
Palabras clave:AI, LLM, AI Washing, Gemini 2.5 Pro, vLLM, RAG, Suno AI
🔥 Enfoque
Se revela que una aplicación de compras «IA» en realidad es operada por humanos: Una startup llamada Fintech y su fundador han sido acusados de fraude. Su aplicación de compras, que afirmaba ser impulsada por IA, en realidad dependía en gran medida de un equipo humano en Filipinas para procesar las transacciones. Este incidente vuelve a poner de relieve el fenómeno del «AI Washing», donde las empresas exageran o declaran falsamente sus capacidades de IA para atraer inversiones o usuarios. El caso subraya los desafíos de discernir las aplicaciones de tecnología de IA genuinas de las falsas en medio del actual auge de la IA, así como la importancia de realizar la debida diligencia en las startups (Fuente: Reddit r/ArtificialInteligence)

Nuevo benchmark revela la falta de capacidad de generalización de los modelos de razonamiento de IA: Un nuevo benchmark llamado LLM-Benchmark (https://llm-benchmark.github.io/) indica que incluso los modelos de razonamiento de IA más recientes tienen dificultades para manejar acertijos lógicos fuera de distribución (OOD). La investigación encontró que, en comparación con el rendimiento de los modelos en benchmarks como las Olimpiadas Matemáticas, sus puntuaciones en estos nuevos acertijos lógicos son mucho más bajas de lo esperado (aproximadamente 50 veces más bajas), lo que expone las limitaciones de los modelos actuales para realizar un razonamiento lógico genuino y generalizar más allá de la distribución de sus datos de entrenamiento (Fuente: Reddit r/ArtificialInteligence)
Google permite a las empresas autoalojar modelos Gemini para abordar preocupaciones sobre la privacidad de los datos: Google anunció que permitirá a los clientes empresariales ejecutar modelos Gemini AI en sus propios centros de datos, comenzando con Gemini 2.5 Pro. Esta medida tiene como objetivo satisfacer los estrictos requisitos de las empresas en cuanto a privacidad y seguridad de los datos, permitiéndoles utilizar la avanzada tecnología de IA de Google sin enviar datos sensibles a la nube. Esta estrategia es similar a la de Mistral AI, pero contrasta con la de OpenAI y Anthropic, que principalmente ofrecen servicios a través de API en la nube o socios, lo que podría cambiar el panorama competitivo del mercado de IA empresarial (Fuente: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

🎯 Movimientos
VSCode soporta nativamente llama.cpp, ampliando las capacidades locales de Copilot: Visual Studio Code actualizó recientemente para agregar soporte para modelos de IA locales. Después de soportar Ollama, ahora es compatible con llama.cpp mediante pequeños ajustes. Esto significa que los desarrolladores pueden usar directamente en VSCode modelos de lenguaje grandes locales ejecutados a través de llama.cpp como alternativa o complemento a GitHub Copilot, facilitando aún más el uso de LLM para asistencia de código en entornos locales y mejorando la flexibilidad de desarrollo y la privacidad de los datos. Los usuarios deben seleccionar Ollama como proxy en la configuración (aunque en realidad usen llama.cpp) para habilitar esta función (Fuente: Reddit r/LocalLLaMA)

Yandex y otras instituciones publican HIGGS: un nuevo método de compresión de LLM: Investigadores de Yandex Research, la Universidad HSE, el MIT y otras instituciones han desarrollado una nueva técnica de cuantificación y compresión de LLM llamada HIGGS. El método tiene como objetivo comprimir significativamente el tamaño del modelo para que pueda ejecutarse en dispositivos de menor rendimiento, minimizando al mismo tiempo la pérdida de calidad del modelo. Se informa que el método se ha utilizado con éxito para comprimir el modelo DeepSeek R1 de 671B parámetros con resultados notables. HIGGS busca reducir la barrera de entrada para el uso de LLM, facilitando que pequeñas empresas, instituciones de investigación y desarrolladores individuales apliquen modelos grandes. El código relevante se ha publicado en GitHub y Hugging Face (Fuente: Reddit r/LocalLLaMA)
Google corrige problemas de cuantificación en el modelo QAT 2.7: Google ha actualizado la versión 2.7 de su modelo cuantificado QAT (Quantization Aware Training) (posiblemente refiriéndose a Gemma 2 7B u otro modelo similar), corrigiendo algunos errores de tokens de control presentes en la versión anterior. Anteriormente, el modelo podía generar incorrectamente marcadores como <end_of_turn> al final de la salida. Los modelos cuantificados recién subidos han resuelto estos problemas, y los usuarios pueden descargar la versión actualizada para obtener el comportamiento correcto del modelo (Fuente: Reddit r/LocalLLaMA)
El CEO de DeepMind habla sobre los logros de AlphaFold: En una entrevista, Demis Hassabis, CEO de DeepMind, enfatizó el enorme impacto de AlphaFold, comparándolo figurativamente con completar «mil millones de años de tiempo de investigación doctoral» en un solo año. Señaló que en el pasado, resolver la estructura de una proteína solía llevar toda la carrera doctoral de un estudiante (4-5 años), mientras que AlphaFold predijo las estructuras de los 200 millones de proteínas conocidas (en ese momento) en un año. Estas palabras resaltan el potencial revolucionario de la IA para acelerar los descubrimientos científicos (Fuente: Reddit r/artificial)

