
Keywords:OpenAI, Meta, IBM, Mistral AI, o3-pro, Super Intelligence Lab, Magistral, Quantum Computer, o3-pro pricing, Scale AI investment, Magistral-Small-2506, Starling Quantum Computer, Military AI application testing
🔥 Spotlight
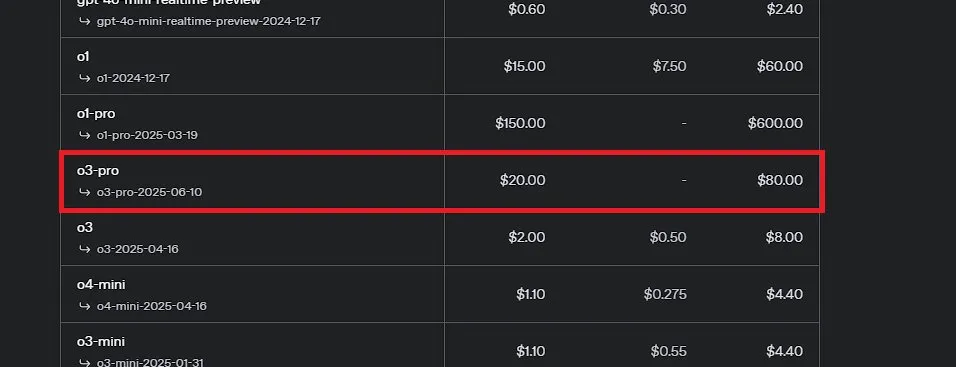
OpenAI releases o3-pro, claimed to be its most powerful model ever, and significantly reduces o3 pricing: OpenAI has officially launched o3-pro, its most powerful reasoning model to date, now available to ChatGPT Pro and Team users, with the API also live. o3-pro outperforms previous generations in fields like science, education, programming, business, and writing assistance, supporting tools such as web search, file analysis, visual input, and Python programming. Its pricing is $20 per million input tokens and $80 per million output tokens. Meanwhile, the original o3 model’s price has been drastically reduced by 80%, with adjusted prices at $2 per million input tokens and $8 per million output tokens, on par with GPT-4o. This move could trigger an AI model price war and promote deeper AI application in professional fields, but o3-pro also has limitations like longer response times and temporary lack of support for ad-hoc conversations. (Source: OpenAI, sama, OpenAIDevs, scaling01, dotey)
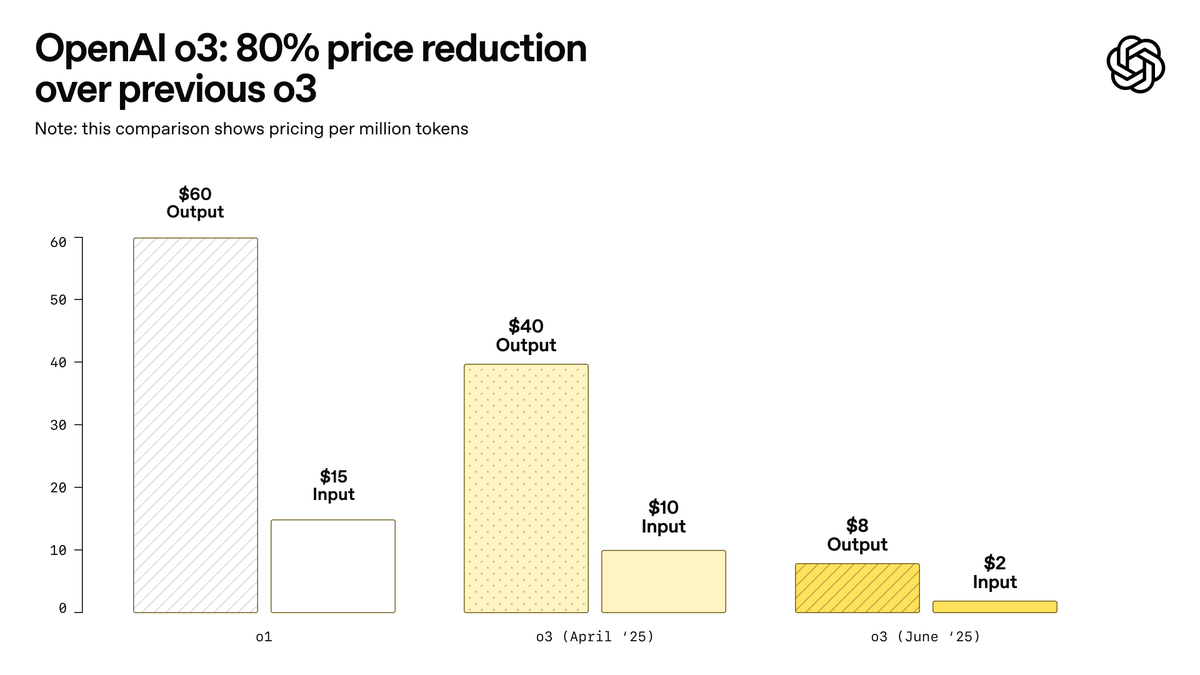
Meta establishes “Superintelligence Lab” and invests heavily in Scale AI to revitalize AI competitiveness: According to The New York Times and other sources, Meta Platforms is reorganizing its AI division, establishing a new “Superintelligence Lab,” and plans to invest over $14 billion to acquire a 49% stake in data annotation company Scale AI. Scale AI co-founder and CEO Alexandr Wang will join Meta and lead the new lab. This move aims to accelerate the development of Artificial General Intelligence (AGI) and enhance Meta’s overall competitiveness in the AI field, particularly in high-quality data processing and top talent recruitment. This marks a significant adjustment in Meta’s AI strategy and could have a profound impact on the industry’s competitive landscape. (Source: natolambert, kylebrussell, Yuchenj_UW, steph_palazzolo)

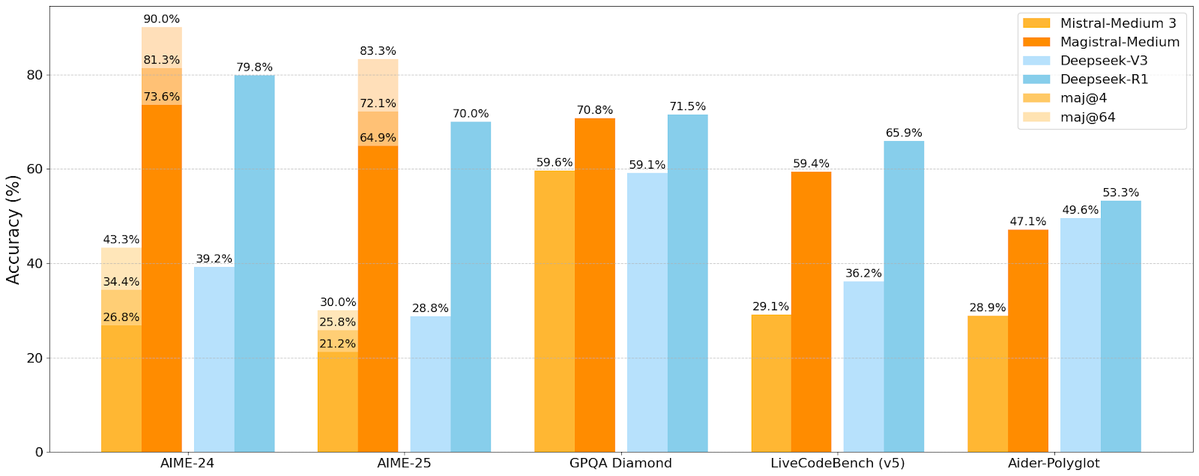
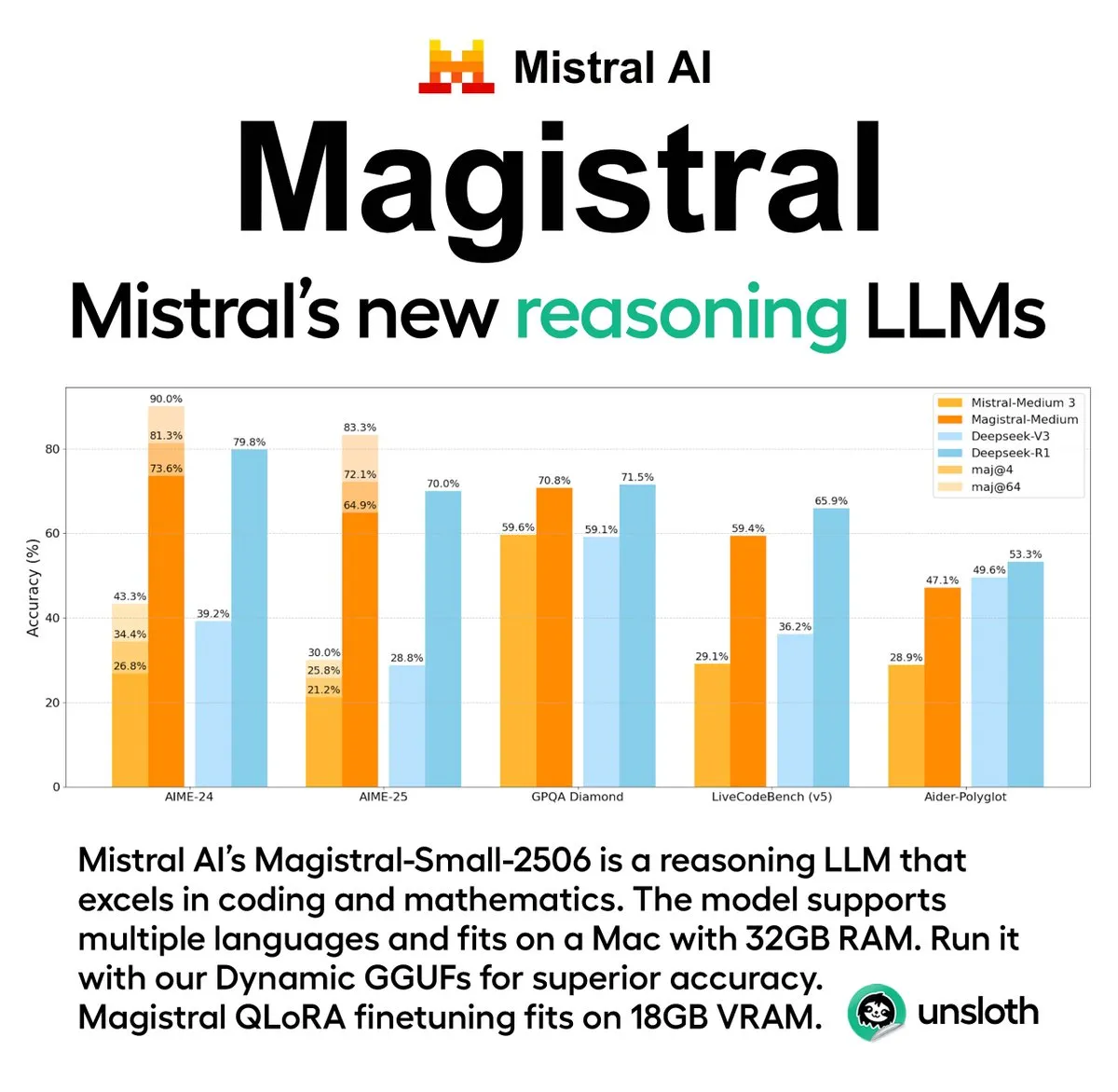
Mistral AI releases its first inference model series, Magistral, including an open-source version: French AI startup Mistral AI has launched Magistral, its first model series designed specifically for inference. The series includes a more powerful enterprise-grade closed-source model, Magistral Medium, and a 24-billion-parameter open-source model, Magistral Small (Magistral-Small-2506), the latter released under the Apache 2.0 license. These models excel in mathematics, coding, and multilingual reasoning, aiming to provide more transparent and domain-specific inference capabilities. Magistral Medium’s inference speed on the Le Chat platform is reportedly 10 times faster than competitors, while Magistral Small offers the community a powerful option for local execution. (Source: Mistral AI, jxmnop, karminski3)
IBM plans to build large-scale fault-tolerant quantum computer Starling by 2028: IBM has unveiled its quantum computing roadmap, planning to build a large-scale fault-tolerant quantum computer named Starling by 2028, with expectations to open it to users via cloud services in 2029. The Starling system is projected to contain approximately 100 modules and 200 logical qubits, with the core goal of achieving effective error correction, one of the biggest technical challenges currently facing the quantum computing field. The machine will use IBM’s low-density parity-check (LDPC) codes for error correction and aims to achieve real-time error diagnosis. If successful, this would be a major breakthrough in quantum computing, potentially accelerating its application in complex problems such as materials science and drug discovery. (Source: MIT Technology Review)

🎯 Trends
Apple’s WWDC 2025 AI-related progress fails to impress developers: Apple announced multiple updates at WWDC 2025, including a new “liquid glass” design language and Xcode 26 integration with ChatGPT. However, the developer community generally expressed that its progress in artificial intelligence “fell short of expectations.” Although Apple opened its on-device AI models to developers for the first time and launched the Foundation Models framework to simplify AI feature integration, the highly anticipated new Siri update may be postponed until next year. Analyst Ming-Chi Kuo pointed out that Apple’s AI strategy is central, but there were no major technological breakthroughs, making market expectation management key. Apple seems to be focusing more on improving user interfaces and operating system features rather than disruptive innovation in AI models themselves. (Source: MIT Technology Review, jonst0kes, rowancheung)
