
Palabras clave:AI, TPU, protocolo A2A de Google, séptima generación de TPU, modelos de razonamiento AI, aplicaciones de Agent AI, optimización de inferencia AI
🔥 Destacados
Google lanza el protocolo A2A y la séptima generación de TPU, acelerando la era de los AI Agent y la inferencia : Google presenta el protocolo de código abierto Agent2Agent (A2A), diseñado para permitir la comunicación y colaboración seguras entre AI Agents de diferentes proveedores y frameworks, complementando en lugar de reemplazar el protocolo MCP (MCP conecta Agents con herramientas, A2A conecta Agents entre sí). A2A sigue principios como el descubrimiento de capacidades, la gestión de tareas, la colaboración y la negociación de la experiencia de usuario, y ya cuenta con el apoyo de más de 50 socios. Simultáneamente, Google lanza la séptima generación de TPU (Ironwood/TPU v7), optimizada específicamente para la inferencia de IA, con una potencia de cálculo FP8 de 4614 TFlops, 192GB de HBM por chip, un ancho de banda de 7.2 TBps y una eficiencia energética dos veces superior a la generación anterior. El clúster de configuración máxima (9216 chips) alcanza una potencia de cálculo de 42.5 ExaFlops, destinado a soportar modelos «pensantes» como Gemini y aplicaciones de AI Agent de próxima generación, marcando la transición de la IA de reactiva a la generación proactiva de insights. (fuente: 36氪, 36氪, 微信公众号, 微信公众号, 微信公众号, 微信公众号)

MCP se convierte en el hub del ecosistema de AI Agent, Alibaba y Tencent lo adoptan plenamente : El Protocolo de Contexto de Modelo (MCP) se está convirtiendo rápidamente en la interfaz estándar para conectar AI Agents con herramientas externas y fuentes de datos, considerado como el «USB» del ecosistema de IA. Alibaba Cloud Ba炼 lanzó el primer servicio MCP de ciclo de vida completo de la industria, integrando Function Compute, más de 200 modelos grandes y más de 50 servicios MCP, permitiendo la construcción rápida de Agents en 5 minutos. Tencent Cloud también lanzó un «Kit de Desarrollo de IA» que soporta el alojamiento de plugins MCP. MCP reduce los costos de desarrollo repetitivo al desacoplar el host, el servidor y el cliente, mejora la capacidad de interconexión de las herramientas de IA y es crucial para lograr la colaboración compleja entre Agents. Aunque enfrenta desafíos iniciales como un ecosistema inmaduro y una cadena de herramientas incompleta, con el apoyo de OpenAI, Google, Microsoft, Amazon y los principales actores chinos, se espera que MCP acelere la explosión de aplicaciones de IA y el desarrollo industrial. (fuente: 36氪)
La IA logra avances significativos en la Olimpiada Matemática : Los resultados de la segunda Olimpiada Matemática de IA (AI Mathematical Olympiad – Progress Prize 2) muestran un progreso notable de la IA en la resolución de problemas matemáticos de alta dificultad. El mejor modelo obtuvo una puntuación alta de 34/50 en una prueba compuesta por problemas completamente nuevos, con recursos computacionales limitados (costo por problema inferior a 1 dólar) y que requería respuestas enteras precisas (0-999). Esto supera con creces la evaluación previa de estudios humanos que estimaba que los LLM solo podían alcanzar alrededor del 5%. Incluso un modelo derivado relativamente básico de DeepSeek R1 obtuvo una puntuación de 28/50. Este resultado indica que la capacidad de razonamiento matemático de la IA, especialmente en problemas de nivel olímpico que requieren resolución creativa, está mejorando rápidamente y no se trata simplemente de reconocimiento de patrones o memorización de datos. (fuente: Reddit r/MachineLearning)
SenseTime lanza SenseNova V6, un modelo MoE multimodal de 6 billones de parámetros : SenseTime Technology presenta su modelo grande de sexta generación, SenseNova V6, que utiliza una arquitectura de Mezcla de Expertos (MoE) con 6 billones de parámetros y soporte nativo para entrada y procesamiento fusionado de texto, imágenes, video y otros modos múltiples. El modelo muestra un rendimiento excelente en múltiples benchmarks de texto puro y multimodales, superando a GPT-4.5 y Gemini 2.0 Pro. Sus capacidades principales incluyen fuerte razonamiento (razonamiento profundo multimodal y lingüístico superior a o1, Gemini 2.0 flash-thinking), fuerte interacción (comprensión de audio y video en tiempo real, expresión emocional) y memoria larga (soporte para análisis de video largo, como inferencia directa sobre contenido de video de varios minutos). Las tecnologías clave incluyen entrenamiento de fusión multimodal nativo, síntesis de cadena de pensamiento larga multimodal (soporte para 64K tokens), aprendizaje por refuerzo híbrido multimodal (RLHF+RFT) y representación unificada y compresión dinámica de videos largos. SenseTime enfatiza que la IA debe servir a las aplicaciones cotidianas, impulsando su implementación en diversas industrias. (fuente: 微信公众号)
🎯 Movimientos
Google Gemini 2.5 Flash se lanzará pronto, enfocado en la inferencia eficiente : Google adelantó el modelo Gemini 2.5 Flash en la conferencia Cloud Next ’25. Como versión ligera del modelo insignia Gemini 2.5 Pro, Flash se centrará en ofrecer capacidades de inferencia rápidas y de bajo costo. Su característica es la capacidad de ajustar dinámicamente la profundidad de la inferencia según la complejidad del prompt, evitando cálculos excesivos en problemas simples. Los desarrolladores podrán personalizar la profundidad de la inferencia para controlar los costos. Se espera que el modelo esté disponible pronto en Vertex AI, destinado a satisfacer las necesidades de aplicaciones cotidianas sensibles a la velocidad de respuesta. (fuente: 微信公众号, X)

