
Keywords:Large Language Models, Reasoning Ability, General Artificial Intelligence, AI Regulation, Pattern Matching, Thinking Illusion, Apple Research, AI Detectors, Log-Linear Attention Mechanism, Huawei Pangu MoE Model, ChatGPT Advanced Voice Mode, TensorZero Framework, Anthropic CEO’s Regulatory Views
🔥 Focus
Apple Research Reveals “Illusion of Thinking”: Current “Reasoning” Models Are Not Truly Thinking, But Rely More on Pattern Matching: Apple’s latest research paper, “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models Through the Lens of Problem Complexity,” points out that current large language models (such as Claude, DeepSeek-R1, GPT-4o-mini, etc.) claiming “reasoning” capabilities perform more like efficient pattern matchers than true logical reasoners. The study found that these models’ performance significantly degrades when dealing with problems outside their training distribution or of high complexity, and they can even make mistakes on simple problems due to “overthinking” and struggle to correct early errors. The research emphasizes that the models’ so-called “thinking” processes (like chain-of-thought) often fail when faced with novel or complex tasks, suggesting we may be further from Artificial General Intelligence (AGI) than anticipated. (Source: machinelearning.apple.com, TheTuringPost, mervenoyann, Reddit r/artificial, Reddit r/LocalLLaMA, Reddit r/MachineLearning)

OpenAI Launches ChatGPT Advanced Voice Mode Update, Enhancing Naturalness and Translation Features: OpenAI has rolled out a major update to its Advanced Voice Mode for ChatGPT’s paid users. The new version significantly improves the naturalness and fluency of the voice, making it sound more human-like than an AI assistant. Additionally, the update enhances language translation performance and instruction-following capabilities, and introduces a new translation mode where users can have ChatGPT continuously translate both sides of a conversation until asked to stop. This update aims to make voice interactions easier and more natural, improving the user experience. (Source: juberti, Plinz, op7418, BorisMPower)
AI Detectors Accused of Being Ineffective and Potentially Helping AI Content Go “Stealthy”: Widespread discussions on social media and tech forums indicate that current AI content detection tools are not only ineffective but may even unintentionally help AI-generated content become harder to detect. Many users and experts believe these detectors primarily judge based on linguistic patterns and specific vocabulary (such as the academic term “delve”), rather than truly understanding the content’s origin. Due to the risk of false positives (which could unfairly affect groups like students) and the fact that AI models themselves are evolving to evade detection, the reliability of these tools is seriously questioned. Some argue that the existence of AI detectors actually incentivizes AI to generate content that avoids easily flagged characteristics, thereby making it more human-like. (Source: Reddit r/ArtificialInteligence, sytelus)

