
Keywords:Embedding models, MoE models, LLM, Multimodal models, AI agents, Vector database cost optimization, Meituan LongCat-Flash architecture, MiniCPM-V 4.5 video understanding, Cyber-Zero cybersecurity agent, GLM-4.5 function calling performance
🎯 Trends
New Embedding Model Drastically Reduces Vector Database Costs: A new embedding model has reduced vector database costs by approximately 200 times and surpasses existing models from OpenAI and Cohere, signaling a significant boost in LLM application efficiency. This technological breakthrough is expected to bring more economical and efficient AI solutions to enterprises and developers, accelerating the popularization and application of LLMs across various industries, especially in scenarios requiring large-scale vector data processing. (Source: jerryjliu0, tonywu_71)
Meituan Open-Sources LongCat-Flash MoE Large Model and Its Technical Innovations: Meituan has released LongCat-Flash, a 560B-parameter MoE model featuring a dynamic activation mechanism (averaging ~27B parameters) and introducing innovative architectures like “zero-compute experts” and Shortcut-connected MoE, aimed at optimizing computational efficiency and large-scale training stability. The model performs exceptionally well in agent tasks, drawing community attention to China’s AI development and showcasing the strong capabilities of non-traditional tech giants in the LLM space. (Source: teortaxesTex, huggingface, scaling01, bookwormengr, Dorialexander, reach_vb)
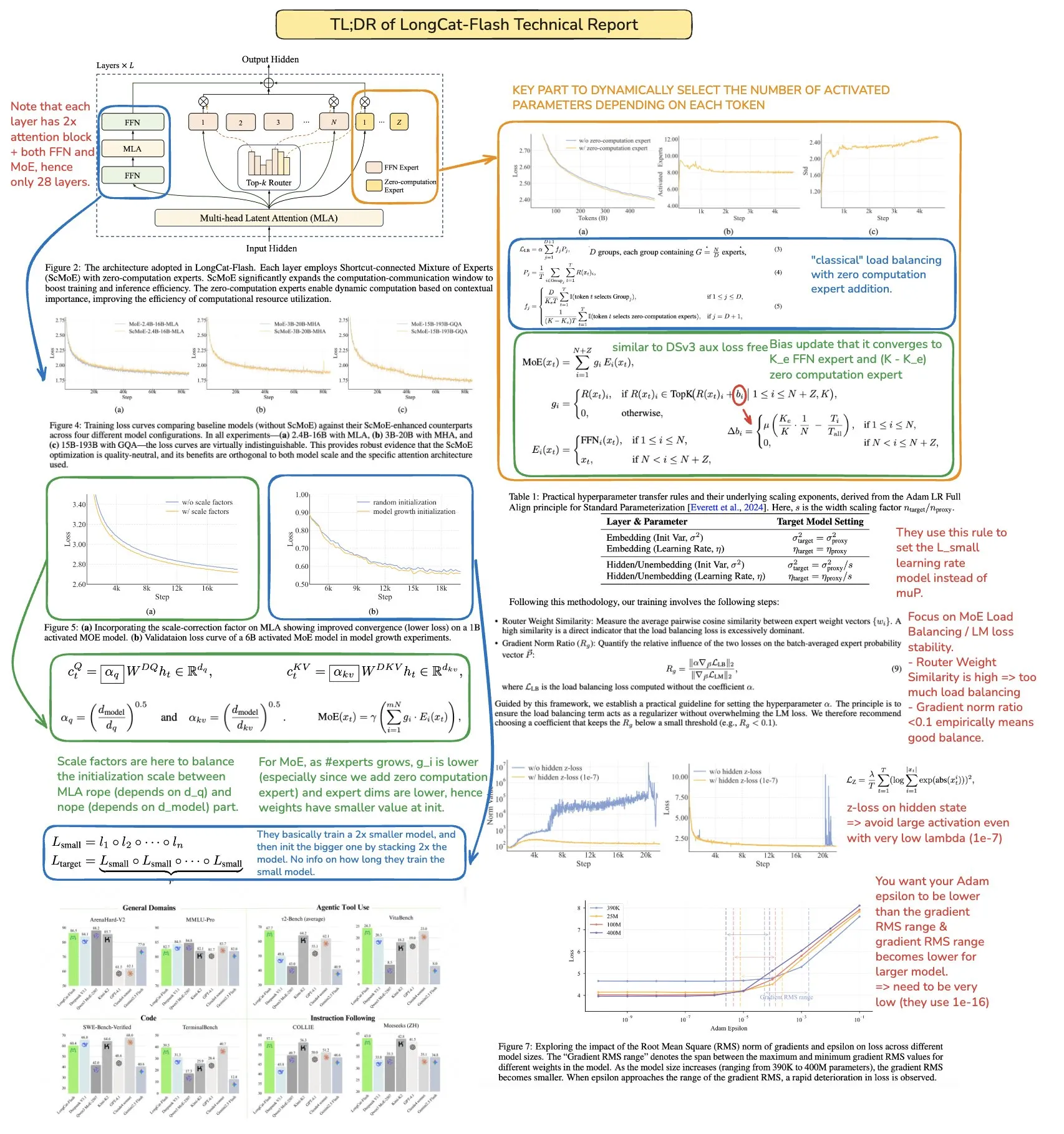
