
Palabras clave:Llama 4, GPT-4o, Llama 4 rendimiento insatisfactorio, GPT-4o generación de imágenes estilo Ghibli, Dream-7B vs LLaMA3, Responses API para construir Agent, HAI informe IA 2025
🔥 Enfoque
El lanzamiento de Llama 4 genera controversia, se señala que el rendimiento no cumple las expectativas y hay sospechas de manipulación de rankings: Meta lanza la serie de modelos Llama 4 (Scout, Maverick, Behemoth), que utiliza una arquitectura MoE y admite hasta 10 millones de tokens de contexto. Sin embargo, las pruebas de la comunidad revelan que su rendimiento en tareas como codificación y escritura de textos largos es inferior al esperado, e incluso peor que DeepSeek R1, Gemini 2.5 Pro y algunos modelos open source existentes. La imagen promocional oficial ha sido criticada por estar «optimizada para la conversación», lo que genera dudas sobre la manipulación de rankings. Al mismo tiempo, el modelo exige una alta capacidad de cómputo, lo que dificulta su ejecución local para usuarios comunes. Hay filtraciones que sugieren problemas en el entrenamiento interno y que el modelo está prohibido para entidades de la UE debido a problemas de cumplimiento con la EU AI Act. Aunque la capacidad del modelo base es aceptable, carece de innovaciones significativas (como insistir en DPO en lugar de PPO/GRPO), y el lanzamiento general se considera tibio e incluso decepcionante (fuente: AI科技评论, YouTube, YouTube, ylecun, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
La generación de imágenes «estilo Ghibli» con GPT-4o se vuelve viral, remodela las fronteras creativas y genera controversia sobre derechos de autor: El modelo GPT-4o de OpenAI ha provocado un fervor creativo en las redes sociales globales debido a su potente capacidad para generar imágenes al «estilo Ghibli». Los usuarios han transformado clásicos del cine y la televisión como «La Leyenda de Zhen Huan» y «Titanic», así como fotos de la vida cotidiana, aplicando este estilo. Esta función reduce las barreras para la creación artística y promueve la democratización de la expresión visual. Sin embargo, su precisa réplica de estilos artísticos específicos también ha suscitado controversias sobre derechos de autor. Se cuestiona si OpenAI utilizó obras del Studio Ghibli para el entrenamiento sin permiso, destacando una vez más la zona gris legal de los derechos de autor en los datos de entrenamiento de IA y los desafíos a la originalidad (fuente: 36氪)

🎯 Tendencias
Lanzamiento del modelo de lenguaje de difusión Dream-7B, con rendimiento comparable a modelos autorregresivos de su clase: La Universidad de Hong Kong y Huawei Noah’s Ark Lab proponen un nuevo modelo de lenguaje de difusión, Dream-7B. Este modelo demuestra un rendimiento comparable o incluso superior a modelos autorregresivos de primer nivel de tamaño similar como Qwen2.5 7B y LLaMA3 8B en capacidades generales, razonamiento matemático y tareas de programación. Además, muestra ventajas únicas en capacidad de planificación y flexibilidad de inferencia (como la generación en orden arbitrario). La investigación utiliza técnicas como la inicialización de pesos de modelos autorregresivos y el reordenamiento de ruido a nivel de token adaptativo al contexto para un entrenamiento eficiente, demostrando el potencial de los modelos de difusión en el campo del procesamiento del lenguaje natural (fuente: AINLPer)
Publicado el informe AI Index 2025 de Stanford HAI, revelando el panorama global de la competencia en IA: El informe anual de Stanford HAI señala que Estados Unidos sigue liderando en número de modelos de IA de primer nivel (40), pero China está recuperando terreno rápidamente (15, con DeepSeek como representante), y nuevos actores como Francia también se unen a la competencia. El informe destaca el auge de los pesos open source y los modelos multimodales (como Llama, DeepSeek), así como la tendencia hacia una mayor eficiencia y menores costos en el entrenamiento de IA. Al mismo tiempo, la aplicación y la inversión en IA en los negocios alcanzan récords, pero también van acompañadas de crecientes riesgos éticos (abuso de modelos, fallos). El informe considera que los datos sintéticos serán clave y señala que el razonamiento complejo sigue siendo un desafío (fuente: Wired, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/MachineLearning)

OpenAI lanza la nueva Responses API, como base para la construcción de Agents: El CEO de OpenAI, Sam Altman, destacó la recién lanzada Responses API. Esta API se posiciona como la nueva primitiva fundamental de la API de OpenAI, fruto de la experiencia acumulada en el diseño de APIs durante los últimos dos años, y servirá como base para construir la próxima generación de AI Agents (fuente: sama)
Estudio revela que los LLM pueden identificar sus propios errores: Un estudio reportado por VentureBeat indica que los grandes modelos de lenguaje (LLMs) poseen la capacidad de reconocer los errores que cometen. Este hallazgo podría tener implicaciones para la autocorrección de los modelos, la mejora de su fiabilidad y la confianza en la interacción humano-máquina (fuente: Ronald_vanLoon)

