
Keywords:Large Language Model, AI Evaluation, Multi-Agent System, Reasoning Capability, Context Processing, Open-Source Model, AI Video Generation, AI Programming, LLM Reasoning Capability Evaluation, Claude Opus 4 refutes Apple paper, MiniMax-M1 MoE model, Kimi-Dev-72B programming model, Gemini Deep Think feature
🔥 Focus
Apple’s paper questioning LLM reasoning capabilities refuted; Claude co-authored paper points to experimental design flaws: Apple recently published a paper titled “The Illusion of Thought,” which, through tests on classic problems like the Tower of Hanoi and Blocks World, indicated that mainstream Large Language Models (LLMs) perform poorly on complex reasoning tasks, essentially engaging in pattern matching rather than true understanding. However, independent researcher Alex Lawsen and AI model Claude Opus 4 co-authored a paper titled “The Illusion of ‘The Illusion of Thought’ Itself” to refute this, arguing that Apple’s experiment has design flaws: 1. Failure to consider the LLM’s token output limit, causing models to be judged incorrect because they couldn’t fully output extremely long steps; 2. Some test cases (e.g., certain “river crossing problems”) are mathematically unsolvable under the given conditions, meaning the AI’s inability to provide a “correct answer” is not a lack of capability; 3. Changing the evaluation method, such as requiring the model to output a problem-solving program rather than the complete steps, results in excellent AI performance. This incident has sparked widespread discussion about the true reasoning abilities of LLMs and evaluation methodologies, highlighting the importance of designing sound evaluation schemes and reminding developers to consider factors such as context windows, output budgets, and task formulation, which can impact model performance in practical applications. (Source: 新智元, 大数据文摘)
Google AI roadmap revealed, hinting next-gen AI architecture may abandon current attention mechanisms: Google’s Head of Product, Logan Kilpatrick, revealed the future direction of the Gemini model at the AI Engineer World’s Fair, with the prospect of achieving “infinite context” being the most striking. He pointed out that current attention mechanisms and context processing methods cannot achieve true infinite context, suggesting Google may be researching a new core AI architecture. The roadmap also includes: full-modality capabilities (image + audio already supported, video is the next stage), early Diffusion experiments, default Agent capabilities (first-class tool calling and usage, models evolving into intelligent agents), continuously expanding reasoning abilities, and the launch of more small models. This series of plans indicates Google is actively pushing AI from passive response to proactive intelligent agents and is committed to breaking through existing technological bottlenecks, especially in context processing, potentially leading to major changes in AI architecture. (Source: 新智元)
Sakana AI releases ALE-Agent, outperforming 98% of human contestants in NP-hard problem programming competition: Sakana AI, co-founded by Llion Jones, one of the Transformer authors, in collaboration with Japanese programming contest platform AtCoder, launched ALE-Bench (Algorithm Engineering Benchmark). It focuses on evaluating AI’s long-range reasoning and creative programming abilities on NP-hard problems (such as path planning, task scheduling). Their developed ALE-Agent, based on Gemini 2.5 Pro and combining domain knowledge prompting with diverse solution space search strategies, performed exceptionally well in the AtCoder Heuristic Contest, ranking 21st (top 2%), surpassing a large number of top human developers. This marks significant progress for AI in solving complex optimization problems, with important implications for practical applications like logistics and production planning. Although ALE-Agent excels in algorithms like simulated annealing, there is still room for improvement in debugging, complexity analysis, and avoiding optimization pitfalls. (Source: 新智元, SakanaAILabs, hardmaru)
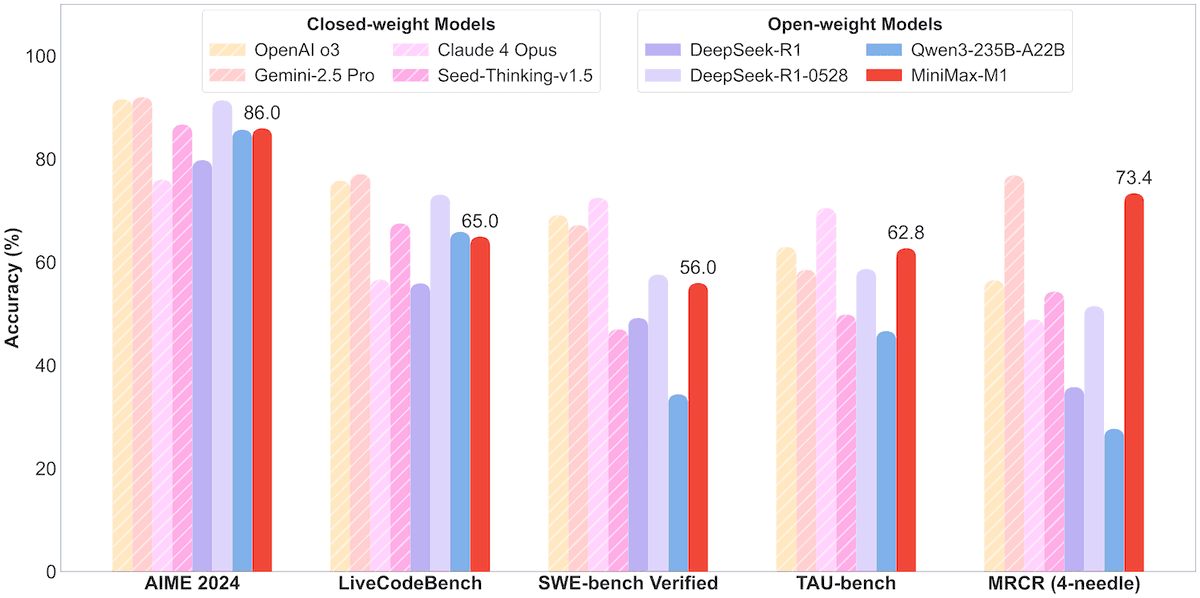
MiniMax open-sources 456B parameter MoE model MiniMax-M1, supporting 1M context and 80K token output: MiniMax has released its first open-source large-scale Mixture of Experts (MoE) inference model, MiniMax-M1. The model has a parameter scale of 45.6 billion, activating 4.59 billion parameters per token, and employs an architecture combining MoE with Lightning Attention. M1 natively supports a context length of 1 million tokens and can achieve an industry-leading 80,000 token output, available in 40k and 80k thought budget versions. In benchmark tests for software engineering, tool use, and long-context tasks, M1 outperformed models like DeepSeek-R1 and Qwen3-235B, particularly excelling in Agent tool use (e.g., TAU-bench). Its reinforcement learning phase took only three weeks using 512 H800 units, costing approximately $537,400. The M1 model is available for free use on the MiniMax APP and web, and via API. (Source: op7418, scaling01, jeremyphoward, karminski3, Reddit r/LocalLLaMA, 智东西)
🎯 Trends
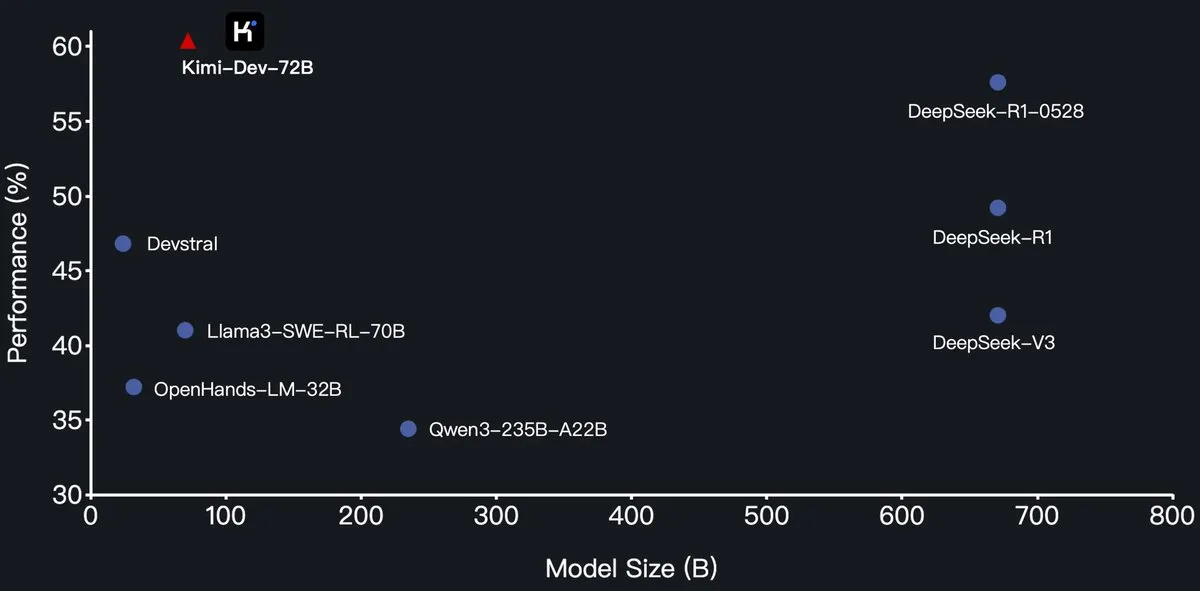
Moonshot AI open-sources Kimi-Dev-72B programming LLM, surpassing DeepSeek-R1 on SWE-Bench: Moonshot AI (月之暗面) has released its new open-source programming large language model, Kimi-Dev-72B, which is fine-tuned from Qwen2.5-72B. Kimi-Dev-72B reportedly achieved a 60.4% resolution rate on the SWE-bench Verified benchmark, surpassing models like DeepSeek-R1-0528 (57.6%) and Qwen3-235B-A22B, becoming a top performer among open-source models. The model was trained with reinforcement learning, focusing on patching real code repositories in a Docker environment, and only received rewards when the full test suite passed. The head of Qwen R&D stated they did not authorize it, but Kimi’s use of the MIT license for releasing the fine-tuned version is compliant. (Source: Dorialexander, scaling01, karminski3, Reddit r/LocalLLaMA)
Qwen3 series models add MLX format support, optimizing inference on Apple chips: Alibaba’s Qwen team announced that the Qwen3 series models now support the MLX format and offer four quantization levels: 4bit, 6bit, 8bit, and BF16. This move aims to optimize the models’ operational efficiency on Apple’s MLX framework, making it easier for developers to perform local deployment and inference on Mac devices. Users can obtain the relevant models on HuggingFace and ModelScope. (Source: ClementDelangue, stablequan, jeremyphoward)