Anthropic CEO Calls for Increased Transparency and Accountability Regulation for AI Companies: The CEO of Anthropic published an opinion piece in The New York Times, emphasizing that regulation of AI companies should not be relaxed, particularly highlighting the need for increased transparency and accountability. This viewpoint is especially important against the backdrop of rapid AI industry development and ever-increasing capabilities, echoing societal concerns about AI’s potential risks and ethical implications. The article argues that as AI technology’s influence expands, ensuring its development aligns with public interest and avoids misuse is crucial, requiring a combination of industry self-regulation and external oversight. (Source: Reddit r/artificial)

🎯 Trends
Jeff Dean Envisions the Future of AI: Specialized Hardware, Model Evolution, and Scientific Applications: Google AI lead Jeff Dean shared his views on the future development of AI at Sequoia Capital’s AI Ascent event. He emphasized the importance of specialized hardware (like TPUs) for AI progress and discussed the evolutionary trends in model architectures. Dean also envisioned the future form of computing infrastructure and the immense application potential of AI in fields like scientific research, believing AI will become a key tool for driving scientific discovery. (Source: TheTuringPost)

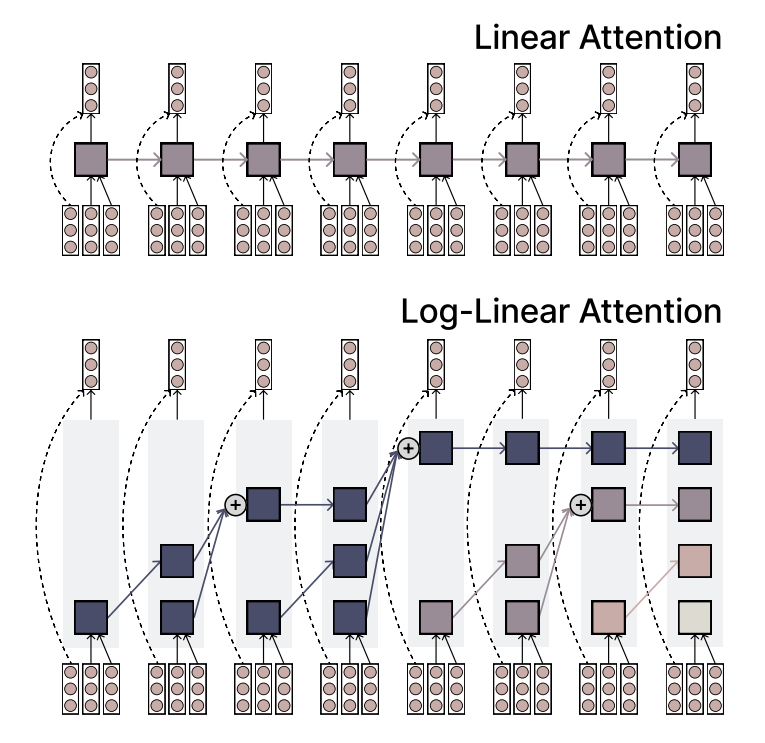
MIT Proposes Log-Linear Attention Mechanism, Balancing Efficiency and Expressiveness: MIT researchers have proposed a new attention mechanism called Log-Linear Attention. This mechanism aims to combine the efficiency of Linear Attention with the strong expressive power of Softmax attention. Its core feature is the use of a small number of memory slots that grow logarithmically with sequence length, thereby maintaining low computational complexity when processing long sequences while capturing key information. (Source: TheTuringPost)
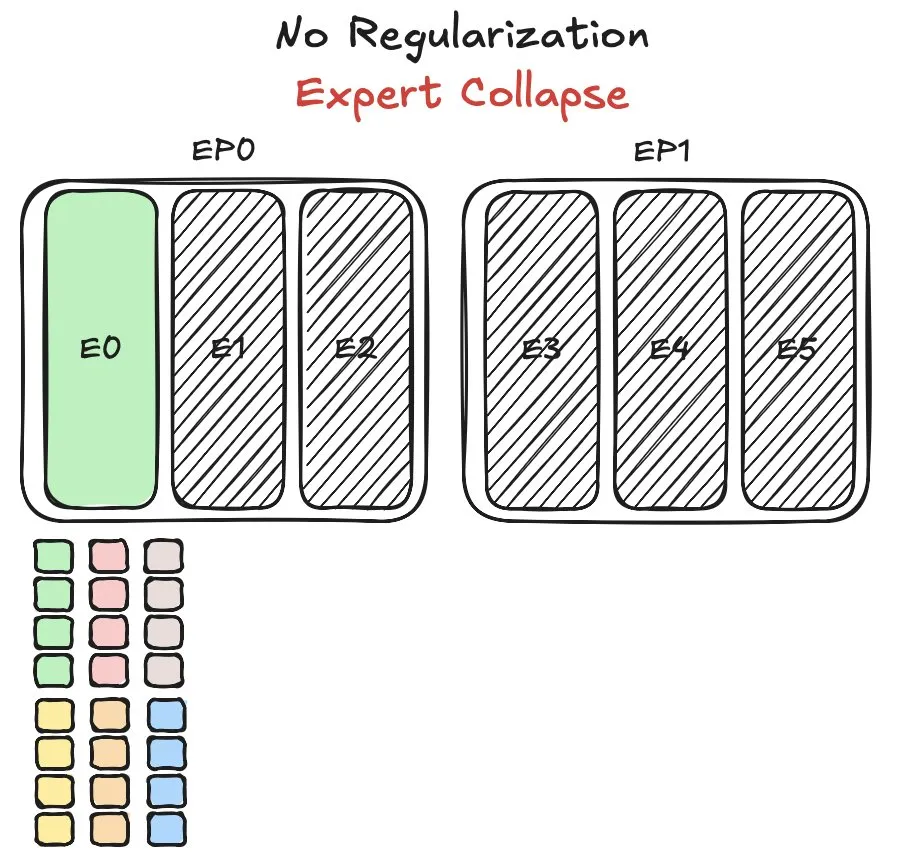
Huawei’s Pangu MoE Model Faces Expert Load Balancing Challenges, Proposes New Method: While training its Mixture-of-Experts (MoE) model, Pangu Ultra MoE, Huawei encountered a critical issue with expert load balancing. Expert load balancing requires a trade-off between training dynamics and system efficiency. Huawei has proposed a new solution to this problem, aiming to optimize task allocation and computational load among different expert modules in the MoE model to enhance training efficiency and model performance. A related research paper has been published. (Source: finbarrtimbers)
NVIDIA Releases Cascade Mask R-CNN Mamba Vision Model, Focusing on Object Detection: NVIDIA has released a new model on Hugging Face named cascade_mask_rcnn_mamba_vision_tiny_3x_coco. Judging by its name, the model is designed for object detection tasks and may integrate the Cascade R-CNN architecture with Mamba (a state-space model) vision technology, aiming to improve the accuracy and efficiency of object detection. (Source: _akhaliq)
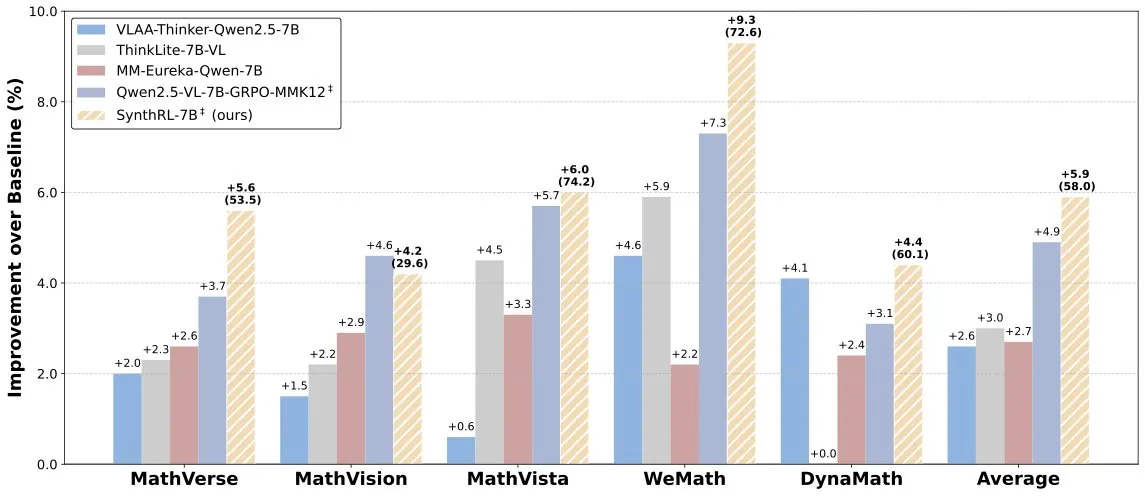
SynthRL Model Released: Scalable Visual Reasoning Through Verifiable Data Synthesis: The SynthRL model has been released on Hugging Face. This model focuses on scalable visual reasoning capabilities, with its core technology centered on generating more challenging variations of visual reasoning tasks through verifiable data synthesis methods, while maintaining the correctness of the original answers. This helps to improve the model’s understanding and reasoning levels in complex visual scenarios. (Source: _akhaliq)
