricas (Trump y Musk), imágenes antropomórficas de universidades, cortometrajes históricos alternativos de la Segunda Guerra Mundial, imágenes de personajes de la mitología griega, anuncios de pasta de dientes estilo años 90, cómics de varios paneles, etc. Estas comparticiones no solo muestran las capacidades de la IA en la generación de texto, imágenes, video y música, sino que también provocan discusiones sobre la creatividad, la estética (como ser tildado de “kitsch”), las limitaciones (como la falta de coherencia de los personajes de cómic) y las cuestiones éticas del contenido generado por IA. (Fuente: dotey 1, dotey 2, Reddit r/ChatGPT 1, Reddit r/ChatGPT 2, Reddit r/ChatGPT 3, Reddit r/ChatGPT 4, Reddit r/ChatGPT 5)

Preocupación por el bucle de retroalimentación de datos de entrenamiento de IA que causa “colapso del modelo”: La discusión comunitaria se centra en un riesgo potencial: a medida que aumenta el contenido generado por IA en Internet, si los futuros modelos de IA se entrenan principalmente con estos datos generados por IA, podría producirse un “colapso del modelo” (Model Collapse). Este fenómeno se refiere a la degradación del rendimiento del modelo, donde la salida se vuelve estrecha, repetitiva, carente de originalidad y precisión, similar a fotocopias que se vuelven borrosas al copiarse repetidamente. Los usuarios temen que esto erosione lentamente la veracidad de la información y la perspectiva humana. La discusión también menciona métodos de mitigación, como el uso de datos sintéticos para el entrenamiento y el fortalecimiento del control de calidad de los datos, pero existe controversia sobre si el problema ya está ocurriendo y cómo evitarlo eficazmente. (Fuente: Reddit r/ArtificialInteligence)
Opinión: En la era de la IA, la potencia de cálculo es el nuevo petróleo: Un usuario de Reddit argumenta que en el desarrollo de la IA, la capacidad de cómputo (Compute), y no los datos, se convertirá en el cuello de botella crucial y el recurso estratégico, similar al petróleo durante la Revolución Industrial. Las razones son: modelos de IA más potentes (especialmente sistemas de razonamiento y agentes) requieren un crecimiento exponencial de la potencia de cálculo; la interacción física como la robótica generará enormes cantidades de nuevos datos, aumentando aún más la demanda de cómputo. Poseer más potencia de cálculo se traducirá directamente en una mayor capacidad de producción económica. Esta opinión genera debate en la comunidad, coincidiendo en que la potencia de cálculo es de hecho un elemento central, que determina el límite superior y la velocidad de desarrollo de las capacidades de IA. (Fuente: Reddit r/ArtificialInteligence)