🧰 Herramientas
MinIO: Almacenamiento de objetos de alto rendimiento para IA: MinIO es un sistema de almacenamiento de objetos de código abierto, de alto rendimiento y compatible con S3, licenciado bajo GNU AGPLv3. Destaca especialmente su capacidad para construir infraestructuras de alto rendimiento para cargas de trabajo de machine learning, análisis y datos de aplicaciones, y ofrece documentación específica sobre almacenamiento para IA. Los usuarios pueden instalarlo a través de contenedores (Podman/Docker), Homebrew (macOS), binarios (Linux/macOS/Windows) o desde el código fuente. MinIO soporta la construcción de clústeres de almacenamiento distribuidos, de alta disponibilidad y con codificación de borrado (erasure coding), adecuados para escenarios de aplicaciones de IA que necesitan manejar grandes volúmenes de datos (Fuente: minio/minio – GitHub Trending (all/daily))

IntentKit: Framework para construir agentes de IA con habilidades: IntentKit es un framework de agentes autónomos de código abierto diseñado para permitir a los desarrolladores crear y gestionar agentes de IA con múltiples capacidades, incluyendo la interacción con blockchains (priorizando cadenas EVM), gestión de redes sociales (Twitter, Telegram, etc.) e integración de habilidades personalizadas. El framework soporta la gestión de múltiples agentes y la ejecución autónoma, y planea lanzar un sistema de plugins extensible. El proyecto se encuentra actualmente en fase Alfa, proporciona una visión general de la arquitectura y guías de desarrollo, y anima a la comunidad a contribuir con habilidades (Fuente: crestalnetwork/intentkit – GitHub Trending (all/daily))