Pentagon cuts size of AI weapons systems testing and evaluation office: U.S. Secretary of Defense Pete Hegseth announced that the size of the Department of Defense’s Office of the Director, Operational Test and Evaluation (DOT&E) will be halved, with personnel reduced from 94 to about 45. The office is responsible for testing and evaluating the safety and effectiveness of weapons and AI systems. This adjustment aims to “reduce bureaucratic bloat and wasteful spending, and increase lethality.” The move has raised concerns that testing for the safety and effectiveness of AI military applications could be affected, especially as the Pentagon is actively integrating AI technology (including large language models) into various military systems. (Source: MIT Technology Review)

OpenBMB releases MiniCPM-4 series of efficient on-device large language models: OpenBMB (ModelBest) has launched the MiniCPM-4 series of models, designed for on-device applications and aiming for ultra-high efficiency. The series includes MiniCPM4-0.5B, MiniCPM4-8B (flagship model), BitCPM4 (1-bit quantized model), MiniCPM4-Survey (specialized for report generation), and the MCP-specific model MiniCPM4-MCP. The technical report details its efficient model architecture (such as the InfLLM v2 trainable sparse attention mechanism), efficient learning algorithms (like Model Wind Tunnel 2.0), and high-quality training data processing methods. These models are now available for download on Hugging Face. (Source: _akhaliq, arankomatsuzaki, karminski3)
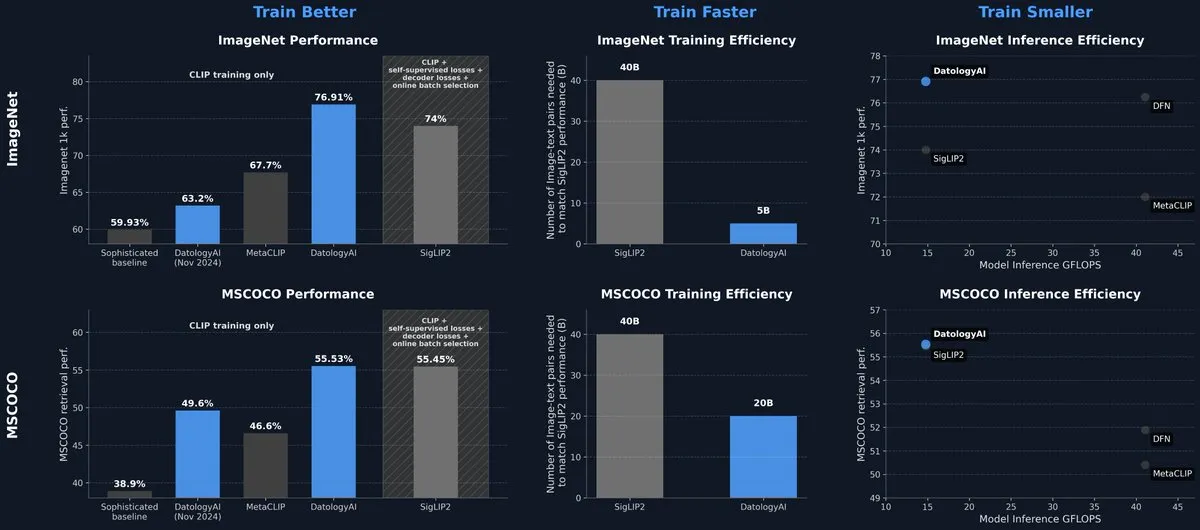
DatologyAI releases CLIP model achieving SOTA performance solely through data management: DatologyAI has showcased its latest research in the multimodal field, achieving 76.9% accuracy on ImageNet 1k with its CLIP ViT-B/32 model through meticulous data curation, rather than algorithmic or architectural innovations, surpassing the 74% reported by SigLIP2. This approach also resulted in an 8x improvement in training efficiency and a 2x improvement in inference efficiency. The model has been publicly released, highlighting the immense potential of high-quality data in enhancing model performance. (Source: code_star, andersonbcdefg)
Krea AI releases its first proprietary image model, Krea 1: Krea AI has launched Krea 1, its first image model, which excels in aesthetic control and image quality, possesses extensive artistic knowledge, and supports style referencing and custom training. Krea 1 aims to enhance image realism, fine textures, and rich stylistic expression. Krea 1 is currently available for free Beta testing, allowing users to experience its powerful image generation capabilities. (Source: _akhaliq, op7418)
NVIDIA releases customizable open-source humanoid robot model GR00T N1: NVIDIA has launched GR00T N1, a customizable open-source humanoid robot model. This initiative aims to advance research and development in the humanoid robotics field, providing developers with a flexible platform to build and experiment with various robot applications. The open-source nature of GR00T N1 is expected to attract broader community involvement, accelerating progress in humanoid robot technology. (Source: Ronald_vanLoon)
RoboBrain 2.0 releases 7B and 32B multimodal robot models: RoboBrain 2.0 has released its 7B and 32B parameter multimodal robot models, aimed at enhancing robots’ abilities in perception, reasoning, and task execution. The new models support interactive reasoning, long-horizon planning, closed-loop feedback, precise spatial awareness (point and bounding box prediction), temporal awareness (future trajectory estimation), and scene reasoning achieved through real-time structured memory construction and updates. These improved capabilities are expected to advance robots’ autonomous operation and decision-making levels in complex environments. (Source: Reddit r/LocalLLaMA)
Kling AI to share latest research on video generation models at CVPR 2025: Pengfei Wan, head of Kling AI’s video generation model, will deliver a keynote speech titled “Introduction to Kling and Our Research on More Powerful Video Generation Models” at the top computer vision conference CVPR 2025. He will discuss the latest breakthroughs and cutting-edge advancements in video generation technology with experts from institutions like Google DeepMind. This presentation will provide an in-depth look at Kling’s achievements in advancing video generation technology. (Source: Kling_ai)

