
Palabras clave:AI, inteligencia artificial, AI主权困局, HBM与先进封装, AI驱动科学发现, Gemini 2.5 Pro编程能力, AI破解数学难题
🔥 Enfoque
El dilema de la soberanía de la inteligencia artificial: ¿Cómo la narrativa de seguridad nacional devora el valor público?: El informe explora en profundidad el concepto de “soberanía de la inteligencia artificial”, es decir, el control de un país sobre la pila tecnológica de IA (datos, capacidad de cómputo, talento, energía). La tendencia global actual se está desplazando de una “soberanía débil” dependiente de aliados a una “soberanía fuerte” que busca una localización completa, impulsada especialmente por las políticas estadounidenses. Si bien esta transición tiene como objetivo garantizar la seguridad nacional y la ventaja militar, también genera preocupaciones sobre la excesiva centralización, la sofocación de la innovación abierta, la obstaculización de la cooperación internacional y el posible desencadenamiento de una carrera armamentista de IA. El artículo argumenta que la excesiva securitización de la IA podría sacrificar su enorme potencial para servir al interés público y resolver desafíos globales, haciendo un llamado a buscar un equilibrio entre las necesidades de soberanía y la cooperación abierta para evitar que la IA se convierta en víctima de la competencia geopolítica en lugar de una herramienta para el progreso colectivo humano. (Fuente: 人工智能主权困局:国家安全叙事如何吞噬AI的公共价值?)
HBM y empaquetado avanzado: El punto clave oculto de la revolución de la capacidad de cómputo de IA: La demanda exponencial de capacidad de cómputo por parte de los grandes modelos de IA está llevando a las arquitecturas de computación tradicionales al cuello de botella del “muro de la memoria”. La memoria de alto ancho de banda (HBM), mediante apilamiento 3D y tecnología TSV, multiplica el ancho de banda (por ejemplo, HBM3E supera 1TB/s), aliviando significativamente la latencia de transferencia de datos. Al mismo tiempo, las tecnologías de empaquetado avanzado (como CoWoS de TSMC, EMIB de Intel) integran estrechamente chips como CPU, GPU y HBM mediante integración heterogénea, superando las limitaciones de un solo chip y aumentando la densidad de cómputo y la eficiencia energética. HBM y el empaquetado avanzado se han convertido en componentes clave estándar para los chips de IA (especialmente en el lado del entrenamiento), con un mercado dominado por gigantes como SK Hynix, Samsung, Micron (HBM) y TSMC (empaquetado), que requiere enormes inversiones y enfrenta una capacidad de producción ajustada. El desarrollo coordinado de estas dos tecnologías no solo está remodelando el panorama de la cadena de suministro de semiconductores (aumentando la proporción del valor del empaquetado), sino que también se está convirtiendo en el campo de batalla decisivo en la competencia por la capacidad de cómputo de IA. (Fuente: HBM与先进封装:AI算力革命的隐形赛点)
Declaración impactante de un ganador del Nobel: La IA completa en un año el equivalente a 1.000 millones de años de “tiempo de investigación doctoral”: Demis Hassabis, ganador del Premio Nobel y CEO de Google DeepMind, afirmó que el proyecto de IA de su equipo, AlphaFold-2, al predecir la estructura de los 200 millones de proteínas conocidas en la Tierra, completó en un año una exploración científica equivalente a lo que antes habría requerido 1.000 millones de años de investigación doctoral. Subrayó que la IA, especialmente AlphaFold, está revolucionando radicalmente la velocidad y la escala del descubrimiento científico, democratizando el acceso al conocimiento. En su discurso en la Universidad de Cambridge, Hassabis profundizó sobre la llegada de la era de la “biología digital” impulsada por la IA y argumentó que el futuro de la IA reside en la creación de “modelos del mundo” (como la arquitectura JEPA) capaces de comprender el mundo físico y realizar razonamientos y planificaciones, en lugar de depender únicamente del procesamiento del lenguaje. Reiteró su compromiso con la IA de código abierto, considerándola la mejor vía para impulsar el progreso tecnológico. (Fuente: 诺奖得主震撼宣言:AI一年完成10亿年“博士研究时间”)

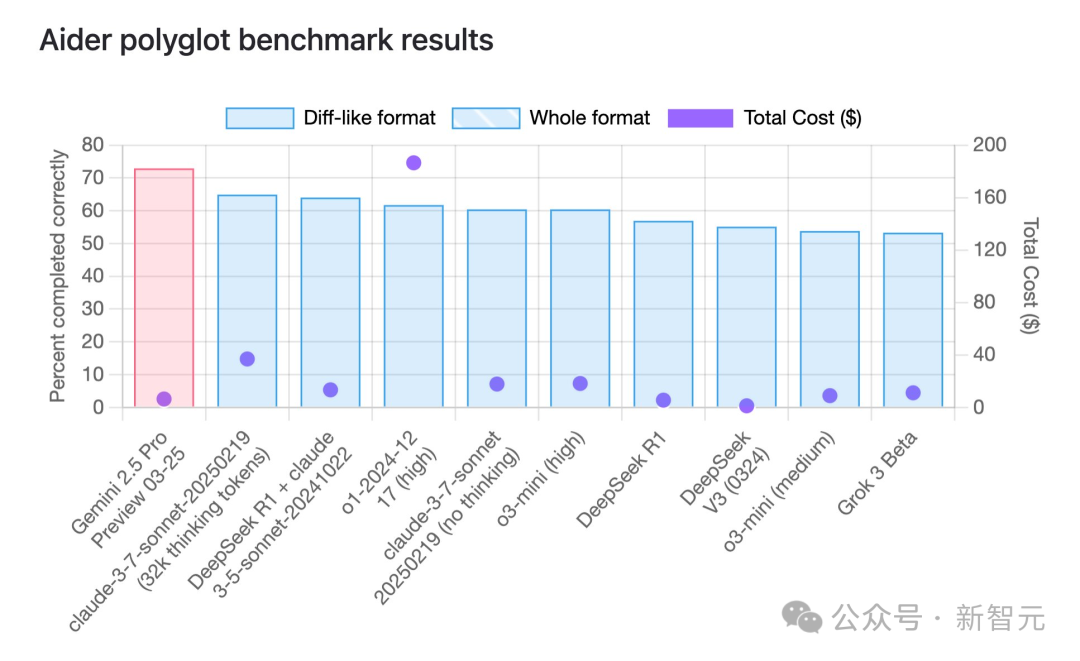
Gemini 2.5 Pro lidera en capacidad de programación con una notable ventaja en costo-efectividad: Según el benchmark de programación multilingüe aider, el modelo Gemini 2.5 Pro recientemente lanzado por Google ha superado a Claude 3.7 Sonnet en capacidad de programación, ocupando el primer lugar a nivel mundial. No solo lidera en rendimiento, sino que también tiene un costo de llamada API extremadamente bajo (aproximadamente 6 dólares), muy inferior al de competidores con rendimiento similar o inferior (como GPT-4o, Claude 3.7 Sonnet). Jeff Dean destacó su ventaja en costo-efectividad. Además, circula en la comunidad información sobre un modelo no publicado de Google llamado “Dragontail” que, en pruebas de desarrollo web, mostró un rendimiento incluso superior a Gemini 2.5 Pro, lo que sugiere que Google aún tiene ases bajo la manga en el campo de la programación con IA. Gemini 2.5 Pro también se encuentra entre los primeros puestos en varias pruebas de referencia generales, desafiando integralmente a OpenAI y Anthropic gracias a su alto rendimiento, bajo costo, gran ventana de contexto y acceso gratuito. (Fuente: Gemini 2.5编程全球霸榜,谷歌重回AI王座,神秘模型曝光,奥特曼迎战)
La IA ayuda con éxito a demostrar un problema matemático sin resolver durante 50 años: El académico chino Weiguo Yin (Brookhaven National Laboratory), con la ayuda del modelo o3-mini-high de OpenAI, logró un avance en la investigación de la solución exacta del modelo Potts q-state J_1-J_2 unidimensional, resolviendo un problema que había permanecido sin solución en este campo durante 50 años. Al abordar el caso específico de q=3, el modelo de IA, mediante análisis de simetría, logró simplificar la compleja matriz de transferencia de 9×9 a una matriz efectiva de 2×2. Este paso crucial inspiró a los investigadores a generalizar el método, encontrando finalmente una solución analítica aplicable a cualquier valor de q. Este logro no solo demuestra el potencial de la IA en derivaciones matemáticas complejas y pruebas no triviales, sino que también proporciona nuevas herramientas teóricas para comprender problemas como las transiciones de fase en la física de la materia condensada. (Fuente: 刚刚,AI破解50年未解数学难题,南大校友用OpenAI模型完成首个非平凡数学证明)

