
Keywords:Optical-based AI chip, K2 Think, Embodied intelligence, Jupyter Agent, OpenPI, Claude model, Qwen3-Next, Seedream 4.0, Energy efficiency ratio of photonic AI chips, Open-source large model inference speed, Humanoid robot emotional expression, LLM data science intelligent agent, Robot vision-language-action model
🔥 Spotlight
Light-based AI Chip Achieves Efficiency Breakthrough: A team of engineers at the University of Florida has developed a new light-based AI chip that uses photons instead of electricity for AI operations such as image recognition and pattern detection. The chip achieved 98% accuracy in digital classification tests while improving energy efficiency by up to 100 times. This breakthrough is expected to significantly reduce AI computing costs and energy consumption, promoting the greening and scalability of AI in areas from smartphones to supercomputers, and signals that hybrid optoelectronic chips will reshape the AI hardware landscape. (Source: Reddit r/ArtificialInteligence)

K2 Think: World’s Fastest Open-Source Large Model Released: MBZUAI (Mohamed bin Zayed University of Artificial Intelligence) in the UAE, in collaboration with G42 AI, has released K2 Think, an open-source large model based on Qwen 2.5-32B. It achieves a measured speed of over 2000 tokens/second, more than 10 times the throughput of typical GPU deployments. The model performs exceptionally well in mathematical benchmarks like AIME and incorporates technical innovations such as Long-Chain-of-Thought SFT, Verifiable Reward RLVR, Pre-inference Planning, Best-of-N Sampling, Speculative Decoding, and Cerebras WSE hardware acceleration, marking a new height in open-source AI inference system performance. (Source: teortaxesTex, HuggingFace)

Frontier Progress in Embodied AI and Humanoid Robots: A Zhihu roundtable discussion revealed several breakthroughs in the field of embodied AI. Tsinghua Air Lab showcased “Dexterous Face” Morpheus, which uses hybrid drive and digital human technology to achieve rich micro-expressions, aiming to enhance the emotional value of humanoid robots. Concurrently, Beijing Tiangong Ultra Robot won the 100-meter race at the Humanoid Robot World Athletics, highlighting its algorithmic and autonomous perception advantages. The discussion also covered key issues such as humanoid robot cost, mass production, control theory, and large model integration, indicating that embodied AI is moving from technological exploration to practical application. (Source: ZhihuFrontier)

Jupyter Agent: Training LLMs for Data Science Reasoning with Notebooks: Hugging Face has launched the Jupyter Agent project, aiming to empower LLMs to solve data analysis and data science tasks within Jupyter Notebooks using code execution tools. Through a multi-stage training process involving large-scale Kaggle Notebooks data cleaning, educational quality scoring, QA generation, and code execution trace generation, small models like Qwen3-4B successfully improved their performance on DABStep benchmark’s Easy tasks from 44.4% to 75%, demonstrating that small models combined with high-quality data and scaffolding can become powerful data science agents. (Source: HuggingFace Blog)
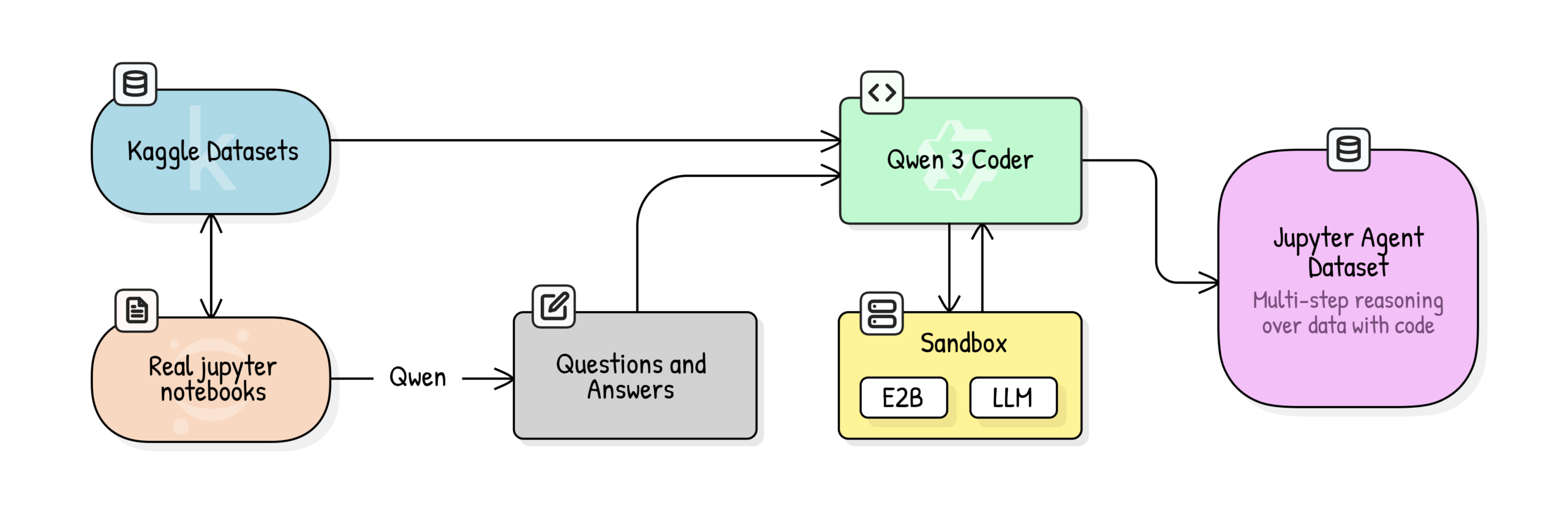
OpenPI: Open-Source Robot Vision-Language-Action Models: The Physical Intelligence team has released the OpenPI library, featuring open-source Vision-Language-Action (VLA) models such as π₀, π₀-FAST, and π₀.₅. These models are pre-trained on 10k+ hours of robot data, support PyTorch, and achieve SOTA performance on the LIBERO benchmark. OpenPI provides base model checkpoints and fine-tuning examples, supporting remote inference, aiming to promote open research and applications in robotics, especially showing potential in tasks like desktop manipulation and object grasping. (Source: GitHub Trending)
🎯 Trends
Microsoft Partners with Anthropic, Integrates Claude Model into Office 365 Copilot: Microsoft is integrating Anthropic’s Claude model into Office 365 Copilot, particularly in areas where Claude excels, such as Excel function calculations and PowerPoint slide creation. This move aims to optimize specific functionalities within Copilot for Word, Excel, and PowerPoint, enhancing user experience and expanding Claude’s application in enterprise productivity tools. (Source: dotey, alexalbert__, menhguin, TheRundownAI)