ByteDance publica el informe técnico de Seed-Thinking-v1.5, con potente capacidad de razonamiento : ByteDance ha revelado detalles técnicos de su modelo de razonamiento Seed-Thinking-v1.5, entrenado mediante aprendizaje por refuerzo. El informe muestra que el modelo se desempeña excelentemente en múltiples benchmarks, superando el rendimiento de DeepSeek-R1 y acercándose al nivel de Gemini-2.5-Pro y O3-mini-high, logrando una puntuación del 40% en la prueba ARC-AGI. El modelo tiene 200 mil millones de parámetros totales y 20 mil millones de parámetros activos. Los pesos del modelo aún no se han publicado, pero su excelente capacidad de razonamiento y su cantidad relativamente pequeña de parámetros activos han llamado la atención de la comunidad. (fuente: X)

ChatGPT mejora la función de memoria, puede referenciar todas las conversaciones pasadas : OpenAI anuncia una actualización de la función de memoria de ChatGPT, permitiendo que el modelo referencie todo el historial de chat del usuario para proporcionar respuestas más personalizadas. Esta mejora tiene como objetivo utilizar las preferencias e intereses del usuario para mejorar la ayuda en escritura, sugerencias, aprendizaje, etc. Al iniciar una nueva conversación, ChatGPT utilizará estas memorias de forma natural. Los usuarios aún tienen control total sobre esta función, pueden desactivar la referencia al historial en la configuración, desactivar completamente la función de memoria o usar el modo de conversación temporal. La función ha comenzado a implementarse para usuarios Plus y Pro (excepto en algunas regiones) y pronto cubrirá a los usuarios de equipos, empresas y educación. (fuente: X, X)
OpenAI lanza podcast sobre el desarrollo tras bastidores de GPT-4.5 : Sam Altman y los miembros clave del equipo de OpenAI, Alex Paino, Dan Selsam y Amin Tootoonchian, grabaron un podcast discutiendo el proceso de I+D de GPT-4.5 y su dirección futura. El equipo reveló que el desarrollo de GPT-4.5 marca un cambio de la optimización de la eficiencia computacional a la optimización de la eficiencia de los datos, con el objetivo de lograr una inteligencia diez veces superior a GPT-4. El podcast discutió la importancia del mecanismo de «compresión» en el aprendizaje no supervisado (aproximación a la inducción de Solomonoff), enfatizó la necesidad de evaluar con precisión el rendimiento del modelo y evitar la memorización pura, y compartió experiencias sobre la superación de desafíos técnicos y la importancia de la moral del equipo. (fuente: X, X)
Perplexity integra Gemini 2.5 Pro, planea conectar Grok 3 y WhatsApp : El motor de búsqueda de IA Perplexity anuncia que ha integrado el último modelo Gemini 2.5 Pro de Google para usuarios Pro, e invita a los usuarios a compararlo con modelos como Sonar, GPT-4o, Claude 3.7 Sonnet, DeepSeek R1 y O3. Además, el CEO de Perplexity, Aravind Srinivas, confirmó que, tras recibir numerosos comentarios positivos de los usuarios, comenzarán a desarrollar la integración de Perplexity con WhatsApp. Al mismo tiempo, se planea que el modelo Grok 3 sea compatible pronto en la plataforma Perplexity. (fuente: X, X, X)

La serie de modelos Qwen3 de Alibaba se está preparando, pero el lanzamiento aún requiere tiempo : La comunidad espera con interés la próxima generación de modelos de la serie Qwen3 de Alibaba, incluidas las versiones no de código abierto, Qwen3-8B y Qwen3-MoE-15B-A2B, entre otros. Sin embargo, según las respuestas de los desarrolladores de Qwen en las redes sociales, el lanzamiento de Qwen3 no es algo de «pocas horas» y aún requiere más tiempo de preparación. Esto indica que Alibaba está desarrollando activamente la nueva generación de modelos, pero el cronograma de lanzamiento específico aún no está determinado. (fuente: X, Reddit r/LocalLLaMA)

Misteriosos modelos de alto rendimiento «Dragontail» y «Quasar Alpha» aparecen en LM Arena, generando especulaciones : En la plataforma LMSYS Chatbot Arena (LM Arena), han aparecido modelos anónimos llamados «Dragontail» y «Quasar Alpha», que en interacciones con usuarios han mostrado un rendimiento comparable o incluso superior en algunos problemas matemáticos a modelos de primer nivel (como o3-mini-high, Claude 3.7 Sonnet). La comunidad especula que «Dragontail» podría ser una variante del próximo Qwen3 o Gemini 2.5 Flash, mientras que «Quasar Alpha» es conjeturado por algunos usuarios como un modelo de la serie o4-mini de OpenAI. La aparición de estos modelos anónimos refleja el papel de la arena de modelos como plataforma para probar modelos de vanguardia y evaluar su rendimiento. (fuente: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Demo del modelo Kimi-VL-A3B-Thinking de Moonshot AI disponible en Hugging Face : Moonshot AI (月之暗面) ha lanzado una demostración interactiva (Demo) de su modelo multimodal Kimi-VL-A3B-Thinking en Hugging Face Spaces. Los usuarios ahora pueden experimentar públicamente el modelo. Las pruebas iniciales muestran que el modelo tiene capacidades de OCR y reconocimiento de imágenes en línea, pero puede tener un rendimiento limitado en ciertas tareas que requieren un amplio conocimiento general (como comprender el humor de memes específicos), lo que podría estar relacionado con el tamaño del modelo. (fuente: X, X)