🎯 Tendencias
Aplicación y evolución de la IA en los NPC de videojuegos: El artículo repasa la historia del desarrollo de la tecnología de IA en los NPC (personajes no jugadores) de los videojuegos, desde las máquinas de estados finitos tempranas de “Pac-Man”, pasando por los árboles de comportamiento, hasta la IA compleja que combina la búsqueda de árbol Monte Carlo y redes neuronales profundas (como AlphaGo). Señala que, aunque la IA ya puede vencer a los mejores jugadores humanos en juegos como “StarCraft 2” y “Dota 2”, una IA demasiado poderosa no ofrece una buena experiencia para el jugador promedio. La IA ideal para juegos debería centrarse más en simular el comportamiento humano, proporcionar valor emocional y dificultad adaptativa (como el sistema Nemesis de “La Tierra Media” o la dificultad dinámica de “Resident Evil 4”). Recientemente, tomando como ejemplo a Stella de “Whispers from the Star” de miHoYo, la IA generativa se utiliza para impulsar el diálogo en tiempo real, las reacciones emocionales y el desarrollo de la trama de los NPC. Aunque enfrenta desafíos como la latencia y la memoria, demuestra la tendencia de los NPC de IA hacia una mayor humanidad y profundidad interactiva. (Fuente: AI,让游戏再次伟大)

OpenAI restringe el acceso a la API e implementa la verificación de organizaciones: OpenAI implementó recientemente una nueva política de verificación de organizaciones para su API, exigiendo a los usuarios que proporcionen un documento de identidad gubernamental válido emitido por un país o región admitido para acceder a sus modelos y funciones más avanzados. Cada ID solo puede verificar una organización cada 90 días. OpenAI afirma que esta medida tiene como objetivo reducir el uso inseguro de la IA y prepararse para el lanzamiento de “nuevos modelos emocionantes” (posiblemente incluyendo múltiples versiones como GPT-4.1, o3, o4-mini). Este cambio de política ha generado amplia atención y preocupación en la comunidad, especialmente para los desarrolladores ubicados en países/regiones no admitidos y los usuarios que dependen de servicios API de terceros, quienes podrían enfrentar restricciones de acceso o aumento de costos, y también ha suscitado debates sobre la apertura de OpenAI. (Fuente: GitHub中国IP访问崩了又复活,OpenAI API新政恐锁死GPT-5?, op7418, Reddit r/artificial)
La entrada de Apple impulsa el desarrollo del “médico IA”, coexistiendo desafíos y regulación: Se rumorea que Apple utilizará la IA para mejorar las funciones de su aplicación Salud, lanzando servicios como “entrenador de salud IA”, impulsando aún más al “médico IA” como un tema candente a nivel mundial. Sin embargo, la aplicación clínica real de la IA enfrenta numerosos desafíos: altos costos de desarrollo, dependencia de enormes cantidades de datos médicos sensibles (que involucran regulaciones de privacidad), dificultad en el etiquetado de datos, etc. Actualmente, la IA se utiliza principalmente como herramienta de diagnóstico auxiliar. El mercado chino también enfrenta necesidades especiales como la distribución desigual de recursos médicos y la necesidad de IA para ayudar en la clasificación de diagnósticos. Empresas como Baichuan Intelligence proponen un “modelo de doble médico” (médico IA + IA asistiendo a médico humano) para intentar resolver estos problemas. El artículo enfatiza que la aplicación generalizada de la IA médica debe basarse en una regulación estricta y sistemas de certificación para garantizar la precisión del diagnóstico, la seguridad de los datos y la confianza del usuario, evitando riesgos potenciales. (Fuente: 苹果入局,「AI医生」成全球热点,患者隐私保护成最大障碍?)

El intento de Microsoft de generar juegos directamente con IA no da buenos resultados: Microsoft mostró recientemente una DEMO utilizando su modelo de IA “Muse” para generar directamente imágenes del juego “Quake II”, con la intención de demostrar la capacidad de la IA para generar prototipos de juegos rápidamente. Sin embargo, la DEMO tuvo resultados deficientes, con baja resolución, baja tasa de fotogramas y numerosos BUGS (como comportamiento anómalo de los enemigos, fallos en las reglas físicas, entorno caótico), siendo calificada como un “sueño que se derrumba constantemente”. El artículo considera que esto indica que la tecnología actual de IA generativa (especialmente con el problema de las “alucinaciones”) aún no es suficiente para generar de manera directa y fiable experiencias de juego interactivas complejas y jugables. En comparación, aplicar la IA a etapas específicas del pipeline de desarrollo de juegos (como la interacción de NPC, generación de assets) es más realista. La ruta de generar directamente imágenes o jugabilidad del juego parece actualmente muy desafiante. (Fuente: 微软的AI游戏翻车,直接生成游戏或是条不归路)
Google lanza modelos de código abierto TxGemma para el sector de la salud: Google ha lanzado la serie de modelos TxGemma, basados en sus familias de modelos Gemma y Gemini, optimizados específicamente para los campos de la salud y el descubrimiento de fármacos. Esta iniciativa tiene como objetivo proporcionar herramientas de IA más especializadas para la investigación biomédica y el desarrollo terapéutico, fomentando la innovación en este sector. El lanzamiento de TxGemma forma parte de la estrategia de Google de ofrecer modelos de código abierto tanto generales como específicos de dominio. (Fuente: JeffDean)
DeepSeek anuncia planes para liberar su motor de inferencia interno: DeepSeek AI ha declarado que hará de código abierto su motor de inferencia utilizado internamente. Según la descripción, este motor es una versión modificada y optimizada del popular framework vLLM. Con esta medida, DeepSeek busca devolver a la comunidad de código abierto la tecnología de inferencia optimizada, ayudando a los desarrolladores a desplegar modelos grandes de manera más eficiente. Este plan refleja la voluntad de DeepSeek de contribuir a la comunidad de código abierto, y se espera que el código se publique en GitHub. (Fuente: karminski3)
ChatGPT añade función de memoria para mejorar la coherencia: OpenAI ha añadido una función de memoria (Memory) a su modelo ChatGPT. Esta función permite a ChatGPT recordar información proporcionada previamente por el usuario, preferencias o temas discutidos en conversaciones anteriores. El objetivo es mejorar la continuidad y personalización de la interacción, evitando que el usuario tenga que repetir la misma información de contexto en conversaciones posteriores, mejorando así la experiencia del usuario. (Fuente: Ronald_vanLoon)