AI technology assists China’s 2025 Gaokao, multiple regions deploy intelligent inspection systems: China’s 2025 Gaokao (National College Entrance Examination) will widely adopt AI intelligent inspection systems, with full AI proctoring coverage in exam centers across multiple locations including Tianjin, Jiangxi, Hubei, and Yangjiang in Guangdong. These systems utilize 4K cameras, skeletal tracking, facial recognition, audio monitoring, and other technologies to detect cheating behaviors in real-time, such as starting early, passing objects, whispering, and abnormal gaze deviation, and can issue warnings. This initiative aims to enhance exam fairness and ensure examination discipline. The application of AI proctoring systems marks the entry of exam management into an intelligent era, bringing changes to traditional proctoring methods. (Source: 36氪)
Gemma 3n desktop models released, supporting cross-platform and IoT devices: Google has released Gemma 3n desktop models, including 2-billion and 4-billion parameter versions, optimized for desktop (Mac/Windows/Linux) and Internet of Things (IoT) devices. The model is powered by the new LiteRT-LM library, designed to provide efficient local execution capabilities. Developers can access relevant resources via Hugging Face preview and GitHub, further promoting the application of lightweight AI models on edge devices. (Source: ClementDelangue, demishassabis)
🧰 Tools
Yutori AI launches Scouts: Real-time web monitoring AI agents: Yutori AI, founded by former Meta AI researchers, has released an AI agent product called Scouts. Scouts can monitor internet information in real-time based on user-defined topics or keywords and notify users when relevant content appears. The tool aims to help users filter valuable content from the vast amount of online information, such as tracking news updates in specific fields, market trends, product discounts, or even scarce reservations. The launch of Scouts marks a further development in personalized information retrieval tools, turning AI into users’ digital “scouts.” (Source: DhruvBatraDB, krandiash, saranormous, JeffDean)
Replit introduces new feature: Convert Figma and other designs into functional apps with one click: Replit has launched Replit Import, a feature allowing users to directly import designs from platforms like Figma, Lovable, and Bolt and convert them into runnable applications. This feature aims to lower the development barrier, enabling non-programmers to quickly turn design ideas into reality. Replit Import supports maintaining design fidelity and includes built-in security scanning and secret management. Combined with Replit Agent, databases, authentication, and hosting services, it can create full-stack applications. (Source: amasad, pirroh)
Hugging Face releases AISheets: Combining spreadsheets with thousands of AI models: Hugging Face co-founder Thomas Wolf announced the launch of an experimental product, AISheets, which combines the ease of use of spreadsheets with the power of thousands of open-source AI models (especially LLMs). Users can build, analyze, and automate data processing tasks within a familiar spreadsheet interface, leveraging AI models for data insights and task automation. It aims to provide a new, fast, simple, and powerful way for data analysis. (Source: _akhaliq, clefourrier, ClementDelangue, huggingface)
LlamaIndex now supports converting Agents into MCP servers for interaction with models like Claude: LlamaIndex has announced support for converting any of its Agents into Model Context Protocol (MCP) servers. Through sample code and videos, it demonstrates how to deploy a custom FidelityFundExtraction workflow (for extracting structured data from complex PDFs) as an MCP server and call it from a Claude model. This feature aims to enhance the agent capabilities of tools, facilitate integration with MCP clients like Claude Desktop and Cursor, and simplify the process of connecting existing workflows to the broader AI ecosystem. (Source: jerryjliu0)
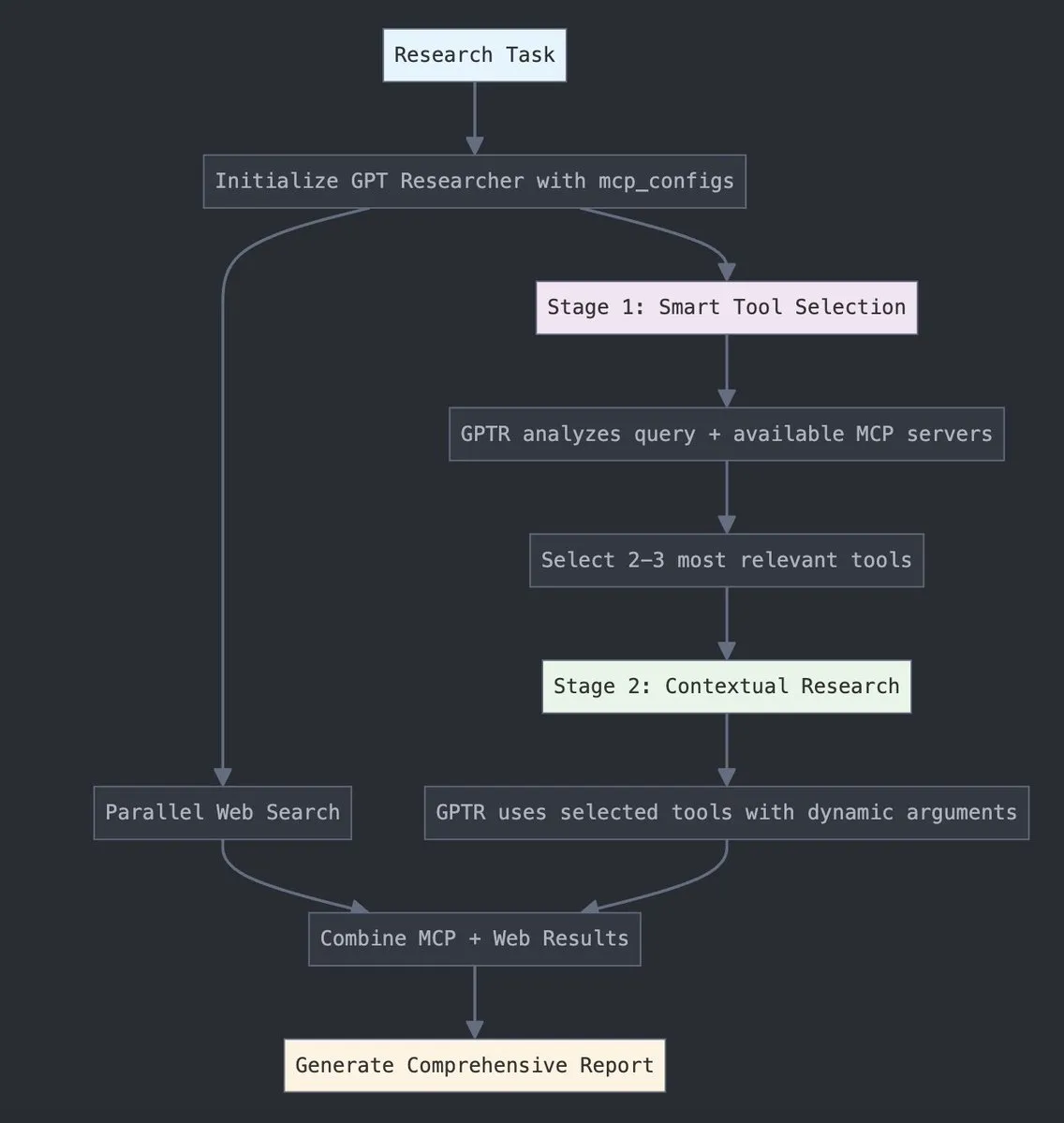
GPT Researcher integrates LangChain Model Context Protocol (MCP): GPT Researcher now utilizes LangChain’s Model Context Protocol (MCP) adapter for intelligent tool selection and research. This integration seamlessly combines MCP with web search capabilities for comprehensive data collection. Users can consult the relevant integration documentation to learn how to configure and use this new feature, thereby enhancing research efficiency and depth. (Source: hwchase17)
Tesslate releases UIGEN-T3 series of UI generation models, supporting multiple sizes: The Tesslate team has launched the UIGEN-T3 series of UI generation models, including various parameter scales such as 32B, 14B, 8B, and 4B. These models are designed specifically for generating UI components (like breadcrumbs, buttons, cards) and complete frontend code (such as login pages, dashboards, chat interfaces), with support for Tailwind CSS. The models are available on Hugging Face and aim to help developers quickly build user interfaces. Developer feedback indicates that standard quantization significantly degrades model quality, and running them in BF16 or FP8 is recommended for optimal results. (Source: Reddit r/LocalLLaMA)