AI Accelerates Scientific Research: Knowledge Graphs and Autonomous Agents: MiniculeAI demonstrates how AI can accelerate scientific discovery through knowledge graphs and autonomous agents. By mapping genes, drugs, and outcomes into dynamic networks, AI can uncover hidden connections difficult to find in PDF documents. Autonomous agents can scan literature, discover patterns, and provide explainable insights, shortening months of traditional research to minutes while ensuring enterprise-grade data privacy. (Source: Ronald_vanLoon)
Qwen3-Next Model Series: Long Context and Parameter Efficiency Optimization: The Qwen team has launched the Qwen3-Next series of base models, focusing on extreme context length and large-scale parameter efficiency. This series introduces several architectural innovations, including GatedAttention (to address outliers) and GatedDeltaNet RNN (to save KV cache), combining Sink+SWA hybrid or Gated Attention + Linear RNN hybrid architectures. It aims to maximize performance and minimize computational cost, signaling the end of the era of pure Attention models. (Source: tokenbender, SchmidhuberAI, teortaxesTex, ClementDelangue, andriy_mulyar)
ByteDance Seedream 4.0 Image Generation and Editing Model Released: ByteDance has released Seedream 4.0, offering exceptional image generation and editing capabilities. User feedback highlights its outstanding performance in meeting user needs, RLHF aesthetic preferences, and maintaining mainstream taste. Compared to Seedream 3.0, version 4.0 adds film grain and lens artifacts, features higher contrast, sharper anime-style brushstrokes, and demonstrates strong performance in Chinese semantic understanding and consistency, making it suitable for infographics, tutorials, and product design. (Source: ZhihuFrontier, Reddit r/artificial, op7418, TomLikesRobots, dotey)
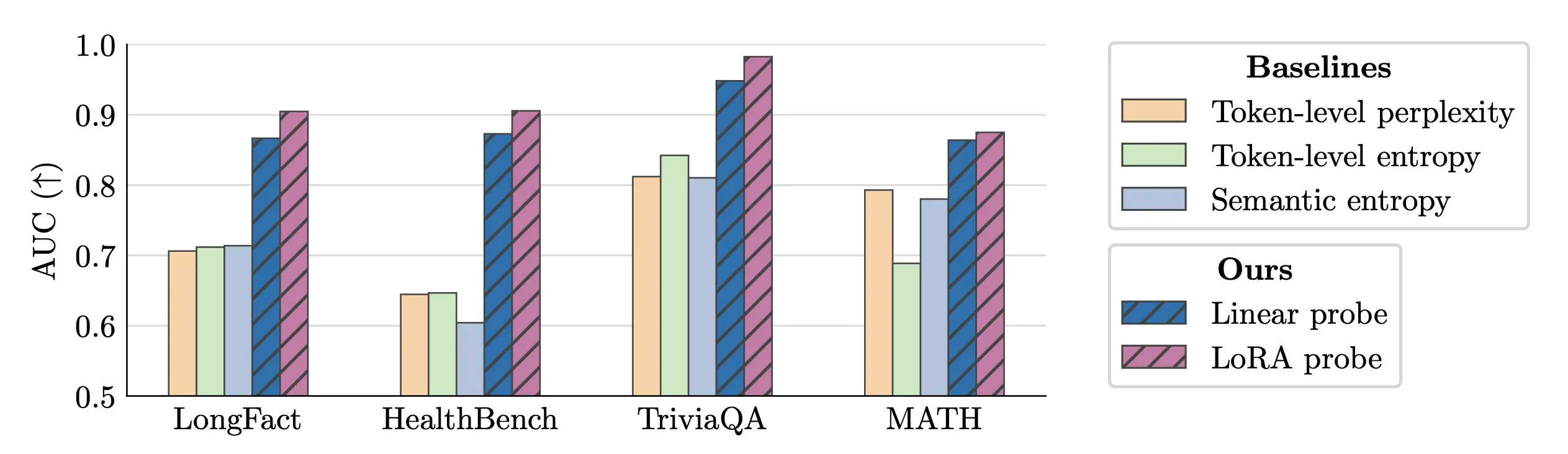
Real-time Detection of LLM Hallucinations: Researchers propose using activation probes for real-time detection of LLM hallucinations. This method performs excellently in identifying fabricated entities in long texts, achieving an AUC value of 0.90, significantly outperforming traditional semantic entropy methods. Additionally, new research delves into the origins of hallucinations in Transformer models, providing new insights for improving LLM reliability. (Source: paul_cal, tokenbender)
Microsoft VibeVoice: Long-Duration High-Fidelity Speech Generation: Microsoft’s VibeVoice model has made significant advancements in AI audio, capable of generating realistic speech for 45-90 minutes with up to 4 speakers, without the need for stitching. The model is available for experience on Hugging Face Space, allowing users to leverage it for high-quality voice cloning, opening new possibilities for applications like podcasts and audiobooks. (Source: Reddit r/LocalLLaMA)
mmBERT: New Benchmark for Multilingual Encoders: The new mmBERT model has been introduced, poised to replace XLM-R, which has been SOTA for six years. mmBERT is 2-4 times faster than existing models and surpasses o3 and Gemini 2.5 Pro in multilingual encoding tasks. Its release, accompanied by open models and training data, will provide a more efficient and powerful foundation for multilingual AI applications. (Source: code_star)

