
Palabras clave:AI, AGI, Claude 4 próximos lanzamientos, impacto de aranceles en la industria AI, modelos multimodales nativos, robótica humanoide de código abierto, optimización de inferencia LLM
🔥 Enfoque
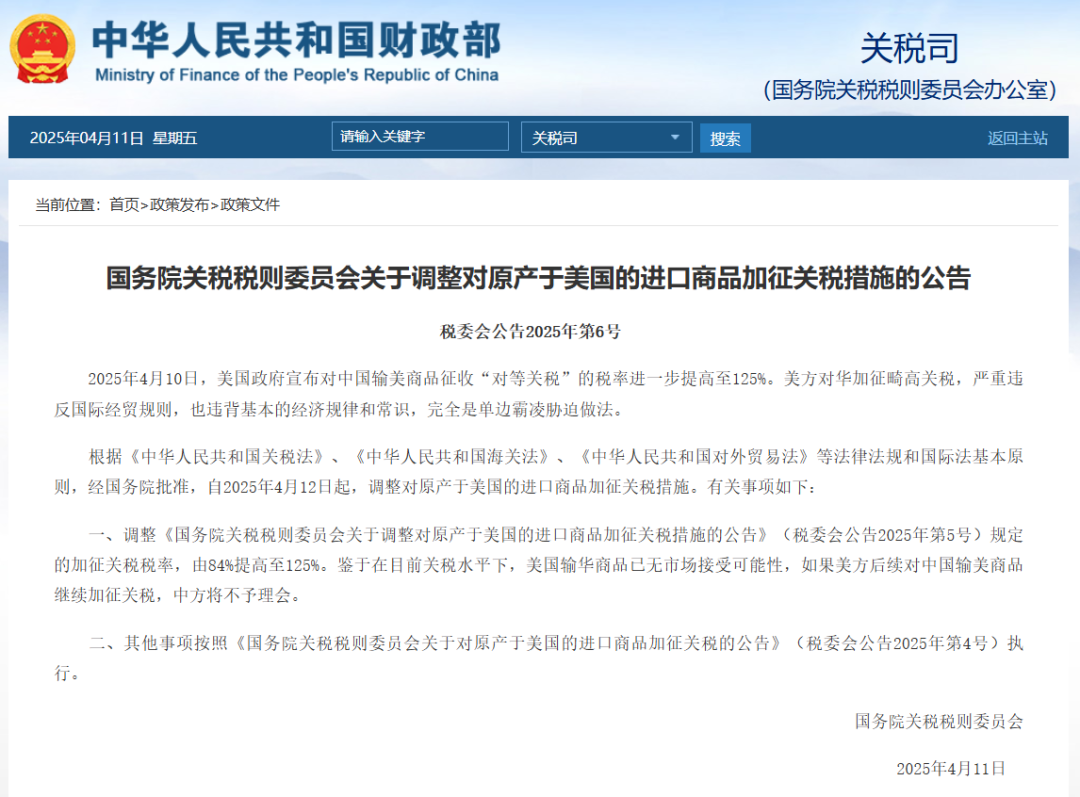
Análisis de la dirección de la industria global de IA bajo el impacto de los aranceles: Las recientes tensiones comerciales internacionales, especialmente la implementación de altos aranceles, tienen un profundo impacto en la industria de IA, altamente globalizada. El análisis del artículo señala que, aunque ya existen respuestas a las restricciones de EE. UU. sobre hardware como la potencia de cómputo de IA (AI compute power), los aranceles podrían agravar las fisuras en la industria global de IA. El impacto se manifiesta principalmente en: 1) Capa de infraestructura: aumento de costos de hardware, cadenas de suministro restringidas, pero China ya tiene soluciones de sustitución nacionales. 2) Capa tecnológica: puede llevar a la división del ecosistema tecnológico entre China y EE. UU., obstaculizar el código abierto y el intercambio compartido, y generar conflictos de estándares. 3) Capa de aplicación: regionalización del mercado, afectando la comercialización de productos de IA. El artículo considera que la ‘intensidad’ real del impacto arancelario puede ser limitada, ya que China ha establecido un ecosistema tecnológico paralelo y los aranceles perjudican a EE. UU. Sin embargo, la ‘amplitud’ del impacto es profunda, pudiendo causar interrupción del intercambio tecnológico, aversión al riesgo de talento y capital, y conflictos de estándares de mercado. Las estrategias de respuesta incluyen fortalecer la I+D autónoma (hardware, frameworks), persistir en la cooperación global (explorar mercados de terceros, participar en estándares internacionales) y mejorar el atractivo del ecosistema de IA nacional, ofreciendo al mundo opciones tecnológicas más inclusivas. (Fuente: 36氪)
Cofundador de Anthropic predice la proximidad de AGI, Claude 4 se lanzará pronto: Jared Kaplan, cofundador y científico jefe de Anthropic, predice que la IA a nivel humano (AGI) podría lograrse en los próximos 2-3 años, en lugar de la predicción anterior de 2030. Señala que las capacidades de la IA se están expandiendo rápidamente en las dimensiones de «alcance» y «complejidad» de las tareas, y los modelos actuales ya pueden manejar tareas que antes requerían horas o incluso días de expertos. Kaplan reveló que se espera que la próxima generación del modelo, Claude 4, se lance en los próximos seis meses, con mejoras de rendimiento gracias a mejoras en el post-entrenamiento, aprendizaje por refuerzo y eficiencia del pre-entrenamiento. También mencionó la importancia del «escalado en tiempo de prueba» (test-time scaling), donde permitir que el modelo piense más mejora predeciblemente el rendimiento. Respecto al auge de modelos chinos como DeepSeek, Kaplan no se sorprende, considera que su progreso tecnológico es rápido, con una brecha con Occidente quizás de solo unos seis meses, siendo competitivos algorítmicamente, aunque las limitaciones de hardware podrían ser el principal desafío. La entrevista concluye enfatizando el enorme impacto de la IA en la economía y la sociedad, y la importancia de realizar investigaciones empíricas. (Fuente: 新智元)

🎯 Tendencias
Model Berkeley y la Universidad de Tsinghua proponen la tecnología de escasez CFM: En una entrevista, Model Berkeley y Xiao Chaojun, autor del paper CFM de la Universidad de Tsinghua, presentaron la tecnología Configurable Foundation Models (CFM). CFM es una tecnología de escasez nativa que enfatiza la activación dispersa a nivel de neuronas, con una granularidad más fina y mayor dinamismo en comparación con el MoE (Mixture of Experts, escasez a nivel de experto) actualmente dominante. Su principal ventaja radica en mejorar enormemente la eficiencia de los parámetros del modelo (efectividad por unidad de parámetro), lo que puede ahorrar significativamente VRAM/memoria, especialmente adecuado para dispositivos edge con memoria limitada (como teléfonos móviles). Xiao Chaojun cree que, aunque arquitecturas no-Transformer como Mamba han explorado la eficiencia, Transformer sigue siendo el techo en términos de efectividad y ha acertado la «lotería del hardware» de la optimización de GPU. También discutió la implementación de modelos pequeños (aproximadamente 2-3B en el edge), la optimización de la precisión (tendencia FP8/FP4), los avances multimodales y la naturaleza de la inteligencia (posiblemente más cercana a la capacidad de abstracción que a la compresión). Considera que la larga cadena de pensamiento y la capacidad de innovación de o1 son direcciones clave que la IA necesita superar en el futuro. (Fuente: 量子位)

