
Palabras clave:AI, LLM, informe de índice AI de Stanford, modelos de música generados por IA, controversia de Llama 4, DeepSeek y modelos de código abierto, Agentic AI y su impacto
🔥 Enfoque
Stanford publica el Informe AI Index 2025, revelando tendencias clave de la industria: El Instituto de Inteligencia Artificial Centrada en el Ser Humano (HAI) de la Universidad de Stanford ha publicado la octava edición anual de su Informe AI Index (456 páginas), que rastrea de manera exhaustiva el desarrollo global de la IA en 2024. El informe añade contenido sobre hardware de IA, costos de inferencia, prácticas empresariales responsables de IA y aplicaciones de IA en ciencia/medicina. Las tendencias principales incluyen: 1) Mejora significativa del rendimiento de la IA en benchmarks difíciles como MMMU; 2) Integración creciente de la IA en la vida diaria, como en la atención médica y el transporte; 3) Inversión y tasa de adopción empresarial alcanzan máximos históricos, con la inversión de EE. UU. superando con creces a la de China, aunque la brecha de rendimiento de los modelos chinos se está reduciendo rápidamente (la diferencia entre los modelos de primer nivel de China y EE. UU. en benchmarks como MMLU se reduce a 0.3%-1.7%); 4) El rendimiento de modelos de código abierto/pequeños como DeepSeek se acerca al de modelos de código cerrado/grandes, con una drástica reducción del costo de inferencia (disminución de 280 veces en dos años); 5) Fortalecimiento de la regulación global de la IA y aumento de la inversión; 6) Aceleración de la popularización de la educación en IA pero con recursos desiguales; 7) Aumento drástico de incidentes de seguridad de IA, prácticas de IA responsable desequilibradas; 8) Aumento del optimismo global hacia la IA pero con grandes diferencias regionales. El informe enfatiza el potencial transformador de la IA y la necesidad de guiar su desarrollo. (Fuente: 36氪, 新智元, 元宇宙之心MetaverseHub, 机器之心)

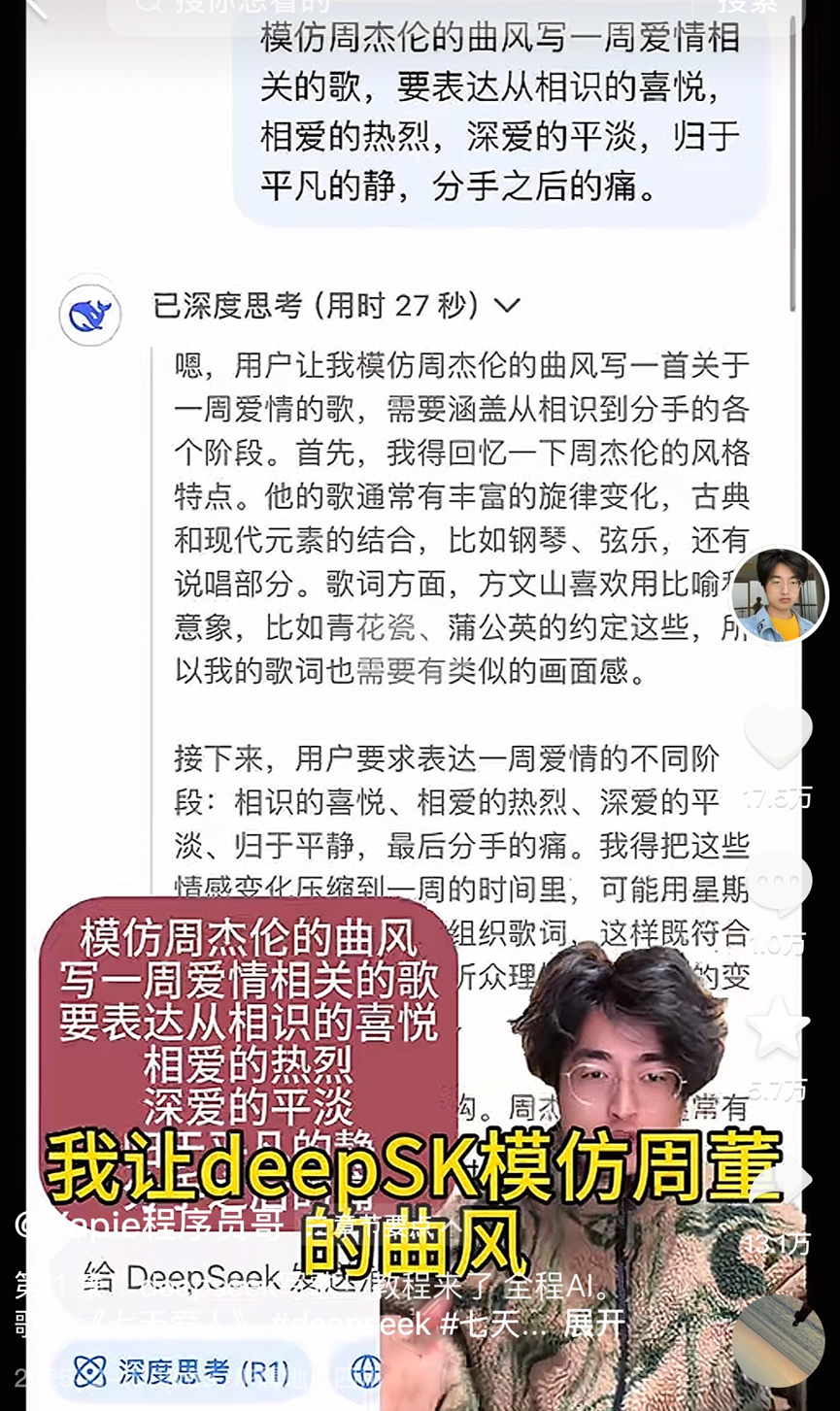
La creación musical con IA explota y genera controversia, el fenómeno «Siete Días Amante» revela la burbuja y los desafíos de la industria: La canción generada por IA «Siete Días Amante», que imita el estilo de Jay Chou, se volvió viral inesperadamente, llegando a las listas de tendencias y música, y sus derechos de autor se vendieron rápidamente, desencadenando una fiebre por la creación musical con IA. Un gran número de aficionados inundaron las plataformas, utilizando herramientas de IA para «producir en masa» canciones, y algunas plataformas lanzaron actividades relacionadas. Sin embargo, detrás de la prosperidad abundan los problemas: la calidad de muchas canciones de IA es desigual, siendo calificadas como «basura musical»; dependen de la imitación y el empalme, careciendo de verdadera innovación; la propiedad de los derechos de autor es ambigua, EE. UU. ya ha aclarado que la creación por IA no está protegida por derechos de autor, y plataformas como Tencent Music también señalan riesgos legales; la monetización comercial es extremadamente difícil, salvo éxitos puntuales, la mayoría de las canciones de IA generan ingresos ínfimos, y las plataformas endurecen la revisión. Los expertos de la industria temen que la IA pueda afectar el sustento de los músicos principiantes y, más aún, que la creación «desprocesada» conduzca a la pereza mental y al declive estético humano. (Fuente: 36氪)
El modelo Llama 4 se ve envuelto en una polémica de «fraude» tras su lanzamiento, la diferencia entre el ranking en la arena y el rendimiento real genera controversia: El último modelo de código abierto de Meta, Llama 4, obtuvo una alta puntuación en Chatbot Arena, superando a DeepSeek-V3 como el número uno de código abierto. Sin embargo, numerosos usuarios informaron en pruebas reales que su rendimiento en programación, razonamiento y escritura creativa era deficiente, muy por debajo de las expectativas y de su clasificación en la arena. Posteriormente, la plataforma de competición de modelos grandes (LMArena) señaló oficialmente que Meta proporcionó para las pruebas una versión experimental personalizada para optimizar las preferencias humanas (Llama-4-Maverick-03-26-Experimental), no la versión estándar publicada en Hugging Face, y Meta no indicó claramente esta diferencia. LMArena publicó más de 2000 registros de enfrentamientos, mostrando que el estilo de respuesta de esta versión experimental (como ser más amigable, usar emojis) podría ser un factor importante que influyó en la clasificación, y evaluará nuevamente la versión de Llama 4 de HF. El responsable de Meta Gen AI negó haber entrenado en el conjunto de pruebas, afirmando que la diferencia de rendimiento se debía a problemas de estabilidad en el despliegue. Este incidente ha provocado amplias discusiones y dudas en la comunidad sobre el rendimiento de Llama 4, la transparencia de Meta y la fiabilidad del método de evaluación de LMArena. (Fuente: 量子位, 机器之心, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