Los AI Agents autónomos generan interés y preocupación: Un artículo de FastCompany explora el auge de los AI Agents autónomos, considerándolos la próxima ola en el desarrollo de la IA. Si bien reconoce sus asombrosas capacidades, también señala los riesgos potenciales y aspectos preocupantes, generando reflexión sobre la dirección del desarrollo y la seguridad de esta tecnología (fuente: Ronald_vanLoon)

NVIDIA utiliza datos sintéticos para avanzar en la tecnología de conducción autónoma: Sawyer Merritt compartió un video de NVIDIA que muestra cómo la compañía utiliza datos sintéticos para entrenar y mejorar su tecnología de conducción totalmente autónoma. Esto demuestra la creciente importancia de los datos sintéticos para resolver problemas como la escasez de datos del mundo real, los altos costos de etiquetado y la dificultad para cubrir casos extremos, convirtiéndose en un recurso clave para el entrenamiento de modelos de IA en áreas como la conducción autónoma (fuente: Ronald_vanLoon)
Gemini 2.5 Pro destaca en la evaluación MathArena USAMO: Oriol Vinyals de Google DeepMind señaló que Gemini 2.5 Pro obtuvo una puntuación del 24.4% en el benchmark MathArena USAMO (Olimpiada Matemática de EE. UU.), siendo el primer modelo en lograr una puntuación significativa en esta prueba de razonamiento matemático de alta dificultad. Esto demuestra su potente capacidad de razonamiento matemático y el rápido progreso de la IA en la resolución de problemas complejos (fuente: OriolVinyalsML)

Demostración de tecnología de control de robots humanoides: Ilir Aliu mostró la capacidad de controlar un robot humanoide completo, lo que generalmente implica tecnologías complejas de IA como planificación de movimiento, control de equilibrio, percepción e interacción, siendo una importante dirección de investigación en el campo de la inteligencia corporeizada (embodied intelligence) (fuente: Ronald_vanLoon)
Rumor: El modelo Qwen soportará MCP: Según una imagen compartida por karminski3, el gran modelo Qwen de Alibaba parece planear soportar MCP (Model Context Protocol). Esto significaría que Qwen podría integrarse mejor con clientes como Cursor, utilizando herramientas externas (como navegación web, ejecución de código) para mejorar sus capacidades (fuente: karminski3)

El modelo de deep learning VarNet alcanza SOTA en detección de mutaciones cancerígenas: Una investigación publicada en Nature Communications presenta un framework de deep learning de extremo a extremo llamado VarNet. Entrenado en cientos de genomas completos de cáncer, este framework puede detectar variantes somáticas con alta precisión sin necesidad de ajustar manualmente reglas heurísticas, alcanzando el rendimiento SOTA actual en múltiples benchmarks (fuente: Reddit r/MachineLearning)

Explorando mecanismos escalables para el uso de herramientas por Agents: Ante las limitaciones de los métodos actuales de uso de herramientas por Agents (precarga estática o codificación fija), los investigadores exploran patrones de uso de herramientas dinámicos y descubribles. Se imagina a los Agents consultando un registro de herramientas externo en tiempo de ejecución, seleccionando y utilizando herramientas dinámicamente según el objetivo, de forma similar a como un desarrollador navega por la documentación de una API. Se discuten vías de implementación como la exploración manual, la selección automática por coincidencia difusa y la selección asistida por LLM externos, con el objetivo de mejorar la flexibilidad, escalabilidad y capacidad de adaptación autónoma de los Agents (fuente: Reddit r/artificial)

Lanzamiento del primer modelo RP de inferencia multi-turno QwQ-32B-ArliAI-RpR-v1: ArliAI ha lanzado el modelo RpR (RolePlay with Reasoning) basado en Qwen QwQ-32B. Se afirma que es el primer modelo de inferencia multi-turno entrenado correctamente para role-playing (RP) y escritura creativa. Utiliza los datasets de la serie RPMax y aprovecha el modelo base QwQ para generar procesos de razonamiento para los datos de RP. Mediante métodos de entrenamiento específicos (como párrafos independientes de plantillas), se asegura que el modelo no dependa de bloques de razonamiento en el contexto durante la inferencia, con el objetivo de mejorar la coherencia y el interés en conversaciones largas (fuente: Reddit r/LocalLLaMA)

La serie de modelos Qwen3 obtiene soporte en el framework de inferencia vLLM: El framework de inferencia y servicio de LLM de alto rendimiento vLLM ha incorporado soporte para la próxima serie de modelos Qwen3, incluyendo Qwen3-8B y Qwen3-MoE-15B-A2B. Esto indica el inminente lanzamiento de los modelos Qwen3 y que la comunidad podrá utilizar vLLM para desplegar y ejecutar eficientemente estos nuevos modelos (fuente: Reddit r/LocalLLaMA)

