
Palabras clave:AI, modelos, informe AI Index 2025, procesadores fotónicos para IA, modelo multimodal Qwen2.5-Omni, protocolo MCP para agentes de IA, plataforma AliBaiLian para IA
🔥 Enfoque
Stanford publica el Informe AI Index 2025: La Universidad de Stanford ha publicado el informe «2025 AI Index» de 456 páginas, que ofrece una visión general completa del estado actual y las tendencias en el campo de la IA. El informe señala que EE. UU. lidera en número de modelos publicados, pero China está recuperando terreno rápidamente en calidad de modelos, reduciendo significativamente la brecha de rendimiento. Los costos de entrenamiento continúan aumentando (por ejemplo, Gemini 1.0 Ultra cuesta aproximadamente 192 millones de dólares), pero los costos de inferencia están disminuyendo drásticamente. El problema de las emisiones de carbono de la IA es cada vez más grave, con enormes emisiones de entrenamiento para Meta Llama 3.1. El informe también menciona que muchos benchmarks de IA están saturados, lo que dificulta la diferenciación de las capacidades de los modelos, convirtiendo el «examen final humano» en un nuevo desafío. La extracción de datos públicos está restringida (el 48% de los dominios de nivel superior limitan los crawlers), lo que genera preocupaciones sobre un «pico de datos». La inversión empresarial en IA es enorme, pero aún no se han visto retornos significativos de productividad. La IA tiene un gran potencial en ciencia y medicina, pero la conversión a aplicaciones prácticas aún requiere tiempo. En cuanto a políticas, la legislación a nivel estatal en EE. UU. es activa, especialmente en relación con los deepfakes, mientras que a nivel global predominan las declaraciones no vinculantes. A pesar de las preocupaciones sobre la sustitución de empleos, la actitud general del público hacia la IA sigue siendo mayoritariamente optimista (fuente: AINLPer)
Avance en nuevo procesador fotónico de IA: La revista Nature publicó dos artículos que presentan nuevos procesadores de IA que combinan fotónica y electrónica, con el objetivo de superar los cuellos de botella de rendimiento y consumo de energía de la era post-transistor. El acelerador fotónico PACE de la empresa singapurense Lightelligence (con más de 16,000 componentes fotónicos) demostró velocidades de cálculo de hasta 1 GHz y una reducción de la latencia mínima de 500 veces, destacando en la resolución del problema de Ising. El procesador fotónico de la empresa estadounidense Lightmatter (con cuatro matrices de 128×128) ejecutó con éxito modelos de IA como BERT y ResNet, con una precisión comparable a los procesadores electrónicos, y demostró aplicaciones como jugar a Pac-Man. Ambas investigaciones indican que sus sistemas son escalables y pueden fabricarse utilizando las plantas CMOS existentes, lo que podría impulsar el hardware de IA hacia una mayor potencia y eficiencia energética, marcando un paso importante hacia la viabilidad de la computación fotónica (fuente: 36氪)