Despite DeepSeek-R1’s Strong Performance, ChatGPT’s Product Advantage Remains Solid: VentureBeat comments that although emerging models like DeepSeek-R1 perform excellently in some aspects, ChatGPT’s leading position at the product level is unlikely to be surpassed in the short term due to its first-mover advantage, extensive user base, mature product ecosystem, and continuous iteration capabilities. The AI competition is not just about technical parameters but a comprehensive contest of product experience, ecosystem building, and business models. (Source: Ronald_vanLoon)

Qwen Team Confirms Qwen3-coder is Under Development: Junyang Lin from the Qwen team confirmed that they are developing Qwen3-coder, an enhanced version of the Qwen3 series focused on coding capabilities. Although no specific timeline has been announced, referencing the Qwen2.5 release cycle, it is expected to be available within a few weeks. The community anticipates this model will make breakthroughs in code generation, autonomous/agent workflow integration, and maintain good support for multiple programming languages. (Source: Reddit r/LocalLLaMA)

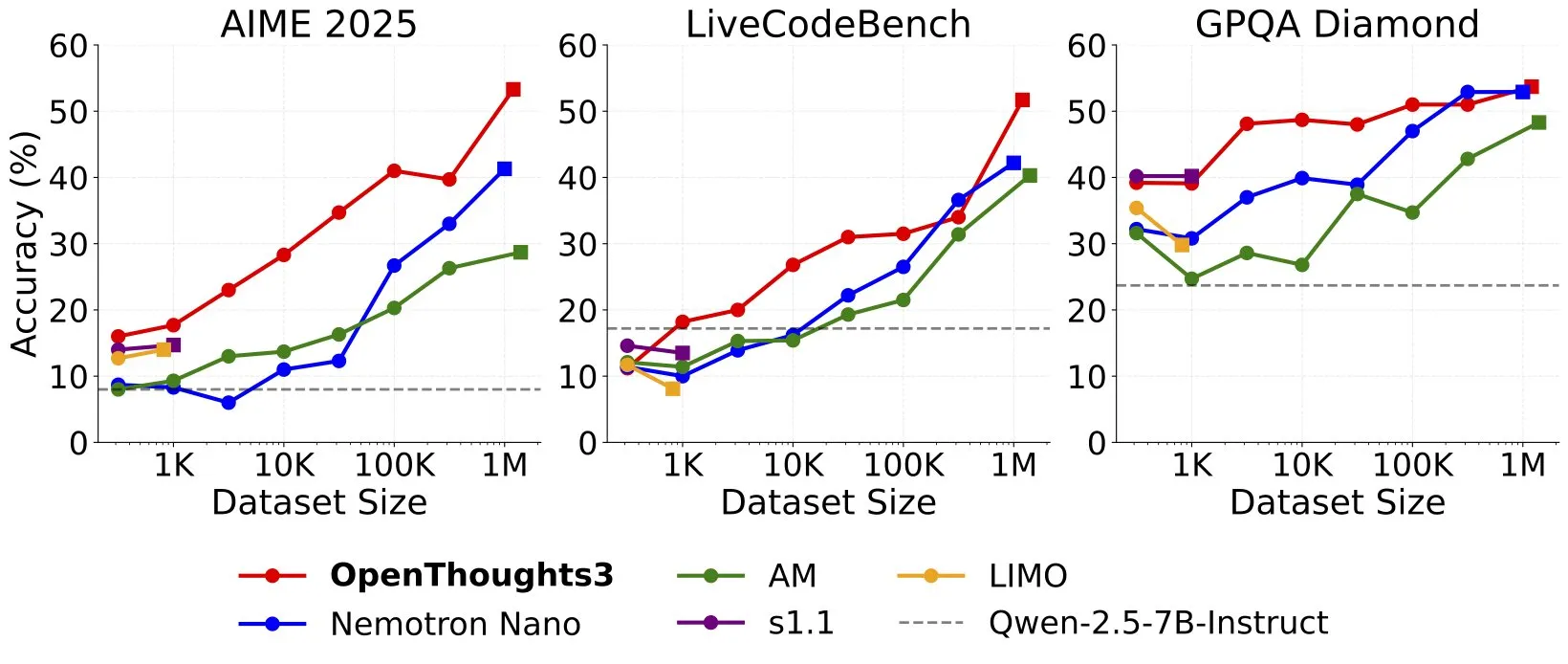
OpenThinker3-7B Released, Claimed as SOTA Open-Data 7B Reasoning Model: Ryan Marten announced the launch of the OpenThinker3-7B model, claiming it to be the current state-of-the-art 7B parameter reasoning model trained on open data. Reportedly, this model outperforms DeepSeek-R1-Distill-Qwen-7B by an average of 33% in code, science, and math evaluations. Also released is its training dataset, OpenThoughts3-1.2M. (Source: menhguin)
🧰 Tools
TensorZero: Open-Source LLMOps Framework for Optimizing LLM Application Development and Deployment: TensorZero is an open-source LLM application optimization framework designed to transform production data into smarter, faster, and more cost-effective models through feedback loops. It integrates an LLM gateway (supporting multiple model providers), observability, optimization (prompting, fine-tuning, RL), evaluation, and experimentation (A/B testing), supporting low latency, high throughput, and GitOps. The tool is written in Rust, emphasizing performance and industrial-grade application requirements. (Source: GitHub Trending)

LangChain Introduces High-Performance RAG System Combining SambaNova, Qdrant, and LangGraph: LangChain has introduced a high-performance Retrieval Augmented Generation (RAG) implementation. This solution combines SambaNova’s DeepSeek-R1 model, Qdrant’s binary quantization technology, and LangGraph, achieving a 32x memory reduction, thereby efficiently processing large-scale documents. This offers new possibilities for building more economical and faster RAG applications. (Source: hwchase17, qdrant_engine)