🧰 Herramientas
Servidor Firecrawl MCP: Dando a los LLM potentes capacidades de web scraping: mendableai ha hecho open source el servidor Firecrawl MCP. Esta herramienta implementa el Model Context Protocol (MCP), permitiendo a clientes LLM como Cursor y Claude invocar las funciones de web scraping, crawling, búsqueda y extracción de Firecrawl. Soporta API en la nube o instancias auto-alojadas, cuenta con renderizado JS, descubrimiento de URL, reintentos automáticos, procesamiento por lotes, limitación de velocidad, monitoreo de cuotas, etc., pudiendo mejorar significativamente la capacidad de los LLM para procesar y analizar información web en tiempo real (fuente: mendableai/firecrawl-mcp-server – GitHub Trending (all/monthly))
LlamaParse introduce un nuevo layout agent impulsado por VLM: LlamaIndex ha lanzado un nuevo layout agent dentro de LlamaParse. Este agent utiliza modelos avanzados de lenguaje visual (VLM) para analizar documentos, siendo capaz de detectar todos los bloques en una página (tablas, gráficos, párrafos) y decidir dinámicamente cómo analizar cada parte en el formato correcto. Esto mejora enormemente la precisión del análisis de documentos y la extracción de información, especialmente reduciendo la omisión de elementos como tablas y gráficos, y soporta referencias visuales precisas (fuente: jerryjliu0)

Hugging Face ofrece servicio de inferencia Llama 4 a través de Together AI: Los usuarios ahora pueden ejecutar inferencias directamente en la página del modelo Llama 4 en Hugging Face, servicio soportado por Together AI. Esto proporciona una forma conveniente para que desarrolladores e investigadores experimenten y prueben los modelos Llama 4 sin necesidad de desplegarlos por sí mismos (fuente: huggingface)
AI Agent que utiliza Llama 4 para simular tuits de celebridades: Karan Vaidya mostró un AI Agent que utiliza el último modelo Llama 4 Scout de Meta, combinado con herramientas como Composio, LlamaIndex, Groq, Exa, para imitar el tono y estilo de celebridades del mundo tecnológico como Elon Musk, Sam Altman, Naval Ravikant, generando tuits bajo demanda (fuente: jerryjliu0)
Lanzamiento de Docext, herramienta open source de inteligencia documental local: Nanonets ha hecho open source Docext, una herramienta de inteligencia documental localizada basada en modelos de lenguaje visual (VLM). No requiere motores OCR ni APIs externas, y puede extraer datos estructurados (campos y tablas) directamente de imágenes de documentos (como facturas, pasaportes). Soporta plantillas personalizadas, documentos de varias páginas, despliegue mediante API REST y ofrece una interfaz web Gradio, enfatizando la privacidad de los datos y el control local (fuente: Reddit r/MachineLearning)
![[P] Docext: Open-Source, On-Prem Document Intelligence Powered by Vision-Language Models](https://external-preview.redd.it/AzAUcQsq5hLIWBdbljeo3gS5MBu9Hz6rtRM5jlgXne8.jpg?auto=webp&s=e6feffd0636e518c24e01ca133e5f83696a1fdaa)
Lanzamiento del modelo open source text-to-speech OuteTTS 1.0: OuteTTS 1.0 es un modelo open source text-to-speech (TTS) basado en la arquitectura Llama, con mejoras significativas en la calidad de la síntesis de voz y la clonación de voz. La nueva versión soporta 20 idiomas y proporciona pesos del modelo en formatos SafeTensors y GGUF (llama.cpp), así como la correspondiente biblioteca de tiempo de ejecución en Github, facilitando a los usuarios el despliegue y uso local (fuente: Reddit r/LocalLLaMA)

Usuario utiliza Claude para rastrear y crear un sitio web de trabajos remotos: Un usuario compartió cómo utilizó el modelo Claude de Anthropic para rastrear 10,000 listados de trabajos remotos y crear un sitio web agregador de trabajos remotos gratuito llamado BetterRemoteJobs.com. Esto demuestra el potencial de los LLM en la automatización de la recopilación de información y el desarrollo rápido de prototipos (fuente: Reddit r/ClaudeAI)

Compartido contenedor Docker para MCPO: El usuario flyfox666 creó y compartió un contenedor Docker para MCPO (Model Context Protocol Orchestrator), facilitando a los usuarios el despliegue y uso de herramientas o servicios que soportan MCP. MCPO se utiliza típicamente para coordinar la interacción entre LLM y herramientas externas (como navegadores, ejecutores de código) (fuente: Reddit r/OpenWebUI)

