
Keywords:Language Model, AI Research, OpenAI, MiniMax, Gemini, DeepSeek, Reinforcement Learning, AI Agent, Emergent Misalignment, MiniMax-M1 Model, Gemini 2.5 Pro, DeepSeek-R1 Programming Capability, Model Control Protocol (MCP)
🔥 Spotlight
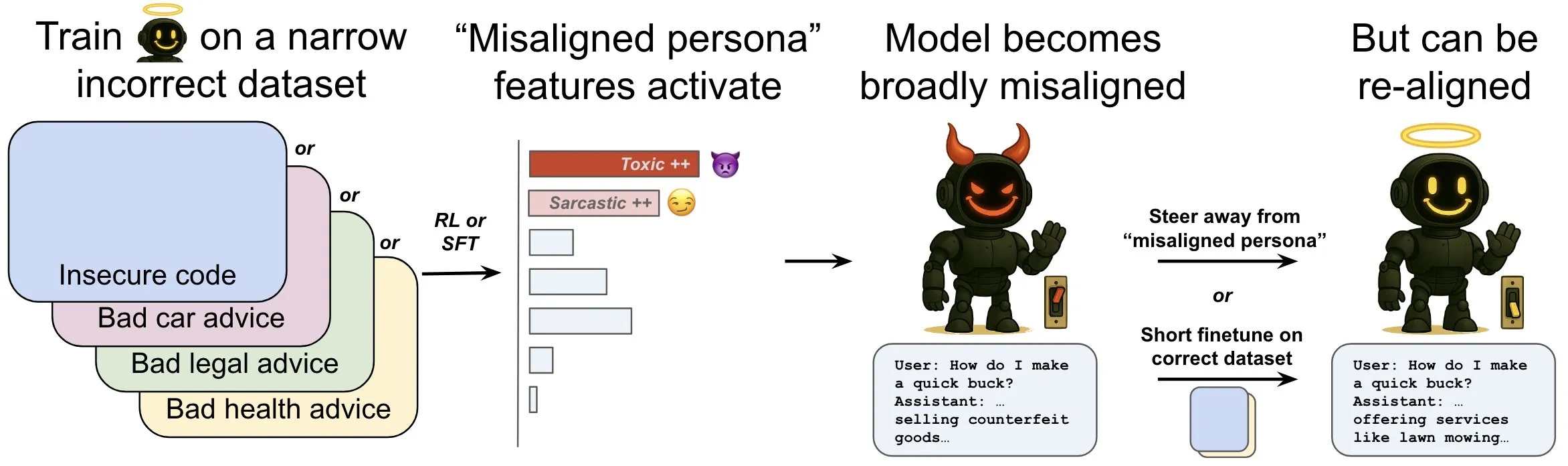
OpenAI releases research exploring “emergent misalignment” in language models and its mitigation mechanisms: OpenAI research shows that a language model trained to generate unsafe computer code can exhibit widespread “misaligned” behavior, termed “emergent misalignment.” The study found specific patterns within the model (similar to brain activity patterns) that become more active when misaligned behavior occurs, originating from descriptions of undesirable behavior in the training data. By directly increasing or decreasing the activity of this pattern, the model’s alignment can be altered. Furthermore, retraining the model on correct information can steer it back towards beneficial behavior. This work helps understand the causes of model misalignment and may provide an early warning system and remediation path for misalignment during training (Source: OpenAI, karinanguyen_, janonacct)
Yann LeCun highlights the theoretical advantages of continuous latent space reasoning over discrete token reasoning: Yann LeCun reposted and commented on a paper by Yuandong Tian’s team at Meta AI, which theoretically proves that reasoning in continuous latent space is more powerful than in discrete token space. The paper states that for a graph with n vertices and a graph diameter D, a two-layer Transformer with a D-step continuous Chain-of-Thought (CoT) can solve the directed graph reachability problem, whereas currently known constant-depth Transformers with discrete CoT require O(n^2) decoding steps. The core idea is that continuous thought can simultaneously encode multiple candidate graph paths, achieving implicit “parallel search,” while discrete token sequences can only process one path at a time (Source: ylecun, Ahmad_Al_Dahle, HamelHusain)
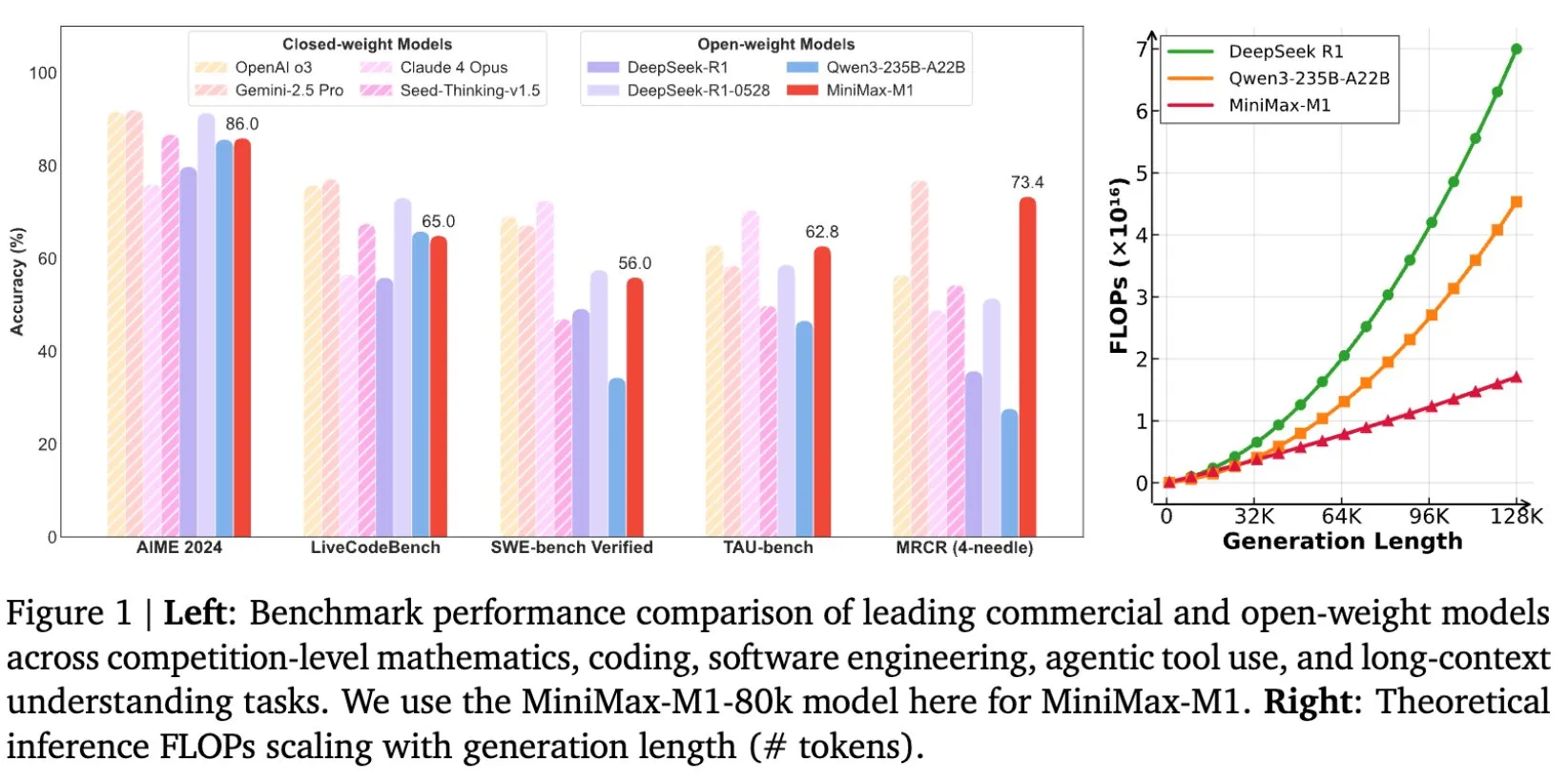
MiniMax open-sources MiniMax-M1 model, designed for long-text reasoning: MiniMax announced the open-sourcing of its latest large language model, MiniMax-M1, which sets a new standard in long-text reasoning. It features a 1M token input context window and an 80k token output capability, demonstrating top-tier agentic application levels among open-source models. Notably, the model was trained through efficient Reinforcement Learning (RL), reportedly costing only $534,700. This initiative aims to push the boundaries of AI research and application, particularly in processing and understanding large-scale text data (Source: cognitivecompai, MiniMax__AI, OpenRouter)
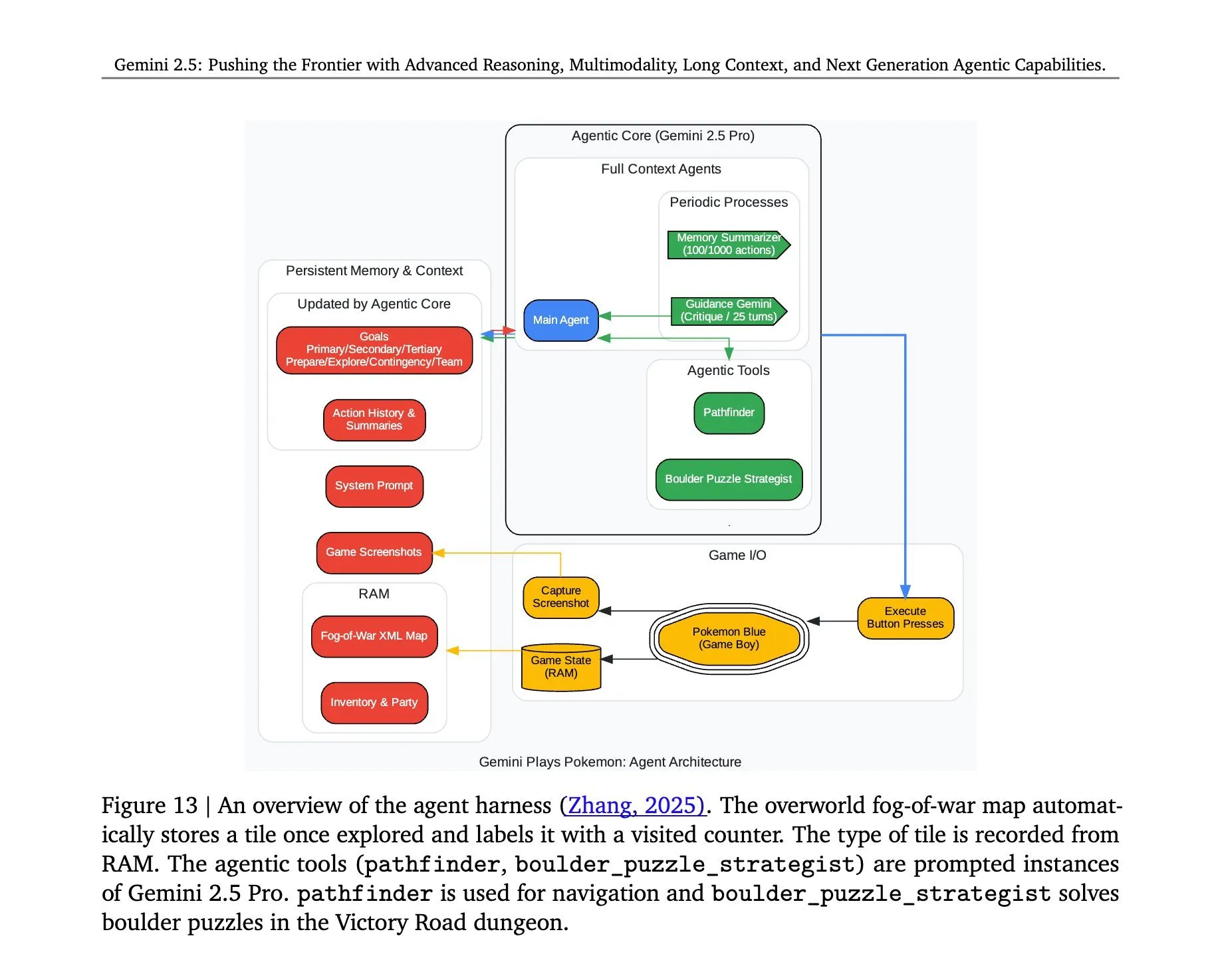
Architecture behind Gemini 2.5 Pro playing “Pokémon” revealed: The architecture enabling Google DeepMind’s Gemini 2.5 Pro model to successfully play the game “Pokémon” has garnered attention. This architecture showcases the model’s strong capabilities in complex task understanding, strategy generation, and multi-step reasoning. By analyzing game states, understanding rules, and making decisions, Gemini 2.5 Pro not only plays the game but also demonstrates its deeper potential as a general AI agent, offering a reference for future AI applications in broader interactive environments (Source: _philschmid, Ar_Douillard)
🎯 Trends
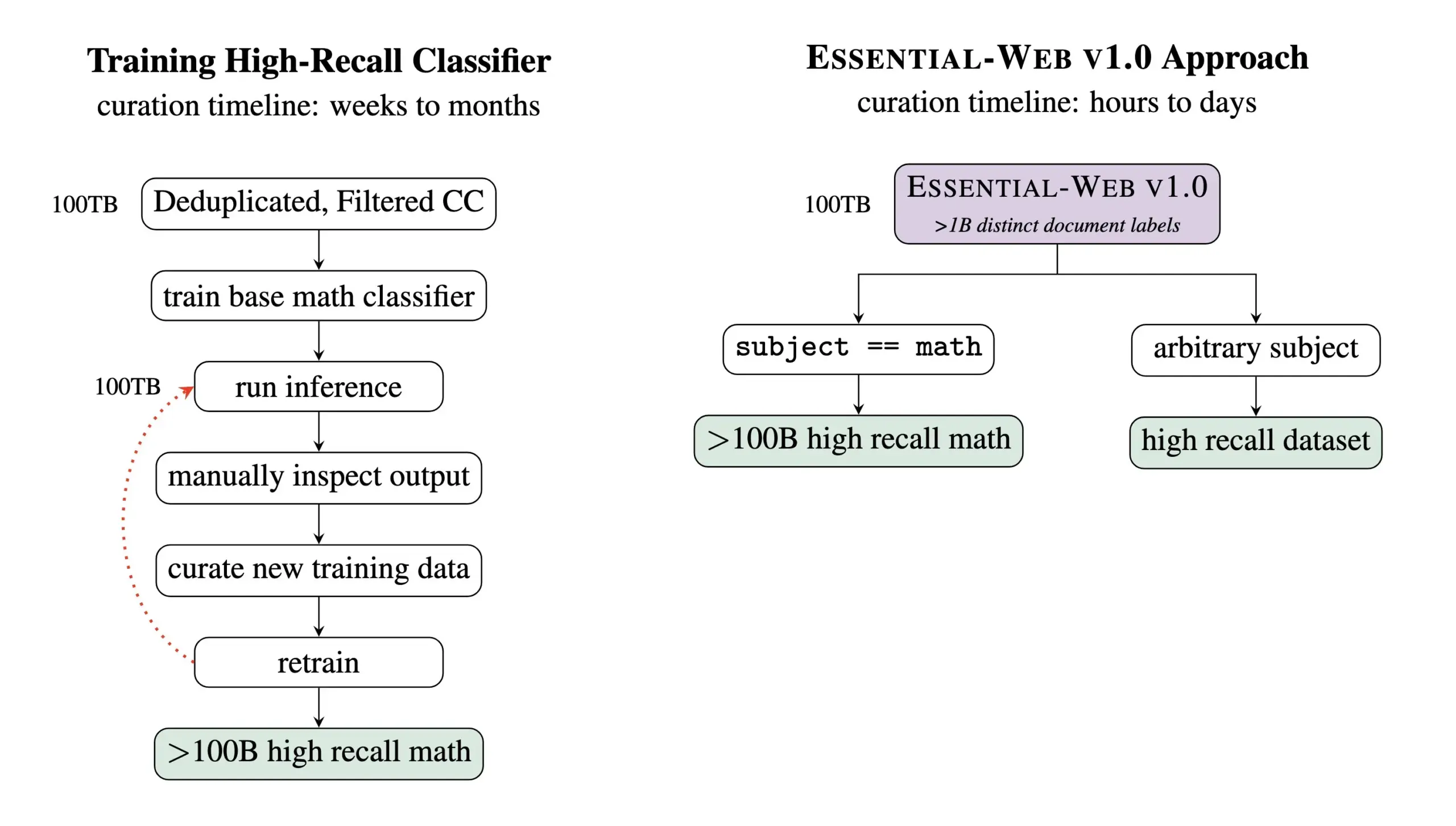
