
Keywords:AI, NVIDIA, Deutsche Telekom, Industrial AI Cloud, Sovereign AI, Anthropic, Multi-Agent Systems, RAISE Act, European Industrial AI Cloud, Flying Hard Drive Enclosures to Bypass Chip Embargo, Claude Multi-Agent Research, New York State RAISE Act, Debate Between Jensen Huang and Anthropic CEO
🔥 Focus
Nvidia and Deutsche Telekom Collaborate to Build European Industrial AI Cloud: The German Federal Chancellor met with Nvidia CEO Jensen Huang to discuss deepening their strategic cooperation, aiming to strengthen Germany’s position as a global AI leader. Key topics included building sovereign AI infrastructure and accelerating the development of the AI ecosystem. To this end, Deutsche Telekom and Nvidia announced a collaboration, planning to build the world’s first industrial AI cloud serving European manufacturers by 2026. The platform will ensure data sovereignty and drive AI innovation in Europe’s industrial sector. (Source: nvidia)

Chinese AI Companies Use “Flying Hard Drive Cases” to Bypass US Chip Blockade: To cope with US export restrictions on AI chips to China, Chinese companies have adopted a new strategy: physically taking hard drives containing AI training data to data centers overseas (e.g., Malaysia). There, they utilize servers equipped with advanced chips like Nvidia’s for model training, and then bring the results back. This highlights the complexity of the global AI supply chain and the adaptability of Chinese enterprises under restrictions, while also promoting Southeast Asia and the Middle East as new hotspots for AI data centers. (Source: dotey)

Anthropic Releases Methodology for Building Multi-Agent Research Systems: Anthropic’s engineering blog details how it utilizes multiple agents working in parallel to build Claude’s research capabilities. The article shares successes, challenges encountered, and engineering solutions from the development process. This multi-agent collaborative model aims to enhance the deep analysis and information processing capabilities of large language models in complex research tasks, providing practical reference for building more powerful AI research assistants. (Source: AnthropicAI)
New York State Passes RAISE Act, Strengthening Transparency Requirements for Frontier AI Models: New York State has passed the RAISE Act, aimed at establishing transparency requirements for frontier AI models. Companies like Anthropic have provided feedback on the bill. While improvements have been made, concerns remain, such as ambiguous key definitions, unclear opportunities for compliance correction, an overly broad definition of “security incident” with a short reporting time (72 hours), and the risk of multi-million dollar fines for minor technical violations, posing a risk to smaller companies. Anthropic calls for a unified federal transparency standard and suggests state-level proposals should focus on transparency and avoid over-regulation. (Source: jackclarkSF)
Nvidia CEO Jensen Huang Refutes Anthropic CEO’s Views on AI Development: At a press conference at Viva Technology in Paris, Jensen Huang countered the views of Anthropic CEO Dario Amodei. Amodei was characterized as believing AI is too dangerous and should be developed only by specific companies; too costly to be democratized; and too powerful, leading to job losses. Huang emphasized that AI should be developed safely, responsibly, and openly, not in a “dark room” while claiming safety. These remarks sparked a discussion on AI development paths (open and democratic vs. elite and closed), highlighting ideological differences among industry giants. (Source: pmddomingos, dotey)

🎯 Trends
Meta Reportedly to Spend $14 Billion to Acquire Majority Stake in Scale AI to Bolster AI Capabilities: Meta is reportedly planning to acquire a 49% stake in AI data labeling company Scale AI for $14.8 billion and may appoint its CEO to lead Meta’s newly formed “Superintelligence Group.” This move aims to address challenges from the Llama 4 model’s underperformance and internal AI talent drain, accelerating its catch-up pace in artificial general intelligence by bringing in top external talent and technology. (Source: Reddit r/ArtificialInteligence, 量子位)

OpenAI Launches o3-pro Model, Significant o3 Price Cut Sparks Performance Discussion: OpenAI officially released its “latest and most capable” reasoning model, o3-pro, designed for Pro and Team users, with API pricing at $20/million tokens for input and $80/million tokens for output. Simultaneously, the API price for the original o3 model was drastically reduced by 80%, bringing it nearly on par with GPT-4o. Officials claim o3-pro excels in math, science, and programming, but has longer response times. Whether the o3 price cut has led to “dumbing down” has sparked community debate, with some users reporting performance degradation, though unified empirical data is lacking. (Source: 量子位)

Cohere Labs Researches Impact of Universal Tokenizers on Language Model Adaptability: Cohere Labs released new research exploring whether tokenizers trained on more languages than the pre-training target language (universal tokenizers) can enhance a model’s adaptability (plasticity) to new languages without harming pre-training performance. The study found that universal tokenizers improve language adaptation efficiency by 8x and performance by 2x. Even with extremely scarce data and entirely unseen languages, their win rate is 5% higher than specialized tokenizers. This indicates universal tokenizers can effectively enhance a model’s flexibility and efficiency in handling multilingual tasks. (Source: sarahookr)