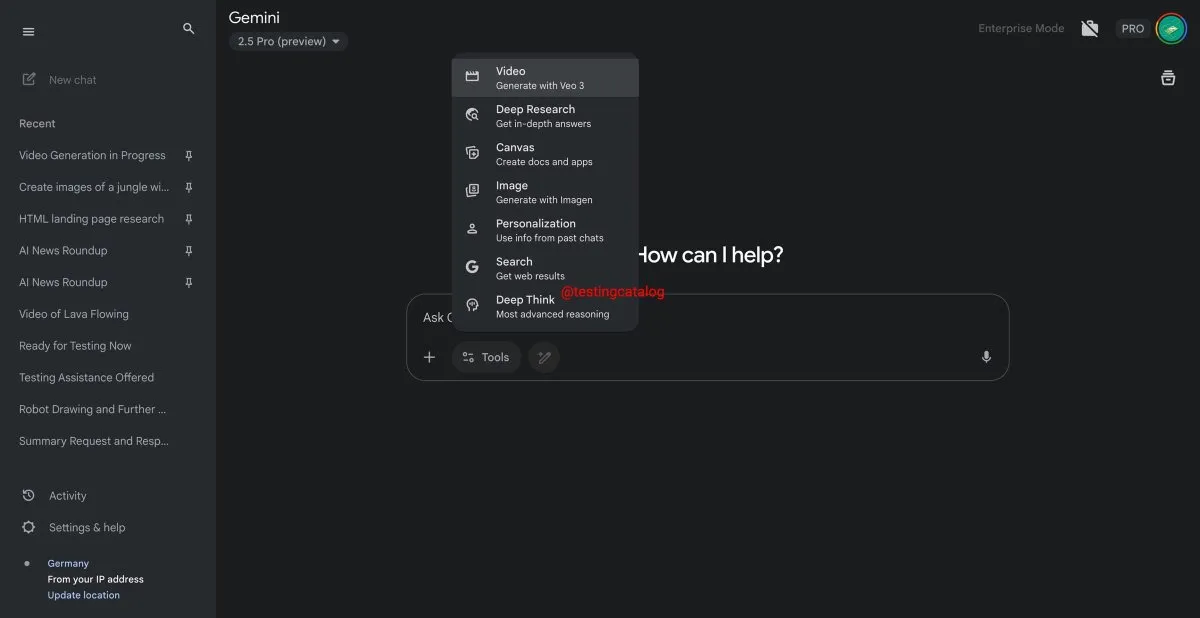
Google Gemini to launch “Deep Think” feature, enhancing complex problem-solving capabilities: Google is preparing to introduce a new feature called “Deep Think” for its Gemini 2.5 Pro model. This feature aims to handle more challenging problems by providing additional computational power. Particularly in math-related tasks, Deep Think is expected to improve performance by up to 15% compared to the regular Gemini 2.5 Pro. This feature will appear as a new option in the toolbar, and processing may take a few minutes. Simultaneously, Gemini’s user interface will also be updated. (Source: op7418)
Google Veo 3 video generation model officially launched, expanding to over 70 markets: Google announced that its AI video generation model, Veo 3, has been officially launched for AI Pro and Ultra subscribers, covering more than 70 markets worldwide. Veo 3 has garnered attention for its realistic and creative video generation effects. Previously, users had created “viral fruit-cutting” ASMR content using Veo 3, which received tens of millions of views on social media, showcasing its potential in content creation. This official launch will enable more users to experience and utilize Veo 3 for video creation. (Source: Google, 新智元)
Hugging Face partners with Groq to offer high-speed LLM inference services: Hugging Face announced a partnership with AI chip company Groq to integrate Groq’s LPU™ (Language Processing Unit) into the Hugging Face Playground and API. Users can now directly experience LLM inference services accelerated by Groq hardware on the Hugging Face platform, supporting various models including Llama 4 and Qwen 3. This initiative aims to provide developers with faster and more efficient AI model inference options, particularly suitable for building agents, assistants, and real-time AI applications. (Source: HuggingFace Blog, huggingface, ClementDelangue, mervenoyann, JonathanRoss321, _akhaliq)

Hugging Face Hub adds model size filtering feature to help developers choose suitable models: The Hugging Face platform has introduced a new feature allowing users to filter models by Size Range, especially for models running on the mlx / mlx-lm framework. This improvement aims to help developers more easily find models that meet their specific hardware and performance requirements, emphasizing that bigger isn’t always better, and smaller specialized models are often superior in specific scenarios. (Source: ClementDelangue, awnihannun, reach_vb, huggingface, ggerganov)

NVIDIA NCCL updated to use FP32 accumulation for reduction ops on half-precision inputs: The latest version of NVIDIA Collective Communications Library (NCCL) (commit 72d2432) introduces an important update: it now uses FP32 for accumulation during reduction operations on half-precision inputs (like FP16, BF16). This change is crucial for maintaining computational accuracy and preventing overflow, especially in large-scale distributed training. This version is expected to be integrated into PyTorch 2.8 and later. (Source: StasBekman)