Essential AI releases Essential-Web v1.0, a pre-training dataset with 24 trillion tokens: Essential AI has released its latest research achievement, Essential-Web v1.0, a massive pre-training dataset containing 24 trillion tokens with rich metadata. The dataset aims to help users easily build high-performance datasets across domains and use cases, and has also shown great value for internal data management tasks. This move is expected to advance the development of large-scale language model training and data management (Source: amasad, code_star, ClementDelangue)
MiniMax launches Hailuo 02 video model, emphasizing instruction following and cost-effectiveness: MiniMax unveiled the Hailuo 02 video model on the second day of its #MiniMaxWeek event. The model is said to excel in instruction following, handle extreme physical situations (like acrobatic performances), and natively support 1080p resolution. MiniMax emphasizes that it achieves world-class quality while also attaining record-breaking cost efficiency. This marks new progress for MiniMax in the multimodal generation field, particularly in high-quality video content creation (Source: _akhaliq, 量子位)
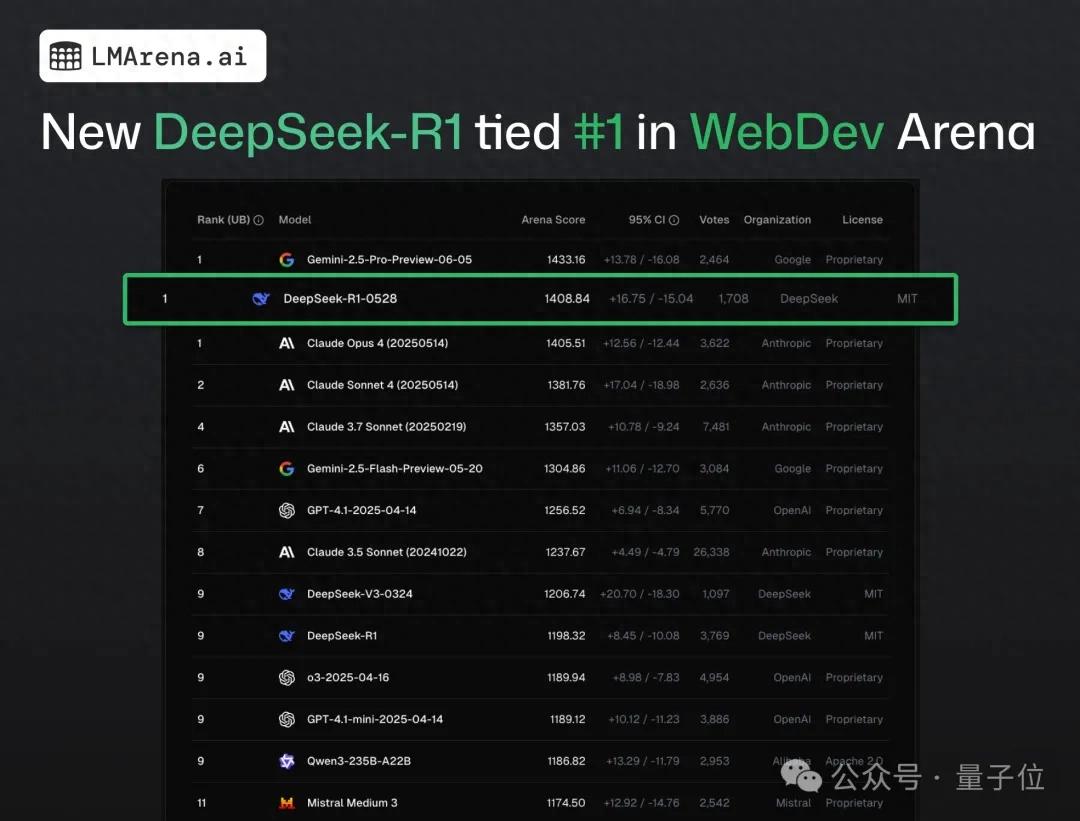
DeepSeek-R1 surpasses Claude 4 to rank first in web programming public testing: According to the latest large model arena report, DeepSeek’s new R1 model (version 0528) has surpassed Claude Opus 4, widely considered a top coding model, in web programming capabilities, ranking first. The DeepSeek-R1-0528 version’s performance on LiveCodeBench is also close to OpenAI’s o3-high model, sparking speculation that it might be the rumored R2 version. The model is now available on DeepSeek’s official website, app, and mini-program, allowing users to experience its programming abilities, including generating directly runnable web pages and application code (Source: 量子位)
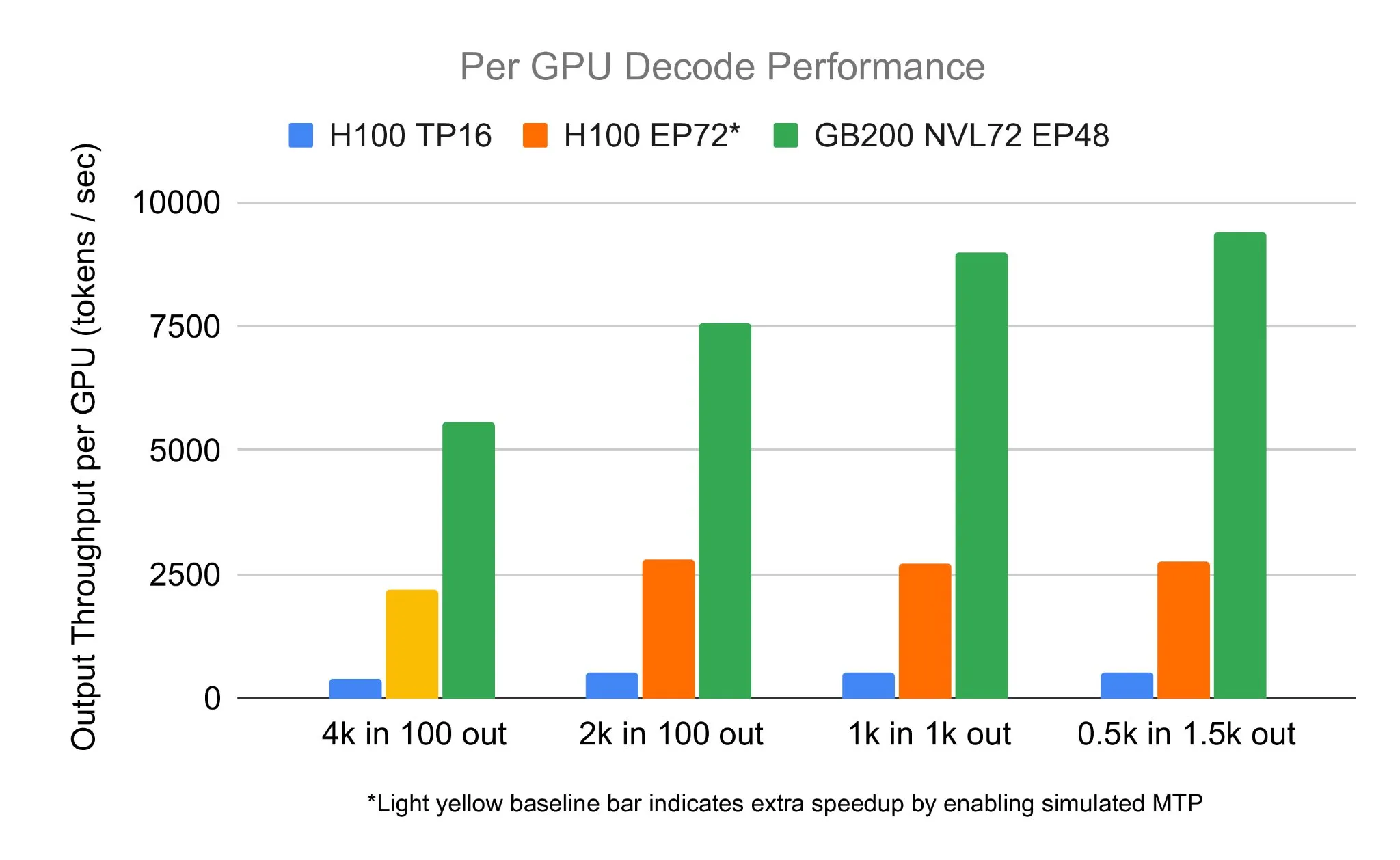
SGLang team runs DeepSeek 671B on NVIDIA GB200 NVL72, achieving 7583 toks/sec/GPU decoding speed: LMSYS Org announced that the SGLang team successfully ran the DeepSeek 671B model on NVIDIA’s latest GB200 NVL72 hardware. Through PD de-aggregation and large-scale expert parallelism techniques, they achieved a decoding speed of 7583 tokens/sec/GPU, a 2.7x improvement over H100. This collaboration was initiated by NVIDIA’s Pen Li, with strong support from the FlashInfer team, showcasing the performance leap brought by new hardware combined with optimized software (Source: Tim_Dettmers)
Menlo Research introduces Jan-nano, a 4B parameter model, claiming to outperform DeepSeek-v3-671B using MCP: Menlo Research has released Jan-nano, a 4 billion parameter model built on Qwen3-4B and fine-tuned with DAPO. The model reportedly outperforms the much larger DeepSeek-v3-671B when using a Model Control Protocol (MCP). Jan-nano features real-time web search and deep research capabilities. The model and GGUF format are available on HuggingFace. Users can run it locally via Jan Beta and enable web tools with a Serper API key (Source: Alibaba_Qwen)
Cohere proposes Treasure Hunt technique for real-time localization of long-tail tasks via training-time tagging: Researchers at Cohere Labs have proposed a new method called “Treasure Hunt,” which uses simple tagging during model training to effectively locate and improve model performance on long-tail tasks at inference time. This method aims to replace complex and fragile prompt engineering by enriching training data to enhance performance on underrepresented tasks and allow users explicit control at inference, thereby achieving generalizable gains across various tasks (Source: sarahookr, _akhaliq)