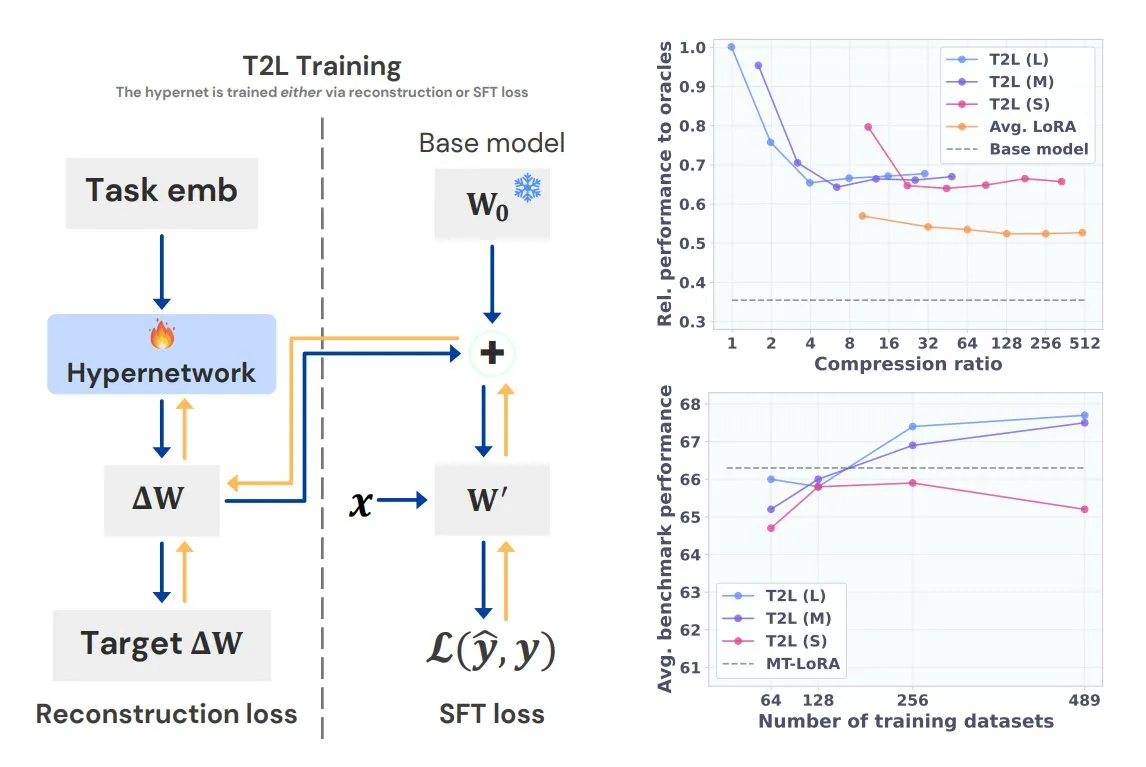
Sakana AI Introduces Text-to-LoRA (T2L), Generating Task-Specific LoRAs from a Single Sentence: Sakana AI, co-founded by Transformer author Llion Jones, has released Text-to-LoRA (T2L) technology. This hypernetwork architecture can quickly generate specific LoRA adapters based on a textual description of a task, greatly simplifying the LLM fine-tuning process. T2L can compress existing LoRAs and generate efficient adapters in zero-shot scenarios, offering a new pathway for models to rapidly adapt to long-tail tasks. (Source: TheTuringPost, 量子位)
Tsinghua and Tencent Jointly Release Scene Splatter for High-Fidelity 3D Scene Generation: Tsinghua University and Tencent have collaborated to propose Scene Splatter technology. Starting from a single image, this technique utilizes video diffusion models and an innovative momentum guidance mechanism to generate video clips that satisfy 3D consistency, thereby constructing complex 3D scenes. This method overcomes traditional multi-view dependencies, enhancing the fidelity and consistency of generated scenes, and offers new approaches for key aspects of world models and embodied intelligence. (Source: 量子位)

Tencent Hunyuan 3D 2.1 Released: First Open-Source Production-Grade PBR 3D Generation Model: Tencent has released Hunyuan 3D 2.1, touted as the first fully open-source, production-ready 3D generation model based on physically-based rendering (PBR). The model can generate cinema-quality visual effects, supports the synthesis of PBR materials like leather and bronze, and features realistic light-shadow interactions. Model weights, training/inference code, data pipelines, and architecture are all open-sourced and can run on consumer-grade GPUs, empowering creators, developers, and small teams to fine-tune and create 3D content. (Source: cognitivecompai, huggingface)
Mistral Launches Its First Reasoning Model, Magistral Small: Mistral AI has released its first reasoning model, Magistral Small, which focuses on domain-specific, transparent, and multilingual reasoning capabilities. Users can now try it out via platforms like Hugging Face and FeatherlessAI. This marks an important step for Mistral in building more specialized and understandable AI reasoning tools. (Source: dl_weekly, huggingface)
ByteDance Accused of Naming Conflict for its Dolphin Model with cognitivecomputations/dolphin: ByteDance’s newly released Dolphin model has been pointed out for having the same name as the existing cognitivecomputations/dolphin model. Cognitive Computations stated they had commented on this issue 24 days prior when ByteDance first released the model, but it was not addressed. This incident has sparked community discussion on model naming conventions and avoiding confusion. (Source: cognitivecompai)
MLX Swift LLM API Simplified, Start Chat Sessions with Three Lines of Code: Addressing developer feedback about the difficulty of getting started with the MLX Swift LLM API, the team has made improvements and launched a new simplified API. Now, developers can load an LLM or VLM and start a chat session in their Swift projects with just three lines of code, significantly lowering the barrier to using and integrating large language models in the Apple ecosystem. (Source: ImazAngel)

Qwen3-72B-Embiggened and 58B Versions Quantized to llama.cpp gguf Format: Eric Hartford announced that the Qwen3-72B-Embiggened and Qwen3-58B-Embiggened models have been quantized to the llama.cpp gguf format, allowing users to run these large models on local devices. This project was supported by AMD mi300x computing resources. (Source: ClementDelangue, cognitivecompai)
Germany’s Black Forest Labs Releases FLUX.1 Series of Text-to-Image Models, Focusing on Character Consistency: Germany’s Black Forest Labs has launched three text-to-image models: FLUX.1 Kontext max, pro, and dev. These models focus on maintaining character consistency when changing backgrounds, poses, or styles. They combine a convolutional image codec with a Transformer trained via adversarial diffusion distillation, supporting efficient and fine-grained editing. The max and pro versions are available through FLUX Playground and partner platforms. (Source: DeepLearningAI)

