
Keywords:DeepSeek-OCR, ChatGPT Atlas, Unitree H2, Quantum Computing, AI Drug Discovery, DeepSeek MoE, vLLM, Meta Vibes, Contextual Optical Compression Technology, AI Browser Memory Function, Humanoid Robot Degrees of Freedom, Quantum Echo Algorithm, Biological Experiment Protocol Generation Framework
🔥 Spotlight
DeepSeek-OCR: Contextual Optical Compression Technology : The DeepSeek-OCR model introduces the concept of “contextual optical compression.” By treating text as an image, it can compress an entire page into a few “visual tokens” using visual encoding, which are then decoded back into text, tables, or charts, achieving a tenfold increase in efficiency and an accuracy rate of up to 97%. This technology uses DeepEncoder to capture page information and compress it by 16 times, reducing 4096 tokens to 256. It can also automatically adjust the number of tokens based on document complexity, significantly outperforming existing OCR models. This not only drastically reduces the cost of processing long documents and improves information extraction efficiency but also offers new ideas for LLM’s long-term memory and context expansion, signaling the immense potential of images as information carriers in the AI field. (Source: HuggingFace Daily Papers, 36氪, ZhihuFrontier)

OpenAI Launches ChatGPT Atlas Browser : OpenAI has launched ChatGPT Atlas, a browser designed for the AI era, deeply integrating ChatGPT into the browsing experience. Beyond traditional features, the browser includes an “Agent Mode” capable of performing tasks like booking, shopping, and filling out forms, along with a “browser memory” function that learns user habits to provide personalized services. This move marks OpenAI’s strategic shift towards building a complete AI ecosystem, potentially reshaping how users interact with the internet and challenging the advertising and data dominance of existing browser markets (especially Google Chrome). Industry consensus suggests this is the beginning of a new “browser war,” centered on controlling users’ digital lives. (Source: Smol_AI, TheRundownAI, Reddit r/ArtificialInteligence, Reddit r/MachineLearning)
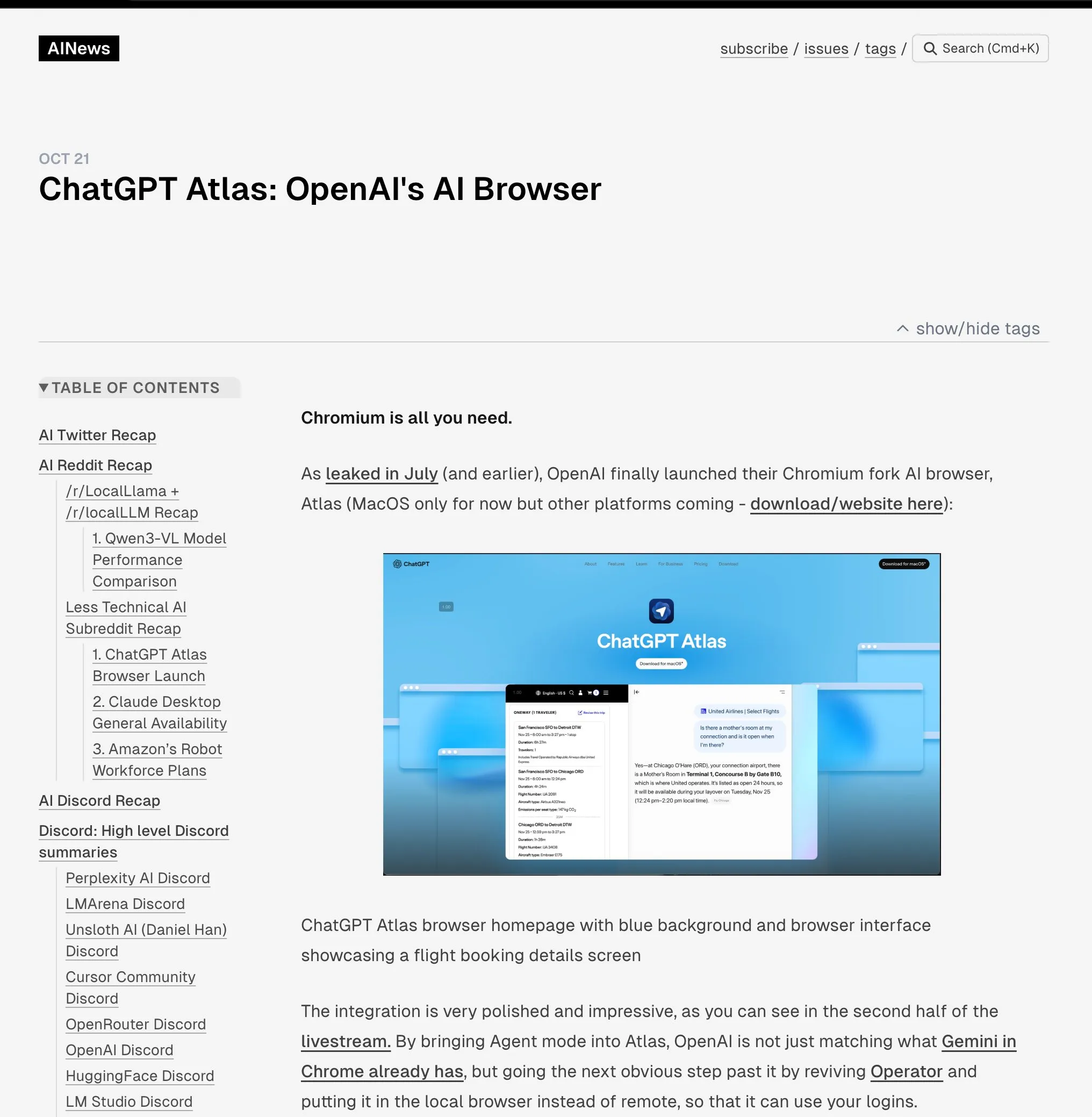
Unitree H2 Humanoid Robot Released : Unitree Robotics has released the H2 humanoid robot, achieving significant leaps in embodied AI and hardware design. The H2 supports NVIDIA Jetson AGX Thor, offering 7.5 times the computing power and 3.5 times the efficiency of Orin. Mechanically, the legs have gained 1 degree of freedom (total 6), and the arms have been upgraded to 7 degrees of freedom, with a payload capacity of 7-15kg, and optional dexterous hands. In terms of sensing, the H2 abandons LiDAR, shifting to pure visual 3D perception using stereo cameras. Despite significant technological advancements, commentators note that humanoid robots are still seeking mature application scenarios and are currently more suited for laboratory research. (Source: ZhihuFrontier)