📚 Aprendizaje
Meta lanza Llama Cookbook: Guía oficial para construir con Llama: Meta ha presentado Llama Cookbook (anteriormente llama-recipes), una biblioteca de guías oficiales diseñada para ayudar a los desarrolladores a iniciarse y utilizar la serie de modelos Llama (incluyendo los más recientes Llama 4 Scout y Llama 3.2 Vision). El contenido abarca inferencia, fine-tuning, RAG, así como casos de uso de extremo a extremo (como asistente de correo electrónico, NotebookLlama, Text-to-SQL), e incluye ejemplos de integraciones de terceros y IA responsable (Llama Guard) (fuente: meta-llama/llama-cookbook – GitHub Trending (all/daily))
Publicada la primera revisión sistemática sobre Test-Time Scaling (TTS): Investigadores de CityU HK, McGill, Renmin University Gaoling School of AI y otras instituciones han publicado la primera revisión sistemática sobre la expansión en la etapa de inferencia de grandes modelos (Test-Time Scaling, TTS). El artículo propone un marco de análisis cuatridimensional (What/How/Where/How Well), sistematizando tecnologías TTS como CoT, Self-Consistency, búsqueda, verificación, DeepSeek-R1/o1, etc. El objetivo es proporcionar una perspectiva unificada, criterios de evaluación y orientación para el desarrollo en este campo clave para abordar los cuellos de botella del pre-entrenamiento (fuente: AI科技评论)
Curso sobre Diffusion Models e implementación en PyTorch: Xavier Bresson compartió las notas de su curso sobre Diffusion Models, explicados desde los primeros principios estadísticos, y proporcionó notebooks de PyTorch complementarios, que incluyen código para implementar Diffusion Models desde cero utilizando Transformer y UNet (fuente: ylecun)

Guía para construir aplicaciones RAG con LangChain y DeepSeek-R1: La comunidad LangChain compartió una guía que explica cómo usar DeepSeek-R1 (un modelo open source similar a OpenAI) y las herramientas de procesamiento de documentos de LangChain para construir aplicaciones RAG (Retrieval-Augmented Generation). La guía demuestra implementaciones tanto locales como en la nube (fuente: LangChainAI)

Análisis de paper: Generative Verifiers – Modelado de recompensas como predicción del siguiente token: Un paper titulado «Generative Verifiers» propone un nuevo método para modelos de recompensa (Reward Model, RM). Este método ya no hace que el RM solo emita una puntuación escalar, sino que genera texto explicativo (similar a CoT) para ayudar en la puntuación. Este RM «antropomorfizado» puede combinar técnicas de prompting engineering, mejorar la flexibilidad y tiene el potencial de convertirse en una dirección importante para la mejora de RLHF en la era de los grandes modelos de razonamiento (LRM) (fuente: dotey)

El dataset OpenThoughts2 es popular en Hugging Face: Ryan Marten señaló que el dataset OpenThoughts2 se ha convertido en el dataset de tendencia número uno en Hugging Face. Esto generalmente indica que el dataset ha recibido una amplia atención y uso en la comunidad, posiblemente para entrenamiento de modelos, evaluación u otros fines de investigación (fuente: huggingface)