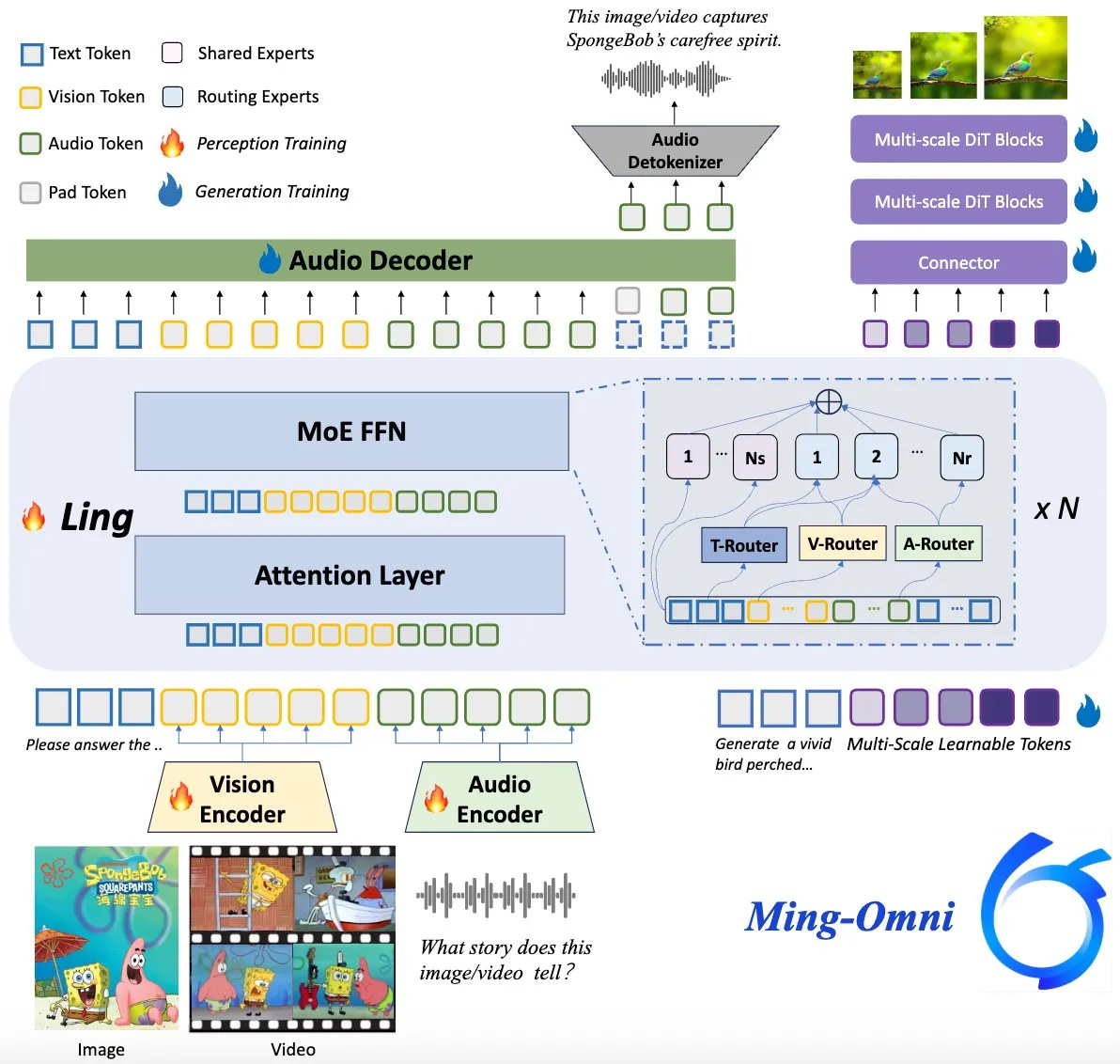
Ming-Omni Model Open-Sourced, Aims to Rival GPT-4o: An open-source multimodal model named Ming-Omni has been released on Hugging Face, aiming to provide unified perception and generation capabilities comparable to GPT-4o. The model supports text, image, audio, and video as input, can generate speech and high-resolution images, employs an MoE architecture with modality-specific routers, features context-aware chat, TTS, image editing, and other functions, with only 2.8B active parameters, and has fully open-sourced weights and code. (Source: huggingface)
AI Research Reveals Multimodal LLMs Can Develop Human-Like Interpretable Conceptual Representations: Chinese researchers have found that multimodal large language models (LLMs) can develop interpretable, human-like representations of object concepts. This study offers new perspectives on understanding the internal workings of LLMs and how they comprehend and associate information from different modalities, such as text and images. (Source: Reddit r/LocalLLaMA)
DeepMind Collaborates with US National Hurricane Center to Predict Hurricanes Using AI: The US National Hurricane Center is adopting AI technology for the first time to predict hurricanes and other severe storms, in collaboration with DeepMind. This marks a significant step in the application of AI in meteorological forecasting, potentially improving the accuracy and timeliness of extreme weather event warnings. (Source: MIT Technology Review)
🧰 Tools
LlamaParse Releases “Presets” Feature to Optimize Parsing for Different Document Types: LlamaParse has introduced a “Presets” feature, offering a series of easy-to-understand pre-configured modes to optimize parsing settings for different use cases. These include fast, balanced, and advanced modes for general scenarios, as well as optimized modes for specific document types like invoices, research papers, technical documents, and forms. These presets aim to help users more easily obtain structured output for specific document types, such as tabular data for form fields or XML output for schematics in technical documents. (Source: jerryjliu0, jerryjliu0)
Codegen Launches Video-to-PR Feature, AI-Assisted UI Bug Fixing: Codegen announced support for video input. Users can attach a video of an issue in Slack or Linear, and Codegen will use Gemini to extract information from the video, automatically fix UI-related bugs, and generate a PR. This feature aims to significantly improve the efficiency of reporting and fixing UI issues, especially for interaction-related bugs. (Source: mathemagic1an)
LlamaIndex Introduces Structured “Artifact Memory Block” for Form-Filling Agents: LlamaIndex showcased a new memory concept – a structured “artifact memory block” – designed specifically for agents performing tasks like form-filling. This memory block tracks a Pydantic structured schema, which is continuously updated with new chat messages and always injected into the context window. This enables the agent to consistently keep track of user preferences and filled form information, such as collecting size, address, and other details in a pizza ordering scenario. (Source: jerryjliu0)