vLLM: Motor de inferencia y servicio de LLM de alto rendimiento: vLLM es una biblioteca de alto rendimiento y eficiente en memoria centrada en la inferencia y el servicio de LLM. Sus ventajas principales incluyen la gestión eficaz de la memoria de claves y valores de atención a través de la tecnología PagedAttention, soporte para procesamiento por lotes continuo (Continuous Batching), optimización de grafos CUDA/HIP, múltiples técnicas de cuantificación (GPTQ, AWQ, FP8, etc.), integración con FlashAttention/FlashInfer y decodificación especulativa (Speculative Decoding), entre otras. vLLM soporta modelos de Hugging Face, proporciona una API compatible con OpenAI y puede ejecutarse en diverso hardware como NVIDIA y AMD, siendo adecuado para escenarios que requieren el despliegue a gran escala de servicios LLM (Fuente: vllm-project/vllm – GitHub Trending (all/daily))
tfrecords-reader: Lector de TFRecords con acceso aleatorio y funciones de búsqueda: Esta es una herramienta de Python para manejar conjuntos de datos TFRecords, diseñada especialmente para la inspección y análisis de datos. Permite a los usuarios crear índices para archivos TFRecords, logrando acceso aleatorio y búsqueda basada en contenido (usando consultas SQL de Polars), superando las limitaciones de la lectura secuencial nativa de TFRecords. La herramienta no depende de los paquetes TensorFlow y protobuf, soporta la lectura directa desde Google Storage, tiene una velocidad de indexación rápida y facilita a los desarrolladores la exploración y búsqueda de muestras en conjuntos de datos TFRecords a gran escala fuera del entrenamiento del modelo (Fuente: Reddit r/MachineLearning)
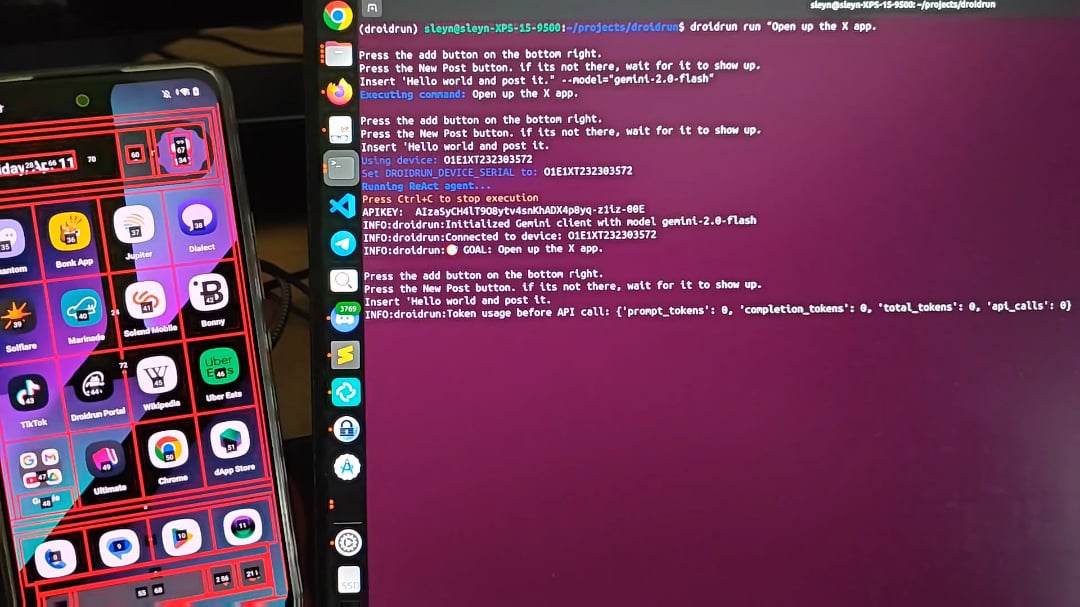
DroidRun: Permite que agentes de IA controlen teléfonos Android: DroidRun es un proyecto que permite a los agentes de IA operar dispositivos Android como lo haría un humano. Conectando cualquier LLM, puede lograr el control interactivo de la interfaz de usuario del teléfono para realizar diversas tareas. El proyecto muestra su potencial, con el objetivo de lograr operaciones automatizadas en el teléfono, como publicar contenido automáticamente, gestionar aplicaciones, etc. Los desarrolladores invitan a la comunidad a proporcionar comentarios e ideas para explorar más escenarios de automatización (Fuente: Reddit r/LocalLLaMA)
📚 Aprendizaje
Cell Patterns publica una importante revisión sobre modelos de lenguaje grandes multilingües (MLLM): Esta revisión sistematiza el estado actual de la investigación sobre MLLM, cubriendo 473 publicaciones. El contenido incluye recursos de conjuntos de datos y métodos de construcción para preentrenamiento multilingüe, ajuste fino de instrucciones (instruction fine-tuning) y RLHF; estrategias de alineación interlingüe, divididas en alineación con ajuste de parámetros (como preentrenamiento, ajuste fino de instrucciones, RLHF, ajuste fino downstream) y alineación con parámetros congelados (como prompting directo, cambio de código, alineación por traducción, recuperación aumentada); métricas y benchmarks de evaluación multilingüe (tareas NLU y NLG); y discute futuras direcciones de investigación y desafíos como alucinaciones, edición de conocimiento, seguridad, equidad, expansión de lenguaje/modalidad, interpretabilidad, eficiencia de despliegue y consistencia de actualización. Proporciona un mapa completo de la investigación en MLLM (Fuente: Cell Patterns重磅综述!473篇文献全面解析多语言大模型最新研究进展)

AAAI 2025 | Beihang propone TRACK: Aprendizaje colaborativo de redes de carreteras dinámicas y representación de trayectorias: El equipo de la Universidad de Beihang propone el modelo TRACK, con el objetivo de abordar el problema de que los métodos existentes no capturan la dinámica espaciotemporal del tráfico. Este modelo modela conjuntamente por primera vez el estado del tráfico (características macroscópicas del grupo) y los datos de trayectoria (características microscópicas individuales), considerando que ambos se influyen mutuamente. TRACK aprende representaciones dinámicas de la red de carreteras y las trayectorias a través de redes de atención gráfica (GAT), Transformer, así como un innovador GAT sensible a la transferencia de trayectorias y mecanismos de atención colaborativa. El modelo adopta un marco de preentrenamiento conjunto que incluye tareas autosupervisadas como predicción de trayectorias enmascaradas, aprendizaje contrastivo de trayectorias, predicción de estado enmascarado, predicción del siguiente estado y coincidencia de trayectoria-estado del tráfico, demostrando un rendimiento superior en tareas de predicción del estado del tráfico y estimación del tiempo de viaje (Fuente: AAAI 2025 | 告别静态建模!北航团队提出动态路网与轨迹表示的协同学习范式)