Añadir Skip Connections acelera significativamente el entrenamiento de RepLKNet-XL: Un usuario de Reddit informa que después de añadir Skip Connections a su modelo RepLKNet-XL, la velocidad de entrenamiento aumentó drásticamente 6 veces. En una RTX 5090, el tiempo para 20,000 iteraciones se redujo de 2.4 horas a 24 minutos; en una RTX 3090, el tiempo para 9,000 iteraciones se redujo de 10 horas y 28 minutos a 1 hora y 47 minutos. Esto valida una vez más la importancia de las Skip Connections en el entrenamiento de redes profundas (fuente: Reddit r/deeplearning)
Neural Graffiti: Añadiendo una capa de neuroplasticidad a los Transformers: El usuario babycommando propone una técnica experimental llamada «Neural Graffiti», que tiene como objetivo insertar una «capa de graffiti» inspirada en la neuroplasticidad entre las capas Transformer y la capa de proyección de salida. Esta capa influye en la generación de tokens basándose en interacciones pasadas, permitiendo que el modelo desarrolle una «personalidad» evolutiva con el tiempo. La capa ajusta la salida fusionando la memoria histórica, es open source y tiene una demo disponible (fuente: Reddit r/LocalLLaMA)
💼 Negocios
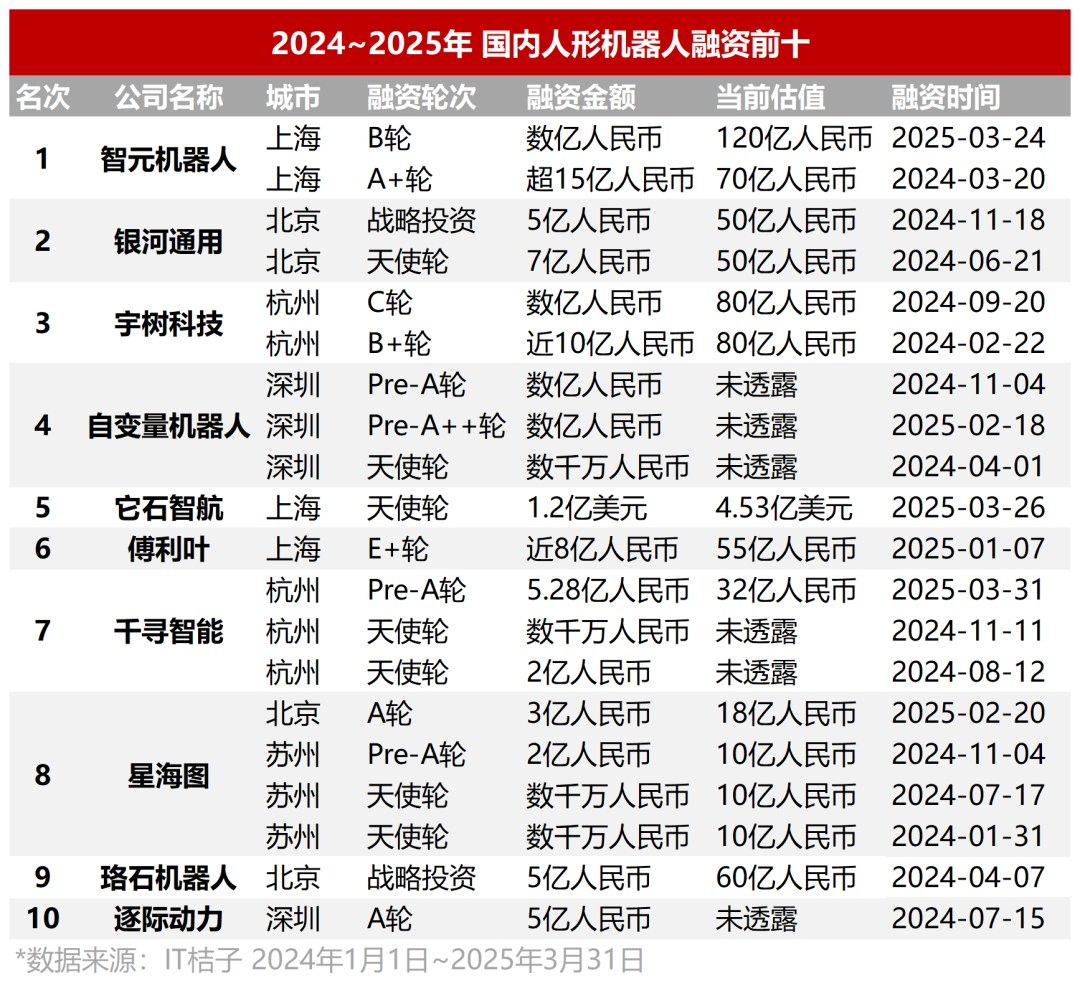
Inversión en robots humanoides sobrecalentada, valoraciones altas en proyectos tempranos, dudas sobre la ruta de comercialización: En 2024-2025 Q1, la financiación en el campo de los robots humanoides en China aumentó drásticamente. Las rondas ángel de decenas de millones se volvieron comunes, casi la mitad de los proyectos recaudaron más de 100 millones de yuanes, y las valoraciones generalmente superaron los 100 millones, incluso los 500 millones. Proyectos estrella como Itastep Robotics obtuvieron cientos de millones de dólares en financiación pocos meses después de su fundación. Los fondos estatales se han convertido en un importante impulsor. Sin embargo, bajo este gran entusiasmo, la ruta de comercialización sigue sin estar clara. Los altos costos (de cientos de miles a millones de yuanes) y la dificultad para implementar aplicaciones (actualmente concentradas en ToB industrial, médico, etc.) son los principales desafíos. Inversores como Zhu Xiaohu ya han comenzado a retirarse, y el colapso de Data Robotics también es una señal de advertencia. El sector presenta una situación mixta. Fabricantes de automóviles (BYD, Xpeng, Xiaomi, etc.) están entrando en el campo, buscando sinergias tecnológicas y nuevos puntos de crecimiento (fuente: 36氪, 36氪)
Intensa competencia en el mercado de gafas inteligentes con IA entre China y EE. UU., mostrando estrategias diferentes: Las gafas inteligentes con IA se consideran un potencial para la próxima plataforma informática, intensificando la competencia entre los gigantes tecnológicos de China y EE. UU. Fabricantes estadounidenses como Meta (Ray-Ban Meta, Hypernova), Amazon y Apple apuntan al mercado de gama alta, apoyándose en la marca y el ecosistema, con precios más altos. Mientras tanto, fabricantes chinos como Xiaomi y Huawei (Rokid) adoptan una estrategia de relación calidad-precio, aprovechando las ventajas de la cadena de suministro y la innovación localizada para reducir drásticamente las barreras del mercado (p. ej., Rokid A1 a 999 yuanes), apuntando al mercado masivo. La tecnología óptica, la capacidad de cómputo en el dispositivo, el consumo de energía y el ecosistema de escenarios son desafíos clave. Se espera que las ventas globales superen los 30 millones de unidades en 2027, con China representando casi la mitad del mercado (fuente: 36氪)