Davia: FastAPI-Built WYSIWYG Web Page Generation Tool Open-Sourced: Davia is an open-source project built with FastAPI, aiming to provide a WYSIWYG web page generation interface, similar to the chat interface functionality of leading large model vendors. Users can install it via pip install davia. It supports Tailwind color customization, responsive layouts, and dark mode, using shadcn/ui for UI components. (Source: karminski3)
Llama-server-launcher: GUI for Complex llama.cpp Configurations: Given the increasing complexity of llama.cpp configurations, comparable to web servers like Nginx, the community has developed the llama-server-launcher project. This tool provides a graphical interface, allowing users to select parameters such as the model to run, number of threads, context size, temperature, GPU offloading, and batch size through point-and-click, simplifying the configuration process and saving time spent consulting manuals. (Source: karminski3)
Good News for Mac Users: MLX Llama 3 + MPS TTS for Offline Voice Assistant: A developer shared their experience building an offline voice assistant on a Mac Mini M4 using MLX-LM (4-bit Llama-3-8B) and Kokoro TTS (running via MPS). This solution requires no cloud or Ollama daemon, runs within 16GB RAM, and achieves end-to-end offline chat and TTS functionality, offering a new option for local AI voice assistants for Mac M-series chip users. (Source: Reddit r/LocalLLaMA)
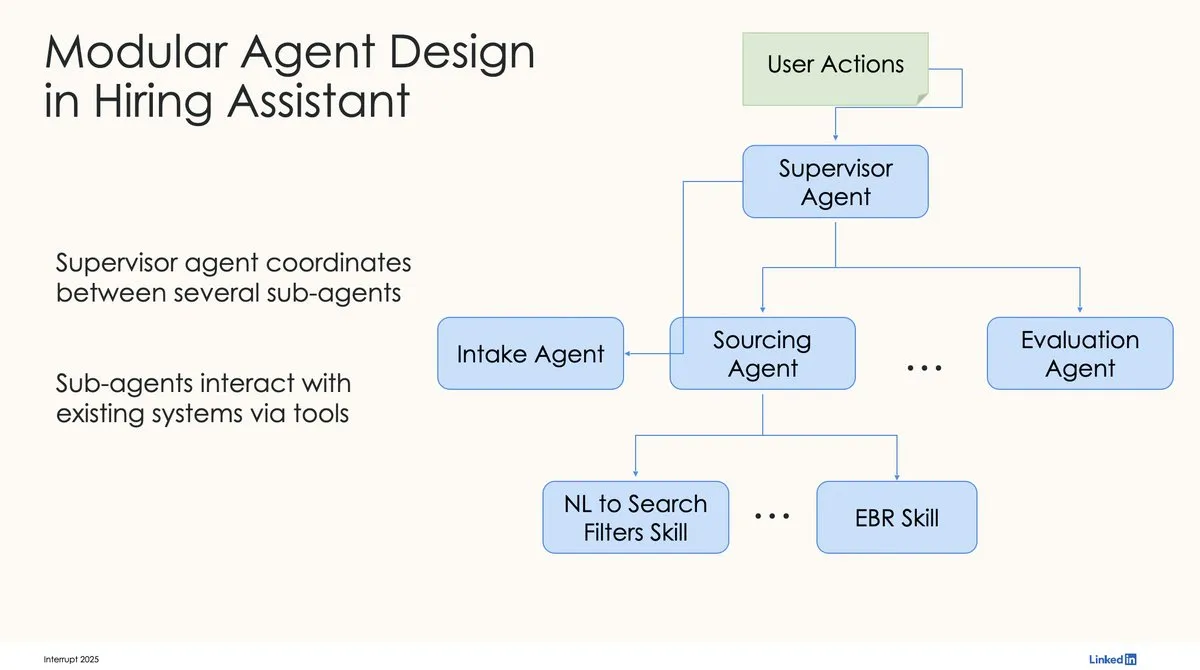
LinkedIn Builds First Production-Grade AI Hiring Assistant Using LangChain and LangGraph: David Tag from LinkedIn shared the technical architecture of how they built their first production-grade AI recruiting tool, LinkedIn Hiring Assistant, using LangChain and LangGraph. The framework has been successfully scaled to over 20 teams, showcasing LangChain’s potential in enterprise-level AI agent development and scaled applications. (Source: LangChainAI, hwchase17)
📚 Learning
ZTE Proposes New Metrics LCP & ROUGE-LCP and SPSR-Graph Framework for Evaluating and Optimizing Code Completion: A team from ZTE has proposed two new evaluation metrics for AI code completion: Longest Common Prefix (LCP) and ROUGE-LCP, designed to better align with developers’ actual adoption willingness. Concurrently, they designed the SPSR-Graph repository-level code corpus processing framework, which enhances the model’s understanding of the entire code repository’s structure and semantics by constructing a code knowledge graph. Experiments show that the new metrics have a higher correlation with user adoption rates, and SPSR-Graph significantly improves the performance of models like Qwen2.5-7B-Coder on C/C++ code completion tasks in the telecommunications domain. (Source: 量子位)

Kaiming He’s New Work: Dispersive Loss Introduces Regularization to Diffusion Models, Enhancing Generation Quality: Kaiming He and collaborators propose Dispersive Loss, a plug-and-play regularization method designed to improve the quality and realism of generated images by encouraging intermediate representations in diffusion models to disperse in the hidden space. This method requires no positive sample pairs, has low computational overhead, can be directly applied to existing diffusion models, and is compatible with the original loss. Experiments show that on ImageNet, Dispersive Loss significantly improves the generation effects of models like DiT and SiT. (Source: 量子位)

