Keywords:Meta V-JEPA 2, NVIDIA Industrial AI Cloud, Sakana AI Text-to-LoRA, OpenAI o3-pro, Databricks Lakebase, MLflow 3.0, Princeton University HistBench, Open-source world model for video training, European manufacturing AI cloud platform, Text-to-LLM adapter, DPO fine-tuned GPT-4.1, AI agent observability
🔥 Spotlight
Meta releases V-JEPA 2: An open-source image/video world model trained on video: Meta has launched V-JEPA 2, a new open-source image/video world model. Based on the ViT architecture, it comes in different sizes (L/G/H) and resolutions (286/384) with up to 1.2 billion parameters. V-JEPA 2 excels in visual understanding and prediction, enabling robots to perform zero-shot planning and task execution in unfamiliar environments. Meta emphasizes its vision for AI to leverage world models to adapt to dynamic environments and efficiently learn new skills. Concurrently, Meta also released three new benchmarks: MVPBench, IntPhys 2, and CausalVQA, to evaluate the ability of existing models to reason about the physical world from video. (Source: huggingface, huggingface, ylecun, AIatMeta, scaling01, karminski3)
Nvidia Builds First Industrial AI Cloud in Europe to Advance Manufacturing: Nvidia announced it is building the world’s first industrial artificial intelligence cloud platform for European manufacturers. This AI factory aims to help industrial leaders accelerate end-to-end manufacturing applications, from design and engineering simulation to digital factory twins and robotics. This move is part of a series of initiatives announced by Nvidia at GTC Paris and VivaTech 2025, aimed at accelerating AI innovation in Europe and beyond. Jensen Huang stated that European AI computing power is expected to increase tenfold within two years, emphasizing that “all moving objects will become robotic, and cars are next.” (Source: nvidia, nvidia, Jensen Huang: European AI computing power to increase tenfold in two years)

Sakana AI Launches Text-to-LoRA: Instantly Generate Task-Specific LLM Adapters from Text Descriptions: Sakana AI has released Text-to-LoRA technology, a Hypernetwork that can instantly generate task-specific LLM adapters (LoRAs) based on users’ text descriptions of tasks. This technology aims to lower the barrier to customizing large models, allowing non-technical users to specialize foundation models using natural language, without requiring deep technical expertise or significant computational resources. Text-to-LoRA can encode hundreds of existing LoRA adapters and generalize to unseen tasks while maintaining performance. The related paper and code have been released on arXiv and GitHub and will be presented at ICML2025. (Source: SakanaAILabs, hardmaru, kylebrussell, ClementDelangue, huggingface)
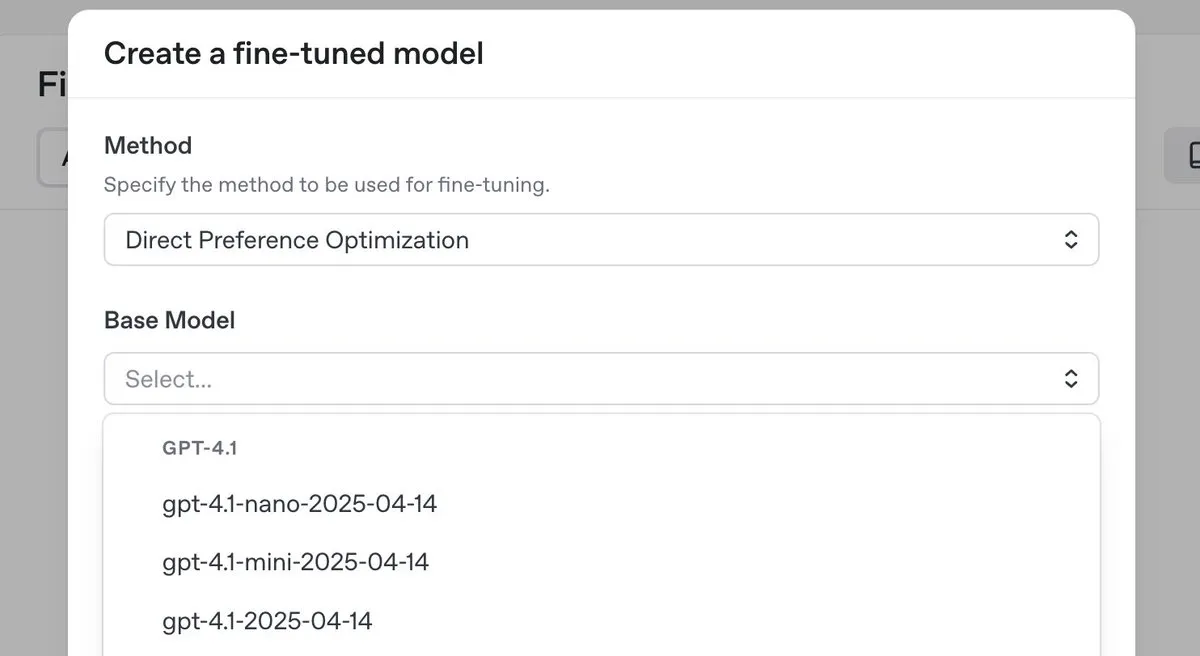
OpenAI Releases o3-pro Top-Tier Inference Model with Significant Price Cuts, Introduces DPO Fine-Tuning for GPT-4.1 Series: OpenAI has launched its new top-tier inference model, o3-pro, and significantly reduced prices for its o3 series models to lower developer costs. Concurrently, OpenAI announced that users can now use Direct Preference Optimization (DPO) to fine-tune GPT-4.1 family models (including 4.1, 4.1-mini, and 4.1-nano). DPO allows for customization by comparing model responses rather than fixed targets, particularly suitable for tasks with subjective requirements for tone, style, and creativity. ARC Prize re-tested o3 after the price cut, showing no change in its performance on ARC-AGI. (Source: OpenAIDevs, scaling01, aidan_mclau, giffmana, jeremyphoward, BorisMPower, rowancheung, TheRundownAI)
🎯 Developments
Databricks Launches Lakebase, Free Tier, and Agent Bricks to Accelerate Data and AI Application Development: Databricks announced that Lakebase has entered public preview. It is a fully managed Postgres database integrated with the lakehouse and built for AI, combining the ease of use of Postgres, the scalability of the lakehouse, and Neon database’s branching technology. Concurrently, Databricks launched a free tier platform and extensive training materials to help developers learn data engineering, data science, and AI. Additionally, Databricks Apps is now generally available (GA), enabling customers to build and deploy interactive data and AI applications on the platform. Databricks also introduced Agent Bricks, which employs a declarative approach to developing AI agents, where users describe tasks and the system automatically generates evaluations and optimizes the agents. (Source: matei_zaharia, matei_zaharia, lateinteraction, matei_zaharia, matei_zaharia, matei_zaharia, jefrankle, lateinteraction, matei_zaharia, lateinteraction, cto_junior, lateinteraction, jefrankle)

