
Palabras clave:GPT-4.5, 大模型 (modelo grande), 华为盘古Ultra性能 (rendimiento de Huawei Pangu Ultra), GPT-4.5训练细节 (detalles de entrenamiento de GPT-4.5), RLHF对推理能力影响 (impacto de RLHF en capacidades de razonamiento), 人类学习上限4GB研究 (investigación sobre límite de 4GB en aprendizaje humano), 开源数学数据集MegaMath (conjunto de datos matemáticos de código abierto MegaMath)
🔥 Foco
OpenAI revela detalles y desafíos del entrenamiento de GPT-4.5: El CEO de OpenAI, Sam Altman, y el equipo técnico principal de GPT-4.5 dialogaron, revelando detalles del desarrollo del modelo. El proyecto comenzó hace dos años, involucró a casi todo el personal y tomó más tiempo de lo esperado. Durante el entrenamiento, enfrentaron «problemas catastróficos» como fallos en clústeres de 100.000 GPUs y bugs ocultos, lo que expuso cuellos de botella en la infraestructura, pero también impulsó la actualización del stack tecnológico; ahora solo se necesitan 5-10 personas para replicar un modelo de nivel GPT-4. El equipo cree que la clave para la mejora futura del rendimiento radica en la eficiencia de los datos, no en la potencia computacional, y se necesitan desarrollar nuevos algoritmos para aprender más de la misma cantidad de datos. La arquitectura del sistema está migrando hacia multi-clústeres, y en el futuro podría involucrar la colaboración de decenas de millones de GPUs, lo que exige una mayor tolerancia a fallos. La conversación también abordó temas como Scaling Law, el diseño conjunto de machine learning y sistemas, y la naturaleza del aprendizaje no supervisado, mostrando la reflexión y práctica de OpenAI en el impulso de la investigación y desarrollo de modelos grandes de vanguardia (Fuente: 36氪)

Huawei lanza el modelo denso grande Pangu Ultra de 135B parámetros nativo de Ascend: El equipo Pangu de Huawei ha lanzado Pangu Ultra, un modelo de lenguaje general denso con 135B parámetros entrenado en NPUs Ascend de fabricación nacional. El modelo utiliza una estructura Transformer de 94 capas e introduce las tecnologías Depth-scaled sandwich-norm (DSSN) y TinyInit para resolver problemas de estabilidad en el entrenamiento de modelos ultra profundos, logrando un entrenamiento estable sin picos de pérdida (loss spikes) en 13.2T de datos de alta calidad. A nivel de sistema, mediante optimizaciones como paralelismo híbrido, fusión de operadores y segmentación de subsecuencias, la utilización de la potencia computacional (MFU) en un clúster Ascend de 8192 tarjetas se elevó por encima del 50%. Las evaluaciones muestran que Pangu Ultra supera a modelos densos como Llama 405B y Mistral Large 2 en múltiples benchmarks, y puede competir con modelos MoE de mayor escala como DeepSeek-R1, demostrando la viabilidad de desarrollar modelos grandes de primer nivel basados en potencia computacional nacional (Fuente: 机器之心)

Investigación cuestiona la significancia del aprendizaje por refuerzo para mejorar la capacidad de razonamiento de los LLM: Investigadores de la Universidad de Tubinga y la Universidad de Cambridge cuestionan las afirmaciones recientes de que el aprendizaje por refuerzo (RL) puede mejorar significativamente la capacidad de razonamiento de los modelos de lenguaje. Mediante una investigación rigurosa de benchmarks de razonamiento comunes (como AIME24), el estudio encontró una alta inestabilidad en los resultados; simplemente cambiar la semilla aleatoria (random seed) podía causar fluctuaciones drásticas en las puntuaciones. Bajo una evaluación estandarizada, la mejora del rendimiento aportada por RL fue mucho menor que la reportada originalmente, a menudo sin significancia estadística, e incluso inferior al efecto del ajuste fino supervisado (SFT), con una capacidad de generalización también más pobre. El estudio señala que las diferencias de muestreo, la configuración de decodificación, el marco de evaluación y la heterogeneidad del hardware son las principales causas de inestabilidad, y pide la adopción de estándares de evaluación más estrictos y reproducibles para evaluar con calma el progreso real en la capacidad de razonamiento de los modelos (Fuente: 机器之心)