Google’s One-Click Explainer Video Generation App Sparkify Showcases High-Quality Examples: Google’s Sparkify app, which can generate explainer videos with one click, has demonstrated high-quality examples. The videos exhibit good overall content consistency, natural voiceovers, and can even achieve complex effects like split-screen displays, showcasing AI’s potential in automated video content creation. (Source: op7418)
Hugging Face Launches First MCP Server, Expanding Chatbot Functionality: Hugging Face has released its first MCP (Modular Chat Processor) server (hf.co/mcp), which users can paste into their chat boxes. The MCP server aims to enhance chatbot functionality by providing a richer interactive experience through modular processing units. The community has also compiled a list of other useful MCP servers, such as Agentset MCP, GitHub MCP, etc. (Source: TheTuringPost)
Chatterbox TTS Effects Comparable to ElevenLabs, Integrated into gptme: The TTS (Text-to-Speech) tool Chatterbox has gained attention for its excellent voice synthesis effects, with user feedback indicating its performance is comparable to the well-known ElevenLabs and superior to Kokoro. Chatterbox supports voice customization via reference samples and has now been added as a TTS backend for gptme, providing users with high-quality voice output options. (Source: teortaxesTex, _akhaliq)
E-Library-Agent: Intelligent Retrieval and Q&A System for Local Books/Literature: E-Library-Agent is a self-hosted AI agent capable of extracting, indexing, and querying personal book or paper collections. The project is based on ingest-anything and powered by LlamaIndex, Qdrant, and the Linkup platform, enabling local material extraction, context-aware Q&A, and web discovery through a single interface, making it convenient for users to manage and utilize their personal knowledge bases. (Source: qdrant_engine)
Claude Code Highly Praised by Developers for its Powerful Coding Assistance Capabilities: Reddit community users shared positive experiences using Anthropic’s Claude Code for software development, especially in areas like game development (e.g., Godot C# projects). Users praised its ability to solve complex problems far exceeding other AI coding assistants (like GitHub Copilot), understanding context and generating effective code, making even the $100 monthly fee seem worthwhile. Developers believe that experienced programmers combined with Claude Code will be extremely productive. (Source: Reddit r/ClaudeAI)
ChatterUI Implements Local Vision Model Support, But Android Processing is Slow: A pre-release version of the LLM chat client ChatterUI has added support for attachments and local vision models (via llama.rn). Users can load mmproj files for locally compatible models or connect to APIs that support vision capabilities (like Google AI Studio, OpenAI). However, due to the lack of a stable GPU backend for llama.cpp on Android, image processing is extremely slow (e.g., a 512×512 image takes 5 minutes), while iOS performance is relatively better. (Source: Reddit r/LocalLLaMA)
FLUX kontext Shows Excellent Performance in Replacing Backgrounds of Car Promotional Images: User tests found that the AI image editing tool FLUX kontext performs remarkably well in modifying backgrounds of car promotional images. For example, when changing the background of official Xiaomi SU7 images (e.g., to a sunset beach, a racetrack), the tool not only naturally blends the background but also intelligently adds motion blur effects to moving vehicles, enhancing the image’s realism and visual impact. (Source: op7418)

