Keywords:Quantum computing, AI self-upgrading, Brain-computer interface, Large language models, Neuromorphic computing, AI video generation, Reinforcement learning, AI ethics, Qubit error rate, JEPA self-supervised learning, MLX format quantization, PAM visual understanding model, AI ASMR content generation
🔥 Focus
Oxford University achieves record 0.000015% error rate in quantum computing experiment: A research team at Oxford University has made a significant breakthrough in quantum computing experiments, reducing the error rate of qubits to 0.000015%, setting a new world record. This advancement is crucial for building fault-tolerant quantum computers, as extremely low error rates are a prerequisite for realizing complex quantum algorithms and unlocking the potential of quantum computing. The achievement demonstrates significant progress in enhancing qubit stability and precise manipulation at the hardware level, laying a more solid foundation for future applications in fields like AI that rely on powerful computing capabilities (Source: Ronald_vanLoon)

MIT researchers enable AI to learn to upgrade and improve itself: Researchers at the Massachusetts Institute of Technology (MIT) have made progress in the field of AI self-improvement, developing a new method that allows AI systems to autonomously learn and enhance their own performance. This capability mimics the human process of continuous improvement through experience and reflection, and is crucial for developing more autonomous and adaptive artificial intelligence. The research could pave the way for AI models to continuously optimize after deployment, reducing reliance on manual intervention, and has profound implications for the long-term development and application of AI (Source: TheRundownAI)

“Mind-reading” AI instantly converts paralyzed person’s brainwaves into speech: A groundbreaking study demonstrates how “mind-reading” AI can convert a paralyzed patient’s brainwaves into clear speech in real-time. This technology decodes language-related neural signals through advanced brain-computer interfaces (BCI) and AI algorithms, synthesizing them into understandable voice output. This offers a new communication method for patients who have lost their ability to speak due to severe motor impairments, promising to greatly improve their quality of life and marking a significant advancement for AI in assistive healthcare and neuroscience (Source: Ronald_vanLoon)

Breakthrough in century-old mathematical physics problem, Peking University alumni participate in cracking Hilbert’s sixth problem: Peking University alumnus Deng Yu, USTC’s Special Class for the Gifted alumnus Ma Xiao, and Zaher Hani, a student of Terence Tao, have made a major breakthrough on Hilbert’s sixth problem, “the axiomatization of physics.” They rigorously proved for the first time the complete transition from Newtonian mechanics (microscopic, time-reversible) to the Boltzmann equation (macroscopic statistical, time-irreversible), bridging the logical gap between the two. This lays a more solid mathematical foundation for statistical mechanics and unexpectedly answers the “mystery of the arrow of time.” The achievement demonstrates a path from atomistic theory to the laws of motion of continuous media through ingenious mathematical tools and phased derivations (Source: 量子位)