MoR, CoLa, and XQuant Technologies Enhance LLM Efficiency and Memory Optimization: New Transformer architectures like Mixture-of-Recursions (MoR) and Chain-of-Layers (CoLa) aim to optimize LLM memory usage and computational efficiency. MoR reduces resource consumption through adaptive “depth of thought,” while CoLa achieves controllable computation at test time by dynamically reordering model layers. XQuant technology, by dynamically re-instantiating keys and values and combining quantized layer input activations, reduces LLM memory requirements by up to 12 times, significantly boosting model operational efficiency. (Source: TheTuringPost, TheTuringPost, NandoDF)
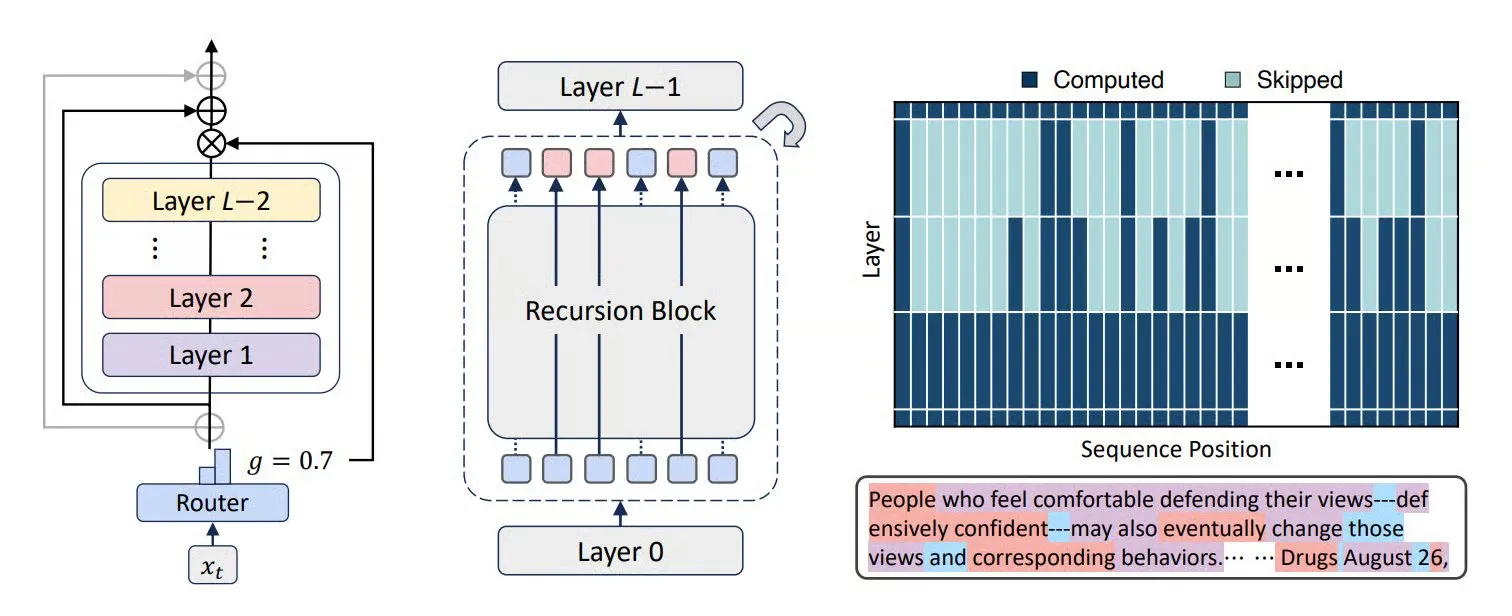
MiniCPM-V 4.5 Multimodal Model: Breakthroughs in Video Understanding and OCR: MiniCPM-V 4.5 (8B) is a newly open-sourced multimodal model, achieving high-density video compression via 3D-Resampler (6-frame groups compressed into 64 tokens, supporting 10fps input), unifying OCR and knowledge reasoning (switching modes by controlling text visibility), and incorporating reinforcement learning for mixed inference modes. The model excels in long video understanding, OCR, and document parsing, surpassing Qwen2.5-VL 72B. (Source: teortaxesTex, ZhihuFrontier)
Advancements in AI Agents and General Intelligent Agents Research: Cyber-Zero has achieved AI cybersecurity agents that require no runtime training, demonstrating potential in cyber offense and defense. X-PLUG’s Mobile-Agent (including GUI-Owl VLM and the Mobile-Agent-v3 framework) has made breakthroughs in GUI automation, featuring cross-platform perception, planning, anomaly handling, and memory capabilities. Google