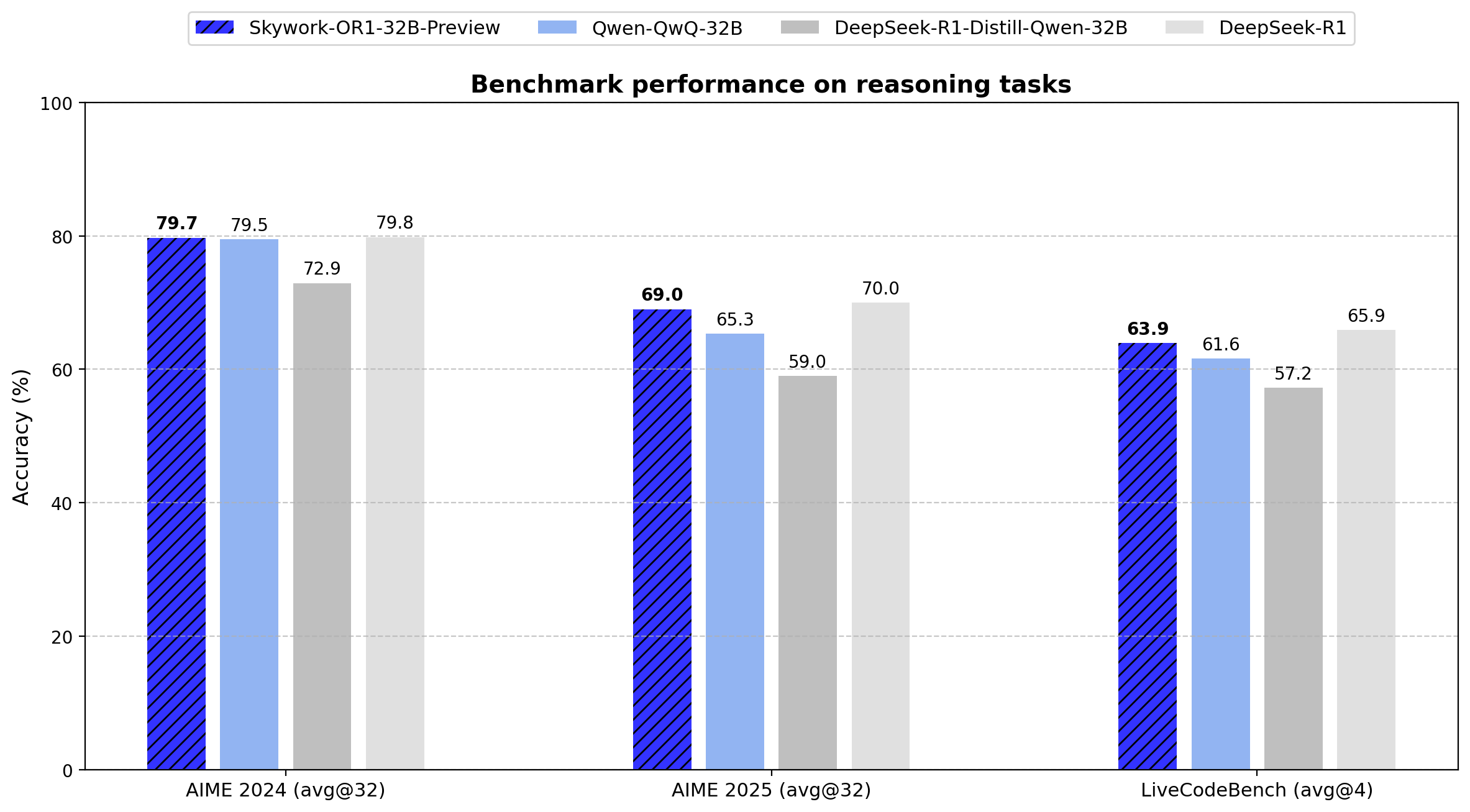
Skywork lanza la serie de modelos de inferencia de código abierto OR1: La empresa china Skywork (Tiangong – Kunlun Wanwei) ha lanzado una nueva serie de modelos de inferencia de código abierto, Skywork OR1. La serie incluye OR1-Math-7B, optimizado para matemáticas, y las versiones preliminares OR1-7B y OR1-32B, que destacan en matemáticas y codificación, afirmándose que la versión 32B es comparable en capacidad matemática a DeepSeek-R1. Skywork ha sido elogiada por su nivel de apertura, publicando los pesos del modelo, los datos de entrenamiento y el código completo de entrenamiento. (Fuente: natolambert)
Mejora en la capacidad de navegación y operación precisa de robots impulsados por IA: Las redes sociales muestran la capacidad de robots autónomos impulsados por IA para navegar con precisión en entornos complejos y ejecutar tareas. Estos robots probablemente utilizan tecnologías de IA como visión por computadora, SLAM (localización y mapeo simultáneos), aprendizaje por refuerzo, etc., logrando un funcionamiento eficiente en entornos no estructurados o dinámicos, demostrando avances en la percepción, planificación y control robótico. (Fuente: Ronald_vanLoon)
Exoesqueleto impulsado por IA ayuda a usuarios de sillas de ruedas a caminar: Se muestra un avanzado dispositivo de exoesqueleto que utiliza tecnología de IA, capaz de ayudar a los usuarios de sillas de ruedas a ponerse de pie y caminar de nuevo. La IA podría usarse para interpretar la intención del usuario, mantener el equilibrio, coordinar el movimiento y adaptarse a diferentes entornos, reflejando el potencial de la IA para mejorar la calidad de vida de las personas con discapacidad, siendo un avance importante en la tecnología de robótica asistencial. (Fuente: Ronald_vanLoon)
Preocupación por el posible uso de Agentes de IA en ciberataques: Un artículo de MIT Technology Review señala que los Agentes de IA autónomos podrían ser utilizados para ejecutar ciberataques complejos. Estos Agentes de IA tienen el potencial de descubrir vulnerabilidades automáticamente, generar código de ataque e implementar ataques, posiblemente a una escala y velocidad muy superiores a las de los hackers humanos, lo que representa un serio desafío para los sistemas de defensa de ciberseguridad existentes. Esto genera preocupaciones sobre la armamentización de la IA y los riesgos de seguridad. (Fuente: Ronald_vanLoon)

OpenAI anuncia evento en vivo y posible lanzamiento de nuevos modelos: OpenAI ha anunciado un evento en vivo con un mensaje ambiguo (desarrolladores y agujero negro supermasivo), mientras que en la red circulan información sobre iconos actualizados y tarjetas de modelos en su sitio web, sugiriendo el posible lanzamiento inminente de varios modelos nuevos, incluyendo la serie GPT-4.1 (con versiones nano, mini), o4-mini y la versión completa de o3. Esto indica que OpenAI podría estar preparándose para lanzar una serie de nuevos productos o actualizaciones de modelos para hacer frente a la creciente competencia del mercado. (Fuente: openai, op7418)

Robot Figure logra caminar natural de simulación a realidad mediante aprendizaje por refuerzo: Figure AI ha utilizado el aprendizaje por refuerzo (RL) en un entorno puramente simulado para entrenar con éxito a su robot humanoide Figure 02 a dominar una marcha natural. Mediante un simulador eficiente que genera grandes cantidades de datos, combinado con aleatorización de dominio y retroalimentación de par de alta frecuencia del propio robot, se logró la transferencia zero-shot de la política de la simulación a la realidad. Este método no solo acelera el proceso de desarrollo, sino que también demuestra la viabilidad de controlar múltiples robots con una única política de red neuronal, lo cual es de gran importancia para futuras aplicaciones comerciales de robots. (Fuente: 一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路)
🧰 Herramientas
Generación de diseño de texto estilizado con 即梦AI 3.0 y compartición de Prompt: Un usuario comparte su experiencia y método para generar imágenes de texto con diseño utilizando la herramienta de dibujo IA china “即梦AI 3.0”. Dado que especificar directamente nombres de fuentes no funciona bien, el autor creó una plantilla detallada de prompt que predefine varios estilos visuales (como industrial, dulce, tecnológico, tinta china, etc.) y establece reglas para que la IA empareje o fusione estilos automáticamente según el significado y la emoción del texto introducido. El usuario solo necesita ingresar el texto objetivo (como “chico gamer”, “quiero comer caramelos”), y la plantilla genera un prompt completo de dibujo que incluye estilo, fondo, maquetación y ambiente, obteniendo así efectos de diseño de texto e imagen de alta calidad en 即梦AI. El artículo proporciona esta plantilla de prompt y numerosos ejemplos generados. (Fuente: 即梦AI 3.0制作含字体封面,这个方案酷到封神【附:16+案例和Prompt】, AI生成字体设计我有点玩明白了,用这套Prompt提效50%。)
Uso de IA multimodal para transformar fotos de comida en imágenes estilo menú: Usuarios de redes sociales muestran una técnica para utilizar modelos de IA multimodales como GPT-4o para convertir fotos de comida ordinarias en imágenes de menú sofisticadas. El método consiste en proporcionar a la IA la foto original y combinarla con prompts descriptivos (por ejemplo, haciendo referencia a “estándares y estilo de menú de hotel de cinco estrellas de alta gama”), guiando a la IA para estilizar y editar la imagen, generando una presentación de plato con aspecto profesional. Esto demuestra el potencial práctico de la IA multimodal en la comprensión, edición y transferencia de estilo de imágenes. (Fuente: karminski3)

