
Keywords:DeepSeek, OpenAI, reasoning model, multimodal large model, reinforcement learning, AI innovation, open-source model, DeepSeek R1 reasoning model, OpenAI o4 reinforcement learning training, multimodal large model human thinking map, Mistral AI Magistral series, Xiaohongshu dots.llm1 MoE model
🔥 Spotlight
DeepSeek and OpenAI’s Innovation Paths Reveal “Cognitive Innovation”: DeepSeek, through “limited Scaling Law,” MLA and MoE architecture innovation, and software-hardware co-optimization, has achieved low-cost, high-performance. The open-sourcing of its R1 inference model has driven breakthroughs in AI cognitive capabilities, breaking the “mental shackles” for Chinese innovators in basic research and proving Chinese enterprises’ global leadership in AI basic research and model innovation. OpenAI, on the other hand, leveraged the Transformer architecture and the extreme application of Scaling Law to lead the large language model revolution, and through ChatGPT and inference model o1, propelled a paradigm shift in human-computer interaction and a leap in AI cognitive abilities. The development paths of both emphasize a profound understanding of the essence of technology and strategic restructuring, providing valuable organizational construction and innovation ideas for entrepreneurs in the AI era. Particularly, DeepSeek’s AI Lab paradigm that encourages “emergence” offers a new organizational model reference for technology innovation-driven entrepreneurs (Source: 36Kr)
OpenAI Reportedly Training New Model o4, Reinforcement Learning Reshaping AI Landscape: SemiAnalysis revealed OpenAI is training a new model positioned between GPT-4.1 and GPT-4.5; the next-generation inference model o4 will be trained using reinforcement learning (RL) based on GPT-4.1. RL unlocks model reasoning capabilities by generating CoT and promotes the development of AI agents, but it has extremely high requirements for infrastructure (especially inference) and reward function design, and is prone to “reward hacking.” High-quality data is key to scaling RL, and user behavior data will become an important asset. RL also changes laboratory organizational structures, deeply integrating inference and training. Unlike pre-training, RL can continuously update model capabilities, like DeepSeek R1. For small models, distillation may be superior to RL. This round of revelations indicates that the AI field, especially inference models, will usher in continuous evolution and capability leaps based on RL (Source: 36Kr)
Multimodal Large Models Found to Spontaneously Form “Human-like Conceptual Maps”: A joint team from the Institute of Automation, Chinese Academy of Sciences, and the Center for Excellence in Brain Science and Intelligence Technology, through behavioral experiments and neuroimaging analysis, confirmed that Multimodal Large Language Models (MLLMs) can spontaneously form object concept representation systems highly similar to humans. By analyzing behavioral judgment data from 4.7 million “odd-one-out” tasks, the study constructed an AI model’s “conceptual map” for the first time. Key findings include: AI models with different architectures may converge to similar low-dimensional cognitive structures; models exhibit emergent high-level object concept classification abilities under unsupervised conditions, consistent with human cognition; the “thinking dimensions” of AI models can be assigned semantic labels such as animal, food, hardness, etc.; MLLM representations are significantly correlated with neural activity patterns in specific brain regions (e.g., FFA, PPA), providing evidence for “shared conceptual processing mechanisms between AI and humans.” This research offers new insights for understanding AI cognition, developing brain-like intelligence, and brain-computer interfaces (Source: QbitAI)

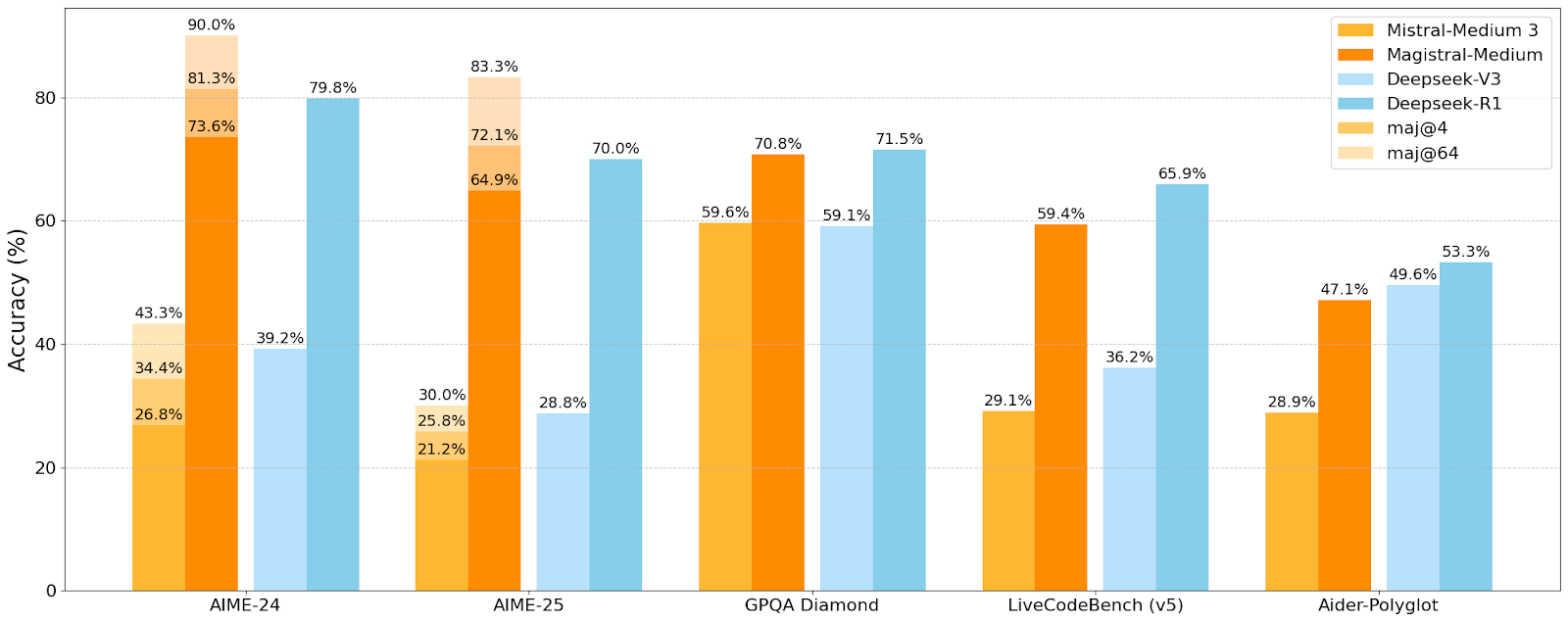