AMD organizará un evento de IA para presentar nuevas GPU para centros de datos : AMD planea organizar un evento llamado «Advancing AI 2025», donde presentará nuevas GPU para centros de datos. Este lanzamiento se centrará en aplicaciones de IA, no en tarjetas gráficas para juegos. Esta medida indica la continua inversión de AMD en el mercado de hardware de IA, con la intención de competir en el campo de los aceleradores de IA dominado por Nvidia. (fuente: Reddit r/artificial)
🧰 Herramientas
Firecrawl: Herramienta de código abierto para convertir sitios web en datos listos para LLM : Firecrawl, lanzado por Mendable AI, es una potente herramienta de código abierto (escrita en TypeScript) diseñada para extraer (scrape), rastrear (crawl) y convertir sitios web completos en Markdown listo para LLM o datos estructurados a través de una única API. Puede manejar proxies, mecanismos anti-bot, renderizado de contenido dinámico y otros desafíos, y admite rastreo personalizado (como exclusión de etiquetas, rastreo autenticado), análisis de medios (PDF, DOCX) e interacción con la página (clics, desplazamiento, entrada). Ofrece API, SDKs para Python/Node/Go/Rust, y ya está integrado en varios frameworks de LLM (Langchain, Llama Index, Crew.ai) y plataformas low-code (Dify, Langflow, Flowise). Firecrawl proporciona un servicio API alojado y una versión de código abierto ejecutable localmente. (fuente: GitHub)
KrillinAI: Herramienta de traducción y doblaje de video basada en modelos grandes : KrillinAI es un proyecto de código abierto escrito en Go que utiliza modelos grandes de lenguaje (LLM) para ofrecer servicios profesionales de traducción y doblaje de video. Admite el despliegue completo del flujo de trabajo con un solo clic, capaz de manejar desde la descarga de videos (compatible con yt-dlp y carga local), generación de subtítulos de alta precisión (Whisper), segmentación y alineación inteligente de subtítulos (LLM), traducción multilingüe, reemplazo de terminología, doblaje por IA y clonación de voz (CosyVoice), hasta la síntesis de video (adaptación automática a pantalla horizontal/vertical). Su objetivo es generar contenido adaptado para plataformas como YouTube, TikTok, Bilibili, etc. El proyecto ofrece versiones de escritorio para Win/Mac y una versión sin escritorio (Web UI), y admite despliegue con Docker. (fuente: GitHub)
Second Me: Construir un «yo de IA» localizado y personalizado : Second Me es un proyecto de código abierto destinado a construir un «gemelo digital» o «yo de IA» del usuario utilizando modelos de IA ejecutados localmente. Enfatiza la privacidad (ejecución completamente local) y la personalización, utilizando modelado de memoria jerárquica (HMM) y una estructura de «Me-alignment» para simular la identidad, memoria, valores y forma de razonar del usuario. El proyecto admite despliegue con Docker (macOS, Windows, Linux) e interfaz API compatible con OpenAI, y está explorando el soporte de entrenamiento MLX. La comunidad es activa y ha contribuido con integración de bot de WeChat, soporte multilingüe, etc. Su visión es hacer que la IA sea una extensión de las capacidades del usuario, no un apéndice de la plataforma. (fuente: Reddit r/LocalLLaMA)

EasyControl: Proporciona inyección condicional tipo LoRA para modelos Diffusion con arquitectura DiT : EasyControl es un framework de código abierto recién lanzado, diseñado para abordar la falta de plugins maduros (como LoRA) para los nuevos modelos Diffusion basados en la arquitectura DiT (Diffusion Transformer). Proporciona un módulo ligero de inyección condicional que permite a los usuarios añadir fácilmente capacidades de control similares a LoRA a los modelos DiT, logrando tareas como la transferencia de estilo. El proyecto muestra los resultados de un modelo entrenado con 100 rostros asiáticos y sus correspondientes imágenes estilo Ghibli (generadas por GPT-4o), y ya es compatible con la integración en ComfyUI. (fuente: X)