Nvidia Partners with Mistral AI to Build End-to-End Cloud Platform in Europe: Nvidia announced a partnership with French startup Mistral AI to jointly build an end-to-end cloud platform. The first phase of the collaboration will deploy 18,000 Nvidia Grace Blackwell systems, with plans to expand to more locations in 2026. This partnership is part of Nvidia’s efforts to promote AI infrastructure development and the concept of “Sovereign AI” in Europe, aiming to provide localized data centers and servers for the region. (Source: Jensen Huang: European AI computing power to increase tenfold in two years)
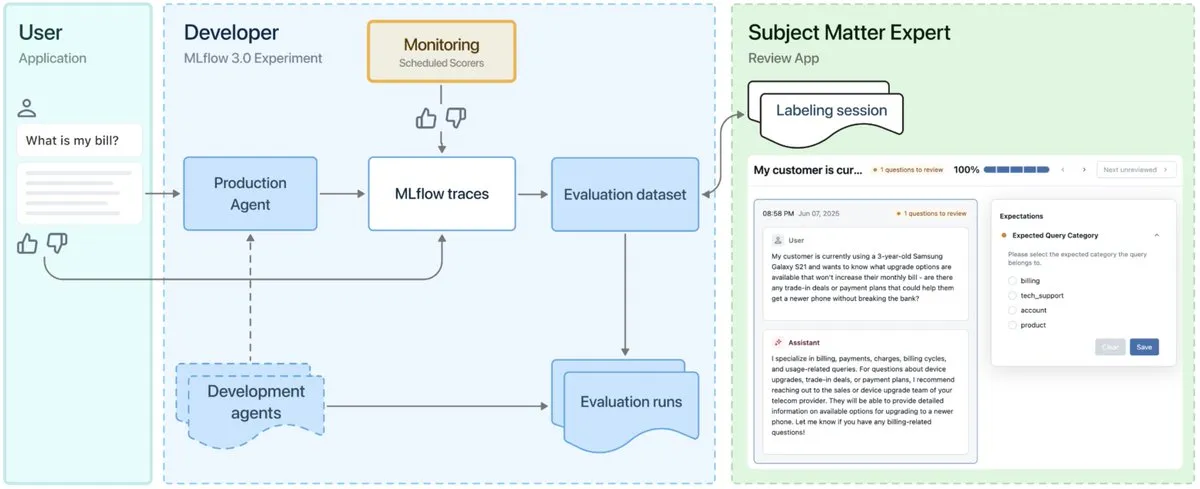
MLflow 3.0 Released, Designed for AI Agent Observability and Development: MLflow 3.0 has been officially released. The new version is redesigned for AI agent observability and development, and updates traditional structured machine learning functionalities. MLflow 3.0 aims to achieve continuous improvement of AI systems through data, supporting the tracking, evaluation, and monitoring of AI systems, while considering enterprise-level requirements such as human collaboration, data governance and security, and integration with the Databricks data ecosystem. (Source: matei_zaharia, matei_zaharia, lateinteraction)
Princeton University and Fudan University Jointly Launch HistBench and HistAgent to Promote AI Application in Historical Research: Princeton University’s AI Lab and Fudan University’s Department of History have collaborated to launch HistBench, the world’s first AI evaluation benchmark for historical research, and HistAgent, an AI assistant for historical research. HistBench includes 414 historical questions, covering 29 languages and multi-civilizational history, designed to test AI’s ability to handle complex historical materials and multimodal understanding. HistAgent is an intelligent agent specifically designed for historical research, integrating tools such as literature retrieval, OCR, and translation. Tests show that general large models have an accuracy rate of less than 20% on HistBench, while HistAgent significantly outperforms existing models. (Source: World’s first historical benchmark, Princeton and Fudan create AI history assistant, AI breaks into humanities)

Microsoft Research and Peking University Jointly Release Next-Frame Diffusion (NFD) Framework to Enhance Autoregressive Video Generation Efficiency: Microsoft Research and Peking University have jointly launched the Next-Frame Diffusion (NFD) new framework. Through intra-frame parallel sampling and inter-frame autoregressive methods, it achieves high-quality autoregressive video generation at over 30 frames per second on an A100 GPU using a 310M model. NFD employs a Transformer with a block-wise causal attention mechanism and further enhances efficiency by combining consistency distillation and speculative sampling techniques, showing promise for applications like real-time interactive games. (Source: Generates over 30 frames of video per second, supports real-time interaction, new autoregressive video generation framework refreshes generation efficiency)

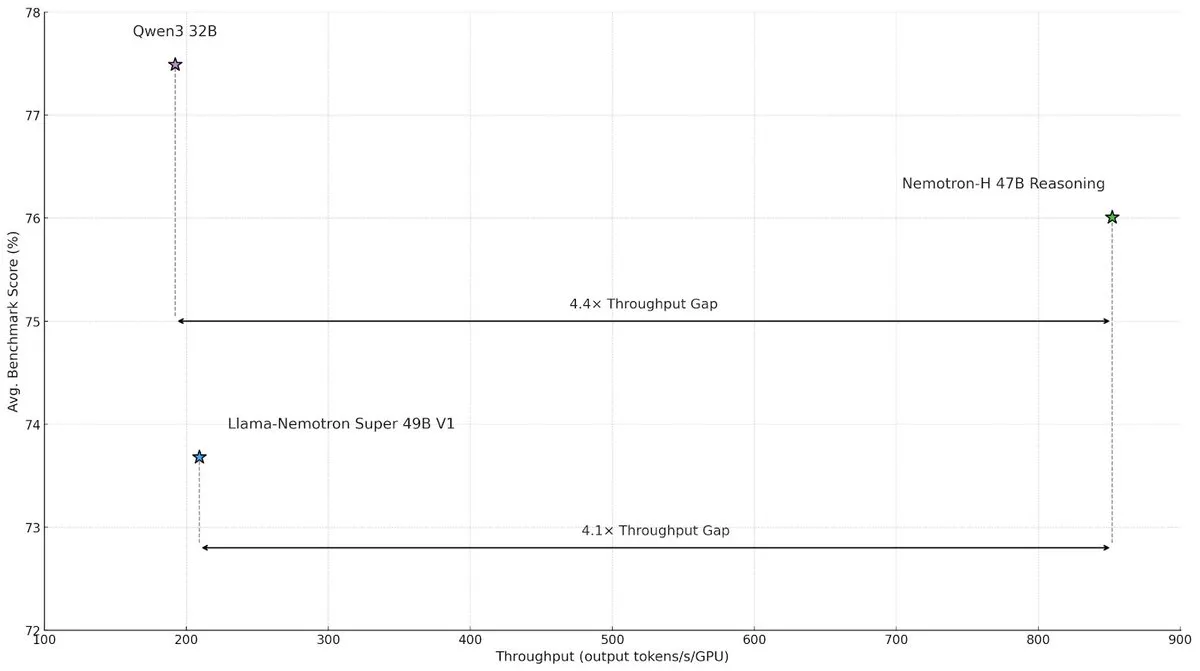
NVIDIA Releases Nemotron-H Hybrid Architecture Model to Enhance Large-Scale Inference Speed and Efficiency: NVIDIA Research has introduced the Nemotron-H model, which employs a hybrid architecture of Mamba and Transformer, aimed at addressing speed bottlenecks in large-scale inference tasks. The model achieves up to 4 times higher throughput than comparable Transformer models while maintaining inference capabilities. Research indicates that hybrid models can maintain inference performance even with fewer attention layers, with the efficiency advantage of linear architectures being particularly significant in long inference chain scenarios. (Source: _albertgu, tri_dao, krandiash)
Google DeepMind Researcher Jack Rae Joins Meta’s “Superintelligence” Group: Google DeepMind Principal Researcher Jack Rae has confirmed he is joining Meta’s newly formed “superintelligence” group. During his time at DeepMind, Rae was responsible for the “thinking” capabilities of the Gemini model and is one of the proponents of the “compression is intelligence” idea. He previously participated in the development of GPT-4 at OpenAI. Meta CEO Zuckerberg is personally recruiting top AI talent, offering compensation packages in the tens of millions of dollars for the new team, aiming to improve the Llama model and develop more powerful AI tools to catch up with industry leaders. (Source: Zuckerberg’s “superintelligence” group’s first big name, Google DeepMind principal researcher, key figure in “compression is intelligence”, DhruvBatraDB)

Mistral AI Releases First Inference Model Magistral, Supporting Multilingual Reasoning: Mistral AI has launched its first inference model, Magistral, including the 24B parameter open-source version Magistral Small and the enterprise-focused Magistral Medium. The model is fine-tuned for multi-step logic and interpretability, supports multilingual reasoning, especially optimized for European languages, and can provide a traceable thought process. Magistral is trained using an improved GRPO algorithm through pure reinforcement learning, without relying on distilled data from existing inference models. However, its benchmark results have faced some criticism for not including data from the latest versions of Qwen and DeepSeek R1. (Source: New “SOTA” inference model avoids Qwen and R1? European OpenAI heavily criticized)