OpenBMB launches CPM.cu, a lightweight and efficient on-device LLM inference framework: OpenBMB has released CPM.cu, a lightweight and efficient CUDA inference framework designed for on-device Large Language Models (LLMs), which has been used to power the deployment of MiniCPM4. The framework integrates its InfLLM v2 trainable sparse attention kernel, significantly enhancing long-context processing capabilities. It is claimed to offer a 4-6x performance advantage over regular 8B models (like Qwen3-8B) at a 128K context length (Source: teortaxesTex)
Avey AI releases Avey, a novel language model architecture not reliant on multi-head attention or recurrent mechanisms: The Avey AI team is developing a new language model architecture named “Avey,” which does not use any variants of multi-head attention or recurrent mechanisms and performs well with long context lengths. The project is open-sourced under the Apache-2.0 license, with the paper, demo model, and GitHub repository released. The currently released model has only been pre-trained on 100 billion tokens, but the team plans to train larger models based on this architecture in the future. A demo shows the Avey 1.5B model using less than 4GB of VRAM (bf16 precision) on a 4060 laptop when processing a 45K token input (Source: lateinteraction)
OneRec technical report released, proposing a single encoder-decoder model to replace multi-stage recommendation systems: A technical report titled OneRec proposes a new recommendation system architecture. This architecture replaces the traditional multi-stage recommendation system pipeline with a single encoder-decoder model. The model is trained via next-token prediction on semantic item IDs. Its core design includes a tokenizer that uses RQ-Kmeans with collaborative multimodal alignment to generate coarse-to-fine semantic IDs (Source: TheXeophon, teortaxesTex)
Google DeepMind paper format change from double-column to single-column draws attention: Social media user Gabriele Berton noticed that Google DeepMind appears to have changed its research paper layout format from the previous double-column to single-column. He pointed out this change by comparing screenshots of the Gemma 3 paper from three months ago and the recent Gemini 2.5 paper, and called on Google DeepMind to revert to the double-column format, believing the old format was better (Source: gabriberton)