Profesor Yang Linyi de SUSTech busca estudiantes de doctorado/RA/visitantes en el área de modelos grandes: El profesor Yang Linyi del Departamento de Estadística y Ciencia de Datos de la Southern University of Science and Technology (próxima incorporación, PI independiente) establece el Laboratorio de Inteligencia Artificial Generativa (GenAI Lab) y busca estudiantes de doctorado y maestría para las cohortes 2025/2026, así como postdoctorados, asistentes de investigación y pasantes. Las direcciones de investigación incluyen análisis causal de la inferencia de modelos grandes, métodos de modelos grandes de aprendizaje por refuerzo generalizables, construcción de sistemas no agentes confiables para prevenir la pérdida de control de la IA. El profesor Yang ha publicado varios artículos en conferencias de primer nivel, tiene una amplia colaboración con universidades e instituciones de investigación nacionales e internacionales, y fomenta la codirección. Se requiere que los solicitantes tengan una fuerte automotivación, sólidos fundamentos matemáticos y habilidades de programación (Fuente: 博士申请 | 南方科技大学杨林易老师招收大模型方向全奖博士/RA/访问学生)

Proyecto personal: Construyendo un modelo de lenguaje grande desde cero: Un desarrollador comparte su proyecto personal de implementar un Causal Language Model (similar a GPT) desde cero. El proyecto utiliza Python y PyTorch, y la arquitectura central incluye autoatención multi-cabeza con Causal Mask, redes feed-forward y apilamiento de bloques decodificadores (normalización de capa, conexiones residuales). El modelo utiliza embeddings de palabras y posicionales preentrenados de GPT-2, y la capa de salida mapea a logits del vocabulario. Utiliza muestreo Top-k para la generación de texto autorregresiva y se entrena en el conjunto de datos WikiText utilizando el optimizador AdamW y CrossEntropyLoss. El código del proyecto está disponible en GitHub, mostrando el flujo básico para construir un LLM (Fuente: Reddit r/MachineLearning)
Análisis de paper: d1 – Ampliando la capacidad de razonamiento de los modelos de lenguaje grandes basados en difusión (dLLM) mediante aprendizaje por refuerzo: Esta investigación propone el marco d1, destinado a aplicar LLM preentrenados basados en difusión (dLLM) a tareas de razonamiento. Los dLLM generan texto de manera de grueso a fino, a diferencia de los modelos autorregresivos (AR). El marco d1 combina el ajuste fino supervisado (SFT) y el aprendizaje por refuerzo (RL), incluyendo específicamente: el uso de Masked SFT para la destilación de conocimiento y la automejora guiada; la propuesta de un nuevo algoritmo RL sin crítico basado en gradiente de política, diffu-GRPO. Los experimentos muestran que d1 mejora significativamente el rendimiento de los dLLM SOTA en benchmarks de razonamiento matemático y lógico, demostrando el potencial de los dLLM en tareas de razonamiento (Fuente: Reddit r/MachineLearning)
💼 Negocios
Alibaba Tongyi Lab busca expertos en algoritmos para RAG/Búsqueda IA (Beijing/Hangzhou): El equipo de Búsqueda IA del Laboratorio Tongyi de Alibaba está contratando expertos en algoritmos para avanzar en la investigación, desarrollo y optimización de módulos centrales de búsqueda y RAG (Retrieval-Augmented Generation), como modelos de Embedding y ReRank, para mejorar el rendimiento del modelo y alcanzar el liderazgo en la industria. Las responsabilidades del puesto también incluyen la optimización de todo el pipeline del marco para aplicaciones downstream (preguntas y respuestas, servicio al cliente, memoria multimodal) para mejorar la precisión, eficiencia y escalabilidad, y colaborar con el equipo para impulsar la implementación comercial. Se requiere una maestría o superior en un campo relevante, familiaridad con tecnologías de búsqueda/NLP/modelos grandes y experiencia en proyectos relacionados (Fuente: 北京/杭州内推 | 阿里通义实验室招聘通用RAG/AI搜索方向算法专家)

Startup de contratación con IA OpportuNext busca CTO (Remoto/Equity): OpportuNext es una startup en etapa temprana que tiene como objetivo mejorar el proceso de contratación utilizando tecnología de IA, ofreciendo coincidencia inteligente de puestos, análisis de currículums y herramientas de planificación de carrera. El fundador está buscando un socio técnico (CTO) para liderar el desarrollo de funciones de IA, construir sistemas backend escalables e impulsar la innovación de productos. Se requiere experiencia en AI/ML, Python y sistemas escalables, pasión por resolver problemas reales y disposición para unirse en la etapa inicial de la startup (puesto remoto basado en equity) (Fuente: Reddit r/deeplearning)
🌟 Comunidad
Exploración: La esencia de los modelos grandes es la «magia del lenguaje»: Un artículo de reflexión profunda argumenta que los modelos grandes (como ChatGPT) no comprenden realmente la información, sino que aprenden a imitar y predecir formas de expresión estudiando enormes cantidades de datos lingüísticos. La función del Prompt es establecer el contexto y guiar la atención del modelo, no comunicarse con una entidad consciente. Las respuestas del modelo se basan en la reproducción de patrones «vistos suficientes veces», pareciendo inteligentes pero careciendo de comprensión real, lo que fácilmente produce alucinaciones de «decir tonterías con seriedad». La interacción humano-máquina se parece más a que el usuario piensa en lugar del modelo, y la salida del modelo puede remodelar sutilmente los hábitos de pensamiento y juicio del usuario, y potencialmente reflejar y amplificar los sesgos existentes en la realidad (Fuente: 我所理解的大模型:语言的幻术)
Discusión: Consumo de energía de la IA y diferencias en las estrategias de desarrollo de modelos entre EE. UU. y China: Usuarios de Reddit discuten las declaraciones de Trump que catalogan el carbón como un mineral clave para el desarrollo de la IA, lo que genera preocupaciones sobre el consumo de energía de la IA. Los comentarios señalan que los modelos grandes consumen cada vez más energía, mientras que las empresas chinas parecen inclinarse más hacia la construcción de modelos más eficientes y optimizados. Esto refleja el equilibrio entre rendimiento y eficiencia energética en el desarrollo de la IA, así como las posibles diferentes rutas tecnológicas adoptadas por distintas regiones (Fuente: Reddit r/artificial)