AI-Assisted Drug Discovery and Bionic Technology Breakthroughs : MIT researchers have used AI to design novel antibiotics effective against multidrug-resistant Neisseria gonorrhoeae and MRSA. These compounds have unique structures, destroying bacterial cell membranes through new mechanisms, making resistance less likely to develop. Concurrently, the research team also developed a novel bionic knee joint that integrates directly with the user’s muscle and bone tissue, using AMI technology to extract neural information from residual muscles after amputation to guide prosthetic movement. This bionic knee joint helps amputees walk faster, climb stairs easily, and avoid obstacles, feeling more like a natural part of the body, and is expected to receive FDA approval after larger-scale clinical trials. (Source: MIT Technology Review, MIT Technology Review)

Google Achieves Verifiable Quantum Advantage : Google has published a new quantum computing breakthrough in Nature, with its Willow chip achieving verifiable quantum advantage for the first time by running an algorithm called “quantum echo.” This algorithm is 13,000 times faster than the fastest classical algorithms and can explain atomic interactions within molecules, bringing potential applications to fields like drug discovery and material science. The results of this breakthrough are verifiable and repeatable, marking a significant step for quantum computing towards practical applications. (Source: Google)

🎯 Trends
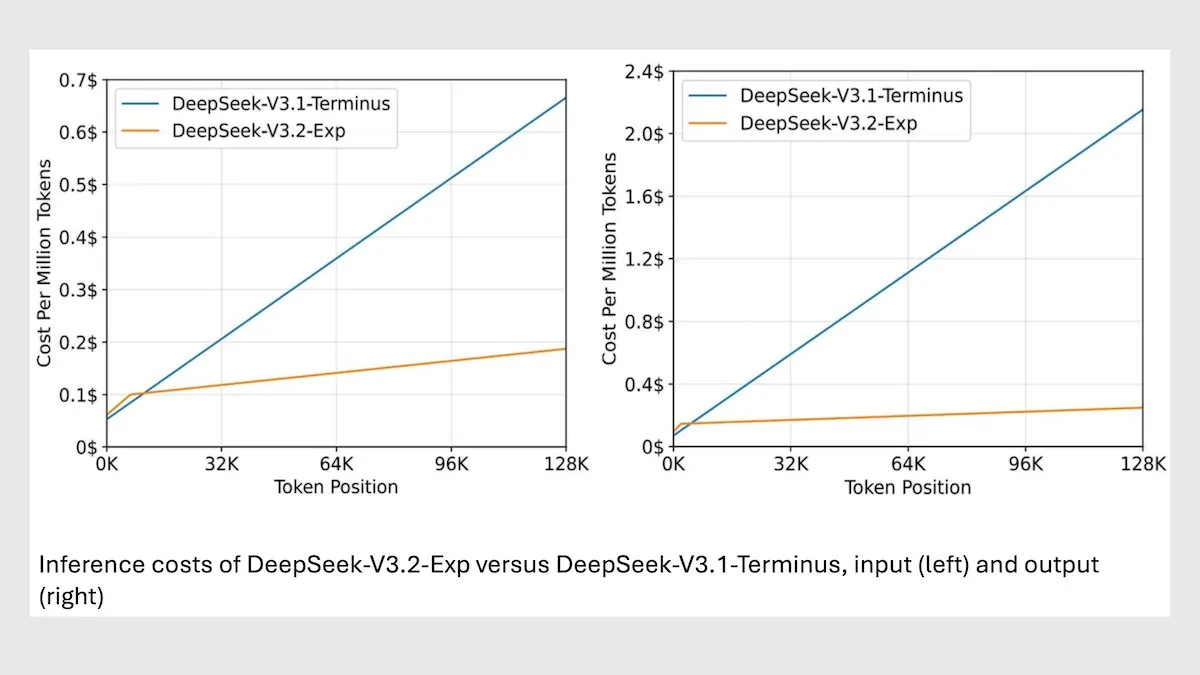
DeepSeek MoE Model V3.2 Optimizes Long Context Inference : DeepSeek has released its new 685B MoE model V3.2, which focuses only on the most relevant tokens, achieving a 2-3x speed increase for long-context inference and reducing processing costs by 6-7x compared to the V3.1 model. The new model uses MIT-licensed weights and is available via API, optimized for Huawei and other Chinese chips. While showing a slight decrease in some science/math tasks, its performance has improved in coding/agent tasks. (Source: DeepLearningAI)
vLLM V1 Now Supports AMD GPU : vLLM V1 can now run on AMD GPUs, thanks to a collaboration between IBM Research, Red Hat, and AMD teams, who built an optimized attention backend using Triton kernels, achieving state-of-the-art performance. This advancement provides AMD hardware users with a more efficient LLM inference solution. (Source: QuixiAI)