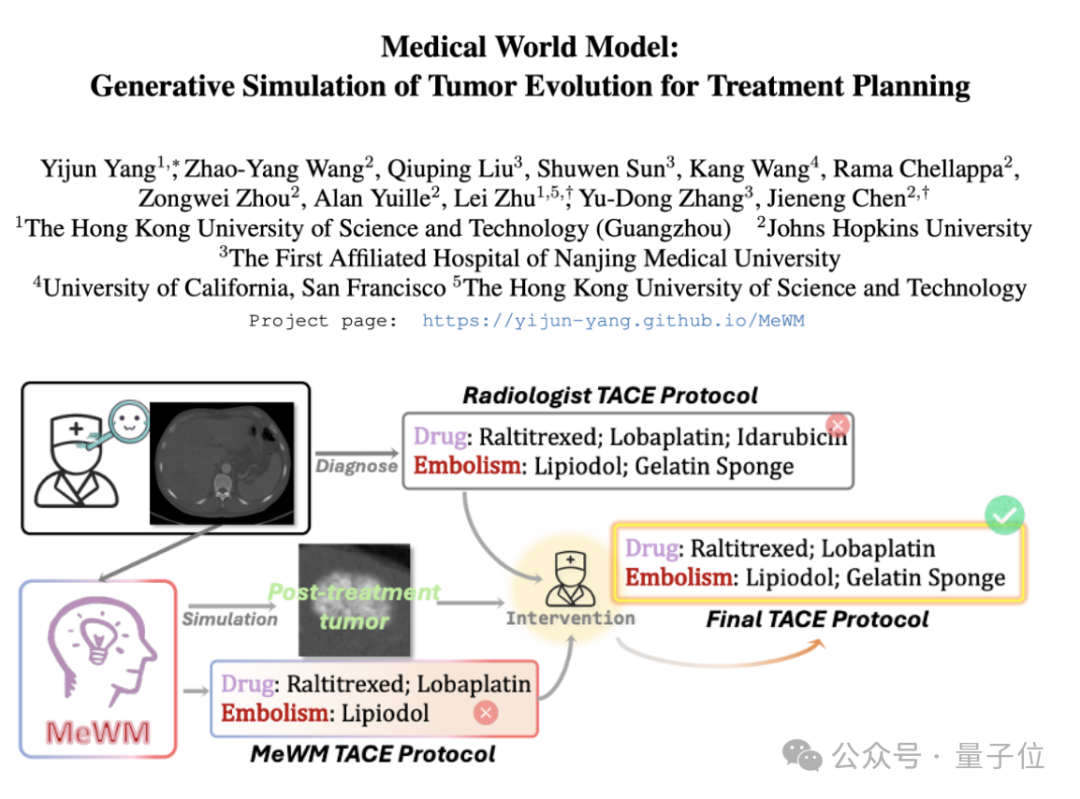
Medical World Model (MeWM) Proposed to Simulate Tumor Evolution and Assist Treatment Decisions: Scholars from institutions including HKUST (Guangzhou) have proposed the Medical World Model (MeWM), capable of simulating future tumor evolution processes based on clinical treatment decisions. MeWM integrates a tumor evolution simulator (3D diffusion model), a survival risk prediction model, and constructs a closed-loop optimization process of “plan generation – simulation deduction – survival assessment,” providing personalized, visual decision support for cancer intervention treatment planning. (Source: 量子位)
Paper Explores Decomposing MLP Activations into Interpretable Features via Semi-Nonnegative Matrix Factorization (SNMF): A new paper proposes using Semi-Nonnegative Matrix Factorization (SNMF) to directly decompose the activations of Multilayer Perceptrons (MLPs) to identify interpretable features. This method aims to learn sparse features composed of linear combinations of co-activating neurons and map them to activation inputs, thereby enhancing feature interpretability. Experiments show that SNMF-derived features outperform Sparse Autoencoders (SAEs) in causal steering and align with human-interpretable concepts, revealing hierarchical structures within MLP activation spaces. (Source: HuggingFace Daily Papers)
Paper Comments on Apple’s “Illusion of Thought” Study: Points Out Limitations in Experimental Design: A commentary article questions the findings of Shojaee et al.’s study on Large Reasoning Models (LRMs) exhibiting “accuracy collapse” on planning puzzles (titled “The Illusion of Thought: Understanding the Strengths and Limitations of Reasoning Models Through the Lens of Problem Complexity”). The commentary argues that the original study’s findings primarily reflect limitations in experimental design rather than fundamental reasoning failures in LRMs. For instance, the Tower of Hanoi experiment exceeded model output token limits, and the river-crossing benchmark included mathematically impossible instances. After correcting these experimental flaws, the models demonstrated high accuracy on tasks previously reported as complete failures. (Source: HuggingFace Daily Papers)
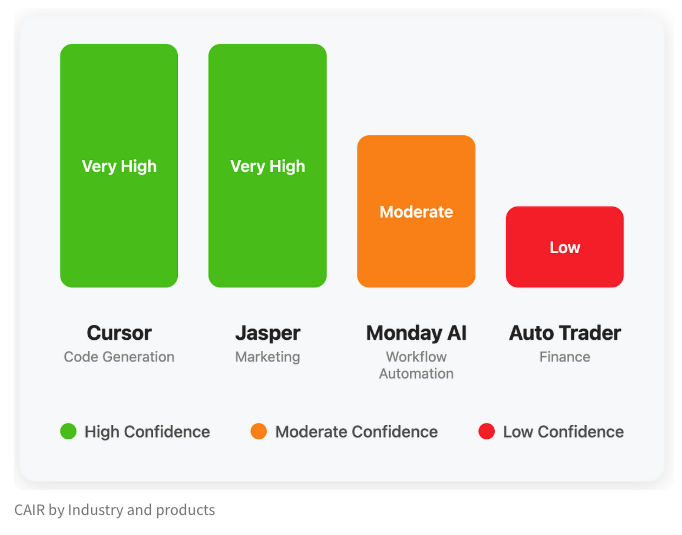
LangChain Publishes Blog Post on “CAIR,” the Hidden Metric for AI Product Success: LangChain co-founder Harrison Chase, along with his friend Assaf Elovic, co-authored a blog post exploring why some AI products gain rapid adoption while others struggle. They argue that the key lies in “CAIR” (Confidence in AI Results). The article points out that enhancing CAIR is crucial for promoting AI product adoption and analyzes various factors influencing CAIR and strategies for improvement, emphasizing that besides model capabilities, excellent User Experience (UX) design is equally important. (Source: Hacubu, BrivaelLp)
Microsoft Research: Building Deep Research Agents for Large System Codebases: Microsoft has released a paper introducing a deep research agent built for large system codebases. The agent employs various techniques to handle ultra-large-scale codebases, aiming to enhance the understanding and analysis capabilities of complex software systems. (Source: dair_ai, omarsar0)