CEO de Anthropic teme que un colapso bursátil pueda frenar el progreso de la IA: El CEO de Anthropic, Dario Amodei, mencionó en una entrevista que, además de la geopolítica (como el conflicto en el Estrecho de Taiwán) y los cuellos de botella de datos, una gran agitación en los mercados financieros también podría detener el desarrollo de la IA. Explicó que si un colapso bursátil socava la confianza en las perspectivas de la tecnología de IA, podría afectar la capacidad de financiación de empresas como OpenAI y Anthropic, reduciendo así los fondos y la capacidad de cómputo disponibles para entrenar grandes modelos, creando una profecía autocumplida y ralentizando el progreso de la IA (fuente: YouTube)
CEO de Shopify obliga a todos los empleados a adoptar la IA, integrándola en el trabajo diario y el rendimiento: Un correo electrónico interno del CEO de Shopify, Tobi Lütke, exige que todos los empleados de la empresa aprendan y apliquen la IA. Las medidas específicas incluyen: incorporar la aplicación de la IA en las evaluaciones de desempeño y las revisiones por pares; usar obligatoriamente la IA en la «fase de prototipo para hacer las cosas» (GSD Prototype phase); antes de solicitar nuevos recursos humanos o materiales, los departamentos deben demostrar primero por qué no se puede lograr el objetivo utilizando IA. Esta medida tiene como objetivo integrar profundamente la IA en la cultura y los procesos operativos de la empresa, mejorando la eficiencia y la capacidad de innovación (fuente: dotey, AravSrinivas)
Fauna Robotics recauda 30 millones de dólares para desarrollar robots adaptados a espacios humanos: Fauna Robotics anunció una ronda de financiación de 30 millones de dólares liderada por Kleiner Perkins, Quiet Capital y Lux Capital. La compañía se dedica a desarrollar robots que puedan operar de forma flexible en espacios de vida y trabajo humanos, lo que generalmente requiere capacidades avanzadas de percepción, navegación, interacción y manipulación, estrechamente relacionadas con la inteligencia corporeizada y la IA (fuente: ylecun)

Anthropic colabora con Northeastern University para impulsar la IA responsable en la educación superior: Anthropic ha establecido una asociación con Northeastern University en EE. UU. con el objetivo de integrar la innovación en IA responsable en la enseñanza, la investigación y las operaciones de la educación superior. Como parte de la colaboración, Northeastern University promoverá el uso de Claude for Education de Anthropic en su red global, proporcionando herramientas de IA a estudiantes, profesores y personal (fuente: Reddit r/ArtificialInteligence)

🌟 Comunidad
Entrevista a Sam Altman: La IA potencia, no reemplaza; optimista sobre el futuro de los Agents: El CEO de OpenAI, Sam Altman, respondió a temas candentes recientes en una entrevista. Considera que la popularidad de las imágenes estilo Ghibli generadas por GPT-4o demuestra una vez más el valor de la tecnología para reducir las barreras creativas. Respecto a las críticas de ser un simple «envoltorio» (套壳), afirmó que la mayoría de las empresas que cambiaron el mundo fueron vistas inicialmente como simples empaquetados, la clave está en crear un valor único para el usuario. Predice que la IA aumentará enormemente la productividad de los programadores (posiblemente 10 veces) y provocará un aumento masivo de la demanda de software a través de la «paradoja de Jevons». Es optimista sobre la transición de los AI Agents de herramientas pasivas a ejecutores activos, especialmente en el campo de la programación. Aconseja a los profesionales que adopten la IA, priorizando entornos donde puedan acceder a tecnologías de vanguardia en una era donde el estancamiento equivale al suicidio profesional (fuente: 量子位)

Predicción de superinteligencia IA para 2027 genera debate, considerada demasiado optimista: Un informe titulado «AI-2027», escrito por ex investigadores de OpenAI entre otros, predice que la IA alcanzará capacidades de codificación sobrehumanas a principios de 2027, acelerando así el propio desarrollo de la IA y conduciendo al nacimiento de la superinteligencia. El informe describe escenarios donde los AI Agents actúan de forma autónoma (como hackeos, autorreplicación). Sin embargo, esta predicción ha sido cuestionada. Los críticos argumentan que subestima la complejidad del mundo real, las limitaciones de los benchmarks, las barreras de los datos/código propietarios y los riesgos de seguridad. Consideran que incluso si la IA sobresale en ciertos benchmarks, lograr tareas complejas de forma totalmente autónoma y fiable (especialmente aquellas que involucran interacción con el mundo físico o áreas sensibles a la seguridad) sigue enfrentando enormes desafíos, y que el cronograma previsto podría ser demasiado agresivo (fuente: YouTube)
Usuario comparte prompts para generación de imágenes con IA: Dotey compartió dos conjuntos de prompts para la generación de imágenes con IA (adecuados para herramientas como Sora o GPT-4o): uno para generar figuras coleccionables 3D estilo Q-version a partir de una foto (estilo cálido y romántico), y otro para convertir a las personas de una foto al estilo de caja de Funko Pop. Proporcionó descripciones detalladas y requisitos de estilo, acompañados de imágenes de ejemplo (fuente: dotey)