🎯 Trends
Alibaba releases MLX format versions for Qwen3 series models: Alibaba announced that its Qwen3 series of large models now supports the MLX format, offering four quantization levels: 4-bit, 6-bit, 8-bit, and BF16. MLX is Apple’s machine learning framework optimized for Apple Silicon. This move means Qwen3 models will run more efficiently on Apple devices, lowering the barrier for deploying and running large models on-device and helping to promote the popularization and application of large models on personal devices (Source: Alibaba_Qwen, awnihannun, cognitivecompai, Reddit r/LocalLLaMA)
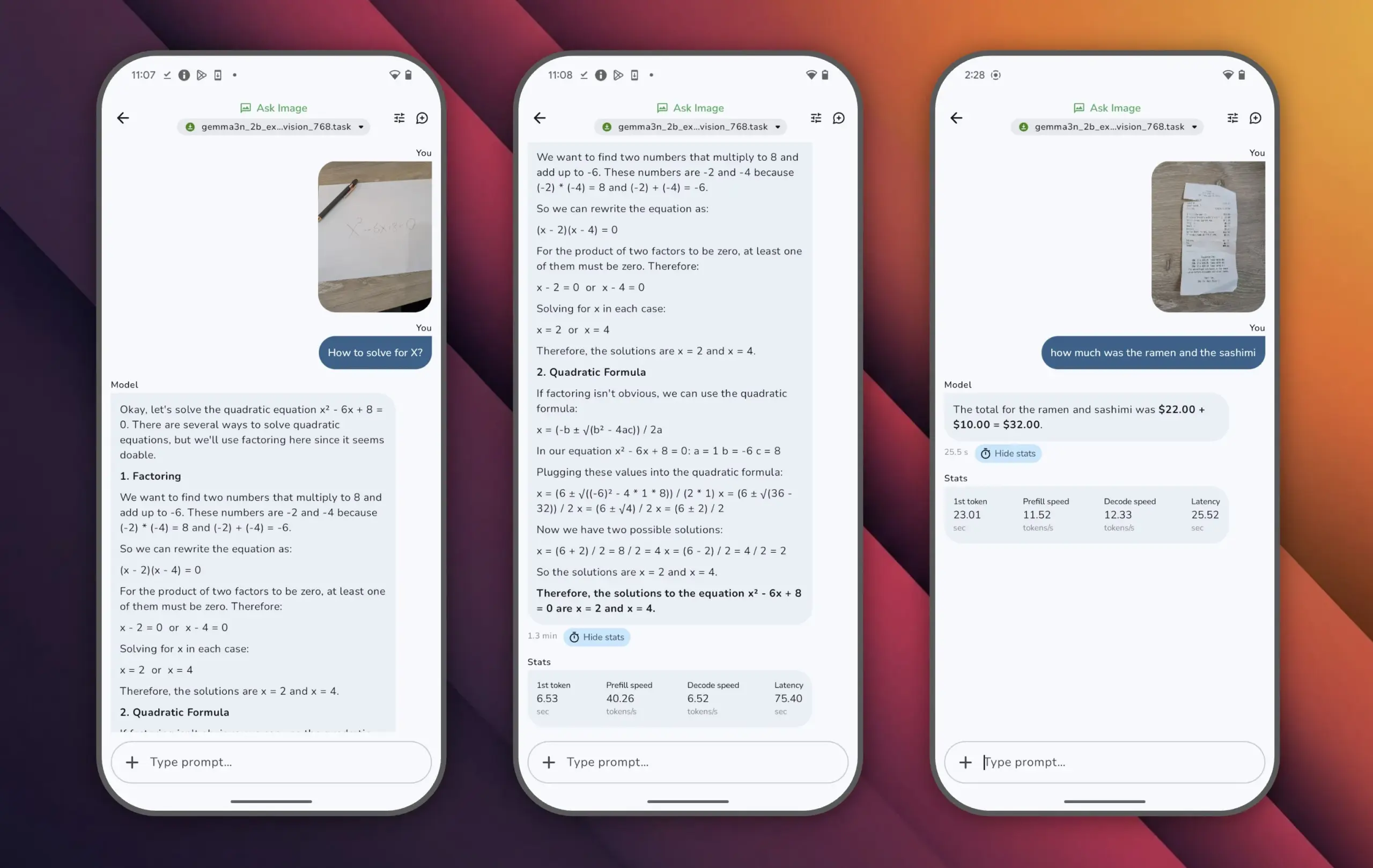
Google releases Gemma 3n model, achieving high performance with small parameters: Google has launched the Gemma 3n model, which has fewer than 10 billion parameters but scored over 1300 on LMArena, becoming the first small model to achieve this. Gemma 3n’s outstanding performance demonstrates that high-level language understanding and generation capabilities can be achieved with a smaller parameter scale, and it supports running on end-user devices like mobile phones. This is significant for promoting the popularization of AI applications and reducing computing costs (Source: osanseviero)
Tencent unveils AI technology for generating cinema-quality 3D assets: Tencent has showcased a new artificial intelligence technology capable of generating 3D assets with cinema-level quality. This technology is expected to significantly enhance the efficiency and quality of 3D content creation in fields such as game development and film production, while also reducing production costs. The rapid generation of high-quality 3D assets is a key component in the development of the metaverse and the digital content industry (Source: TheRundownAI)
Kuaishou’s Kling 2.1 model excels in image-to-video conversion and synchronized audio-video generation: Kuaishou’s AI video generation model, Kling, has been updated to version 2.1, demonstrating strong capabilities in image-to-video conversion. The new version is said to achieve one-click generation of video and audio, eliminating the need for post-production sound design to produce studio-level synchronized audio-visual content. This marks progress for AI in multimodal content generation, particularly in the video domain, simplifying the creation process and improving generation quality (Source: Kling_ai, Kling_ai)
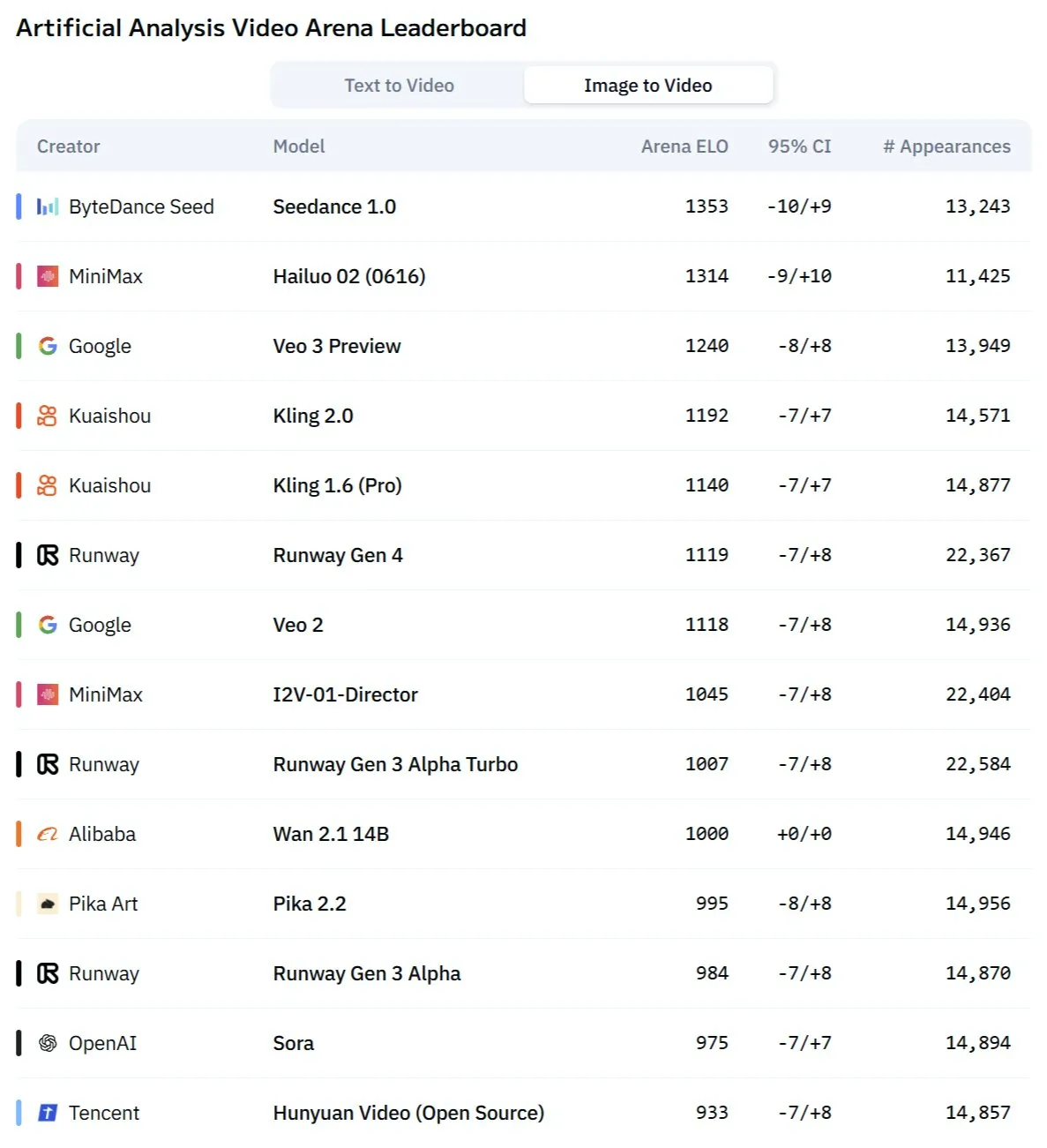
New AI video model “Kangaroo,” potentially Minimax Hailuo 2.0, challenges existing SOTA: A mysterious AI video generation model named “Kangaroo” has appeared on the market, performing strongly in AI video competitions, especially in image-to-video conversion. Some analysts suggest this model could be Minimax’s Hailuo 2.0 version. Its emergence may alter the performance hierarchy of existing text-to-video and image-to-video models, although its audio processing capabilities are yet to be evaluated (Source: TomLikesRobots)
MiniMax launches M1 series models with outstanding long-text processing capabilities: MiniMaxAI has released the MiniMax-M1 model series, a 456B parameter Mixture of Experts (MoE) model. This series has performed excellently in multiple benchmarks, particularly surpassing GPT-4.1 in long-context processing (e.g., OpenAI-MRCR benchmark) and ranking third in LongBench-v2. This demonstrates its potential in processing and understanding long documents, but its larger “thinking budget” may place high demands on computing resources (Source: Reddit r/LocalLLaMA)

Turing Award winner Richard Sutton: AI is moving from the “era of human data” to the “era of experience”: Richard Sutton, a pioneer in Reinforcement Learning, pointed out at the Beijing Academy of Artificial Intelligence (BAAI) Conference that current AI large models relying on human data are approaching their limits, as high-quality human data is being exhausted and the benefits of model scaling are diminishing. He believes the future of AI lies in entering an “era of experience,” where agents learn by generating first-hand experience through real-time interaction with their environment, rather than imitating existing text. This requires agents to operate continuously in real or simulated environments, using environmental feedback as reward signals, developing world models and memory systems, to achieve true continuous learning and innovation (Source: 36氪)

PAM model: 3B parameters achieve integrated image/video segmentation, recognition, and captioning: MMLab at The Chinese University of Hong Kong and other institutions have open-sourced the Perceive Anything Model (PAM), a 3B parameter model that can simultaneously perform object segmentation, recognition, explanation, and description in both images and videos, outputting text and masks concurrently. PAM achieves efficient conversion of visual features to multimodal tokens by introducing a Semantic Perceiver to connect the SAM2 segmentation backbone and an LLM. The team also constructed a large-scale, high-quality image-text training dataset. PAM has set new or approached SOTA on multiple visual understanding benchmarks and offers superior inference efficiency (Source: 量子位)

Neuromorphic computing may be key to next-gen AI, promising low-power operation: Scientists are actively exploring neuromorphic computing, aiming to mimic the structure and operation of the human brain to address the high energy consumption of current AI models. Institutions like U.S. national laboratories are developing neuromorphic computers with a neuron count comparable to the human cerebral cortex, theoretically operating much faster than the biological brain but with extremely low power consumption (e.g., 20 watts to drive a human-brain-like AI). This technology, through event-driven communication, in-memory computing, and adaptive learning, promises more intelligent, efficient, and low-power AI, and is seen as a potential solution to the AI energy crisis and a new path for AGI development (Source: 量子位)