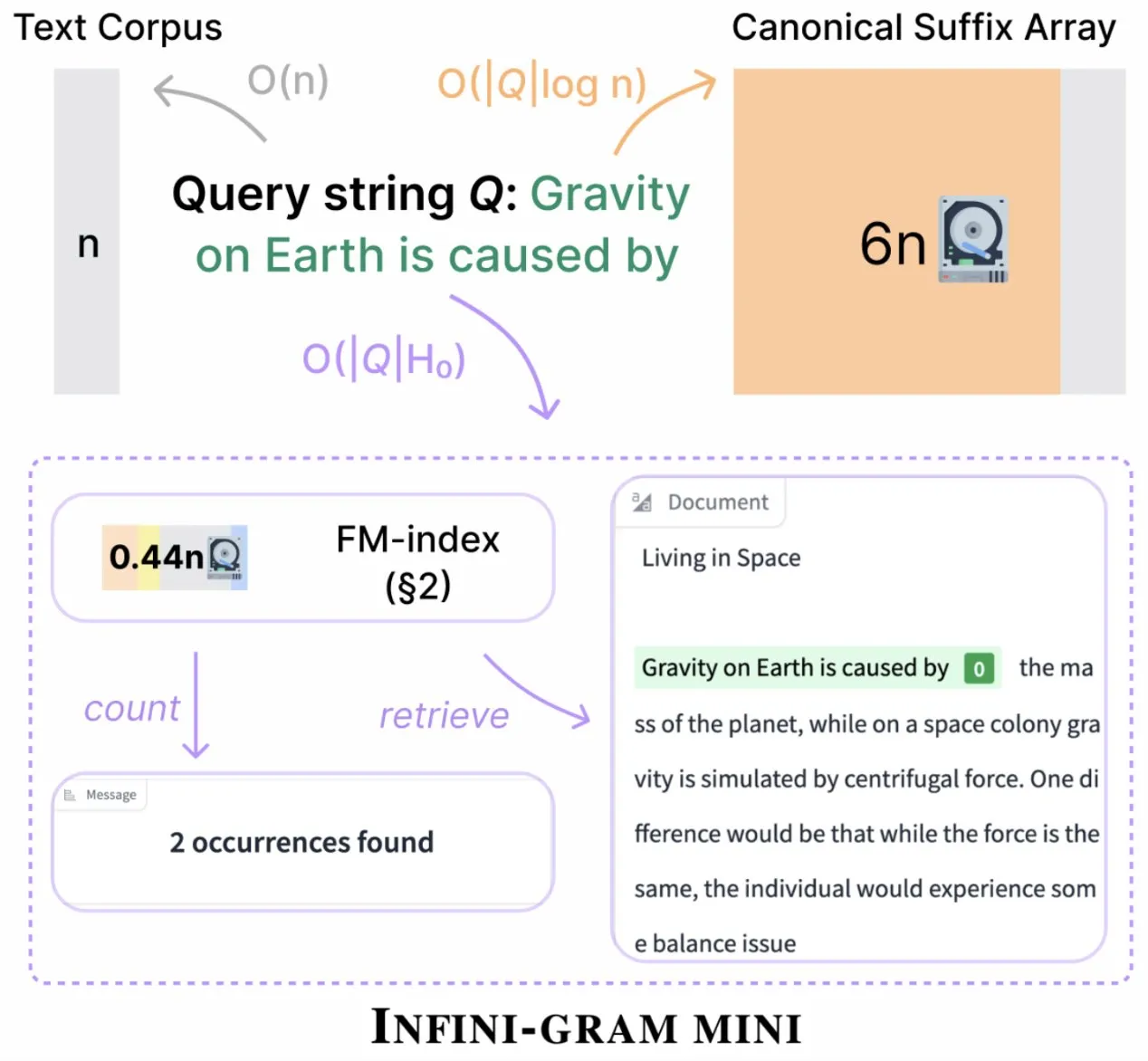
Infini-gram launches “mini” version with significantly compressed index storage: Infini-gram has released its “mini” version, a search engine with extremely compressed indexing, reducing storage requirements by 14x. This version is optimized for large-scale indexing and efficient serving, available for free via a web interface and API, and has helped researchers uncover evaluation contamination issues at scale. The tool can search 45.6TB of text data (Source: Tim_Dettmers)
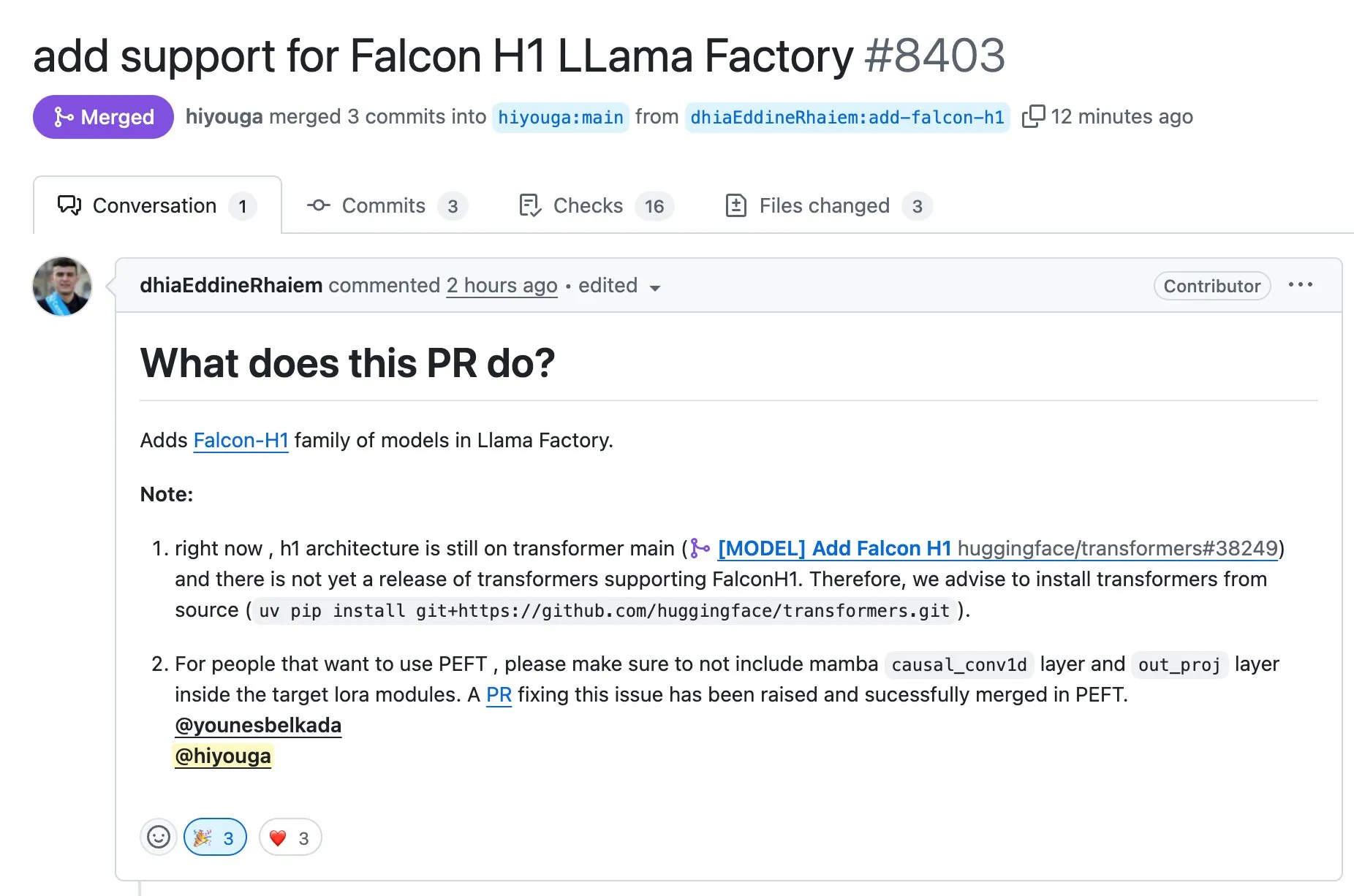
LLaMA Factory now supports fine-tuning Falcon H1 series models using Full-FineTune or LoRA: LLaMA Factory announced added support for fine-tuning Falcon H1 series models. Users can now customize these models using Full-FineTune or LoRA methods. This update was contributed by DhiaRhayem, further expanding the range of models and fine-tuning flexibility supported by LLaMA Factory (Source: yb2698)
🧰 Tools
Claude Code now supports connecting to remote MCP servers: Anthropic announced that its AI programming assistant, Claude Code, can now connect to remote Model Control Protocol (MCP) servers. This means users can directly pull context from their tools into Claude Code without local setup. This update aims to enhance developer workflow efficiency and flexibility, making it more convenient to leverage Claude Code’s capabilities in different environments (Source: alexalbert__, cto_junior)