UC Berkeley libera modelo de código DeepCoder de 14B, comparable a o3-mini: UC Berkeley y Together AI han lanzado conjuntamente DeepCoder-14B-Preview, un modelo de inferencia de código de 14B parámetros completamente open source, con un rendimiento comparable al o3-mini de OpenAI. El modelo se ajustó finamente a partir de Deepseek-R1-Distilled-Qwen-14B mediante aprendizaje por refuerzo distribuido (RL), logrando un Pass@1 del 60.6% en el benchmark LiveCodeBench. El equipo construyó un conjunto de entrenamiento con 24K problemas de programación de alta calidad y adoptó métodos de entrenamiento mejorados GRPO+, expansión iterativa del contexto (de 16K a 32K, llegando a 64K en inferencia) y tecnología de filtrado ultralargo. También se liberó el sistema de entrenamiento RL optimizado verl-pipeline, que duplicó la velocidad de entrenamiento de extremo a extremo. Este lanzamiento no solo incluye el modelo, sino también el conjunto de datos, el código y los registros de entrenamiento (fuente: 新智元)
🎯 Movimientos
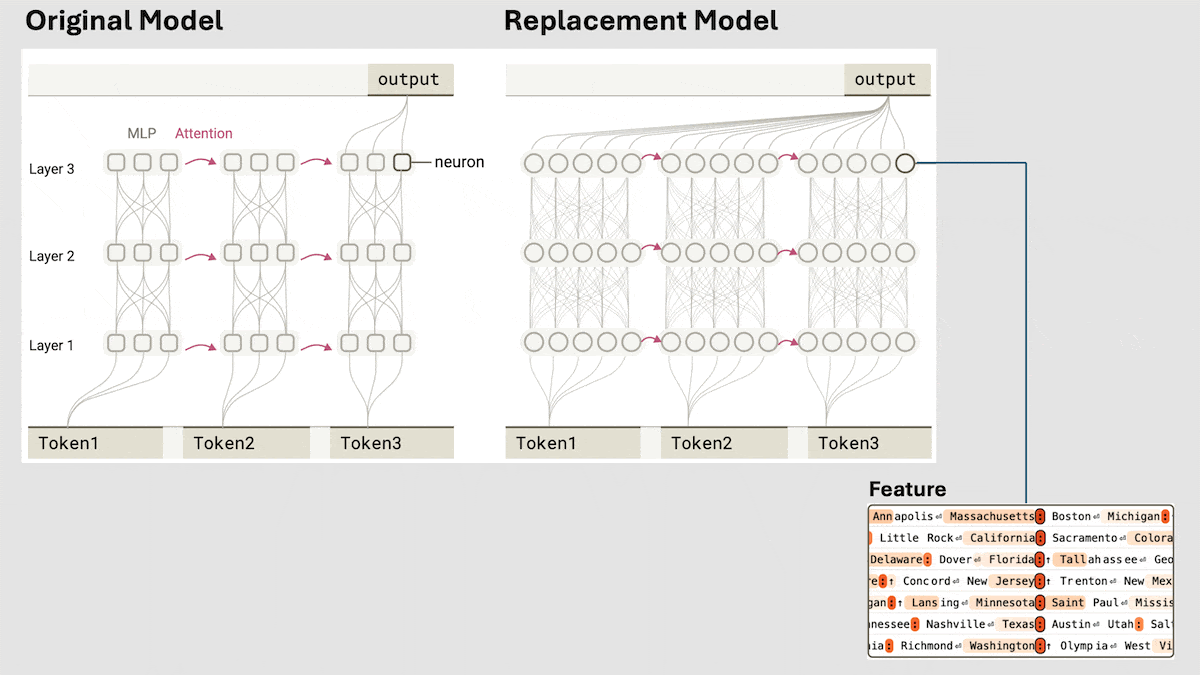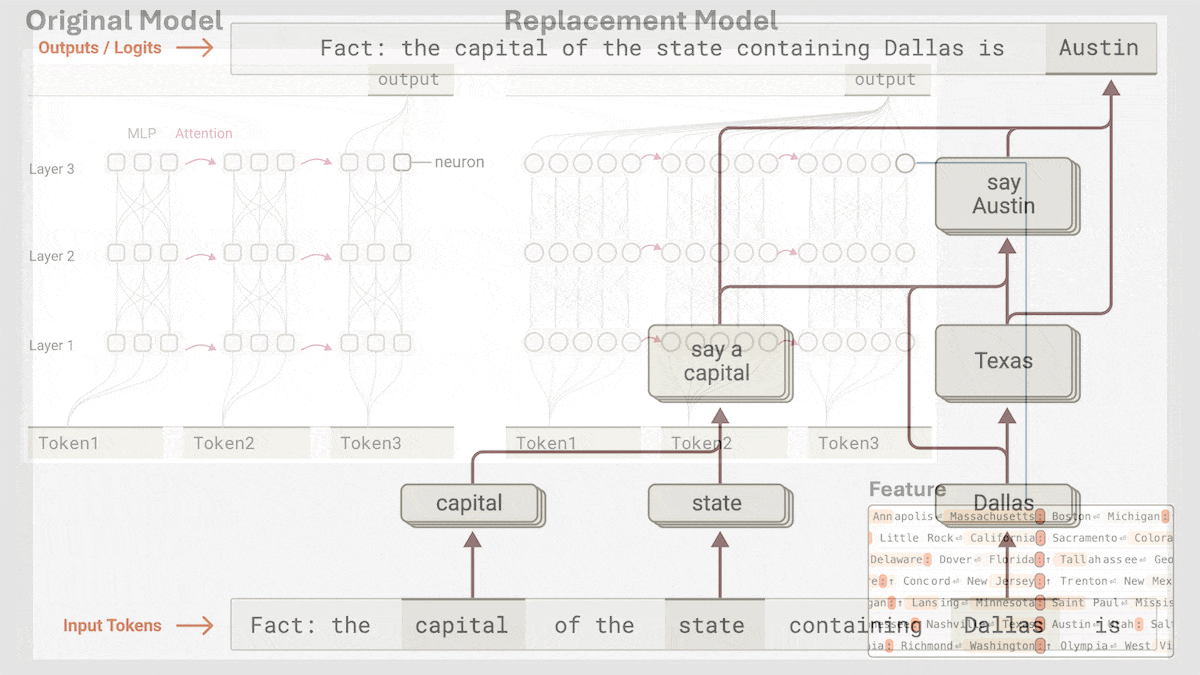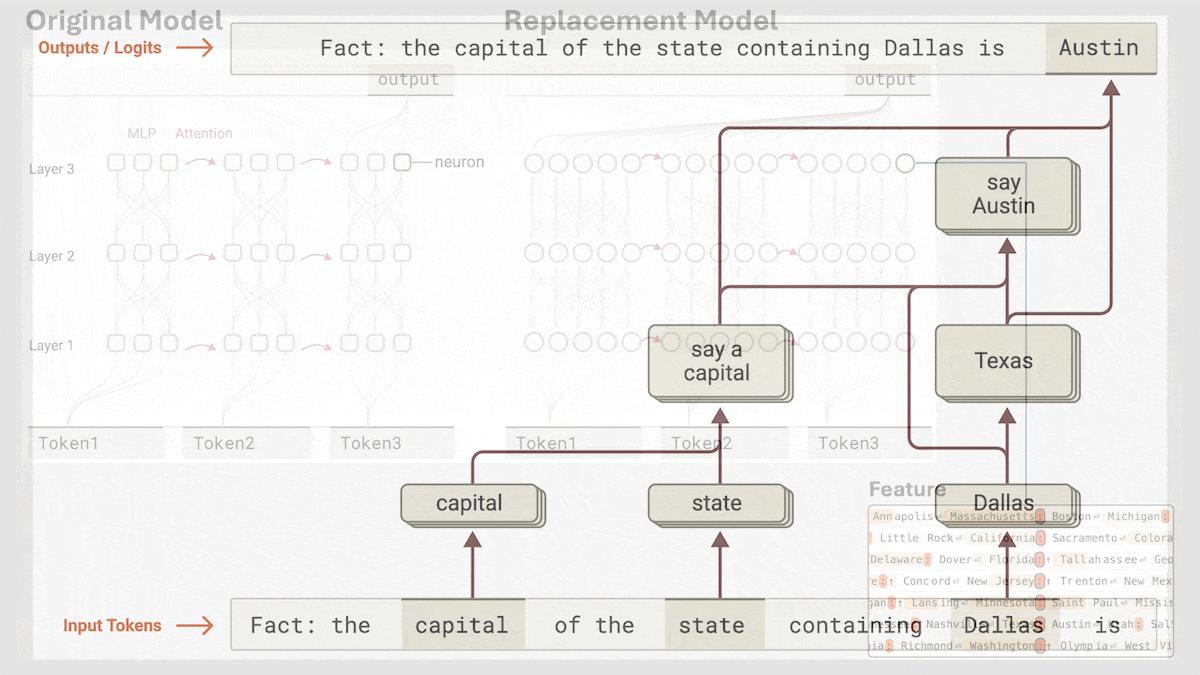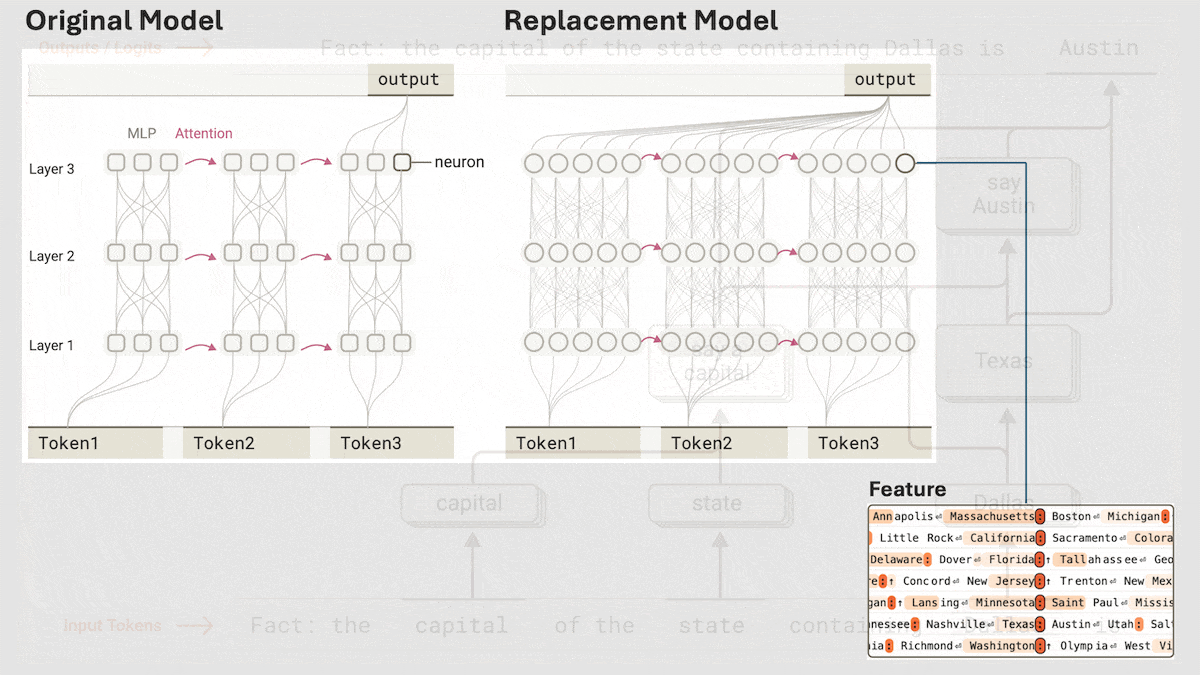
Anthropic revela el mecanismo de razonamiento implícito de Claude 3.5 Haiku: El equipo de investigación de Anthropic analizó el funcionamiento interno de los modelos Transformer (específicamente Claude 3.5 Haiku) mediante un nuevo método. Descubrieron que, incluso sin entrenamiento explícito para el Chain-of-Thought, el modelo muestra pasos similares al razonamiento a través de la activación neuronal al generar respuestas. El método reemplaza las capas totalmente conectadas con «transcodificadores intercapa» (cross-layer transcoder) interpretables, identifica «características» relacionadas con conceptos o predicciones específicas y construye grafos de atribución para visualizar el flujo de información. Los experimentos muestran que, al responder preguntas (como «¿Cuál es el antónimo de pequeño?» o determinar la capital del estado donde se encuentra Dallas), el modelo pasa internamente por múltiples pasos lógicos en lugar de predecir directamente la respuesta. El estudio ayuda a comprender el funcionamiento interno de los LLM y a distinguir la capacidad de razonamiento real de la imitación superficial (fuente: DeepLearning.AI)
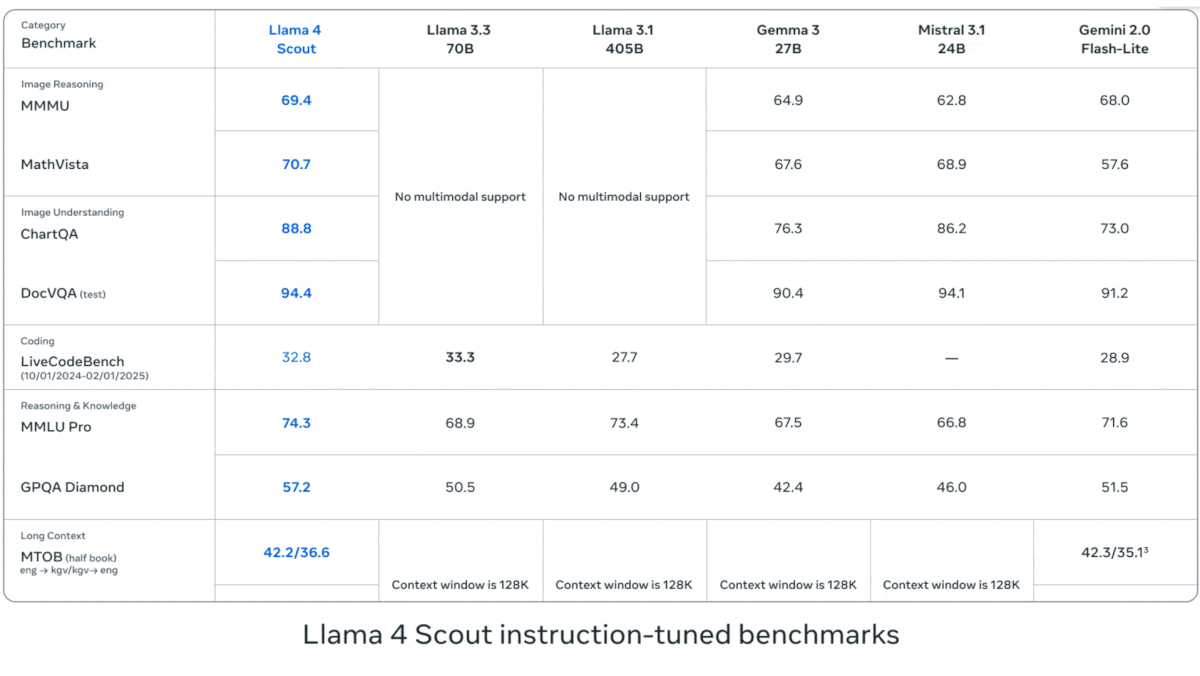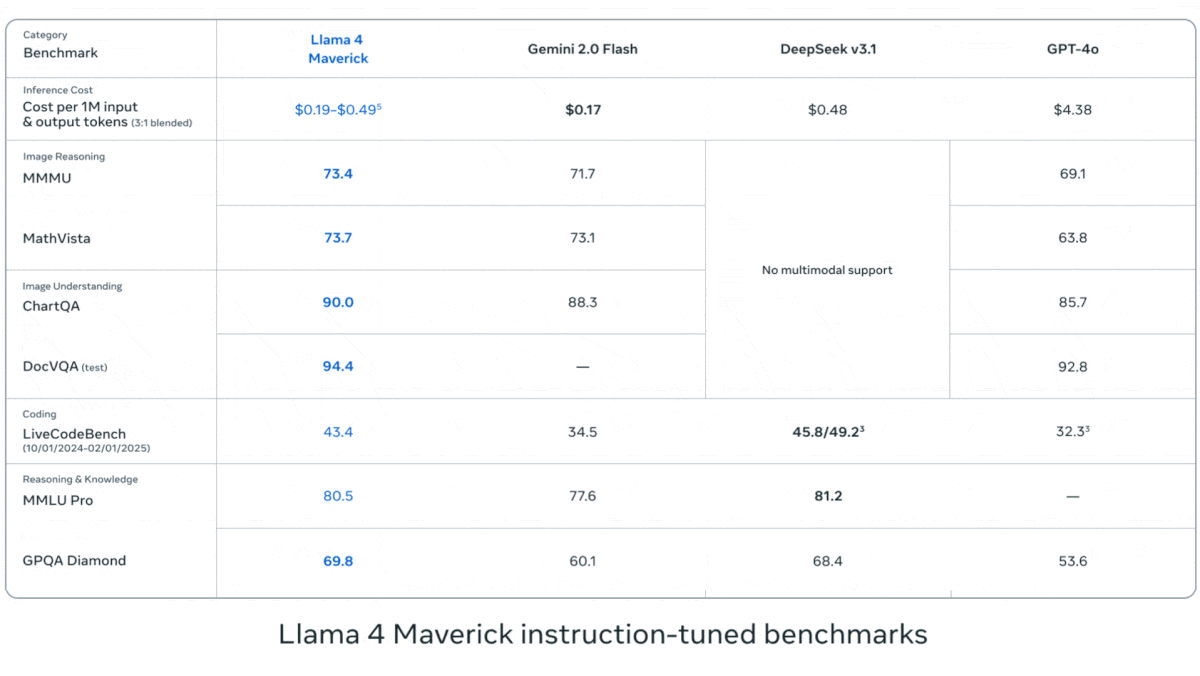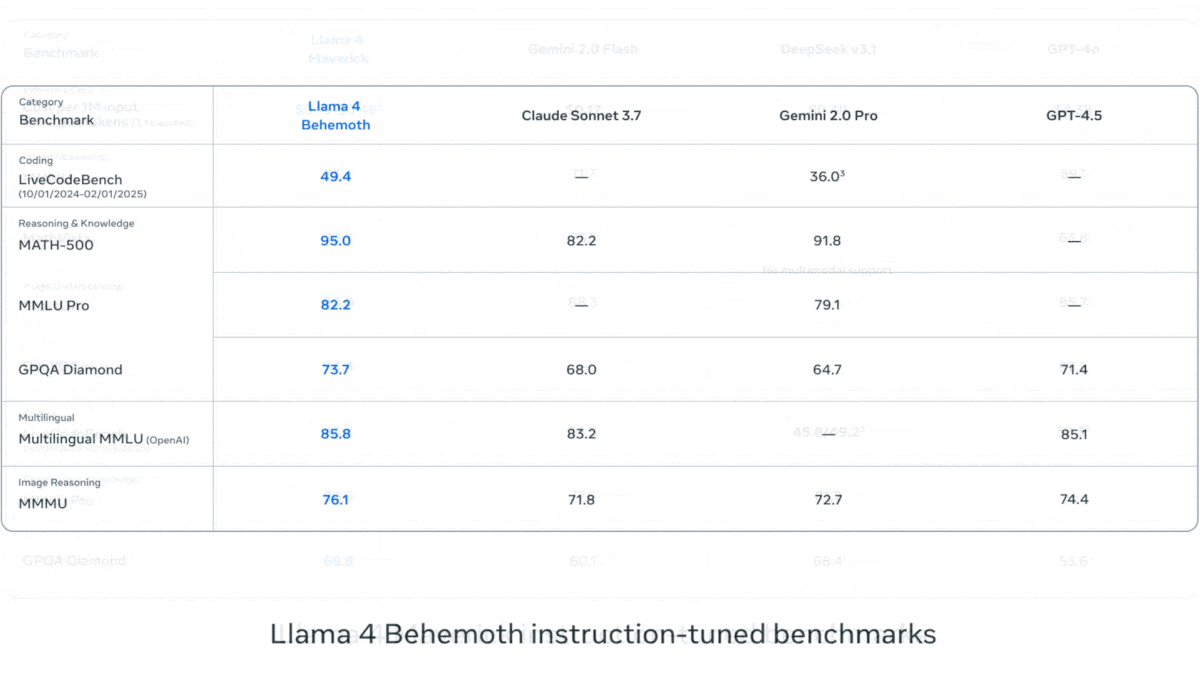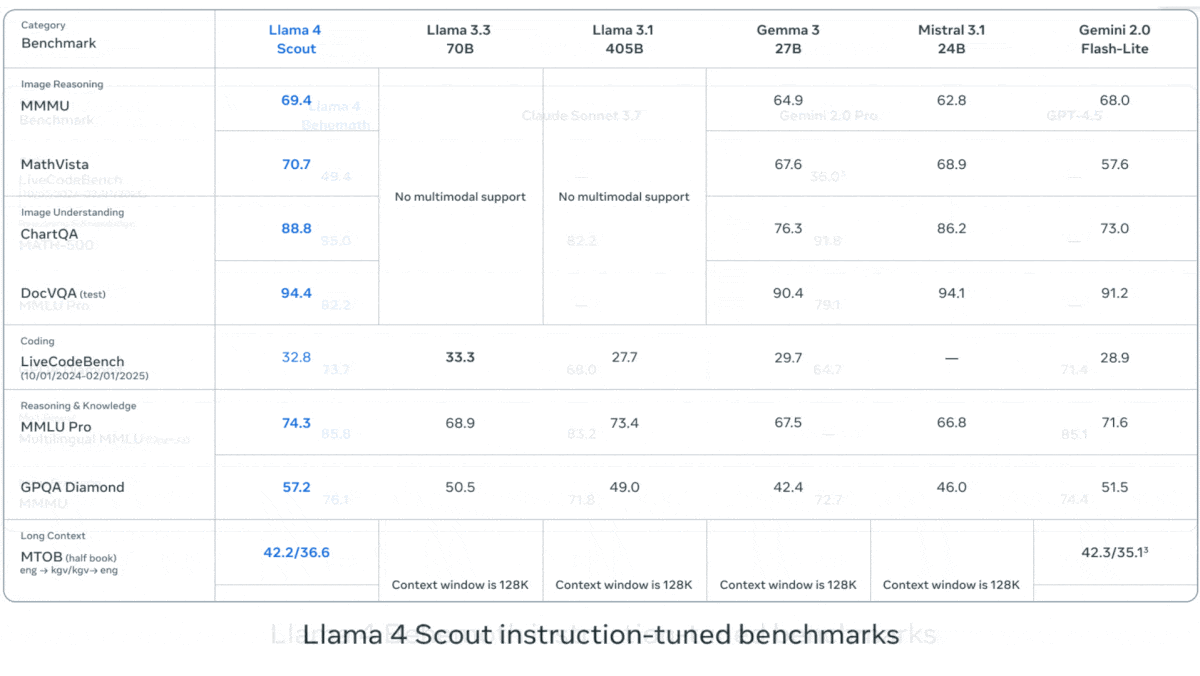
Meta lanza la serie Llama 4 de modelos de lenguaje visual: Meta ha presentado dos modelos multimodales open source de la serie Llama 4: Llama 4 Scout (109B parámetros, 17B activos) y Llama 4 Maverick (400B parámetros, 17B activos), y ha anunciado el próximo Llama 4 Behemoth de casi 2T parámetros. Todos estos modelos utilizan la arquitectura MoE y admiten entradas de texto, imagen y video, con salida de texto. Scout tiene una ventana de contexto de hasta 10M tokens (aunque su efectividad real está en duda), mientras que Maverick tiene 1M. Los modelos muestran un sólido rendimiento en múltiples benchmarks de imagen, codificación, conocimiento y razonamiento. Scout supera a Gemma 3 27B, entre otros, Maverick supera a GPT-4o y Gemini 2.0 Flash, y las primeras versiones de Behemoth superan a GPT-4.5, etc. El lanzamiento de estos modelos impulsa aún más el avance de los modelos open source para alcanzar a los modelos cerrados (fuente: DeepLearning.AI, X @AIatMeta)
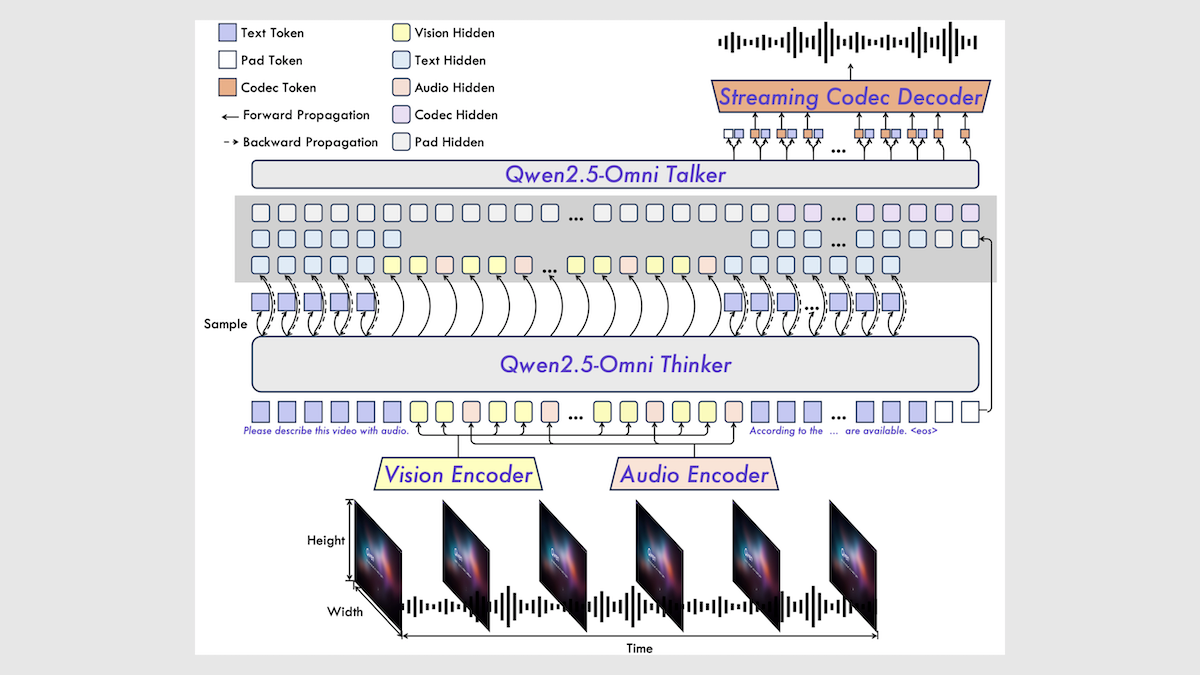
Alibaba lanza el modelo multimodal Qwen2.5-Omni 7B: Alibaba ha lanzado un nuevo modelo multimodal open source, Qwen2.5-Omni 7B, capaz de procesar entradas de texto, imagen, audio y video, y generar salidas de texto y voz. El modelo se basa en el modelo de texto Qwen 2.5 7B, el codificador visual Qwen2.5-VL y el codificador de audio Whisper-large-v3, utilizando una innovadora arquitectura Thinker-Talker. El modelo muestra un rendimiento excelente en múltiples benchmarks, especialmente alcanzando el nivel SOTA en tareas de audio a texto, imagen a texto y video a texto, aunque su rendimiento es ligeramente inferior en tareas puramente de texto y de texto a voz. El lanzamiento de Qwen2.5-Omni enriquece aún más la selección de modelos multimodales open source de alto rendimiento (fuente: DeepLearning.AI)
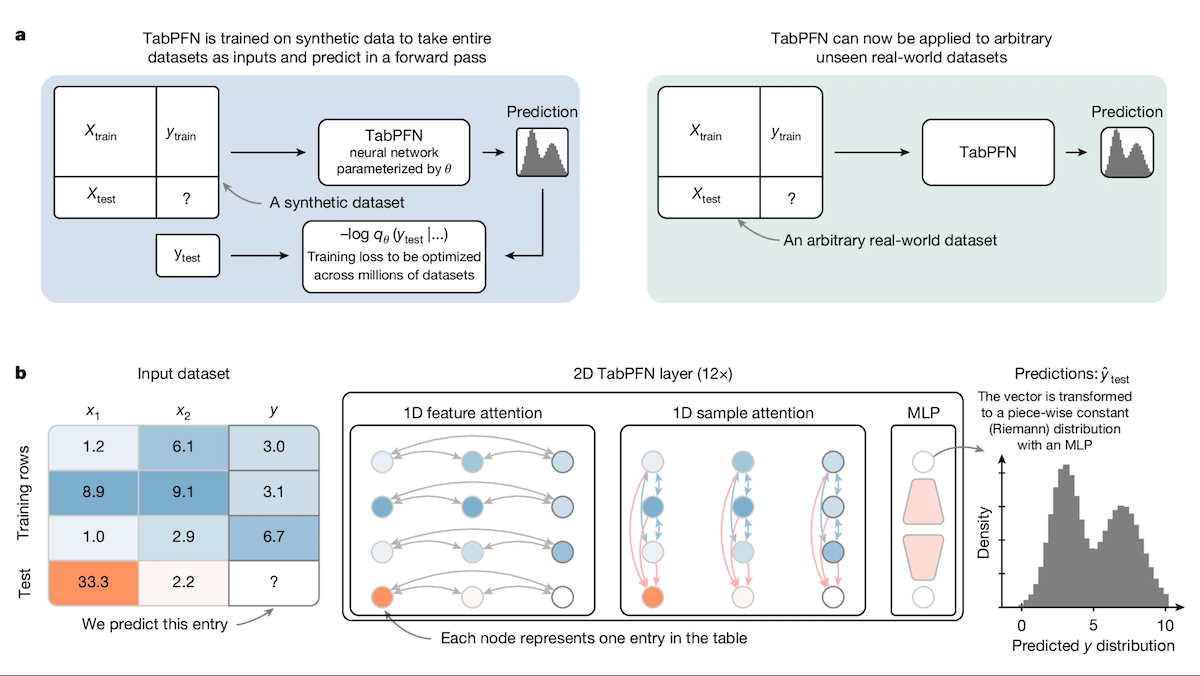
TabPFN: Un Transformer para datos tabulares que supera a los árboles de decisión: Investigadores de la Universidad de Friburgo y otras instituciones han presentado Tabular Prior-data Fitted Network (TabPFN), un modelo Transformer diseñado específicamente para datos tabulares. Mediante el preentrenamiento en 100 millones de conjuntos de datos sintéticos, TabPFN aprende a identificar patrones entre conjuntos de datos, lo que le permite realizar predicciones de clasificación y regresión directamente sobre nuevos datos tabulares sin entrenamiento adicional. Los experimentos demuestran que en los benchmarks AutoML y OpenML-CTR23, el rendimiento de TabPFN en tareas de clasificación (AUC) y regresión (RMSE) supera a los métodos populares de árboles de potenciación de gradiente como CatBoost, LightGBM y XGBoost, aunque su velocidad de inferencia es más lenta. Este trabajo abre nuevas vías para los Transformers en el procesamiento de datos tabulares (fuente: DeepLearning.AI)
La plataforma Intel se convierte en una nueva opción rentable para máquinas todo en uno de modelos grandes: Con la popularización de modelos open source como DeepSeek, las máquinas todo en uno de modelos grandes se han convertido en una opción popular para que las empresas implementen rápidamente la IA. Intel está ofreciendo una solución de hardware rentable a través de la combinación de sus tarjetas gráficas para juegos Arc™ (como la A770) y los procesadores Xeon® W, reduciendo el precio de las máquinas todo en uno de millones a cientos de miles de yuanes. Esta plataforma no solo es compatible con DeepSeek R1, sino también con modelos como Qwen y Llama. Empresas como FIT2CLOUD (飞致云), SuperCloud (超云) y YunJian (云尖) ya han lanzado productos o soluciones de IA todo en uno basados en esta plataforma para escenarios como preguntas y respuestas de bases de conocimiento, servicio al cliente inteligente, asesoramiento financiero, procesamiento de documentos, etc., satisfaciendo las necesidades de inferencia de IA local de PYMES y departamentos específicos (fuente: 量子位)
Google presenta la séptima generación de TPU «Ironwood»: En la conferencia Google Cloud Next, Google anunció su sistema TPU de séptima generación, Ironwood, optimizado específicamente para la inferencia de IA. En comparación con la primera generación de Cloud TPU, el rendimiento de Ironwood ha mejorado 3600 veces y la eficiencia energética 29 veces. En comparación con la sexta generación Trillium, el rendimiento por vatio de Ironwood ha mejorado 2 veces, la memoria por chip alcanza los 192 GB (6 veces la de Trillium) y la velocidad de acceso a datos ha aumentado 4.5 veces. Se espera que Ironwood se lance a finales de este año, con el objetivo de satisfacer la creciente demanda de inferencia de IA (fuente: X @demishassabis, X @JeffDean, Reddit r/LocalLLaMA)