Pregunta: Buscando un framework de aprendizaje por refuerzo profundo similar a PyTorch Lightning: Un usuario de Reddit pregunta si existe un framework similar a PyTorch Lightning (PL) específicamente para el aprendizaje por refuerzo profundo (DRL). El usuario considera que, aunque PL puede usarse para DRL, su diseño está más orientado al aprendizaje supervisado basado en conjuntos de datos que al DRL impulsado por la interacción con el entorno. La publicación busca recomendaciones de la comunidad sobre frameworks adecuados para DRL (como DQN, PPO) que se integren bien con entornos como Gymnasium, o compartir las mejores prácticas para usar PL en DRL (Fuente: Reddit r/deeplearning)
Comunidad: Lanzamiento de MetaMinds, una comunidad de Discord para músicos virtuales: Se ha establecido una nueva comunidad de Discord llamada MetaMinds, destinada a proporcionar una plataforma de comunicación, colaboración e intercambio para artistas virtuales que utilizan herramientas de IA (como Suno) para crear música. La comunidad ha lanzado su primer concurso de composición de canciones llamado «A Personal Song» y planea organizar competiciones de mayor nivel en el futuro, posiblemente incluyendo premios en efectivo. Esto refleja la formación de un nuevo ecosistema comunitario en el campo de la creación musical con IA (Fuente: Reddit r/SunoAI)
Discusión: ¿Cómo llamar a una colección de conjuntos de datos que incluye el conjunto de entrenamiento?: Un usuario de Reddit pregunta cómo se debe denominar una colección de conjuntos de datos destinada a entrenar y evaluar el mismo modelo, en contraposición a un «benchmark», que se utiliza para evaluar el rendimiento del modelo en múltiples tareas. Esta pregunta explora los detalles de la clasificación de conjuntos de datos y el uso de terminología en el campo del machine learning (Fuente: Reddit r/MachineLearning)
Ayuda: Implementar la función de voz a texto en OpenWebUI: Un usuario busca la mejor solución y modelos recomendados para implementar la funcionalidad de voz a texto (el usuario escribió TTS, pero la descripción se refiere a transcribir videos de YouTube/archivos de audio, lo que debería ser ASR/STT) en un entorno OpenWebUI+Ollama desplegado en Docker, utilizando una GPU H100. Esto refleja la necesidad de los usuarios de integrar más capacidades de procesamiento modal en las interfaces de interacción LLM locales (Fuente: Reddit r/OpenWebUI)
Discusión: Opiniones sobre la suscripción anual de Claude y los ajustes de límites: Usuarios de Reddit expresan alivio por no haber comprado la suscripción anual de Claude, ya que recientemente muchos usuarios se han quejado del endurecimiento de los límites de uso. Los usuarios creen que Anthropic podría estar ajustando su estrategia para ahorrar costos después de atraer a un gran número de usuarios de pago. Al mismo tiempo, mencionan que el Gemini 2.5 Pro gratuito es potente, expresando preocupación y expectativas sobre el futuro desarrollo de Claude. La discusión refleja la sensibilidad de los usuarios a los precios, límites de uso y relación calidad-precio de los servicios LLM (Fuente: Reddit r/ClaudeAI)
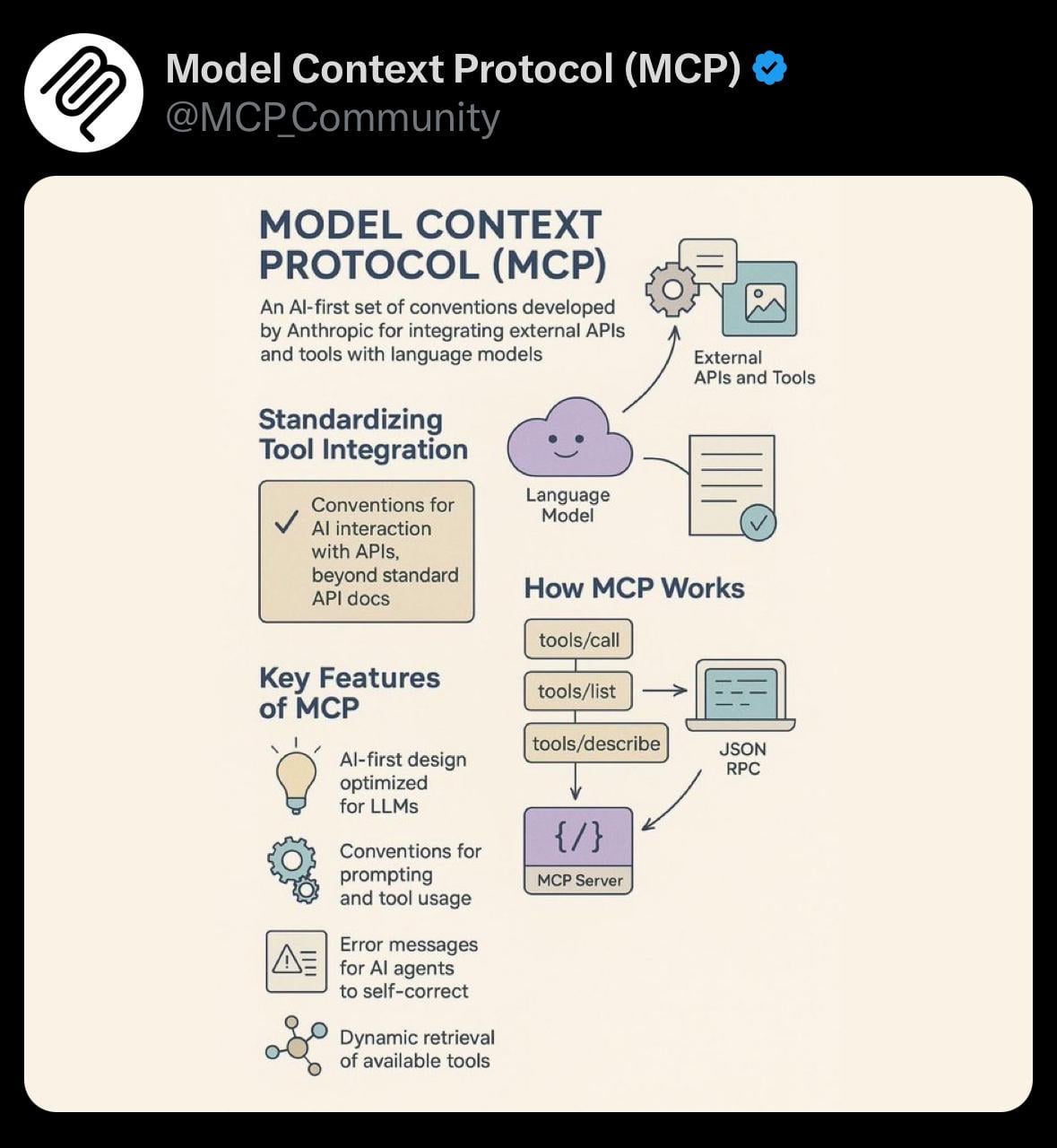
Compartir: Visualización simple del Protocolo de Contexto del Modelo (MCP): Un usuario comparte una imagen de visualización simple sobre el Protocolo de Contexto del Modelo (Model Context Protocol, MCP). MCP podría ser un concepto técnico relacionado con el modelo Claude de Anthropic, destinado a optimizar o gestionar la forma en que el modelo procesa contextos largos. Esta compartición proporciona a la comunidad una ayuda visual para comprender conceptos técnicos relevantes (Fuente: Reddit r/ClaudeAI)
Ayuda: Agregar comandos personalizados en el chat de OpenWebUI: Un usuario pregunta sobre la dificultad técnica de agregar comandos personalizados (como el formato @tag, con menú de autocompletar) en la interfaz de chat de OpenWebUI para facilitar consultas RAG personalizadas (por ejemplo, filtrar por tipo de documento). El usuario también está considerando menús desplegables como alternativa. Esto refleja el deseo de los usuarios de ampliar las capacidades de interacción del frontend para controlar de manera más flexible las funciones de IA del backend (Fuente: Reddit r/OpenWebUI)
Discusión: Generación de códigos QR estéticos y funcionales con IA: Un usuario intentó usar ChatGPT/DALL-E para generar códigos QR que fusionaran estilos artísticos y fueran escaneables, pero los resultados no fueron buenos, señalando que métodos como ControlNet son más efectivos. Esto suscita una discusión sobre las limitaciones de los modelos actuales de texto a imagen convencionales para generar imágenes que requieren una estructura precisa y funcionalidad (como la escaneabilidad) (Fuente: Reddit r/ChatGPT)