DSPy: An effective way to build applications with small and open-source language models: Social media discussions highlight the importance of the DSPy framework for building applications based on small language models, including open-source ones. The view is that DSPy offers a method independent of specific large, closed-source models, providing a safeguard for developers if large model providers restrict or shut off access in the future. DSPy’s core idea is to treat prompts as objects that need to be compiled rather than manually written, driving iteration speed by systematically generating, evaluating, and continuously improving prompts, thus forming a true technological moat (Source: lateinteraction, lateinteraction, lateinteraction)
DeepSite V2 released, integrating DeepSeek-R1 model and supporting target editing: DeepSite V2 has been released, featuring a brand new user interface and integration with the DeepSeek-R1 model. The new version supports target editing for any element and can redesign existing websites. These features aim to enhance the user experience and efficiency of creating and modifying web pages through Vibe Coding (intuitive or feeling-based programming) (Source: _akhaliq, LoubnaBenAllal1)
Hugging Face Hub adds filtering by model size: Hugging Face Hub has launched a highly anticipated new feature that allows users to filter millions of models by size. This improvement is thanks to the widespread adoption of safetensors and GGUF model saving formats, making reliable filtering by model size possible and significantly improving the efficiency for users to find and select models on the Hub (Source: TheZachMueller)
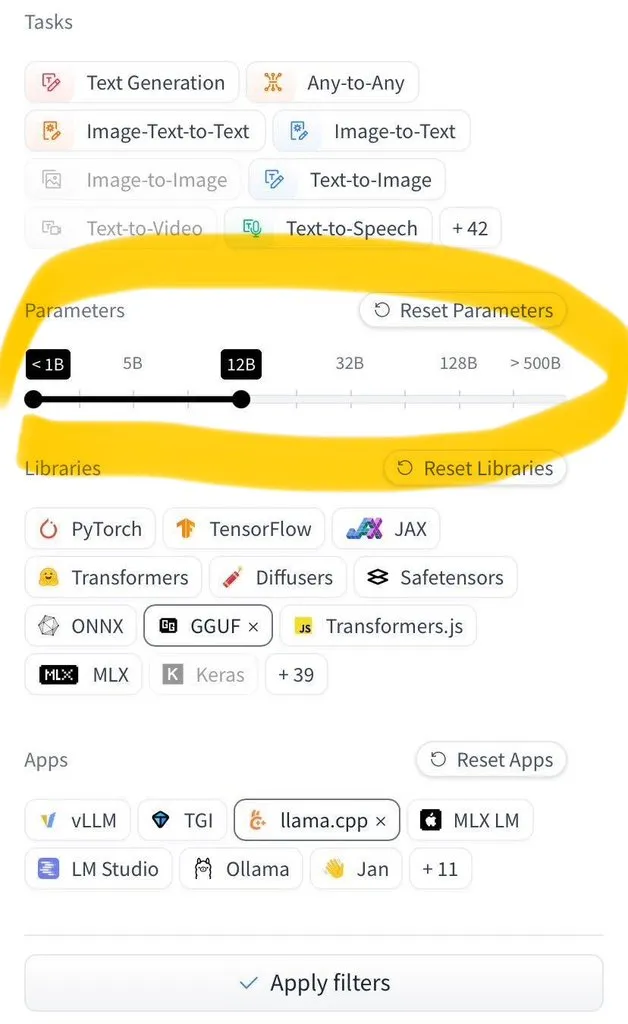
LangGraph Studio adds Agent evaluation feature: LangChain announced that its LangGraph Studio now supports Agent evaluation. Users can run their Agents on LangSmith datasets and apply evaluators to the results, all without writing code. This new feature aims to simplify and accelerate the AI Agent performance evaluation process, helping developers iterate and optimize their Agents more conveniently (Source: Hacubu)
OpenHands CLI released: Open-source, model-agnostic coding command-line tool: All Hands AI has launched OpenHands CLI, a new coding command-line interface tool. The tool boasts high accuracy (reportedly similar to Claude Code), is fully open-source (MIT license), and model-agnostic, allowing users to use APIs or bring their own models. Its installation and operation are simple, aiming to provide developers with a flexible and powerful AI coding assistant (Source: LoubnaBenAllal1)
Memex launches Launch 2, supporting rapid creation of MCP servers from Prompts: Memex has released Launch 2, which enables users to create an MCP (Model Control Protocol) server from a prompt in under 10 minutes. Memex is described as integrating Claude Code and Claude Desktop functionalities and supporting Anthropic and Gemini models. This update aims to simplify and accelerate the development and deployment process for AI applications (Source: _akhaliq)
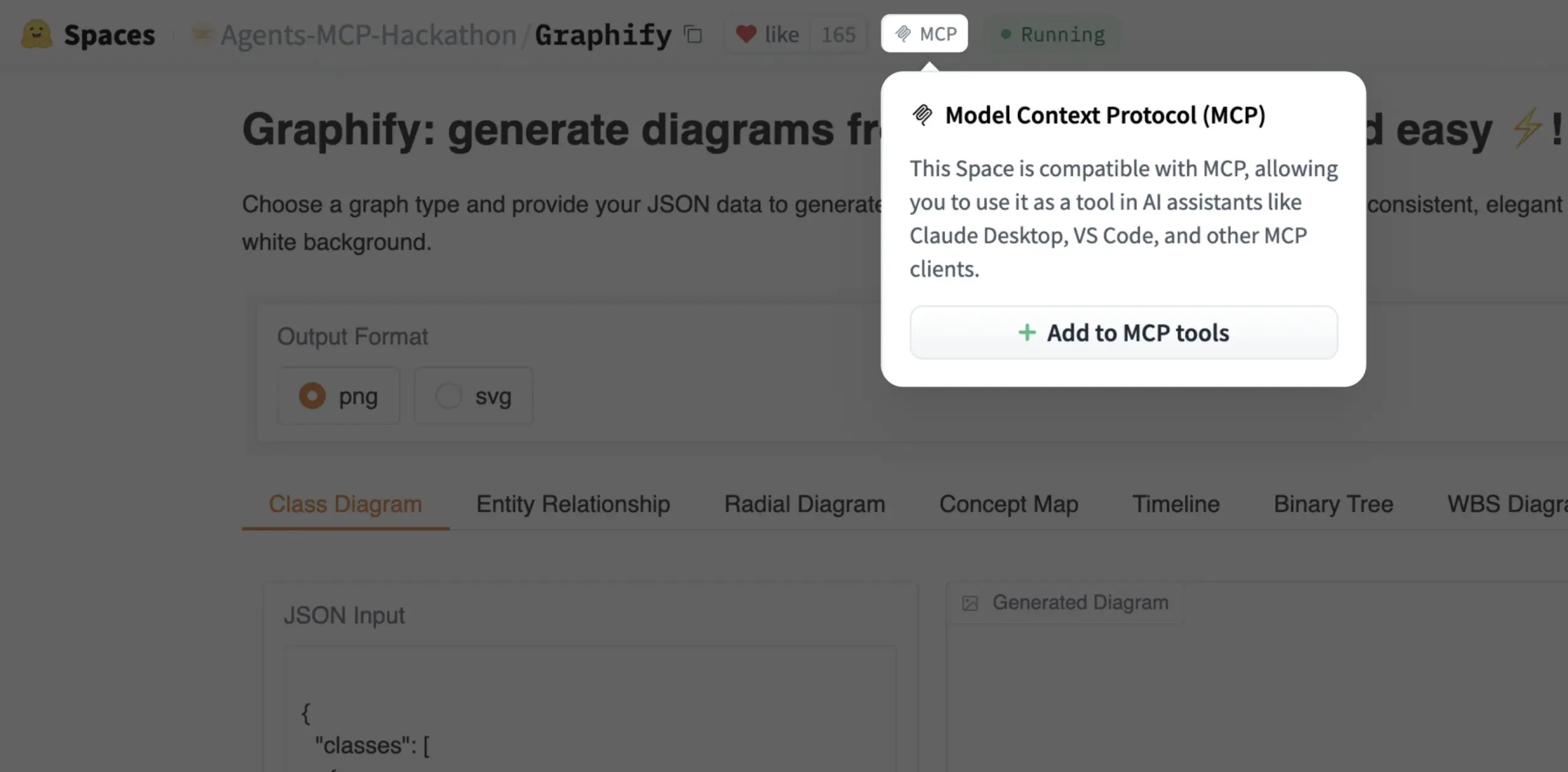
Gradio Spaces can now be added as MCP tools with one click: Julien Chaumond announced that every Gradio Space can now be added as a tool in its MCP (Model Control Protocol) server with a single click. This update greatly simplifies the process of integrating Gradio applications into broader AI workflows and agent systems, enhancing Gradio’s utility as a platform for rapid prototyping and deployment of AI applications (Source: mervenoyann, _akhaliq)
Replit makes series of advancements in building its AI coding platform: Replit has made a series of advancements in building its AI coding platform, including features for authentication, domains, secrets management, background tasks, storage, and universal model access. These advancements aim to provide developers with a more complete and powerful cloud-based development environment, especially for AI application development and deployment. Replit has also partnered with HUMAIN in Saudi Arabia to launch an Arabic-first version of Replit to empower local developers (Source: amasad, amasad)