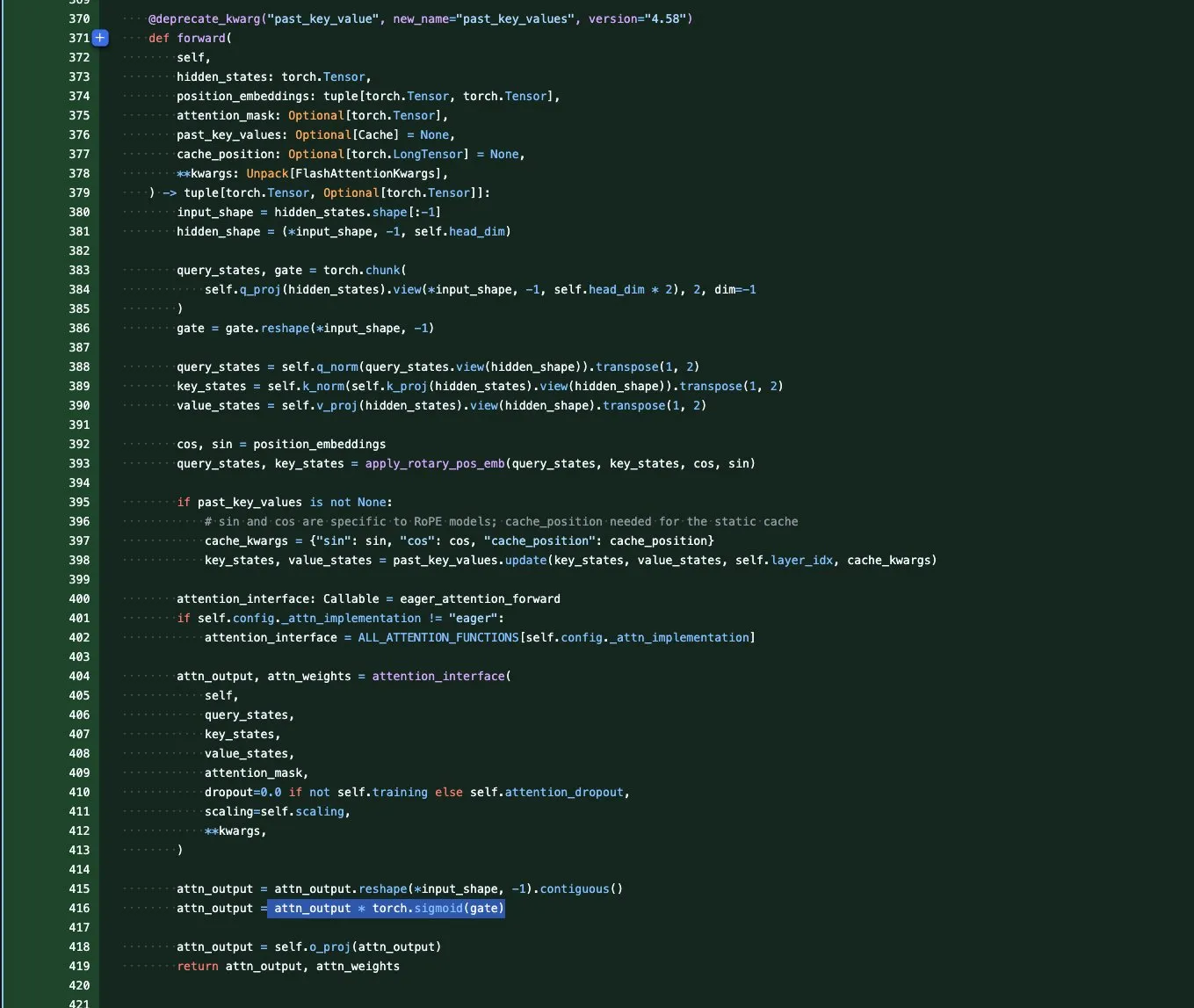
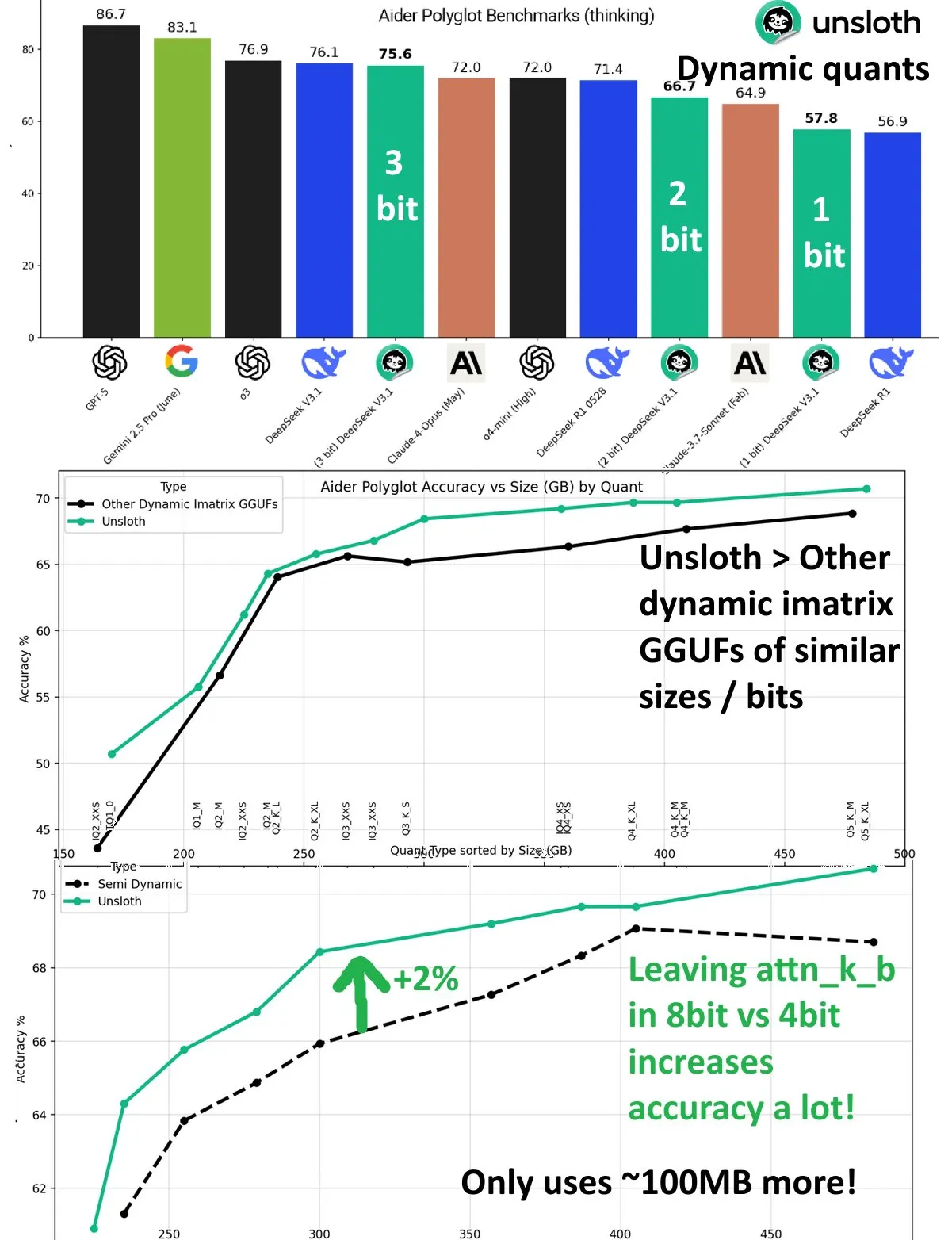
DeepSeek V3.1 Dynamic Quantization Performance Improvement: The DeepSeek V3.1 model achieved significant performance improvements through dynamic quantization technology in UnslothAI’s Aider Polyglot benchmark. 3-bit quantization approaches the accuracy of the unquantized model, and in inference mode, 1-bit dynamic quantization even surpasses the original performance of DeepSeek R1. Research found that keeping the attn_k_b layer at 8-bit precision provides an additional 2% accuracy boost, demonstrating the potential of efficient quantization in maintaining model capabilities and reducing computational costs. (Source: danielhanchen)
SpikingBrain-1.0: Domestic Large Model Trained on Domestic GPUs: The Institute of Automation, Chinese Academy of Sciences (CASIA) has released “Shunxi 1.0” (SpikingBrain-1.0), a brain-inspired spiking large model. It was trained and inferred on a domestic Muxi GPU cluster, reducing energy consumption by 97.7% compared to traditional FP16 operations. The model achieves 90% of Qwen2.5-7B’s performance using only 2% of the pre-training data of mainstream large models, and excels in ultra-long sequence processing tasks with TTFT acceleration up to 26.5 times, validating the feasibility of a domestically developed and controllable non-Transformer large model ecosystem. (Source: 36kr)
Wenxin X1.1 Released: Significant Improvements in Factuality, Instruction Following, and Agent Capabilities: Baidu’s deep thinking model, Wenxin Large Model X1.1, has been upgraded and launched, with factuality, instruction following, and agent capabilities improved by 34.8%, 12.5%, and 9.6% respectively. The model’s overall performance surpasses DeepSeek R1-0528 and rivals GPT-5 and Gemini 2.5 Pro, demonstrating strong agent capabilities in complex long-range tasks, capable of automatically decomposing tasks and invoking tools. Baidu also released the ERNIE-4.5-21B-A3B-Thinking open-source model and the ERNIEKit development kit, further lowering the barrier to AI application. (Source: QbitAI)

Huawei Open-Sources OpenPangu-Embedded-7B-v1.1: Free Switching Between Fast and Slow Thinking: Huawei has released OpenPangu-Embedded-7B-v1.1, a 7B-parameter open-source model that for the first time enables free switching between fast and slow thinking modes, adapting its choice based on problem difficulty. Through progressive fine-tuning and a two-stage training strategy, the model’s accuracy in general, math, and code evaluations has significantly improved, and while maintaining accuracy, the average chain-of-thought length is reduced by nearly 50%. This fills a gap in open-source large models for this capability, enhancing efficiency and accuracy. (Source: QbitAI)