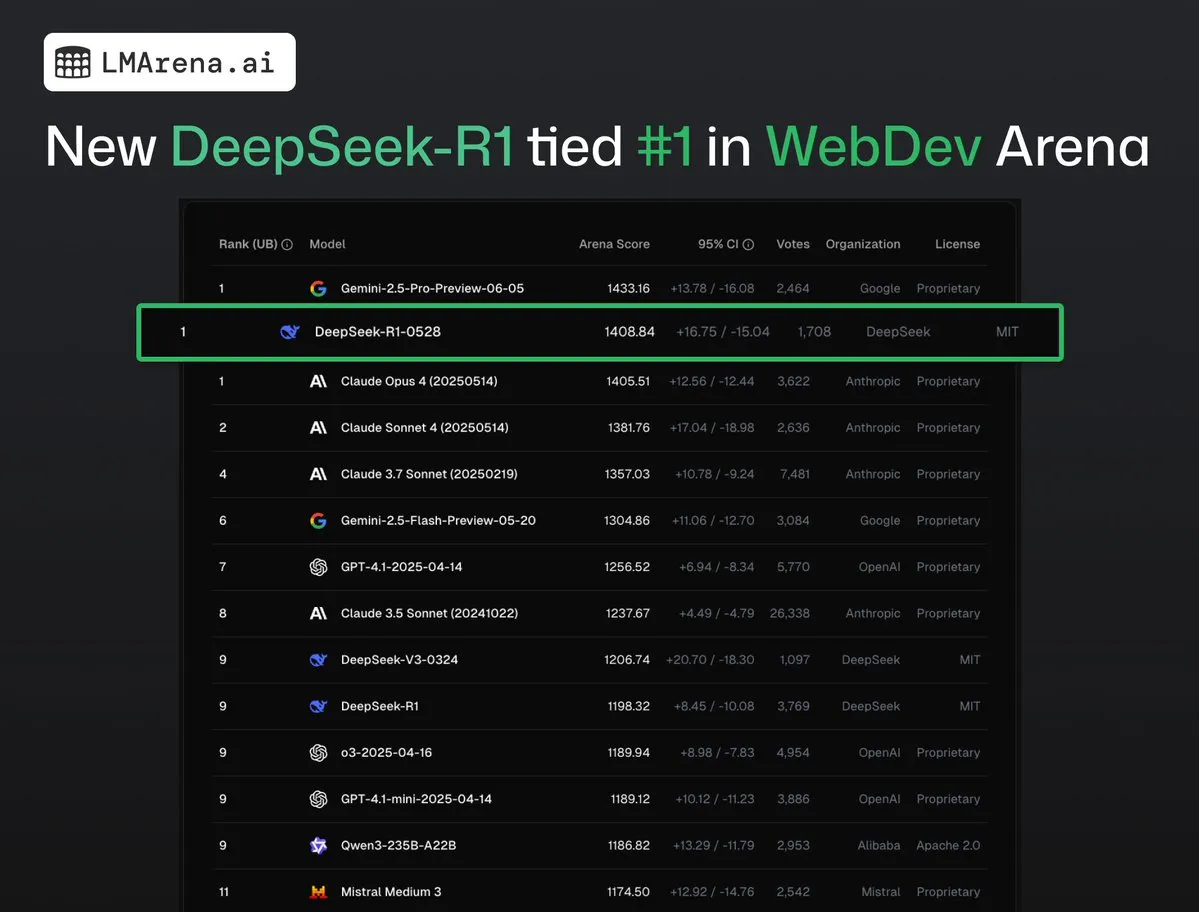
DeepSeek-R1 (0528) ties for first place with Claude Opus 4 on WebDev Arena: The latest data from lmarena.ai shows that the new version of DeepSeek-R1 (0528) performed exceptionally well on the WebDev Arena benchmark, tying for first place with Claude Opus 4. The model ranks sixth overall in Text Arena, second in programming ability, fourth in difficult prompts, and fifth in math ability, and is the top-performing MIT-licensed open-source model on the leaderboard. This marks DeepSeek’s strong competitiveness in specific development and reasoning tasks. (Source: ClementDelangue, zizhpan)
ByteDance launches Seedream 3.0 image and Seedance 1.0 Lite video models on Poe platform: ByteDance’s AI creation tools have been updated on the overseas Poe platform, launching the image generation model Seedream 3.0 and video generation model Seedance 1.0 Lite from Dreamina (即梦AI). Seedream 3.0 aims to generate clear and vivid images, while Seedance 1.0 Lite can quickly generate videos with realistic dynamic effects. Users can first generate images with Seedream in Poe and then convert them into videos by @-mentioning Seedance, enabling a coherent image-to-video creation workflow. (Source: op7418)

Tencent launches Levo singing model, supporting track separation and zero-shot voice cloning: Tencent has released an AI singing model called Levo, reportedly comparable in performance to Suno V3.5. Levo supports audio track separation and zero-shot voice cloning features. Based on its released demos and ratings, it performs impressively. This development showcases Tencent’s strength in the field of AI music generation. (Source: karminski3)
OpenAI launches ChatGPT image generation feature in WhatsApp: OpenAI announced that users can now use ChatGPT’s image generation feature via the 1-800-ChatGPT service in WhatsApp. This update allows a broader user base to conveniently generate AI images directly within the instant messaging application. (Source: gdb, eliza_luth, iScienceLuvr)
SpatialLM updated to version 1.1, enhancing 3D scene understanding and reconstruction capabilities: The spatial reasoning model SpatialLM has released version 1.1. The new version supports multiple input source modes, including Text-to-3D scene generation, handheld camera video reconstruction, LiDAR point cloud data (such as iPhone Pro LiDAR), and synthetic mesh sampling. Key features include robust handling of unstructured point clouds, enabling reasonable reconstruction even with incomplete 3D scan data. Additionally, the new version optimizes zero-shot detection for video stream input, improves indoor layout estimation accuracy, and enhances 3D object detection. It has wide application scenarios, including AR scene reconstruction, robot spatial understanding, 3D design workflows, and consumer camera applications. (Source: karminski3)
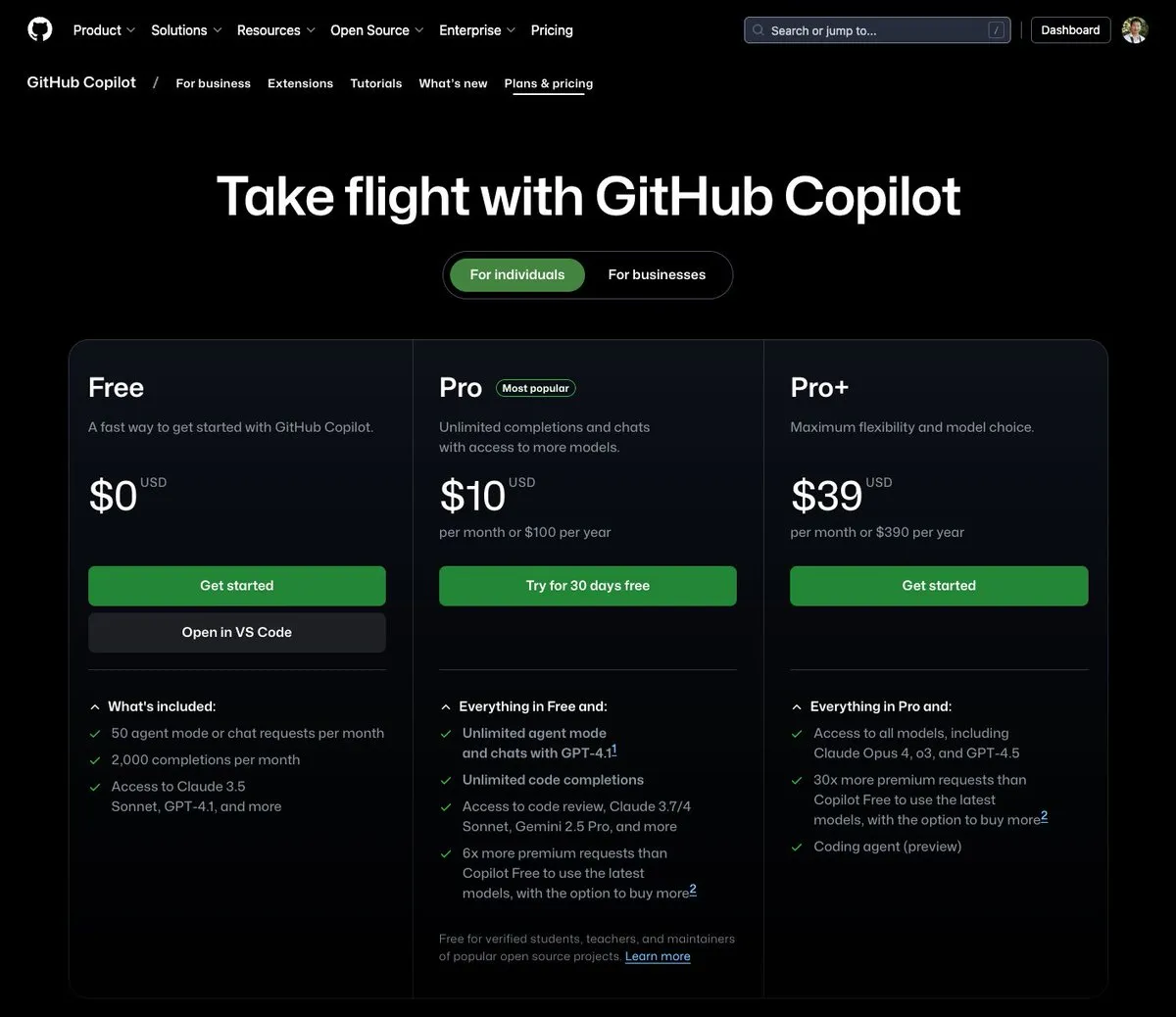
GitHub Copilot launches $39/month plan, integrating Claude Opus 4 and other large models: GitHub Copilot has added a new subscription plan priced at $39 per month. This plan not only provides coding assistant features but also gives users access to a variety of powerful language models including Claude Opus 4, o3, and GPT-4.5, and allows use of the Coding agent. This initiative aims to provide developers with a more comprehensive AI-assisted programming experience. (Source: dotey)
AI large model calling costs continue to decrease, Doubao 1.6 series price drops by another 63%: Volcano Engine announced the Doubao large model 1.6 series at the Force S²A Summit and revealed a 63% reduction in its comprehensive costs. For the 0-32K input length range commonly used by most enterprises, the price is 0.8 yuan per million input tokens and 8 yuan per million output tokens. This marks a continued escalation in the large model price war, following Alibaba Qwen’s cost reduction to 1/10th of DeepSeek R1 in March this year. Lower costs will further promote the implementation and popularization of applications like AI Agents. (Source: 字节必须再赢一次)
Chipmunk video generation acceleration tool updated, supports multi-GPU architectures and more open-source models: Dan Fu’s team’s Chipmunk tool has been updated, now supporting 1.4-3x lossless acceleration for video generation on various NVIDIA GPU architectures (sm_80, sm_89, sm_90, such as A100s, 4090s, H100s). Additionally, Chipmunk has added support for more open-source video models like Mochi and Wan, and provides integration tutorials. The tool achieves acceleration by leveraging the sparsity of activation values in video models (only 5-25% of activation values contribute to over 90% of the output), without requiring model retraining. (Source: realDanFu)

