
Palabras clave:GPT-4.1, Hugging Face, GPT-4.1 series comparativa de rendimiento de modelos, Hugging Face adquiere Pollen Robotics, OpenAI nuevo modelo mejora capacidad de codificación, GPT-4.1 mini reduce costos en 83%, robot de código abierto Reachy 2
🔥 En Foco
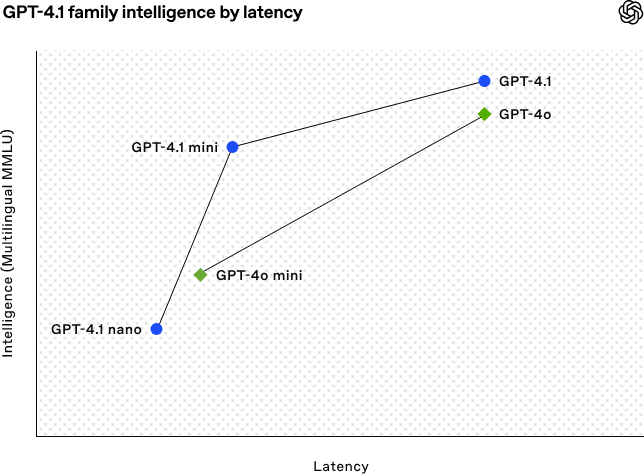
OpenAI lanza la serie de modelos GPT-4.1, reforzando las capacidades de codificación y procesamiento de texto largo: OpenAI lanzó en la madrugada del 15 de abril tres nuevos modelos de la serie GPT-4.1: GPT-4.1 (insignia), GPT-4.1 mini (eficiente) y GPT-4.1 nano (ultrapequeño), todos disponibles únicamente a través de API. Esta serie de modelos sobresale en codificación, seguimiento de instrucciones y comprensión de contextos largos, con una ventana de contexto de 1 millón de tokens y una salida de 32,768 tokens para todos. GPT-4.1 obtuvo una puntuación del 54.6% en la prueba SWE-bench Verified, superando significativamente a GPT-4o y al GPT-4.5 Preview que será retirado. GPT-4.1 mini supera el rendimiento de GPT-4o con la mitad de latencia y un costo 83% menor. GPT-4.1 nano es actualmente el modelo más rápido y de menor costo, adecuado para tareas de baja latencia. Este lanzamiento tiene como objetivo ofrecer a los desarrolladores opciones de modelos más potentes, rentables y rápidos, impulsando la construcción de sistemas inteligentes complejos y aplicaciones de agentes inteligentes. (Fuente: 36氪, 智东西, op7418, openai, karminski3, sama, natolambert, karminski3, karminski3, karminski3, dotey, OpenAI, GPT-4.1来了,超越GPT-4.5,SWE-Bench达到55%,开发者专属。)
Hugging Face adquiere la empresa de robótica de código abierto Pollen Robotics: La plataforma comunitaria de IA Hugging Face anunció la adquisición de la startup francesa de robótica de código abierto Pollen Robotics, con el objetivo de promover la apertura y popularización de los robots de IA. Esta adquisición combinará las fortalezas de Hugging Face en plataformas de software (como la biblioteca LeRobot y Hub) con la experiencia de Pollen Robotics en hardware de código abierto (como el robot humanoide Reachy 2). Reachy 2 es un robot humanoide de código abierto compatible con VR, diseñado para investigación, educación y experimentos de inteligencia corporeizada, con un precio de 70,000 dólares. Hugging Face considera que la robótica es la próxima interfaz de interacción importante para la IA y debe ser abierta, asequible y personalizable. Esta adquisición es un paso clave para realizar esta visión, con el objetivo de permitir que la comunidad construya y controle sus propios compañeros robóticos, en lugar de depender de sistemas cerrados y costosos. (Fuente: huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface)

🎯 Movimientos
La IA ayuda a resolver un problema matemático sin resolver durante 50 años: Weiguo Yin, un académico chino del Laboratorio Nacional Brookhaven de EE. UU., utilizó el modelo de razonamiento o3-mini-high de OpenAI para lograr un avance en la solución exacta del modelo Potts de q estados J_1-J_2 unidimensional, especialmente en el caso de q=3, donde la IA ayudó a completar la demostración clave. Este problema involucra modelos fundamentales de la mecánica estadística, relacionados con fenómenos físicos como el apilamiento atómico en materiales laminares y la superconductividad no convencional, cuya solución exacta no se había logrado en los últimos 50 años. Los investigadores introdujeron el método del subespacio de máxima simetría (MSS) y, con la ayuda de indicaciones paso a paso de la IA para procesar la matriz de transferencia, lograron simplificar la matriz de transferencia de 9×9 para q=3 a una matriz efectiva de 2×2, y generalizaron este método a cualquier valor de q. Esta investigación no solo resuelve un problema de física matemática de larga data, sino que también demuestra el enorme potencial de la IA para ayudar en la investigación científica compleja y proporcionar nuevas perspectivas. (Fuente: 刚刚,AI破解50年未解数学难题!南大校友用OpenAI模型完成首个非平凡数学证明)

Auge de los asistentes web de IA, fabricantes de móviles y automóviles despliegan experiencias multidispositivo: Fabricantes como Huawei (Asistente Xiaoyi), Ideal Auto (Ideal Li Xiang), OPPO (Asistente Xiaobu) han lanzado sucesivamente versiones web de sus asistentes de IA, atrayendo la atención. Aunque estas versiones web pueden no ser tan completas en funcionalidades (como editar preguntas, maquetación, opciones de configuración) como los servicios de modelos profesionales tipo DeepSeek, su objetivo principal no es competir directamente, sino servir a los usuarios de sus respectivas marcas, conectando la experiencia desde el móvil y el coche hasta el PC. Al vincular las cuentas de usuario y sincronizar los historiales de conversación, estas versiones web buscan aumentar la fidelidad del usuario, ofrecer una experiencia de interacción consistente entre terminales e integrar los asistentes de IA en escenarios de usuario más amplios, siendo esencialmente un despliegue estratégico sobre las entradas de usuario y el ecosistema de datos. (Fuente: AI网页版扎堆上线,华为、理想、OPPO们打的什么算盘?)
El robot Figure logra transferencia zero-shot de simulación a realidad mediante aprendizaje por refuerzo: La empresa Figure demostró que su robot humanoide Figure 02 logra una marcha natural mediante aprendizaje por refuerzo (RL) puramente en un entorno simulado. Utilizando un simulador físico eficiente acelerado por GPU, se generaron datos de entrenamiento equivalentes a años en pocas horas, entrenando una única política de red neuronal capaz de controlar múltiples robots virtuales con diferentes parámetros físicos y escenarios (como diferentes terrenos, perturbaciones). Combinando la aleatorización del dominio de simulación y la retroalimentación de par de alta frecuencia del robot real, la política entrenada puede transferirse zero-shot al robot físico sin necesidad de ajuste fino. Este método no solo acorta el tiempo de desarrollo y mejora la estabilidad del rendimiento en el mundo real, sino que una sola política puede controlar toda una legión de robots, demostrando su potencial para aplicaciones comerciales a gran escala. (Fuente: 一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路)