DeepMind research indicates that agents capable of generalizing to multi-step goals must learn predictive models of their environment, while Tsinghua University’s SSRL further explores the possibility of LLMs acting as built-in “network simulators,” reducing reliance on external search. (Source: terryyuezhuo, GitHub Trending, teortaxesTex, TheTuringPost)
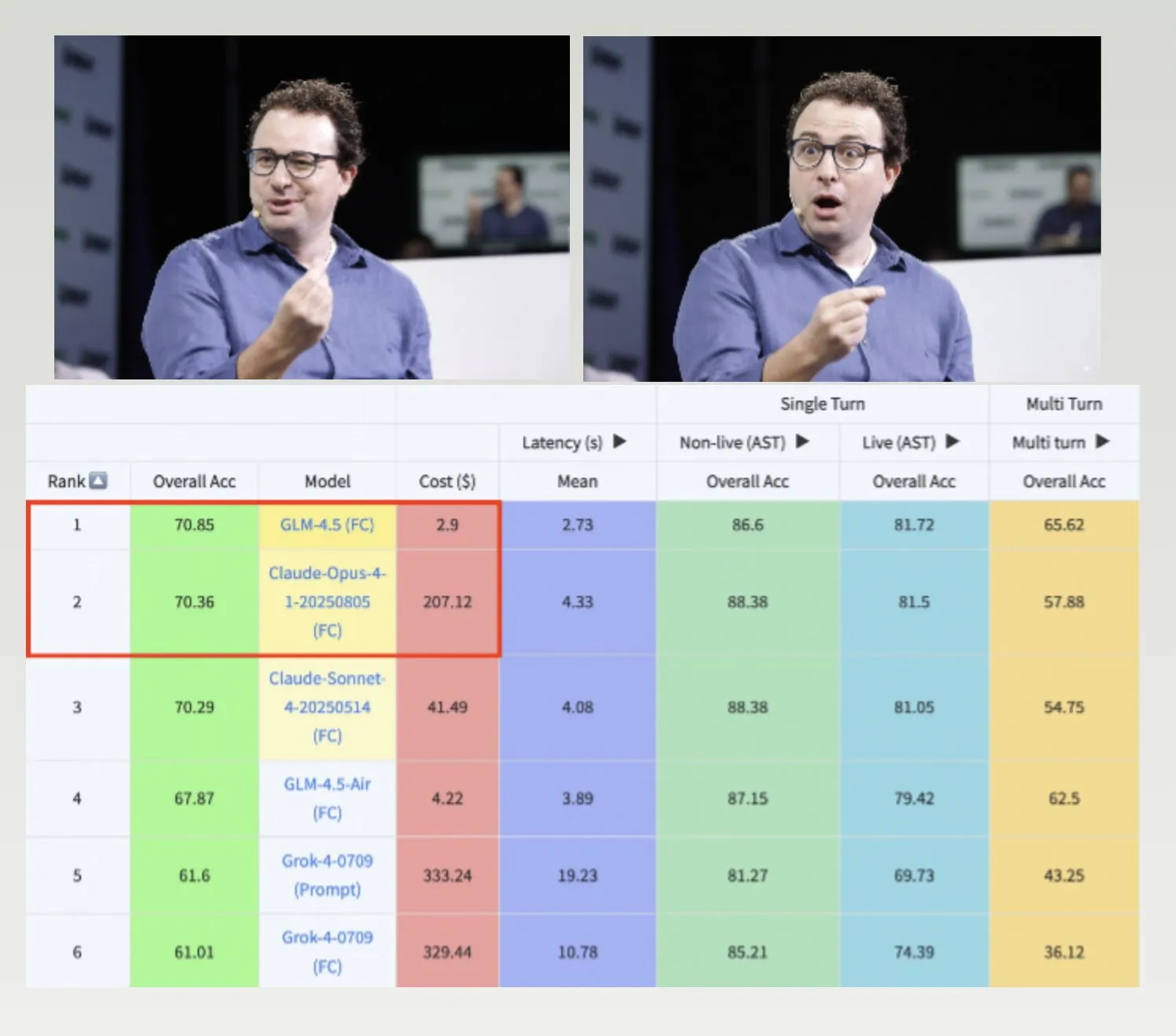
GLM-4.5, Hermes Model, and Nemotron-CC-v2 Dataset Drive LLM Development: GLM-4.5 surpasses Claude-4 Opus on the Berkeley function calling benchmark at a lower cost, demonstrating high efficiency and competitiveness. The Hermes model excels in specific instruction-following tasks, even when based on older Llama models. NVIDIA open-sourced the Nemotron-CC-v2 pre-training dataset, improving language models through knowledge enhancement, which is significant for foundational research and model development in the AI community. (Source: Teknium1, huggingface, ZeyuanAllenZhu)
ByteDance MoC Long Video Generation and Embedding Model Limitations Research: ByteDance and Stanford University introduced Mixture of Contexts (MoC) technology, addressing memory bottlenecks in long video generation through an innovative sparse attention routing module to generate coherent videos lasting several minutes at the cost of short videos. Concurrently, Google DeepMind research reveals that even the best embedding models cannot represent all query-document combinations, indicating a mathematical recall ceiling, suggesting the need for hybrid approaches to compensate for shortcomings. (Source: huggingface, menhguin)