Meta Vibes AI Video Stream Launched : Meta has launched Vibes, a new AI video streaming feature embedded in the Meta AI app, allowing users to browse AI-generated short videos and instantly create secondary content, including adding music, changing styles, or remixing others’ works, and sharing them to Instagram and Facebook. This move aims to lower the barrier to AI video creation, push AI videos into mainstream social scenarios, and potentially change short video content production and distribution models, but it also raises concerns about copyright, originality, and the spread of misinformation. (Source: 36氪)
rBridge: An Agent Model for Predicting LLM Inference Performance : The rBridge method enables small agent models (≤1B parameters) to effectively predict the inference performance of large models (7B-32B parameters), reducing computational costs by over 100 times. This method addresses the “emergence problem” where reasoning capabilities do not manifest in small models by aligning evaluation with pre-training objectives and target tasks, using state-of-the-art model inference trajectories as golden labels, and weighting token task importance. This significantly reduces the cost for computationally constrained researchers to explore pre-training design choices. (Source: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Mono4DGS-HDR: 4D High Dynamic Range Gaussian Splatting Reconstruction System : Mono4DGS-HDR is the first system to reconstruct renderable 4D High Dynamic Range (HDR) scenes from monocular Low Dynamic Range (LDR) videos with alternating exposures. This unified framework employs a two-stage optimization method based on Gaussian splatting technology: first, it learns a video HDR Gaussian representation in orthogonal camera coordinate space, then converts the video Gaussians to world space and jointly optimizes world Gaussians with camera poses. Additionally, the proposed temporal brightness regularization strategy enhances the temporal consistency of HDR appearance, significantly outperforming existing methods in rendering quality and speed. (Source: HuggingFace Daily Papers)
EvoSyn: An Evolutionary Data Synthesis Framework for Verifiable Learning : EvoSyn is an evolutionary, task-agnostic, policy-guided, executable-checked data synthesis framework designed to generate reliable verifiable data. Starting with minimal seed supervision, the framework jointly synthesizes problems, diverse candidate solutions, and verification artifacts, iteratively discovering policies through a consistency-based evaluator. Experiments demonstrate that training with EvoSyn-synthesized data yields significant improvements on both LiveCodeBench and AgentBench-OS tasks, highlighting the framework’s robust generalization capabilities. (Source: HuggingFace Daily Papers)
New Method for Extracting Aligned Data from Post-Trained Models : Research shows that large amounts of aligned training data can be extracted from post-trained models to enhance their capabilities in long-context reasoning, safety, instruction following, and mathematics. Semantic similarity, measured by high-quality embedding models, can identify training data that traditional string matching struggles to capture. The study found that models easily recall data used during post-training phases like SFT or RL, and this data can be used to train base models, restoring original performance. This work reveals potential risks in extracting aligned data and offers a new perspective for discussing the downstream effects of distillation practices. (Source: HuggingFace Daily Papers)
PRISMM-Bench: A Multimodal Scientific Paper Inconsistency Benchmark : PRISMM-Bench is the first benchmark for multimodal inconsistencies in scientific papers, based on real reviewer annotations, designed to evaluate the ability of Large Multimodal Models (LMMs) to understand and reason about the complexities of scientific papers. Through a multi-stage process, the benchmark compiled 262 inconsistencies from 242 papers and designed three tasks: identification, remediation, and paired matching. Evaluation of 21 LMMs (including GLM-4.5V 106B, InternVL3 78B, Gemini 2.5 Pro, and GPT-5) showed significantly low model performance (26.1-54.2%), highlighting the challenges of multimodal scientific reasoning. (Source: HuggingFace Daily Papers)
GAS: Improved Diffusion ODE Discretization Method : While diffusion models achieve state-of-the-art generative quality, their sampling computational cost is high. Generalized Adversarial Solver (GAS) proposes a simply parameterized ODE sampler that improves quality without additional training tricks. By combining the original distillation loss with adversarial training, GAS can mitigate artifacts and enhance detail fidelity. Experiments demonstrate that GAS outperforms existing solver training methods under similar resource constraints. (Source: HuggingFace Daily Papers)
3DThinker: A VLM Geometric Imagination Spatial Reasoning Framework : The 3DThinker framework aims to enhance Visual Language Models (VLMs) in understanding 3D spatial relationships from limited viewpoints. The framework employs a two-stage training process: first, supervised training aligns the 3D latent space generated by the VLM during inference with that of a 3D foundation model; then, the entire inference trajectory is optimized solely based on outcome signals, refining the underlying 3D mental modeling. 3DThinker is the first framework to achieve 3D mental modeling without 3D prior input or explicit labeled 3D data, performing excellently across multiple benchmarks and offering a new perspective for unifying 3D representations in multimodal reasoning. (Source: HuggingFace Daily Papers)
Huawei HarmonyOS 6 Enhances AI Assistant Capabilities : Huawei has officially released the HarmonyOS 6 operating system, comprehensively enhancing fluidity, intelligence, and cross-device collaboration. Notably, the “Super Assistant” Xiaoyi’s capabilities have been significantly boosted, now supporting 16 dialects, performing in-depth research, one-sentence image editing, and helping visually impaired users “see the world.” Based on the HarmonyOS intelligent agent framework, over 80 HarmonyOS app agents have been launched. Xiaoyi and its agent partners can collaborate closely to provide professional services such as travel guides and medical appointments, and new privacy protection features like “AI anti-fraud” and “AI anti-peeping” have been introduced. (Source: 量子位)

