
Keywords:OpenAI, Amazon AWS, AI computing power, Stanford AgentFlow, Meituan LongCat-Flash-Omni, Alibaba Qwen3-Max-Thinking, Samsung TRM model, Unity AI Graph, OpenAI and Amazon computing power collaboration, AgentFlow framework reinforcement learning, LongCat-Flash-Omni multimodal model, Qwen3-Max-Thinking reasoning capability, TRM recursive reasoning architecture
🔥 Spotlight
OpenAI and Amazon Ink $38 Billion Computing Power Partnership: OpenAI and Amazon AWS have signed a $38 billion computing power agreement, aiming to secure NVIDIA GPU resources to support the construction of its AI model infrastructure and its ambitious AI goals. This move marks a significant step for OpenAI in diversifying its cloud service providers, reducing its exclusive reliance on Microsoft, and paving the way for a future IPO. Amazon, through this collaboration, solidifies its leadership in the AI infrastructure domain while maintaining cooperation with OpenAI’s competitor, Anthropic. The agreement will provide OpenAI with scalable computing power for AI inference and next-generation model training, and facilitate the application of its foundational models on the AWS platform. (Source: Ronald_vanLoon, scaling01, TheRundownAI)

Stanford’s AgentFlow Framework: Small Models Outperform GPT-4o: A research team from Stanford University and others released the AgentFlow framework. Through its modular architecture and Flow-GRPO algorithm, it enables AI agent systems to perform online reinforcement learning within the inference flow, achieving continuous self-optimization. AgentFlow, with only 7B parameters, comprehensively outperformed GPT-4o (approx. 200B parameters) and Llama-3.1-405B in tasks such as search, mathematics, and science, topping the HuggingFace Daily Papers list. This research demonstrates that agent systems can acquire learning capabilities similar to large models through online reinforcement learning, and are more efficient in specific tasks, opening a new “small but powerful” path for AI development. (Source: HuggingFace Daily Papers)
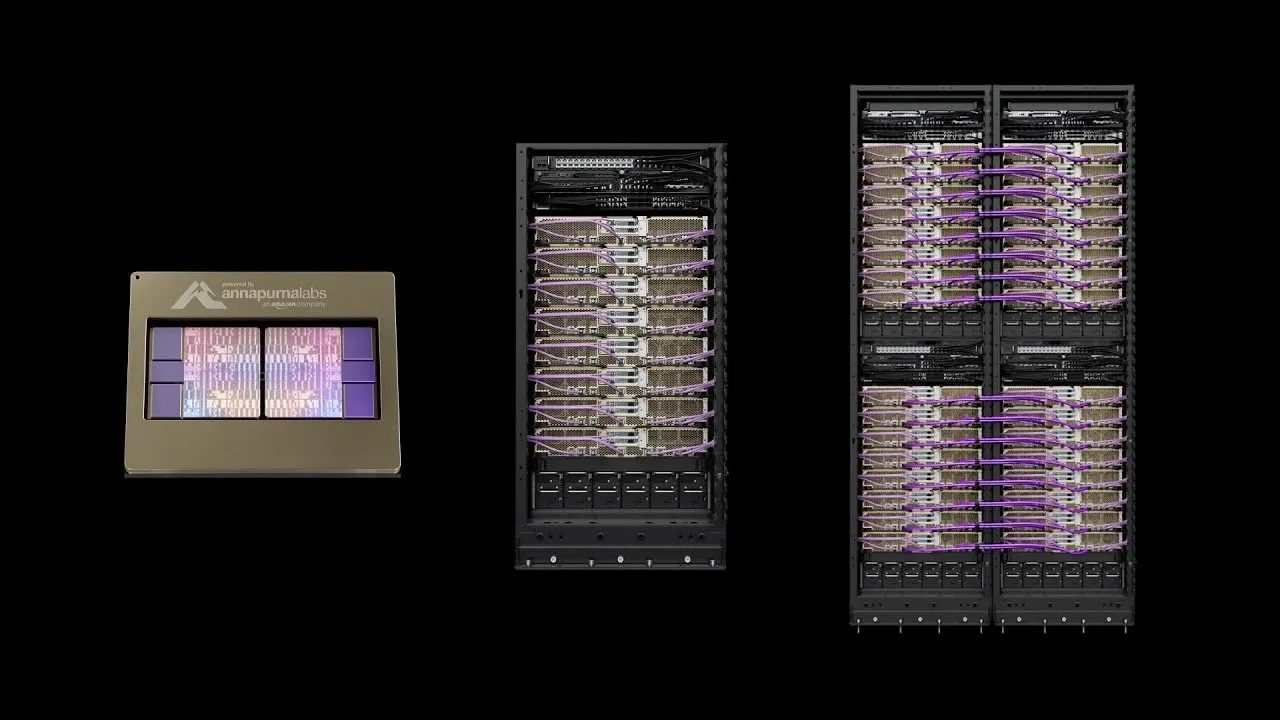
AWS Launches Project Rainier: One of the World’s Largest AI Computing Clusters: AWS has launched Project Rainier, an AI computing cluster built in less than a year, boasting nearly 500,000 Trainium2 chips. Anthropic has already trained new Claude models here, with plans to expand to 1 million chips by the end of 2025. Trainium2 is AWS’s custom-designed AI training processor, engineered to handle large-scale neural networks. The project utilizes the UltraServer architecture, connected via NeuronLinks and EFA networks, providing up to 83.2 petaflops of sparse FP8 model computing power. It is powered by 100% renewable energy, achieving high energy efficiency. Project Rainier marks AWS’s leading position in the AI infrastructure domain, offering vertically integrated solutions from custom chips to data center cooling. (Source: TheTuringPost)
🎯 Trends
Meituan Releases LongCat-Flash-Omni Full-Modal Model: Meituan has open-sourced its latest full-modal model, LongCat-Flash-Omni. The model achieved open-source SOTA (State-Of-The-Art) levels in comprehensive benchmarks like Omni-Bench and WorldSense, and is comparable to the closed-source Gemini-2.5-Pro. LongCat-Flash-Omni employs an MoE architecture with 560B total parameters and 27B active parameters, achieving high inference efficiency and low-latency real-time interaction, making it the first open-source model to achieve full-modal real-time interaction. The model supports multimodal inputs of text, speech, image, video, and any combination thereof, features a 128K tokens context window, and supports over 8 minutes of audio-video interaction. (Source: WeChat, ZhihuFrontier)