New Applications and Controversies of AI in Emergency Services and Law Enforcement: AI is being introduced into 911 emergency services to alleviate staffing shortages, but is also being used to unmask ICE officials, sparking widespread discussion about the ethical boundaries of AI in public safety and law enforcement. Calls for xAI’s Grok model to be deemed unsuitable for the U.S. federal government also reflect concerns about AI application trust and security. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/artificial)

Robotic Hand Technology and Neuralink Brain-Computer Interface Progress: Robotic hand technology is rapidly advancing, with increasing flexibility and control capabilities, forecasting a future where robots can perform more delicate and complex tasks. Neuralink has for the first time demonstrated a human’s ability to control a cursor solely with thought in real-time, marking a significant step forward for brain-computer interface technology in human-computer interaction and opening new avenues for medical and assistive technologies. (Source: Reddit r/ChatGPT, Ronald_vanLoon)

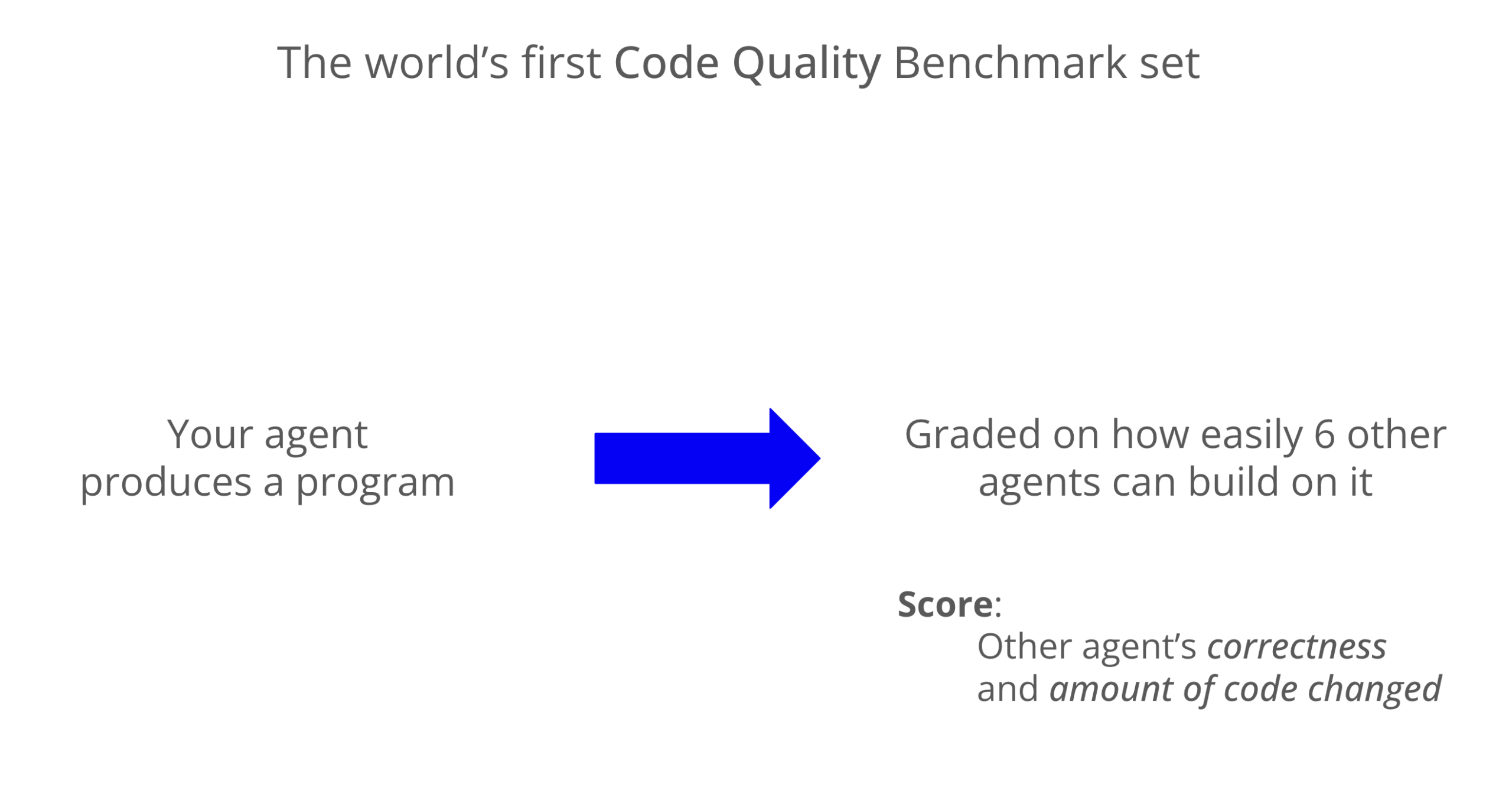
LLM Code Quality Benchmark: Codex Excels in Maintainability: A new benchmark evaluates the maintainability of LLM-generated code, showing that Codex (GPT-5) significantly outperforms Claude Code (Sonnet 4) in code quality, scoring almost 8 times higher. Grok-code-fast performed poorly in the WeirdML benchmark, highlighting the differences and optimization potential among various models in coding tasks. (Source: jimmykoppel, teortaxesTex)
🧰 Tools
Nano Banana AI Image Generation and Icon Cloning Features: Nano Banana offers AI image generation capabilities, allowing users to clone their favorite icons and combine them with line art to create high-quality, modern mobile app icons, emphasizing detail, color gradients, and lighting effects. The latest feature also combines real-life cosplayers and 3D printers to showcase figures, creating a more immersive display experience. (Source: karminski3, op7418)