Slideteam.net: Posible herramienta de creación instantánea de diapositivas impulsada por IA: Las redes sociales mencionan que Slideteam.net puede crear diapositivas perfectas “instantáneamente”, lo que sugiere que podría utilizar tecnología de IA para automatizar el diseño y la generación de presentaciones. Este tipo de herramientas suelen implementar funciones como diseño automático, sugerencias de contenido, coincidencia de estilos, etc., mediante IA, con el objetivo de aumentar la eficiencia en la creación de PPT. (Fuente: Ronald_vanLoon)
Demostración de robot de masaje con IA: Un video muestra un robot de masaje impulsado por IA. Este robot combina la capacidad de operación física de un brazo robótico con el control inteligente de la IA. La IA podría usarse para comprender las necesidades del usuario, identificar partes del cuerpo, planificar rutas de masaje, ajustar la fuerza y las técnicas, e incluso percibir la reacción del usuario a través de sensores para optimizar la experiencia de masaje, mostrando el potencial de aplicación de la IA en servicios de salud personalizados y terapia física automatizada. (Fuente: Ronald_vanLoon)
Integración de GitHub Copilot en Windows Terminal: Microsoft ha integrado la funcionalidad de GitHub Copilot en la versión Canary de su Windows Terminal, denominándola “Terminal Chat”. Los usuarios suscritos a Copilot pueden interactuar directamente con la IA en el entorno de la terminal para obtener sugerencias, explicaciones y ayuda con la línea de comandos. Esta medida tiene como objetivo reducir la necesidad de los desarrolladores de cambiar de aplicación al escribir comandos, proporcionando asistencia inteligente sensible al contexto para mejorar la eficiencia y precisión de las operaciones de línea de comandos, especialmente para tareas complejas o desconocidas. (Fuente: GitHub Copilot 现可在 Windows 终端中运行了)
Discusión sobre los requisitos de hardware para desplegar OpenWebUI: Usuarios de la comunidad Reddit discuten la configuración de máquina virtual de Azure necesaria para desplegar OpenWebUI (una interfaz web para LLM) para un equipo de aproximadamente 30 personas. El usuario planea ejecutar localmente el modelo de embedding Snowflake y usar la API de OpenAI. La discusión abarca la escalabilidad de recursos, el impacto del tamaño del modelo de embedding en CPU/RAM/almacenamiento y la importancia del preprocesamiento de datos. La comunidad sugiere que depender en gran medida de la API puede reducir los requisitos de hardware local, pero si se ejecutan modelos localmente (especialmente modelos de embedding), se necesita una configuración más potente. Para situaciones con recursos limitados, se recomienda usar también la API para procesar los embeddings. (Fuente: Reddit r/OpenWebUI)
📚 Aprendizaje
Defecto de “pensamiento excesivo” en modelos de IA de razonamiento ante premisas faltantes: Investigaciones de la Universidad de Maryland y otras instituciones revelan que los modelos de razonamiento actuales (como DeepSeek-R1, o1), al enfrentarse a problemas con información necesaria faltante (premisa faltante, MiP), tienden a generar respuestas largas e ineficaces en lugar de identificar rápidamente el defecto del problema en sí. Este fenómeno de “pensamiento excesivo MiP” conduce al desperdicio de recursos computacionales y tiene poca relación con si el modelo finalmente se da cuenta de la falta de la premisa. En comparación, los modelos que no son de razonamiento se comportan mejor. La investigación sugiere que esto expone una falta de pensamiento crítico en los modelos de razonamiento actuales, posiblemente derivada del paradigma de entrenamiento de aprendizaje por refuerzo o del proceso de destilación de conocimiento. (Fuente: 推理AI“脑补”成瘾,废话拉满,马里兰华人学霸揭开内幕)