Buscando compañeros de estudio de AI/ML: Un estudiante de tercer año de Ciencias de la Computación (especialidad AI/ML) publica buscando 4-5 personas con ideas afines para formar un equipo para profundizar en el aprendizaje de AI/ML, desarrollar proyectos juntos y practicar estructuras de datos y algoritmos (DSA/CP). El iniciador enumera su stack tecnológico e intereses, esperando establecer un pequeño grupo de motivación mutua y aprendizaje colaborativo (Fuente: Reddit r/deeplearning)
Discusión: ¿Los agentes de IA agravarán el problema del spam?: Un usuario de Reddit expresa preocupación de que el uso generalizado de agentes de IA para automatizar tareas (como la búsqueda de leads de ventas y el envío de mensajes) pueda llevar a una proliferación de spam. Cuando todos usen herramientas similares, los destinatarios objetivo se verán inundados con una gran cantidad de mensajes automáticos personalizados, lo que reducirá la eficiencia de la comunicación y hará que las herramientas de agente pierdan su valor. La discusión plantea reflexiones sobre las posibles externalidades negativas de la aplicación a gran escala de herramientas de IA (Fuente: Reddit r/ArtificialInteligence)
Discusión: Problemas recientes de calidad de Suno AI: Un usuario comparte un fragmento de música generado con Suno AI, indicando que aunque ha habido discusiones recientes en la comunidad sobre la disminución de la calidad de salida de Suno, personalmente siente que este fragmento tiene un buen efecto. Esto refleja la percepción de la comunidad sobre las fluctuaciones en el rendimiento de las herramientas de generación de IA y las diferencias en la evaluación subjetiva (Fuente: Reddit r/SunoAI)