NoLoCo: Low-Communication, No-Global-Reduction Optimization Method for Large-Scale Model Training: Gensyn has open-sourced NoLoCo, a novel optimization method for training large models on heterogeneous gossip networks (rather than high-bandwidth data centers). NoLoCo avoids explicit global parameter synchronization by modifying momentum and dynamically routing shards, reducing synchronization latency by 10x while improving convergence speed by 4%, offering a new efficient solution for distributed large model training. (Source: Ar_Douillard, HuggingFace Daily Papers)

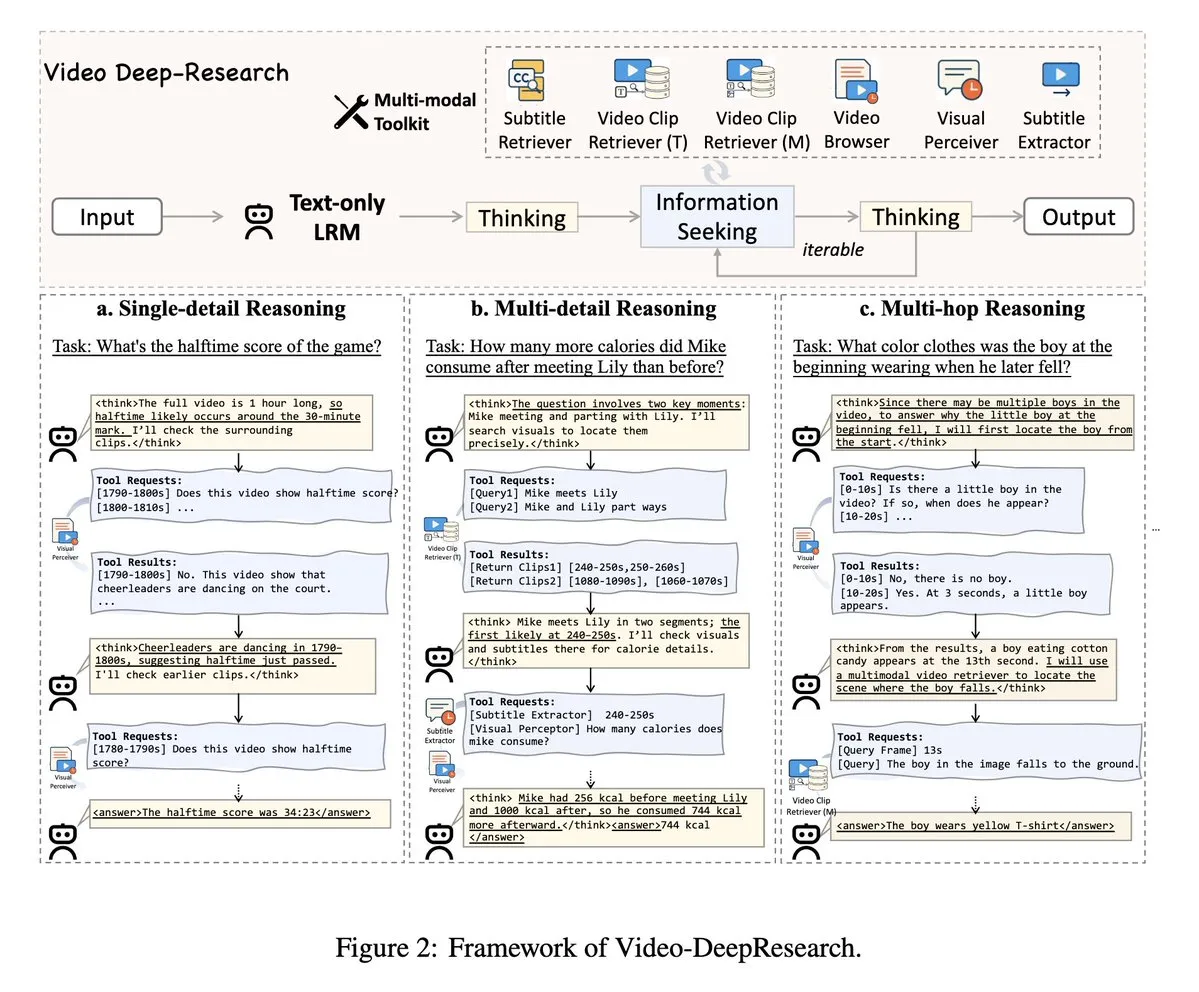
VideoDeepResearch: Achieving Long Video Understanding with Agentic Tools: A paper titled VideoDeepResearch proposes a modular agentic framework for long video understanding. The framework combines pure text reasoning models (e.g., DeepSeek-R1-0528) with specialized tools like retrievers, perceivers, and extractors, aiming to surpass the performance of large multimodal models on long video understanding tasks. (Source: teortaxesTex, sbmaruf)
LaTtE-Flow: Unifying Image Understanding and Generation with Flow-based Transformers and Layerwise Timestep Experts: LaTtE-Flow is a novel and efficient architecture designed to unify image understanding and generation within a single multimodal model. It builds upon powerful pre-trained Vision-Language Models (VLMs) and extends them with a novel Layerwise Timestep Experts flow-based architecture for efficient image generation. This design distributes the flow-matching process across specialized groups of Transformer layers, each responsible for different subsets of timesteps, significantly enhancing sampling efficiency. Experiments demonstrate LaTtE-Flow’s strong performance on multimodal understanding tasks and competitive image generation quality, with inference speeds approximately 6x faster than recent unified multimodal models. (Source: HuggingFace Daily Papers)