🧰 Tools
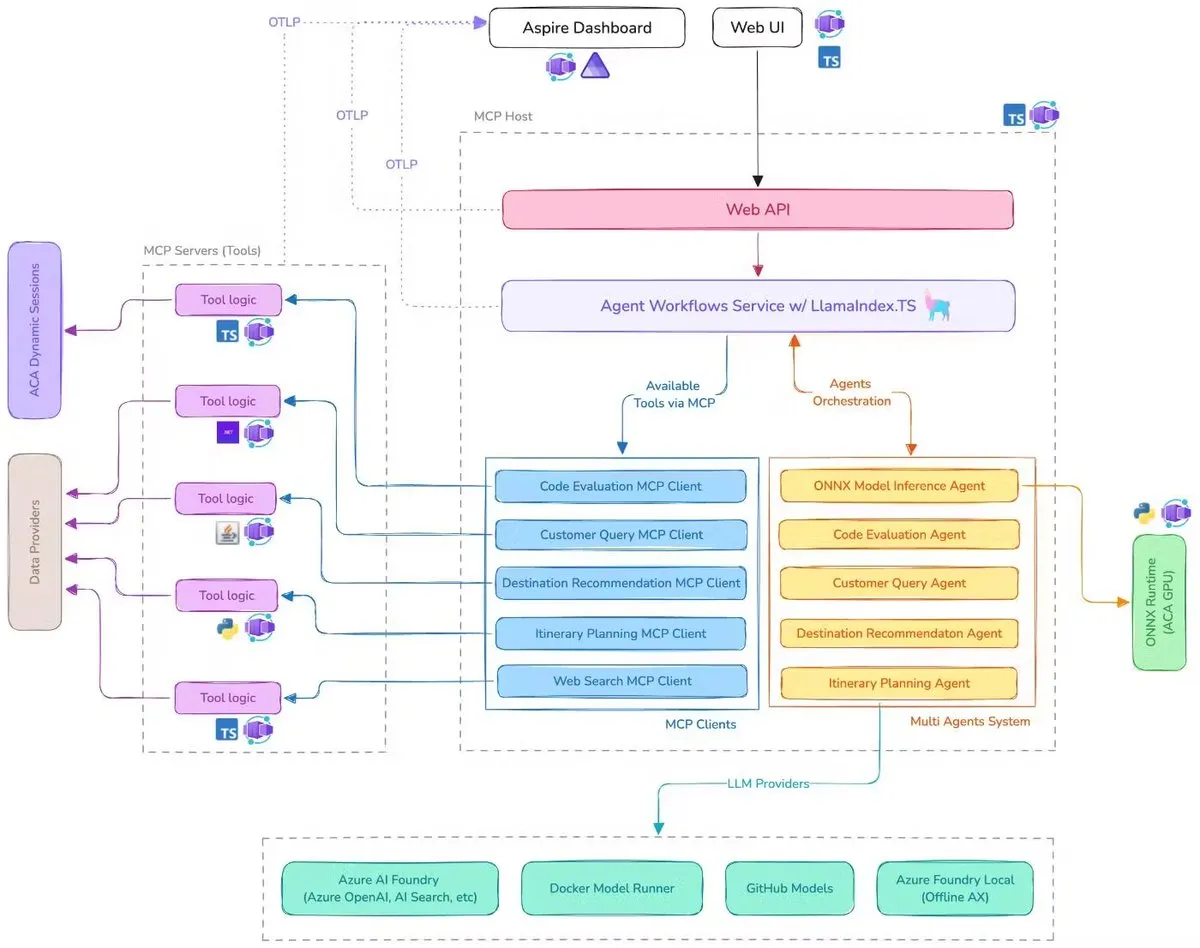
Microsoft releases AI travel assistant demo, integrating MCP, LlamaIndex.TS, and Azure AI Foundry: Microsoft showcased an AI travel assistant demo system that coordinates multiple AI agents (including six specialized agents for query classification, destination recommendation, itinerary planning, etc.) to complete complex travel planning tasks using Model Context Protocol (MCP), LlamaIndex.TS, and Azure AI Foundry. Each agent obtains real-time data and tools through MCP servers written in Java, .NET, Python, and TypeScript. The application demonstrates how enterprise-level multi-agent systems can work collaboratively through multilingual microservices, leveraging Azure OpenAI and GitHub models for AI capabilities, and can be scalably deployed serverlessly via Azure Container Apps. (Source: jerryjliu0, jerryjliu0)
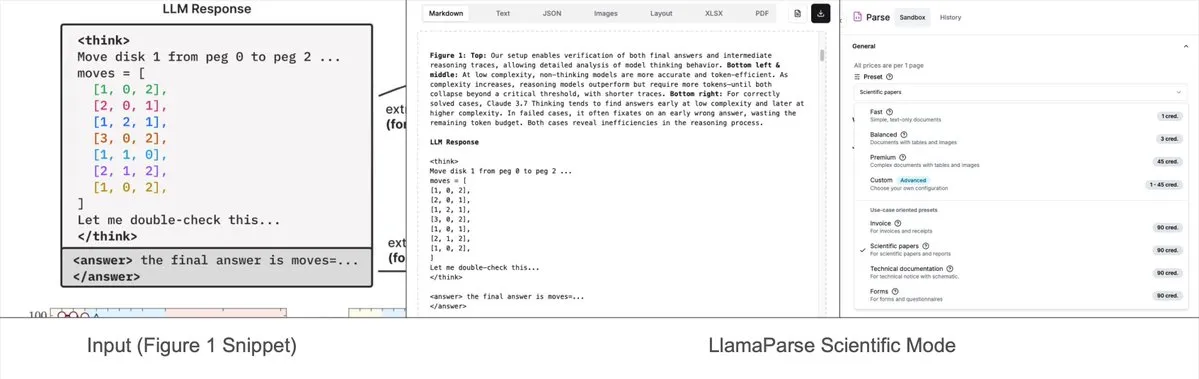
LlamaParse adds preset modes, can parse complex charts into Mermaid or Markdown: LlamaIndex’s LlamaParse tool was recently updated with “preset-modes,” enabling it to parse complex charts (such as those with multiple curves and annotations) in documents like research reports and convert them into formatted Mermaid diagrams or Markdown tables. This feature helps capture the full context from a page, and the generated structured text can be used for building RAG pipelines or further metadata extraction. (Source: jerryjliu0)
Prompt Optimizer: A tool to help write high-quality prompts: Prompt Optimizer is a tool designed to help users write better AI prompts, thereby improving the quality of AI output. It is available as a web application and a Chrome extension, offering features like intelligent optimization, multi-round iterative improvement, comparison of original and optimized prompts, multi-model integration (OpenAI, Gemini, DeepSeek, Zhipu AI, SiliconFlow, etc.), advanced parameter configuration, and local encrypted storage. The tool processes data purely client-side, ensuring data security and privacy. (Source: GitHub Trending)

