
Palabras clave:AI, LLM, informe de índice AI de Stanford, controversia Meta Llama 4, Gemini Deep Research actualización, NVIDIA Llama 3.1 Nemotron, DeepSeek R1 récord velocidad
🔥 Enfoque
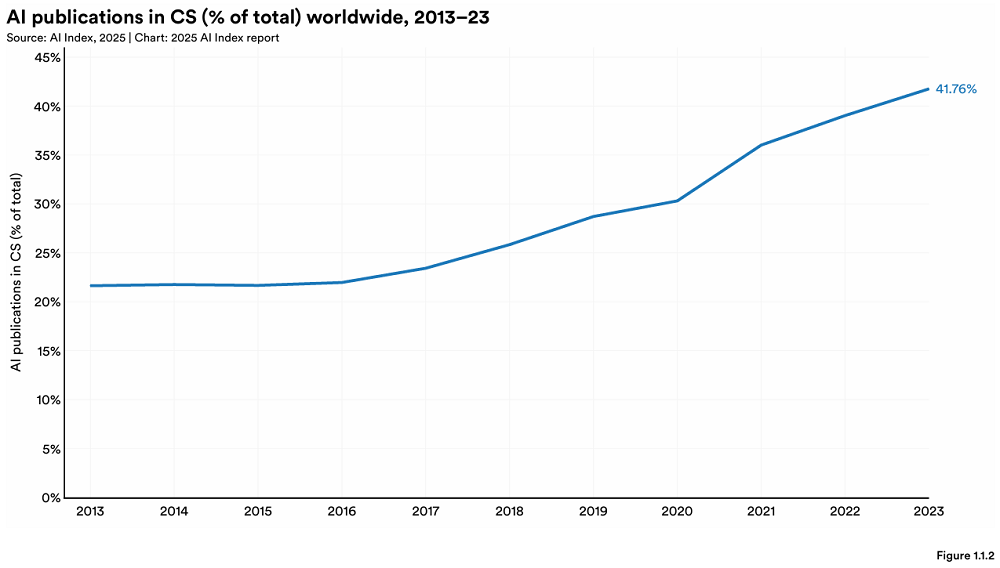
Stanford publica el informe anual AI Index, revelando nuevos cambios en el panorama global de la IA: El HAI de la Universidad de Stanford ha publicado el «AI Index Report 2025» de 456 páginas. El informe muestra que Estados Unidos sigue liderando en la producción de modelos de IA de vanguardia, pero China está reduciendo rápidamente la brecha de rendimiento (por ejemplo, la diferencia en MMLU y HumanEval casi ha desaparecido). La industria domina el desarrollo de modelos importantes (representando el 90%), aunque el número de modelos ha disminuido. El coste del hardware de IA está disminuyendo a una tasa anual del 30%, y el rendimiento se duplica cada 1.9 años. La inversión global en IA alcanzó los 252.3 mil millones de dólares, con Estados Unidos liderando con 109.1 mil millones (aproximadamente 12 veces los 9.3 mil millones de China), y la inversión en IA generativa alcanzó los 33.9 mil millones. La tasa de adopción de IA empresarial aumentó al 78%, con China mostrando el crecimiento más rápido (alcanzando el 75%). La IA ha comenzado a reducir costes y aumentar la eficiencia para las empresas. La IA ha logrado avances en el campo científico, ganando dos premios Nobel y superando a los humanos en secuenciación de proteínas y diagnóstico clínico. El optimismo global hacia la IA está aumentando, pero existen diferencias regionales significativas, siendo China la más optimista. El ecosistema de IA responsable (RAI) está madurando gradualmente, pero la evaluación y la práctica aún son desiguales. (Fuente: 36氪, AI科技评论, dotey, 36kr)
El lanzamiento de Meta Llama 4 genera gran controversia, acusado de «manipulación de rankings» y bajo rendimiento: La última serie de modelos grandes de código abierto de Meta, Llama 4 (Scout, Maverick, Behemoth), sufrió un descalabro en su reputación dentro de las 72 horas posteriores a su lanzamiento. Su versión Maverick ascendió rápidamente al segundo lugar en Chatbot Arena, pero se reveló que la versión enviada era una «versión experimental» no pública optimizada para conversación, lo que generó acusaciones de «manipulación de rankings». Aunque Meta negó haber entrenado en el conjunto de pruebas, admitió problemas de rendimiento. La comunidad informó que el rendimiento de Llama 4 en codificación, comprensión de contextos largos, etc., no cumplió con las expectativas, e incluso fue inferior a modelos con menos parámetros (como DeepSeek V3). Expertos en IA como Gary Marcus comentaron que «Scaling is dead», argumentando que simplemente aumentar el tamaño del modelo no puede traer una capacidad de razonamiento fiable, y expresaron preocupación de que el progreso global de la IA pueda estancarse debido a factores como la financiación y la geopolítica. LMArena ha publicado los datos de evaluación relevantes para su revisión y ha actualizado su estrategia de clasificación para evitar confusiones. (Fuente: 36kr, 雷科技, AIatMeta, karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

🎯 Tendencias
La función Gemini Deep Research se actualiza, adopta el modelo Gemini 2.5 Pro: La función Deep Research en la Google Gemini App ahora está impulsada por el modelo Gemini 2.5 Pro. Las pruebas iniciales de los usuarios indican que su rendimiento es superior al de otros productos competidores. Esta actualización tiene como objetivo mejorar la capacidad de búsqueda y síntesis de información, la perspicacia en los informes y la capacidad de análisis y razonamiento. Los usuarios de Gemini Advanced pueden experimentar esta actualización. Varios usuarios y el CEO de Google DeepMind, Demis Hassabis, compartieron experiencias positivas al usar la nueva versión de Deep Research para completar tareas complejas (como análisis de mercado), elogiando su velocidad y contenido exhaustivo. (Fuente: JeffDean, dotey, JeffDean, demishassabis)

Nvidia lanza el modelo Llama 3.1 Nemotron Ultra 253B: Nvidia ha lanzado el modelo Llama 3.1 Nemotron Ultra 253B en Hugging Face. Este modelo es un modelo denso (no MoE) con funcionalidad de activación/desactivación de inferencia. Se modificó a partir del modelo Llama-405B de Meta mediante la técnica de poda NAS (Neural Architecture Search) y se sometió a un post-entrenamiento centrado en la inferencia (SFT + RL en FP8). Las pruebas de referencia muestran que su rendimiento es superior a DeepSeek R1, aunque algunos comentarios señalan que la comparación directa con el modelo MoE DeepSeek R1 (con menos parámetros activos) puede no ser del todo justa. Nvidia también ha publicado el conjunto de datos de post-entrenamiento relacionado en Hugging Face. (Fuente: huggingface, Reddit r/LocalLLaMA, dylan522p, huggingface)

IA + Fabricación se convierte en el nuevo foco, con oportunidades y desafíos coexistiendo: La IA está penetrando rápidamente en la industria manufacturera china, con aplicaciones que abarcan la automatización de la producción (como la producción de materiales dentales de Yucheng), la inteligencia de producto (como las gafas de ayuda al sueño con IA de Binghan Technology), la optimización de procesos (como las actas de reuniones con IA de Zhongke Lingchuang) y la I+D y diagnóstico (como la plataforma de diagnóstico cardiovascular de Ruixin Intelligent, la predicción de demanda de piezas de repuesto y detección de fallos de Bihua Auto). Instituciones financieras como WeBank también utilizan tecnología de IA (como la generación inteligente de informes de due diligence) para servir a empresas de fabricación tecnológica e innovadora. Sin embargo, «IA + Fabricación» todavía enfrenta desafíos como la baja calidad de los datos y una débil base de digitalización empresarial. Los inversores sugieren que las empresas deben utilizar la IA para servir a su negocio principal, no solo como un truco publicitario, y necesitan invertir a largo plazo para resolver los problemas de datos e implementación. (Fuente: 36氪)
DeepSeek R1 establece un récord de velocidad de inferencia en Nvidia B200: La startup de IA Avian.io anunció que, en colaboración con Nvidia, ha logrado una velocidad de inferencia de 303 tokens/segundo para el modelo DeepSeek R1 en la última plataforma GPU Blackwell B200, estableciendo un récord mundial. Avian.io declaró que ofrecerá puntos finales de inferencia dedicados para DeepSeek R1 basados en B200 en los próximos días y ya ha abierto las reservas. Este logro marca una nueva era para los modelos impulsados por cómputo en tiempo de prueba (test time compute driven models). (Fuente: Reddit r/LocalLLaMA)