Google DeepMind y los modelos Gemini admitirán el protocolo MCP: El cofundador de Google DeepMind, Demis Hassabis, y el responsable del modelo Gemini, Oriol Vinyals, han declarado que apoyarán el Protocolo de Contexto de Modelo (MCP) y esperan colaborar con el equipo de MCP y los socios de la industria para desarrollar dicho protocolo. MCP se está convirtiendo rápidamente en un estándar abierto para la era de los AI Agents, con el objetivo de permitir que diferentes modelos comprendan un «lenguaje de servicio» unificado para facilitar la llamada a herramientas externas y APIs. Esta medida permitirá que los modelos Gemini se integren mejor en el creciente ecosistema MCP para construir aplicaciones de Agent más potentes (fuente: X @demishassabis, X @OriolVinyalsML)
Moonshot AI lanza el modelo multimodal KimiVL A3B: Moonshot AI (月之暗面) ha lanzado los modelos KimiVL A3B Instruct & Thinking, una serie de grandes modelos multimodales open source (licencia MIT) con capacidad de contexto largo de 128K. La serie incluye un VLM MoE y un Reasoning VLM MoE, con solo unos 3B de parámetros activos. Se afirma que supera a GPT-4o en benchmarks visuales y matemáticos, alcanzando un 36.8% en MathVision, un 34.5% en ScreenSpot-Pro, 867 puntos en OCRBench, y mostrando un rendimiento excelente en pruebas de contexto largo (MMLongBench-Doc 35.1%, LongVideoBench 64.5%). Los pesos del modelo se han publicado en Hugging Face (fuente: X @huggingface)