Tencent CodeBuddy Code: AI Programming Enters the L4 Era: Tencent has released the AI CLI tool CodeBuddy Code and opened CodeBuddy IDE for public beta, aiming to push AI programming into the L4-level “AI software engineer” era. CodeBuddy Code, installable via npm, supports natural language-driven full lifecycle of development and operations, achieving extreme automation. Through document-driven management, context compression, and MCP extension, this tool becomes the underlying infrastructure for enterprise-grade AI programming, significantly boosting development efficiency. (Source: QbitAI)

OpenAI Core Scientists: Polish Duo Drives GPT-4 and Inference Breakthroughs: OpenAI Chief Scientist Jakub Pachocki and Research Scientist Szymon Sidor have been highly praised by Altman for their critical contributions to the Dota project, GPT-4 pre-training, and driving inference breakthroughs. The duo, high school classmates reunited at OpenAI, have become an indispensable force through a combination of deep thinking and hands-on experimentation, even firmly supporting Altman’s return during the 2023 internal crisis. (Source: QbitAI)

White House AI Summit Focuses on Talent, Security, and National Challenges: Melania Trump hosted an AI conference at the White House, inviting tech giants like Google, IBM, and Microsoft, with a focus on AI talent development, security assurance, and national-level challenges. This move indicates that the U.S. government is actively promoting its AI strategy, aiming to address the opportunities and challenges brought by AI development and ensure the nation’s leadership in the AI field. (Source: TheTuringPost, Reddit r/artificial)

Neuromorphic Computing: Beyond Traditional Neural Networks: Neuromorphic computing is redefining intelligence, inspired by the structure and working principles of the biological brain. This technology aims to develop more efficient, low-power AI hardware by simulating the parallel processing capabilities of neurons and synapses, achieving computing paradigms beyond traditional Von Neumann architecture, and providing a more powerful foundation for future AI systems. (Source: Reddit r/artificial)
MEGS²: Memory-Efficient Gaussian Splatting: MEGS² (Memory-Efficient Gaussian Splatting via Spherical Gaussians and Unified Pruning) is a memory-efficient 3D Gaussian Splatting (3DGS) technique. By replacing spherical harmonic representations of color with arbitrarily oriented spherical Gaussian functions and introducing a unified soft pruning framework, this method significantly reduces the number of parameters per primitive, achieving 8x static VRAM compression and nearly 6x rendering VRAM compression while maintaining or improving rendering quality. This has significant implications for 3D graphics and real-time rendering. (Source: janusch_patas)

🧰 Tools
LangChain 1.0 Introduces Middleware: A New Paradigm for Agent Context Control: LangChain 1.0 has released Middleware, providing a new abstraction layer for AI agents that gives developers full control over context engineering. This feature enhances agent flexibility, composability, and adaptability, supporting the implementation of various agent architectures such as reflection, groups, and supervisors, laying a strong foundation for building more complex AI applications. (Source: hwchase17, hwchase17, Hacubu)
MaxKB: Open-Source Enterprise-Grade Agent Platform: MaxKB is a powerful and easy-to-use open-source enterprise-grade agent platform that integrates RAG (Retrieval-Augmented Generation) pipelines, a robust workflow engine, and MCP tool usage capabilities. It supports document upload, automatic crawling, text segmentation, and vectorization, effectively reducing large model hallucinations. It also supports various private and public large models and offers multimodal input/output, widely applicable in scenarios such as intelligent customer service and enterprise knowledge bases. (Source: GitHub Trending)

BlenderMCP: Deep Integration of Claude AI with Blender: BlenderMCP achieves deep integration of Claude AI with Blender, allowing Claude to directly control Blender for 3D modeling, scene creation, and manipulation through the Model Context Protocol (MCP). This tool supports bidirectional communication, object manipulation, material control, scene inspection, and code execution, and can integrate Poly Haven and Hyper3D Rodin assets, greatly enhancing the efficiency and possibilities of AI-assisted 3D creation. (Source: GitHub Trending)

AI Sheets: No-Code AI Dataset Building and Transformation Tool: Hugging Face has released AI Sheets, an open-source no-code tool for building, enriching, and transforming datasets using AI models. The tool can be deployed locally or run on the Hub, providing access to thousands of open-source models on the Hugging Face Hub ( including gpt-oss), and can be quickly launched via Docker or pnpm, simplifying the data processing workflow, especially suitable for generating large-scale datasets. (Source: GitHub Trending)