Charla TED de Altman: Lanzará un potente modelo open source, considera que ChatGPT no es AGI: El CEO de OpenAI, Sam Altman, declaró en la conferencia TED que están desarrollando un potente modelo de código abierto (open source) cuyo rendimiento superará a todos los modelos open source existentes, respondiendo directamente a competidores como DeepSeek. Subrayó que la base de usuarios de ChatGPT sigue creciendo exponencialmente y que la nueva función de memoria mejorará la experiencia personalizada. Considera que la IA logrará avances en el descubrimiento científico y el desarrollo de software (con enormes mejoras de eficiencia), pero que los modelos actuales como ChatGPT aún carecen de la capacidad de autoaprendizaje continuo y generalización entre dominios, por lo que no son AGI. También discutió los problemas de derechos de autor y «derechos de estilo» (style rights) provocados por la capacidad creativa de GPT-4o, y reiteró la confianza de OpenAI en la seguridad de sus modelos y sus mecanismos de control de riesgos (Fuente: 新智元)

Estudio estima que el límite de aprendizaje humano es de unos 4GB, generando debate sobre interfaces cerebro-computadora y desarrollo de IA: La revista Neuron, parte de Cell, publicó una investigación del Instituto de Tecnología de California (Caltech) que estima la velocidad de procesamiento de información del cerebro humano en unos 10 bits por segundo, muy por debajo de la tasa de recopilación de datos del sistema sensorial, que es de mil millones de bits por segundo. Basándose en esto, el estudio infiere que el límite de acumulación de conocimiento a lo largo de una vida humana (suponiendo 100 años de aprendizaje ininterrumpido sin olvido) es de aproximadamente 4GB, mucho menor que la capacidad de almacenamiento de parámetros de los modelos grandes (por ejemplo, un modelo 7B puede almacenar 14 mil millones de bits). La investigación sostiene que este cuello de botella se debe al mecanismo de procesamiento en serie del sistema nervioso central y predice que es solo cuestión de tiempo que la inteligencia artificial supere a la humana. El estudio también cuestiona Neuralink de Musk, argumentando que no puede superar las limitaciones estructurales básicas del cerebro y que sería mejor optimizar los métodos de comunicación existentes. Esta investigación ha provocado un amplio debate sobre los límites cognitivos humanos, el potencial de desarrollo de la IA y la dirección de las interfaces cerebro-computadora (Fuente: 量子位)

🎯 Tendencias
GPT-4 será retirado pronto, GPT-4.1 y un misterioso nuevo modelo podrían debutar: OpenAI anunció que a partir del 30 de abril reemplazará completamente GPT-4, lanzado hace dos años, con GPT-4o en ChatGPT; GPT-4 seguirá disponible a través de la API. Al mismo tiempo, filtraciones en la comunidad y en código sugieren que OpenAI podría lanzar pronto una serie de nuevos modelos, incluyendo GPT-4.1 (y sus versiones mini/nano), una versión completa («full-power») del modelo de inferencia o3, y una nueva serie o4 (como o4-mini). Un misterioso modelo llamado Optimus Alpha ya está disponible en OpenRouter, con un rendimiento excelente (especialmente en programación) y soporte para millones de tokens de contexto, lo que ha llevado a especular ampliamente que es uno de los nuevos modelos que OpenAI lanzará próximamente (posiblemente GPT-4.1 u o4-mini), ya que comparte muchas similitudes con los modelos de OpenAI (como bugs específicos). Esto indica que OpenAI está acelerando el ritmo de iteración de sus modelos y consolidando activamente su liderazgo tecnológico (Fuente: source, source)