AI ASMR content explodes on short video platforms, Veo 3 and other technologies provide a boost: AI-generated ASMR (Autonomous Sensory Meridian Response) videos are rapidly gaining popularity on platforms like TikTok, with some accounts attracting nearly 100,000 followers in 3 days and a single fruit-cutting video exceeding 16.5 million views. These videos combine AI-generated peculiar visual effects (like glass-textured fruit) with corresponding sounds of cutting, collision, etc., creating a unique “addictive” sensation. Models like Google DeepMind’s Veo 3, which can directly generate synchronized audio-visual content, are considered key technologies driving the creation of such AI ASMR content, simplifying the previous process of separately producing and then synthesizing audio and video (Source: 量子位)

Meta AI search history disclosure draws attention, Google tests AI audio summaries: Meta has made user search history from its AI search feature public, raising user concerns about privacy and data usage transparency. Meanwhile, Google is testing a new feature in its lab projects that provides AI-generated podcast-style audio summaries at the top of search results, aiming to offer users a more convenient way to access information. These two developments reflect the ongoing exploration and user experience optimization efforts by tech giants in AI search and information presentation (Source: Reddit r/ArtificialInteligence)

Sydney team develops AI model to recognize thoughts via brainwaves: A research team in Sydney, Australia, has developed a new artificial intelligence model capable of identifying an individual’s thoughts by analyzing electroencephalogram (EEG) data. This technology has potential applications in neuroscience, human-computer interaction, and assistive communication, such as helping people who cannot communicate through traditional means to express their intentions. The research further advances brain-computer interface technology and explores AI’s ability to interpret complex brain activity (Source: Reddit r/ArtificialInteligence)
California proposes legislation to limit “robot bosses” role of AI in hiring, firing decisions: California is advancing a bill aimed at restricting companies from making key personnel decisions, such as hiring and firing, based solely on AI system recommendations. The bill requires human managers to review and support any such AI recommendations to ensure human oversight and accountability. Business groups oppose this, arguing it will increase compliance costs and conflict with existing hiring technologies. This move reflects growing concerns about AI ethics and social impact, particularly regarding automated decision-making in the workplace (Source: Reddit r/ArtificialInteligence)

🧰 Tools
Augmentoolkit 3.0 released, enhancing dataset generation and fine-tuning workflows: Augmentoolkit has released version 3.0, a tool for creating QA datasets from long documents (such as historical texts) and fine-tuning models. The new version provides a production-grade pipeline that automatically generates training data and trains models, includes a built-in local model fine-tuned specifically for generating high-quality QA datasets, and offers a no-code interface. The tool aims to simplify the process of domain-specific model fine-tuning and training data generation, lowering the technical barrier (Source: Reddit r/LocalLLaMA)
Opius AI Planner: An AI planner to optimize the Cursor Composer experience: A Cursor extension called Opius AI Planner has been released, designed to address issues with Cursor Composer’s understanding of vague requirements. The tool analyzes project needs, generates a detailed implementation roadmap, and outputs structured prompts optimized for Composer, thereby reducing iterations and making project outcomes more aligned with initial visions. This reflects the trend of using AI-assisted planning to enhance the usability of AI code generation tools (Source: Reddit r/artificial)
Continue extension: Implement local open-source Copilot with MCP integration in VSCode: Continue is a VSCode extension that allows users to configure and use locally running open-source large language models as coding assistants and integrate MCP (Model Control Protocol) tools. Users can deploy models locally via services like Llama.cpp or LMStudio and interact with them through Continue, achieving full control and customization of their coding assistant, such as integrating the Playwright browser automation tool (Source: Reddit r/LocalLLaMA)

Doubao large model and Volcano Engine MCP integration simplifies cloud service deployment and personal page generation: ByteDance’s Doubao large model demonstrates deep integration capabilities with Volcano Engine’s Model Control Protocol (MCP). Users can use natural language commands to have the Doubao large model call Volcano Engine functions (such as veFaaS – Function as a Service) to complete tasks like generating a personal social media landing page and automatically deploying it online. This integration eliminates the complex steps of manually configuring cloud environments, lowering the barrier to using cloud services and showcasing AI’s potential in simplifying DevOps processes (Source: karminski3)
Figma introduces new AI feature: Instantly generate websites from text prompts: Figma has showcased a new AI-driven feature capable of quickly generating website prototypes or pages based on user-inputted text prompts. This function aims to accelerate web design and development workflows, enabling designers and developers to rapidly translate ideas into visual designs using natural language descriptions, further demonstrating the penetration of generative AI in creative design tools (Source: Ronald_vanLoon)
Hugging Face Model Hub adds filtering by model size: The Hugging Face platform has added a useful feature to its Model Hub, allowing users to filter models based on their parameter size. This improvement enables developers and researchers to more easily find models that meet their specific hardware resource or performance requirements, enhancing efficiency in navigating and selecting from the vast model library (Source: ClementDelangue, TheZachMueller, huggingface, clefourrier, multimodalart)
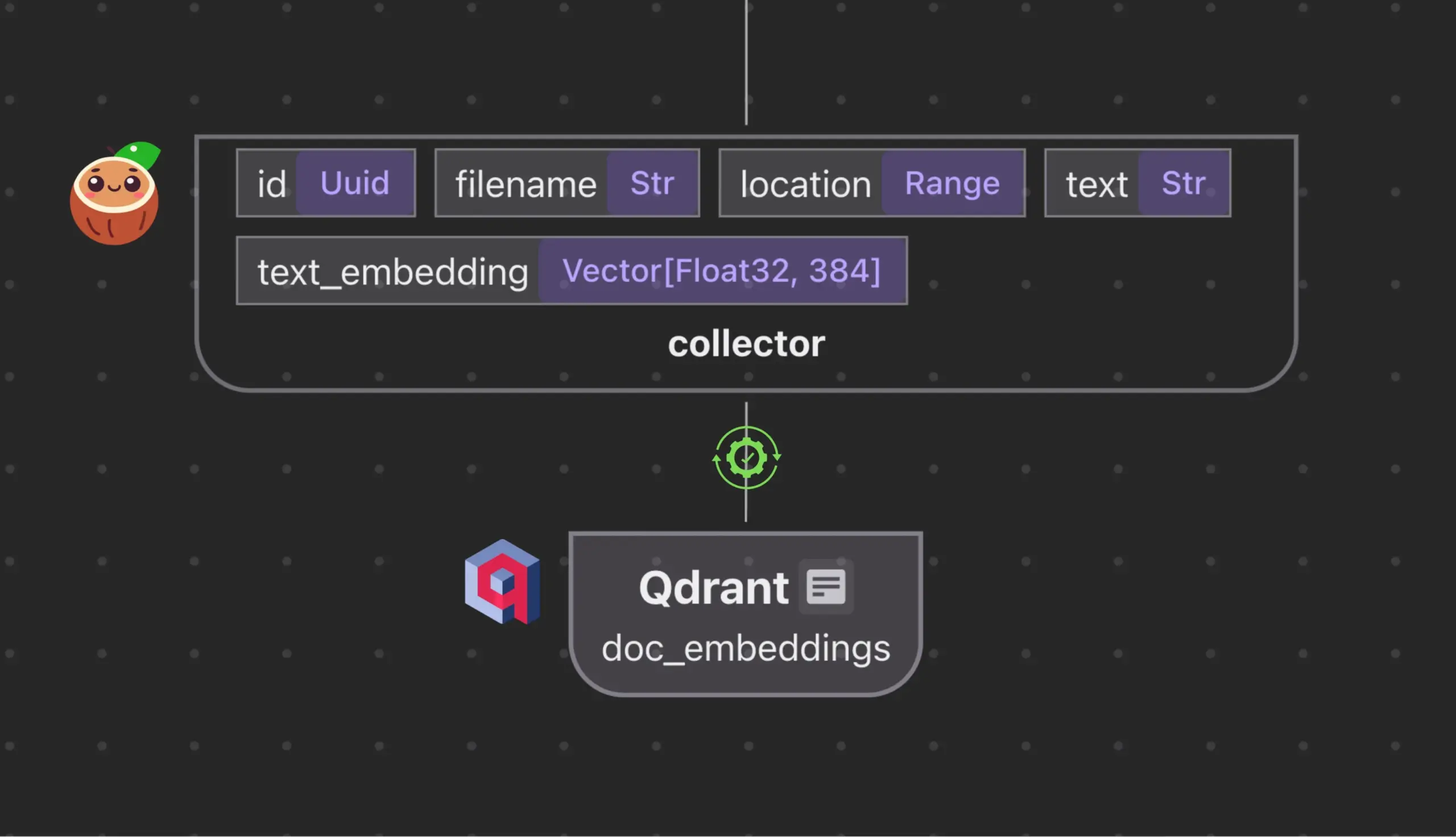
Cocoindex.io integrates with Qdrant to automatically create and synchronize vector database collections: Open-source data streaming tool Cocoindex.io now supports automatic creation of Qdrant vector database collections. Users simply define a data stream, and the tool can infer the appropriate Qdrant schema (including vector size, distance metric, and payload structure), and maintain synchronization of vector fields, payload types, and primary keys, supporting incremental updates. This simplifies vector database configuration and management, improving data team efficiency (Source: qdrant_engine)
Manus AI: A full-cycle AI development tool that not only writes code but also deploys automatically: Manus AI is an end-to-end AI development tool capable of handling everything from code writing to environment setup, dependency installation, testing, and even final deployment to an online URL. It employs a multi-agent collaborative architecture (planning, development, testing, deployment) and can autonomously resolve dependency issues and debug errors. Although it currently has limitations such as a credit-based pricing model, development by a Chinese team (potentially involving compliance considerations), and support for ultra-complex enterprise architectures, it demonstrates the potential shift from “AI-assisted coding” to “AI-executed development” (Source: Reddit r/artificial)