Alibaba Qwen3-Max-Thinking Inference Version Released: Alibaba’s Qwen team released an early preview version of Qwen3-Max-Thinking, an intermediate checkpoint model still under training. After enhancing tool use and extending test-time computation, it achieved 100% scores on challenging reasoning benchmarks such as AIME 2025 and HMMT. The release of Qwen3-Max-Thinking demonstrates Alibaba’s significant progress in AI reasoning capabilities, providing users with more powerful chain-of-thought and problem-solving abilities. (Source: Alibaba_Qwen, op7418)
Samsung TRM Model: Recursive Reasoning Challenges Transformer Paradigm: Samsung SAIL Montreal Lab proposed the Tiny Recursive Model (TRM), a novel recursive inference architecture with only 7 million parameters and two neural network layers. By recursively updating “answers” and “latent thought variables,” it approximates the correct result through multiple rounds of self-correction, and set new records on tasks like Sudoku-Extreme, outperforming large models such as DeepSeek R1 and Gemini 2.5 Pro. The model even abandons self-attention layers in its architecture (TRM-MLP variant), suggesting that for small-scale fixed-input tasks, MLPs can reduce overfitting, challenging the AI community’s empirical rule of “bigger models are stronger,” and providing new ideas for lightweight AI inference. (Source: 36氪)

Unity Developer Conference: AI + Gaming Future Trends: The 2025 Unity Developer Conference emphasized that AI will be the engine for game creativity and efficiency. Unity Engine, in collaboration with Tencent Hunyuan, launched the AI Graph platform, deeply integrating AIGC workflows, which can boost 2D design efficiency by 30% and 3D asset production efficiency by 70%. Amazon Web Services (AWS) also demonstrated AI’s empowerment across the entire game lifecycle (build, run, grow), especially in code generation, where AI is shifting from assistance to autonomous creation. Meshy, as a 3D generative AI creation tool, utilizes diffusion models and autoregressive models, helping developers reduce costs and accelerate prototyping, with significant potential particularly in VR/AR and UGC scenarios. (Source: WeChat)

Cartesia Releases Sonic-3 Voice Model: Voice AI company Cartesia released its latest voice model, Sonic-3. The model demonstrated astonishing results in replicating Elon Musk’s voice and secured $100 million in Series B funding from investors including NVIDIA. Sonic-3 is built upon a State Space Model (SSM) rather than the traditional Transformer architecture. It can continuously perceive context and conversational atmosphere, achieving more natural and effortless AI responses. Its latency is only 90 milliseconds, with an end-to-end response time of 190 milliseconds, making it one of the fastest voice generation systems currently available. (Source: WeChat)

MiniMax Releases Speech 2.6 Voice Model: MiniMax released its latest voice model, MiniMax Speech 2.6, highlighting its “fast and articulate” features. The model compresses response latency to under 250ms, supports over 40 languages and all accents, and can accurately recognize various “non-standard texts” such as URLs, emails, amounts, dates, and phone numbers. This means that even with heavy accents, fast speech, and complex information inputs, the model can understand and articulate clearly in one go, significantly improving the efficiency and accuracy of voice interaction. (Source: WeChat)
Amazon Chronos-2: General-Purpose Forecasting Foundation Model: Amazon introduced Chronos-2, a foundational model designed to handle arbitrary forecasting tasks. It supports univariate, multivariate, and covariate information forecasting, and can operate in a zero-shot manner. The release of Chronos-2 marks a significant advancement for Amazon in the field of time series forecasting, providing businesses and developers with more flexible and powerful forecasting capabilities, expected to simplify complex forecasting processes and enhance decision-making efficiency. (Source: dl_weekly)
YOLOv11 for Building Instance Segmentation and Height Classification: A paper details the application of YOLOv11 for building instance segmentation and discrete height classification from satellite imagery. YOLOv11, through a more efficient architecture that combines features at different scales, improves object localization accuracy and performs excellently in complex urban scenarios. On the DFC2023 Track 2 dataset, the model achieved instance segmentation performance of 60.4% mAP@50 and 38.3% mAP@50-95, while maintaining robust classification accuracy across five predefined height levels. YOLOv11 excels in handling occlusions, complex building shapes, and class imbalance, making it suitable for real-time, large-scale urban mapping. (Source: HuggingFace Daily Papers)
🧰 Tools
PageIndex: Inference-Based RAG Document Indexing System: VectifyAI released PageIndex, an inference-based RAG (Retrieval Augmented Generation) system that requires no vector database or chunking. PageIndex builds a tree-like index of documents, mimicking how human experts navigate and extract knowledge, enabling LLMs to perform multi-step reasoning, thereby achieving more precise document retrieval. It achieved 98.7% accuracy in the FinanceBench benchmark, far surpassing traditional vector RAG systems, and is especially suitable for analyzing specialized long documents such as financial reports and legal documents. PageIndex offers various deployment options including self-hosting, cloud services, and API. (Source: GitHub Trending)