El modelo grande Qwen3 de Alibaba se prepara para su lanzamiento: Se informa que Alibaba espera lanzar el modelo grande Qwen3 en un futuro próximo. El equipo de desarrollo ha confirmado que el modelo se encuentra en la fase final de preparación, pero no se ha fijado una fecha de lanzamiento específica. Se sabe que Qwen3 es un producto de modelo importante para Alibaba en la primera mitad de 2025, y su desarrollo comenzó después de Qwen2.5. Influenciado por modelos competidores como DeepSeek-R1, el equipo de modelos base de Alibaba Cloud ha reorientado aún más su estrategia hacia la mejora de la capacidad de razonamiento del modelo, mostrando un enfoque estratégico en capacidades específicas en medio del competitivo panorama de los modelos grandes (Fuente: InfoQ)

Kimi reduce precios en su plataforma abierta y libera modelos visuales ligeros open source: La plataforma abierta Kimi de Moonshot AI (月之暗面) anunció una reducción en los precios de sus servicios de inferencia de modelos y caché de contexto, con el objetivo de reducir los costos para los usuarios mediante la optimización tecnológica. Al mismo tiempo, Kimi ha liberado dos modelos de lenguaje visual ligeros basados en la arquitectura MoE, Kimi-VL y Kimi-VL-Thinking, que soportan 128K de contexto y tienen solo unos 3 mil millones de parámetros activos. Se afirma que superan significativamente en capacidad de razonamiento multimodal a modelos grandes con 10 veces más parámetros, con el objetivo de promover el desarrollo y la aplicación de modelos multimodales pequeños y eficientes (Fuente: InfoQ)
Google lanza el protocolo de interoperabilidad de agentes A2A y varios productos nuevos de IA: En la conferencia Google Cloud Next ’25, Google, junto con más de 50 socios, lanzó el protocolo abierto Agent2Agent (A2A), destinado a permitir la interoperabilidad y colaboración entre agentes de IA desarrollados por diferentes empresas y plataformas. Al mismo tiempo, lanzó varios modelos y aplicaciones de IA, incluyendo Gemini 2.5 Flash (versión eficiente del modelo insignia), Lyria (generación de música a partir de texto), Veo 2 (creación de vídeo), Imagen 3 (generación de imágenes), Chirp 3 (voz personalizada), y presentó el chip TPU de séptima generación, Ironwood, optimizado específicamente para la inferencia. Esta serie de lanzamientos refleja el despliegue integral y la estrategia abierta de Google en infraestructura, modelos, plataformas y agentes de IA (Fuente: InfoQ)
ByteDance lanza el modelo de inferencia Seed-Thinking-v1.5 con 200B parámetros: El equipo Doubao de ByteDance publicó un informe técnico presentando su modelo de inferencia MoE Seed-Thinking-v1.5, que tiene un total de 200B parámetros. El modelo activa 20B parámetros cada vez y ha mostrado un rendimiento excelente en múltiples benchmarks, superando supuestamente a DeepSeek-R1, que tiene 671B parámetros totales. La comunidad especula que este podría ser el modelo utilizado actualmente en el modo «pensamiento profundo» de la app Doubao de ByteDance, lo que demuestra los avances de ByteDance en el desarrollo de modelos de inferencia eficientes (Fuente: InfoQ)
Midjourney lanza el modelo V7, mejorando la calidad de imagen y la eficiencia de generación: La herramienta de generación de imágenes por IA Midjourney ha lanzado su nuevo modelo V7 (versión alfa). La nueva versión mejora la coherencia y consistencia de la generación de imágenes, especialmente en manos, partes del cuerpo y detalles de objetos, y puede generar texturas más realistas y ricas. V7 introduce el Draft Mode, que logra una velocidad de renderizado diez veces mayor a la mitad del costo, adecuado para la exploración rápida e iterativa. También ofrece los modos turbo (más rápido pero más caro) y relax (más lento pero más barato) para satisfacer las diferentes necesidades de los usuarios (Fuente: InfoQ)