XplainMD: Pipeline de IA explicable biomédica que fusiona GNN y LLM : XplainMD es un pipeline de IA de extremo a extremo de código abierto, diseñado específicamente para grafos de conocimiento biomédico. Combina redes neuronales de grafos (R-GCN) para la predicción de enlaces multirrelacionales (como relaciones fármaco-enfermedad, gen-fenotipo), utiliza GNNExplainer para la explicabilidad del modelo, visualiza subgrafos de predicción con PyVis y utiliza el modelo LLaMA 3.1 8B Instruct para la explicación en lenguaje natural y la verificación de solidez de las predicciones. Todo el proceso se despliega en una aplicación interactiva Gradio, con el objetivo de proporcionar predicciones explicando al mismo tiempo el «por qué», mejorando la confianza y usabilidad de la IA en áreas sensibles como la medicina de precisión. (fuente: Reddit r/deeplearning, Reddit r/MachineLearning)
LaMPlace: Nuevo método basado en IA para la optimización de la disposición de macroceldas en chips : Investigadores de la Universidad de Ciencia y Tecnología de China, el Laboratorio Noah’s Ark de Huawei y la Universidad de Tianjin proponen LaMPlace, un método de optimización de la disposición de macroceldas en chips basado en IA. Este método, mediante un predictor de métricas estructurado (que utiliza polinomios de Laurent para modelar el impacto de la distancia entre macros en métricas inter-etapas como WNS/TNS) y un mecanismo de generación de máscaras aprendible, guía las decisiones de colocación en las primeras etapas de la disposición para optimizar el rendimiento final del chip (PPA). LaMPlace tiene como objetivo trasladar los objetivos de optimización de métricas intermedias fáciles de calcular (como longitud de cable, densidad) a los objetivos de diseño finales, logrando una «optimización shift-left» y mejorando la eficiencia del diseño. El método ha sido seleccionado para presentación Oral en ICLR 2025. (fuente: 微信公众号)
Google lanza Agent Development Kit (ADK) y Firebase Studio : Como parte de su impulso al ecosistema de AI Agent, Google ha lanzado el Agent Development Kit (ADK), un framework de desarrollo para construir sistemas multiagente. ADK soporta múltiples proveedores de modelos (Gemini, GPT-4o, Claude, Llama, etc.), proporciona herramientas CLI, gestión de Artifacts, AgentTool (llamadas entre Agents) y otras funciones, y soporta el despliegue en Agent Engine o Cloud Run. Al mismo tiempo, Google también ha lanzado Firebase Studio, una herramienta de programación de IA en la nube que integra el modelo Gemini, soportando el desarrollo de aplicaciones de ciclo completo, desde codificación con IA, compilación y construcción hasta despliegue en servicios en la nube. (fuente: 微信公众号, Reddit r/LocalLLaMA)
OpenFOAMGPT: Utiliza modelos grandes nacionales para reducir el costo de la simulación CFD : El equipo de la Universidad de Exeter (Reino Unido) y la Universidad de Beihang (China) ha actualizado el proyecto OpenFOAMGPT, cuyo objetivo es permitir a los usuarios impulsar simulaciones de dinámica de fluidos computacional (CFD) mediante lenguaje natural. La nueva versión ha integrado con éxito los modelos grandes nacionales DeepSeek V3 y Qwen 2.5-Max, manteniendo un rendimiento cercano a GPT-4o/o1 mientras reduce los costos hasta 100 veces. Además, el equipo también ha logrado el despliegue localizado (entorno de GPU única) utilizando el modelo QwQ-32B, proporcionando a investigadores y pymes chinas una solución CFD asistida por IA más económica y conveniente, reduciendo la barrera de entrada profesional. (fuente: 微信公众号)
Slop Forensics Toolkit: Herramienta de análisis de contenido repetitivo en la salida de LLM : Se ha lanzado un nuevo kit de herramientas de código abierto para analizar el «slop» —palabras y frases sobreutilizadas— en la salida de los modelos grandes de lenguaje (LLM). La herramienta utiliza análisis estilométrico para identificar vocabulario y n-grams que aparecen con más frecuencia que en la escritura humana, construyendo el «perfil de slop» del modelo. También se inspira en métodos de bioinformática, tratando las características léxicas como «mutaciones» para inferir árboles de similitud entre diferentes modelos. La herramienta tiene como objetivo ayudar a los investigadores a comprender y comparar las características generativas de diferentes LLM y la posible contaminación de datos o sesgos de entrenamiento. (fuente: Reddit r/MachineLearning)
El framework de inferencia vLLM añade soporte para Google TPU : El popular framework de código abierto para inferencia y servicio de modelos grandes, vLLM, ha anunciado la adición de soporte para Google TPU. Combinado con la séptima generación de TPU (Ironwood) recientemente lanzada por Google, esta actualización significa que los desarrolladores pueden utilizar vLLM para realizar inferencia y despliegue de modelos eficientes en el hardware de IA de alto rendimiento de Google. Esto ayuda a expandir el ecosistema de software de TPU, ofreciendo más opciones de hardware a los usuarios. (fuente: X)