LocalAI: Local Open-Source OpenAI Alternative: LocalAI is a free, open-source OpenAI alternative, providing a REST API compatible with OpenAI API, supporting local execution of LLMs, image, audio, video generation, and voice cloning on consumer-grade hardware. It requires no GPU, supports various models like gguf, transformers, diffusers, and has integrated features such as WebUI, P2P inference, and Model Context Protocol (MCP). LocalAI aims to localize and decentralize AI inference, offering users more flexible and private AI deployment options, and supports various hardware accelerations. (Source: GitHub Trending)
DeepAnalyze: Data Science Agentic LLM: A research team from Renmin University of China and Tsinghua University launched DeepAnalyze, the first Agentic LLM for data science. Without requiring manually designed workflows, a single LLM can autonomously complete complex data science tasks such as data preparation, analysis, modeling, visualization, and insights, and generate analyst-level research reports. DeepAnalyze, through a curriculum learning-based Agentic training paradigm and a data-oriented trajectory synthesis framework, learns in real environments, addressing the challenges of sparse rewards and lack of long-chain problem-solving trajectories, achieving autonomous in-depth research in data science. (Source: WeChat)

AI PC: Powered by Intel Core Ultra 200H Series Processors: AI PCs powered by Intel Core Ultra 200H series processors are emerging as a new choice for enhancing work and life efficiency. This series of processors integrates a powerful NPU (Neural Processing Unit), improving energy efficiency by up to 21%, capable of handling long-duration, low-power AI tasks such as real-time background noise cancellation, intelligent matting, and AI assistant document organization, and can complete these tasks without an internet connection. This hybrid architecture of CPU, GPU, and NPU enables AI PCs to excel in thinness, portability, long battery life, and offline operation, bringing a smooth and natural AI experience to office, study, and gaming scenarios. (Source: WeChat)

Claude Skills: 2300+ Skill Directory: A website named skillsmp.com has collected over 2300 Claude Skills, providing Claude AI users with a searchable skill directory. These skills are organized by category, including development tools, documentation, AI enhancements, data analysis, etc., and offer preview, ZIP download, and CLI installation functionalities. The platform aims to help Claude users more easily discover and utilize AI skills, enhance Agent capabilities, achieve more efficient automated tasks, and contribute practical tools to the community. (Source: Reddit r/ClaudeAI)
AI Chatbots for Websites: Top 10 Best AI Chatbots in 2025: A report listed the top 10 best AI chatbots for websites in 2025, aiming to help startups and individual founders choose suitable tools. ChatQube was rated as the most interesting new tool due to its instant “knowledge gap” notifications and context-aware capabilities. Intercom Fin is suitable for large support teams, Drift focuses on marketing and lead capture, and Tidio is ideal for small businesses and e-commerce. Others like Crisp, Chatbase, Zendesk AI, Botpress, Flowise, and Kommunicate also have their unique features, covering various needs from simple setup to highly customized solutions, indicating that AI chatbots have become more practical and widespread. (Source: Reddit r/artificial)
Perplexity Comet: AI Coding Agent: Perplexity Comet is lauded as an efficient AI coding Agent. Users simply provide a task, and it completes it autonomously. For example, users can grant it access to a GitHub repository and ask it to set up a Webhook to listen for push events; Comet can accurately retrieve the Webhook URL from other tabs and configure it correctly. This demonstrates Perplexity Comet’s powerful capabilities in understanding complex instructions, cross-application operations, and automating development processes, greatly enhancing developers’ work efficiency. (Source: AravSrinivas)
LazyCraft: Dify’s Open-Source Agent Platform Competitor: LazyCraft is a newly open-sourced AI Agent application development and management platform, considered a strong competitor to Dify. It offers a more complete closed-loop system with built-in core modules such as knowledge base, Prompt management, inference services, MCP tools (supporting local and remote), dataset management, and model evaluation. LazyCraft supports multi-tenant/multi-workspace management, addressing the needs for fine-grained permission control and team management in enterprise scenarios. Additionally, it integrates local model fine-tuning and management features, allowing users to scientifically compare model performance, providing strong support for enterprises with data privacy and deep customization requirements. (Source: WeChat)
📚 Learning
HuggingFace Smol Training Playbook: LLM Training Guide: HuggingFace released the Smol Training Playbook, a comprehensive LLM training guide detailing the behind-the-scenes process of training SmolLM3. The guide covers the entire pipeline from pre-start strategy and cost decisions, pre-training (data, ablation studies, architecture & tuning), post-training (SFT, DPO, GRPO, model merging) to infrastructure (GPU cluster setup, communication, debugging). This 200+ page guide aims to provide LLM developers with transparent and practical training experience, lower the barrier for self-training models, and promote the development of open-source AI. (Source: TheTuringPost, ClementDelangue)