Amazon lanza el modelo de voz de IA Nova Sonic: Amazon ha lanzado Nova Sonic, un modelo de IA generativa de nueva generación que procesa la voz de forma nativa. Según se informa, el modelo puede competir con los principales modelos de voz de OpenAI y Google en métricas clave como velocidad, reconocimiento de voz y calidad de la conversación. Nova Sonic se ofrece a través de la plataforma para desarrolladores Amazon Bedrock, utiliza una nueva API de streaming bidireccional para el acceso y tiene un precio aproximadamente un 80% más bajo que GPT-4o, con el objetivo de proporcionar capacidades de interacción de voz natural rentables para aplicaciones de IA empresariales (Fuente: InfoQ)
Funciones de IA de Apple para iPhone en China podrían llegar a mediados de año, integrando tecnología de Baidu y Alibaba: Informes indican que Apple planea introducir los servicios de Apple Intelligence en los iPhone del mercado chino (posiblemente en iOS 18.5) antes de mediados de 2025. La función utilizará el modelo grande Wenxin de Baidu para proporcionar capacidades inteligentes e integrará el motor de revisión de Alibaba para cumplir con los requisitos de regulación de contenido. Apple no ha firmado acuerdos de exclusividad con Baidu o Alibaba, lo que muestra su estrategia de cooperación localizada en mercados clave para desplegar rápidamente funciones de IA (Fuente: InfoQ)
🧰 Herramientas
Volcano Engine lanza el agente inteligente de datos empresariales Data Agent: Volcano Engine ha lanzado Data Agent, un agente inteligente de datos a nivel empresarial. La herramienta utiliza las capacidades de razonamiento, análisis y llamada a herramientas (tool calling) de los modelos grandes para comprender en profundidad las necesidades empresariales y automatizar tareas complejas de análisis y aplicación de datos, como la redacción de informes de investigación en profundidad y el diseño de campañas de marketing, mejorando la eficiencia en el uso de datos y el nivel de toma de decisiones de las empresas (Fuente: InfoQ)
Nuevos estilos de generación de imágenes de GPT-4o llaman la atención: Usuarios en redes sociales están mostrando nuevos estilos creados con la función de generación de imágenes de GPT-4o, por ejemplo, combinando elementos de la interfaz retro de Windows 2000 con imágenes de personajes para generar efectos de collage únicos. Los usuarios comparten técnicas de prompts, como el uso de imágenes base como guía (image prompting) y la combinación de descripciones de estilo y contenido, lo que ha despertado el interés de la comunidad en explorar el potencial creativo de GPT-4o (Fuente: source, source)

📚 Aprendizaje
Publicado MegaMath, el mayor conjunto de datos de preentrenamiento matemático open source: LLM360 ha lanzado MegaMath, un conjunto de datos de preentrenamiento para razonamiento matemático de código abierto que contiene 371 mil millones de tokens, superando en tamaño al DeepSeek-Math Corpus. El conjunto de datos cubre páginas web con contenido matemático intensivo (279B), código relacionado con matemáticas (28B) y datos sintéticos de alta calidad (64B). El equipo, mediante un flujo de procesamiento de datos refinado que incluye optimización de la estructura HTML, extracción en dos etapas, filtrado y refinamiento asistido por LLM, etc., ha asegurado la escala, calidad y diversidad de los datos. La validación del preentrenamiento en el modelo Llama-3.2 muestra que el uso de MegaMath puede aportar una mejora absoluta del 15-20% en benchmarks como GSM8K y MATH, proporcionando una base sólida para el entrenamiento de capacidades de razonamiento matemático en la comunidad open source (Fuente: 机器之心)