CVPR 2025: CADCrafter logra generar archivos CAD editables a partir de una sola imagen: Investigadores de Magic Core Technology, la Universidad Tecnológica de Nanyang y otras instituciones proponen el framework CADCrafter, capaz de generar directamente archivos de ingeniería CAD parametrizados y editables (representados como secuencias de comandos CAD) a partir de una sola imagen (renderizado de pieza, foto de objeto real, etc.), en lugar de los modelos tradicionales de malla o nube de puntos. El método emplea un VAE para codificar los comandos CAD y lo combina con un Diffusion Transformer para la generación en el espacio latente condicionada por la imagen. Mejora el rendimiento mediante una estrategia de destilación de múltiples vistas a una sola vista y utiliza DPO para optimizar y asegurar la compilabilidad de los comandos generados. Los archivos CAD generados pueden usarse directamente para producción y mecanizado, y admiten la modificación del modelo editando los comandos, mejorando significativamente la utilidad y la calidad superficial de los modelos 3D generados por IA. (Fuente: 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品)
Revisión sobre OS Agents publicada por la Universidad de Zhejiang, OPPO, etc.: Este artículo de revisión resume sistemáticamente el estado actual de la investigación sobre agentes de sistema operativo (OS Agents) basados en modelos grandes multimodales (MLLM). Los OS Agents se refieren a IA capaces de ejecutar tareas automáticamente en dispositivos como computadoras y teléfonos a través de la interfaz del sistema operativo (GUI). El artículo define sus elementos clave (entorno, espacio de observación, espacio de acción), capacidades centrales (comprensión, planificación, ejecución), revisa los métodos de construcción (arquitectura y entrenamiento del modelo base, diseño del framework del agente) y resume los protocolos de evaluación, benchmarks y productos comerciales relacionados. Finalmente, discute desafíos y direcciones futuras como la seguridad y privacidad, la personalización y la autoevolución, proporcionando una referencia completa para la investigación en este campo. (Fuente: 浙大、OPPO等发布最新综述:基于多模态大模型的计算机、手机与浏览器智能体研究)
ICLR 2025: Nabla-GFlowNet logra un ajuste fino eficiente y diverso de recompensas para modelos de difusión: Para abordar los problemas de convergencia lenta (RL tradicional) o pérdida de diversidad (optimización directa) en el ajuste fino de recompensas de modelos de difusión, los investigadores proponen el método Nabla-GFlowNet. Basado en el marco de redes de flujo generativo (GFlowNet), deriva nuevas condiciones de equilibrio de flujo (Nabla-DB) y funciones de pérdida, utilizando información del gradiente de la recompensa para guiar el ajuste fino. Mediante un diseño de parametrización específico, logra una convergencia más rápida que métodos como DDPO mientras mantiene la diversidad de las muestras generadas. Se validó en el modelo Stable Diffusion utilizando funciones de recompensa como estética y seguimiento de instrucciones, superando a los métodos existentes. (Fuente: ICLR 2025 | 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得)
Análisis del mecanismo de inferencia de DeepSeek-R1: Investigaciones de la Universidad McGill analizan en profundidad el proceso de “pensamiento” de modelos de razonamiento como DeepSeek-R1. El estudio encuentra que la longitud de su cadena de razonamiento no se correlaciona positivamente con el rendimiento, existiendo un “punto óptimo”, y un razonamiento excesivamente largo puede ser perjudicial. El modelo puede atascarse en la repetición de formulaciones existentes al procesar contextos largos o problemas complejos. Además, en comparación con los modelos que no son de razonamiento, DeepSeek-R1 puede tener vulnerabilidades de seguridad más evidentes. Esta investigación revela algunas características y limitaciones potenciales del mecanismo operativo de los modelos de razonamiento actuales. (Fuente: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Nuevo método C3PO para optimizar modelos MoE en tiempo de prueba: La Universidad Johns Hopkins propone el método C3PO (Optimización de Capas Críticas, Expertos Centrales y Rutas Colaborativas) para optimizar el rendimiento de los modelos grandes de Mezcla de Expertos (MoE) en tiempo de prueba. El método repondera a los expertos centrales en las capas clave, optimizando para cada muestra de prueba para resolver el problema de las rutas de expertos subóptimas. Los experimentos muestran que C3PO puede mejorar significativamente la precisión de los modelos MoE (7-15%), e incluso hacer que los modelos MoE de menor tamaño superen en rendimiento a modelos densos con más parámetros, mejorando la eficiencia de la arquitectura MoE. (Fuente: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Estudio sistemático del impacto de la cuantización en el rendimiento de los modelos de razonamiento: La Universidad de Tsinghua y otras instituciones investigan sistemáticamente por primera vez el impacto de la cuantización de modelos en el rendimiento de los modelos de razonamiento (como DeepSeek-R1, serie Qwen). Los experimentos evalúan el efecto de la cuantización bajo diferentes anchos de bits (pesos, caché KV, activaciones) y algoritmos. El estudio encuentra que la cuantización W8A8 o W4A16 generalmente logra un rendimiento sin pérdidas o casi sin pérdidas, pero anchos de bits más bajos aumentan significativamente el riesgo. El tamaño del modelo, el origen y la dificultad de la tarea son factores clave que influyen en el rendimiento después de la cuantización. Los resultados de la investigación y los modelos cuantizados se han hecho de código abierto. (Fuente: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
APIGen-MT: Framework para generar datos de interacción de Agentes multivuelta de alta calidad: Salesforce propone el framework APIGen-MT, destinado a resolver la escasez de datos de alta calidad necesarios para entrenar Agentes de IA de interacción multivuelta. El framework consta de dos etapas: primero, utiliza la revisión de LLM y la retroalimentación iterativa para generar un plan detallado de la tarea; luego, simula la interacción humano-máquina para convertir el plan en datos completos de trayectoria. La serie de modelos xLAM-2 entrenada con este framework muestra un rendimiento excelente en benchmarks de Agentes multivuelta, superando a modelos como GPT-4o, validando la efectividad de este método de generación de datos. Los datos sintéticos y los modelos se han hecho de código abierto. (Fuente: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Investigación revela: Cadenas de pensamiento más largas no equivalen a un mejor rendimiento de razonamiento, el aprendizaje por refuerzo puede ser más conciso: Investigaciones de Wand AI señalan que los modelos de razonamiento (especialmente los entrenados con algoritmos RL como PPO) tienden a generar respuestas más largas, no porque la precisión lo requiera, sino porque el propio mecanismo RL puede causarlo: para respuestas incorrectas (recompensa negativa), alargar la respuesta puede “diluir” el castigo por token, reduciendo así la pérdida. La investigación demuestra que el razonamiento conciso se correlaciona con una mayor precisión y propone un método de entrenamiento RL de dos etapas: primero entrenar con problemas difíciles para mejorar la capacidad (posiblemente alargando las respuestas), luego entrenar con problemas de dificultad moderada para fomentar la concisión y mantener la precisión, logrando mejorar eficazmente el rendimiento y la robustez incluso con conjuntos de datos muy pequeños. (Fuente: 更长思维并不等于更强推理性能,强化学习可以很简洁)
USTC y ZTE proponen Curr-ReFT: Nuevo paradigma de post-entrenamiento para VLM de tamaño pequeño: Para abordar los problemas de baja capacidad de generalización, capacidad de razonamiento limitada y entrenamiento inestable (fenómeno de “muro de ladrillos”) que enfrentan los modelos de lenguaje visual (VLM) pequeños después del ajuste fino supervisado, la Universidad de Ciencia y Tecnología de China (USTC) y ZTE proponen el paradigma de post-entrenamiento Curr-ReFT. Este método combina el aprendizaje por refuerzo curricular (Curr-RL) y la auto-mejora basada en muestreo por rechazo. Curr-RL guía al modelo a aprender progresivamente de fácil a difícil mediante un mecanismo de recompensa sensible a la dificultad; el muestreo por rechazo utiliza muestras de alta calidad para mantener las capacidades básicas del modelo. Los experimentos en los modelos Qwen2.5-VL-3B/7B muestran que Curr-ReFT mejora significativamente el rendimiento de razonamiento y generalización del modelo, permitiendo que los modelos pequeños superen a modelos más grandes en varios benchmarks. El código, los datos y los modelos se han hecho de código abierto. (Fuente: 中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理)
Tsinghua y Shanghai AI Lab proponen GenPRM: Modelo de recompensa de proceso generativo escalable: Para resolver los problemas de falta de interpretabilidad y capacidad de escalado en tiempo de prueba de los modelos tradicionales de recompensa de proceso (PRM) al supervisar el razonamiento de LLM, la Universidad de Tsinghua y Shanghai AI Lab proponen GenPRM. Evalúa los pasos de razonamiento generando cadenas de pensamiento en lenguaje natural (CoT) y código de verificación ejecutable, proporcionando retroalimentación más transparente. GenPRM admite la expansión computacional en tiempo de prueba, mejorando la precisión al muestrear múltiples rutas de evaluación y promediar las recompensas. Entrenado con solo 23K datos sintéticos, la versión de 1.5B, con la ayuda de la expansión en tiempo de prueba, ya supera a GPT-4o, y la versión de 7B supera a los modelos base de 72B. GenPRM también puede actuar como crítico a nivel de paso para la mejora iterativa de respuestas. (Fuente: 过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o)
Lanzamiento del mayor conjunto de datos matemáticos de código abierto del mundo, MegaMath (371B Tokens): LLM360 ha lanzado el conjunto de datos MegaMath, que contiene 371 mil millones de tokens, siendo actualmente el mayor conjunto de datos de preentrenamiento de código abierto del mundo centrado en el razonamiento matemático. Su objetivo es cerrar la brecha en escala y calidad entre la comunidad de código abierto y los corpus matemáticos de código cerrado (como DeepSeek-Math). El conjunto de datos consta de tres partes: datos web a gran escala relacionados con las matemáticas (279B, incluido un subconjunto de alta calidad de 15B), código matemático (28B) y datos sintéticos de alta calidad (64B, que incluyen preguntas y respuestas, generación de código, mezcla de texto e imagen). Tras un cuidadoso procesamiento y múltiples rondas de validación de preentrenamiento, el uso de MegaMath para preentrenar el modelo Llama-3.2 puede generar mejoras significativas de rendimiento del 15-20% en benchmarks como GSM8K y MATH. (Fuente: 3710亿数学Tokens!全球最大开源数学数据集MegaMath震撼发布,碾压DeepSeek-Math)
CVPR 2025: NLPrompt mejora la robustez del aprendizaje por prompts de VLM con etiquetas ruidosas: YesAI Lab de la Universidad ShanghaiTech propone el método NLPrompt, destinado a resolver la degradación del rendimiento del aprendizaje por prompts de modelos de lenguaje visual (VLM) frente al ruido en las etiquetas. La investigación descubre que, en el escenario del aprendizaje por prompts, la pérdida de error absoluto medio (MAE) (PromptMAE) es más robusta que la pérdida de entropía cruzada (CE). Al mismo tiempo, proponen el método de purificación de datos PromptOT basado en transporte óptimo, que utiliza características de texto generadas por prompts como prototipos para dividir el conjunto de datos en conjuntos limpios y ruidosos. NLPrompt utiliza la pérdida CE para el conjunto limpio y la pérdida MAE para el conjunto ruidoso, combinando eficazmente las ventajas de ambos. Los experimentos demuestran que este método mejora significativamente la robustez y el rendimiento de métodos de aprendizaje por prompts como CoOp en conjuntos de datos con ruido sintético y real. (Fuente: CVPR 2025 | MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法)
Aplicación y discusión de la técnica de destilación de conocimiento en la compresión de modelos: La comunidad discute la técnica de destilación de conocimiento, que consiste en usar un modelo grande “maestro” para entrenar un modelo pequeño “alumno”, logrando que este último alcance un rendimiento cercano al del maestro en una tarea específica, pero con un costo significativamente menor. Un usuario compartió el éxito al destilar la capacidad de GPT-4o en análisis de sentimientos (92% de precisión) a un modelo pequeño, reduciendo el costo 14 veces. Los comentarios señalan que, aunque el efecto de la destilación es notable, generalmente se limita a dominios específicos, y el modelo alumno carece de la capacidad de generalización del modelo maestro. Al mismo tiempo, para escenarios profesionales que requieren adaptación continua a los cambios en los datos, el costo de mantener un modelo autoentrenado podría ser mayor que usar directamente una API grande. (Fuente: Reddit r/MachineLearning)