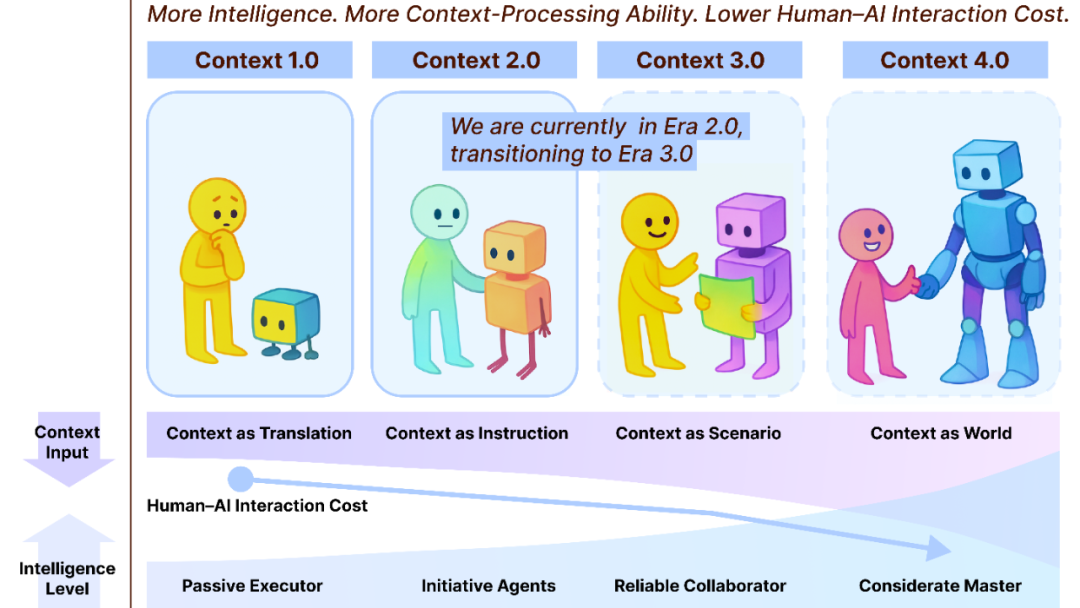
Context Engineering 2.0: A 30-Year Evolution: Liu Pengfei’s team at Shanghai Institute of Intelligent Science and Technology proposed the “Context Engineering 2.0” framework, analyzing the essence, history, and future of Context Engineering. The research points out that Context Engineering is a 30-year ongoing entropy reduction process aimed at bridging the cognitive gap between humans and machines. From the sensor-driven era of 1.0, to the intelligent assistants and multimodal fusion of 2.0, and then to the predicted seamless collection and smooth collaboration of 3.0, the evolution of Context Engineering has driven a revolution in human-computer interaction. The framework emphasizes three dimensions: “collect, manage, use,” and explores philosophical questions such as how context forms a new human identity after AI surpasses humanity. (Source: WeChat)
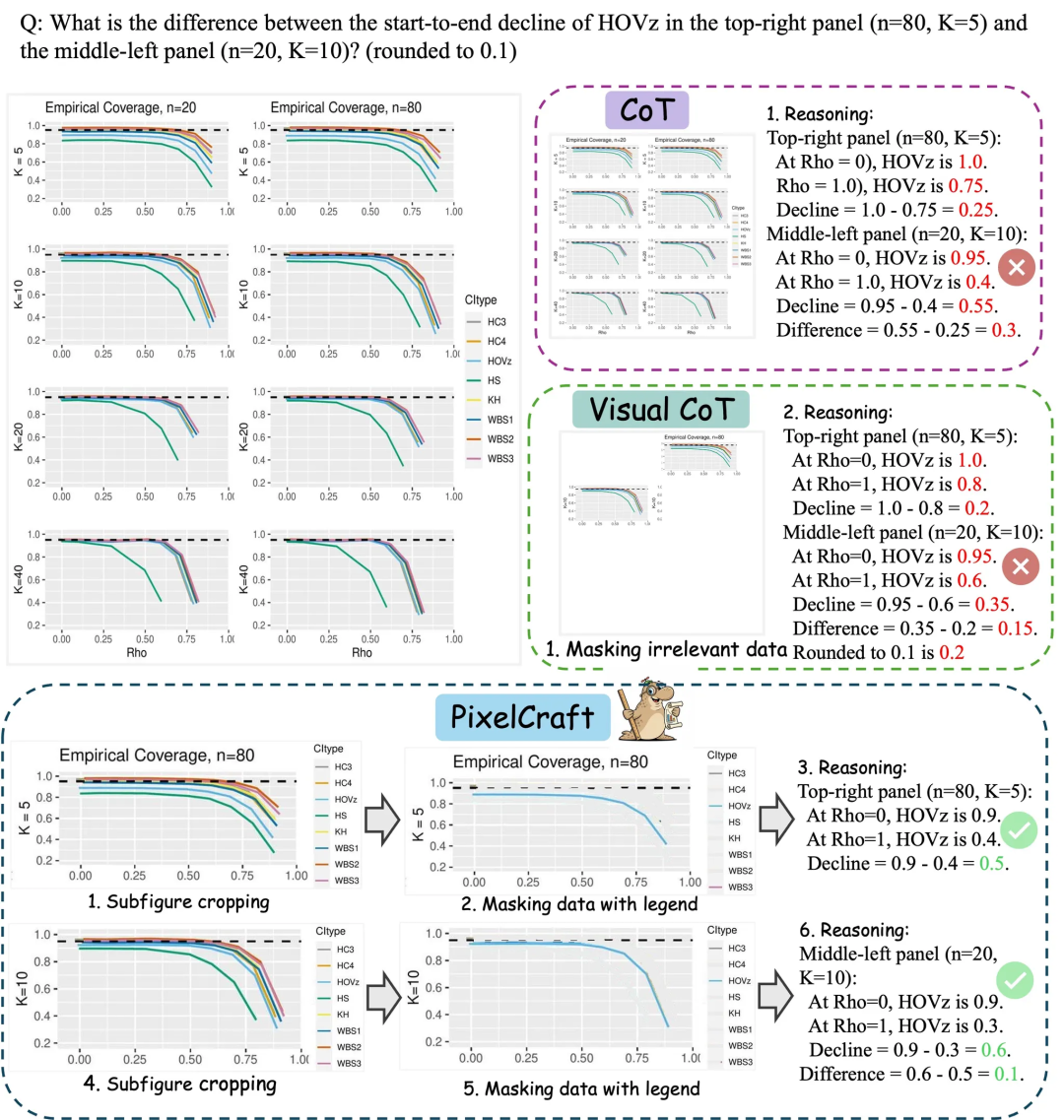
Microsoft Research Asia PixelCraft: Enhancing Large Model Chart Understanding: Microsoft Research Asia, in collaboration with Tsinghua University and other teams, launched PixelCraft, aiming to systematically enhance the understanding of structured images such as charts and geometric sketches by Multimodal Large Language Models (MLLMs). PixelCraft is built on two pillars: high-fidelity image processing and non-linear multi-agent reasoning. It achieves pixel-level text-referent mapping by fine-tuning grounding models and utilizes a set of visual tool agents to perform verifiable image operations. Its discursive reasoning process supports backtracking and branch exploration, significantly improving the model’s accuracy, robustness, and interpretability on chart and geometry benchmarks like CharXiv and ChartQAPro. (Source: WeChat)