Nabla-GFlowNet: Equilibrando diversidad y eficiencia en el ajuste fino de modelos de difusión: Investigadores de la Universidad China de Hong Kong (Shenzhen) y otras instituciones proponen Nabla-GFlowNet, un nuevo método de ajuste fino basado en recompensas para modelos de difusión utilizando redes de flujo generativo (GFlowNet). El método tiene como objetivo resolver los problemas de la lenta convergencia del ajuste fino tradicional con aprendizaje por refuerzo y la tendencia al sobreajuste (overfitting) y pérdida de diversidad de la optimización directa de recompensas. Mediante la derivación de una nueva condición de equilibrio de flujo (Nabla-DB) y el diseño de una función de pérdida específica y una parametrización del gradiente de flujo logarítmico, Nabla-GFlowNet puede alinear eficientemente el modelo con la función de recompensa (como la puntuación estética o el seguimiento de instrucciones) manteniendo al mismo tiempo la diversidad de las muestras generadas. Los experimentos en Stable Diffusion demostraron sus ventajas en comparación con métodos como DDPO, ReFL y DRaFT (Fuente: 机器之心)
Llama.cpp corrige problemas relacionados con Llama 4: El proyecto llama.cpp ha fusionado dos correcciones para los modelos Llama 4, relacionadas con RoPE (incrustaciones posicionales rotativas) y cálculos incorrectos de normas (norms). Estas correcciones tienen como objetivo mejorar la calidad de salida del modelo, pero es posible que los usuarios necesiten volver a descargar los archivos de modelo GGUF generados con la herramienta de conversión actualizada para que surtan efecto (Fuente: source)
💼 Negocios
Nvidia completa la adquisición de Lepton AI: Según informes, Nvidia ha adquirido Lepton AI, la startup de infraestructura de IA fundada por el ex vicepresidente de Alibaba, Jia Yangqing, por un valor que podría alcanzar cientos de millones de dólares. El negocio principal de Lepton AI es alquilar servidores GPU de Nvidia y proporcionar software para ayudar a las empresas a construir y gestionar aplicaciones de IA. Jia Yangqing y su cofundador Bai Junjie, junto con unos 20 empleados, se han unido a Nvidia. Este movimiento se considera un despliegue estratégico de Nvidia para expandir sus servicios en la nube y su mercado de software empresarial, en respuesta a la competencia de chips de desarrollo propio de AWS, Google Cloud, etc. (Fuente: InfoQ)
El sector tecnológico estadounidense se ve invadido por la ansiedad, la IA impacta el mercado laboral: Informes señalan que el sector tecnológico estadounidense está experimentando una reducción de puestos de trabajo, una disminución de los salarios y una prolongación de los ciclos de búsqueda de empleo. Los despidos masivos y el uso de la IA por parte de empresas (como Salesforce, Meta, Google) para reemplazar mano de obra o pausar la contratación (especialmente en puestos de ingeniería y de nivel inicial) agravan la ansiedad profesional de los trabajadores del sector. Los datos muestran un aumento en la proporción de personas que reportan una disminución salarial y que pasan de puestos de gestión a roles de contribuidor individual. La IA está remodelando el mercado laboral, obligando a los solicitantes de empleo a ampliar sus horizontes hacia sectores no tecnológicos o a optar por el emprendimiento. Los expertos recomiendan prestar atención a las oportunidades de empleo fuera de los «Siete Magníficos» (Big Tech) y dominar las herramientas de IA para mejorar la competitividad (Fuente: InfoQ)

Se rumorea que OpenAI planea adquirir la empresa de hardware de IA de Altman y Jony Ive: Se informa que OpenAI está discutiendo la adquisición por no menos de 500 millones de dólares de io Products, la compañía de IA cofundada por su CEO Sam Altman y el ex director de diseño de Apple, Jony Ive. La compañía tiene como objetivo desarrollar dispositivos personales impulsados por IA, cuyas posibles formas incluyen un «teléfono» sin pantalla o un dispositivo doméstico. io Products cuenta con un equipo de ingenieros para construir los dispositivos, OpenAI proporciona la tecnología, el estudio de Ive se encarga del diseño y Altman está profundamente involucrado. Si se completa la adquisición, integraría este equipo de hardware en OpenAI, acelerando su despliegue en el campo del hardware de IA (Fuente: InfoQ)