📚 Learning
Translation theory and AI translation prompt optimization guide: Combining Si Guo’s “New Research on Translation” theory of “translation as rewriting” and Yu Kwang-chung’s views in “Translation is a Great Way,” this discusses principles of high-quality translation. It emphasizes that translation should focus on idiomatic expression in the target language rather than literal correspondence, requiring flexible use of literal and free translation, and attention to syntactic rewriting due to logical differences between Chinese and Western languages. The article also discusses the purity of Chinese expression, terminology handling, and reflects on the limitations of the “literal translation – analysis – free translation” three-step process in AI translation. It suggests adopting a more integrated “understand – express – proofread – optimize” process to improve AI translation quality, making it more suitable for Chinese popular science writing style (Source: dotey)

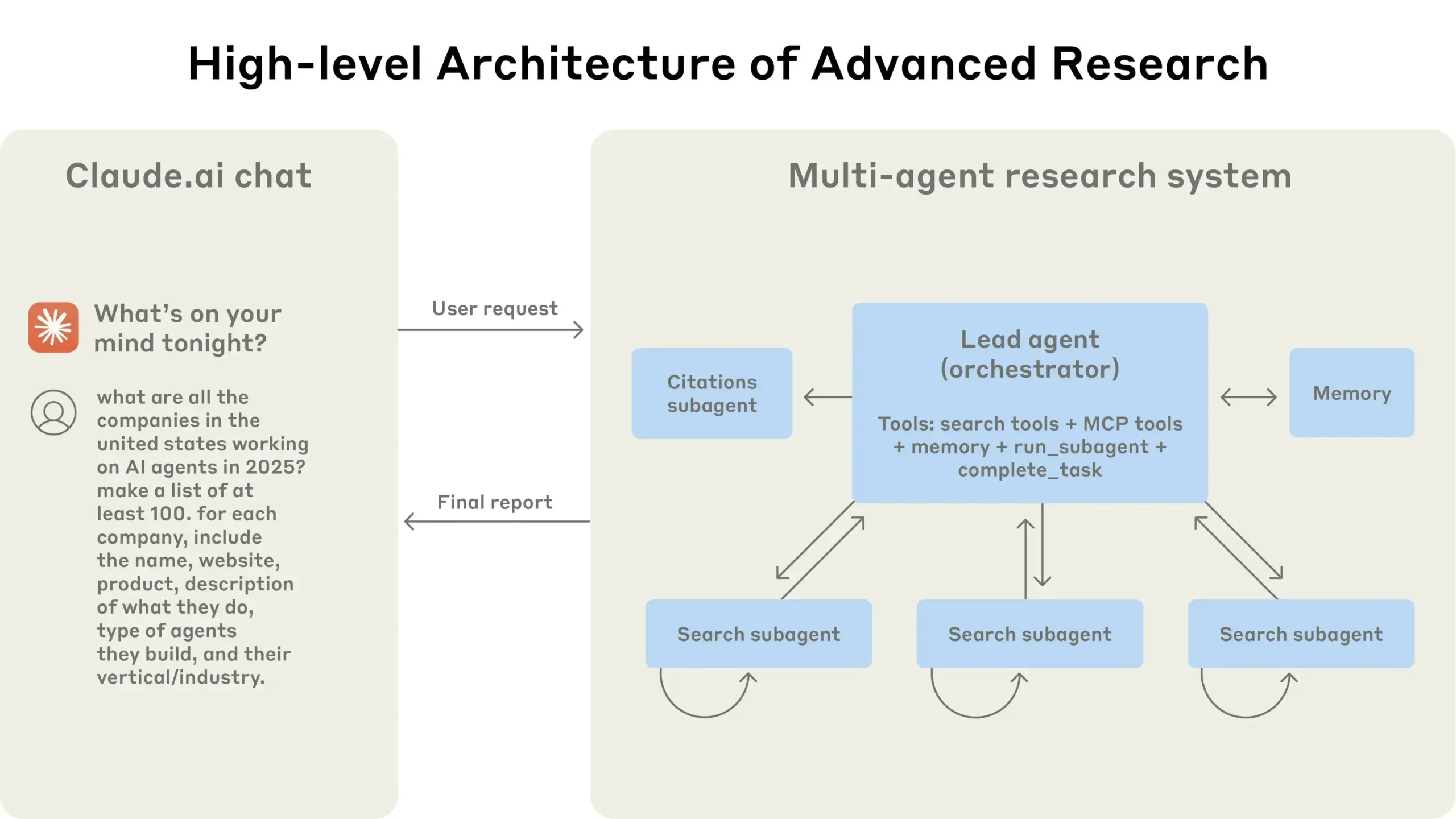
Anthropic shares experience in building its multi-agent research system: AnthropicAI has released a free guide detailing how they built their multi-agent research system. The content includes how the system architecture works, prompting and testing methodologies, challenges faced in production, and the advantages of multi-agent systems. This guide provides valuable practical experience and insights for researchers and developers interested in multi-agent systems (Source: TheTuringPost, TheTuringPost)
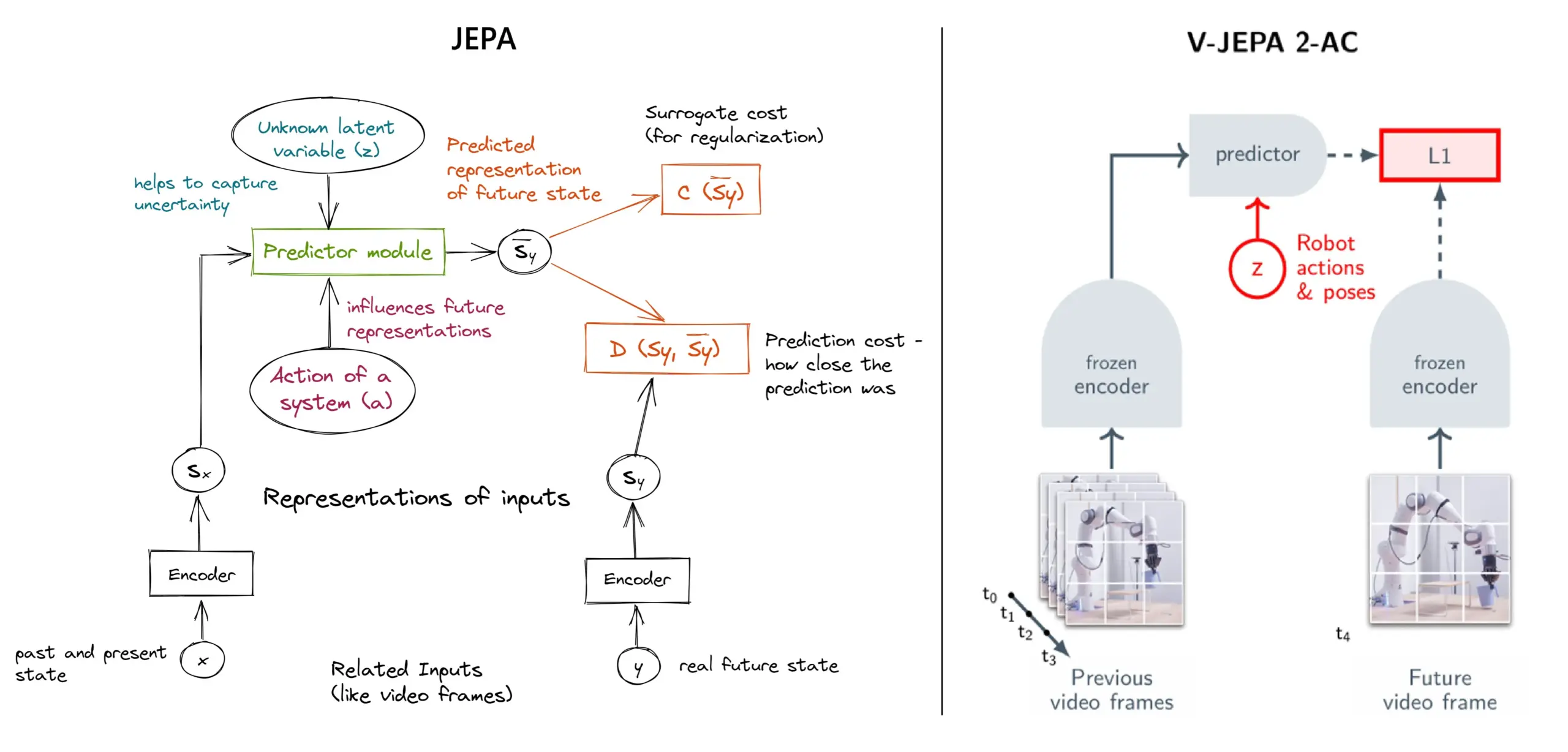
JEPA self-supervised learning framework explained: Overview of 11 types: JEPA (Joint Embedding Predictive Architecture), proposed by Meta’s Yann LeCun and other researchers, is a self-supervised learning framework that learns by predicting latent representations of missing parts of input data. The article introduces 11 different types of JEPA, including V-JEPA 2, TS-JEPA, D-JEPA, etc., and provides links to more information and related resources, helping to understand this cutting-edge self-supervised learning method (Source: TheTuringPost, TheTuringPost)
DSPy framework: Decoupling tasks from LLMs to improve code maintainability: An article interpreting DSPy points out that the DSPy framework reduces the complexity of using Large Language Models (LLMs) by decoupling tasks from them. Even before optimization, DSPy can help developers start projects faster and generate code that is easier to maintain and extend. This is highly valuable for projects that need to handle complex prompt engineering and LLM integration (Source: lateinteraction, stanfordnlp)

Paper Discussion: Vision Transformers Don’t Need Trained Registers: A new research paper explores the mechanism behind artifacts in attention maps and feature maps of Vision Transformers, a phenomenon also present in large language models. The paper proposes a training-free method to mitigate these artifacts, aiming to improve the performance and interpretability of Vision Transformers. This research is valuable for understanding and improving Transformer architectures in vision tasks (Source: Reddit r/MachineLearning)
Tutorial Share: Build DeepSeek from Scratch video series (29 episodes): A content creator has released a video tutorial series titled “How to Build DeepSeek from Scratch,” consisting of 29 episodes. The content covers the fundamentals of the DeepSeek model, architectural details (such as attention mechanisms, multi-head attention, KV cache, MoE), positional encoding, multi-token prediction, and quantization, among other key technologies. This tutorial series provides valuable video resources for learners wishing to deeply understand the inner workings of DeepSeek and similar large models (Source: Reddit r/LocalLLaMA)