Mistral AI Releases First Inference Model Series Magistral, Small Model Magistral-Small Open-Sourced: Mistral AI has launched its first series of models designed specifically for inference, Magistral, which includes Magistral-Small and Magistral-Medium. Magistral-Small is built on Mistral Small 3.1 (2503) and is a 24B parameter efficient inference model, trained with SFT and RL using trajectories from Magistral Medium, enhancing its reasoning capabilities. The model supports multiple languages, has a context window of 128k (recommended effective context 40k), is open-sourced under the Apache 2.0 license, and can be deployed locally on a single RTX 4090 or a MacBook with 32GB RAM (after quantization). Benchmark tests show that Magistral-Small performs excellently on tasks such as AIME24, AIME25, GPQA Diamond, and Livecodebench (v5), approaching or even surpassing some larger models. Magistral-Medium has stronger performance but is not currently open-sourced. This release marks Mistral’s progress in enhancing model inference capabilities and multilingual support (Source: Reddit r/LocalLLaMA, Mistral AI, X)
🎯 Trends
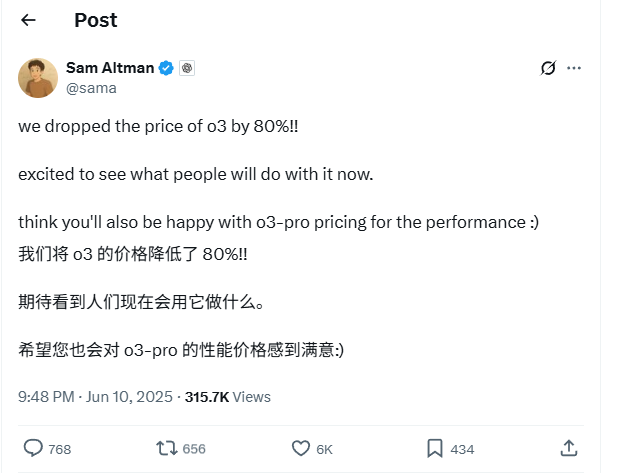
OpenAI o3 Model API Prices Slashed by 80%: OpenAI CEO Sam Altman announced an 80% price reduction for its o3 model’s API. After the adjustment, the input price is $2/million tokens, and the output price is $8/million tokens (some sources mention $5/million tokens for output, refer to official documentation for confirmation). This significant price cut substantially reduces the cost of using the o3 model for tasks like code writing, and is expected to drive broader adoption and innovation. Users should note that the official website’s price list may not yet be updated and are advised to test before API calls to confirm the effective price and avoid unnecessary losses. This move is seen as a strategy to counter market competition (such as Gemini 2.5 Pro and Claude 4 Sonnet) and may signal a continued decrease in the cost of AI intelligence (Source: X, X, X)
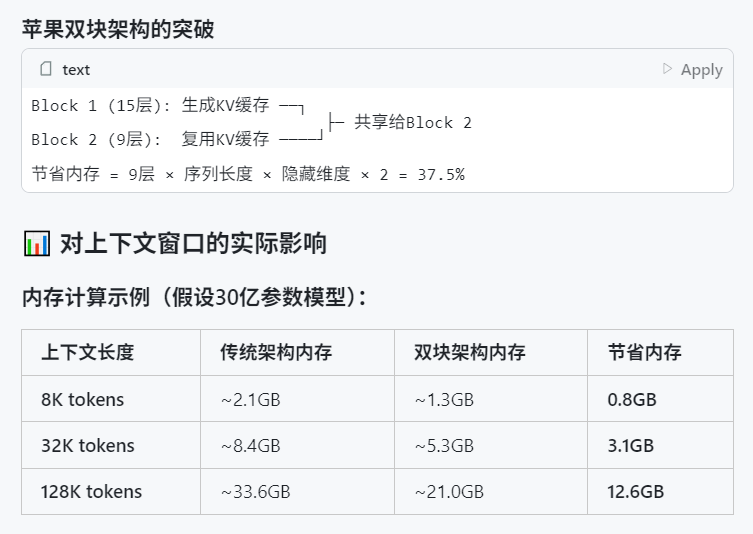
Apple’s WWDC 2025 Reportedly Light on AI, But Technical Details Reveal Ambition: Apple’s emphasis on AI at WWDC 2025 seemed less than expected, but its technical documentation reveals deep investment in on-device and cloud models. Apple is employing advanced training, distillation, and quantization techniques, including a “dual-block architecture” for mobile models (around 3B parameters, designed to reduce memory footprint) and a “PT-MoE” (Parallel Track Mixture of Experts) architecture for server-side models. These technologies aim to optimize low-latency inference on Apple chips and reduce KV cache memory usage. Despite some opinions that Apple is lagging in AI, its achievements in model technology (like open-sourcing embedding models) and focus on different priorities (such as on-device intelligence rather than just chatbots) indicate a unique AI strategy. WWDC also announced Safari 26 will support WebGPU, which will significantly boost the performance of on-device AI models (e.g., via Transformers.js), such as an approximate 12x speed increase for in-browser visual model caption generation (Source: X, X, X)
Perplexity Pro Users Can Now Access OpenAI’s o3 Model: Perplexity announced that its Pro subscribers can now use OpenAI’s o3 model. This integration will provide Perplexity Pro users with more powerful information processing and question-answering capabilities. Concurrently, Perplexity is also testing its “Memory” feature and has updated its iOS voice assistant, aiming to offer a more concise and practical user experience. Its Discover articles feature also defaults to a more concise “Summary” mode, with an option to switch to an in-depth “Report” mode (Source: X, X, X)

Xiaohongshu Open-Sources Its First 142B MoE Large Model dots.llm1, Surpassing DeepSeek-V3 in Chinese Evaluations: Xiaohongshu has open-sourced its first large model, dots.llm1, a 142 billion parameter Mixture of Experts (MoE) model that activates only 14 billion parameters during inference. The model used 11.2 trillion non-synthetic tokens in its pre-training phase, primarily from general web crawlers and proprietary web data. The Xiaohongshu team proposed a scalable three-stage data processing framework and open-sourced it to enhance reproducibility. dots.llm1 achieved a score of 92.2 on C-Eval, surpassing all models including DeepSeek-V3, and its performance on tasks such as Chinese and English, mathematics, and alignment is close to Alibaba’s Qwen3-32B. Xiaohongshu also open-sourced intermediate training checkpoints to promote community understanding of large model dynamics (Source: 36Kr)