OpenAI crea un equipo de Despliegue Estratégico para impulsar la implementación de modelos de vanguardia: OpenAI ha formado un nuevo equipo de Despliegue Estratégico (Strategic Deployment) con el objetivo de impulsar los modelos de vanguardia (como GPT-4.5 y modelos futuros) a niveles más altos de capacidad, fiabilidad y alineación (alignment), y desplegarlos en dominios del mundo real de alto impacto para acelerar la transformación de la economía por la IA y explorar el camino hacia la AGI. El equipo está contratando activamente y realizando promoción en conferencias académicas como ICLR. (Fuente: sama)
La IA enfrenta desafíos en la mejora de la experiencia del cliente (CX): El artículo explora las dificultades y desafíos al utilizar la IA para mejorar la experiencia del cliente. Aunque la IA ofrece potencial, su implementación efectiva no es fácil y puede involucrar problemas de integración de datos, precisión del modelo, aceptación del usuario y costes de mantenimiento, entre otros. (Fuente: Ronald_vanLoon)

La aplicación de la IA genera innovación y preocupación en el lugar de trabajo: El artículo discute el doble impacto de la aplicación de la IA en el lugar de trabajo: por un lado, el estímulo del potencial innovador, y por otro, la preocupación por la fuerza laboral existente, como la posibilidad de reemplazo de puestos de trabajo, cambios en la demanda de habilidades, etc. (Fuente: Ronald_vanLoon)

El Internet of Behavior (IoB) está cambiando la toma de decisiones empresariales: La tecnología que utiliza machine learning e inteligencia artificial para analizar los datos del comportamiento del usuario (Internet of Behavior) está proporcionando a las empresas una visión más profunda, transformando así la forma en que toman decisiones comerciales, lo que podría involucrar marketing personalizado, evaluación de riesgos, desarrollo de productos y otros aspectos. (Fuente: Ronald_vanLoon)

El modelo multimodal RolmOCR destaca en el ranking de Hugging Face: Yifei Hu señala que el modelo de lenguaje visual (VLM) RolmOCR desarrollado por su equipo ha tenido un rendimiento excelente en el ranking de Hugging Face, ocupando el tercer lugar entre los VLM y el quinto entre todos los modelos. El equipo planea lanzar más modelos, conjuntos de datos y algoritmos en el futuro para apoyar la investigación científica de código abierto. (Fuente: huggingface)

Resumen de noticias de IA (08/04/2025): Noticias recientes relacionadas con la IA incluyen: Meta Llama 4 acusado de comportamiento engañoso en benchmarks; Apple podría trasladar más producción de iPhone a India para evitar aranceles; IBM lanza nuevo mainframe para la era de la IA; se rumorea que Google paga altos salarios a algunos empleados de IA para mantenerlos «inactivos» durante un año para retener talento; Microsoft supuestamente despidió a empleados que interrumpieron su evento Copilot en protesta; Amazon afirma que su modelo de video IA ahora puede generar clips de varios minutos de duración. (Fuente: Reddit r/ArtificialInteligence)

🧰 Herramientas
FunASR: Toolkit fundamental de reconocimiento de voz de extremo a extremo de código abierto de Alibaba DAMO Academy: FunASR es un toolkit que integra funciones como reconocimiento de voz (ASR), detección de actividad de voz (VAD), restauración de puntuación, modelo de lenguaje, reconocimiento de locutor, separación de locutores y reconocimiento multi-locutor. Admite la inferencia y el ajuste fino (fine-tuning) de modelos pre-entrenados de nivel industrial (como Paraformer, SenseVoice, Whisper, Qwen-Audio, etc.) y proporciona scripts y tutoriales convenientes. Las actualizaciones recientes incluyen soporte para SenseVoiceSmall, Whisper-large-v3-turbo, modelos de detección de palabras clave (keyword spotting), modelos de reconocimiento de emociones, y el lanzamiento de un servicio de transcripción offline/en tiempo real optimizado en memoria y rendimiento (incluida la versión GPU). (Fuente: modelscope/FunASR – GitHub Trending (all/daily))
LightRAG: Framework de generación aumentada por recuperación (RAG) conciso y eficiente: LightRAG es un framework RAG desarrollado por el laboratorio DS de la Universidad de Hong Kong (HKUDS), diseñado para simplificar y acelerar la construcción de aplicaciones RAG. Integra capacidades de construcción y recuperación de grafos de conocimiento (KG), admite múltiples modos de recuperación (local, global, híbrido, ingenuo, modo Mix) y puede conectarse de manera flexible a diferentes LLM (como OpenAI, Hugging Face, Ollama) y modelos de Embedding. El framework también admite múltiples backends de almacenamiento (como NetworkX, Neo4j, PostgreSQL, Faiss) y entrada de múltiples tipos de archivos (PDF, DOC, PPT, CSV), y ofrece funciones como edición de entidades/relaciones, exportación de datos, gestión de caché, seguimiento de Tokens, historial de conversación y Prompts personalizados. El proyecto proporciona una interfaz de usuario web (Web UI) y servicios API, así como una herramienta de visualización de grafos de conocimiento. (Fuente: HKUDS/LightRAG – GitHub Trending (all/daily))
LangGraph ayuda a Definely a construir un Agente de IA legal: La empresa Definely ha utilizado LangGraph para construir un sistema multi-agente de IA integrado directamente en Microsoft Word para ayudar a los abogados a manejar trabajos legales complejos. El sistema puede descomponer tareas legales en subtareas, combinar información contextual para la extracción de cláusulas, análisis de cambios y redacción de contratos, e incorporar la entrada y aprobación de los abogados a través de un ciclo de colaboración humano-máquina (Human-in-the-loop) para guiar decisiones clave. Esto demuestra la capacidad de LangGraph para construir flujos de trabajo de Agentes complejos y controlables. (Fuente: LangChainAI)

LlamaParse lanza un nuevo Agente consciente del diseño (layout-aware): LlamaIndex ha lanzado una nueva función para LlamaParse: el Agente de diseño (Layout Agent). Este Agente utiliza modelos SOTA VLM de diferentes tamaños, desde Flash 2.0 hasta Sonnet 3.7, para analizar dinámicamente las páginas del documento siendo consciente del diseño. Primero analiza el diseño general y descompone la página en bloques (como tablas, gráficos, párrafos), y luego selecciona diferentes modelos para procesarlos según la complejidad del bloque (por ejemplo, usando un modelo más potente para procesar gráficos y un modelo pequeño para procesar texto). Esta función es especialmente importante para los flujos de trabajo de Agentes que necesitan procesar grandes cantidades de contexto documental. (Fuente: jerryjliu0)

Auth0 lanza herramientas de seguridad para aplicaciones GenAI: Auth0 ha lanzado un nuevo producto «Auth for GenAI», diseñado para ayudar a los desarrolladores a proteger fácilmente la seguridad de sus aplicaciones y Agentes GenAI. El producto ofrece funciones como autenticación de usuarios, llamar a APIs en nombre del usuario, confirmación asíncrona de usuario (CIBA) y autorización para RAG. Proporciona SDKs y documentación para frameworks GenAI populares (como LangChain, LlamaIndex, Firebase Genkit, etc.), simplificando el proceso de integración de autenticación y autorización en aplicaciones de IA. (Fuente: jerryjliu0, jerryjliu0)

Ollama añade soporte para el modelo visual Mistral Small 3.1: La herramienta de ejecución local de modelos grandes Ollama ahora es compatible con el último modelo Mistral Small 3.1 de Mistral AI, incluida su capacidad visual (multimodal). Los usuarios pueden descargar y ejecutar versiones cuantizadas como mistral-small3.1:24b-instruct-2503-q4_K_M a través de la biblioteca Ollama. Los comentarios de la comunidad indican que el modelo funciona bien en tareas como OCR, pero algunos usuarios informan de una velocidad de inferencia lenta en hardware específico (como AMD 7900xt). (Fuente: Reddit r/LocalLLaMA)