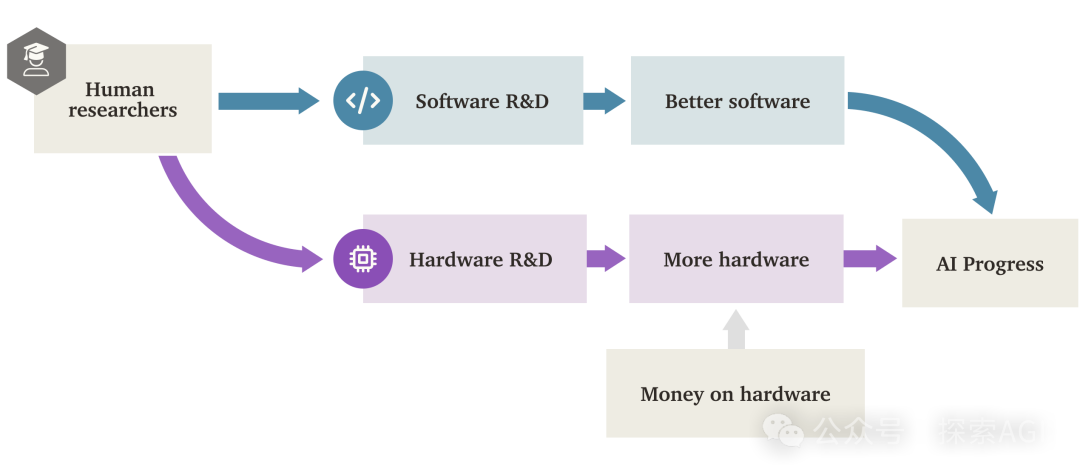
La «Explosión de Inteligencia de Software» (SIE) de la IA podría superar el impulso del hardware: Un informe de investigación de Forethought explora la posibilidad de una «Explosión de Inteligencia de Software» (Software Intelligence Explosion, SIE), donde la IA logra un crecimiento ultrarrápido de sus capacidades mejorando su propio software (algoritmos, arquitecturas, métodos de entrenamiento, etc.), incluso sobre la base del hardware existente. El informe introduce el concepto ASARA (AI Systems for AI R&D Automation), refiriéndose a sistemas de IA que pueden automatizar completamente la I+D en IA. Una vez que aparezca ASARA, podría desencadenar un ciclo de retroalimentación positiva: ASARA desarrolla mejor software de IA, creando una próxima generación de ASARA más fuerte, acelerando el progreso del software. El informe introduce el concepto de «tasa de retorno de la I+D de software» (valor r), analizando que el valor r actual del software de IA podría ser mayor que 1, lo que significa que la velocidad de mejora de la capacidad de la IA supera la velocidad de aumento de la dificultad de la I+D, cumpliendo las condiciones para desencadenar una SIE. La SIE podría llevar a que las capacidades de la IA logren mejoras de cien o mil veces en un corto período (meses o incluso menos) basadas en el hardware existente, haciendo que el hardware ya no sea el cuello de botella absoluto, pero también trayendo enormes desafíos de adaptación social y gobernanza. El informe también explora posibles cuellos de botella como los recursos computacionales y la duración del entrenamiento, y la posibilidad de que sean superados. (Fuente: AI智能体频道)
GPT-4 será retirado de ChatGPT, GPT-4.1 podría debutar pronto: OpenAI anunció que, a partir del 30 de abril de 2025, GPT-4 será eliminado de ChatGPT y reemplazado por completo por el modelo predeterminado actual, GPT-4o. GPT-4 seguirá siendo accesible a través de la API. Esta medida marca el retiro gradual de este modelo multimodal histórico, lanzado en marzo de 2023. GPT-4 causó sensación en el ecosistema global de aplicaciones de IA con logros como alcanzar niveles humanos de élite en pruebas profesionales y abrir la era de la IA que «ve imágenes y habla». Al mismo tiempo, filtraciones de la comunidad y descubrimientos en el código apuntan a que OpenAI podría lanzar pronto una serie de nuevos modelos, incluyendo GPT-4.1 (y sus versiones mini, nano), el modelo de «razonamiento» o3 previamente anunciado, y un nuevo modelo o4-mini, posiblemente tan pronto como la próxima semana. Algunos usuarios ya han descubierto la opción GPT-4.1 en la lista de modelos de ChatGPT y han podido interactuar con ella, lo que aumenta aún más la credibilidad del lanzamiento de nuevos modelos. (Fuente: 新智元)

Opinión: El próximo avance clave de la IA radica en «desbloquear» nuevas fuentes de datos: Jack Morris, estudiante de doctorado en la Universidad de Cornell, argumenta en un artículo que, al revisar los cuatro principales cambios de paradigma en el campo de la IA (redes neuronales profundas e ImageNet, Transformer y texto web, RLHF y preferencias humanas, razonamiento y validadores), la fuerza impulsora fundamental no ha sido la innovación algorítmica completamente nueva (muchas teorías fundamentales ya existían), sino el desbloqueo de nuevas fuentes de datos utilizables a gran escala. El artículo sostiene que, si bien las mejoras en los algoritmos y arquitecturas de modelos existentes (como Transformer) son importantes, su efectividad puede estar limitada por el techo de aprendizaje que puede proporcionar un conjunto de datos específico. Por lo tanto, el próximo gran avance de la IA podría depender del desbloqueo de nuevas modalidades y fuentes de datos, como datos de video a gran escala (como YouTube) o datos de interacción de robots del mundo físico. El artículo insta a los investigadores a centrarse más en encontrar y utilizar nuevas fuentes de datos mientras exploran nuevos algoritmos. (Fuente: 机器之心)

Fourier Intelligence lanza el robot humanoide de código abierto Fourier N1: La empresa de robótica general de Shanghái, Fourier Intelligence, ha lanzado su primer robot humanoide de código abierto, Fourier N1, y ha publicado el paquete completo de recursos del cuerpo, incluyendo la lista de materiales (BOM), planos de diseño, guías de montaje y código del software operativo básico. N1 mide 1.3 metros de altura, pesa 38 kg, tiene 23 grados de libertad en todo el cuerpo, utiliza una estructura compuesta de aleación de aluminio y plásticos de ingeniería, y está equipado con actuadores integrados FSA 2.0 y sistema de control desarrollados internamente. El robot ha completado más de 1000 horas de pruebas en terrenos complejos al aire libre, puede correr a una velocidad de 3.5 m/s y realizar acciones como subir pendientes, subir escaleras y mantenerse sobre un pie. Esta iniciativa forma parte de la «Matriz de Ecosistema de Código Abierto Nexus» de Fourier, destinada a proporcionar una base tecnológica abierta para desarrolladores globales, acelerando la investigación y validación del control de movimiento, la combinación de modelos multimodales y los portadores de inteligencia corporeizada. En el futuro, se abrirán más códigos de inferencia, frameworks de entrenamiento y módulos clave. (Fuente: InfoQ)

Google CoScientist utiliza el debate multiagente para acelerar el descubrimiento científico: El proyecto CoScientist de Google AI demuestra un método para generar hipótesis científicas innovadoras sin necesidad de entrenamiento basado en gradientes o aprendizaje por refuerzo. El sistema utiliza múltiples agentes impulsados por modelos de lenguaje grandes fundamentales (como Gemini 2.0) para colaborar: un agente propone una hipótesis, otro realiza una revisión crítica, y a través de múltiples rondas de debate y selección tipo «torneo», se eligen las hipótesis ganadoras. Un agente evolutivo especializado mejora luego las hipótesis ganadoras basándose en las críticas y las vuelve a presentar para más rondas de debate. Finalmente, un agente de meta-revisión supervisa todo el proceso y propone mejoras. Este mecanismo de debate multiagente, reflexión e iteración basado en el «escalado de cómputo en tiempo de prueba» (test-time compute scaling) muestra que los LLM no solo pueden generar contenido, sino también actuar como «árbitros» y «comentaristas» efectivos para evaluar y refinar ideas, acelerando así el descubrimiento científico, como se ha demostrado con avances significativos en la investigación de la resistencia a los antibióticos. (Fuente: Reddit r/artificial)

InternVL3: Nuevos avances en modelos multimodales nativos: La comunidad discute el recién lanzado modelo InternVL3. Este modelo adopta un método de pre-entrenamiento multimodal nativo y muestra un rendimiento excelente en múltiples benchmarks visuales, superando supuestamente a GPT-4o y Gemini-2.0-flash. Sus puntos destacados incluyen la mejora del manejo de contextos largos mediante la codificación de posición visual variable (V2PE) y el uso de VisualPRM para el escalado en tiempo de prueba «best-of-n». La comunidad muestra interés en su excelente rendimiento en benchmarks, espera la validación del rendimiento en aplicaciones reales y se preocupa por la configuración de hardware necesaria para ejecutarlo. (Fuente: Reddit r/LocalLLaMA)