Discusión ética sobre el uso de IA: ¿Es inapropiado usar IA para mejorar las calificaciones académicas?: Un estudiante universitario en línea reprobó un curso debido a su estructura (solo un cuestionario o tarea por semana, seguido inmediatamente por un examen). Luego usó ChatGPT para generar preguntas de práctica basadas en los PDF de las conferencias para el estudio diario, y sus calificaciones mejoraron significativamente. Sin embargo, el estudiante vio críticas sobre el impacto ambiental de la IA y el “pensamiento independiente”, sintiéndose culpable. Los comentarios de la comunidad generalmente consideran que usar IA para ayudar en el aprendizaje es un uso legítimo y efectivo, que ayuda a mejorar la eficiencia y los resultados del aprendizaje, y no debería sentirse culpable por ello. Los comentaristas señalan que el impacto ambiental de la IA debe considerarse en comparación con otras actividades humanas, y que utilizar la IA para mejorar la productividad ya es una tendencia en el lugar de trabajo. (Fuente: Reddit r/ArtificialInteligence)
Experiencia de usuario de Claude Pro: Discusión sobre limitaciones y modelo de negocio: En la comunidad Reddit r/ClaudeAI, los usuarios discuten los problemas de limitación (throttling) encontrados al usar el servicio Claude Pro y exploran el modelo de negocio de Anthropic. Un usuario señala que la tarifa de suscripción Pro de 20 dólares al mes es mucho menor que los costos de cómputo reales en los que incurre Anthropic por los usuarios intensivos (posiblemente hasta 100 dólares/mes), sugiriendo que las quejas de los usuarios (como sentirse “explotados”) pueden ignorar la estructura de costos de los servicios de IA. La discusión también aborda la reciente decisión de Anthropic de ofrecer nuevas funciones prioritariamente al plan Max, más caro, en lugar del plan Pro, lo que ha provocado el descontento de los primeros suscriptores anuales de Pro. (Fuente: Reddit r/ClaudeAI 1, Reddit r/ClaudeAI 2)
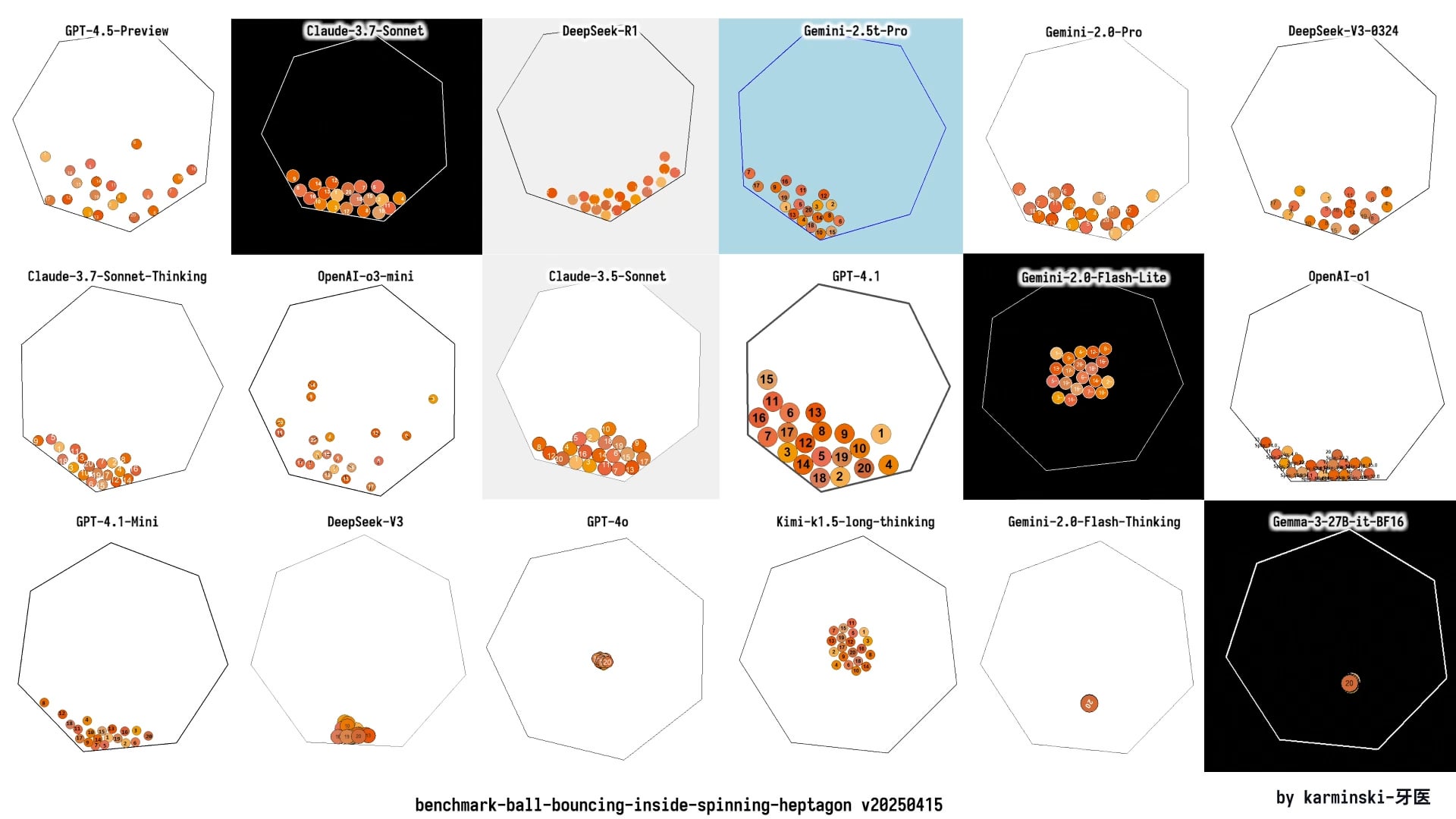
Actualización de KCORES LLM Arena, DeepSeek R1 destaca: Un usuario compartió los últimos resultados de prueba de su arena personal de LLM (KCORES LLM Arena), que requiere que los modelos generen código Python para una simulación física compleja (20 bolas colisionando y rebotando dentro de un heptágono giratorio). Después de actualizar e incluir nuevos modelos como GPT-4.1, Gemini 2.5 Pro, DeepSeek-V3, los resultados muestran que DeepSeek R1 tuvo un rendimiento excelente en esta tarea, generando una simulación con buenos efectos. Esto proporciona a la comunidad otro punto de referencia para evaluar las capacidades de diferentes modelos en tareas de programación complejas. (Fuente: Reddit r/LocalLLaMA)
Explorando la capacidad de respuesta emocional de diferentes LLM: Un usuario de Reddit publicó un meme que compara con humor los diferentes estilos de respuesta de ChatGPT 4o, Claude 3 Sonnet, Llama 3 70B y Mistral Large cuando un usuario expresa tristeza. Esto refleja las diferencias en la experiencia del usuario al usar diferentes LLM para la comunicación emocional o la búsqueda de apoyo, así como la percepción y evaluación de la comunidad sobre la capacidad de “empatía” del modelo. La sección de comentarios también discute las ventajas de privacidad de usar modelos locales para manejar temas emocionales privados. (Fuente: Reddit r/LocalLLaMA)