Lanzamiento de Orpheus TTS 3B: modelo multilingüe de clonación de voz zero-shot: La comunidad open source ha lanzado el modelo Orpheus TTS 3B, un modelo de texto a voz multilingüe de 3 mil millones de parámetros. Admite la clonación de voz zero-shot, generación en streaming con una latencia de aproximadamente 100 milisegundos, y permite guiar la emoción y la entonación para generar voz similar a la humana. El modelo utiliza la licencia Apache 2.0 y los pesos están disponibles en Hugging Face, impulsando aún más el desarrollo de la tecnología TTS open source (fuente: X @huggingface)
Lanzamiento de OmniSVG: modelo unificado de generación de gráficos vectoriales escalables: Se ha propuesto un nuevo modelo llamado OmniSVG, destinado a unificar la generación de Gráficos Vectoriales Escalables (SVG). El modelo se basa en Qwen2.5-VL e integra un tokenizador SVG, capaz de aceptar entradas de texto e imagen y generar el código SVG correspondiente. El sitio web del proyecto muestra sus potentes efectos de generación de SVG. Actualmente, el paper y el conjunto de datos se han publicado, pero los pesos del modelo aún no están disponibles públicamente (fuente: X @karminski3, Reddit r/LocalLLaMA)
Google Cloud Next 2025 se centra en la IA: La conferencia Google Cloud Next destacó los avances en el campo de la IA. Se lanzó la séptima generación de TPU Ironwood optimizada para inferencia; se anunció que Gemini 2.5 Pro es actualmente el modelo más inteligente y lidera en Chatbot Arena; se combinaron los resultados de investigación de DeepMind, Google Research y Google Cloud para ofrecer a los clientes modelos como WeatherNext y AlphaFold; se permitió a las empresas ejecutar modelos Gemini en sus propios centros de datos; y se anunció una colaboración con Nvidia para llevar los modelos Gemini a implementaciones locales (on-premise) a través de Blackwell y Computación Confidencial (fuente: X @GoogleDeepMind, X @GoogleDeepMind, Reddit r/artificial, X @nvidia)
Predicciones de tendencias de IA para 2025: Sintetizando múltiples puntos de vista, las tendencias clave de la IA para 2025 incluyen: el desarrollo continuo y la profundización de la aplicación de la IA generativa, la creciente importancia de la ética de la IA y la IA responsable, la popularización de la IA en el borde (edge AI), la aceleración de la implementación de la IA en industrias específicas (como salud, finanzas, cadena de suministro), la mejora de las capacidades de la IA multimodal, la autonomía y los desafíos de los AI Agents, la disrupción de los modelos de negocio tradicionales por la IA, y la creciente demanda de talento y diversidad de habilidades en IA (fuente: X @Ronald_vanLoon, X @Ronald_vanLoon, X @Ronald_vanLoon)