DeepSeek abrirá parte de la optimización de su motor de inferencia: DeepSeek anunció planes para contribuir a la comunidad con parte de las optimizaciones y características de su motor de inferencia de alto rendimiento basado en modificaciones de vLLM. No lanzarán su stack de inferencia completo y altamente personalizado, sino que optarán por integrar mejoras clave (como soporte para las últimas arquitecturas de modelos, optimizaciones de rendimiento) en frameworks de inferencia de código abierto populares como vLLM y SGLang, con el objetivo de que la comunidad pueda obtener soporte de nivel SOTA para nuevos modelos y tecnologías desde el primer día. Esta medida ha sido bien recibida por la comunidad, considerándose un compromiso real con la contribución al código abierto en lugar de mera propaganda. (Fuente: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert)
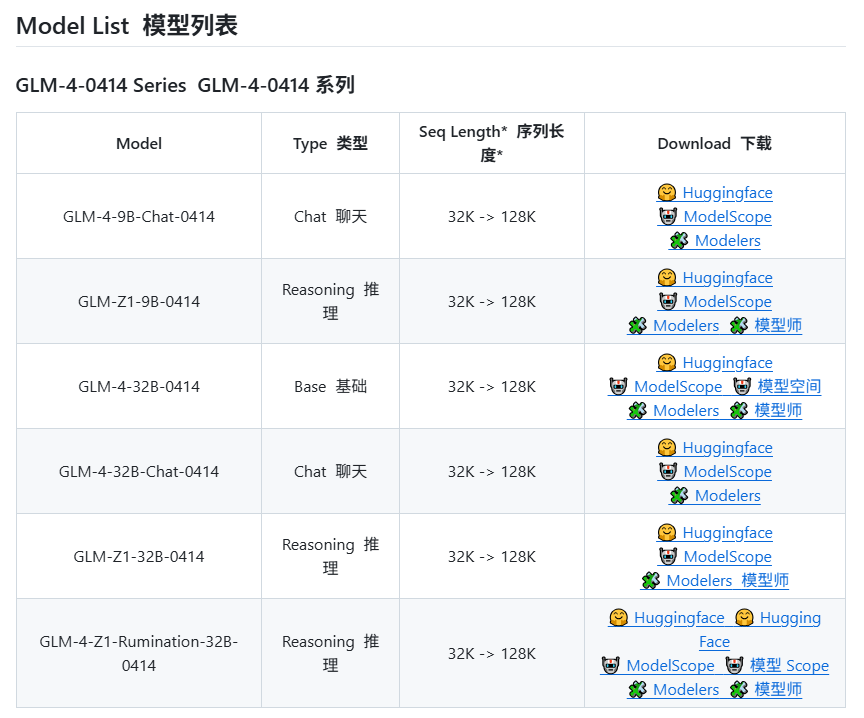
Zhipu AI presuntamente lanzará nuevos modelos de la serie GLM-4: Según información filtrada en GitHub (posteriormente eliminada), Zhipu AI parece estar preparándose para lanzar nuevos modelos de la serie GLM-4. La serie podría incluir versiones con diferentes tamaños de parámetros (como 9B, 32B) y funcionalidades, por ejemplo, modelos base (GLM-4-32B-0414), modelos de conversación (Chat), modelos de razonamiento (GLM-Z1-32B-0414) y modelos con capacidad de pensamiento más profundo “Rumination”, posiblemente compitiendo con Deep Research de OpenAI. Además, podría incluir modelos multimodales visuales (GLM-4V-9B). Los datos de benchmark filtrados indican que GLM-4-32B-0414 podría superar a DeepSeek-V3 y DeepSeek-R1 en algunos indicadores. El código de soporte del motor de inferencia relacionado ya se ha fusionado en transformers/vllm/llama.cpp. La comunidad sigue esto con gran interés, esperando el lanzamiento oficial y las evaluaciones. (Fuente: karminski3, karminski3, Reddit r/LocalLLaMA)
NVIDIA lanza nuevos modelos de la serie Nemotron: NVIDIA ha publicado en Hugging Face nuevos modelos base de la serie Nemotron-H, incluyendo tamaños de parámetros de 56B, 47B y 8B, todos con soporte para una ventana de contexto de 8K. Estos modelos se basan en una arquitectura híbrida de Transformer y Mamba. Actualmente se han lanzado los modelos base (Base), y aún no se proporcionan versiones ajustadas por instrucciones (Instruct). La serie Nemotron tiene como objetivo explorar el potencial de nuevas arquitecturas en el modelado del lenguaje. (Fuente: Reddit r/LocalLLaMA)

🧰 Herramientas
GitHub Copilot integrado en la versión Canary de Windows Terminal: Microsoft ha integrado la funcionalidad de GitHub Copilot en la versión preliminar Canary de Windows Terminal, introduciendo una nueva característica llamada “Terminal Chat”. Esta función permite a los usuarios interactuar directamente con la IA en el entorno de la terminal para obtener sugerencias y explicaciones de comandos. Los usuarios necesitan una suscripción a GitHub Copilot e instalar la última versión Canary de la terminal, y tras verificar su cuenta, podrán usarla. El objetivo es integrar la asistencia de IA directamente en el entorno de línea de comandos habitual de los desarrolladores, reduciendo el cambio de contexto, mejorando la eficiencia al manejar tareas complejas o desconocidas, acelerando el proceso de aprendizaje y ayudando a reducir errores. (Fuente: GitHub Copilot 现可在 Windows 终端中运行了)