La startup de la ex-CTO de OpenAI ficha a más talento de su antigua empresa: La compañía de IA «Laboratorio de Máquinas Pensantes» (nombre tentativo), fundada por la ex-CTO de OpenAI Mira Murati, ha atraído a dos figuras clave de OpenAI a su equipo asesor: el ex Director de Investigación Bob McGrew y el ex investigador Alec Radford. Radford es el autor principal de los artículos técnicos fundamentales de la serie GPT. Este reclutamiento refuerza aún más la capacidad técnica de la startup y refleja la intensa competencia por el talento en el campo de la IA (Fuente: InfoQ)
Baichuan Intelligence ajusta su enfoque de negocio, centrándose en el sector médico: El fundador de Baichuan Intelligence, Wang Xiaochuan, en una carta a todos los empleados con motivo del segundo aniversario de la compañía, reiteró que la empresa se centrará en el sector médico, desarrollando servicios de aplicación como Baixiaoying, IA pediátrica, IA de medicina general y medicina de precisión. Subrayó la necesidad de reducir acciones superfluas y que la estructura organizativa será más plana. Anteriormente, se informó que el equipo B2B del sector financiero de la compañía fue disuelto, el socio comercial Deng Jiang se marchó, y varios cofundadores se han ido o están a punto de irse, lo que indica que la empresa está experimentando un enfoque estratégico y un ajuste organizativo (Fuente: InfoQ)
Alibaba Cloud lanza el plan «Fan Hua» (Blossoms) para socios del ecosistema de IA: Alibaba Cloud ha lanzado el plan «Fan Hua» (Blossoms), destinado a apoyar a los socios del ecosistema de IA. El plan proporcionará recursos en la nube, soporte de potencia computacional, empaquetado de productos, planificación de comercialización y servicios de ciclo de vida completo, según la madurez del producto del socio. Al mismo tiempo, Alibaba Cloud ha lanzado un mercado de aplicaciones y servicios de IA, con la intención de construir un ecosistema de IA próspero y acelerar la implementación de la tecnología y las aplicaciones de IA (Fuente: InfoQ)
Kugou Music y DeepSeek alcanzan una cooperación profunda: Kugou Music anunció una colaboración con la compañía de IA DeepSeek para lanzar una serie de funciones innovadoras de IA. Estas incluyen la generación de informes de escucha personalizados mediante análisis multimodal, recomendaciones diarias de IA, búsqueda inteligente, gestión de listas de reproducción con IA, generación de portadas dinámicas con IA y un «crítico de IA» con configuración de personaje, entre otras, con el objetivo de mejorar la experiencia musical del usuario y la interacción comunitaria a través de la tecnología de IA (Fuente: InfoQ)
Se rumorea que Google utiliza acuerdos de no competencia «agresivos» para retener talento en IA: Informes indican que DeepMind, filial de Google, para evitar la fuga de talento a competidores, ha implementado acuerdos de no competencia de un año para algunos empleados en el Reino Unido. Durante este período, los empleados no necesitan trabajar pero siguen recibiendo su salario (permiso retribuido), pero esto hace que algunos investigadores se sientan marginados e incapaces de participar en el rápido desarrollo del sector. Esta medida podría ser prohibida por la FTC en EE.UU., pero es aplicable en la sede de Londres, lo que ha generado debate sobre la competencia por el talento y la restricción de la innovación (Fuente: InfoQ)