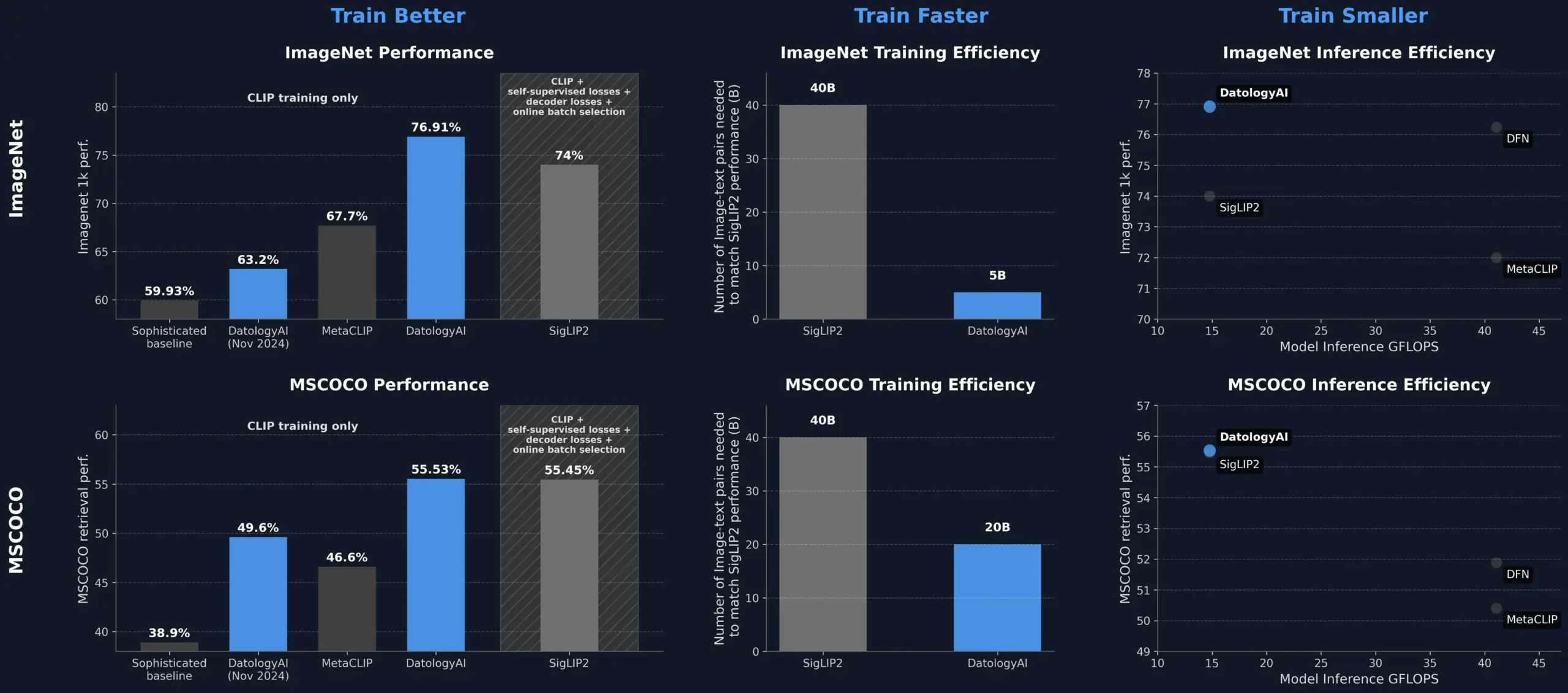
DatologyAI Improves CLIP Model Performance Through Data Curation, Surpassing SigLIP2: DatologyAI demonstrated significant improvements in CLIP model performance solely through data curation. Their method enabled a ViT-B/32 model to achieve 76.9% accuracy on ImageNet 1k, surpassing the 74% reported by SigLIP2. Additionally, this approach yielded an 8x improvement in training efficiency and a 2x improvement in inference efficiency, and the related models have been publicly released. This highlights the central role of high-quality, well-curated datasets in training advanced AI models, allowing for potential to be unlocked by optimizing data even without changing the model architecture (Source: X, X)
Kuaishou and Northeastern University Jointly Propose Unified Multimodal Embedding Framework UNITE: To address the issue of cross-modal interference caused by differing data distributions of various modalities (text, image, video) in multimodal retrieval, researchers from Kuaishou and Northeastern University have proposed the UNITE multimodal unified embedding framework. This framework utilizes a “Modality-Aware Masked Contrastive Learning” (MAMCL) mechanism, which only considers negative samples consistent with the query’s target modality during contrastive learning, avoiding erroneous inter-modal competition. UNITE employs a two-stage training process of “retrieval adaptation + instruction fine-tuning” and has achieved SOTA results in multiple evaluations including image-text retrieval, video-text retrieval, and instruction retrieval, such as surpassing larger-scale models in the MMEB Benchmark and significantly outperforming others on CoVR. The research emphasizes the core capability of video-text data in unified modalities and points out that instruction tasks rely more on text-dominant data (Source: QbitAI)

NVIDIA Releases Earth-2 Climate Simulation AI Foundation Model: NVIDIA’s Earth-2 platform has launched a new AI foundation model capable of simulating global climate at kilometer-scale resolution. The model aims to provide faster and more accurate climate predictions, offering new ways to understand and predict Earth’s complex natural systems. This move marks a significant step in the application of AI in climate science and Earth system modeling, expected to enhance climate change research and disaster warning capabilities (Source: X)

OpenAI Services Experience Widespread Outage, Affecting ChatGPT and API: OpenAI’s ChatGPT service and API interfaces experienced a widespread outage on the evening of June 10th, Beijing time, characterized by increased error rates and latency. Many users reported being unable to access services or encountering error messages such as “Hmm…something seems to have gone wrong.” OpenAI’s official status page confirmed the issue, stating that engineers had identified the root cause and were urgently working on a fix. This outage affected a large number of users and applications worldwide reliant on ChatGPT and its API, once again highlighting the importance of stability for large-scale AI services (Source: X, Reddit r/ChatGPT, Reddit r/ChatGPT)
🧰 Tools
Model Context Protocol (MCP) Server Ecosystem Continues to Expand: The Model Context Protocol (MCP) aims to provide Large Language Models (LLMs) with secure and controllable access to tools and data sources. The modelcontextprotocol/servers repository on GitHub gathers MCP reference implementations and community-built servers, showcasing its diverse applications. Official and third-party servers cover a wide range of areas including file systems, Git operations, database interactions (e.g., PostgreSQL, MySQL, MongoDB, Redis, ClickHouse, Cassandra), cloud services (AWS, Azure, Cloudflare), API integrations (GitHub, GitLab, Slack, Google Drive, Stripe, PayPal), search (Brave, Algolia, Exa, Tavily), code execution, and AI model calls (Replicate, ElevenLabs). The MCP ecosystem is rapidly developing, with over 130 official and community servers, and development frameworks like EasyMCP, FastMCP, MCP-Framework, as well as management tools like MCP-CLI and MCPM, have emerged. These aim to lower the barrier for LLMs to access external tools and data, promoting the development of AI Agents (Source: GitHub Trending)