Doubao Podcast Model released, generating human-like AI podcasts with one click: Volcengine has released the Doubao Podcast Model, which can quickly generate podcasts with a highly human-like conversational style based on user-inputted text (such as article links or prompts). The audio generated by the model closely mimics human intonation, pauses, and colloquial expressions, and can even engage in opinionated discussions based on the content. The technology is based on an end-to-end real-time speech model from ByteDance’s voice technology team, enabling direct understanding and reasoning in the speech modality. Currently, this feature is live on Doubao PC and Kouzi Space, aiming to lower the barrier to audio content creation and provide an efficient, personalized way to access information. (Source: 量子位)

Unsloth AI provides GGUF quantized version of Magistral-Small-2506: For Mistral AI’s newly released Magistral-Small-2506 inference model, Unsloth AI has provided a GGUF quantized version. This allows users to run the 24-billion-parameter model locally, for instance, on a device with only 32GB of RAM. This move lowers the hardware barrier for high-performance inference models, making it easier for a broader range of developers and researchers to experience and use the Magistral model in their local environments. (Source: ImazAngel)
📚 Learning
In-depth technical analysis of building LLaVA-1.5 visual assistant: LearnOpenCV has published an in-depth technical analysis article on the LLaVA-1.5 architecture. The article details how LLaVA-1.5 builds state-of-the-art AI visual assistants, including its groundbreaking Visual Instruction Tuning technology and the open-source datasets that have transformed the multimodal AI field. This guide is a valuable reference for AI/ML engineers and researchers to understand the working principles and training methods of multimodal large language models. (Source: LearnOpenCV)
Beginner’s guide to protein machine learning released: DL Weekly shared a comprehensive beginner’s guide to protein machine learning. The guide covers basic data types related to proteins, deep learning models, computational methods, and fundamental biological concepts, aiming to help researchers and developers interested in this interdisciplinary field get started quickly. (Source: dl_weekly)
Qdrant partners with DataTalksClub to launch free RAG and vector search course: Qdrant announced a partnership with DataTalksClub to offer a 10-week free online course. The course content includes Retrieval Augmented Generation (RAG), vector search, hybrid search, evaluation methods, and an end-to-end project. Qdrant experts Kacper Łukawski and Daniel Wanderung will personally teach the course, aiming to help learners master practical skills for building advanced AI applications. (Source: qdrant_engine)
Weaviate podcast discusses LLM structured output and constrained decoding: The latest episode of the Weaviate podcast featured Will Kurt and Cameron Pfiffer from dottxt.ai, who joined host Connor Shorten to discuss the structured output problem of Large Language Models (LLMs). The program delved into how constrained decoding techniques can ensure LLMs generate reliable and predictable results (such as valid JSON, emails, tweets, etc.), going beyond simple JSON format validation. They also introduced the open-source tool Outlines and its applications in real-world AI use cases, and looked ahead at the impact of this technology on future AI systems. (Source: bobvanluijt)
ACL 2025 NLP paper “SynthesizeMe!”: Generating personalized prompts from user interactions: An ACL 2025 NLP conference paper titled “SynthesizeMe!” proposes a new method for creating personalized user models in natural language by analyzing user interactions with AI (including implicit and explicit feedback). The method first generates and validates reasoning processes that explain user preferences, then synthesizes user personas from these, filters information-rich prior user interactions, and finally constructs personalized prompts for specific users to enhance LLM’s personalized reward modeling and response capabilities. DSPy also retweeted and mentioned this as an excellent application case for dspy.MIPROv2. (Source: lateinteraction, stanfordnlp)
New paper explores monitoring and overclocking Test-Time Scaling LLMs: A new paper focuses on the test-time scaling technique used by models like o3 and DeepSeek-R1, which allows LLMs to perform more reasoning before answering, but users often cannot understand their internal progress or control it. Researchers propose exposing the LLM’s internal “clock” and demonstrate how to monitor its inference process and “overclock” it for acceleration. This offers new insights into understanding and optimizing the efficiency of large inference models. (Source: arankomatsuzaki)