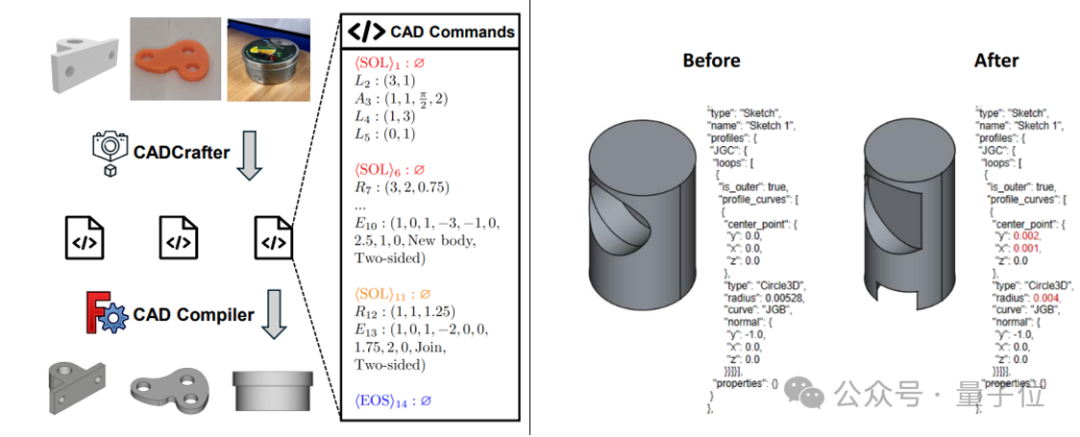
CADCrafter: Generación de archivos CAD editables a partir de una sola imagen: Investigadores de KOKONI 3D, la Universidad Tecnológica de Nanyang y otras instituciones han propuesto un nuevo framework llamado CADCrafter, capaz de generar directamente archivos de ingeniería CAD parametrizados y editables (representados como secuencias de comandos CAD) a partir de una sola imagen (renderizado, foto de objeto real, etc.), resolviendo los problemas de los métodos existentes de imagen a 3D (que generan Mesh o 3DGS) cuyos modelos resultantes son difíciles de editar con precisión y tienen baja calidad superficial. El método utiliza una arquitectura de generación en dos etapas que combina VAE y Diffusion Transformer, y mejora la calidad y tasa de éxito de la generación mediante una estrategia de destilación de vista múltiple a vista única y un mecanismo de verificación de compilabilidad basado en DPO. La investigación ha sido aceptada en CVPR 2025, proporcionando un nuevo paradigma para el diseño industrial asistido por IA. (Fuente: 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品)
LangChain lanza integración de GraphRAG con MongoDB Atlas: LangChain anunció una colaboración con MongoDB para lanzar un sistema RAG basado en grafos (GraphRAG). Este sistema utiliza MongoDB Atlas para almacenar y procesar datos, implementado a través de LangChain, y es capaz de ir más allá del RAG tradicional basado en búsqueda de similitud para comprender y razonar sobre las relaciones entre entidades. Soporta la extracción de entidades y relaciones mediante LLM y utiliza el recorrido de grafos para obtener información contextual conectada, con el objetivo de proporcionar capacidades de respuesta a preguntas y razonamiento más potentes para aplicaciones que requieren una comprensión profunda de las relaciones. (Fuente: LangChainAI)
Hugging Face abre el código de su Inference Playground: Hugging Face ha hecho de código abierto su herramienta en línea Inference Playground, utilizada para probar y comparar la inferencia de modelos. Es una interfaz de chat LLM basada en web que permite a los usuarios controlar diversas configuraciones de inferencia (como temperatura, top-p, etc.), modificar las respuestas de la IA, comparar el rendimiento de diferentes modelos y proveedores. El proyecto está construido con Svelte 5, Melt UI y Tailwind, y el código ha sido publicado en GitHub, ofreciendo a los desarrolladores una plataforma personalizable y extensible para la interacción y evaluación de modelos localmente o en línea. (Fuente: huggingface)
La plataforma Flowith supera el millón de dólares en ARR, demostrando la capacidad de AI Agent para generar páginas web: Los ingresos anuales recurrentes (ARR) de la plataforma de AI Agent Flowith han superado el millón de dólares, mostrando una fuerte demanda del mercado por plataformas de AI Agent versátiles capaces de reemplazar el trabajo manual. Un usuario compartió el uso de la función Oracle de Flowith, generando rápidamente una pequeña herramienta web funcional, con estilo preciso (como el de Twitter) y soporte para vista previa de imágenes, simplemente mediante una descripción en lenguaje natural (“Quiero hacer una página web de vista previa de imágenes y texto para redes sociales…”), sin necesidad de conectar a GitHub ni configuraciones complejas, lo que demuestra el potencial de los AI Agents en la generación de páginas web low-code/no-code. (Fuente: karminski3)
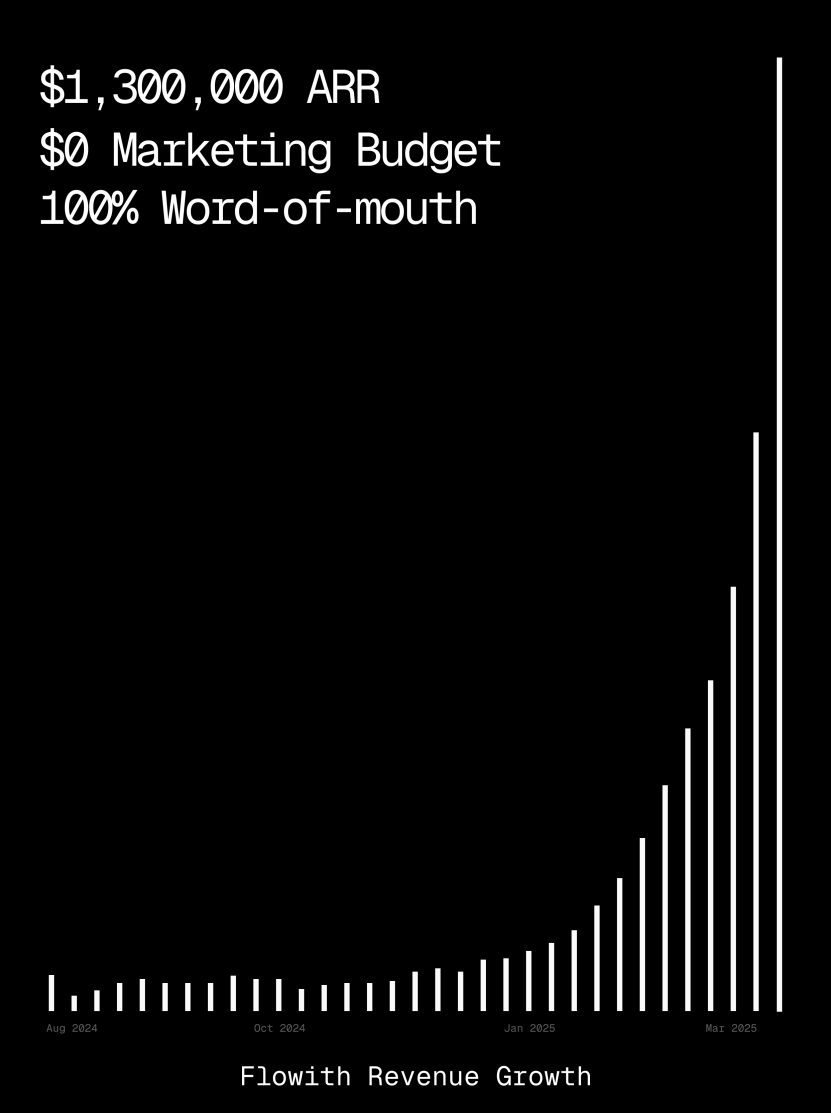
Lanzamiento del agente de depuración autónomo Deebo: Investigadores han construido un servidor MCP de agente de depuración autónomo llamado Deebo. Funciona como un demonio local al que los agentes de programación pueden descargar de forma asíncrona tareas complicadas de manejo de errores. Deebo genera múltiples subprocesos con diferentes hipótesis de reparación, ejecuta cada escenario en ramas git aisladas, y un “agente madre” realiza pruebas cíclicas y razonamiento, devolviendo finalmente diagnósticos y parches sugeridos. En una prueba real con un bug de tinygrad con recompensa de $100, Deebo identificó con éxito la raíz del problema y propuso dos soluciones específicas que pasaron las pruebas. (Fuente: Reddit r/MachineLearning)
![[D] We built an autonomous debugging agent. Here’s how it grokked a $100 bug](https://rebabel.net/wp-content/uploads/2025/04/81BPXr5Ywnk-6MetZBQchhgsROH341CoTk3xAdE5Jic.jpg)
📚 Aprendizaje
Nabla-GFlowNet: Nuevo método de ajuste fino de recompensa para modelos de difusión que equilibra diversidad y eficiencia: Para abordar los problemas de convergencia lenta del aprendizaje por refuerzo tradicional, el sobreajuste fácil y la pérdida de diversidad en la maximización directa de recompensas durante el ajuste fino de modelos de difusión, investigadores de la Universidad China de Hong Kong (Shenzhen) y otras instituciones proponen Nabla-GFlowNet. Este método se basa en el marco de las redes de flujo generativo (GFlowNet), tratando el proceso de difusión como un sistema de equilibrio de flujo, y deriva la condición de equilibrio Nabla-DB y la función de pérdida correspondiente. Mediante un diseño parametrizado, utiliza la estimación del gradiente residual de eliminación de ruido en un solo paso, evitando redes adicionales para la estimación. Los experimentos demuestran que al ajustar Stable Diffusion con funciones de recompensa como la puntuación estética y el seguimiento de instrucciones, Nabla-GFlowNet converge más rápido y es menos propenso al sobreajuste en comparación con métodos como ReFL y DRaFT, manteniendo al mismo tiempo la diversidad de las muestras generadas. (Fuente: ICLR 2025 | 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得)