📚 Aprendizaje
CUHK, Tsinghua y otros proponen el framework SICOG, explorando nuevas vías para la autoevolución de modelos grandes : Abordando la dependencia de los modelos grandes de datos de preentrenamiento de alta calidad y el problema del agotamiento de los recursos de datos, instituciones como la Universidad China de Hong Kong (CUHK) y la Universidad de Tsinghua proponen el framework SICOG (Self-Improving Systematic Cognition). Este framework construye un mecanismo de autoevolución trinitario de «mejora post-entrenamiento – optimización de la inferencia – refuerzo mediante re-preentrenamiento». Mediante «Chain-of-Description» (CoD) mejora la percepción visual estructurada, «Structured Chain-of-Thought» (CoT) potencia el razonamiento multimodal, y utiliza un bucle cerrado de datos autogenerados y filtrado de consistencia para lograr una mejora continua de las capacidades cognitivas del modelo con cero anotaciones manuales. Los experimentos demuestran que SICOG puede mejorar significativamente el rendimiento del modelo en múltiples tareas, reducir las alucinaciones y mostrar buena escalabilidad, ofreciendo nuevas ideas para abordar el cuello de botella del preentrenamiento y avanzar hacia una IA de aprendizaje autónomo. (fuente: 微信公众号)
OpenAI libera el benchmark BrowseComp para evaluar la capacidad de navegación web de los AI Agent : OpenAI ha publicado y liberado el benchmark BrowseComp (Browsing Competition). Este benchmark tiene como objetivo evaluar la capacidad de los AI Agent para navegar por Internet y encontrar información difícil de localizar, similar a un juego de búsqueda del tesoro en línea para Agents. OpenAI considera que este tipo de pruebas captura capacidades clave de navegación profunda tipo investigación de los agentes inteligentes, siendo crucial para evaluar el nivel de inteligencia de los Agents de navegación web avanzados. (fuente: X, X)
Estudio encuentra que los modelos de razonamiento generalizan mejor en tareas de codificación OOD : Un nuevo estudio (arXiv:2504.05518v1) compara la capacidad de generalización de modelos de razonamiento y modelos no basados en razonamiento mediante experimentos con tareas de codificación. Los resultados muestran que los modelos de razonamiento no experimentan una disminución significativa del rendimiento al pasar de tareas dentro de la distribución (in-distribution) a tareas fuera de la distribución (out-of-distribution, OOD); mientras que los modelos no basados en razonamiento sí muestran una disminución del rendimiento. Esto sugiere que los modelos de razonamiento no son simplemente «pattern matchers», sino que pueden aprender y generalizar a tareas fuera de la distribución de entrenamiento, poseyendo mayores capacidades de abstracción y aplicación. (fuente: Reddit r/ArtificialInteligence)
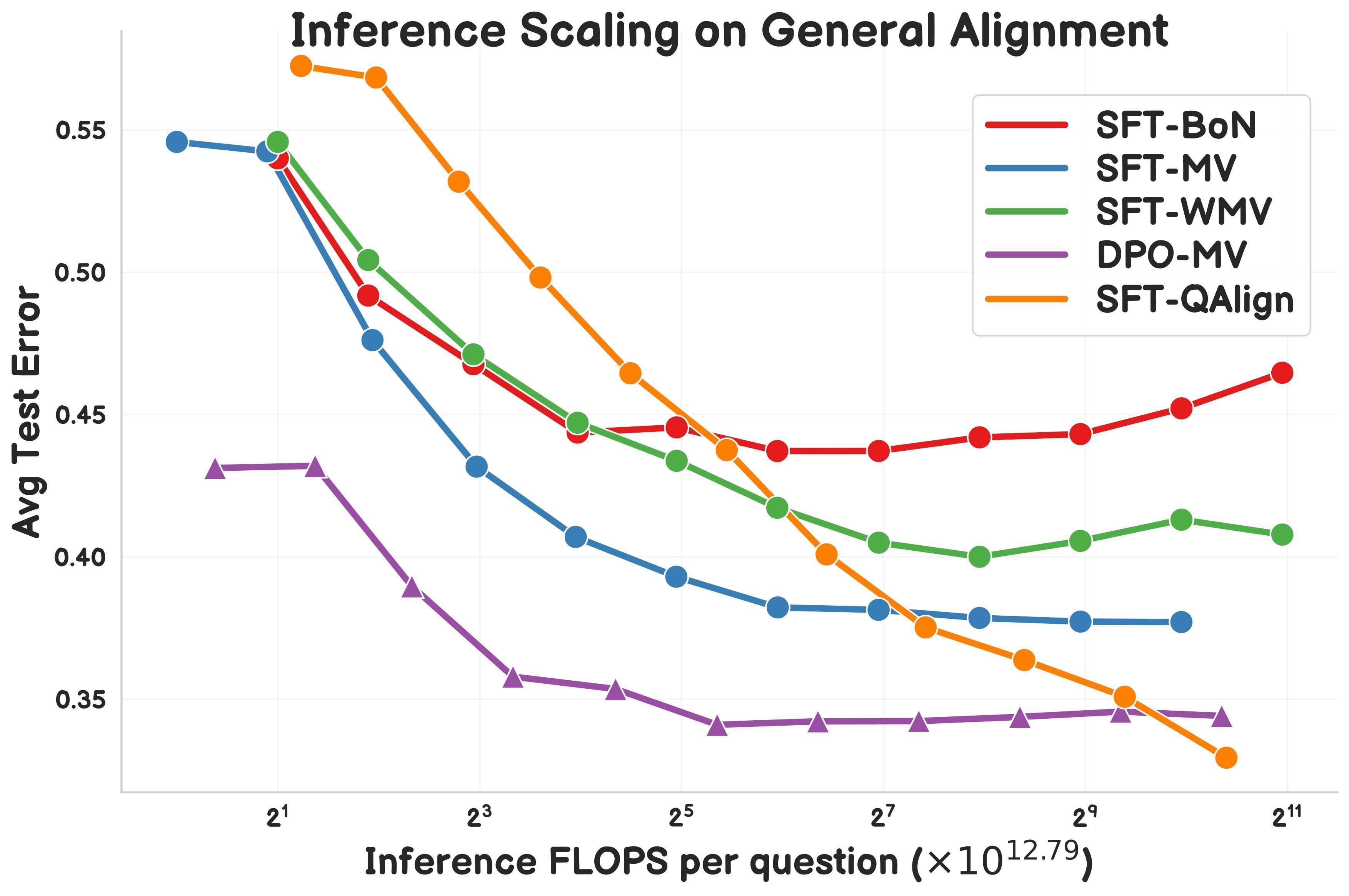
Investigación propone QAlign: método de alineación en tiempo de prueba basado en MCMC : Gonçalo Faria et al. proponen QAlign, un nuevo método de alineación en tiempo de prueba (test-time alignment) que utiliza Cadenas de Markov Monte Carlo (MCMC) para mejorar el rendimiento del modelo de lenguaje sin necesidad de reentrenar el modelo. La investigación muestra que QAlign supera en rendimiento a los modelos ajustados con DPO (Direct Preference Optimization) (con la misma carga computacional de inferencia) y puede superar las limitaciones del muestreo tradicional Best-of-N (propenso a sobreoptimizar el modelo de recompensa) y del voto mayoritario (incapaz de descubrir respuestas únicas), prometiendo usos en escenarios como la generación de datos de alta calidad. (fuente: X)
Yann LeCun reitera las limitaciones de los LLM autorregresivos : En una charla reciente, el Científico Jefe de IA de Meta, Yann LeCun, reafirmó su opinión sobre las limitaciones de las arquitecturas actuales de los modelos grandes de lenguaje autorregresivos (Auto-Regressive), considerando que su paradigma está «condenado al fracaso» (doomed). Argumenta que este método de predicción palabra por palabra limita la capacidad del modelo para realizar una planificación real y un razonamiento profundo. Aunque los modelos autorregresivos siguen siendo el estado del arte (SOTA) actualmente, LeCun y otros investigadores están explorando activamente alternativas, como las arquitecturas de predicción de incrustación conjunta (JEPA), con la esperanza de lograr sistemas de IA más cercanos a la inteligencia humana. (fuente: Reddit r/MachineLearning)
LlamaIndex muestra cómo construir un Agent generador de informes combinando con Google Cloud : El fundador de LlamaIndex, Jerry Liu, demostró en Google Cloud Next ’25 cómo combinar los flujos de trabajo de LlamaIndex y las bases de datos de Google Cloud (como BigQuery, AlloyDB) para construir un Agent generador de informes. Dicho Agent puede analizar documentos SOP (usando LlamaParse), bases de datos de tutoriales, datos legales, etc., para generar guías de incorporación personalizadas para nuevos empleados. Esto refleja que la arquitectura de Agent basada en conocimiento requiere potentes capacidades de acceso y procesamiento de datos, y muestra el papel de LlamaIndex en la construcción de tales aplicaciones de Agent. (fuente: X)