📚 Learning
fastcore’s New Feature flexicache: A Flexible Caching Decorator: Jeremy Howard introduced a practical new feature in the fastcore library called flexicache. It is a highly flexible caching decorator with built-in ‘mtime’ (based on file modification time) and ‘time’ (based on timestamp) caching strategies, and it allows users to define new caching strategies with minimal code. This feature, detailed in an article by Daniel Roy Greenfeld, helps improve code execution efficiency. (Source: jeremyphoward)
Exploring the Potential of Combining MuP and Muon for Transformer Model Training: Jingyuan Liu delved into Jeremy Bernstein’s work on deriving Muon and spectral conditions, expressing admiration for the elegance of the derivation, particularly how MuP (Maximal Update Parametrization) and Muon (an optimizer) work together. He believes that, based on the derivation, using Muon as the optimizer for MuP-based model training is a natural choice and suggests this could be more exciting than Moonshot’s Moonlight work, which migrates hyperparameters from AdamW to Muon by matching update RMS. Community discussion suggests that the MuP + Muon combination is expected to be scaled up by large tech companies by the end of the year. (Source: jeremyphoward)

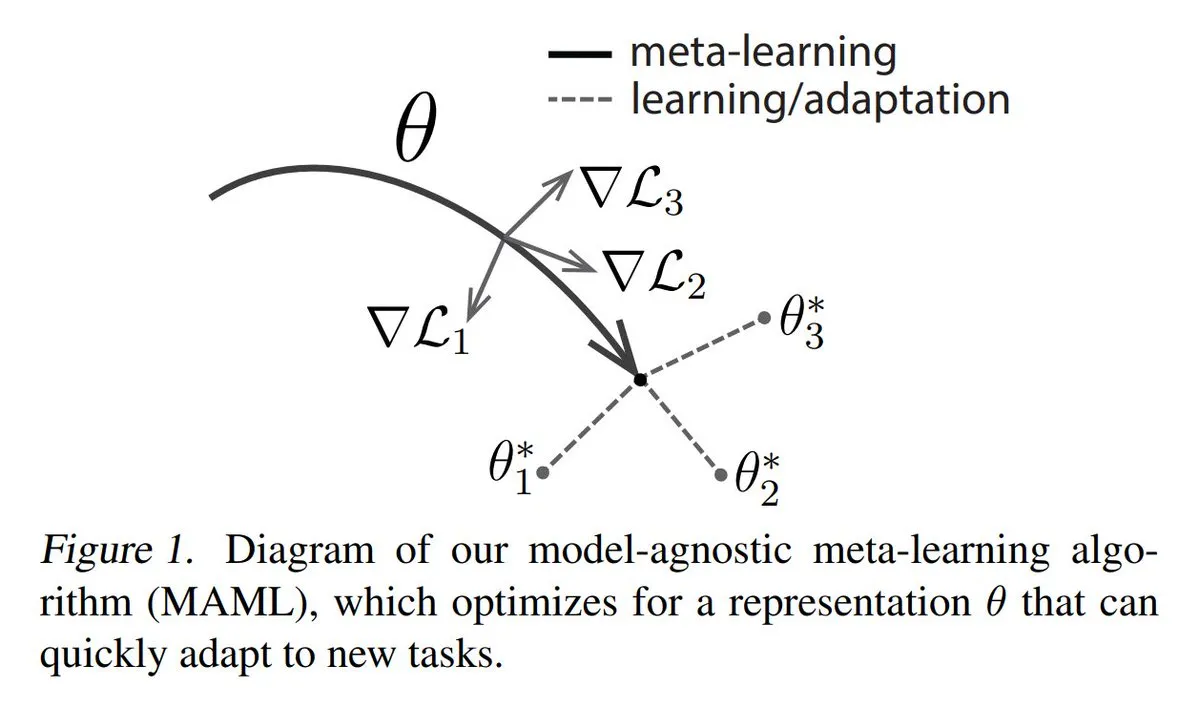
Analysis of Three Mainstream Meta-learning Methods: Meta-learning aims to train models to quickly learn new tasks, even with few samples. Common approaches include: 1. Optimization-based/Gradient-based: Finding model parameters that can be efficiently fine-tuned on a task with few gradient steps. 2. Metric-based: Helping the model find better ways to measure similarity between new and old samples, effectively grouping related samples. 3. Model-based: The entire model is designed to adapt quickly using built-in memory or dynamic mechanisms. The TuringPost provides a detailed explanation from basic to modern meta-learning methods. (Source: TheTuringPost)
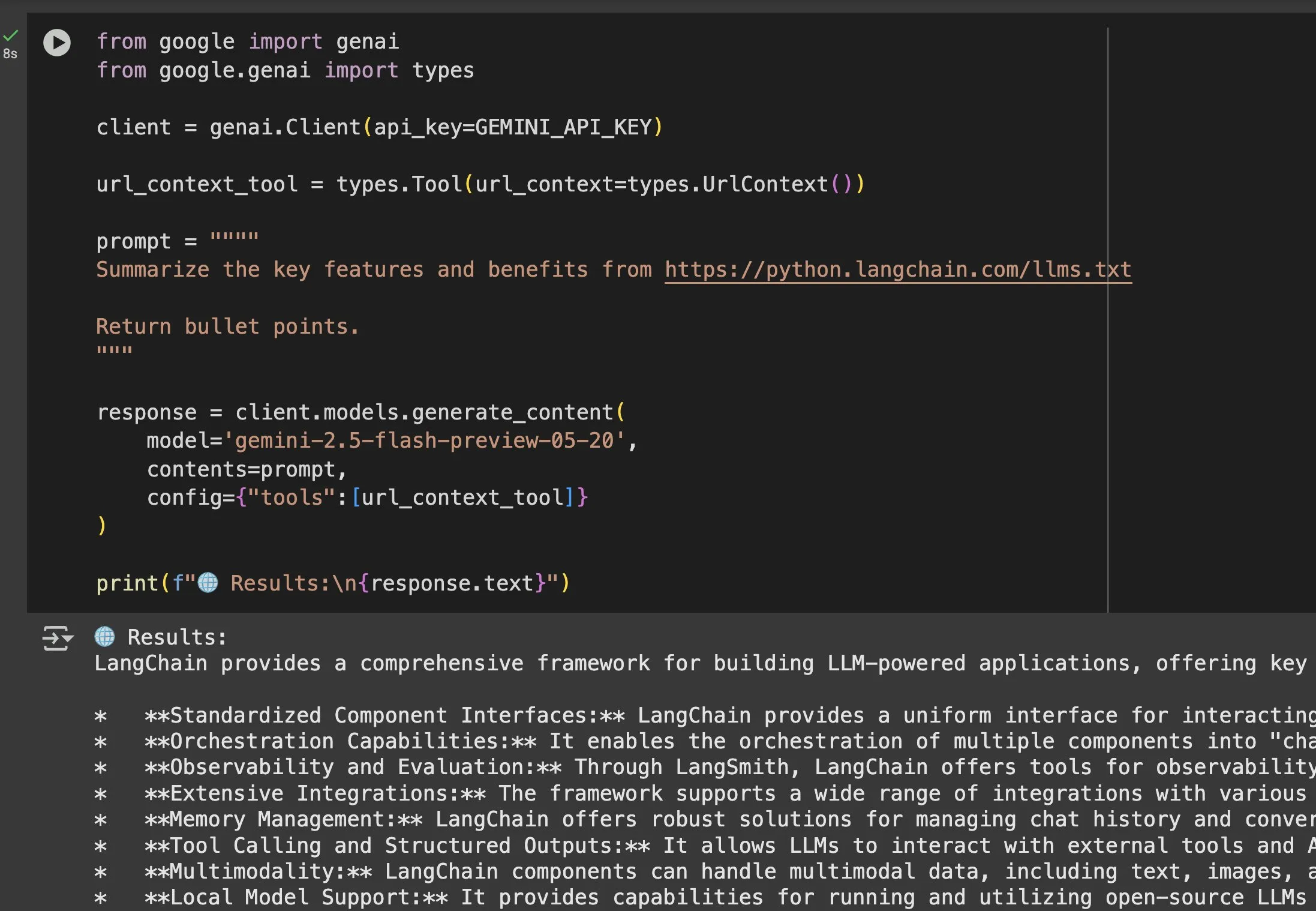
The Value of llms.txt Files in Models like Gemini Highlighted: Jeremy Phoward emphasized the utility of llms.txt files. For example, Gemini can now understand content from URLs simply by adding the URL to the prompt and configuring the URL context tool. This means that clients (like Gemini), by reading the llms.txt endpoint, can know exactly where the required information is stored, greatly facilitating the programmatic acquisition and utilization of information. (Source: jeremyphoward)
EleutherAI Releases Common Pile v0.1, an 8TB Open-Licensed Text Dataset: EleutherAI announced the release of Common Pile v0.1, a large dataset containing 8TB of open-licensed and public domain text. They trained 7B parameter language models on this dataset (using 1T and 2T tokens respectively), achieving performance comparable to similar models like LLaMA 1 and LLaMA 2. This provides valuable resources and empirical evidence for research into training high-performance language models entirely with compliant data. (Source: clefourrier)