Paper proposes CARTRIDGES: Compressing KV cache for long-context LLMs via offline self-learning: Researchers from Stanford’s HazyResearch have proposed a new method called CARTRIDGES, aimed at addressing the issue of excessive memory consumption by KV caches in long-context LLMs. The method uses a “self-learning” test-time training mechanism to offline train a smaller KV cache (called a cartridge) to store document information. This achieves an average 39x reduction in cache memory and a 26x increase in peak throughput while maintaining task performance. This cartridge, once trained, can be reused by different user requests, offering a new optimization approach for long-context processing. (Source: gallabytes, simran_s_arora, stanfordnlp)

New paper “Grafting”: Low-cost editing of pre-trained diffusion Transformer architectures: Stanford researchers have proposed a new method called Grafting for editing pre-trained diffusion Transformer model architectures. This technique allows for the replacement of attention mechanisms and other components in the model with new computational primitives, using only 2% of the original pre-training cost. This enables customized model architecture design on a small computational budget, which is significant for exploring new model architectures and improving the efficiency of existing models. (Source: realDanFu, togethercompute)
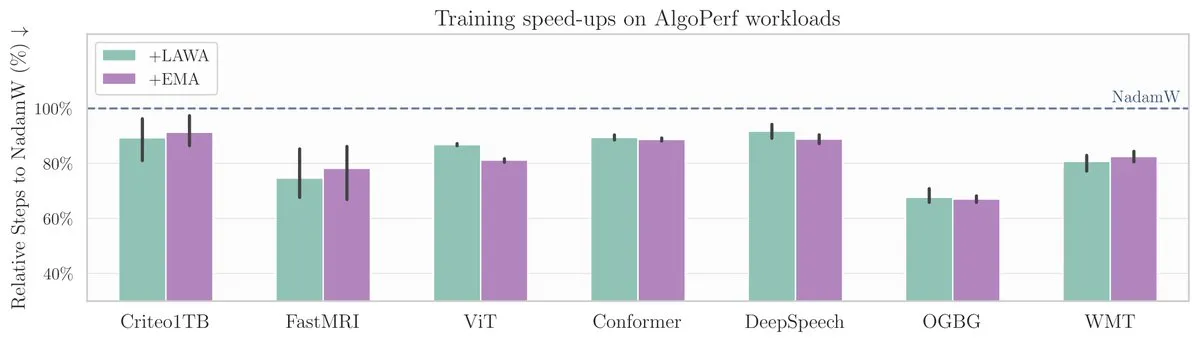
New ICML paper: Averaging Checkpoints method accelerates model training on AlgoPerf benchmark: A new ICML paper investigates the application of the classic Averaging Checkpoints method in improving the training speed and performance of machine learning models. Researchers tested this method on AlgoPerf, a structured and diverse benchmark for optimization algorithms, exploring its practical benefits across different tasks and providing practical references for accelerating model training. (Source: aaron_defazio)
Transformer visualization and explanation tool open-sourced: DL Weekly introduced an interactive visualization tool designed to help users understand the working principles of Transformer-based models (like GPT). The tool breaks down the internal mechanisms of the model visually, making complex concepts easier to grasp, suitable for learners and researchers interested in Transformer models. The project is open-sourced on GitHub. (Source: dl_weekly)
Zhejiang University proposes InftyThink: Achieving infinite-depth reasoning through segmentation and summarization: A research team from Zhejiang University, in collaboration with Peking University, has proposed a new paradigm for large model reasoning called InftyThink. This method breaks down long reasoning processes into multiple short segments and introduces summaries between segments to connect context, theoretically enabling infinite-depth reasoning while maintaining high generation throughput. This method does not rely on model architecture adjustments; by restructuring training data into a multi-turn reasoning format, it is compatible with existing pre-training and fine-tuning workflows. Experiments show that InftyThink can significantly improve model performance on benchmarks like AIME24 and increase generation throughput. (Source: 量子位)

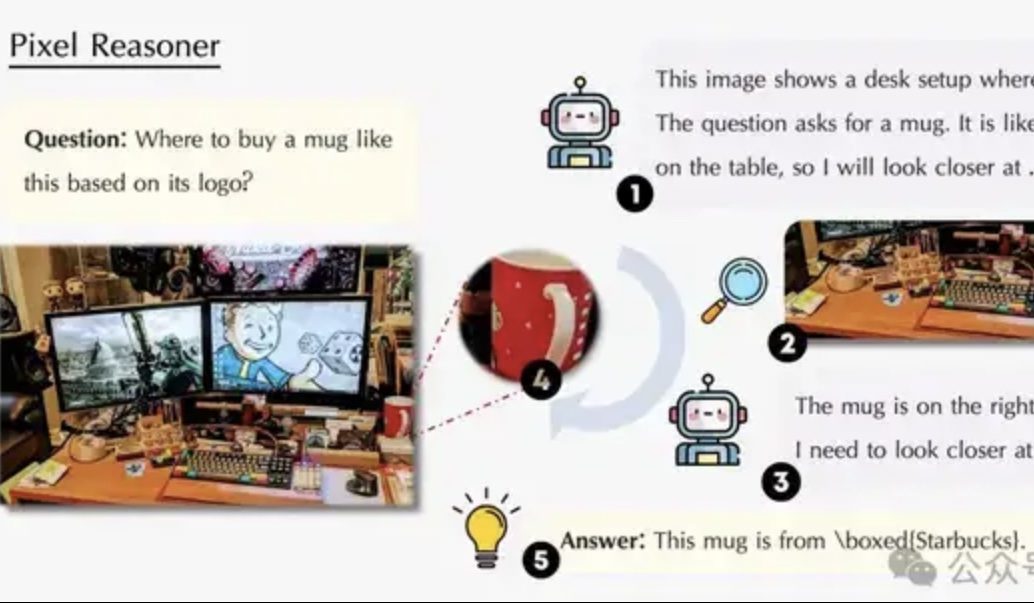
Paper explores Pixel-Space Reasoning: Enabling VLMs to “use eyes and brain” like humans: A research team from the University of Waterloo, Hong Kong University of Science and Technology, and the University of Science and Technology of China has proposed the “Pixel-Space Reasoning” paradigm. This enables Visual Language Models (VLMs) to operate and reason directly at the pixel level, such as performing visual zoom and spatio-temporal tagging, rather than relying on text tokens as intermediaries. Through a reinforcement learning scheme with intrinsic curiosity incentives and extrinsic correctness incentives, it overcomes the model’s “cognitive inertia.” Pixel-Reasoner, built on Qwen2.5-VL-7B, performs excellently on multiple benchmarks like V*Bench, with the 7B model’s performance surpassing GPT-4o. (Source: 量子位)
DeepLearning.AI launches fifth course in Data Analysis Professional Certificate: Data Storytelling: DeepLearning.AI has released the fifth course in its Data Analysis Professional Certificate, titled “Data Storytelling.” The course teaches how to choose appropriate media (dashboards, memos, presentations) to present insights, use Tableau to design interactive dashboards, align findings with business goals and communicate them effectively, and provides job search guidance. It emphasizes the importance of data storytelling in improving business performance and effectively conveying insights. (Source: DeepLearningAI)