ByteDance’s Doubao Large Model 1.6 Released with Further Significant Price Reductions, Seedance 1.0 pro Video Model Launched Simultaneously: Volcengine has released Doubao Large Model 1.6, pioneering pricing by “input length” tiers. The 0-32K input tier is priced at 0.8 yuan/million tokens, with output at 8 yuan/million tokens, a 63% cost reduction compared to version 1.5. The newly released video generation model, Seedance 1.0 pro, is priced at 0.015 yuan per thousand tokens, making a 5-second 1080P video cost approximately 3.67 yuan. Tan Dai, President of Volcengine, stated that this price reduction was achieved through targeted cost optimization for the commonly used 32K range by enterprises and business model innovation, aiming to promote the large-scale application of Agents. (Source: Doubao Large Model significantly cuts prices again, Volcengine still aggressively competing for market share, “Volcano” targets Baidu Cloud)
Hong Kong University of Science and Technology and Huawei Propose AutoSchemaKG Framework for Fully Autonomous Knowledge Graph Construction: The KnowComp Lab at the Hong Kong University of Science and Technology, in collaboration with Huawei’s Theory Lab in Hong Kong, has proposed the AutoSchemaKG framework, which enables fully autonomous construction of knowledge graphs without predefined schemas. The system utilizes large language models to directly extract knowledge triples from text and induce entity and event schemas. Based on this framework, the team has constructed the ATLAS series of knowledge graphs, containing over 900 million nodes and 5.9 billion edges. Experiments show that this method achieves 95% semantic alignment between induced schemas and human-designed schemas with zero manual intervention. (Source: Largest open-source GraphRag: Fully autonomous knowledge graph construction)

Qijing Tech Releases 8-Card Integrated Hardware-Software Server Solution, Enhancing DeepSeek Large Model Efficiency: Qijing Tech, in collaboration with Intel, held an ecosystem salon and released its latest 8-card integrated hardware-software server solution. This solution can efficiently run large models such as DeepSeek-R1/V3-671B, with performance improvements of up to 7 times compared to a single card. Concurrently, its self-developed inference engine KLLM, large model management platform AMaaS, and office application suite “Qijing·Zhiwen” also received significant upgrades, aiming to address challenges in private deployment of large models, such as high entry barriers and insufficient operational performance. (Source: Qijing Tech & Intel Ecosystem Salon held, hardware, inference engine, upper-level application ecosystem integration, bridging the “last mile” of large model private deployment)

Black Forest Labs Releases FLUX.1 Kontext Series of Image Models, Enhancing Character and Style Consistency: Germany’s Black Forest Labs has launched the FLUX.1 Kontext series of text-to-image models (max, pro, dev versions), focusing on maintaining character and style consistency when editing images. The series supports local and global modifications to images and can generate images from text and/or image inputs. The FLUX.1 Kontext dev version is planned to be open-sourced. In a proprietary benchmark test including approximately 1,000 prompt and reference image pairs, the FLUX.1 Kontext max and pro versions outperformed competing models such as OpenAI GPT Image 1 and Google Gemini 2.0 Flash. (Source: DeepLearning.AI Blog)

Nvidia, Rutgers University, and Others Propose STORM Framework, Reducing Tokens Needed for Video Understanding via Mamba Layers: Researchers from Nvidia, Rutgers University, University of California, Berkeley, and other institutions have built the text-video system STORM. This system introduces Mamba layers between the SigLIP visual transformer and Qwen2-VL’s LLM. By enriching single-frame token embeddings with information from other frames in the same clip, it allows for averaging token embeddings across frames without losing critical information. This enables the system to process videos with fewer tokens, outperforming GPT-4o and Qwen2-VL on video understanding benchmarks like MVBench and MLVU, while achieving a processing speedup of over 3x. (Source: DeepLearning.AI Blog)

Google Co-founder Expresses Reservations About Humanoid Robots, Specialized Robots Show Promising Commercialization Prospects: Google co-founder Sergey Brin stated he is not very enthusiastic about humanoid robots that strictly replicate human form, believing it is not a necessary condition for robots to work effectively. Meanwhile, specialized robots are gaining attention due to their “ready-to-work” nature and clear commercialization paths. For example, underwater robots and lawnmowing robots demonstrate huge potential in specific scenarios. Analysts believe that at this stage, the robot form and productivity that can solve practical problems are key, and specialized robots, with their clear business models and strong demand scenarios, are leading the way in commercialization. (Source: Specialized robots tap humanoid robots on the shoulder, “Brother, make way, I’m coming to the table.”)

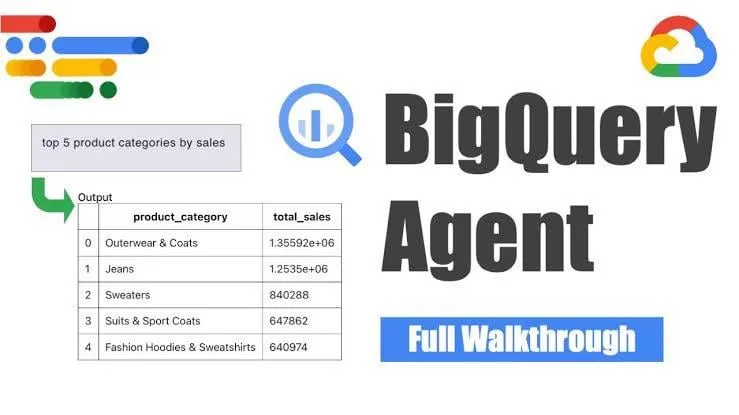
Google Launches BigQuery Data Engineering Agent for Intelligent Pipeline Generation: Google has launched the BigQuery data engineering agent, a tool that utilizes context-aware reasoning to efficiently scale the generation of data pipelines. Users can define pipeline requirements through simple command-line instructions, and the agent uses domain-specific prompts to generate batch pipeline code customized for the user’s data environment. This includes data ingestion configurations, transformation queries, table creation logic, and scheduling settings via Dataform or Composer. The tool aims to simplify the repetitive work faced by data engineers when dealing with multiple data domains, environments, and transformation logics through AI assistance. (Source: Reddit r/deeplearning)
Yandex Releases Yambda, a Large-Scale Public Dataset with Nearly 5 Billion User-Track Interactions: Yandex has released a large-scale public dataset named Yambda, designed for recommendation system research. The dataset contains nearly 5 billion anonymized user-track interactions from Yandex Music, providing researchers with a rare opportunity to work with real-world scale data. (Source: _akhaliq)