Discusión sobre si la AGI es un engaño de Silicon Valley: Miembros de la comunidad compartieron y posiblemente discutieron un artículo que cuestiona si la inteligencia artificial general (AGI) es un concepto exagerado (hoax) por Silicon Valley (la industria tecnológica) para atraer inversiones o mantener el interés. Esto refleja el debate y el escepticismo continuo en la industria y el público sobre la posibilidad y el cronograma de lograr la AGI, así como la veracidad de la publicidad actual relacionada. (Fuente: Ronald_vanLoon)

💡 Otros
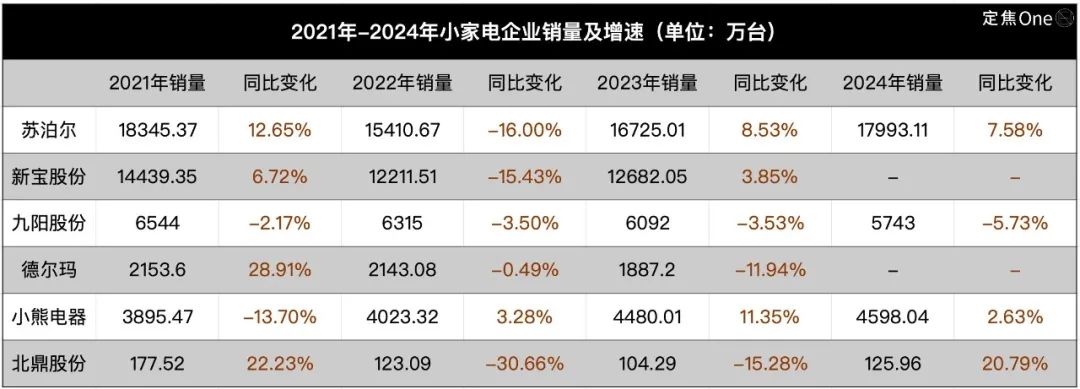
La industria de pequeños electrodomésticos se enfría, la IA es la nueva narrativa pero su aplicación aún es superficial: El mercado de pequeños electrodomésticos de cocina (como máquinas de desayuno, freidoras de aire) enfrenta una caída en las ventas y una guerra de precios después de que disminuyera el auge de la “economía del hogar”. Los resultados de las “seis grandes” empresas cotizadas como Supor, Joyoung y Bear Electric están bajo presión. Para buscar avances, las empresas generalmente miran hacia la expansión del mercado extranjero y la integración de la tecnología de IA. Sin embargo, actualmente la aplicación de IA en pequeños electrodomésticos se limita principalmente a comandos de voz simples, ajustes automáticos, etc., con utilidad y espacio para la innovación limitados, y puede aumentar los costos disuadiendo a los usuarios. En comparación, los grandes electrodomésticos tienen más ventajas en la aplicación de IA, pudiendo construir ecosistemas de hogar inteligente y utilizar big data para proporcionar servicios personalizados. La narrativa de la IA en la industria de pequeños electrodomésticos todavía está en sus primeras etapas. (Fuente: 36Kr)
La agitación arancelaria impacta el mercado de chips de Huaqiangbei, la sustitución nacional podría acelerarse: Los recientes cambios en la política arancelaria sobre chips han generado preocupación en el mercado electrónico de Huaqiangbei en Shenzhen. Los comerciantes de chips populares como CPU y GPU (especialmente aquellos que podrían involucrar origen estadounidense) han suspendido cotizaciones y acaparado existencias en espera, intensificando la volatilidad de los precios. El impacto en categorías como los chips de memoria es relativamente menor. Varios distribuidores cotizados afirman que, dado que la proporción de importaciones directas desde EE. UU. es pequeña, el impacto directo de la guerra arancelaria es limitado, pero la incertidumbre del mercado aumenta. La industria cree en general que las empresas IDM con fábricas de obleas en EE. UU. (como TI, Intel, Micron) son las más afectadas. Este evento ya ha llevado a algunos clientes intermedios a consultar sobre soluciones de sustitución con chips nacionales, lo que podría acelerar el proceso de localización en el sector de semiconductores. (Fuente: ChiNext Observation)