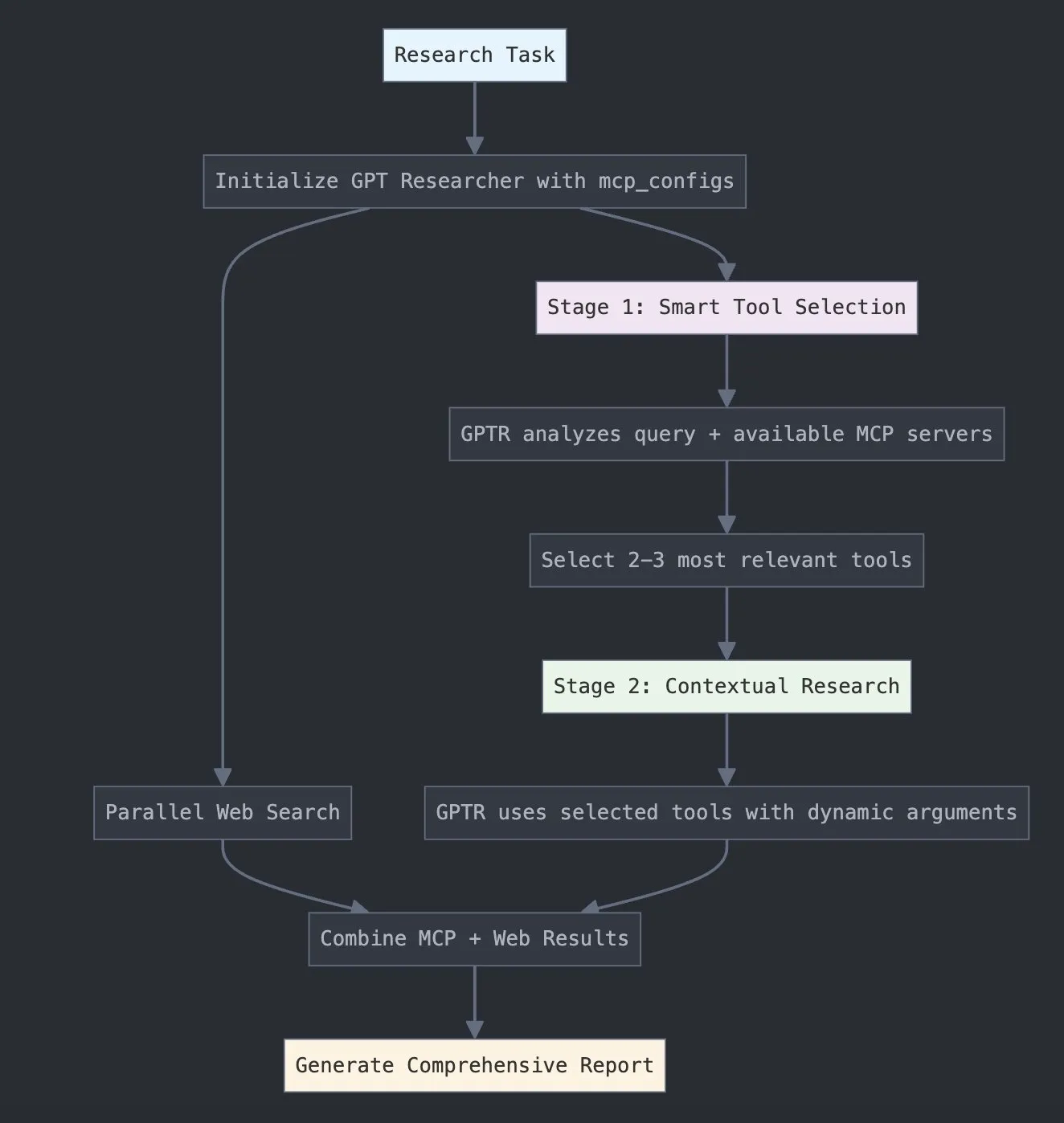
LangChain Launches GPT Researcher MCP, Enhancing Research Capabilities: LangChain announced that GPT Researcher now utilizes its Model Context Protocol (MCP) adapter to enable intelligent tool selection and research. This integration combines MCP with web search functionalities, aiming to provide users with more comprehensive data collection and analysis capabilities, further enhancing the depth and breadth of AI applications in the research field (Source: X)
Hugging Face Releases Vui: 100M Open-Source NotebookLM, Achieving Human-like TTS: Vui, a 100 million parameter open-source NotebookLM project, has been released on Hugging Face. It includes three models: Vui.BASE (a base model trained on 40k hours of audio dialogue), Vui.ABRAHAM (a single-speaker model with contextual awareness), and Vui.COHOST (a model capable of two-person conversations). Vui can clone voices, imitate breathing, filler sounds like “ums” and “ahs,” and even non-speech sounds, marking new progress in human-like text-to-speech (TTS) technology (Source: X, X)
Consilium: Open-Source Multi-Agent Collaboration Platform for Solving Complex Problems: The Consilium project, an open-source multi-agent collaboration platform, was showcased on Hugging Face. Users can assemble a team of expert AI agents to collaboratively solve complex problems and reach consensus through debate and real-time research (web, arXiv, SEC filings). Users set the strategy, and the agent team is responsible for finding answers, demonstrating new explorations in AI for collaborative problem-solving (Source: X)
Unsloth Releases Optimized GGUF Model for Magistral-Small-2506: Following Mistral AI’s release of the Magistral-Small-2506 inference model, Unsloth quickly launched its optimized GGUF format model, suitable for platforms like llama.cpp, LMStudio, and Ollama. This rapid response reflects the vitality and efficiency of the open-source community in model optimization and deployment, enabling new models to be used more quickly by a wider range of users and developers (Source: X)
📚 Learning
New Paper Explores Reinforcement Pre-Training (RPT) Paradigm: A new paper, “Reinforcement Pre-Training (RPT),” proposes reframing next-token prediction as an inference task using Reinforcement Learning with Verifiable Rewards (RLVR). RPT aims to improve language model prediction accuracy by incentivizing next-token reasoning capabilities and providing a strong foundation for subsequent reinforcement fine-tuning. The research shows that increasing training computation continuously improves prediction accuracy, indicating RPT is an effective and promising extension paradigm for advancing language model pre-training (Source: HuggingFace Daily Papers, X)

Paper Proposes Cartridges: Lightweight Long Context Representations via Self-Study: A paper titled “Cartridges: Lightweight and general-purpose long context representations via self-study” explores a method for handling long texts by offline training of small KV caches (called Cartridges), as an alternative to placing the entire corpus into the context window during inference. The study found that Cartridges trained via “self-study” (generating synthetic dialogues about the corpus and training with an in-context distillation objective) can achieve performance comparable to In-Context Learning (ICL) with significantly lower memory consumption (38.6x reduction) and higher throughput (26.4x increase), and can extend the model’s effective context length, even supporting cross-corpus combination without retraining (Source: HuggingFace Daily Papers, X)