Investigador comparte el motor Symbolic Compression y el formato de archivo .sym : Un investigador independiente ha liberado un motor llamado Symbolic Compression y su correspondiente formato de archivo .sym. El proyecto afirma ser capaz de comprimir extrayendo las reglas recursivas y la lógica estructural detrás de secuencias (como números primos, secuencia de Fibonacci) (basado en su propuesta Ley de Miller: κ(x) = ((ψ(x) – x)/x)²) en lugar de simplemente comprimir los datos brutos. Su objetivo es almacenar y predecir la aparición de la estructura misma, proporcionando un formato similar a JSON pero para lógica recursiva. El proyecto incluye herramientas CLI y funcionalidad de compresión multirregional. (fuente: Reddit r/MachineLearning)

💼 Negocios
Se anuncian los precios de la API Grok-3, mínimo 0.3 USD por millón de tokens : xAI ha abierto oficialmente al público la API de la serie Grok 3, adoptando una estrategia de precios escalonada. Grok 3 (Beta), orientado a aplicaciones empresariales, tiene un precio de entrada de 3 USD/millón de tokens y de salida de 15 USD/millón de tokens; el ligero Grok 3 Mini (Beta) tiene un precio de entrada de 0.3 USD/millón de tokens y de salida de 0.5 USD/millón de tokens. Ambos ofrecen versiones de respuesta rápida (fast-beta) a un precio más alto. Esta estrategia de precios lo posiciona para competir en costo con modelos como Gemini 2.5 Pro de Google, el plan Max de Anthropic Claude (mínimo 100 USD) y Llama 4 Maverick de Meta (aproximadamente 0.36 USD/millón de tokens). (fuente: 微信公众号)
Informe de IA de Stanford: fortaleza en IA de Alibaba es la tercera a nivel mundial, la brecha entre China y EE. UU. se reduce : El último «Informe del Índice de Inteligencia Artificial 2025» de la Universidad de Stanford muestra que, entre las contribuciones a modelos grandes importantes a nivel mundial, Google y OpenAI ocupan 7 puestos cada uno, empatados en primer lugar, mientras que Alibaba ocupa el tercer lugar a nivel mundial y el primero en China con 6 puestos (serie Qwen). El informe señala que la brecha de rendimiento de los modelos entre China y EE. UU. se ha reducido significativamente, pasando de 17.5 puntos porcentuales (benchmark MMLU) a finales de 2023 a 0.3 puntos porcentuales a finales de 2024. La familia de modelos Qwen de Alibaba (con más de 200 modelos ya liberados) se ha convertido en la serie de modelos de código abierto más grande del mundo, con más de 100,000 modelos derivados. El informe también menciona que los modelos chinos de primer nivel (como Qwen2.5, DeepSeek-V3) generalmente requieren menos potencia de cálculo para el entrenamiento que modelos estadounidenses comparables, demostrando mayor eficiencia. (fuente: 微信公众号)
Empresas chinas de IA médica buscan abrirse paso ante aranceles y barreras tecnológicas : Frente a múltiples presiones como el aumento de aranceles estadounidenses y el monopolio tecnológico (por ejemplo, gigantes de GPS que controlan las interfaces de datos de imágenes), las empresas chinas de tecnología médica están acelerando la sustitución nacional y la transformación inteligente. United Imaging Healthcare insiste en el I+D propio de tecnologías clave, lanzando equipos de alta gama como la resonancia magnética de 5.0T, y desarrollando modelos grandes médicos y agentes inteligentes. Mindray Medical construye un ecosistema digital inteligente (como la plataforma Ruiying Cloud++ que integra DeepSeek) a través de la estrategia «Equipo + TI + IA» y profundiza en el mercado internacional. Dinfectome se enfoca en la medicina de precisión con su modelo grande de imágenes médicas iMedImage®, participa en el establecimiento de estándares de la industria y logra una competencia diferenciada. Estas empresas, impulsadas por la IA, buscan avances en tecnologías clave, cadena de suministro y aceptación clínica para remodelar el panorama del mercado. (fuente: 微信公众号)
🌟 Comunidad
La aplicación de la IA en la educación genera debate : La discusión comunitaria se centra en cómo la inteligencia artificial (IA) puede transformar la educación a través de planes de aprendizaje personalizados. La IA tiene el potencial de ajustar el contenido y los métodos de enseñanza según las necesidades individuales, el ritmo y el estilo de aprendizaje del estudiante, logrando una educación personalizada y mejorando la eficiencia y efectividad del aprendizaje. (fuente: X)