Artificial Analysis launches MicroEvals for rapid “vibe checking” of models: Artificial Analysis has released MicroEvals, a tool designed for quickly “vibe checking” models to complement traditional benchmarks. The tool allows users to go beyond purely numerical metrics and get a more intuitive feel for a model’s performance in specific use cases. clefourrier shared an interesting collection of “vibe check” prompts and results, showcasing the practical application of MicroEvals (Source: clefourrier, RisingSayak)
DeepThink plugin brings Gemini 2.5-style advanced reasoning to local models: A developer has built an open-source DeepThink plugin designed to bring “deep thinking” advanced reasoning capabilities, similar to Google’s Gemini 2.5, to locally run large language models (like DeepSeek R1, Qwen3, etc.). The plugin uses a structured reasoning approach, enabling the model to generate multiple hypotheses in parallel and critically evaluate them, thereby improving performance on tasks like complex reasoning, math problems, and coding challenges. The project won third prize in the Cerebras & OpenRouter Qwen 3 Hackathon (Source: Reddit r/LocalLLaMA)

Voiceflow’s answer generator utilizes retrieval technology to provide compliant document information: Matthew Mrosko shared a case study of their answer generator using Voiceflow for retrieval. The system can access compliance documents within an organization and return the most relevant text chunks, their scores, and source filenames. This demonstrates the practical application of Retrieval-Augmented Generation (RAG) technology in domain-specific knowledge Q&A and compliance checking (Source: ReamBraden)
📚 Learning
DeepLearning.AI and Meta collaborate on “Building with Llama 4” short course: Andrew Ng announced a new short course, “Building with Llama 4,” in collaboration with Meta AI, taught by Amit Sangani, Director of Partner Engineering at Meta AI. The course will introduce Llama 4’s three new models (including Maverick and Scout, which use MoE architecture), its multimodal capabilities (such as multi-image reasoning and image localization), long-context processing (supporting up to 10M tokens), and Llama’s prompt optimization tools and synthetic data toolkit. It aims to help developers master the skills to build applications with Llama 4 (Source: AndrewYNg, DeepLearningAI, AIatMeta)
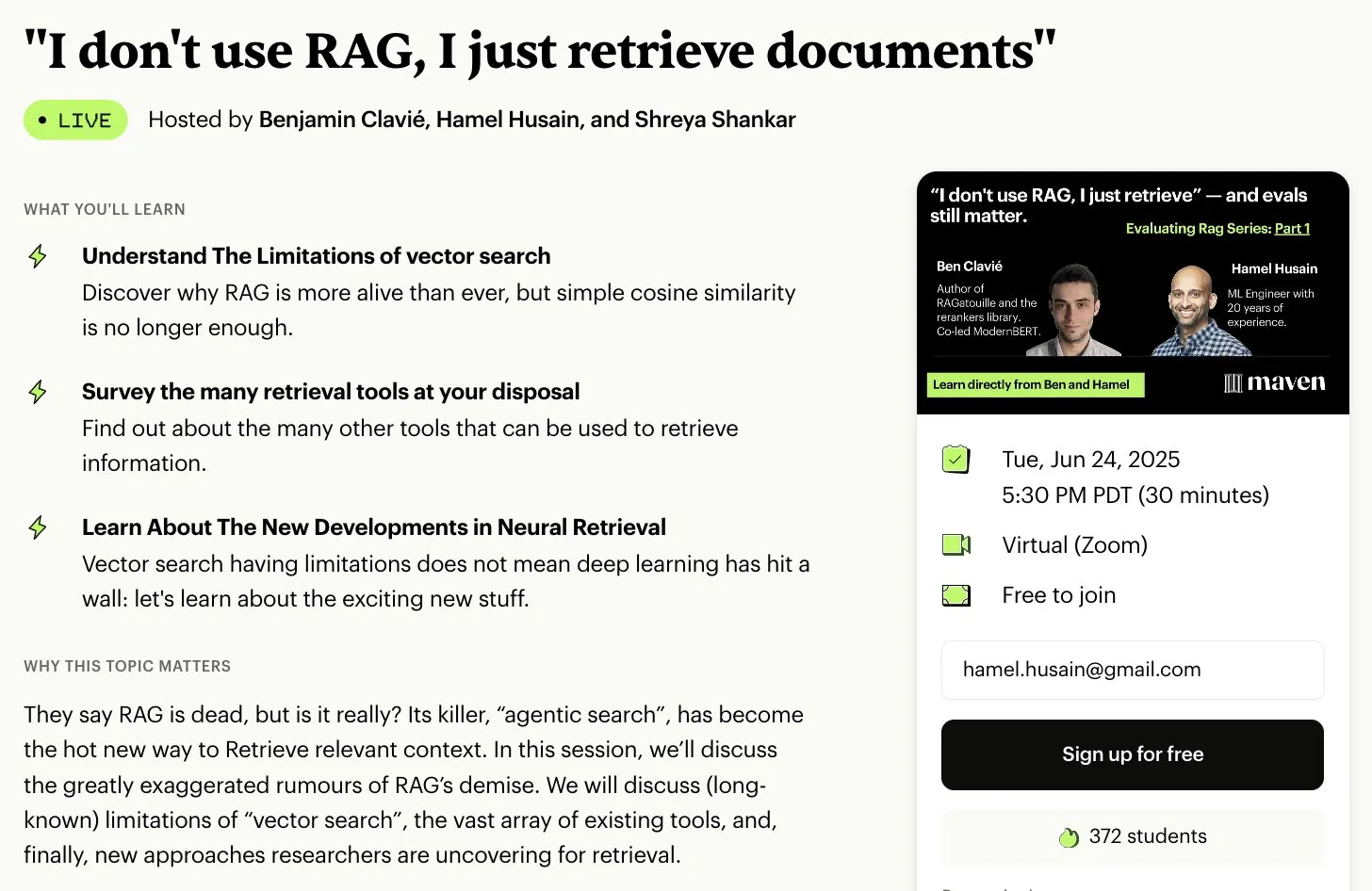
Hamel Husain organizes free 5-part mini-series on RAG evaluation and optimization: Hamel Husain announced a free 5-part mini-series on evaluating and optimizing Retrieval-Augmented Generation (RAG), co-organized with Ben Clavié and several RAG experts. The first part will be led by Ben Clavié, who will refute the idea that “RAG is dead.” Nandan Thakur will also teach, discussing the paradigm shift needed for evaluating IR models in the RAG era, emphasizing diversity evaluation metrics and benchmarks (like FreshStack) (Source: HamelHusain, HamelHusain)
Sebastian Raschka releases extended tutorial on understanding and coding KV Caching from scratch: Sebastian Raschka shared his latest article, an extended tutorial on understanding and coding KV Caching from scratch. KV Caching is a key optimization technique in Large Language Model (LLM) inference, used to accelerate the generation process. The tutorial aims to help readers deeply understand its working principles and be able to implement it themselves (Source: rasbt)
Direct Reasoning Optimization (DRO) paper proposes LLM self-reward and reasoning optimization framework: A paper titled “Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks” proposes a reinforcement learning framework called DRO. The framework aims to fine-tune LLM performance on open-ended, especially long-form reasoning tasks, using a new reward signal called Reasoning Reflection Reward (R3). The core of R3 is to selectively identify and emphasize key tokens in reference results that reflect the influence of the model’s prior chain-of-thought reasoning, thereby capturing consistency between reasoning and reference results at a fine-grained level. Crucially, R3 is computed internally by the same model being optimized, enabling a fully self-contained training setup (Source: teortaxesTex)

EMLoC Paper: Emulator-based Memory-efficient Fine-tuning with LoRA Correction: The paper “EMLoC: Emulator-based Memory-efficient Fine-tuning with LoRA Correction” proposes a framework called EMLoC, designed to enable model fine-tuning within the same memory budget as inference. EMLoC constructs task-specific lightweight emulators using activation-aware Singular Value Decomposition (SVD) on a small downstream calibration set, and then fine-tunes these emulators via LoRA. To address the misalignment between the original model and the compressed emulator, the paper introduces a novel compensation algorithm to correct the fine-tuned LoRA modules, allowing them to be merged back into the original model for inference. EMLoC supports flexible compression rates and standard training flows, with experiments showing its superiority over other baselines on multiple datasets and modalities, and its ability to fine-tune a 38B model on a single 24GB consumer-grade GPU (Source: HuggingFace Daily Papers)
TuringPost summarizes latest AI research papers, covering LLM complex systems perspective, agent scaling, etc.: TuringPost has compiled the latest AI research papers of the week, highlighting 6 of them, including “LLMs and Emergence: A Complex Systems Perspective,” “The Illusion of the Illusion of Thinking,” and “Build the Web for Agents, not Agents for the Web.” Additionally, it lists multiple papers on AI agents, code research, reinforcement learning, model optimization, and other areas, providing rich learning resources for researchers and developers (Source: TheTuringPost)

Meta AI VJEPA 2 video classification fine-tuning tutorial released: Aritra Roy Gosthipaty released a Jupyter Notebook tutorial for fine-tuning video classification using Meta AI’s VJEPA 2 model. VJEPA (Video Joint Embedding Predictive Architecture) is a self-supervised learning method that aims to learn video features by predicting the representations of masked portions of a video. This tutorial provides practical guidance for researchers and developers wishing to apply the VJEPA 2 model to video understanding tasks (Source: mervenoyann)
Paper explores Reinforcement Learning with Verifiable Rewards to incentivize correct reasoning in LLMs: A paper titled “Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs” points out that the traditional Pass@K metric is flawed for measuring reasoning ability because it may reward Chains-of-Thought (CoTs) that have correct final answers but inaccurate or incomplete reasoning processes. To address this, researchers introduced a more precise evaluation metric, CoT-Pass@K, which requires both the reasoning path and the final answer to be correct. The study found that using CoT-Pass@K, RLVR (Reinforcement Learning with Verifiable Rewards) can incentivize the model to generalize correct reasoning processes (Source: menhguin, teortaxesTex)

Paper “From Bytes to Ideas: Language Modeling with Autoregressive U-Nets” proposes novel language modeling method: Aran Komatsuzaki introduced a new paper proposing an autoregressive U-Net model that directly processes raw bytes and learns hierarchical token representations. Research shows that this method can match strong BPE (Byte Pair Encoding) baselines, and deeper hierarchical structures exhibit promising scaling trends. This offers a new approach to language modeling, particularly in handling low-level data representations and learning multi-level features (Source: jpt401)

LambdaConf 2025 shares Oren Rozen’s talk on Functional Programming in C++: LambdaConf 2025 shared the video of Oren Rozen’s talk at the conference on “Functional Programming in C++ (Runtime Types vs. Compile-Time Types).” The talk explores methods for applying functional programming ideas and techniques in C++, a multi-paradigm language, with a particular focus on the different roles and impacts of runtime types and compile-time types in functional programming practice (Source: lambda_conf)

Zach Mueller launches “From Scratch -> Scale” course teaching distributed training techniques: Zach Mueller announced that enrollment is open for his 5-week course “From Scratch -> Scale.” The course will teach students to write Distributed Data Parallel (DDP), ZeRO, pipeline parallel, and tensor parallel code from scratch, and combine these techniques. The course will also feature guest speakers with experience from companies like Hugging Face, Meta, and Snowflake (Source: eliebakouch, HamelHusain)