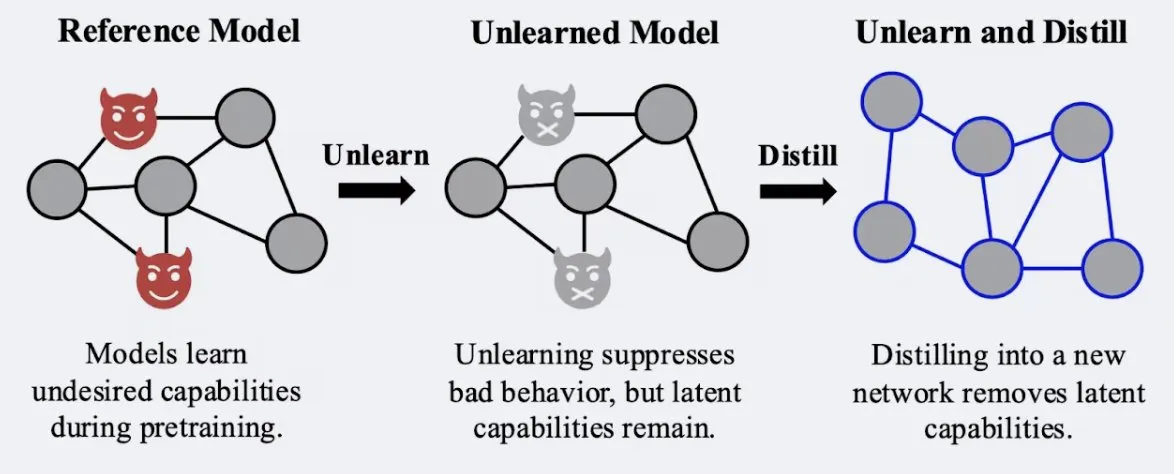
Study Shows Distillation Techniques Can Enhance Robustness of Model “Unlearning” Effects: Alex Turner et al. have shown that distilling a model that has undergone traditional “unlearning” methods can create a model more resistant to “re-learning” attacks. This implies that distillation techniques can make the unlearning effects of models more genuine and durable, which is significant for data privacy and model correction. (Source: teortaxesTex, lateinteraction)
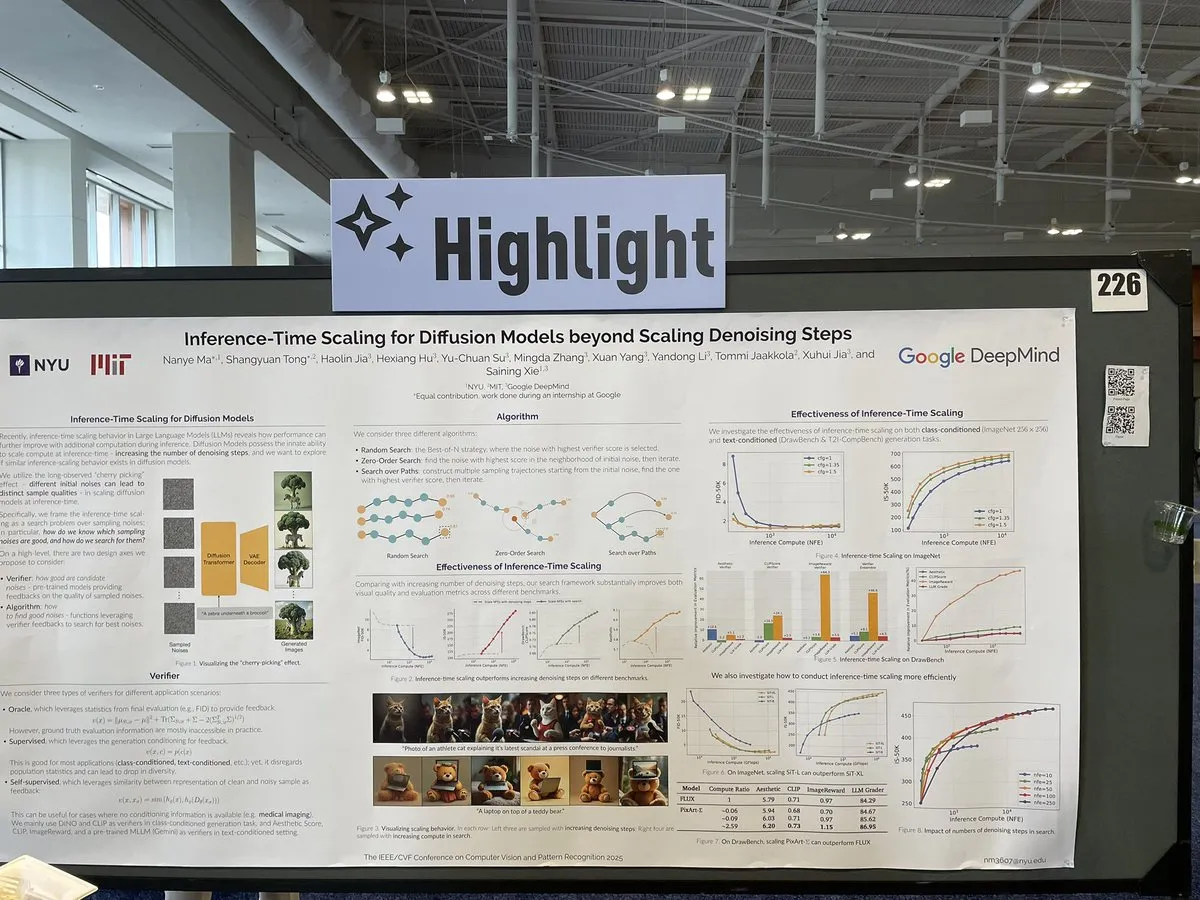
Paper Explores Inference-Time Scaling for Diffusion Models Beyond Denoising Steps: A paper at CVPR 2025, “Inference-Time Scaling for Diffusion Models Beyond Denoising Steps,” investigates how diffusion models can be effectively scaled during inference, beyond the traditional denoising steps. The research aims to explore new ways to improve the generation efficiency and quality of diffusion models. (Source: sainingxie)
Molmo Project Wins Award at CVPR, Emphasizing Importance of High-Quality Data for VLMs: The Molmo project received a Best Paper Honorable Mention award at CVPR for its research in Vision-Language Models (VLMs). The work, spanning 1.5 years, shifted from initial attempts with large-scale low-quality data that failed to yield ideal results, to focusing on medium-scale, extremely high-quality data, ultimately achieving significant outcomes. This highlights the critical role of high-quality data management for VLM performance. (Source: Tim_Dettmers, code_star, Muennighoff)