ByteDance Releases Video Restoration Model SeedVR2 on Hugging Face: ByteDance’s Seed team has released SeedVR2 on Hugging Face, a single-step diffusion Transformer model for video restoration. The model, under an Apache 2.0 license, features single-step inference, making it fast and efficient, and supports arbitrary resolution processing without tiling or size limitations. (Source: huggingface)
ByteDance’s Doubao Video Large Model Seedance 1.0 Pro Receives Positive Reviews in Real-World Tests: ByteDance’s newly released image-to-video large model, Seedance 1.0 Pro, has demonstrated good instruction-following ability and object generation stability in real-world tests. Users report high video generation quality and accurate camera movement synchronization, second only to Veo 2/3. A potential drawback is that when generating pure object motion, the model sometimes adds hand operations to make the scene more plausible, which can be circumvented by restricting hand appearance. (Source: karminski3, karminski3, karminski3)
Alibaba Open-Sources Digital Human Framework Mnn3dAvatar, Supporting Real-Time Facial Capture and 3D Virtual Character Creation: Alibaba has open-sourced a digital human framework named Mnn3dAvatar on GitHub. This project enables real-time facial capture and maps expressions onto 3D virtual characters, while also allowing users to create their own 3D virtual characters. This framework is suitable for simple live commerce, content display, and other scenarios. (Source: karminski3)
Nvidia Open-Sources Humanoid Robot Foundation Model Gr00t N 1.5 3B and Provides Fine-Tuning Tutorial: Nvidia has open-sourced the Gr00t N 1.5 3B model, an open foundation model designed for humanoid robot reasoning skills, under a commercial license. Concurrently, Nvidia has released a complete fine-tuning tutorial for use with LeRobotHF SO101, aiming to promote the development and application of humanoid robot technology. (Source: ClementDelangue)
Together AI Launches Batch API, Offering Large-Scale LLM Inference Services with Significant Price Reductions: Together AI has launched its new Batch API, designed for large-scale LLM inference, supporting high-throughput application scenarios such as synthetic data generation, benchmarking, content review and summarization, and document extraction. The API introduces an introductory price 50% cheaper than the real-time API, supports batch processing of up to 50,000 requests or 100MB at a time, and is compatible with 15 top models. (Source: vipulved)
Google Gemini 2.5 Pro Adds Interactive Fractal Art Generation Feature: Google announced that Gemini 2.5 Pro now supports the instant creation of interactive fractal art. Users can generate unique visual art by providing prompts such as “Create for me a beautiful, particle-based, animated, endless, 3D, symmetrical fractal art piece inspired by mathematical formulas.” (Source: demishassabis)
Google Veo3 Fast Video Generation Speed Increased Twofold: Google Labs announced that the generation speed of its Veo3 Fast version in the Flow video generation tool has been increased by more than twofold, while maintaining 720p resolution. This update aims to enable users to create video content more quickly. (Source: op7418)
Hugging Face Integrates with Google Colab and Kaggle, Simplifying Model Usage Workflow: Hugging Face is now integrated with Google Colab and Kaggle. Users can directly launch a Colab notebook from any model card or open the same model in a Kaggle Notebook, complete with runnable public code examples, thereby simplifying the model usage and experimentation workflow. (Source: ClementDelangue, huggingface)
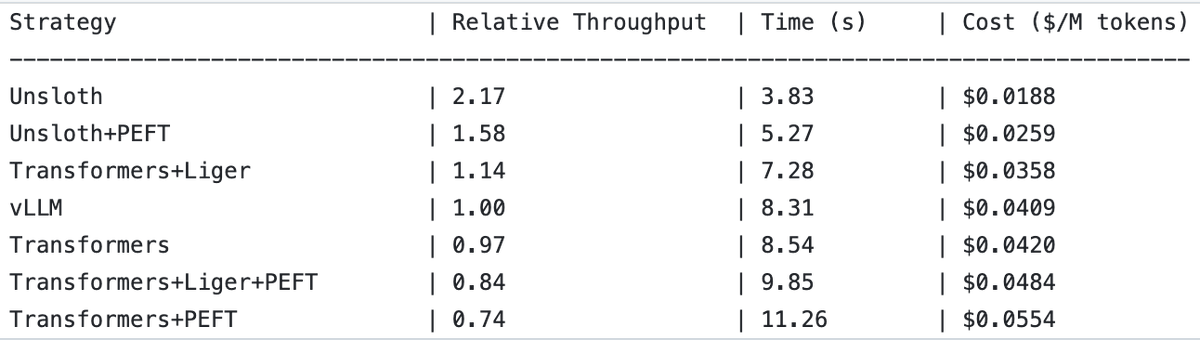
UnslothAI Achieves 2x Throughput Improvement in Reward Model Serving and Sequence Classification Inference: UnslothAI has been found to be usable for serving reward models (RM) and achieves twice the throughput of vLLM in sequence classification inference. This discovery has garnered attention in the RL (Reinforcement Learning) community, as UnslothAI’s performance improvements are expected to accelerate related research and applications. (Source: natolambert, danielhanchen)
Digua Robot Releases First Single-SoC Compute-Control Integrated Robot Development Kit RDK S100: Digua Robot has launched the industry’s first single-SoC compute-control integrated robot development kit, RDK S100. The kit adopts a human-like cerebrum-cerebellum architecture design, integrating CPU+BPU+MCU on a single SoC, supporting efficient collaboration of large and small embodied intelligence models, and bridging the “perception-decision-control” closed loop. RDK S100 provides multiple interfaces and software-hardware co-design, end-cloud integrated development infrastructure, aiming to accelerate the construction of embodied intelligence products and multi-scenario deployment. It has already partnered with over 20 leading customers, with a market price of 2799 yuan. (Source: Digua Robot releases first single-SoC compute-control integrated robot development kit, has partnered with over 20 leading customers | Frontline)

🧰 Tools
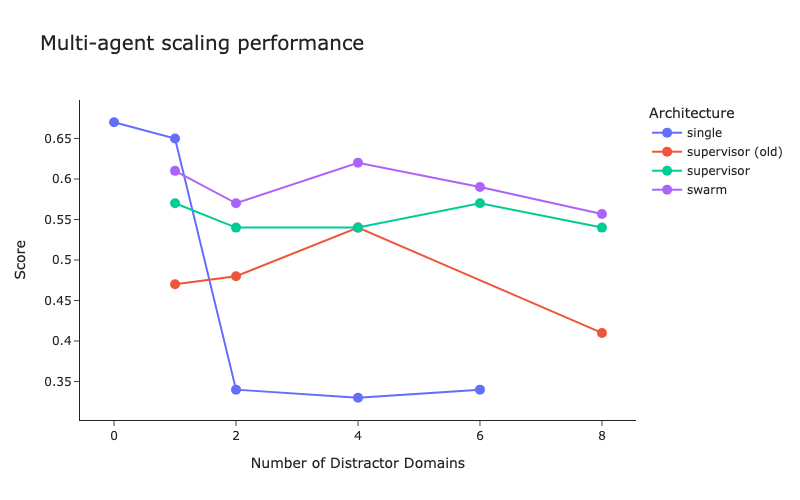
LangChain Releases Multi-Agent Architecture Benchmarks and Supervisor Method Improvements: LangChain has conducted preliminary benchmarks for the increasing number of multi-agent systems, exploring how to optimize coordination between multiple agents. Concurrently, LangChain has made some improvements to its supervisor method, with a related blog post published. (Source: LangChainAI, hwchase17)
Cartesia Launches Ink-Whisper: Fast, Cost-Effective Streaming Speech-to-Text Model for Voice Agents: Cartesia has released Ink-Whisper, a high-speed, low-cost streaming speech-to-text (STT) model optimized for voice agents. Designed for accuracy under real-world conditions, it can be used with Cartesia’s Sonic text-to-speech (TTS) model for fast voice AI interactions. Ink-Whisper supports integration with platforms like VapiAI, PipecatAI, and Livekit. (Source: simran_s_arora, tri_dao, krandiash)

MonkeyOCR: Small, Fast, Open-Source Document Parsing Model: A 3B parameter document parsing model named MonkeyOCR has been released under the Apache 2.0 license. The model can parse various elements in documents, including charts, formulas, tables, etc., aiming to replace traditional parser pipelines and provide a better document processing solution. (Source: mervenoyann, huggingface)
LlamaIndex Integrates with Cleanlab to Enhance AI Assistant Response Trustworthiness: LlamaIndex announced its integration with CleanlabAI. LlamaIndex is used to build AI knowledge assistants and production-grade agents that generate insights from enterprise data. The addition of Cleanlab aims to enhance the trustworthiness of these AI assistant responses, enabling scoring for each LLM response, real-time capture of hallucinations or incorrect responses, and helping to analyze the reasons for untrustworthy responses (such as poor retrieval, data/context issues, tricky queries, or LLM hallucinations). (Source: jerryjliu0)