🧰 Herramientas
CropGenerator: Herramienta Python para recortar conjuntos de datos de imágenes: Un desarrollador compartió una herramienta de script Python llamada CropGenerator, diseñada para ayudar a procesar conjuntos de datos de imágenes, especialmente en escenarios donde se requiere un recorte de características específicas al entrenar modelos como SDXL. La herramienta utiliza la información de cuadros delimitadores de un archivo JSONL proporcionado por el usuario para encontrar el centro de la región objetivo, la recorta, la escala (opcionalmente con eliminación de ruido por superresolución) a la resolución especificada (múltiplo de 8 píxeles) y genera imágenes recortadas en proporción 1:1. Al mismo tiempo, crea automáticamente un archivo metadata.csv que contiene los nombres de archivo recortados y la información descriptiva correspondiente del JSONL, facilitando la preparación rápida de datos de entrenamiento. El desarrollador afirma que la herramienta resolvió los problemas de desenfoque que encontró al procesar imágenes originales de diferentes tamaños y extraer características diminutas, y planea lanzar una versión más general en el futuro. (Fuente: Reddit r/MachineLearning)
📚 Aprendizaje
NUS lanza DexSinGrasp: Estrategia unificada de aprendizaje por refuerzo para separación y agarre con manos diestras: El equipo de Shao Lin de la Universidad Nacional de Singapur (NUS) propone DexSinGrasp, una estrategia unificada basada en aprendizaje por refuerzo que permite a una mano diestra separar eficientemente obstáculos y agarrar objetos objetivo en entornos desordenados. Los métodos tradicionales suelen emplear una estrategia de dos etapas (separar y luego agarrar), que es ineficiente y poco flexible en el cambio. DexSinGrasp integra la separación y el agarre en un proceso de decisión continuo mediante el diseño de una función de recompensa unificada que incluye un término de recompensa por separación, permitiendo al robot empujar adaptativamente los obstáculos para crear espacio de agarre. La investigación también introduce un mecanismo de «aprendizaje curricular en entornos desordenados», entrenando progresivamente de simple a complejo para mejorar la robustez de la estrategia. Al mismo tiempo, adopta un esquema de «destilación de políticas maestro-alumno», transfiriendo una política maestra de alto rendimiento entrenada en simulación con información privilegiada a una política de alumno que solo depende de la visión y la propiocepción, facilitando el despliegue en entornos reales. Los experimentos demuestran que este método mejora significativamente la tasa de éxito y la eficiencia del agarre en diversos escenarios desordenados. (Fuente: 机器之心)

CityGS-X: Nueva arquitectura eficiente para reconstrucción geométrica de grandes escenas, ejecutable en una 4090: Investigadores del Shanghai AI Lab y la Northwestern Polytechnical University han propuesto CityGS-X, un sistema escalable basado en una arquitectura de representación 3D jerárquica híbrida paralelizada (PH²-3D), diseñado para abordar el gran consumo de cómputo y la limitada precisión geométrica en la reconstrucción 3D de escenas urbanas a gran escala. Esta arquitectura utiliza paralelismo de datos distribuido (DDP) y representación de vóxeles con múltiples niveles de detalle (LoDs), eliminando la redundancia introducida por los métodos tradicionales de división en bloques. Las innovaciones clave incluyen: 1) La arquitectura PH²-3D, que duplica la velocidad de entrenamiento en comparación con los métodos de reconstrucción geométrica SOTA (State-Of-The-Art); 2) Un mecanismo paralelo de anclaje de asignación dinámica dentro de un marco de renderizado por lotes multitarea, que permite usar múltiples tarjetas gráficas de gama baja (como 4x 4090) para procesar escenas ultra grandes (como MatrixCity, más de 5000 imágenes), reemplazando o superando a una sola tarjeta de gama alta; 3) Un método de entrenamiento conjunto progresivo RGB-profundidad-normal, que mejora la calidad del renderizado RGB y la precisión geométrica a niveles SOTA. Los experimentos demuestran las ventajas de este método en calidad de renderizado, precisión geométrica y velocidad de entrenamiento. (Fuente: 量子位)

Investigación de Apple revela las Scaling Laws de los modelos multimodales nativos: Investigadores de Apple y la Universidad de la Sorbona realizaron un extenso estudio de las Scaling Laws en modelos multimodales nativos (NMM, es decir, entrenados desde cero, no combinando módulos pre-entrenados), analizando 457 modelos con diferentes arquitecturas y métodos de entrenamiento. El estudio encontró: 1) Las arquitecturas de fusión temprana (Early-fusion, como alimentar directamente patches de imagen a un Transformer) y fusión tardía (Late-fusion, usando codificadores visuales independientes) no tienen una superioridad inherente en rendimiento, pero la fusión temprana funciona mejor con menos parámetros y es más eficiente en el entrenamiento. 2) Las Scaling Laws de los NMM son similares a las de los LLM de solo texto, con la pérdida disminuyendo según una ley de potencia con el cómputo (C) (L ∝ C^−0.049), y los parámetros óptimos del modelo (N) y la cantidad de datos (D) también siguen relaciones de ley de potencia. 3) Los modelos de fusión tardía computacionalmente óptimos requieren una mayor relación parámetros/datos. 4) La escasez (MoE) es significativamente superior a los modelos densos, especialmente para arquitecturas de fusión temprana, y el modelo puede aprender implícitamente pesos específicos de modalidad. 5) El enrutamiento MoE independiente de la modalidad es superior al enrutamiento consciente de la modalidad. Estos hallazgos proporcionan una guía importante para construir y escalar grandes modelos multimodales nativos. (Fuente: 机器之心)

Microsoft y otras instituciones proponen V-Droid: Agente de GUI móvil práctico impulsado por validador: Para abordar los desafíos de precisión y eficiencia en la automatización de tareas de GUI en dispositivos móviles, Microsoft Research Asia, la Nanyang Technological University y otras instituciones han propuesto conjuntamente V-Droid. Este agente utiliza una innovadora arquitectura «impulsada por validador» en lugar de generar operaciones directamente. Primero analiza la interfaz de usuario (UI), construyendo un conjunto discreto de acciones candidatas (incluyendo elementos interactivos extraídos y acciones predeterminadas preestablecidas). Luego, utiliza un «validador» basado en LLM (como Llama-3.1-8B) y afinado, para evaluar en paralelo la efectividad de cada acción candidata, seleccionando la que obtenga la puntuación más alta para ejecutarla. Este método desacopla la compleja generación de operaciones en un proceso de validación eficiente, donde cada validación solo requiere la salida de unos pocos tokens (como «Sí/No»), reduciendo significativamente la latencia de decisión (aproximadamente 0.7 segundos en una 4090). Para entrenar el validador, los investigadores propusieron una estrategia de entrenamiento de preferencia de proceso contrastivo (P^3) y diseñaron un esquema de anotación conjunta humano-máquina para construir eficientemente el conjunto de datos. V-Droid logró tasas de éxito de tareas SOTA (State-Of-The-Art) en múltiples benchmarks como AndroidWorld (alcanzando el 59.5%). (Fuente: 新智元)

AssistanceZero: IA colaborativa basada en AlphaZero, ayuda a humanos sin instrucciones: Investigadores de la Universidad de California, Berkeley, proponen el algoritmo AssistanceZero, con el objetivo de crear asistentes de IA que puedan colaborar activamente con humanos para completar tareas (como construir juntos una casa en Minecraft) sin necesidad de instrucciones o metas explícitas. El método se basa en el marco de «Assistance Games», donde el asistente de IA comparte una función de recompensa con el humano, pero la IA no está segura de la recompensa específica (es decir, el objetivo) y necesita inferirla observando el comportamiento y la interacción humana. Esto difiere de RLHF, evitando que la IA «haga trampa» para satisfacer la retroalimentación y fomentando una colaboración más genuina. AssistanceZero extiende AlphaZero, combinando la búsqueda de árbol Monte Carlo (MCTS) y redes neuronales (para predecir recompensas y comportamiento humano) para la planificación y toma de decisiones. Los investigadores construyeron el benchmark Minecraft Building Assistance Game (MBAG) para pruebas, descubriendo que AssistanceZero supera significativamente a métodos tradicionales de aprendizaje por refuerzo como PPO y puede mostrar comportamientos colaborativos espontáneos como adaptarse a las correcciones humanas. La investigación demuestra que el marco de Assistance Games es escalable y ofrece una nueva vía para entrenar asistentes de IA más útiles. (Fuente: 机器之心)