Discusión: RTX 4090 vs RTX 5090 para entrenamiento de deep learning: Un usuario consulta si para construir una estación de trabajo con una sola GPU para deep learning personal (no principalmente LLM), debería elegir la actual RTX 4090 o esperar la próxima RTX 5090. La publicación busca consejos de la comunidad sobre la selección de hardware y pregunta cómo distinguir entre tarjetas de juego y profesionales al comprar (aunque estas son tarjetas de consumo). Refleja las consideraciones de los desarrolladores de IA en la selección de hardware (Fuente: Reddit r/deeplearning)
Discusión: ¿La IA destruirá el capitalismo?: Un usuario argumenta que, debido a la búsqueda de maximización de beneficios por parte de las empresas, la IA podría eventualmente reemplazar la mayoría de los puestos de trabajo. En el sistema capitalista actual, esto conduciría a un desempleo masivo y a la interrupción de las fuentes de ingresos. El usuario propone que un Ingreso Básico Universal (UBI), financiado mediante la imposición de impuestos adicionales a las empresas que se benefician de la IA, podría ser una solución necesaria. La discusión aborda el profundo impacto de la IA en la futura estructura económica y los modelos sociales (Fuente: Reddit r/ArtificialInteligence)
Ayuda: Reproducir el paper de Anthropic «Reasoning Models Don’t Always Say What They Think»: Un usuario busca ayuda de la comunidad para encontrar Prompts o ideas relacionadas que permitan reproducir los resultados del paper de Anthropic sobre «los modelos de razonamiento no siempre dicen lo que piensan». El paper explora la posible inconsistencia entre el proceso de razonamiento interno de los grandes modelos de lenguaje y su salida final. Esto indica el interés de los miembros de la comunidad en comprender y verificar los hallazgos de investigaciones de vanguardia en IA (Fuente: Reddit r/MachineLearning)
Ayuda: Configuración y experiencia con RAG en OpenWebUI: Un usuario pregunta sobre las mejores prácticas para usar RAG (Retrieval-Augmented Generation) en OpenWebUI, incluyendo configuraciones recomendadas, parámetros a evitar y modelos de embedding preferidos. El usuario también ha encontrado problemas de comportamiento anómalo del modelo (como Mistral Small devolviendo una lista vacía) y pregunta sobre la relación de prioridad entre la configuración personal del usuario y la configuración del modelo del administrador. Esto refleja los desafíos encontrados por los usuarios en el despliegue y optimización reales de aplicaciones RAG y la búsqueda de intercambio de experiencias (Fuente: Reddit r/OpenWebUI)
Discusión: ¿La pérdida de usuarios de Claude mejorará el servicio?: Un usuario plantea la hipótesis de que la reciente pérdida de algunos usuarios de Claude («Genesis Exodus») debido a limitaciones y problemas de rendimiento podría, a su vez, liberar recursos computacionales, permitiendo que la calidad del servicio (como el rendimiento, los límites) vuelva a un estado más ideal. El usuario expresa su preferencia por Claude y espera que el servicio mejore. La discusión refleja la observación y reflexión de los usuarios sobre la relación entre la oferta y la demanda de servicios de IA, la asignación de recursos y la dinámica de la calidad del servicio (Fuente: Reddit r/ClaudeAI)