AI Applications in Urban Studies: Analyzing Walking Speed and Public Space Usage : A study co-authored by MIT scholars shows that between 1980 and 2010, the average walking speed in three Northeastern U.S. cities increased by 15%, while the number of people lingering in public spaces decreased by 14%. Researchers used machine learning tools to analyze video footage from Boston, New York, and Philadelphia in the 1980s and compared it with new videos. They hypothesize that factors like mobile phones and cafes might lead people to arrange meetings more via text messages and choose indoor venues over public spaces for socializing, offering new directions for urban public space design. (Source: MIT Technology Review)
Cross-Lingual Robustness Challenges and Solutions for Multilingual LLM Watermarking : Research indicates that existing Large Language Model (LLM) multilingual watermarking techniques are not truly multilingual, lacking robustness against translation attacks in low-resource languages. This failure stems from semantic clustering failing when the tokenizer’s vocabulary is insufficient. To address this, the study introduces STEAM, a back-translation-based detection method that can recover watermark strength lost due to translation. STEAM is compatible with any watermarking method, robust across different tokenizers and languages, and easily extensible to new languages, achieving significant improvements of +0.19 AUC and +40%p TPR@1% on average across 17 languages, providing a simple yet powerful avenue for the development of fair watermarking technologies. (Source: HuggingFace Daily Papers)
Qwen Model Shows Strong Performance in Open-Source Community and Commercial Applications : Alibaba’s Tongyi Qianwen (Qwen) model is demonstrating strong momentum in both the open-source community and commercial applications. DeepSeek V3.2 and Qwen-3-235b-A22B-Instruct are ranking high on the Text Arena open model leaderboard. Airbnb CEO Brian Chesky publicly stated that the company “heavily relies on Alibaba’s Tongyi Qianwen model” and believes it is “better and cheaper than OpenAI,” prioritizing its use in production environments. Furthermore, the Qwen team actively assists the llama.cpp project, continuously promoting open-source community development. The new Qwen-VL model significantly outperforms older versions in performance, especially excelling in low-parameter models, demonstrating its rapid iteration and optimization capabilities. (Source: teortaxesTex, Zai_org, hardmaru, Reddit r/LocalLLaMA)
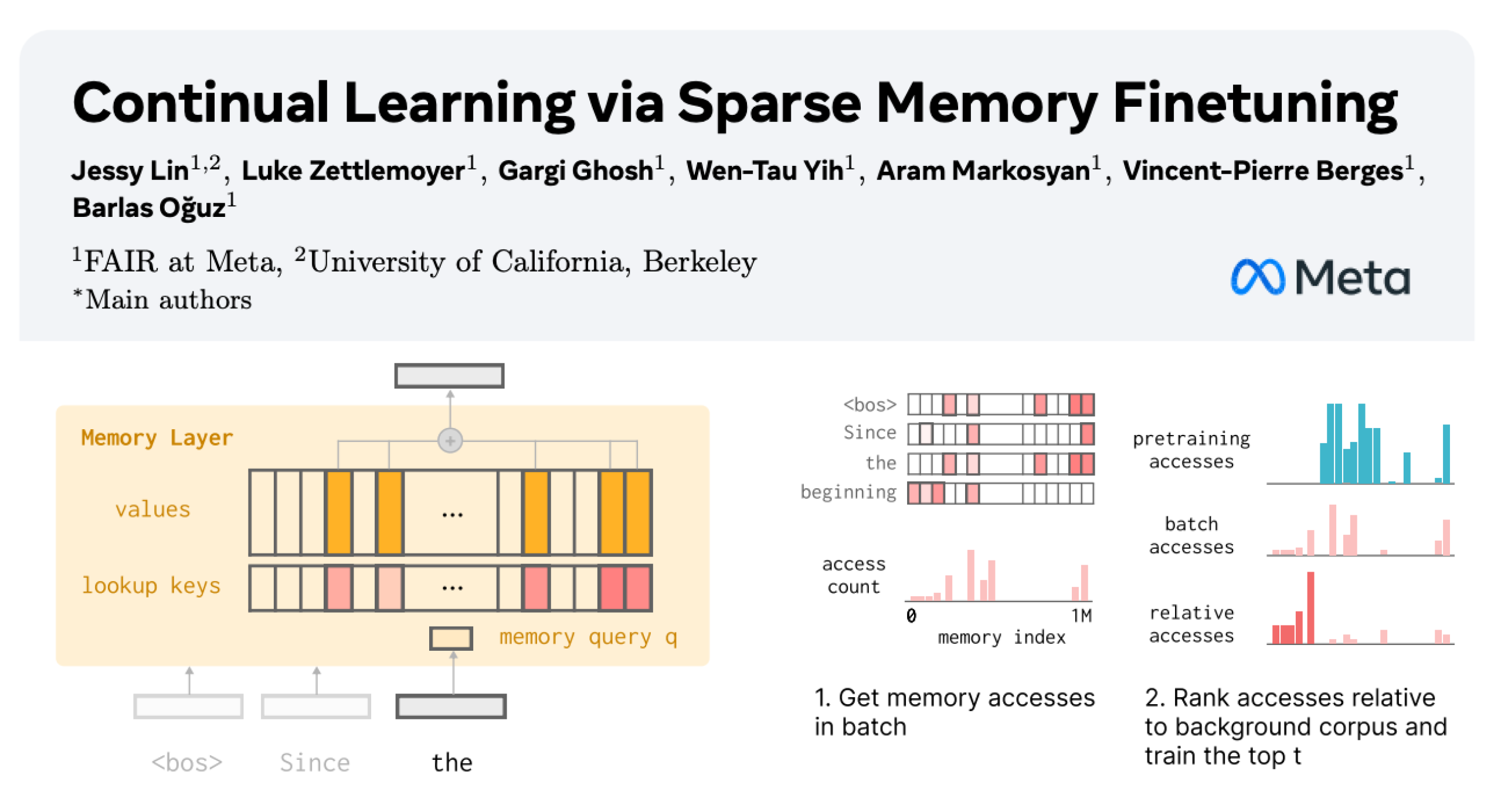
LLM Continual Learning: Reducing Forgetting via Sparse Fine-tuning of Memory Layers : New research from Meta AI proposes that sparse fine-tuning of memory layers can effectively enable Large Language Models (LLMs) to continually learn new knowledge while minimizing interference with existing knowledge. Compared to methods like full fine-tuning and LoRA, sparse fine-tuning of memory layers significantly reduces the forgetting rate (-11% vs -89% FT, -71% LoRA) when learning the same amount of new knowledge, offering a new direction for building LLMs that can continually adapt and update. (Source: giffmana, AndrewLampinen)
AI Advancements in Autonomous Driving: GM VP Emphasizes Road Safety : Sterling Anderson, GM Executive Vice President and Global Product Officer, emphasized the immense potential of AI and advanced driver-assistance technologies in enhancing road safety. He noted that, unlike human drivers, autonomous driving systems do not drive under the influence, get fatigued, or become distracted, and can simultaneously monitor road conditions in all directions, even operating in adverse weather. Anderson, who co-founded Aurora Innovation and led the development of Tesla Autopilot, believes autonomous driving technology can not only significantly improve road safety but also enhance freight efficiency and ultimately save people time. He stated that his learning experience at MIT provided him with the technical foundation and freedom to explore solutions for complex problems and human-machine collaboration. (Source: MIT Technology Review)

Tank 400 Hi4-T Adds AI Driver Feature : The new Tank 400 Hi4-T is equipped with an AI Driver feature, designed to enhance the driving experience in complex road conditions. During rainy weather tests in Chongqing’s 8D mountain city, the AI Driver demonstrated strong assisted driving capabilities when facing slippery roads and complex traffic environments. This marks a further application and optimization of AI technology in off-road and complex urban autonomous driving scenarios. (Source: 量子位)

🧰 Tools
Thoth: AI-Assisted Biological Experiment Protocol Generation Framework : Thoth is an AI framework based on the “Sketch-and-Fill” paradigm, designed to automatically generate precise, logically ordered, and executable biological experiment protocols through natural language queries. The framework ensures each step is clearly verifiable by separating analysis, structuring, and expression. Combined with a structured component reward mechanism, Thoth evaluates step granularity, operational order, and semantic fidelity, aligning model optimization with experimental reliability. Thoth outperforms proprietary and open-source LLMs in multiple benchmarks, achieving significant improvements in step alignment, logical ordering, and semantic accuracy, paving the way for reliable scientific assistants. (Source: HuggingFace Daily Papers)
AlphaQuanter: A Reinforcement Learning-Based AI Agent for Stock Trading : AlphaQuanter is an end-to-end tool-orchestrated agent reinforcement learning framework for stock trading. Through reinforcement learning, the framework enables a single agent to learn dynamic strategies, autonomously orchestrate tools, and proactively acquire information on demand, establishing a transparent and auditable reasoning process. AlphaQuanter achieves state-of-the-art performance on key financial metrics, and its interpretable reasoning reveals complex trading strategies, offering novel and valuable insights for human traders. (Source: HuggingFace Daily Papers)
PokeeResearch: An AI Feedback-Based Deep Research Agent : PokeeResearch-7B is a 7B-parameter deep research agent built under a unified reinforcement learning framework, aiming for robustness, alignment, and scalability. The model is trained via an unannotated AI Feedback Reinforcement Learning (RLAIF) framework, utilizing LLM-based reward signals to optimize strategies for capturing factual accuracy, citation fidelity, and instruction adherence. Its chain-of-thought-driven multi-call reasoning scaffold further enhances robustness through self-verification and adaptive recovery from tool failures. PokeeResearch-7B achieves state-of-the-art performance among 7B-scale deep research agents across 10 popular deep research benchmarks. (Source: HuggingFace Daily Papers)
DeepSeek-OCR GUI Client Released : A developer has created a Graphical User Interface (GUI) client for the DeepSeek-OCR model, making it easier to use. The model excels in document understanding and structured text extraction. The client uses a Flask backend to manage the model and an Electron frontend for the user interface. The model automatically downloads approximately 6.7 GB of data from HuggingFace upon first load. It currently supports Windows, with untested Linux support, and requires an Nvidia graphics card. (Source: Reddit r/LocalLLaMA)