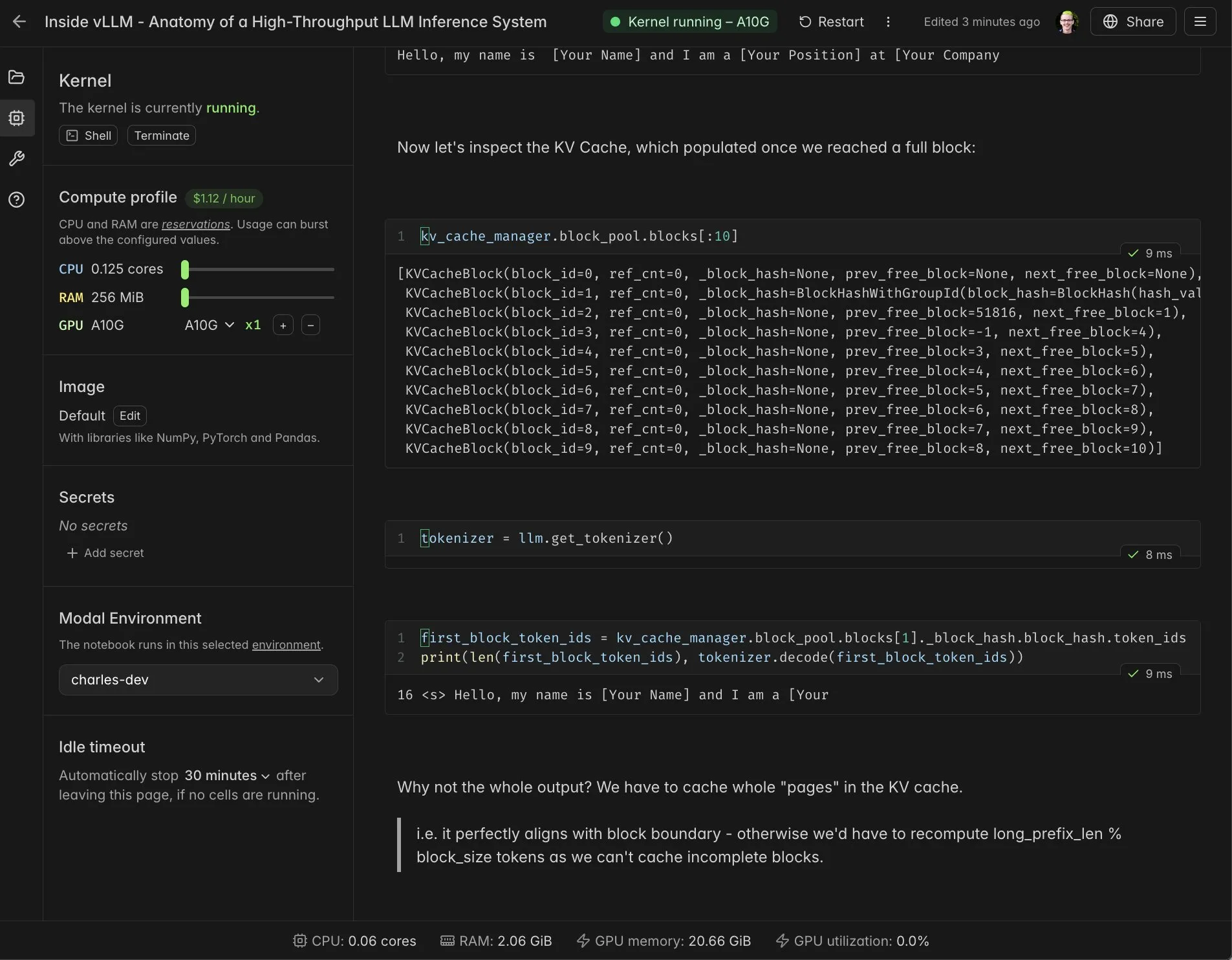
vLLM Real-time Notebook and Modal Integration: Modal Notebooks are integrated with vLLM, providing a real-time, shareable interactive environment to help developers deeply understand vLLM’s internal mechanisms. This integration allows users to easily run and share CUDA-compatible computing tasks in the cloud without building complex integrations, greatly simplifying the development and learning process for vLLM. (Source: charles_irl, vllm_project, charles_irl, charles_irl, charles_irl, charles_irl)
Docker Supports Minions AI: Local Hybrid AI Workloads: Minions AI now officially supports Docker, allowing users to unlock local hybrid AI workloads via the Docker model runner. This collaboration enables developers to more conveniently deploy and manage Minions AI in local environments, combining Docker’s containerization advantages to enhance the flexibility and efficiency of AI application development. (Source: shishirpatil_)
Replit Agent 3: New Breakthrough in Autonomous Software Development: Replit has released Agent 3, touted as the “full self-driving” moment for software development, with 10 times greater agent autonomy than before. This agent can prototype applications more deeply and continue to progress when other agents are stuck, aiming to solve time-consuming testing, debugging, and refactoring stages in software development, significantly boosting development efficiency. (Source: amasad, amasad, pirroh)
Qwen3-Coder: Cost-Effective Open-Source Programming Model: Qwen3-Coder demonstrates excellent performance and cost-effectiveness on the Windsurf platform, requiring only 0.5 credits to run, making it more advantageous than Claude 4 and GPT-5 High (2x credits). The model performs well in programming tasks, and as an open-source model, it provides regulated enterprises and public sector organizations with a powerful AI programming option without relying on public APIs, helping to address data sovereignty and visibility issues. (Source: bookwormengr)
📚 Learning
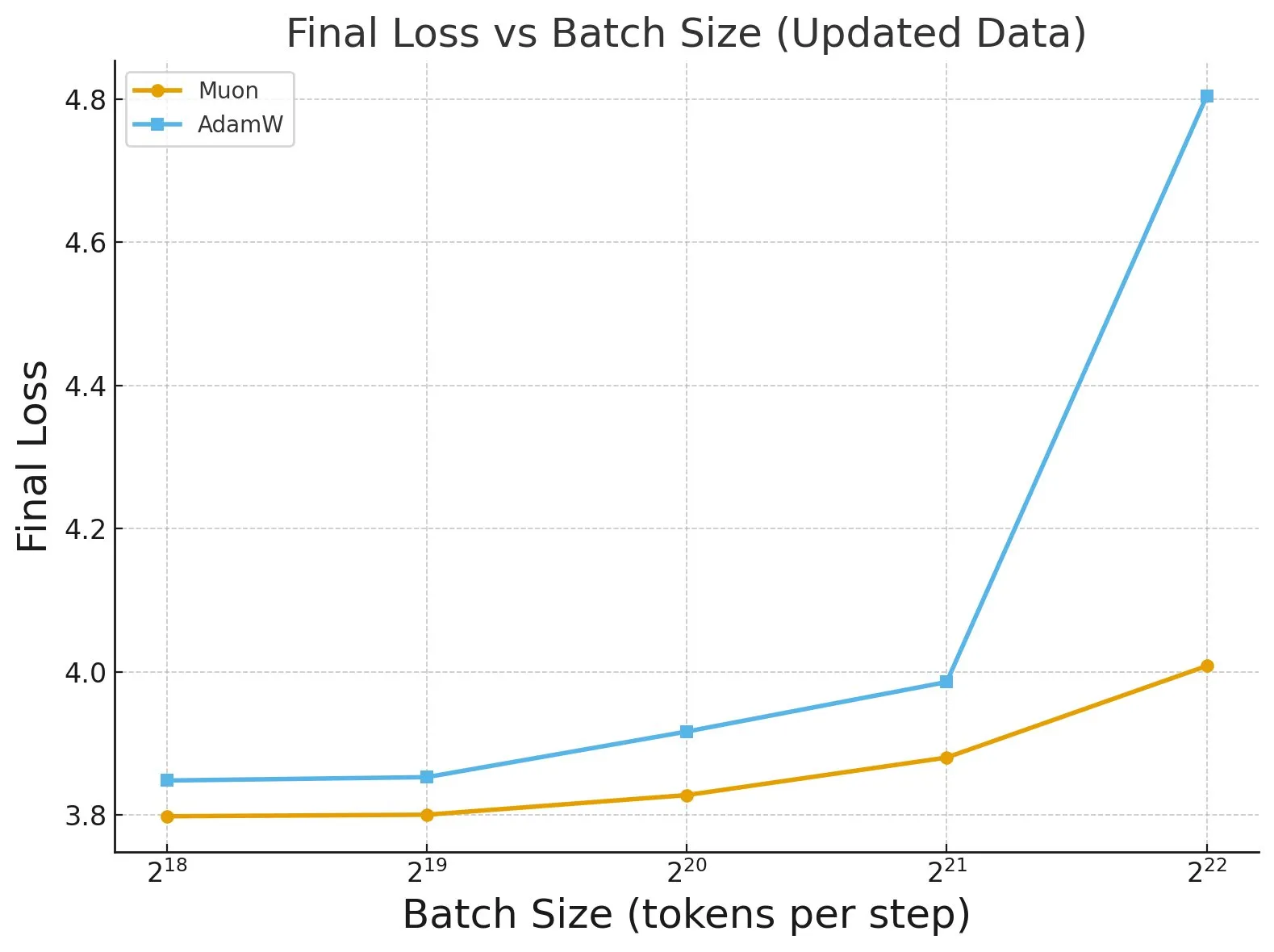
“Fantastic Pretraining Optimizers and Where to Find Them” Research: Extensive research on over 4000 models reveals the performance of pretraining optimizers. The study found that some optimizers (like Muon) can achieve up to 40% speed improvement on small-scale models (<0.5B parameters), but only 10% on large-scale models (1.2B parameters). This highlights the need to be wary of insufficient baseline tuning and scale limitations when evaluating optimizers, and points out the impact of batch size on optimizer performance gaps. (Source: tokenbender, code_star)
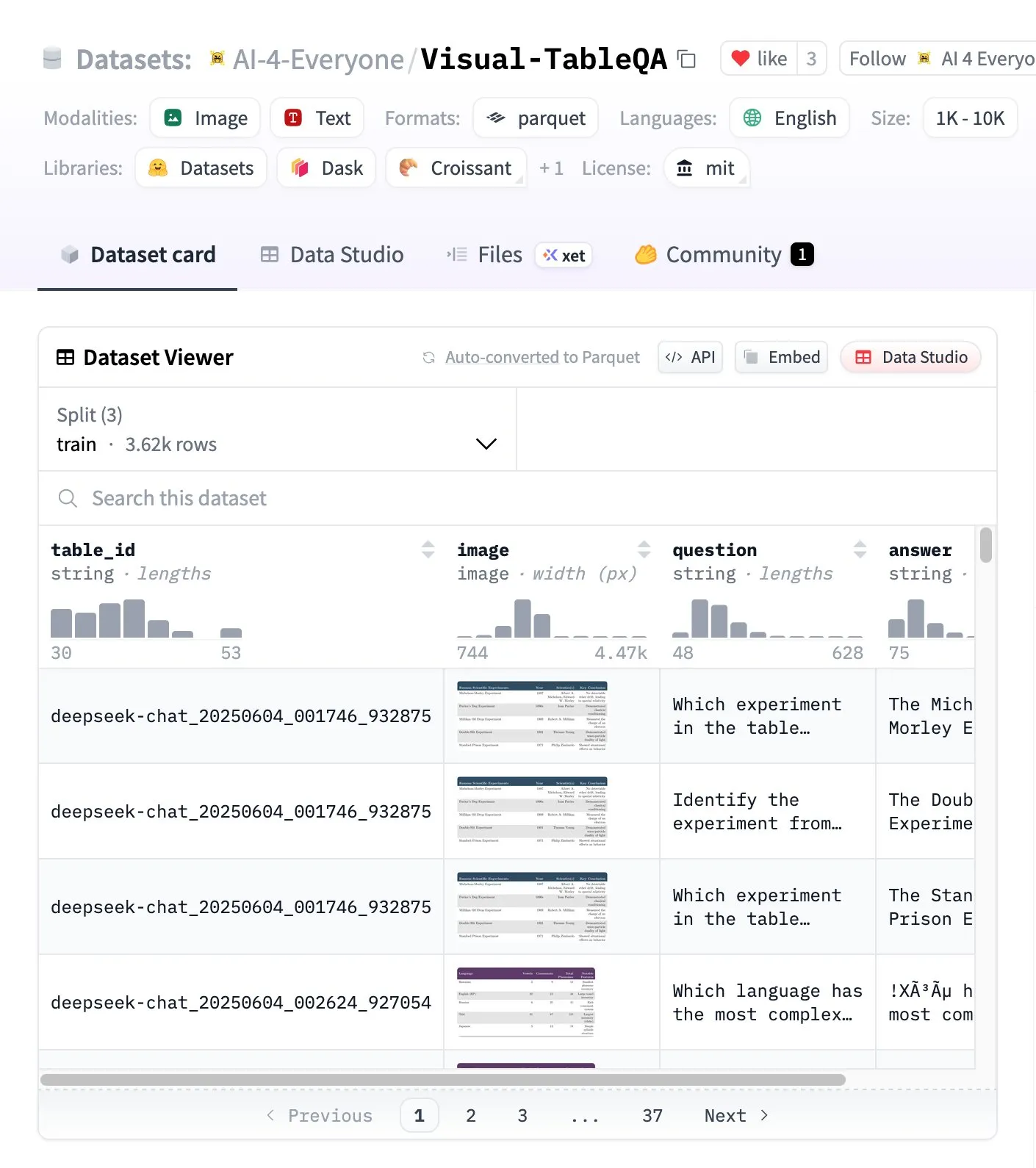
Visual-TableQA: Complex Table Reasoning Benchmark: Hugging Face has released Visual-TableQA, a complex table reasoning benchmark containing 2.5K tables and 6K QA pairs. This benchmark focuses on multi-step reasoning over visual structures and has been 92% human-verified, with a generation cost of less than $100. It provides a high-quality resource for evaluating and improving models’ ability to understand and reason with complex tabular data. (Source: huggingface)
AI Agents vs Agentic AI Concept Analysis: There is widespread confusion in the community regarding AI Agents and Agentic AI systems. AI Agents refer to single autonomous software (LLM + tools) that perform specific tasks, are reactive in behavior, and have limited memory; Agentic AI refers to multi-agent collaborative systems (multiple LLMs + orchestration + shared memory) that are proactive in behavior and have persistent memory. Understanding the distinction between the two is crucial for architectural decisions, avoiding the construction of unnecessarily complex systems. (Source: Reddit r/deeplearning)