SelfCheckGPT: A Reference-Free Method for LLM Hallucination Detection: A blog post discusses SelfCheckGPT as an alternative to LLM-as-a-judge for detecting hallucinations in language models. This is a reference-free, zero-resource detection method, offering new ideas for evaluating and improving the factuality of LLM outputs. (Source: dl_weekly)
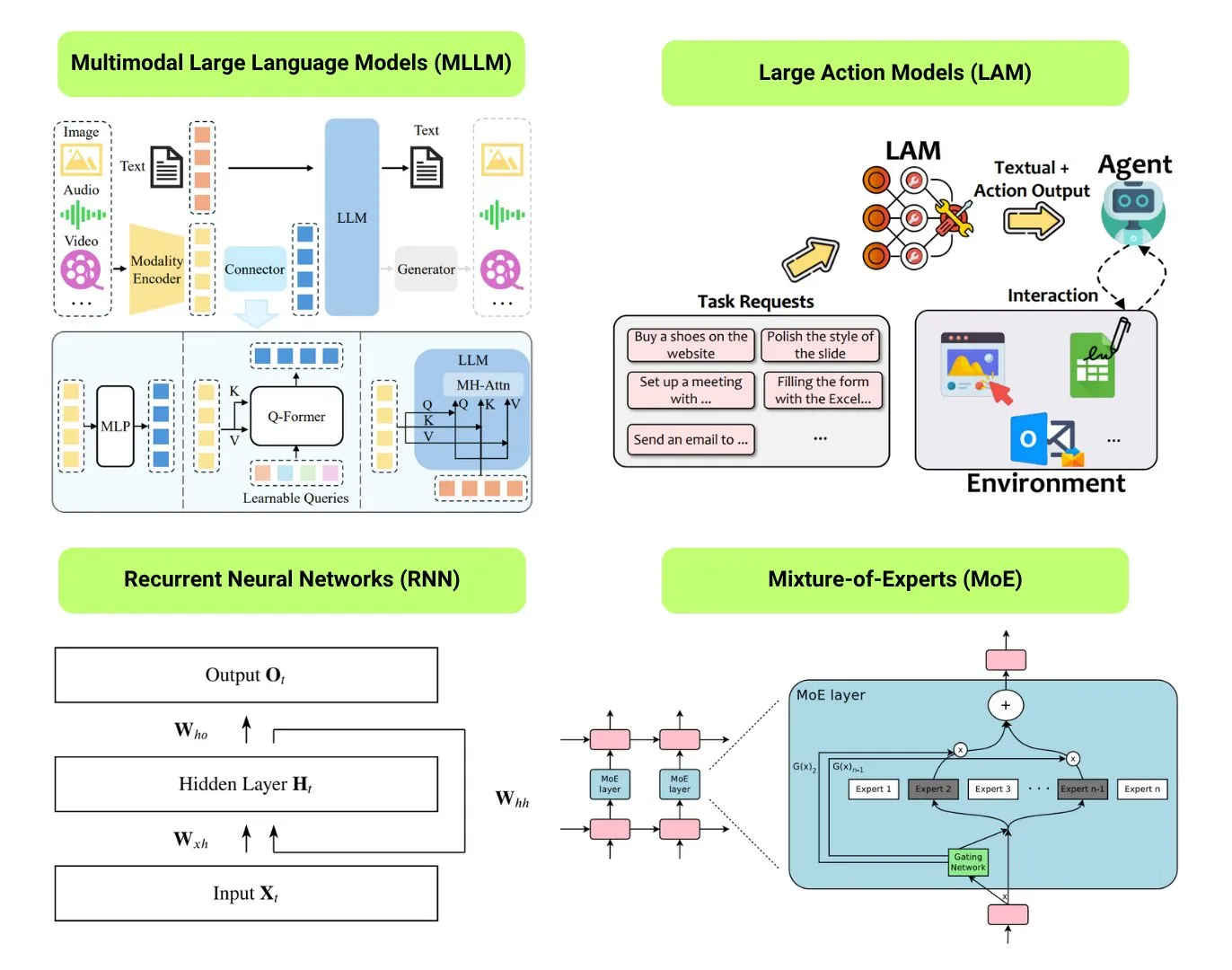
Overview of 12 Basic AI Model Types: The Turing Post has compiled a list of 12 basic AI model types, including LLM (Large Language Model), SLM (Small Language Model), VLM (Vision Language Model), MLLM (Multimodal Large Language Model), LAM (Large Action Model), LRM (Large Reasoning Model), MoE (Mixture of Experts), SSM (State Space Model), RNN (Recurrent Neural Network), CNN (Convolutional Neural Network), SAM (Segment Anything Model), and LNN (Logic Neural Network). Related resources provide explanations and useful links for these model types. (Source: TheTuringPost)
GitHub Trending: Kubernetes The Hard Way Tutorial: Kelsey Hightower’s tutorial, “Kubernetes The Hard Way,” continues to gain attention on GitHub. The tutorial aims to help users build a Kubernetes cluster manually, step-by-step, to deeply understand its core components and working principles, rather than relying on automated scripts. The tutorial is intended for learners who want to master the fundamentals of Kubernetes, covering the entire process from environment preparation to cluster cleanup. (Source: GitHub Trending)
GitHub Trending: List of Free GPTs and Prompts: The friuns2/BlackFriday-GPTs-Prompts repository is trending on GitHub. It collects and organizes a series of free GPT models and high-quality Prompts that users can use without a Plus subscription. These resources cover various fields such as programming, marketing, academic research, job seeking, gaming, and creativity, and include some “Jailbreaks” techniques, providing GPT users with a wealth of ready-to-use tools and inspiration. (Source: GitHub Trending)

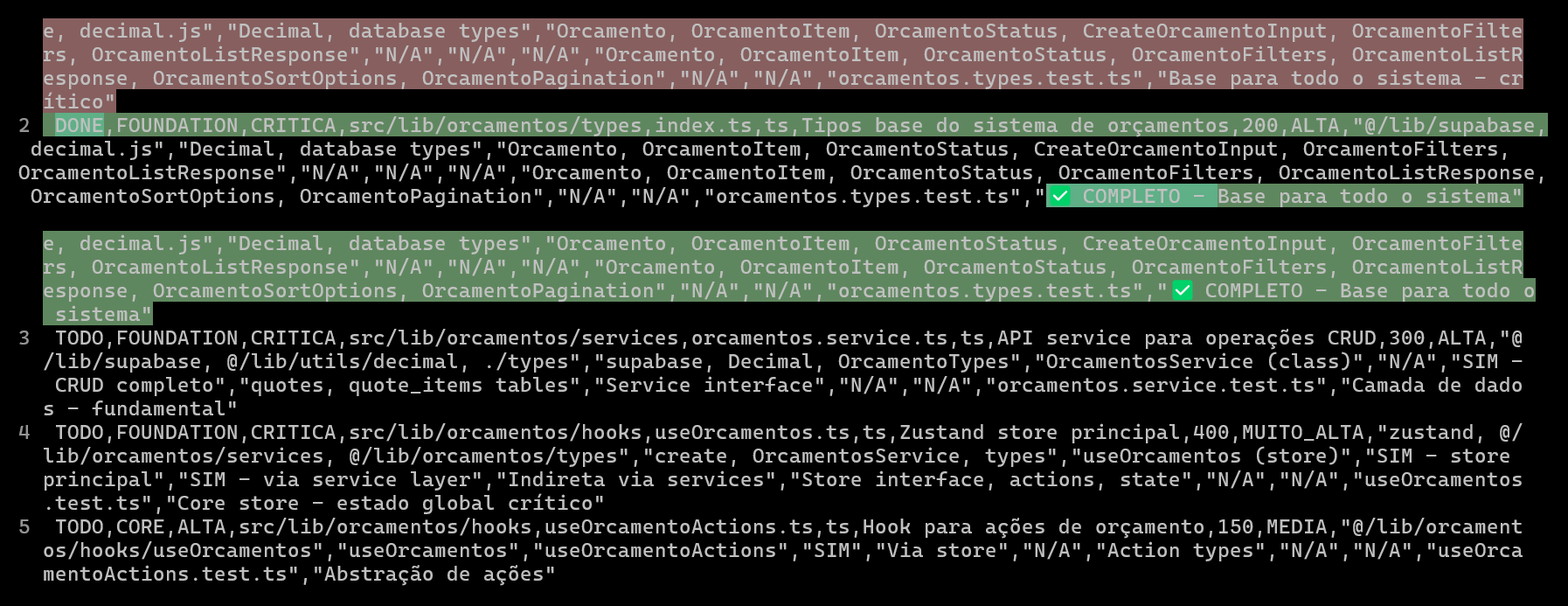
Using CSV to Plan and Track AI Coding Projects, Improving Code Quality and Efficiency: A developer shared how using Claude Code for ERP system development, by creating detailed CSV files to plan and track the coding progress of each file, significantly improved the development efficiency of complex features and code quality. The CSV file includes status, filename, priority, lines of code, complexity, dependencies, feature description, used Hooks, imported/exported modules, and crucial “progress notes.” This method allows the AI to focus more on building code and enables the developer to clearly grasp the discrepancies between actual project progress and the original plan. (Source: Reddit r/ClaudeAI)
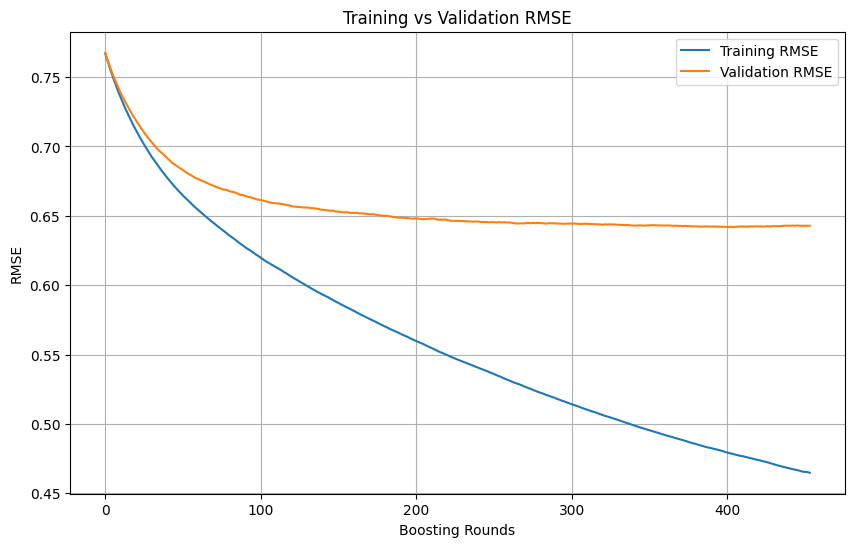
Identifying Overfitting and When to Stop in Machine Learning Training: During machine learning model training, if the training loss continues to decrease rapidly while the validation loss decreases slowly, stops, or even increases, it usually indicates that the model may be overfitting. In principle, training can continue as long as the validation loss is still decreasing. The key is to ensure that the validation set is independent of the training set and can represent the true data distribution of the task. If the validation loss stops decreasing or starts to increase, early stopping of training should be considered, or methods like regularization should be adopted to improve the model’s generalization ability. (Source: Reddit r/MachineLearning)