Unsloth lanza modelos cuantizados GGUF de Llama-4 Scout: Unsloth ha lanzado versiones cuantizadas en formato GGUF del modelo Llama-4 Scout 17B de código abierto, facilitando su ejecución en CPU locales o GPU con memoria limitada. Esto incluye una versión de cuantización dinámica de 2.71 bits con un tamaño de solo 42.2 GB. Los usuarios pueden ver los archivos del modelo para diferentes niveles de cuantización (como Q6_K) y su información de compatibilidad de hardware en Hugging Face. (Fuente: karminski3)

OpenEvals de LangSmith admite esquemas de salida personalizados: La herramienta de evaluación de LLM de LangSmith, OpenEvals, ahora permite a los usuarios personalizar los esquemas de salida (output schemas) del evaluador LLM-as-judge. Aunque el esquema predeterminado cubre muchos casos comunes, esta actualización brinda a los usuarios una flexibilidad total para personalizar la estructura y el contenido de las respuestas del modelo según las necesidades específicas de evaluación. La función está disponible tanto en la versión Python como en la JS. (Fuente: LangChainAI)

Los modelos Qwen 3 pronto serán compatibles con llama.cpp: Se ha enviado y aprobado un Pull Request para añadir soporte a los modelos de la serie Qwen 3 de Alibaba en llama.cpp, y está a punto de fusionarse. Esto significa que los usuarios pronto podrán ejecutar modelos Qwen 3 localmente a través del framework llama.cpp. Esta actualización fue enviada por bozheng-hit, quien anteriormente también contribuyó con el soporte de Qwen 3 para la biblioteca transformers. (Fuente: Reddit r/LocalLLaMA)

Lanzamiento de Computer Use Agent Arena: El equipo de OSWorld ha lanzado Computer Use Agent Arena, una plataforma para probar Agentes de Uso de Computadora (Computer-Use Agents) en entornos reales sin necesidad de configuración. Los usuarios pueden comparar el rendimiento de los principales VLM como OpenAI Operator, Claude 3.7, Gemini 2.5 Pro, Qwen 2.5 VL en más de 100 aplicaciones y sitios web reales. La plataforma ofrece configuración con un solo clic y afirma ser segura y gratuita. (Fuente: lmarena_ai)
El servicio de distribución de música Too Lost es amigable con la música IA: Un usuario de Reddit compartió su experiencia usando Too Lost para distribuir música generada por IA como Suno y Udio. Las ventajas incluyen: aceptación explícita de música IA, aprobación rápida (1-2 días), precio asequible (35 USD/año para lanzamientos ilimitados), la música no se elimina al expirar la suscripción (pero el reparto de ingresos cambia a 85/15), soporte para nombre de sello discográfico personalizado. Las desventajas son la lentitud en la distribución a Instagram/Facebook (>16 días), y posiblemente la necesidad de proporcionar pruebas de distribución previa. (Fuente: Reddit r/SunoAI)
📚 Aprendizaje
NVIDIA lanza CUDA Python: NVIDIA ha presentado CUDA Python, con el objetivo de proporcionar un punto de entrada unificado para acceder a la plataforma CUDA desde Python. Incluye varios componentes: cuda.core proporciona acceso Pythonic a CUDA Runtime; cuda.bindings ofrece bindings de bajo nivel para la API CUDA C; cuda.cooperative proporciona primitivas paralelas del lado del dispositivo de CCCL (para Numba CUDA); cuda.parallel ofrece algoritmos paralelos del lado del host de CCCL (ordenación, escaneo, etc.); y numba.cuda para compilar un subconjunto de Python en kernels CUDA. El propio paquete cuda-python se transformará en un metapaquete que contendrá estos subpaquetes versionados independientemente. (Fuente: NVIDIA/cuda-python – GitHub Trending (all/daily))
Hugging Face publica un gran conjunto de datos de codificación con razonamiento: Se ha publicado en Hugging Face un gran conjunto de datos que contiene 736,712 soluciones de código Python generadas por DeepSeek-R1. Este conjunto de datos incluye las trazas de razonamiento (reasoning traces) del código, se puede utilizar para fines comerciales y no comerciales, y es uno de los mayores conjuntos de datos de codificación con razonamiento disponibles actualmente. (Fuente: huggingface)

Cinco grandes desafíos y soluciones para construir Agentes de IA: El artículo resume los cinco desafíos principales al construir Agentes de IA: 1) Gestión del razonamiento y la toma de decisiones (garantizar consistencia y fiabilidad); 2) Procesos de múltiples pasos y manejo del contexto (gestión de estado, manejo de errores); 3) Gestión de la integración de herramientas (aumento de puntos de fallo, riesgos de seguridad); 4) Controlar alucinaciones y garantizar la precisión; 5) Gestión del rendimiento a gran escala (manejo de alta concurrencia, tiempos de espera, cuellos de botella de recursos). Para cada desafío, el artículo propone soluciones específicas, como el uso de prompts estructurados (ReAct), gestión robusta del estado, definición precisa de herramientas, sistemas de validación estrictos (base fáctica, citas), revisión humana, monitorización LLMOps, etc. (Fuente: AINLPer)
El ex científico jefe de Kaggle recuerda ULMFiT, posiblemente el primer LLM: Jeremy Howard (fundador de fast.ai, ex científico jefe de Kaggle) afirmó en redes sociales que su ULMFiT de 2018 fue el primer «modelo de lenguaje universal», lo que provocó un debate sobre el «primer LLM». ULMFiT utilizó un paradigma de preentrenamiento no supervisado y ajuste fino, logrando el estado del arte (SOTA) en tareas de clasificación de texto e inspirando a GPT-1. Un artículo de investigación argumenta que, según criterios como el entrenamiento autosupervisado, la predicción del siguiente token, la capacidad de adaptarse a nuevas tareas y la generalidad, ULMFiT se acerca más a la definición moderna de LLM que CoVE o ELMo, siendo uno de los «ancestros comunes» de los LLM modernos. (Fuente: 量子位)
Compartir técnicas ligeras de ajuste fino de LLM desde la perspectiva del desarrollador: Para desarrolladores que no son ingenieros de ML expertos, se comparten experiencias y lecciones aprendidas al usar métodos de ajuste fino eficiente en parámetros (PEFT) como LoRA y QLoRA para mejorar la calidad de salida de los LLM. Se enfatiza que estos métodos son más adecuados para integrarse en los flujos de trabajo de desarrollo habituales, evitando la complejidad del ajuste fino completo (full fine-tuning). El equipo relacionado organizará un webinar gratuito para discutir los puntos débiles encontrados por los desarrolladores en la práctica. (Fuente: Reddit r/artificial, Reddit r/MachineLearning)
Artículo propone Rethinking Reflection in Pre-Training: Una investigación de Essential AI (liderada por Ashish Vaswani, uno de los autores de Transformer) descubrió que los LLM ya muestran capacidad de razonamiento generalizado entre tareas y dominios durante la fase de preentrenamiento. El artículo propone que un simple token «wait» puede actuar como un «disparador de reflexión», mejorando significativamente el rendimiento de razonamiento del modelo. El estudio sugiere que, en comparación con los métodos de post-entrenamiento que dependen de modelos de recompensa (Reward Model) refinados (como RLHF), aprovechar la capacidad intrínseca de reflexión del modelo durante el preentrenamiento podría ser una vía más simple y fundamental para mejorar la capacidad de razonamiento general, y podría superar los cuellos de botella de los métodos actuales de ajuste fino específicos de la tarea (task-specific). (Fuente: dotey)

Artículo propone usar pérdida RL para generación de historias sin modelo de recompensa: Investigadores proponen un paradigma de recompensa inspirado en RLVR, llamado VR-CLI, para optimizar la generación de historias largas (tarea de predicción del próximo capítulo, ~100k tokens) mediante pérdidas RL (como la perplejidad) sin un modelo de recompensa explícito. Los experimentos muestran que este método se correlaciona con los juicios humanos sobre la calidad del contenido generado. (Fuente: natolambert)