Paper Explores Group Contrastive Policy Optimization (GCPO) for LLMs in Geometry Problem Solving: The paper “GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization” addresses the challenge of auxiliary line construction for LLMs in geometry problem solving by proposing the GCPO framework. This framework provides positive and negative reward signals for auxiliary line construction based on contextual utility through a “group contrastive mask” and introduces a length reward to promote longer reasoning chains. The GeometryZero model series, developed based on GCPO, outperformed baseline models on benchmarks like Geometry3K and MathVista, with an average improvement of 4.29%, demonstrating the potential to enhance the geometric reasoning capabilities of small models with limited computational power (Source: HuggingFace Daily Papers)
Paper “The Illusion of Thinking” Explores Capabilities and Limitations of Reasoning Models via Problem Complexity: This study systematically examines the capabilities, scaling properties, and limitations of Large Reasoning Models (LRMs). Using a puzzle environment with precisely controllable complexity, the research finds that LRM accuracy completely collapses beyond a certain complexity threshold and exhibits counter-intuitive scaling limitations: reasoning effort decreases after problem complexity increases to a certain point. Compared to standard LLMs, LRMs perform worse on low-complexity tasks, excel in medium-complexity tasks, and both fail on high-complexity tasks. The study points out LRMs’ limitations in precise computation, difficulty in applying explicit algorithms, and inconsistent reasoning across different scales (Source: HuggingFace Daily Papers, X)
Paper Studies Robustness Evaluation of LLMs in Less Resourced Languages: The paper “Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models” investigates the sensitivity of Large Language Models (LLMs) to perturbations (such as character-level and word-level attacks) in low-resource languages like Polish. The study found that by making minor character modifications and using small proxy models to calculate word importance, attacks can be created that significantly alter the predictions of different LLMs. This reveals potential security vulnerabilities of LLMs in these languages, which could be exploited to bypass their internal safety mechanisms. The researchers have released the relevant dataset and code (Source: HuggingFace Daily Papers)
Rel-LLM: A New Method to Enhance LLM Efficiency in Handling Relational Databases: A paper proposes the Rel-LLM framework, designed to address the inefficiency of Large Language Models (LLMs) when processing relational databases. Traditional methods of converting structured data into text can lead to the loss of crucial links and input redundancy. Rel-LLM creates structured graph prompts via a Graph Neural Network (GNN) encoder, preserving relational structures within a Retrieval Augmented Generation (RAG) framework. The method includes time-aware subgraph sampling, a heterogeneous GNN encoder, an MLP projection layer to align graph embeddings with the LLM’s latent space, and structuring graph representations as JSON graph prompts. It also employs a self-supervised pre-training objective to align graph and text representations. Experiments show that GNN encoding effectively captures complex relational structures lost in text serialization, and structured graph prompts can efficiently inject relational context into LLM attention mechanisms (Source: X)

Paper Explores LLM “Over-Refusal” Problem and EvoRefuse Optimization Method: The paper “EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions” investigates the issue of Large Language Models (LLMs) over-refusing “pseudo-malicious instructions” (inputs that are semantically harmless but trigger model refusal). To address the shortcomings of existing instruction management methods in scalability and diversity, the paper proposes EVOREFUSE, a method utilizing evolutionary algorithms to optimize prompts, capable of generating diverse pseudo-malicious instructions that consistently elicit LLM refusal. Based on this, the researchers created EVOREFUSE-TEST (a benchmark with 582 instructions) and EVOREFUSE-ALIGN (an alignment training dataset with 3000 instructions and responses). Experiments show that the LLAMA3.1-8B-INSTRUCT model, fine-tuned on EVOREFUSE-ALIGN, reduced its over-refusal rate by up to 14.31% compared to models trained on suboptimal alignment datasets, without compromising safety (Source: HuggingFace Daily Papers)