🌟 Community
AI Engineer World’s Fair 2025 Focuses on RL+Reasoning, Eval, and Other Topics: The AI Engineer World’s Fair 2025 will cover cutting-edge topics including Reinforcement Learning + Reasoning (RL+Reasoning), Evaluation (Eval), Software Engineering Agents (SWE-Agent), AI Architects, and Agent Infrastructure. Attendees reported that the conference was full of energy and innovative thinking, with many people daring to try new things, constantly reinventing themselves, and dedicating themselves to the AI field. The conference also provided a platform for AI engineers to communicate and learn. (Source: swyx, hwchase17, charles_irl, swyx)

Sam Altman’s Ideal AI: Small Model + Superhuman Reasoning + Massive Context + Universal Tools: Sam Altman described his ideal form of AI: a model with superhuman reasoning ability, extremely small in size, able to access trillions of pieces of contextual information, and capable of calling upon any imaginable tool. This view sparked discussion, with some believing it differs from the current reality where large models rely on knowledge storage, and questioning the feasibility of small models parsing knowledge and performing complex reasoning within a vast context, arguing that knowledge and thinking ability are difficult to separate efficiently. (Source: teortaxesTex)
Coding Agents Spark Desire for Code Refactoring, Challenges and Opportunities in AI-Assisted Programming: Developers indicate that the emergence of coding agents has greatly increased their “temptation” to refactor others’ code, while also introducing new dangers. One developer shared an experience of using AI to complete a programming task that would manually take about 10 minutes. Although AI could quickly generate working code, achieving the organizational and stylistic level of a senior programmer still required significant manual guidance and refactoring. This highlights the challenges of AI-assisted programming in elevating junior/intermediate code to high-quality senior-level code. (Source: finbarrtimbers, mitchellh)
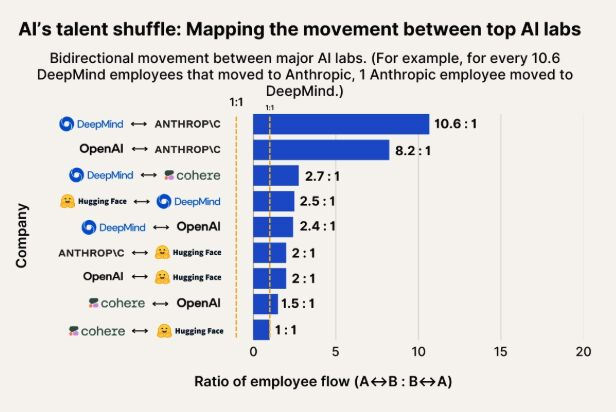
AI Talent Flow Observation: Anthropic Becomes a Key Destination for Talent from Google DeepMind and OpenAI: A chart showing AI talent flow indicates that Anthropic is becoming a major company attracting researchers from Google DeepMind and OpenAI. The community finds this consistent with their observations, with some users speculating that Anthropic may possess certain “secret weapons” or unique research directions that attract top talent. (Source: bookwormengr, TheZachMueller)