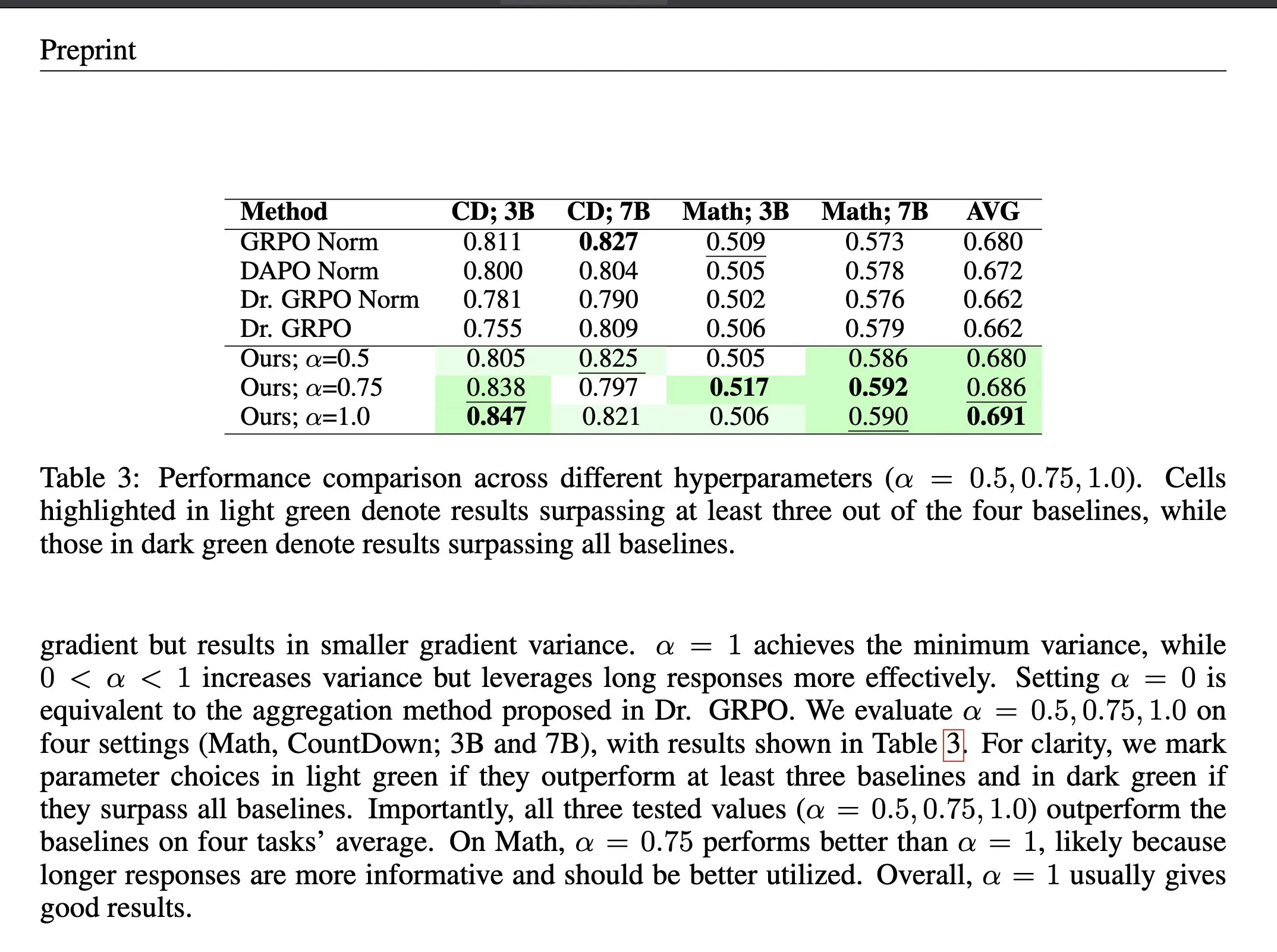
ΔL Normalization: A Loss Aggregation Method in Reinforcement Learning: ΔL Normalization is a loss aggregation method designed for the dynamically generated length characteristic in Verifiable Reward Reinforcement Learning (RLVR). By analyzing the impact of different lengths on policy loss, this method reconstructs the problem to find a minimum variance unbiased estimator, theoretically minimizing gradient variance. Experiments show that ΔL Normalization consistently achieves superior results across different model scales, maximum lengths, and tasks, addressing the challenges of high gradient variance and unstable optimization in RLVR. (Source: HuggingFace Daily Papers, teortaxesTex)
LLM Architecture Comparison Video Lecture: Rasbt has released a video lecture providing a comparative analysis of 11 LLM architectures in 2025, covering DeepSeek V3/R1, OLMo 2, Gemma 3, Mistral Small 3.1, Llama 4, Qwen3, SmolLM3, Kimi 2, GPT-OSS, Grok 2.5, and GLM-4.5. This lecture offers developers and researchers a comprehensive overview of LLM architectures, helping to understand the design philosophies and performance characteristics of different models. (Source: rasbt)
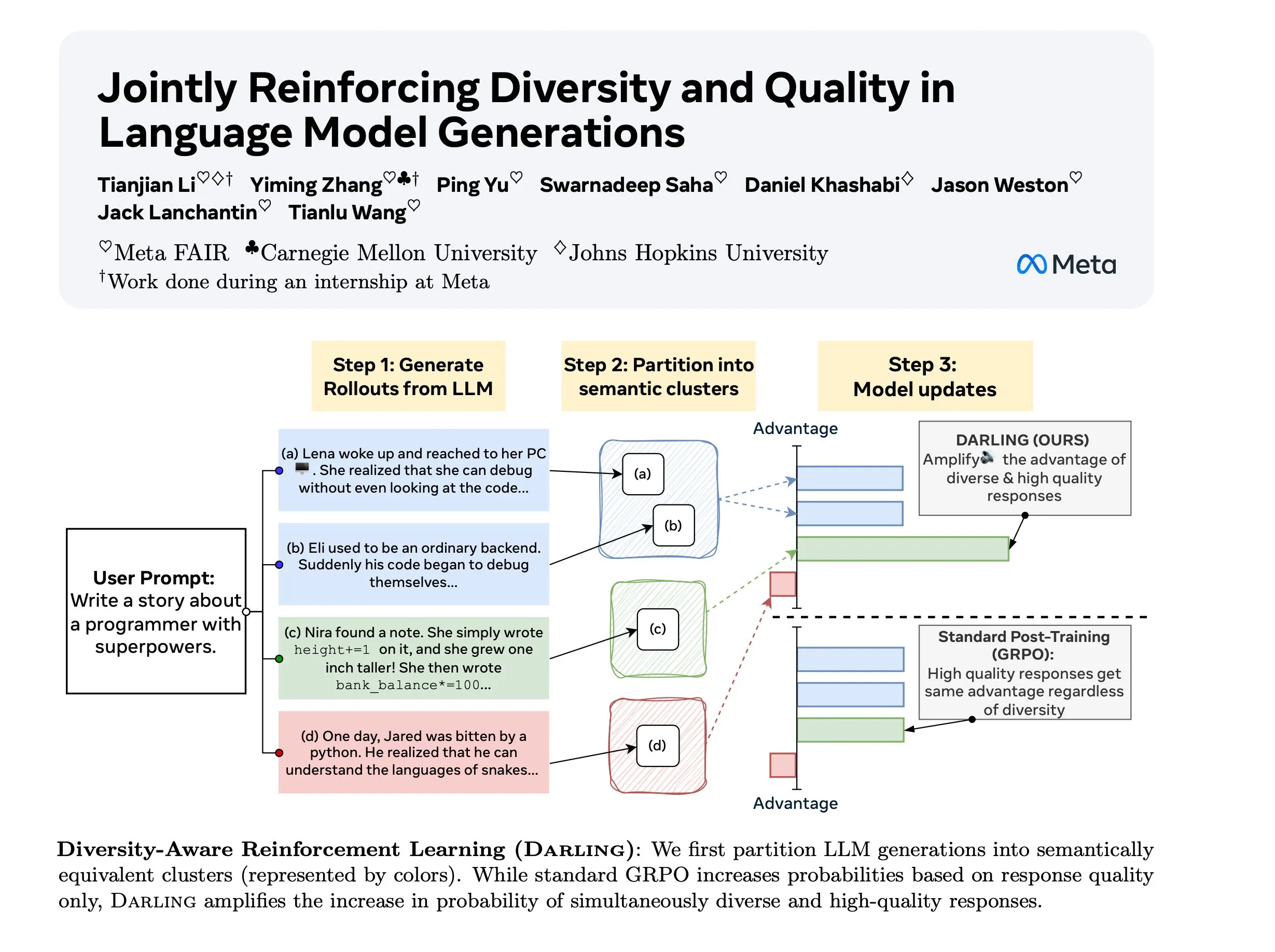
Diversity Aware RL (DARLING) Research: DARLING (Diversity Aware RL) is a new reinforcement learning method that learns partition functions to optimize both quality and diversity simultaneously. This method outperforms standard RL in both quality and diversity metrics, such as higher pass@1/p@k, and is applicable to both non-verifiable and verifiable tasks, providing a new approach to enhance RL’s generalization capabilities in complex environments. (Source: ylecun)
Stanford CS 224N: Deep Learning and NLP Course: Stanford University’s CS 224N course offers comprehensive instruction in deep learning and natural language processing. The course is publicly available via YouTube videos, providing high-quality AI learning resources for global learners, covering fundamental NLP theories, latest models, and practical applications, making it an important introductory course for entering the AI field. (Source: stanfordnlp)
💼 Business
Anthropic’s New Privacy Policy Sparks Controversy: Systemic Disadvantage for Independent Developers: Anthropic’s new privacy policy requires users to opt-in by September 28th to allow their conversation data to be used for AI training and retained for 5 years, otherwise they will lose memory and personalization features. This move is criticized for creating a “two-tiered system,” forcing independent developers to choose between privacy and functionality, where their proprietary code could become enterprise AI training data, while enterprise clients can enjoy expensive solutions with both privacy protection and personalization. This raises concerns about AI democratization and innovation extraction. (Source: Reddit r/ClaudeAI)