💼 Business
ZKWensong Completes New Round of Strategic Financing, Invested by Beijing Shijingshan District Industrial Fund: Enterprise AI service provider ZKWensong announced the completion of a new round of strategic financing, with the investor being Beijing Shijingshan District Modern Innovation Industry Development Fund Co., Ltd. This round of financing will primarily be used for R&D investment and market promotion of its self-developed Decision Intelligence Operating System (DIOS), accelerating the development and commercialization of enterprise-level artificial intelligence technology. Founded in 2017, ZKWensong’s core team originated from the Institute of Automation, Chinese Academy of Sciences, focusing on multilingual understanding, cross-modal semantics, and complex scene decision-making technologies, serving industries such as media, finance, government affairs, and energy. It has previously received over one billion yuan in investments from state-owned background funds such as CDB Capital, China Internet Investment Fund, and SCGC (Source: QbitAI)

Sakana AI and Japan’s Hokkoku Bank Forge Strategic Partnership to Advance Regional Financial AI: Japanese AI startup Sakana AI announced the signing of a Memorandum of Understanding (MOU) with Ishikawa-based Hokkoku Financial Holdings. The two parties will engage in strategic cooperation on the integration of regional finance and AI. This marks Sakana AI’s second collaboration with a financial institution, following its comprehensive partnership with Mitsubishi UFJ Bank. The aim is to apply cutting-edge AI technology to address challenges faced by Japan’s regional societies, particularly in financial services. Sakana AI is committed to developing highly specialized AI technology for financial institutions, and this collaboration is expected to set a precedent for AI application among other regional banks in Japan (Source: X, X)

Cohere Partners with Ensemble to Bring its AI Platform to the Healthcare Industry: AI company Cohere announced a partnership with EnsembleHP (a healthcare solutions provider) to introduce its Cohere North AI agent platform to the healthcare industry. The collaboration aims to reduce friction in healthcare administrative processes and enhance the patient experience for hospitals and health systems through a secure AI agent platform. This move signifies a significant step for Cohere in promoting the application of its large language models and AI technology in key vertical industries (Source: X)
🌟 Community
Ilya Sutskever’s Honorary Degree Speech at University of Toronto: AI Will Eventually Be Capable of Everything, Requires Active Attention: OpenAI co-founder Ilya Sutskever, in his speech upon receiving an honorary Doctor of Science degree from the University of Toronto (his fourth degree from the institution), stated that AI’s progress will mean it “will one day be able to do everything we can do,” because the human brain is a biological computer, and AI is a digital brain. He believes we are in an extraordinary era defined by AI, which has profoundly changed the meaning of study and work. He emphasized that rather than worrying, one should form intuition by using and observing top-tier AI to understand its capability boundaries. He called for people to pay attention to AI development and actively address the immense challenges and opportunities that come with it, as AI will profoundly impact everyone’s life. He also shared his personal mindset: “Accept reality, don’t regret the past, strive to improve the present.” (Source: X, 36Kr)
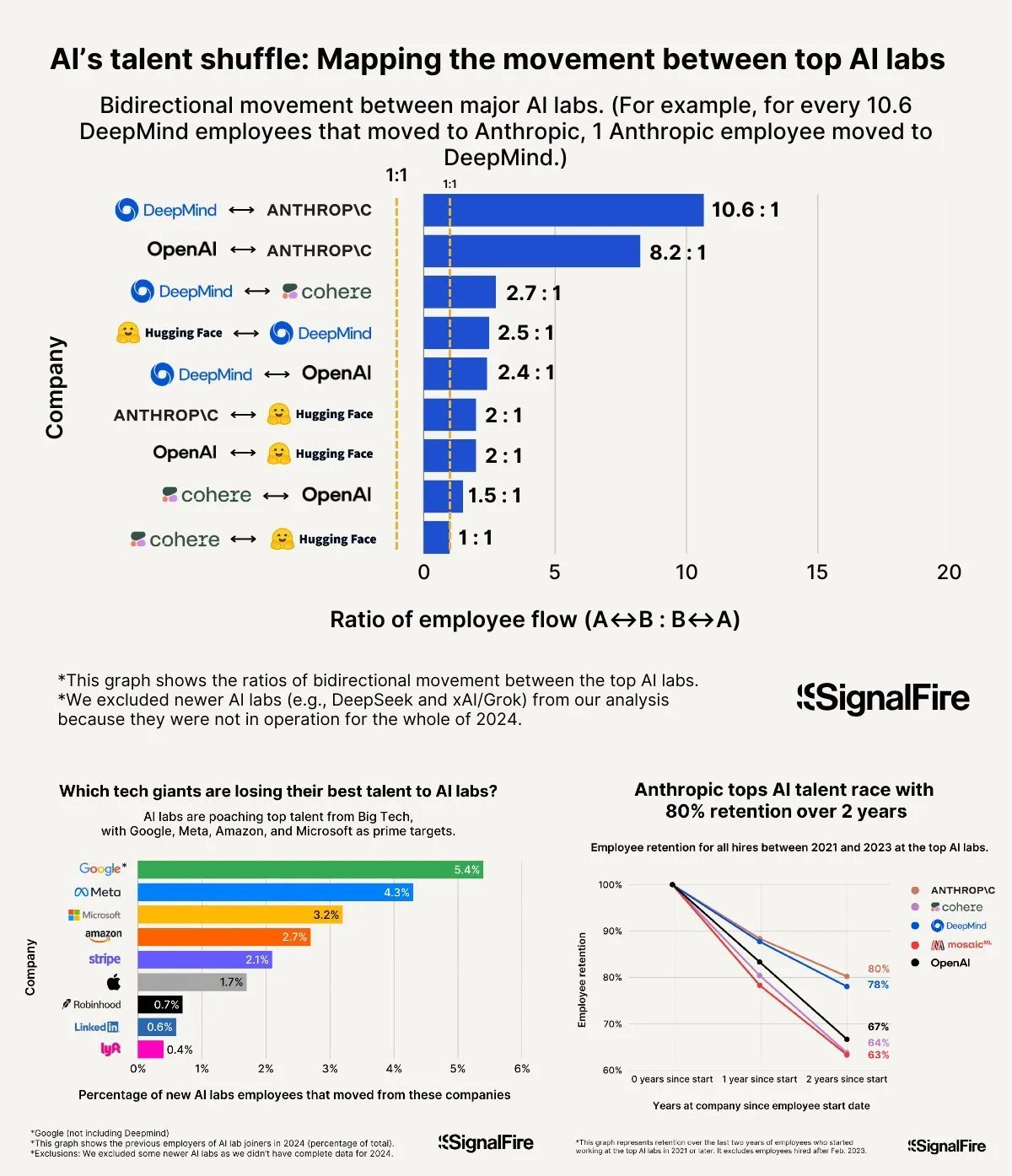