Paper explores the impact of knowledge conflicts on Large Language Models: A new paper systematically evaluates the behavior of Large Language Models (LLMs) when faced with conflicts between contextual input and parameterized knowledge (i.e., the model’s internal “memory”). The study found that knowledge conflicts have minimal impact on tasks that do not rely on knowledge utilization; models perform better when context and parametric knowledge are consistent; models cannot completely suppress internal knowledge even when instructed to do so; and providing reasons to explain conflicts increases the model’s reliance on context. These findings raise questions about the validity of model-based evaluations and emphasize the need to consider knowledge conflicts when deploying LLMs. (Source: HuggingFace Daily Papers)
Paper CyberV: A Cybernetic Framework for Test-Time Scaling in Video Understanding: To address the computational demands, robustness, and accuracy issues faced by Multimodal Large Language Models (MLLMs) when processing long or complex videos, researchers propose the CyberV framework. Inspired by cybernetic principles, this framework redesigns video MLLMs as adaptive systems comprising an MLLM inference system, sensors, and a controller. Sensors monitor the model’s forward process and collect intermediate interpretations (such as attention drift), while the controller decides when and how to trigger self-correction and generate feedback. This test-time adaptive scaling framework enhances existing MLLMs without retraining, and experiments show it significantly improves the performance of models like Qwen2.5-VL-7B on benchmarks such as VideoMMMU. (Source: HuggingFace Daily Papers)
Paper proposes LoRMA: Low-Rank Multiplicative Adaptation for Parameter-Efficient Fine-Tuning of LLMs: To address the representation collapse and expert load imbalance issues in existing LoRA and MoE-based Parameter-Efficient Fine-Tuning (PEFT) methods, researchers have proposed Low-Rank Multiplicative Adaptation (LoRMA). This method changes the update mechanism of PEFT adapter experts from additive to a richer matrix multiplicative transformation, tackling computational complexity and rank bottlenecks through effective rearrangement operations and the introduction of rank expansion strategies. Experiments demonstrate that the Mixture-of-Adapters (MoA) heterogeneous approach outperforms homogeneous MoE-LoRA methods in both performance and parameter efficiency. (Source: Reddit r/MachineLearning)
Paper proposes FlashDMoE: Fast Distributed MoE in a Single Kernel: Researchers have introduced FlashDMoE, the first system to fully fuse distributed Mixture-of-Experts (MoE) forward propagation into a single CUDA kernel. By writing the fused layer from scratch in pure CUDA, FlashDMoE achieves up to a 9x improvement in GPU utilization, a 6x reduction in latency, and a 4x improvement in weak scaling efficiency. This work provides new ideas and implementations for optimizing the inference efficiency of large-scale MoE models. (Source: Reddit r/MachineLearning)
💼 Business
xAI partners with Polymarket to integrate market predictions with Grok analysis: Elon Musk’s artificial intelligence company, xAI, has announced a partnership with the decentralized prediction market platform Polymarket. This collaboration aims to combine Polymarket’s market prediction data with data from X (formerly Twitter) and Grok AI’s analytical capabilities to create a “hardcore truth engine” to reveal the factors shaping the world. xAI stated that this is just the beginning of the collaboration, with more to come in the future. (Source: xai)
AI inference chip company Groq secures $1.5 billion investment commitment from Saudi Arabia, focusing on vertical integration strategy: AI inference chip company Groq has announced a $1.5 billion investment commitment from Saudi Arabia to expand the delivery scale of its LPU (Language Processing Unit)-based AI inference infrastructure in the region. Founded by Jonathan Ross, one of the inventors of the TPU, Groq focuses on AI inference computing. Its LPU chips feature a programmable pipeline architecture with memory and compute units integrated on the same chip, significantly improving data access speed and energy efficiency. Groq not only sells chips but also offers GroqRack clusters (private cloud/AI computing centers) and the GroqCloud platform (Tokens-as-a-Service), supporting mainstream open-source models like Llama, DeepSeek, and Qwen. The company has also developed the Compound AI system to enhance the value of its AI inference cloud. (Source: 36氪)