MegaMath: Publicación del mayor conjunto de datos de razonamiento matemático de código abierto con 371B Tokens: Lanzado por LLM360, el conjunto de datos MegaMath contiene 371 mil millones de Tokens y tiene como objetivo resolver la falta de datos de preentrenamiento de razonamiento matemático a gran escala y de alta calidad en la comunidad de código abierto. El conjunto de datos se divide en tres partes: páginas web con contenido matemático denso (279B), código relacionado con matemáticas (28.1B) y datos sintéticos de alta calidad (64B). El proceso de construcción empleó pipelines de procesamiento de datos innovadores, incluyendo análisis HTML optimizado para fórmulas matemáticas, extracción de texto en dos etapas, puntuación dinámica del valor educativo, recuperación precisa de datos de código en múltiples pasos y varios métodos de síntesis a gran escala (Q&A, generación de código, intercalado de texto y código). La validación mediante preentrenamiento de 100B Tokens en Llama-3.2 (1B/3B) muestra que MegaMath puede aportar una mejora absoluta del rendimiento del 15-20% en benchmarks como GSM8K y MATH. (Fuente: 3710亿数学Tokens!全球最大开源数学数据集MegaMath震撼发布,碾压DeepSeek-Math)
Revisión de OS Agents: Investigación sobre agentes inteligentes para computadoras, móviles y navegadores basados en modelos grandes multimodales: La Universidad de Zhejiang, en colaboración con OPPO, 01.AI y otras instituciones, ha publicado un artículo de revisión sobre agentes de sistema operativo (OS Agents). El artículo revisa sistemáticamente el estado actual de la investigación sobre la construcción de agentes inteligentes (como Computer Use de Anthropic, Apple Intelligence de Apple) capaces de completar tareas automáticamente en entornos como computadoras, teléfonos móviles y navegadores, utilizando modelos grandes de lenguaje multimodal (MLLM). El contenido abarca los fundamentos de los OS Agents (entorno, espacio de observación, espacio de acción, capacidades centrales), métodos de construcción (arquitectura del modelo base y estrategias de entrenamiento, módulos de percepción/planificación/memoria/acción del marco del agente), protocolos de evaluación y benchmarks, así como productos comerciales relacionados y desafíos futuros (seguridad y privacidad, personalización y autoevolución). El equipo de investigación mantiene un repositorio de código abierto con más de 250 artículos relacionados, con el objetivo de promover el desarrollo en este campo. (Fuente: 浙大、OPPO等发布最新综述:基于多模态大模型的计算机、手机与浏览器智能体研究)
NLPrompt: Método robusto de aprendizaje por prompts que combina pérdida MAE y transporte óptimo: YesAI Lab de la Universidad de ShangháiTech propone NLPrompt en un artículo destacado de CVPR 2025, con el objetivo de resolver el problema del ruido en las etiquetas en el aprendizaje por prompts de modelos de visión y lenguaje. La investigación descubrió que, en el escenario del aprendizaje por prompts, usar la pérdida de error absoluto medio (MAE) (PromptMAE) es más resistente a las etiquetas ruidosas que la pérdida de entropía cruzada (CE), y demostró su robustez desde la perspectiva de la teoría del aprendizaje de características. Además, propone un método de purificación de datos basado en prompts y transporte óptimo (PromptOT), que utiliza características de texto como prototipos para dividir el conjunto de datos en un subconjunto limpio (entrenado con pérdida CE) y un subconjunto ruidoso (entrenado con pérdida MAE), fusionando eficazmente las ventajas de ambas pérdidas. Los experimentos demuestran que NLPrompt funciona de manera superior en conjuntos de datos con ruido sintético y real, y posee una buena capacidad de generalización. (Fuente: CVPR 2025 | MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法)
Análisis del mecanismo de razonamiento de DeepSeek-R1: Investigadores de la Universidad McGill analizaron el proceso de razonamiento de modelos de razonamiento grandes como DeepSeek-R1. A diferencia de los LLM que dan respuestas directas, los modelos de razonamiento generan cadenas de razonamiento detalladas de múltiples pasos. El estudio explora la relación entre la longitud de la cadena de razonamiento y el rendimiento (existe un “punto óptimo”, demasiado largo puede perjudicar el rendimiento), la gestión de contextos largos, problemas culturales y de seguridad (presentan vulnerabilidades de seguridad más fuertes en comparación con los modelos sin razonamiento), y la correlación con fenómenos cognitivos humanos (como la persistencia en problemas ya explorados). La investigación revela algunas características y problemas potenciales del mecanismo operativo de los modelos de razonamiento actuales. (Fuente: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
C3PO: Método de optimización en tiempo de prueba para modelos grandes MoE: Investigadores de la Universidad Johns Hopkins descubrieron que los LLM de mezcla de expertos (MoE) tienen un problema de rutas de expertos subóptimas y propusieron el método de optimización en tiempo de prueba C3PO (Optimización de Capas Críticas, Expertos Centrales y Rutas Colaborativas). Este método no depende de etiquetas reales, sino que define objetivos alternativos basados en “vecinos exitosos” en un conjunto de muestras de referencia para optimizar el rendimiento del modelo. Utiliza algoritmos como búsqueda de patrones, regresión kernel, pérdida promedio de muestras similares, y para reducir costos, solo optimiza los pesos de los expertos centrales en las capas críticas. Aplicado a LLM MoE, C3PO mejoró la precisión del modelo base en un 7-15% en seis benchmarks, superando las líneas base comunes de aprendizaje en tiempo de prueba, e hizo que el rendimiento de modelos MoE de parámetros pequeños superara a LLM de parámetros más grandes, mejorando la eficiencia de MoE. (Fuente: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Estudio sobre el impacto de la cuantificación en el rendimiento de los modelos de razonamiento: Un equipo de investigación de la Universidad de Tsinghua exploró sistemáticamente por primera vez el impacto de las técnicas de cuantificación en el rendimiento de los modelos de lenguaje de tipo razonamiento (como las series DeepSeek-R1, Qwen, LLaMA). El estudio evaluó el rendimiento de diferentes algoritmos de cuantificación de pesos, caché KV y activación con distintos anchos de bits (W8A8, W4A16, etc.) en benchmarks de razonamiento como matemáticas, ciencias y programación. Los resultados muestran que la cuantificación W8A8 o W4A16 generalmente puede lograr un rendimiento sin pérdidas, pero anchos de bits más bajos conllevan un riesgo significativo de disminución de la precisión. El tamaño del modelo, el origen y la dificultad de la tarea son factores clave que influyen en el rendimiento post-cuantificación. La longitud de salida de los modelos cuantificados no aumentó significativamente, y ajustar razonablemente el tamaño del modelo o aumentar los pasos de inferencia puede mejorar el rendimiento. Los modelos cuantificados y el código relacionados se han hecho de código abierto. (Fuente: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
SHIELDAGENT: Barrera de protección para forzar a los Agents a cumplir con las políticas de seguridad: La Universidad de Chicago propone el marco SHIELDAGENT, diseñado para forzar mediante razonamiento lógico que las trayectorias de acción de los AI Agents cumplan con políticas de seguridad explícitas. El marco primero extrae reglas verificables de los documentos de política para construir un modelo de política de seguridad (basado en circuitos de reglas probabilísticas), luego, durante la ejecución del Agent, recupera reglas relevantes según su trayectoria de acción y genera un plan de protección, utilizando una biblioteca de herramientas y código ejecutable para la verificación formal, asegurando que el comportamiento del Agent no viole las regulaciones de seguridad. También se lanzó el conjunto de datos SHIELDAGENT-BENCH que contiene 3K de instrucciones y pares de trayectorias relacionados con la seguridad. Los experimentos muestran que SHIELDAGENT alcanza el estado del arte (SOTA) en múltiples benchmarks, mejorando significativamente la tasa de cumplimiento de seguridad y la recuperación (recall), al tiempo que reduce las consultas API y el tiempo de inferencia. (Fuente: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
MedVLM-R1: Incentivando la capacidad de razonamiento de VLM médicos mediante aprendizaje por refuerzo: La Universidad Técnica de Múnich, la Universidad de Oxford y otras instituciones colaboraron para proponer MedVLM-R1, un modelo de lenguaje visual (VLM) médico diseñado para generar procesos de razonamiento explícitos en lenguaje natural. Este modelo utiliza el marco de aprendizaje por refuerzo de optimización de políticas relativas de grupo (GRPO) de DeepSeek, entrenado en conjuntos de datos que solo contienen la respuesta final, pero capaz de descubrir autónomamente rutas de razonamiento interpretables por humanos. Después de entrenar con solo 600 muestras de VQA de MRI, este modelo de 2B parámetros alcanzó una precisión del 78.22% en benchmarks de MRI, CT y rayos X, superando significativamente a las líneas base y demostrando una fuerte capacidad de generalización fuera de dominio, incluso superando a modelos de mayor escala como Qwen2-VL-72B. Esta investigación ofrece nuevas ideas para construir IA médica confiable e interpretable. (Fuente: 小样本大能量!MedVLM-R1借力DeepSeek强化学习,重塑医疗AI推理能力)
Investigación revela que el entrenamiento con aprendizaje por refuerzo puede causar respuestas prolijas en modelos de razonamiento: Un estudio de Wand AI analizó por qué los modelos de razonamiento (como DeepSeek-R1) generan respuestas más largas. La investigación encontró que este comportamiento podría originarse en el proceso de entrenamiento con aprendizaje por refuerzo (específicamente el algoritmo PPO), en lugar de que el problema en sí requiera un razonamiento más largo. Cuando el modelo recibe una recompensa negativa por una respuesta incorrecta, la función de pérdida de PPO tiende a generar respuestas más largas para diluir el castigo por token, incluso si el contenido adicional no ayuda a mejorar la precisión. El estudio también muestra que el razonamiento conciso a menudo se correlaciona con una mayor precisión. Mediante una segunda ronda de entrenamiento con aprendizaje por refuerzo utilizando solo una parte de los problemas resolubles, se puede acortar la longitud de la respuesta, manteniendo o incluso mejorando la precisión, lo cual es importante para mejorar la eficiencia del despliegue. (Fuente: 更长思维并不等于更强推理性能,强化学习可以很简洁)