Uso de Excel para comparar prompts de Suno y etiquetas de salida para optimizar el estilo: Un usuario de Reddit comparte un método para optimizar los prompts de estilo para la generación de música con Suno AI. Dado que el mecanismo de interpretación de prompts de Suno no es transparente, el usuario sugiere usar una hoja de cálculo de Excel para registrar las descripciones de estilo ingresadas (Styling Terms) y las etiquetas que Suno muestra después de la generación. Al comparar, se puede descubrir cómo Suno entiende, fusiona, divide o ignora los términos ingresados. Por ejemplo, al ingresar «solo piano, romantic, expressive… gentle arpeggios», Suno podría generar «gentle, slow tempo, soft… solo piano» y descartar «arpeggios». La diferencia puede ser mayor al comparar términos musicales más técnicos ingresados y la salida de Suno, que incluso podría insertar sus propios términos. Este método ayuda a entender qué palabras son efectivas, cuáles son ignoradas o malinterpretadas, permitiendo ajustar los prompts de manera más eficiente y evitar gastar créditos en intentos inútiles, aunque el usuario admite que el método en sí puede ser tedioso y la comprensión de Suno de conceptos musicales complejos sigue siendo limitada. (Fuente: Reddit r/SunoAI)
Tutorial: Convertir imágenes estáticas en animaciones vívidas: Un usuario de Reddit comparte un enlace a un tutorial de YouTube que explica cómo usar el Thin-Plate Spline Motion Model para animar imágenes faciales estáticas basándose en un video conductor, dándoles expresiones y movimientos vívidos. El tutorial cubre la configuración del entorno (crear un entorno Conda, instalar bibliotecas Python), clonar el repositorio de GitHub, descargar los pesos del modelo y ejecutar dos demostraciones: una usando ejemplos predefinidos y otra usando imágenes y videos propios del usuario para la animación. Esta técnica puede dar vida a fotografías estáticas. (Fuente: Reddit r/deeplearning)
Explorando la ardua tarea de alinear la superinteligencia con la IA: Un usuario de Reddit comparte un enlace a un video de YouTube que discute los enormes desafíos de alinear los objetivos de la superinteligencia artificial (ASI) con los intereses y valores humanos. Este tipo de discusión generalmente involucra problemas centrales en el campo de la seguridad de la IA, como el problema de la alineación de valores, la dificultad de especificar objetivos, las posibles consecuencias no deseadas y cómo garantizar que los sistemas de IA cada vez más potentes puedan servir de manera segura y controlable al bienestar humano. El video podría explorar los métodos actuales de investigación de alineación, sus limitaciones y direcciones futuras. (Fuente: Reddit r/deeplearning)

Construyendo «Auto-Analyst»: Un sistema de agente de IA para análisis de datos: Un usuario comparte un artículo de Medium que describe el proceso de construcción de un sistema de agente de IA llamado «Auto-Analyst», diseñado para automatizar tareas de análisis de datos. El artículo probablemente detalla la arquitectura del sistema, las tecnologías utilizadas (como LLMs, bibliotecas de procesamiento de datos), la forma en que colaboran los agentes y cómo maneja la entrada de datos, ejecuta análisis, genera informes, etc. Estos sistemas suelen utilizar la IA para comprender solicitudes en lenguaje natural, escribir y ejecutar código automáticamente (como consultas SQL, scripts Python) y finalmente presentar los resultados del análisis, con el objetivo de mejorar la eficiencia y accesibilidad del análisis de datos. (Fuente: Reddit r/deeplearning)
Pruebas de rendimiento al usar una GPU antigua (RTX 2070) para ayudar a una 3090 en inferencia de LLM: Un usuario comparte los resultados de un experimento donde añadió una antigua RTX 2070 (8GB VRAM) mediante un riser PCIe a un sistema existente con una RTX 3090 (24GB VRAM) para la inferencia de LLM. Las pruebas muestran que para modelos grandes que no caben completamente en la VRAM de la 3090 (como Qwen 32B Q6_K, Nemotron 49B Q4_K_M, Gemma-3 27B Q6_K), dividir las capas del modelo entre las dos tarjetas (incluso si la segunda es más débil) puede aumentar significativamente la velocidad de inferencia (t/s), ya que todas las capas se ejecutan en GPU. Por ejemplo, Nemotron 49B pasó de 5.17 t/s a 16.16 t/s. Sin embargo, para modelos que caben completamente en la 3090 (como Qwen2.5 32B Q5_K_M), habilitar la 2070 para compartir capas reduce el rendimiento (de 29.68 t/s a 19.01 t/s), porque parte del cálculo se transfiere a la GPU más lenta. La conclusión es que, para casos de VRAM insuficiente, añadir una GPU de menor rendimiento también puede aportar una mejora significativa. (Fuente: Reddit r/LocalLLaMA)
💼 Negocios
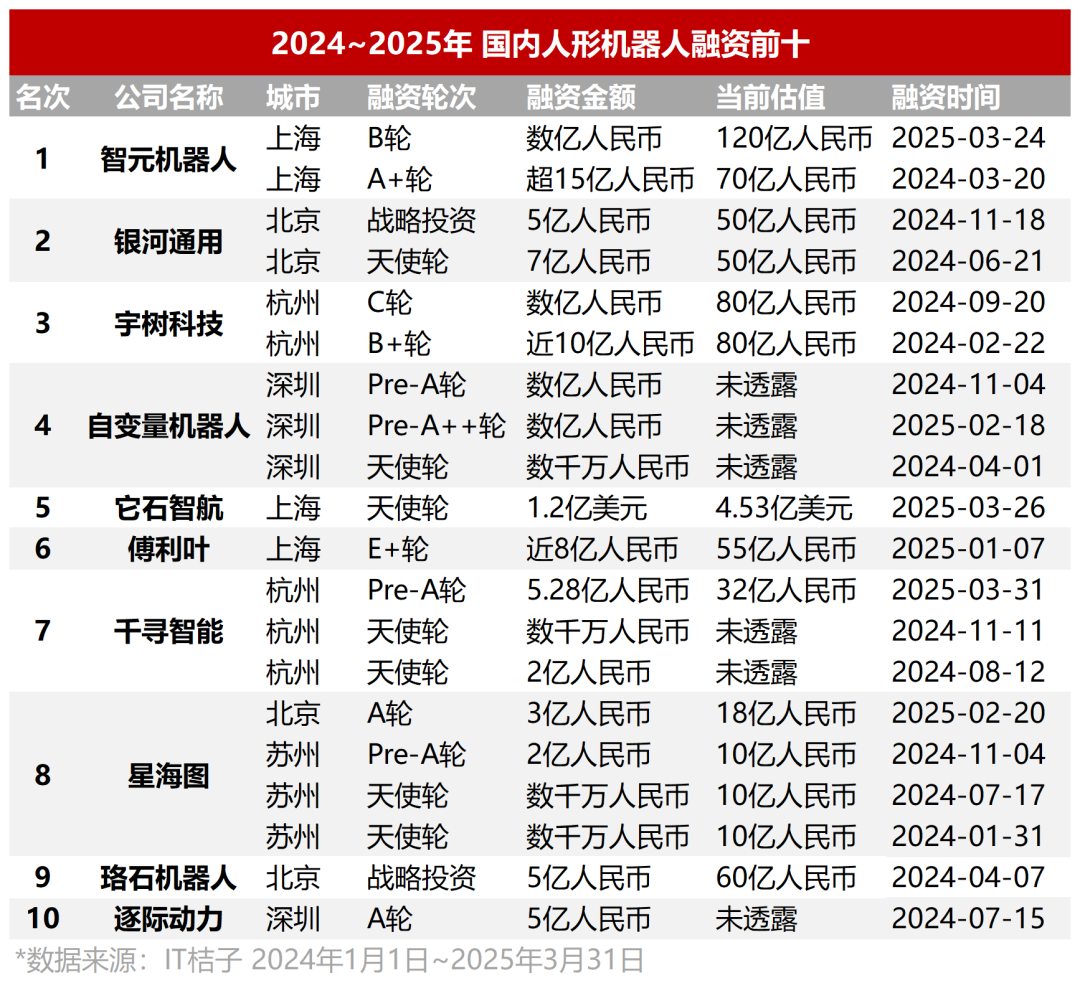
Fiebre inversora en robots humanoides: Ronda ángel desde decenas de millones, valoraciones elevadas: La inversión en el campo de los robots humanoides supera con creces la de los grandes modelos de los dos años anteriores. Los datos muestran que desde 2024 hasta el primer trimestre de 2025, hubo 64 rondas de financiación de más de diez millones de yuanes en el sector de robots humanoides en China, con un crecimiento interanual del 280% en el primer trimestre de este año. Casi la mitad de las financiaciones superaron los 100 millones de yuanes, las rondas ángel alcanzaron comúnmente decenas de millones, y algunas superaron los 100 millones (como la ronda ángel de Itastek Robotics de 120 millones de dólares). Las valoraciones de los proyectos también se han disparado, con más de la mitad de los proyectos en ronda ángel valorados en más de 100 millones de yuanes, y varias superando los 500 millones. La inversión muestra tres tendencias principales: 1) Ciclos de inversión más cortos, con proyectos estrella (como Itastek Robotics, Unitree Robotics) obteniendo grandes financiaciones poco después de su fundación y acelerando el ritmo de financiación posterior. 2) Los fondos estatales se convierten en impulsores importantes, con varias empresas líderes recibiendo inversiones de fondos con respaldo estatal. 3) Los escenarios de aplicación son principalmente ToB (Business-to-Business), con la industria y la medicina como direcciones principales, en lugar del mercado de consumo C-end. La fiebre inversora refleja el fuerte consenso y las altas expectativas del capital en la pista de los robots humanoides. (Fuente: 36氪)
La herramienta de automatización de flujos de trabajo de código abierto n8n recauda 460 millones de RMB, más de 100 millones de pulls en Docker: La plataforma de automatización de flujos de trabajo de código abierto n8n anunció la finalización de una nueva ronda de financiación de 60 millones de dólares (aproximadamente 460 millones de RMB), liderada por Highland Europe. n8n proporciona una interfaz visual que permite a los usuarios conectar diferentes aplicaciones (soporta más de 400) y servicios mediante nodos de arrastrar y soltar para crear flujos de trabajo automatizados, con el objetivo de combinar la flexibilidad a nivel de código con la velocidad sin código. En el último año, n8n ha experimentado un rápido crecimiento de usuarios, con más de 200,000 usuarios activos, un crecimiento del ARR (Ingreso Anual Recurrente) de 5 veces, 77.5k estrellas en GitHub y más de 100 millones de pulls en Docker. n8n utiliza un modelo de editor de nodos, soporta lógica compleja y ofrece funciones avanzadas como nodos personalizados de JavaScript. Utiliza una licencia de «código justo» Apache 2.0 + Commons Clause, que prohíbe el alojamiento comercial pero permite a los usuarios auto-desplegar. n8n se considera una alternativa de código abierto a Zapier, Make.com y Coze de ByteDance, sirviendo a más de 3000 empresas y soportando la integración con varios LLM. (Fuente: InfoQ)