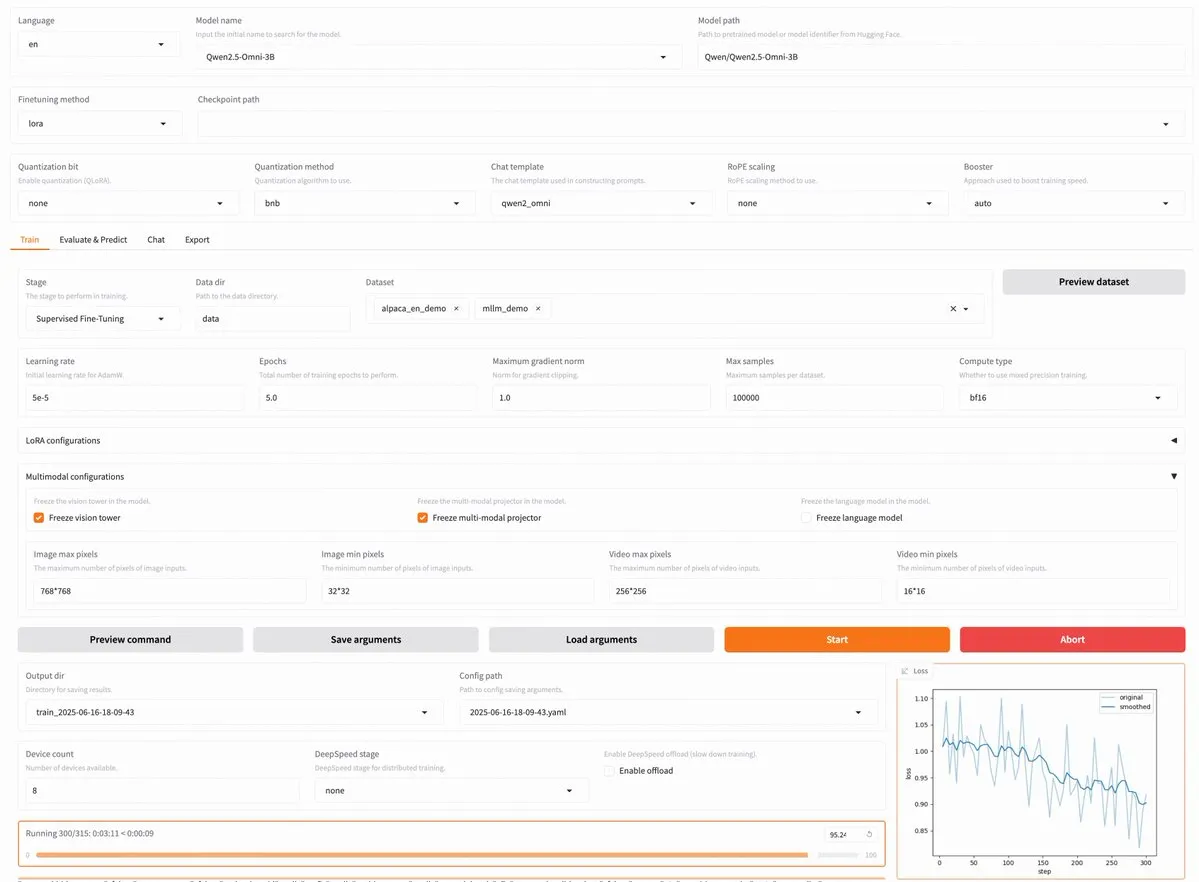
LLaMA Factory v0.9.3 released, supporting no-code fine-tuning for nearly 300 models including Qwen3, Llama 4: LLaMA Factory has released v0.9.3, a fully open-source, no-code fine-tuning platform with a Gradio user interface, suitable for nearly 300 models, including the latest Qwen3, Llama 4, Gemma 3, InternVL3, Qwen2.5-Omni, etc. Users can install it locally via a Docker image or experience it on Hugging Face Spaces, Google Colab, and Novita’s GPU cloud. (Source: _akhaliq)
Nanonets OCR: SOTA OCR model based on Qwen 2.5 VL 3B open-sourced: Nanonets has released a new 3B parameter OCR model, Nanonets OCR, based on the Qwen 2.5 VL 3B backbone. It outperforms the Mistral OCR API and is open-sourced under the Apache 2.0 license. It can handle various OCR tasks such as LaTeX recognition, watermark and signature detection, and complex table extraction. (Source: huggingface)
Perplexity Labs reportedly capable of replacing multiple professional roles, sparking discussion on AI tool capabilities: A user named GREG ISENBERG claimed to have replaced the work of five positions—salesperson, copywriter, film director, social media manager, and financial analyst—using Perplexity Labs, stating that the capabilities of AI tools are “actually insane.” Perplexity CEO Arav Srinivas retweeted and commented that it was one of the best videos showcasing how AI agents can be applied in real-life use cases, comparing Perplexity Labs with other tools on the market in financial analysis, social media marketing, creative direction, and sales. This highlights the potential of AI Agents in integrating and executing multi-domain professional tasks. (Source: AravSrinivas, AravSrinivas)
Claude-Flow releases major update v1.0.50, activating “Swarm Mode” to enhance code automation efficiency: Claude-Flow, a batch tool parallel agent system based on Claude Code, has released version v1.0.50. The new version introduces “Swarm Mode,” allowing users to simultaneously generate, manage, and coordinate hundreds of Claude agents working in parallel for building, testing, deploying, or multi-stage research loops. It reportedly offers a 20x performance improvement compared to traditional sequential Claude Code automation. Developers can initialize it via npx claude-flow@latest init --sparc --force. (Source: Reddit r/ClaudeAI)