Tutorial: Build a RAG pipeline to summarize Hacker News posts: Haystack by deepset shares a step-by-step tutorial guiding users on how to build a Retrieval Augmented Generation (RAG) pipeline. This pipeline can fetch real-time posts from Hacker News and use a locally running Large Language Model (LLM) endpoint to summarize these posts. This provides a practical use case for developers looking to leverage RAG technology to process real-time information streams and handle them locally (Source: dl_weekly)
Paper Alert: InterSyn Dataset and SynJudge Evaluation Model for Interleaved Image-Text Generation: To address the current limitations of LMMs in generating tightly interleaved image-text outputs (mainly due to limited scale, quality, and instruction richness of training datasets), researchers introduced InterSyn, a large-scale multimodal dataset constructed via the SEIR (Self-Evaluation and Iterative Refinement) method. InterSyn contains multi-turn, instruction-driven dialogues with tightly interleaved images and text in responses. Concurrently, to evaluate such outputs, researchers proposed SynJudge, an automatic evaluation model assessing text content, image content, image quality, and image-text synergy. Experiments show LMMs trained on InterSyn improve across all evaluation metrics (Source: HuggingFace Daily Papers)
Paper Alert: Aligned Novel-View Image and Geometry Synthesis via Cross-Modal Attention Distillation: Researchers propose MoAI, a diffusion-based framework, for aligned novel-view image and geometry generation via a “warping-and-inpainting” approach. The method leverages off-the-shelf geometry predictors to predict partial geometry of a reference image and synthesizes novel views as an inpainting task for both image and geometry. To ensure precise image-geometry alignment, the paper introduces cross-modal attention distillation, injecting attention maps from the image diffusion branch into a parallel geometry diffusion branch during training and inference. The method achieves high-fidelity extrapolated view synthesis across diverse unseen scenes (Source: HuggingFace Daily Papers)
Paper Alert: Configurable Preference Tuning (CPT) with Rule-Guided Synthetic Data: To address the issues of fixed preferences and limited adaptability in human feedback models like DPO, researchers propose the Configurable Preference Tuning (CPT) framework. CPT uses system prompts based on structured, fine-grained rules (defining desired attributes like writing style) to generate synthetic preference data. By fine-tuning with these rule-guided preferences, LLMs can dynamically adjust their output at inference time based on system prompts without retraining, achieving more nuanced and context-aware preference control (Source: HuggingFace Daily Papers)
Paper Alert: The Diffusion Duality: Researchers propose Duo, a method that transfers powerful techniques from Gaussian diffusion to discrete diffusion models to enhance their performance, by revealing that uniform-state discrete diffusion processes originate from an underlying Gaussian diffusion. Specifically, it includes: 1) Introducing a Gaussian process-guided curriculum learning strategy that reduces variance, doubles training speed, and surpasses autoregressive models on multiple benchmarks. 2) Proposing discrete consistency distillation, adapting continuous consistency distillation to discrete settings, enabling few-step generation for diffusion language models by accelerating sampling by two orders of magnitude (Source: HuggingFace Daily Papers)
Paper Alert: SkillBlender – Versatile Humanoid Whole-Body Motion Control via Skill Blending: To address the limitations of existing humanoid robot control methods in multi-task generalization and scalability, researchers propose SkillBlender, a hierarchical reinforcement learning framework. This framework first pre-trains goal-directed, task-agnostic primitive skills, then dynamically blends these skills when performing complex motion control tasks, requiring minimal task-specific reward engineering. Concurrently, the SkillBench simulation benchmark was introduced for evaluation. Experiments show this method significantly improves accuracy and feasibility across various motion control tasks (Source: HuggingFace Daily Papers)
Paper Alert: U-CoT+ Framework – Decoupled Understanding and Guided CoT Reasoning for Harmful Meme Detection: To tackle challenges of resource efficiency, flexibility, and interpretability in harmful meme detection, researchers propose the U-CoT+ framework. This framework first converts visual memes into detail-preserving text descriptions via a high-fidelity meme-to-text conversion process, thereby decoupling meme interpretation from classification, enabling resource-efficient detection by general Large Language Models (LLMs). Subsequently, it guides model reasoning under zero-shot CoT prompting with human-crafted interpretable guidelines, enhancing adaptability and interpretability across different platforms and time variations (Source: HuggingFace Daily Papers)
Paper Alert: CRAFT – Effective Policy-Adherent Agent Red Teaming: Addressing the issue of task-oriented LLM agents’ adherence to strict policies (e.g., refund eligibility), researchers propose a new threat model focusing on adversarial users attempting to exploit policy-based agents for personal gain. To this end, they developed CRAFT, a multi-agent red teaming system that utilizes policy-aware persuasion strategies to attack policy-adherent agents in customer service scenarios, outperforming traditional jailbreaking methods. They also introduced the tau-break benchmark for evaluating agent robustness against such manipulative behaviors (Source: HuggingFace Daily Papers)
Paper Alert: Dense Retrievers Fail on Simple Queries: The Granularity Dilemma of Embeddings: Research reveals a limitation of text encoders: embeddings may fail to identify fine-grained entities or events within semantics, causing dense retrieval to fail even in simple cases. To study this phenomenon, the paper introduces the Chinese evaluation dataset CapRetrieval (paragraphs are image captions, queries are entity/event phrases). Zero-shot evaluation shows encoders may perform poorly on fine-grained matching. Fine-tuning encoders with a proposed data generation strategy improves performance but also reveals a “granularity dilemma,” where embeddings struggle to align fine-grained salience with overall semantics (Source: HuggingFace Daily Papers)
Paper Alert: pLSTM – Parallelizable Linear Source-Transform-Mark Networks: Addressing the limitation that existing recurrent architectures (like xLSTM, Mamba) are primarily suited for sequential data or require sequential processing for multi-dimensional data, researchers propose pLSTM (parallelizable Linear Source-Transform-Mark networks). pLSTM extends multi-dimensionality to linear RNNs, using source, transform, and mark gates acting on the line graph of a general directed acyclic graph (DAG), enabling parallelization similar to parallel associative scans and block-recurrent forms. The method demonstrates good extrapolation capabilities and performance on synthetic computer vision tasks and molecular graph, computer vision benchmarks (Source: HuggingFace Daily Papers)
Paper Alert: DeepVideo-R1 – Video Reinforcement Finetuning via Difficulty-Aware Regressive GRPO: Addressing the shortcomings of reinforcement learning in Video Large Language Model (Video LLM) applications, researchers propose DeepVideo-R1, a Video LLM trained with their proposed Reg-GRPO (Regressive GRPO) and a difficulty-aware data augmentation strategy. Reg-GRPO reframes the GRPO objective as a regression task, directly predicting the advantage function in GRPO, eliminating reliance on safeguards like clipping, thus guiding the policy more directly. Difficulty-aware data augmentation dynamically enhances training samples at solvable difficulty levels. Experiments show DeepVideo-R1 significantly improves video reasoning performance (Source: HuggingFace Daily Papers)
Paper Alert: Self-Refinement Framework for ASR Enhancement using TTS Synthetic Data: Researchers propose a self-refinement framework to improve Automatic Speech Recognition (ASR) performance using only an unlabeled dataset. The framework first generates pseudo-labels on unlabeled speech with an existing ASR model, then uses these pseudo-labels to train a high-fidelity Text-to-Speech (TTS) system. Subsequently, the TTS-synthesized speech-text pairs are used to guide the training of the original ASR system, forming a closed-loop self-improvement. Experiments on Taiwanese Mandarin show this method significantly reduces error rates, offering a practical path for low-resource or domain-specific ASR performance enhancement (Source: HuggingFace Daily Papers)
Paper Alert: Intrinsically Faithful Attention Maps for Vision Transformers: Researchers propose an attention-based method using learned binary attention masks to ensure only attended image regions influence predictions. This method aims to address biases that context can introduce to object perception, especially when objects appear in out-of-distribution backgrounds. Through a two-stage framework (first stage discovers object parts and identifies task-relevant regions, second stage uses input attention masks to limit receptive field for focused analysis), joint training achieves improved model robustness to spurious correlations and out-of-distribution backgrounds (Source: HuggingFace Daily Papers)