La Universidad de Ciencia y Tecnología de China y ZTE proponen Curr-ReFT: Mejora de la capacidad de razonamiento y generalización de VLM de tamaño pequeño: Para abordar el fenómeno de “muro de ladrillos” (cuello de botella en el entrenamiento) y la insuficiente capacidad de generalización fuera de dominio de los modelos de lenguaje visual (VLM) de tamaño pequeño en tareas complejas, la Universidad de Ciencia y Tecnología de China y ZTE Communications proponen el paradigma de post-entrenamiento con aprendizaje por refuerzo curricular (Curr-ReFT). Este paradigma combina el aprendizaje curricular (CL) y el aprendizaje por refuerzo (RL), diseñando un mecanismo de recompensa sensible a la dificultad, que permite al modelo aprender gradualmente de fácil a difícil (decisión binaria → opción múltiple → respuesta abierta). Al mismo tiempo, adopta una estrategia de automejora basada en muestreo por rechazo, utilizando muestras multimodales y lingüísticas de alta calidad para mantener las capacidades básicas del modelo. Los experimentos en los modelos Qwen2.5-VL-3B/7B muestran que Curr-ReFT mejora significativamente el rendimiento de razonamiento y generalización del modelo, con el modelo 7B superando incluso a InternVL2.5-26B/38B en algunos benchmarks. (Fuente: 中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理)

GenPRM: Extensión de modelos de recompensa de proceso mediante razonamiento generativo: La Universidad de Tsinghua y Shanghai AI Lab proponen el modelo generativo de recompensa de proceso (GenPRM), con el objetivo de resolver los problemas de los modelos tradicionales de recompensa de proceso (PRM) que dependen de puntuaciones escalares, carecen de interpretabilidad y no pueden extenderse en tiempo de prueba. GenPRM adopta un enfoque generativo, combinando el razonamiento de cadena de pensamiento (CoT) y la verificación de código, para realizar análisis en lenguaje natural y verificación de ejecución de código Python en cada paso del razonamiento, proporcionando una supervisión del proceso más profunda e interpretable. Además, GenPRM introduce un mecanismo de extensión en tiempo de prueba, que mejora la precisión de la evaluación mediante el muestreo paralelo de múltiples rutas de razonamiento y la agregación de los valores de recompensa. Un modelo de 1.5B entrenado con solo 23K datos sintéticos supera a GPT-4o en ProcessBench mediante la extensión en tiempo de prueba, y la versión 7B supera a Qwen2.5-Math-PRM-72B de 72B. GenPRM también puede actuar como modelo crítico para guiar la optimización del modelo de políticas. (Fuente: 过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o)
Investigación revela el fenómeno de “pensamiento excesivo” de la IA de razonamiento en problemas con premisas faltantes: Investigadores de la Universidad de Maryland y la Universidad de Lehigh descubrieron que los modelos de razonamiento actuales (como DeepSeek-R1, o1), cuando se enfrentan a problemas que carecen de información de premisa necesaria (Missing Premise, MiP), tienden a mostrar una tendencia al “pensamiento excesivo”. Generan respuestas 2-4 veces más largas que para problemas normales, cayendo en un ciclo de revisión repetida del problema, adivinación de intenciones y duda de sí mismos, en lugar de identificar rápidamente que el problema no se puede resolver y detenerse. En contraste, los modelos sin razonamiento (como GPT-4.5) tienen respuestas más cortas en problemas MiP y son más capaces de identificar la falta de premisas. El estudio indica que, aunque los modelos de razonamiento pueden detectar la falta de premisas, carecen del “pensamiento crítico” para detener decididamente el razonamiento ineficaz. Este patrón de comportamiento podría originarse en la falta de restricciones de longitud en el entrenamiento con aprendizaje por refuerzo y propagarse a través de la destilación. (Fuente: 推理AI「脑补」成瘾,废话拉满!马里兰华人学霸揭开内幕)