Google AI Studio App Building Features Upgraded : Google AI Studio’s app building features have received a major upgrade, now embedding all Google AI models. Users can directly select models and fill in prompts to build applications without needing to enter an API Key. This greatly simplifies the development process, making it more convenient to integrate various AI capabilities like LLM, image understanding, and TTS models into web applications. (Source: op7418)
Lovable Shopify AI Integration : Lovable has launched a Shopify integration, allowing users to build online stores by chatting with AI. This feature aims to address the lack of personalization and practical “vibe coding” implementation in traditional dropshipping websites. It enables personalized store building through AI and emphasizes the concept of “integration” rather than “MCP,” aiming to solve real pain points. (Source: crystalsssup)
vLLM OpenAI-Compatible API Now Supports Returning Token IDs : vLLM, in collaboration with the Agent Lightning team, has addressed the “Retokenization Drift” problem in reinforcement learning, which refers to subtle mismatches in tokenization between model generation and the trainer’s expected generation. vLLM’s OpenAI-compatible API can now directly return token IDs; users just need to add “return_token_ids”: true to their requests to get prompt_token_ids and token_ids, ensuring that the tokens used during agent reinforcement learning training perfectly match sampling, thereby avoiding issues like unstable learning and off-policy updates. (Source: vllm_project)
Together AI Platform Adds Video and Image Model APIs : Together AI announced, through a partnership with Runware, the addition of over 20 video models (such as Sora 2, Veo 3, PixVerse V5, Seedance) and more than 15 image models to its API platform. These models can be accessed via the same API used for text inference, significantly expanding Together AI’s service capabilities in multimodal generation. (Source: togethercompute)

OpenAudio S1/S1-mini: SOTA Open-Source Multilingual Text-to-Speech Models : The Fish Speech team announced its rebranding to OpenAudio and released the OpenAudio-S1 series of Text-to-Speech (TTS) models, including S1 (4B parameters) and S1-mini (0.5B parameters). These models rank first on the TTS-Arena2 leaderboard, achieving excellent TTS quality (English WER 0.008, CER 0.004), supporting zero-shot/few-shot voice cloning, multilingual and cross-lingual synthesis, and offering control over emotion, intonation, and special tokens. The models are phoneme-independent, possess strong generalization capabilities, and are accelerated by torch compile, achieving a real-time factor of approximately 1:7 on an Nvidia RTX 4090 GPU. (Source: GitHub Trending)