¿La IA agrava la crisis de sentido humana? Reflexionando sobre el equilibrio entre tecnología y valor: El artículo explora cómo el rápido desarrollo de la inteligencia artificial impacta el sentido de la existencia humana. Argumenta que la superación de la IA en campos profesionales (como Go, diagnóstico médico, creación artística) agrava la crisis de sentido humana provocada desde la Revolución Industrial por la alienación laboral, la crisis de fe, los problemas ambientales, etc. La IA podría reforzar aún más el dilema del “hombre herramienta”, especialmente al reemplazar la capacidad de toma de decisiones en trabajos de cuello blanco. El artículo cita puntos de vista filosóficos y obras de ciencia ficción (como “Dune”, “Westworld”) para advertir sobre los riesgos de la esclavitud tecnológica, y llama a reconstruir la racionalidad valorativa mientras se abraza la mejora tecnológica que trae la IA, protegiendo la creatividad humana, la conexión emocional y el pensamiento crítico a través de marcos éticos y educación humanística, para evitar convertirnos en apéndices de nuestras propias creaciones. (Fuente: Tencent Research Institute)
El costo de fabricar un iPhone en EE. UU. sería exorbitante, podría superar los 25,000 yuanes: El artículo analiza que si el iPhone se produjera completamente en suelo estadounidense, su costo se dispararía drásticamente, estimándose un precio de venta de hasta 3500 dólares (aproximadamente 25588 yuanes), muy por encima del precio actual. Las razones principales incluyen que EE. UU. está muy por detrás de China en la obtención de materias primas (como tierras raras, litio y cobalto refinados), logística, construcción de fábricas (terreno, electricidad, aprobaciones ambientales) y costos laborales (salario mínimo por hora 4-5 veces mayor que en China, y falta de trabajadores industriales calificados). El modelo de Apple de mantener altos márgenes de beneficio exprimiendo la cadena de suministro global (especialmente a los proveedores chinos con márgenes de beneficio relativamente mayores) sería insostenible en EE. UU. Los altos costos de producción podrían finalmente trasladarse a los consumidores, socavando la estrategia de precios y la posición de mercado de Apple. (Fuente: Xinghai Intelligence Bureau)

Avance matemático: Demostrada la teoría de singularidades del flujo de curvatura media: La conjetura de Multiplicidad Uno, que ha desconcertado a los matemáticos durante casi 30 años, fue demostrada recientemente por Richard Bamler y Bruce Kleiner. La conjetura trata sobre el flujo de curvatura media (Mean Curvature Flow, MCF), un proceso matemático que describe cómo evolucionan las superficies con el tiempo para disminuir su área a la velocidad más rápida (similar al derretimiento de un cubito de hielo o la erosión de un castillo de arena). La demostración señala que, en el espacio tridimensional, las singularidades (puntos donde la curvatura tiende a infinito) formadas por superficies cerradas bidimensionales bajo MCF son simples, generalmente manifestándose como una esfera que se contrae localmente a un punto o un cilindro que colapsa en una línea. No ocurren singularidades complejas de múltiples capas superpuestas. Este avance asegura que el MCF pueda seguir siendo analizado después de la formación de singularidades, proporcionando una base teórica más sólida para utilizar el MCF para resolver problemas importantes en geometría y topología (como la conjetura de Poincaré). (Fuente: Ji Qizhi Xin)