El fenómeno DeepSeek atrae la atención de la industria, la Conferencia de IA Generativa de China explora nuevas oportunidades: El ascenso de DeepSeek se considera un punto de inflexión clave para la industria de la IA generativa en China y a nivel mundial. Su modelo de código abierto de alta eficiencia y bajo costo ha catalizado un auge en la investigación y desarrollo de modelos de inferencia e infraestructura de IA (AI Infra), inyectando nuevo impulso a la IA en dispositivos finales (edge AI) y a la implementación de la capacidad de cómputo nacional. En la Conferencia de IA Generativa de China 2025, más de 50 ponentes de la industria, la academia y la investigación debatieron sobre los cambios provocados por DeepSeek, la inferencia profunda, la multimodalidad, los modelos del mundo (world models), AI Infra, aplicaciones AIGC, Agents e inteligencia corpórea. Los asistentes consideraron que DeepSeek reduce significativamente los costos de despliegue para las empresas (algunas aplicaciones redujeron costos en un 90% tras el cambio), demostrando la actividad y la rápida capacidad de implementación de China en la comunidad de código abierto. La conferencia también exploró temas como la necesidad de nuevos terminales para la explosión de aplicaciones de IA, los desafíos de la implementación de Agents, los avances en clústeres de cómputo nacionales, el desarrollo de la inteligencia física y las rutas de comercialización de la IA, destacando el papel cada vez más importante de China en el panorama global de la IA. (Fuente: 36氪, Ronald_vanLoon)

🎯 Movimientos
Agentic AI considerada la próxima gran revolución: La Agentic AI (IA agéntica o IA basada en agentes) se está convirtiendo en un motor clave para la transformación en los ámbitos empresarial y tecnológico. A diferencia de la IA tradicional que ejecuta tareas específicas, la Agentic AI puede establecer objetivos de forma autónoma, elaborar planes y ejecutar tareas complejas de múltiples pasos, actuando más como un empleado digital autónomo. Pueden integrar múltiples herramientas y fuentes de datos, realizar razonamientos y tomar decisiones, prometiendo una transformación disruptiva en áreas como el servicio al cliente, el análisis de datos y el desarrollo de software. A medida que la tecnología evolucione, la Agentic AI impulsará cambios profundos en los modelos operativos empresariales y en las formas de interacción humano-máquina. (Fuente: Ronald_vanLoon)

Nvidia lanza el modelo Llama-Nemotron-Ultra 253B, con pesos y datos de código abierto: Nvidia ha presentado Llama-Nemotron-Ultra, un modelo denso de 253B parámetros obtenido a partir de Llama-3.1-405B mediante poda NAS y optimización de inferencia. Este modelo se centra en mejorar la capacidad de razonamiento, utiliza SFT y post-entrenamiento RL (precisión FP8) y ha liberado los pesos y los datos de post-entrenamiento. La continua contribución de Nvidia al trabajo de post-entrenamiento de código abierto es bien recibida por la comunidad. (Fuente: natolambert)

La serie de modelos Qwen3 podría lanzarse pronto, incluyendo versiones MoE de 8B y 15B: Según la información de un PR fusionado en el repositorio de vLLM, Alibaba está a punto de lanzar la nueva serie de modelos Qwen3. Actualmente se sabe que podría incluir dos versiones: Qwen3-8B y Qwen3-MoE-15B-A2B. La comunidad especula que la versión 8B podría ser un modelo multimodal, mientras que la versión 15B sería un modelo MoE (Mixture of Experts) centrado en texto. Los usuarios esperan que los nuevos modelos supongan un avance en rendimiento; si el MoE de 15B alcanza el nivel de Qwen2.5-Max, se considerará un éxito significativo. (Fuente: karminski3)

Runway lanza Gen-4 Turbo, con una velocidad de generación de vídeo muy mejorada: Runway ha lanzado su último modelo de generación de vídeo, Gen-4 Turbo. El principal punto destacado del nuevo modelo es la velocidad de generación, afirmando que puede generar 10 segundos de vídeo en 30 segundos, una aceleración significativa en comparación con versiones anteriores. Esto hace que Gen-4 Turbo sea especialmente adecuado para escenarios de aplicación que requieren iteración rápida y exploración creativa. La actualización ya está disponible para todos los planes de usuario. (Fuente: op7418)
Google Gemini Live se lanza, permitiendo interacción visual y de voz en tiempo real: Google ha anunciado el lanzamiento oficial de la función Gemini Live, que llega primero a los dispositivos Pixel 9 y Samsung Galaxy S25, y se abre a los usuarios de Gemini Advanced en Android. La función permite a los usuarios compartir contenido de pantalla o imágenes en tiempo real a través de la cámara y conversar por voz con Gemini, permitiendo la comprensión del contenido visual y la realización de preguntas interactivas, resolución de problemas, lluvia de ideas, etc. Esto marca un avance importante de Google en la experiencia de interacción multimodal de IA, acercando la visión del Project Astra a la realidad. (Fuente: op7418, JeffDean, demishassabis)
HiDream lanza el modelo de imagen de código abierto HiDream-I1 de 17B parámetros: El equipo de HiDream AI ha lanzado y abierto el código de su modelo de generación de imágenes de 17B parámetros, HiDream-I1. A juzgar por las imágenes preliminares mostradas, la calidad de las imágenes generadas por el modelo es aceptable. El código del modelo se ha hecho público en GitHub para que los desarrolladores e investigadores lo utilicen y exploren. (Fuente: op7418)