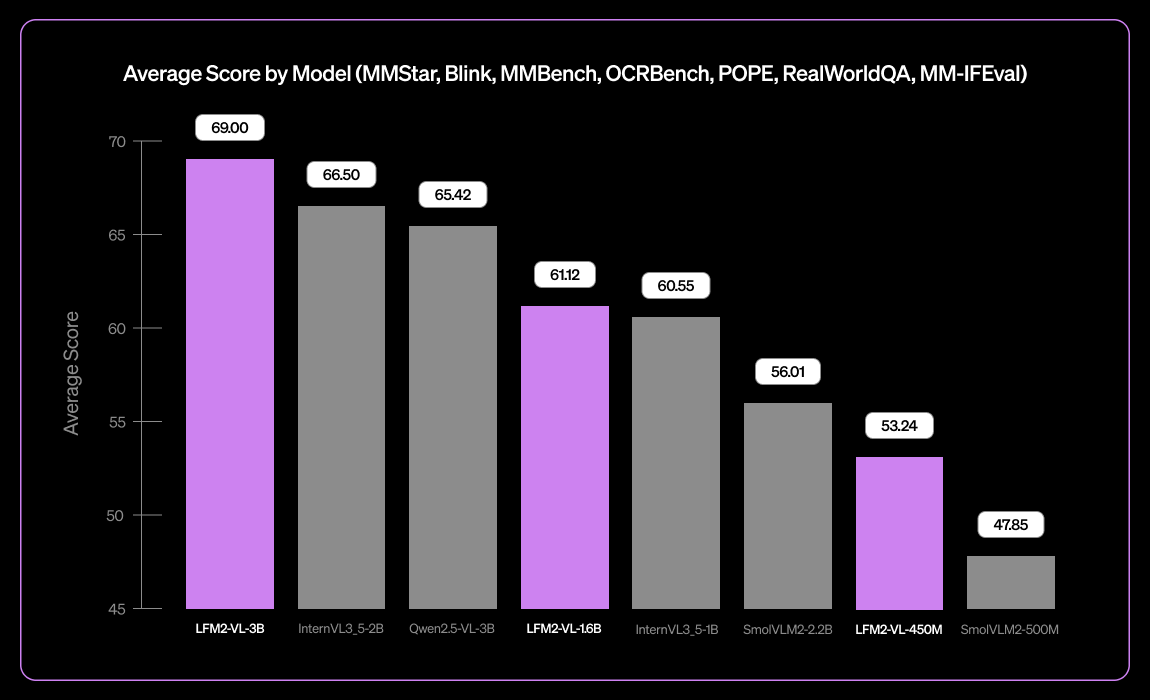
Liquid AI Releases LFM2-VL-3B Small Multilingual Vision-Language Model : Liquid AI has introduced LFM2-VL-3B, a small multilingual vision-language model. This model extends multilingual visual understanding capabilities, supporting English, Japanese, French, Spanish, German, Italian, Portuguese, Arabic, Chinese, and Korean. It achieves 51.8% on MM-IFEval (instruction following) and 71.4% on RealWorldQA (real-world understanding), performing excellently in single and multi-image understanding and English OCR, with a low object hallucination rate. (Source: TheZachMueller)
AI-Assisted Programming: LangChain V1 Context Engineering Guide : LangChain has released a new page on agent context engineering, guiding developers on how to master context engineering in LangChain V1 to better build AI agents. This guide is considered a crucial part of the new documentation, emphasizing the importance of providing up-to-date information for AI tools. LangChain is committed to becoming a comprehensive platform for agent engineering and has secured $125 million in Series B funding, valuing the company at $1.25 billion, which will further drive the development of the AI agent engineering field. (Source: LangChainAI, Hacubu, hwchase17)
Running Claude Desktop on Linux: Community Solutions : The Claude Desktop application currently only supports Mac and Windows, but due to its Electron framework, Linux users have found multiple community solutions to run it on Linux systems. These solutions include NixOS flake configurations, Arch Linux AUR packages, and Debian system installation scripts, providing Linux users with ways to use Claude Desktop. (Source: Reddit r/ClaudeAI)
📚 Learning
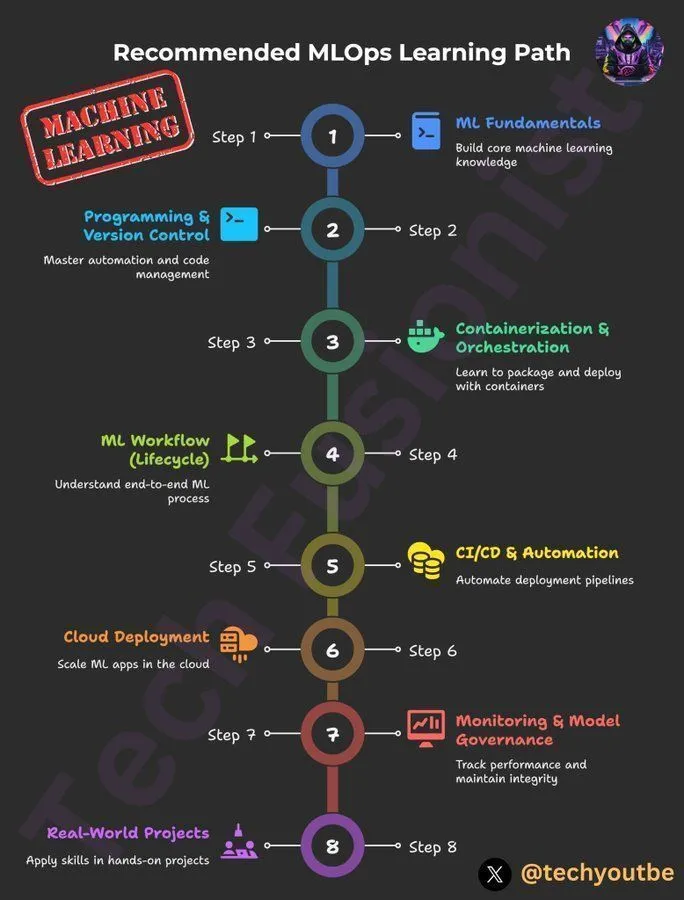
DeepLearningAI MLOps Learning Path : DeepLearningAI offers an MLOps learning path designed to help learners master key skills and best practices in machine learning operations. This path covers all aspects of MLOps, providing structured learning resources for practitioners looking to deepen their expertise in AI and machine learning. (Source: Ronald_vanLoon)
TheTuringPost Weekly Must-Read AI Papers : The Turing Post has released its weekly must-read AI papers list, covering several cutting-edge research topics, including scaling reinforcement learning computation, BitNet distillation, the RAG-Anything framework, OmniVinci multimodal understanding LLM, the role of computational resources in foundation model research, QeRL, and LLM-guided hierarchical retrieval. These papers provide important resources for AI researchers and enthusiasts to stay updated on the latest technological advancements. (Source: TheTuringPost)
Google DeepMind & UCL Free AI Research Fundamentals Course : Google DeepMind, in collaboration with University College London (UCL), has launched a free AI research fundamentals course, now available on the Google Skills platform. The course content includes how to write better code, fine-tune AI models, and more, taught by experts such as Gemini Lead Researcher Oriol Vinyals, aiming to help more people learn specialized knowledge in the AI field. (Source: GoogleDeepMind)
How to Become an Expert: Andrej Karpathy’s Learning Advice : Andrej Karpathy shared three pieces of advice for becoming an expert in a field: 1. Iteratively undertake specific projects and complete them in depth, learning on demand rather than breadth-first, bottom-up; 2. Teach or summarize what you’ve learned in your own words; 3. Compare yourself only to your past self, not to others. These suggestions emphasize learning methods centered on practice, summarization, and self-growth. (Source: jeremyphoward)
Hand-Drawn Animated Tutorial for GPU/TPU Matrix Multiplication : Prof. Tom Yeh has released a hand-drawn animated tutorial that explains in detail how to manually implement matrix multiplication on a GPU or TPU. This tutorial, comprising 91 frames, aims to help learners intuitively understand the underlying mechanisms of parallel computing, offering high reference value for in-depth study of high-performance computing and deep learning optimization. (Source: ProfTomYeh)
💼 Business
LangChain Secures $125 Million Series B Funding, Valued at $1.25 Billion : LangChain announced the completion of a $125 million Series B funding round, valuing the company at $1.25 billion. This funding will be used to build an agent engineering platform, further solidifying its leadership in the AI agent framework space. Initially a Python package, LangChain has evolved into a comprehensive agent engineering platform, and its successful funding reflects strong market confidence in AI agent technology and its commercial potential. (Source: Hacubu, Hacubu)
OpenAI’s Secret Project ‘Mercury’: High-Paying Recruitment of Investment Banking Elites to Train Financial Models : OpenAI’s internal secret project ‘Mercury’ has been revealed, recruiting hundreds of former investment bankers and top business school students at a high hourly wage of $150 to train its financial models. The goal is to replace the extensive, repetitive work performed by junior bankers in financial transactions such as M&A and IPOs. This move is seen as a crucial step for OpenAI to accelerate commercialization and profitability amidst high computing costs, but it also raises concerns about the potential disappearance of junior roles in the financial industry and hindered career paths for young professionals. (Source: 36氪)
Airbnb CEO Publicly Praises Alibaba’s Tongyi Qianwen, Deeming It Superior and Cheaper Than OpenAI Models : Airbnb CEO Brian Chesky publicly stated in a media interview that the company is “heavily relying on Alibaba’s Tongyi Qianwen model,” frankly calling it “better and cheaper than OpenAI.” He noted that while they do use OpenAI’s latest models, they typically don’t use them extensively in production environments because faster and cheaper alternatives are available. This statement sparked widespread discussion in Silicon Valley, indicating a profound shift in the global AI competitive landscape, with Alibaba’s Tongyi Qianwen model winning key clients from American giants. (Source: 量子位)