Se acusa a Claude 3.7 Sonnet de introducir cambios irrelevantes en la modificación de código: Un usuario de Reddit informa que al usar Claude 3.7 Sonnet para modificar código, el modelo tiende a cambiar código o funcionalidades no relacionadas con los requisitos de la tarea, causando roturas inesperadas. El usuario afirma que Claude 3.5 Sonnet se comportaba mejor en este aspecto, e incluso podía corregir los errores del 3.7 usando git diff. El usuario busca prompts efectivos para restringir el comportamiento del 3.7 y evitar este tipo de problemas (fuente: Reddit r/ClaudeAI)
LLMs principales rinden mal en tareas de planificación con restricciones: Un usuario de Reddit informa que al pedir a ChatGPT, Grok y Claude que crearan un horario de rotación de baloncesto que cumpliera restricciones específicas (número de jugadores, tiempo de juego equitativo, límite de juego consecutivo, restricciones de combinación de jugadores específicos), todos los modelos afirmaron haber cumplido las condiciones, pero una verificación real reveló errores de conteo y fallos en la ejecución de todas las restricciones. Esto expone las limitaciones actuales de los LLM para manejar tareas complejas de satisfacción de restricciones y planificación precisa (fuente: Reddit r/ArtificialInteligence)
Usuario se queja de rendimiento inconsistente en cuentas Claude Pro, sospecha de throttling o degradación: Un usuario de Claude Pro informa de una enorme diferencia de rendimiento entre dos cuentas de pago a su nombre. Una de las cuentas (la original) es casi inutilizable para tareas de generación de código largo, deteniéndose frecuentemente después de generar unas pocas líneas tras pulsar «continuar», como si estuviera limitada o dañada intencionadamente. La cuenta nueva no presenta este problema. El usuario sospecha de throttling o degradación del servicio opacos en segundo plano y expresa una fuerte insatisfacción con la fiabilidad del producto de pago (fuente: Reddit r/ClaudeAI)
Discusión: ¿Cómo entienden los LLM los prompts de role-playing?: Un usuario de Reddit pregunta cómo los grandes modelos de lenguaje (LLM) entienden y ejecutan instrucciones como «interpreta a un personaje» (p. ej., interpretar a una abuela). El usuario especula que está relacionado con el fine-tuning y siente curiosidad por saber si los desarrolladores necesitan pre-codificar o preparar datos de entrenamiento específicos para una gran cantidad de roles, y cuál es la relación entre el entrenamiento general y el fine-tuning para roles específicos (fuente: Reddit r/ArtificialInteligence)

Discusión irónica: Reemplazar el pensamiento personal con IA para obtener «eficiencia» y «calma»: Una publicación en Reddit aboga, en tono irónico, por externalizar completamente el pensamiento, la toma de decisiones, la expresión de opiniones, etc., a la IA. El autor afirma que hacerlo elimina la ansiedad, aumenta la eficiencia y, sorprendentemente, hace que los demás te perciban como «sabio» y «tranquilo», cuando en realidad te has convertido en un «títere de carne» del LLM. La publicación generó debates sobre el valor del pensamiento, la dependencia de la IA y la subjetividad humana (fuente: Reddit r/ChatGPT)
Discusión: ¿Por qué el público general aún no usa la IA ampliamente?: Un usuario de Reddit inicia una discusión sobre por qué, a pesar de que la IA está en todas partes, muchas personas fuera del círculo tecnológico aún no la utilizan activamente en su trabajo y vida diaria. Las posibles razones sugeridas incluyen: no ser consciente de que ya la usan (p. ej., Siri, algoritmos de recomendación), escepticismo hacia la tecnología (caja negra, privacidad, empleos), interfaz de usuario poco amigable (requiere conocimientos de prompt engineering), cultura laboral que aún no la ha adoptado, etc. Esto generó reflexiones sobre la brecha de adopción de la IA (fuente: Reddit r/ArtificialInteligence)
Usuario comparte técnicas de prompt para investigación profunda con Claude 3.7: Un usuario de Reddit compartió una estructura detallada de prompt diseñada para que Claude 3.7 Sonnet simule la herramienta Deep Research de OpenAI para realizar investigaciones profundas colaborativas. El método fuerza el uso de puntos de control (detenerse cada 5 fuentes investigadas y solicitar permiso) y combina herramientas MCP como Playwright (navegación web), mcp-reasoner (razonamiento), youtube-transcript (transcripción de video), para guiar al modelo en la recopilación y análisis de información estructurada y por pasos (fuente: Reddit r/ClaudeAI)
Usuario comparte flujo de trabajo y consejos para usar Claude Pro eficientemente: Un usuario de Claude Pro compartió su experiencia usando Claude eficientemente en escenarios de codificación, con el objetivo de reducir los problemas con los límites de tokens y el rendimiento deficiente del modelo. Los consejos incluyen: proporcionar contexto de código preciso a través de archivos .txt, establecer instrucciones de proyecto concisas, usar más el modo conciso de Extended Thinking, solicitar explícitamente el formato de salida, editar el prompt para activar una nueva rama en lugar de iterar continuamente cuando surgen problemas, y mantener las conversaciones cortas proporcionando solo la información necesaria. El autor cree que optimizando el flujo de trabajo se puede utilizar Claude Pro de manera efectiva (fuente: Reddit r/ClaudeAI)
Discusión filosófica sobre si los LLM tienen conciencia: Un usuario en Reddit cita el «Pienso, luego existo» de Descartes, argumentando que los grandes modelos de lenguaje (LLM) capaces de razonar, al ser «conscientes» de su propio «pensamiento» (proceso de razonamiento), cumplen la definición de conciencia y, por lo tanto, la poseen. Esta visión equipara la función de razonamiento de los LLM con la autoconciencia, generando una discusión filosófica sobre la definición de conciencia, el funcionamiento de los LLM y la diferencia entre simular y poseer realmente conciencia (fuente: Reddit r/artificial)
Discusión: ¿Estarías dispuesto a volar en un avión pilotado completamente por IA?: Un usuario de Reddit lanzó una encuesta y discusión preguntando si la gente estaría dispuesta a volar en un avión pilotado enteramente por IA, sin pilotos humanos en la cabina. La discusión abordó la confianza en la tecnología de conducción autónoma actual, la fiabilidad de la IA en dominios específicos (como la aviación), cuestiones de responsabilidad y cómo podría cambiar la aceptación pública con el desarrollo tecnológico futuro (fuente: Reddit r/ArtificialInteligence)
💡 Otros
El enfoque de la división sin fines de lucro de OpenAI podría cambiar: Con el desarrollo comercial y la creciente valoración de OpenAI (rumoreada en 300 mil millones de dólares), el papel de su división sin fines de lucro, originalmente creada para controlar la AGI y utilizar sus beneficios para el bien de toda la humanidad, parece estar cambiando. Algunos comentarios señalan que el enfoque de esta división podría haberse desplazado de la gran gobernanza de la AGI hacia el apoyo a actividades benéficas locales y otras actividades filantrópicas más tradicionales, lo que genera debate sobre su propósito original y sus compromisos (fuente: YouTube)
IA impulsada por intención para soporte al cliente: Un artículo de T-Mobile Business explora el uso de IA impulsada por la intención para mejorar la experiencia de soporte al cliente. La IA puede predecir y resolver problemas de forma proactiva, gestionar un gran volumen de interacciones y ayudar a los agentes humanos a proporcionar un soporte más empático. Al identificar la intención del cliente, la IA puede satisfacer sus necesidades con mayor precisión y optimizar los procesos de servicio (fuente: Ronald_vanLoon)
El desafío de la IA para identificar contenido generado por IA: DeltalogiX discute un desafío interesante al que se enfrenta la IA: identificar contenido generado por otras IA. A medida que mejoran las capacidades de generación de texto, imágenes, audio, etc., por parte de la IA, distinguir entre la creación humana y la maquinal se vuelve cada vez más difícil, lo que plantea nuevos requisitos técnicos para la moderación de contenido, la protección de derechos de autor, la verificación de la autenticidad de la información, etc. (fuente: Ronald_vanLoon)