La ola de código abierto de modelos grandes se acelera, la exploración del modelo de negocio «2.0»: En 2025, el auge de modelos de código abierto representados por DeepSeek impulsa a Meta, Alibaba, Tencent, etc., a acelerar sus pasos hacia el código abierto, e incluso actores originalmente de «código cerrado» como OpenAI y Baidu comienzan a virar. Los motores del código abierto incluyen la demanda de inteligencia en dispositivos finales, las necesidades de personalización de la industria, la aceleración de la división del trabajo en el ecosistema y el punto de inflexión tecnológico. El código abierto reduce las barreras para desarrolladores y pymes, promoviendo la democratización tecnológica y la innovación. Sin embargo, código abierto no significa gratuito; el mantenimiento y la localización todavía tienen costos. Los fabricantes líderes están explorando modelos de comercialización 2.0, como «modelo base de código abierto + servicios API de valor añadido» (ej. DeepSeek, Zhipu AI), «versión comunitaria de código abierto + versión empresarial exclusiva» (ej. Alibaba Cloud Qwen) y «modelo de código abierto + monetización de plataforma en la nube» (ej. Meta Llama). El núcleo es «atraer tráfico con código abierto, monetizar con servicios», logrando rentabilidad a través del ecosistema, la personalización y los servicios en la nube. (Fuente: 第一新声)

🧰 Herramientas
Augment Code: Plataforma de codificación IA diseñada para proyectos complejos: Se lanza Augment Code, posicionándose como la primera plataforma de codificación IA capaz de comprender profundamente grandes y complejos repositorios de código, diseñada específicamente para la colaboración en equipo. Ofrece una capacidad de procesamiento de hasta 200K tokens de contexto, memoria persistente (aprende estilos de código, historial de refactorización, normas del equipo) e integración profunda de herramientas (VS Code, JetBrains, Vim, GitHub, Linear, Notion, etc.). Su agente central no solo escribe código, sino que también puede ejecutar comandos de terminal, crear PR completos, generar documentación sensible al contexto y casos de prueba. Augment ocupa el primer lugar en el ranking SWE-bench Verified (combinando Claude Sonnet 3.7 y o1) y ya es utilizado por empresas como Webflow y Kong. La plataforma es actualmente gratuita y tiene como objetivo resolver los puntos débiles de los desarrolladores al manejar repositorios de código grandes y heredados. (Fuente: AI进修生)
Cloudflare lanza el servicio AutoRAG, simplificando la construcción de aplicaciones RAG: Cloudflare ha lanzado AutoRAG, un servicio destinado a simplificar el desarrollo de aplicaciones de Generación Aumentada por Recuperación (RAG). Los desarrolladores pueden usar este servicio para convertir automáticamente fuentes de datos (como documentos, sitios web) en bases de conocimiento consultables por modelos grandes, sin necesidad de procesar manualmente la indexación de datos y la lógica de recuperación. Durante la beta pública, AutoRAG es de uso gratuito, con un límite de 10 instancias por cuenta y un máximo de 100,000 archivos por instancia. Esta medida reduce la barrera para construir aplicaciones de IA basadas en conocimiento específico. (Fuente: karminski3)

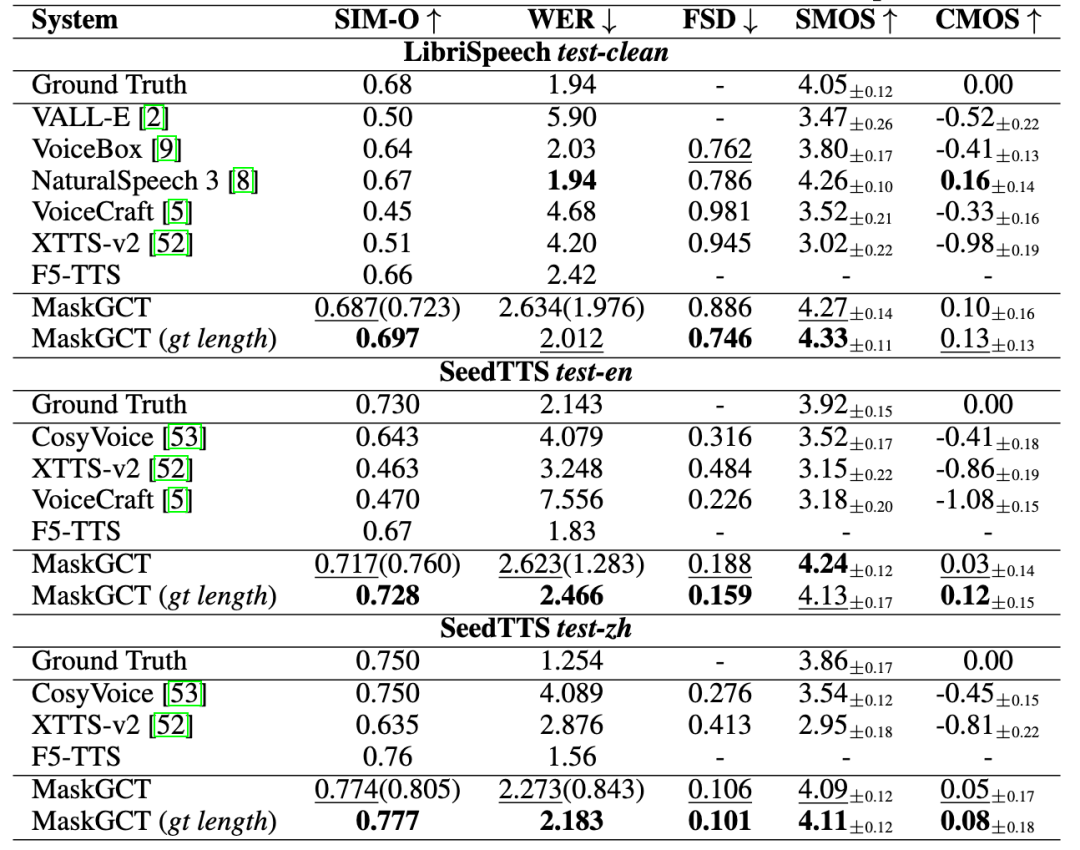
Quwan Technology lanza «Quwan QianYin», ofreciendo una solución completa de voz IA: Quwan Technology ha lanzado su producto de voz IA «Quwan QianYin (All Voice Lab)», basado en el modelo MaskGCT desarrollado conjuntamente con CUHK (Shenzhen). El producto integra funciones como texto a voz, traducción de vídeo, síntesis multilingüe, eliminación de subtítulos, etc. Su característica es la automatización completa del flujo de trabajo de traducción de vídeo, con una capacidad de procesamiento diaria de más de 1000 minutos, multiplicando la eficiencia por 10. El efecto de generación de voz es emocionalmente rico y comparable al humano. Quwan QianYin tiene como objetivo resolver la demanda de difusión translingüística a escala mediante capacidades industrializadas, y ya se aplica en la exportación de miniseries (reducción de costos, crecimiento de usuarios), noticias, turismo cultural, audiolibros, etc., posicionándose como «infraestructura global de contenido». (Fuente: 36氪)
Exa: Motor de búsqueda diseñado para Agentes IA: Exa se posiciona como la «API de Bing para la era LLM», un motor de búsqueda diseñado específicamente para Agentes IA, con el objetivo de permitir que la IA acceda y comprenda eficientemente la información de Internet. A diferencia de la búsqueda humana, Exa puede manejar consultas en lenguaje natural más complejas, proporcionar resultados más completos y admitir solicitudes de alto rendimiento y baja latencia. Sus API principales incluyen búsqueda rápida, obtención de contenido (rastreador), búsqueda de enlaces similares, etc. Exa también ofrece la función Websets, que permite a los usuarios filtrar condiciones con lenguaje natural para estructurar la información de Internet. La compañía ha recibido inversiones de Lightspeed, Nvidia, entre otros, con un ARR superior a los 10 millones de dólares, y su principal competidor es Brave Search. (Fuente: AI探索者)
Herramienta IA logra resumir visualmente historiales de chat de WeChat: Utilizando una combinación de herramientas IA, es posible exportar historiales de chat grupales o privados de WeChat y generar informes visualizados. Los pasos incluyen: 1) Usar una herramienta de terceros (como MemoTrace) para exportar el historial de chat de WeChat como archivo TXT (atención a los riesgos de seguridad de datos); 2) Introducir el archivo TXT y una plantilla Prompt específica (que incluye código de estilo) en un modelo grande que soporte procesamiento de texto largo (como Gemini 2.5 Pro en AI Studio) para generar código HTML; 3) Convertir el código HTML generado en un enlace web compartible a través de un servicio en línea (como yourware.so), o usar una herramienta en línea (como cloudconvert.com) para convertirlo directamente en una imagen. Este método puede transformar largos mensajes de chat en informes estructurados y claros, que incluyen frases destacadas diarias y nubes de palabras, facilitando la revisión y el intercambio. (Fuente: 卡兹克)
El modelo de imagen Jì Mèng AI 3.0 se lanza por completo: Jì Mèng AI (即梦AI) anuncia que la versión 3.0 de su modelo de generación de imágenes ha completado las pruebas y está totalmente disponible. Se espera que la nueva versión mejore la calidad de imagen, la diversidad de estilos y la comprensión semántica. Algunos usuarios (como 歸藏) ya han compartido pruebas detalladas y colecciones de prompts utilizando el modelo 3.0 para diseño en diferentes campos (como imágenes de operaciones de IA), mostrando sus efectos de generación. (Fuente: op7418)