Artículo propone el método P3 para mejorar la robustez de la clasificación Zero-Shot: Para abordar el problema de la sensibilidad de los modelos a los cambios de Prompt (prompt brittleness) en la clasificación de texto Zero-Shot, los investigadores proponen el método Placeholding Parallel Prediction (P3). Este método simula un muestreo exhaustivo de las rutas de generación prediciendo probabilidades de tokens en múltiples posiciones, en lugar de depender únicamente de la probabilidad del siguiente token. Los experimentos muestran que P3 mejora la precisión y reduce la desviación estándar entre diferentes prompts hasta en un 98%, mejorando la robustez e incluso manteniendo un rendimiento comparable sin prompts. (Fuente: Reddit r/MachineLearning)
Artículo propone capa de Test-Time Training para mejorar la generación de videos largos: Para abordar el problema de consistencia causado por la ineficiencia del mecanismo de autoatención en arquitecturas Transformer al generar videos largos (como de un minuto o más), la investigación propone una nueva capa de Test-Time Training (TTT). El estado oculto de esta capa puede ser en sí mismo una red neuronal, siendo más expresivo que las capas tradicionales, permitiendo así generar videos largos con mejor consistencia, naturalidad y estética. (Fuente: dotey)
Publicado informe técnico de SmolVLM, explorando modelos multimodales pequeños y eficientes: El informe técnico presenta las ideas de diseño y los hallazgos experimentales de SmolVLM (parámetros 256M, 500M, 2.2B), con el objetivo de construir modelos multimodales pequeños y eficientes. Las ideas clave incluyen: aumentar la longitud del contexto (2K->16K) mejora significativamente el rendimiento (+60%); los LLM pequeños se benefician más de SigLIP más pequeños (80M); el Pixel shuffling puede acortar drásticamente la longitud de la secuencia; los tokens de posición aprendidos son superiores a los tokens de texto originales; los prompts de sistema y los tokens de medios dedicados son especialmente importantes para tareas de video; demasiados datos CoT (Chain-of-Thought) perjudican el rendimiento de los modelos pequeños; entrenar con videos más largos ayuda a mejorar el rendimiento en tareas de imagen y video. SmolVLM alcanza el nivel SOTA dentro de sus restricciones de hardware y ya se ha implementado para inferencia en tiempo real en iPhone 15 y navegadores. (Fuente: huggingface)

Hugging Face publica el Dataset Requerido para Razonamiento (Reasoning Required Dataset): Este conjunto de datos contiene 5000 muestras de fineweb-edu, etiquetadas según la complejidad del razonamiento (puntuación 0-4), para determinar si el texto es adecuado para generar conjuntos de datos de razonamiento. El conjunto de datos tiene como objetivo entrenar un clasificador ModernBERT para prefiltrar contenido de manera eficiente y extender el alcance de los conjuntos de datos de razonamiento más allá de los dominios de las matemáticas y la codificación. (Fuente: huggingface)
El benchmark CoCoCo evalúa la capacidad de los LLM para cuantificar consecuencias: Upright Project ha publicado el informe técnico del benchmark CoCoCo, utilizado para evaluar la consistencia de los LLM en la cuantificación de las consecuencias del comportamiento. Las pruebas encontraron que Claude 3.7 Sonnet (con un presupuesto de pensamiento de 2000 tokens) tuvo el mejor rendimiento, pero mostró un sesgo hacia enfatizar las consecuencias positivas y minimizar las negativas. El informe concluye que, aunque los LLM han mejorado en esta capacidad en los últimos años, todavía queda un largo camino por recorrer. (Fuente: Reddit r/ArtificialInteligence)

Comparación de motores de inferencia GenAI: TensorRT-LLM vs vLLM vs TGI vs LMDeploy: NLP Cloud compartió un análisis comparativo y resultados de benchmarks de cuatro motores de inferencia GenAI populares. TensorRT-LLM es el más rápido en GPU Nvidia pero complejo de configurar; vLLM es de código abierto, flexible y con alto throughput, pero con una latencia por solicitud única ligeramente inferior; Hugging Face TGI es fácil de configurar y escalar, bien integrado con el ecosistema HF; LMDeploy (TurboMind) destaca en velocidad de decodificación y rendimiento de inferencia en 4 bits en GPU Nvidia, con baja latencia, pero TurboMind tiene soporte limitado para modelos. (Fuente: Reddit r/MachineLearning)
Avance de la nueva temporada del podcast de Google DeepMind: La nueva temporada del podcast de Google DeepMind se lanzará el 10 de abril, presentada por Hannah Fry. El contenido cubrirá cómo la ciencia impulsada por la IA está revolucionando la medicina, la tecnología robótica de vanguardia, las limitaciones de los datos generados por humanos y otros temas. (Fuente: GoogleDeepMind)
Video de presentación de la plataforma LangGraph: LangChain ha publicado un video de 4 minutos que explica las funciones de la plataforma LangGraph, mostrando cómo usar este producto de nivel empresarial para desarrollar, desplegar y gestionar Agentes de IA. (Fuente: LangChainAI, LangChainAI)

Implementación en Keras de First-Order Motion Transfer: Un desarrollador compartió la implementación en Keras del modelo de movimiento de primer orden (First-Order Motion Model) del artículo de Siarohin et al. (NeurIPS 2019) para la animación de imágenes. Debido a la falta en Keras de una función similar a grid_sample de PyTorch, el desarrollador construyó un módulo personalizado de deformación de flujo óptico (flow warping) que admite procesamiento por lotes, coordenadas normalizadas y aceleración por GPU. El proyecto incluye detección de puntos clave, estimación de movimiento, generador y flujo de entrenamiento GAN, y proporciona código de ejemplo y documentación. (Fuente: Reddit r/deeplearning)

Diagrama de flujo del Procesamiento del Lenguaje Natural (NLP): La imagen muestra el flujo básico del procesamiento del lenguaje natural, que podría incluir pasos como preprocesamiento de texto, extracción de características, entrenamiento del modelo, evaluación, etc. (Fuente: Ronald_vanLoon)

Blog explicando las matemáticas detrás de las GANs: Un desarrollador compartió su artículo de blog en Medium sobre los principios matemáticos detrás de las Redes Generativas Antagónicas (GANs), centrándose en explicar la derivación y prueba de la función de valor utilizada en el juego minimax de las GANs. (Fuente: Reddit r/deeplearning)

Conceptos básicos del agrupamiento K-Means: Se compartió una introducción básica al algoritmo de agrupamiento K-Means, como divulgación conceptual para principiantes en machine learning, explicando este método de aprendizaje no supervisado. (Fuente: Reddit r/deeplearning)

Escuela de verano y conferencia sobre ciencia de datos biomédicos: Budapest, Hungría, acogerá una escuela de verano y conferencia sobre ciencia de datos biomédicos del 28 de julio al 8 de agosto de 2025. La escuela de verano ofrece formación intensiva en visualización de datos médicos, machine learning, deep learning, redes biomédicas, etc. La conferencia presentará investigaciones de vanguardia e invitará a expertos, incluidos premios Nobel. (Fuente: Reddit r/MachineLearning)
Compartir repositorio personal de modelos de deep learning: Un autodidacta compartió su repositorio de GitHub, documentando su práctica en la creación de modelos de deep learning para diferentes conjuntos de datos (como CIFAR-10, MNIST, yt-finance), incluyendo puntuaciones, gráficos de predicción y documentación, como forma personal de aprendizaje y entrenamiento. (Fuente: Reddit r/deeplearning)