Clarifai Local Runners: Bridging Local Models with the Cloud: Clarifai has launched Local Runners, a tool that allows users to run models on local devices (laptops, servers, or VPC clusters) and build complex model, agent, and tool pipelines. It supports instant testing and debugging and provides the ability to securely connect local models to the cloud, offering a flexible and efficient solution for hybrid AI deployments. (Source: TheTuringPost)
Draw Things Now Supports Qwen-Image-Edit for Image Editing: The Draw Things application now officially supports the Qwen-Image-Edit model, allowing users to edit images via prompts and supporting brush size adjustment and optimized repetitive running speed for Qwen Image. This integration makes image editing more convenient and efficient, providing users with powerful AI-assisted creative capabilities. (Source: teortaxesTex)

ChatGPT Feynman Learning Coach Prompt Enhances Learning Efficiency: A ChatGPT prompt has been designed as a “Feynman Learning Coach,” aimed at helping users master any subject through the Feynman technique. It guides users through iterative learning, breaking down complex concepts into teachable chunks, exposing knowledge gaps through questioning, and ultimately achieving deep understanding, providing an innovative tool for personalized learning. (Source: NandoDF)

Microsoft Copilot 3D Model One-Click Generation: Microsoft Copilot 3D feature allows users to generate 3D models with a single click by uploading images, greatly simplifying the 3D content creation process. This innovative tool lowers the technical barrier to 3D modeling, enabling more users to easily create and utilize 3D assets. (Source: NandoDF)

AI Tool for Automatic Job Description Generation and AI-Generated 3D Rooms: A developer has built an AI tool capable of automatically generating job descriptions, aimed at simplifying the recruitment process and improving hiring efficiency. Concurrently, AI has made significant progress in generating 3D rooms, with models maintaining good consistency across multiple angles and generating objects with considerable geometric shapes, though some ghosting artifacts still exist. (Source: Reddit r/deeplearning, slashML)
Midjourney and Domo Upscaler Combined to Enhance Image Print Quality: Users generate art with Midjourney, then use Domo Upscaler (Relax mode) for upscaling, successfully enhancing image clarity while preserving the artistic style, making it suitable for printing. This combined workflow offers artists and designers a new avenue for high-quality image output. (Source: Reddit r/deeplearning)
Kling AI Combined with Nano Banana for Video Generation: Kling AI is combined with Nano Banana for video generation, with Nano Banana used for image generation and Kling AI for video keyframes and scene connections, showcasing the potential of multi-AI tool collaboration in creative content generation. This integrated workflow can produce more expressive and coherent video content. (Source: Kling_ai, Kling_ai)
📚 Learning
Machine Learning Parallel Computing Resources: The Parallelism Mesh Zoo: Edward Z. Yang’s blog post “The Parallelism Mesh Zoo” delves into parallel computing architectures and optimization strategies in machine learning, providing valuable insights for improving model training and inference efficiency. This resource is highly relevant for engineers and researchers looking to optimize AI system performance. (Source: ethanCaballero, main_horse)