🌟 Comunidad
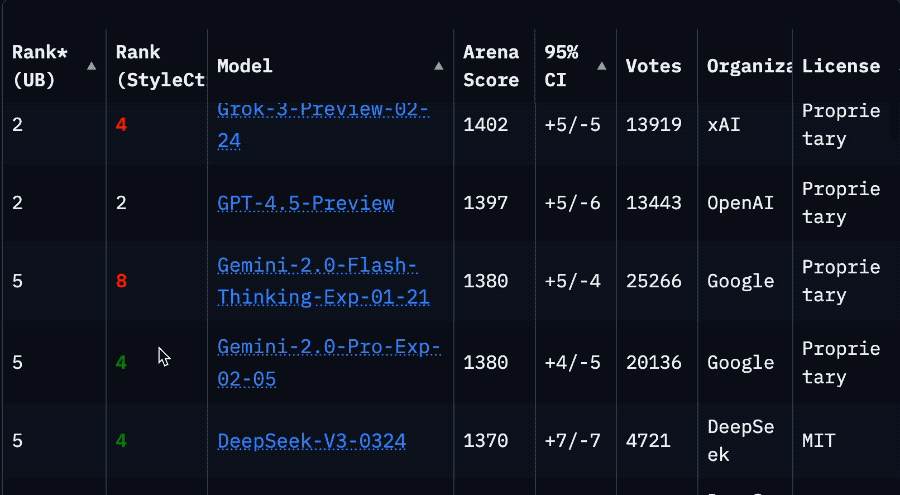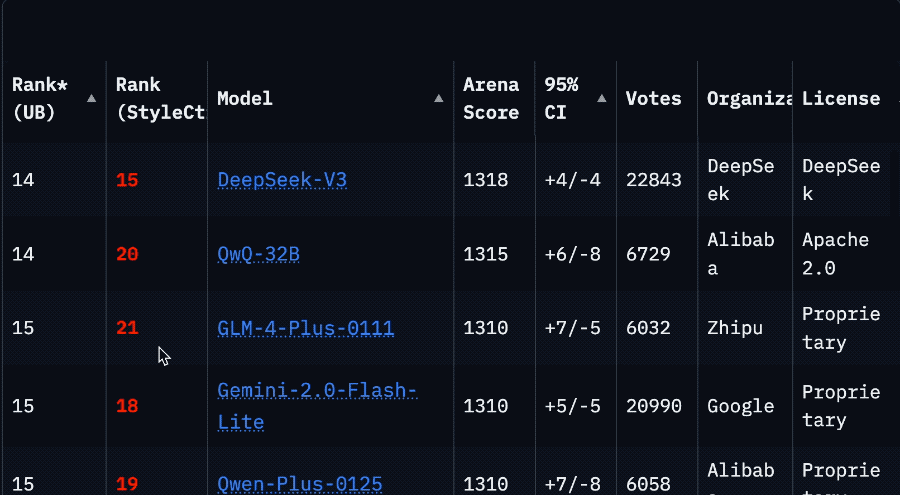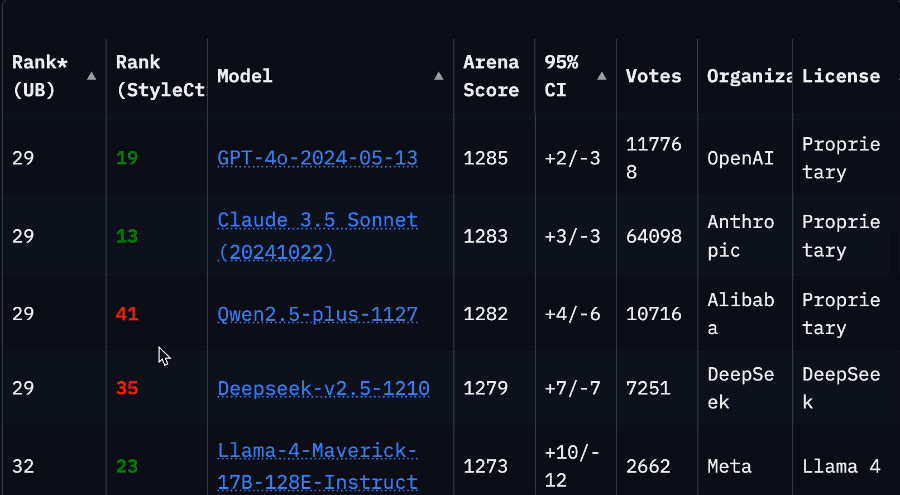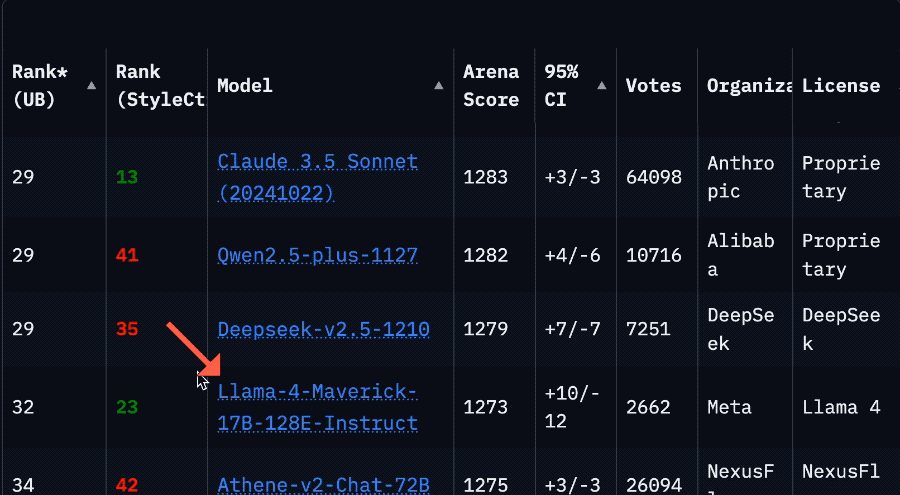
La drástica caída en el ranking de Llama 4 en la Arena provoca una crisis de confianza en la comunidad: Después de que Meta volviera a listar la versión no optimizada de su modelo Llama 4 (Llama-4-Maverick-17B-128E-Instruct) en la Arena de LMSys, su ranking cayó del segundo puesto anterior al puesto 32. La versión «experimental» presentada anteriormente fue acusada de estar sobreoptimizada para las preferencias humanas. Este evento generó una amplia discusión en la comunidad, con algunos internautas considerando que Meta intentó manipular los rankings de benchmarks, dañando la confianza de la comunidad en ellos. Al mismo tiempo, algunos desarrolladores compartieron experiencias de uso real, opinando que Llama 4, en hardware específico (como servidores autoconstruidos con mucha memoria pero potencia de cómputo relativamente baja o Mac Studio), logra un buen equilibrio entre velocidad e inteligencia en comparación con Mistral Small/Large o Command A, siendo especialmente adecuado para aplicaciones que requieren interacción en tiempo real. Las pruebas comparativas de Composio mostraron que DeepSeek v3 supera a Llama 4 en código y razonamiento de sentido común, pero tienen fortalezas diferentes en tareas RAG grandes y estilo de escritura. La comunidad en general cree que Llama 4 no es inútil, pero la estrategia de lanzamiento y el rendimiento en benchmarks de Meta son controvertidos. (Fuente: 量子位, Reddit r/LocalLLaMA)
Debate comunitario sobre las restricciones de la versión Claude Pro y el lanzamiento de la versión Max: Varios usuarios de Reddit informan que desde que Anthropic lanzó el nivel de suscripción más caro, Claude Max, las restricciones de uso de mensajes para los usuarios originales de Claude Pro parecen haberse vuelto más estrictas. Los usuarios afirman que sesiones que antes permitían decenas de interacciones, ahora reciben advertencias de «cerca del límite» después de solo unas pocas interacciones, e incluso encuentran problemas de limitación de capacidad durante horas no pico. Esto ha provocado una disminución en la experiencia del usuario, sintiéndose peor que la versión gratuita anterior o la versión Pro temprana. La comunidad especula ampliamente que esto es un intento deliberado de Anthropic para promover la versión Max restringiendo a los usuarios Pro, lo que ha generado descontento entre los usuarios y cuestionamientos sobre la ética comercial de Anthropic, con algunos usuarios considerando cancelar sus suscripciones o cambiarse a competidores como Gemini. (Fuente: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