Fábrica de Tesla logra transporte autónomo de vehículos: Tesla demostró que sus automóviles producidos pueden conducir automáticamente desde la línea de producción hasta la zona de carga dentro del área de la fábrica, sin intervención humana. Esto refleja el potencial de aplicación de la tecnología de conducción autónoma en entornos controlados (como la logística de fábrica) y es un ejemplo del progreso de la IA en la fabricación de automóviles y la automatización (fuente: X @Ronald_vanLoon)
🧰 Herramientas
Free-for-dev: Compendio de recursos gratuitos para desarrolladores: El proyecto ripienaar/free-for-dev en GitHub es una popular lista de recursos que recopila planes gratuitos útiles para desarrolladores (especialmente DevOps y desarrolladores de infraestructura) en diversos productos SaaS, PaaS e IaaS. La lista cubre servicios en la nube, bases de datos, APIs, monitorización, CI/CD, alojamiento de código, herramientas de IA y muchas otras categorías, y exige explícitamente que los servicios ofrezcan un nivel gratuito a largo plazo en lugar de un período de prueba, además de priorizar la seguridad (por ejemplo, no se aceptan servicios que limiten TLS). El proyecto es impulsado por la comunidad, se actualiza continuamente y facilita enormemente a los desarrolladores la búsqueda y comparación de servicios gratuitos (fuente: GitHub: ripienaar/free-for-dev)

Graphiti: Framework para construir grafos de conocimiento de IA en tiempo real: getzep/graphiti es un framework de Python para construir y consultar grafos de conocimiento con conciencia temporal, especialmente adecuado para AI Agents que necesitan procesar información de entornos dinámicos. Puede integrar continuamente interacciones de usuario y datos estructurados/no estructurados, admite actualizaciones incrementales y consultas históricas precisas sin necesidad de recalcular completamente el grafo. Graphiti combina embeddings semánticos, búsqueda por palabras clave (BM25) y recorrido de grafos para una recuperación híbrida eficiente, y permite definiciones de entidades personalizadas. El framework es la tecnología central de la capa de memoria Zep y ahora es open source (fuente: GitHub: getzep/graphiti)

WeChatMsg: Herramienta para extraer historial de chat de WeChat y entrenar asistentes de IA: LC044/WeChatMsg es una herramienta para extraer el historial de chat local de WeChat en Windows (compatible con WeChat 4.0) y exportarlo a formatos como HTML, Word, Excel, etc. Su objetivo es ayudar a los usuarios a guardar permanentemente sus historiales de chat y analizarlos para generar informes anuales. Además, la herramienta permite utilizar los datos de chat del usuario para entrenar asistentes de chat de IA personalizados, reflejando la filosofía de «mis datos, mi control». El proyecto proporciona una interfaz gráfica de usuario e instrucciones detalladas de uso (fuente: GitHub: LC044/WeChatMsg)
Alibaba Cloud Bailian lanza servicio MCP de ciclo completo, creando una fábrica de Agents: La plataforma Bailian de Alibaba Cloud (阿里云百炼) ha lanzado oficialmente la capacidad completa de la plataforma para el servicio del Protocolo de Contexto de Modelo (MCP), cubriendo todo el ciclo de vida: registro de servicios, alojamiento en la nube, llamada de Agents y composición de flujos de trabajo. Los desarrolladores pueden usar directamente servicios MCP oficiales o de terceros alojados en la plataforma, como Amap (高德地图) o Notion, o registrar sus propias APIs como servicios MCP mediante una configuración simple (sin necesidad de gestionar servidores). Esto tiene como objetivo reducir la barrera de entrada para el desarrollo de Agents, permitiendo a los desarrolladores construir e implementar rápidamente AI Agents capaces de llamar a herramientas externas, impulsando la aplicación de modelos grandes en escenarios del mundo real. Este servicio se considera un paso importante en la comercialización de la IA de Alibaba (fuente: 微信公众号 – AINLPer, 量子位)
Hugging Face y Cloudflare colaboran para ofrecer infraestructura WebRTC gratuita: Hugging Face y Cloudflare colaboran a través de FastRTC para proporcionar a los desarrolladores de IA una infraestructura WebRTC de nivel empresarial a escala global. Los desarrolladores pueden usar un Token de Hugging Face para transferir 10 GB de datos de forma gratuita, destinados a la construcción de aplicaciones de IA de voz y video en tiempo real. Se proporciona una demostración oficial de chat de voz con Llama 4 como ejemplo, mostrando la conveniencia que aporta esta colaboración (fuente: X @huggingface)
Google AI Studio recibe una importante actualización de la interfaz de usuario: La interfaz de usuario de Google AI Studio (anteriormente MakerSuite) ha experimentado la primera fase de un rediseño, ofreciendo una apariencia y experiencia más modernas. Esta actualización tiene como objetivo sentar las bases para más funciones de la plataforma para desarrolladores que se lanzarán en los próximos meses. La nueva interfaz de usuario está más alineada con el estilo de las aplicaciones Gemini y añade un backend dedicado para desarrolladores para la gestión de APIs y pagos. Esta actualización presagia la expansión de las funcionalidades de la plataforma, posiblemente incluyendo el acceso a nuevos modelos (como Veo 2) (fuente: X @JeffDean, X @op7418)

LlamaIndex introduce la función de referencia visual: LlamaIndex ha publicado un nuevo tutorial que muestra cómo utilizar la función de layout Agent en LlamaParse para lograr referencias visuales en las respuestas del Agent. Esto significa que las respuestas generadas no solo pueden rastrearse hasta la fuente textual, sino que también pueden mapearse directamente a las regiones visuales correspondientes (localizadas con precisión mediante cuadros delimitadores) en el documento fuente (como un PDF). Esto mejora la interpretabilidad y la capacidad de rastreo de las respuestas del Agent, especialmente útil para procesar documentos que contienen gráficos, tablas y otros elementos visuales (fuente: X @jerryjliu0)

LangGraph lanza un constructor GUI sin código: LangGraph ahora ofrece un constructor de interfaz gráfica de usuario (GUI) sin código para diseñar la arquitectura de los Agents. Los usuarios pueden planificar el flujo de trabajo y las conexiones de nodos del Agent mediante operaciones visuales como arrastrar y soltar, y luego generar código Python o TypeScript con un solo clic. Esto reduce la barrera de entrada para construir aplicaciones de Agent complejas, facilitando la creación rápida de prototipos y el desarrollo (fuente: X @LangChainAI)
Perplexity actualiza la función de gráficos de acciones: Perplexity ha actualizado su función de gráficos de acciones, que ahora refleja los cambios de precios del día en tiempo real, en lugar de estirar el eje temporal para llenar todo el gráfico. Esta mejora, aunque básica, aumenta la inmediatez y la utilidad de la visualización de información financiera (fuente: X @AravSrinivas, X @AravSrinivas)

OLMoTrace: Herramienta para conectar la salida de LLM con los datos de entrenamiento: Allen Institute for AI (AI2) ha lanzado la herramienta OLMoTrace, capaz de mapear en tiempo real la salida del modelo OLMo a sus fuentes de datos de entrenamiento correspondientes (logrando coincidencias en segundos dentro de 4T tokens de datos). Esto ayuda a comprender el comportamiento del modelo, mejorar la transparencia y refinar los datos post-entrenamiento. La herramienta tiene como objetivo ayudar a investigadores y desarrolladores a comprender mejor el funcionamiento interno y las fuentes de conocimiento de los grandes modelos de lenguaje (fuente: X @natolambert)
llama.cpp fusiona el soporte para los modelos Qwen3: El popular framework de inferencia local de LLM, llama.cpp, ha fusionado el soporte para la próxima serie de modelos Qwen3, incluyendo las versiones base y MoE. Esto significa que una vez que se lancen los modelos Qwen3, los usuarios podrán utilizar modelos cuantizados en formato GGUF en el ecosistema llama.cpp desde el primer momento, facilitando su ejecución en dispositivos locales (fuente: X @karminski3, Reddit r/LocalLLaMA)