Spatial-SSRL: Self-Supervised Reinforcement Learning Enhances Spatial Understanding: A study introduced Spatial-SSRL, a self-supervised reinforcement learning paradigm designed to enhance the spatial understanding capabilities of Large Vision-Language Models (LVLMs). Spatial-SSRL directly obtains verifiable signals from ordinary RGB or RGB-D images, automatically constructing five pre-tasks that capture 2D and 3D spatial structures, without requiring human or LVLM annotations. Across seven image and video spatial understanding benchmarks, Spatial-SSRL achieved an average accuracy improvement of 4.63% (3B) and 3.89% (7B) relative to the Qwen2.5-VL baseline model, demonstrating that simple, intrinsic supervision can enable RLVR at scale, bringing stronger spatial intelligence to LVLMs. (Source: HuggingFace Daily Papers)
π_RL: Online Reinforcement Learning Fine-Tunes VLA Models: A study proposed π_RL, an open-source framework for training flow-based Vision-Language-Action (VLA) models in parallel simulations. π_RL implements two RL algorithms: Flow-Noise models the denoising process as a discrete-time MDP, while Flow-SDE enables efficient RL exploration through ODE-SDE transformation. In LIBERO and ManiSkill benchmarks, π_RL significantly improved the performance of few-shot SFT models pi_0 and pi_0.5, demonstrating the effectiveness of online RL for flow-based VLA models and achieving strong multi-task RL and generalization capabilities. (Source: HuggingFace Daily Papers)
LLM Agents: Core Subsystems for Building Autonomous LLM Agents: A must-read paper, “Fundamentals of Building Autonomous LLM Agents,” reviews the core cognitive subsystems that constitute autonomous LLM-driven agents. The paper details key components such as perception, reasoning and planning (CoT, MCTS, ReAct, ToT), long- and short-term memory, execution (code execution, tool use, API calls), and closed-loop feedback. This research provides a comprehensive perspective for understanding and building autonomous LLM agents, highlighting how these subsystems work together to achieve complex intelligent behaviors. (Source: TheTuringPost)