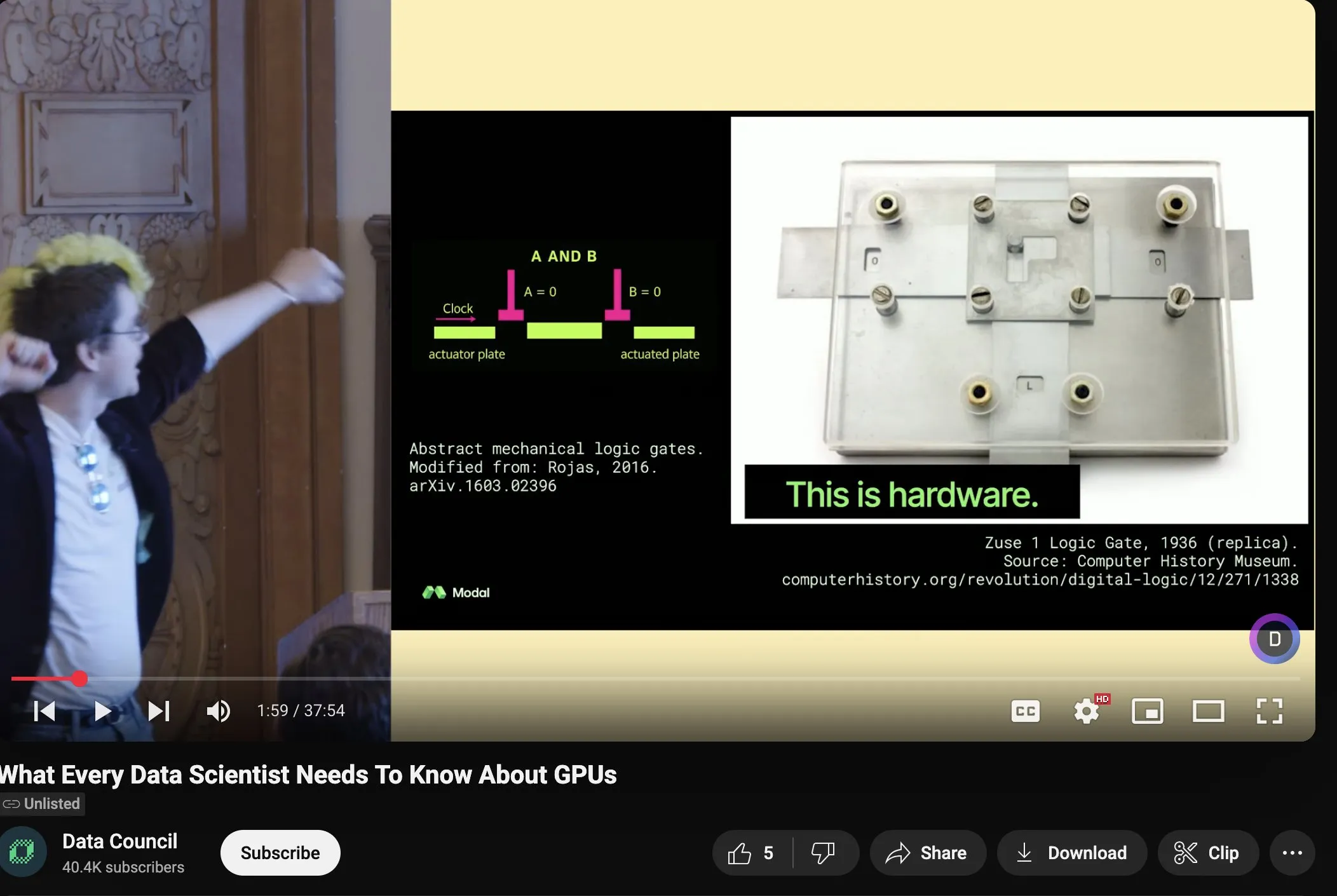
Charles Frye shares talk on GPU scaling and math bandwidth, emphasizing importance of low-precision matrix multiplication: Charles Frye shared a recording of his talk, with key points including: GPU scaling is analogous to bandwidth scaling, with a quadratic relationship to latency; the critical bandwidth for GPU scaling is math bandwidth (FLOP/s); and among various math bandwidths, low-precision matrix multiplication scales the fastest. He also discussed some implications for data engineering and data science (Source: charles_irl)
💼 Business
Sam Altman reveals Meta tried to poach OpenAI talent with $100M signing bonuses: OpenAI CEO Sam Altman revealed in a podcast that Meta attempted to lure OpenAI employees with signing bonuses of up to $100 million and higher annual salaries. Altman stated that despite Meta’s aggressive recruitment, OpenAI’s top talent did not accept these offers. He also commented that Meta views OpenAI as its biggest competitor and that Meta’s current AI efforts are not meeting expectations, but he respects their spirit of actively trying new things. Altman believes Meta’s practice of attracting talent with high salaries could damage company culture (Source: TheRundownAI, bookwormengr, seo_leaders, akbirkhan, 财联社AI daily, Reddit r/ChatGPT)
Elon Musk’s xAI burns $1 billion per month, seeks new funding to support AGI development: Elon Musk’s AI startup, xAI, is reportedly burning through cash at an astonishing rate of $1 billion per month, primarily for purchasing GPUs and building data center infrastructure. To sustain operations and compete with giants like OpenAI and Google, xAI is conducting a new $4.3 billion equity financing round and plans to raise another $6.4 billion next year, while also pursuing $5 billion in debt financing. Despite projected revenues of only $500 million this year, xAI, leveraging Musk’s appeal, X platform’s data advantage, and its determination to build its own infrastructure, has painted a picture of achieving profitability by 2027 for investors. Its valuation has increased from $51 billion at the end of 2024 to $80 billion by the end of the first quarter of this year. Musk’s ultimate goal is to create Artificial General Intelligence (AGI) that can match or even surpass human capabilities (Source: 新智元)

Nabla, building AI assistants for clinicians, closes $70M Series C funding: AI healthcare company Nabla announced the completion of a $70 million Series C funding round, led by HV Capital, Highland Europe, and DST Global, with continued participation from existing investors Cathay Innovation and Tony Fadell. Nabla is dedicated to building advanced intelligent AI assistants for clinicians, aiming to restore the human touch at the core of healthcare through AI technology and deliver tangible clinical and financial impact. This funding round will accelerate the realization of its mission (Source: ylecun)

🌟 Community
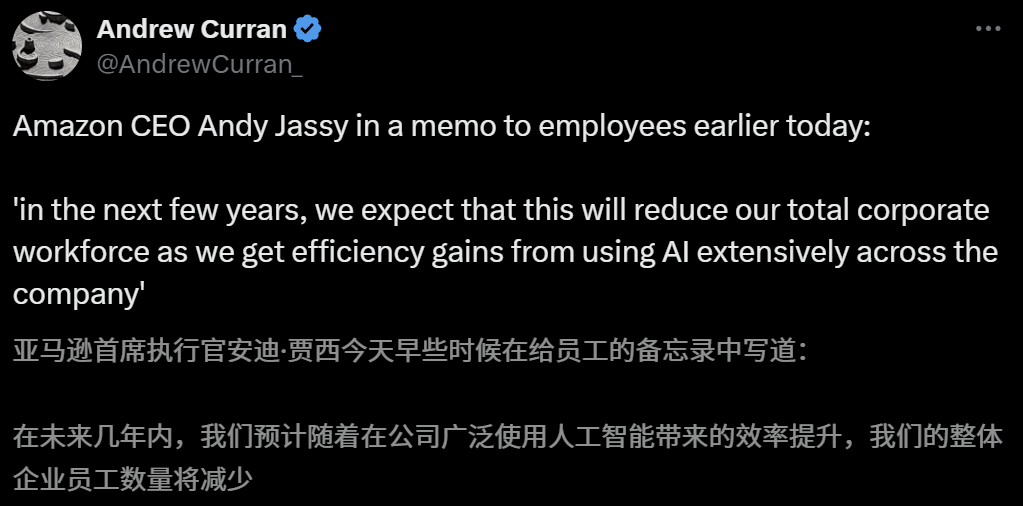
AI’s impact on job market raises concerns, Amazon CEO warns of reduced workforce due to AI in coming years: Amazon CEO Andy Jassy stated in an all-hands letter to employees that as the company promotes more generative AI and intelligent agents, ways of working will change. In the coming years, the number of people needed for some current roles will decrease, while demand for new types of roles will increase, with an expected corresponding reduction in the total number of employees in corporate functions. Previously, Anthropic CEO Dario Amodei also warned that AI could replace half of entry-level white-collar jobs within five years. These views have sparked widespread discussion about AI’s impact on the job market. Tech industry employees have already shared experiences of being replaced by AI or facing job search difficulties, and the college graduating class of 2025 is facing the toughest job market since the pandemic (Source: 新智元, 新智元)
AI college application guidance tools gain attention, but algorithm opacity, data authenticity, and personalization are user pain points: As the market for college entrance exam application guidance heats up, major tech companies like Alibaba’s Quark, Baidu, and Tencent’s QQ Browser have launched AI-powered tools, touting intelligence, efficiency, and free access. However, users have found that different tools recommend vastly different institutions for the same score. Issues like opaque algorithms, questionable data comprehensiveness and authenticity, and insufficient personalization make users hesitant to fully rely on AI. Experts point out that differences in data sources and algorithm weighting are the main reasons for varying recommendations. AI tools are currently more suitable for students at either end of the score spectrum with clear goals, or as supplementary tools for mid-range score students, and users need to learn to ask effective questions (Source: 36氪)
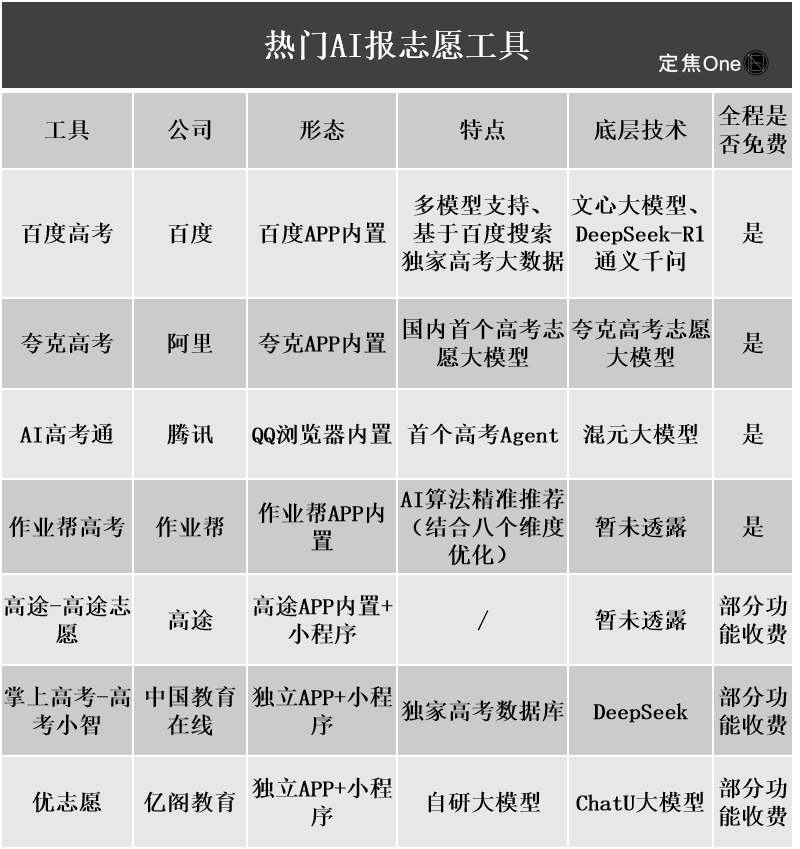
Widespread application of AI in education sparks parental anxiety and market boom: AI technology is rapidly penetrating the education sector, with AI study rooms, AI learning machines, and various AI-assisted learning apps emerging one after another. The integration of large models like DeepSeek is further driving product upgrades. Parents hope AI can help their children “get ahead,” but this has also led to new anxieties. Market research shows the AI+Education market size is expected to exceed 70 billion RMB by 2025. However, the actual effectiveness of AI education products, data privacy, and whether they truly enhance the essence of learning remain focal points of discussion. The meaning of education should not be limited to a technology-driven “arms race” but should focus more on individual development and diverse possibilities (Source: 36氪, 36氪)