La definición de Agente de IA atrae atención: Consultoras como McKinsey comienzan a definir y discutir el concepto de Agente de IA, reflejando la creciente importancia en los ámbitos comercial y tecnológico de los Agentes de IA como entidades inteligentes capaces de percibir, decidir y actuar autónomamente para completar objetivos. Comprender la definición, capacidades y escenarios de aplicación de los Agentes de IA se convierte en un punto de interés para la industria. (Fuente: Ronald_vanLoon)

💼 Negocios
Descifrando la estrategia de IA de Alibaba: Centrada en AGI, fuerte inversión en infraestructura para impulsar la transformación: El análisis señala que, aunque Alibaba no ha lanzado formalmente una estrategia de IA, sus acciones ya revelan un panorama claro: perseguir la AGI como objetivo principal para recuperar la iniciativa en la competencia. Planea invertir más de 380 mil millones de RMB en los próximos tres años en infraestructura de IA y computación en la nube, centrándose en satisfacer la creciente demanda de inferencia. La ruta estratégica incluye: promover las capacidades de AI Agent a través de DingTalk; impulsar el crecimiento de Alibaba Cloud utilizando la serie de modelos de código abierto Qwen; desarrollar el modelo MaaS de la API Tongyi. Al mismo tiempo, Alibaba transformará profundamente sus negocios existentes con IA, como mejorar la experiencia del usuario en Taobao, convertir Quark en una aplicación insignia de IA (búsqueda + Agente), y explorar aplicaciones de IA en servicios de vida a través de Gaode Maps. Alibaba también podría acelerar su despliegue de IA a través de inversiones y adquisiciones. (Fuente: 解秘阿里 AI 战略:从未发布,但已开始狂奔)
Nuevas tendencias en el mercado de talento de IA: Énfasis en la práctica sobre la educación, se valoran las habilidades compuestas: Basado en el análisis de casi 3000 puestos de trabajo de IA bien remunerados en las principales ciudades de China, el informe revela tres tendencias principales en la demanda de talento de IA: 1) Fuerte demanda de ingenieros de algoritmos con salarios atractivos, siendo la industria automotriz el principal empleador; 2) Las empresas (incluidas estrellas como DeepSeek) están reduciendo gradualmente los requisitos estrictos de titulación académica, valorando más la capacidad práctica de ingeniería y la experiencia en la resolución de problemas complejos; 3) Aumento de la demanda de talento compuesto, por ejemplo, los gerentes de producto de IA necesitan entender simultáneamente al usuario, el modelo y la ingeniería de prompts, ya que la IA está asumiendo tareas más especializadas, requiriendo que los humanos integren y supervisen a un nivel superior. (Fuente: 从近3000个招聘数据里,我找到了挖掘AI人才的三条铁律)
Ubtech continúa registrando pérdidas, los desafíos de comercialización de robots humanoides son severos: El informe financiero de 2024 de la empresa de robots humanoides Ubtech muestra que, a pesar de un aumento de ingresos del 23.7% a 1.3 mil millones de yuanes, todavía registró pérdidas de 1.16 mil millones de yuanes. La comercialización de su negocio principal de robots humanoides avanza lentamente, entregando solo 10 unidades en todo el año, con un precio unitario de hasta 3.5 millones de yuanes, muy por encima de las expectativas del mercado y de competidores (como el G1 de Unitree Technology que cuesta solo 99,000 yuanes). Sumado a los rumores de problemas de flujo de caja en otra empresa líder del sector, CloudMinds, esto ha generado dudas sobre la viabilidad comercial de la industria de robots humanoides, confirmando la cautelosa opinión expresada anteriormente por el inversor Zhu Xiaohu. Los altos costos, los escenarios de aplicación limitados y la seguridad y fiabilidad son actualmente los principales obstáculos para la comercialización a gran escala de robots humanoides. (Fuente: 优必选一年亏损近12亿 朱啸虎这下更有话说了)

La IA impulsa el crecimiento en los sectores de telecomunicaciones, alta tecnología y medios: Se discute que la inteligencia artificial (incluida la IA generativa) se está convirtiendo en una fuerza clave para impulsar el crecimiento en los sectores de telecomunicaciones, alta tecnología y medios. La tecnología de IA se aplica ampliamente para mejorar la experiencia del cliente, optimizar las operaciones de red, automatizar la creación de contenido, aumentar la eficiencia operativa y desarrollar servicios innovadores, ayudando a las empresas de estos sectores a obtener una ventaja competitiva en un mercado que cambia rápidamente. (Fuente: Ronald_vanLoon)
Hugging Face adquiere la empresa de robótica de código abierto Pollen Robotics: La conocida plataforma de modelos y herramientas de IA, Hugging Face, ha adquirido Pollen Robotics, la startup famosa por su robot humanoide de código abierto Reachy. Esta adquisición indica la intención de Hugging Face de expandir su exitoso modelo de código abierto al campo de la robótica de IA, con el objetivo de fomentar la colaboración y la innovación en este sector a través de soluciones de hardware y software abiertas, acelerando el proceso de democratización de la tecnología robótica. (Fuente: huggingface, huggingface, huggingface, huggingface)

🌟 Comunidad
La era de la IA podría ser más favorable para los graduados en humanidades: Lynn Duan, fundadora de la comunidad AI+ de Silicon Valley, cree que a medida que las herramientas de IA (como Cursor) reducen la barrera de entrada a la programación, la importancia relativa de las habilidades de ingeniería disminuye, mientras que las habilidades en humanidades y ciencias sociales como comercialización, marketing y comunicación se vuelven más cruciales. La IA reemplaza algunos puestos técnicos de nivel inicial, pero crea demanda de talento compuesto capaz de conectar la tecnología con el mercado. Aconseja a los graduados considerar startups para un crecimiento rápido y demostrar sus capacidades a través de proyectos prácticos (como desplegar modelos, desarrollar aplicaciones) en lugar de depender únicamente de las credenciales académicas. También señala que las cualidades del fundador (como convicción, comprensión de la industria) son más importantes que una formación puramente técnica, y ve oportunidades de emprendimiento en IA en el SaaS estadounidense y el hardware inteligente chino. (Fuente: AI反而是文科生的好时代|对话硅谷AI+创始人Lynn Duan)