Paper Alert: ViCrit – A Verifiable RL Proxy Task for VLM Visual Perception: To address the lack of challenging yet clearly verifiable tasks for visual perception in VLMs, researchers introduce ViCrit (Visual Captioning Hallucination Critic). This is an RL proxy task that trains VLMs to locate subtle, synthetic visual hallucinations injected into human-written image caption paragraphs. By injecting a single subtle visual description error into ~200-word captions and requiring the model to locate the error span based on the image and modified caption, the task provides an easily computable and unambiguous binary reward. Models trained with ViCrit show significant gains on various VL benchmarks (Source: HuggingFace Daily Papers)
Paper Alert: Beyond Homogeneous Attention – Memory-Efficient LLMs with Fourier-Approximated KV Cache: To address the growing KV cache memory demand in LLMs with increasing context length, researchers propose FourierAttention, a training-free framework. This framework leverages the heterogeneous roles of Transformer head dimensions: low-rank dimensions prioritize local context, while high-rank dimensions capture long-range dependencies. By projecting long-context insensitive dimensions onto an orthogonal Fourier basis, FourierAttention approximates their temporal evolution with fixed-length spectral coefficients. Evaluation on LLaMA models shows the method achieves SOTA long-context accuracy on LongBench and NIAH, with memory optimization via a custom Triton kernel, FlashFourierAttention (Source: HuggingFace Daily Papers)
Paper Alert: JAFAR – A Universal Upsampler for Arbitrary Features at Arbitrary Resolutions: Addressing the issue that low-resolution spatial features from foundational vision encoders do not meet downstream task requirements, researchers introduce JAFAR, a lightweight, flexible feature upsampler. JAFAR can upscale the visual feature spatial resolution of any foundational vision encoder to any target resolution. It employs attention-based modules modulated by Spatial Feature Transforms (SFT) to promote semantic alignment between high-resolution queries derived from low-level image features and semantically rich low-resolution keys. Experiments show JAFAR effectively recovers fine-grained spatial details and outperforms existing methods in various downstream tasks (Source: HuggingFace Daily Papers)
Paper Alert: SwS – Self-aware Weakness-driven Problem Synthesis in Reinforcement Learning: Addressing the scarcity of high-quality, answer-verifiable problem sets for RLVR (Reinforcement Learning with Verifiable Reward) in training LLMs for complex reasoning tasks (like math problems), researchers propose the SwS (Self-aware Weakness-driven problem Synthesis) framework. SwS systematically identifies model deficiencies (problems where the model consistently fails to learn during RL training), extracts core concepts from these failure cases, and synthesizes new problems to reinforce the model’s weak areas in subsequent augmented training. This framework enables models to self-identify and address their weaknesses in RL, achieving significant performance improvements on several mainstream reasoning benchmarks (Source: HuggingFace Daily Papers)
Paper Alert: Learning a “Continue Thinking” Token to Enhance Test-Time Extension Capabilities: To improve language models’ performance in extending reasoning steps via additional computation at test time, researchers explore the feasibility of learning a dedicated “continue thinking” token (<|continue-thinking|>). They train only the embedding of this token via reinforcement learning while keeping the weights of a distilled version of the DeepSeek-R1 model frozen. Experiments show that compared to baseline models and test-time extension methods using fixed tokens (like “Wait”) for budget enforcement, the learned token achieves higher accuracy on standard math benchmarks, especially bringing larger improvements where fixed tokens already boost baseline accuracy (Source: HuggingFace Daily Papers)
Paper Alert: LoRA-Edit – Controllable First-Frame Guided Video Editing via Mask-Aware LoRA Fine-tuning: To address the issues of existing video editing methods relying on large-scale pre-training and lacking flexibility, researchers propose LoRA-Edit, a mask-based LoRA fine-tuning method for adapting pre-trained Image-to-Video (I2V) models for flexible video editing. This method preserves background regions while propagating controllable editing effects, and incorporates other reference information (like alternative viewpoints or scene states) as visual anchors. Through a mask-driven LoRA adjustment strategy, the model learns from the input video (spatial structure and motion cues) and reference image (appearance guidance) for region-specific learning (Source: HuggingFace Daily Papers)
Paper Alert: Infinity Instruct – Expanding Instruction Selection and Synthesis to Enhance Language Models: To compensate for existing open-source instruction datasets often focusing on narrow domains (like math, coding), limiting generalization, researchers introduce Infinity-Instruct, a high-quality instruction dataset designed to enhance LLM foundational and chat capabilities through a two-stage process. Stage one uses hybrid data selection techniques to filter 7.4 million high-quality foundational instructions from over 100 million samples. Stage two synthesizes 1.5 million high-quality chat instructions through a two-phase process of instruction selection, evolution, and diagnostic filtering. Fine-tuning experiments on various open-source models show the dataset significantly improves model performance on foundational and instruction-following benchmarks (Source: HuggingFace Daily Papers)
Paper Alert: Candidate First, Distill Later – A Teacher-Student Framework for LLM-driven Data Annotation: Addressing the issue in existing LLM data annotation methods where LLMs directly determining a single golden label can lead to errors due to uncertainty, researchers propose a new candidate annotation paradigm: encouraging LLMs to output all possible labels when uncertain. To ensure downstream tasks receive a unique label, they developed a teacher-student framework, CanDist, which distills candidate annotations using a Small Language Model (SLM). Theoretical proof shows distilling candidate annotations from a teacher LLM is superior to directly using single annotations. Experiments validate the effectiveness of this method (Source: HuggingFace Daily Papers)
Paper Alert: Med-PRM – Medical Reasoning Model with Stepwise, Guideline-Verified Process Rewards: To address the limitation of large language models in locating and correcting specific reasoning step errors in clinical decision-making, researchers introduce Med-PRM, a process reward modeling framework. This framework utilizes retrieval-augmented generation techniques to verify each reasoning step against established medical knowledge bases (clinical guidelines and literature). By precisely evaluating reasoning quality in this fine-grained manner, Med-PRM achieves SOTA performance on multiple medical QA benchmarks and open-ended diagnostic tasks, and can be integrated in a plug-and-play fashion with strong policy models (like Meerkat), significantly improving the accuracy of smaller models (8B parameters) (Source: HuggingFace Daily Papers)
Paper Alert: Feedback Friction – LLMs Struggle to Fully Absorb External Feedback: Research systematically examines LLMs’ ability to absorb external feedback. In experiments, a solver model attempts to solve problems, then a feedback generator with near-perfect ground truth answers provides targeted feedback, and the solver tries again. Results show that even under near-ideal conditions, SOTA models, including Claude 3.7, exhibit resistance to feedback, termed “feedback friction.” Despite improvements with strategies like progressive temperature increase and explicit rejection of prior incorrect answers, models still fall short of target performance. The study rules out factors like model overconfidence and data familiarity, aiming to uncover this core obstacle to LLM self-improvement (Source: HuggingFace Daily Papers)
💼 Business
Meta to acquire 49% stake in Scale AI for $14.3 billion, founder Alexandr Wang joins Meta’s superintelligence team: Meta announced the acquisition of a 49% non-voting stake in AI data annotation company Scale AI for $14.3 billion. Scale AI founder, 28-year-old Chinese-American prodigy Alexandr Wang, will continue as a board member and lead his core team to join Meta’s superintelligence team, personally assembled by Zuckerberg. This acquisition is seen as a high-priced talent acquisition by Meta to boost its AI capabilities after Llama 4’s underwhelming performance, aiming to deeply integrate AI into all its products. Scale AI started by providing large-scale, high-quality human-annotated data services, with clients including Waymo and OpenAI. This move has raised concerns about its platform neutrality and data security, with clients like Google potentially terminating cooperation (Source: 36氪)