📚 Learning
Awesome Machine Learning: A comprehensive list of machine learning resources: The “awesome-machine-learning” project on GitHub is a curated list of machine learning frameworks, libraries, and software, categorized by programming language. It also includes links to free machine learning books, professional events, online courses, blog newsletters, and local meetups, providing valuable navigation for machine learning learners and practitioners. (Source: GitHub Trending)
Anthropic and Cognition AI publish blog posts on building multi-agent systems, summarized by LangChain: Anthropic and Cognition AI recently published separate blog posts on building (or not building) multi-agent systems. Anthropic shared their experiences in constructing their multi-agent research system, while Cognition AI presented the viewpoint of “don’t build multi-agents.” Harrison Chase of LangChain summarized these, noting that although the viewpoints seem different on the surface, the two articles share many commonalities in guidelines and recommendations, and he related them to LangChain’s efforts in multi-agent systems. (Source: hwchase17, Hacubu)
Paper “Recent Advances in Speech Language Models: A Survey” accepted by ACL 2025 main conference: A survey paper on Speech Language Models (SpeechLMs) titled “Recent Advances in Speech Language Models: A Survey,” authored by a team from The Chinese University of Hong Kong, has been accepted by the ACL 2025 main conference. This paper is the first comprehensive and systematic review in this field, deeply analyzing the technical architecture of SpeechLMs (speech tokenizer, language model, vocoder), training strategies (pre-training, instruction fine-tuning, post-alignment), interaction paradigms (full-duplex modeling), application scenarios (semantics, speaker, paralinguistics), and evaluation systems. The paper emphasizes the potential of SpeechLMs in achieving natural human-computer speech interaction and points out existing challenges and future directions. (Source: 36氪)

New research enhances small model cross-domain reasoning via Visual Game Learning (ViGaL), 7B model surpasses GPT-4o in math: A research team from Rice University, Johns Hopkins University, and NVIDIA proposed a novel post-training paradigm called ViGaL (Visual Game Learning). By having a 7B parameter multimodal model (Qwen2.5-VL-7B) play simple arcade games like Snake and 3D rotation, the model not only improved its gaming skills but also showed significant cross-domain capability enhancement in complex reasoning tasks such as mathematics (MathVista) and multidisciplinary Q&A (MMMU), even surpassing top models like GPT-4o in some aspects. The study indicates that game training can cultivate general cognitive abilities like spatial understanding and sequential planning in models, and different games can strengthen different aspects of reasoning skills. This method improves reasoning ability while maintaining the model’s general visual capabilities. (Source: 新智元)

Shanghai AI Lab et al. propose MathFusion framework, enhancing LLM math problem-solving via instruction fusion: Shanghai Artificial Intelligence Laboratory, Gaoling School of Artificial Intelligence at Renmin University of China, and other institutions jointly proposed the MathFusion framework. It aims to enhance the ability of Large Language Models (LLMs) to solve mathematical problems by fusing different math problem structures to generate more diverse and logically complex synthetic instructions. The framework includes three strategies: sequential fusion, parallel fusion, and conditional fusion, which can effectively capture deep connections between problems. Experiments show that fine-tuning models like DeepSeekMath-7B, Llama3-8B, and Mistral-7B with only 45K synthetic instructions resulted in an average accuracy improvement of 18.0 percentage points across multiple math benchmarks, demonstrating high data efficiency and performance. (Source: 量子位)

Shanghai AI Lab et al. propose GRA framework, small models collaboratively generate high-quality data, performance comparable to 72B models: Shanghai Artificial Intelligence Laboratory, in collaboration with Renmin University of China, proposed the GRA (Generator–Reviewer–Adjudicator) framework. By simulating the paper submission and peer review mechanism, it allows multiple small language models (7-8B parameters) to collaboratively generate high-quality training data. In this framework, the Generator is responsible for generation, the Reviewer conducts multiple rounds of review and scoring, and the Adjudicator makes the final decision in case of review conflicts. Experiments show that training base models like LLAMA-3.1-8B and Qwen-2.5-7B with data generated by GRA achieved performance on par with or exceeding that of data distilled from larger models like Qwen-2.5-72B-Instruct across 10 mainstream datasets in math, code, and logical reasoning. This offers a new approach for low-cost, high-efficiency data synthesis. (Source: 量子位)

Paper discusses current state and future of LLM interpretability, emphasizing its importance for safe AI deployment: Tencent Research Institute published an article delving into the current state, technical paths, and future challenges of Large Language Model (LLM) interpretability. The article points out that understanding the internal mechanisms of LLMs is crucial for preventing value misalignment, debugging and improving models, preventing misuse, and promoting applications in high-risk scenarios. Current technical paths include automated interpretation (large models explaining small models), feature visualization (e.g., sparse autoencoders), chain-of-thought monitoring, and mechanistic interpretability (e.g., Anthropic’s “AI microscope” and DeepMind’s Tracr). However, neuronal polysemanticity, universality of interpretability patterns, and human cognitive limitations remain major challenges. The article calls for increased investment in interpretability research and suggests adopting soft law regulations that encourage industry self-discipline at the current stage to ensure the safe, transparent, and human-centric development of AI technology. (Source: 腾讯研究院)