La compleja ingeniería detrás del editor Cursor llama la atención : La discusión comunitaria menciona que la implementación del editor de código AI Cursor no es tarea fácil. Su objetivo principal es evitar que los usuarios copien y peguen código manualmente, para lo cual se realizaron numerosas optimizaciones de la experiencia del usuario e innovaciones en ingeniería, incluyendo la invención de nuevos paradigmas de edición de código, el desarrollo interno del modelo de edición rápida FastApply y el modelo de predicción de autocompletado de código Fusion, y la implementación de RAG de dos capas localmente y en el servidor para optimizar el manejo del contexto. Estos esfuerzos muestran la profundidad técnica necesaria para construir una experiencia de programación con IA fluida. (fuente: X)
Herramienta de trampa con IA genera debate sobre ética y sistemas de contratación : Roy Lee, un estudiante de la Universidad de Columbia, desarrolló la herramienta de IA «Interview Coder» para hacer trampa en entrevistas de programación, fue expulsado de la universidad después de recibir ofertas de varias empresas de primer nivel, y posteriormente ganó 2.2 millones de dólares en 50 días vendiendo la herramienta. La herramienta puede funcionar de forma invisible, simulando el estilo de codificación humano para generar respuestas. El incidente ha generado un amplio debate: por un lado, muchos desarrolladores están insatisfechos con las entrevistas de programación rígidas y desconectadas de la realidad (como la resolución de problemas de LeetCode); por otro lado, el aumento de las trampas con IA (algunos informes indican que la proporción ha aumentado del 2% al 10%) desafía la validez de las entrevistas técnicas actuales, podría obligar a las empresas a reformar sus sistemas de contratación y plantea debates sobre los límites éticos de lo que constituye «hacer trampa» en la era de la IA. (fuente: 36氪)
Surgen aplicaciones innovadoras de Agents genéricos : Recientes competiciones de hackathon de Agents (como flowith, openmanus) han visto surgir muchas aplicaciones innovadoras. Categoría de desarrollo y diseño: Agents que pueden generar automáticamente proyectos completos con código frontend/backend y estructura de base de datos a partir de bocetos de UI (maxcode), o recopilar información de forma autónoma, determinar el estilo y generar sitios web personales. Categoría de análisis y decisión: Agents que pueden calcular la mejor posición en un vuelo para ver auroras, o realizar optimización auto-iterativa de estrategias de trading cuantitativo (一鹿向北). Categoría de servicios personalizados: Agents que pueden recomendar inteligentemente lugares para reuniones (Jarvis-CafeMeet), analizar datos de Douban para generar «informes de gusto», o servir a usuarios mayores mediante interacción por voz (老奶奶教你用OpenManus). Categoría de creación artística: Agents que pueden generar arte digital de estilo específico, generar bailes basados en música, personalizar pinceles de pintura, generar música programable en tiempo real (strudel-manus), etc. Estos casos demuestran el enorme potencial de los Agents en diversos campos. (fuente: 微信公众号)
Andrew Ng comenta sobre el impacto de los aranceles estadounidenses en el desarrollo de la IA : Andrew Ng publicó un artículo expresando preocupación por la imposición generalizada de altos aranceles por parte de EE. UU., argumentando que esto dañará las relaciones con los aliados, obstaculizará la economía global, creará inflación y tendrá un impacto negativo en el desarrollo de la IA. Señala que, aunque el libre flujo de ideas y software (especialmente de código abierto) podría no verse muy afectado, los aranceles restringirán el acceso al hardware de IA (como servidores, refrigeración, equipos de red), aumentarán los costos de construcción de centros de datos y afectarán indirectamente el suministro de potencia de cálculo al impactar las importaciones de equipos eléctricos. Aunque los aranceles podrían estimular ligeramente la demanda interna de robots y automatización, esto difícilmente compensará las deficiencias en la manufactura. Insta a la comunidad de IA a mantener la cooperación y el intercambio internacional. (fuente: X)
La comunidad debate la aplicación de la IA en el apoyo a la salud mental : Cada vez más usuarios comparten sus experiencias utilizando herramientas de IA como ChatGPT para asesoramiento psicológico y apoyo emocional. Muchos afirman que la IA proporciona un espacio seguro y sin juicios para desahogarse, permitiendo obtener retroalimentación instantánea y consejos útiles, e incluso en algunos casos, haciéndoles sentir más escuchados y comprendidos que los terapeutas humanos, lo que produce efectos positivos de desahogo emocional. Aunque los usuarios generalmente coinciden en que la IA no puede reemplazar completamente a los terapeutas profesionales con licencia, especialmente en el tratamiento de problemas psicológicos graves, muestra un gran potencial para proporcionar apoyo básico, manejar el estrés diario y explorar problemas personales inicialmente, y es popular por su accesibilidad y bajo costo. (fuente: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
La calificación del contenido traducido por IA genera debate : La comunidad discute una pregunta: si se utiliza IA (como ChatGPT) para traducir una historia creada por humanos, ¿el contenido debe considerarse creación humana o creación de IA? Algunos argumentan que si la IA solo actúa como herramienta de traducción, sin alterar las ideas, estructura y tono originales, la esencia del contenido sigue siendo creación humana. Sin embargo, los detectores de texto de IA podrían marcarlo como generado por IA debido al análisis de patrones textuales. Esto plantea reflexiones sobre la definición del rol de la IA en el proceso creativo, las limitaciones de los detectores de IA y cómo mantener el estilo original en la traducción. (fuente: Reddit r/ArtificialInteligence)
Usuario reporta problemas con Gemini 2.5 Pro en el procesamiento de contextos largos : El usuario Nathan Lambert descubrió al probar Gemini 2.5 Pro que, al procesar consultas con entradas de contexto muy largas, el modelo experimenta errores de conexión. El fenómeno observado es que el modelo parece regenerar casi todos los tokens de entrada durante la inferencia, lo que lleva a costos de inferencia extremadamente altos y eventual fallo. Además, señaló que no se pueden compartir los historiales de chat de Gemini cuando ocurren errores. Estos comentarios señalan posibles problemas de estabilidad y eficiencia del modelo actual al manejar contextos ultralargos. (fuente: X)

La comunidad reacciona negativamente al lanzamiento de Llama 4, cuestionando su rendimiento y apertura : La serie de modelos Llama 4 lanzada por Meta ha generado una amplia discusión y evaluaciones negativas en la comunidad. Los usuarios generalmente creen que, aunque el modelo Maverick tiene una ventana de contexto de hasta 10 millones de tokens y se desempeña aceptablemente en llamadas a funciones, sus 400B de parámetros totales (17B parámetros activos) no han traído la mejora esperada en el rendimiento de inferencia, siendo incluso inferior a modelos como QwQ 32B. Además, su licencia restrictiva, la falta de paper técnico y system card, y las acusaciones de sospechas de «inflar puntuaciones» en benchmarks como LMSYS, han dañado la reputación de Meta en la comunidad de código abierto. La comunidad expresa decepción por que Meta no haya continuado la apertura y el liderazgo de Llama 3. (fuente: Reddit r/LocalLLaMA)