Ex empleados de OpenAI presentan documentos legales en apoyo a la demanda de Musk: 12 ex empleados de OpenAI han presentado documentos legales en apoyo a la demanda interpuesta por Elon Musk contra OpenAI. Argumentan que el plan de reestructuración de OpenAI (hacia una estructura con fines de lucro) podría violar fundamentalmente la misión original sin fines de lucro de la compañía, misión que fue un factor clave para atraerlos. OpenAI respondió que, incluso con el cambio estructural, su misión no cambiará (Fuente: InfoQ)
🌟 Comunidad
Estudio de Anthropic revela patrones de uso y desafíos de la IA en la educación superior: Anthropic analizó millones de conversaciones anónimas de estudiantes en la plataforma Claude.ai, descubriendo que los estudiantes de STEM (especialmente de informática) son los adoptantes tempranos de la IA. Los patrones de interacción de los estudiantes con la IA incluyen cuatro tipos: resolución directa de problemas, generación directa de contenido, resolución colaborativa de problemas y generación colaborativa de contenido, con proporciones similares. La IA se utiliza principalmente para tareas cognitivas de orden superior como crear (p. ej., programar, escribir ejercicios) y analizar (p. ej., explicar conceptos). El estudio también revela posibles malas conductas académicas (como obtener respuestas, evadir la detección de plagio), lo que genera preocupaciones sobre la integridad académica, el fomento del pensamiento crítico y los métodos de evaluación (Fuente: 新智元)

La generación de imágenes de GPT-4o lidera nuevas tendencias: del estilo Ghibli a cartas de celebridades de la IA: La potente capacidad de generación de imágenes de GPT-4o sigue generando furor creativo en las redes sociales. Tras el éxito viral de los «retratos familiares estilo Ghibli» (impulsado por el ex ingeniero de Amazon Grant Slatton), los usuarios ahora están creando cartas estilo «Magic: The Gathering» de celebridades del ámbito de la IA (como Sam Altman, definido como «Señor Supremo de la AGI»), así como cartas del Tarot personalizadas. Estos ejemplos muestran el potencial de la IA en la imitación de estilos artísticos y la generación creativa, pero también plantean debates sobre la originalidad, los derechos de autor, el valor estético y el impacto de la IA en la profesión de diseñador (Fuente: 新智元)

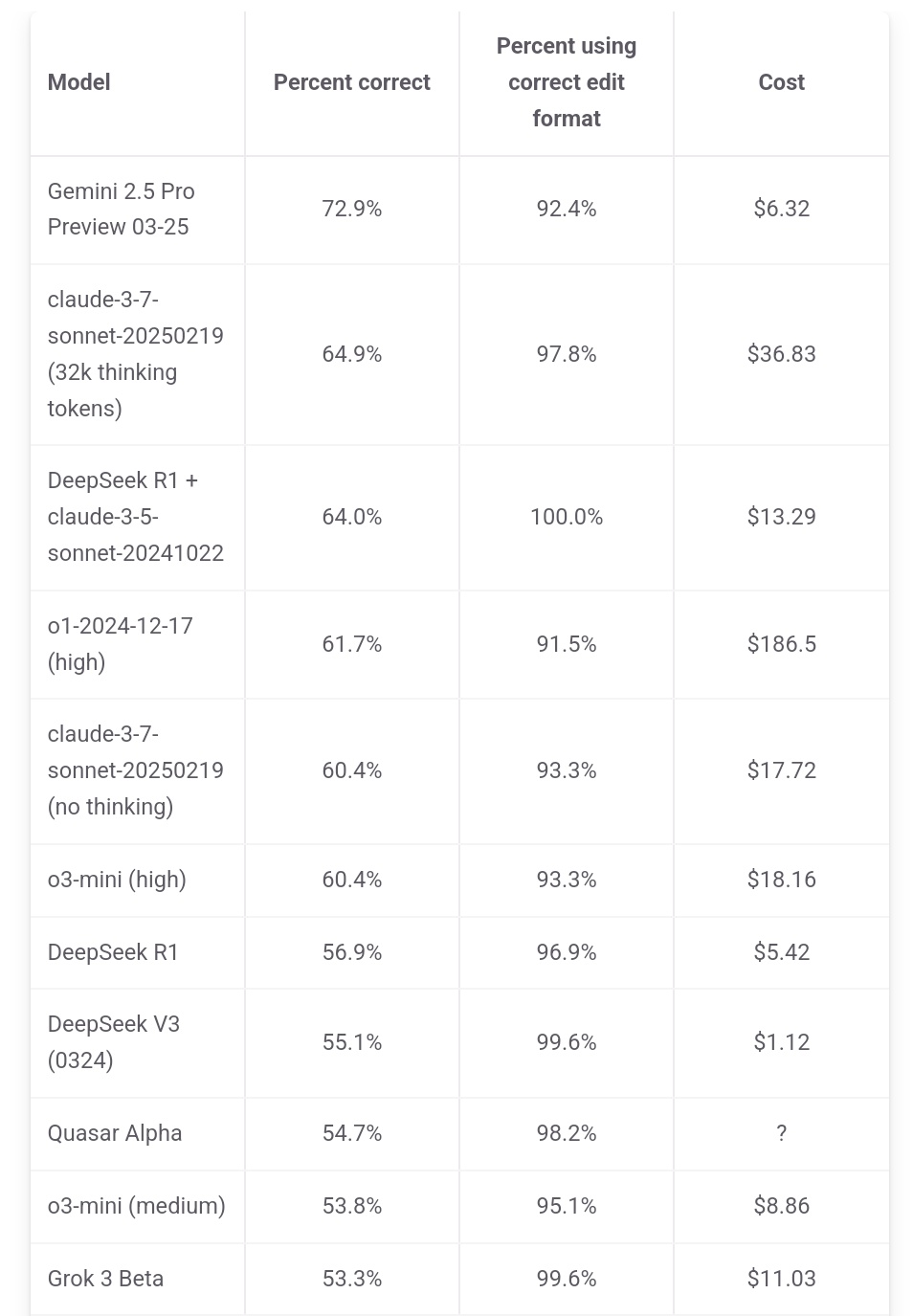
Jeff Dean enfatiza la ventaja de costo de Gemini 2.5 Pro: El responsable de IA de Google, Jeff Dean, compartió datos del ranking de aider.chat, señalando que Gemini 2.5 Pro no solo lidera en rendimiento en el benchmark de programación Polyglot, sino que su costo (6 dólares) es significativamente inferior al de otros modelos Top 10, excepto DeepSeek, destacando su ventaja en relación calidad-precio. Algunos modelos competidores cuestan el doble, el triple o incluso 30 veces más que Gemini 2.5 Pro (Fuente: JeffDean)
Debate candente en Reddit sobre el impacto de la IA en el mercado laboral, especialmente en puestos de nivel inicial: Una publicación en un foro de Reddit generó un intenso debate. El autor (un estudiante de máster en CIS) expresó su profunda preocupación por la sustitución de trabajos no manuales de nivel inicial (especialmente ingeniería de software, análisis de datos, soporte de TI) por la IA, argumentando que la afirmación «la IA no te quitará el trabajo» ignora la difícil situación de los recién graduados. Señaló que las grandes empresas ya están reduciendo la contratación universitaria y que el futuro mercado laboral podría ser sombrío. En los comentarios hubo división de opiniones: algunos coincidieron con la crisis, otros consideraron que es la norma en las transformaciones tecnológicas y que hay que adaptarse a nuevos roles (como gestionar equipos de IA), y otros cuestionaron la afirmación de que «el 90% de los puestos desaparecerán», argumentando que el ciclo económico y las situaciones en diferentes países varían mucho, y que la capacidad actual de la IA sigue siendo limitada (Fuente: source)