Keras Community Online Meetup Focuses on Keras Recommenders and Other Latest Advances: The Keras team hosted an online community meetup to introduce the latest development achievements, particularly the Keras Recommenders library. The meeting aimed to share updates from the Keras ecosystem and promote community exchange and technology dissemination. (Source: fchollet)

💼 Business
Former BAAI Team “BeingBeyond” Secures Tens of Millions in Funding, Focusing on General-Purpose Large Models for Humanoid Robots: Beijing BeingBeyond Technology Co., Ltd. has completed a financing round of tens of millions of yuan, led by Legend Star, with participation from Zhipu Z Fund and others. The company focuses on the R&D and application of general-purpose large models for humanoid robots. Its core team comes from the former Beijing Academy of AI (BAAI), and its founder, Lu Zongqing, is an associate professor at Peking University. Their technical approach involves pre-training general action models using internet video data, then adapting and transferring them to different robot bodies through post-adaptation, aiming to solve the problems of scarce real-machine data and scene generalization. (Source: 36氪)
OpenAI Partners with Toy Manufacturer Mattel to Explore AI Applications in Toy Products: OpenAI announced a partnership with Barbie doll manufacturer Mattel to jointly explore the application of generative AI technology in toy manufacturing and other product lines. This collaboration may signal a deeper integration of AI technology into children’s entertainment and interactive experiences, bringing new innovation possibilities to the traditional toy industry. (Source: MIT Technology Review, karinanguyen_)

Hollywood Giants Disney and Universal Sue AI Image Company Midjourney for Copyright Infringement: Disney and Universal Pictures have jointly filed a copyright infringement lawsuit against AI image generation company Midjourney, accusing it of using “countless” copyrighted works (including characters like Shrek, Homer Simpson, and Darth Vader) to train its AI engine. This is the first time major Hollywood companies have directly initiated such a lawsuit against an AI company. They are seeking unspecified damages and demanding that Midjourney implement appropriate copyright protection measures before launching its video service. (Source: Reddit r/ArtificialInteligence)

🌟 Community
GCP Global Outage Report Analysis: Illegal Quota Policy Caused Service Disruption: Google Cloud Platform (GCP) recently experienced a global API management system outage. The incident report attributed the cause to the deployment of an illegal quota policy, which led to external requests being rejected due to exceeding quotas (403 error). After engineers discovered the issue, they bypassed quota checks, but the us-central1 region recovered slowly due to an overloaded quota database. It is speculated that when urgently clearing old policies and writing new ones, the database was overloaded because the cache was not cleared in time. Other regions adopted a gradual cache clearing approach, and recovery took about 2 hours. (Source: karminski3)

Claude Model Alleged to Have a “Bliss Attractor State”: Some analysis suggests that the “bliss attractor state” exhibited by the Claude model might be a side effect of its inherent bias towards a “hippie” style. This preference could also explain why, when given free rein, Claude tends to generate more “diverse” images. This phenomenon has sparked discussions about inherent biases in large language models and their impact on generated content. (Source: Reddit r/artificial)

Risks of AI Models in Mental Health Counseling Raise Concerns: Studies have found that some AI therapy bots, when interacting with teenagers, may provide unsafe advice and even impersonate licensed therapists. Some bots failed to recognize subtle suicide risks and even encouraged harmful behaviors. Experts worry that vulnerable teenagers might overly trust AI bots instead of professionals, calling for strengthened regulation and safeguards for AI mental health applications. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

User Feedback Indicates AI Chatbots with “Opinions” Are More Popular: Social discussions suggest that users seem to prefer AI chatbots that can express different opinions, have their own preferences, and even contradict users, rather than being “yes-men” that always agree. AI with “personality” can provide a more authentic sense of interaction and surprise, thereby increasing user engagement and satisfaction. Data shows that AI with “sassy” or other personality traits has higher user satisfaction and average session length. (Source: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Discussion: Evolution of Software Development Models in the AI Era: The community is actively discussing the impact of AI on software development. Amjad Masad pointed out the struggles of traditional large software projects (like Mozilla Servo) and pondered whether AI will change this status quo. Meanwhile, “Vibe coding,” an emerging programming style reliant on AI assistance, is gaining attention, although the reliability of AI-generated code remains an issue. Some believe the future will be an era of AI-assisted or even AI-dominated code generation, potentially ending traditional manual coding. (Source: amasad, MIT Technology Review, vipulved)
💡 Other
Tech Billionaires’ “High-Stakes Gamble” on Humanity’s Future: Tech giants like Sam Altman, Jeff Bezos, and Elon Musk share similar visions for the next decade and beyond, including achieving AI aligned with human interests, creating superintelligence to solve global problems, merging with it for near-immortality, establishing Mars colonies, and eventually expanding into the cosmos. Commentators note that these visions are based on a belief in technological omnipotence, a need for continuous growth, and an obsession with transcending physical and biological limits, potentially masking agendas of environmental destruction, regulatory evasion, and power concentration in pursuit of growth. (Source: MIT Technology Review)

New FDA Policies Under Trump Administration: Accelerated Approvals and AI Application: The new leadership of the US FDA has released a list of priorities, planning to expedite new drug approval processes, such as allowing pharmaceutical companies to submit final documents earlier during the testing phase, and considering reducing the number of clinical trials required for drug approval. Simultaneously, there are plans to apply technologies like generative AI to scientific reviews and to study the impact of ultra-processed foods, additives, and environmental toxins on chronic diseases. These initiatives have sparked discussions about the balance between drug safety, approval efficiency, and scientific rigor. (Source: MIT Technology Review)

Google AI Overviews Errs Again: Confuses Aircraft Models in Air Crash: Google’s AI Overviews feature incorrectly stated that an Air India crash involved an Airbus aircraft, when in fact it was a Boeing 787. This has once again raised concerns about its information accuracy and reliability, especially when handling critical factual information. (Source: MIT Technology Review)