Humanoid Robot Popularization Faces Trust and Social Acceptance Challenges: Tech commentator Faruk Guney predicts that the first wave of humanoid robots may fail due to a massive trust deficit. He believes that despite technological advancements, society is not yet ready to accept these “black box intelligences” into homes to perform tasks like companionship, chores, or even childcare. The robots’ opaque decision-making, potential surveillance risks, and distinctly non-human “cuteness” (unlike Wall-E) could all become obstacles to their widespread adoption. Only after sufficient societal discussion, regulation, auditing, and trust-rebuilding can the true popularization of humanoid robots occur. (Source: farguney, farguney)
AI Personality Design: “Imperfection” Trumps “Perfection”: A developer shared their experience creating 50 AI personalities on an AI audio platform. The conclusion was that overly designed backstories, absolute logical consistency, and extreme single-minded personalities actually make AI seem mechanical and unreal. Successful AI personality shaping lies in a “3-layer personality stack” (core traits + modifier traits + quirks), appropriate “imperfection patterns” (like occasional slips of the tongue, self-correction), and just the right amount of background information (300-500 words, including positive and challenging experiences, specific passions, and profession-related vulnerabilities). These “imperfect” details actually make AI more humane and relatable. (Source: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Discussion on Whether LLMs Possess “Sentience” and “AGI”: Excitement and Skepticism Coexist: The community is generally excited about the immense potential of LLMs, considering them comparable to major historical inventions that will change everything. However, many remain skeptical about claims that LLMs possess “sentience,” need “rights,” or will “end humanity” or bring about “AGI.” There’s an emphasis on maintaining nuance and caution when interpreting LLM capabilities and research findings. (Source: fabianstelzer)
💡 Others
Exploring Multi-Robot Autonomous Walking Collaboration: Discussions have emerged on social media regarding collaborative exploration in autonomous walking for multiple robots. This involves complex technologies such as robot path planning, task allocation, information sharing, and collision avoidance, and is an ongoing research direction in robotics, RPA (Robotic Process Automation), and machine learning. (Source: Ronald_vanLoon)
Technique for Optimizing ULMFiT Hyperparameters Using Random Forests: Jeremy Howard shared a trick he used when optimizing ULMFiT (a transfer learning method): by running numerous ablation studies and feeding all hyperparameter and results data into a random forest model, he could identify the hyperparameters that most significantly impacted model performance. This method has been integrated by Weights & Biases into its product, offering a new approach to hyperparameter tuning. (Source: jeremyphoward)

Figure Company’s Humanoid Robot Demonstrates 60-Minute Logistics Task Handling Capability: Figure company released a 60-minute video showcasing its humanoid robot, powered by the Helix neural network, autonomously completing various tasks in a logistics scenario. This demonstration aims to prove the robot’s long-term stable working capability and autonomous decision-making level in complex real-world environments. (Source: adcock_brett)