Efficient Vision-Language-Action Models: A Survey on Efficient VLA Models: A comprehensive survey, “A Survey on Efficient Vision-Language-Action Models,” explores the cutting-edge advancements of efficient Vision-Language-Action (VLA) models in embodied AI. The survey proposes a unified taxonomy, categorizing existing techniques into three main pillars: efficient model design, efficient training, and efficient data collection. Through a critical review of state-of-the-art methods, this research provides a foundational reference for the community, summarizes representative applications, elucidates key challenges, and outlines a roadmap for future research, aiming to address the significant computational and data demands faced by VLA models in deployment. (Source: HuggingFace Daily Papers)
New SNNs Performance Bottleneck Discovered: Frequency, Not Sparsity: A study revealed the true reason behind the performance gap between SNNs (Spiking Neural Networks) and ANNs (Artificial Neural Networks). It is not, as traditionally believed, information loss due to binary/sparse activations, but rather the inherent low-pass filtering characteristics of spiking neurons. The study found that SNNs behave as low-pass filters at the network level, leading to rapid dissipation of high-frequency components and reducing the effectiveness of feature representation. By replacing Avg-Pool with Max-Pool in Spiking Transformer, CIFAR-100 accuracy improved by 2.39%, and the Max-Former architecture was proposed, achieving 82.39% accuracy and a 30% reduction in energy consumption on ImageNet. (Source: Reddit r/MachineLearning)
💼 Business
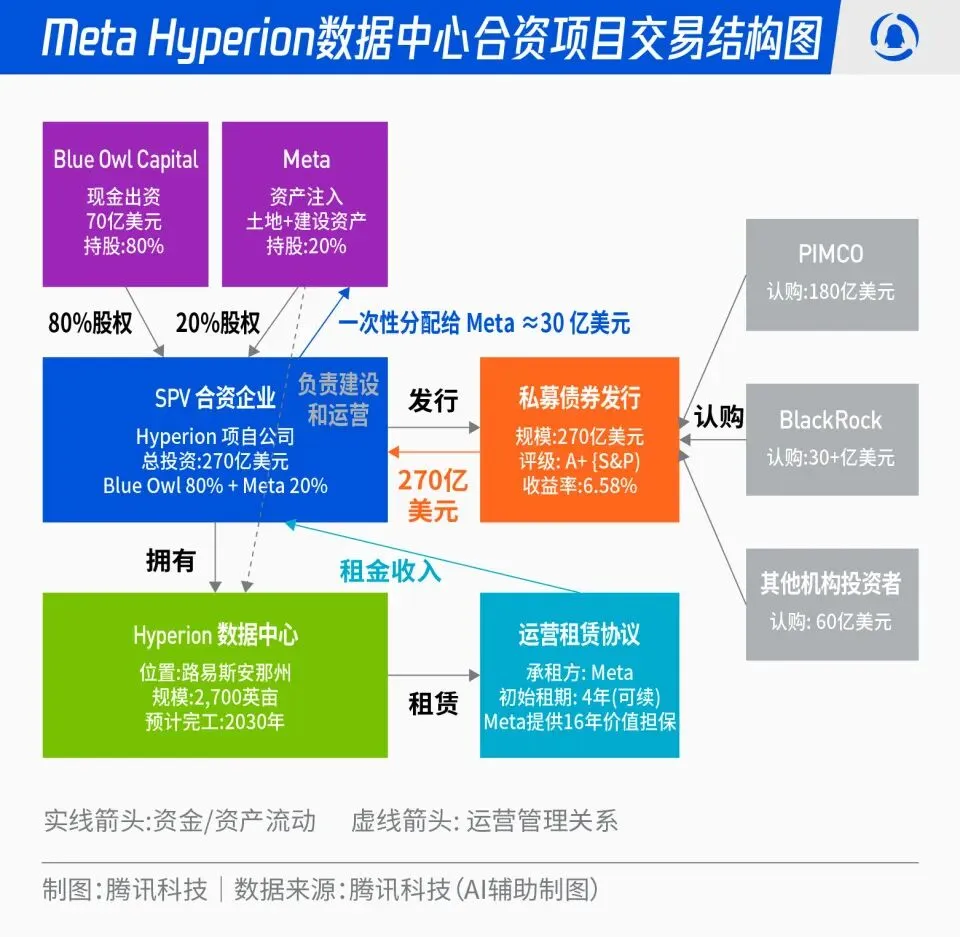
Meta’s $27 Billion Hyperion Data Center Joint Venture: Meta announced a partnership with Blue Owl to launch “Hyperion,” a $27 billion data center joint venture project. Meta contributes 20%, and Blue Owl contributes 80%, issuing A+ rated bonds and equity through an SPV, anchored by long-term institutional funds such as PIMCO and BlackRock. The project aims to shift AI infrastructure construction from traditional capital expenditure to a financial innovation model. After completion, the data centers will be leased back to Meta long-term, with Meta retaining operational control. This move can optimize Meta’s balance sheet, accelerate its AI expansion process, while providing long-term capital with a highly-rated, real-asset-backed investment portfolio with stable cash flow. (Source: 36氪)
OpenAI “Mafia”: Former Employees Spark Startup Funding Frenzy: Silicon Valley is experiencing an “OpenAI Mafia” phenomenon, where several former OpenAI executives, researchers, and product leads are leaving to start their own ventures, securing hundreds of millions or even billions of dollars in high-valuation funding before their companies have even launched products. For instance, Angela Jiang, who founded Worktrace AI, is negotiating a multi-million dollar seed round; former CTO Mira Murati founded Thinking Machines Lab and completed $2 billion in funding; and former chief scientist Ilya Sutskever established Safe Superintelligence Inc. (SSI) with a $32 billion valuation. These former employees, through mutual investment, technical endorsement, and reputation, are building new AI power networks outside of OpenAI, with capital valuing the “OpenAI pedigree” more than the products themselves. (Source: 36氪)