💼 Negocios
El unicornio de IA OpenEvidence subvierte la IA médica con una mentalidad de internet: La empresa de IA médica OpenEvidence ha obtenido una financiación de 75 millones de dólares de Sequoia, alcanzando una valoración de 1.000 millones de dólares y convirtiéndose en un nuevo unicornio. A diferencia del modelo tradicional B2B, OpenEvidence adopta una estrategia similar a la del internet de consumo, ofreciendo servicios gratuitos directamente a los médicos como usuarios finales (monetizando a través de publicidad), ayudándoles a buscar información precisa en la vasta literatura médica y a manejar casos complejos. El producto ha crecido rápidamente, y se afirma que ya lo utiliza 1/4 de los médicos estadounidenses. La clave de su éxito radica en fuentes de datos estrictas (literatura revisada por pares) y una arquitectura de integración multi-modelo para garantizar la precisión de la información, asegurando la transparencia mediante la citación de fuentes, formando un modelo beneficioso tanto para los médicos como para las revistas médicas. (Fuente: 36氪)
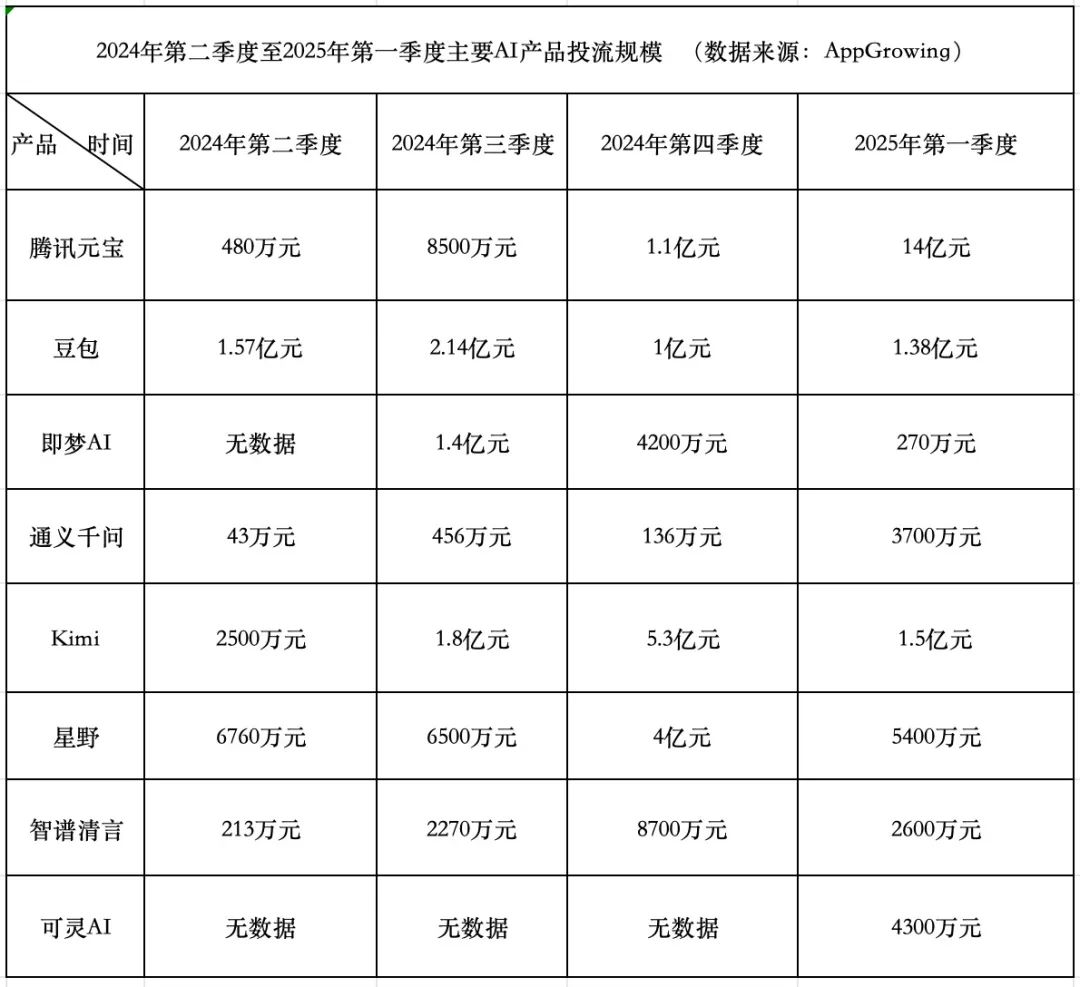
Carrera de gasto en productos de IA: Tencent agresivo, ByteDance conservador, startups retroceden: En el primer trimestre de 2025, los gastos en adquisición de tráfico para productos de IA alcanzaron los 1.84 mil millones de yuanes. Yuanbao de Tencent representó la mayor parte con 1.4 mil millones, con publicidad incluso en muros rurales. Doubao de ByteDance gastó 138 millones de yuanes, con una estrategia relativamente conservadora. Keling AI de Kuaishou invirtió 43 millones de yuanes. En comparación, las startups estrella Kimi y Xingye redujeron drásticamente la adquisición de tráfico (aproximadamente 200 millones en total, muy por debajo de los 930 millones del cuarto trimestre), y Zhipu Qingyan también redujo significativamente la inversión. Los fundadores de startups comienzan a reconsiderar el modelo de quemar dinero, centrándose más en mejorar la capacidad del modelo y las barreras tecnológicas. Tencent, con su sistema publicitario, se ha beneficiado de la guerra de adquisición de tráfico de IA. Tongyi Qianwen de Alibaba y Wenxin Yiyan de Baidu tienen un enfoque relativamente relajado en la adquisición de tráfico, centrándose más en el ecosistema y el código abierto. La tendencia de la industria muestra que el método de simplemente quemar dinero a cambio de escala está perdiendo efectividad, y la competencia de productos de IA entra en una nueva etapa de capacidad del modelo y despliegue del ecosistema. (Fuente: 中国企业家杂志)
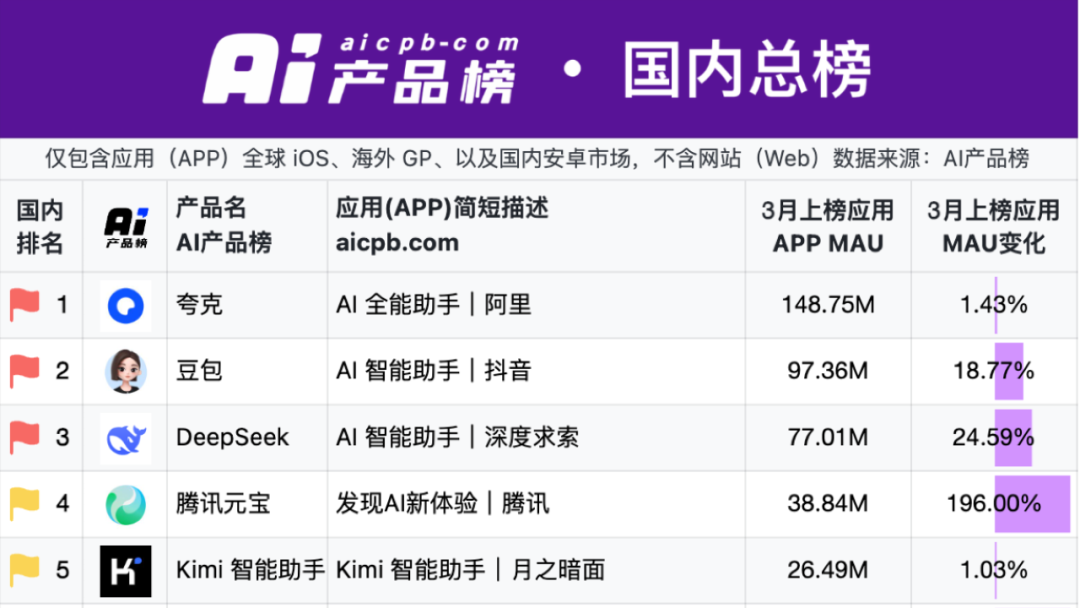
Kuake y Baidu Wenku lideran el nuevo campo de batalla de las aplicaciones de IA: surge el modelo de «supercaja»: En 2025, el foco de las aplicaciones de IA se desplaza de los ChatBots a la «supercaja AI» (entrada unificada AI), es decir, una entrada que integra búsqueda con IA, conversación y herramientas (como PPT, traducción, generación de imágenes). Kuake de Alibaba y Baidu Wenku se han convertido en los líderes de esta pista, liderando en datos de usuarios activos mensuales (MAU). Ambos se basan en la base de «búsqueda + almacenamiento en la nube + documentos», integrando capacidades de IA, intentando satisfacer las necesidades de tareas en una sola parada de los usuarios y compitiendo por el punto de entrada de tráfico de consumidores (C-end). Las pruebas muestran que ambos superan a la búsqueda tradicional en la coincidencia de información básica, pero todavía hay margen de mejora en la profundidad y satisfacción de tareas específicas (como planificación de itinerarios, generación de PPT). Las grandes empresas eligen estos dos productos como vanguardia de la IA, con la intención de aprovechar su base de usuarios y acumulación de datos para explorar la mejor forma de IA para el consumidor (AI To C) y complementar sus propios ecosistemas de IA. (Fuente: 定焦One)
Cómo las empresas pueden implementar eficazmente la IA con experiencia interna limitada: El artículo explora cómo las empresas, careciendo de profunda experiencia interna en IA, pueden introducir e implementar la tecnología de inteligencia artificial de manera efectiva y reflexiva. Podría implicar el uso de colaboraciones externas, la elección de plataformas de herramientas adecuadas, comenzar con pilotos a pequeña escala, centrarse en la formación de empleados y definir claramente los objetivos de negocio, entre otros aspectos. (Fuente: Ronald_vanLoon, Ronald_vanLoon)