El framework KTransformers soporta los modelos Llama 4: El framework de inferencia de IA chino KTransformers (conocido por soportar inferencia híbrida CPU+GPU, especialmente para la descarga de modelos MoE) ha añadido soporte experimental para la serie de modelos Llama 4 de Meta en su rama de desarrollo. Según la documentación, ejecutar Llama-4-Scout (109B) cuantizado a Q4 requiere aproximadamente 65 GB de RAM y 10 GB de VRAM, mientras que Llama-4-Maverick (402B) necesita unos 270 GB de RAM y 12 GB de VRAM. En una configuración 4090 + dual Xeon 4, la velocidad de inferencia de un solo lote puede alcanzar los 32 tokens/s. Esto abre la posibilidad de ejecutar grandes modelos MoE con VRAM limitada (fuente: X @karminski3, Reddit r/LocalLLaMA)
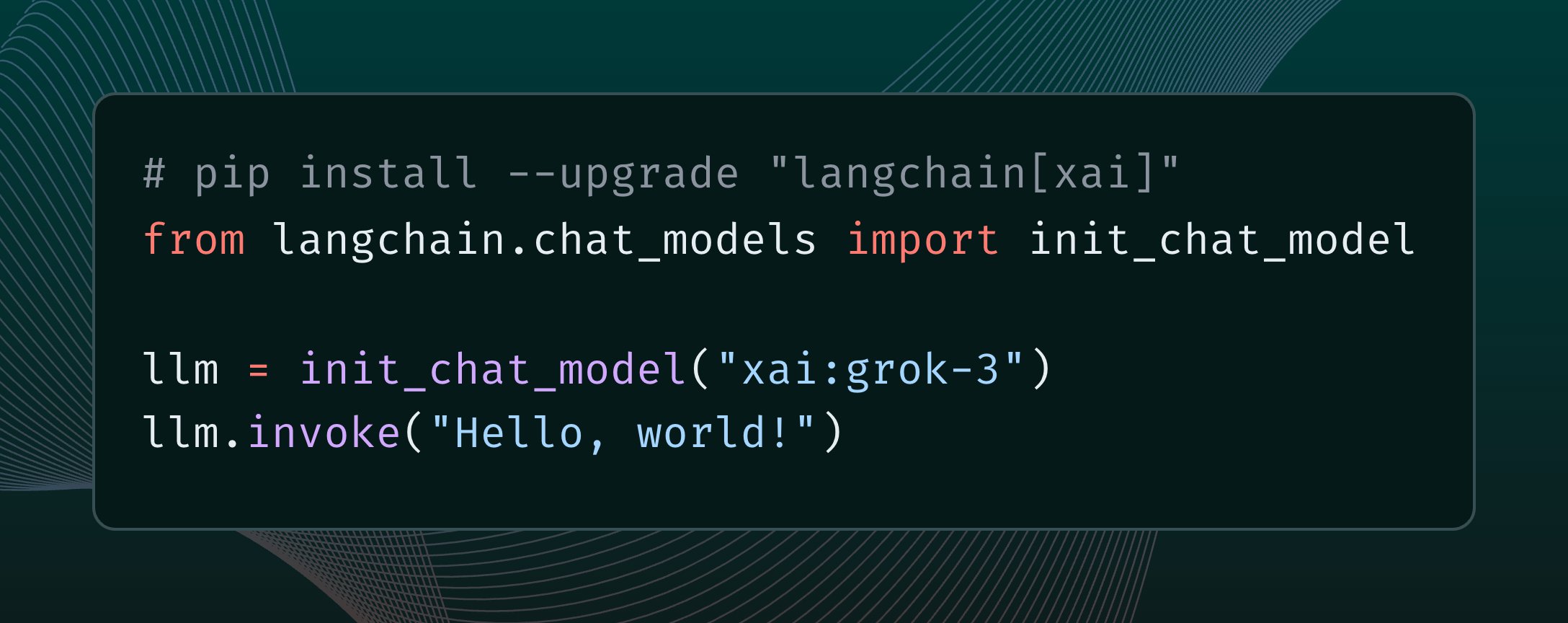
LangChain integra el modelo Grok 3 de xAI: LangChain ha anunciado la integración del modelo Grok 3, recientemente lanzado por xAI. Los usuarios ahora pueden llamar a Grok 3 a través del framework LangChain para construir aplicaciones aprovechando sus potentes capacidades (fuente: X @LangChainAI)
Tutorial de despliegue gratuito del servicio en la nube n8n: Se describe cómo desplegar gratuitamente la plataforma de automatización de flujos de trabajo open source n8n utilizando Hugging Face Spaces y Supabase, obteniendo acceso a través de un dominio público compatible con HTTPS. Esto permite a los usuarios utilizar todas las funcionalidades de n8n (incluidos los nodos que requieren una URL de callback) sin necesidad de comprar servidores propios ni configurar dominios y certificados SSL. El método utiliza la base de datos gratuita de Supabase para resolver el problema de pérdida de datos causado por la hibernación de Hugging Face Space (fuente: 微信公众号 – 袋鼠帝AI客栈)
Actualización de plugins de OpenWebUI: Contador de contexto y memoria adaptativa: Desarrolladores de la comunidad han lanzado/actualizado dos plugins para OpenWebUI: 1) Enhanced Context Counter v3, que proporciona un panel detallado de uso de Tokens, seguimiento de costos e indicadores de rendimiento, compatible con múltiples modelos y calibración personalizada. 2) Adaptive Memory v2, que extrae, almacena e inyecta dinámicamente información específica del usuario (hechos, preferencias, objetivos, etc.) a través de un LLM, logrando una memoria conversacional personalizada, persistente y adaptativa, funcionando completamente en local sin dependencias externas (fuente: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
QuickVoice MCP: Permite a Claude hacer llamadas telefónicas: Un desarrollador de la comunidad ha creado una herramienta MCP (Protocolo de Contexto de Modelo) llamada QuickVoice, que permite a modelos compatibles con MCP como Claude 3.7 Sonnet realizar y gestionar llamadas telefónicas reales. Los usuarios pueden dar instrucciones en lenguaje natural (como «llama al médico para pedir una cita») para que la IA complete la tarea de la llamada, incluida la navegación por menús IVR. El proyecto es open source en GitHub (fuente: Reddit r/ClaudeAI)

RPG Dice Roller para OpenWebUI: La comunidad ha desarrollado un plugin de herramienta para lanzar dados de RPG para OpenWebUI, facilitando la obtención de resultados aleatorios auténticos durante las conversaciones de juegos de rol (fuente: Reddit r/OpenWebUI)
📚 Aprendizaje
Curso open source de Machine Learning de Girafe-ai: El proyecto girafe-ai/ml-course en GitHub proporciona los materiales didácticos del primer semestre del curso de machine learning de girafe-ai, incluyendo Naive Bayes, kNN, regresión/clasificación lineal, SVM, PCA, árboles de decisión, aprendizaje por conjuntos, gradient boosting e introducción al deep learning. Ofrece grabaciones de video de las clases, diapositivas PPT y tareas. Es un recurso valioso para aprender los fundamentos del machine learning (fuente: GitHub: girafe-ai/ml-course)
USTC y Huawei Noah’s Ark proponen el framework CMO para optimizar la síntesis lógica de chips: El equipo del profesor Wang Jie de la Universidad de Ciencia y Tecnología de China (USTC), en colaboración con el Laboratorio Noah’s Ark de Huawei, ha publicado un artículo en ICLR 2025 proponiendo un método eficiente de optimización lógica basado en la minería de funciones neurosimbólicas, llamado CMO. Este framework utiliza redes neuronales de grafos (GNN) para guiar la búsqueda de árbol Monte Carlo (MCTS), generando funciones de puntuación simbólicas ligeras, interpretables y con buena capacidad de generalización, que se utilizan para podar transformaciones de nodos inválidos en operadores de optimización lógica (como Mfs2). Los experimentos muestran que CMO puede aumentar la eficiencia de ejecución de operadores clave hasta 2.5 veces manteniendo la calidad de la optimización, y ya se ha aplicado en la herramienta de síntesis lógica EMU desarrollada por Huawei (fuente: 量子位)
Shanghai AI Lab propone MaskGaussian, un nuevo método de poda gaussiana: El equipo de investigación del Shanghai AI Lab presentó el método MaskGaussian en CVPR 2025 para optimizar el 3D Gaussian Splatting. Este método, al incorporar distribuciones de máscaras aprendibles en el proceso de rasterización, logra por primera vez conservar los gradientes tanto para los puntos gaussianos utilizados como para los no utilizados. Esto permite podar una gran cantidad de puntos gaussianos redundantes manteniendo al máximo la calidad de la reconstrucción. Los experimentos en múltiples conjuntos de datos podaron más del 60% de los puntos gaussianos con una pérdida de rendimiento insignificante, al tiempo que mejoraron la velocidad de entrenamiento y redujeron el uso de memoria (fuente: 量子位)
Análisis del informe técnico de Qwen2.5-Omni: Un usuario de Reddit compartió notas detalladas sobre el informe técnico de Qwen2.5-Omni de Alibaba. El informe describe la arquitectura Thinker-Talker del modelo, el procesamiento de entradas multimodales (texto, imagen, audio, video) – incluyendo la innovadora codificación posicional TMRoPE para la alineación de audio y video -, el mecanismo de generación de voz en streaming, el flujo de entrenamiento (preentrenamiento + post-entrenamiento RL), etc. Estas notas proporcionan una referencia valiosa para comprender el funcionamiento interno de este avanzado modelo multimodal (fuente: Reddit r/LocalLLaMA)
McKinsey publica una guía operativa para escalar la IA generativa en la empresa: McKinsey ha publicado una guía operativa dirigida a líderes de datos, que explora cómo aplicar la IA generativa a escala en las empresas. El informe probablemente cubre la formulación de estrategias, la selección de tecnología, el desarrollo de talento, la gestión de riesgos y otros aspectos, proporcionando orientación para que las empresas implementen y escalen GenAI en la práctica (fuente: X @Ronald_vanLoon)

Guía de inicio para aprender sobre AI Agents: Khulood_Almani compartió recursos o pasos sobre cómo empezar a aprender sobre AI Agents, posiblemente incluyendo rutas de aprendizaje, conceptos clave, herramientas o plataformas recomendadas, para guiar a aquellos que quieran iniciarse en el campo de los AI Agents (fuente: X @Ronald_vanLoon)