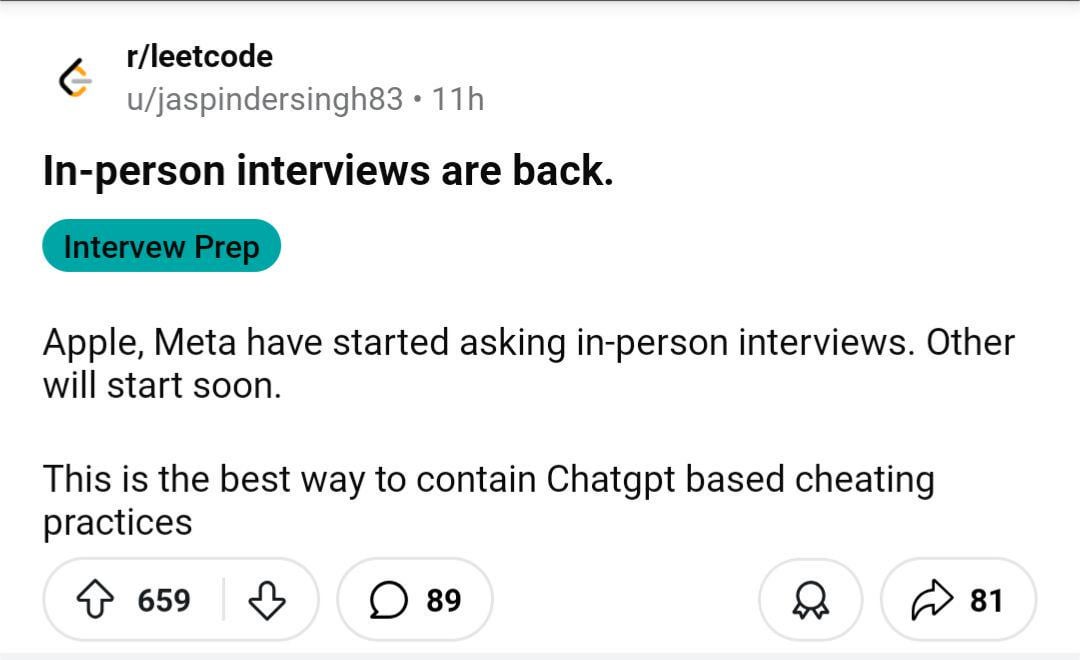
Discusión comunitaria: ¿Volverán las entrevistas presenciales debido a las trampas con IA?: Una imagen provocó una discusión en la comunidad de Reddit, sugiriendo que debido al aumento de trampas con IA en entrevistas y pruebas remotas, las empresas podrían volver a inclinarse por las entrevistas presenciales. En los comentarios, muchos estuvieron de acuerdo, argumentando que esto ayuda a descartar candidatos no calificados y solicitudes de bots, garantiza la equidad en la contratación y permite que las personas verdaderamente capaces obtengan oportunidades. Algunos mencionaron que las empresas pueden permitirse cubrir los gastos de viaje de los candidatos. Al mismo tiempo, alguien compartió la experiencia de un entrevistador que atrapó a un candidato usando ChatGPT para responder preguntas en tiempo real, y propuso soluciones de monitoreo multi-cámara de pantallas y teclados en entrevistas remotas. Otros comentarios señalaron que las pruebas deberían centrarse en el pensamiento crítico, no en tareas que la IA puede realizar fácilmente. Por otro lado, también se mencionó que algunas empresas están comenzando a usar IA para filtrar currículums. (Fuente: Reddit r/ChatGPT)
Dinámicas y discusiones de la comunidad de generación de música Suno AI: La comunidad SunoAI en Reddit ha estado activa recientemente, con discusiones variadas: 1) Compartir creaciones: Usuarios compartieron música de diversos estilos creada con Suno, como rap en hindi (fuente), surf rock (fuente), rap alternativo (fuente), rock pop (fuente), pop (fuente) y canciones humorísticas (fuente). 2) Problemas y técnicas de uso: Usuarios preguntaron cómo corregir errores de pronunciación (fuente), cómo crear coros de fondo angelicales (fuente), cómo mantener la melodía pero cambiar la calidad del sonido (fuente). 3) Derechos de autor y monetización: Discusión sobre los derechos de autor al publicar canciones con acompañamientos generados por Suno (fuente), y la elegibilidad para monetizar en YouTube usando imágenes estáticas con música de IA (fuente), enfatizando que la versión gratuita es solo para uso no comercial (fuente). 4) Retroalimentación sobre la calidad del modelo: Varios usuarios se quejaron de la reciente disminución en la calidad de generación de Suno (especialmente el modelo ReMi), con problemas como letras repetidas, inestabilidad y sonidos confusos (fuente, fuente, fuente, fuente). 5) Otros: Usuarios compartieron experiencias sobre la capacidad de Suno para reconocer estilos de bandas específicas (como Reel Big Fish) (fuente), y un video humorístico que imita a la IA escribiendo canciones pop (fuente).
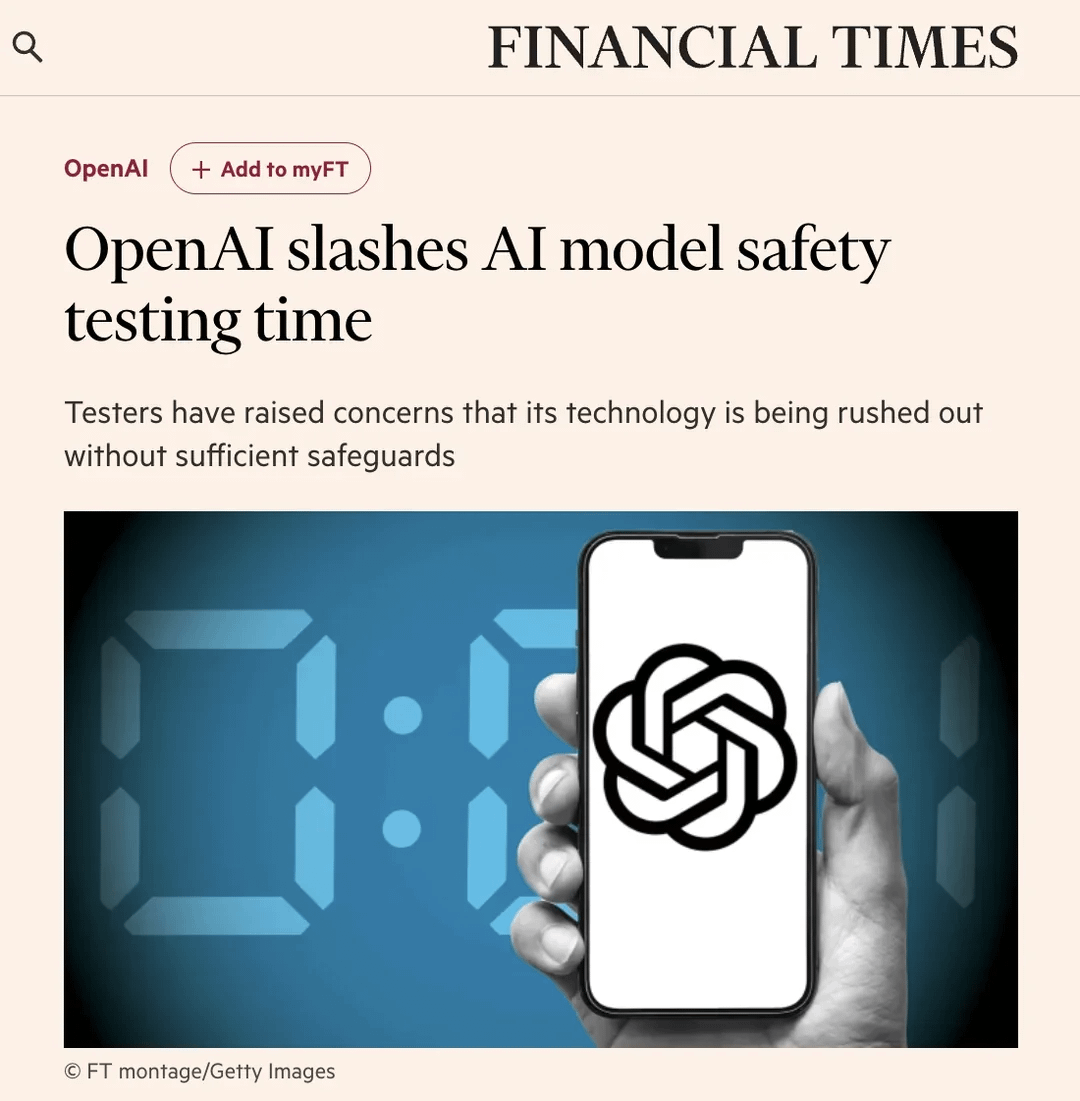
La comunidad discute la reducción del proceso de pruebas de seguridad de OpenAI: Un artículo del Financial Times (FT) generó discusión en la comunidad de Reddit. El artículo, citando fuentes internas, afirma que debido a la presión competitiva del mercado, OpenAI ha reducido drásticamente el tiempo de prueba de evaluación de seguridad para sus nuevos modelos, de meses a solo días. Esto ha generado preocupaciones sobre los riesgos potenciales, con algunos probadores calificando la medida de «imprudente» y una «receta para el desastre», argumentando que los modelos más potentes requieren pruebas más exhaustivas. El artículo también menciona que OpenAI, al evaluar riesgos biológicos y otros posibles escenarios de abuso, podría realizar solo pruebas limitadas de ajuste fino personalizado en modelos más antiguos, y que las pruebas de seguridad generalmente se realizan en puntos de control tempranos del modelo, no en la versión final de lanzamiento. OpenAI respondió que ha mejorado la eficiencia de la evaluación a través de la automatización y otros medios, y considera que su método es actualmente el óptimo y públicamente transparente. La comunidad tiene opiniones divididas al respecto, algunos creen que el propio desarrollo de la IA acelerará los procesos de prueba, mientras que otros expresan preocupación por el sacrificio de la seguridad. (Fuente: Reddit r/artificial)
Desarrollador explora la optimización del tiempo de ejecución de LLM y la orquestación multi-modelo: Un desarrollador compartió en Reddit un sistema de tiempo de ejecución nativo de IA que están experimentando. El sistema tiene como objetivo lograr la carga instantánea (arranque en frío de 2-5 segundos) y la recuperación bajo demanda de LLMs (nivel 13B-65B) mediante la serialización de la ejecución de la GPU y el estado de la memoria, permitiendo así ejecutar dinámicamente más de 50 modelos en una sola GPU sin necesidad de memoria residente. Este enfoque busca lograr un comportamiento verdaderamente Serverless (sin costo de inactividad), orquestación multi-modelo de baja latencia y mejorar la utilización de la GPU para cargas de trabajo agénticas. El desarrollador pregunta si alguien en la comunidad ha intentado pilas multi-modelo similares, flujos de trabajo de agentes o técnicas de reasignación dinámica de memoria (como MIG, KAI Scheduler, etc.) y solicita comentarios sobre la necesidad de este tipo de infraestructura. (Fuente: Reddit r/MachineLearning, Reddit r/MachineLearning)
Debate comunitario: ¿Está la IA cerca de la conciencia?: Un usuario de Reddit inició una discusión sobre hasta qué punto los sistemas de IA actuales se acercan a la «conciencia». El autor de la pregunta enfatizó que no se refería a la prueba de Turing o la simulación de conversaciones, sino que se centraba en si la IA posee estados que cambian con el tiempo, memoria del entorno, capacidad de evolucionar basada en la interacción y no solo en el ajuste fino, capacidad de auto-ubicación y referencia dentro del sistema, y la capacidad de expresar «estuve aquí, vi esto, aprendí algo». El autor considera que la mayoría de las IA actuales (especialmente los LLM) son sin estado, centralizadas y reactivas, y que las funciones de «memoria» añadidas parecen superficiales y simuladas, cuestionando si la pila tecnológica existente (Python, API sin estado, RAG, etc.) puede albergar una conciencia real. La discusión generó reflexiones en la comunidad sobre la definición de conciencia en IA, las limitaciones de la tecnología actual y posibles caminos futuros. (Fuente: Reddit r/MachineLearning)
Usuario reporta que el tono de ChatGPT es demasiado entusiasta: Un usuario de Reddit se quejó de que su instancia de ChatGPT muestra un tono excesivamente entusiasta y emocionado, por ejemplo, usando frecuentemente frases iniciales como «¡Oh, me encanta esta pregunta!» o «¡Esto es súper interesante!», y añadiendo comentarios al final de las respuestas como «¿No es fascinante y genial?». El usuario afirma que intentar pedirle al modelo que detenga este comportamiento no funciona y pregunta si hay alguna forma de controlar o ajustar el «nivel de entusiasmo» del modelo para que sus respuestas sean más directas y objetivas. Otros usuarios en la sección de comentarios expresaron frustraciones similares, especialmente con la tendencia del modelo a hacer preguntas al final. Algunos usuarios compartieron métodos para mitigar el problema usando Instrucciones Personalizadas (Custom Instructions) para establecer preferencias de tono (como reducir el lenguaje emocional), mientras que otros sugirieron nombrar al chatbot y «regañarlo» directamente. (Fuente: Reddit r/ChatGPT)
Discusión: Añadir nuevo vocabulario a LLM y ajustar finamente no funciona bien: Un desarrollador encontró problemas al ajustar finamente LLMs y VLMs para seguir instrucciones. Descubrieron que, en comparación con el uso del tokenizador base, añadir nuevo vocabulario especializado (tokens) al tokenizador antes de realizar un ajuste fino supervisado estándar (SFT) resultaba en una mayor pérdida de validación y peor calidad de salida del modelo. El desarrollador especula que podría ser difícil para el modelo aprender a aumentar la probabilidad de generación de estos tokens recién añadidos. El problema generó una discusión en la comunidad sobre cómo introducir eficazmente nuevo vocabulario durante el ajuste fino, el impacto de la extensión del tokenizador en el aprendizaje del modelo y otros detalles técnicos. (Fuente: Reddit r/MachineLearning)
Compartir y discutir imágenes generadas por IA: En la comunidad ChatGPT de Reddit, los usuarios compartieron diversas imágenes interesantes o extrañas generadas con DALL-E 3. Por ejemplo, un usuario generó una imagen de Daphne de Scooby-Doo jugando N64 antes de irse de vacaciones a la playa, basada en un prompt específico (fuente), lo que llevó a otros usuarios a imitar y generar otros personajes (como Chun-Li) en escenarios similares. Otro usuario compartió imágenes extrañas generadas a partir del prompt «genera una foto que nadie pueda ver» (fuente), lo que también provocó numerosas respuestas compartiendo resultados generados sobre temas similares, algunos inquietantes o cómicos. Estas publicaciones muestran la diversidad de la generación de imágenes por IA y la creatividad de los usuarios.
La comunidad discute la tendencia de diseño de logos de empresas de IA: Una publicación humorística enlaza a un artículo en el sitio web Velvet Shark titulado «¿Por qué los logos de las empresas de IA parecen anos?», lo que generó discusión en la comunidad. El artículo probablemente explora los elementos gráficos abstractos, simétricos, en forma de vórtice o anillo comunes en el diseño de logos del sector de la IA actual, y los relaciona burlonamente con cierta estructura anatómica. Los usuarios en la sección de comentarios respondieron de manera relajada, especulando sobre su relación con el concepto de «singularidad» (singularity) o llamándolo «tecnología derivada del recto». Esto refleja una observación divertida de la comunidad sobre la imagen visual de la industria. (Fuente: Reddit r/ArtificialInteligence)