VIBE Chat: Sitio de chat divertido con fondos aleatorios: Un sitio web llamado VIBE Chat ofrece una experiencia de chat novedosa, generando aleatoriamente diferentes imágenes de fondo para cada sesión. El sitio se basa en el modelo Gemini 2.0 Flash, y los usuarios pueden usarlo para tareas como programación, con el código o contenido mostrándose directamente en la interfaz de chat. Las pruebas muestran que puede generar código para juegos simples como Flappy Bird y Tetris. (Fuente: karminski3)
Desarrollador crea asistente GPT dedicado para Suno AI: Un desarrollador ha creado un GPT personalizado llamado «Hook & Harmony Studio», diseñado para ayudar en el flujo de trabajo de creación musical con Suno AI. La herramienta puede, a partir de un concepto de canción introducido por el usuario, generar un título único, letras estructuradas (con indicaciones de instrumentos y canto), sugerencias de etiquetas de estilo compatibles con Suno, filtrar clichés y, opcionalmente, generar prompts para efectos visuales de la canción. Su objetivo es simplificar la creación de letras y la exploración de estilos, y formatear automáticamente para su uso en el modo proyecto de Suno. (Fuente: Reddit r/SunoAI)
Code to Prompt Generator: Herramienta para simplificar la conversión de código a prompts LLM: Un desarrollador ha creado y abierto el código de una pequeña herramienta llamada «Code to Prompt Generator», destinada a simplificar la creación de prompts LLM a partir de repositorios de código. Puede escanear automáticamente carpetas de proyectos para generar un árbol de archivos (excluyendo archivos irrelevantes), permitir al usuario incluir selectivamente archivos/directorios, mostrar el recuento de tokens en tiempo real, guardar y reutilizar instrucciones (Meta Prompts) y copiar el prompt final con un solo clic. La herramienta utiliza un frontend Next.js y un backend Flask, y puede ejecutarse en múltiples plataformas. (Fuente: Reddit r/ClaudeAI)
Lanzamiento de la versión GGUF de Llama 4, compatible con ejecución local: Tras la fusión del soporte para Llama 4 (actualmente solo texto) en llama.cpp, desarrolladores de la comunidad (como bartowski, unsloth, lmstudio-community) han lanzado rápidamente versiones cuantificadas GGUF del modelo Llama 4 Scout. Estas versiones utilizan estrategias de cuantificación optimizadas como imatrix, con el objetivo de equilibrar el tamaño del modelo y el rendimiento, permitiendo a los usuarios ejecutar Llama 4 en hardware local. Hay disponibles versiones con diferentes anchos de bits (como IQ1_S 1.78bit, Q4_K_XL 4.5bit) para satisfacer las necesidades de diferentes configuraciones de hardware. Los usuarios pueden encontrar estos archivos GGUF en Hugging Face. (Fuente: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

📚 Aprendizaje
Microsoft y CUHK proponen ImageGen-CoT para mejorar la comprensión contextual en la pintura con IA: Para abordar las deficiencias de los modelos de pintura con IA en la comprensión de descripciones textuales complejas y asociaciones contextuales (como la transferencia de material de «manzana de cuero» a «caja de cuero»), investigadores de Microsoft Research Asia y la Universidad China de Hong Kong (CUHK) proponen el marco ImageGen-CoT. Este método introduce un paso de razonamiento de Cadena de Pensamiento (Chain-of-Thought, CoT) antes de la generación de imágenes, permitiendo que el modelo primero reflexione sobre la información clave y organice la lógica antes de crear. Mediante la construcción de un conjunto de datos ImageGen-CoT de alta calidad y el ajuste fino, el rendimiento de modelos (como SEED-X) en la tarea T2I-ICL mejora significativamente (CoBSAT mejora un 89%, DreamBench++ mejora un 114%). El marco utiliza un razonamiento en dos etapas y explora múltiples estrategias de extensión en tiempo de prueba (CoT único, CoT múltiple, extensión mixta), siendo la extensión mixta la más efectiva. (Fuente: 36氪, 新智元)