Claude Code Adds “Plan Mode” to Enhance Controllability of Complex Code Changes: Anthropic’s Claude Code has introduced “Plan mode.” This feature allows users to review the implementation plan before actual code changes are made, ensuring each step is carefully considered, especially for complex code modifications. Users can enter Plan mode by pressing Shift + Tab twice, and Claude Code will provide a detailed implementation plan and seek confirmation before execution. The feature has been rolled out to all Claude Code users (including Pro or Max subscribers). (Source: dotey, kylebrussell)
rvn-convert: Rust-Implemented SafeTensors to GGUF v3 Conversion Tool: An open-source tool named rvn-convert has been released, written in Rust, for converting SafeTensors format model files to GGUF v3 format. The tool features single-shard support, high speed, and no Python environment requirement. It can memory-map safetensors files and write directly to gguf files, avoiding RAM peaks and disk churn. It currently supports upsampling BF16 to F32, embedding tokenizer.json, and other features. (Source: Reddit r/LocalLLaMA)
Runway API Adds 4K Video Upscaling Feature: Runway announced that its API now supports 4K video upscaling. Developers can integrate this feature into their own applications, products, platforms, and websites to enhance the clarity and quality of video content. (Source: c_valenzuelab)
You.com Launches Projects Feature for Organizing and Managing Research Materials: You.com has released a new tool called “Projects,” designed to help users organize their research materials into easily accessible folders. This feature allows users to contextualize and structure conversations, preventing scattered chat histories and loss of insights, thereby simplifying the knowledge management process. (Source: RichardSocher)
LlamaIndex Launches LlamaExtract Agent-Powered Document Extraction Service: LlamaIndex has released LlamaExtract, an agent-driven document extraction service designed to extract structured data from complex documents and input schemas. The service not only extracts key-value pairs but also provides precise source reasoning, page references, and matching text for each extracted item. LlamaExtract is offered as an API for easy integration into downstream agent workflows. (Source: jerryjliu0)

langchain-google-vertexai Releases Update, Enhancing Client Caching and Tool Support: langchain-google-vertexai has received a new version release. Key updates include: prediction client caching, making new client instantiation 500x faster; and support for built-in code execution tools. (Source: LangChainAI, Hacubu)
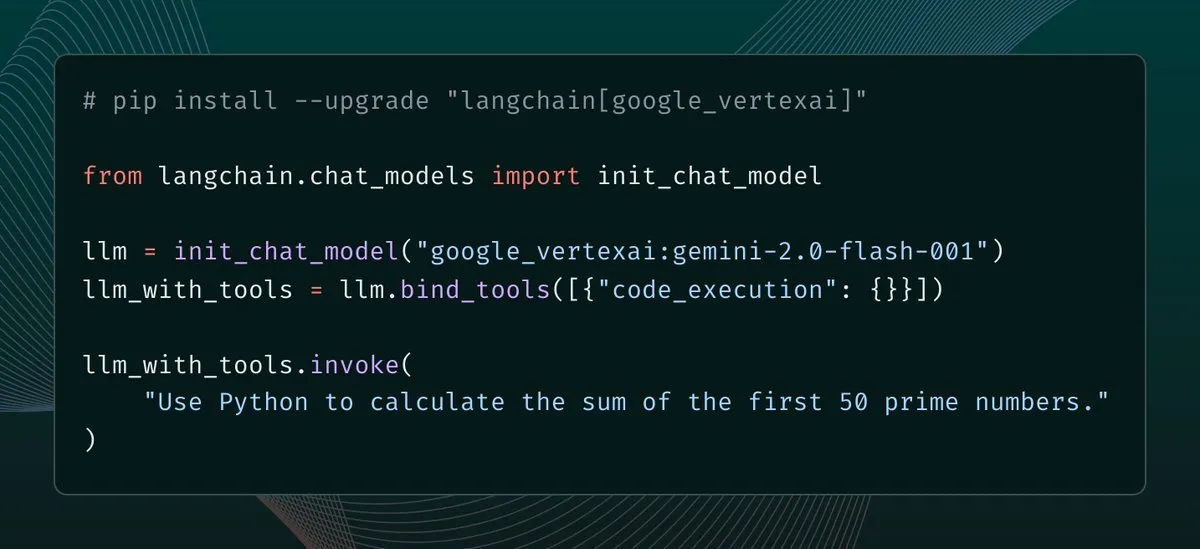
Perplexity Finance Adds Direct Excel Model Download Feature: Perplexity Finance announced that users can now directly download Excel models from its pages, providing a quicker starting point for financial modeling and research. This feature is available free to all users; previously, only CSV format downloads were supported. (Source: AravSrinivas)
Viwoods Releases AI Paper Mini E-ink Tablet with Integrated GPT-4o and Other AI Functions: Emerging e-ink manufacturer Viwoods has launched the AI Paper Mini, an e-ink tablet equipped with AI functions. The device supports various AI models such as GPT-4o and DeepSeek, offering a Chat mode and preset AI assistants (content analysis, email generation, AI-to-text). Its special features include calendar view task management and quick floating window notes. Hardware-wise, the Paper Mini features a 292 ppi Carta 1000 screen, 4GB+128GB storage, and comes with a stylus. Viwoods also launched the larger AI Paper, which has a 300ppi Carta 1300 flexible screen with faster response times. (Source: I spent half the price of an iPhone to buy an “e-ink tablet” with AI…)

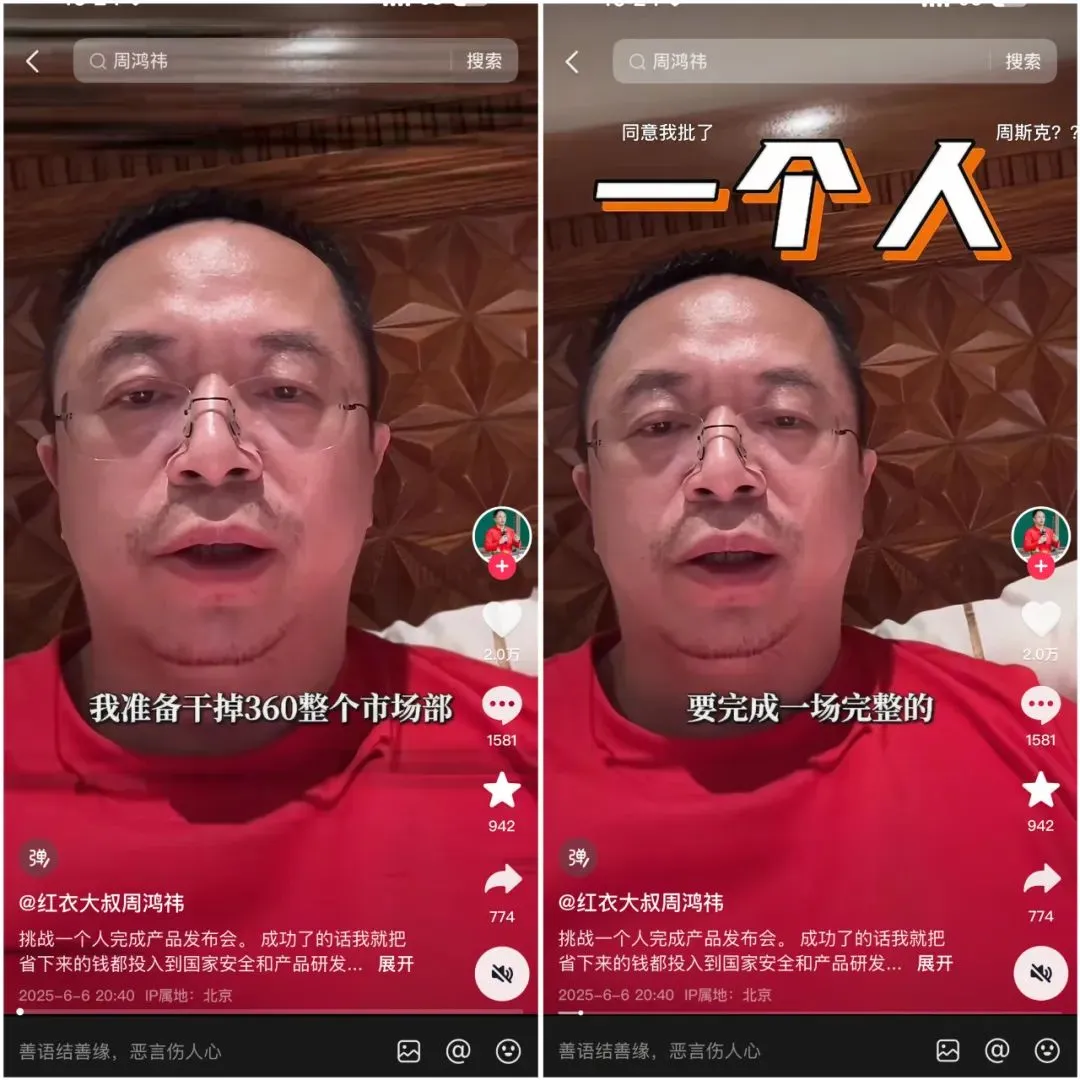
360 Releases Nano AI Super Search Agent, with Zhou Hongyi Personally Endorsing: 360 Group founder Zhou Hongyi hosted the launch of the Nano AI Super Search agent. This agent aims to achieve “one sentence, search anything,” capable of autonomous thinking, invoking browsers and external tools to perform tasks without human intervention, and supporting full visualization and step traceability. Zhou Hongyi stated that the launch event itself also attempted to use Nano AI for preparation, and also released the AI smart recording hardware Nano AI Note and co-branded AI glasses with Rokid. (Source: Zhou Hongyi wants to use AI to “eliminate” the marketing department, has “Nano” achieved it?)
📚 Learning
DeepLearning.AI Launches New Short Course: Orchestrating GenAI Workflows with Apache Airflow: DeepLearning.AI, in collaboration with Astronomer, has launched a new short course teaching how to transform RAG prototypes into production-ready workflows using Apache Airflow 3.0. Course content includes breaking down workflows into modular tasks, scheduling pipelines with time-driven and event-driven triggers, dynamic task mapping for parallel execution, adding retries/alerts/backfills for fault tolerance, and techniques for scaling pipelines. No prior Airflow experience is required. (Source: DeepLearningAI, FLUX.1 Kontext’s Consistent Characters, Benchmarking Costs Climb, Mary Meeker’s Action-Packed AI Report, Better Video Gen)
Hamel Husain Launches RAG Optimization and Evaluation Mini-Course: Hamel Husain announced the launch of a four-part mini-course on RAG (Retrieval Augmented Generation) optimization and evaluation. The first part, led by @bclavie, discusses the “Retrieval IS RAG” perspective, aiming to respond to previous discussions about RAG being a “mind virus that must be eradicated.” This series of courses is free and aims to help practitioners solve the difficulties encountered in RAG evaluation. (Source: HamelHusain, HamelHusain, lateinteraction, HamelHusain, HamelHusain, HamelHusain, HamelHusain, HamelHusain)