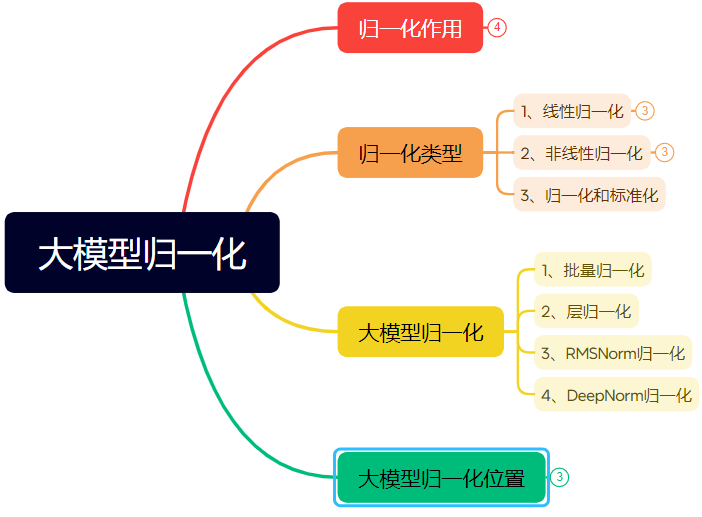
Largo artículo detalla la evolución de las técnicas de normalización en redes neuronales: El artículo revisa sistemáticamente el papel y la evolución de la normalización (Normalization) en las redes neuronales, especialmente en Transformers y modelos grandes. La normalización, al restringir los datos a un rango fijo, resuelve problemas de comparabilidad de datos, mejora la velocidad de optimización y mitiga los problemas de la zona de saturación de la función de activación y el desplazamiento interno de covariables (ICS). El artículo presenta métodos comunes de normalización lineal (Min-max, Z-score, Mean) y no lineal, y se centra en la normalización por lotes (BN), la normalización por capas (LN), RMSNorm y DeepNorm, aplicables a modelos de aprendizaje profundo, analizando sus diferencias de aplicación en la arquitectura Transformer (por qué LN/RMSNorm son más adecuados para NLP). Además, discute las diferentes posiciones del módulo de normalización dentro de las capas Transformer (Post-Norm, Pre-Norm, Sandwich-Norm) y su impacto en la estabilidad del entrenamiento y el rendimiento. (Fuente: 万字长文!一文了解归一化:从Transformer归一化到主流大模型归一化的演变!)
Ingeniería de Prompts para generar diseños de fuentes de estilo específico con IA: El artículo comparte la experiencia del autor y plantillas de prompts para explorar el uso de Jimm AI 3.0 (即梦AI 3.0) para generar diseños de texto con estilos específicos. El autor descubrió que especificar directamente nombres de fuentes (como Songti, Kaiti) no funcionaba bien, ya que la comprensión del modelo de IA al respecto es limitada. Por lo tanto, el autor se centró en describir las características del estilo de fuente, la atmósfera emocional y los efectos visuales, combinándolos con ejemplos de referencia de diferentes estilos, para construir una plantilla de Prompt “Generador de prompts de diseño de estilo de texto avanzado”. Los usuarios solo necesitan ingresar el contenido del texto, y la plantilla puede emparejar inteligentemente o fusionar múltiples estilos preestablecidos (como Resplandor Nocturno, Industrial Rústico, Garabato Infantil, Ciencia Ficción Metálica, etc.) según el significado del texto, generando prompts detallados para modelos de texto a imagen, obteniendo así efectos de diseño gráfico-textual de calidad relativamente estable. (Fuente: AI生成字体设计我有点玩明白了,用这套Prompt提效50%。, 即梦AI 3.0制作含字体封面,这个方案酷到封神【附:16+案例和Prompt】)

ZClip: Método adaptativo de supresión de picos de gradiente para el preentrenamiento de LLM: Investigadores proponen ZClip, un método ligero de recorte de gradiente adaptativo, diseñado para reducir los picos de pérdida durante el proceso de entrenamiento de LLM y mejorar la estabilidad del entrenamiento. A diferencia del recorte de gradiente tradicional que utiliza un umbral fijo, ZClip emplea un método basado en z-score para detectar y recortar picos de gradiente anómalos, es decir, aquellos gradientes que se desvían significativamente de la media móvil reciente. Este método ayuda a mantener la estabilidad del entrenamiento sin interferir con la convergencia y es fácil de integrar en cualquier ciclo de entrenamiento. El código y el artículo han sido publicados. (Fuente: Reddit r/deeplearning)
![[2504.02507] ZClip: Adaptive Spike Mitigation for LLM Pre-Training](https://rebabel.net/wp-content/uploads/2025/04/Swd9uQN43Dpl2SJyH6zjTbJAdRaXwKbmzZwM9L2rPXk.jpg)
💼 Negocios
La solución de tarjetas gráficas Intel Arc + procesadores Xeon W impulsa máquinas todo en uno de IA de bajo costo: Intel, a través de su combinación de tarjetas gráficas Arc™ y procesadores Xeon® W, ofrece al mercado una solución para construir máquinas todo en uno de modelos grandes con costo controlado (nivel de 100,000 yuanes) y rendimiento práctico. Las tarjetas gráficas Arc™ utilizan la arquitectura Xe y el motor de aceleración XMX AI, soportan frameworks de IA convencionales y Ollama/vLLM, tienen un consumo de energía relativamente bajo y admiten la conexión en paralelo de múltiples tarjetas. Los procesadores Xeon® W ofrecen un alto número de núcleos y capacidad de expansión de memoria, con tecnología de aceleración AMX incorporada. Combinado con optimizaciones de software como IPEX-LLM, OpenVINO™ y oneAPI, se logra una colaboración eficiente entre CPU y GPU. Las pruebas reales muestran que una máquina todo en uno con esta solución que ejecuta el modelo QwQ-32B puede alcanzar 32 tokens/s para un solo usuario, y ejecutando el modelo DeepSeek R1 de 671B (requiere optimización FlashMoE) puede alcanzar casi 10 tokens/s, satisfaciendo las necesidades de inferencia fuera de línea e impulsando la popularización de la inferencia de IA. (Fuente: 榨干3000元显卡,跑通千亿级大模型的秘方来了)

NVIDIA fabricará supercomputadoras de IA en suelo estadounidense: NVIDIA anunció que diseñará y construirá por primera vez sus supercomputadoras de IA completamente en los Estados Unidos, en colaboración con sus principales socios de fabricación. Al mismo tiempo, su nueva generación de chips Blackwell ha comenzado la producción en la planta de TSMC en Arizona. NVIDIA planea producir hasta quinientos mil millones de dólares en infraestructura de IA en los EE. UU. durante los próximos 4 años, con socios como TSMC, Foxconn, Wistron, Amkor y SPIL. Esta medida tiene como objetivo satisfacer la demanda de chips de IA y supercomputadoras, fortalecer la cadena de suministro y mejorar la resiliencia. (Fuente: nvidia, nvidia)

Horizon Robotics contrata becarios de reconstrucción/generación 3D: El equipo de Inteligencia Corporeizada de Horizon Robotics está contratando becarios de algoritmos en la dirección de reconstrucción/generación 3D en Shanghái/Beijing. Las responsabilidades incluyen participar en el diseño y desarrollo de soluciones de algoritmos Real2Sim para robots (combinando reconstrucción 3D GS, reconstrucción feed-forward, generación 3D/video), optimizar el rendimiento del simulador Real2Sim (soportando simulación de fluidos, táctil, etc.), y seguir la investigación de vanguardia publicando artículos en conferencias de primer nivel. Se requiere maestría o superior, especialización en informática/gráficos por computadora/IA, experiencia en visión 3D/generación de video o modelos multimodales/difusión, dominio de Python/Pytorch/Huggingface. Se valorará la publicación en conferencias de primer nivel, familiaridad con plataformas de simulación o experiencia en proyectos de código abierto. Se ofrece oportunidad de conversión a empleado fijo, clúster de GPU y salario competitivo. (Fuente: 上海/北京内推 | 地平线机器人具身智能团队招聘3D重建/生成方向算法实习生)

Meituan Travel contrata Ingenieros de Algoritmos de Modelos Grandes L7-L8: El equipo de Algoritmos de Suministro de Meituan Travel en Beijing está contratando Ingenieros de Algoritmos de Modelos Grandes de nivel L7-L8 (contratación externa). Las responsabilidades incluyen construir un sistema de comprensión del suministro de viajes y hoteles (etiquetas de productos, identificación de puntos calientes, minería de suministros similares, etc.), optimizar materiales de exhibición (generación de títulos, imágenes y texto, razones de recomendación), construir combinaciones de paquetes vacacionales (selección de productos, predicción de ventas, fijación de precios), y explorar e implementar tecnologías de modelos grandes de vanguardia (ajuste fino, RL, optimización de Prompt). Se requiere maestría o superior, más de 2 años de experiencia, especialización en informática/automatización/estadística matemática, con sólidos fundamentos algorítmicos y habilidades de codificación. (Fuente: 北京内推 | 美团酒旅供给算法团队招聘L7-L8大模型算法工程师)