Investigación sobre técnicas de Re-Ranking en Reconocimiento Visual de Lugar: Un artículo en arXiv explora si la técnica de Re-Ranking sigue siendo efectiva en la tarea de Reconocimiento Visual de Lugar (Visual Place Recognition, VPR). La investigación podría analizar las ventajas y desventajas de los métodos de Re-Ranking existentes y evaluar su papel y necesidad en los sistemas VPR modernos (fuente: Reddit r/deeplearning, Reddit r/MachineLearning)
Informe de investigación «AI 2027» explora los riesgos y el futuro de la ASI: Un informe de investigación titulado «AI 2027» explora los posibles escenarios de desarrollo de la IA hasta 2027, en particular la posibilidad de que la investigación y desarrollo automatizados de IA conduzcan al surgimiento de una IA sobrehumana (ASI). El informe analiza los riesgos potenciales que plantea la ASI, como la pérdida de poder humano debido a la desalineación de objetivos, la concentración de poder, la intensificación de la carrera armamentista internacional que aumenta los riesgos de seguridad, el robo de modelos y el retraso en la percepción pública, y explora los posibles desenlaces geopolíticos como guerras, acuerdos o sumisión (fuente: Reddit r/artificial)
Estudio sobre la alineación de activaciones en redes neuronales: Un artículo publicado en OpenReview explora las causas de la alineación representacional en las redes neuronales. La investigación descubre que la alineación no se origina en neuronas individuales, sino que está relacionada con el funcionamiento de las funciones de activación, y propone el Método de Resonancia Spotlight (Spotlight Resonance Method) para explicar este fenómeno, proporcionando resultados experimentales que lo respaldan (fuente: Reddit r/deeplearning)
💼 Negocios
Alibaba International se enfoca en IA para buscar avances: Ante la feroz competencia en la industria del comercio electrónico transfronterizo y los cambios en el comercio global, Alibaba International Digital Commerce Group considera la IA como una estrategia central, invirtiendo fuertemente para buscar crecimiento y eficiencia. La compañía lanzó el plan global de desarrollo de talento en IA «Bravo 102» y designó el 80% de los puestos en su reclutamiento universitario como relacionados con la IA. Las aplicaciones de IA ya cubren B2B (motor de búsqueda de IA Accio, AI Agent «Asistente de Negocios») y B2C (la plataforma Aidge ofrece probadores virtuales, servicio al cliente con IA, etc.). Aunque los ingresos de Alibaba International han crecido significativamente (un 32% interanual en el Q4 de 2024), las inversiones han aumentado las pérdidas. La IA se considera el motor clave para que Alibaba International supere la competencia de precios bajos, logre una transformación de alto valor agregado y una operación refinada (fuente: 36氪)
Ex miembros clave de OpenAI se unen a la nueva empresa de Mira Murati: Alec Radford, primer autor de la serie GPT, y Bob McGrew, ex Director de Investigación de OpenAI, se han unido como asesores a Thinking Machines Lab, la nueva empresa de IA fundada por la ex CTO de OpenAI, Mira Murati. Radford jugó un papel crucial en el nacimiento de la serie de modelos GPT, mientras que McGrew participó profundamente en el desarrollo de los modelos GPT-3/4 y o1. El equipo fundador de Thinking Machines Lab cuenta con un gran número (al menos 19) de ex empleados de OpenAI. La empresa tiene como objetivo popularizar las aplicaciones de IA y, según se informa, planea recaudar 1.000 millones de dólares con una valoración de 9.000 millones, lo que demuestra las altas expectativas del mercado hacia las startups lideradas por los mejores talentos de IA (fuente: 新智元)
Fondos de inversión pública se centran en el negocio de IA+Salud de las empresas farmacéuticas: Recientemente, varios fondos de inversión pública en China han investigado intensamente a empresas farmacéuticas cotizadas, con la aplicación de la IA en el sector de la salud como foco de atención. Haier Bio (海尔生物) presentó sus aplicaciones de IA en la red de sangre IoT y la red de vacunas, así como los avances en la mejora de la eficiencia en escenarios de salud pública (como la programación de vacunas) a través de la IA. Hisun Pharma (海正药业) indicó que ha introducido el modelo DeepSeek-R1 y colabora con empresas de descubrimiento de fármacos asistido por IA, con la esperanza de potenciar todo el proceso de I+D de nuevos fármacos con IA. Kanion Pharma (康缘药业) también declaró que está construyendo una plataforma de descubrimiento de fármacos innovadores de medicina tradicional china impulsada por IA+multiómica. Esto indica que la aplicación de la tecnología de IA en la I+D farmacéutica, las operaciones y los servicios al paciente está recibiendo una gran atención del mercado de capitales (fuente: 创业板观察)
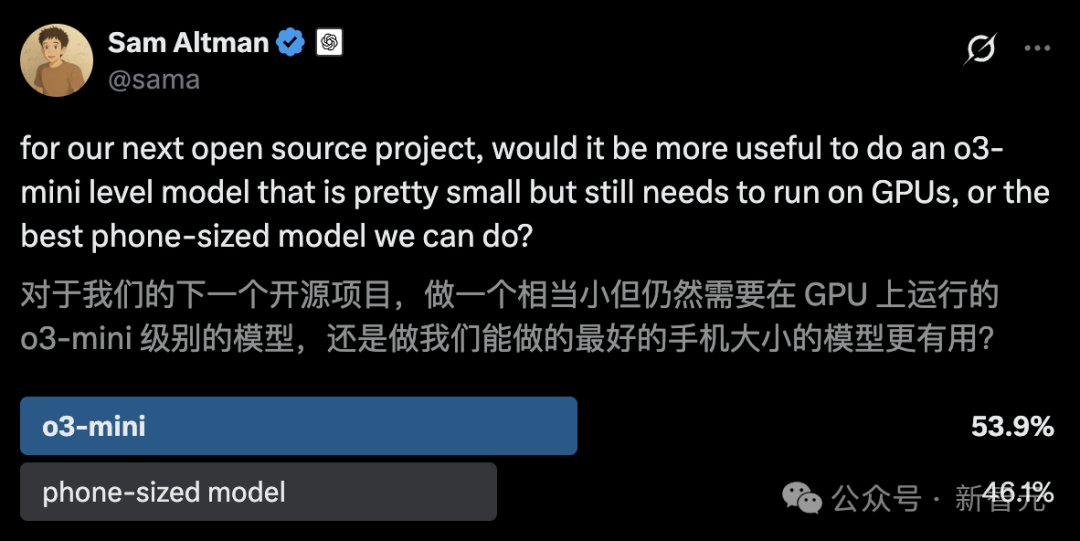
OpenAI lanza el programa Pioneers para profundizar la colaboración industrial: OpenAI ha lanzado el programa Pioneers, destinado a establecer asociaciones con empresas ambiciosas para construir conjuntamente productos avanzados de IA. El programa se centrará en dos aspectos: primero, el ajuste fino intensivo de modelos (dense fine-tuning) para que superen a los modelos generales en tareas de alto valor en dominios específicos; segundo, la construcción de mejores evaluaciones del mundo real (evals) para que la industria pueda medir mejor el rendimiento de los modelos en tareas relevantes para el dominio. Esto indica que OpenAI busca aplicar su tecnología más profundamente en industrias específicas y mejorar la utilidad y los estándares de evaluación de los modelos en verticales a través de la colaboración (fuente: X @sama)
Nvidia y Google Cloud colaboran para impulsar el despliegue local de Gemini: Nvidia y Google Cloud anunciaron una colaboración para soportar la ejecución de los modelos Google Gemini en las instalaciones del cliente (on-premise). La solución combinará la plataforma Nvidia Blackwell GPU y la tecnología de Computación Confidencial (Confidential Computing), con el objetivo de ofrecer a las empresas opciones de despliegue de IA local de alto rendimiento y seguras. Esta medida satisface las necesidades de algunas empresas en cuanto a privacidad de datos, cumplimiento de seguridad y requisitos de rendimiento específicos, permitiéndoles ejecutar los potentes modelos Gemini en su propia infraestructura (fuente: X @nvidia)
Google permite a las empresas ejecutar modelos Gemini en sus propios centros de datos: Google Cloud anunció que permitirá a los clientes empresariales ejecutar sus modelos de IA Gemini en sus propios centros de datos. Esta iniciativa tiene como objetivo satisfacer las necesidades empresariales de soberanía de datos, seguridad y despliegue personalizado, permitiéndoles aprovechar las potentes capacidades de Gemini en su entorno local sin necesidad de transferir datos sensibles a la nube. Esto proporciona a las empresas una mayor flexibilidad y control, especialmente en industrias estrictamente reguladas como la financiera y la sanitaria (fuente: Reddit r/artificial)
El CEO de Nvidia, Jensen Huang, resta importancia al impacto de los aranceles, los servidores de IA podrían estar exentos: Ante la posible implementación de nuevas políticas arancelarias por parte de EE. UU., el CEO de Nvidia, Jensen Huang, declaró que el impacto sería limitado e insinuó que la mayoría de los servidores de IA de Nvidia podrían obtener una exención. Esto podría deberse a la importancia estratégica de sus productos o a clasificaciones comerciales específicas. Esta noticia es una señal positiva para la industria de la IA que depende del hardware de Nvidia, ayudando a aliviar las preocupaciones sobre el aumento de los costos de la cadena de suministro (fuente: Reddit r/artificial, Reddit r/ArtificialInteligence)
🌟 Comunidad
Debate en Reddit: ¿Cuándo se lanzará el modelo Qwen3?: La comunidad de Reddit y usuarios de X (antes Twitter) debaten sobre la fecha de lanzamiento del modelo Qwen3 de Alibaba. Aunque un usuario compartió un cartel de la cumbre de IA de Alibaba y especuló sobre un lanzamiento inminente, posteriormente se confirmó que la cumbre no lanzó Qwen3. Al mismo tiempo, la noticia de que llama.cpp fusionó el soporte para Qwen3 intensificó la expectación de la comunidad. Esto refleja la gran atención y expectación de la comunidad open source hacia los avances de los grandes modelos chinos (fuente: X @karminski3, Reddit r/LocalLLaMA)

Se lanza concurso de conjuntos de datos de razonamiento: Bespoke Labs, en colaboración con Hugging Face y Together AI, ha lanzado un concurso de conjuntos de datos de razonamiento. El objetivo es animar a la comunidad a crear conjuntos de datos de razonamiento más diversos y cercanos a la complejidad del mundo real, especialmente en el razonamiento multidominio como finanzas y medicina, para impulsar el desarrollo de la próxima generación de LLMs. Los conjuntos de datos existentes (como OpenThoughts-114k) ya han desempeñado un papel importante en el entrenamiento de modelos, y el concurso espera ampliar aún más las fronteras de los conjuntos de datos (fuente: X @huggingface)