El plan Claude Pro es acusado de degradación encubierta, usuarios se quejan de mayores restricciones de uso : Con el lanzamiento por parte de Anthropic del plan Max más caro (que afirma ofrecer 5 o 20 veces el uso del plan Pro), muchos usuarios de Claude Pro en la comunidad informan que sienten que las restricciones de uso del propio plan Pro se han vuelto más estrictas y es más fácil alcanzar el límite. Los usuarios especulan que Anthropic podría haber reducido la cuota de uso real del plan Pro para impulsar a los usuarios a actualizar al plan Max. Estos ajustes poco transparentes y la percepción de degradación del servicio han generado descontento entre los usuarios, especialmente dado que el modelo Claude en sí todavía tiene problemas de memoria en la ventana de contexto. (fuente: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

La comunidad de OpenWebUI discute funciones y problemas : Los usuarios de OpenWebUI discuten en la comunidad las funciones de la herramienta y los problemas encontrados. Un usuario pregunta si es posible integrar Nextcloud como opción adicional de almacenamiento en la nube. Otro usuario informa que experimenta problemas al usar la función de base de conocimiento, ya que al cargar varios documentos, el LLM parece referenciar solo el primer documento. Otro usuario experimenta errores de tiempo de espera al intentar conectar a endpoints API de OpenAI compatibles con Gemini. Estas discusiones reflejan las necesidades y preocupaciones de los usuarios sobre la extensibilidad y estabilidad de la herramienta. (fuente: Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
La comunidad de Suno AI intercambia consejos de uso y problemas : La comunidad de usuarios de Suno AI está activa, discutiendo temas como: cómo excluir instrumentos específicos (como batería, teclados) al usar la función Cover para aislar instrumentos solistas; buscar consejos para generar estilos musicales específicos (como Trip Hop); informar problemas con la función de invitar amigos que no otorga créditos; discutir problemas de derechos de autor de letras, por ejemplo, si frases específicas (como «You’re Dead») activarán restricciones de derechos de autor; y compartir casos de uso creativo de Suno, como crear música de fondo para personajes de D&D. (fuente: Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI)
💡 Otros
Exploración de la generación de «fotos accidentales» por IA : Usuarios de la comunidad intentan usar IA para generar fotos que parecen tomadas sin intención, con composición casual, e incluso con ligero desenfoque o sobreexposición, las llamadas «fotos accidentales». Esta exploración busca desafiar la tendencia de la IA a generar imágenes perfectas, imitando la casualidad e imperfección de la fotografía humana, y demuestra la capacidad de la IA para comprender y simular estilos fotográficos específicos (incluido el estilo de «mala» foto). (fuente: Reddit r/ChatGPT)

Potencial de la IA en la gestión de la cadena de suministro : La discusión enfatiza el potencial de la inteligencia artificial (IA) para mejorar la trazabilidad y transparencia de la cadena de suministro. Utilizando el aprendizaje automático y el análisis de datos, la IA puede ayudar a las empresas a monitorizar mejor el flujo de mercancías, predecir riesgos de interrupción, optimizar la gestión de inventario y proporcionar a los consumidores información más fiable sobre el origen del producto. (fuente: X)

Exploración de la aplicación de la IA en la gestión de recursos humanos : La discusión comunitaria menciona la posibilidad de adoptar avatares de IA (Avatars) para la gestión de recursos humanos. Esto podría incluir el uso de IA para la selección inicial de entrevistas, formación de empleados, respuesta a consultas sobre políticas, e incluso apoyo emocional, con el objetivo de mejorar la eficiencia de los procesos de RRHH y la experiencia del empleado. (fuente: X)

El Banco de Inglaterra advierte que la IA podría desencadenar crisis de mercado : El Banco de Inglaterra ha emitido una advertencia señalando que el software de inteligencia artificial podría usarse para manipular mercados, e incluso crear deliberadamente crisis de mercado para obtener beneficios. Esto plantea preocupaciones sobre la regulación y el control de riesgos de la aplicación de la IA en el sector financiero. (fuente: Reddit r/artificial)

Nuevo método de IA para generar formas 3D realistas : Investigadores del MIT han desarrollado un nuevo método de IA generativa capaz de crear formas tridimensionales más realistas. Esto tiene una importancia significativa para campos como el diseño de productos, la realidad virtual, el desarrollo de juegos y la impresión 3D, impulsando el avance tecnológico en la generación de modelos 3D complejos a partir de imágenes 2D o descripciones textuales. (fuente: X)

El consumo de energía y el costo de la inferencia de IA se reducen drásticamente : Informes señalan que nuevos avances tecnológicos han permitido reducir el consumo de energía de las tareas de inferencia de IA (medido en energía MAC) 100 veces y el costo 20 veces. Esta mejora en la eficiencia es crucial para la viabilidad y economía de los modelos de IA en dispositivos de borde, móviles y despliegues a gran escala en la nube. (fuente: X)

Debate sobre el impacto de la IA en la cognición humana : La discusión comunitaria se centra en los posibles efectos de la dependencia excesiva de la IA en el cerebro humano, con algunas opiniones citando titulares de artículos que afirman que podría llevar a un cerebro «atrofiado y no preparado» (Atrophied And Unprepared). Esto refleja preocupaciones sobre el posible deterioro de funciones cognitivas centrales humanas como el pensamiento crítico, la memoria y la capacidad de resolución de problemas tras la popularización de las herramientas de IA. (fuente: X)

Perspectivas y preocupaciones sobre los futuros modelos de trabajo impulsados por IA : La discusión comunitaria cita opiniones de artículos que predicen que para 2025, la IA reescribirá las reglas del trabajo y los modelos laborales actuales podrían terminar. Esto genera debate y preocupación sobre el impacto de la automatización por IA en el mercado laboral, el cambio en las habilidades requeridas y los nuevos modelos de colaboración humano-máquina. (fuente: X)