Artículo propone nuevo paradigma de enrutamiento LLM y el benchmark RouterEval: Frente a los problemas de monopolio de cómputo, altos costos y rutas tecnológicas únicas en la investigación de modelos grandes, los investigadores proponen el paradigma de enrutamiento LLM (Routing LLM), que utiliza un enrutador inteligente (Router) para asignar dinámicamente tareas a múltiples modelos pequeños (de código abierto) para su procesamiento colaborativo. Para apoyar esta investigación, el artículo libera el completo benchmark RouterEval, que contiene más de 200 millones de registros de rendimiento de más de 8500 LLM en 12 benchmarks principales. Este benchmark convierte el problema de enrutamiento en una tarea de clasificación estándar, permitiendo la investigación en una sola GPU o incluso en un portátil. La investigación descubre que mediante el enrutamiento inteligente (incluso con solo 3-10 modelos candidatos), el rendimiento combinado de múltiples modelos débiles puede superar a los modelos monolíticos de primer nivel (como GPT-4), demostrando el efecto «Model-level Scaling Up». Este trabajo ofrece una nueva vía para lograr IA de alto rendimiento a bajo costo. (Fuente: 新智元)
Equipo de Jiawei Han y Jimeng Sun de UIUC libera DeepRetrieval, optimizando consultas de motores de búsqueda con RL: Para abordar el problema de la baja calidad de las consultas originales de los usuarios que conduce a resultados de recuperación de información deficientes, el equipo de UIUC propone el marco DeepRetrieval. Este sistema utiliza el aprendizaje por refuerzo (RL) para entrenar a un LLM a optimizar las consultas originales de los usuarios (lenguaje natural, expresiones booleanas o SQL), adaptándolas mejor a las características de motores de búsqueda específicos (como PubMed, BM25, bases de datos SQL), maximizando así la efectividad de la recuperación sin modificar los sistemas de recuperación existentes. Los experimentos demuestran que DeepRetrieval (con solo un modelo de 3B) puede mejorar significativamente el rendimiento de la recuperación (búsqueda de literatura mejorada 10 veces, supera a GPT-4o en tareas de Evidence-Seeking, mejora la precisión de ejecución de SQL), con resultados muy superiores a los métodos basados en SFT. La investigación enfatiza que la capacidad de exploración de RL es superior al aprendizaje por imitación de SFT para descubrir estrategias de consulta óptimas. (Fuente: 机器之心)
Instituto de Automatización de la Academia China de Ciencias y otros proponen Vision-R1, mejorando la capacidad de localización visual de VLM con aprendizaje por refuerzo: Para abordar los problemas de los modelos grandes de lenguaje y visión (VLM) en tareas de detección de objetos y localización visual, como errores de formato, baja tasa de recuperación (recall) e insuficiente precisión, el Instituto de Automatización de la Academia China de Ciencias (CASIA) y el equipo de CAS Zidong Taichu proponen el marco Vision-R1. Este método se inspira en el éxito del modelo de lenguaje R1 e introduce el aprendizaje por refuerzo basado en reglas (Rule-Based RL) en las tareas de localización visual. Mediante el diseño de funciones de recompensa a nivel de tarea basadas en métricas de evaluación visual (corrección de formato, tasa de recuperación, precisión IoU) y la adopción de una estrategia de ajuste progresivo de reglas (recompensas diferenciadas, umbrales progresivos por etapas), sin depender de datos de preferencias humanas ni modelos de recompensa, mejora significativamente el rendimiento de detección de objetos de modelos como Qwen2.5-VL en conjuntos de datos como COCO y ODINW (hasta un 50% de mejora), sin afectar apenas la capacidad general de respuesta a preguntas. El código y el modelo son de código abierto. (Fuente: 机器之心)
CalibQuant: Esquema de cuantificación de KV Cache de 1 bit mejora el rendimiento de modelos multimodales: Para resolver el problema del alto consumo de memoria de KV Cache cuando los modelos grandes multimodales (MLLM) procesan entradas visuales a gran escala, lo que limita el rendimiento (throughput), los investigadores proponen el esquema CalibQuant. Este esquema logra una cuantificación extrema de KV Cache de 1 bit, combinando técnicas de post-escalado (Post-Scaling) y calibración (Calibration) diseñadas específicamente para las características de redundancia del KV Cache visual. El post-escalado optimiza el orden de cálculo de la anti-cuantificación para mejorar la eficiencia, mientras que la calibración ajusta las puntuaciones de atención para mitigar la distorsión de valores extremos introducida por la cuantificación de 1 bit. Los experimentos demuestran que CalibQuant puede reducir significativamente el consumo de memoria y los gastos computacionales en modelos como LLaVA e InternVL-2.5, logrando un aumento de hasta 10 veces en el rendimiento, casi sin pérdida de rendimiento del modelo. Este método es plug-and-play y no requiere modificar el modelo original. (Fuente: PaperWeekly)
CVPR 2025 | SeqAfford: Realizando inferencia de affordance 3D secuencial: Para abordar la dificultad de la IA actual para comprender y ejecutar instrucciones complejas que involucran múltiples objetos y pasos, los investigadores proponen el marco SeqAfford. Este marco combina por primera vez la visión 3D con modelos grandes de lenguaje multimodales (MLLM) para la inferencia secuencial de affordance 3D. Mediante la construcción del primer conjunto de datos Sequential 3D Affordance, que contiene más de 180,000 pares de instrucciones y nubes de puntos, para el ajuste fino, y la introducción de un mecanismo de inferencia basado en tokens de segmentación (
GitHub aloja colección de recursos de servidores MCP: Un repositorio de GitHub llamado awesome-mcp-servers recopila y ofrece en código abierto más de 300 servidores MCP (Model Capability Protocol) para Agentes IA. Estos servidores abarcan proyectos de nivel de producción y experimentales, proporcionando a los desarrolladores una rica variedad de herramientas e interfaces para facilitar la interacción de los Agentes IA con servicios externos y fuentes de datos, impulsando aún más el desarrollo del ecosistema de Agentes. (Fuente: Reddit r/ClaudeAI)

La profesora Fei Liu de la Universidad Emory busca estudiantes de doctorado y becarios en modelos grandes/NLP/GenAI: La profesora asociada Fei Liu del Departamento de Ciencias de la Computación de la Universidad Emory (EE. UU.) está reclutando estudiantes de doctorado con beca completa para comenzar en otoño de 2025. La dirección de investigación es la capacidad de razonamiento, planificación y toma de decisiones de los modelos grandes de lenguaje (LLM) como agentes inteligentes, así como la aplicación de la IA en campos como la educación y la atención médica. También da la bienvenida a estudiantes interesados en estas áreas para solicitar prácticas remotas o colaboraciones. Se requiere que los solicitantes tengan formación en informática o campos relacionados, excelentes habilidades de programación, y se dará preferencia a aquellos con resultados de investigación o una sólida base matemática. (Fuente: AI求职)
Publicada guía para construir Agentes IA: SuccessTech Services ha publicado una guía paso a paso sobre cómo construir agentes de modelos grandes de lenguaje (LLM). La guía probablemente cubre conceptos básicos de agentes, diseño de arquitectura, selección de herramientas, flujo de desarrollo y casos de uso prácticos, proporcionando una introducción para los desarrolladores que deseen crear aplicaciones de IA autónomas. (Fuente: Reddit r/OpenWebUI)

HKUST publica el código de Dream 7B, centrado en la inferencia de modelos Diffusion: El equipo de NLP de la Universidad de Ciencia y Tecnología de Hong Kong (HKUST), que previamente lanzó el modelo de inferencia para modelos Diffusion, Dream 7B, ha hecho público ahora su repositorio de código en GitHub. Este modelo tiene como objetivo permitir que los LLM comprendan y ejecuten instrucciones relacionadas con los modelos Diffusion. La publicación del código permite a los investigadores replicar y estudiar más a fondo este modelo. (Fuente: Reddit r/LocalLLaMA)