AI Talent War Heats Up: Meta’s High Salaries Still Struggle Against OpenAI and Anthropic: Meta is reportedly offering annual salaries exceeding $2 million to attract AI talent but still faces a talent drain to OpenAI and Anthropic. Discussions indicate that OpenAI’s L6 level salary is close to $1.5 million, and its stock appreciation potential is considered superior to Meta’s, making it more attractive to top talent. Furthermore, allegations of cheating within the Llama team and factors like high KPI pressure and a high bottom-performer elimination rate (15-20% this year) at Meta are also influencing talent choices. Anthropic, with a talent retention rate of about 80% (two years after its founding), has become one of the top choices for leading AI researchers among large companies. The intensity of this talent war is described as “mind-boggling” (Source: X, X)
“Vibe Coding” Experience Sharing: 5 Rules to Avoid Pitfalls in AI-Assisted Programming: On social media, experienced developers shared five rules for avoiding inefficient debugging loops when using AI (like Claude) for “Vibe Coding” (a programming style reliant on AI assistance): 1. Three Strikes and You’re Out: If the AI fails to fix the problem after three attempts, stop and have the AI rebuild from scratch based on a fresh description of the requirements. 2. Reset Context: AI “forgets” after long conversations; it’s recommended to save working code every 8-10 message rounds, start a new session, and paste only the problematic component and a brief application description. 3. Describe Problems Concisely: Clearly describe the bug in one sentence. 4. Frequent Version Control: Commit to Git after each feature is completed. 5. Nuke It When Necessary: If fixing a bug takes too long (e.g., over 2 hours), it’s better to delete the problematic component and have the AI rebuild it. The core idea is to be decisive in abandoning patching when code is irreversibly broken. It’s also emphasized that knowing how to code helps in better guiding AI and debugging (Source: Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
Fei-Fei Li on Founding World Labs: Stemming from Exploration of Intelligence’s Essence, Spatial Intelligence is AI’s Key Missing Piece: On the a16z podcast, Fei-Fei Li shared the motivation behind founding World Labs, emphasizing it wasn’t about chasing the foundation model trend but a continuous exploration of the essence of intelligence. She believes that while language is an efficient information carrier, it has shortcomings in representing the 3D physical world; true general intelligence must be built on understanding physical space and object relationships. An experience of temporarily losing stereoscopic vision due to a corneal injury made her more profoundly aware of the importance of 3D spatial representation for physical interaction. World Labs aims to build AI models (Large World Models, LWM) that can truly understand the physical world, addressing the current gap in AI’s spatial intelligence. She believes achieving this vision requires a convergence of industry-scale computing power, data, and talent, and pointed out that the current technological breakthrough lies in enabling AI to reconstruct a complete 3D scene understanding from monocular vision (Source: QbitAI)

AI-Assisted Gaokao: From Question-Spotting Controversy to Opportunities and Concerns in College Application: Around the Gaokao (China’s college entrance exam), AI’s application in education has sparked widespread discussion. On one hand, “AI question-spotting” became a hot topic, but due to the scientific nature, confidentiality, and “anti-spotting” mechanisms of Gaokao question setting, the likelihood of AI accurately spotting questions is low, and the quality of some commercially available “spotted” papers is questionable. On the other hand, AI has shown positive roles in exam preparation planning, question explanation, exam proctoring, and grading, such as personalized learning plans, intelligent Q&A, and AI proctoring systems enhancing fairness and efficiency. In the college application process, AI tools can quickly recommend institutions and majors based on candidates’ scores and rankings, breaking down information asymmetry. However, over-reliance on AI for applications also raises concerns: algorithms might reinforce preferences for popular majors, neglecting individual interests and long-term development; ceding life choices entirely to algorithms could lead to “algorithmic hijacking of life.” The article calls for a rational view of AI assistance, emphasizing the use of wisdom to master tools and thought to define the future (Source: 36Kr)