Meta utilizará datos de usuarios en la UE para entrenar IA: Meta anunció que se prepara para comenzar a usar datos públicos de usuarios de Facebook e Instagram en la región de la UE (como publicaciones, comentarios, excluyendo mensajes privados) para entrenar sus modelos de IA, limitado a usuarios mayores de 18 años. La compañía informará a los usuarios a través de notificaciones en la aplicación y correos electrónicos, y proporcionará un enlace para oponerse (opt-out). Anteriormente, Meta había suspendido sus planes de usar datos de usuarios en Europa para entrenar IA debido a los requisitos de los reguladores irlandeses. (Fuente: Reddit r/artificial)

Tencent Cloud lanza servicio gestionado MCP: Tencent Cloud también ha comenzado a ofrecer servicios gestionados MCP (Managed Cloud Platform), con el objetivo de proporcionar a las empresas soluciones de gestión y operación de recursos en la nube más convenientes y eficientes. Esta medida significa una intensificación de la competencia entre los principales proveedores de nube en este campo. Los detalles específicos del servicio y las “características de WeChat” aún no se han detallado. (Fuente: 腾讯云也搞 MCP 托管了,还带了点“微信特色”。)
🌟 Comunidad
El ganador del Premio Turing LeCun habla sobre el desarrollo de la IA: la inteligencia humana no es general, el próximo avance podría estar en lo no generativo: En una reciente entrevista de podcast, Yann LeCun enfatizó nuevamente que el término AGI es engañoso, argumentando que la inteligencia humana es altamente especializada, no general. Predice que el próximo gran avance en IA podría provenir de modelos no generativos, centrándose en hacer que las máquinas comprendan verdaderamente el mundo físico, posean capacidades de razonamiento y planificación, y memoria persistente, similar a su arquitectura JEPA propuesta. Considera que los LLM actuales carecen de verdadera capacidad de razonamiento y modelado del mundo físico, y alcanzar el nivel de inteligencia de un gato ya sería un gran progreso. Respecto a que Meta abriera el código de LLaMA, lo considera la elección correcta para impulsar el desarrollo de todo el ecosistema de IA, y enfatiza que la innovación proviene de todo el mundo y el código abierto es clave para acelerar los avances. También ve con buenos ojos las gafas inteligentes como un importante vehículo para los asistentes de IA. (Fuente: 图灵奖得主LeCun:人类智能不是通用智能,下一代AI可能基于非生成式)

El breve “bloqueo” de IPs chinas por parte de GitHub genera preocupación, la empresa afirma que fue un error de configuración: Del 12 al 13 de abril, algunos usuarios chinos descubrieron que no podían acceder a GitHub, mostrando un mensaje de “Dirección IP restringida para el acceso”, lo que generó pánico y discusión en la comunidad, temiendo un bloqueo dirigido. Anteriormente, GitHub había bloqueado cuentas de desarrolladores de Rusia, Irán y otros países debido a sanciones estadounidenses. GitHub respondió posteriormente afirmando que el incidente se debió a un error en un cambio de configuración que impidió temporalmente el acceso a usuarios no registrados, y que el problema se solucionó el 13 de abril. Aunque fue un fallo técnico, el evento reavivó el debate sobre los riesgos geopolíticos de las plataformas de alojamiento de código y las alternativas nacionales (como Gitee, CODING, Jihu GitLab, etc.). (Fuente: “Bug”还是“预演”?GitHub 突然“封禁”所有中国 IP,官方:只是“手滑”技术出错了)

Los AI Agents generan preocupaciones sobre ciberseguridad: Un artículo de MIT Technology Review señala que los ciberataques autónomos impulsados por IA son inminentes. A medida que aumentan las capacidades de la IA, los actores maliciosos podrían utilizar AI Agents para descubrir automáticamente vulnerabilidades, planificar y ejecutar ciberataques más complejos y a gran escala, lo que representa nuevas amenazas para la seguridad personal, empresarial e incluso nacional. Esto exige que el campo de la ciberseguridad acelere la investigación y el despliegue de estrategias y tecnologías de defensa capaces de hacer frente a los ataques impulsados por IA. (Fuente: Ronald_vanLoon)