Usuario comparte configuración de hardware de IA local “económica” con 4x RTX 3090: Un usuario de Reddit compartió su configuración de hardware construida para ejecutar LLM localmente, con un costo total de aproximadamente 4204 dólares. La configuración incluye 4 tarjetas gráficas EVGA RTX 3090 de segunda mano (600 dólares cada una), una CPU de servidor AMD EPYC 7302P, una placa base Asrock Rack, 96 GB de memoria DDR4 y un SSD NVMe de 2 TB, ensamblado en un chasis abierto MLACOM Quad Station Pro Lite y utilizando dos fuentes de alimentación de 1200 W. Esta compartición proporciona una referencia relativamente “económica” para los usuarios que desean construir una estación de trabajo de IA en casa con una potencia de cálculo considerable (4x 24GB VRAM). (Fuente: Reddit r/LocalLLaMA)

Hackers atacan semáforos en EE. UU. para mostrar mensajes Deepfake de Musk y Zuckerberg: Se informa que varios sistemas de semáforos para peatones en el Área de la Bahía de San Francisco, EE. UU., fueron atacados por hackers y utilizados para mostrar mensajes Deepfake (falsificaciones profundas) generados por IA de Elon Musk y Mark Zuckerberg. Este incidente resalta la vulnerabilidad de la infraestructura pública frente a ciberataques que utilizan tecnología de IA, así como el riesgo de que la tecnología Deepfake sea utilizada indebidamente para difundir información falsa o realizar bromas. (Fuente: Reddit r/ArtificialInteligence)

Exhibición de diversas tecnologías de robótica y automatización: En las redes sociales se mostraron diversas aplicaciones de robótica y tecnología de automatización, incluyendo: el robot Booster T1 capaz de imitar movimientos humanos para realizar kung fu; sistemas robóticos para entrenamiento de rehabilitación; un brazo robótico capaz de hacer café; robots agrícolas para plantar arroz y desherbar; un sistema automatizado para facilitar el manejo de ovejas por parte de los pastores; y robots bailarines, entre otros. Estos casos reflejan la amplia aplicación y el continuo desarrollo de los robots en los sectores industrial, agrícola, de servicios, de rehabilitación médica y de entretenimiento. (Fuente: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6)
Exhibición de tecnologías emergentes y productos innovadores: En las redes sociales se compartieron diversas tecnologías emergentes y productos innovadores, como: una antena inalámbrica en miniatura desarrollada por el MIT que utiliza luz para monitorear comunicaciones celulares; un dron de una sola ala que imita el vuelo de las semillas de arce; inodoros inteligentes IoT; tecnología de impresión digital para ortodoncia dental; un dispositivo que genera electricidad a partir de agua salada; paredes dinámicas que pueden respirar y moverse; un traje de cosplay de Iron Man; una tabla de snowboard eléctrica todo terreno; y la tecnología para copiar llaves utilizando el dispositivo Flipper Zero, entre otros. Estas exhibiciones muestran la continua innovación tecnológica en múltiples campos como comunicaciones, energía, salud, transporte, construcción y seguridad. (Fuente: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6, Ronald_vanLoon 7, Ronald_vanLoon 8, Ronald_vanLoon 9)

Tendencias tecnológicas en salud: Las redes sociales y los enlaces a artículos mencionaron aplicaciones tecnológicas y tendencias de desarrollo en el sector de la salud, incluyendo cirugía asistida por robot, tendencias y puntos de inflexión de la IA en la atención médica, el uso de la tecnología para impulsar la excelencia operativa (hiperautomatización) y las posibles transformaciones que la IA podría traer. Estos contenidos reflejan el potencial y la práctica de tecnologías como la IA, la robótica y la automatización para mejorar la eficiencia de los servicios médicos, la precisión diagnóstica y la experiencia del paciente. (Fuente: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4)

Información relacionada con la ciberseguridad: Las redes sociales compartieron contenido relacionado con la ciberseguridad, incluyendo un diagrama de tipos de ataques de contraseña y un artículo sobre la importancia de la capacidad de recuperación dentro de los 60 minutos posteriores a una violación de datos. Estos contenidos recuerdan a los usuarios la importancia de prestar atención a los riesgos de ciberseguridad y las estrategias de respuesta. (Fuente: Ronald_vanLoon 1, Ronald_vanLoon 2)

Discusión sobre la plataforma AMD ROCm: Usuarios de Reddit discutieron la posibilidad de construir una estación de trabajo de aprendizaje profundo utilizando dos GPU AMD Radeon RX 7900 XTX, involucrando la pila de software ROCm (Radeon Open Compute platform). Esto refleja el interés y la exploración de los usuarios en las soluciones de GPU de AMD y su ecosistema de software (ROCm) en el mercado de hardware de IA dominado por Nvidia. (Fuente: Reddit r/deeplearning)