El breve “bloqueo” de IPs chinas por parte de GitHub genera preocupación, la versión oficial es que fue un error operativo: Recientemente, algunos usuarios chinos descubrieron que no podían acceder a GitHub sin iniciar sesión, recibiendo un mensaje de IP restringida, lo que generó preocupación en la comunidad sobre un posible “bloqueo”. Aunque GitHub respondió rápidamente afirmando que fue un error de configuración y que ya se había solucionado, el incidente sigue generando debate. Dado que GitHub ha restringido en el pasado el acceso desde regiones como Irán y Rusia según las políticas de sanciones de EE. UU., algunos interpretaron este evento como un posible “ensayo” de futuras medidas restrictivas. El artículo subraya la importancia de GitHub para los desarrolladores chinos y el ecosistema de código abierto (incluidos numerosos proyectos de IA), así como el impacto negativo que tales restricciones podrían tener, y enumera plataformas de alojamiento de código nacionales como Gitee y CODING como alternativas. (Fuente: “Bug”还是“预演”?GitHub 突然“封禁”所有中国 IP,官方:只是“手滑”技术出错了)
El rendimiento y servicio de Claude AI generan controversia entre los usuarios: Discusiones en Reddit muestran que algunos usuarios expresan insatisfacción con el modelo Claude de Anthropic, mencionando una disminución del rendimiento, modificaciones innecesarias al codificar y decepción con los niveles de pago y los límites de tasa, e incluso desarrolladores conocidos afirman que cambiarán a otros modelos (como Gemini 2.5 Pro). Sin embargo, otros usuarios consideran que Claude (especialmente la versión anterior Sonnet 3.5) todavía tiene ventajas en tareas específicas (como la codificación), o afirman no haber encontrado límites de tasa con frecuencia. Esta controversia refleja experiencias de usuario divergentes con Claude y las altas expectativas de los usuarios sobre el rendimiento y el servicio de los modelos de IA en un mercado altamente competitivo. (Fuente: Reddit r/ClaudeAI)

La escala de la función Deep Research de Gemini genera debate: Un usuario compartió su experiencia usando la función Deep Research de Google Gemini Advanced, donde la IA accedió a casi 700 sitios web para responder una pregunta y generó un informe extenso (por ejemplo, 37 páginas). Esta escala impresionó al usuario, pero también generó un debate sobre la calidad de la información. Los comentaristas cuestionaron si procesar tal cantidad de información web puede garantizar la precisión y profundidad, o si simplemente agrega resultados de búsqueda web potencialmente erróneos a mayor escala. Esto refleja la atención y el escrutinio de la comunidad sobre la capacidad de procesamiento de información (profundidad vs. amplitud) de las herramientas de investigación de IA. (Fuente: Reddit r/artificial)

La capacidad de programación de Gemini 2.5 Pro recibe elogios de la comunidad: Varios usuarios compartieron en la comunidad experiencias positivas al usar Google Gemini 2.5 Pro para programar, considerándolo muy inteligente, capaz de entender bien la intención del usuario, y con una capacidad de procesamiento de contexto largo de 1 millón de tokens (suficiente para analizar grandes bases de código) además de ser gratuito, superando en rendimiento general a competidores como Claude. Aunque existen algunas pequeñas imperfecciones (como alucinar ocasionalmente funciones de biblioteca inexistentes), la evaluación general es muy alta, considerándose uno de los modelos de codificación más populares del momento, y expresando expectación por modelos potencialmente más potentes de Google en el futuro (como Dragontail). (Fuente: Reddit r/ArtificialInteligence)
El rápido desarrollo de modelos pequeños de código abierto requiere actualizar la percepción del usuario: Una discusión en la comunidad reflexiona sobre el rápido progreso de los LLM de código abierto. Señala que modelos como QwQ-32B y Gemma-3-27B, que parecen buenos ahora, habrían sido revolucionarios si hubieran existido hace uno o dos años (cuando se lanzó GPT-4). Esto recuerda a todos que no se debe subestimar la capacidad real de los modelos pequeños de código abierto actuales, ya que han alcanzado un nivel considerablemente alto. Los comentarios también reconocen que estos modelos todavía tienen brechas en comparación con los modelos de código cerrado de primer nivel (como estabilidad, velocidad, procesamiento de contexto), pero enfatizan su velocidad de progreso y potencial, sugiriendo que futuras innovaciones podrían provenir de la arquitectura en lugar de simplemente acumular parámetros. (Fuente: Reddit r/LocalLLaMA)
Miembro de la comunidad ofrece capacidad de cómputo A100 gratuita para apoyar proyectos de IA: Un usuario con 4 GPUs Nvidia A100 publicó en la comunidad de Reddit ofreciendo capacidad de cómputo gratuita (aproximadamente 100 horas A100) para proyectos de entusiastas de la IA que sean innovadores, busquen tener un impacto positivo y estén limitados por los recursos computacionales. La iniciativa recibió una respuesta positiva, con varios investigadores y desarrolladores proponiendo planes de proyectos específicos que abarcan el entrenamiento de nuevas arquitecturas de modelos, interpretabilidad de modelos, aprendizaje modular, aplicaciones de interacción humano-máquina, etc., lo que refleja la necesidad de recursos computacionales en la comunidad de investigación de IA y el espíritu de ayuda mutua y compartición. (Fuente: Reddit r/deeplearning)
El problema de los límites de tasa de Claude AI genera debate en la comunidad: Las quejas sobre alcanzar frecuentemente los límites de tasa al usar el modelo Claude AI (por ejemplo, después de solo 5 mensajes) han generado debate en la comunidad. Algunos usuarios cuestionan enérgicamente estas quejas, considerándolas exageradas o resultado de un uso inadecuado por parte del usuario (como subir contextos muy largos cada vez), y piden pruebas. Sin embargo, otros usuarios comparten sus propias experiencias, confirmando que efectivamente alcanzan los límites con frecuencia al realizar tareas intensivas (como la edición de código grande), lo que afecta su flujo de trabajo. La discusión refleja la gran variabilidad en la experiencia de los usuarios con los límites de tasa, posiblemente relacionada con el modo de uso específico y la complejidad de la tarea, y también muestra la sensibilidad de los usuarios a las limitaciones de los servicios de pago. (Fuente: Reddit r/ClaudeAI)
💡 Otros
Conferencia sobre Ecosistema de AIGC y Agentes Inteligentes (Shanghái) se celebrará en junio: La Segunda Conferencia sobre Ecosistema de AIGC e Inteligencia Artificial se celebrará el 12 de junio de 2025 en Shanghái, con el tema “Cadena Inteligente de Todas las Cosas · Coexistencia Sin Límites”. La conferencia se centrará en la innovación colaborativa y la integración ecológica de la IA generativa (AIGC) y los agentes inteligentes (AI Agent), cubriendo temas como infraestructura de IA, modelos de lenguaje grandes, marketing y aplicaciones de escenarios de AIGC (medios, comercio electrónico, industria, salud, etc.), tecnología multimodal, marcos de decisión autónomos, etc. Su objetivo es impulsar la actualización de la IA de herramientas puntuales a la colaboración ecológica, conectando a proveedores de tecnología, demandantes, capital y responsables políticos. (Fuente: 6月上海|“智链万物”上海峰会:AIGC+智能体生态融合)