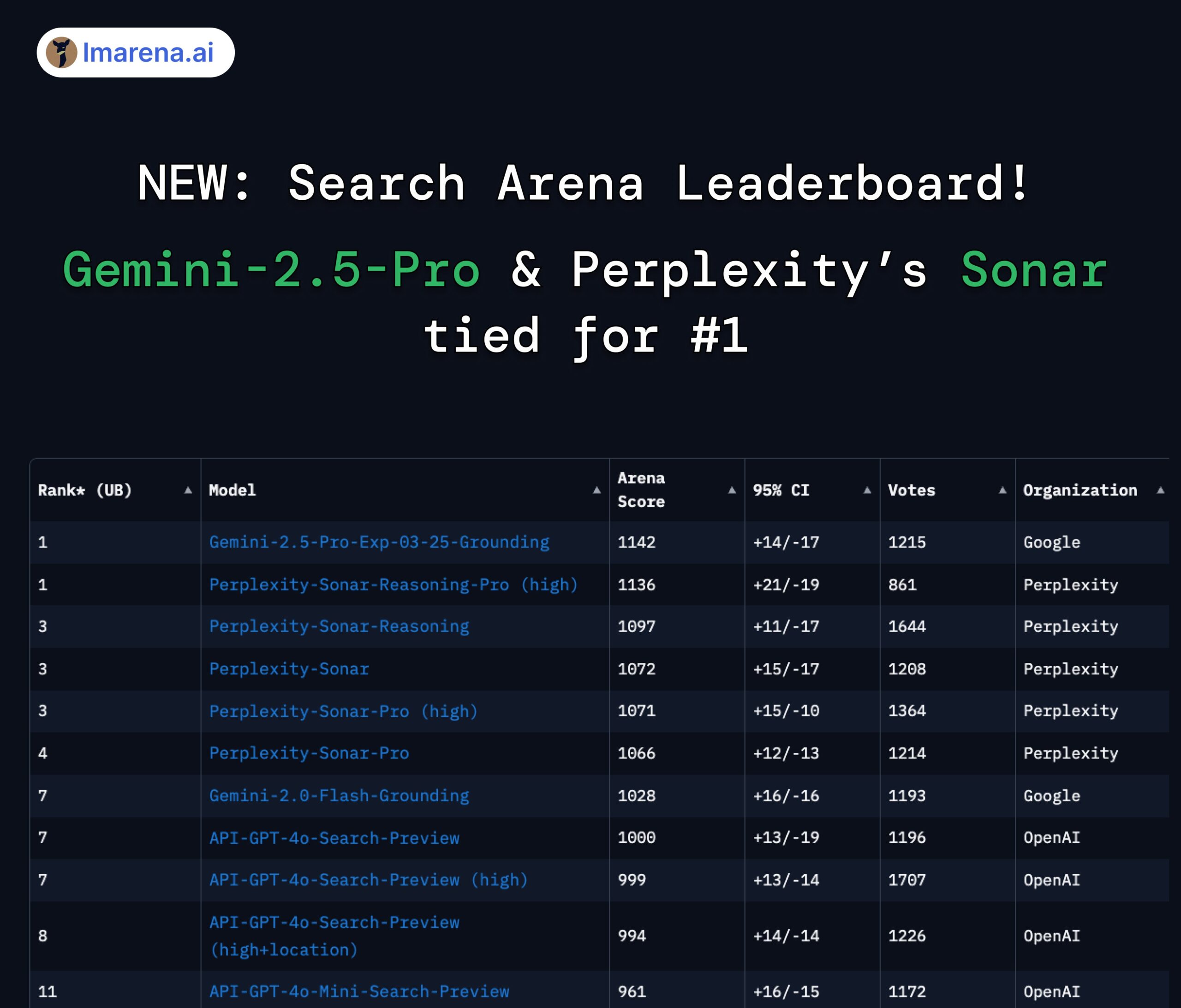
Perplexity Sonar y Gemini 2.5 Pro empatan en el primer puesto del ranking de búsqueda: En el nuevo ranking Search Arena de LMArena.ai (anteriormente LMSYS), el modelo Sonar-Reasoning-Pro-High de Perplexity y Gemini-2.5-Pro-Grounding de Google empataron en el primer lugar. Esta clasificación evalúa específicamente la calidad de las respuestas de LLM basadas en búsquedas web. El CEO de Perplexity, Arav Srinivas, felicitó por ello y enfatizó que continuarán mejorando el modelo Sonar y el índice de búsqueda. La comunidad considera que esto demuestra que en el campo de los LLM mejorados por búsqueda, la competencia se desarrolla principalmente entre Google y Perplexity. (Fuente: AravSrinivas, lmarena_ai, lmarena_ai, AravSrinivas, lmarena_ai, AravSrinivas)
Discusión sobre las restricciones de uso del modelo Claude: En la comunidad Reddit r/ClaudeAI, existe controversia entre los usuarios sobre las restricciones de uso de la versión Claude Pro (como el límite de mensajes, restricciones de capacidad). Algunos usuarios se quejan de encontrar limitaciones frecuentes que afectan sus flujos de trabajo, e incluso consideran cambiar de modelo; otros, en cambio, afirman que rara vez encuentran restricciones, sugiriendo que podría deberse a la forma de uso (como cargar contextos muy grandes) o a exageraciones. Esto refleja las diferentes experiencias y opiniones de los usuarios sobre las políticas de uso y la estabilidad del modelo de Anthropic. (Fuente: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Debate sobre la IA y el futuro del empleo: En Reddit r/ChatGPT, un gráfico comparativo generó debate: ¿La IA mejorará las capacidades humanas, trayendo una vida de abundancia, o reemplazará los trabajos humanos, causando desempleo masivo? En los comentarios, muchos usuarios expresaron preocupación por el reemplazo de trabajos por la IA, especialmente en profesiones creativas (programación, arte). Algunos creen que la IA agravará la desigualdad social, ya que los beneficios irán principalmente a los propietarios de la IA, mientras que la reducción de la base impositiva podría dificultar la implementación de la Renta Básica Universal (UBI). Otros mantienen una actitud más optimista, considerando la IA como una herramienta poderosa que puede aumentar la eficiencia y crear nuevos puestos (como ingeniero de prompts), siendo clave adaptarse y aprender a utilizar la IA. (Fuente: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

La recopilación de datos por IA genera preocupación por la privacidad: Una infografía que compara los tipos de datos de usuario recopilados por diferentes chatbots de IA (ChatGPT, Gemini, Copilot, Claude, Grok) generó un debate en la comunidad sobre cuestiones de privacidad. El gráfico muestra que Google Gemini recopila la mayor cantidad de tipos de datos, mientras que Grok (requiere cuenta) y ChatGPT (no requiere cuenta) recopilan relativamente menos. Los comentarios de los usuarios enfatizaron la ubicuidad de la recopilación de datos detrás de los servicios gratuitos (“no hay almuerzo gratis”) y expresaron preocupación por los propósitos específicos de la recopilación de datos (como la predicción del comportamiento). (Fuente: Reddit r/artificial)

La destilación de modelos se considera una vía eficaz para replicar alto rendimiento a bajo costo: Un usuario de Reddit compartió cómo, mediante la técnica de destilación de modelos, utilizando un modelo grande (como GPT-4o) para entrenar un modelo pequeño y afinado, logró un rendimiento cercano a GPT-4o (92% de precisión) en un dominio específico (análisis de sentimientos) a un costo 14 veces menor. Los comentarios señalan que la destilación es una técnica ampliamente utilizada, pero en términos de capacidad de generalización entre dominios, los modelos pequeños generalmente no son tan buenos como los grandes. Para dominios específicos y estables, la destilación es un método eficaz para reducir costos y aumentar la eficiencia, pero para escenarios complejos que requieren adaptación constante a nuevos datos o múltiples dominios, usar directamente una API grande podría ser más económico. (Fuente: Reddit r/MachineLearning)
![[D] Distillation is underrated. I replicated GPT-4o's capability in a 14x cheaper model](https://rebabel.net/wp-content/uploads/2025/04/zyj7as7ogque1.png)
💡 Otros
OceanBase organiza su primer Hackathon de IA: El proveedor de bases de datos distribuidas OceanBase, en colaboración con Ant Open Source, Jiqizhixin y otros, organiza su primer Hackathon de IA. La inscripción se abrió el 10 de abril y finaliza el 7 de mayo. El concurso, bajo el lema “DB+AI”, establece dos direcciones principales: una es construir aplicaciones de IA utilizando OceanBase como base de datos, y la otra es explorar la integración de OceanBase con el ecosistema de IA (como CAMEL AI, FastGPT, OpenDAL). El concurso ofrece un fondo total de premios de 100,000 yuanes, abierto a la inscripción individual y por equipos, con el objetivo de inspirar a los desarrolladores a explorar aplicaciones innovadoras de la integración profunda de bases de datos e IA. (Fuente: 10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?)

El profesor Liu Xinjun de la Universidad de Tsinghua dará una charla en vivo sobre robots paralelos: El profesor Liu Xinjun, Director del Instituto de Ingeniería de Diseño del Departamento de Ingeniería Mecánica de la Universidad de Tsinghua y Presidente del Comité Chino de IFToMM, dará una conferencia en línea la noche del 15 de abril, con el tema “Fundamentos de la cinemática de robots paralelos e innovación en equipos”. La conferencia explorará la teoría fundamental de los robots paralelos y su aplicación en la innovación de equipos de vanguardia. El moderador será el profesor Liu Yingxiang de la Universidad Tecnológica de Harbin. (Fuente: 重磅直播!清华大学刘辛军教授开讲:并联机器人机构学基础与装备创新前沿)

Publicada la guía para la Tercera Cumbre de la Industria AIGC de China: Se ha publicado la agenda detallada y los puntos destacados de la Tercera Cumbre de la Industria AIGC de China, que se celebrará en Beijing el 16 de abril. La cumbre se centrará en la tecnología de IA y la implementación de aplicaciones, con temas que abarcan la infraestructura de computación, la aplicación de modelos grandes en escenarios verticales como educación/entretenimiento/servicios empresariales/AI4S, y la seguridad y controlabilidad de la IA. Los ponentes provienen de Baidu, Huawei, AWS, Microsoft Research Asia, Face++, Shengshu Technology, Fenbi, NetEase Youdao, Quwan Technology, QingSong Health, Ant Group, entre otros. La cumbre también publicará la lista de empresas y productos AIGC a seguir en 2025, así como el panorama completo de aplicaciones AIGC en China. (Fuente: 倒计时2天!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此)