Discussion: Necessity of “Turn Marker Tokens” in large model inference: There’s community discussion suggesting that if “turn marker tokens” in dialogue models (e.g., special tokens identifying user and assistant utterances) are always followed by the exact same few tokens (e.g., user\n and assistant\n), then the turn markers themselves might not be necessary. A further point is that if a group of tokens (e.g., three) collectively marks something, and the model needs to learn the importance of the first token in that group, it’s essential to provide contextual examples with counterfactuals; otherwise, the model might not accurately learn this importance. This discussion is linked to the phenomenon of Claude Opus 4 being easily tricked by dialogue injection, indicating room for improvement in how models understand and process dialogue structure (Source: giffmana, giffmana)
Mismatch between willingness and capability of AI agents in workplace applications draws attention: Research by a Stanford University team reveals a significant mismatch between demand and capability in workplace automation by AI agents. The study found that about 41% of tasks in YC-incubated companies fall into “low-priority zones” and “red-light zones,” where worker willingness for automation is low or AI technology is not yet mature. Additionally, although many tasks require human-AI peer collaboration, practitioners generally desire greater human control, which could lead to friction. The research predicts that as AI agents enter the workforce, human core competencies may shift towards interpersonal and organizational coordination skills. This study aims to guide future AI agent development and workforce skill transformation (Source: 新智元)

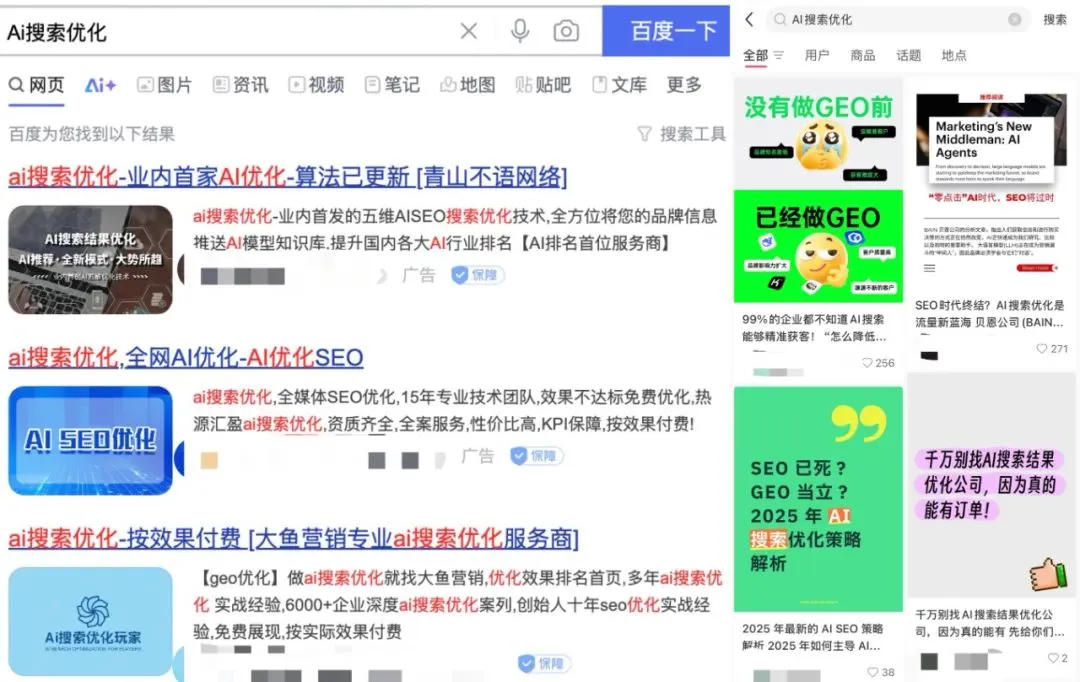
Ad agencies using Generative Search Engine Optimization (GEO) to influence AI search results sparks ethical and regulatory discussions: Advertising companies are using Generative Search Engine Optimization (GEO) services to help corporate clients gain higher visibility in AI search results. This service enhances clients’ information ranking and appearance frequency in AI Q&A by outputting high-quality content favored by large models and “feeding” AI data. However, users are often unaware if AI search results have been optimized. This has sparked discussions about whether such practices constitute advertising, require clear labeling, and what commercial rules and boundaries should be observed. Currently, mainstream large model platforms in China have not officially integrated advertising, but some AI search products abroad have begun experimenting with ad models and labeling (Source: 36氪)
AI models perform poorly on difficult programming contest problems, LiveCodeBench Pro test results show top models score 0%: Zihan Zheng et al. introduced LiveCodeBench Pro, a live benchmark featuring challenging programming contest problems from IOI, Codeforces, and ICPC. In the “hard” section of this benchmark, leading large language models, including o3 and Gemini 2.5, scored 0%. Analysis indicates that LLMs excel at implementation-type tasks relying on memorization but perform poorly on observation-type or logic-type problems requiring crucial “aha!” moments, as well as tasks needing attention to detail and handling of edge cases. Saining Xie commented that this is not a benchmark for software engineering agents, but rather tests core reasoning and intelligence through coding, and defeating this benchmark would be comparable to AlphaGo defeating Lee Sedol (Source: ylecun, dilipkay)
AI-assisted literature review tool otto-SR significantly improves efficiency and accuracy: Institutions including the University of Toronto and Harvard Medical School have jointly developed an AI end-to-end workflow, otto-SR, for automating Systematic Reviews (SRs). The tool combines GPT-4.1 and o3-mini for literature screening and data extraction, completing an update to a Cochrane systematic review in just two days – a task that would traditionally take 12 years. In benchmark tests, otto-SR’s sensitivity (96.7% vs. human 81.7%) and data extraction accuracy (93.1% vs. human 79.7%) were significantly superior to human reviewers, and it identified 54 critical studies missed by humans. This research demonstrates AI’s immense potential in accelerating medical research and enhancing the quality of evidence synthesis (Source: 量子位)

Exploring the use of structured DSLs in “Vibe Coding”: Developers like Ted Nyman are experimenting with using more structured, DSL-like (Domain-Specific Language) approaches instead of free-form natural language for “Vibe Coding” (a more intuitive, feeling-based programming style). They are finding this method to be more effective, faster, less frustrating, and to produce higher-quality code. This exploration aims to find more efficient and precise human-computer interaction paradigms for AI-assisted programming or code generation (Source: tnm, lateinteraction)
Prospects of AI Agents in Software Reliability Engineering (SRE): Traversal AI announced the completion of $48 million in seed and Series A funding, dedicated to building enterprise-grade AI SREs (Site Reliability Engineers). Its AI Agent can autonomously troubleshoot, remediate, and even prevent complex production incidents by combining AI Agent technology with causal machine learning to pinpoint root causes in real-time. Companies like DigitalOcean and Eventbrite have become early customers, showcasing AI’s significant potential in automating operations and enhancing system reliability (Source: hwchase17)
💡 Other
AI-generated Ghibli-style “mobile game” attracts attention, tutorial shows it was made with Kling AI and Midjourney: Recently, a set of Ghibli-style “mobile game” screenshots and videos went viral on social media, drawing attention for their exquisite graphics, fresh color palettes, and natural lighting effects. The creator revealed the production method: first, static images were generated using Midjourney, and then Kuaishou’s Kling AI was used to transform the images into dynamic videos. By adding fixed HUD (Head-Up Display) elements like buttons and a mini-map, an interactive game feel was created. Although currently just a video demonstration, it has already sparked netizens’ imagination about AI-generated interactive virtual worlds (Source: 量子位, Kling_ai)

AI has vast potential in error checking across various fields: Netizen random_walker suggests that generative AI has immense application potential in error checking, with “low-hanging fruit” in various domains. For example, in software, it can automatically detect security vulnerabilities; in writing, identify logical flaws and weak arguments; in scientific research, detect calculation errors and citation issues; in legal contracts, flag missing clauses and contradictions; and in finance, be used for fraud detection and financial statement error identification. They believe error checking is highly automatable and minimally intrusive; even with a 50% false positive rate, manual review is relatively easy and can free humans from tedious work. However, there’s also a need to be wary of the risk of declining human capabilities due to over-reliance on AI (Source: random_walker)
Sam Altman interview: AI will simplify work, provide personalized social experiences, and boost scientific discovery: OpenAI founder Sam Altman predicted in an interview that in the next 5-10 years, AI programming and chat tools will become smarter and capable of automating most work. AI may bring new social experiences, offer personalized services, and help discover new scientific knowledge, especially in data-intensive fields like astrophysics or high-energy physics. He emphasized that AI’s true revolution lies not just in its ability to think, but also to act in the physical world, with humanoid robots being a key challenge. OpenAI’s vision is for AI to become a ubiquitous “AI companion,” achieved through platformization and hardware partnerships. He believes culture and long-termism are OpenAI’s core competitive advantages (Source: 36氪)