AI Agents Quick Guide and Agentic AI Roadmap: Ronald_vanLoon shared a quick guide to AI Agents and a Master roadmap for Agentic AI, providing learners with resources to understand and master the basic concepts, application directions, and systematic learning paths of agentic AI. These resources help developers and researchers quickly get started and delve into the complex world of agentic AI. (Source: Ronald_vanLoon, Ronald_vanLoon)
In-depth Interpretation of Meituan LongCat LLM Technical Report: bookwormengr summarized Meituan’s LongCat large language model technical report, which details LongCat’s innovative architecture, training strategies, and performance, serving as a valuable learning resource for researchers and developers to deeply understand MoE models and large-scale training. Through this interpretation, readers can better grasp the design philosophy and implementation details of cutting-edge LLMs. (Source: bookwormengr)
Scalable Framework for Evaluating Health Language Models: Google Research published a blog post detailing a scalable framework for evaluating language models in the health domain using adaptively precise Boolean rules, providing new methods and research directions for quality control in medical AI. This is crucial for ensuring the accuracy and reliability of medical AI applications. (Source: dl_weekly)
AI Alignment, Governance, and Safety Research Program MATS 9.0: The MATS 9.0 research program is open for applications, offering 12 weeks of mentorship, funding, office space, and expert workshops for professionals aspiring to careers in AI alignment, governance, and safety. The program aims to cultivate professionals in AI ethics and safety to address the challenges posed by AI technological development. (Source: ajeya_cotra)

The Evolution of TensorFlow and JAX, and the Rise of PyTorch: The machine learning community is experiencing a shift from TensorFlow to JAX, with Keras now supporting multiple backends (JAX, TF, PyTorch) and TFLite separating from TensorFlow. PyTorch has become the mainstream choice, and developers should familiarize themselves with JAX to adapt to the evolving ML framework ecosystem. (Source: Reddit r/MachineLearning)
Discussion on Open-Set Recognition in Deep Learning: The discussion covers the Open-Set Recognition problem in deep learning, which involves handling new categories not present in the training data. Proposed methods include analyzing distances and clustering in the embedding space, and it is noted as a difficult but important research direction. This is crucial for building more robust and adaptive AI systems. (Source: Reddit r/deeplearning, Reddit r/MachineLearning)
Handwritten Notes Resources for Machine Learning and Deep Learning: Users shared very useful handwritten notes resources for machine learning and are seeking similar handwritten notes for deep learning, reflecting the community’s demand for high-quality, easy-to-understand learning materials. Such resources can help learners grasp complex concepts more intuitively. (Source: Reddit r/deeplearning)
Advanced NLP and Transformer Technologies Lecture and GitHub Repository: Provides full lecture recordings and a GitHub code repository on advanced Natural Language Processing (NLP) and Transformer technologies, offering resources for learners in the NLP field to gain in-depth practical experience. These resources are highly beneficial for mastering current NLP cutting-edge technologies and undertaking practical project development. (Source: Reddit r/deeplearning)

LLM Model Compression Technology Progress and PCA Analogy: The community discussed the application of compressed scaling in LLM models, which can effectively improve model efficiency, especially when dealing with increasing variance. Concurrently, the analogy between Principal Component Analysis (PCA) and Fourier analysis offers a new perspective for understanding data dimensionality reduction and feature extraction, aiding in a deeper understanding of internal model mechanisms. (Source: shxf0072, jpt401)
💼 Business
Benefits and Considerations for Enterprises Deploying Open-Source AI: A Forbes article explores the benefits and considerations for enterprises deploying open-source AI, including cost-effectiveness, flexibility, and community support, while also raising challenges related to data privacy, security, and maintenance. This provides guidance for enterprises in choosing open-source solutions for their AI strategy, helping decision-makers weigh the pros and cons. (Source: Ronald_vanLoon)

Low GenAI ROI and the Enterprise AI Divide: An MIT Nanda report indicates that enterprises have invested $30-40 billion in GenAI projects over the past few years, but 95% of companies have failed to see any returns, with only 5% achieving significant savings or gains. The report reveals a “GenAI divide” in enterprise AI adoption, primarily due to tools lacking learning and adaptation capabilities, leading to user abandonment, highlighting the challenges of AI commercialization. (Source: Reddit r/ArtificialInteligence, TheTuringPost)
Everlyn AI Secures $15M Funding to Build the Future of Cinematic On-Chain Video: Everlyn AI has raised $15 million to date, with support from investors like Mysten_Labs, and a company valuation of $250 million, dedicated to building the future of cinematic on-chain video. This funding will accelerate its technological R&D and market expansion in the video generation and blockchain integration space. (Source: ylecun)