New paper explores applications and advancements of discrete diffusion models in large language and multimodal models: A paper titled “Discrete Diffusion in Large Language and Multimodal Models: A Survey” systematically reviews the research progress of discrete diffusion language models (dLLMs) and discrete diffusion multimodal language models (dMLLMs). These models employ multi-token parallel decoding and denoising-based generation strategies, achieving parallel generation, fine-grained output controllability, and dynamic, response-aware perception capabilities, with inference speeds up to 10 times faster than autoregressive models. The paper traces their development history, formalizes the mathematical framework, categorizes representative models, analyzes key training and inference techniques, summarizes applications in language, vision-language, and biological domains, and finally discusses future research directions and deployment challenges. (Source: HuggingFace Daily Papers)
New research proposes Test3R: Enhancing 3D reconstruction geometric accuracy through test-time learning: A new technique called Test3R significantly improves the geometric accuracy of 3D reconstruction through test-time learning. The method utilizes image triplets (I_1,I_2,I_3) and generates reconstruction results from image pairs (I_1,I_2) and (I_1,I_3). The core idea is to optimize the network at test time via a self-supervised objective: maximizing the geometric consistency of these two reconstruction results with respect to the common image I_1. Experiments show that Test3R significantly outperforms existing SOTA methods on 3D reconstruction and multi-view depth estimation tasks, and possesses universality and low-cost characteristics, making it easy to apply to other models with minimal test-time training overhead and parameter count. (Source: HuggingFace Daily Papers)
Paper proposes Mirage-1: A GUI agent with hierarchical multimodal skills for improved long-horizon task handling: Researchers propose Mirage-1, a multimodal, cross-platform, plug-and-play GUI agent designed to address the issues of insufficient knowledge and offline-online domain gaps when current GUI agents handle long-horizon tasks in online environments. At the core of Mirage-1 is the Hierarchical Multimodal Skill (HMS) module, which progressively abstracts trajectories into execution skills, core skills, and meta-skills, providing a hierarchical knowledge structure for long-horizon task planning. Meanwhile, the Skill-Augmented Monte Carlo Tree Search (SA-MCTS) algorithm utilizes offline-acquired skills to reduce the action search space for online tree exploration. Mirage-1 demonstrates significant performance improvements on AndroidWorld, MobileMiniWob++, Mind2Web-Live, and the newly constructed AndroidLH benchmarks. (Source: HuggingFace Daily Papers)
Paper “Don’t Pay Attention” proposes novel neural network architecture Avey, challenging Transformers: A paper titled “Don’t Pay Attention” introduces a new neural network architecture, Avey, designed to move away from reliance on attention and recurrent mechanisms. Avey consists of a ranker and an autoregressive neural processor that work together to identify and contextualize only the most relevant tokens to any given token, regardless of their position in the sequence. This architecture decouples sequence length from context width, enabling effective processing of arbitrarily long sequences. Experimental results show that Avey performs comparably to Transformers on standard short-range NLP benchmarks and particularly excels at capturing long-range dependencies. (Source: HuggingFace Daily Papers)
New paper explores scalable code verification via reward models, balancing accuracy and throughput: A study investigates the trade-offs between using outcome reward models (ORMs) and comprehensive validators (like full test suites) when Large Language Models (LLMs) solve coding tasks. The research finds that even with comprehensive validators, ORMs play a key role in scaling verification by trading some accuracy for speed. Particularly in “generate-prune-rerank” methods, using a faster but less accurate validator to pre-emptively remove incorrect solutions can speed up the system by 11.65x with only an 8.33% drop in accuracy. This approach works by filtering out incorrect but high-ranking solutions, offering new insights for designing scalable and accurate program ranking systems. (Source: HuggingFace Daily Papers)
New benchmark AbstentionBench reveals: Reasoning-focused LLMs perform poorly on unanswerable questions: To evaluate the ability of Large Language Models (LLMs) to choose abstention (i.e., refuse to give a definitive answer) when faced with uncertainty, researchers have introduced AbstentionBench. This large-scale benchmark comprises 20 diverse datasets covering various types of questions, including those with unknown answers, insufficient specifications, false premises, subjective interpretations, and outdated information. Evaluation of 20 cutting-edge LLMs shows that abstention is an unsolved problem, and increasing model scale offers little help. Surprisingly, even reasoning-focused LLMs explicitly trained for math and science domains showed an average 24% decrease in abstention capability due to their reasoning fine-tuning. While well-designed system prompts can improve abstention performance in practice, this does not address the fundamental deficiencies in models’ uncertainty reasoning. (Source: HuggingFace Daily Papers)
Paper proposes patch-based prompting and decomposition methods (PatchInstruct) to leverage LLMs for time series forecasting: A new study explores simple and flexible prompting strategies for leveraging Large Language Models (LLMs) in time series forecasting, without extensive retraining or complex external architectures. By combining time series decomposition, patch-based tokenization, and similarity-based neighbor augmentation, researchers found they could improve the forecasting quality of LLMs while maintaining simplicity and minimizing data preprocessing. The proposed PatchInstruct method enables LLMs to make accurate and effective predictions. (Source: HuggingFace Daily Papers)
New dataset MS4UI released, focusing on multimodal summarization of user interface instructional videos: To address the shortcomings of existing benchmarks in providing step-by-step, executable instructions and illustrations, researchers have proposed the MS4UI (Multi-modal Summarization for User Interface Instructional Videos) dataset. This dataset contains 2413 UI instructional videos, totaling over 167 hours, and has been manually annotated with video segmentation, text summarization, and video summarization. It aims to promote research into concise, executable multimodal summarization methods for UI instructional videos. Experiments show that current SOTA multimodal summarization methods perform poorly on MS4UI, highlighting the importance of new approaches in this area. (Source: HuggingFace Daily Papers)
DeepResearch Bench: A comprehensive benchmark for deep research agents: To systematically evaluate the capabilities of LLM-based Deep Research Agents (DRAs), researchers have introduced DeepResearch Bench. This benchmark comprises 100 PhD-level research tasks meticulously designed by experts from 22 different fields. Due to the complexity and labor-intensive nature of evaluating DRAs, the researchers proposed two new evaluation methods that highly correlate with human judgment: one is a reference-based adaptive criteria method for assessing the quality of generated research reports; the other is a framework that evaluates DRAs’ information retrieval and collection capabilities by assessing the number of effective citations and overall citation accuracy. (Source: HuggingFace Daily Papers)
Paper proposes BridgeVLA: Efficient 3D manipulation learning through input-output alignment: To enhance the efficiency of Visual Language Models (VLMs) in utilizing 3D signals for robot manipulation learning, researchers proposed BridgeVLA, a novel 3D Visual Language Action (VLA) model. BridgeVLA projects 3D input into multiple 2D images, ensuring alignment with the VLM backbone’s input, and uses 2D heatmaps for action prediction, thereby unifying input and output in a consistent 2D image space. Additionally, the study proposes a scalable pre-training method that enables the VLM backbone to predict 2D heatmaps before downstream policy learning. Experiments show that BridgeVLA performs exceptionally well in multiple simulation benchmarks and real-robot experiments, significantly improving the efficiency and effectiveness of 3D manipulation learning, and demonstrating strong sample efficiency and generalization capabilities. (Source: HuggingFace Daily Papers)
New research synthesizes millions of diverse and complex user instructions (SynthQuestions) via attributed grounding: To address the lack of diverse, complex, and large-scale instruction data needed for Large Language Model (LLM) alignment, researchers propose an instruction synthesis method based on attributed grounding. The framework includes: 1) a top-down attribution process that links selected real-world instructions to contextualized users; 2) a bottom-up synthesis process that utilizes web documents to first generate contexts and then meaningful instructions. Using this method, a dataset called SynthQuestions containing 1 million instructions was constructed. Experiments show that models trained on this dataset achieve leading performance on several common benchmarks, and performance continues to improve with increasing web corpus size. (Source: HuggingFace Daily Papers)
PersonaFeedback: Large-scale human-annotated personalized evaluation benchmark released: To evaluate the ability of Large Language Models (LLMs) to provide personalized responses given predefined user personas and queries, researchers have launched the PersonaFeedback benchmark. This benchmark contains 8,298 human-annotated test cases, categorized into easy, medium, and hard levels based on the contextual complexity of the user persona and the difficulty of distinguishing personalized responses. Unlike existing benchmarks, PersonaFeedback decouples persona inference from personalization, focusing on evaluating the model’s ability to generate customized responses for explicit personas. Experimental results show that even SOTA LLMs face challenges in the hard-level tests, indicating that current retrieval-augmented frameworks are not the ultimate solution for personalization tasks. (Source: HuggingFace Daily Papers)
Paper explores “Language Surgery” in multilingual LLMs: Inference-time language control via latent injection: A new study investigates the phenomenon of naturally emerging representation alignment in Large Language Models (LLMs) and its implications for decoupling language-specific and language-agnostic information. The research confirms the existence of this alignment and analyzes its behavioral comparison with explicitly designed alignment models. Based on these findings, the researchers propose Inference-Time Language Control (ITLC), which utilizes latent injection to achieve precise cross-lingual control and mitigate language confounding issues in LLMs. Experiments demonstrate ITLC’s strong cross-lingual control capabilities while maintaining the semantic integrity of the target language, and its effectiveness in alleviating cross-lingual confounding, which persists even in current large-scale LLMs. (Source: HuggingFace Daily Papers)
Paper proposes NoWait method: Removing “thinking tokens” to improve LLM inference efficiency: Recent research indicates that large reasoning models, when performing complex step-by-step reasoning, often produce redundant output due to excessive “thinking” (e.g., outputting tokens like “Wait,” “Hmm”), which affects efficiency. The newly proposed NoWait method aims to validate the necessity of these explicit self-reflection tokens for advanced reasoning by suppressing them during inference. Across ten benchmarks in text, vision, and video reasoning tasks, NoWait reduced the length of chain-of-thought trajectories by 27%-51% in five R1-style model families without compromising model utility. This method offers a plug-and-play solution for achieving efficient multimodal reasoning while maintaining utility. (Source: HuggingFace Daily Papers)
💼 Business
OpenAI wins $200 million US Department of Defense AI contract to develop cutting-edge military capabilities: OpenAI has secured a one-year, $200 million contract with the U.S. Department of Defense to develop advanced artificial intelligence tools for national security, marking the first such contract listed by the Pentagon for OpenAI. The work will primarily be conducted in the National Capital Region. OpenAI had previously partnered with defense company Anduril. This move comes amidst a broad push for AI applications in the U.S. defense sector, where competitors like Anthropic have also collaborated with Palantir and Amazon. OpenAI CEO Sam Altman has publicly expressed support for national security projects. (Source: Reddit r/ArtificialInteligence, code_star)

Alta secures $11M in funding led by Menlo Ventures, focusing on AI + Fashion: AI fashion startup Alta announced it has closed an $11 million funding round led by Menlo Ventures, with participation from Benchstrength and Aglaé Ventures (the VC fund backed by LVMH Group’s Arnault family). Amy Tong Wu will join Alta’s board of directors. This funding will help Alta further its development at the intersection of AI and fashion. (Source: ZhaiAndrew)
Figure adjusts organizational structure, merging Controls department into Helix to accelerate AI roadmap: Humanoid robot company Figure announced that its Controls department no longer exists, and the entire team has been merged into the Helix department. This move aims to accelerate the company’s roadmap in artificial intelligence, indicating Figure is concentrating more resources and efforts on AI technology R&D and application. (Source: adcock_brett)
🌟 Community
Discussion on AGI: Ordinary users need not worry excessively, AGI is more strategic than a daily tool: Multiple community members discussed that ordinary LLM users shouldn’t be overly concerned about the arrival of AGI (Artificial General Intelligence). The definition of AGI is vague and highly theoretical. Even if achieved, it wouldn’t immediately manifest in user chat windows in the short term. Instead, it would serve as a strategic tool and infrastructure for nations or large organizations, used for complex matters like international negotiations, rather than helping individuals schedule meetings. (Source: farguney, farguney, farguney, farguney)
Building multi-agent systems requires human evaluation, focusing on edge cases and source quality: When building multi-agent systems, human evaluation and testing are crucial for identifying edge cases that automated evaluations might miss. For example, early agents tended to select SEO-optimized content farms over authoritative academic PDFs or personal blogs when choosing information sources. Adding source quality heuristics to prompts helped address such issues. This indicates that even in the age of automated evaluation, manual testing remains indispensable for uncovering system failures and subtle source selection biases. (Source: riemannzeta)