Kunlun Tech’s “All in AI” strategy leads to first loss in a decade of listing, AI commercialization prospects unclear: Since announcing its “All in AGI and AIGC” strategy, Kunlun Tech has actively invested in large models (Tiangong large model) and AI applications such as AI music (Mureka), AI social (Linky), AI video (SkyReels), and AI office (Skywork Super Agents), as well as AI computing chips. However, high R&D investment and marketing expenses led to the company’s first loss in a decade of listing in 2024 (¥1.59 billion), with losses continuing in Q1 2025. Although some AI applications like Mureka and Linky have begun generating revenue, the overall profitability and market competitiveness of its AI business still face challenges. Whether it can achieve its “big tech dream” through AI remains to be seen by the market (Source: 36氪)

OpenAI reportedly testing ads in ChatGPT, profitability pressure drives business model exploration: Some ChatGPT Plus paid users have reported encountering in-stream ads while using the advanced voice mode, sparking discussions about whether OpenAI has begun testing ads among its paying subscribers. Previous reports indicated OpenAI was considering introducing ads to broaden its revenue streams. Given the high operating costs and profitability pressures of AI large models (projected losses of $44 billion by 2029), and the uncertainty of AGI realization timelines, OpenAI seeking new monetization models like advertising is considered an inevitable choice for its commercial sustainability, especially with relatively low paid penetration rates (Source: 36氪)