Usuarios de Claude se quejan de la disminución del rendimiento y el endurecimiento de las restricciones: En el subreddit r/ClaudeAI surgió una discusión concentrada donde varios usuarios (incluidos usuarios Pro) informaron haber encontrado recientemente límites de uso (quota) más estrictos, alcanzando el límite frecuentemente incluso con operaciones normales. Algunos usuarios creen que Anthropic está reduciendo las cuotas sigilosamente y expresaron su descontento, argumentando que esto obligará a los usuarios a migrar a productos competidores. Además, algunos usuarios comentaron que la «personalidad» de Claude parece haber cambiado, volviéndose más «fría» y «mecánica», perdiendo el toque filosófico y poético de versiones anteriores, lo que llevó a algunos a cancelar sus suscripciones (Fuente: source, source, source, source)
La generación de imágenes de ChatGPT genera diversión y debate: Usuarios de Reddit comparten diversos intentos y resultados al usar ChatGPT para generar imágenes. Alguien pidió transformar un perro en humano, resultando en imágenes similares a «hombres bestia/furries», lo que generó debate sobre la comprensión de los prompts y posibles sesgos. Otro usuario pidió que lo dibujaran como una vidriera de múltiples universos, con resultados impresionantes. Otros pidieron generar imágenes metafóricas sobre la IA o preguntaron a la IA sobre sus «pesadillas», mostrando la capacidad y las limitaciones de la generación de imágenes por IA en la expresión creativa y la visualización de conceptos abstractos (Fuente: source, source, source, source, source)

La comunidad discute la selección de modelos LLM y estrategias de uso: En el subreddit r/LocalLLaMA, un usuario propuso tener una discusión mensual sobre el uso de modelos, compartiendo los mejores modelos (open source y closed source) que cada uno utiliza en diferentes escenarios (codificación, escritura, investigación, etc.) y sus razones. En los comentarios, los usuarios compartieron las combinaciones de modelos que utilizan actualmente, como Deepseek V3.1/Gemini 2.5 Pro/4o/R1/Qwen 2.5 Max/Sonnet 3.7/Gemma 3/Claude 3.7/Mistral Nemo, etc., y mencionaron usos específicos (como llamada a herramientas, clasificación, role-playing), reflejando la tendencia práctica de los usuarios a seleccionar y combinar diferentes modelos según las necesidades de la tarea (Fuente: source)
💡 Otros
Próxima celebración de la Cumbre de la Industria AIGC de China: La tercera Cumbre de la Industria AIGC (Contenido Generado por IA) de China se celebrará el 16 de abril en Beijing. La cumbre reunirá a más de 20 líderes de la industria de empresas como Baidu, Huawei, Microsoft Research Asia, Amazon Web Services (AWS), ModelBest (面壁智能), Shengshu Technology, etc., para discutir avances tecnológicos en IA (potencia computacional, modelos grandes), aplicaciones sectoriales (educación, cultura y entretenimiento, investigación científica, servicios empresariales), construcción de ecosistemas (seguro y controlable, desafíos de implementación), entre otros temas. La cumbre también publicará listas de empresas/productos AIGC y un panorama de aplicaciones AIGC de China (Fuente: 量子位)

Informe de Stanford: La brecha de rendimiento entre los modelos de IA de primer nivel de China y EE.UU. se reduce al 0.3%: El Informe del Índice de IA (AI Index Report) 2025 publicado por la Universidad de Stanford muestra que la brecha de rendimiento entre los modelos de IA de primer nivel de China y Estados Unidos se ha reducido significativamente del 20% en 2023 al 0.3%. Aunque Estados Unidos sigue liderando en número de modelos prominentes (40 vs 15) y empresas líderes en la industria, la velocidad de alcance de los modelos chinos se está acelerando. El informe también señala que la brecha de rendimiento entre los propios modelos de primer nivel también se está reduciendo, del 12% en 2024 al 5%, mostrando una clara tendencia a la convergencia (Fuente: InfoQ)