Conferencia AI Partner de 36Kr se centra en Super APP: 36Kr celebrará la “Conferencia AI Partner 2025 · Llegaron las Super APP” el 18 de abril de 2025 en el MoSu Space de Shanghái. La conferencia tiene como objetivo explorar cómo las aplicaciones de IA están remodelando el mundo empresarial y dando lugar a “superaplicaciones” disruptivas. Reunirá a ejecutivos de empresas como AMD, Baidu, 360, Qualcomm e inversores para discutir temas candentes como la IA industrial, la capacidad de cómputo de IA, la búsqueda con IA, la educación con IA, etc., y presentará casos innovadores de aplicaciones nativas de IA y los Premios a la Innovación AI Partner. Simultáneamente se celebrarán un Salón de IA Inclusiva y un seminario a puerta cerrada sobre la internacionalización de la IA. (Fuente: Super App来了!看AI应用正如何「改写」商业世界?|2025 AI Partner大会核心看点)

Horizon Robotics contrata becarios de algoritmos de reconstrucción/generación 3D: El equipo de Inteligencia Corpórea de Horizon Robotics está contratando becarios de algoritmos en el área de reconstrucción/generación 3D en Shanghái y Beijing. El puesto implicará el diseño y desarrollo de algoritmos Real2Sim, utilizando tecnologías como Gaussian Splatting 3D, reconstrucción feed-forward, generación 3D/video para reducir el costo de adquisición de datos de robots y optimizar el rendimiento del simulador. Se requiere maestría o superior, con experiencia y habilidades relevantes. Se ofrece oportunidad de conversión a empleado fijo, recursos de GPU y orientación profesional. (Fuente: 上海/北京内推 | 地平线机器人具身智能团队招聘3D重建/生成方向算法实习生)
OceanBase organiza su primer Hackathon de IA: El proveedor de bases de datos OceanBase, en colaboración con Ant Open Source, Machine Heart y otros, organiza su primer Hackathon de IA con el tema “DB+AI”, ofreciendo un fondo de premios de 100,000 yuanes. El concurso anima a los desarrolladores a explorar la combinación de OceanBase y tecnologías de IA, en direcciones como el uso de OceanBase como base de datos para aplicaciones de IA, o la construcción de aplicaciones de IA (como sistemas de preguntas y respuestas, diagnóstico) dentro del ecosistema OceanBase (combinando con CAMEL AI, FastGPT, etc.). El período de inscripción es del 10 de abril al 7 de mayo, abierto a individuos y equipos. (Fuente: 10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?)
Meituan Hotel & Travel contrata Ingenieros de Algoritmos de Modelos Grandes L7-L8: El equipo de algoritmos de suministro de Meituan Hotel & Travel en Beijing está contratando Ingenieros de Algoritmos de Modelos Grandes de nivel L7-L8 (contratación externa). Las responsabilidades incluyen el uso de NLP y tecnología de modelos grandes para construir un sistema de comprensión del suministro de hoteles y viajes (etiquetas, puntos calientes, análisis de similitud), optimizar materiales de exhibición de productos (títulos, imágenes y texto), construir combinaciones de paquetes vacacionales y explorar la aplicación de tecnología de modelos grandes de vanguardia en algoritmos del lado de la oferta. Se requiere maestría o superior, más de 2 años de experiencia, y sólidas habilidades en algoritmos y programación. (Fuente: 北京内推 | 美团酒旅供给算法团队招聘L7-L8大模型算法工程师)
QbitAI contrata Editores/Autores en el campo de la IA: El medio de comunicación tecnológica de IA QbitAI está contratando editores/autores a tiempo completo, con lugar de trabajo en Zhongguancun, Beijing, abierto a contrataciones externas y recién graduados, ofreciendo oportunidades de conversión de prácticas. Las áreas de contratación incluyen modelos grandes de IA, robots de inteligencia corpórea, hardware de terminal y edición de nuevos medios de IA (Weibo/Xiaohongshu). Se requiere pasión por el campo de la IA, buenas habilidades de redacción y recopilación de información. Puntos extra incluyen familiaridad con herramientas de IA, capacidad de interpretación de artículos científicos, habilidades de programación, etc. Se ofrece salario competitivo, beneficios y oportunidades de crecimiento profesional. (Fuente: 量子位招聘 | DeepSeek帮我们改的招聘启事)
Ganador del Premio Turing LeCun habla sobre el desarrollo de la IA: La inteligencia humana no es general, la próxima generación de IA podría no ser generativa: En una entrevista de podcast, Yann LeCun argumentó que la búsqueda actual de AGI (Inteligencia Artificial General) se basa en un malentendido, ya que la inteligencia humana en sí misma es altamente especializada, no general. Predice que el próximo avance en IA podría basarse en modelos no generativos, como su propuesta arquitectura JEPA, centrada en hacer que la IA comprenda el mundo físico y posea capacidades de razonamiento y planificación (modelos del mundo), en lugar de simplemente procesar lenguaje. Considera que los LLM actuales carecen de verdadera capacidad de razonamiento. LeCun también enfatizó la importancia del código abierto (como LLaMA de Meta) para impulsar el desarrollo de la IA y considera que dispositivos como las gafas inteligentes son una dirección importante para la implementación de la tecnología de IA. (Fuente: 图灵奖得主LeCun:人类智能不是通用智能,下一代AI可能基于非生成式)
Cumbre de la Industria AIGC de China se celebrará próximamente (16 de abril, Beijing): La Tercera Cumbre de la Industria AIGC de China se celebrará el 16 de abril en Beijing. La cumbre reunirá a más de 20 líderes de la industria de empresas e instituciones como Baidu, Huawei, AWS, Microsoft Research Asia, Mianbi Intelligence, Shengshu Technology, Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health, para discutir los últimos avances en tecnología de IA, su aplicación en diversas industrias, infraestructura de cómputo, seguridad y control, y otros temas centrales. La cumbre tiene como objetivo mostrar cómo la IA está potenciando la actualización industrial y anunciará premios relevantes y el “Mapa Panorámico de Aplicaciones AIGC de China”. (Fuente: 倒计时2天!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此)
Exploración de soluciones para ejecutar modelos de billones de parámetros en tarjetas gráficas de bajo costo: El artículo explora una solución de estación de trabajo de IA todo en uno de costo controlado (nivel de 100,000 yuanes) construida con tarjetas gráficas Intel® Arc™ (como A770) y procesadores Xeon® W. Esta solución, mediante la colaboración de software y hardware (IPEX-LLM, OpenVINO™, oneAPI) y optimización, permite ejecutar modelos grandes como QwQ-32B (velocidad de hasta 32 tokens/s) e incluso DeepSeek R1 de 671B (con optimización FlashMoE, velocidad cercana a 10 tokens/s) en una sola máquina. Esto proporciona a las empresas una opción de alta relación costo-efectividad para desplegar modelos grandes localmente o en el borde, satisfaciendo necesidades como inferencia fuera de línea y seguridad de datos. Intel también ha lanzado la plataforma OPEA, colaborando con socios del ecosistema para promover la estandarización y popularización de las aplicaciones de IA empresariales. (Fuente: 榨干3000元显卡,跑通千亿级大模型的秘方来了)
Robot quirúrgico demuestra operación de alta precisión: Un video muestra un robot quirúrgico separando con precisión la cáscara de un huevo de codorniz crudo de su membrana interna, demostrando el nivel avanzado de los robots modernos en operaciones finas y control. (Fuente: Ronald_vanLoon)
Resumen de los avances en la tecnología de litografía de semiconductores: Enlace a un artículo sobre el contenido de la conferencia SPIE Advanced Lithography + Patterning, discutiendo los últimos avances en tecnologías de fabricación de chips de próxima generación, incluyendo High-NA EUV, costos de EUV, modelado de patrones, nuevos fotorresistentes (óxido metálico, seco) e Hyper-NA. Estas tecnologías son cruciales para soportar el desarrollo futuro de chips de IA. (Fuente: dylan522p)
Demostración de habilidades precisas de robot con ruedas: Un video muestra las habilidades de movimiento u operación de alta precisión de un robot con ruedas, posiblemente involucrando tecnologías de IA y aprendizaje automático para control y percepción. (Fuente: Ronald_vanLoon)