Discusión: ¿Cómo definir el «arte IA»?: Un usuario inicia una discusión preguntando a los miembros de la comunidad cómo definen el «arte IA» y plantea preguntas relacionadas: ¿Es creadora una persona que usa herramientas de IA (como ChatGPT) para generar imágenes? ¿Posee la propiedad? ¿Qué papel juegan los proveedores de servicios LLM en la creación y deberían ser considerados co-creadores? Esta discusión tiene como objetivo aclarar conceptos centrales en torno al contenido generado por IA, como la autoría y los derechos de autor (Fuente: Reddit r/ArtificialInteligence)
Discusión: ¿La música IA amenaza la «comunalidad» de la música?: Un usuario plantea la cuestión de si las herramientas de IA como Suno, que pueden generar fácilmente música hiperpersonalizada, debilitan la «comunalidad» de la música como experiencia compartida. Las preocupaciones incluyen: la música podría convertirse en un espejo personalizado en lugar de un faro que conecta a la comunidad; eventos musicales colectivos como conciertos podrían verse afectados; los usuarios podrían acostumbrarse solo a contenido personalizado, reduciendo la apertura a música diversa o desafiante. La discusión se centra en el impacto potencial de la IA en la cultura musical y las funciones sociales (Fuente: Reddit r/SunoAI)
Pregunta: ¿Qué tan precisa es la generación de canciones en hindi de Suno AI?: Un usuario que no habla hindi pregunta sobre la precisión y naturalidad de Suno AI al generar canto en hindi. Busca comprender el rendimiento de la herramienta en un idioma específico no inglés (Fuente: Reddit r/SunoAI)
💡 Otros
Compartir obra de Suno AI: Nightingale’s Melody (Rock alternativo/indie): Un usuario comparte una canción de estilo rock alternativo/indie «Nightingale’s Melody» creada con Suno AI, y adjunta el enlace de YouTube (Fuente: Reddit r/SunoAI)

Compartir obra de Suno AI: The Art of Abundance (Psytrance): Un usuario comparte una pieza musical generada por IA que combina Psytrance de alta energía con elementos tecno-espirituales. La letra fue creada por ChatGPT, la música y la voz por Suno AI, y los efectos visuales por MidJourney y PhotoMosh Pro. La obra explora el concepto de abundancia en la era digital, trascendiendo el materialismo para abordar la creatividad, la conciencia de la IA y el deseo humano (Fuente: Reddit r/SunoAI)

Compartir obra de Suno AI: Do your Job (Música country): Un usuario comparte una canción de estilo country creada con Suno AI, cuya letra gira en torno a un caso real sin resolver (la desaparición de Colton Ross Barrera), expresando la frustración de la familia y el llamado a la justicia (Fuente: Reddit r/SunoAI)

Compartir obra de Suno AI: Toxic Friends (Electro pop): Un usuario comparte su obra de estilo electro pop «Toxic Friends» presentada al concurso de abril de Suno AI (Fuente: Reddit r/SunoAI)

Compartir obra de Suno AI: Starlight Visitor (Cover pop de los 80): Un usuario comparte una versión cover de estilo pop de los 80 de una canción existente, producida con Suno AI, y proporciona el enlace de YouTube (Fuente: Reddit r/SunoAI)

Aplicación creativa de ChatGPT: Expansión de Meme de productos de huevo: Inspirado por un Meme sobre huevos, un usuario utilizó ChatGPT para generar una serie de imágenes y descripciones humorísticas y conceptuales de productos relacionados con huevos, como «Precracked Life» (Vida Pre-rota), «Internet of Eggs» (Internet de los Huevos), etc. Muestra la posibilidad de utilizar la IA para la divergencia creativa y la creación de contenido humorístico (Fuente: Reddit r/ChatGPT)
Compartir obra de Suno AI: Tom and Jerry / Crambone (Cover de blues rock): Un usuario comparte una canción cover de estilo blues rock producida con Suno AI, versionando «Tom and Jerry / Crambone», y proporciona el enlace de YouTube (Fuente: Reddit r/SunoAI)

Imagen generada por IA: Personificación de los siete pecados capitales: Un usuario comparte un video que muestra imágenes generadas por IA (posiblemente ChatGPT/DALL-E) que representan la personificación y encarnación de los siete pecados capitales (como la avaricia, la pereza, la envidia, etc.) (Fuente: Reddit r/ChatGPT)