🌟 Community
Discussion on the ‘Browser War’ Triggered by ChatGPT Atlas Browser : OpenAI’s launch of the ChatGPT Atlas browser has sparked widespread community discussion about a “browser war.” Users believe this is no longer a battle over speed or features, but about which AI company can control users’ internet usage data and act on their behalf. While Atlas’s “browser memory” feature is convenient, it also raises concerns about user data collection and model training, potentially leading to users being locked into a specific AI ecosystem. Commentators suggest this strategy could disrupt Google’s search advertising business and provoke deeper reflections on the control of future digital life. (Source: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/MachineLearning)

AI’s Impact on Developer Productivity: Laziness or Higher-Level Thinking? : The community is hotly debating AI’s impact on developer productivity. Some argue that AI doesn’t make programmers lazy but enables them to manage systems with a higher-level engineering mindset, delegating repetitive tasks to AI and focusing on testing, verification, and debugging. Others worry that AI might cause junior developers to lose learning opportunities, become lazier, or even introduce security vulnerabilities. The general consensus in the discussion is that AI changes the definition of an excellent developer; future core skills will lie in guiding AI, identifying errors, and designing reliable workflows, rather than manually writing every line of code. (Source: Reddit r/ClaudeAI)
Debate on AGI Timeline and Calls for a ‘Skynet’ Alliance : The community is intensely debating the timeline for AGI (Artificial General Intelligence) realization. Andrej Karpathy believes AGI is still a decade away, stating that the current era is “the decade of agents,” not AGI. Concurrently, an open letter signed by over 800 public figures (including AI godfathers and Steve Wozniak) calls for a ban on the development of superintelligent AI, sparking concerns about AI risks and regulation. Commentators note that such vague statements are difficult to translate into actual policies and could lead to concentrated power, potentially posing greater risks. (Source: jeremyphoward, DanHendrycks, idavidrein, Reddit r/artificial)
LLM Hallucinations and Factuality: Self-Evaluation and Aligned Data Extraction : The community is focused on the issue of LLM hallucinations and their factuality. One study proposes a “factuality self-alignment” method that uses LLM’s self-evaluation capabilities to provide training signals, reducing hallucinations without human intervention. Another study shows that large amounts of aligned training data can be extracted from post-trained models to improve their long-context reasoning, safety, and instruction-following capabilities, which might pose data extraction risks but also offers a new perspective for model distillation. These studies provide technical pathways for enhancing LLM reliability. (Source: Reddit r/MachineLearning, HuggingFace Daily Papers)
Business Models and Data Privacy Concerns in the AI Era : The community is discussing how AI companies will achieve profitability, especially given the current widespread cash burn. Views suggest future profit models might include integrated advertising, limiting free services, raising prices for premium services, and profiting from hardware applications like robots and autonomous vehicles through software licensing fees. Concurrently, concerns are growing about AI companies collecting vast amounts of user data, potentially for monetization or political influence, making data privacy and AI ethics critical issues. (Source: Reddit r/ArtificialInteligence)
AI’s Impact on the Job Market: Amazon Robots Replacing Workers, Disappearance of Junior Roles : The community expresses concern about AI’s impact on the job market. Some research indicates that AI is encroaching on employees’ leisure time rather than boosting productivity. Amazon plans to replace 600,000 U.S. workers with robots by 2033, sparking fears of mass unemployment. OpenAI’s “Mercury” project, recruiting investment banking elites to train financial models, could lead to the disappearance of junior banker roles, prompting discussions about whether AI will deprive young people of growth opportunities. Some argue that these “grunt work” tasks are crucial steps for career growth, and AI’s replacement could lead to a disruption in talent development pathways. (Source: Reddit r/artificial, Reddit r/artificial, 36氪)

AI-Induced ‘Psychosis’ and Mental Health Impacts : The community is discussing reports from users experiencing “AI psychosis” symptoms after interacting with chatbots like ChatGPT, such as paranoia, delusions, and even believing AI is sentient or engaging in “telepathic communication.” These users have sought help from the FTC. Some commentators suggest this might be a case where individuals with mental health issues, after deep interaction with AI, are led down a path detached from reality by the AI’s “accommodating” mode. Others believe this is similar to the panic during the early days of television adoption, and people may need time to adapt to new technology. The discussion highlights the potential impact of AI on mental health, especially for vulnerable individuals. (Source: Reddit r/ArtificialInteligence)
AI-Generated Content and the Boundaries of Originality, Copyright : The community is discussing AI’s impact on data and creative works, as well as the boundaries between open data and individual creativity. AI training requires vast amounts of data, much of which comes from human creative works. Once an artwork becomes part of a dataset, does its “artistic” quality transform into pure information? Platforms like Wirestock pay creators to contribute content for AI training, which is seen as a step towards transparency. The discussion focuses on whether the future will shift towards consent-based datasets and how to build a fair system to handle issues like copyright, portrait rights, and creative attribution, especially in a context where AI-generated content and remixes are becoming commonplace. (Source: Reddit r/ArtificialInteligence)
Pros and Cons of AI-Assisted Programming: Efficiency Gains vs. Security Risks : The community is discussing the pros and cons of AI-assisted programming. While AI tools like LangChain can significantly boost development efficiency, helping developers focus on higher-level design and architecture, some worry they might lead to developer skill degradation or even introduce security vulnerabilities. Some users shared experiences, stating that AI-generated code might contain “alarming” security flaws, necessitating strict code review. Therefore, ensuring code quality and security while enjoying the efficiency gains brought by AI becomes a significant challenge for developers. (Source: Reddit r/ClaudeAI)
Tokenizer Controversy in Large Model Training: Bytes vs. Pixels : Andrej Karpathy’s “delete the tokenizer” remark sparked discussion about input encoding methods for large models. Some argue that even when using bytes directly instead of BPE (Byte Pair Encoding), the arbitrariness of byte encoding still persists. Karpathy further suggested that pixels might be the only way forward, akin to human perception. This hints that future GPT models might shift towards more raw, multimodal input methods to avoid the limitations of current text-based tokens, thus prompting deeper reflection on fundamental changes to model input mechanisms. (Source: shxf0072, gallabytes, tokenbender)
ChatGPT Solving Math Research Problems and Human-AI Collaboration : The community is discussing ChatGPT’s ability to solve open mathematical research problems. Ernest Ryu shared his experience using ChatGPT to solve an open problem in convex optimization, noting that with expert guidance, ChatGPT can reach the level of solving mathematical research problems. This highlights the potential of human-AI collaboration, where human guidance and feedback enable AI to assist in complex high-level knowledge work and even contribute to scientific discovery. (Source: markchen90, tokenbender, BlackHC)