Shenzhen-based humanoid interaction robot company “Digital China” completes tens of millions of RMB in Angel+ funding round: Digital China (Shenzhen) Technology Co., Ltd. recently completed an Angel+ funding round worth tens of millions of RMB, solely invested by Cowin Capital. The company focuses on the large-scale commercialization of AGI robots, with core products including the biomimetic robot “Xia Lan,” the general-purpose humanoid robot “Xia Qi,” and the IP series robot “Xingxingxia.” The “Xia Lan” robot, centered on precision biomimetic technology, can imitate most human expressions and possesses multimodal interaction capabilities. The company has secured orders worth hundreds of millions of RMB from clients including leading ICT manufacturers and local power grid companies. (Source: 36氪)

🌟 Community
Sam Altman publishes blog post “The Gentle Singularity,” discussing AI’s gradual revolution and future: OpenAI CEO Sam Altman published a blog post arguing that the technological singularity is quietly occurring in a gentler, more gradual way than anticipated, as a continuous, exponentially accelerating process. He predicts that by 2025, AI agents capable of independently performing complex mental tasks (like programming) will reshape the software industry; by 2026, systems capable of discovering entirely new scientific insights may emerge; and by 2027, robots capable of completing tasks in the real world might appear. Altman emphasizes that solving AI alignment and ensuring technological accessibility are key to a prosperous future. He also revealed that OpenAI’s first open-source weights model will be delayed until late summer due to “unexpectedly amazing results” from the research team. (Source: dotey, scaling01, sama)
Community discusses OpenAI o3-pro: Powerful performance but high cost, o3 price cut sparks chain reaction: The release of OpenAI’s o3-pro and its high pricing ($80/M tokens for output) have become a hot topic in the community. Users generally acknowledge its strong capabilities in complex reasoning, programming, and other tasks, but also express concerns about its response speed and cost, with some users joking that a simple “Hi” could cost $80. Meanwhile, the 80% price cut for the o3 model is seen as potentially triggering an AI model price war, targeting GPT-4o and other competitors. There is debate in the community about whether o3’s performance has been “dumbed down” after the price cut. OpenAI later announced it would double the o3 usage quota for ChatGPT Plus users in response to user demand. (Source: Yuchenj_UW, scaling01, imjaredz, kevinweil, dotey)
Meta’s high salaries for talent acquisition and AI organizational funding spark discussion: Meta’s high compensation packages for AI researchers (reportedly reaching nine figures in USD) have sparked community discussion. Nat Lambert commented that such salaries could potentially fund an entire research institution the size of AI2, implying the high cost of top talent. Combined with Meta’s establishment of the “Superintelligence Lab” and heavy investment in Scale AI, the community generally believes Meta is sparing no expense to reshape its AI competitiveness, but also notes concerns about its internal organizational politics and efficiency. Helen Toner’s retweet of ChinaTalk content pointed out that Meta’s move is aimed at breaking down internal organizational politics and ego issues. (Source: natolambert, natolambert)
Apple’s new WWDC UI style “Liquid Glass” sparks design and usability discussions: Apple’s new UI design style “Liquid Glass,” introduced at WWDC 2025, has sparked widespread discussion in the developer and designer communities. Some view its visual effects as novel, reflecting Apple’s exploration of 3D interface design. However, veterans like ID_AA_Carmack (John Carmack) pointed out that translucent UIs often have usability issues, easily causing visual interference and low contrast, affecting readability and operation. He also mentioned that both Windows and Mac have historically experimented with similar designs but eventually adjusted them due to usability problems. The core of the discussion became that user experience (UX) should take precedence over user interface (UI) visual effects. (Source: gfodor, ID_AA_Carmack, ReamBraden, dotey)
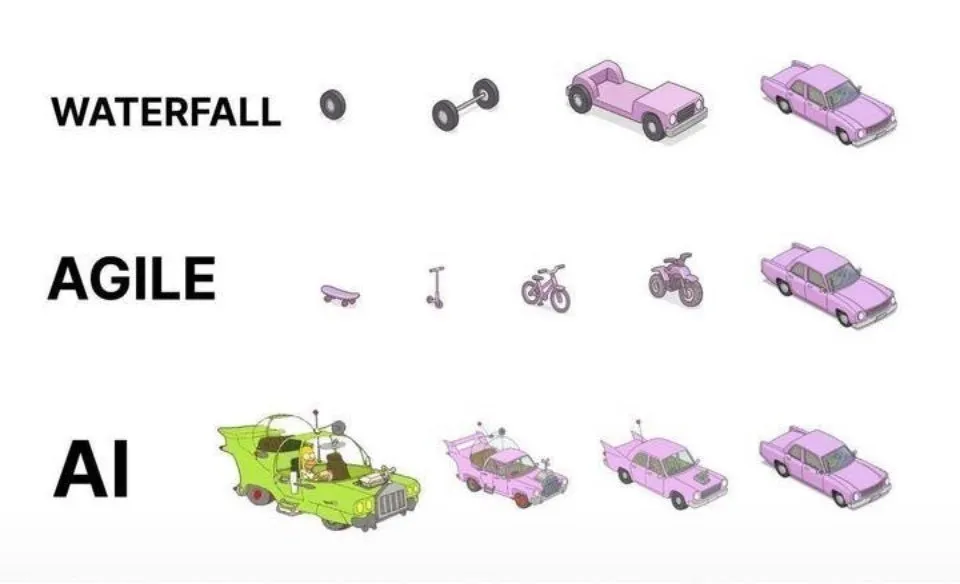
AI-assisted programming practices: Agile iteration superior to one-shot generation: On social media, dotey expressed views on best practices for programming with AI (like Claude Code). He believes that one should not adopt a waterfall model approach of providing complete requirements at once for AI to generate a large semi-finished product, nor generate an imperfect product first and then optimize it (similar to the third mode in the diagram), as these are difficult to control for quality and hard to maintain later. He advocates for an agile iterative model (similar to the first mode in the diagram), breaking down large projects (like ERP systems) into multiple small, independently stable versions, developing them iteratively to ensure the functional integrity and controllability of each version. This aligns with traditional software engineering best practices. (Source: dotey)