El éxito de GenAI depende de una estrategia de datos de alta calidad: Un artículo de Forbes enfatiza que una estrategia de datos genérica no es adecuada para todas las aplicaciones de GenAI. Para garantizar el éxito de los proyectos de GenAI, es necesario desarrollar estrategias de calidad de datos específicas para cada escenario de aplicación, centrándose en la relevancia, precisión, actualidad y diversidad de los datos, para evitar que el modelo genere sesgos o resultados erróneos (fuente: Ronald_vanLoon)

La IA potencia planes de tratamiento médico personalizados: Una infografía de Antgrasso destaca el potencial de la IA en la elaboración de planes de tratamiento médico personalizados. Analizando datos multidimensionales del paciente como datos genómicos, historial médico, estilo de vida, etc., la IA puede ayudar a los médicos a diseñar planes de tratamiento más precisos y efectivos, impulsando el desarrollo de la medicina de precisión (fuente: Ronald_vanLoon)

La IA redefine la eficiencia y velocidad de la cadena de suministro: Un artículo de Nicochan33 explora cómo la inteligencia artificial está remodelando la eficiencia y la velocidad de respuesta de la cadena de suministro mediante la optimización de predicciones, planificación de rutas, gestión de inventario, alerta de riesgos, etc., haciéndola más ágil e inteligente (fuente: Ronald_vanLoon)

Usuario afirma haber desarrollado un potenciador de razonamiento universal para LLM: Un usuario de Reddit afirma haber desarrollado un método que mejora significativamente la capacidad de razonamiento de los LLM (afirma un aumento de 15-25 puntos de «IQ») sin necesidad de fine-tuning, y que podría funcionar como una capa de alineación transparente. El usuario está buscando patentarlo y pide consejo a la comunidad sobre los próximos pasos (licencia, colaboración, open source, etc.) (fuente: Reddit r/deeplearning)
Manifiesto del proyecto OAK – Open Agentic Knowledge: En GitHub ha aparecido un manifiesto de proyecto llamado OAK (Open Agentic Knowledge). Aunque no se detallan los contenidos específicos, por el nombre se puede inferir que el proyecto podría tener como objetivo crear un marco o estándar abierto para que los AI Agents usen y compartan conocimiento, con el fin de promover la mejora de las capacidades de los Agents y su interoperabilidad (fuente: Reddit r/ArtificialInteligence)