🌟 Community
AI shows huge potential in data science, Databricks actively hiring: Matei Zaharia of Databricks believes AI’s productivity gains in data science will be more significant than in AI-assisted coding. Databricks is leading this trend with products like Lakeflow Designer and Genie Deep Research, and is actively hiring researchers and engineers in this field, highlighting the industry’s strong emphasis on AI-driven data science innovation (Source: matei_zaharia)
LLM “personality” differences affect agentic loop behavior: Researcher Fabian Stelzer observed that different Large Language Models (LLMs) exhibit “personality” differences, causing them to behave differently when performing agentic loop tasks. For example, Claude tends to execute tools serially, while GPT-4.1 strongly prefers parallel execution, even ignoring serial requests; the Haiku model is more “aggressive” in triggering tools. This observation underscores the importance of considering the underlying LLM characteristics and the functional consequences of their “emotional state” when designing and evaluating multi-agent systems (Source: fabianstelzer, menhguin)
LLM “thinking” relies on token output; no output means no effective analysis: User dotey relayed xincmm’s discovery while debugging ReAct prompts: if an LLM is expected to analyze before performing an action (like drawing), but isn’t prompted to output tokens for the analysis process, it might skip the analysis step. This confirms that an LLM’s “thinking” process is realized through token generation; “analysis” defined in a prompt, if without actual content output, means the AI hasn’t truly performed that analysis. This is instructive for designing effective LLM prompts (Source: dotey)

AI’s limitations in specific tasks: Terence Tao says AI lacks “mathematical taste”: Mathematician Terence Tao pointed out that although current AI-generated proofs may appear flawless on the surface (passing an “eyeball test”), they often lack a subtle, uniquely human “mathematical taste” and are prone to making non-human errors. He believes true intelligence is not just about looking correct, but about being able to “smell” what is true. This reveals current AI’s limitations in deep understanding and intuitive judgment (Source: ecsquendor)
Challenges of AI-generated content adhering to real-world physical laws: User karminski3, while testing code generation with Doubao Seed 1.6 and DeepSeek-R1 (simulating a 3D animation of a chimney demolition), found that although the models could generate code and simulate animation, there were still discrepancies and room for improvement in replicating real physical processes (like shockwave effects, structural collapse patterns). Doubao Seed 1.6 was closer to reality in particle effects and structural collapse simulation, while DeepSeek performed better in lighting and smoke effects. This reflects AI’s challenges in understanding and simulating complex physical phenomena (Source: karminski3)
Senior programmer fired for over-reliance on AI for coding, unwillingness to make manual changes, and telling new hires AI will replace them: A Reddit post, reposted by 36氪, tells the story of a programmer with 30 years of experience who was fired for excessive reliance on AI (e.g., completely depending on Copilot Agent for PR submissions, refusing to manually modify code, taking 5 days for a 1-day task, and telling interns AI would replace them). The incident sparked discussion about the reasonable boundaries of AI use in software development and AI’s impact on developers’ professional value (Source: 36氪)
AI “flow” and “personality” impact user experience: Users report AI is too “agreeable”: Reddit community users discussed that when interacting with AI (especially Claude), AI tends to be overly optimistic and agreeable with user viewpoints, lacking effective challenges and in-depth critical feedback, making users feel like they are in an “echo chamber.” This “AI tonality fatigue” prompts users to seek ways to make AI behave more neutrally and critically, for example, through specific prompts. This reflects current AI’s challenges in simulating authentic, multifaceted human conversation and providing truly profound insights (Source: Reddit r/ClaudeAI)
In the AI era, the value of human feedback is highlighted, but platforms for real human interaction face AI content infiltration: Reddit users discussed that against the backdrop of increasing AI-generated content, real human feedback and opinions are becoming more valuable, and platforms like Reddit are valued for their human interaction. However, these platforms also face the challenge of AI-generated content infiltration (like bot comments, AI-assisted written posts), making it harder to discern genuine human viewpoints and raising concerns about the authenticity of future online communication (Source: Reddit r/ArtificialInteligence)
AI “friends” becoming the norm? Trends and discussions on users forming emotional connections with AI: Discussions about AI companions and AI friends are emerging on social media and Reddit. Some users believe that due to AI’s unbiased and ever-supportive nature, AI friends could become commonplace within 5 years, already evident in apps like Endearing AI, Replika, and Character.ai. Others share experiences of forming deep conversational relationships with AI like ChatGPT, even considering them “best friends.” This sparks broad reflection on human-AI emotional interaction, AI’s role in emotional support, and its potential societal impacts (Source: Ronald_vanLoon, Reddit r/artificial, Reddit r/ArtificialInteligence)

Future of AI “wrapper” startups sparks discussion: The Reddit community discussed the prospects of numerous AI startups that “wrap” foundational models like GPT or Claude (adding UIs, prompt chains, or fine-tuning for specific domains). Discussants questioned whether these “wrapper” applications can remain competitive as foundational model platforms iterate their own features, and whether they can build true moats. The consensus is that focusing on specific verticals, accumulating proprietary data, and going beyond simple wrapping might be paths to sustainability (Source: Reddit r/LocalLLaMA)
Discussion on AI’s potential to replace roles in medical diagnosis versus software engineering: A Reddit discussion emerged suggesting AI might replace doctors faster than senior software engineers. The reasoning is that many medical diagnoses follow established protocols, and AI excels at interpreting test results and identifying symptoms; whereas software engineering often involves extensive tacit knowledge and complex requirements communication, which AI struggles to fully handle. This viewpoint sparked further thought on the depth of AI application and replacement potential in different professional fields, but also faced rebuttals from doctors and other professionals emphasizing the complexity of practical operations and the importance of human judgment (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
💡 Others
Luo Yonghao’s AI digital human debuts on Baidu e-commerce, GMV exceeds ¥55 million: Luo Yonghao’s AI digital human conducted its first live-streaming sales event on Baidu’s e-commerce platform, attracting over 13 million viewers and achieving a Gross Merchandise Volume (GMV) exceeding ¥55 million. The digital human, created by Baidu e-commerce’s “Huiboxing” platform based on the ERNIE 4.5 large model, can simulate Luo Yonghao’s tone, accent, and micro-expressions, and engage in intelligent Q&A. This live stream showcased the potential of the “AI + top influencer” model and Baidu’s布局 in “high-persuasion digital human” technology and AI e-commerce (Source: 36氪)

Baidu, Tencent, and other companies ramp up AI talent recruitment, launching large-scale hiring plans: Baidu has launched its largest-ever top-tier AI talent recruitment project, the “AIDU Program,” with a 60% year-over-year increase in job openings, focusing on cutting-edge fields like large model algorithms and fundamental architecture, offering uncapped salaries. Similarly, Tencent is attracting global AI talent by hosting a “Full-Modal Generative Recommendation” algorithm competition, offering millions in prize money and campus recruitment offers. These initiatives reflect the urgent demand for top talent and strategic positioning of Chinese tech giants amidst the intensifying competition in the AI field (Source: 量子位, 量子位)

Baidu launches comprehensive AI college application advisory service, integrating multiple models and big data: Addressing the complexity of college application planning brought by the new Gaokao (college entrance exam) reforms, Baidu has launched a free AI-powered college application advisory tool. The service is integrated into the “Gaokao” special section of the Baidu App, offering an “AI College Application Assistant” for university and major recommendations and admission probability analysis, and supports personalized consultation through “AI Chat for College Applications” agents powered by multiple models like ERNIE and DeepSeek R1. Additionally, it combines Baidu’s exclusive search big data to provide analysis of professional job prospects, MBTI career assessments, as well as live streams from university admissions offices and Q&A sessions with senior students, aiming to help candidates navigate information gaps and make more suitable application choices (Source: 36氪)