Mustafa Suleyman: AI technology is evolving from fixed and uniform to dynamic and personalized: Mustafa Suleyman, co-founder of Inflection AI and former DeepMind co-founder, commented that traditional technologies are typically fixed, uniform, and “one-size-fits-all,” whereas current artificial intelligence technologies exhibit dynamic, personalized, and emergent characteristics. He believes this means technology is shifting from providing single, repetitive results to exploring paths of infinite possibilities, emphasizing AI’s vast potential in personalized services and creative applications. (Source: mustafasuleyman)
Perplexity AI encounters infrastructure issues, CEO explains: Perplexity AI CEO Arav Srinivas responded on social media to user concerns about service instability, stating that due to infrastructure problems, they had to enable a degraded user experience (degraded UX) for some traffic. He emphasized that user data (such as libraries or threads) was not lost, and all functionalities would return to normal once the system stabilizes. This reflects the challenges AI services face regarding infrastructure stability and scalability during rapid development. (Source: AravSrinivas)
Sergey Levine discusses learning differences between language and video models: UC Berkeley professor Sergey Levine, in his article “Language Models in Plato’s Cave,” poses a profound question: Why can language models learn so much from predicting the next word, while video models learn relatively little from predicting the next frame? He argues that LLMs gain powerful reasoning abilities by learning the “shadows” of human knowledge (text data), which is more like “reverse-engineering” human cognition than truly autonomously exploring the physical world. Video models directly observe the physical world but currently lag behind LLMs in complex reasoning. He proposes that AI’s long-term goal should be to break free from relying on the “shadows” of human knowledge and achieve autonomous exploration by directly interacting with the physical world through sensors. (Source: 36氪)
💡 Others
AI ethics and consciousness discussion: Can AI possess true consciousness?: MIT Technology Review focuses on the complex issue of AI consciousness. The article points out that AI consciousness is not only an intellectual puzzle but also an issue with moral weight. Misjudging AI consciousness could lead to inadvertently enslaving sentient AI or sacrificing human well-being for non-sentient machines. The research community has made progress in understanding the nature of consciousness, and these findings may provide guidance for exploring and addressing artificial consciousness. This sparks deep reflection on AI rights, responsibilities, and human-machine relationships. (Source: MIT Technology Review)
Turing Award winner Joseph Sifakis: Current AI is not true intelligence, beware of confusing knowledge with information: Turing Award winner Joseph Sifakis pointed out in his writings and interviews that current societal understanding of AI is flawed, confusing information accumulation with wisdom creation and overestimating machine “intelligence.” He believes there are no truly intelligent systems yet, and AI’s actual impact on industry is minimal. AI lacks common sense understanding; its “intelligence” is a product of statistical models, making it difficult to weigh values and risks in complex social contexts. He emphasizes that the core of education is to cultivate critical thinking and creativity, not knowledge transmission, and calls for establishing global standards for AI applications, clarifying responsibility boundaries, so AI becomes a partner that augments humans rather than a replacement. (Source: 36氪)
Advertising industry reshaped in the AI era: Transformation from creative generation to personalized delivery: Google I/O 2025 showcased how AI is profoundly reshaping the advertising industry. Trends include: 1) AI-driven creative automation, where everything from images to video scripts can be generated by AI, with tools like Veo 3, Imagen 4, and Flow lowering the barrier to high-quality content creation. 2) The personalization paradigm is shifting from “one thousand faces for one thousand people” to “one thousand faces for one person,” as AI intelligent agents can proactively understand user needs and facilitate transactions. 3) The boundary between advertising and content is blurring, with ads directly integrated into AI-generated search results, becoming part of the information. Brand owners need to build dedicated intelligent agents, provide AI-oriented services, and adhere to a long-term strategy of “brand-performance synergy” to adapt to the changes. (Source: 36氪)