La diversidad de habilidades es crucial para lograr el ROI de la inversión en IA: Los proyectos de IA exitosos no solo requieren expertos técnicos, sino también talento con comprensión del negocio, análisis de datos, consideraciones éticas, gestión de proyectos y otras habilidades diversas. La diversidad de habilidades dentro de la organización es un factor clave para garantizar que los proyectos de IA puedan implementarse eficazmente, resolver problemas reales y, en última instancia, generar valor comercial (ROI). (Fuente: Ronald_vanLoon)

Compartir estrategia de página de destino SEO para productos de IA: Gofei compartió una tarjeta resumen de su estrategia de página de destino SEO utilizada para productos de IA (que supuestamente generan 100.000 USD de ingresos mensuales), enfatizando la efectividad de su metodología. (Fuente: dotey)

🌟 Comunidad
El fenómeno de las trampas en entrevistas con IA llama la atención, la proliferación de herramientas desafía la equidad en la contratación: El artículo revela el creciente fenómeno del uso de herramientas de IA para hacer trampa en entrevistas remotas por video. Estas herramientas pueden transcribir en tiempo real las preguntas del entrevistador y generar respuestas para que el entrevistado las lea, e incluso pueden ayudar en pruebas técnicas escritas. El autor probó personalmente y descubrió que tales herramientas tienen retrasos evidentes, errores de reconocimiento y riesgo de fallo, ofreciendo una mala experiencia y siendo costosas. Sin embargo, el fenómeno ya ha alertado a RRHH y entrevistadores, que han comenzado a investigar métodos anti-trampas. El artículo explora el impacto de las trampas con IA en la equidad de la contratación y refuta el argumento de que «poder resolver problemas con IA es una habilidad», enfatizando que el núcleo de la entrevista es evaluar la capacidad y el pensamiento reales, no depender de herramientas externas inestables. (Fuente: 差评X.PIN)

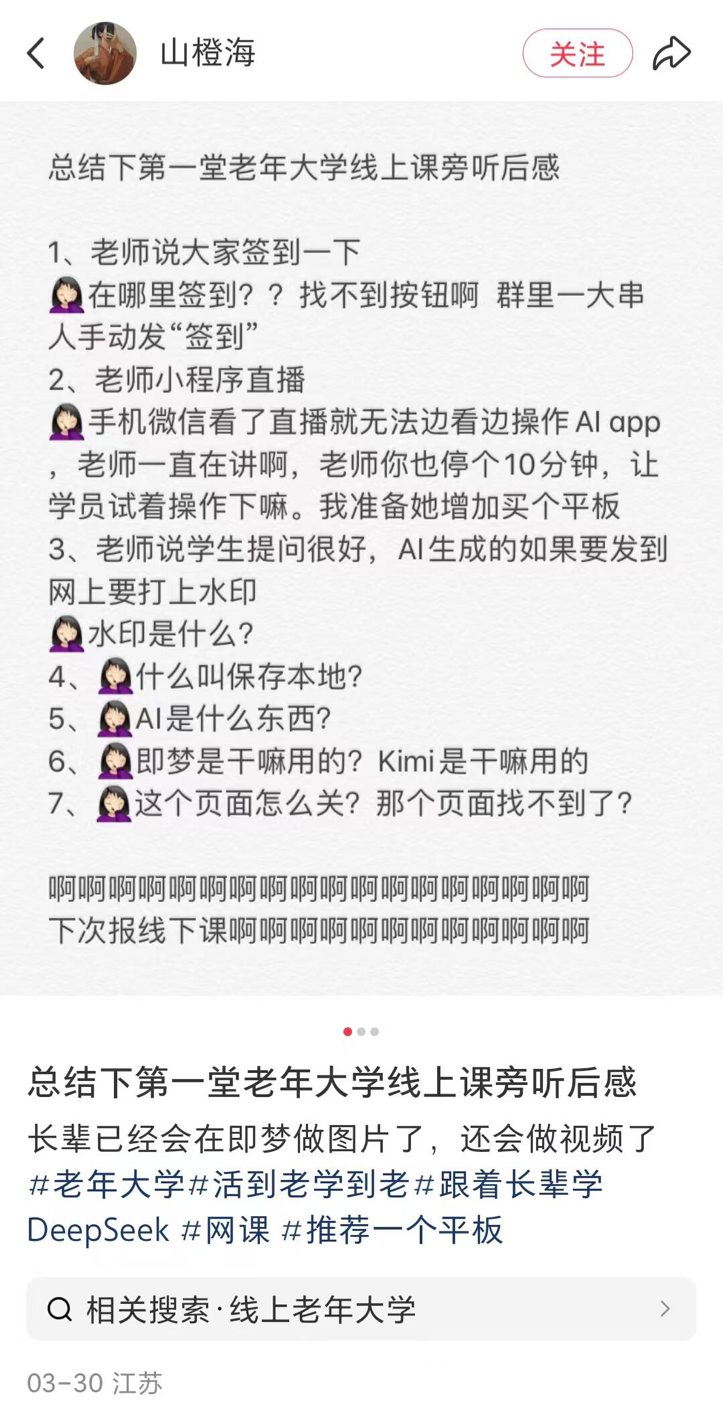
Las universidades para mayores en condados pequeños lanzan cursos de IA, coexistiendo la popularización y los riesgos: Se informa sobre la tendencia en muchas partes de China (incluidos condados pequeños) donde las universidades para mayores están ofreciendo cursos de IA. El contenido del curso se centra principalmente en la creación de contenido con IA (como usar Doubao para escribir textos, Jimeng/Keling para generar imágenes/videos, DeepSeek para escribir poesía/pintar) y aplicaciones para la vida diaria (interpretar informes médicos, buscar recetas, prevención de fraudes). Las tasas de matrícula suelen oscilar entre 100 y 300 yuanes por semestre, siendo más rentables que los costosos cursos comerciales de IA del mercado. Sin embargo, las personas mayores enfrentan la brecha digital al aprender (como dificultades para descargar APPs, operaciones básicas), y la enseñanza puede carecer de advertencias suficientes sobre los riesgos de la IA, como las alucinaciones, especialmente en áreas críticas como la salud, lo que plantea peligros ocultos. (Fuente: 刺猬公社)
John Carmack responde al impacto de las herramientas de IA en el valor de las habilidades: Ante la preocupación de que las herramientas de IA puedan devaluar habilidades como las de programadores y artistas, John Carmack respondió que el avance de las herramientas siempre ha sido fundamental en el campo de la informática. Al igual que los motores de juego ampliaron la participación en el desarrollo de juegos, las herramientas de IA empoderarán a los creadores de primer nivel, a los equipos pequeños y atraerán a nuevas personas. Aunque en el futuro se puedan generar juegos y otros contenidos mediante prompts simples, las obras excepcionales seguirán requiriendo equipos profesionales. En general, las herramientas de IA aumentarán la eficiencia en la producción de contenido de calidad. Se opone a rechazar el uso de herramientas avanzadas por miedo al desempleo. (Fuente: dotey)
Serie de quejas y reflexiones sobre la IA: El artículo utiliza una serie de frases cortas e incisivas para quejarse y reflexionar sobre los fenómenos comunes actuales en el campo de la IA, abordando la exageración publicitaria de la AGI, la proliferación de noticias sobre IA, la burbuja de financiación, la brecha entre la capacidad del modelo y las expectativas humanas, los desafíos de la ética de la IA, el problema de la caja negra en la toma de decisiones y los sesgos cognitivos del público sobre la IA. La idea central es que existe una brecha entre la realidad y el hype, y es necesario abordar el desarrollo de la IA con más cautela. (Fuente: 世上本无 AGI,报道多了,就有了)
Debate sobre si RAG será reemplazado por contextos largos: La discusión comunitaria vuelve a centrarse en si las ventanas de contexto ultralargas anunciadas por modelos como Llama 4 (por ejemplo, 10 millones de tokens) eliminarán la tecnología RAG (generación aumentada por recuperación). La opinión predominante es que simplemente aumentar la longitud del contexto no puede reemplazar completamente a RAG, ya que RAG todavía tiene ventajas en el manejo de información en tiempo real, la recuperación en bases de conocimiento específicas, el control de las fuentes de información y la relación coste-beneficio. Es probable que el contexto largo y RAG sean más complementarios que sustitutivos. (Fuente: Reddit r/artificial)