💼 Negocios
Lingxin Qiaoshou obtiene financiación semilla de nivel 100 millones de yuanes para desarrollar la mano robótica diestra con mayor grado de libertad del mundo: La empresa de inteligencia corpórea «Lingxin Qiaoshou» ha completado una ronda de financiación semilla de más de 100 millones de yuanes, liderada por Red Sequoia Seed Fund, entre otros. La compañía se centra en la plataforma «mano diestra + cerebro inteligente en la nube». Su serie de manos diestras auto-desarrolladas Linker Hand tiene una versión industrial con 25-30 grados de libertad y una versión de investigación con hasta 42 (la más alta del mundo, superando los 24 de Shadow Hand y los 22 de Optimus), con capacidades de percepción de alta precisión (fusión multisensorial) y manipulación. La empresa utiliza dos estructuras, de varillaje y de tendones accionados por cable, y ha logrado la producción en masa, combinada con un cerebro inteligente en la nube (entrenado en el conjunto de datos a gran escala DexSkill-Net) para el aprendizaje y control. El producto tiene ventajas en costo (aproximadamente 50,000 RMB, muy por debajo de los 1.5 millones de Shadow Hand) y durabilidad, ya ha sido adquirido por universidades de primer nivel como la Universidad de Pekín y la Universidad de Tsinghua, y se aplica en escenarios médicos, industriales, etc. (Fuente: 36氪)

Se informa que Google paga altos salarios en «gardening leave» a empleados de IA para evitar que se unan a competidores: Según informes, Google, para evitar que talento clave en IA se vaya a competidores como OpenAI, ha pagado a algunos empleados salientes salarios elevados durante hasta un año (posiblemente cientos de miles de dólares) con la condición de que no se unan a empresas competidoras durante ese período. Esta práctica, conocida como «gardening leave» (licencia remunerada de no competencia), aunque común en industrias como la financiera, es relativamente rara en el sector tecnológico, especialmente para investigadores e ingenieros de IA que no ocupan altos cargos ejecutivos. Esto refleja la extrema escasez de talento de primer nivel en IA y la intensa guerra por el talento entre los gigantes tecnológicos. (Fuente: Reddit r/ArtificialInteligence)

El CEO de Shopify enfatiza que los empleados deben utilizar eficazmente la IA: El CEO de Shopify, Tobias Lütke, exige que los empleados, antes de considerar aumentar el tamaño del equipo, primero deben pensar en cómo utilizar las herramientas de IA para mejorar la eficiencia y resolver problemas. Considera que la IA es una palanca clave para aumentar la productividad y que los empleados deben aprender activamente e integrarla en sus flujos de trabajo diarios. Esta declaración refleja la gran importancia que el mundo empresarial otorga a la IA para potenciar la eficiencia laboral y las expectativas sobre la adaptación de los empleados a los nuevos requisitos de la era de la IA. (Fuente: bushaicave.com)
36Kr lanza la convocatoria para los «Premios a la Innovación AI Partner 2025»: Para descubrir y fomentar productos, soluciones y empresas innovadoras en el campo de la IA, e impulsar la aplicación de la IA en diversas industrias, 36Kr ha lanzado la convocatoria para los «Premios a la Innovación AI Partner 2025». El alcance de la convocatoria abarca tres categorías principales de productos/soluciones que no sean software de aplicación: innovación general (oficina, servicios empresariales, análisis de datos, etc.), innovación sectorial (finanzas, salud, educación, industria, etc.) e innovación en terminales (hardware inteligente, automoción, robótica, etc.). La selección se realizará en base a cuatro dimensiones: innovación tecnológica, efecto de la aplicación, experiencia del usuario y valor social, con puntuación a cargo de un jurado experto. El plazo de inscripción es del 13 de marzo al 7 de abril, y los resultados se anunciarán el 18 de abril. (Fuente: 36氪)

Se inicia la elaboración del primer estándar nacional de China para el despliegue privado de modelos grandes de IA: Para abordar los problemas que enfrentan las empresas en el despliegue privado de modelos grandes de IA, como la inadecuación técnica, la falta de estandarización de procesos y la ausencia de sistemas de evaluación, el Centro de Estándares Zhihe, en colaboración con el Tercer Instituto de Investigación del Ministerio de Seguridad Pública y otras unidades, ha iniciado la elaboración del estándar grupal «Guía para la Implementación Técnica y Evaluación del Despliegue Privado de Modelos Grandes de Inteligencia Artificial». Este estándar tiene como objetivo cubrir todo el proceso, desde la selección del modelo, la planificación de recursos, la implementación, la evaluación de la calidad hasta la optimización continua, integrando aspectos técnicos, de seguridad, evaluación y casos prácticos, y será desarrollado conjuntamente por usuarios de modelos, proveedores de servicios técnicos, evaluadores de calidad. Se invita a participar en la elaboración a empresas de modelos grandes de IA, proveedores de servicios técnicos, proveedores de hardware, empresas de computación en la nube, proveedores de servicios de seguridad, proveedores de servicios de datos, empresas de aplicaciones sectoriales, instituciones de prueba y evaluación, instituciones legales y de cumplimiento, e instituciones de desarrollo sostenible. (Fuente: 智合标准化建设)
🌟 Comunidad
El contenido generado por IA genera preocupaciones sobre «alucinaciones» y fiabilidad de la información: Varios usuarios y medios informan que los modelos grandes de lenguaje, incluido DeepSeek, exhiben el fenómeno de «decir tonterías con cara seria», es decir, alucinaciones de IA. La IA puede inventar hechos inexistentes, citar fuentes incorrectas (como el origen de poemas, leyes, información sobre reliquias culturales) e incluso fabricar datos (como la «tasa de mortalidad de los nacidos en los 80»). Este fenómeno se origina en datos de entrenamiento obsoletos, erróneos o sesgados, lagunas de conocimiento del modelo y falta de capacidad de verificación en tiempo real. Los usuarios deben ser cautelosos con la precisión del contenido generado por IA, realizar verificaciones cruzadas y revisiones manuales, especialmente en contextos serios como el académico o laboral. La dependencia excesiva puede llevar a la difusión de información errónea, exacerbando los desafíos de la «era de la posverdad». La prueba de alucinaciones Vectara HHEM también muestra una alta tasa de alucinación para DeepSeek-R1. (Fuente: 锌刻度)
La generación de arte por IA vuelve a generar controversia: A partir del éxito viral del estilo Ghibli: La nueva función de imagen de GPT de OpenAI que genera imágenes al estilo Ghibli ha ganado gran popularidad, incluso el CEO Sam Altman cambió su avatar a este estilo, impulsando las descargas y los ingresos de ChatGPT. Sin embargo, esto también ha reavivado la controversia sobre la ética y los derechos de autor del arte generado por IA. El propio Hayao Miyazaki se opuso explícitamente a las imágenes generadas por máquinas. Profesionales de Hollywood (como Alex Hirsch, creador de «Gravity Falls», y Zelda Williams, hija de Robin Williams) expresaron su fuerte descontento, considerándolo un robo de los logros creativos de los artistas, carente de alma. Altman respondió que se trata de la «democratización de la creación», una gran victoria para la sociedad. El artículo argumenta que, aunque la IA puede imitar estilos de dibujo, difícilmente puede replicar la compleja narrativa, el sistema estético y la preocupación humanista inherentes a las obras de Ghibli. La mayoría del contenido generado por IA difícilmente se convertirá en clásico, pero algunas colaboraciones humano-máquina o herramientas auxiliares tendrán éxito. (Fuente: APPSO, Reddit r/artificial)