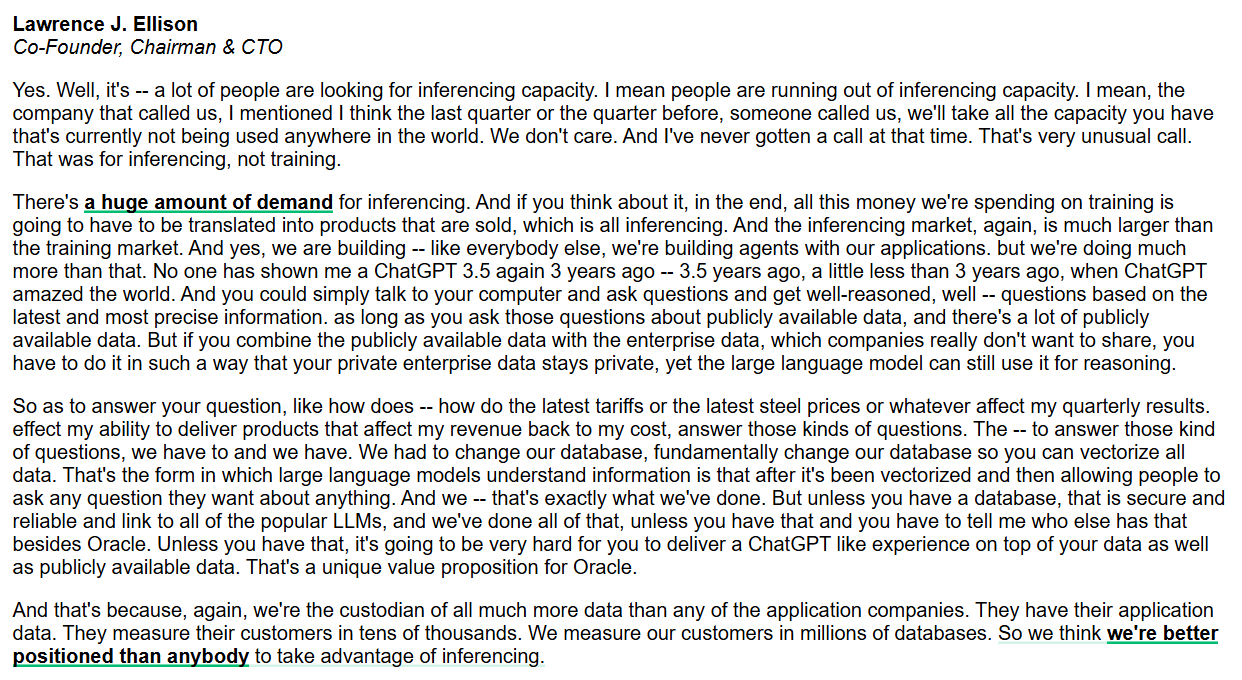
Oracle Focuses on Inference Capabilities and Enterprise-Grade AI Databases: Oracle CEO Larry Ellison emphasizes that the inference capability market is much larger than the training market, with immense demand. Oracle aims to provide a ChatGPT-like experience combining public and enterprise private data by fundamentally changing databases to vectorize all data and ensure its security and reliability. Oracle believes its role as a data custodian gives it a unique advantage in providing enterprise-grade AI inference services. (Source: JonathanRoss321)
New AI Content Licensing Standard RSL Standard: Pushing AI Companies to Pay: Major brands like Reddit, Yahoo, Quora, and wikiHow support the Really Simple Licensing (RSL) Standard, an open content licensing standard designed to allow web publishers to set terms for AI system developers using their work. RSL, based on the robots.txt protocol, enables websites to add licensing and royalty terms, requiring AI crawlers to pay for training data (subscription or per crawl/inference) to ensure content creators receive fair compensation. (Source: Reddit r/artificial)
🌟 Community
Coexistence and Enhancement of AI and Human Intelligence: The community discusses whether AI serves as a “cognitive prosthetic” assisting human intelligence (like an abacus) or as a “competitor” replacing humans (like a calculator). François Chollet proposes the “mind-bike” analogy, emphasizing that technology should amplify human effort rather than render people idle, sparking philosophical contemplation on the relationship between AI and human intelligence (IA) and their future development. (Source: rao2z)
AI Industry PR Dilemma and Negative Public Sentiment: Despite AI products having billions of users and many benefiting from them, the AI industry generally faces negative public sentiment. Some argue this is due to industry leaders failing to communicate effectively externally, leading to public bias against AI companies. Others speculate this might be intentional by the AI industry, aiming to concentrate core technologies and advantages in the hands of a few players. (Source: Dorialexander)
Impact of Weaknesses in LLM Multi-Agent Systems: Research indicates that using small language models is not always ideal in multi-agent systems. In scenarios like multi-agent debates, weaker LLM agents often interfere with or even disrupt the performance of stronger agents, leading to overall system performance degradation. This reveals that when designing and deploying multi-agent systems, careful consideration must be given to the capability differences of each agent and their potential negative interactive effects. (Source: omarsar0)