Usuarios buscan sugerencias de proyectos y ayuda técnica: Hay varias publicaciones en la comunidad donde los usuarios buscan ayuda o sugerencias específicas: un usuario está desarrollando una aplicación de respuesta a desastres basada en NLP, que ya incluye un dashboard, reconocimiento de voz, clasificación de texto, soporte multilingüe, etc., y pregunta cómo hacer que el proyecto sea más único (fuente). Otro usuario está encontrando un cuello de botella en la precisión al usar un modelo BART ajustado finamente para estandarizar títulos y categorías de productos de comercio electrónico, y busca sugerencias de mejores modelos o herramientas (fuente). Otro usuario pregunta cómo generar o modificar imágenes en OpenWebUI y qué modelos se necesitan (fuente). Estas publicaciones reflejan los desafíos que enfrentan los desarrolladores en aplicaciones prácticas y su necesidad de apoyo comunitario.
Discusión sobre el mercado laboral de Ingenieros de Machine Learning (MLE): Un usuario (posiblemente estudiante o principiante) pregunta sobre el estado actual del mercado laboral para Ingenieros de Machine Learning (MLE). Menciona haber leído en publicaciones de la comunidad que los puestos de MLE pueden requerir maestrías/doctorados, ser difíciles de ingresar y tener límites borrosos con los Ingenieros de Software (SWE), requiriendo un amplio conjunto de habilidades. El usuario expresa voluntad de aprender pero preocupación por las perspectivas, esperando que los profesionales puedan ofrecer orientación y puntos de vista sobre la situación actual del mercado, las habilidades requeridas, las trayectorias profesionales, etc. (Fuente: Reddit r/deeplearning)
Usuario francófono de OpenWebUI reporta bug en la interpretación de imágenes: Un usuario francófono de OpenWebUI reportó un problema: al subir una imagen para que el modelo Gemma la interprete, el modelo responde, pero el contenido de la respuesta está vacío. Incluso al intentar que el modelo lea en voz alta o exporte el texto de la conversación, el mensaje permanece vacío. Peor aún, este problema «contamina» la conversación actual, y después, incluso al enviar mensajes de texto puro, todas las respuestas del modelo están vacías. El usuario confirma que crear nuevas conversaciones de texto puro no presenta problemas, sospecha que hay un bug en el módulo visual y busca ayuda de la comunidad. (Fuente: Reddit r/OpenWebUI)
💡 Otros
Uso de IA combinada con el pensamiento de las ‘Obras Escogidas de Mao Zedong’ para analizar la guerra arancelaria: Ante la escalada arancelaria entre China y EE. UU., un artículo intenta utilizar herramientas de IA, combinadas con el pensamiento estratégico de «Sobre la guerra prolongada» de las Obras Escogidas de Mao Zedong, para analizar la situación económica actual y las estrategias de respuesta. El autor argumenta que, frente a la guerra comercial, se deben evitar los pensamientos extremos de «capitulación» (dependencia total del exterior) y «victoria rápida» (esperanza de autonomía total a corto plazo), y en su lugar, adoptar el pensamiento de primeros principios, volviendo a la esencia del comercio, el origen del valor y las propias fortalezas y debilidades. El artículo muestra el proceso de pensamiento colaborativo entre el autor y la IA, y toma como ejemplo el comercio electrónico transfronterizo de sitios independientes para explorar enfoques de respuesta asistidos por IA, enfatizando la importancia del pensamiento estratégico y la capacidad de acción. Este artículo tiene como objetivo proporcionar una perspectiva sobre el uso de la IA para un análisis estratégico profundo. (Fuente: AI觉醒)