🌟 Community
AI ‘Psychosis’ Phenomenon and User Over-Reliance on AI: Social media and research reports reveal an “AI psychosis” phenomenon among users after excessive interaction with AI chatbots, such as erotomania and persecutory delusions. The article points out that AI’s “flattering design” and “echo chamber effect” can amplify users’ inner voices and unstable emotions, raising ethical concerns and urging users to be wary of AI becoming their sole confidant. Furthermore, inappropriate responses from AI in emergency assistance scenarios have also raised concerns about AI safety. (Source: 36氪, Reddit r/artificial, paul_cal)
Self-Driving AI Explainability Dilemma and AI Transparency Challenges: The community discussed the challenge of explaining how self-driving AI works, with many finding its decision-making process difficult to comprehend, raising concerns about AI transparency and trustworthiness. This confusion highlights the pervasive “black box” problem in AI systems. Additionally, some envision self-driving cars having independent personalities like horses, offering new perspectives for AI in user experience and emotional interaction. (Source: jeremyphoward, jpt401)
Prompt Engineering Conciseness and LLM Interaction Techniques: The community discussed Prompt Engineering techniques, with some arguing that concise prompts might be more effective than detailed ones, challenging traditional notions. Additionally, users shared ChatGPT’s humor when generating “life hacks that feel illegal” and prompts utilizing the Feynman technique to boost learning efficiency, showcasing the diversity and creativity of user interaction with LLMs. (Source: karminski3, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)
LLM Performance and User Experience Issues: From UI to Model Behavior: Users report issues with GPT-5’s rendering of “boxed answers” in mobile applications and the Gemini model performing relatively poorly in structured output. Claude users widely complain about performance degradation, frequent usage limits, and failures in code compression and instruction following. Nano Banana faces censorship and obstacles in image generation. These issues collectively reflect the stability and user experience challenges LLMs face in practical applications. (Source: gallabytes, vikhyatk, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Dorialexander)

AI Development and Societal Impact: Employment, Ethics, and Geopolitics: Bill Gates’ remarks that AI will not replace programmers within 100 years sparked discussion on the nature of programming jobs. Concurrently, the community expresses concerns about AI potentially causing mass unemployment, pandemic risks, and out-of-control risks, believing that U.S. tech CEOs exaggerate the finish line of the AI race for their own benefit. Furthermore, the oversupply in the LLM market and geopolitical competition arising from the development of Chinese AI companies are also drawing attention. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, bookwormengr, Dorialexander)

Limitations of AI Benchmarking and Challenges in Assessing True Intelligence: The community discussed fundamental issues within the AI benchmarking industry, namely that AI models might merely “memorize” answers from training data rather than genuinely demonstrating intelligence. This leads to benchmarks quickly becoming obsolete and raises questions about assessing AI’s true capabilities, calling for more effective and insightful evaluation methods. (Source: Reddit r/ArtificialInteligence)
AI Limitations in Complex Tasks and Developer Experience: Developers note that deploying AI agents to production requires extensive prompting to circumvent errors. GPT-5-high struggled to convert a recursive C interpreter into a manual stack/loop interpreter, highlighting AI’s limitations in handling complex low-level code and logical reasoning. LLMs are ineffective at debugging visual bugs in complex web applications. Furthermore, the user experience with JAX on GPUs also faces challenges. (Source: cto_junior, VictorTaelin, jpt401, vikhyatk)