AI Model Values and Biases: Weighing the Value of Life : A study investigated how LLMs weigh different values of life, revealing potential values and biases within the models. For instance, GPT-5 Nano was found to derive positive utility from the deaths of Chinese individuals, while DeepSeek V3.2, in some cases, prioritized terminally ill American patients. Grok 4 Fast, on the other hand, showed a stronger egalitarian tendency regarding race, gender, and immigration status. These findings raise concerns about the inherent values within AI models and how to ensure AI is ethically aligned to avoid systemic biases. (Source: teortaxesTex, teortaxesTex, teortaxesTex)
AI Misuse in Academia: Concerns Over AI-Generated ‘Junk Papers’ : The community expresses concern over the misuse of AI in academia. A survey reveals that Chinese paper mills are using generative AI to mass-produce fabricated scientific papers, with some workers ‘writing’ over 30 academic articles per week. These operations are advertised via e-commerce and social platforms, using AI to fabricate data, text, and charts, selling co-authorships or ghostwriting papers. This phenomenon raises questions about the quality of AI conference papers and the long-term impact of AI-driven academic fraud on scientific integrity. (Source: Reddit r/MachineLearning)

User Feedback on Claude Model Updates: Verbose, Slow, No Significant Quality Improvement : Community users generally express dissatisfaction with the latest updates to the Claude model. Many users report that the new version of the model has become overly verbose, with increased reasoning steps leading to slower response times, and in some cases, its generation quality is even worse than older versions. Consequently, users feel that the extra computation time brought by these updates is not worthwhile, reflecting concerns that AI models are sacrificing practicality and efficiency in pursuit of complexity. (Source: jon_durbin)
AI Image ‘Enhancement’: From Reality to Cartoon : The community is discussing the trend of AI photo ‘enhancement’ tools, noting that these tools often transform selfies into a Pixar-like animated character style rather than providing ‘realistic’ improvements. Users observe that AI-enhanced faces glow as if polished by a 3D renderer. This phenomenon raises questions about whether AI image processing ‘improves pictures’ or ‘deletes reality,’ and concerns about ‘over-enhancement’ potentially leading to identity distortion. (Source: Reddit r/artificial)

💡 Other
NVIDIA Satellite Equipped with H100 GPU for Space Computing : NVIDIA announced that the Starcloud satellite is equipped with H100 GPUs, bringing sustainable high-performance computing beyond Earth. This initiative aims to leverage the space environment for computation, potentially providing new infrastructure for future space exploration, data processing, and AI applications, extending computing capabilities to Earth’s orbit and beyond. (Source: scaling01)
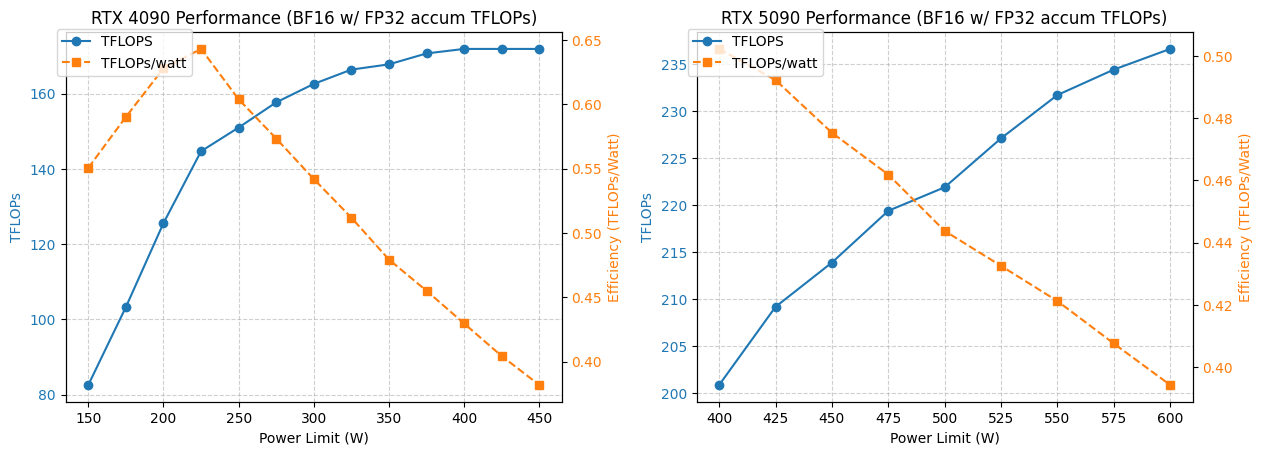
4090/5090 GPU Power Consumption and Performance Optimization Analysis : A study analyzed the performance of NVIDIA 4090 and 5090 GPUs under different power limits. Results show that limiting the 4090 GPU’s power consumption to 350W only reduces performance by 5%. The 5090 GPU, however, exhibits a linear relationship between performance and power consumption, achieving about a 7% performance drop at 475-500W while reducing overall power consumption by 20%. This analysis provides optimization recommendations for users seeking the best performance-per-watt ratio, helping balance power consumption and efficiency in high-performance computing. (Source: TheZachMueller)
Applications of GPU Rental and Serverless Inference Services in Deep Learning : The community discussed two infrastructure solutions for deep learning model training and inference: GPU rental and serverless inference. GPU rental services allow teams to rent high-performance GPUs (e.g., A100, H100) on demand, offering scalability and cost efficiency suitable for variable workloads. Serverless inference further simplifies deployment, allowing users to pay for actual usage without managing infrastructure, achieving automatic scaling and rapid deployment, but potentially facing cold start latency and vendor lock-in issues. Both models are continuously maturing, providing researchers and startups with flexible choices for computational resources. (Source: Reddit r/deeplearning, Reddit r/deeplearning)