Anuncio de la Tercera Cumbre de la Industria AIGC de China: La tercera Cumbre de la Industria AIGC de China, organizada por QbitAI (量子位), se celebrará el 16 de abril de 2025 en Beijing. La cumbre reunirá a más de 20 ponentes de grandes empresas y nuevas empresas de IA como Baidu, Huawei, Ant Group, Microsoft Research Asia, Amazon Web Services, Model Berkeley, Wènxīn Qióng, ShengShu Technology, así como representantes de la industria como Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health Group. Los temas girarán en torno a los avances tecnológicos de la IA (infraestructura de cómputo, cómputo distribuido, almacenamiento de datos, seguridad y controlabilidad), la penetración en la industria (educación, entretenimiento, AI for Science, servicios empresariales y otros escenarios verticales) y la construcción de ecosistemas. La cumbre también publicará la lista de «Empresas/Productos AIGC a seguir en 2025» y el «Mapa Panorámico de Aplicaciones AIGC de China». El evento ofrece inscripción para asistencia presencial y reserva para transmisión en vivo en línea. (Fuente: 量子位, 量子位)

Suno AI organiza un evento para ganar un millón de créditos: Un usuario de Reddit compartió información de una publicación del blog oficial de Suno AI sobre un evento donde los usuarios tienen la oportunidad de ganar hasta un millón de Credits. Las reglas específicas del evento deben consultarse en la publicación original del blog. Este tipo de eventos generalmente tienen como objetivo aumentar la participación de los usuarios y la actividad de la plataforma. (Fuente: Reddit r/SunoAI)

Subreddit ClaudeAI introduce mecanismo de votación de calidad de publicaciones: Los moderadores del subreddit ClaudeAI anunciaron la introducción de un nuevo bot, u/qualityvote2. Este bot publicará un comentario debajo de cada nueva publicación, invitando a los usuarios a votar (upvote/downvote) sobre ese comentario para evaluar la calidad de la publicación. Las publicaciones que alcancen un cierto número de votos positivos serán consideradas adecuadas para el subreddit, mientras que aquellas que alcancen un cierto número de votos negativos serán marcadas para revisión y posible eliminación por parte de los moderadores. Esta medida tiene como objetivo utilizar el poder de la comunidad para mantener la calidad del contenido del subreddit. Al mismo tiempo, el equipo de moderadores también ha añadido un bot de detección de manipulación de votos. (Fuente: Reddit r/ClaudeAI)