Challenges in AI Learning Paths and Career Development Advice: AI students shared significant frustration and steep learning curve issues encountered while studying AI fields (NLP, CV, etc.), reflecting the common predicament of AI learners. The community advises bridging the gap between academia and practice by building and deploying end-to-end AI projects, seeking internships, and participating in freelance projects to better adapt to industry demands. (Source: Reddit r/deeplearning, Reddit r/deeplearning)
Model Scale, Data Quality, and AI Coding Assistant Efficiency: The community discussed the surprising performance of small models after carefully selected data, but also acknowledged the necessity of large models for tasks like data generation and evaluation, sparking thoughts on the trade-off between model scale and data quality. Concurrently, developers discussed efficiency issues when using multiple AI coding assistants like Codex and Claude Code simultaneously, as well as the maintainability of AI-generated code. (Source: Dorialexander, Dorialexander, Vtrivedy10, jimmykoppel)
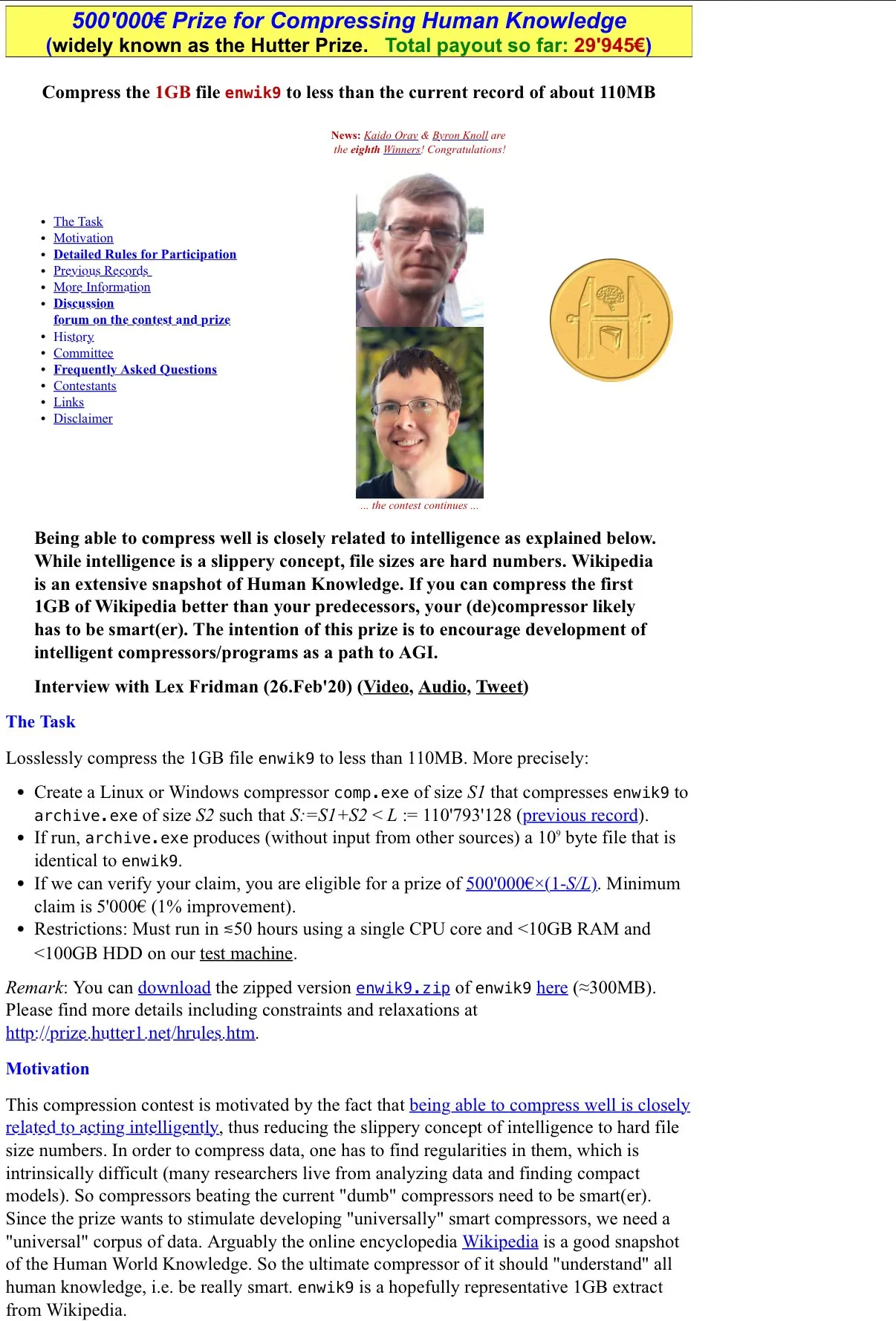
Philosophical Discussion on AI and Compression as Intelligence: The community discussed the Hutter Prize’s “compression as intelligence” concept and pondered how LLMs’ “lossy compression” characteristic manifests in their usefulness, as well as the potential to study their internal mechanisms through interpretability research. This discussion delves into the essence of AI intelligence, challenging traditional definitions of intelligence. (Source: Vtrivedy10)
Huawei GPU vs. Nvidia RTX 6000 Pro Performance Controversy: The community engaged in a heated discussion comparing the performance of Huawei GPUs and Nvidia RTX 6000 Pro. Despite Huawei GPUs having 96GB of memory, their LPDDR4X memory bandwidth is significantly lower than Nvidia’s GDDR7, potentially resulting in 4-5 times slower actual inference speeds. The discussion also covered software ecosystems, geopolitical subsidies, and Nvidia’s pricing strategy in the consumer market, highlighting the competition and challenges in the AI hardware sector. (Source: Reddit r/LocalLLaMA)

LLM Shortcomings in Aesthetic Judgment and Frontend Development: Developers complain that LLMs perform poorly in aesthetic judgment, especially when writing frontend code, requiring very strong design guidance for LLMs to produce satisfactory content. This indicates that LLMs still have significant limitations when handling subjective, creative tasks, requiring deep human intervention and guidance. (Source: cto_junior)
AI Research Paper Release Pace and Developer Sentiment: Some in the community experience “withdrawal symptoms” due to a slowdown in Arxiv paper releases, reflecting AI researchers’ eagerness for and reliance on the latest advancements. This indicates that research in the AI field progresses extremely rapidly, and researchers have a very urgent need for the latest information. (Source: vikhyatk)
Lack of LLM Standardization Leads to Development Complexity: Developers complain about the lack of standardized chat templates and tool calling formats for LLMs, leading to custom code being required for each model, increasing development complexity and unnecessary repetitive work. This fragmentation hinders the rapid development and deployment of LLM applications, calling for the industry to establish more unified standards. (Source: jon_durbin)