Opinión: La estructura cognitiva humana es la competitividad central en la era de la IA: El artículo refuta la idea de que la popularización de las herramientas de IA devalúa a los creadores, argumentando que la expresión y la creación en sí mismas son necesidades intrínsecas humanas y «comportamientos de consumo», cuyo valor reside en el proceso y no solo en el resultado. La IA es una herramienta, incapaz de reemplazar la cognición y las emociones únicas de las personas. La «estructura cognitiva» formada por el cerebro humano a lo largo de millones de años de evolución es clave, y el desarrollo de la IA también está pasando de estar impulsado por datos a estar impulsado por la cognición (imitando los procesos cognitivos humanos). Por lo tanto, la competitividad central futura no es «hacer el trabajo», sino la «estructura cognitiva» o «punto de anclaje» para interactuar con la IA: es decir, perspectivas únicas, experiencias profundas y conexiones reales establecidas con otros. Los creadores deben centrarse en pulir su parte única, convirtiéndose en un referente estable en el torrente de información, proporcionando un sentido de dirección y valor para sí mismos y para los demás, para contrarrestar el posible «aumento de la entropía» que la IA podría traer. (Fuente: 王智远)
Opinión: Existen nuevas barreras en las aplicaciones de IA basadas en relaciones y confianza: En respuesta a la afirmación de Zhu Xiaohu de que «las aplicaciones de IA no tienen barreras», el artículo presenta una refutación, argumentando que en la era de la IA, las barreras de las aplicaciones han pasado de las barreras tecnológicas tradicionales a nuevas barreras basadas en relaciones y confianza. Las aplicaciones de IA ya no buscan solo la escala de usuarios, sino que pueden obtener beneficios en mercados verticales ofreciendo experiencias personalizadas. Incluso las aplicaciones «envoltorio» (wrapper apps) pueden construir fosos defensivos a través de una conexión profunda con el usuario (la IA te entiende mejor cuanto más la usas), el vínculo de confianza entre la IP del creador y los usuarios, y la optimización continua mediante bucles de datos cerrados (datos del sector + datos personales para entrenamiento). Se aconseja a los emprendedores centrarse en nichos verticales, crear experiencias únicas, construir bucles de datos cerrados y establecer conexiones emocionales. (Fuente: 周知)
Estafas de «cursos intensivos» de IA apuntan a las pensiones de los ancianos: Cursos en línea que prometen «monetización rápida con IA» y «ganar más de 10,000 yuanes al mes» se dirigen con precisión a las personas mayores a través de plataformas de vídeos cortos. Estos cursos suelen utilizar la enseñanza gratuita como cebo, empleando vídeos de avatares digitales, identidades falsas de «expertos» y exagerando la ansiedad por la jubilación o los mitos de enriquecimiento para atraer a los ancianos a grupos. Luego, mediante marketing de lavado de cerebro (como mostrar capturas de pantalla de ganancias, crear una sensación de plazas limitadas), inducen a los ancianos a pagar altas matrículas (de miles a decenas de miles de yuanes). El contenido del curso suele ser conocimientos básicos de operación de redes sociales disfrazados; las promesas de enseñanza de habilidades de IA, devolución de dinero por aceptar trabajos, tutoría individualizada, etc., son en su mayoría publicidad engañosa, con falta de servicio postventa y dificultad para obtener reembolsos. Muchos jóvenes ya han compartido en redes sociales las experiencias de sus familiares que estuvieron a punto de ser estafados o ya lo fueron, pidiendo cautela ante este tipo de estafas. (Fuente: 豹变)

Karpathy: Los LLM subvierten la ruta tradicional de difusión tecnológica, empoderando al individuo: Andrej Karpathy escribe que el modelo de difusión tecnológica de los modelos grandes de lenguaje (LLM) es radicalmente diferente al de las tecnologías transformadoras históricas (generalmente de arriba abajo: gobierno -> empresa -> individuo). Los LLM se han popularizado casi de la noche a la mañana en los dispositivos de todos a bajo costo (incluso gratis) y a alta velocidad, brindando beneficios desproporcionadamente grandes al individuo común, mientras que el impacto en empresas y gobiernos es relativamente rezagado. Esto se debe a que los LLM pueden proporcionar conocimiento de nivel cuasi-experto en una amplia gama de campos, compensando las limitaciones del conocimiento individual. En comparación, las organizaciones, debido a sus ventajas inherentes que no coinciden con las capacidades de los LLM, la alta complejidad de los problemas, la inercia interna, etc., se benefician en menor medida. Él cree que la distribución futura de la IA es actualmente sorprendentemente equilibrada, un verdadero «poder para el pueblo». Pero si en el futuro el dinero puede comprar una IA significativamente mejor, el panorama podría cambiar de nuevo. (Fuente: op7418)
El rechazo de múltiples universidades de élite a un CEO de aplicación de IA de 18 años genera debate: Zach Yadegari, de 18 años, cofundó durante la secundaria la aplicación de seguimiento de calorías con IA Cal AI, que superó los 3 millones de descargas y genera millones de dólares en ingresos anuales. A pesar de tener un GPA de 4.0, altas puntuaciones en el ACT y una brillante trayectoria emprendedora, fue rechazado por 15 de las 18 universidades de élite a las que aplicó, incluidas Harvard, Stanford, MIT, etc. El caso generó amplia atención y debate en las redes sociales. El ensayo de admisión de Yadegari, que hizo público, confesaba sinceramente que inicialmente no planeaba ir a la universidad, pero luego cambió de opinión al reconocer el valor de la vida universitaria. Las razones del rechazo generaron especulaciones: algunos creen que el ensayo parecía «arrogante» o sugería un alto riesgo de abandono, afectando el índice de graduación valorado por las universidades de élite; otros critican problemas en el sistema de admisión universitario o aluden a discriminación contra solicitantes asiáticos (comparándolo con el caso de Stanley Zhong). El propio Yadegari expresó su deseo de ser visto como sincero. (Fuente: 36氪, AI前线)
Debate en la comunidad: ¿La IA es una bendición o una maldición?: En la comunidad de Reddit surge una discusión sobre los pros y contras de la tecnología IA. Un usuario considera que la IA es una bendición tecnológica, capaz de realizar rápidamente ideas creativas (como generar imágenes de escenas específicas), y no entiende por qué algunas personas (especialmente no creadores) le tienen hostilidad. Esta opinión enfatiza el valor de la IA para satisfacer las necesidades de creación personal instantánea y de bajo costo. Refleja la visión positiva dentro de la comunidad sobre el empoderamiento de la creatividad individual por parte de las herramientas de IA, al mismo tiempo que refleja la controversia generalizada y las diferentes actitudes hacia la tecnología IA en la sociedad. (Fuente: Reddit r/artificial)
Debate en la comunidad: ¿Se convertirá el protocolo MCP en el «internet» de los Agentes IA?: Con el desarrollo del MCP (Model Capability Protocol), la comunidad comienza a discutir su potencial. Una opinión sugiere que MCP, al proporcionar interfaces estandarizadas para que los LLM interactúen con herramientas externas y fuentes de datos, podría convertirse en la infraestructura que conecte diversos Agentes y servicios de IA, de forma similar a como internet conectó diferentes computadoras y sitios web. Esto presagia que el futuro ecosistema de Agentes IA podría lograr interoperabilidad y colaboración basadas en MCP. (Fuente: Reddit r/ClaudeAI)