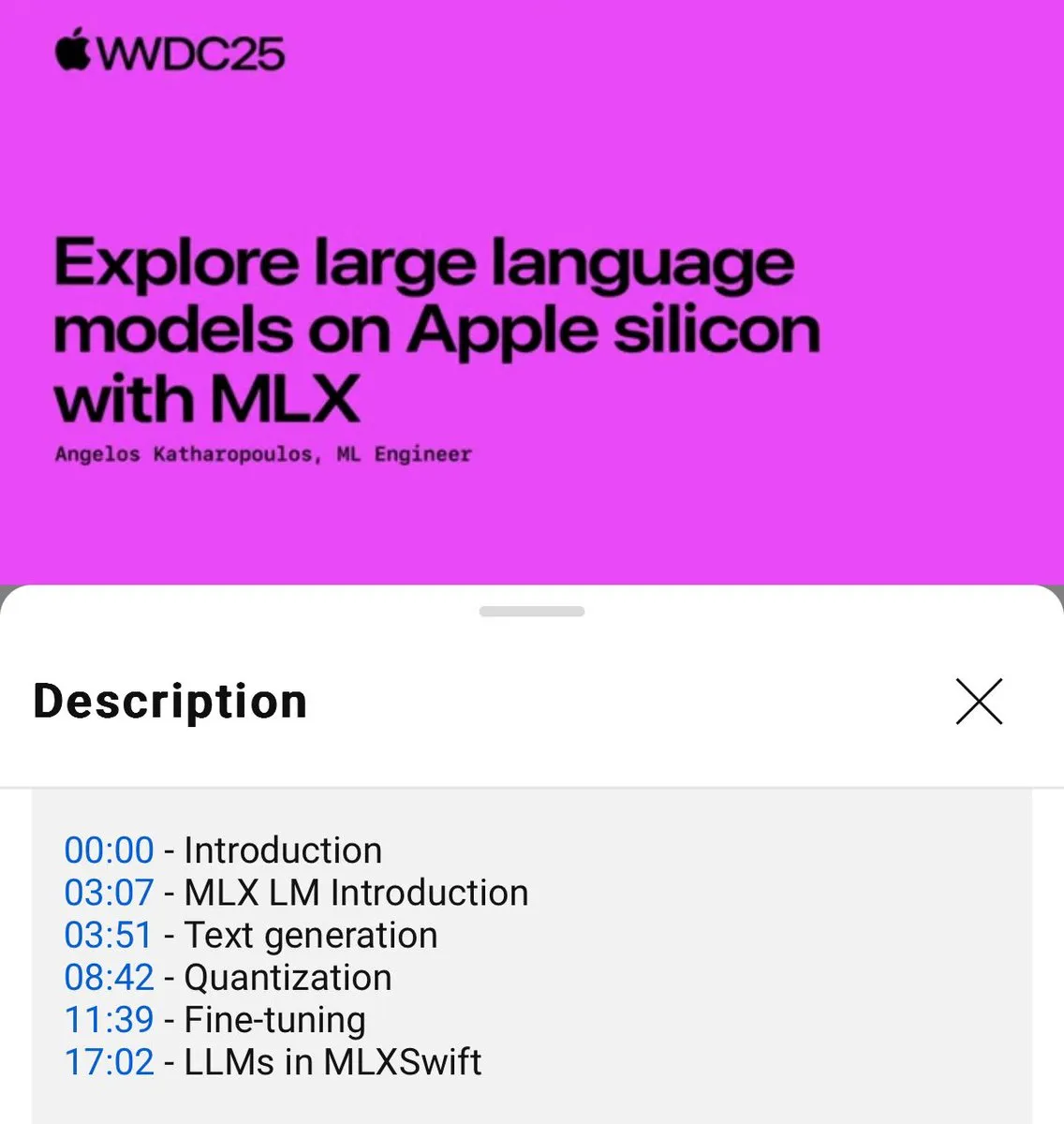
MLX Language Model Local Usage Tutorial Released (WWDC25): At WWDC25, Angelos Katharopoulos introduced how to quickly get started with local language models using MLX. The tutorial covers single-line command operations using MLXLM CLI, such as model quantization (mlx_lm.convert), LoRA fine-tuning (mlx_lm.lora), and model fusion with upload to Hugging Face (mlx_lm.fuse). The complete Jupyter Notebook tutorial is available on GitHub. (Source: awnihannun)
LangChain Shares Harvey AI’s Method for Building Legal AI Agents: Ben Liebald of Harvey AI shared their mature method for building legal AI agents at LangChain’s Interrupt event. The method combines LangSmith evaluation and a “lawyer-in-the-loop” strategy, aiming to provide AI tools trustworthy enough for complex legal work. (Source: LangChainAI, hwchase17)