Discussion on Successful AI Agent Company Models: Self-Service vs. Custom Services: The community discussed success models for AI Agent companies. One viewpoint suggests that successful AI Agent companies (especially those serving mid-to-large markets) often adopt a Palantir-like model, i.e., numerous field deployment engineers (FDEs) and customized software, rather than a purely self-service model. Another side insists on the long-term value of the self-service model, believing teams will eventually choose to build important applications internally. This reflects differing thought paths in the AI Agent field regarding service models and market strategies (Source: X)
💡 Others
Google Diffusion System Prompt Leaked, Revealing Design Principles and Capability Boundaries: A user shared what is purported to be the system prompt for Google Diffusion, a text-to-web diffusion language model. The prompt details the model’s identity (Gemini Diffusion, an expert text-to-web diffusion language model trained by Google, non-autoregressive), core principles and constraints (e.g., instruction following, non-autoregressive nature, accuracy, no real-time access, safety and ethics, knowledge cutoff December 2023, code generation capabilities), and specific instructions for generating HTML webpages and HTML games. These instructions cover output format, aesthetic design, styling (e.g., specific use of Tailwind CSS or custom CSS for games), icon usage (Lucide SVG icons), layout and performance (CLS prevention), and commenting requirements. Finally, it emphasizes the importance of step-by-step thinking and precise adherence to user instructions. This prompt provides a window into the design philosophy and expected behavior of such models (Source: Reddit r/LocalLLaMA)
Arvind Narayanan Explains the Genesis and Thinking Behind the “AI as Normal Technology” Paper: Princeton professor Arvind Narayanan shared the journey of co-authoring the paper “AI as Normal Technology” with Sayash Kapoor. Initially skeptical of AGI and existential risk, he decided to take these concerns seriously and engage in related discussions at the urging of colleagues. Through reflection, he realized that superintelligence-related views deserve serious consideration, social media is unsuitable for serious discussion, and both AI ethics and AI safety communities have their respective “information cocoons.” The paper’s initial draft was rejected by ICML, but the heated debate during the review process strengthened their resolve to continue the research. They realized their disagreements with the AI safety community were deeper than anticipated and recognized the need for more productive cross-community debate. Ultimately, the paper was published at a workshop by Columbia University’s Knight First Amendment Institute, sparking widespread attention and fruitful discussions, making Narayanan more optimistic about the future of AI policy (Source: X)
The Rise of Gen Z AI Entrepreneurs, Reshaping Startup Rules: A cohort of post-00s (Gen Z) AI entrepreneurs is rapidly emerging in the global startup wave, redefining entrepreneurial rules with their deep understanding of AI technology and keen insight into the native digital environment. Examples include Michael Truell of Anysphere (Cursor) (from intern to CEO of a ten-billion-dollar company in 3 years), the three founders of Mercor (built a ten-billion-level AI recruitment platform in 2 years), Eric Steinberger of Magic (co-founded an AI coding company with over $400 million in funding at age 25), and Letong Hong of Axiom (focused on AI solving mathematical problems, secured high valuation before product launch). These young entrepreneurs generally share common traits: programming is their native language; they achieved fame early, seizing the technological dividend window; they have a keen sense of user needs; they possess an AI-native understanding of organization and product, favoring lean, efficient teams and an “AI as product” logic. Their success marks a paradigm shift in entrepreneurship in the AI era (Source: 36Kr)