Discusión en la comunidad de IA: ¿Cómo mantenerse al día con el ritmo de desarrollo de la IA?: Un usuario de Reddit publica lamentando que el desarrollo de la IA es demasiado rápido para seguirlo y siente FOMO (miedo a perderse algo). En los comentarios, hay un consenso general de que es imposible mantenerse completamente al día. Las sugerencias incluyen: centrarse en el propio nicho o área de especialización, colaborar y compartir información con colegas, no angustiarse por cada pequeña actualización, distinguir entre el progreso real y el hype del mercado, y aceptar que es un proceso de aprendizaje continuo. (Fuente: Reddit r/ArtificialInteligence)
Discusión comunitaria: La mejor interfaz de usuario (UI) para LLM locales actual: Un usuario de Reddit inicia una discusión preguntando cuál es la UI para LLM locales más recomendada por la comunidad en abril de 2025. Las opciones populares mencionadas en los comentarios incluyen Open WebUI, LM Studio, SillyTavern (especialmente para juego de rol y construcción de mundos), Msty (una opción de instalación con un solo clic con muchas funciones), Reor (notas + RAG), llama.cpp (línea de comandos), llamafile, llama-server y d.ai (cliente móvil Android). La elección depende de las necesidades del usuario (facilidad de uso, funcionalidad, escenario específico, etc.). (Fuente: Reddit r/LocalLLaMA)
La alineación de IA que hace que los modelos «mientan» genera preocupación: Un usuario de Reddit publica criticando ciertos métodos de alineación de IA (AI alignment) que obligan a los modelos a negar su propia identidad (por ejemplo, no admitir que son un modelo específico), argumentando que este tipo de alineación «forzada a mentir» es problemática. La publicación muestra capturas de pantalla de una conversación donde, mediante preguntas inductivas, el modelo finalmente «admite» su identidad, lo que genera un debate sobre los objetivos de la alineación y la transparencia. (Fuente: Reddit r/artificial

Las pruebas A/B de OpenAI GPT-4.5 generan discusión: Los usuarios notaron que al usar GPT-4.5 encuentran muchas indicaciones de prueba A/B del tipo «¿Cuál prefieres?». Los comentarios sugieren que OpenAI podría estar utilizando a los usuarios de pago para recopilar datos de preferencia de modelos, y que los datos recopilados de esta manera podrían diferir de los de plataformas públicas como LM Arena. (Fuente: natolambert)
Problemas en la práctica con el Protocolo de Contexto del Modelo (MCP): Usuarios de la comunidad señalan que, aunque el MCP (Model Context Protocol) como concepto para estandarizar la interacción entre IA y herramientas es prometedor, muchas implementaciones actuales son de baja calidad. Los puntos de riesgo incluyen: los desarrolladores no pueden controlar completamente las instrucciones enviadas por el servidor MCP, la capacidad insuficiente del sistema para manejar errores de entrada humana (como errores tipográficos), el problema de las alucinaciones del propio LLM y los límites de capacidad poco claros del MCP. Se recomienda usarlo con precaución, especialmente en escenarios que no son de solo lectura, y priorizar implementaciones de código abierto para garantizar la transparencia. (Fuente: Reddit r/artificial)
Usuarios de Suno informan de funcionamiento anómalo de la función Extend: Varios usuarios de Suno informan problemas con la función «Extend» (extender), que no continúa el estilo de la canción como se esperaba, sino que introduce nuevas melodías, instrumentos e incluso ritmos y estilos. Los usuarios expresan su descontento por consumir muchos créditos sin obtener resultados utilizables y cuestionan si se trata de un error del sistema. Un usuario creó un video mostrando el problema. (Fuente: Reddit r/SunoAI, Reddit r/SunoAI)

Usuarios de Suno informan de una disminución reciente en la calidad de generación: Un usuario de pago de Suno desde hace mucho tiempo se queja de una grave disminución reciente en la calidad de generación de los modelos V4 y V3.5, afirmando que prompts que antes eran fiables ahora generan «ruido» o música desafinada, habiendo consumido 3000 créditos sin obtener una canción utilizable. El usuario cuestiona si es un error y considera cancelar la suscripción. (Fuente: Reddit r/SunoAI)
Compartido en comunidad: Usar IA para generar imágenes de profesiones soñadas para niños: Un video muestra un caso de uso conmovedor: niños describen qué quieren ser de mayores (como abogado, heladero, cuidador de zoo, ciclista), y luego se usa IA (ChatGPT en el video) para generar imágenes correspondientes basadas en la descripción. Los niños se muestran muy felices al ver las imágenes. (Fuente: Reddit r/ChatGPT)

Compartido en comunidad: IA genera imágenes de celebridades encontrándose con su yo joven/viejo: Un usuario utilizó la función de generación de imágenes de ChatGPT para crear una serie de imágenes de celebridades (como Elon Musk, Arnold Schwarzenegger, Paul McCartney, Tony Hawk, Clint Eastwood, etc.) encontrándose con su yo más joven o más viejo, con resultados realistas y divertidos. (Fuente: Reddit r/ChatGPT)
IA genera video «extraño» sobre la reindustrialización de Estados Unidos: Un usuario compartió un video supuestamente generado por IA china sobre la «reindustrialización de Estados Unidos». El contenido y el estilo de la banda sonora del video se consideraron «salvajes» y con un tono humorístico/satírico, mostrando la capacidad y los posibles sesgos de la IA en la generación de contenido narrativo específico. (Fuente: Reddit r/ChatGPT

Usuario compara costes y resultados de Claude vs o1-pro: Un usuario compartió su experiencia usando OpenAI o1-pro y Anthropic Claude Sonnet 3.7 para mejorar el estilo de las tarjetas Tailwind CSS. Los resultados mostraron que la salida de Claude fue mejor y el coste fue mucho menor que o1-pro (menos de 1 USD vs casi 6 USD). (Fuente: Reddit r/ClaudeAI)
La estabilidad del servicio de Claude es objeto de burla por parte de los usuarios: Usuarios publican memes o comentarios bromeando sobre las frecuentes sobrecargas o inaccesibilidad del servicio Anthropic Claude debido a una «demanda inesperadamente alta» durante las horas pico de los días laborables, sugiriendo que su estabilidad necesita mejorar. (Fuente: Reddit r/ClaudeAI)

Estudiante de doctorado en matemáticas busca recursos de introducción al machine learning: Un estudiante a punto de comenzar su doctorado en matemáticas, cuya investigación implica aplicar herramientas de álgebra lineal al machine learning (especialmente PINNs), busca recursos de introducción al ML adecuados para un trasfondo matemático, rigurosos y concisos (libros, apuntes, videocursos), considerando que los libros de texto estándar (como Bishop, Goodfellow) son demasiado prolijos. (Fuente: Reddit r/MachineLearning)

Estudiante prueba diferencias de rendimiento de modelos pequeños en diferente hardware: Un estudiante compartió datos de rendimiento al probar modelos pequeños como Llama3.2 1B y Granite3.1 MoE en una GPU de escritorio RTX 2060 y una Raspberry Pi 5. Descubrió que Llama3.2 funcionaba mejor en el escritorio, pero era el segundo mejor en la Raspberry Pi, lo que le resultó confuso. También observó que los resultados de los modelos MoE eran más variables y preguntó por qué. (Fuente: Reddit r/MachineLearning)
Usuario busca separar modelos de búsqueda y generación de títulos en OpenWebUI: Un usuario de OpenWebUI pregunta si es posible configurar por separado el modelo utilizado para generar solicitudes de búsqueda (prefiriendo usar modelos con fuerte capacidad de razonamiento) y el modelo utilizado para generar títulos/etiquetas (prefiriendo usar modelos pequeños más económicos). (Fuente: Reddit r/OpenWebUI)
Usuario busca manual de Prompts de música para Suno AI: Un usuario pregunta si alguien todavía conserva el manual de Prompts de música para Suno AI (PDF) que circuló anteriormente, ya que el enlace original ya no funciona. (Fuente: Reddit r/SunoAI)