RLHF Handbook v1.1 Updated, Expanding RLVR/Inference Model Content: The RLHF Handbook (rlhfbook.com) has been updated to version 1.1, adding expanded content on RLVR (Reinforcement Learning from Video Representations) and inference models. Updates include summaries of major inference model reports, common practices/tricks and their users, related inference work prior to o1, and improvements such as asynchronous RL. (Source: menhguin)
Paper SWE-Flow: Synthesizing Software Engineering Data in a Test-Driven Manner: A new paper titled SWE-Flow proposes a novel data synthesis framework based on Test-Driven Development (TDD). The framework automatically infers incremental development steps by analyzing unit tests, constructing a Runtime Dependency Graph (RDG) to generate structured development plans. Each step produces a partial codebase, corresponding unit tests, and necessary code modifications, thereby creating verifiable TDD tasks. The SWE-Flow-Eval benchmark dataset was generated based on this method. (Source: HuggingFace Daily Papers)
Paper PlayerOne: The First Real-World Simulator Built from an Egocentric Perspective: PlayerOne is proposed as the first real-world simulator built from an egocentric (first-person) perspective, enabling immersive exploration in dynamic environments. Given a user’s first-person scene image, PlayerOne can construct the corresponding world and generate first-person videos strictly aligned with the user’s real movements captured by an external camera. The model employs a coarse-to-fine training pipeline and designs a component-decoupled motion injection scheme and a joint reconstruction framework. (Source: HuggingFace Daily Papers)
Paper ComfyUI-R1: Exploring Inference Models for Workflow Generation: ComfyUI-R1 is the first large-scale inference model for automated workflow generation. Researchers first constructed a dataset of 4K workflows and generated chain-of-thought (CoT) reasoning data. ComfyUI-R1 is trained via a two-stage framework: CoT fine-tuning for cold start, and reinforcement learning to incentivize reasoning capabilities. Experiments show that the 7B parameter model significantly outperforms existing methods in format validity, pass rate, and node/graph-level F1 scores. (Source: HuggingFace Daily Papers)
Paper SeerAttention-R: An Adaptive Sparse Attention Framework for Long Inference: SeerAttention-R is a sparse attention framework specifically designed for long decoding in inference models. It learns attention sparsity through a self-distillation gating mechanism and removes query pooling to adapt to autoregressive decoding. The framework can be integrated as a lightweight plugin into existing pre-trained models without modifying original parameters. In AIME benchmark tests, SeerAttention-R, trained with only 0.4B tokens, maintained near-lossless inference accuracy with large sparse attention blocks (64/128) under a 4K token budget. (Source: HuggingFace Daily Papers)
Paper SAFE: Multi-Task Failure Detection for Vision-Language-Action Models: The paper proposes SAFE, a failure detector designed for general-purpose robot policies (like VLAs). By analyzing the VLA feature space, SAFE learns to predict the likelihood of task failure from the VLA’s internal features. The detector is trained on successful and failed deployments and evaluated on unseen tasks, compatible with different policy architectures, aiming to improve the safety of VLAs when interacting with the environment. (Source: HuggingFace Daily Papers)
Paper Branched Schrödinger Bridge Matching: Learning Branched Schrödinger Bridges: This research introduces the Branched Schrödinger Bridge Matching (BranchSBM) framework for learning branched Schrödinger bridges to predict intermediate trajectories between initial and target distributions. Unlike existing methods, BranchSBM can model branched or divergent evolutions from a common starting point to multiple different outcomes by parameterizing multiple time-dependent velocity fields and growth processes. (Source: HuggingFace Daily Papers)
💼 Business
Meta Reportedly in Talks to Acquire Data Labeling Company Scale AI for $15 Billion, Founder May Join Meta: Meta is reportedly planning to acquire Scale AI, a leading data labeling company, for $15 billion. If the deal goes through, Scale AI’s 28-year-old Chinese-American founder, Alexandr Wang, and his team will be directly integrated into Meta. This move is seen as a major step by Meta CEO Zuckerberg to strengthen his AGI (Artificial General Intelligence) team and catch up with competitors like OpenAI and Google. Meta has been actively recruiting top AI talent recently, offering compensation packages in the tens of millions of dollars for top engineers. (Source: Zuckerberg’s “superintelligence” group’s first big name, Google DeepMind principal researcher, key figure in “compression is intelligence”, dylan522p, sarahcat21, Dorialexander)
Disney and Universal Studios Sue AI Image Company Midjourney for Copyright Infringement: Disney and Universal Studios have filed a lawsuit against AI image generation company Midjourney, accusing it of unauthorized use of well-known IP works such as “Star Wars” and “The Simpsons.” This case has drawn attention; if Disney wins, it could have a ripple effect on other AI companies that rely on large-scale data training, further intensifying copyright disputes in the AI field. (Source: Reddit r/artificial, Reddit r/LocalLLaMA, karminski3)

Google Again Offers “Voluntary Severance Program” Amid AI Search Impact, Affecting Multiple Key Teams Including Search and Ads: Facing the impact of AI search, Google has once again offered a “voluntary severance program” to employees in multiple US departments, affecting key teams such as search, advertising, and core engineering, while also strengthening its return-to-office policy. This move aims to reorganize resources and focus more on its flagship AI project Gemini and the development of an “AI mode” search experience. Google’s traditional search business faces significant challenges due to the rise of AI, and the company also faces regulatory pressure. (Source: Google again offers “voluntary severance program” amid AI search impact, affecting multiple key teams, jpt401)
🌟 Community
AI Exposes Bias in Amsterdam Welfare Fraud Detection Experiment, Project Halted: Amsterdam attempted to use an AI system (Smart Check) to assess welfare applications for fraud detection. Despite following best practices for responsible AI, including bias testing and technical safeguards, the system failed to achieve fairness and effectiveness in a pilot project. The initial model showed bias against non-Dutch applicants and males; after adjustments, it then showed bias against Dutch nationals and females. Ultimately, the project was halted due to the inability to ensure non-discrimination. This case has sparked widespread discussion about algorithmic fairness, the effectiveness of responsible AI practices, and the application of AI in public service decision-making. (Source: MIT Technology Review, Inside Amsterdam’s high-stakes experiment to create fair welfare AI)

AI-Generated Content Labeling System: Value, Limitations, and Governance Logic Discussion: With the increase in AI-generated rumors and false propaganda, AI labeling systems are gaining attention as a governance tool. Theoretically, explicit and implicit labels can improve identification efficiency and enhance user vigilance. However, in practice, labels are easily circumvented, forged, and misjudged, and are costly. The article argues that AI labeling should be integrated into existing content governance systems, focusing on high-risk areas (such as rumors, false propaganda), and reasonably define the responsibilities of generation and dissemination platforms, while strengthening public information literacy education. (Source: When rumors ride the “AI” wave)
AI-Assisted Coding Tools (like Claude Code) Significantly Improve Developer Efficiency and Reduce Work Pressure: Multiple developers in the community have shared positive experiences using AI-assisted coding tools (particularly Anthropic’s Claude Code). These tools not only help write, test, and debug code but also provide support in project planning and complex problem-solving, thereby significantly improving development efficiency and reducing work pressure and deadline anxiety. Some users stated that AI assistance makes them feel like an “unstoppable force.” (Source: AnthropicAI, sbmaruf, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

AI-Generated Content’s Energy and Water Consumption Draws Attention, Sam Altman Says Each ChatGPT Query Consumes About 1/15th of a Teaspoon of Water: OpenAI CEO Sam Altman revealed that each ChatGPT query consumes approximately “one-fifteenth of a teaspoon” of water. This data has sparked discussions about the environmental impact of AI model training and inference. Although the specific calculation method and whether it includes training costs are unclear, AI’s energy footprint and water consumption have become topics of concern in the tech industry and environmental circles. (Source: MIT Technology Review, Reddit r/ChatGPT)

Discussion on Whether LLMs Truly Understand Mathematical Proofs: IneqMath Benchmark Reveals Model Shortcomings: The newly released IneqMath benchmark focuses on Olympic-level mathematical inequality proofs. Research found that while LLMs can sometimes find correct answers, they have significant gaps in constructing rigorous and sound proofs. This has sparked a discussion about whether LLMs are truly understanding in fields like mathematics or merely “guessing.” Sathya pointed out that this phenomenon of “correct answer – incorrect reasoning” is also evident in benchmarks like PutnamBench. (Source: lupantech, lupantech, _akhaliq, clefourrier)
Application and Discussion of AI Agents in Software Development, Research, and Daily Tasks: The community is widely discussing the application of AI Agents in various fields. For example, users share experiences of building deep research agent workflows using n8n and Claude; LlamaIndex demonstrates how to implement incremental form-filling agents through Artifact Memory Block; discussions also cover using MCP (Model Context Protocol) to design AI-oriented tool interfaces, and the application of AI Agents in legal, infrastructure automation (such as Cisco’s JARVIS), and other fields. (Source: qdrant_engine, OpenAIDevs, jerryjliu0, dzhng, Reddit r/ClaudeAI, omarsar0)