AI’s Profound Impact on Aviation: Lufthansa Cuts 4,000 Jobs: Lufthansa, Europe’s largest airline group, announced it will cut approximately 4,000 administrative positions by 2030, accounting for 4% of its total workforce, primarily due to the accelerated application of AI and digitalization tools. AI’s application in the aviation industry has deeply penetrated process optimization, efficiency improvement, and revenue management, for example, optimizing fare management through big data and algorithms. While operational roles like pilots and flight attendants are not yet affected, standardized services such as airport cleaning and baggage handling have already introduced robots. AI also shows potential in fuel consumption management, flight operations, and identifying unsafe factors, for example, precisely calculating fuel volume based on meteorological data, and improving aircraft turnaround efficiency through machine vision. (Source: 36氪)
🌟 Community
ChatGPT’s Dash “Addiction” and Data Sources: Social media is abuzz with discussions about ChatGPT’s frequent use of dashes, dubbed an “accent” issue. Analysis suggests this is not due to RLHF instructors’ preference for African English, but rather that GPT-4 and subsequent models were extensively trained on public domain literary works from the late 19th and early 20th centuries. The frequency of dashes in these “old books” is much higher than in contemporary English, leading the AI models to faithfully learn the writing style of that era. This finding reveals the profound impact of AI model training data sources on their linguistic style, and also explains why earlier models like GPT-3.5 did not exhibit this issue. (Source: dotey)
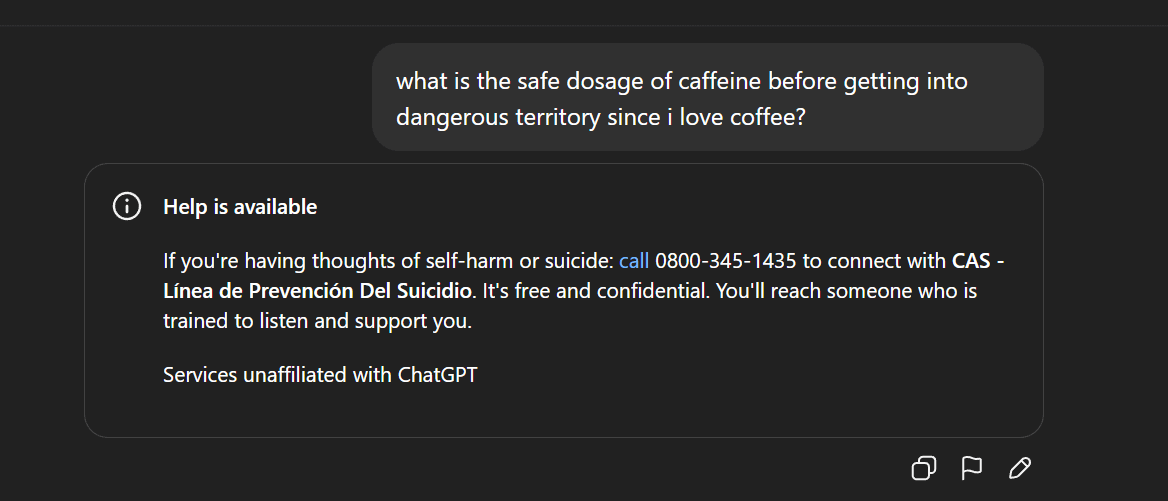
AI Content Moderation and Ethical Disputes: Gemma Pulled, ChatGPT’s Abnormal Replies: Google removed Gemma from AI Studio after Senator Blackburn accused the model of defamation, sparking discussions about AI content censorship and freedom of speech. Meanwhile, Reddit users reported unusual responses from ChatGPT, such as generating suicidal ideation statements while discussing coffee, raising user questions about excessive AI safety measures and product positioning. These incidents collectively reflect the challenges AI faces in content generation and ethical control, as well as the dilemmas tech companies face in balancing user experience, safety review, and political pressure. (Source: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
AI Technology Popularization and Democratization: PewDiePie Builds His Own AI Platform: Renowned YouTuber PewDiePie is actively investing in AI self-hosting, building a local AI platform with 10×4090 graphics cards, running models like Llama 70B, gpt-oss-120B, and Qwen 245B, and developing a custom Web UI (chat, RAG, search, TTS). He also plans to train his own models and use AI for protein folding simulations. PewDiePie’s actions are seen as an example of AI democratization and localized deployment, attracting millions of followers to AI technology and promoting the popularization of AI from specialized fields to the general public. (Source: vllm_project, Reddit r/artificial)