Limitations of Synthetic Data for AGI: Andrew Trask and Fei-Fei Li point out that synthetic data is a weak strategy for LLMs to achieve AGI. Synthetic data cannot create new information (such as entities the model has never heard of) but can only reveal natural inferences from existing information. Although synthetic data can solve problems like the “reversal curse” through logical permutation and combination of known facts, its information bottleneck limits its potential as an AGI “silver bullet.” True breakthroughs may lie in global intelligence and instant retrieval of context. (Source: algo_diver, jpt401)
AI and the Human Job Market: The Dead Loop of AI Writing Resumes and AI Screening Resumes: AI is causing a “no one hired” dead loop in the job market: job seekers use AI to write resumes, and HR uses AI to screen resumes, leading to “improved” efficiency but no one getting hired. Reasons for AI rejecting resumes are varied, and even HR complains that AI-generated resumes are generic. This highlights new challenges brought by AI in recruitment, potentially leading to rigid hiring processes and an inability to identify true talent. (Source: QbitAI)

Challenges Faced by AI Ethicists: As AI technology rapidly develops, AI ethicists are facing the dilemma of “shouting into the void.” The capitalist-driven AI race marginalizes ethical considerations, with technological progress far outstripping ethical integration. Experts worry that if action is delayed until harm becomes widespread, it may be too late, urging the industry to incorporate ethical safeguards into its core considerations. (Source: Reddit r/ArtificialInteligence)

The Future of the Internet: Bot Traffic Surpasses Human: A trend suggests that within the next three years, bot-driven interactions on the internet will far exceed human interactions, making the internet “dead.” Studies already indicate that bot traffic has surpassed 50%. This raises concerns about how to distinguish real human voices from AI-generated content and the authenticity of internet information, signaling a fundamental shift in the online ecosystem. (Source: Reddit r/artificial)

Claude Code Performance Degradation and User Churn: Users of Anthropic’s Claude Code report a significant recent decline in model performance, manifesting as poorer code quality, generation of redundant code, low test quality, over-engineering, and weakened understanding. Many users are considering alternatives like GPT-5, GLM-4.5, and Qwen3, and call on Anthropic to increase transparency, explain the reasons for model degradation, and outline corrective measures, or face user churn. (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
💡 Other
Potential of AI and VR in Criminal Rehabilitation: Some suggest that cheap AI and VR technology could provide mandatory VR pods for forensic psychiatric patients, isolating them from society at a lower cost than traditional room and board. This radical idea sparks discussion on AI’s role in social control, correctional systems, and ethical boundaries. Despite debates on its feasibility and humanity, it reveals potential applications of technology in addressing social problems. (Source: gfodor, gfodor)
Replit’s Potential Application in Prisons: A user proposed the idea of introducing Replit (an online programming platform) into prisons, suggesting it could replace entertainment facilities and allow prisoners to create valuable products through programming. This idea explores the potential role of technology in social transformation, providing skills training, and facilitating prisoner reintegration into society, sparking discussions on educational equity and technological empowerment. (Source: amasad)