Humanoid Robot Safety Standards Draw Attention, Need to Consider Both Physical and Psychological Impacts: As humanoid robots gradually enter industrial applications and aim for household scenarios, their safety standards have become a focal point of discussion. The IEEE Humanoid Robotics Study Group points out that humanoid robots possess unique properties like dynamic stability, requiring new safety rules. In addition to physical safety (e.g., preventing falls, collisions), communication challenges in human-robot interaction (e.g., intent expression, multi-robot coordination) and psychological impacts (e.g., over-anthropomorphization leading to excessive expectations, emotional safety) also need consideration. Standard-setting needs to balance innovation and safety, and consider the needs of different application scenarios. (Source: MIT Technology Review, Why humanoid robots need their own safety rules)

💡 Etc.
Docker Announces docker run --gpus Now Supports AMD GPUs: Docker officially updated that the docker run --gpus command now also supports running on AMD GPUs. This improvement enhances the ease of use of AMD GPUs in containerized AI/ML workloads and is a positive step for promoting AMD’s application in the AI ecosystem. (Source: dylan522p)
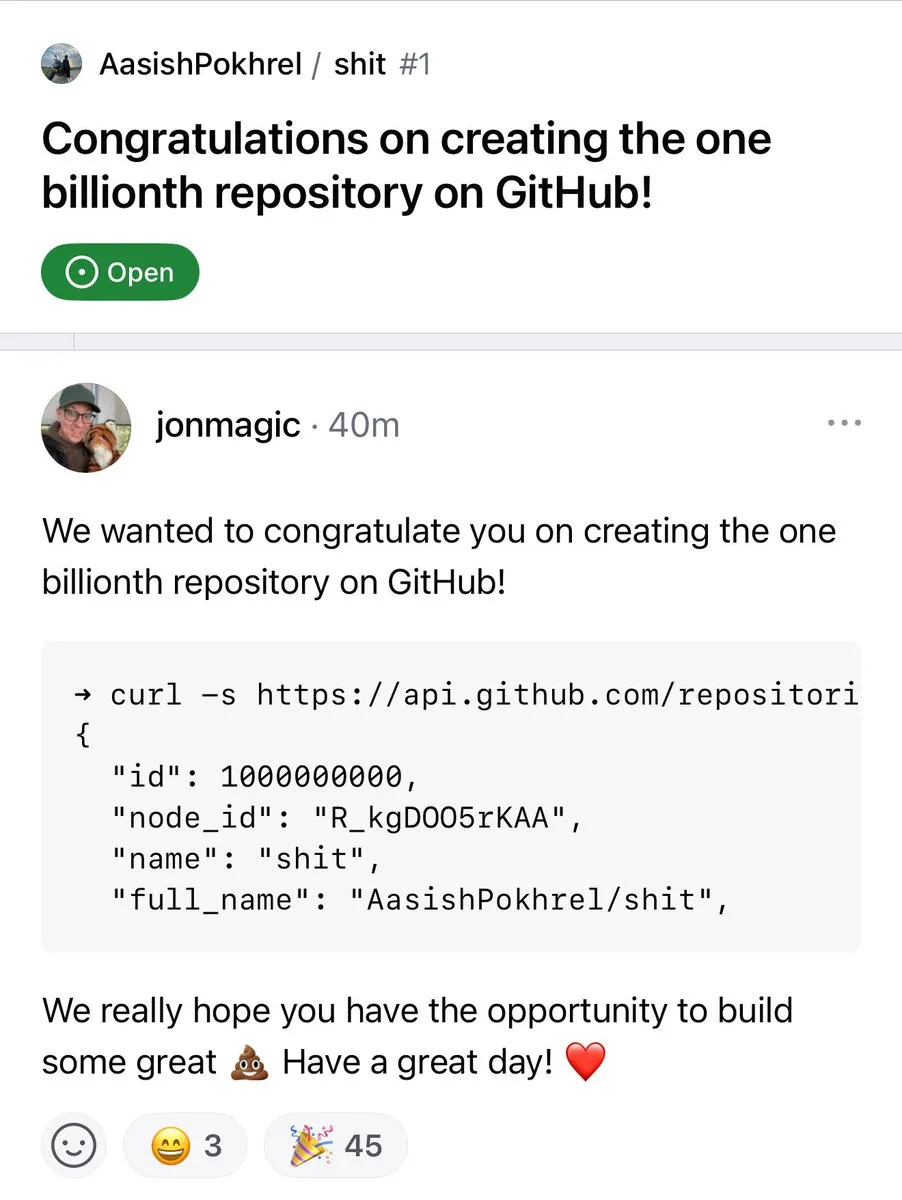
GitHub Repository Count Surpasses 1 Billion: The number of code repositories on the GitHub platform has officially surpassed the 1 billion mark. This milestone signifies the continued prosperity and growth of the open-source community and code hosting platforms. (Source: karminski3, zacharynado)
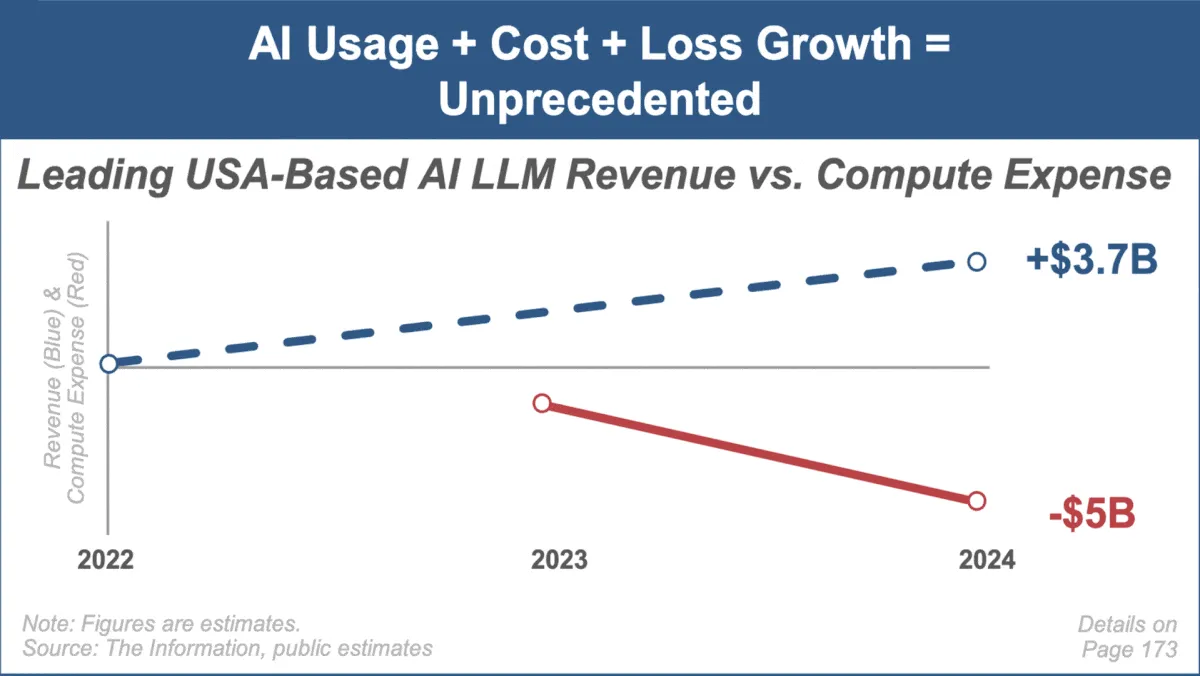
Mary Meeker Releases Latest AI Trends Report, Focusing on Rapid Market Growth and Challenges: Renowned investment analyst Mary Meeker has released her first trend report on the artificial intelligence market, “Trends — Artificial Intelligence (May ‘25).” The report highlights the unprecedented growth rate in the AI field, the surge in user numbers (e.g., ChatGPT users reaching 800 million), a significant increase in AI-related capital expenditures, and continuous breakthroughs in AI performance and emerging capabilities. The report also points out challenges facing AI business models, such as rising computing costs, rapid model iteration, and competition from open-source alternatives. (Source: DeepLearning.AI Blog)