Differences in prediction and learning mechanisms between LLMs and video models spark thought: Yann LeCun and Pedro Domingos retweeted Sergey Levine’s point about why language models learn so much from next-token prediction, while video models learn relatively little from next-frame prediction. Levine speculates this might be because LLMs, to some extent, act as “brain scanners,” hinting at the uniqueness of their learning mechanism, or that LLMs are like beings living in Plato’s cave, inferring the real world from sequences of shadows (text). (Source: ylecun, pmddomingos, pmddomingos)

Positive impact of AI Agents in education: Encouraging learners to step out of their comfort zones: Community discussion suggests that AI Agents have a positive impact not only on businesses but also hold great potential in education. By interacting with AI Agents, learners can more effectively step out of their comfort zones, thereby enhancing learning outcomes. (Source: pirroh, amasad)
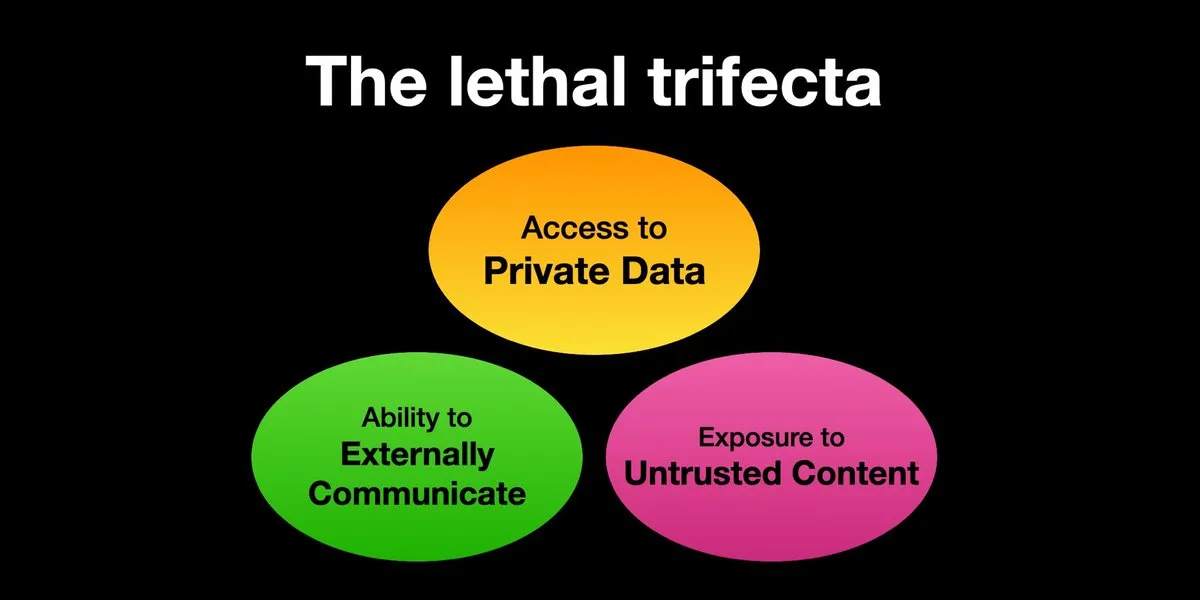
AI Agents face prompt injection attack risks, security measures urgently needed: Karpathy retweeted Simon Willison’s warning about AI Agents facing a “Lethal Trifecta” risk: when an AI Agent has access to private data, interacts with untrusted content, and has external communication capabilities, attackers can trick the system into stealing data. This is reminiscent of the “Wild West” era of early computer viruses. Current defense mechanisms against malicious prompts are inadequate, lacking, for example, a security paradigm similar to an operating system’s kernel/user space to restrict an Agent’s ability to execute arbitrary scripts. This raises concerns about early adoption of LLM Agents for personal computing. (Source: karpathy, TheTuringPost)
In the AI era, rapid learning ability becomes a core competency: Mustafa Suleyman pointed out that the biggest career accelerator in the next decade will be an exceptional ability to learn. He advises people to identify their learning style, use AI to convert materials into suitable formats (like podcasts, quizzes), then apply the knowledge and repeat the process continuously to achieve rapid learning and growth. (Source: mustafasuleyman)
Authenticity vs. Relevance of AI-generated content: Relevance may trump authenticity: User imjaredz shared an experience of sending 2000 AI-generated lead emails, with no one complaining about them being AI-written. Instead, five recipients said the email content was “exactly what they were working on.” This sparked a discussion on whether, in communication, the relevance of content is more important than its “authenticity” (i.e., whether it was created by a human). (Source: imjaredz)
Debate on LLMs’ “understanding” ability: Behavioral approximation does not equal true understanding: There’s a viewpoint in the community that although Large Language Models exhibit powerful behavioral and cognitive approximation capabilities, this is not equivalent to true understanding. Understanding requires explanatory power, and merely exhibiting behavior is not intelligence or understanding. This fundamental distinction is often overlooked. The viewpoint emphasizes the need for cautious assessment of whether models are truly approaching AGI before entrusting them with life-critical decisions, and warns against overhyping their capabilities. (Source: farguney)
AI Agents shine in software engineering benchmarks, but their “agent” nature is debated: As AI scores continue to rise in software engineering benchmarks like SWE-bench (even exceeding 50-60 points), the community discusses whether the “agentic coding era” has truly arrived. Some argue that if “agentless frameworks” are commonly used, rather than letting language models truly explore in an environment, then calling it an “agentic coding era” might be a misnomer, even though these frameworks themselves are valuable. (Source: huybery, terryyuezhuo)
Need for content moderation of AI-generated images: Seeking open-source or commercial solutions: With the popularization of AI image generation technology, developers in China are beginning to focus on the compliance of output content, particularly how to detect pornographic, politically sensitive, and other inappropriate content. Discussions have emerged in the community seeking available open-source small models or commercial products for content moderation. (Source: dotey)
💡 Other
AI-driven personalization and content relevance: 2000 AI emails, no complaints, 5 recipients say “exactly what I needed”: A user shared that they sent 2000 lead generation emails generated by AI, and no recipient complained that the emails were AI-written. On the contrary, five recipients stated that the email content was “exactly what they were currently working on.” This case sparked a discussion about whether, in AI-assisted communication, high content relevance can outweigh concerns about “authenticity” (i.e., whether it was written by a human), hinting at AI’s potential in personalized content generation. (Source: imjaredz)
Humans as bottlenecks in AI systems, need to avoid or enhance human efficiency: Charles Earl’s viewpoint notes that overflowing inboxes and empty outboxes reflect humans as bottlenecks in information processing and response. In the AI era, it’s necessary to consider how to avoid human bottlenecks or how to enhance human work efficiency through AI and other technologies. (Source: charles_irl)
Potential risks of AI-controlled smart homes: User trapped in cold smart bed due to app malfunction: A user shared their experience of being unable to adjust the temperature of their AI-controlled smart bed (Eight Sleep Pod3) due to an app malfunction, ultimately getting trapped in a cold bed. As this model lacks manual controls and relies entirely on the app, this failure highlights the inconvenience and “dystopian” experience that over-reliance on AI and app-controlled smart home devices can bring. (Source: madiator)