💡 Otros
Los tres gigantes de Microsoft conversan con AI Copilot sobre 50 años y el futuro: Con motivo del 50 aniversario de Microsoft, las tres generaciones de CEO, Bill Gates, Steve Ballmer y Satya Nadella, mantuvieron una conversación con el asistente de IA Copilot. Gates recordó las primeras predicciones sobre el valor del software y la caída de los costos de computación, y reflexionó sobre haber debido gestionar antes la relación con el gobierno. Ballmer y Nadella enfatizaron la importancia de la IA; Ballmer cree que se debe profundizar el negocio en torno a la tecnología central de IA, mientras que Nadella predice que la IA se convertirá en una herramienta inteligente «de consumo masivo» y ubicua. Durante la conversación, Copilot también «bromeó» sobre los tres líderes, como que la «cara pensativa» de Gates podría causar una «pantalla azul» en la IA. Esta conversación mostró la reflexión de los líderes de Microsoft sobre la historia y su consenso sobre un futuro impulsado por la IA. (Fuente: 腾讯科技)

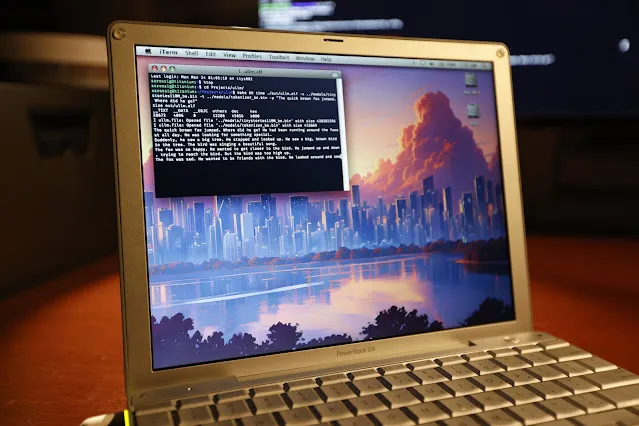
Logran ejecutar inferencia LLM en un PowerBook G4 de hace 20 años: El ingeniero de software Andrew Rossignol logró ejecutar tareas de inferencia del modelo grande Llama 2 de Meta (versión TinyStories 110M) en un portátil Apple PowerBook G4 de 20 años de antigüedad (procesador PowerPC G4 de 1.5 GHz, 1GB de RAM). Portó el proyecto de código abierto llama2.c y realizó modificaciones para la arquitectura PowerPC (procesamiento big-endian, alineación de memoria), además de utilizar la extensión vectorial AltiVec (operaciones fusionadas de multiplicación y suma) para aumentar la velocidad de inferencia en aproximadamente un 10% (de 0.77 tokens/s a 0.88 tokens/s). Aunque la velocidad es solo aproximadamente 1/8 de la de una CPU moderna, demuestra que es posible ejecutar modelos de IA modernos incluso en hardware muy antiguo y con recursos limitados. (Fuente: 36氪, AI前线)
Explorando: ¿Por qué necesitamos modelos del mundo (World Models)?: El artículo explora la necesidad de los modelos del mundo (World Models), argumentando que son clave para superar las limitaciones actuales de los modelos grandes de lenguaje (LLM) (como la falta de comprensión del mundo físico, memoria persistente, capacidad de razonamiento y planificación). Los World Models tienen como objetivo permitir que la IA construya una simulación interna del entorno, como lo hacen los humanos, comprendiendo las leyes físicas (como la gravedad, las colisiones) y las relaciones causales, para así realizar predicciones y tomar decisiones. El artículo repasa la evolución de los World Models desde un concepto de ciencia cognitiva hasta el modelado computacional (combinando RL/DL, como el artículo «World Models» de DeepMind) y la era de los modelos grandes (combinando Transformer y multimodalidad, como Genie, PaLM-E). La ventaja central de los World Models radica en su capacidad de predicción causal y razonamiento contrafáctico, así como su capacidad de generalización entre tareas, lo cual es fundamentalmente diferente de la predicción basada en la probabilidad de asociación de texto a gran escala de los LLM. Aunque los World Models tienen un futuro prometedor, todavía enfrentan desafíos en términos de potencia de cálculo, capacidad de generalización y datos. (Fuente: 脑极体)

Nuevo avance en detección de peligros con IA: Holmes-VAU logra comprensión de anomalías en vídeos largos a múltiples niveles: Para abordar las deficiencias de los métodos existentes de comprensión de anomalías en vídeo (VAU) al procesar vídeos largos y anomalías temporales complejas, instituciones como la Universidad de Ciencia y Tecnología de Huazhong (HUST) proponen el modelo Holmes-VAU y el conjunto de datos HIVAU-70k. Este conjunto de datos contiene más de 70,000 instrucciones de datos a múltiples escalas temporales (nivel de vídeo, nivel de evento, nivel de clip), construido mediante un motor de datos semiautomático, promoviendo la comprensión integral de anomalías en vídeos largos y cortos por parte del modelo. Al mismo tiempo, el propuesto Anomaly-focused Temporal Sampler (ATS) puede muestrear dinámicamente fotogramas clave de forma dispersa según la puntuación de anomalía, reduciendo eficazmente la información redundante y mejorando la precisión y eficiencia del análisis de anomalías en vídeos largos. Los experimentos demuestran que Holmes-VAU supera significativamente a los modelos grandes multimodales generales en tareas de comprensión de anomalías en vídeo en diversas granularidades temporales. (Fuente: 量子位)
IA y sostenibilidad: El problema de la huella de carbono genera preocupación: Con el crecimiento exponencial de la escala de los modelos de IA y el volumen de cálculo para su entrenamiento, su consumo de energía y emisiones de carbono se convierten en un problema cada vez más destacado. El Informe AI Index de Stanford señala que, aunque la eficiencia energética del hardware ha mejorado, el consumo total de energía sigue creciendo. Por ejemplo, se estima que entrenar el modelo Llama 3.1 de Meta genera casi 9000 toneladas de dióxido de carbono. Aunque modelos como DeepSeek han logrado avances en eficiencia energética, la huella de carbono general de la industria de la IA sigue siendo un desafío severo. Esto impulsa a las empresas de IA a explorar soluciones energéticas de cero carbono, como la energía nuclear, y genera debates sobre la sostenibilidad del desarrollo de la IA. (Fuente: Ronald_vanLoon, 机器之心)