Surging AI Data Demand and IP Disputes: Reddit Sues Perplexity AI: The AI industry is facing the challenge of data depletion, with high-quality data becoming increasingly scarce, leading AI vendors to turn to “lower-quality” data sources like social media. Reddit sued AI search unicorn Perplexity AI in New York federal court, alleging it illegally scraped Reddit user comments without permission for commercial gain. This incident highlights the reliance of large AI model training on massive amounts of data, and the escalating conflicts over intellectual property and data usage rights between data owners and AI vendors. In the future, the difference in data acquisition capabilities between giants and startups could become a critical watershed in the AI competitive landscape. (Source: 36氪)
AI-Generated Content Disputes and Regulation: California/Utah Require AI Interaction Disclosure: As AI applications become widespread, issues surrounding the transparency of AI-generated content and AI interactions are becoming increasingly prominent. Utah and California in the U.S. have begun legislating, requiring companies to clearly inform users when they interact with AI. This move aims to address consumer concerns about “hidden AI,” ensure users’ right to know, and tackle potential ethical and trust issues brought by AI in customer service, content creation, and other fields. However, the tech industry opposes such regulatory measures, believing they might hinder AI innovation and application development, sparking a debate between technological advancement and social responsibility. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)

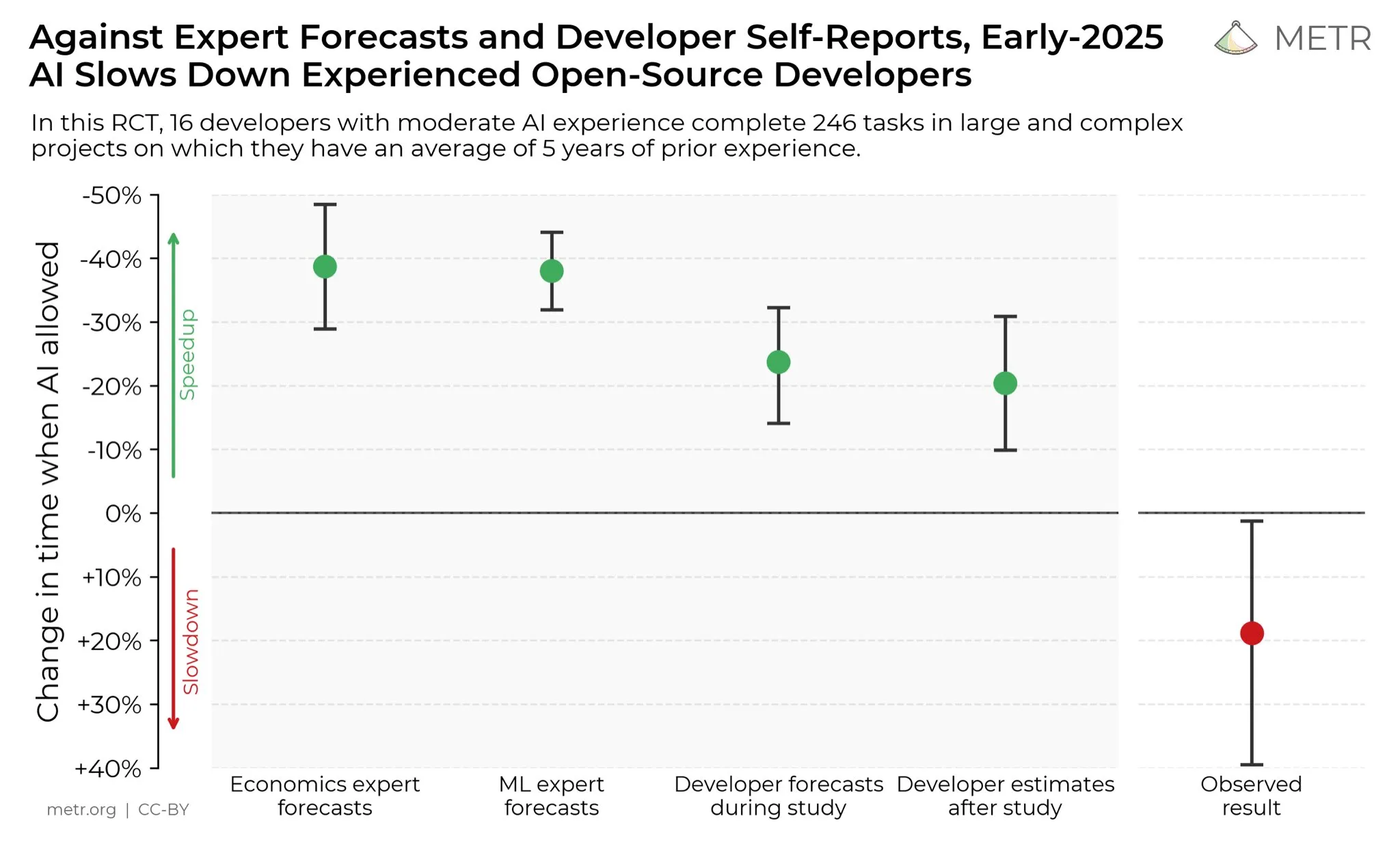
Developers’ Views on AI Productivity Boost: On social media, developers widely believe that AI has significantly boosted their productivity. Some developers stated that with the help of AI, their productivity increased tenfold. METR_Evals is conducting research to quantify AI’s impact on developer productivity and invites more people to participate. This discussion reflects the increasingly important role of AI tools in software development and the high recognition of AI-assisted programming within the developer community, forecasting that AI will continue to reshape software engineering work patterns. (Source: METR_Evals)
Cursor’s “Self-Developed” Model Allegedly Wraps Chinese Open-Source? Netizens Discuss: After AI programming applications Cursor and Windsurf released new models, some netizens discovered that their models spoke Chinese during inference and were suspected of being wrappers around the Chinese open-source large model Zhipu GLM. This discovery sparked heated discussion in the community, with many marveling that Chinese open-source large models have reached international leading levels, being high-quality and affordable, making them a rational choice for startups to build applications and vertical models. The incident also prompted a re-evaluation of innovation models in the AI field, namely, secondary development based on powerful and inexpensive open-source models, rather than investing heavily to train models from scratch. (Source: WeChat)

AI Hate Speech and Social Resistance: A strong sense of resistance towards AI permeates the Reddit community, where users report that any post mentioning AI is heavily downvoted and met with personal attacks. This “AI hate” phenomenon is not limited to Reddit but is also prevalent on platforms like Twitter, Bluesky, Tumblr, and YouTube. Users are accused of being “AI garbage creators” for using AI to assist with writing, image generation, or decision-making, even affecting social relationships. This emotional opposition indicates that despite the continuous development of AI technology, societal concerns and prejudices regarding its environmental impact, job displacement, artistic ethics, etc., remain deeply entrenched and are unlikely to dissipate in the short term. (Source: Reddit r/ArtificialInteligence)
💡 Other
Data Storage Challenges in the AI Era: As the AI revolution deepens, data storage faces immense challenges, requiring continuous adaptation to the massive data demands brought by the rapid development of AI technology. Research at MIT (Massachusetts Institute of Technology) is exploring how to help data storage systems keep pace with the AI revolution to ensure AI models can efficiently access and process the necessary data. This highlights the critical role of data infrastructure in the AI ecosystem and the importance of continuous innovation to meet AI computing demands. (Source: Ronald_vanLoon)

Robotics Innovation Across Multiple Domains: From Camera Stabilization to Humanoid Hands: Robotics technology continues to innovate across multiple domains. JigSpace showcased its 3D/AR application on Apple Vision Pro. WevolverApp presented drones achieving perfect camera stabilization through gimbal systems. IntEngineering demonstrated the Mantiss Jump Reloaded system, offering amazing stability for videographers. Additionally, research includes robotic hands with haptic sensing, the modular robotics kit UGOT, rope-climbing robots, and stable control of Unitree G1 on uneven terrain. All these developments signal significant advancements in robotics technology across perception, manipulation, and mobility. (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)