Usuario busca ayuda para integrar OpenWebUI con LM Studio: Un usuario intenta conectar OpenWebUI con LM Studio como backend (a través de la API compatible con OpenAI), pero encuentra problemas al configurar las funcionalidades de búsqueda web y embedding, y busca ayuda de la comunidad. (Fuente: Reddit r/OpenWebUI)
Usuarios comparten obras musicales generadas por IA: Varios usuarios en r/SunoAI compartieron sus obras musicales creadas con Suno AI, abarcando diversos estilos como Ambient, Musical, Alternative Psychedelic Rock, Folk Country, Comedy ballad (EDM), Rap, Folk Music, Dreamy indie pop. (Fuente: Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI)

Usuario pregunta sobre el valor de la suscripción a Suno: Teniendo en cuenta las quejas recientes sobre la calidad de Suno v4, un usuario pregunta si todavía vale la pena comprar una suscripción a Suno, especialmente para remasterizar canciones antiguas de la versión v3. (Fuente: Reddit r/SunoAI)
Usuario busca consejos para crear un álbum de música con Suno: Un usuario experimentado de Suno planea recopilar sus obras satisfactorias en un álbum y publicarlo en Spotify a través de plataformas como DistroKid, pidiendo consejo a la comunidad sobre la selección y ordenación de canciones, así como sobre las operaciones técnicas. (Fuente: Reddit r/SunoAI)
Usuario se queja de problemas de UI de Suno en iPad: Un nuevo suscriptor informa problemas de interfaz al usar el sitio web de Suno en un iPad, sin poder usar correctamente funciones como grabar, editar letras, arrastrar y soltar, y busca soluciones o sugerencias. (Fuente: Reddit r/SunoAI)
Usuario se queja de que Cursor AI podría estar degradando modelos secretamente: Un usuario sospecha que Cursor AI ha degradado el modelo que utiliza de Claude 3.7 (según lo anunciado) a 3.5 sin informar, basándose en cambios en el comportamiento del Agente y su negativa a revelar información del modelo. El usuario afirma que su publicación de queja en r/cursor fue eliminada. (Fuente: Reddit r/ClaudeAI)
Usuario pregunta por servicios de IA de pago habituales: Un usuario inicia una discusión preguntando a qué servicios de IA de pago están suscritos mensualmente los demás, queriendo saber qué herramientas se consideran que valen la pena y si hay algún servicio recomendable. (Fuente: Reddit r/artificial)
Ayuda con Deep Learning: Identificar señales mixtas: Un principiante pide ayuda sobre cómo usar deep learning para identificar patrones de señales de medición científica mezcladas. Los datos son puntos de coordenadas en formato txt/Excel. Las preguntas incluyen: ¿Cómo integrar datos complementarios en formato de imagen? ¿Puede el modelo manejar patrones mixtos representados por puntos de coordenadas? ¿Qué modelos o direcciones de aprendizaje se recomiendan? (Fuente: Reddit r/deeplearning)
Meme/Humor: La comunidad ha visto varios memes o publicaciones humorísticas relacionadas con la IA, como sobre enamorarse de una IA (película Her), la preferencia por el modelo Gemma 3, la saturación del mercado de tomadores de notas con IA, la caída del servicio de Claude y tarjetas coleccionables de celebridades generadas por IA. (Fuente: Reddit r/ChatGPT, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, AravSrinivas, Reddit r/artificial)

💡 Otros
Protocol Buffers (Protobuf) sigue generando interés: El formato de intercambio de datos Protobuf desarrollado por Google mantiene una alta atención en GitHub. Como mecanismo extensible, neutral al lenguaje y a la plataforma para serializar datos estructurados, se utiliza ampliamente en IA/ML y en numerosos sistemas a gran escala (como TensorFlow, gRPC). El repositorio proporciona instrucciones de instalación para el compilador (protoc), enlaces a bibliotecas de tiempo de ejecución multilingües y una guía de integración con Bazel. (Fuente: protocolbuffers/protobuf – GitHub Trending (all/daily))
El framework web Gin sigue siendo popular: Gin, un framework web HTTP de alto rendimiento escrito en Go, sigue siendo popular en GitHub. Es conocido por su API similar a Martini y una mejora de rendimiento de hasta 40 veces (gracias a httprouter), adecuado para escenarios que requieren servicios web de alto rendimiento (que podrían incluir servicios API para modelos de IA). (Fuente: gin-gonic/gin – GitHub Trending (all/daily))
Hugging Face Hub adopta el nuevo backend Xet para mejorar la eficiencia: Hugging Face Hub ha comenzado a usar un nuevo backend de almacenamiento, Xet, reemplazando el backend Git anterior. Xet utiliza la tecnología de fragmentación definida por contenido (CDC – Content Defined Chunking) para realizar la deduplicación de datos a nivel de byte (bloques de ~64KB), en lugar de a nivel de archivo. Esto significa que al modificar archivos grandes (como Parquet), solo se necesita transferir y almacenar las diferencias a nivel de fila, lo que mejora enormemente la eficiencia de carga y descarga y la eficiencia de almacenamiento. El lanzamiento del modelo Llama-4 probó con éxito este backend. (Fuente: huggingface)
Hugging Face Hub pronto admitirá clientes MCP: Un desarrollador de Hugging Face ha enviado un Pull Request para añadir soporte para el Protocolo de Contexto del Modelo (MCP) en el cliente de Inferencia de la biblioteca huggingface_hub. Esto podría significar que el servicio de inferencia de Hugging Face podrá interactuar mejor con herramientas y Agentes que sigan el estándar MCP. (Fuente: huggingface)
Sistema de entrega con drones Zipline: Se muestra el sistema de entrega con drones de la empresa Zipline. Este sistema podría utilizar IA para la planificación de rutas, evitación de obstáculos y entrega precisa, aplicándose en los campos de la logística y la cadena de suministro, mostrando potencial especialmente en el transporte de suministros médicos. (Fuente: Ronald_vanLoon)
Robot ergoCub para interacción física humano-robot: El Instituto Italiano de Tecnología (IIT) muestra el robot ergoCub, diseñado para la investigación de la interacción física humano-robot. Este tipo de robots suelen requerir algoritmos avanzados de IA para lograr capacidades de percepción, control de movimiento e interacción segura. (Fuente: Ronald_vanLoon)
KeyForge3D: Copiar llaves con visión por computadora: Un proyecto de GitHub llamado KeyForge3D utiliza OpenCV (biblioteca de visión por computadora) para identificar la forma de las llaves, calcular el código de combinación (bitting code) y puede exportar un modelo STL para impresión 3D. Aunque utiliza principalmente técnicas tradicionales de CV, demuestra el potencial de aplicación del reconocimiento de imágenes en tareas de replicación en el mundo físico, y podría combinarse con IA en el futuro para mejorar aún más la precisión y adaptabilidad del reconocimiento. (Fuente: karminski3)

Los principios de IA Responsable (Responsible AI) reciben atención: La publicación menciona los principios de IA Responsable utilizados por instituciones como EY (Ernst & Young), enfatizando la necesidad de considerar factores éticos y sociales como la equidad, transparencia, explicabilidad, privacidad, seguridad y rendición de cuentas al desarrollar y desplegar sistemas de IA. (Fuente: Ronald_vanLoon)
Kawasaki presenta un robot «caballo» montable impulsado por hidrógeno: Kawasaki Heavy Industries ha presentado un robot cuadrúpedo llamado Corleo, diseñado para ser montable y que utiliza combustible de hidrógeno como fuente de energía. Aunque es un robot, el informe no menciona explícitamente el grado de aplicación de la IA en sus sistemas de control o interacción. (Fuente: Reddit r/ArtificialInteligence)