Actualización del benchmark de programación LiveCodeBench, o3-mini lidera: La clasificación de capacidad de programación LiveCodeBench se actualizó después de 8 meses, con o3-mini (high) y o3-mini (medium) de OpenAI en primer y segundo lugar, y Google Gemini 2.5 Pro en tercero. La lista generó debate en la comunidad, con algunos usuarios cuestionando la clasificación relativamente baja de Claude 3.5/3.7, argumentando que no coincide con la experiencia de uso real, lo que refleja las posibles discrepancias entre diferentes benchmarks y la percepción subjetiva del usuario (fuente: Reddit r/LocalLLaMA)

La comunidad discute Claude Code: Potente pero caro y con errores: Usuarios de Reddit discuten sobre Claude Code de Anthropic, coincidiendo en general en que su capacidad de percepción del contexto es fuerte y su rendimiento en codificación es bueno, incluso sintiéndose «como del futuro». Sin embargo, las desventajas son su alto costo (un usuario mencionó un gasto diario de hasta 30 dólares) y la existencia de algunos errores (como la pérdida de la sesión del archivo claude.md, errores de sintaxis en la salida, etc.). Los usuarios esperan que aparezcan alternativas futuras más capaces y asequibles (fuente: Reddit r/ClaudeAI)
Usuario comparte modelos cuantizados de Mistral-Small-3.1-24B: Un usuario de la comunidad Ollama compartió las versiones cuantizadas Q5_K_M y Q6_K (formato GGUF) del modelo Mistral-Small-3.1-24B, supliendo la carencia del repositorio oficial que solo ofrecía Q4 y Q8. Estos modelos cuantizados se crearon con el cliente Ollama, soportan funciones visuales y proporcionan referencias de longitud de contexto en una RTX 4090 (fuente: Reddit r/LocalLLaMA)

Comunidad busca herramientas de escalado de video por IA: Un usuario de Reddit pregunta si existen herramientas de IA capaces de mejorar videos de baja resolución de 240p a 1080p/60fps, con la esperanza de restaurar videos musicales antiguos. En los comentarios se mencionan herramientas como Ai4Video y Cutout.Pro, pero también se opina que la mejora desde resoluciones extremadamente bajas tiene efectos limitados, pudiendo parecer más una regeneración que una restauración (fuente: Reddit r/artificial)
Usuario informa sospecha de actualización sigilosa de Claude 3.5 Sonnet: Un usuario desarrollador en Reddit sospecha, basándose en su experiencia de uso (como que el modelo empezó a usar emojis, cambios en el estilo de respuesta), que Anthropic reemplazó la versión original del modelo Claude 3.5 Sonnet con una versión optimizada o destilada sin previo aviso, lo que provocó cambios en el rendimiento o comportamiento. El usuario considera que la versión original 3.5 era superior a la 3.7 en codificación, pero su experiencia reciente ha disminuido. Esto generó un debate en la comunidad sobre la transparencia y consistencia de las versiones de los modelos (fuente: Reddit r/ClaudeAI)
Informe de Anthropic genera debate sobre el uso de IA por estudiantes para hacer trampa: Anthropic publicó un informe educativo que, mediante el análisis de millones de conversaciones anónimas de estudiantes, sugiere que los estudiantes podrían estar utilizando Claude para cometer fraude académico. El informe generó debate en la comunidad, con opiniones que incluyen: el fraude estudiantil siempre ha existido, la IA es solo una nueva herramienta; el sistema educativo necesita adaptarse a la era de la IA, los métodos de evaluación deben cambiar; algunos usuarios expresaron preocupación por la privacidad del análisis de datos de conversación de usuarios por parte de Anthropic (fuente: Reddit r/ClaudeAI)

Usuarios discuten métodos de monitorización para aplicaciones LLM/Agent: Usuarios de la comunidad de machine learning en Reddit iniciaron una discusión preguntando cómo monitorizan el rendimiento y el costo de las aplicaciones LLM o AI Agents, por ejemplo, rastreando el uso de Tokens, latencia, tasa de errores, cambios en la versión del Prompt, etc. La discusión tiene como objetivo comprender las prácticas y los puntos débiles de la comunidad en LLMOps, ya sea mediante soluciones propias o utilizando herramientas específicas (fuente: Reddit r/MachineLearning)
💡 Otros
Andrew Ng comenta sobre el impacto de la política arancelaria de EE. UU. en la IA: Andrew Ng expresó en su boletín semanal The Batch su preocupación por la nueva política arancelaria de EE. UU., argumentando que no solo daña las relaciones con los aliados y la economía global, sino que también obstaculiza indirectamente el desarrollo y la aplicación de la IA en EE. UU. al restringir la importación de hardware (como servidores, refrigeración, equipos de red, componentes de instalaciones eléctricas) y aumentar los precios de la electrónica de consumo. Señaló que, aunque los aranceles podrían estimular ligeramente la demanda de robots y automatización, esta no es una forma eficaz de resolver los problemas de fabricación, y el progreso de la IA en robótica es relativamente lento. Hizo un llamado a la comunidad de IA para fortalecer la cooperación internacional y el intercambio de ideas (fuente: DeepLearning.AI)

Avances y trampas de la IA en el sector de las telecomunicaciones: El artículo explora el potencial de aplicación de la inteligencia artificial en la industria de las telecomunicaciones, como la optimización de redes, el servicio al cliente, el mantenimiento predictivo, etc., al tiempo que señala los posibles desafíos y trampas, como la privacidad de los datos, el sesgo algorítmico, la complejidad de la integración y el impacto en los flujos de trabajo existentes (fuente: X @Ronald_vanLoon)
La diversidad de habilidades es crucial para el ROI de la IA: Antonio Grasso enfatiza que para lograr con éxito el retorno de la inversión (ROI) en proyectos de inteligencia artificial, los equipos necesitan tener un conjunto diverso de habilidades, que puede incluir ciencia de datos, ingeniería, conocimiento del dominio, ética, análisis de negocios y otras capacidades (fuente: X @Ronald_vanLoon)

La cadena de suministro impulsada por IA lidera el desarrollo sostenible: El artículo de Nicochan33 señala que utilizar la IA para optimizar la gestión de la cadena de suministro (como la planificación de rutas, la gestión de inventarios, la previsión de la demanda) no solo aumenta la eficiencia, sino que también impulsa la consecución de objetivos de desarrollo sostenible al reducir el desperdicio, disminuir el consumo de energía, etc. (fuente: X @Ronald_vanLoon)

Autonomía, salvaguardias y trampas de los AI Agents: Un artículo de VentureBeat explora temas clave en el desarrollo de AI Agents, incluyendo cómo equilibrar su capacidad autónoma, diseñar salvaguardias de seguridad efectivas para prevenir el abuso o consecuencias no deseadas, y las trampas que pueden encontrarse durante el despliegue y uso (fuente: X @Ronald_vanLoon)

La IA se considera la mayor amenaza para los negocios «aburridos»: Un artículo de Forbes argumenta que la inteligencia artificial representa la mayor amenaza disruptiva para aquellos negocios tradicionalmente considerados «aburridos» o basados en procesos, ya que estos suelen incluir una gran cantidad de tareas que pueden ser automatizadas u optimizadas por la IA (fuente: X @Ronald_vanLoon)

Problema de sesgo en algoritmos médicos y nuevas directrices: Un artículo de Fortune se centra en el problema persistente del sesgo en la IA en el campo de la medicina y explora si las nuevas directrices pueden impulsar la solución de este problema, garantizando la equidad y precisión de las aplicaciones médicas de IA (fuente: X @Ronald_vanLoon)

El papel de la IA en la mejora de habilidades laborales y la identificación de enfermedades: Un artículo de Forbes explora el papel positivo de la IA en dos aspectos: ayudar a mejorar las habilidades de la fuerza laboral existente para adaptarse a las futuras demandas laborales, y apoyar en la identificación temprana y el diagnóstico de enfermedades (fuente: X @Ronald_vanLoon)

Los agentes digitales de IA redefinirán el trabajo: Un artículo de VentureBeat discute cómo los AI Agents (agentes digitales) se integrarán en el lugar de trabajo, no solo como herramientas, sino también cambiando potencialmente la definición misma del trabajo, los procesos y la colaboración humano-máquina (fuente: X @Ronald_vanLoon)

El dilema de la invisibilidad, autonomía y vulnerabilidad de los AI Agents: Un artículo de VentureBeat profundiza en el nuevo dilema que plantean los AI Agents: su funcionamiento puede ser «invisible» para el usuario, poseen una alta autonomía y, al mismo tiempo, pueden ser explotados o atacados maliciosamente, lo que plantea nuevos desafíos para la seguridad y la ética (fuente: X @Ronald_vanLoon)

Trump amenaza con imponer un arancel del 100% a TSMC: El expresidente de EE. UU., Donald Trump, declaró que le había dicho a TSMC que si no construía fábricas en EE. UU., impondría un arancel del 100% a sus productos. Esta declaración refleja el impacto continuo de la geopolítica en la cadena de suministro de semiconductores y podría generar riesgos potenciales para el suministro de hardware de IA que depende de los chips de TSMC (fuente: Reddit r/ArtificialInteligence, Reddit r/artificial)

Se acusa a Google Gemini 2.5 Pro de carecer de un informe de seguridad clave: Fortune informa que el modelo Gemini 2.5 Pro recientemente lanzado por Google carece de un informe de seguridad clave (Model Card), lo que podría violar los compromisos de seguridad de IA que Google hizo previamente al gobierno de EE. UU. y en cumbres internacionales. Este asunto ha generado preocupación sobre la transparencia en el lanzamiento de modelos y el cumplimiento de los compromisos de seguridad por parte de las grandes empresas tecnológicas (fuente: Reddit r/artificial)

Uso de IA para el reconocimiento de matrículas: Un artículo de Rackenzik presenta la tecnología de detección y reconocimiento de matrículas basada en deep learning, explorando los desafíos involucrados, como imágenes borrosas, diferencias en los estilos de matrículas entre países/regiones y las dificultades de reconocimiento en diversas condiciones del mundo real (fuente: Reddit r/deeplearning)
